數組還是HashSet?
我記得大約在半年前,有個朋友問我一個問題,現在有一個選型:
一個性能敏感場景,有一個集合,需要確定某一個元素在不在這個集合中,我是用數組直接
Contains還是使用HashSet<T>.Contains?

大家肯定想都不用想,都選使用HashSet<T>,畢竟HashSet<T>的時間複雜度是O(1),但是後面又附加了一個條件:
這個集合的元素很少,就4-5個。
那這時候就有一些動搖了,只有4-5個元素,是不是用數組Contains或者直接遍歷會不會更快一些?當時我也覺得可能元素很少,用數組就夠了。
而最近在編寫程式碼時,又遇到了同樣的場景,我決定來做一下實驗,看看元素很少的情況下,是不是使用數組優於HashSet<T>。
測試
我構建了一個測試,分別嘗試在不同的容量下,查找一個元素,使用數組和HashSet的區別,程式碼如下所示:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSet
{
private HashSet<string> _hashSet;
private string[] _strings;
[Params(1,2,4,64,512,1024)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_strings = Enumerable.Range(0, Size).Select(s => s.ToString()).ToArray();
_hashSet = new HashSet<string>(_strings);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _strings.Contains("8192");
[Benchmark]
public bool HashSetContains() => _hashSet.Contains("8192");
}
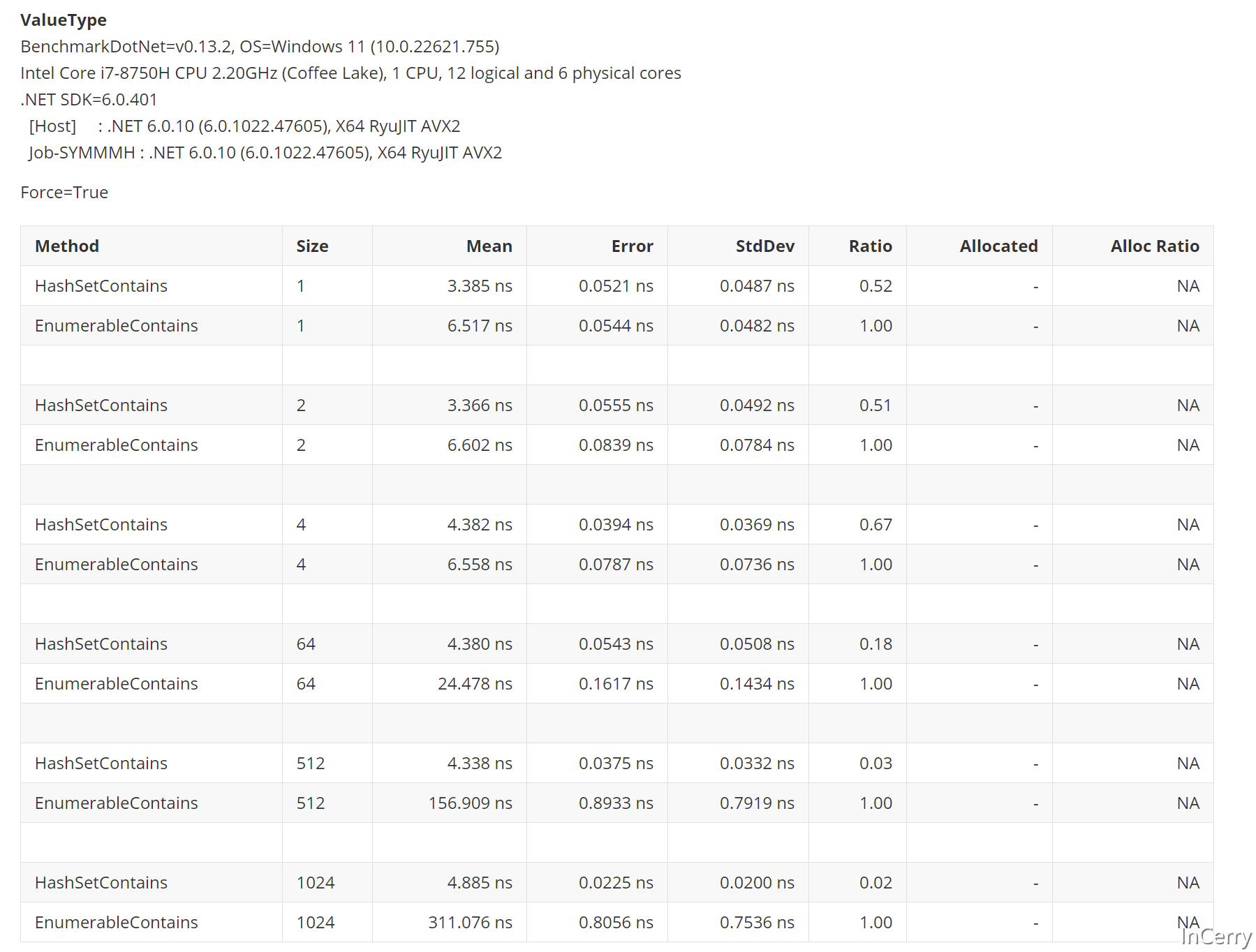
大家猜猜結果怎麼樣,就算Size只為1,那麼HashSet也比數組Contains遍歷快40%。

那麼故事就這麼結束了嗎?所以無論如何場景我們都直接無腦使用HashSet就行了嗎?大家看滑動條就知道,故事沒有這麼簡單。
