論文解讀(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
論文資訊
論文標題:Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
論文作者:Yizhen Zheng, Shirui Pan, Vincent Cs Lee, Yu Zheng, Philip S. Yu
論文來源:2022,NeurIPS
論文地址:download
論文程式碼:download
1 Introduction
GCL 需要大量的 Epoch 在數據集上訓練,本文的啟發來自 GCL 的代表性工作 DGI 和 MVGRL,因為 Sigmoid 函數存在的缺陷,因此,本文提出 Group Discrimination (GD) ,並基於此提出本文的模型 Graph Group Discrimination (GGD)。
Graph ContrastiveLearning 和 Group Discrimination 的區別:
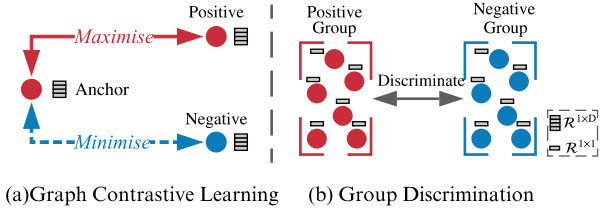
- GD directly discriminates a group of positive nodes from a group of negative nodes.
- GCL maximise the mutual information (MI) between an anchor node and its positive counterparts, sharing similar semantic information while doing the opposite for negative counterparts.
貢獻:
- 1) We re-examine existing GCL approaches (e.g., DGI and MVGRL), and we introduce a novel and efficient self-supervised GRL paradigm, namely, Group Discrimination (GD).
- 2) Based on GD, we propose a new self-supervised GRL model, GGD, which is fast in training and convergence, and possess high scalability.
- 3) We conduct extensive experiments on eight datasets, including an extremely large dataset, ogbn-papers100M with billion edges.
2 Rethinking Representative GCL Methods
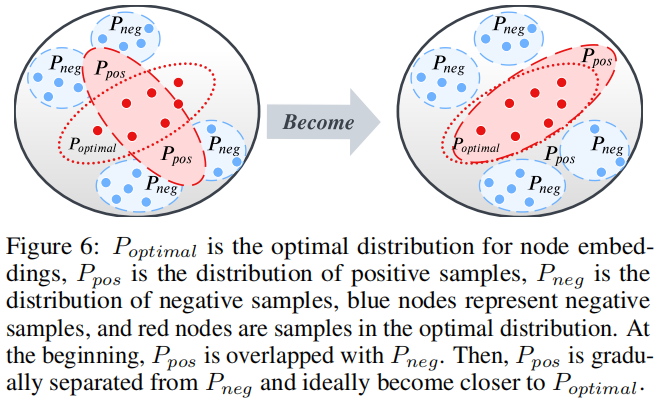
本節以經典的 DGI 、MVGRL 為例子,說明了互資訊最大化並不是對比學習的貢獻因素,而是一個新的範式,群體歧視(group discrimination)。
2.1 Rethinking GCL Methods
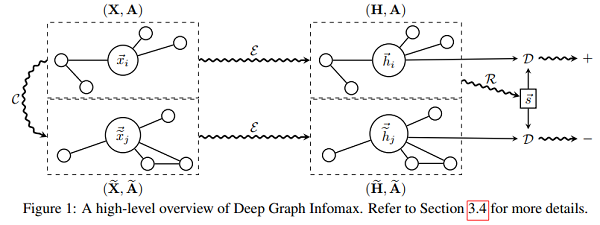
回顧一下 DGI :
程式碼:


class DGI(nn.Module):
def __init__(self, g, in_feats, n_hidden, n_layers, activation, dropout):
super(DGI, self).__init__()
self.encoder = Encoder(g, in_feats, n_hidden, n_layers, activation, dropout)
self.discriminator = Discriminator(n_hidden)
self.loss = nn.BCEWithLogitsLoss()
def forward(self, features):
positive = self.encoder(features, corrupt=False)
negative = self.encoder(features, corrupt=True)
summary = torch.sigmoid(positive.mean(dim=0))
positive = self.discriminator(positive, summary)
