大數據關鍵技術:自然語言處理入門篇
分詞與詞向量
自然語言處理簡介
自然語言處理概況
什麼是自然語言處理?
自然語言處理( Natural Language Processing, NLP)是電腦科學領域與人工智慧領域中的一個重要方向。它研究能實現人與電腦之間用自然語言進行有效通訊的各種理論和方法。自然語言處理是一門融語言學、電腦科學、數學於一體的科學。
自然語言處理主要應用於機器翻譯、輿情監測、自動摘要、觀點提取、文本分類、問題回答、文本語義對比、語音識別、中文OCR等方面。
(1) 電腦將自然語言作為輸入或輸出:
- 輸入對應的是自然語言理解;
- 輸出對應的是自然語言生成;
(2) 關於NLP的多種觀點:
- A、人類語言處理的計算模型:
- ——程式內部按人類行為方式操作
- B、 人類交流的計算模型:
- ——程式像人類一樣交互
- C、有效處理文本和語音的計算系統
(3) NLP的應用:
A、機器翻譯(Machine Translation)…….
B、MIT翻譯系統(MIT Translation System)……
C、文本摘要(Text Summarization)……
D、對話系統(Dialogue Systems)……
E、其他應用(Other NLP Applications):
——語法檢查(Grammar Checking)
——情緒分類(Sentiment Classification)
——ETS作文評分(ETS Essay Scoring)
自然語言處理相關問題
為什麼自然語言處理比較難?
(1) 歧義
「At last, a computer that understands you like your mother」
對於這句話的理解:
A、 它理解你就像你的母親理解你一樣;
B、 它理解你喜歡你的母親;
C、 它理解你就像理解你的母親一樣
D、 我們來看看Google的翻譯:終於有了一台像媽媽一樣懂你的電腦(看上去Google的理解更像選項A)。
A到C這三種理解好還是不好呢?
(2) 不同層次的歧義
A、 聲音層次的歧義——語音識別:
——「 … a computer that understands you like your mother」
——「 … a computer that understands you lie cured mother」
B、語義(意義)層次的歧義:
Two definitions of 「mother」:
——a woman who has given birth to a child
——a stringy slimy substance consisting of yeast cells and bacteria; is added to cider or wine to produce vinegar
C、話語(多語)層次的歧義、句法層次的歧義:
NLP的知識瓶頸
我們需要:
——有關語言的知識;
——有關世界的知識;
可能的解決方案:
——符號方法 or 象徵手法:將所有需要的資訊在電腦里編碼;
——統計方法:從語言樣本中推斷語言特性;
(1)例子研究:限定詞位置
任務:在文本中自動地放置限定詞
樣本:Scientists in United States have found way of turning lazy monkeys into workaholics using gene therapy. Usually monkeys work hard only when they know reward is coming, but animals given this treatment did their best all time. Researchers at National Institute of Mental Health near Washington DC, led by Dr Barry Richmond, have now developed genetic treatment which changes their work ethic markedly. 」Monkeys under influence of treatment don』t procrastinate,」 Dr Richmond says. Treatment consists of anti-sense DNA – mirror image of piece of one of our genes – and basically prevents that gene from working. But for rest of us, day when such treatments fall into hands of our bosses may be one we would prefer to put off.
(2)相關語法規則
a) 限定詞位置很大程度上由以下幾項決定:
i. 名詞類型-可數,不可數;
ii. 照應-特指,類指;
iii. 資訊價值-已有,新知
iv. 數詞-單數,複數
b) 然而,許多例外和特殊情況也扮演著一定的角色,如:
i. 定冠詞用在報紙名稱的前面,但是零冠詞用在雜誌和期刊名稱前面
(3) 符號方法方案
a) 我們需要哪些類別的知識:
i. 語言知識:
-靜態知識:數詞,可數性,…
-上下文相關知識:共指關係
ii. 世界知識:
- 引用的唯一性(美國現任總統),名詞的類型(報紙與雜誌),名詞之間的情境關聯性(足球比賽的得分),……
iii. 這些資訊很難人工編碼!
