用python爬取3萬多條評論,看韓國人如何評價韓國電影《寄生蟲》?
- 2020 年 3 月 3 日
- 筆記
↑ 關注 + 星標 ~ 有趣的不像個技術號
每晚九點,我們準時相約
大家好,我是朱小五
今天給大家帶來一個關於電影的數據分析文章。
別走啊,這次不是豆瓣,也不是貓眼
真的
今天分析的電影是韓國電影《寄生蟲》。
它是由韓國導演奉俊昊自編自導的影片,一舉拿下最佳影片、最佳導演、最佳原創劇本和最佳國際電影四座奧斯卡獎盃,創造歷史成為奧斯卡史上首部非英語最佳影片。
nb plus!
這次帶大家看看韓國人如何評價這部韓國電影的?
獲取數據
數據從哪獲取呢?
我們先打開韓國最大門戶網站NAVER

找到영화(電影)板塊,搜索기생충(寄生蟲)並打開

上面介紹部分跟貓眼專業版一樣,各種評分、演職員表、評分男女比例、年齡分布。
在評論區部分,它其實有點像是豆瓣和貓眼的綜合體,無論看沒看過都可以評價打分,不過看過的會單獨有個小標識。
我們下划到評論區
下圖中可以看到,目前有36360條評價,我們想要獲取的數據是黑框中的內容。
包括每條留言的評論人昵稱、評論時間、評分、評論內容以及這條評論得到的贊或踩。

下面開始爬取評論數據
利用requests和pyquery爬取數據,展示部分源碼,完整見文末。
def main(): data = [] for i in range(1,200): #爬取多少頁 url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=161967&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=newest&page='+str(i) print('準備採集第{}頁數據'.format(i)) html = restaurant(url) doc = pq(html) for i in range(0,10): print(i) dic = {} dic['star'] = doc('li:nth-child(' + str(i+1) +') > div.star_score > em').text() dic['text'] = doc('#_filtered_ment_' + str(i)).text() dic['datetime'] = doc('li:nth-child(' + str(i+1) +') > div.score_reple > dl > dt > em:nth-child(2)').text() dic['name'] = doc('li:nth-child(' + str(i+1) +') > div.score_reple > dl > dt > em:nth-child(1) > a').text() dic['zan'] = doc('li:nth-child(' + str(i+1) +') > div.btn_area > a._sympathyButton > strong').text() dic['cai'] = doc('li:nth-child(' + str(i+1) +') > div.btn_area > a._notSympathyButton > strong').text() data.append(dic) #time.sleep(random.random()) pd.DataFrame(data).to_csv('寄生蟲評論.csv',encoding="utf_8",index = False) return data
運行結果:

歪瑞古德!
這樣我們就成功獲取了韓國人評價韓國電影《寄生蟲》的評論數據!
數據整理
我們簡單看一下數據

共35940條,比上文截圖時候少了一點,這是因為我爬取和寫這篇文章的時候有一點時間間隔,所以這個小問題請忽略。

另外,非常明顯,評論欄位缺失了很多。
我查看了一下,認為是在這個網站觀看過電影的人可以只打分,不寫評論。
(有點像在貓眼上買了電影票,評論時候同樣可以只打分,不寫評論)
簡單補齊它吧,直接刪除還是會影響整體的評分的。
def data_cleaning(df): cols = df.columns for col in cols: if df[col].dtype == 'object': df[col].fillna('缺失數據', inplace = True) else: df[col].fillna(0, inplace = True) return(df)
這樣我們就補全了缺失值
簡單看一下平均分吧


