[數據結構-線性表1.2] 鏈表與 LinkedList(.NET 源碼學習)
- 2022 年 11 月 8 日
- 筆記
- C#相關知識, 演算法&數據結構學習心得
[數據結構-線性表1.2] 鏈表與 LinkedList<T>
【註:本篇文章源碼內容較少,分析度較淺,請酌情選擇閱讀】
關鍵詞:鏈表(數據結構) C#中的鏈表(源碼) 可空類型與特性(底層原理 源碼) 迭代器的實現(底層原理) 介面IEqualityCompare<T>(源碼) 相等判斷(底層原理)
鏈表,一種元素彼此之間具有相關性的數據結構,主要可分為三大類:單向鏈表、雙向鏈表、循環鏈表。其由「鏈」和「表」組成,「鏈」指當前元素到其他元素之間的路徑(指針);「表」指當前單元存儲的內容(數據)。本文主要對 C# 中 LinkedList 的源碼進行簡要分析。
【# 請先閱讀注意事項】
【註:
(1) 文章篇幅較長,可直接轉跳至想閱讀的部分。
(2) 以下提到的複雜度僅為演算法本身,不計入演算法之外的部分(如,待排序數組的空間佔用)且時間複雜度為平均時間複雜度。
(3) 除特殊標識外,測試環境與程式碼均為 .NET 6/C# 10。
(4) 默認情況下,所有解釋與用例的目標數據均為升序。
(5) 默認情況下,圖片與文字的關係:圖片下方,是該幅圖片的解釋。
(6) 文末「 [ # … ] 」的部分僅作補充說明,非主題(演算法)內容,該部分屬於 .NET 底層運行邏輯,有興趣可自行參閱。
(7) 本文內容基本為本人理解所得,可能存在較多錯誤,歡迎指出並提出意見,謝謝。】
一、鏈表概述及常見類型
【註:該部分在網路上已有很多資料,故不作為重點】
數組作為一個最初的順序儲存方式的數據結構,其可通過索引訪問的靈活性,使用為我們 的程式設計帶來了大量的便利。但是,數組最大的缺點就是:為了保證在存儲空間上的連續性,在插入和刪除時需要移動大量的元素,造成大量的消耗時間,以及高冗餘度。為了避免這樣的問題,因此引入了另一種數據結構鏈表。
鏈表通過不連續的儲存方式、動態記憶體大小,以及靈活的指針使用(此處的指針是廣義上的指針,不僅僅只代表 C/C++ 中的指針,還包括一些標記等),巧妙的簡化了上述的缺點。其基本思維是,利用結構體或類的設置,額外開闢出一份記憶體空間去作「表」本身,其內部包含本身的值,以及指向下一個結點的指針,一個個結點通過指針相互串聯,就形成了鏈表。但優化了插入與刪除的額外時間消耗,隨之而來的缺點就是:鏈表不支援索引訪問。
(一) 單向鏈表
以下僅簡單寫一下基本構成和方法。

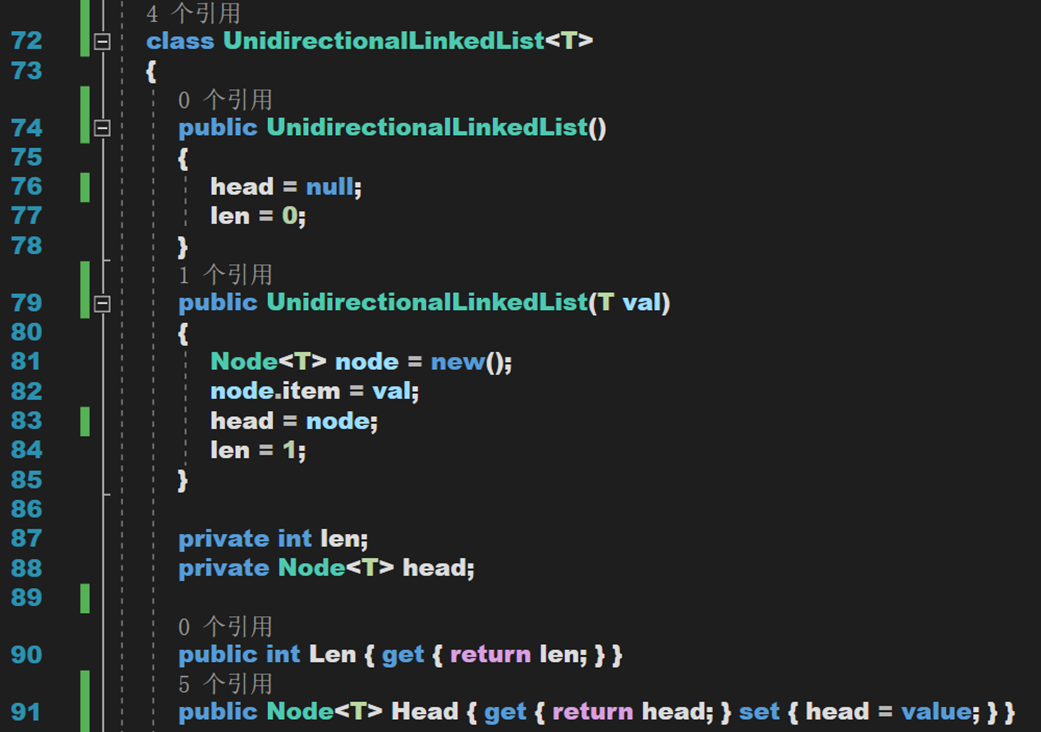
首先定義「表」,即每個結點。其包含自身數據與指向下一個表的指針。其中一個默認構造方法,一個帶參構造方法用於兩種不同形式的初始化。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
再定義一下「鏈「
- Line 74~85:構造方法,默認方法初始化頭結點為空;鏈表長度為零;帶參方法用處初始化單個結點。
- Line 87~88:定義私有欄位,包括鏈表長度、頭節點。
- Line 90~91:公共屬性,用於外部訪問私有欄位。通過公共屬性訪問私有欄位,符合面向對象的設計原則,體現了對欄位的封裝,增強了程式碼在運行時的安全性。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
接下來定義常用方法
1. 首尾添加
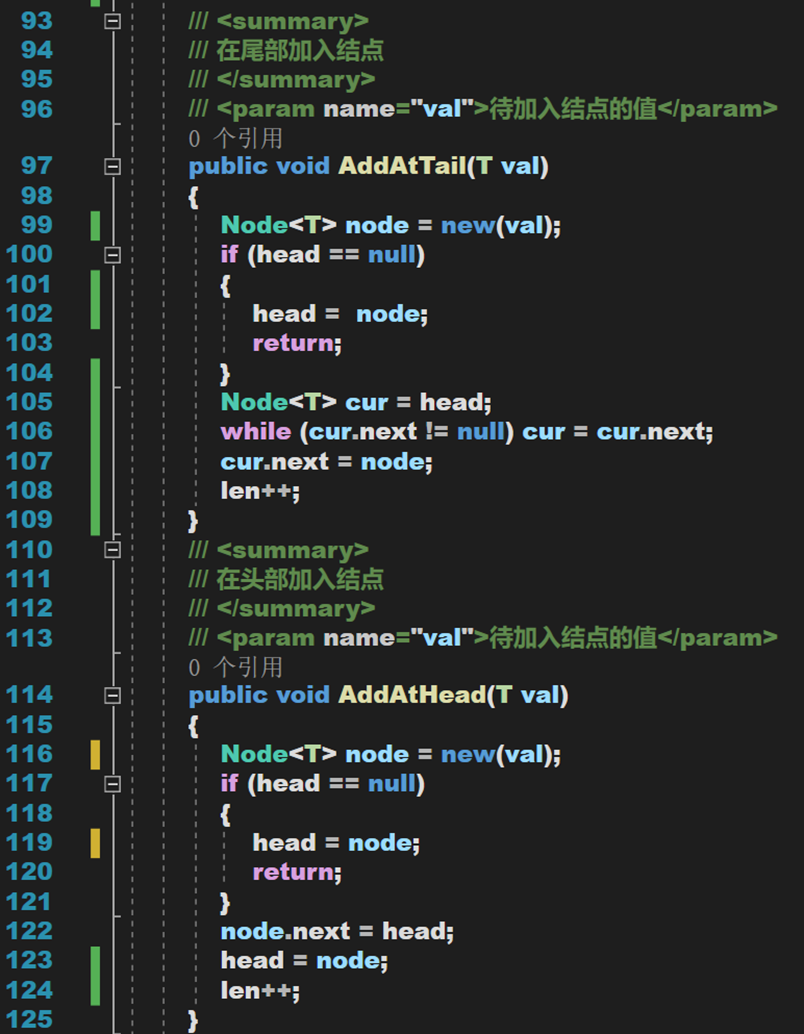
2. 插入

- Line 140:關於這個循環條件,循環到 idx – 1 ,使 cur 停在執行位置的前一個位置。若停在操作位置,則無法設定前一個結點的 next 屬性。
3. 刪除
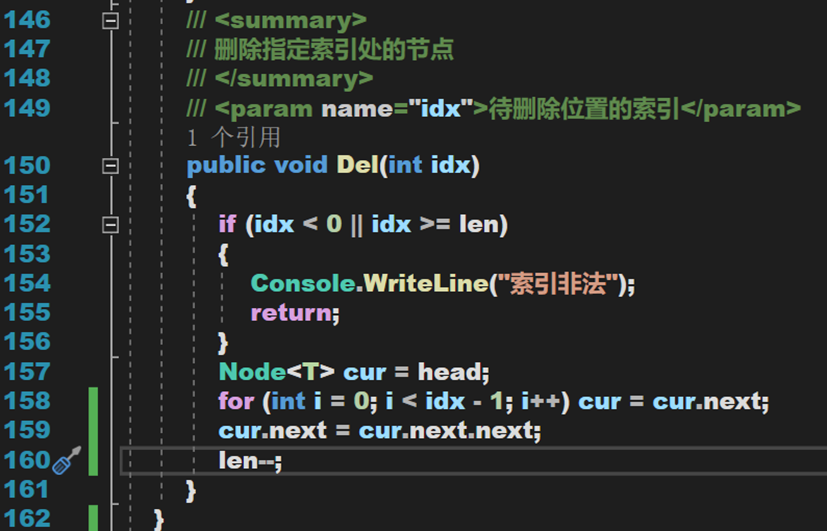
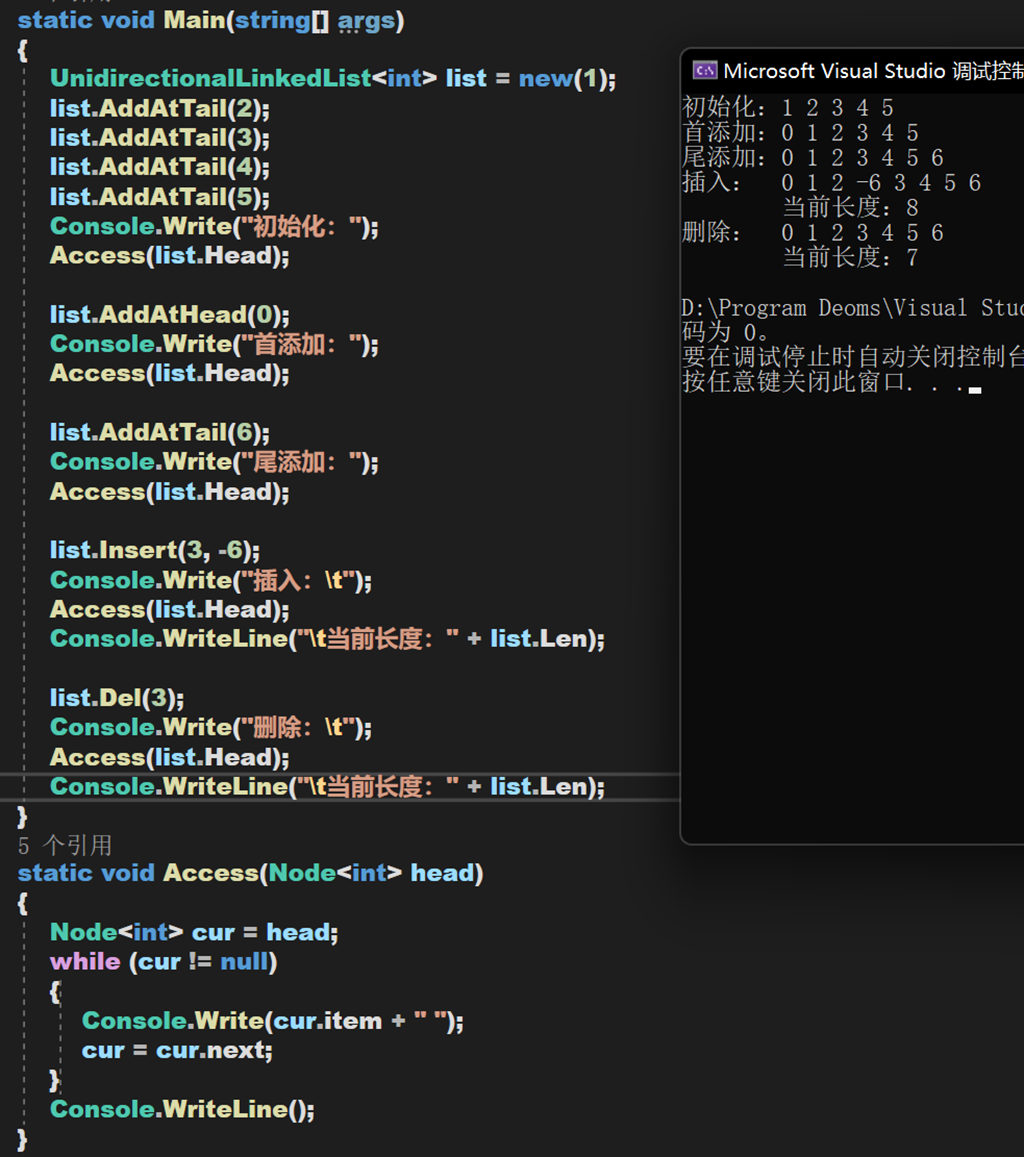
實現效果
(二) 雙向鏈表
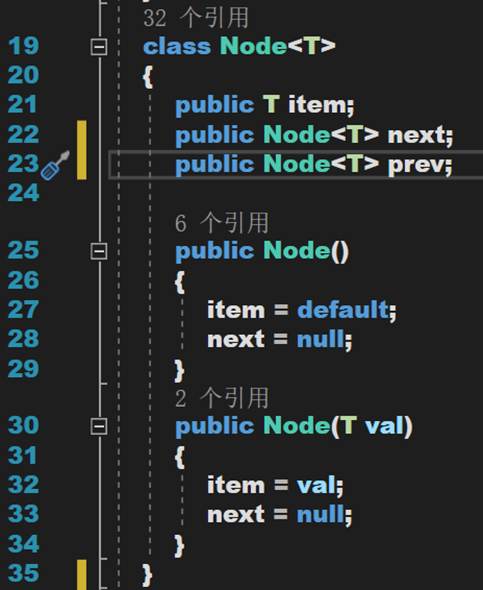
雙向鏈表在單向的基礎上增加了指向前的指針
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
「鏈「的構造方法及相關欄位和屬性不變,只是在方法的實現時,需要增加對 prev 的賦值
1. 首尾添加
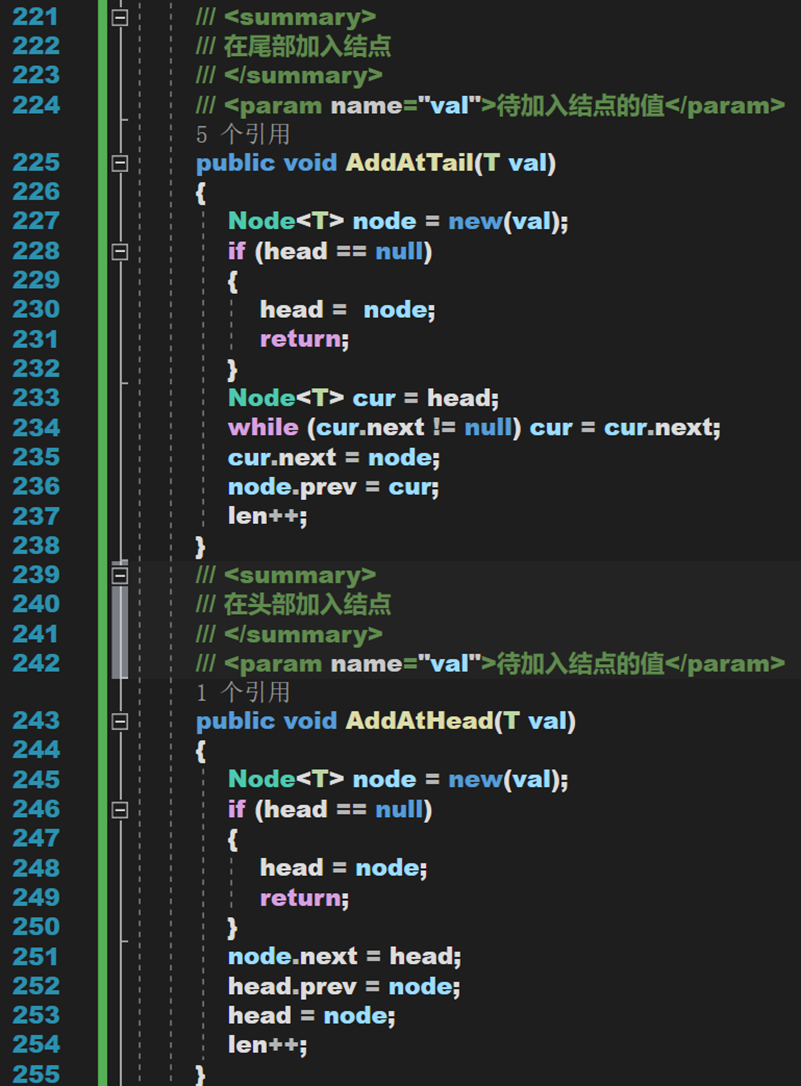
- Line 168、185:注意,應當先對原 head 的 prev 指針賦值,再修改 head 的指向。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
2. 插入

