實際應用效果不佳?來看看提升深度神經網路泛化能力的核心技術(附程式碼)

💡 作者:韓信子@ShowMeAI
📘 深度學習實戰系列://www.showmeai.tech/tutorials/42
📘 本文地址://www.showmeai.tech/article-detail/317
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

神經網路是一種由神經元、層、權重和偏差組合而成的特殊機器學習模型,隨著近些年深度學習的高速發展,神經網路已被廣泛用於進行預測和商業決策並大放異彩。
神經網路之所以廣受追捧,是因為它們能夠在學習能力和性能方面遠遠超過任何傳統的機器學習演算法。 現代包含大量層和數十億參數的網路可以輕鬆學習掌握互聯網海量數據下的模式和規律,並精準預測。

隨著AI生態和各種神經網路工具庫(Keras、Tensorflow 和 Pytorch 等)的發展,搭建神經網路擬合數據變得非常容易。但很多時候,在用於學習的訓練數據上表現良好的模型,在新的數據上卻效果不佳,這是模型陷入了『過擬合』的問題中了,在本篇內容中,ShowMeAI將給大家梳理幫助深度神經網路緩解過擬合提高泛化能力的方法。

💡 數據增強
📌 技術介紹
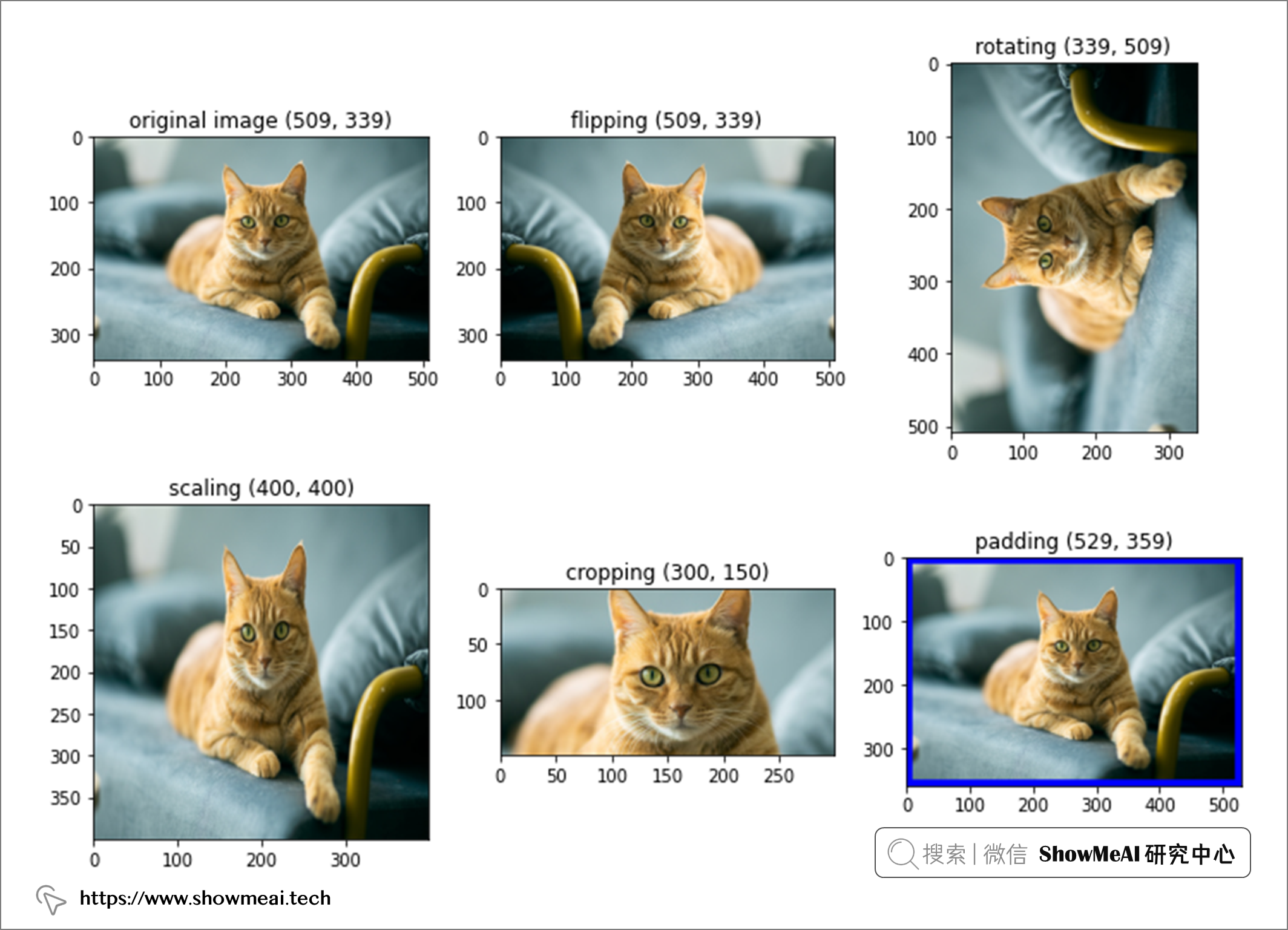
緩解過擬合最直接的方法是增加數據量,在數據量有限的情況下可以採用數據增強技術。 數據增強是從現有訓練樣本中構建新樣本的過程,例如在電腦視覺中,我們會為卷積神經網路擴增訓練影像。
具體體現在電腦視覺中,我們可以對影像進行變換處理得到新突破,例如位置和顏色調整是常見的轉換技術,常見的影像處理還包括——縮放、裁剪、翻轉、填充、旋轉和平移。
📌 手動數據處理&增強
我們可以基於PIL庫手動對影像處理得到新影像以擴增樣本量
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT) ### 翻轉
roated_img = img.transpose(Image.ROTATE_90) ## 旋轉
scaled_img = img.resize((400, 400)) ### 影像縮放
cropped_img = img.crop((100,50,400,200)) # 裁剪
# 顏色變換
width, height = img.size
pad_pixel = 20
