基於強化學習的測試日誌智慧分析實踐
摘要:測試日誌智慧分析是提升智慧化測試效率的一個關鍵步驟。
本文分享自華為雲社區《【智慧化測試專題】基於強化學習的測試日誌智慧分析實踐》,作者: DevAI 。
隨著軟體規模的不斷擴增,加快測試時間降低成本、實現智慧化測試是至關重要的,而測試日誌智慧分析是提升智慧化測試效率的一個關鍵步驟。當前由自動化測試階段產生的大量日誌,主要依賴人工分析,而人工分析工作量大、耗時較長,以華為某產品線為例,每月都會產生30-40萬的測試失敗日誌,而人工分析每天僅能分析20-30條日誌。此外人工分析時,很大一部分工作是分析重複或同類問題,且測試人員分析經驗復用困難,嚴重製約測試效率。
測試日誌智慧分析是從日誌採集、日誌解析與預處理、失敗日誌根因分析及分類以及數據可視化的一整套解決方案。日誌分析的發展從傳統的基於規則引擎的演算法,到現在的基於機器學習與AI技術的演算法方案,其自動化程度得到了很大的提升, 然而它依然會面臨著一些問題:1)演算法和業務之間存在一定的資訊差,業務需要理解演算法層面所需要的關鍵資訊,才可能使得所提供的資訊是有效的。2)演算法方面也需要協同產品方面的專家,來進行特徵提取,而專家資源受限。3)其解決方案需要針對不同產品特性進行調參、優化模型等,但模型需要海量歷史數據和標準化的標註,業務方標註準確率堪憂。
針對上述問題,我們基於強化學習和主動學習,提出了一種失敗測試日誌分析方案,其主要流程如圖1所示。該方案包括了:1) 數據採集 2)數據預處理3)特徵生成 4)模型生成 5)智慧分析等模組。

1. 數據採集
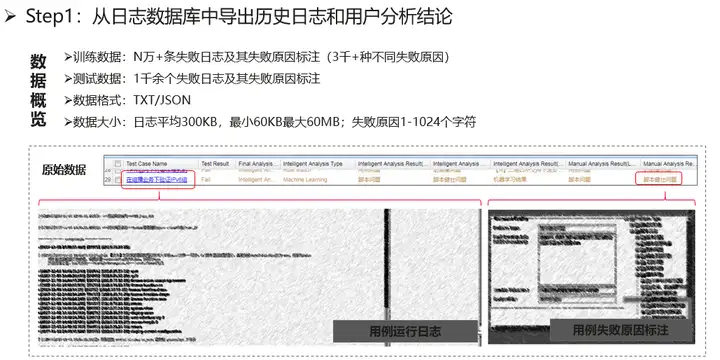
日誌智慧分析的任務是有監督/半監督學習任務,我們需要事先對數據進行收集與標註,針對測試人員標註好的數據,我們按8:2的比例進行訓練數據和測試數據的切分。平均地,訓練數據的量級可達到萬級以上,測試數據的量級可達到千級/萬級以上。
2. 數據預處理
測試日誌文本通常是非結構化的日誌文本,文本長度通常較長,單個日誌大小平均可達300KB,我們需要事先進行文本清洗和預處理,來過濾與失敗類別無關的資訊,聚焦到與任務相關的有效資訊上。預處理步驟會先移除不需要的格式,比如解析html格式文本,提取相應的日誌內容;接著,提取的日誌內容會分別經過基於通用規則的方法和基於用戶自定義規則的方法,來進行數據的清洗和分詞。這裡的通用規則是綜合多個業務提煉的規則,用戶自定義規則則是用戶針對當前業務生成的規則和自定義詞典(包括專業名詞和停用詞等),可適配到各個業務。

3. 特徵生成
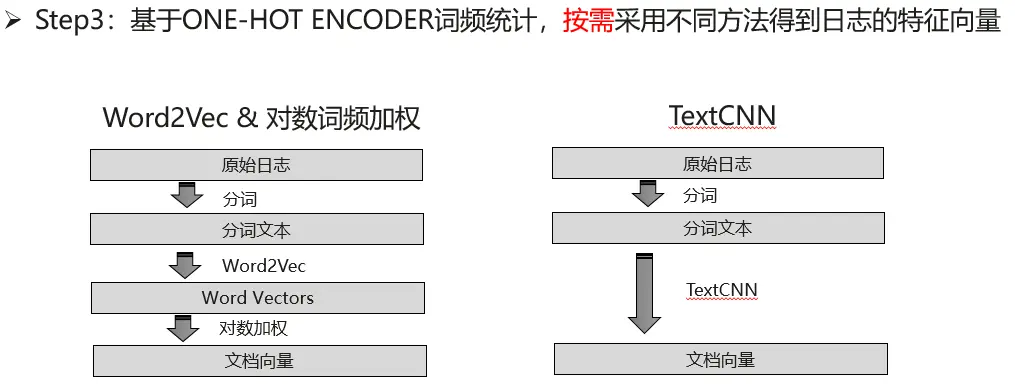
