文本相似性演算法實現(二)-分組及分句熱度統計
- 2020 年 3 月 3 日
- 筆記
1. 場景描述
軟體老王在上一節介紹到相似性熱度統計的4個需求(文本相似性熱度統計(python版)),本次介紹分組及分組分句熱度統計(需求1和需求2)。
2. 解決方案
分組熱度統計首先根據某列進行分組,然後再對這些句進行熱度統計,主要是分組處理,分句僅僅是按照標點符號做了下拆分,在程式碼說明中可以替換下就可以了。
2.1 完整程式碼
完整程式碼,有需要的朋友可以直接拿走,不想看程式碼介紹的,可以直接拿走執行就行。
import jieba.posseg as pseg import jieba.analyse import xlwt # 寫入Excel表的庫 import pandas as pd from gensim import corpora, models, similarities import re #停詞函數 def StopWordsList(filepath): wlst = [w.strip() for w in open(filepath, 'r', encoding='utf8').readlines()] return wlst def str_to_hex(s): return ''.join([hex(ord(c)).replace('0x', '') for c in s]) # jieba分詞 def seg_sentence(sentence, stop_words): stop_flag = ['x', 'c', 'u', 'd', 'p', 't', 'uj', 'f', 'r'] sentence_seged = pseg.cut(sentence) outstr = [] for word, flag in sentence_seged: if word not in stop_words and flag not in stop_flag: outstr.append(word) return outstr if __name__ == '__main__': # 1 這些是jieba分詞的自定義詞典,軟體老王這裡添加的格式行業術語,格式就是文檔,一列一個詞一行就行了, # 這個幾個詞典軟體老王就不上傳了,可注釋掉。 jieba.load_userdict("g1.txt") jieba.load_userdict("g2.txt") jieba.load_userdict("g3.txt") # 2 停用詞,簡單理解就是這次詞不分割,這個軟體老王找的網上通用的。 spPath = 'stop.txt' stop_words = StopWordsList(spPath) # 3 excel處理 wbk = xlwt.Workbook(encoding='ascii') sheet = wbk.add_sheet("軟體老王sheet") # sheet名稱 sheet.write(0, 0, '軟體老王1-類別') sheet.write(0, 1, '軟體老王2-原因') sheet.write(0, 2, '軟體老王3-統計數量') sheet.write(0, 3, '導航-鏈接到明細sheet表') inputfile = '軟體老王-source2.xlsx' data = pd.read_excel(inputfile) # 讀取數據 grp1 = data.groupby('類別') rcount = 1 for name, group in grp1: print(grp1) texts = [] orig_txt = [] key_list = [] name_list = [] sheet_list = [] name = name.replace('n', '').replace('/', '') for i in range(len(group)): row = group.iloc[i].values cell = row[1] if cell is None: continue if not isinstance(cell, str): continue item = cell.strip('nr').split('t') string = item[0] if string is None or len(string) == 0: continue else: textstr = seg_sentence(string, stop_words) texts.append(textstr) orig_txt.append(string) # 4 相似性處理 dictionary = corpora.Dictionary(texts) feature_cnt = len(dictionary.token2id.keys()) corpus = [dictionary.doc2bow(text) for text in texts] tfidf = models.LsiModel(corpus) index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=feature_cnt) result_lt = [] word_dict = {} count =0 for keyword in orig_txt: count = count+1 print('開始執行,第'+ str(count)+'行') if keyword in result_lt or keyword is None or len(keyword) == 0: continue kw_vector = dictionary.doc2bow(seg_sentence(keyword, stop_words)) sim = index[tfidf[kw_vector]] result_list = [] for i in range(len(sim)): if sim[i] > 0.5: if orig_txt[i] in result_lt and orig_txt[i] not in result_list: continue result_list.append(orig_txt[i]) result_lt.append(orig_txt[i]) if len(result_list) >0: word_dict[keyword] = len(result_list) if len(result_list) >= 1: name = name.strip('nr').replace('n', '').replace('/', '').replace(',', '').replace('。', '').replace( '*', '') name = re.sub(u"([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])", "", name) sname = name[0:10] + '_' + re.sub(u"([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])", "", keyword[0:10])+ '_' + str(len(result_list)+ len(str_to_hex(keyword))) + str_to_hex(keyword)[-5:] sheet_t = wbk.add_sheet(sname) # Excel單元格名字 for i in range(len(result_list)): sheet_t.write(i, 0, label=result_list[i]) # 5 按照熱度排序 -軟體老王 with open("rjlw.txt", 'w', encoding='utf-8') as wf2: # 打開文件 orderList = list(word_dict.values()) orderList.sort(reverse=True) count = len(orderList) for i in range(count): for key in word_dict: if word_dict[key] == orderList[i]: key_list.append(key) name_list.append(name) word_dict[key] = 0 wf2.truncate() # 6 寫入目標excel for i in range(len(key_list)): sheet.write(i+rcount, 0, label=name_list[i]) sheet.write(i+rcount, 1, label=key_list[i]) sheet.write(i+rcount, 2, label=orderList[i]) if orderList[i] >= 1: shname = name_list[i][0:10] + '_' + re.sub(u"([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])", "", key_list[i][0:10]) + '_'+ str(orderList[i]+ len(str_to_hex(key_list[i])))+ str_to_hex(key_list[i])[-5:] link = 'HYPERLINK("#%s!A1";"%s")' % (shname, shname) sheet.write(i+rcount, 3, xlwt.Formula(link)) rcount = rcount + len(key_list) key_list = [] name_list = [] orderList = [] texts = [] orig_txt = [] sheet_list =[] wbk.save('軟體老王-target2.xls') 2.2 程式碼說明
以上的程式碼中有很明確的注釋就不再一一介紹了,重點說幾個。
(1)分組處理跟文本相似性熱度統計演算法實現(一)-整句熱度統計相似,不同的是首先按照某一列做了分組處理,然後進行相似性統計,相似性這塊一樣,其實不同的主要是excel處理這塊的內容。
(2)excle分組用的是pandas包,python中excel數據分組處理。
(3)關於需求2,分組分句,程式碼如下:
for i in range(len(group)): row = group.iloc[i].values cell = row[1] if cell is None: continue if not isinstance(cell, str): continue item = cell.strip('nr').split('t') string = item[0] #軟體老王,這裡按照標點符號對原因進行拆分,然後再進行處理。 lt = re.split(',|。|!|?', string) for t in lt: if t is None or t.strip() == '' or len(t.strip()) == 0: continue else: textstr = seg_sentence(t, stop_words) texts.append(textstr) orig_txt.append(t)2.3 效果圖
(1)軟體老王-source2.xlsx
| 類別 | 原因 |
|---|---|
| 軟體老王1 | 主機不能加電 |
| 軟體老王1 | 有時不能加電 |
| 軟體老王1 | 開機加電 |
| 軟體老王2 | 自檢報錯或死機 |
| 軟體老王2 | 機器噪音大 |
| 軟體老王3 | 噪音問題 |
| 軟體老王1 | 噪音太大 |
| 軟體老王1 | 噪音雜訊 |
| 軟體老王1 | 聲音太大 |
| 軟體老王2 | 聲音太大 |
| 軟體老王3 | 聲音太大 |
(2)軟體老王-target2.xls
| 軟體老王1-類別 | 軟體老王2-原因 | 軟體老王3-統計數量 | 導航-鏈接到明細sheet表 |
|---|---|---|---|
| 軟體老王1 | 主機不能加電 | 3 | 軟體老王1_主機不能加電_2707535 |
| 軟體老王1 | 噪音太大 | 2 | 軟體老王1_噪音太大_18a5927 |
| 軟體老王1 | 聲音太大 | 1 | 軟體老王1_聲音太大_17a5927 |
| 軟體老王2 | 自檢報錯或死機 | 1 | 軟體老王2_自檢報錯或死機_29b673a |
| 軟體老王2 | 機器噪音大 | 1 | 軟體老王2_機器噪音大_2135927 |
| 軟體老王2 | 聲音太大 | 1 | 軟體老王2_聲音太大_17a5927 |
| 軟體老王3 | 噪音問題 | 1 | 軟體老王3_噪音問題_17e9898 |
| 軟體老王3 | 聲音太大 | 1 | 軟體老王3_聲音太大_17a5927 |
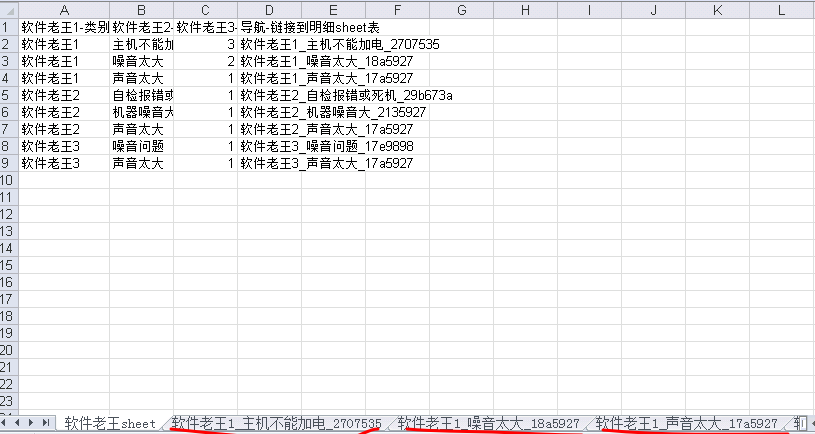
(3)簡單說明
從數據中可以看出來,例如:聲音太大,分屬三類,首先分類,然後再比對相似性。
I』m 「軟體老王」,如果覺得還可以的話,關注下唄,後續更新秒知!歡迎討論區、同名公眾號留言交流!


