java 入土–集合詳解
java 集合
集合是對象的容器,實現了對對象的常用的操作,類似數組功能。
和數組的區別:
- 數組長度固定,集合長度不固定
- 數組可以存儲基本類型和引用類型,集合只能存儲引用類型
- 使用時需要導入類
Collection 介面
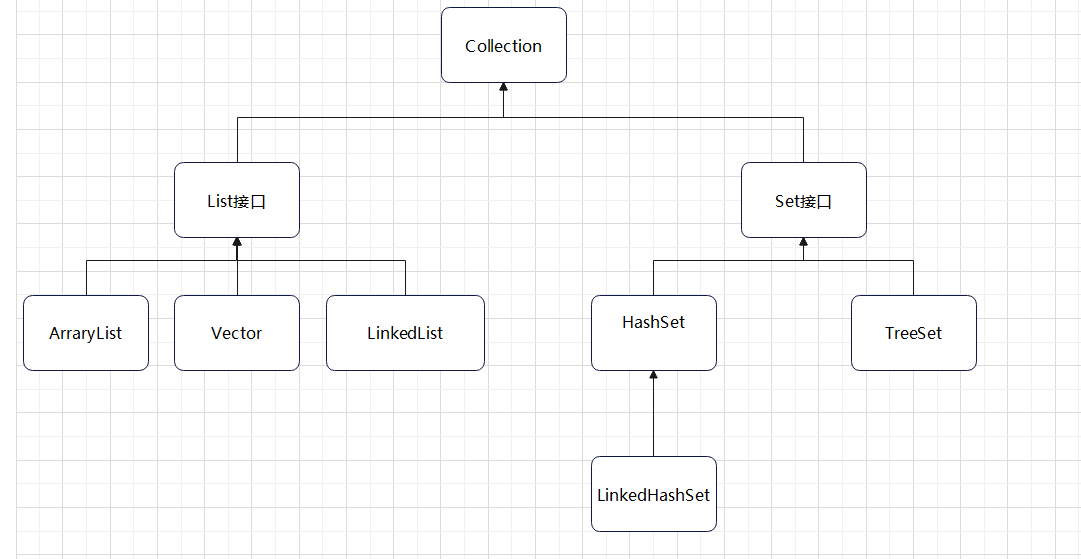
Collection 繼承 Iterable 介面,實現子類可放多個 object 元素,Collection 介面無直接實現類,是通過子類介面 Set 與 List 實現。
是單列集合的頂層實現介面,他表示一組對象,這些對象也稱 Collectioin 的元素。
JDK 不提供此介面的任意直接實現,他提供更具體的子介面(如 Set 和 List)的實現。
List
list 集合是 collection 的子介面,元素有序,且添加順序與取出順序一致,支援索引。
List 是一個介面,繼承自 Collection 介面。
List 是一個有序集合,用戶可以精確的控制列表中的每一個元素的插入位置。可以通過整數索引訪問元素,並搜索列表中的元素。
與 Set 集合不同,列表通常允許重複元素。
List 集合特點:
- 有序
- 可重複
List 集合的特有方法:
-
add(index,E)指定位置添加元素
-
remove(index)刪除指定位置的元素
-
set(index,E)修改指定位置的元素
-
get(index)獲取指定位置的元素
-
List 集合的幾種常用方法
List<> list = new ArraryList();
list.add(obj)//末尾添加元素
list.add(index,obj)//在指定位置添加元素
list.remove(obj)//刪除元素
list.indexof(obj)//返回第一次出現的位置
list.lastIndexOf(obj)//返回最後出現的位置
list.set(indes,obj)//設置指定位置的元素,相當於替換
list.get(index)//返回指定位置的元素
list.contains(obj)//查找當前元素是否存在。
list.size()//返回list的長度
list.clear()//清空集合
list.isEmpty()//判斷是否為空
list.removeAll(list)//刪除多個元素。
Arraylist
Arrarylist 的底層維護了一個 Object 類型的 elementData 數組,其底層就是一個數組。
ArrayList 集合:可調整大小的數組的實現 List 介面。 實現所有可選列表操作,並允許所有元素,包括 null 。
底層是數組, 查詢快,增刪慢於 LinkedList 集合
- 無參構造擴容
若使用無參構造,初始的 elementData 為 0,第一次添加元素,擴容為 10,若再次擴容,則擴容為 elementData 的 1.5 倍。0->10->15->22…. - 有參構造擴容
若使用 new Arrarylist(int n)初始化數組,則為指定大小,擴容時也是按照 elementData 的 1.5 倍
Vector
Vector 是 List 的子類,繼承 AbstractList 介面,實現 List 介面,底層也是一個 Object[] elementData 數組。
Vector 是執行緒同步的,是執行緒安全的,開發中若需要執行緒同步,用 Vextor 集合。
LinkedList
Linked 的意思是鏈接,字面意思來看,該集合是一個鏈表,事實也正是如此,LinkedList 的底層是實現了雙向鏈表和雙端隊列。
可以添加任意的重複元素,包括 null。
由於是鏈表,所以不需要擴容,增刪效率高。
//鏈表實現演示
public class Node {
private Object item;//對象
public Node first;
public Node last;
public Node(Object name) {
this.item = name;
}
}
LinkedList 集合特有功能
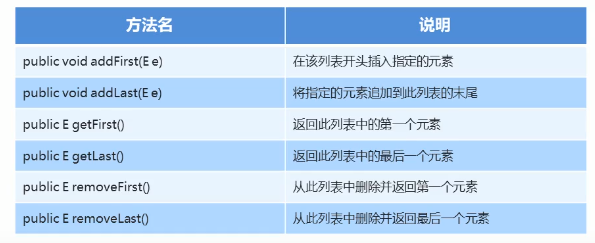
LinkedList<String> link = new LinkedList<String>();
link.add("hello");
link.add("world");