一般地,先修改新結點的資訊,再修改原結點的資訊。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
3. 刪除
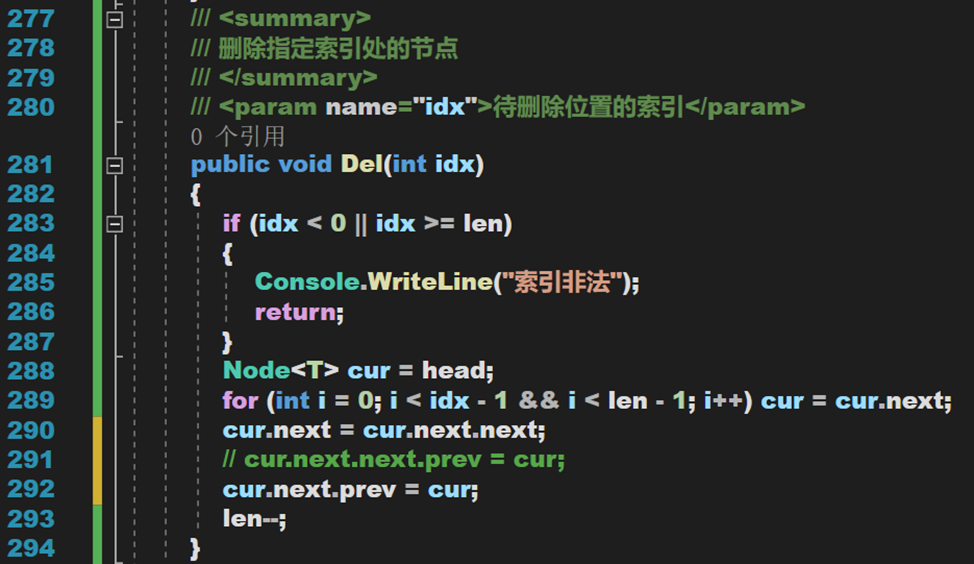
- Line 292:此處已經更新了 cur.next 的指向,所以並不是 Line 291 的語句。
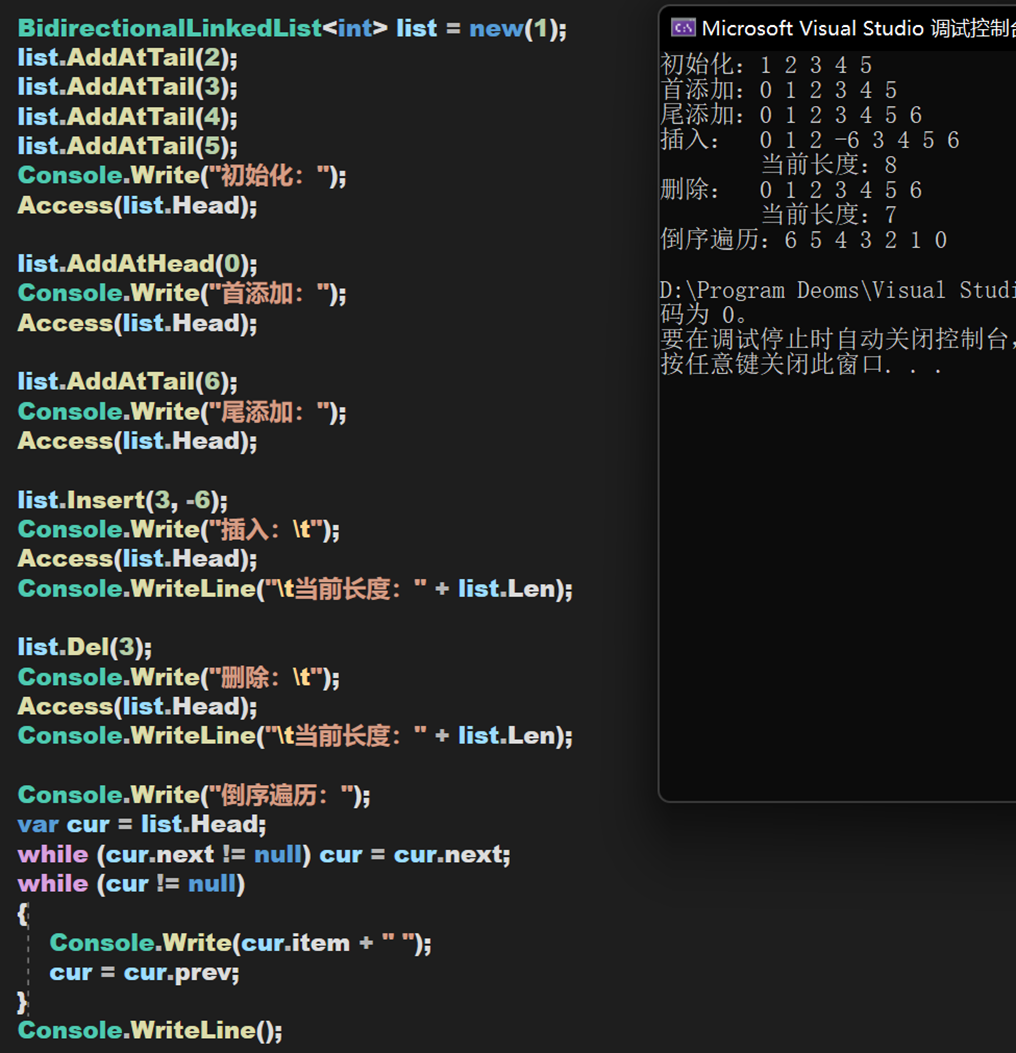
實現效果
(三) 循環鏈表
循環,就是把尾部結點的 next 指針繼續指向下,指向 head。大同小異,本節內容在此不作演示,詳細請參閱:(理論基礎 —— 線性表 —— 循環鏈表 – 老程式設計師111 – 部落格園 (cnblogs.com))
總結一
1. 對比一下數組、集合與鏈表
(1) 對於數組:
- 長度固定,初始化後長度不可變。
- 在記憶體中的存儲單元是連續分配的。
- 可存儲基本數據類型、引用數據類型。
- 每個數組只能存儲類型相同的元素。
- 可通過下標與迭代器訪問。
(2) 對於集合:
- 長度(容量)可變,一般初始容量為 4,滿後在現有容量基礎上 *2 作為新的容量。
- 在記憶體中的存儲單元是隨機分配的,可能連續也可能分散。
- 可存儲基本數據類型、引用數據類型。
- 對於同一個 ArrayList 可以存儲不同類型的數據;對於泛型集合,每個只能存儲類型相同的數據。
- 可通過下標與迭代器訪問。
(3) 對於鏈表:
- 長度可變,隨結點數量變化而變化。
- 在記憶體中的存儲單元是隨機分配的,可能連續也可能分散。
- 結點可存儲基本數據類型、引用數據類型。
- 每個鏈表只能存儲類型相同的元素。
- 不可通過下標或迭代器訪問,只能遍歷訪問。
2. 三者的優缺點
(1) 數組:
- 優點:可在 O( 1 ) 時間複雜度內完成查找。
- 缺點:不能擴容;對於元素的插入與刪除需 O( n ) 才能完成。其中,插入的這個動作為 O( 1 ),移動元素的動作為 O( n )。
(2) 集合:
- 優點:長度可變;記憶體易分配;可在O( 1 )內完成查找。(一般地,集合底層結構為數組或鏈表)
- 缺點:因為底層與數組、鏈表相同,因此對於插入與刪除較慢。
(3) 鏈表:
- 優點:可以任意加減元素,在添加或者刪除元素時只需要改變前後兩個元素結點的指針域指向地址即可,所以添加、刪除很快, O( 1 );
- 缺點:因為含有大量的指針域,佔用空間較大;不支援下標與迭代器訪問,因此查找元素需要遍歷,非常耗時。
二、C# 中的鏈表 LinkedList<T>
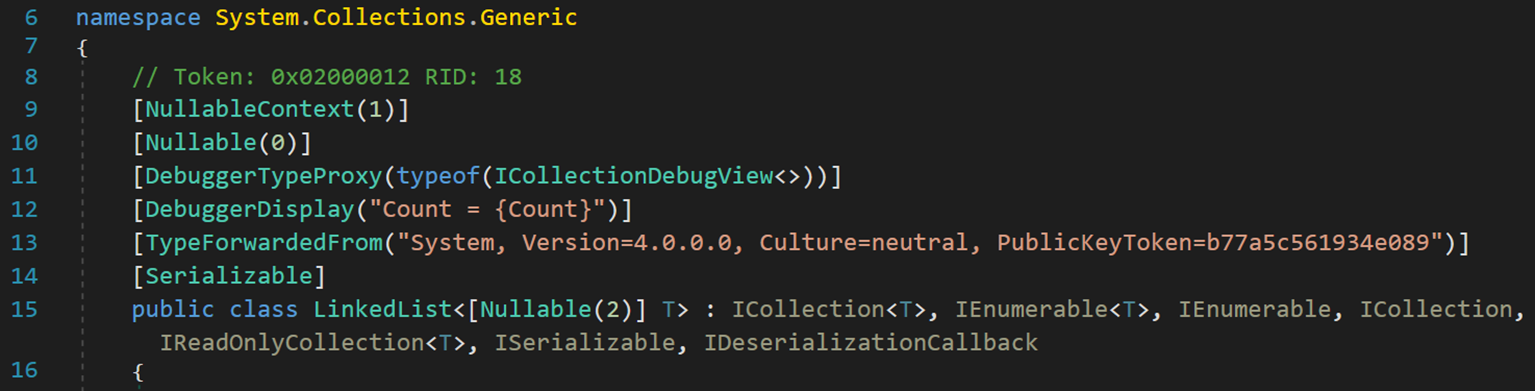
C# 中的LinkedList 為雙向鏈表(雙重鏈接鏈表),位於程式集 System.Collections.dll中的命名空間 System.Collections.Generic 之下。
簡單解釋一下其擁有的特性:【註:特性基本介紹請參閱本人的文章([演算法2-數組與字元串的查找與匹配] (.NET源碼學習) – PaperHammer – 部落格園 (cnblogs.com))】
- Line 9:NullableContext() 表示可空的上下文。括弧中的值對應的功能如下圖:

這裡解釋一下「上下文」:
上下文並不是一個具體的東西,就和閱讀小說一樣,需要結合前後進行理解。
在計組中也出現過上下文的概念,CPU 在用戶態與內核態相互切換時,需要保留當前任務的上下文資訊,並掛起該任務,直到優先順序更高的任務結束後,再根據上下文資訊,繼續原任務。這裡的上下文資訊相當於對某個進程當前的狀態描述。
根據這樣的方式,那麼此處對於LinkedList 的該特性可以解釋為對其當前狀態描述的可空性。
- Line 10:Nullable() 表示存儲的元素是否可空。其中,0表示可空可不空;1 表示不為空;2表示可為空。
【註:有關特性 Nullable 的詳細介紹會在文末進行補充說明】
- Line 11:DebuggerTypeProxy() 用於指定代理類型的顯示。其會對被修飾的對象指定某個類型的代理或替身,並更改類型在調試器窗口中的顯示方式。查看具有代理的變數時,代理將代替「顯示」中的原始類型。 調試器變數窗口僅顯示代理類型的公共成員。不會顯示私有成員。這裡的 typeof(ICollectionDebugView<>) 就是 LinkedList 的代理類型。
說人話就是,在調試過程中,若要查看變數內部的元素,則會顯示代理類型的相關成員,不會顯示原本類型的相關成員。其主要作用是,在調試時得到最希望最關心的資訊。
【更多有關該特性的內容會在今後專門發文詳解】
- Line 12:DebuggerDisplay() 可以幫助我們直接在局部變數窗格或者滑鼠划過的時候就看到對象中我們最希望了解的資訊。
- Line 13:TypeForwardedFrom() 獲取被修飾對象的來源。
- Line 14:Serializable 可序列化標誌。
解釋一下「序列化」:
有時為了使用介質轉移對象,並且把對象的狀態保持下來,就需要把對象所有資訊保存下來,這個過程就叫做序列化。通俗點,就是把人的魂(對象)收伏成一個石子(可傳輸的介質)。各種序列化類各自有各自的做法,這些序列化類只是讀取這個標籤,之後就按照自己的方式去序列化。
【註:下一篇會對序列化與反序列化進行補充說明】
(一) 三個構造方法
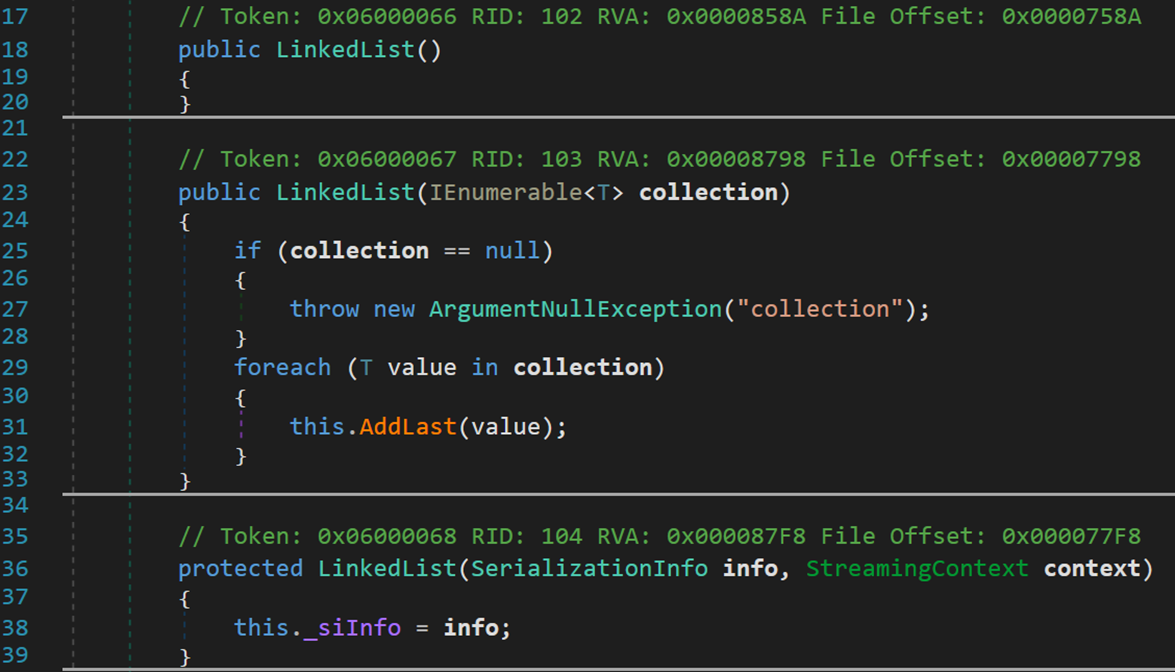
- Line 18:無參默認構造函數。
- Line 23:以非空集合進行初始化的構造函數,利用范型臨時變數迭代器,自動以集合中的元素生成鏈表。
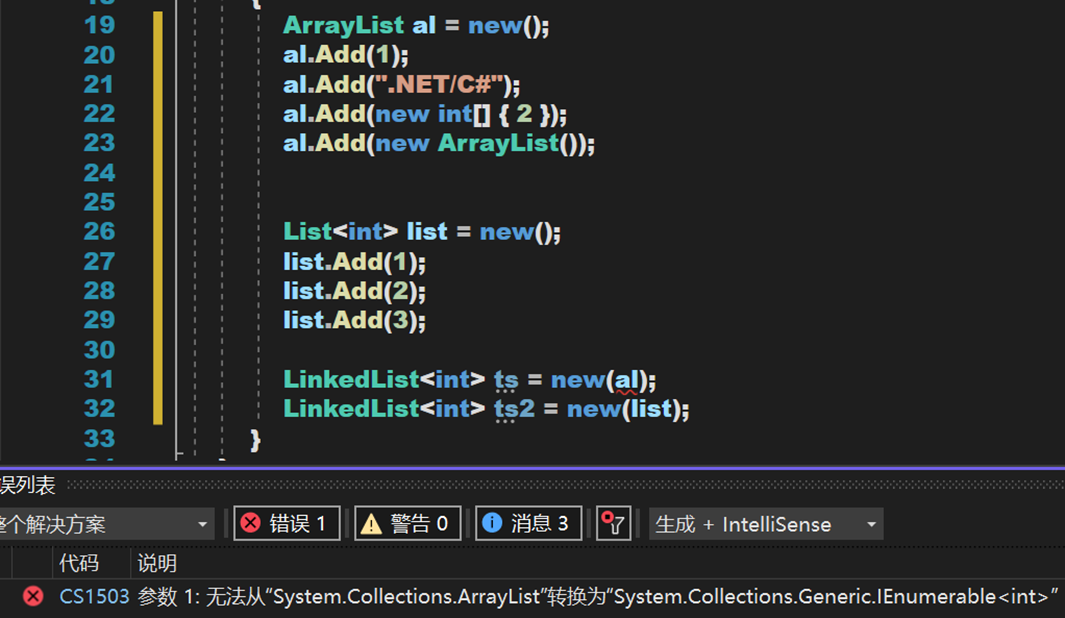
![]()
注意,由於 ArrayList 內部存儲的元素並不是同一個類型,因此其並未繼承泛型介面 IEnumerable<T>,其只繼承了普通介面 IEnumerable,因此不能將其通過構造函數直接轉化為鏈表。
- Line 36:傳入了一個對象進行序列化或反序列化所需的全部數據,將這些數據賦值給欄位 _siInfo。contest 表示該對象的數據流的資訊,作用是說明給定序列化流的源和目標,並提供另一個調用方定義的上下文。
(二) 六個屬性
1. Count
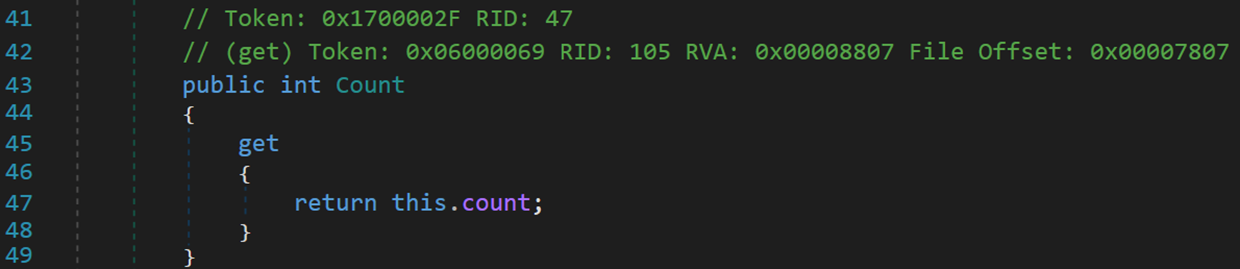
只讀屬性,返回鏈表長度。
2. First
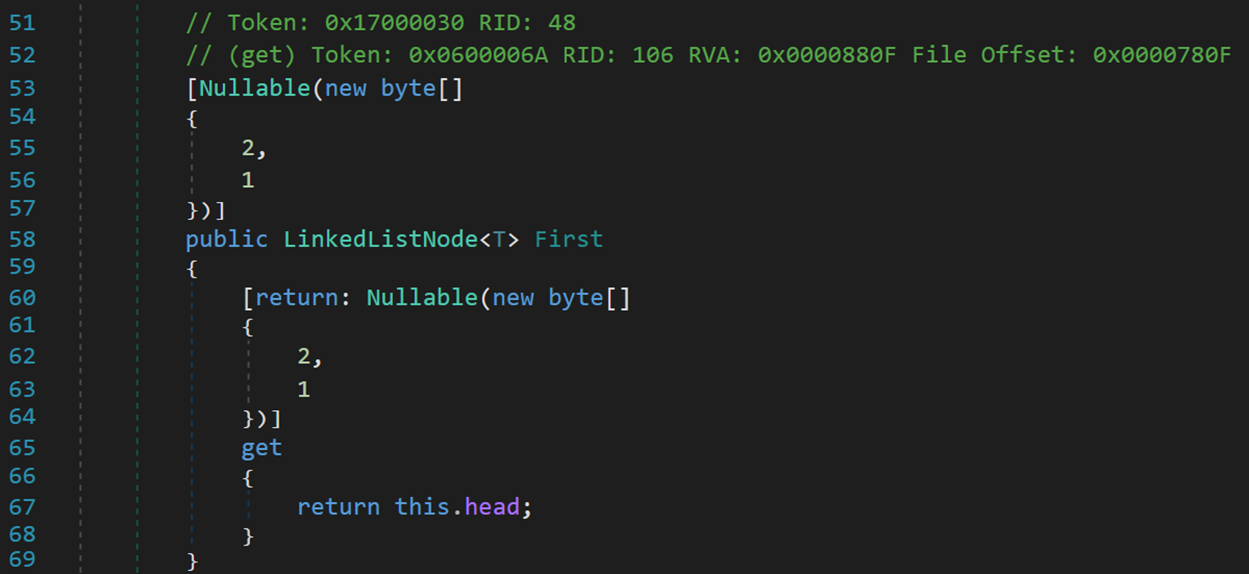
只讀屬性,返回鏈表頭結點,若不存在則根據特性 Nullable 返回空。每個數字對應修飾的對象,此處 2表示可為空,對應 Linkedlist;1表示不能為空,對應 <T>。
一般地,被 Nullable 修飾的變數可以為空。以 Nullable 作為特性,可以修飾方法、屬性等,拓寬了數據可為空的範圍。
3. Last

只讀屬性,返回鏈表尾結點。因為LinkedList 默認是雙向鏈表,因此 tail == head.prev。
4. IsReadOnly、IsSynchronized與SyncRoot
註:這三個屬性為非公共屬性,只限於類自己內部調用。
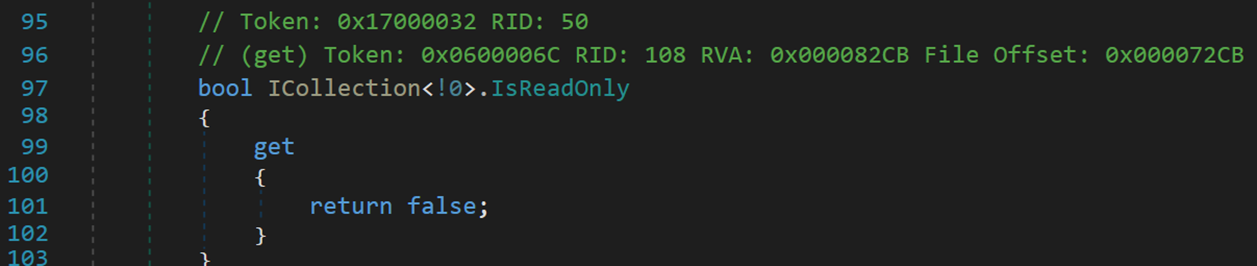

只讀屬性,分別表示 LinkedList 的非只讀、對堆棧的訪問不同步 (執行緒安全)、獲取可用於同步對 ICollection 的訪問的對象。其中,符號<!0>可能表示非 NULL
這三個屬性在此處似乎只有定義,並沒有在其他地方調用,推測其作用是作為該對象的一種標識屬性,在進行某些操作時,供 CLR 檢測訪問是否允許執行該操作。
【註:礙於篇幅,後兩個屬性將在之後的文章進行補充說明】
(三) 五個欄位
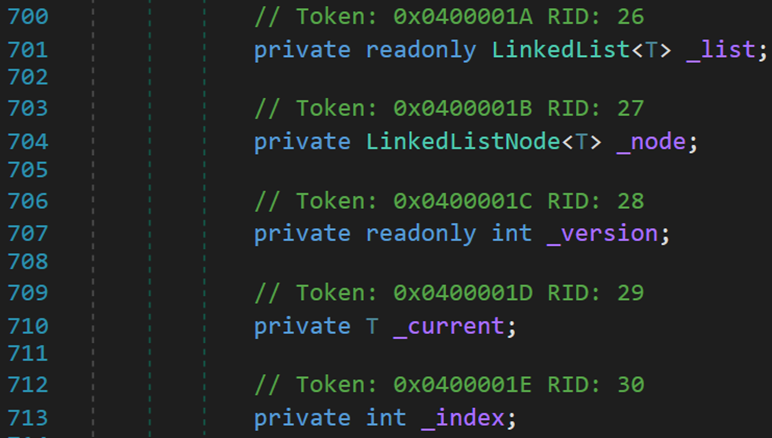
- Line 701:_list 表示當前的鏈表對象,僅用於內部訪問。
- Line 704:_node 表示鏈表中的每個結點。其內部包含:結點所在的鏈表、該結點的下一個結點與上一個結點、當前結點存儲的值。
- Line 707:_version 執行修改操作的次數。
- Line 710:_current 用於在枚舉器中,記錄當前所在的結點。
- Line 713:_index 用於在枚舉器中,記錄當前結點所對應的索引值。
(四) 一個結構 -> 迭代器 or 枚舉器
1. 結構體的構造方法