canvas = Image.new(img.mode, (width+pad_pixel, height+pad_pixel), 'blue')
canvas.paste(img, (pad_pixel//2,pad_pixel//2))
顏色增強處理通過改變影像的像素值來改變影像的顏色屬性。更細一點講,可以通過改變亮度、對比度、飽和度、色調、灰度、膨脹等來處理。
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
enhancer = ImageEnhance.Brightness(img)
img2 = enhancer.enhance(1.5) ## 更亮
img3 = enhancer.enhance(0.5) ## 更暗
imageenhancer = ImageEnhance.Contrast(img)
img4 = enhancer.enhance(1.5) ## 提升對比度
img5 = enhancer.enhance(0.5) ## 降低對比度
enhancer = ImageEnhance.Sharpness(img)
img6 = enhancer.enhance(5) ## 銳化

雖然可以通過使用像 pillow 和 OpenCV 這樣的影像處理庫來手動執行影像增強,但更簡單且耗時更少的方法是使用 📘Keras API 來完成。
關於keras的核心知識,ShowMeAI為其製作了速查手冊,歡迎大家通過如下文章快查快用:
Keras 是一個用 Python 編寫的深度學習 API,可以運行在機器學習平台 Tensorflow 之上。 Keras 有許多可提高實驗速度的內置方法和類。 在 Keras 中,我們有一個 📘ImageDataGenerator類,它為影像增強提供了多個選項。
keras.preprocessing.image.ImageDataGenerator()
📘參數:
- featurewise_center: 布爾值。將輸入數據的均值設置為 0,逐特徵進行。
- samplewise_center: 布爾值。將每個樣本的均值設置為 0。
- featurewise_std_normalization: Boolean. 布爾值。將輸入除以數據標準差,逐特徵進行。
- samplewise_std_normalization: 布爾值。將每個輸入除以其標準差。
