Mysql InnoDB Redo log
一丶什麼是redo
innodb是以也為單位來管理存儲空間的,增刪改查的本質都是在訪問頁面,在innodb真正訪問頁面之前,需要將其載入到記憶體中的buffer pool中之後才可以訪問,但是在聊事務的時候,事務具備持久性,如果只在記憶體中修改了頁面,而在事務提交後發生了系統崩潰,導致記憶體數據丟失,就會發生提交事務所作的更改還沒來得及持久化到磁碟。
那麼如何保證到提交的事務,所作更改一定持久化到磁碟了昵?
最簡單粗暴的固然是,每次事務提交都將其所作更改持久化到磁碟。這種操作又存在如下問題:
- 刷新一個完整的頁面,十分浪費IO,有時候事務所作的更改只是一個小小的位元組,但由於innodb是以頁為單位的對磁碟進行io操作的,這時候需要把一個完整的頁刷新到磁碟,為了一個位元組刷新16k的內容,是不划算的
- 隨機io刷新緩慢,一個事務包含多個資料庫操作,一個資料庫操作包含對多個頁面的修改,比如修改的數據不在相鄰的頁,存在多個不同的索引B+樹需要維護,這時候需要刷新這些零散的頁面,進行大量的隨機IO
InnoDB是如何實現事務提交的持久化——記錄下更改的內容
在事務提交的時候只記錄下,事務做了什麼變更到redolog,中這樣即使系統崩潰了,重啟之後只需要按照redo log上的內容進行恢復,重新更新數據頁,那麼該事務還是具備持久性的,這便是重做日誌——redo log。使用redo log的好處:
- redo log佔用空間小:在存儲事務所作變更的時候,需要存儲變更數據頁所在的表空間,頁號,偏移量以及需要更新的值時,需要的空間很少。
- redo log是順序寫入磁碟的,在執行事務的過程中,在執行每一條語句的時候,就可能產生若干條redo log,這些日誌都是按照產生的順序寫入磁碟的,也就是使用順序io
二丶redo log 日誌的格式
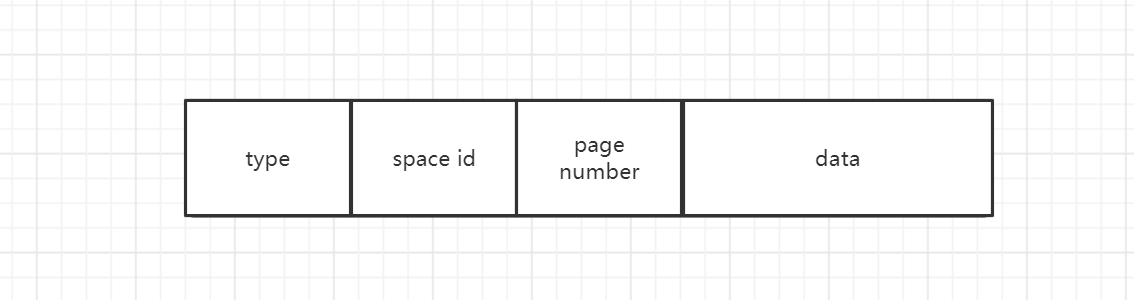
- type:redo log日誌的類型
- space id:表空間號
- page number:頁號
- data:日誌內容
通常一個執行語句是會修改到許多頁面的,比如一個表具備多個索引,進行更新的時候需要維護聚簇索引和各種非聚簇索引,表中存在多少個索引就會可能會更新到多少個B+樹,針對一顆B+樹來說,極可能更新到葉子節點,也可能更新到非葉子節點,甚至還伴隨著創建新頁面,頁面分裂,在內節點頁面添加目錄項等等操作。
