什麼是ForkJoin?看這一篇就能掌握!
摘要:ForkJoin是由JDK1.7之後提供的多執行緒並發處理框架。
本文分享自華為雲社區《【高並發】什麼是ForkJoin?看這一篇就夠了!》,作者: 冰 河。
在JDK中,提供了這樣一種功能:它能夠將複雜的邏輯拆分成一個個簡單的邏輯來並行執行,待每個並行執行的邏輯執行完成後,再將各個結果進行匯總,得出最終的結果數據。有點像Hadoop中的MapReduce。
ForkJoin是由JDK1.7之後提供的多執行緒並發處理框架。ForkJoin框架的基本思想是分而治之。什麼是分而治之?分而治之就是將一個複雜的計算,按照設定的閾值分解成多個計算,然後將各個計算結果進行匯總。相應的,ForkJoin將複雜的計算當做一個任務,而分解的多個計算則是當做一個個子任務來並行執行。
Java並發編程的發展
對於Java語言來說,生來就支援多執行緒並發編程,在並發編程領域也是在不斷發展的。Java在其發展過程中對並發編程的支援越來越完善也正好印證了這一點。
- Java 1 支援thread,synchronized。
- Java 5 引入了 thread pools, blocking queues, concurrent collections,locks, condition queues。
- Java 7 加入了fork-join庫。
- Java 8 加入了 parallel streams。
並發與並行
並發和並行在本質上還是有所區別的。
並發
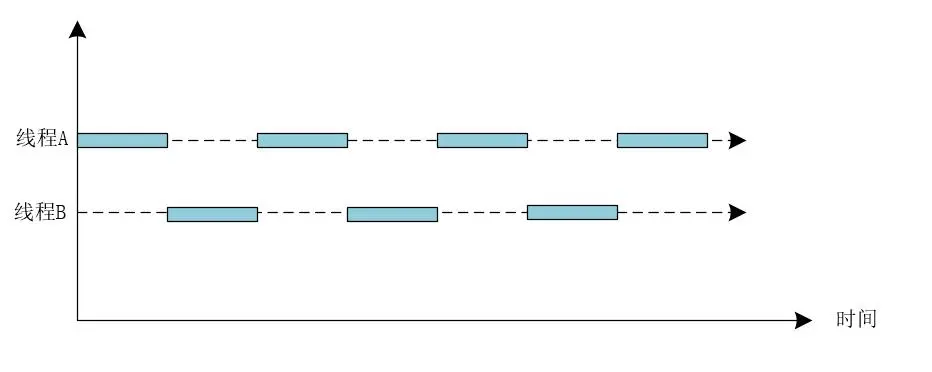
並髮指的是在同一時刻,只有一個執行緒能夠獲取到CPU執行任務,而多個執行緒被快速的輪換執行,這就使得在宏觀上具有多個執行緒同時執行的效果,並發不是真正的同時執行,並發可以使用下圖表示。
並行
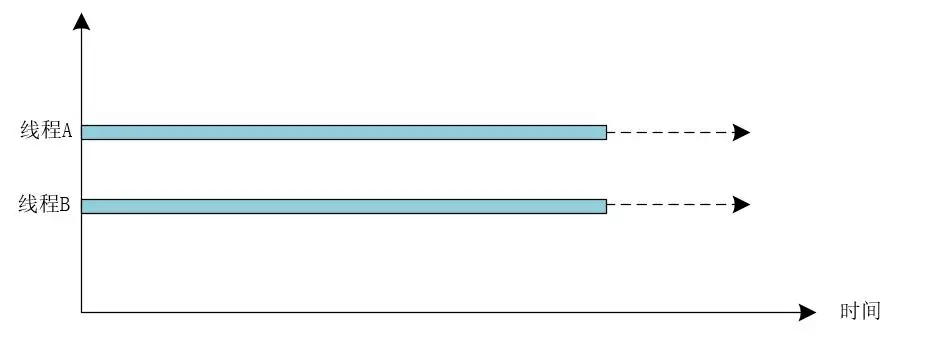
並行指的是無論何時,多個執行緒都是在多個CPU核心上同時執行的,是真正的同時執行。
分治法
基本思想
把一個規模大的問題劃分為規模較小的子問題,然後分而治之,最後合併子問題的解得到原問題的解。
步驟
①分割原問題;
②求解子問題;
③合併子問題的解為原問題的解。
我們可以使用如下偽程式碼來表示這個步驟。
if(任務很小){ 直接計算得到結果 }else{ 分拆成N個子任務 調用子任務的fork()進行計算 調用子任務的join()合併計算結果 }
在分治法中,子問題一般是相互獨立的,因此,經常通過遞歸調用演算法來求解子問題。
典型應用
- 二分搜索
- 大整數乘法
- Strassen矩陣乘法
- 棋盤覆蓋
- 合併排序
- 快速排序
- 線性時間選擇
- 漢諾塔
ForkJoin並行處理框架
ForkJoin框架概述
Java 1.7 引入了一種新的並發框架—— Fork/Join Framework,主要用於實現「分而治之」的演算法,特別是分治之後遞歸調用的函數。
ForkJoin框架的本質是一個用於並行執行任務的框架, 能夠把一個大任務分割成若干個小任務,最終匯總每個小任務結果後得到大任務的計算結果。在Java中,ForkJoin框架與ThreadPool共存,並不是要替換ThreadPool