日誌文本特徵向量構建主要選取了基於word2vec的向量化方法和基於TextCNN的向量化方法來。日誌文檔特徵向量是利用word2vec方法生成的詞向量與對數詞頻加權平均後的結果,以及TextCNN直接生成文檔向量。
4. 模型生成與智慧分析
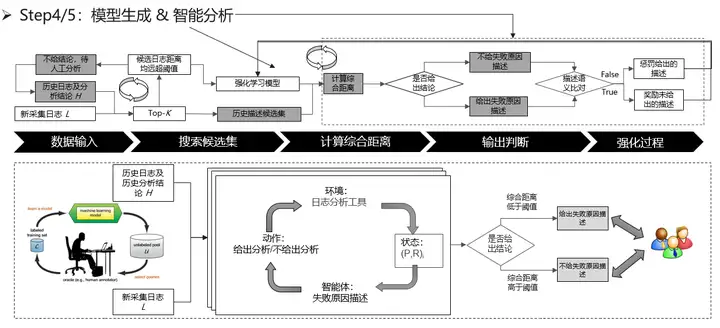
模型生成與智慧分析主要是結合了強化學習和主動學習,來對是否給出正確預測進行獎罰。對於新採集到的日誌,會跟日誌庫中的數據進行比較,選出top-k個距離最近的日誌樣本,若距離超出一定閾值,則不給出分析結論,若符合閾值內的樣本則加入候選集中,並且強化學習模型會計算候選集的得分,根據得分判斷是否給出失敗原因描述。最後由人工去確認失敗原因是否正確以此是否做出獎勵或懲罰,從而不斷優化強化學習模型。
5. 性能分析
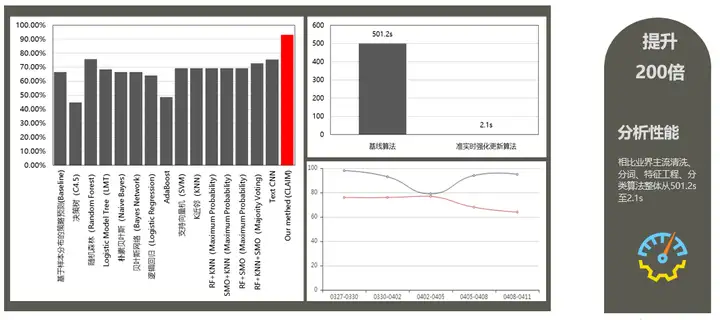
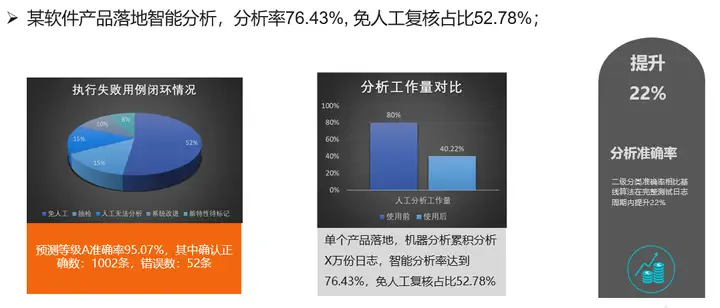
相比於業界主流方法,該模型的分析準確率能夠達到90%以上,演算法時間整體從501.2s提升在2.1s左右。另外智慧分析模型在某產品落地時,免人工複核佔比52.78%。
6. 自助接入
測試日誌智慧分析已經落地華為100多個產品線,為用戶提供了自主接入、自主訓練、結果分析的功能:提供自動的預處理規則管理、預處理效果展示,支援用戶一鍵式自助訓練模型,觀測模型分析準確率與結果。
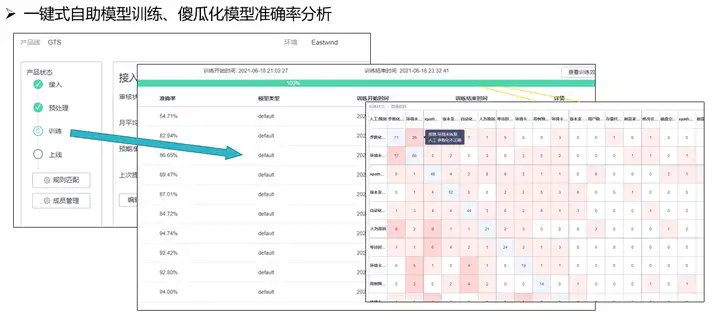
7. 總結
在華為多個產品業務背景下,本文提出了一種有效的日誌智慧分析方案,可以學習歷史測試日誌,對現網失敗用例根因智慧定界,大大減少了重複問題的定位,減輕了測試人員的工作量,另外針對不同產品的數據特徵,可以適配合適的模型方案,並提供了用戶自助接入與分析的功能。相比於基於規則的分析方法,本文方法不需要維護複雜的規則表以及規則衝突的情況,另外相比於傳統監督學習的方法,本文方法更適用於有大量人工標記且數據稀疏的情況,來提升預測結果的準確性。我們也將持續地關注業界學界的最佳實踐及新模型,以探索更優的解決方案。
文章來自PaaS技術創新Lab,PaaS技術創新Lab隸屬於華為雲,致力於綜合利用軟體分析、數據挖掘、機器學習等技術,為軟體研發人員提供下一代智慧研發工具服務的核心引擎和智慧大腦。我們將聚焦軟體工程領域硬核能力,不斷構築研發利器,持續交付高價值商業特性!加入我們,一起開創研發新「境界」!
PaaS技術創新Lab主頁鏈接://www.huaweicloud.com/lab/paas/home.html

