真正「搞」懂HTTP協議03之時間穿梭
上一篇我們簡單的介紹了一下DoD模型和OSI模型,還著重的講解了TCP的三次握手和四次揮手,讓我們在空間層面,稍稍宏觀的了解了HTTP所依賴的底層模型,那麼這一篇,我們來追溯一下HTTP的歷史,看一看HTTP在歷史上經歷了哪些發展和過程,才讓這個協議一直經久不衰。
最開始,在20世紀60年代,也就是1950年到1960年之間,那時候我爹還沒出生呢……但是美國國防部高等研究計劃署(ARPA)建立了ARPA網,他有四個分布在各地的節點,被認為是互聯網的始祖。資訊時代的號角也在此刻吹響,人們即將迎來快速發展的網路時代。
在70年代,我爹五六歲的時候,基於對 ARPA 網的實踐和思考,研究人員發明出了著名的 TCP/IP 協議。由於具有良好的分層結構和穩定的性能,TCP/IP 協議迅速戰勝其他競爭對手流行起來,並在 80 年代中期進入了 UNIX 系統內核,促使更多的電腦接入了互聯網。
你看,這些東西存活了這麼久,可以說是經歷了無數的實踐和總結,是我們最需要去學習和學懂的底層的不變的知識。這也是為什麼網路基礎是大學電腦專業一門十分重要的學科的原因。
換句話說,這些東西是我們作為程式設計師所需要學習的那些不變的知識。
從一篇論文開始
在1989年的一個夏天,這時候我還沒出生,時任歐洲核子研究中心的蒂姆·伯納斯 – 李(Tim Berners-Lee)在一個明媚的下午,終於完成了他耗費心血的一篇論文,提出了在互聯網上構建超鏈接文檔系統的構想。在這篇論文中,他確立了三項核心技術:URI、HTML和HTTP。
而這個時候,想必HTTP的發明者也不一定可預見HTTP會在未來發展到如此地步。
HTTP/0.9:宏偉的藍圖
在20世紀90年代,這個時候我剛出生沒多久,互聯網世界非常的簡陋,電腦的處理能力也不行,存儲能力就更別提了,最主要的是體積還大的不行。能在網上看看新聞都是天大的奇蹟了。這個時候的網速當然也十分有限,所以在網路上使用的協議也都是以純文本傳輸,也就能看看純文字的內容,嗯~~廢了這麼大勁,我還不如去看報紙,確實,這時候報紙要遠比網頁好看,畢竟報紙還能有黑白圖片。
基於這樣的背景,此時的HTTP設計的也十分簡陋,採用了純文本的格式,並且只有GET方法從伺服器獲取HTML文檔,並且在響應請求後立即關閉連接,僅僅只是這樣。
但,正是因為最開始的HTTP如此簡單,才在未來賦予了它無限的可能。因為,把簡單的變複雜,遠比把複雜的變簡單要容易很多。
那麼我們簡單總結下這個時候的HTTP的特點:
- 只有請求行,沒有請求頭和請求體(這樣說不太準確,我們後面再聊)。