link.add("hello world");
//添加元素
link.addFirst("fist");
link.addLast("last");
System.out.println(link);
System.out.println("------------------");
//獲取元素
System.out.println(link.getFirst());
System.out.println(link.getLast());
System.out.println("------------------");
//刪除元素
link.removeFirst();
link.removeLast();
System.out.println(link);
System.out.println("------------------");
List 的最常用的三種遍歷方法
//以ArraryList為例
public static void main(String[] args) {
List list = new ArrayList();
List list = new ArrayList();
list.add("11");
list.add("12");
//普通for循環
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//增強for
for (Object o : list) {
System.out.println(o.toString());
}
//iterator循環
//通過列表迭代器添加元素,不會出現並發修改異常
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
實例:將 Student 對象添加到集合,三種方式遍歷
Student student = new Student("張三",18);
Student student2 = new Student("wangjiaqi",13);
ArrayList<Student> array = new ArrayList<Student>();
array.add(student);
array.add(student2);
//增強for
for (Student students : array) {
System.out.println(students.getName()+students.getAge());
}
//迭代器
Iterator<Student> it = array.iterator();
while (it.hasNext()) {
Student students = it.next();
System.out.println(students.getName()+students.getAge());
}
//普通for
for(int i = 0; i < array.size(); i++){
Student students = array.get(i);
System.out.println(students.getName()+students.getAge());
}
Set
Set 介面也是單例的,是無序的,增加和取出順序是不確定的,無索引不可重複,null 最多有一個。
繼承自 Collection 介面,
Set 的方法與 List 的方法相差不大,但不能用索引的方式遍歷。
HashSet
HashSet 實現 Set 介面,其底層是 HashMap,由於 HashMap 的底層是數組+鏈表+紅黑樹,所以 HashSet 的底層就是數組+鏈表+紅黑樹,存儲時,底層通過 equles()和 hash()方法來確定存儲位置,所以存入與取出的順序不一致。
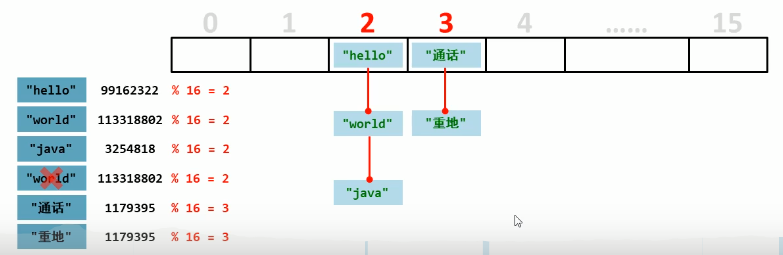
HashSet 的初始大小是 16 長度大小的數組,當數組的容量達到 16 的 0.75 倍時,會進行提前擴容,也就是數組在滿足 12 時,會進行擴容,其擴容倍數為 2 倍。
註:當數組長度大於 64,同時鏈表長度大於 8 時,hashSet 變為紅黑樹存儲,優化存儲結構。
要注意重寫 hashCode 與 equlse 方法才能使不同對象的相同內容實現不重複。
LinkedHashSet
