高保真神經網路音頻編碼器
高保真神經網路音頻編碼器
本文介紹了meta推出的音頻AI Codec,其整體風格深受Google的SoundStream的影響。在其影響下改進了原有的肩背起,引入語言模型進一步降低碼率,並提出了一種提升穩定性的訓練策略。
論文題目:High Fidelity Neural Audio Compression
作者:Alexandre Défossez, Jade Copet, Gabriel Symmaeve, Yossi Adi (Meta AI, FAIR Team)

背景動機
- 與之前的AI Codec的動機相同,本文同樣希望藉助深度學習設計一款端到端多碼率、立體聲音頻編碼器,實現對語音和音樂的低碼率壓縮並高品質還原。
- 神經網路天然的抽象特徵提取能力使其具有相比傳統編碼器更強的訊號表徵壓縮能力,低碼率的問題相對並不困難;
- 難點主要有兩點:1. 音頻的動態範圍過大;2. 模型效率問題(計算複雜度和參數量)
本文貢獻:
- 為解決音頻動態範圍過大的問題,使用龐大多樣的訓練集以及用鑒別器作為感知損失(這點似乎相比SoundStream)也並未見有什麼突破;
- 限制在單核CPU上實時運行,並採用殘差矢量量化(Residual Vector Quantization, RVQ)提高編碼效率;
- 提出了語言模型進一步降低碼率;
- 鑒別器採用多解析度複數譜STFT鑒別器;
- 提出了一種balancer以保證GAN訓練的穩定性
模型架構

模型採用的基於GAN的模型,生成器採用時域編碼器-量化器-解碼器結構,鑒別器採用多解析度的STFT鑒別器。
編解碼器:編解碼器採用SEANET,編碼器由一層一維卷積對時域波形進行特徵提取後經過B個用於降取樣的殘差單元(即convolurion blocks),而後加入了兩層LSTM用於序列建模,最後經過一層卷積得到音頻的潛在表徵。解碼器則是編碼器的鏡像,其中殘差單元的卷積被替換為反卷積用於上取樣。根據文中採用的下取樣因子(通過卷積的stride實現){2,4,5,8},其編碼器將音頻下取樣320倍(2x4x5x8=320),即傳輸的一幀中壓縮了320個取樣點,因此在取樣率為24kHz時1s的音頻經編碼器輸出的時間維數為24000/320=75,48kHz時為48000/320=150。通過卷積的Padding和調整Nomalization去設置模型是否流式。
量化器:量化器採用殘差矢量量化RVQ,關於RVQ的詳細介紹參看 和 。每個碼書包含1024個向量(entries),對於取樣率為24kHz的音頻,最多使用32個碼書,即最大碼率為32x \(\log_2(1024)\) /13.3=24kbps。為了支援多碼率,訓練過程中碼書數量被設置為{2,4,8,16,32},分別對應1.5kbps,3kbps,6kbps,12kbps,24kbps;且每個碼率在訓練時所使用的鑒別器是不同的。
語言模型和熵編碼:此部分可選,使用Transormer語音模型對RVQ得到的索引映射到新隱藏空間的概率分布,對對應概率密度函數的累積分布函數進行Range Coder熵編碼,從而進一步降低碼率。
鑒別器:採用多解析度複數STFT鑒別器,而非TTS中常見的多解析度Mel譜鑒別器,也沒加Multiple-period 鑒別器MPD(消融實驗顯示多解析度複數STFT鑒別器性能更優,額外引入MPD有少量性能提升,但考慮訓練時長捨棄)。每個解析度的鑒別器有二維卷積組成,結構如圖所示(注意:其中正文和圖中的卷積核尺寸不一致,3×8 v.s. 3×9)。
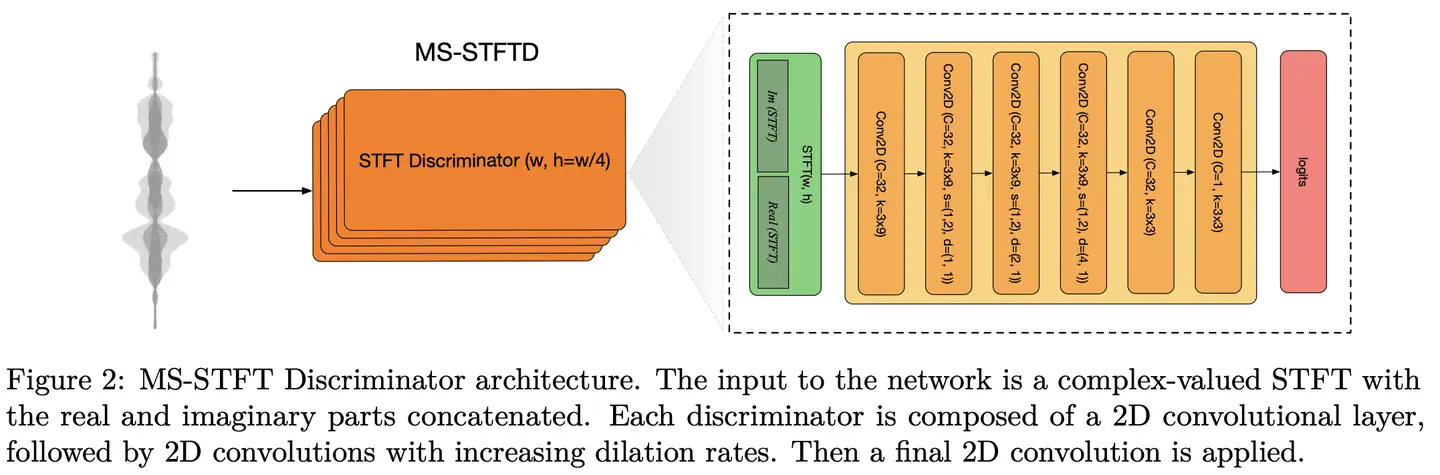
鑒別器採用hinge loss訓練,為保證生成器和鑒別器訓練平衡穩定,鑒別器以2/3的概率更新其參數