- zca_epsilon: ZCA 白化的 epsilon 值,默認為 1e-6。
- zca_whitening: 布爾值。是否應用 ZCA 白化。
- rotation_range: 整數。隨機旋轉的度數範圍。
- width_shift_range: 浮點數、一維數組或整數
- float: 如果 <1,則是除以總寬度的值,或者如果 >=1,則為像素值。
- 1-D 數組: 數組中的隨機元素。
- int: 來自間隔
(-width_shift_range, +width_shift_range)之間的整數個像素。 width_shift_range=2時,可能值是整數[-1, 0, +1],與width_shift_range=[-1, 0, +1]相同;而width_shift_range=1.0時,可能值是[-1.0, +1.0)之間的浮點數。
- height_shift_range: 浮點數、一維數組或整數
- float: 如果 <1,則是除以總寬度的值,或者如果 >=1,則為像素值。
- 1-D array-like: 數組中的隨機元素。
- int: 來自間隔
(-height_shift_range, +height_shift_range)之間的整數個像素。 height_shift_range=2時,可能值是整數[-1, 0, +1],與height_shift_range=[-1, 0, +1]相同;而height_shift_range=1.0時,可能值是[-1.0, +1.0)之間的浮點數。
- shear_range: 浮點數。剪切強度(以弧度逆時針方向剪切角度)。
- zoom_range: 浮點數 或
[lower, upper]。隨機縮放範圍。如果是浮點數,[lower, upper] = [1-zoom_range, 1+zoom_range]。 - channel_shift_range: 浮點數。隨機通道轉換的範圍。
- fill_mode: {“constant”, “nearest”, “reflect” or “wrap”} 之一。默認為 ‘nearest’。輸入邊界以外的點根據給定的模式填充。
- cval: 浮點數或整數。用於邊界之外的點的值,當
fill_mode = "constant"時。 - horizontal_flip: 布爾值。隨機水平翻轉。
- vertical_flip: 布爾值。隨機垂直翻轉。