初始化內部欄位,為之後的迭代器遍歷與結點做準備。
2. 兩個屬性

- Line 625:Current屬性,返回當前所指向的結點。
- Line 637:IEnumerator.Current屬性,迭代過訪問程中,若存在還未訪問到的元素,則返回當前迭代器所指向的對象。
3. MoveNext()方法
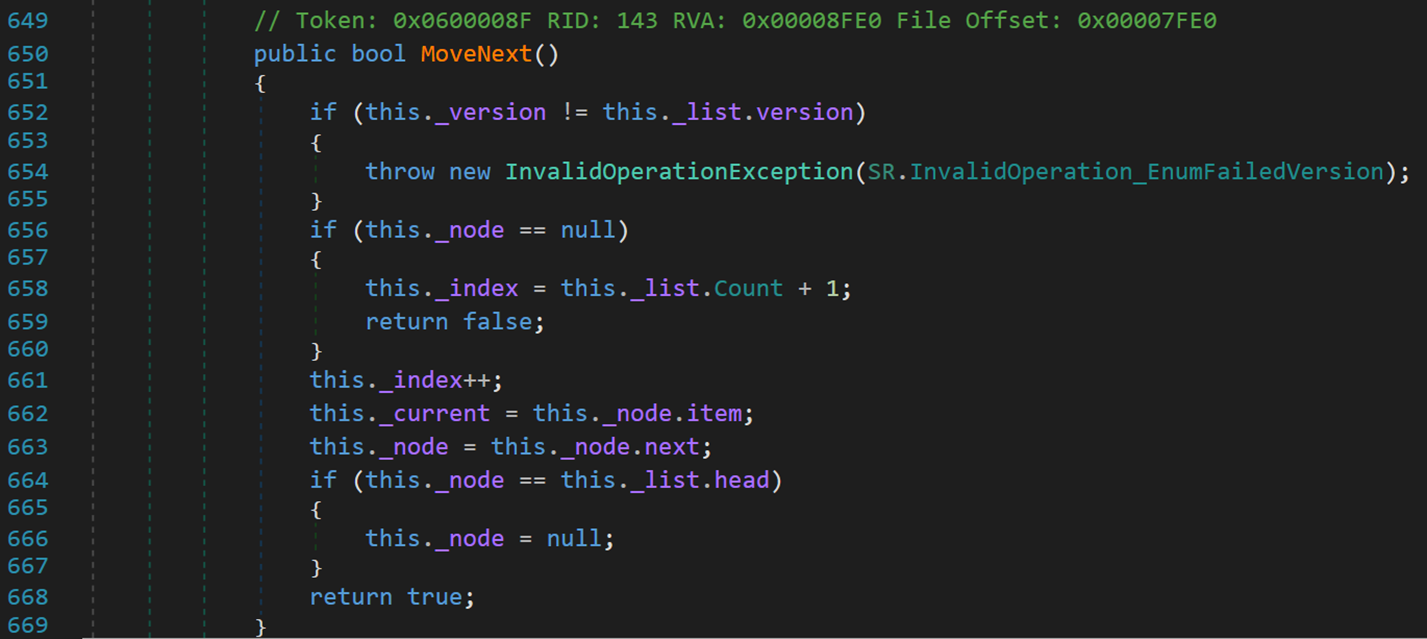
將指向當前結點對象的引用,向後移動到下一個結點。配合迭代器訪問,逐一向後遍曆元素。
- Line 652:若兩個 version 不相同,無法執行操作。在文章([數據結構1.2-線性表] 動態數組ArrayList(.NET源碼學習) – PaperHammer – 部落格園 (cnblogs.com))中,簡要分析了 version 在ArrayList 中的作用,在執行某些操作後,會使版本號+1。主要是一些會修改集合內部元素的操作。因此 version 可以是做是一個集合的標識符。
在枚舉器的構造方法里,已將 _list.version 賦值給 version,理論上每次進行枚舉迭代均會更新 version。因此該判斷語句的目的可能是防止經過淺層拷貝的兩個集合,在職u型某些操作後,調用另一個不屬於自身的迭代器。
【有關淺層拷貝請參閱([數據結構1.1-線性表] 數組 (.NET源碼學習) – PaperHammer – 部落格園 (cnblogs.com))】
- Line 656:若 node 為 null,說明沒有元素可以繼續向下訪問,則返回 false。
- Line 661~663:index 指針向後移動;_current 記錄當前結點;訪問下一個結點。
- Line 664:若再次訪問到頭結點,則終止。
4. Reset()方法
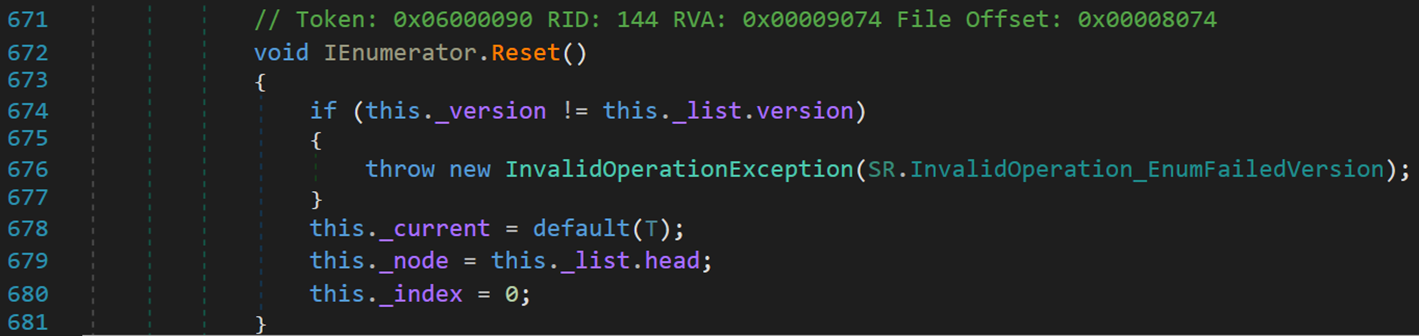
在每次調用完枚舉器後,需要恢復原有的資訊,以便下一次繼續調用。可以理解為回溯。
【註:有關迭代器的實現原理,會在文末進行補充說明】
(五) 常用方法
1. 添加 AddFirst()、AddLast() 與 AddBefore()、AddAtfer()
首先是方法 AddFirst()。其有兩個重載方法,不同之處體現在返回值類型與參數。
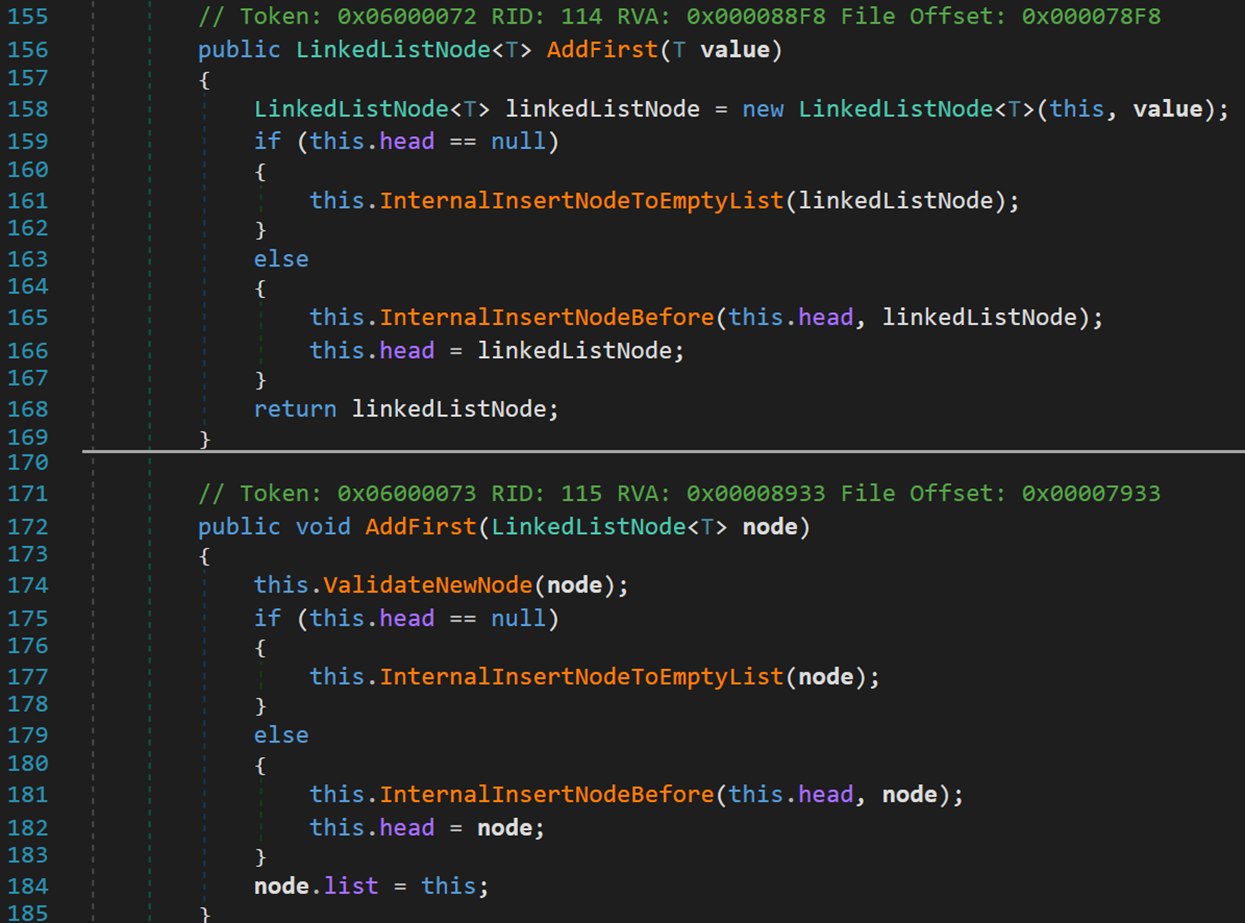
- Line 156:返回類型為某一結點,參數為某一值。
- Line 161:若頭結點為空,說明當前鏈表內沒有結點,則調用方法InternalInsertNodeToEmptyList()。
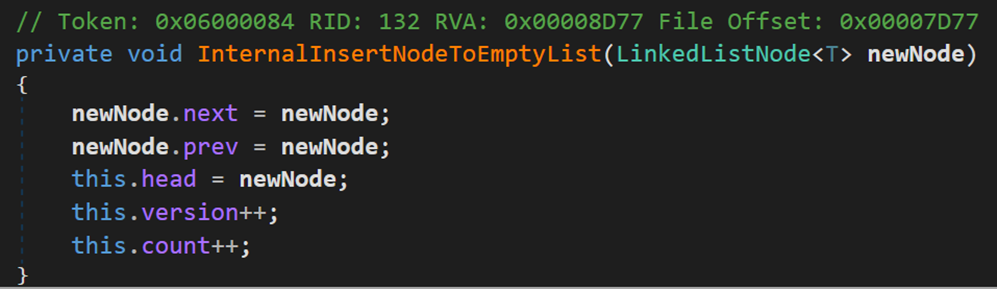
該方法的作用是:在空表中創建一個結點,其既是頭結點,也是尾結點。
- Line 165:若頭結點不為空,說明此時表中已經存在節點,則調用方法InternalInsertNodeBefore(),將新結點加入到當前頭結點之前,成為新的頭結點。
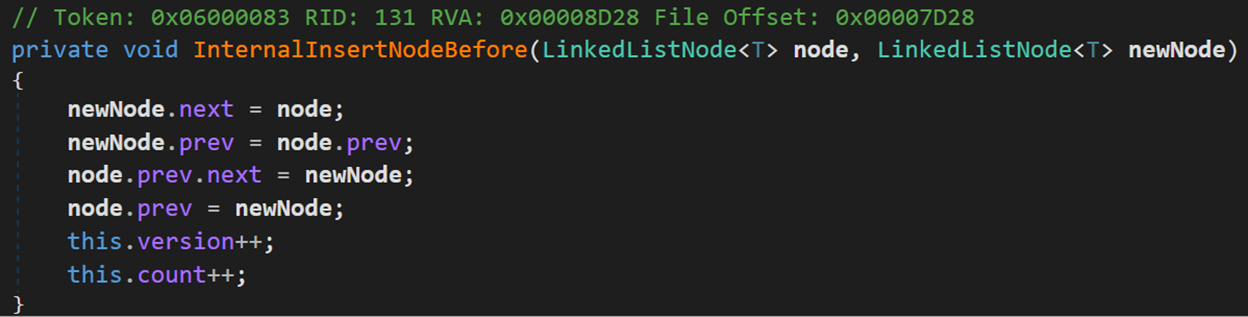
- Line 168、184:最終的返回結果/指向是頭結點。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
方法 AddLast() 與 AddFirst() 大同小異,在此不做過多分析
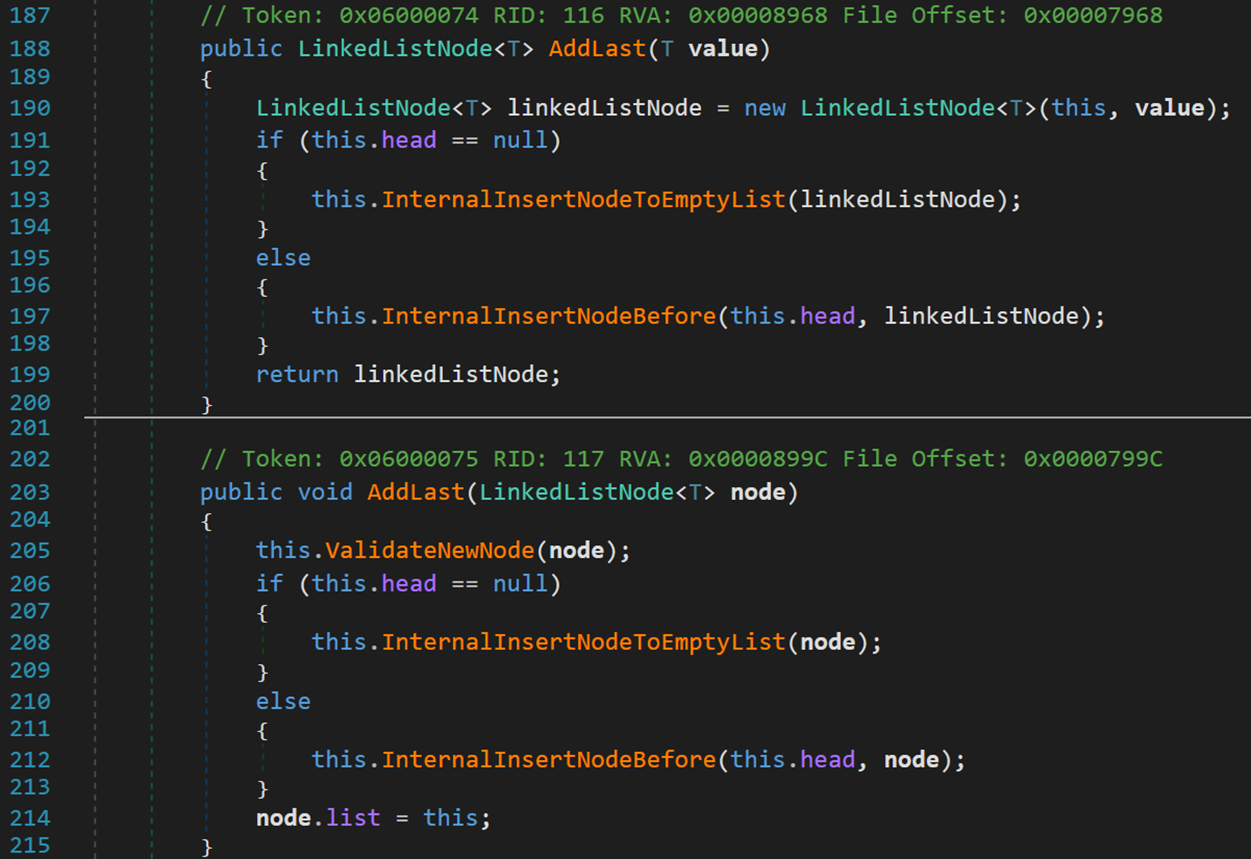
- Line 199、214:執行完畢後,返回/指向的結點是尾結點。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
接下來是方法 AddBefore(),其和前兩個方法一樣,均有兩個重載方法,主要是返回類型與參數不同。
(1) 對於無返回值、待添加元素為鏈表(結點)的方法

- Line 121:node 為目標結點,在其之後進行添加;newNode 為新結點。
- Line 123、124:方法 ValidateNode() 與 ValidateNewNode() 用於判斷 node 的合法性

