我的Spark學習筆記
一、架構設計
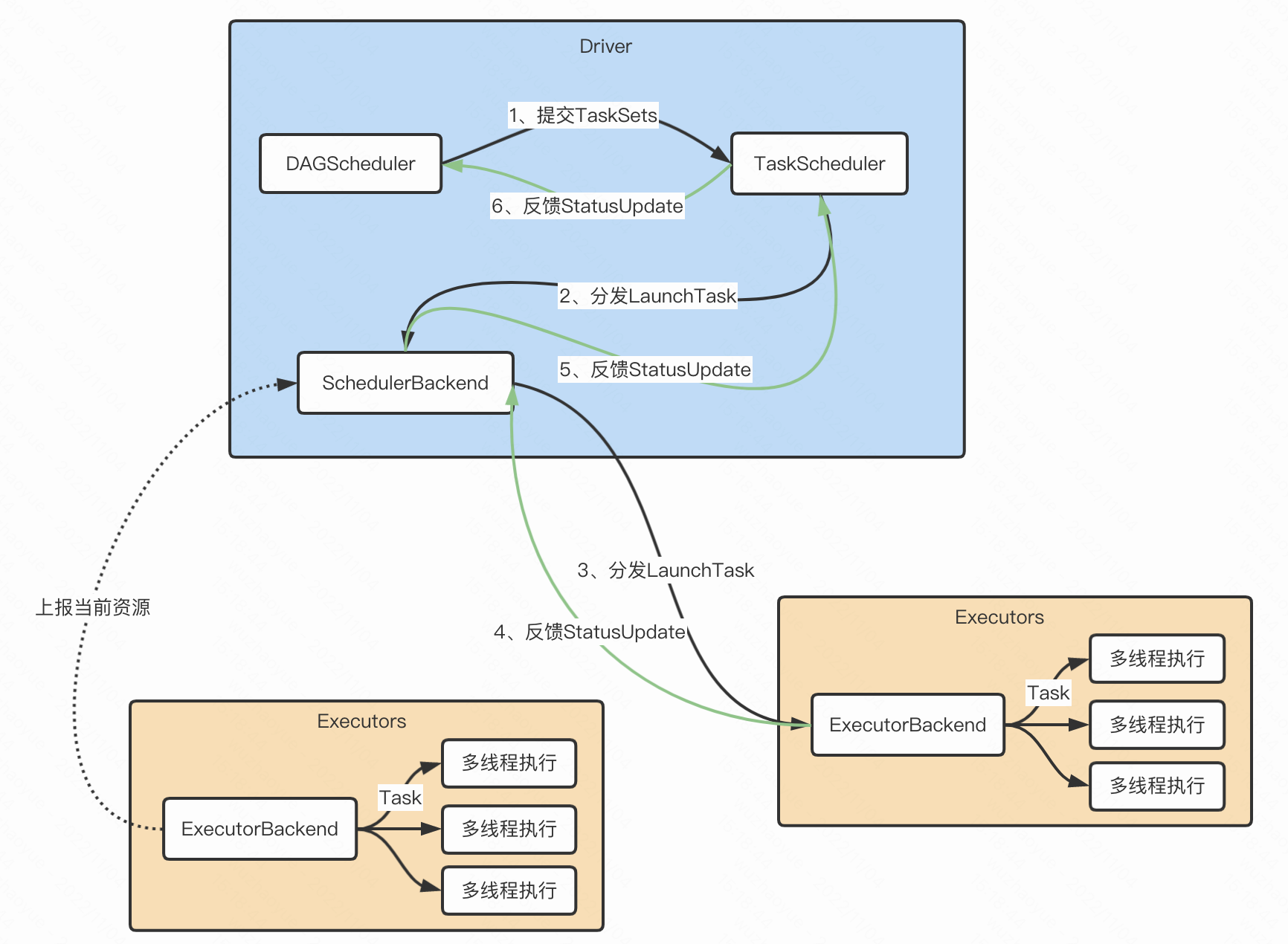
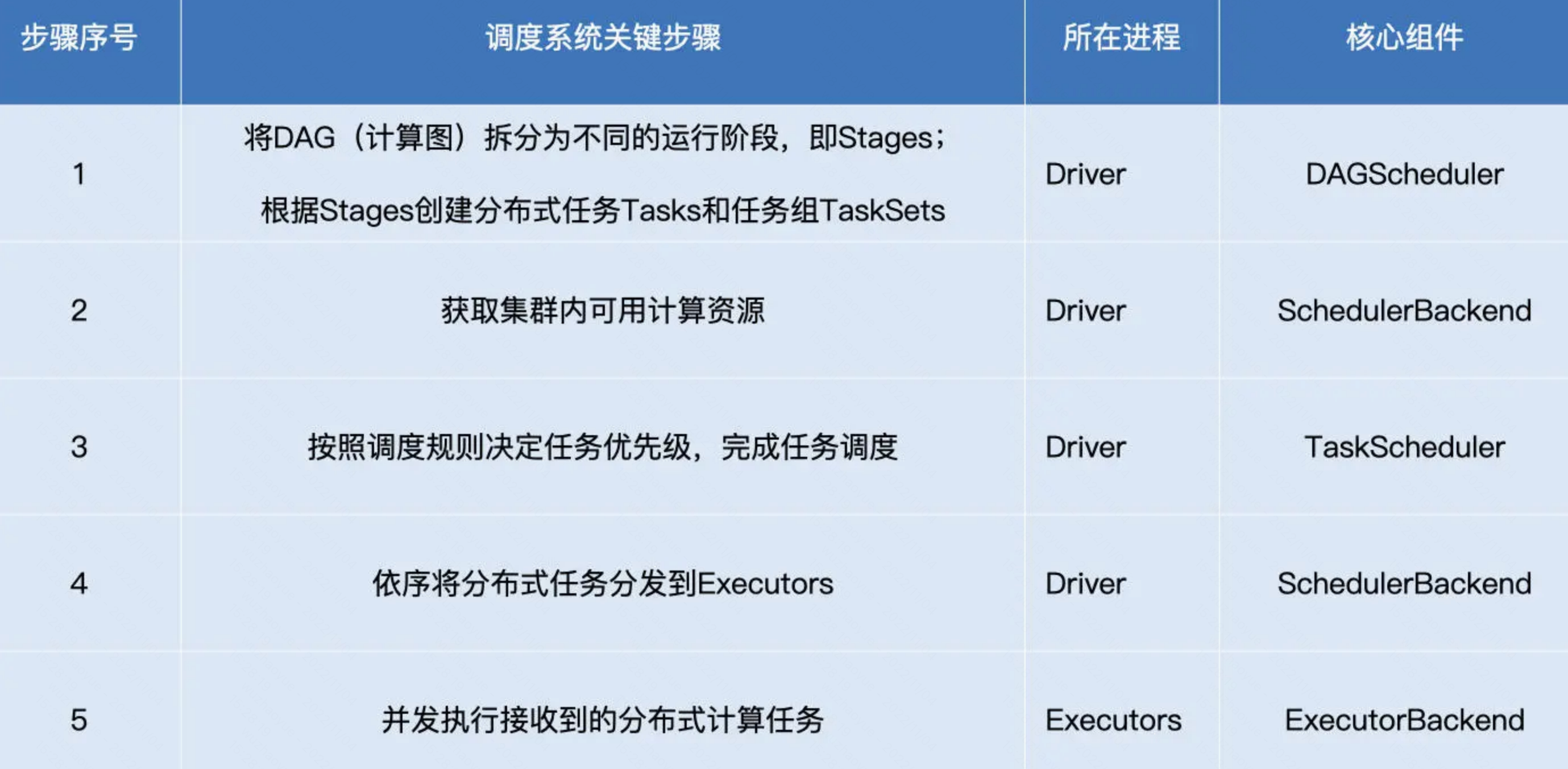
- Driver根據用戶程式碼構建計算流圖,拆解出分散式任務並分發到 Executors 中去;每個Executors收到任務,然後處理這個 RDD 的一個數據分片子集
- DAGScheduler根據用戶程式碼構建 DAG;以 Shuffle 為邊界切割 Stages;基於 Stages 創建 TaskSets,並將 TaskSets 提交給 TaskScheduler 請求調度
- TaskScheduler 在初始化的過程中,會創建任務調度隊列,任務調度隊列用於快取 DAGScheduler 提交的 TaskSets。TaskScheduler 結合 SchedulerBackend 提供的 WorkerOffer,按照預先設置的調度策略依次對隊列中的任務進行調度,也就是把任務分發給SchedulerBackend
- SchedulerBackend 用一個叫做 ExecutorDataMap 的數據結構,來記錄每一個計算節點中 Executors 的資源狀態。會與集群內所有 Executors 中的 ExecutorBackend 保持周期性通訊。SchedulerBackend收到TaskScheduler過來的任務,會把任務分發給ExecutorBackend去具體執行
- ExecutorBackend收到任務後多執行緒執行(一個執行緒處理一個Task)。處理完畢後回饋StatusUpdate給SchedulerBackend,再返回給TaskScheduler,最終給DAGScheduler
二、常用運算元
2.1、RDD概念
Spark 主要以一個 彈性分散式數據集_(RDD)的概念為中心,它是一個容錯且可以執行並行操作的元素的集合。有兩種方法可以創建 RDD:在你的 driver program(驅動程式)中 _parallelizing 一個已存在的集合,或者在外部存儲系統中引用一個數據集,例如,一個共享文件系統,HDFS,HBase,或者提供 Hadoop InputFormat 的任何數據源。
從記憶體創建RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 從記憶體創建RDD
object MakeRDDFromMemory {
def main(args: Array[String]): Unit = {
// 準備環境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
// 並行度,如果不設置則默認當前運行環境的最大可用核數
sparkConf.set("spark.default.parallelism", "2")
val sc = new SparkContext(sparkConf)
// 從記憶體中創建RDD,將記憶體中集合的數據作為處理的數據源
val seq = Seq[Int](1, 2, 3, 4, 5, 6)
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
// numSlices表示分區的數量,不傳默認spark.default.parallelism
val rdd2: RDD[Int] = sc.makeRDD(seq, 3)
// 將處理的數據保存成分區文件
rdd2.saveAsTextFile("output")
sc.stop()
}
}
從文件中創建RDD
import org.apache.spark.{SparkConf, SparkContext}
// 從文件中創建RDD(本地文件、HDFS文件)
object MakeRDDFromTextFile {
def main(args: Array[String]): Unit = {