- 伺服器也不會返回任何頭資訊,只返回客戶端想要的數據就可以了。
- 返回的文本內容是用ASCII字元流來傳輸的。
HTTP/1.0:不標準的標準
雖然HTTP0.9這麼簡單,但是它已經可以滿足當時的需求了。不過,隨著世界的發展,在1994年底出現了撥號上網服務,同年網景推出了一款瀏覽器,從此萬維網就不再是單純的限制於學術交流,而是進入了高速發展的階段。並且在這個時期,還出現了JPEG的圖片格式,以及MP3格式等。也就是說,大眾對於媒體展示的需求越發的繽紛了起來。
基於澎湃的技術發展和用戶需求,HTTP0.9肯定無法滿足大眾的需要,最基本的就是網頁中不只有純粹的HTML文本了,還有圖片,音頻,影片等等。因此ASCII編碼肯定滿足不了各種媒體的編碼方式。
於是HTTP1.0就引入了請求頭和響應頭,通過這樣的方式來讓客戶端和伺服器進行協商,在發起請求的時候,瀏覽器會告訴伺服器我期望你返回給我什麼類型的文件,採取什麼樣的壓縮方式等等。
在客戶端發送請求行與伺服器協商的時候,可能有些需求伺服器是處理不了的,於是就需要伺服器返回給客戶端一個狀態,告知客戶端處理的結果,這樣就引入了狀態碼。
同時為了減輕伺服器的訪問壓力,HTTP1.0還提供了Cache的快取機制。
你看,所有的技術發展,都是由客戶需求推動的。
HTTP1.0是我們能在RFC中最早可查閱的關於HTTP的一份規範性文檔,哦抱歉,說是規範有點不太貼切,HTTP1.0還並不算是一個規範,在原文中叫做memo,也就是算是一個備忘錄。我們可以在RFC的目錄中篩選一下,找到這個:
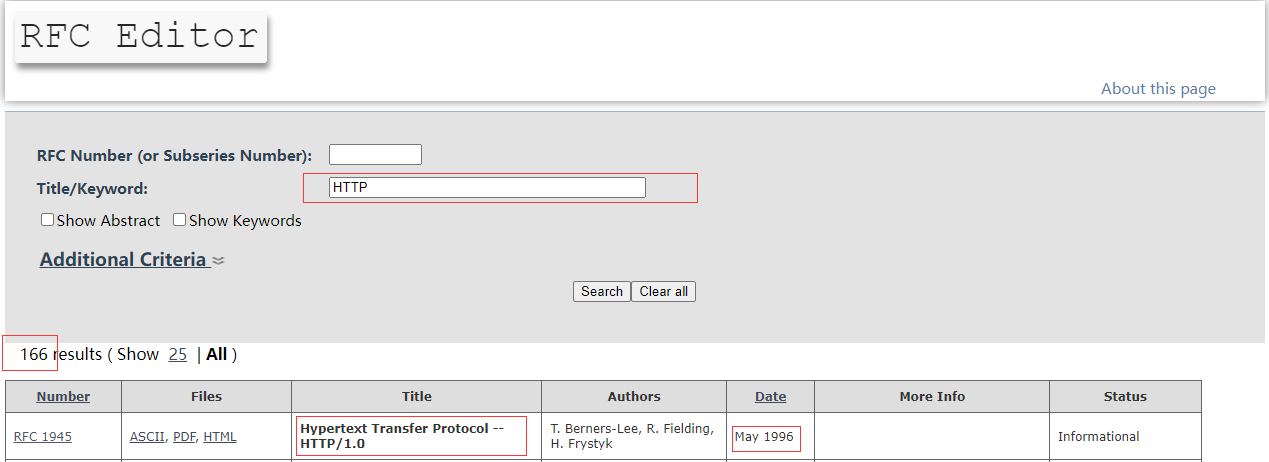
我們可以看到,到目前為止,關於HTTP的第一份文檔就是在1996年五月份的這份RFC1945,它在最開始有這麼一段話:
This memo provides information for the Internet community. This memo does not specify an Internet standard of any kind.
Distribution of this memo is unlimited.
大致意思就是說,這個備忘錄提供了一些關於在網路上通訊的討論。並且本備忘錄不定義任何類型的互聯網標準,並且本協議允許隨意傳播。然後,我們還可以在下面的文章內容中找到一個關於RFC1945所囊括的範圍是什麼的一句話:
This document defines both the 0.9 and 1.0 versions of the HTTP protocol.