剛剛我們是引用類型的比較,那值類型怎麼樣?結論就是一樣的結果,就算只有1個元素也比數組的Contains快。
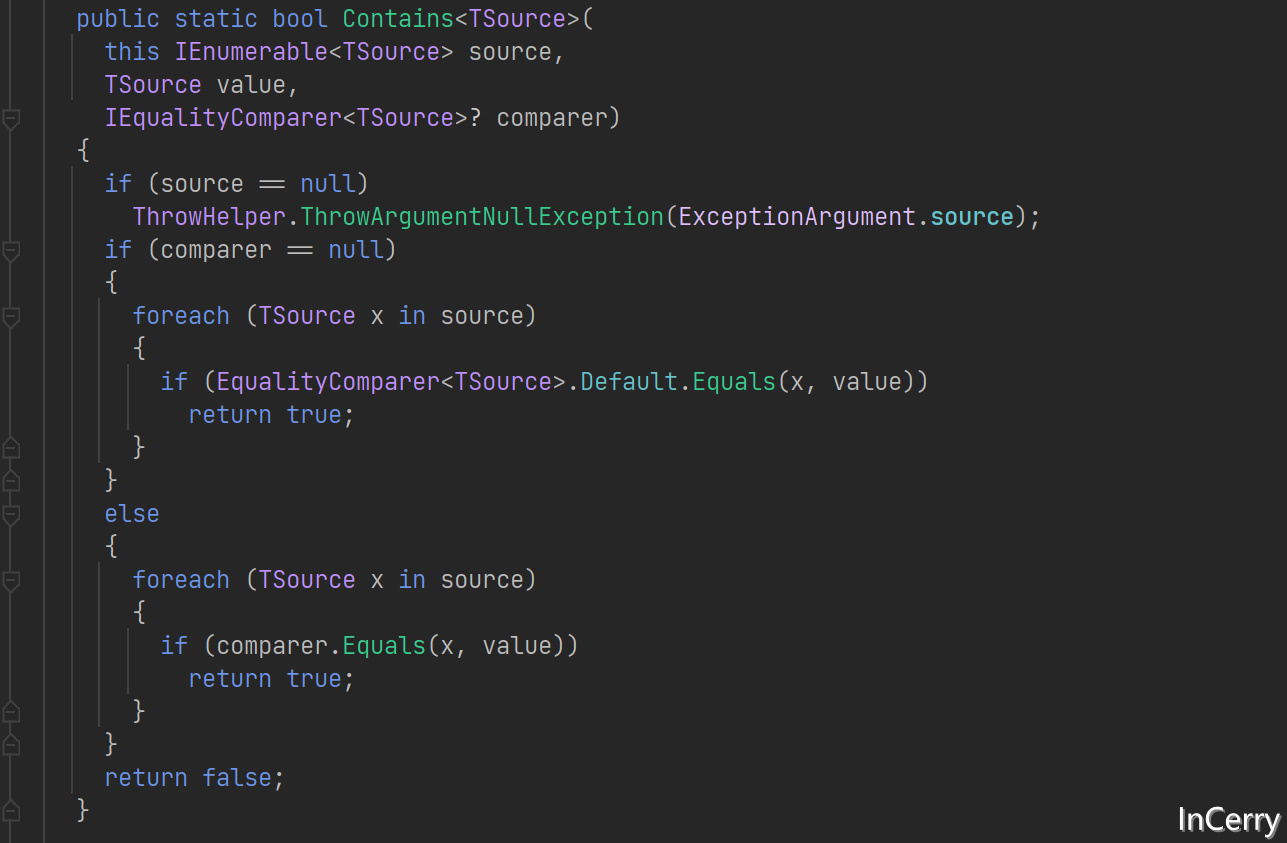
那麼問題出在哪裡?點進去看一下數組Contains方法的實現就清楚了,這個東西使用的是Enumerable迭代器匹配。
那麼我們直接來個原始的,Array.IndexOf匹配和for循環匹配試試,於是有了如下程式碼:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSetValueType
{
private HashSet<int> _hashSet;
private int[] _arrays;
[Params(1,4,16,32,64)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_arrays = Enumerable.Range(0, Size).ToArray();