// 準備環境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// 從文件中創建RDD,將文件中的數據作為處理的數據源
// path路徑默認以當前環境的根路徑為基準。可以寫絕對路徑,也可以寫相對路徑
//val rdd: RDD[String] = sc.textFile("datas/1.txt")
// path路徑可以是文件的具體路徑,也可以目錄名稱
//val rdd = sc.textFile("datas")
// path路徑還可以使用通配符 *
//val rdd = sc.textFile("datas/1*.txt")
// path還可以是分散式存儲系統路徑:HDFS
val rdd = sc.textFile("hdfs://localhost:8020/test.txt")
rdd.collect().foreach(println)
sc.stop()
}
}2.2、常用運算元
map運算元:數據轉換
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// map運算元
object map {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// 轉換函數
def mapFunction(num: Int): Int = {
num * 2
}
// 多種方式如下
// val mapRDD: RDD[Int] = rdd.map(mapFunction)
// val mapRDD: RDD[Int] = rdd.map((num: Int) => {
// num * 2
// })
// val mapRDD: RDD[Int] = rdd.map((num: Int) => num * 2)
// val mapRDD: RDD[Int] = rdd.map((num) => num * 2)
// val mapRDD: RDD[Int] = rdd.map(num => num * 2)
val mapRDD: RDD[Int] = rdd.map(_ * 2)
mapRDD.collect().foreach(println)
sc.stop()
}
}mapPartitions運算元:數據轉換(分區批處理)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* mapPartitions VS map
*
* map 傳入的是分區中的每個元素,是對每個元素就進行一次轉換和改變,但不會減少或增多元素
* mapPartitions 傳入的參數是Iterator返回值也是Iterator,所傳入的計算邏輯是對一個Iterator進行一次運算,可以增加或減少元素
*
*
* Map 運算元因為類似於串列操作,所以性能比較低,而是 mapPartitions 運算元類似於批處理,所以性能較高。
* 但是 mapPartitions 運算元會長時間佔用記憶體,這樣會導致記憶體OOM。而map會在記憶體不夠時進行GC。
*
* 詳細參考 //blog.csdn.net/AnameJL/article/details/121689987
*/
object mapPartitions {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// mapPartitions: 可以以分區為單位進行數據轉換操作,但是會將整個分區的數據載入到記憶體進行引用。
// 在記憶體較小,數據量較大的場合下,容易出現記憶體溢出。
val mpRDD: RDD[Int] = rdd.mapPartitions(iter => {
println("批處理當前分區數據")
iter.map(_ * 2)
})
mpRDD.collect().foreach(println)
sc.stop()
}
}mapPartitionsWithIndex運算元:分區索引 + 數據迭代器