理論上說red log只需要記錄下insert 語句對頁面所有的修改即可,但是插入數據到一個頁面,也伴隨著對這個頁面的File Header,Pahe Header等等資訊的修改
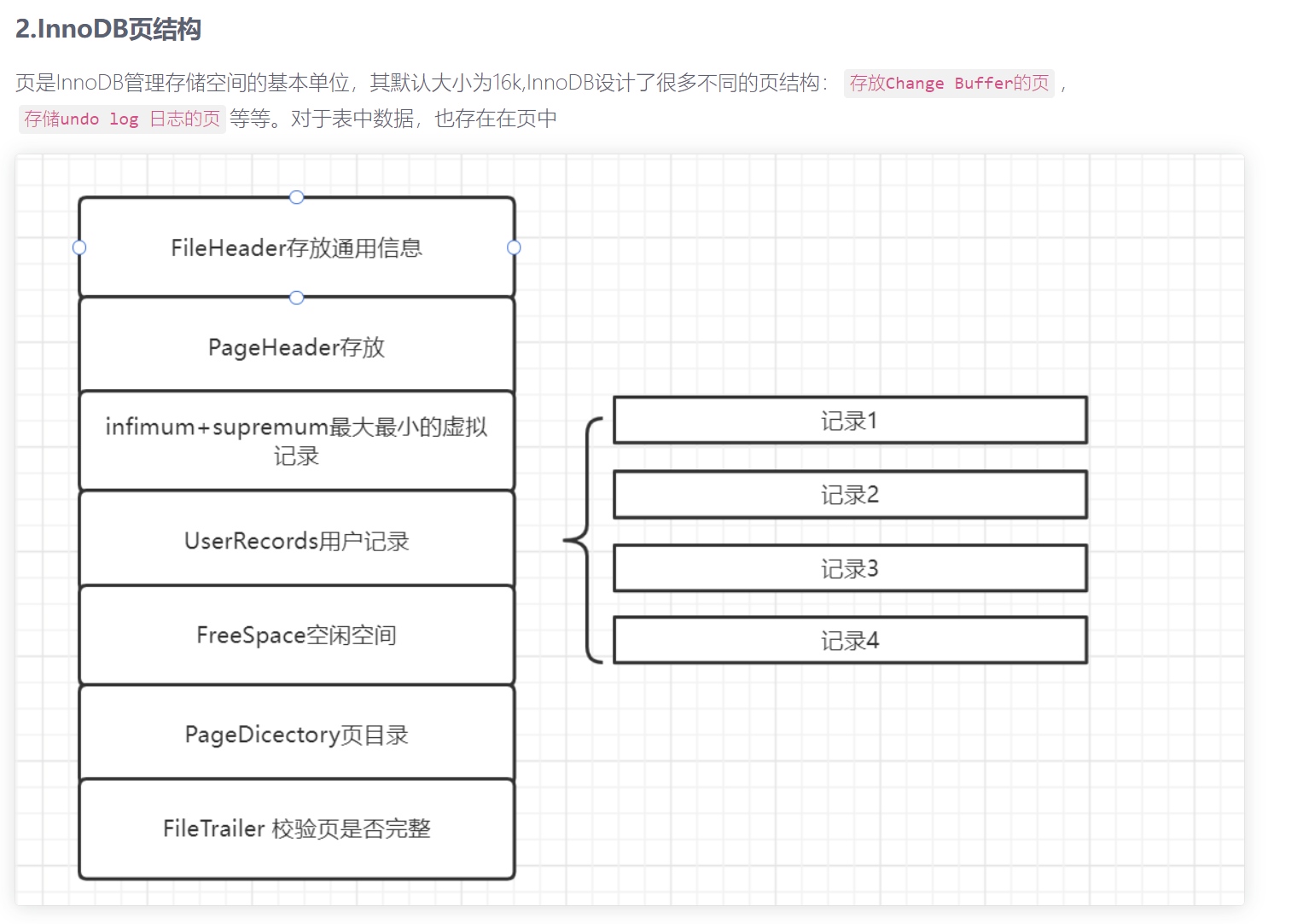
可見,將一條記錄插入到一個頁面,需要更改的地方很多,為此redo log定義了許多不同的日誌格式,從物理層面來說:redo log指明了需要在哪一個表空間,的哪一個頁進行什麼修改內容,從邏輯層面來說:redo log在mysql崩潰恢復後,並不能直接使用這些日誌記錄的內容,而是需要調用一些函數,將頁面進行恢復
三丶Mini-Transaction
mysql把底層頁面的一次原子訪問過程稱為一個Mini-Transaction(MTR)(比如向B+樹中插入一條記錄的過程算作一個MTR,即使這個sql涉及到多個B+樹)一個MTR可以包含一組redo log,在進行崩潰恢復的時候需要把這一組MTR看作是一個不可分割的整體(B+樹中插入一條記錄,可能涉及到葉子節點,非葉子點的改動,不能說只新增了葉子節點,但是沒用更新非葉子節點,需要保證這個過程的原子性)
一個事務可以包含多個語句,一個語句可以包含多個MTR,一個MTR可以包含多個redo log日誌,那麼innodb是如何確認多個redo log屬於一個MTR的昵
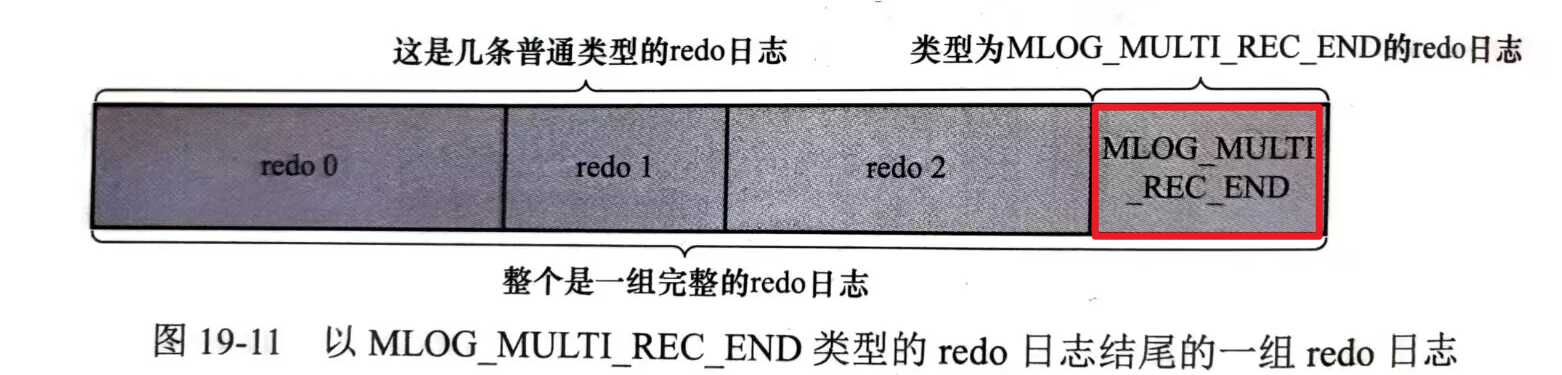
多個redo log以最後一條類型為MLOG_MULTI_REC_END類型的日誌結尾,那麼視為前面的redo log為同一MTR中的日誌。系統在進行崩潰恢復的時候,只有解析到MLOG_MULTI_REC_END類型的日誌的時候,才認為解析到了一組完整的redo log日誌,才會進行恢復。
有些需要保證原子性的操作,只會產生一條redo log,比如更新Max Row ID(innodb在用戶沒用指定主鍵的時候,將此值存儲在頁中,沒增大到256的整數倍的時候,才會更新寫回磁碟),這個時候會將其的type欄位的第一個比特置為1,表示這個單個redo log 便是一個原子性操作,而不是加上一個MLOG_MULTI_REC_END類型的日誌。
四丶redo log日誌寫入過程