(4)統計方法方案
a) 樸素方法:
i. 收集和你的領域相關的大量的文本
ii. 對於其中的每個名詞,計算它和特定的限定詞一起出現的概率
iii. 對於一個新名詞,依據訓練語料庫中最高似然估計選擇一個限定詞
b) 實現:
i. 語料:訓練——華爾街日報(WSJ)前21節語料,測試——第23節
ii. 預測準確率:71.5%
c) 結論:
i. 結果並不是很好,但是對於這樣簡單的方法結果還是令人吃驚
ii. 這個語料庫中的很大一部分名詞總是和同樣的限定詞一起出現,如:
-「the FBI」,「the defendant」, …
(5)作為分類問題的限定詞位置
a) 預測:
b) 代表性的問題:
i. 複數?(是,否)
ii. 第一次在文本中出現?
iii. 名詞(辭彙集的成員)
c) 圖表例子略
d) 目標:學習分類函數以預測未知例子
(6)分類方法
a) 學習X->Y的映射函數
b) 假設已存在一些分布D(X,Y)
c) 嘗試建立分布D(X,Y)和D(X|Y)的模型
(7)分類之外
a) 許多NLP應用領域可以被看作是從一個複雜的集合到另一個集合的映射:
i. 句法分析: 串到樹
ii. 機器翻譯: 串到串
iii. 自然語言生成:數據詞條到串
b) 注意,分類框架並不適合這些情況!
自然語言處理:單詞計數
語料庫及其性質
(1) 什麼是語料庫(Corpora)
i. 一個語料庫就是一份自然發生的語言文本的載體,以機器可讀形式存儲;
(2) 單詞計數(Word Counts)
i. 在文本中最常見的單詞是哪些?
ii. 在文本中有多少個單詞?
iii. 在大規模語料庫中單詞分布的特點是什麼?
(3) 我們以馬克吐溫的《湯姆索耶歷險記》為例:
單詞(word) 頻率(Freq) 用法(Use)
the 3332 determiner (article)
and 2972 conjunction
a 1775 determiner
to 1725 preposition, inf. marker
of 1440 preposition
was 1161 auxiliary verb
it 1027 pronoun
in 906 preposition
that 877 complementizer
Tom 678 proper name
虛詞佔了大多數
(4) 這個例句里有多少個單詞:
They picnicked by the pool, then lay back on the grass and looked at the stars.
i. 「型」(Type) ——語料庫中不同單詞的數目,詞典容量
ii. 「例」(Token) — 語料中總的單詞數目
iii. 註:以上定義參考自《自然語言處理綜論》
iv. 湯姆索耶歷險記(Tom Sawyer)中有:
1. 詞型— 8, 018
2. 詞例— 71, 370
3. 平均頻率— 9(註:詞例/詞型)
(5) 詞頻的頻率:
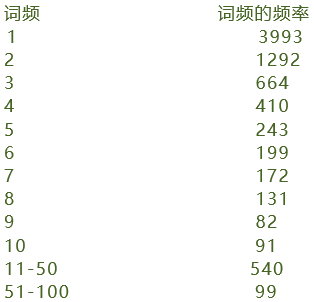
大多數詞在語料庫中僅出現一次!
自然語言處理的一般步驟
(1) 文本預處理(分詞、去除停用詞、詞幹化)
(2) 統計詞頻
(3) 文本向量化
分詞相關知識
(1) Tokenization
i. 目標:將文本切分成單詞序列
ii. 單詞指的是一串連續的字母數字並且其兩端有空格;可能包含連字元和撇號但是沒有其它標點符號
iii. Tokenizatioan 容易嗎?
(2) 什麼是詞?