本文檔定義了0.9和1.0兩個HTTP版本。換句話說,在RFC1945中,也就是到了HTTP1.0的時候,才真正的形成了一份類似文檔的備忘錄,但是,它還算不上是標準。可以從文檔內容看得出來1.0比0.9多了好多好多東西。
HTTP/1.1:我是真標準
而隨著互聯網的繼續發展,網景的 Netscape Navigator 和微軟的 Internet Explorer 開始了著名的「瀏覽器大戰」,都希望在互聯網上佔據主導地位。這場大戰的商業意義和糾紛我們暫且不提,但是它確實,實實在在的推動了Web的發展,在1999年,HTTP1.1版本正式出現,此刻的HTTP協議才算是一個真正的標準,所有要用到HTTP的應用或者設備都必須遵守該協議。
那我想問你個問題,基於RFC的文檔,是直接從1.0就到了1.1么?中間沒有別的了?首先1.0版本的RFC編號是1945,而1.1版本的編號想必大家耳熟能詳就是2616,當然RFC可不僅僅只是為HTTP服務的,所以通過編號的跨度好像也不能解答我上面的問題。
但是,這張圖可以:
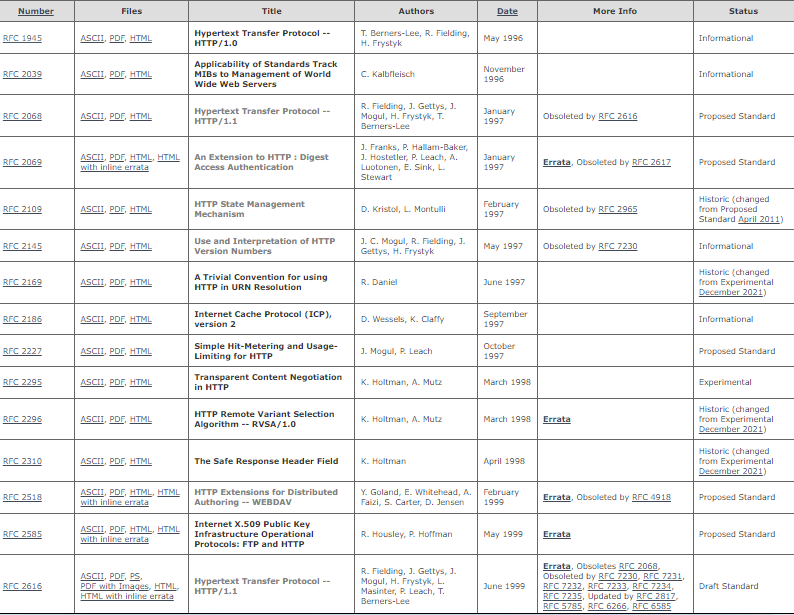
從上圖我們著重看一下RFC1945、RFC2068、RFC2616,換句話說,當1.0版本的備忘錄出現之後,到RFC2616的1.1版本,中間還有個RFC2068,當然,我們從上圖中也可以看到RFC2068已經被RFC2616覆蓋了,並且2616也被7230等後續文檔所完善和覆蓋。
而且,在某一個文檔真正標準化之前,實際上還有很多關於某些特性的討論,不多說,大家有興趣可以在文末的連接中自己取證。
HTTP1.1在原有的HTTP1.0的基礎上做了不少的性能改進,雖然說是一個小範圍的改變,但是這些改變所帶來的影響可不小。我們下面就就簡單的看看HTTP1.1相對於1.0版本都做了哪些核心的優化。
1、增加持久連接
HTTP/1.0每進行一次HTTP通訊,都需要經歷建立連接、傳輸數據、斷開連接的操作。換句話說,我發送一點點HTTP數據,就要額外的發送十幾個包,後面我會用實際的過程帶大家看為啥會是十幾個包。這實在是有點難受。
但是為啥當時這樣就可以呢?因為當時傳輸數據的體積小,頁面也沒啥引用的外部連接,全是HTML文本,所以也不會有什麼太大的問題,但是隨著發展,頁面的體積和引用越來越大,這種方式顯然已經無法支撐日益發展的需求了。
那麼HTTP/1.1為了解決這個問題,增加了持久連接的方法,它的特點是在一個TCP連接上可以傳輸多個HTTP請求,只要瀏覽器或者伺服器沒有明確斷開,那麼TCP連接就會一直保持。
持久連接在HTTP/1.1中是默認開始的,如果你不想開啟持久連接,可以在HTTP的請求頭中加上Connection:close。
目前瀏覽器中對同一個域名,默認允許同時建立6個TCP持久連接,注意!是瀏覽器默認允許。
2、不成熟的HTTP管線化
我們想像一下,在TCP這條馬路上,只能一條單行道,所有跑在這條馬路上的車都無法超越前面的車,假如前面的車追尾了,後面所有的車都只能等待前面的事故處理完才能繼續同行。