_hashSet = new HashSet<int>(_arrays);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _arrays.Contains(42);
[Benchmark]
public bool ArrayContains() => Array.IndexOf(_arrays,42) > -1;
[Benchmark]
public bool ForContains()
{
for (int i = 0; i < _arrays.Length; i++)
{
if (_arrays[i] == 42) return true;
}
return false;
}
[Benchmark]
public bool HashSetContains() => _hashSet.Contains(42);
}
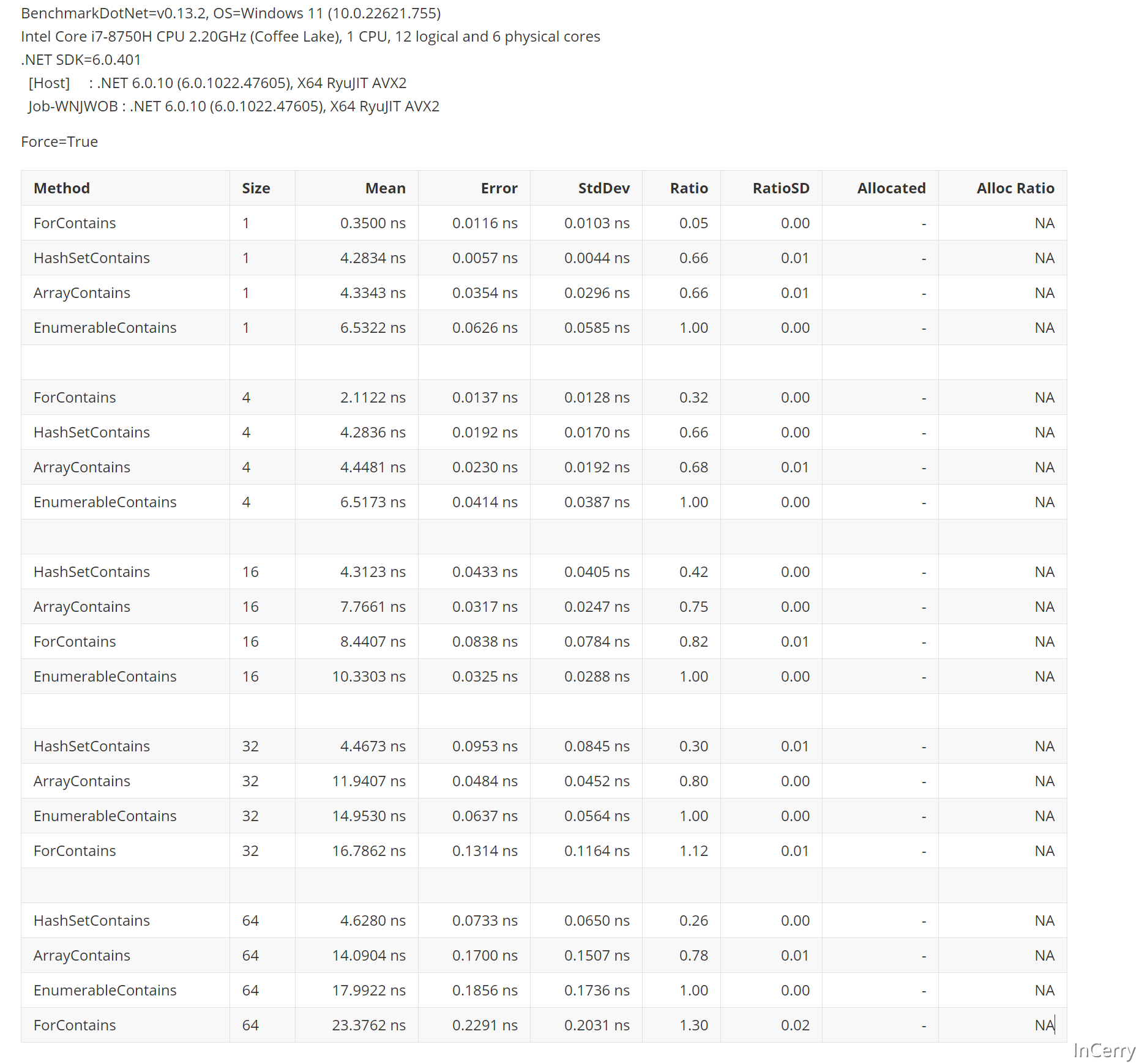
接下來結果就和我們預想的差不多了,在數組元素小的時候,使用原始的for循環比較會快,然後HashSet就變為最快的了,在更多元素的場景中Array.IndexOf會比for更快:
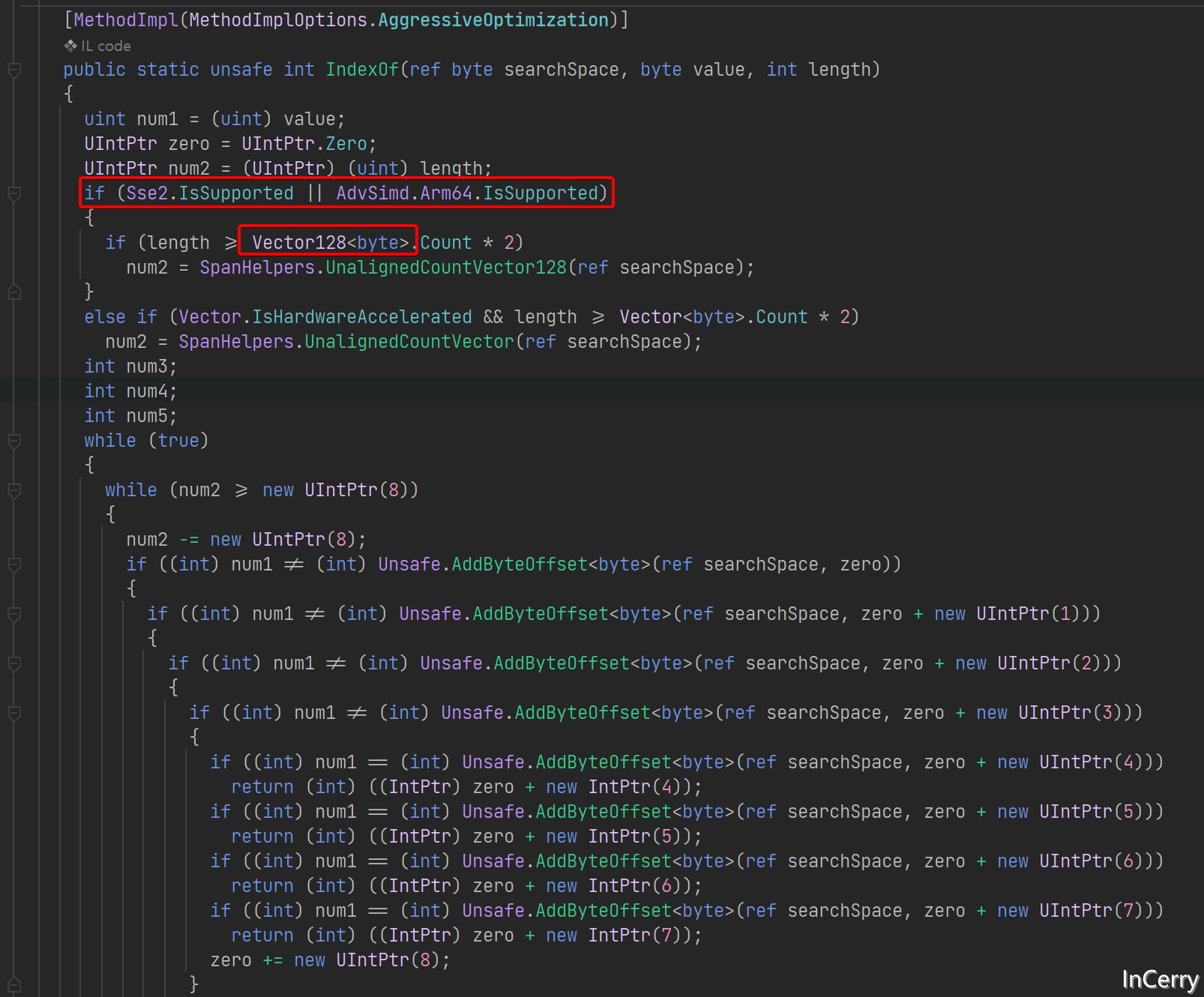