import org.apache.spark.{SparkConf, SparkContext}
// 分區索引
object mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val mpiRDD = rdd.mapPartitionsWithIndex(
//(分區索引, 數據迭代器)
(index, iter) => {
println("index:" + index, "iter[" + iter.mkString(",") + "]")
}
)
mpiRDD.collect().foreach(println)
sc.stop()
}
}flatMap運算元:數據扁平化
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 將處理的數據進行扁平化後再進行映射處理,所以運算元也稱之為扁平映射
object flatMap {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[List[Int]] = sc.makeRDD(List(
List(1, 2), List(3, 4)
))
// 多個list合併成一個list
val flatRDD: RDD[Int] = rdd.flatMap(list => list)
flatRDD.collect().foreach(println)
sc.stop()
}
}glom運算元:分區內數據合併
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 將同一個分區的數據直接轉換為相同類型的記憶體數組進行處理,分區不變
object glom {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 把每一個分區內數據合併成Array
val glomRDD: RDD[Array[Int]] = rdd.glom()
glomRDD.collect().foreach(array => {
println(array.mkString(","))
})
sc.stop()
}
}groupBy運算元:數據分組
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 將數據根據指定的規則進行分組, 分區默認不變,但是數據會被打亂重新組合,我們將這樣的操作稱之為 shuffle。
// 極限情況下,數據可能被分在同一個分區中一個組的數據在一個分區中,但是並不是說一個分區中只有一個組,分組和分區沒有必然的關係
object groupBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// groupBy會將數據源中的每一個數據進行分組判斷,根據返回的分組key進行分組,相同的key值的數據會放置在一個組中
// val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(num => num % 2)
val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(_ % 2)
groupRDD.collect().foreach(println)
sc.stop()
}
}
filter運算元:數據過濾
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 將數據根據指定的規則進行篩選過濾,符合規則的數據保留,不符合規則的數據丟棄。
// 當數據進行篩選過濾後,分區不變,但是分區內的數據可能不均衡,生產環境下,可能會出現數據傾斜。
object filter {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val filterRDD: RDD[Int] = rdd.filter(num => num % 2 != 0)