換句話說,假如前一個HTTP請求因為某些原因沒有返回結果,那麼就會阻塞後面所有的請求,這就是著名的隊頭阻塞問題。
在HTTP/1.1中,試圖通過管線化的技術來解決隊頭阻塞的問題,在HTTP/1.1中的管線化,會將多個HTTP請求整批提交給伺服器的技術,也就是說,雖然馬路還是單行道,但是我可以把車疊在一起,一下子發送一批。但是馬路上跑的時候可以這樣,到了收費站,你還是要下來挨個排隊收費。
3、支援虛擬主機
在HTTP/1.0中,每個域名綁定了一個唯一的IP地址,因此一個伺服器只能支援一個域名。但是隨著虛擬主機技術的發展,需要實現在一台物理主機上綁定多個虛擬主機,每個虛擬主機都有自己單獨的域名,這些單獨的域名都公用同一個IP。
因此,HTTP/1.1增加了Host欄位,用來表示當前的域名地址,這樣伺服器就可以根據不同的Host值做不同的處理。
4、支援對動態生成的內容
在HTTP/1.0中需要在響應頭中完整的設置數據的大小,這樣瀏覽器才能根據設置數據的大小來接受數據。但是隨著伺服器端的技術發展,很多頁面都是動態生成的,在傳輸數據之前無法知道完整的數據大小,這樣肯定不行的,瀏覽器根本不知道什麼時候數據傳輸完畢。
HTTP/1.1就完美的解決了這個問題,通過把數據包分割成若干個任意大小的數據塊,每個數據塊都會附上當前數據塊的長度,最後發送一個長度為0作為結束的標誌,這樣就提供了對動態內容的支援。
5、客戶端Cookie
想像一下為什麼我們需要cookie呢?cookie的作用是什麼?你還記得HTTP是無狀態的了么?每次發送響應,然後就沒有然後了,那當我們需要記錄用戶狀態時怎麼做呢?HTTP/1.1就引入了客戶端Cookie機制,讓客戶端可以存儲一段數據,傳遞給伺服器,這樣伺服器就能從保存的數據中讀取一定的資訊。來實現一定程度的狀態保持和用戶識別。
當然,因為Cookie可以在客戶端存儲數據的特性,也在一定情況下當作快取來使用,可以通過瀏覽器的API來獲取Cookie,但是其實這樣做是不安全的,你也可以通過響應頭來限制客戶端訪問Cookie。
當然,還可以設置Cookie的過期時間,設置Cookie的作用域等等。這個我們後面再具體說。
6、安全機制
HTTP/1.1相比於HTTP/1.0增加很多安全機制,這些安全機制都融合進了HTTP的欄位使用中,比如SameSite、Referer、Origin,比如Cookie的HttpOnly等等。我們先知道這回事。
HTTPS:給你的錢包上個鎖
HTTP/1.1已經新增了很多安全機制,那HTTP就真的安全了么?答案顯然是否定的,因為HTTP本身的特性:明文傳輸。所以HTTP自己根本無法解決傳輸數據的安全性問題,獲取HTTP傳輸的數據非常容易。
這就導致了你在網路上的任何訪問都可能引起你實際的損失和個人資訊的透明。在一些購物、政府場景下,對於資訊的安全要求更是極高,但是我也說了,HTTP自身是解決不了的。那咋整?