- rescale: 重縮放因子。默認為 None。如果是 None 或 0,不進行縮放,否則將數據乘以所提供的值(在應用任何其他轉換之前)。
- preprocessing_function: 應用於每個輸入的函數。這個函數會在任何其他改變之前運行。這個函數需要一個參數:一張影像(秩為 3 的 Numpy 張量),並且應該輸出一個同尺寸的 Numpy 張量。
- data_format: 影像數據格式,{“channels_first”, “channels_last”} 之一。”channels_last” 模式表示影像輸入尺寸應該為
(samples, height, width, channels),”channels_first” 模式表示輸入尺寸應該為(samples, channels, height, width)。默認為 在 Keras 配置文件~/.keras/keras.json中的image_data_format值。如果你從未設置它,那它就是 “channels_last”。 - validation_split: 浮點數。Float. 保留用於驗證的影像的比例(嚴格在0和1之間)。
- dtype: 生成數組使用的數據類型。
📌 基於 TensorFlow 的數據增強
如果要基於 TensorFlow 實現數據增強,示例程式碼如下:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range= [0.5, 1.5],
rescale=1./255,
shear_range=0.2,
zoom_range=0.4,
horizontal_flip=True,
fill_mode='nearest',
zca_epsilon=True)
path = '/content/drive/MyDrive/cat.jpg' ## Image Path
img = load_img(f"{path}")
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
### 基於數據增強構建25張圖片並存入aug_img文件夾
for batch in datagen.flow(x, batch_size=1, save_to_dir="/content/drive/MyDrive/aug_imgs", save_prefix='img', save_format='jpeg'):