1.redo log block
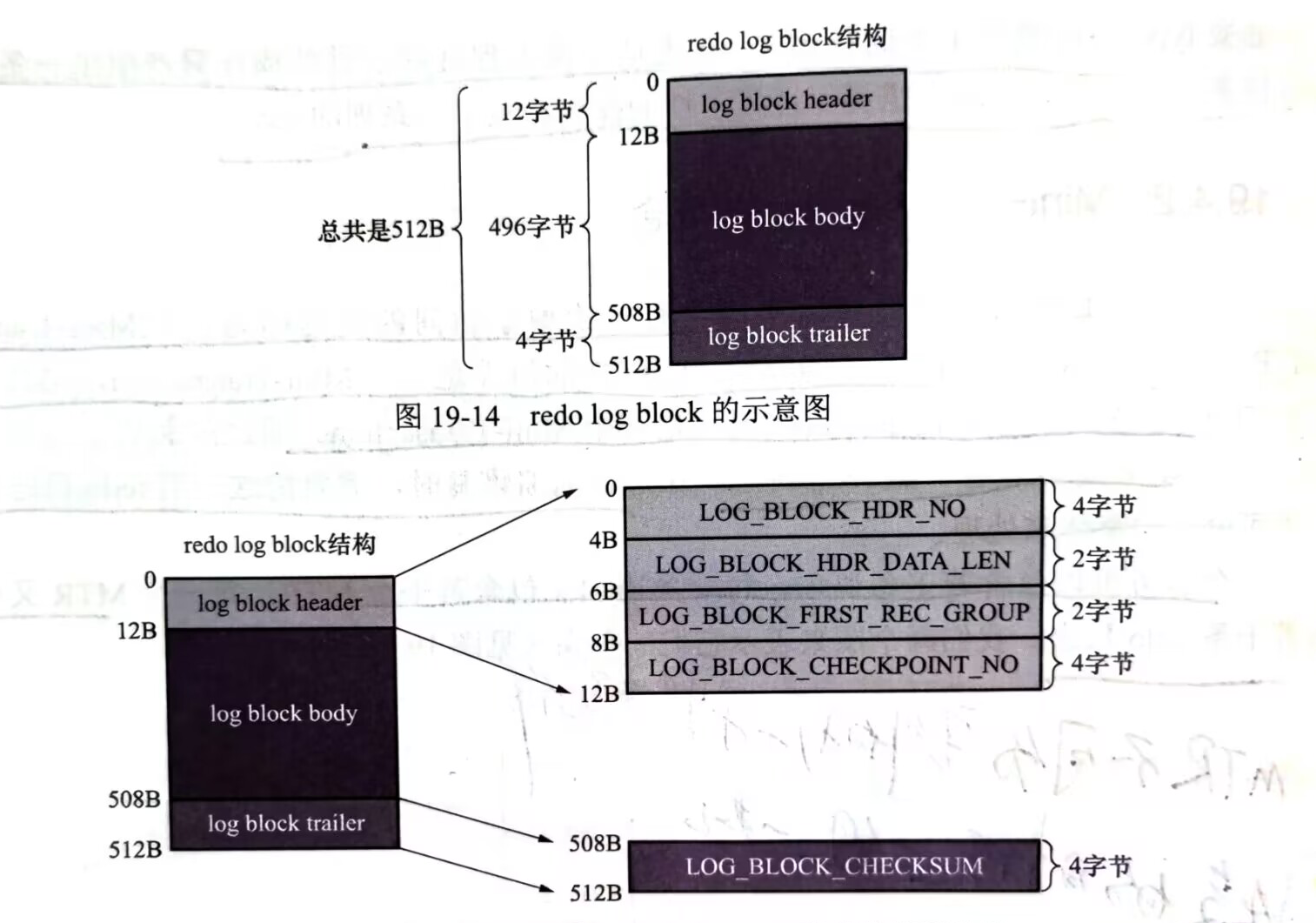
innodb 將通過MTR生成的redo log放在大小為512位元組的block中,其中存儲redo log的部分只有log block body其餘的兩部分存儲一些統計資訊
- log block header
- log_block_hdr_no:每一個block 具備一個大於0的唯一編號,此屬性便是記錄編號值
- log_block_hdr_data_len:記錄當前lock block使用了多少位元組(從12開始,因為lock block header佔用了12位元組),隨著越來越多的日誌寫入block最後最大為512位元組
- log_block_first_rec_group:一個MTR包含多個日誌,這個欄位記錄該block中第一個MTR生成redo log日誌記錄組的偏移量。
- log_block_checkpoint_no:表示checkpoint的序號
- log block trailer
- log_block_check_sum:表示block檢驗和,用於正確性校驗
2.redo log buffer
為了解決磁碟寫入過慢的問題,innodb採用了redo log buffer,寫入redo log不會直接寫入磁碟,而是在服務啟動的時候申請一片連續的記憶體空間,用作緩衝redo log的寫入
innodb_log_buffer_size可以指定其大小,默認16mb
3.redo log寫入log buffer
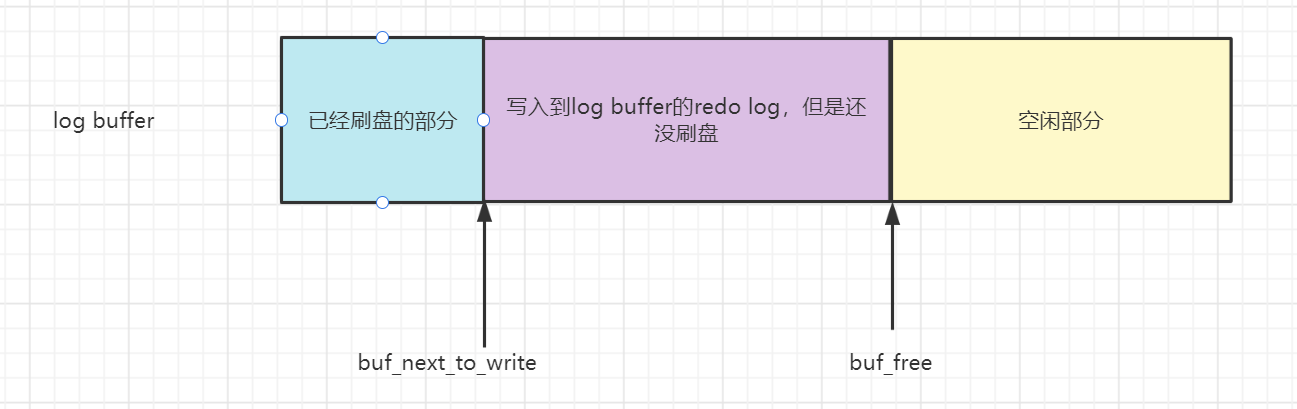
innodb保存了一個buf_free的全局變數用於記錄log buffer中空閑位置的偏移量,讓後續redo log的寫入從buf_free的位置開始寫。
不同的事務是可以並發運行的,並發的寫入redo log buffer中,每當一個MTR執行完成時,伴隨著該MTR生成的redo log被寫入到log buffer中,多個不同事務的MTR可能時交替寫如到log buffer中的
五丶redo log持久化
1.redo log buffer中的內容何時持久化到磁碟
MTR運行過程中產生的一組redo log會在MTR結束的時候被複制到log buffer中,但是何時落盤昵?