看來這就是韓國觀眾的打分(9.07)比網民對《寄生蟲》蟲的評價(8.48)要高。
這與中國的情況也是相似的,同一部電影貓眼淘票票的分數普遍比豆瓣上要高。
畢竟真金白銀去看電影的人,肯定會認為它是一部好片子才去看。
只要不像被《愛情公墓》一樣詐騙,基本觀眾的分數不會太低。
後面想講韓國網友的評論做一個詞雲,這樣的話我們就需要先將評論中的韓文翻譯成中文。
翻譯評論
採用哪個翻譯軟體呢?
嘗試了幾個常見的翻譯,發現結果都大同小異。
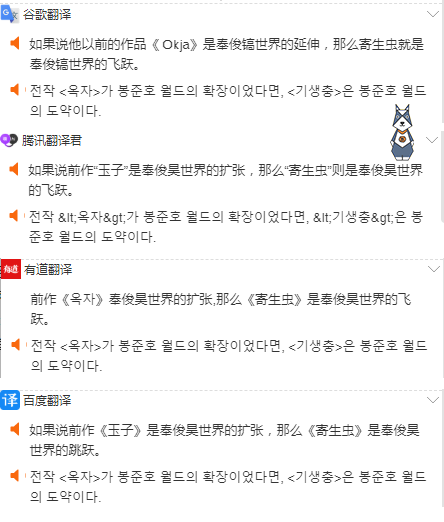
乾脆採用了之前自己用過的有道翻譯小介面。
def translate(text): url = 'http://fanyi.youdao.com/translate?&doctype=json&type=KR2ZH_CN&i='+ text requ_text = requests.get(url) json_text = requ_text.json() data = json_text['translateResult'][0][0]['tgt'] time.sleep(2+random.random()) print('翻譯中') return data
將評論列翻譯,並新建一列用以做詞雲
ata['text_t'] = data.apply(lambda x :translate(x['text']), axis=1)
運行結果

額,這個翻譯一言難盡,不過大體意思還是可以看懂的,不太影響做詞雲。
接下來我們開始嘗試做做圖。
分析與可視化
正常利用python分析電影評論都有一個環節是男女比例和評分比例,這次我們並沒有獲得相關數據,那麼就用NAVER網站提供的結果圖簡單的講一下吧。

觀看人群的性別比例非常均衡,各佔50%。
各年齡段均有分布,其中[20,30)的觀看人群最多。為什麼10-20歲的青少年觀看這麼少呢?後面詞雲部分會回答這個問題。

在上圖普通網民的評價中,女性評分更高一些。隨著年齡的增長,評分越低,難道是越是年齡大的人越看透了韓國的現狀?
他們主要的欣賞點依次是「導演」、「연기」、「故事」、「視覺效果」、「電影原聲」。
(其中的「연기」用翻譯軟體都是翻譯成煙,難道是特效的意思?懂韓文的同學可以留言一下)

至於看過電影的觀眾打分比普通網民會高,平均9.07分,而且男性比女性要略高。其他方面大體相似,就不講了。
我們再看一下,韓國觀眾對電影《寄生蟲》評論數量的時間走勢。
plt.figure(figsize=(8,5), dpi=200) x = score_by_time.index.date y = score_by_time.values plt.plot(x,y,c="g",marker=".",ls="-") plt.title("韓國電影《寄生蟲》評論數走勢圖") plt.xlabel("月份") plt.ylabel("評論數")
結果如下

可以明顯看到,評論數量在電影《寄生蟲》上映後達到一個高峰,而後隨著時間的推移,數量逐漸減少。
之後有兩個小高峰,分別是2019年8月初和2020年2月初。
通過查找新聞資訊,收集到了兩個消息:
1、韓國電影《寄生蟲》,預計將在8月6日公開流媒體服務(就相當於中國的愛奇藝、優酷類似的平台)。
2、《寄生蟲》2月10日拿下四項奧斯卡大獎後,在韓國的熱度繼續上升。
這樣大家應該就解釋清楚兩個小高峰的問題啦。
最後我們再利用有道翻譯好的評論數據做個WordCloud詞雲吧。

在對主創人員的討論中,奉俊昊導演的功力和宋康昊的傑出演技被多次提及,電影中提到的「氣味」「果醬」「戒指」也被多次探討,故事中對社會與現實的反思也是熱門的討論話題。
前文我提到了為什麼10-20歲的青少年觀看這麼少呢?而且詞雲中「15」這個關鍵詞也比較突出。
這是因為韓國於1998年建立電影分級制度。規定電影分為5個等級:全民、12歲以上、15歲以上、18歲以上可以觀看和限制放映。
而《寄生蟲》在韓國獲得了「15歲以上可以觀影」的等級判定。
對作品內容就不做評價了。
以上。
這篇文章的靈感在去年看《寄生蟲》就有了,結果就拖延拖延;
到了今年《寄生蟲》獲得奧斯卡,結果又因為那段時間工作忙,沒時間寫,就拖到了現在。
所以說,大家多多點在看,這樣我就不好意思拖延不發原創了,是不是