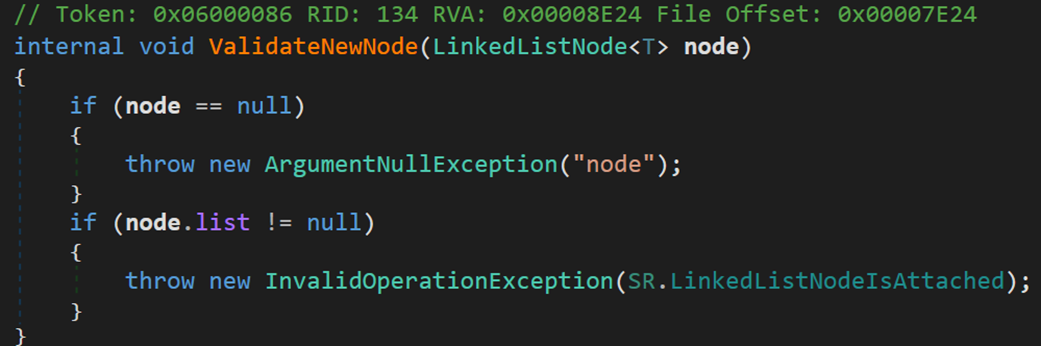
是否為空;是否為該鏈表的成員(目的可能是防止多執行緒同步訪問出現的錯誤調用)
- Line 125:方法 InternalInsertNodeBefore() 實現添加操作。
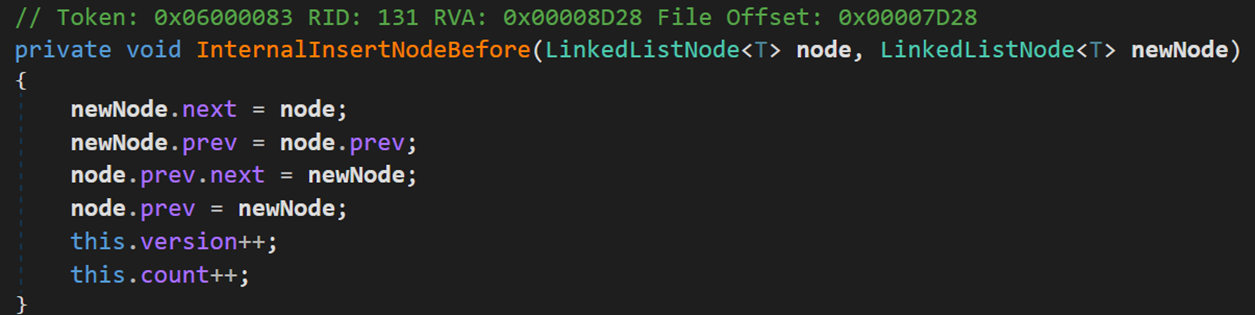
就是普通的雙向鏈表的插入。
(2) 對於返回類型為 LinkedList<T>,添加元素為某個值的方法
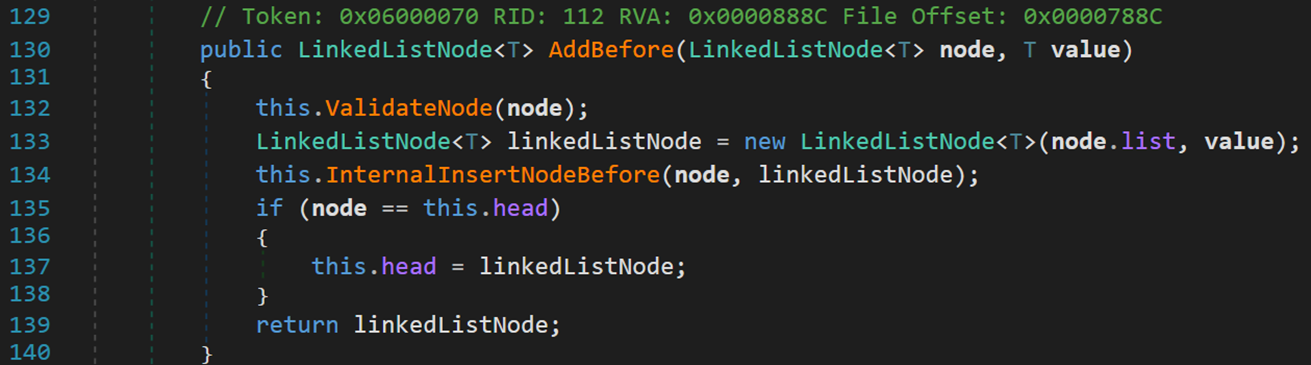
- Line 132~134:判斷 node 合法性;初始化一個以 node 為首,node 值為 value的新鏈表;將新鏈表連接到 node 之前。
- Line 137:當 node 為頭結點時,添加後需要更新頭結點。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
方法 AddAfter() 大同小異,不做過多分析
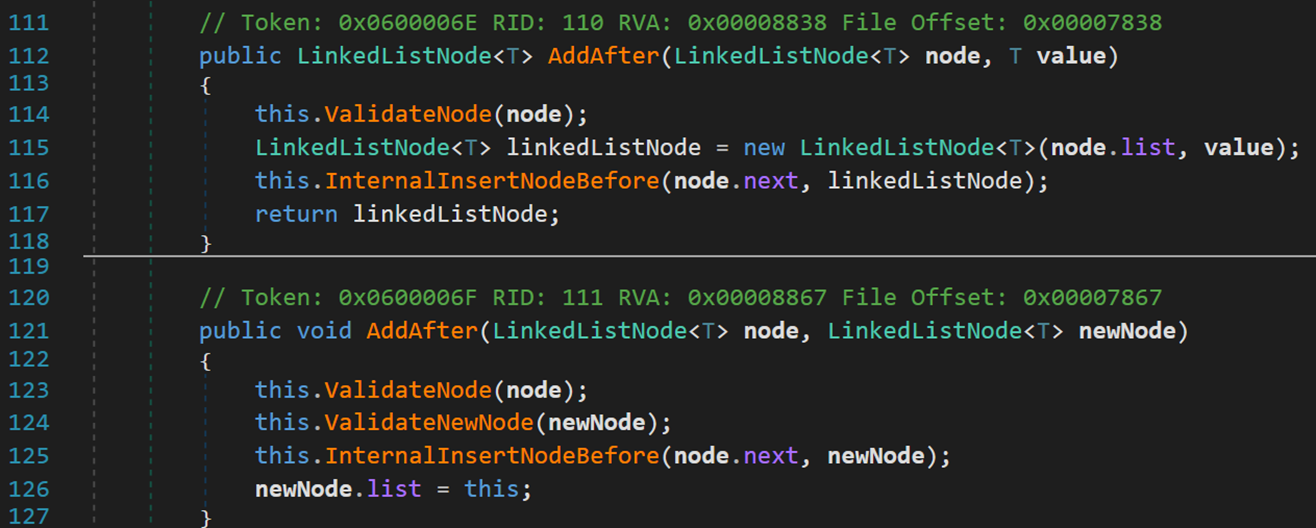
2. 包含 Contains() [ Find() 方法]

方法套方法,Find 可以用來查找元素,其在其他的方法(如:Remove())中也可以使用,為了減少冗餘,因此此處直接復用了方法 Find() 來實現。
復用的思想在競賽、開發中十分常用,既能有效減少工程量,還能提高程式碼可讀性。
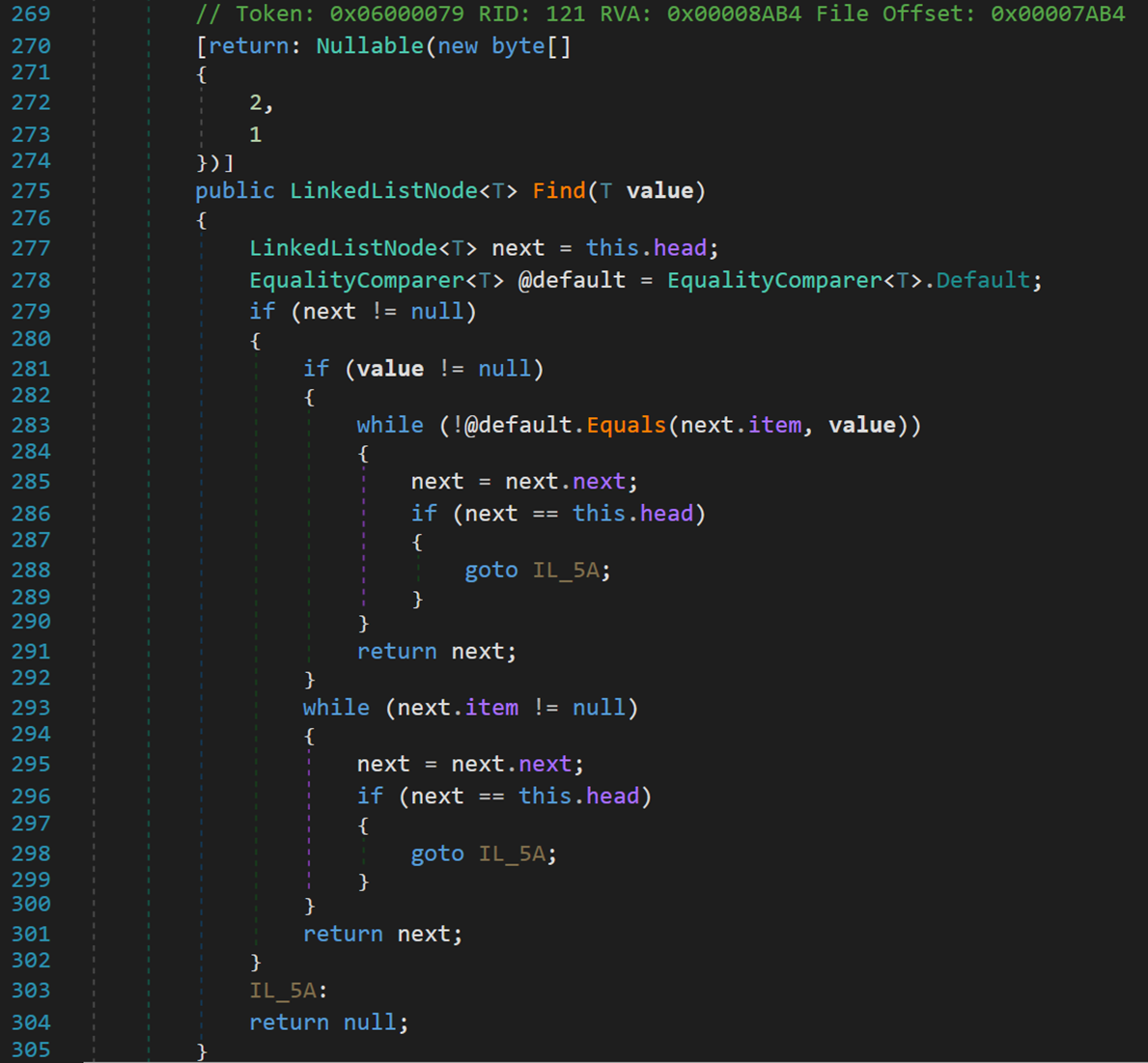
- Line 270:Nullable 特性,其中 LinkedList 可為空;<T> 不可為空。
- Line 277:next 表示當前即將訪問的元素,從 head 開始。
- Line 278:定義了一個默認比較方式的變數,用於之後調用比較方法。EqualityCompare<T> 類型,一個抽象類,內部提供了一個 Equals() 方法,進行對象間的比較。
【思考:為什麼需要定義該類型的變數,調用該類中的比較方法,而不直接用判斷運算符 「==」 或 Object.Equals() 方法?文末進行解釋】
- Line 279:若 next 為空,即 head 為空,說明沒有元素在鏈表中,則直接返回值為空的 next( Line: 304 )。
- Line 281:若要查找的對象值為空,則不進行比較操作,直接判斷是否存在空元素。
- Line 283:若當前結點值 item != value 則向後訪問下一個結點,繼續比較,直到找到符合的結點或再次訪問到頭結點。
- Line 288、298:若沒有找到符合的結點,則直接轉調並返回 null。
3. 查找 FindLast()
從方法名來看,其作用是找到值 value 在鏈表中出現的最後一次所對應的結點。

相比方法 Find(),只是將 next 換成了 prev,其他地方大同小異,主要來分析一下這個 prev 的作用。
當 linkedListNode == prev 時,說明已經遍歷完了一遍,此時還未找到目標元素,返回 null。
4. 刪除 Remove()
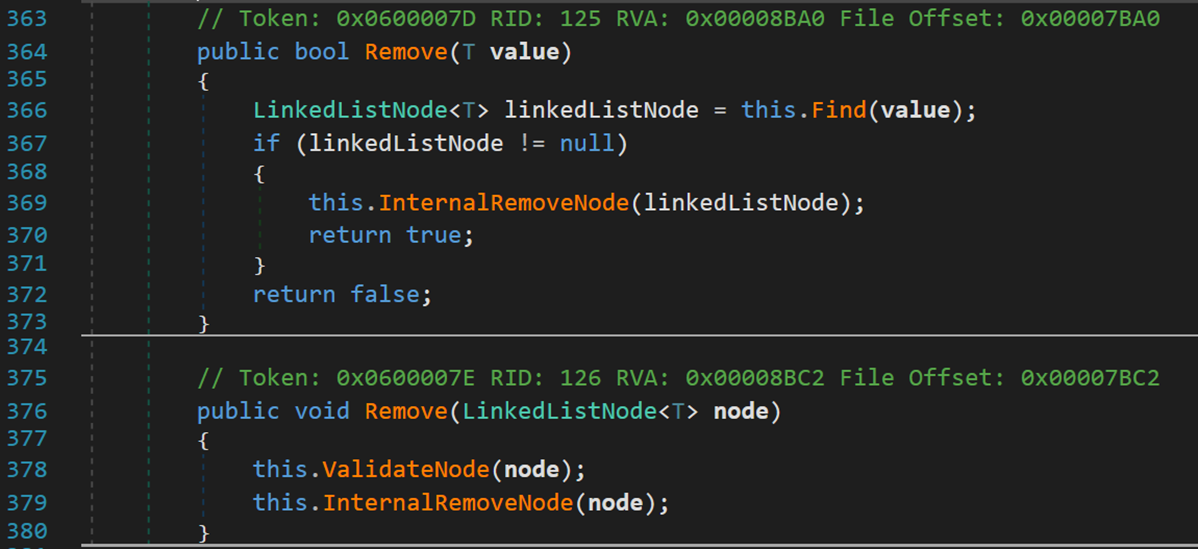
其基本思路說判斷合法性,然後執行操作。其中 ValidateNode 在之前提到過,用於判斷結點合法性。
下面看一下方法 InternalRemoveNode()