-
log buffer 空間不足
如果寫入log buffer的redo log日誌量已經佔滿log buffer的一半時,會進行刷盤
-
事務提交時
之所以使用redo log,是由於其佔用記憶體小,可以順序IO寫回磁碟,為了保證事務的持久性,需要把修改頁面對應的redo log刷新到磁碟,這樣系統崩潰時也可以將已提交的事務使用redo log進行恢復
-
將某個臟頁刷新到磁碟前
將buffer pool中的臟頁刷盤的時候,會保證將其之前產生的redo log刷盤
-
後台執行緒,每秒一次的頻率將redo log buffer中刷盤
-
正常關閉mysql伺服器時
-
做checkpoint時
2.redo log 日誌文件組
mysql的數據目錄下默認有兩個redo log日誌文件,默認名稱為ib_logfile0和ib_logfile1,log buffer中的內容便是刷新到著兩個文件中。可以通過以下系統變數進行設置
innodb_log_group_home_dir:指定redo log日誌文件所在目錄innodb_log_file_size:指定每一個redo log日誌文件大小innodb_log_file_in_group:指定redo log日誌文件的個數
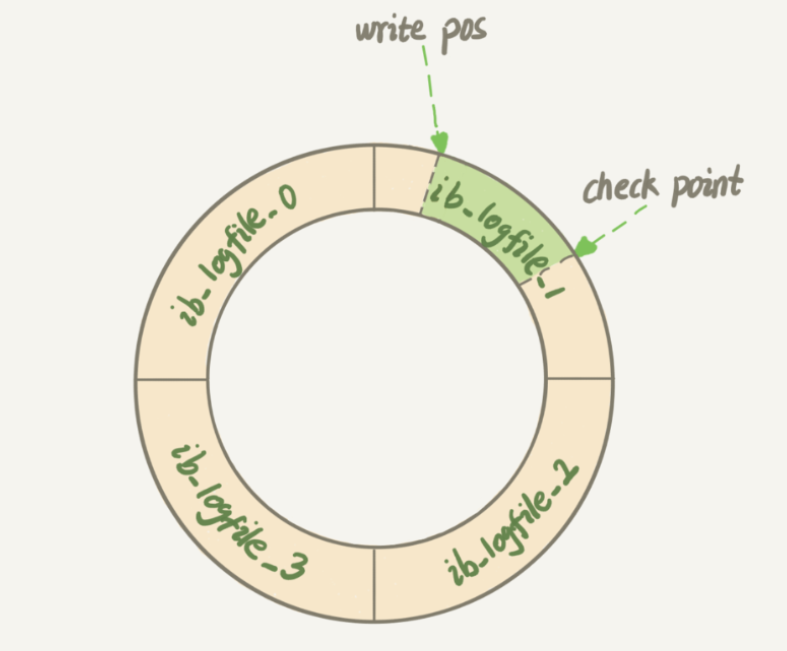
日誌文件不知一個,而是以一個日誌文件組的形式出現的,都是ib_logfile數字格式的名稱,在持久化redo log的時候,首先從ib_logfile0開始寫,然後寫ib_logfile1直到寫到最後一個文件,這時候需要做checkpoint,後繼續從ib_logfile0寫,從頭開始寫,寫到末尾就又回到開頭循環寫,如下圖
3.redo log日誌文件格式
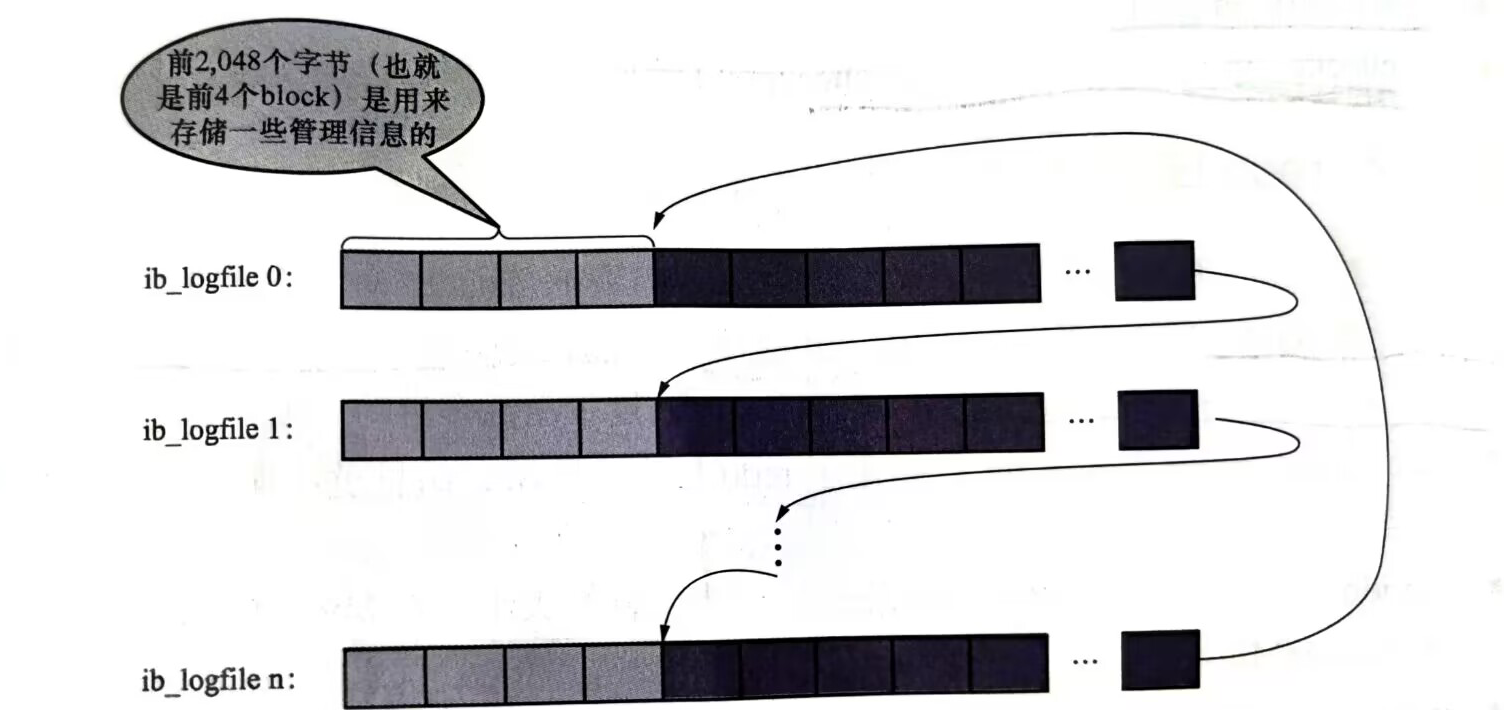
每一個redo log文件前2048個位元組(四個redo log block大小)用來存儲管理資訊,後續的位置存儲log buffer中redo log block鏡像
前2048位元組分為四個block,如上圖
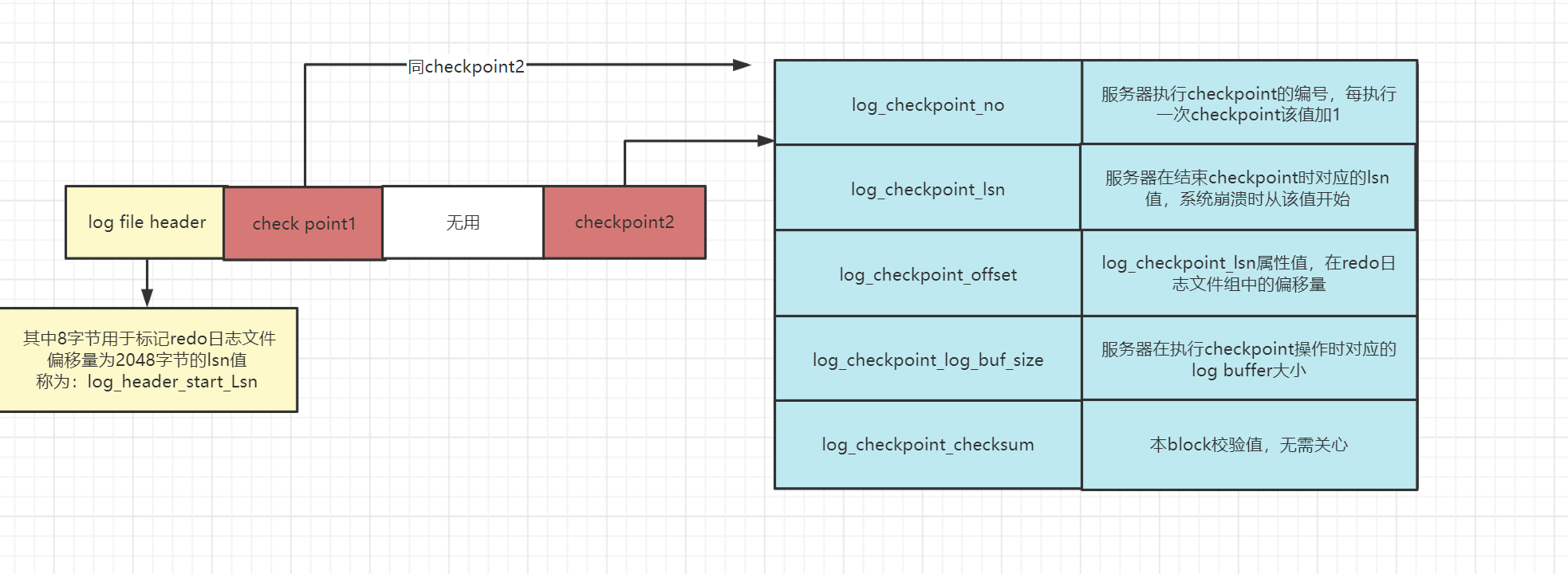
- log file header 描述該日誌的一些整體屬性
- checkpoint1 & checkpoint2,格式相同
- log_checkpoint_no:伺服器執行checkpoint的編號,每執行一次checkpoint該值加1
- log_checkpoint_lsn:伺服器在結束checkpoint時對應的lsn值,系統崩潰時從該值開始