至於為什麼在元素多的情況Array.IndexOf會比for更快,那是因為Array.IndexOf底層使用了SIMD來優化,在之前的文章中,我們多次提到了SIMD,這裡就不贅述了。
既然如此我們再來確認一下,到底多少個元素以內用for會更快,可以看到16個元素以內,for循環會快於HashSet:
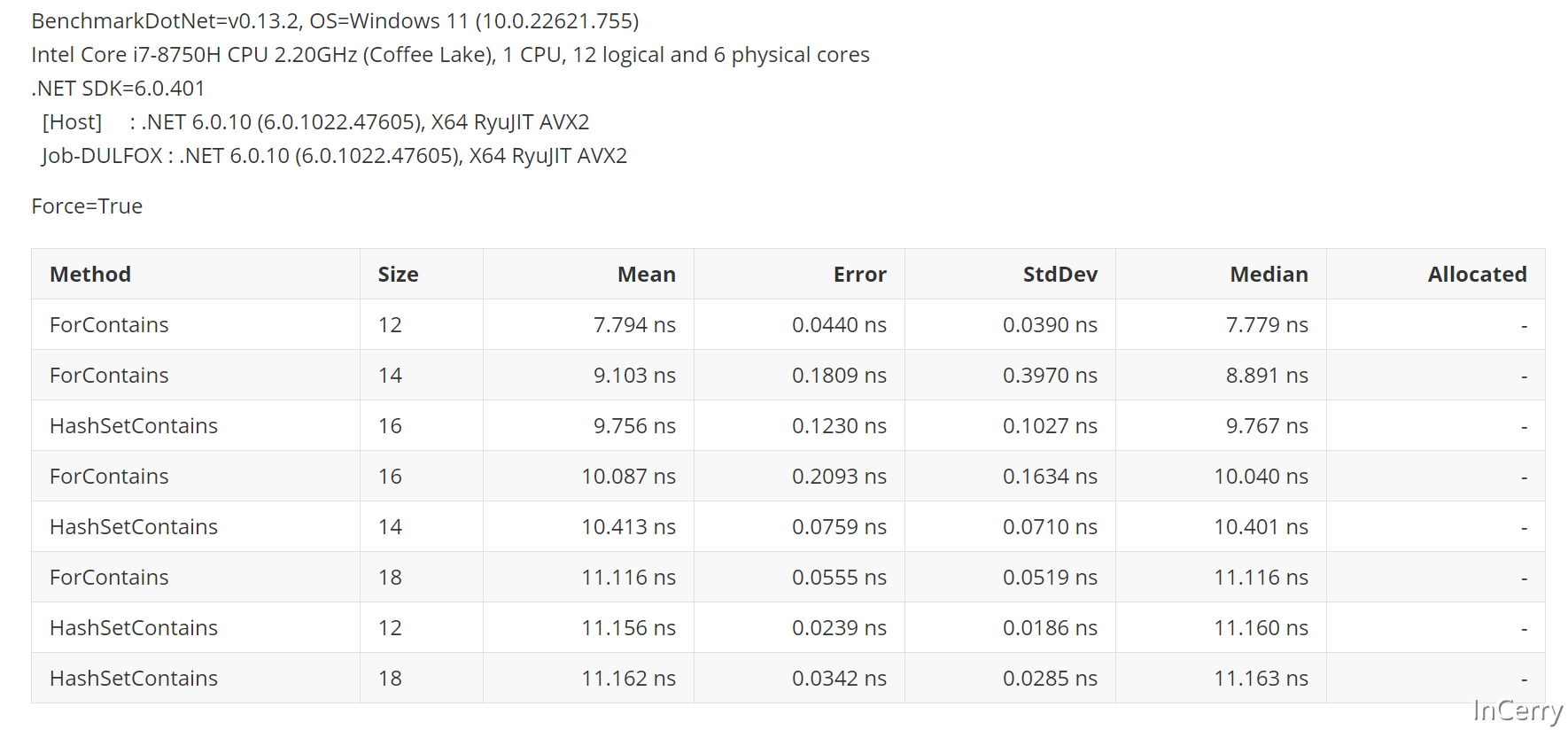
總結
所以我們應該選擇HashSet<T>還是數組呢?這個就需要分情況簡單的總結一下:
- 在小於16個元素場景,使用
for循環匹配會比較快。 - 16-32個元素的場景,速度最快是
HashSet<T>然後是Array.IndexOf、for、IEnumerable.Contains。 - 大於32個元素的場景,速度最快是
HashSet<T>然後是Array.IndexOf、IEnumerable.Contains、for。
從這個上面來看,大於32個元素就不合適直接用for比較了。不過這些差別都很小,除非是性能非常敏感的場景,可以忽略不計,本文解決了筆者的一些困擾,簡單記錄一下。