i += 1
if i > 25:
break

💡 Dropout 隨機失活
關於隨機失活的詳細原理知識,大家可以查看ShowMeAI製作的深度學習系列教程和對應文章
📌 技術介紹
Dropout 層是解決深度神經網路中過度擬合的最常用方法。 它通過動態調整網路來減少過擬合的概率。
Dropout 層 隨機 在訓練階段以概率rate隨機將輸入單元丟棄(可以認為是對輸入置0),未置0的輸入按 1/(1 – rate) 放大,以使所有輸入的總和保持不變。
丟棄率rate 是主要參數,範圍從 0 到 1。0.5 的rate取值意味著 50% 的神經元在訓練階段從網路中隨機丟棄。
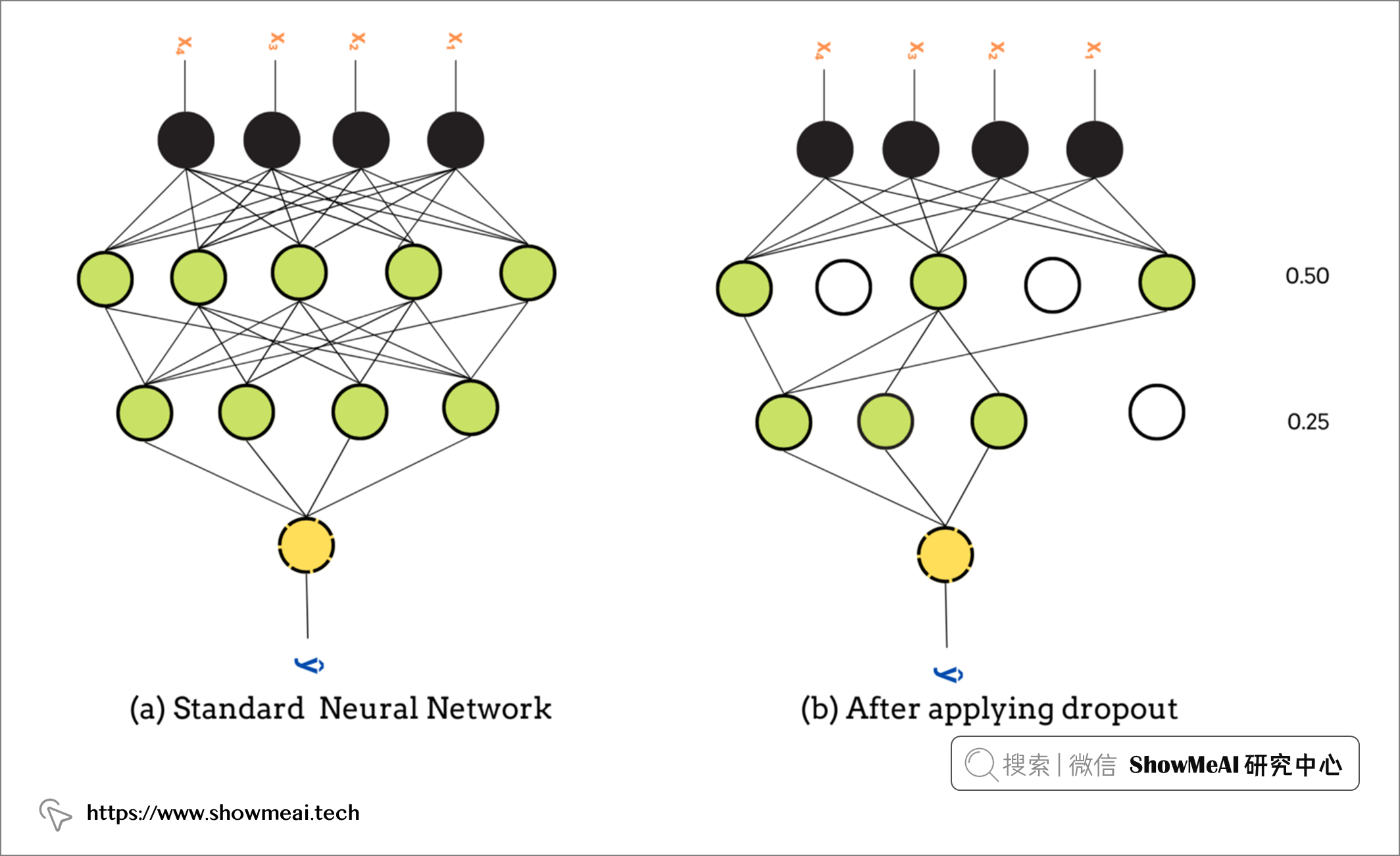
TensorFlow中的dropout使用方式如下
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None)
📘參數
rate: 在 0 和 1 之間浮動,丟棄概率。noise_shape:1D 整數張量,表示將與輸入相乘的二進位 dropout 掩碼的形狀。seed: 隨機種子。
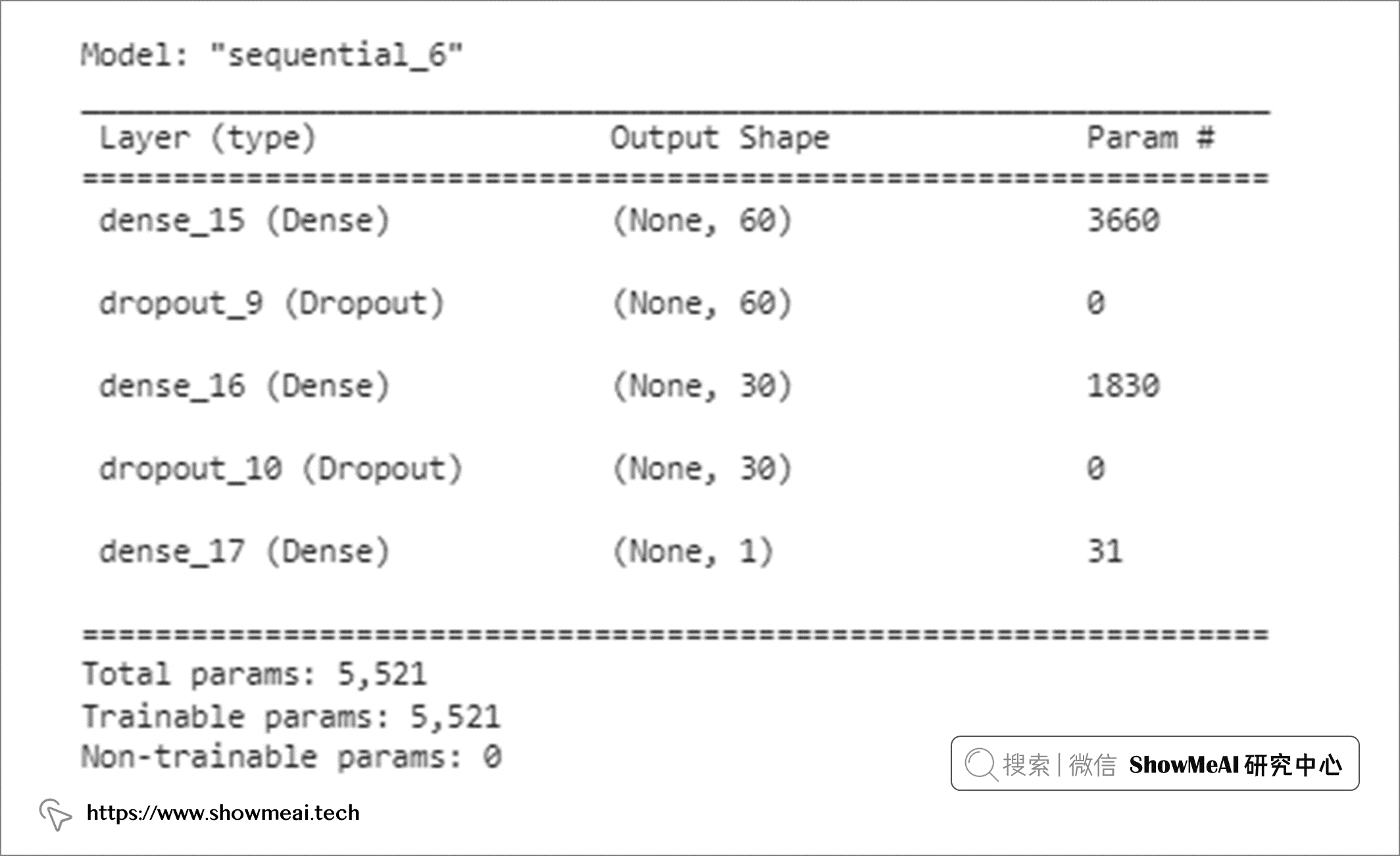
📌 基於TensorFlow應用Dropout
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
model = Sequential()
model.add(Dense(60, input_shape=(60,), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(30, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
在向神經網路添加 dropout 層時,有一些技巧大家可以了解一下:
- 一般會使用 20%-50% 的小的 dropout 值,太大的 dropout 值可能會降低模型性能,同時選擇非常小的值不會對網路產生太大影響。
- 一般在大型網路中會使用dropout層以獲得最大性能。
- 輸入層和隱層上都可以使用 dropout,表現都良好。
💡 L1 和 L2 正則化
關於正則化的詳細原理知識,大家可以查看ShowMeAI製作的深度學習系列教程和對應文章
📌 技術介紹