- log_checkpoint_offset:log_checkpoint_lsn屬性值,在redo日誌文件組中的偏移量
- log_checkpoint_log_buf_size:伺服器在執行checkpoint操作時對應的log buffer大小
- log_checkpoint_checksum:本block校驗值,無需關心
4.LSN——log squence number記錄當總共寫入的redo 日誌量
innodb的一個全局變數,用於記錄當總共寫入的redo 日誌量,初始值為8704(未產生一條redo日誌也是8704)。並不是記錄刷到磁碟的redo log日誌總量,而是寫入到log buffer中的redo log日誌量
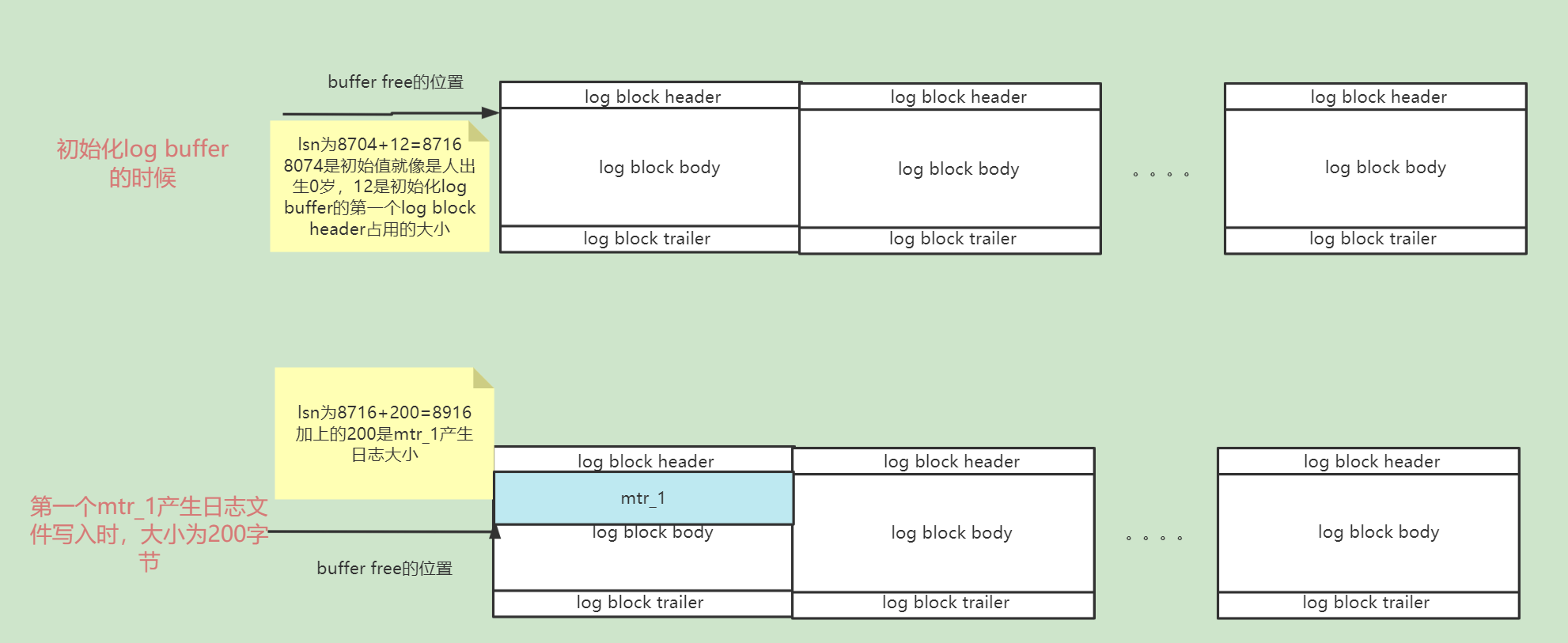
每一組MTR生成的redo log都有唯一一個lsn值與之對應,其中lsn越小表示對應的redo log產生越早
5.flushed_to_disk_lsn記錄刷新到磁碟中的redo日誌量
redo log總是先寫入到redo log buffer然後才會被刷新磁碟中的,所有需要有一個變數記錄下一次從log buffer中刷盤的起始位置——buf_next_to_write
flushed_to_disk_lsn記錄刷新到磁碟的redo log 日誌量
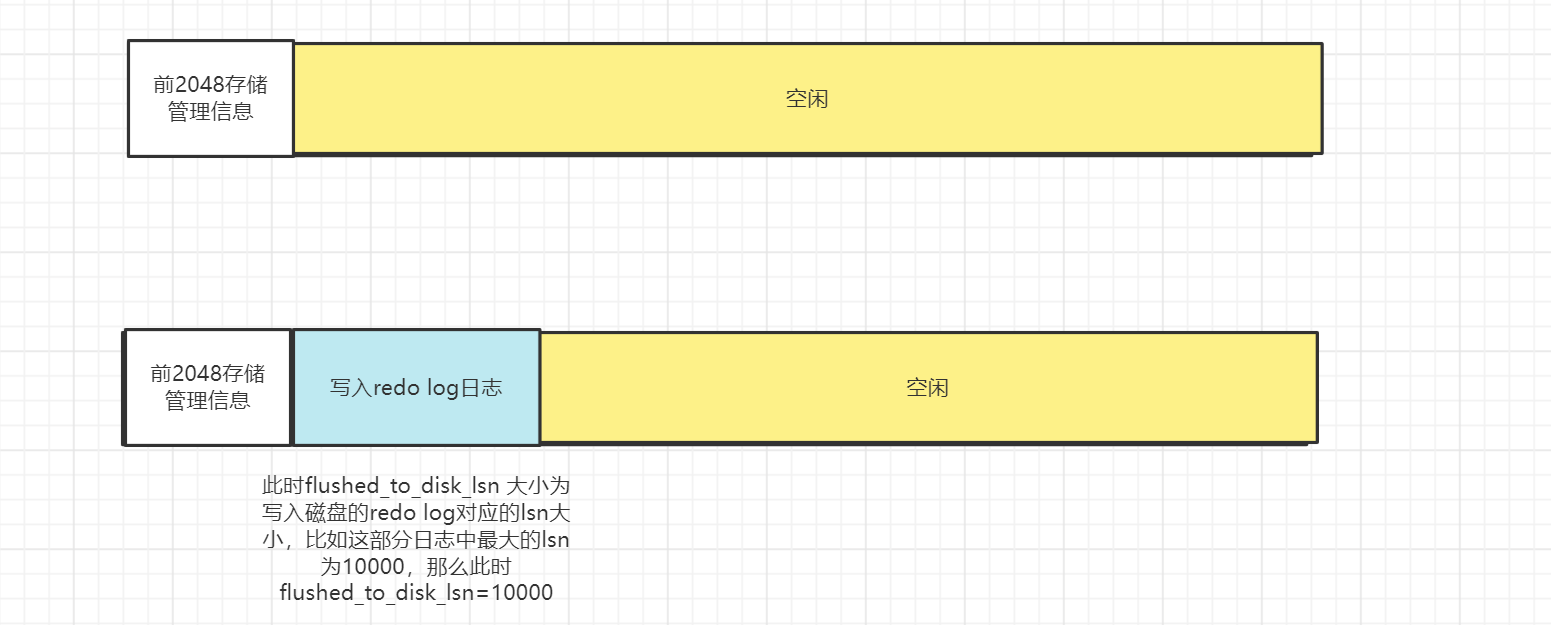
當存在新的日誌寫入到log buffer的時候,首先lsn(log squence number記錄當總共寫入的redo 日誌量)會增大,但是flushed_to_disk_lsn大小不變(因為沒刷盤)隨著log buffer中的內容刷新到磁碟,flushed_to_disk_lsn將隨之增大,當flushed_to_disk_lsn = lsn的時候說明所有log buffer中的日誌都刷新到了磁碟
6.buffer pool 中flush 鏈表中的lsn
MTR是對底層頁面的一次原子訪問,在訪問過程中會產生一組不可以分割的redo log,在MTR結束的時候會把這一組redo log記錄到log buffer中。除此之外在MTR結束的時候還需要:把MTR執行過程中修改的頁面加入到Buffer pool中的flush鏈表中,畢竟刷新臟頁到磁碟是buffer pool的任務。
當這個頁面第一次被修改的時候就會將其對應的控制塊插入到flush 鏈表頭部,後續再次修改不會移動控制塊,因為其已經在flush 鏈表中,所有說flush 鏈是按照頁面第一次修改的時間進行排序的,在這個過程中會記錄兩個重要的屬性到臟頁的控制塊中:
-
oldest_modification
第一次修改修改buffer pool某個緩衝頁(先把頁讀到buffer pool的緩衝頁,然後進行修改)時,
記錄下修改該頁面MTR開始時對應的lsn(注意這個開始時) -
newest_modification
每次修改頁面,都會
記錄下修改該頁面MTR結束時的lsn,該屬性記錄最近一次修改後對應的lsn
例如第一個MTR1修改了頁A,在oldest_modification記錄下開始時的lsn為8716,newest_modification記錄下MTR1結束時的lsn
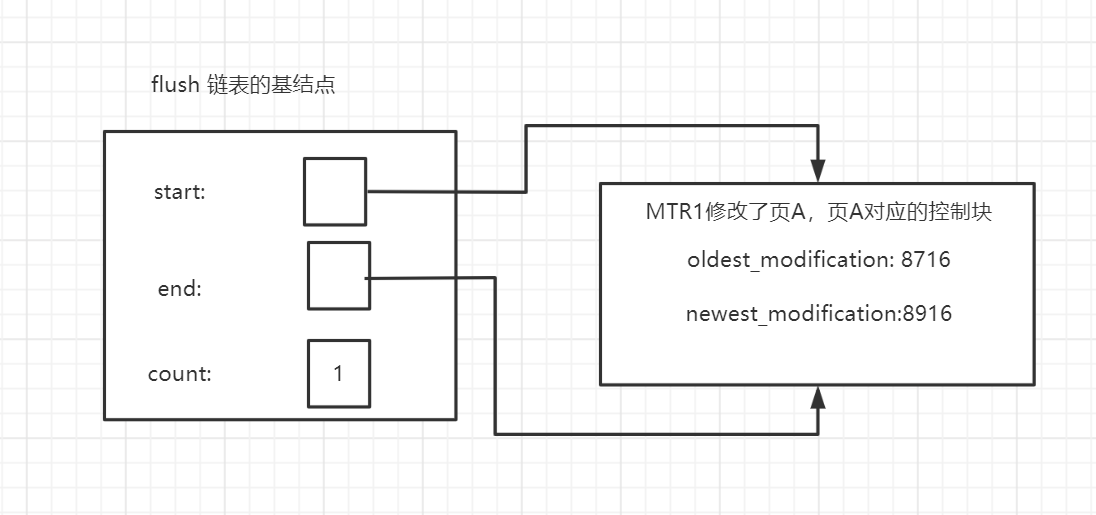
MTR2後續修改了頁B和頁C,頁B,頁C最開始不在flush鏈表中,背修改後加入到鏈表的頭部,也就是說,越靠近頭部,修改的時間就越晚,如下:

如果此時在flush鏈表中的頁被修改,只需要更新newest_modification即可。flush鏈表按照第一次被更新時候的lsn排序,也就是按照oldest_modification進行排序,多次修改位於flush鏈表中的頁只會更新其newest_modification
7.checkpoint
由於redo log日誌文件文件是有限的,所有需要循環使用redolog 日誌文件組中的文件。redo log存在的目的是系統崩潰後恢復臟頁,如果對應的臟頁已經刷新到磁碟中,那麼即使系統崩潰,重啟之後頁不需要使用redo log恢復該頁面看,對應的redo log日誌也沒存在的必要了,佔用的磁碟空間可以進行重複使用,被其他redo log日誌覆蓋。那麼如何判斷哪些redo 日誌佔用的磁碟空間可以覆蓋昵,其對應的臟頁已經刷新到磁碟了昵?
innodb使用checkpoint_lsn記錄可以被覆蓋的redo log日誌總量
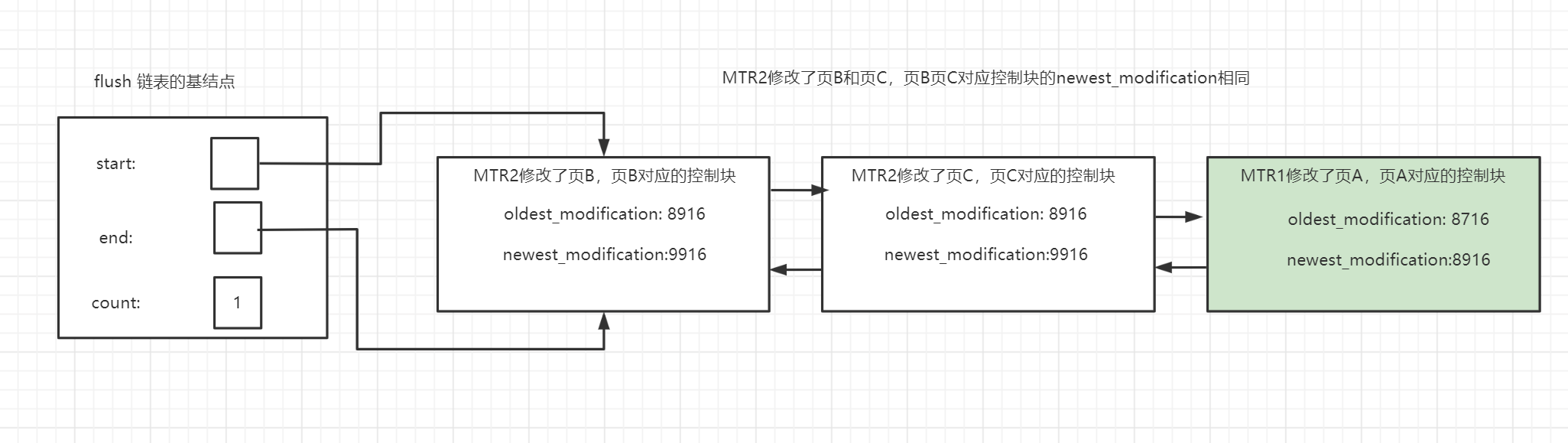
假如頁A已經被刷新到磁碟了,那麼頁A對應的控制塊會從flush鏈表中移除,MTR1生成的日誌可以被覆蓋了,就進行一個增加checkpoint_lsn的操作,這個過程稱作執行一次checkpoint(刷新臟頁到磁碟和執行一次checkpoint是兩回事,通常是不同執行緒上執行的,並不意味著每次刷新臟頁的時候都會執行一次checkpoint)
執行一次checkpoint的操作可以分為兩個步驟:
-
計算當前系統中可以覆蓋的redo日誌對應的lsn最大是多少
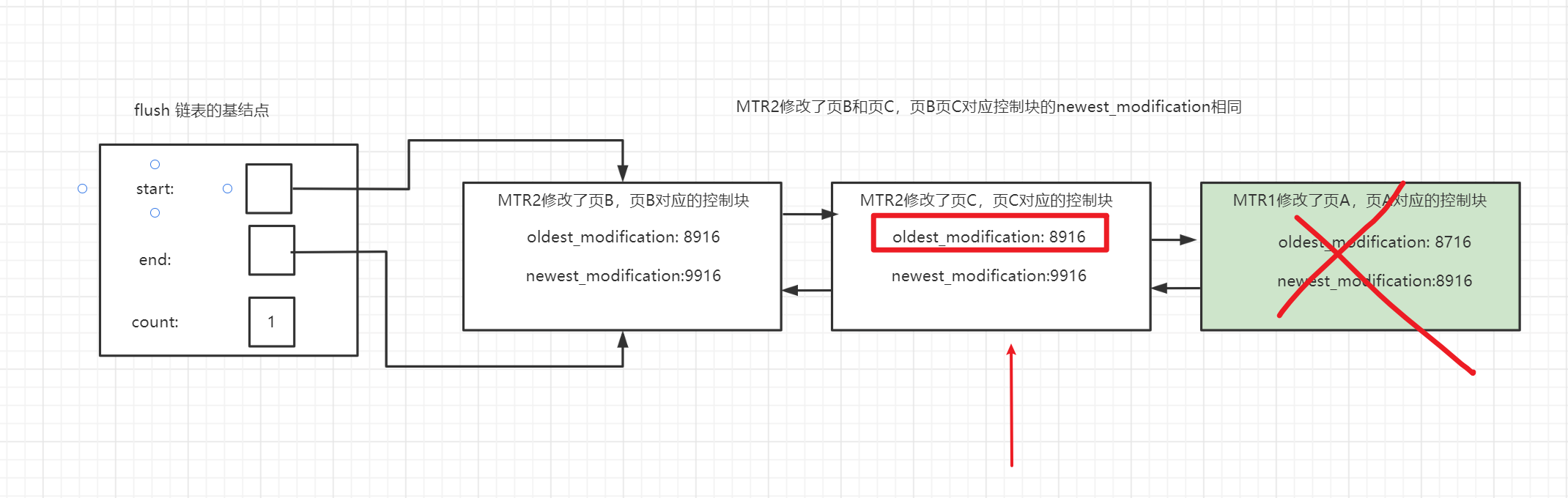
比如頁A已經被刷盤了,此時flush鏈表的尾部便是頁C,其