其實,在Java 8中引入的並行流計算,內部就是採用的ForkJoinPool來實現的。例如,下面使用並行流實現列印數組元組的程式。
public class SumArray { public static void main(String[] args){ List<Integer> numberList = Arrays.asList(1,2,3,4,5,6,7,8,9); numberList.parallelStream().forEach(System.out::println); } }
這段程式碼的背後就使用到了ForkJoinPool。
說到這裡,可能有讀者會問:可以使用執行緒池的ThreadPoolExecutor來實現啊?為什麼要使用ForkJoinPool啊?ForkJoinPool是個什麼鬼啊?! 接下來,我們就來回答這個問題。
ForkJoin框架原理
ForkJoin框架是從jdk1.7中引入的新特性,它同ThreadPoolExecutor一樣,也實現了Executor和ExecutorService介面。它使用了一個無限隊列來保存需要執行的任務,而執行緒的數量則是通過構造函數傳入,如果沒有向構造函數中傳入指定的執行緒數量,那麼當前電腦可用的CPU數量會被設置為執行緒數量作為默認值。
ForkJoinPool主要使用**分治法(Divide-and-Conquer Algorithm)**來解決問題。典型的應用比如快速排序演算法。這裡的要點在於,ForkJoinPool能夠使用相對較少的執行緒來處理大量的任務。比如要對1000萬個數據進行排序,那麼會將這個任務分割成兩個500萬的排序任務和一個針對這兩組500萬數據的合併任務。以此類推,對於500萬的數據也會做出同樣的分割處理,到最後會設置一個閾值來規定當數據規模到多少時,停止這樣的分割處理。比如,當元素的數量小於10時,會停止分割,轉而使用插入排序對它們進行排序。那麼到最後,所有的任務加起來會有大概200萬+個。問題的關鍵在於,對於一個任務而言,只有當它所有的子任務完成之後,它才能夠被執行。
所以當使用ThreadPoolExecutor時,使用分治法會存在問題,因為ThreadPoolExecutor中的執行緒無法向任務隊列中再添加一個任務並在等待該任務完成之後再繼續執行。而使用ForkJoinPool就能夠解決這個問題,它就能夠讓其中的執行緒創建新的任務,並掛起當前的任務,此時執行緒就能夠從隊列中選擇子任務執行。
那麼使用ThreadPoolExecutor或者ForkJoinPool,性能上會有什麼差異呢?
首先,使用ForkJoinPool能夠使用數量有限的執行緒來完成非常多的具有父子關係的任務,比如使用4個執行緒來完成超過200萬個任務。但是,使用ThreadPoolExecutor時,是不可能完成的,因為ThreadPoolExecutor中的Thread無法選擇優先執行子任務,需要完成200萬個具有父子關係的任務時,也需要200萬個執行緒,很顯然這是不可行的,也是很不合理的!!