正則化是一種通過懲罰損失函數來降低網路複雜性的技術。 它為損失函數添加了一個額外的權重約束部分,它在模型過於複雜的時候會進行懲罰(高loss),簡單地說,正則化限制權重幅度過大。
L1 正則化的公式如下:

L2 正則化公式如下:

📌 基於TensorFlow應用正則化
在TensorFlow搭建神經網路時,我們可以直接在添加對應的層次時,通過參數設置添加正則化項。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
# 構建模型
model = Sequential()
# 添加正則化
model.add(Dense(60, input_shape=(60,), activation='relu', kernel_regularizer=keras.regularizers.l1(0.01)))
model.add(Dropout(0.2))
# 添加正則化
model.add(Dense(30, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
💡 Early Stopping / 早停止
📌 技術介紹
在深度學習中,一個 epoch指的是完整訓練數據進行一輪的訓練。迭代輪次epoch的多少對於模型的狀態影響很大:如果我們的 epoch 設置太大,訓練時間越長,也更可能導致模型過擬合;但過少的epoch可能會導致模型欠擬合。
Early stopping早停止是一種判斷迭代輪次的技術,它會觀察驗證集上的模型效果,一旦模型性能在驗證集上停止改進,就會停止訓練過程,它也經常被使用來緩解模型過擬合。
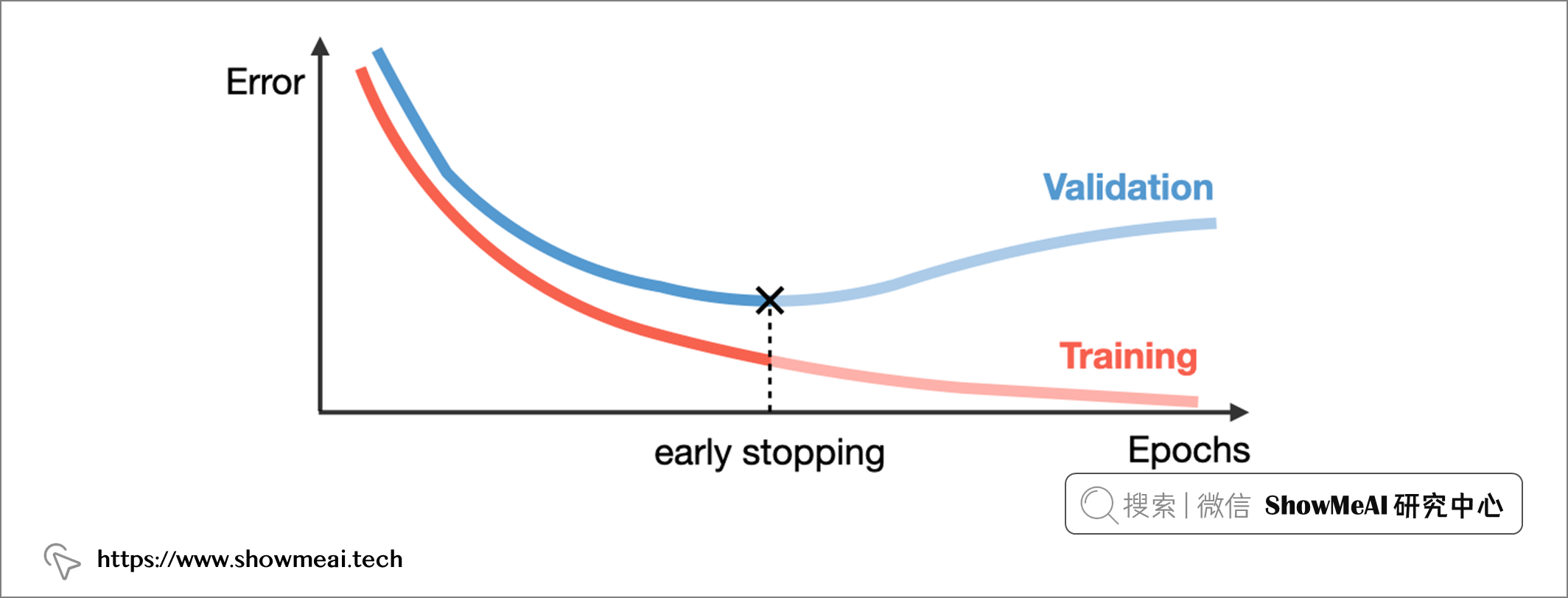
📌 基於TensorFlow應用Early stopping
Keras 有一個回調函數,可以直接完成early stopping。
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=0,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=False
)
📘參數
- monitor: 被監測的數據。
- min_delta: 在被監測的數據中被認為是提升的最小變化, 例如,小於 min_delta 的絕對變化會被認為沒有提升。
- patience: 沒有進步的訓練輪數,在這之後訓練就會被停止。