和添加方法中的那個 InternalInsert…() 基本一致,改變結點的指向即可,記得最後要修改結點數量。
(六) 結點類 LinkedListNode<T>
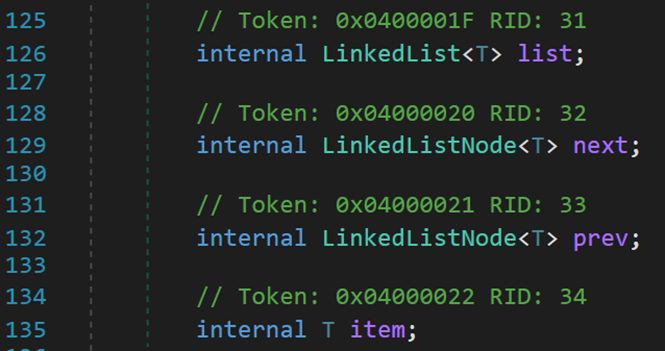
包含四個欄位:list 結點所在的鏈表;next 結點的下一個節點;prev 結點的上一個結點;item 結點內部存儲的元素。
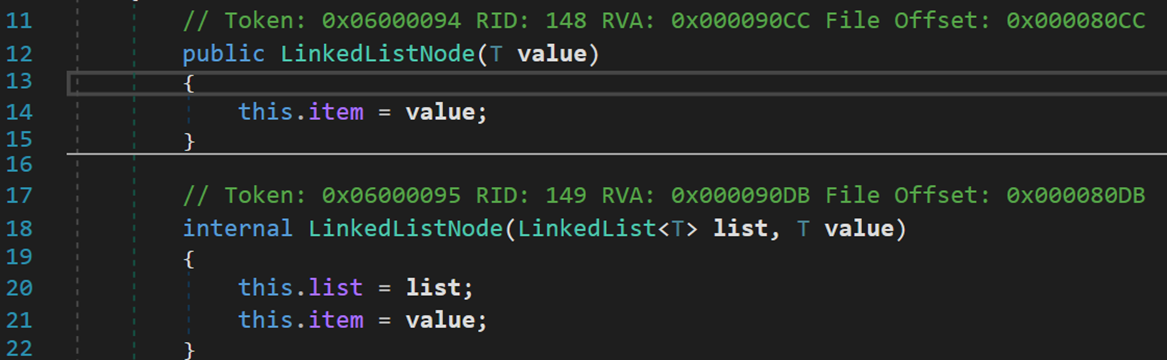
兩種初始化的方式,沒有默認構造器。也就是說,在定義節點時必須對其賦值(默認為 null)。但鏈表 LinkedList 是有默認構造器的。
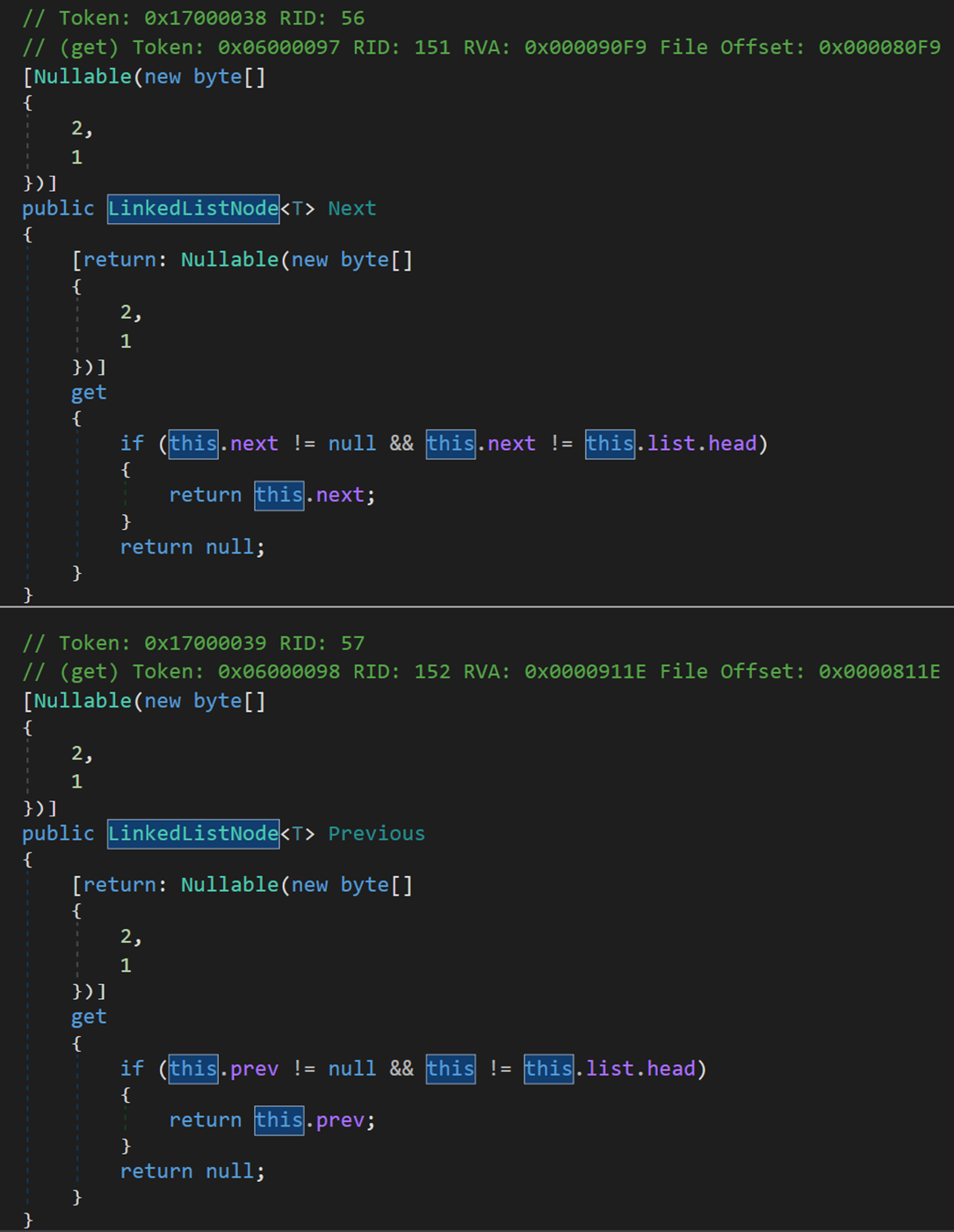
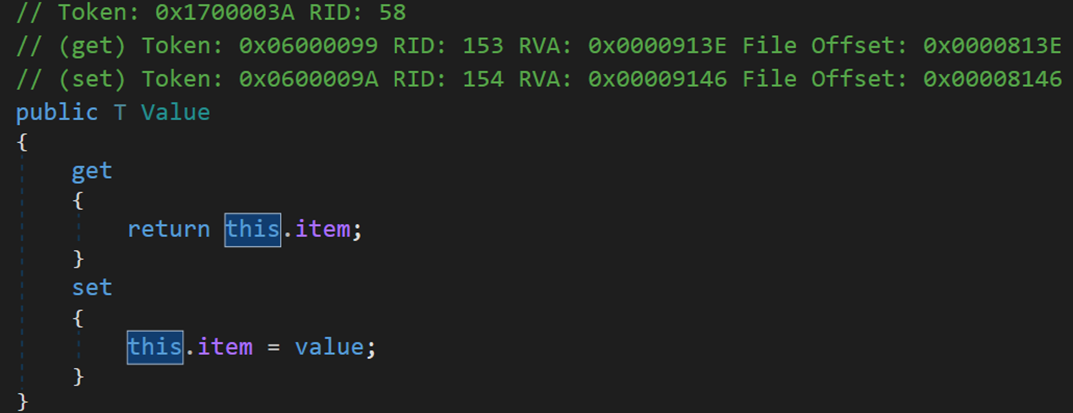
對結點包括以下三種查詢操作(Next、Previous、Value):
三、C# 與 Java 中的鏈表結構
單個數據結構其實沒有太多要講的內容,既然 C# 與 Java 是兩大較為著名的 OO 語言,那在此就對比一下二者在實現鏈表結構時的異同。
(一) 結點類 Node<E>
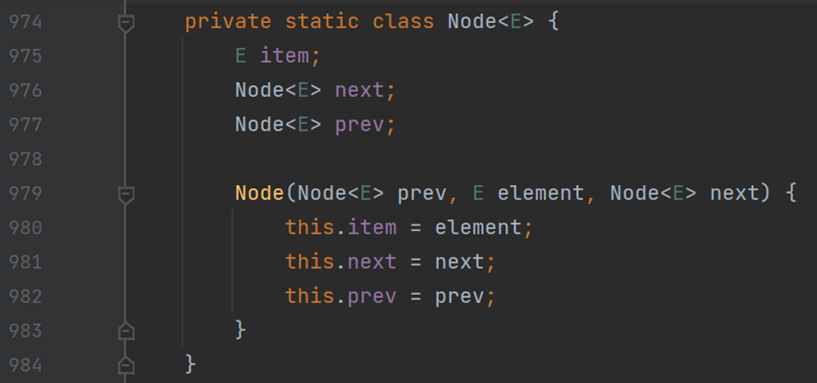
可以知道,Java 中的鏈表結構也是雙向鏈表。
(二) 構造方法

Java 中的 LinkedList 有兩個構造方法。不過差別不大,只不過 C# 中的 LinekdList<T> 還多了一個可列化的元素集。
(三) 屬性
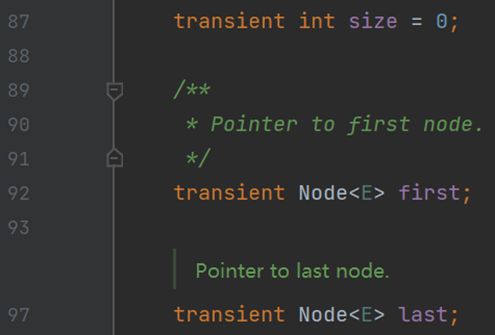
註:在 Java 中此類變數稱作屬性,沒有欄位的概念;在 C# 中此類變數稱作欄位,而屬性是針對欄位而設計的訪問器,用於增強安全性。
除去 C# LinkedList 中的三個特殊欄位,其餘與 Java LinkedList 一致。
(四) 方法:添加 add()、addFirst() 與 addLast() 方法


可以看到,C# 中的添加方法內置方法 InternalInsert…();Java 中也和 C# 類似,均調用其他來實現。鑒於相似性,下面就只展示一下方法 linkLast() 不做分析。
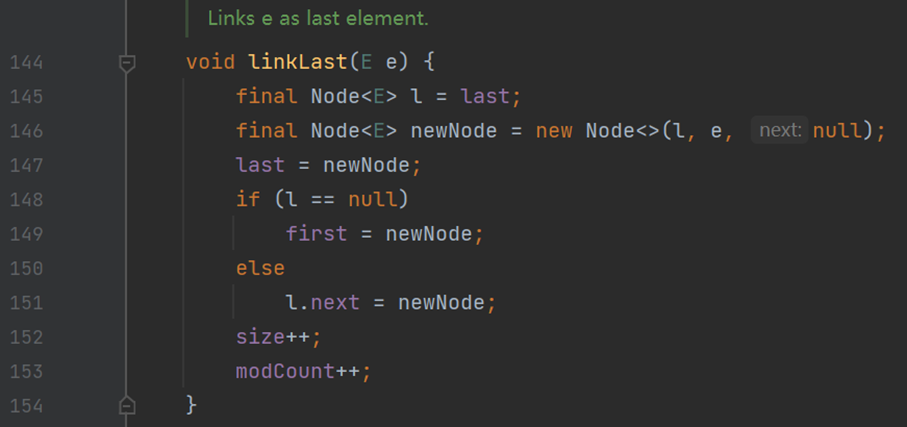
總結
區別不大。硬要說,就可能是運行時 CLR(公共語言運行庫) 於 JVM(Java 虛擬機) 優化性能的差異了。
[# 有關可空類型、Nullable<T>與特性 [Nullable] ]
一、可空類型
眾所周知,在C# 中,值類型時不可空的,引用類型是可空的:
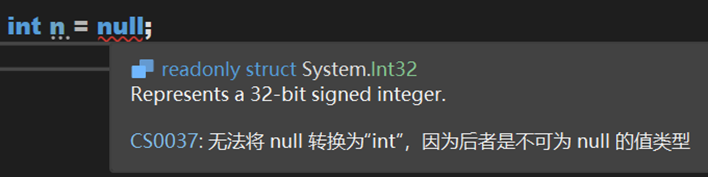
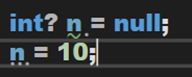
過了一段時間,大概在 C# 5 時期,引入了可空值類型,長這樣:
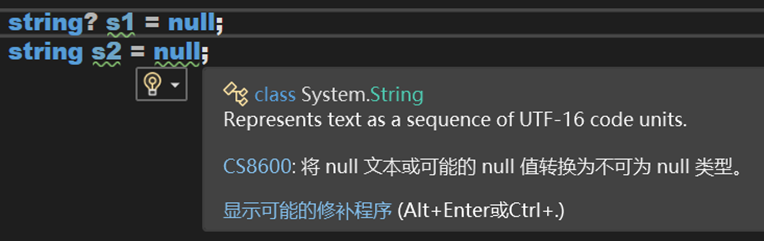
然後又又又過了一段時間,應該是在 C# 8 引入了,可空引用類型:
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
調用一下反彙編,看看加了一個問號會不會對數據類型產生影響

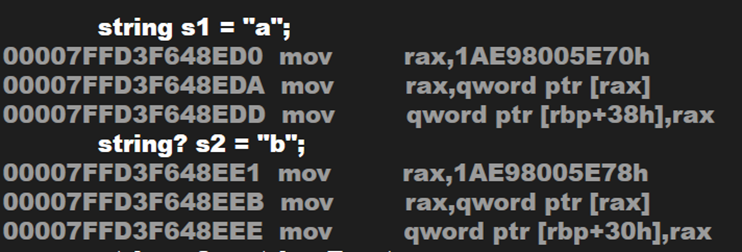
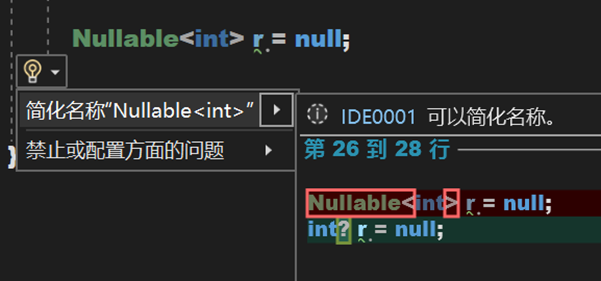
string? 依然是 string,int? 不再是 int,而是變成了 Nullable 類型,相當於:
二、為什麼要引入可空引用類型?
分析一下這個有意思的 CS8600 警告:
|
嚴重性 |
程式碼 |
說明 |
|
警告 |
CS8600 |
將 null 文本或可能的 null 值轉換為不可為 null 類型。 |
嘿!我大引用類型什麼時候變成不可為 null 類型了?根據微軟文檔的解釋:該警告的目的是將應用程式在運行時引發 System.NullReferenceException 的可能性降至最低。簡單說就是降低程式碼在運行時引發空引用異常的概率,這一做法會讓程式在運行時帶來一些效率上的提高。至於是怎麼提高的,應該是避免了異常的頻繁發生,導致程式頻繁終止。(個人觀點,僅供參考)。
三、Nullable<T> 的實現
[注意:Nullable<T> 和 Nullable 是兩個不同的概念,前一個是結構體,後一個是類;當然二者都是數據類型]
(一) 一個構造方法

- Line 14:特性 [NonVersionable]

上述文本摘自 Reference Source .NET Framework 4.8。直譯:這個特性用於表示特定成員的實現或結構布局不能以不兼容的方式在給定的平台進行更改。這允許跨模組內聯方法和數據結構,這些方法和結構的實現在ReadyToRun的本機映像中永遠不會改變,對這些成員或類型的任何更改都將破壞對ReadyToRun的更改。說人話大概就是,不允許在某些平台上亂改被其修飾的對象,以此保證在本機映像和實際使用時的一致性,避免在不同的環境下同一個內容出現不同的形式。
- Line 18:表示當前對象是否存儲了元素。
(二) 兩個只讀屬性
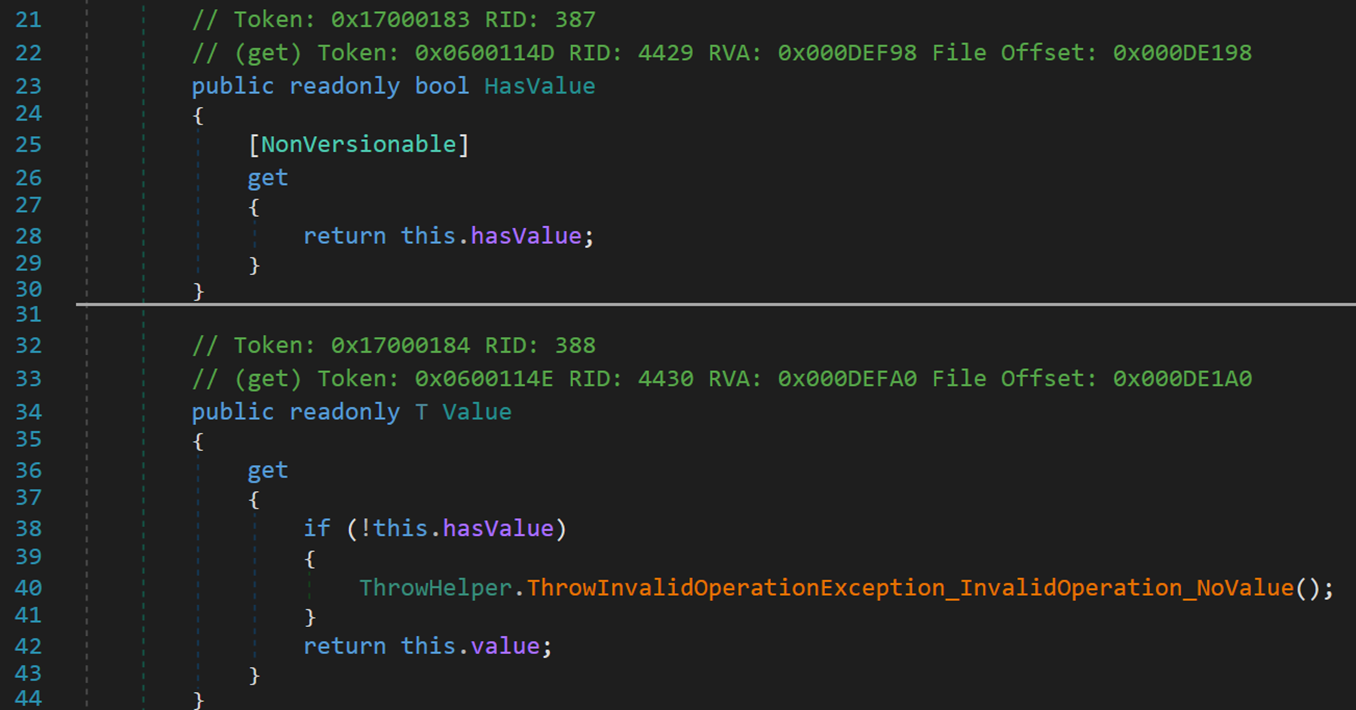
判斷是否存儲了元素以及返回存儲的元素。
(三) 兩個欄位