filterRDD.collect().foreach(println)
sc.stop()
}
}
sample運算元:數據取樣隨機抽取
import org.apache.spark.{SparkConf, SparkContext}
// 根據指定的規則從數據集中抽取數據
object sample {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 1)
// 抽取數據不放回(伯努利演算法)
// 伯努利演算法:又叫 0、 1 分布。例如扔硬幣,要麼正面,要麼反面。
// 具體實現:根據種子和隨機演算法算出一個數和第二個參數設置幾率比較,小於第二個參數要,大於不要
// 第一個參數:抽取的數據是否放回, false:不放回
// 第二個參數:抽取的幾率,範圍只能在[0,1]之間,0:全不取; 1:全取;
// 第三個參數:隨機數種子
val dataRDD1 = dataRDD.sample(false, 0.5)
// 抽取數據放回(泊松演算法)
// 第一個參數:抽取的數據是否放回, true:放回; false:不放回
// 第二個參數:重複數據的幾率,範圍大於等於0,可以大於1 表示每一個元素被期望抽取到的次數
// 第三個參數:隨機數種子
// 例如數據集內有10個,fraction為1的話抽取10個, 0.5的話抽取5個,2的話抽取20個
val dataRDD2 = dataRDD.sample(true, 2)
println(dataRDD1.collect().mkString(","))
println(dataRDD2.collect().mkString(","))
sc.stop()
}
}
distinct運算元:數據去重
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object distinct {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))
val rdd1: RDD[Int] = rdd.distinct()
val rdd2: RDD[Int] = rdd.distinct(2)
// 底層相當於這樣寫
val rdd3 = rdd.map(x => (x, null)).reduceByKey((x, _) => x).map(_._1)
println(rdd.collect().mkString(","))
println(rdd1.collect().mkString(","))
println(rdd2.collect().mkString(","))
println(rdd3.collect().mkString(","))
sc.stop()
}
}
coalesce運算元:數據(shuffle可選)重新分區
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 根據數據量縮減分區,用於大數據集過濾後,提高小數據集的執行效率
* 當 spark 程式中,存在過多的小任務的時候,可以通過 coalesce 方法,收縮合併分區,減少分區的個數,減小任務調度成本
*/
object coalesce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 默認3個分區
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
// coalesce方法默認情況下不會將分區的數據打亂重新組合,默認shuffer=false
// 這種情況下的縮減分區可能會導致數據不均衡,出現數據傾斜,如果想要讓數據均衡,可以進行shuffle處理
// 縮減成2個分區並shuffer
val newRDD: RDD[Int] = rdd.coalesce(2, true)
newRDD.saveAsTextFile("output")
sc.stop()
}
}