工作竊取演算法
假如我們需要做一個比較大的任務,我們可以把這個任務分割為若干互不依賴的子任務,為了減少執行緒間的競爭,於是把這些子任務分別放到不同的隊列里,並為每個隊列創建一個單獨的執行緒來執行隊列里的任務,執行緒和隊列一一對應,比如A執行緒負責處理A隊列里的任務。但是有的執行緒會先把自己隊列里的任務幹完,而其他執行緒對應的隊列里還有任務等待處理。幹完活的執行緒與其等著,不如去幫其他執行緒幹活,於是它就去其他執行緒的隊列里竊取一個任務來執行。而在這時它們會訪問同一個隊列,所以為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常會使用雙端隊列,被竊取任務執行緒永遠從雙端隊列的頭部拿任務執行,而竊取任務的執行緒永遠從雙端隊列的尾部拿任務執行。
工作竊取演算法的優點:
充分利用執行緒進行並行計算,並減少了執行緒間的競爭。
工作竊取演算法的缺點:
在某些情況下還是存在競爭,比如雙端隊列里只有一個任務時。並且該演算法會消耗更多的系統資源,比如創建多個執行緒和多個雙端隊列。
Fork/Join框架局限性:
對於Fork/Join框架而言,當一個任務正在等待它使用Join操作創建的子任務結束時,執行這個任務的工作執行緒查找其他未被執行的任務,並開始執行這些未被執行的任務,通過這種方式,執行緒充分利用它們的運行時間來提高應用程式的性能。為了實現這個目標,Fork/Join框架執行的任務有一些局限性。
(1)任務只能使用Fork和Join操作來進行同步機制,如果使用了其他同步機制,則在同步操作時,工作執行緒就不能執行其他任務了。比如,在Fork/Join框架中,使任務進行了睡眠,那麼,在睡眠期間內,正在執行這個任務的工作執行緒將不會執行其他任務了。
(2)在Fork/Join框架中,所拆分的任務不應該去執行IO操作,比如:讀寫數據文件。
(3)任務不能拋出檢查異常,必須通過必要的程式碼來出來這些異常。
ForkJoin框架的實現
ForkJoin框架中一些重要的類如下所示。
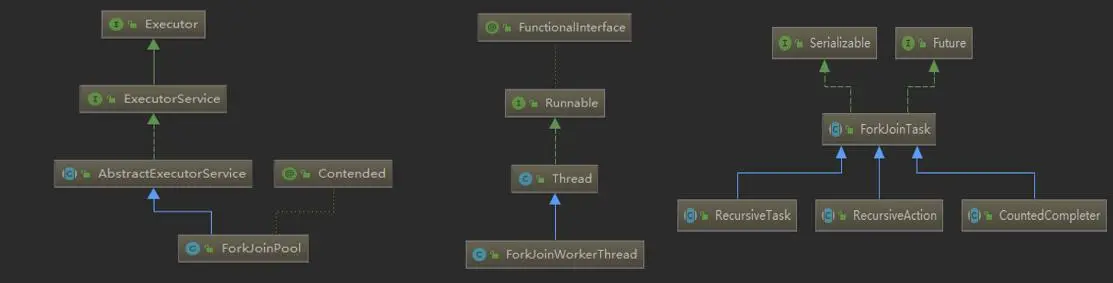
ForkJoinPool 框架中涉及的主要類如下所示。
1.ForkJoinPool類
實現了ForkJoin框架中的執行緒池,由類圖可以看出,ForkJoinPool類實現了執行緒池的Executor介面。
我們也可以從下圖中看出ForkJoinPool的類圖關係。
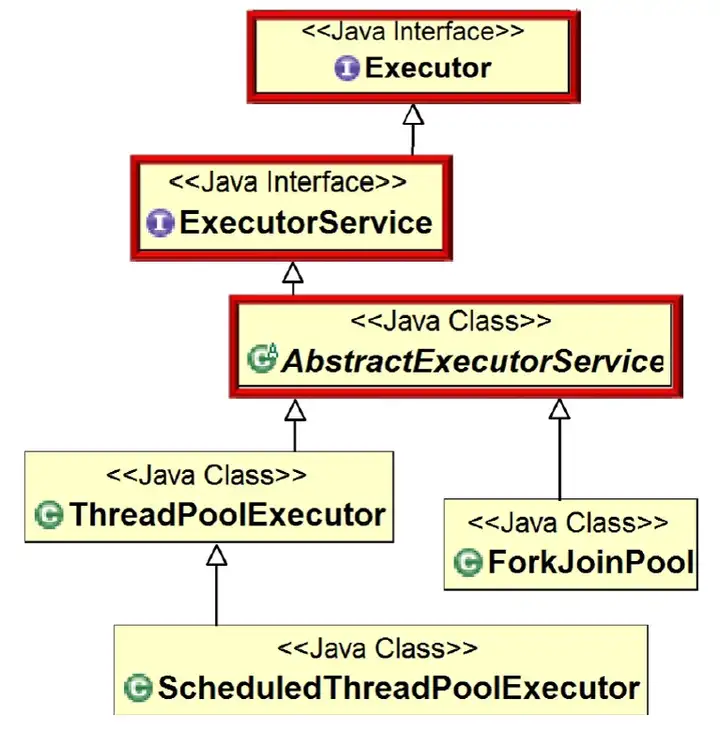
其中,可以使用Executors.newWorkStealPool()方法創建ForkJoinPool。
ForkJoinPool中提供了如下提交任務的方法。 public void execute(ForkJoinTask<?> task) public void execute(Runnable task) public <T> T invoke(ForkJoinTask<T> task) public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) public <T> ForkJoinTask<T> submit(Callable<T> task) public <T> ForkJoinTask<T> submit(Runnable task, T result) public ForkJoinTask<?> submit(Runnable task)