negative = self.discriminator(negative, summary)
l1 = self.loss(positive, torch.ones_like(positive))
l2 = self.loss(negative, torch.zeros_like(negative))
return l1 + l2
View Code
本文研究 DGI 結論:一個 Sigmoid 函數不適用於權重被 Xavier 初始化的 GNN 生成的 summary vector,且 summary vector 中的元素非常接近於相同的值。
接著嘗試將 Summary vector 中的數值變換成不同的常量 (from 0 to 1):
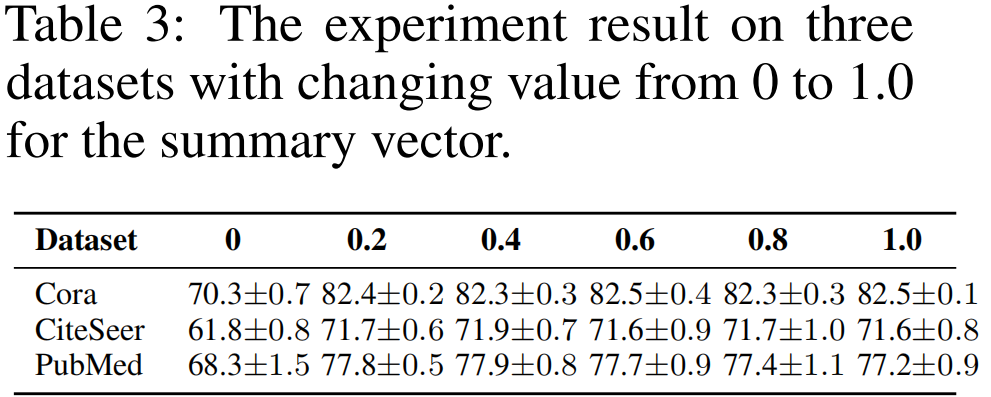
結論:
-
- 將 summary vector 中的數值變成 0,求解相似度時導致所有的 score 變成 0,也就是 postive 項的損失函數變成 負無窮,無法優化;
- summary vector 設置其他值,導致 數值不穩定;
DGI 的簡化:
① 將 summary vector 設置為 單位向量(縮放對損失不影響);
② 去掉 Discriminator (Bilinear :先做線性變換,再求內積相似度)的權重向量;【雙線性層的 $W$ 其實就是一個線性變換層】
$\begin{aligned}\mathcal{L}_{D G I} &=\frac{1}{2 N}\left(\sum\limits _{i=1}^{N} \log \mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)+\log \left(1-\mathcal{D}\left(\tilde{\mathbf{h}}_{i}, \mathbf{s}\right)\right)\right) \\&\left.=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\mathbf{h}_{i} \cdot \mathbf{s}\right)+\log \left(1-\tilde{\mathbf{h}}_{i} \cdot \mathbf{s}\right)\right)\right) \\&=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\operatorname{sum}\left(\mathbf{h}_{i}\right)\right)+\log \left(1-\operatorname{sum}\left(\tilde{\mathbf{h}}_{i}\right)\right)\right)\end{aligned} \quad\quad\quad(1)$
Bilinear :
$\mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)=\sigma_{s i g}\left(\mathbf{h}_{i} \cdot \mathbf{W} \cdot \mathbf{s}\right)\quad\quad\quad(2)$
實驗:替換 $\text{Eq.1}$ 中的 aggregation function ,即 sum 函數
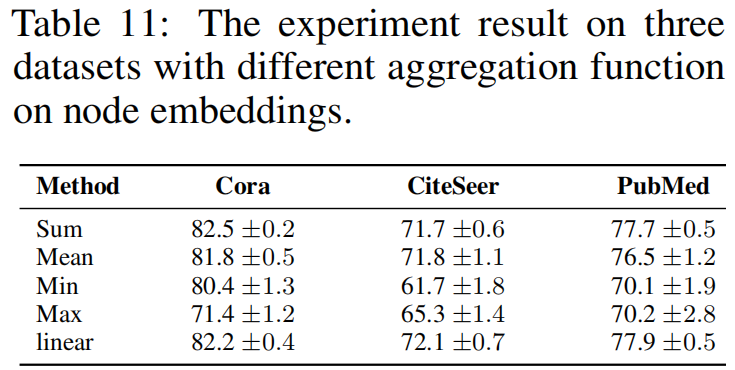
替換形式為:
$\mathcal{L}_{B C E}=-\frac{1}{2 N}\left(\sum\limits _{i=1}^{2 N} y_{i} \log \hat{y}_{i}+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right)\quad\quad\quad(3)$
其中,$\hat{y}_{i}=\operatorname{agg}\left(\mathbf{h}_{i}\right)$ ,$y_{i} \in \mathbb{R}^{1 \times 1}$ ,$\hat{y}_{i} \in \mathbb{R}^{1 \times 1}$。論文中闡述 $y_{i}$ 和 $\hat{y}_{i}$ 分別代表 node $i$ 是否是 postive sample ,及其預測輸出。Q :當 aggregation function 採用 $\text{mean}$ 的時候,對於 postive sample $i$ ,$\hat{y}_{i}$ 值會趨於 $1$ 么?
DGI 真正所做的是區分正確拓撲生成的一組節點和損壞拓撲生成的節點,如 Figure 1 所示。可以這麼理解,DGI 是使用一個固定的向量 $s$ 去區分兩組節點嵌入矩陣(postive and negative)。
Note:方差大的稍微大一點的 method ,就是容易被詆毀。
3 Methodology
整體框架:
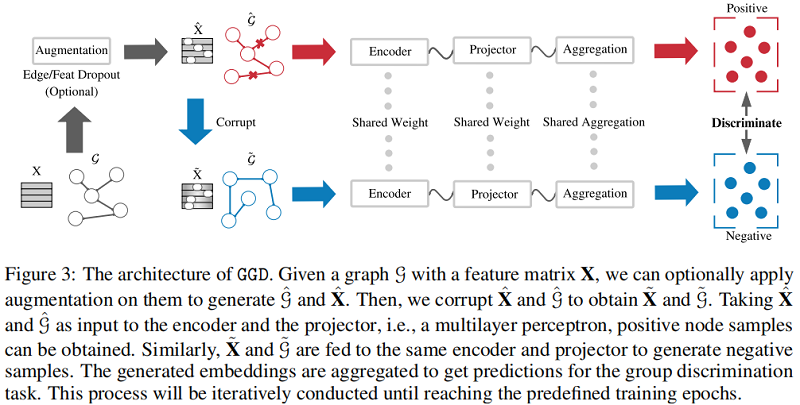
組成部分:
-
- Siamese Network :模仿 MVGRL 的架構;
- Data Augmentation :提供相似意義資訊,帶來的是時間成本;【dropout edge、feature mask】
- Loss function : $\text{Eq.3}$;
首先:固定 GNN encoder、MLP predict 的參數,獲得初步的節點表示 $\mathbf{H}_{\theta}$;
其次:MVGRL 多視圖對比工作給本文深刻的啟發,所以考慮引入全局資訊 :$ \mathbf{H}_{\theta}^{\text {global }}=\mathbf{A}^{n} \mathbf{H}_{\theta}$;
最後:得到局部表示和全局表示的聚合 $\mathbf{H}=\mathbf{H}_{\theta}^{\text {global }}+\mathbf{H}_{\theta}$ ;