repartition運算元:數據shuffle重新分區
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 該操作內部其實執行的是 coalesce 操作,參數 shuffle 的默認值為 true。
* 無論是將分區數多的RDD 轉換為分區數少的 RDD,還是將分區數少的 RDD 轉換為分區數多的 RDD,
* repartition操作都可以完成,因為無論如何都會經 shuffle 過程。
* 直接用repartition就行,coalesce就別用了
*/
object repartition {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 3)
// coalesce運算元可以擴大分區的,但是如果不進行shuffle操作,是沒有意義,不起作用。
// 所以如果想要實現擴大分區的效果,需要使用shuffle操作
/**
* 底層就是coalesce
* def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
* coalesce(numPartitions, shuffle = true)
* }
*/
// 縮減分區
val newRDD1: RDD[Int] = rdd.repartition(2)
// 擴大分區
val newRDD2: RDD[Int] = rdd.repartition(4)
rdd.saveAsTextFile("output0")
newRDD1.saveAsTextFile("output1")
newRDD2.saveAsTextFile("output2")
sc.stop()
}
}
sortBy運算元:數據排序
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 該操作用於排序數據。在排序之前,可以將數據通過 f 函數進行處理,之後按照 f 函數處理的結果進行排序,默認為升序排列。
* 排序後新產生的 RDD 的分區數與原 RDD 的分區數一致。 中間存在shuffle的過程。
*/
object sortBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 例子1
val rdd = sc.makeRDD(List(6, 2, 4, 5, 3, 1), 2)
val newRDD: RDD[Int] = rdd.sortBy(n => n)
println(newRDD.collect().mkString(","))
newRDD.saveAsTextFile("output")
// 例子2
val rdd2 = sc.makeRDD(List(("1", 1), ("3", 2), ("2", 3)), 2)
// sortBy方法可以根據指定的規則對數據源中的數據進行排序,默認為升序,第二個參數可以改變排序的方式
// sortBy默認情況下,不會改變分區。但是中間存在shuffle操作
val newRDD1 = rdd2.sortBy(t => t._1.toInt, false) // 降序
val newRDD2 = rdd2.sortBy(t => t._1.toInt, true) // 升序
newRDD1.collect().foreach(println)
newRDD2.collect().foreach(println)
sc.stop()
}
}
intersection union subtract zip:兩個數據源 交 並 差 拉鏈
/**
* 兩個數據源 交 並 差 拉鏈
*/
object intersection_union_subtract_zip {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 交集,並集和差集要求兩個數據源數據類型保持一致
val rdd1 = sc.makeRDD(List(1, 2, 3, 4))