oldest_modification=8916那麼說明redo log日誌對應lsn值小於8916的均可被覆蓋,checkpoint_lsn的值會被設置為8916 -
將checkpoint_lsn和對應的日誌文件組偏移量和這次checkpoint的編號寫入到日誌文件的管理資訊中(checkpoint1,checkpoint2)
innodb使用
checkpoint_no記錄當前系統執行了多少次checkpoint,根據lsn值計算除redo log日誌的偏移量(lsn初始值為8704,redo日誌文件組偏移量為2048)計算得到checkpoint_offset,將checkpoint_no,checkpoint_lsn,checkpoint_offeset寫回到redo log日誌文件組管理資訊中,關於checkpoint的資訊,當checkpoint_no為偶數的時候會寫回到checkpoint1,反之寫入到checkpoint2中。

8.控制事務提交時刷新redo log日誌的選項——innodb_flush_log_at_trx_commit
如果每次事務提交時都要求將redolog刷新到磁碟,那麼帶來的IO代價必然影響到引擎執行效率,innodb具備innodb_flush_log_at_trx_commit配置項,來進行控制。其選項值的不同代表著不同的策略:
- 0:表示事務提交不立即向磁碟同步redo log,而是交由後台執行緒處理。這樣的好處時加快處理請求的速度,但是如果服務崩潰,後台執行緒也沒來得及刷新redo log,這時候會丟失事務對頁面的處理
- 1:表示每次事務提交都需要將redo log同步到磁碟,可以保證事務的持久性,這也是
innodb_flush_log_at_trx_commit的默認值 - 2:表示事務提交時,將redo log寫到作業系統的緩衝區中,但是並不需要真正持久化到磁碟,這樣事務的持久性在作業系統沒有崩潰的時候還是可以保證,但是如果作業系統也崩潰那麼還是無法保證持久性
六丶redo log用於崩潰恢復
1.確定恢復的起點
如果redo log對應的lsn小於checkpoint的話,意味這部分日誌對應的臟頁已經刷新到了磁碟中,是不需要進行恢復的。但是大於checkpoint的redo log,也許時需要恢復的,也許不需要,因為刷新臟頁到磁碟是非同步進行的,可能刷新臟頁到磁碟但是沒來得及修改checkpoint。這時候需要從對應lsn的值為checkpoint_lsn的redo log開始恢復