hasValue 用於表示當前對象是否存儲了某個值;value 表示存儲的值。
(四) 兩個重載運算符
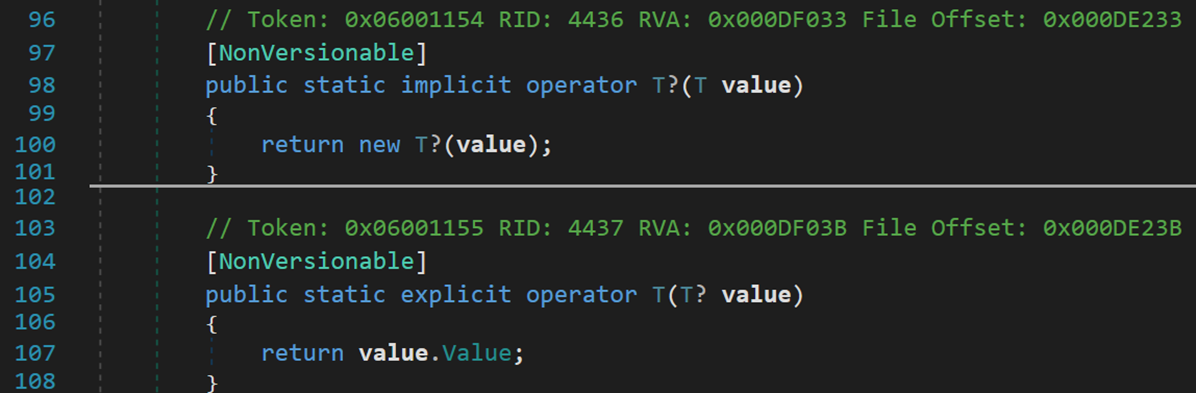
implicit 用於聲明隱式的自定義類型轉換運算符,實現2個不同類型的隱式轉換。使用隱式轉換操作符之後,在編譯時會跳過異常檢查,可能會出現某些異常或資訊丟失。
explicit 用於聲明必須通過顯示轉換來調用的自定義的類型轉換運算符。不同於隱式轉換,顯式轉換運算符必須通過轉換的方式來調用,如果缺少了顯式轉換,在編譯時會產生錯誤。
簡單來說,這兩個關鍵字用於聲明類型轉換的運算符,針對自定義類型間的轉換,一種為隱式轉換,另一種為顯示轉換。
- Line 98:將 value 從類型 T 隱式轉換為 T?
- Line 105:將 value 從類型 T? 顯示轉換為 T
(五) 常用方法
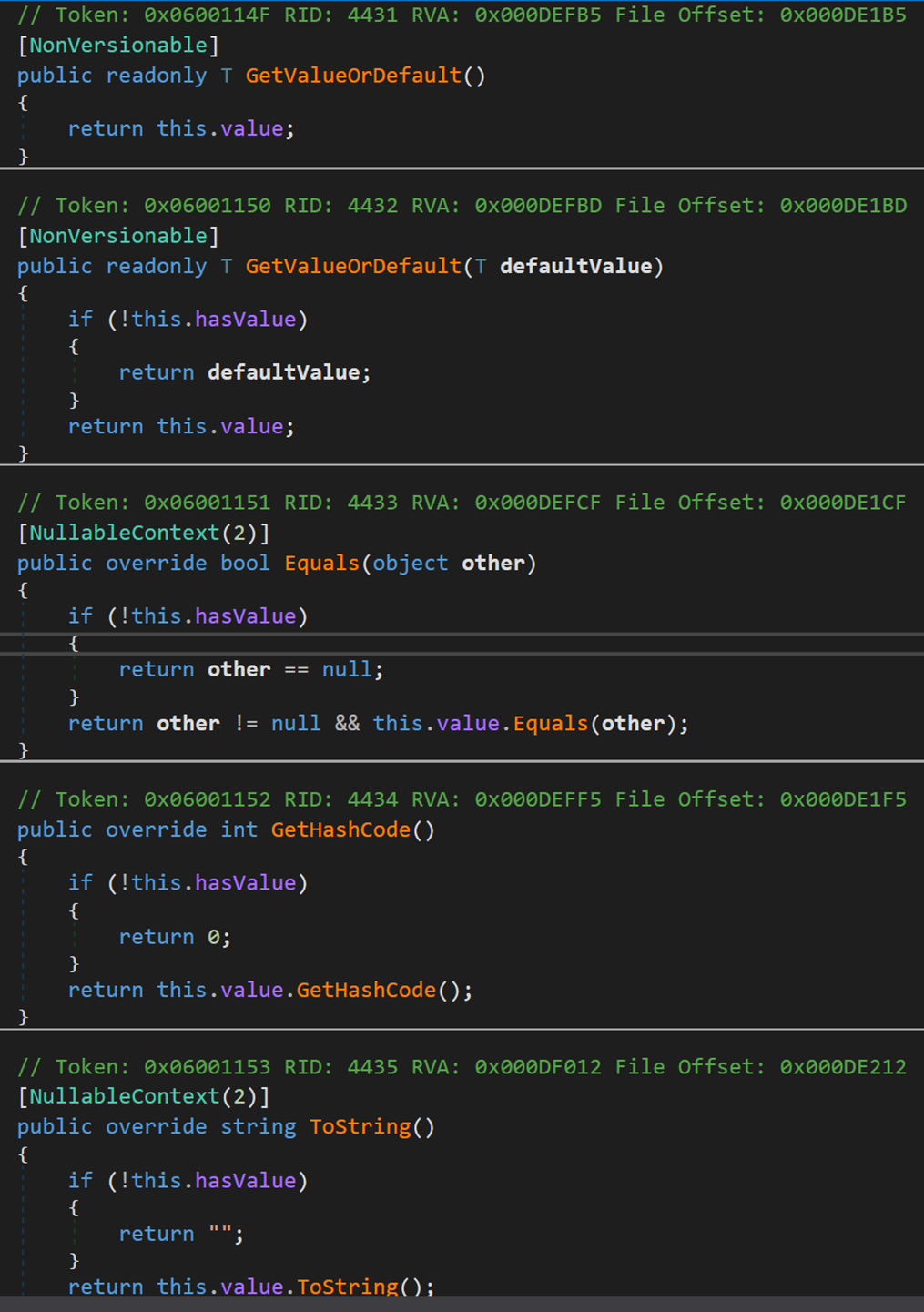
其包含的方法和其他類型中的方法大致相同,在此不作解釋。
四、(空)合併運算符 ??
單個問號在 C# 中是三元表達式的結構之一,也是定於可空類型的符號。而兩個問號被定義為合併運算符,其工作原理如下:對於表達式 <par> = <par1> ?? <par2> 如果左操作數 par1 的值不為 null,則合併運算符返回該值,即 par1;否則,它會計算右操作數並返回其結果。如果左操作數的計算結果為不為 null,則 ?? 運算符不會計算其右操作數。
僅當左操作數的計算結果為 null 時,Null 合併賦值運算符 ??= 才會將其右操作數的值賦值給其左操作數。 如果左操作數的計算結果為非 null,則 ??= 運算符不會計算其右操作數。其中 ??= 運算符的左操作數必須是變數、屬性或索引器元素。
舉例如下:
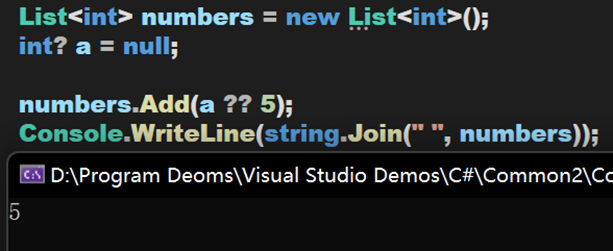
此時 a 為 null,因此返回 5
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——

此時 a 不為 null,因此返回 a 的值。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
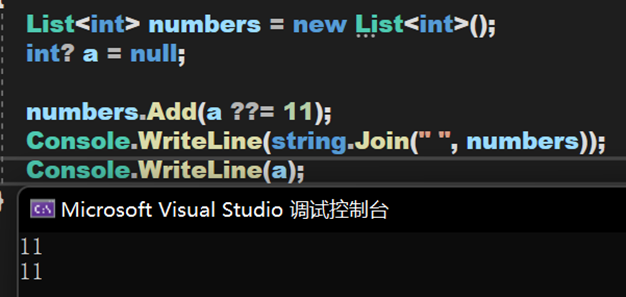

同理可得,a 為空返回11;a 不為空返回 a。
五、可空容忍 !

其實這是一個補充,在程式碼中如果我們判斷出某個變數在使用時一定不為null,但是編譯器會在可空上下文中拋出警告,這是一個不太正常的行為,可空容忍可以消除這種警告,將不可為空的引用類型轉換成可為空的引用類型。


假如我們知道 obj 和 obj.ToString() 在這裡一定不為空,那麼就可以在 obj 與 ToString() 的結果後加上可空容忍運算符,將其轉換為不可空類型,以此消除警告。
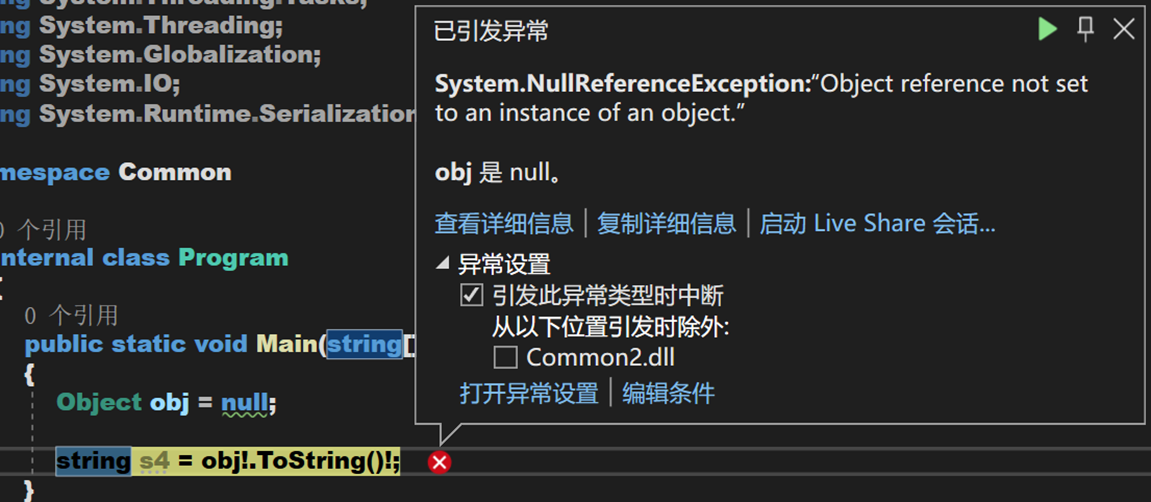
這樣操作後,obj 不可再被賦值為 null。
六、更多的可空特性
【註:
1. 特性一般用來解決警告問題,並不能解決錯誤或進行強制類型轉換。
2. 特性的修飾更多地,只起到標識告知的作用。】
需要引入命名空間

(一) AllowNull
性質:前置條件,即放在修飾對象前。
作用:將不可為 null 的參數、欄位或屬性使其可以為 null。【注意,這裡的「不可為」指的是警告內容,不是數據類型上的不可為空】
舉例:
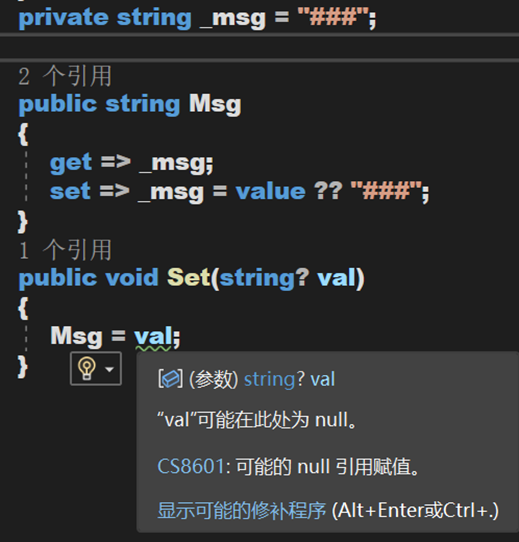
現在有一個欄位,當通過屬性獲取欄位值的時候,一定不會獲得到 null,因為在 set 裡面指定了非 null 的默認值。然而在方法 Set() 里是允許設置 null 到這個屬性,但屬性 Msg 是不可為空的。於是,為了解決警告的出現,要麼將欄位定義為可空,要麼將這個加上特性 [AllowNull]。這樣,獲取此欄位的時候會得到非 null 值,但設置的時候卻可以傳遞 null。
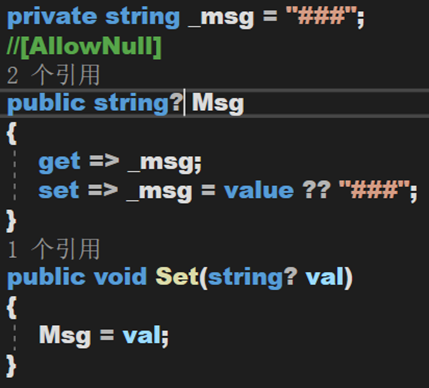