val rdd2 = sc.makeRDD(List(3, 4, 5, 6))
// 交集 : 【3,4】
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
println(rdd3.collect().mkString(","))
// 並集 : 【1,2,3,4,3,4,5,6】
val rdd4: RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))
// 差集 : 【1,2】
val rdd5: RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
// 拉鏈 : 【1-3,2-4,3-5,4-6】
val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(rdd6.collect().mkString(","))
// 拉鏈操作兩個數據源的類型可以不一致,但要求分區中數據數量保持一致
val rdd7 = sc.makeRDD(List("a", "b", "c", "d"))
val rdd8 = rdd1.zip(rdd7)
println(rdd8.collect().mkString(","))
sc.stop()
}
}
partitionBy運算元:數據按照指定規則重新進行分區
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* partitionBy:數據按照指定規則重新進行分區。Spark 默認的分區器是 HashPartitioner
* repartition coalesce:將分區增加或縮小,數據是無規則的
*/
object partitionBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// PairRDDFunctions才支援partitionBy,所以需要先轉換成mapRDD
val mapRDD: RDD[(Int, Int)] = rdd.map(num => (num, 1))
// partitionBy根據指定的分區規則對數據進行重分區
val newRDD = mapRDD.partitionBy(new HashPartitioner(2))
newRDD.partitionBy(new HashPartitioner(2))
newRDD.saveAsTextFile("output")
sc.stop()
}
}
reduceByKey運算元:按相同key聚合
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 可以將數據按照相同的 Key 對 Value 進行聚合
*/
object reduceByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// reduceByKey : 相同的key的數據進行value數據的聚合操作
// scala語言中一般的聚合操作都是兩兩聚合,spark基於scala開發的,所以它的聚合也是兩兩聚合
// reduceByKey中如果key的數據只有一個,是不會參與運算的。
val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey((x: Int, y: Int) => {
println(s"x = ${x}, y = ${y}")
x + y
})
reduceRDD.collect().foreach(println)
sc.stop()
}
}
groupByKey運算元:根據key對數據分組
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* 將數據源的數據根據 key 對 value 進行分組
*
*
* reduceByKey 和 groupByKey的區別?