redo log日誌文件組有checkpoint1和checkpoint2記錄checkpoint_lsn的值,我們需要選取最近發生的checkpoint資訊,也就是將二者中的checkpoint_no拿出來比較比較,誰大說明誰存儲了最近一次checkpoint資訊,從而拿到最近發生checkpoint的checkpoint_lsn以及其對應的在redo 日誌文件組中偏移量checkpoint_offset
2.確定恢復的終點

寫入redo log到redo日誌文件中redo log block中時,是順序寫入的,先寫滿一個block再寫下一個block,每一個block的log block header部分有一個log_block_hdr_data_len來記錄當前lock block使用了多少位元組(從12開始,因為lock block header佔用了12位元組),隨著越來越多的日誌寫入block最後最大為512位元組`,所有如果此值小於512那麼說明,當前這個block就是崩潰恢復需要掃描的最後一個block。
在mysql進行崩潰恢復的時候,只需要從checkpoint_lsn在日誌文件組中對應的偏移量開始,掃描到第一個log_block_hdr_data_len值不為512的block為止
3.如何進行崩潰恢復
現在確定了需要恢復的redo log,那麼如何進行恢復昵,每一個redo log格式如下
3.1化隨機io為順序io
其space id記錄了表空間號,page number記錄了頁號,也許這一堆redo log整體上表空間號,頁號是不具備順序的,如果直接遍歷每一個redo log然後對錶空間中的頁進行恢復,是會帶來很多隨機io的,所以innodb使用hash表進行優化,將相同表空間號和頁號作為key,這樣相同表空間和頁的日誌就會在同一個hash桶中形成鏈表中,然後遍歷每一個hash表的操作,一次性將一個頁進行恢復,化隨機io為順序io
3.2跳過不需要刷新頁
首先小於最近一次checkpoint_lsn的redo log肯定是不需要進行恢復,但是大於的也不一定需要恢復,因為可能在做崩潰前的checkpoint的時候,後台執行緒也許將LRU鏈表和flush鏈表中的一些臟頁刷新到磁碟了,那麼恢復的時候這些臟頁也不需要進行恢復。那麼怎麼判斷這些不需要恢復的臟頁昵?——每一個頁面具備file header,其中有一個屬性為file_page_lsn的屬性,記錄了最近一次修改頁面時對應的lsn值(即臟頁在buffer pool控制塊中的newest_modification)如果執行某次checkpoint發現頁中的lsn大於最近一次checkpoint的checkpoint_lsn的時候,那麼說明此頁不需要進行更新。