i. English:
1. 「Wash. vs wash」
2. 「won』t」, 「John』s」
3. 「pro-Arab」, 「the idea of a child-as-required-yuppie-possession must be motivating them」, 「85-year-old grandmother」
ii. 東亞語言:
詞之間沒有空格
(3) 分詞(Word Segmentation)
i. 基於規則的方法: 基於詞典和語法知識的形態分析
ii. 基於語料庫的方法: 從語料中學習(Ando&Lee, 2000))
iii. 需要考慮的問題: 覆蓋面,歧義,準確性
1.基於詞典:基於字典、詞庫匹配的分詞方法;(字元串匹配、機械分詞法)
2.基於統計:基於詞頻度統計的分詞方法;
3.基於規則:基於知識理解的分詞方法。
中文分詞——jieba分詞
中文分詞是中文文本處理的一個基礎步驟,也是中文人機自然語言交互的基礎模組,在進行中文自然語言處理時,通常需要先進行分詞。
中文在基本文法上有其特殊性,具體表現在:
1.與英文為代表的拉丁語系語言相比,英文以空格作為天然的分隔符,而中文由於繼承自古代漢語的傳統,詞語之間沒有分隔。 古代漢語中除了連綿詞和人名地名等,詞通常就是單個漢字,所以當時沒有分詞書寫的必要。而現代漢語中雙字或多字詞居多,一個字不再等同於一個詞。
2.在中文裡,「詞」和「片語」邊界模糊
現代漢語的基本表達單元雖然為「詞」,且以雙字或者多字詞居多,但由於人們認識水平的不同,對詞和短語的邊界很難去區分。
例如:「對隨地吐痰者給予處罰」,「隨地吐痰者」本身是一個詞還是一個短語,不同的人會有不同的標準,同樣的「海上」「酒廠」等等,即使是同一個人也可能做出不同判斷,如果漢語真的要分詞書寫,必然會出現混亂,難度很大。
jieba分詞演算法使用了基於前綴詞典實現高效的詞圖掃描,生成句子中漢字所有可能生成詞情況所構成的有向無環圖(DAG), 再採用了動態規劃查找最大概率路徑,找出基於詞頻的最大切分組合,對於未登錄詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法。