父類是 HashSet,底層是 LinkedHashMap,維護了一個數組+雙向鏈表,也是以 hsash 值來確定位置。存儲結構是雙向鏈表,所以是有序的,不允許有雙向鏈表。
- 擴容機制
- 第一次時,數組 table 擴容到 16,底層是存儲在 LinkedHashMap$Entry 對象節點上,數組是 HashMap$Node[],在數組中存放 LinkedHashMap$Entry 對象。
TreeSet
底層是 TreeMap,可以進行排序,當我們使用無參構造器,創建 TreeSet 時,仍然是無序的.
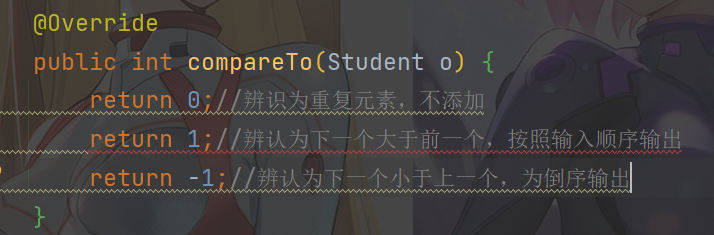
當我們需要按照某種方式進行排序時,需要使用 TreeSet 提供的一個構造器,可以傳入一個比較器[匿名內部類]並指定排序規則
//具體的比較規則還需根據實際進行重寫,這裡舉一個例子。
TreeSet<Object> objects = new TreeSet<>(new Comparator<Object>() {
@Override
public int compare(Object o1, Object o2) {
return o1.toString().compareTo(o2.toString());
}
});
TreeSet 介面間接實現了 Set 介面,是一個有序的集合,它的作用是提供有序的 Set 集合
TreeSet 的特點
-
元素有序:按照構造方法進行排序
- TreeSet()根據元素的自然排序進行排序
- TreeSet(Comparator comparator):根據指定的比較器進行排序,自然排序需要在類中實現 comparator 介面
-
沒有索引,不能用普通 for 循環遍歷
-
繼承 Set 集合,無重複元素

TreeSet<Integer> ts = new TreeSet<Integer>();//自然排序
ts.add(10);
ts.add(20);
ts.add(4);
for (Integer i : ts) {
System.out.println(i);//輸出4,10,20
}

通過指定比較器進行排序
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {//o1是o2是的下一個
int num = o1.getAge() - o2.getAge();
int num2 = num == 0 ? o1.getName().compareTo(o2.getName()) : num;
return num2;
}
});
//創建對象
Student s1 = new Student("maoyaning", 32);
Student s2 = new Student("asdfds", 53);
Student s3 = new Student("khljn", 24);
Student s4 = new Student("sdfwfds",24);
//添加集合元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for (Student s : ts) {
System.out.println(s.getName() + " " + s.getAge());
}
Set 兩種循環遍歷:
由於 Set 集合的底層,所以無法用下標遍歷,因此只能用增強 for 和 iterator 進行遍歷
- 增強 for
for (String str : set) {
System.out.println(str);
}
- 迭代器
Set set = new HashSet();
Iterator it = set.iterator();
while (it.hasNext()) {
String str = it.next();
System.out.println(str);
}
Map 介面
Map<K,V>,是一個介面,將鍵映射到值,不能包含重複的鍵,每個鍵只能映射一個值。

Map 介面用於存儲具有映射關係的數據,key-value。
底層:
- 在創建 Map 集合時,Map 的底層會創建 EntrySet 集合,用於存放 Entry 對象,而一個 Entry 對象具有 key 和 value,同時創建 Set 數組指向 key,創建 collection 對象指向 value,取出時,實際上是調用 set 和 collection 數組的地址進行調用,從而提高遍歷效率。