2.ForkJoinWorkerThread類
實現ForkJoin框架中的執行緒。
3.ForkJoinTask<V>類
ForkJoinTask封裝了數據及其相應的計算,並且支援細粒度的數據並行。ForkJoinTask比執行緒要輕量,ForkJoinPool中少量工作執行緒能夠運行大量的ForkJoinTask。
ForkJoinTask類中主要包括兩個方法fork()和join(),分別實現任務的分拆與合併。
fork()方法類似於Thread.start(),但是它並不立即執行任務,而是將任務放入工作隊列中。跟Thread.join()方法不同,ForkJoinTask的join()方法並不簡單的阻塞執行緒,而是利用工作執行緒運行其他任務,當一個工作執行緒中調用join(),它將處理其他任務,直到注意到目標子任務已經完成。
我們可以使用下圖來表示這個過程。
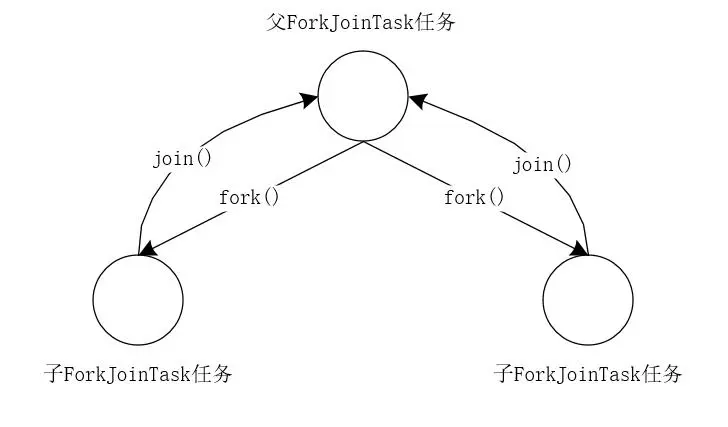
ForkJoinTask有3個子類:
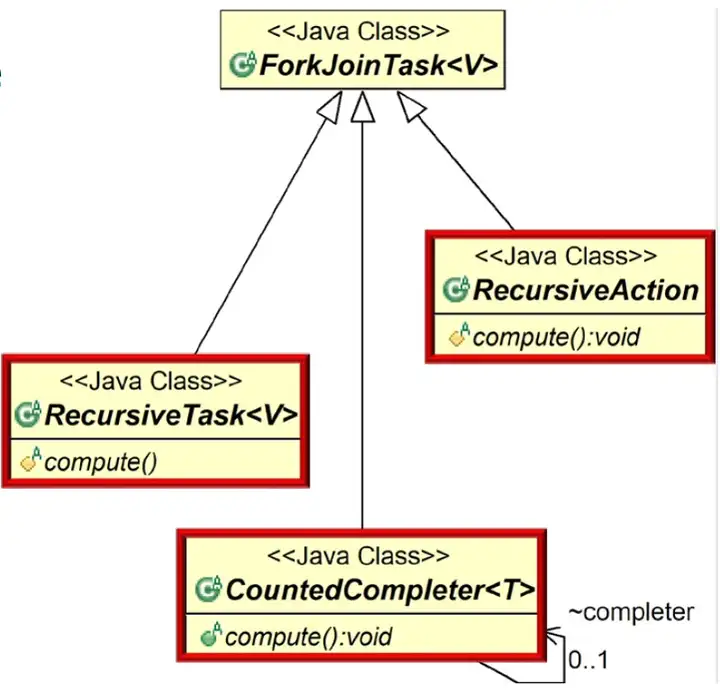
- RecursiveAction:無返回值的任務。
- RecursiveTask:有返回值的任務。
- CountedCompleter:完成任務後將觸發其他任務。
4.RecursiveTask<V> 類
有返回結果的ForkJoinTask實現Callable。
5.RecursiveAction類
無返回結果的ForkJoinTask實現Runnable。
6.CountedCompleter<T> 類
在任務完成執行後會觸發執行一個自定義的鉤子函數。
ForkJoin示常式序
package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; @Slf4j public class ForkJoinTaskExample extends RecursiveTask<Integer> { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任務足夠小就計算任務 boolean canCompute = (end - start) <= threshold; if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } } else { // 如果任務大於閾值,就分裂成兩個子任務計算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 執行子任務 leftTask.fork(); rightTask.fork(); // 等待任務執行結束合併其結果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合併子任務 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一個計算任務,計算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //執行一個任務 Future<Integer> result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } }