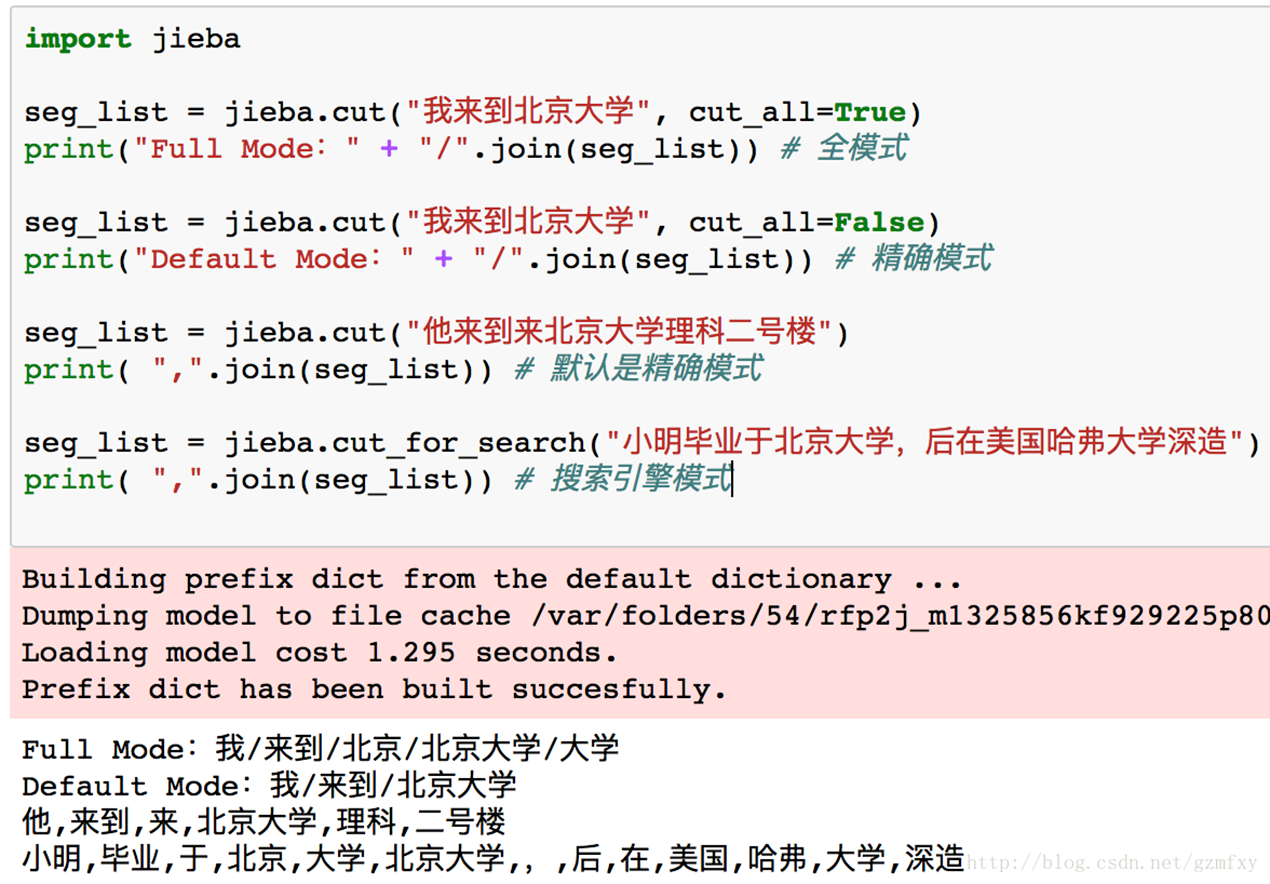
jieba分詞支援三種分詞模式:
-
精確模式, 試圖將句子最精確地切開,適合文本分析:
-
全模式,把句子中所有的可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義;
-
搜索引擎模式,在精確模式的基礎上,對長詞再詞切分,提高召回率,適合用於搜索引擎分詞。
jieba分詞還支援繁體分詞和支援自定義分詞。
jieba分詞器安裝
在python2.x和python3.x均兼容,有以下三種:
-
全自動安裝:easy_install jieba 或者 pip install jieba / pip3 install jieba
-
半自動安裝: 先下載,網址為: //pypi.python.org/pypi/jieba, 解壓後運行: python setup.py install
-
手動安裝: 將jieba目錄放置於當前目錄或者site-packages目錄,
jieba分詞可以通過import jieba 來引用
jieba分詞主要功能
先介紹主要的使用功能,再展示程式碼輸出。jieba分詞的主要功能有如下幾種:
-
jieba.cut:該方法接受三個輸入參數:需要分詞的字元串; cut_all 參數用來控制是否採用全模式;HMM參數用來控制是否適用HMM模型
-
jieba.cut_for_search:該方法接受兩個參數:需要分詞的字元串;是否使用HMM模型,該方法適用於搜索引擎構建倒排索引的分詞,粒度比較細。
-
待分詞的字元串可以是unicode或者UTF-8字元串,GBK字元串。注意不建議直接輸入GBK字元串,可能無法預料的誤解碼成UTF-8,
-
jieba.cut 以及jieba.cut_for_search返回的結構都是可以得到的generator(生成器), 可以使用for循環來獲取分詞後得到的每一個詞語或者使用
-
jieb.lcut 以及 jieba.lcut_for_search 直接返回list
-
jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定義分詞器,可用於同時使用不同字典,jieba.dt為默認分詞器,所有全局分詞相關函數都是該分詞器的映射。
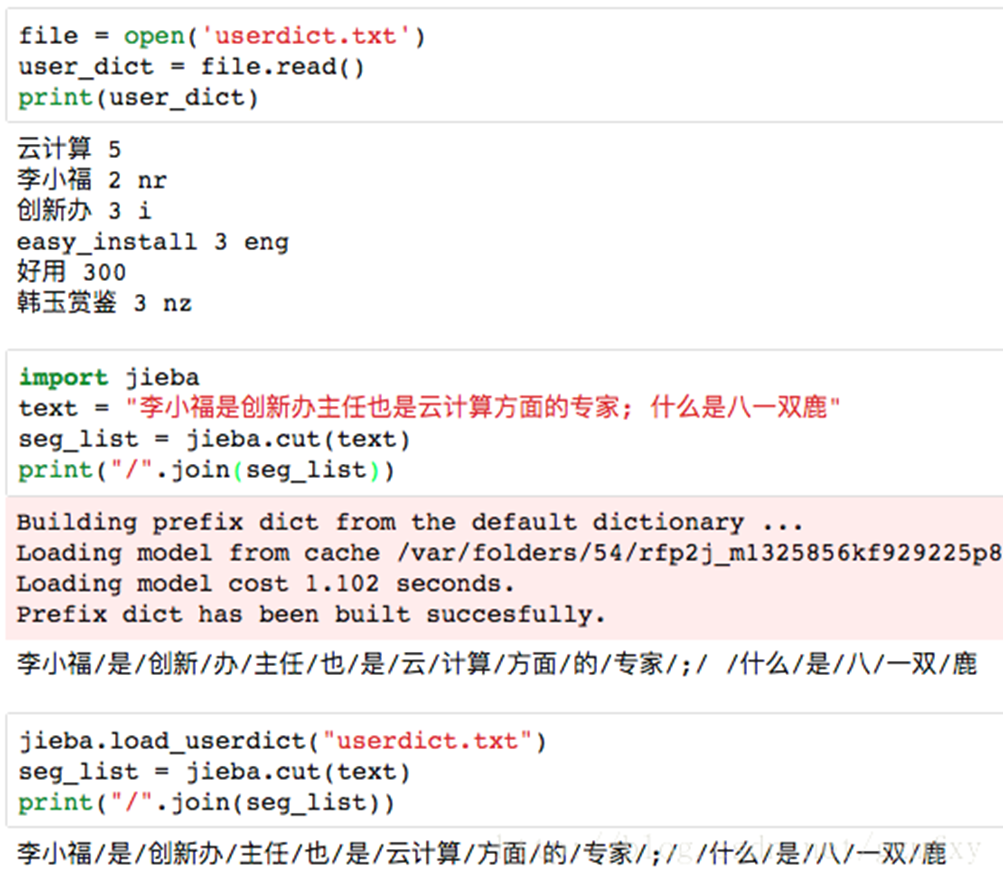
jieba分詞器添加自定義詞典
jieba分詞器還有一個方便的地方是開發者可以指定自己的自定義詞典,以便包含詞庫中沒有的詞,雖然jieba分詞有新詞識別能力,但是自行添加新詞可以保證更高的正確率。
使用命令:
jieba.load_userdict(filename) # filename為自定義詞典的路徑
在使用的時候,詞典的格式和jieba分詞器本身的分詞器中的詞典格式必須保持一致,一個詞佔一行,每一行分成三部分,一部分為詞語,一部分為詞頻,最後為詞性(可以省略),用空格隔開。下面其中userdict.txt中的內容為小修添加的詞典,而第二部分為小修沒有添加字典之後對text文檔進行分詞得到的結果,第三部分為小修添加字典之後分詞的效果。
這裡介紹基於TF-IDF演算法的關鍵詞抽取, 只有關鍵詞抽取並且進行詞向量化之後,才好進行下一步的文本分析,可以說這一步是自然語言處理技術中文本處理最基礎的一步。
jieba分詞中含有analyse模組,在進行關鍵詞提取時可以使用下列程式碼
import jieba.analyse
jieba.analyse.extrac_tags(sentence,topK=20,withweight=False,allowPos=())
#sentence為待提取的文本,
#toPK為返回幾個TF/tDF權重最大的關鍵詞,默認值為20
#withweight為是否一併返回關鍵詞權重值,默認值為False
#a11 owPOS僅包含指定詞性的詞,默認值為空,既不篩選
jieba.analyse.TFIDF(idf_path=None)#新建rF-IDF實例,idf path為IDF頻率文件
jieba.analyse.textrank(sentence,topK=20,withweight=False,allowPOS=('ns','n','vn','v'))