基於這樣的前提,HTTPS誕生了,但是實際上來說,HTTPS就是HTTP,只不過在HTTP的上一層不再是TCP了,而是SSL/TLS,換句話說,就是在HTTP和TCP中間又加了一層:
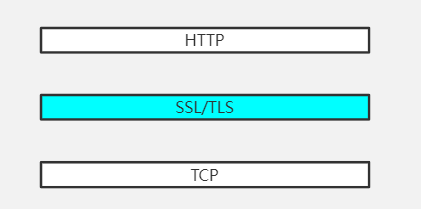
所以你看,其實HTTPS就是HTTP,它的一切都是HTTP賦予的,只不過,HTTP的報文要經過SSL/TLS層的加工處理後才交給TCP。SSL和TLS其實是一個東西,最開始的時候是SSL,後來標準化了之後就叫做TLS了。
HTTP/2:HTTP的極限
現在絕大多數網站所使用的還是HTTP/1.1,這個毋庸置疑。在現在的階段,HTTP/2在Top1000的網站上也得到了不錯的應用,比如Google、蘋果等等。而在未來,可能會在真正實行的時候直接大力推廣使用HTTP/3了,當然,真正的想在應用中廣泛使用HTTP/3也不會那麼快。
那麼我們來簡單看下,相比於HTTP/1.1,它有哪些劃時代的增強吧。
HTTPS幫助我們解決了HTTP數據傳輸的安全性問題,並且標準已經十分成熟。所以無論是2也好,還是3也罷,後續的努力,都是在為了性能所奮鬥。
一個核心優化就是二進位報文傳輸,雖然這樣不利於閱讀,但是在機器的理解和識別上卻變得十分簡單快速。並且基於二進位又引入了流的概念,我們可以把整個HTTP報文分割成一個又一個小的包,然後每個包會賦予一個唯一的ID,這些包按照次序組裝起來就是HTTP的報文了。這個東東有一個大名鼎鼎的稱呼,叫做多路復用。
除了多路復用,HTTP/2還可以設置請求的優先順序、壓縮頭欄位、伺服器推送等等。
最後,我為什麼會起這樣一個標題呢?因為在使用TCP作為傳輸協議的基礎上,想要再在應用層層面提升性能已經是無計可施了,因為TCP的一些自身特性,以及設備僵化等等原因,其實HTTP/2可以說是性能的極限了。所以,基於這樣的原因,才有了HTTP/3。
HTTP/3:面向未來的協議
為什麼會有HTTP/3呢?HTTP/3又做了什麼事情進一步優化HTTP協議的性能呢?
出現HTTP/3的主要問題還是為了解決HTTP/2無法解決的性能問題,那HTTP/2為啥無法解決呢?因為HTTP/2是基於TCP的,雖然HTTP/2在應用層的層面解決了隊頭阻塞的問題,但是到了TCP這裡,你還是要在TCP這條馬路上傳輸數據包啊,TCP還是會隊頭阻塞,所以,你要想真正的解決隊頭阻塞的問題,就只能完全捨棄有問題的這個協議。
但是我之前也說了,TCP是存在設備僵化的,也就是現在全球的設備都在使用TCP,你想讓每一個電腦都換成新發明的協議么?顯然這不現實,那咋整呢?嗯,一個辦法是要麼搞一個新協議,這個新協議可以兼容TCP,一個辦法是換一個沒有TCP協議的問題的協議。
嗯,所以HTTP/3就不再使用TCP作為傳輸層協議了,而是使用UDP,UDP是無連接的,根本就不需要三次握手四次揮手啥的,所以天然就比TCP快很多。這也是為什麼新的HTTP/3沒有選擇去創造一個兼容TCP的協議,因為你只要是需要面向連接的協議,那就跑不出這樣的圍牆,所以乾脆我就不用你了。
但是用UDP協議還是有很多問題。那咋整呢,於是在UDP和HTTP/3之間加了一層QUIC,在UDP的基礎上實現了就像TCP那樣的可靠傳輸,所以HTTP/3基於UDP和QUIC,拋棄了TCP的缺點,保證了TCP的優點。這就是面向未來的協議啦。
當然,現在的HTTP/3還有很多不穩定、不確定、待商榷的內容,但是終有一天吧,我們想要的,我們都能做到。
小結
- 本篇啊,我們簡單的過了一下HTTP的過去、現在和未來,那你知道為什麼我在到了某一個階段就不再附上時間節點了么?
- 從過去到未來,我們最想要解決的HTTP的性能問題是什麼?
- 多路復用是咋復用的?