在進行 map 元素添加時,map.put()方法在底層上是通過 hashcode 與 equals 方法進行比較,當 key 相同時,會進行替換。
要注意的是,HashSet 的底層也是 HashMap,也是以鍵值對的形式進行存儲的,只不過在進行錄入時,把 value 值設置為一個常數,所以在 HashSet 中,不能存儲相同的值(會進行覆蓋)。
而在 Map 中,可以存儲相同的 value 值,但是 Key 不能重複,也就是說在 Map 中,key 可以有 null,但是只能有一個,value 可以有多個 null。
實際開發中,常用 HashMap,TreeMap,LinkedHAshMap,和 HashTable 的子類 properties。
Map 集合的方法
Map<String, String> map = new HashMap<String, String>();
//put方法添加元素
map.put("01","maoyaning");
map.put("02","guojing");
//remove方法刪除元素
map.remove("01");
//clear方法移除所有元素
map.clear();
//containsKey方法判斷是否包含指定的鍵
System.out.println(map.containsKey("01"));
//containsValue方法判斷是否含有指定的值
System.out.println(map.containsValue("maoyaning"));
//size返回集合的鍵值對個數
System.out.println(map.size());
//isEmpty判斷集合是否為空
System.out.println(map.isEmpty());
Map 集合的獲取功能
Map<String, String> map = new HashMap<String, String>();
map.put("zhangwuji","01");
map.put("asdf","dsf");
//get方法,根據鍵,返回值單個值
System.out.println(map.get("zhangwuji"));
//keySet獲取所有鍵的集合
Set<String> keySet = map.keySet();//獲取key的Set集合
//增強for循環迭代獲取key值
for (String key : keySet) {
System.out.println(map.get(key));
}
//values獲取所有值的集合
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
/**在創建 Map 集合時,
Map 的底層會創建 EntrySet 集合,
用於存放 Entry 對象,
而一個 Entry 對象具有 key 和 value,
同時創建 Set 數組指向 key,
創建 collection 對象指向 value,
取出時,實際上是調用 set 和 collection 數組的地址進行調用,
從而提高遍歷效率。*/
Map 集合的遍歷
//方法一
Map<String, String> map = new HashMap<String, String>();
map.put("01","mao");
map.put("02","ya");
//Map集合的遍歷方法
//獲取所有鍵的集合,用KeySet方法實現
Set<String> set = map.keySet();
//遍歷每一個鍵
for (String key : set) {
//根據鍵找到值
String value = map.get(key);
System.out.println(value);
}
//方法二
//通過entryset方法獲得鍵值對集合
//獲取所有鍵值對對象的集合
Set<Map.Entry<String, String>> entries = map.entrySet();
//遍歷鍵值對對象集合,得到每一個鍵值對對象
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
//方法三
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey()+next.getValue());
}