4 Experiments
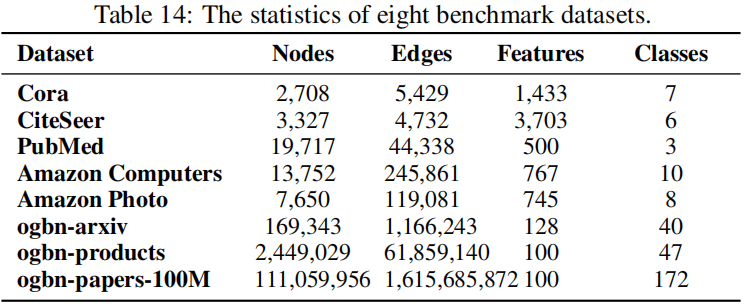
4.1 Datasets
4.2 Result
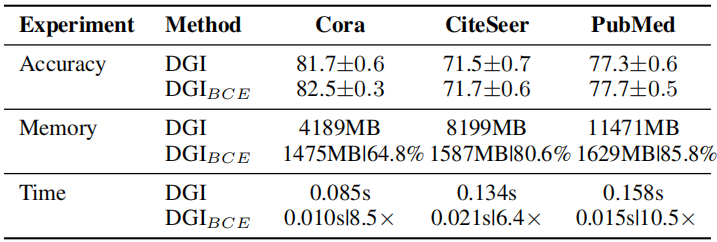
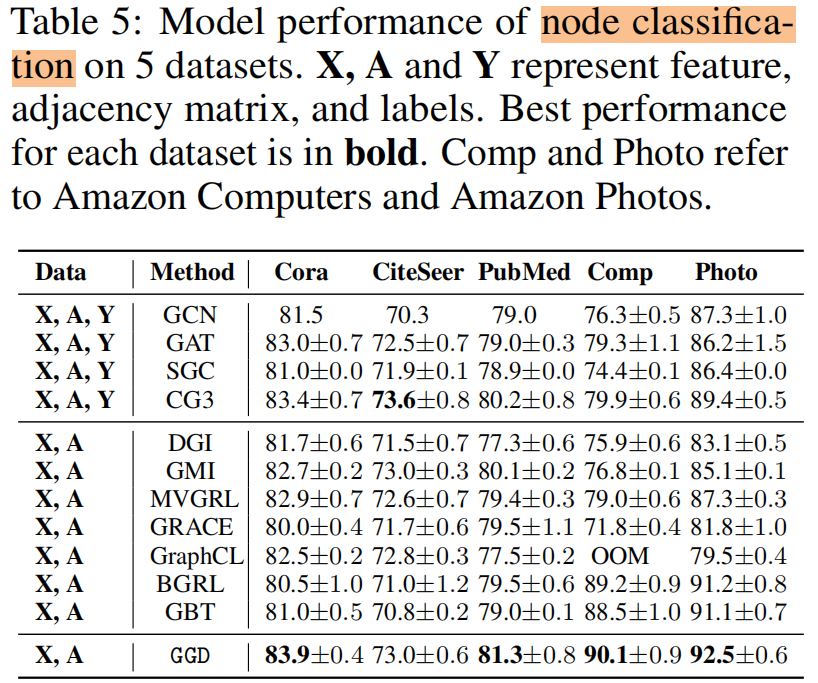
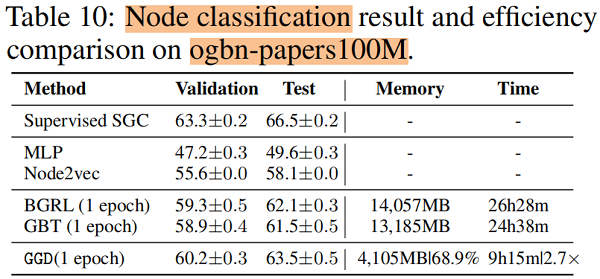
節點分類
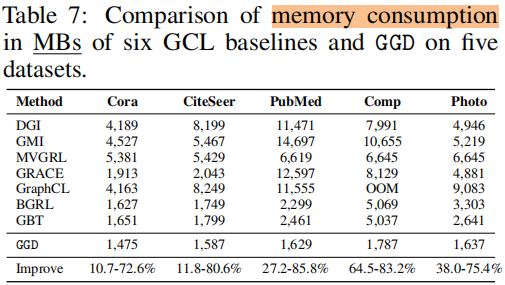
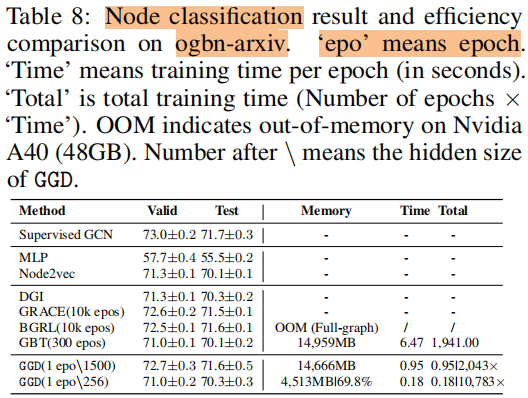
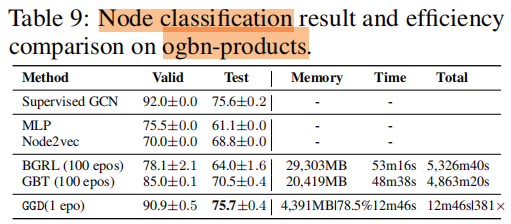
訓練時間 和 記憶體消耗


5 Future Work
For example, can we extend the current binary Group Discrimination scheme (i.e., classifying nodes generated with different topology) to discrimination among multiple groups?