*
* 從 shuffle 的角度: reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey
* 可以在 shuffle 前對分區內相同 key 的數據進行預聚合(combine)功能,這樣會減少落盤的數據量。
* 而 groupByKey 只是進行分組,不存在數據量減少的問題, reduceByKey 性能比較高。
*
* 從功能的角度: reduceByKey 其實包含分組和聚合的功能。 groupByKey 只能分組,不能聚合。
* 所以在分組聚合的場合下,推薦使用 reduceByKey。如果僅僅是分組而不需要聚合,那麼還是只能使用 groupByKey。
*/
object groupByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// groupByKey : 將數據源中的數據,相同key的數據分在一個組中,形成一個對偶元組
// 元組中的第一個元素就是key,
// 元組中的第二個元素就是相同key的value的集合
val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
groupRDD.collect().foreach(println)
val groupRDD2: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
groupRDD2.collect().foreach(println)
val groupRDD3 = rdd.groupByKey(2)
val groupRDD4 = rdd.groupByKey(new HashPartitioner(2))
sc.stop()
}
}
aggregateByKey運算元:將數據根據不同的規則進行分區內計算和分區間計算
import org.apache.spark.{SparkConf, SparkContext}
/**
* 將數據根據不同的規則進行分區內計算和分區間計算
*
*/
object aggregateByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("a", 4)
), 2)
// aggregateByKey存在函數柯里化,有兩個參數列表
// 第一個參數列表,需要傳遞一個參數,表示為初始值
// 主要用於當碰見第一個key的時候,和value進行分區內計算
// 第二個參數列表需要傳遞2個參數
// 第一個參數表示分區內計算規則
// 第二個參數表示分區間計算規則
// 取出每個分區內相同key的最大值 然後分區間相加
rdd.aggregateByKey(0)((x, y) => math.max(x, y), (x, y) => x + y)
.collect.foreach(println)
sc.stop()
}
}
foldByKey運算元:和aggregateByKey類似
import org.apache.spark.{SparkConf, SparkContext}
/**
* 當分區內計算規則和分區間計算規則相同時,aggregateByKey就可以簡化為foldByKey
*/
object foldByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// rdd.aggregateByKey(0)(_+_, _+_).collect.foreach(println)
// 如果聚合計算時,分區內和分區間計算規則相同,spark提供了簡化的方法,用下面的替換上面的
rdd.foldByKey(0)(_ + _).collect.foreach(println)
sc.stop()
}
}
combineByKey運算元:和aggregateByKey類似
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 最通用的對 key-value 型 rdd 進行聚集操作的聚集函數(aggregation function)。
* 類似於aggregate(), combineByKey()允許用戶返回值的類型與輸入不一致。
*/
object combineByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// combineByKey : 方法需要三個參數
// 第一個參數表示:將相同key的第一個數據進行結構的轉換,實現操作
// 第二個參數表示:分區內的計算規則
// 第三個參數表示:分區間的計算規則
val newRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRDD.collect().foreach(println)
sc.stop()
}
}
reduceByKey、 foldByKey、 aggregateByKey、 combineByKey 的區別
reduceByKey: 相同 key 的第一個數據不進行任何計算,分區內和分區間計算規則相同
foldByKey: 相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則相同
aggregateByKey:相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則可以不相同
combineByKey:當計算時,發現數據結構不滿足要求時,可以讓第一個數據轉換結構,分區內和分區間計算規則不相同
join運算元:相同key連接
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 在類型為(K,V)和(K,W)的 RDD 上調用,返回一個相同 key 對應的所有元素連接在一起的(K,(V,W))的 RDD
*/
object join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("a", 2), ("c", 3), ("b", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 5), ("c", 6), ("a", 4)
))
// join : 兩個不同數據源的數據,相同的key的value會連接在一起,形成元組
// 如果兩個數據源中key沒有匹配上,那麼數據不會出現在結果中
// 如果兩個數據源中key有多個相同的,會依次匹配,可能會出現笛卡爾乘積,數據量會幾何性增長,會導致性能降低。
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
sc.stop()
}
}
leftOuterJoin rightOuterJoin:左外連接 右外連接
import org.apache.spark.{SparkConf, SparkContext}
/**
* 左外連接 右外連接
*/
object leftOuterJoin_rightOuterJoin {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2) //, ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6)
))
val leftJoinRDD = rdd1.leftOuterJoin(rdd2)
val rightJoinRDD = rdd1.rightOuterJoin(rdd2)
leftJoinRDD.collect().foreach(println)
rightJoinRDD.collect().foreach(println)
sc.stop()
}
}
cogroup運算元:分組 連接
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 分組 連接
*/
object cogroup {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2) //, ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6), ("c", 7)
))
// cogroup : connect + group (分組,連接)
val cgRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
sc.stop()
}
}
參考資料:Spark中文文檔 尚矽谷Spark教程