生成器的損失函數
包括重構損失、感知損失(實為對抗損失)以及RVQ的commitment loss三部分:

重構損失包括時域和頻域兩部分,時域損失是波形的L1損失

頻域損失是多時間尺度的Mel譜損失

對抗損失採用hinge loss和特徵匹配損失,分別為:


commitment loss用於使VQ選擇的向量滿足量化後的變數與未量化的變數間最相近,採用歐式距離度量則為:

除了commitment loss之外,其他生成器loss均採用本文提出的平衡器以穩定訓練,即在梯度更新時則反向傳播 \(\sum_{i}{\tilde{g}\_{i}}\) ,其中 \(g_i\) 由第 \(i\) 個損失函數對應的梯度 \(g_i=\frac{\partial{l_i}}{\partial{x}}\) 對其指數平均項 \(\langle ||g_i||\rangle_{\beta}\)歸一化後重加權得到,定義為

訓練參數:300 epochs, with one epoch being 2,000 updates with the Adam optimizer with a batch size of 64 examples of 1 second each, a learning rate of 3 · 10−4 , \(\beta_1\) = 0.5, and \(\beta_2\) = 0.9. All the models are traind using 8 A100 GPUs. We use the balancer introduced in Section 3.4 with weights \(\lambda_t\) = 0.1, \(\lambda_f\) = 1, \(\lambda_g\) = 3, \(\lambda_{feat}\) = 3 for the 24 kHz models.
數據與結果
數據源:speech:DNS Challenge 4 and the Common Voice dataset; general audio: AudioSet and FSD50K; music: Jamendo dataset
數據增廣策略:多數據源混合;加混響;音量標準化並隨機化增益-10~6 dB;無clip
結果:
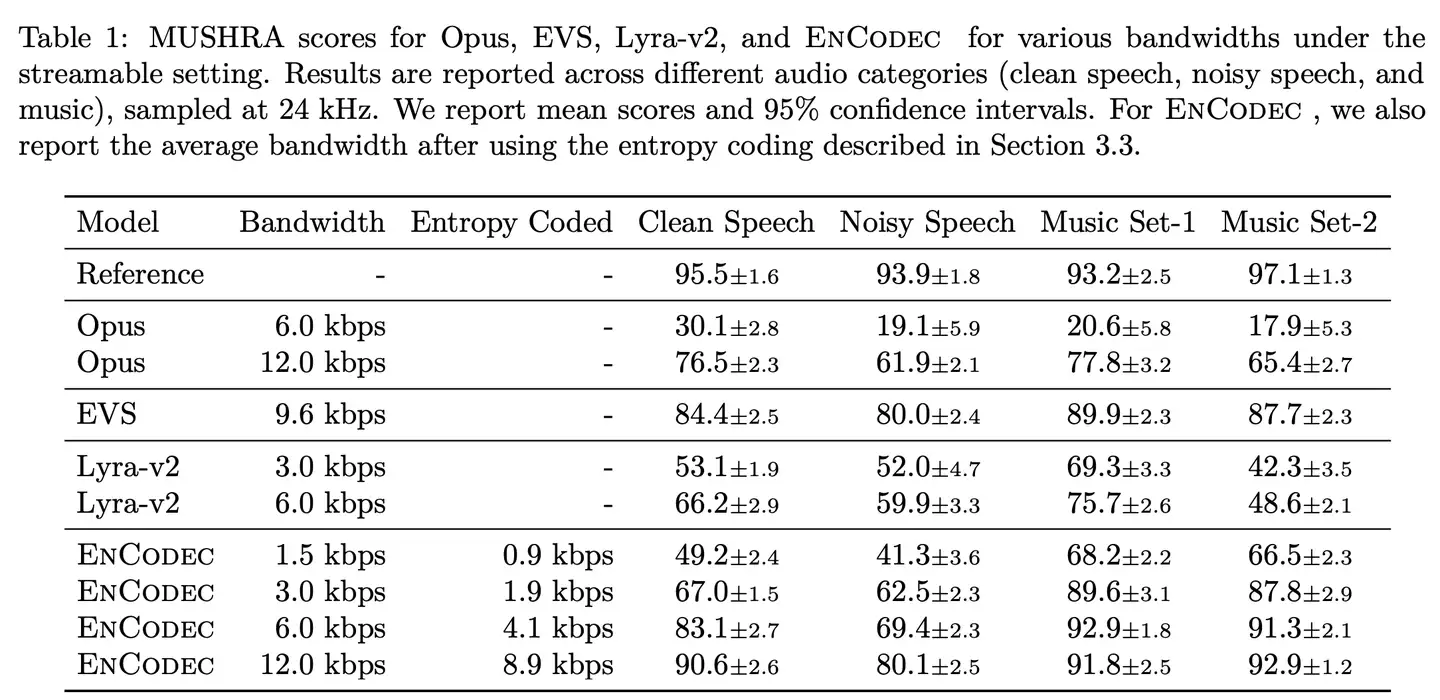
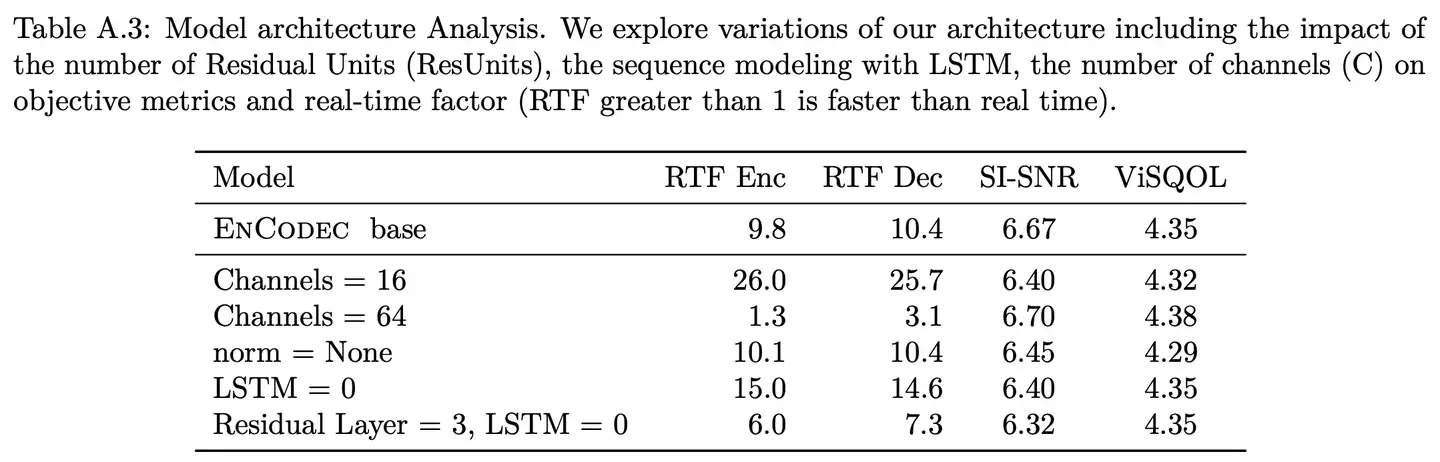
- 通道數對性能影響較小但顯著影響實時率
- 殘差模組和LSTM都顯著影響實時率