- verbose: 詳細資訊模式。
- mode: {auto, min, max} 其中之一。 在
min模式中, 當被監測的數據停止下降,訓練就會停止;在max模式中,當被監測的數據停止上升,訓練就會停止;在auto模式中,方向會自動從被監測的數據的名字中判斷出來。 - baseline: 要監控的數量的基準值。 如果模型沒有顯示基準的改善,訓練將停止。
- restore_best_weights: 是否從具有監測數量的最佳值的時期恢復模型權重。 如果為 False,則使用在訓練的最後一步獲得的模型權重。
from tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(monitor='loss', patience=2)history = model.fit(
X_train,
y_train,
epochs= 100,
validation_split= 0.20,
batch_size= 50,
verbose= "auto",
callbacks= [early_stopping]
)
💡 總結
ShowMeAI在本篇內容中,對緩解過擬合的技術做了介紹和應用講解,大家可以在實踐中選擇和使用。『數據增強』技術將通過構建和擴增樣本集來緩解模型過擬合,dropout 層通過隨機丟棄一些神經元來降低網路複雜性,正則化技術將懲罰網路訓練得到的大幅度的權重,early stopping 會防止網路過度訓練和學習。
參考資料
- 📘 Keras://keras.io/
- 📘 ImageDataGenerator://keras.io/zh/preprocessing/image/
- 📘 AI垂直領域工具庫速查表 | Keras 速查表://www.showmeai.tech/article-detail/110
- 📘 深度學習教程:吳恩達專項課程 · 全套筆記解讀://www.showmeai.tech/tutorials/35
- 📘 深度學習教程 | 深度學習的實用層面://www.showmeai.tech/article-detail/216
- 📘 深度學習與電腦視覺教程:斯坦福CS231n · 全套筆記解讀://www.showmeai.tech/tutorials/37
- 📘 深度學習與CV教程(7) | 神經網路訓練技巧 (下)://www.showmeai.tech/article-detail/266