即,將不可為空的屬性 Msg 標記為可為空(可以傳入空值),但傳入空時會保持其默認值。
大多數情況下,屬性或 in、out 和 ref 參數需要此特性。 當變數通常為非 null 時,[AllowNull] 是最佳選擇,但需要允許 null 作為前提條件。
(二) 其餘可空特性
特性一般主要用於處理警告方面的問題,使得程式更加規範化,在此不作過多演示,更多內容,請參考下表(來自:C# 編譯器解釋的屬性:可為 null 的靜態分析 | Microsoft Learn)
|
Attribute |
Category |
含義 |
|
不可為 null 的參數、欄位或屬性可以為 null。 |
||
|
可為 null 的參數、欄位或屬性應永不為 null。 |
||
|
不可為 null 的參數、欄位、屬性或返回值可能為 null。 |
||
|
可為 null 的參數、欄位、屬性或返回值將永不為 null。 |
||
|
當方法返回指定的 bool 值時,不可為 null 的參數可以為 null。 |
||
|
當方法返回指定的 bool 值時,可以為 null 的參數不會為 null。 |
||
|
如果指定參數的自變數不為 null,則返回值、屬性或自變數不為 null。 |
||
|
當方法返回時,列出的成員不會為 null。 |
||
|
當方法返回指定的 bool 值時,列出的成員不會為 null。 |
||
|
方法或屬性永遠不會返回。 換句話說,它總是引發異常。 |
||
|
如果關聯的 bool 參數具有指定值,則此方法或屬性永遠不會返回。 |
七、特性 [Nullable]
特性,在之前的文章中也講述過,主要是進行修飾,使得對象具有某些額外性質。
Nullable,屬於內部密封類 NullableAttribute,派生自類 Attribute。
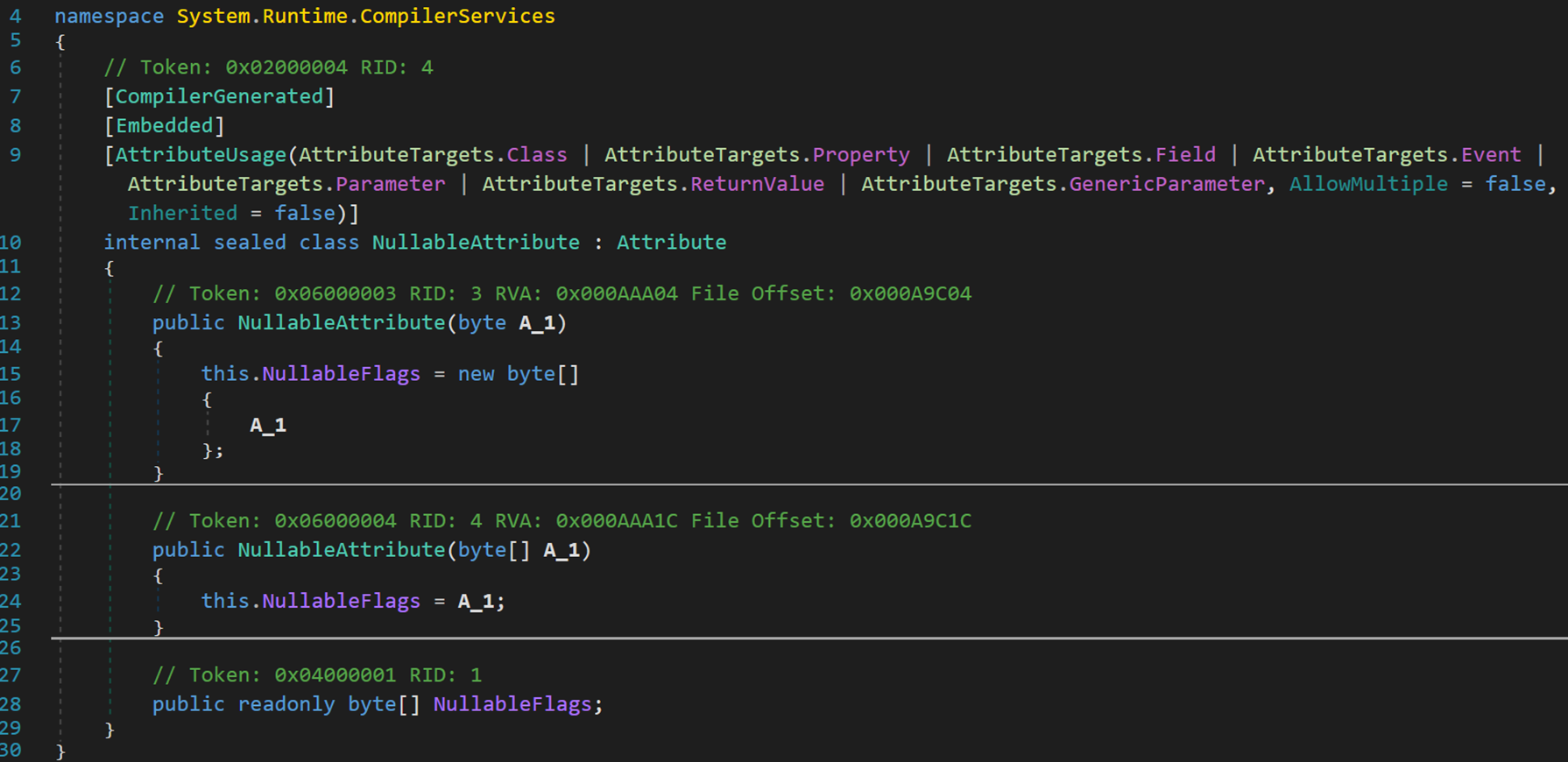
- Line 13、22:該特性有兩種表示方式,就是經常看到的:在括弧里寫上數字或一個數組
![]()
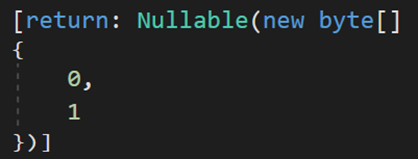
- Line 28:最後均存儲到名為 NullableFlags的 byte 數組中,據名稱可以推測,每個不同的數字賦予了 Nullable 這個特性不同的額外功能。
根據 C# 的編譯器roslyn的GitHub頁面(roslyn/nullable-metadata.md at main · dotnet/roslyn · GitHub):Each type reference in metadata may have an associated NullableAttribute with a byte[] where each byte represents nullability: 0 for oblivious, 1 for not annotated, and 2 for annotated. 也就是說,該數組中的有效值僅為0、1、2,且具有不同的含義。【由於無法找到相關文檔,也無法進行相關實驗操作,數值所代表的含義在此暫不做分析,後續可能會補上】
總結
- 可空引用類型是在編譯時起作用,在運行時和普通的引用類型沒有任何區別,它主要是在編譯時結合可空上下文,幫助我們分析程式碼中可能出現空指針引用異常的地方,這是一個非常好的語法糖,我們只需要遵守上面三種規則,就可以很大程度減少空指針異常的幾率,其實,如果仔細看的話,.NET 基礎庫已經遵守了這個規則,比如object 類的 ToString() 方法和 Equals() 方法等。
- 添加這些特性將為編譯器提供有關 API 規則的更多資訊。當調用程式碼在可為 null 的上下文中編譯時,編譯器將在調用方違反這些規則時發出警告。這些特性不會啟用對實現進行更多檢查。
- 添加可為 null 的引用類型提供了一個初始辭彙表,用於描述 API 對可能為 null 的變數的期望。這些特性提供了更豐富的辭彙來將變數的 null 狀態描述為前置條件和後置條件。 這些特性更清楚地描述了期望,並為使用 API 的開發人員提供了更好的體驗。在為可為 null 的上下文中更新庫時,添加這些特性可指導用戶正確使用 API。這些特性有助於全面描述參數和返回值的 null 狀態。
[# 有關迭代器的實現原理]
在講 LINQ 時,提到過迭代器 Iterator,也分析了其源碼,感興趣的可參閱本人的文章([演算法1-排序](.NET源碼學習)& LINQ & Lambda – PaperHammer – 部落格園 (cnblogs.com))[# 有關Iterator的源碼]
[# 有關介面 IEqualityComparer<T> 與 相等判斷]
在 C# 中,用來比較元素/對象是否相等有以下幾種方式:運算符 「==」,方法 Equals(),方法 SequenceEqual(),介面 IEquatable<T>,介面 IEqualityComparer<T>。
一、運算符「==「
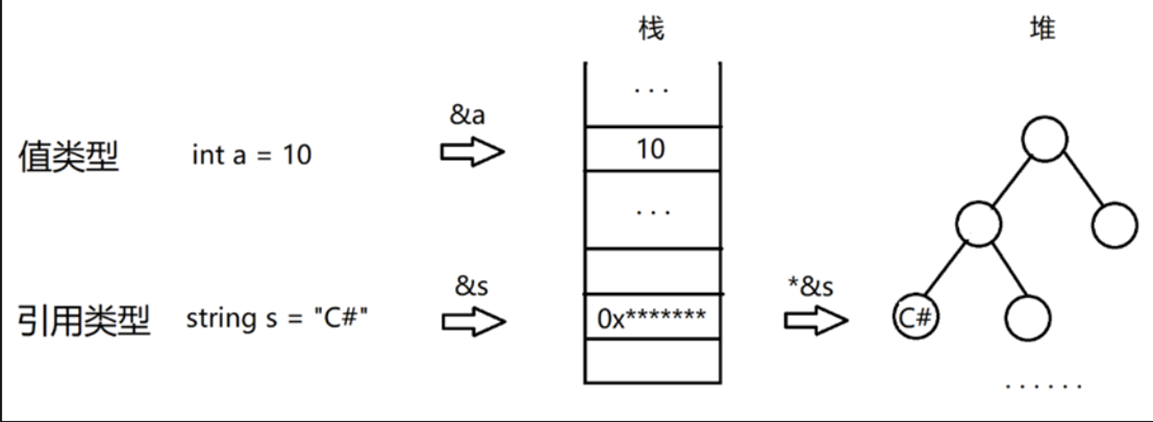
其比較規則較為簡單:「==」 是對方法 Equals() 的重載,對於值類型,比較的是值內容(即,棧中的內容);對於引用類型,比較的是引用地址(即,堆/堆棧中的內容)。
(一) 值類型:

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
(二) 引用類型
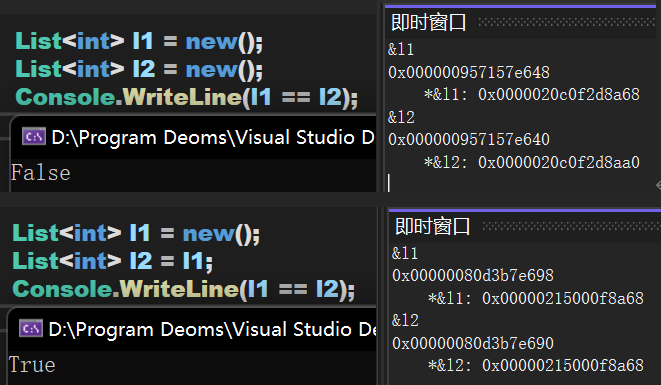
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
雖然在之前的文章中提到過,這裡還是再解釋一下即使窗口裡的資訊。此處顯示了兩個地址:一個是 &x 後的地址;另一個時 *&x 後的地址。
對於 C# 而言總會將變數本身存儲在棧中,變數內部的值存儲在相應的位置(值類型在棧中,引用類型在堆/堆棧中)。對於獲取到的第一個地址,是變數在棧中存儲的位置,也就是說:C# 中的 &x 獲取的是變數在棧中的位置。
而 *&x 的含義是:解析地址 &x,即讀取其中的值。對於值類型而言,其值就存儲在棧中,因此解析後直接得到對應的值;對於引用類型而言,其值存儲在堆/堆棧中,因此解析後會得到一個堆中的位置,這個位置就是存儲實際值的位置。
二、方法 Equals()
類 Object:

類 RuntimeHelpers:

方法 Equals() 最初被定義在類 RuntimeHelpers 中,再由類 Object 與類 ValueType 進行擴展,而 C# 中其他所有類型(包括值類型、引用類型、自定義類型)均派生自這兩個類,並重寫了這個方法,因此對於任意一個變數均可使用這個方法;且均有各自的比較據。
【關於方法 Equals() 的更多說明與應用,請參閱C# 有關List<T>的Contains與Equals方法 – PaperHammer – 部落格園 (cnblogs.com)】
小結一
在 C# 中,對於值類型的比較不管是用 「==」 還是 Equals 都是對於其內容的比較,也就是說對於其值的比較,相等則返回 true 不相等則返回 false;
但是對於除 string 類型以外的引用類型 「==」 比較的是對象在棧上的引用是否相同,而 Equals 則比較的是對象在堆上的內容是否相同。
三、方法 Comapre()
該方法主要用於字元串間的比較,比較的是字元串的大小,根據字元對應的 ASCII 碼進行比較。
對於 Compare(s1, s2):s1 == s2 返回 0;s1 > s2 返回 1;s1 < s2 返回 -1。
四、泛型類型 EqualityCompare<T>



該類是一個抽象類,位於程式集 CoreLib.dll 中的 命名空間 System.Collections.Generic

包含 8 個方法,一個屬性。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
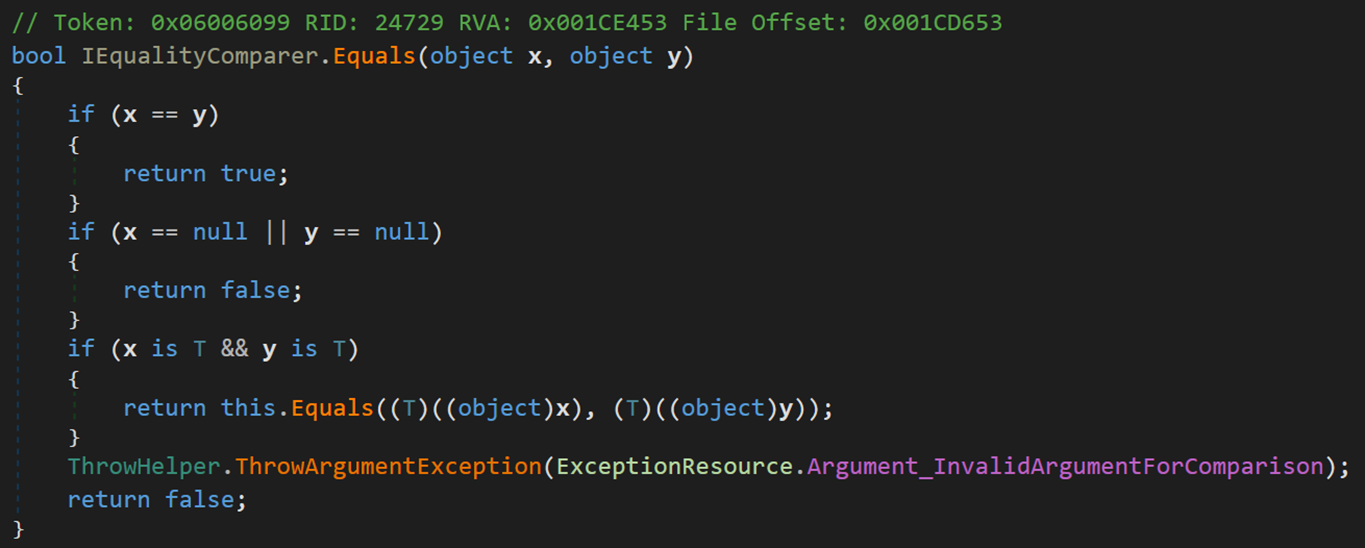
此處主要關注方法 IEqualityComparer.Equals(object x, object y)
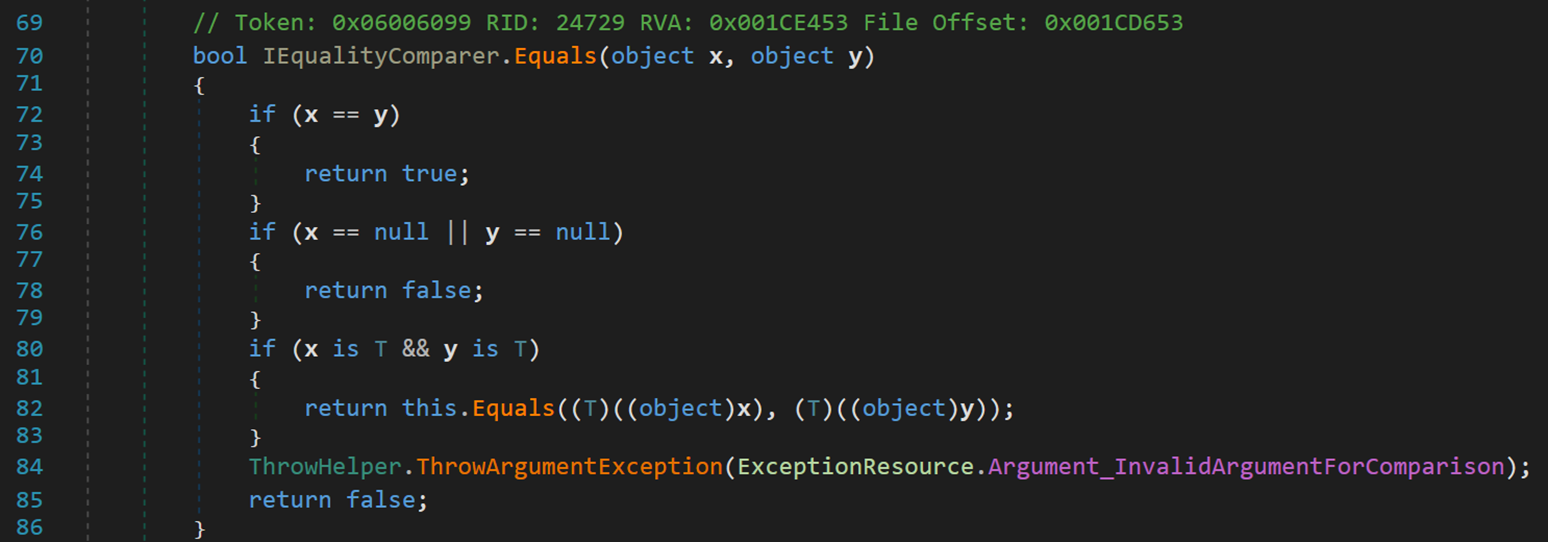
其實該方法的比較依舊主要過運算符 「==」 完成。
- Line 82:當兩個對象不相等且均不為空時,在確保二者為相同類型的情況下,將其轉換為各具體類型,按照具體類型的比較規則進行比較。
總結
對於比較,其實並不複雜,只需要區分開值類型與引用類型的比較規則就可以。雖然有許多工具都可以用來比較,但其比較的本質依舊是不變的。