#直接使用,介面相同,注意磨人過濾詞性
jieba.analyse.TextRank()
#新建自定義TextRank.實例
基本思想:
1、將待抽取關鍵詞的文本進行分詞
2、以固定窗口大小(默認為5,通過span屬性調整),詞之間的共現關係,構建圖計算圖中節點的PageRank,注意是無向帶權圖
利用jieba進行關鍵詞抽取
一個例子:分別使用兩種方法對同一文本進行關鍵詞抽取,並且顯示相應的權重值。

jieba分詞的詞性標註
jieba分詞還可以進行詞性標註,標註句子分詞後每個詞的詞性,採用和ictclas兼容的標記法,這裡知識簡單的句一個列子。
#jieba.posseg.POSTokenizer(tokenizer=None)
#新建自定義分詞器,tokenizer參數可以指定內部使用的
#jieba.Tokenizer分詞器,jieba.posseg.dt為默認詞性標註分詞器
import jieba.posseg as pseg
words=pseg.cut("我愛北京大學")
for word,flag in words:
print('%s %s' %(word,flag))
文本向量化表示
文本表示是自然語言處理中的基礎工作,文本表示的好壞直接影響到整個自然語言處理系統的性能。文本向量化就是將文本表示成一系列能夠表達文本語義的向量,是文本表示的一種重要方式。目前對文本向量化大部分的研究都是通過詞向量化實現的,也有一部分研究者將句子作為文本處理的基本單元,於是產生了doc2vec和str2vec技術。
詞袋模型
詞袋模型和表示方法
從書店圖書管理員談起。假設書店有3排書架,分別擺放「文學藝術」、「教育考試」、「烹飪美食」3種主題的書籍,現在新到了3本書分別是《唐詩三百首》、《英語辭彙》《中式面點》,你是一名圖書管理員,要怎樣將這些書擺放到合適的書架上呢?實際上你擺放圖書的過程就是分類的過程。如下圖所示:
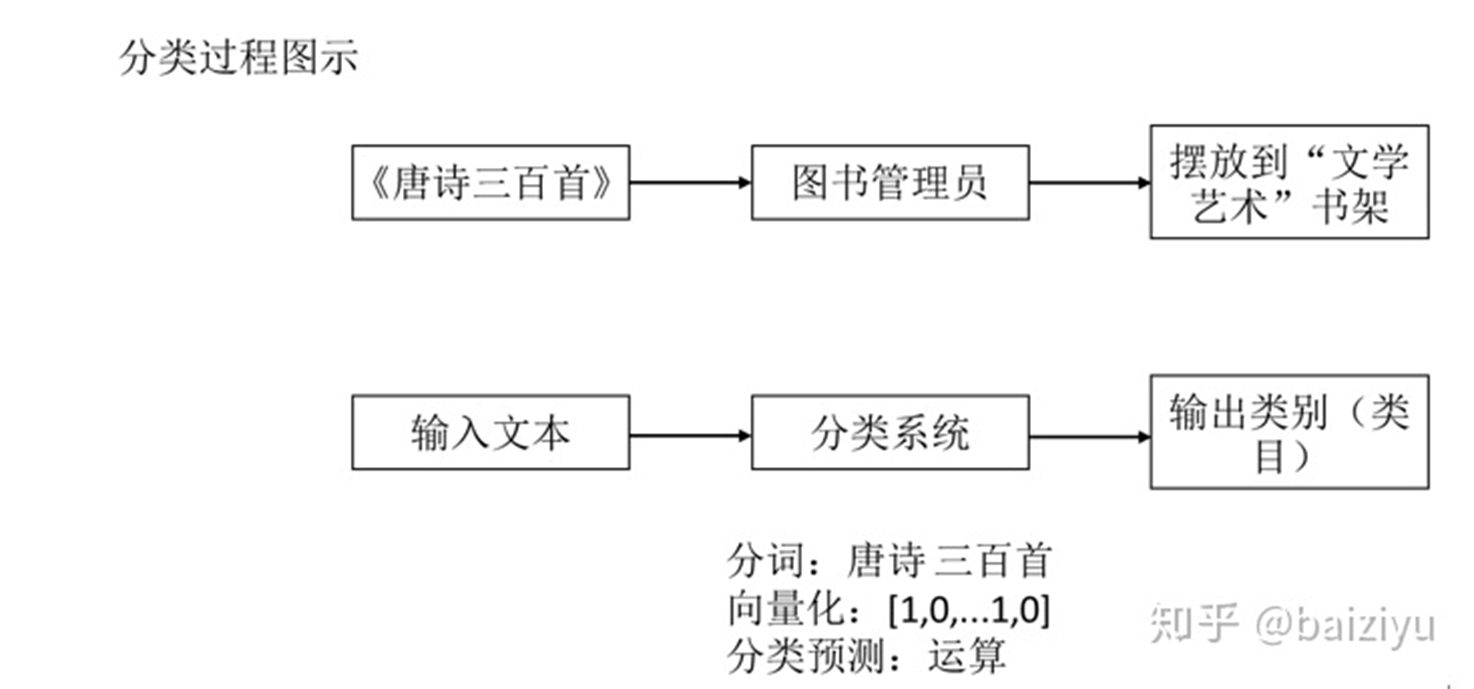
文本向量化表示就是用數值向量來表示文本的語義。文本分類領域使用了資訊檢索領域的詞袋模型,詞袋模型在部分保留文本語義的前提下對文本進行向量化表示。
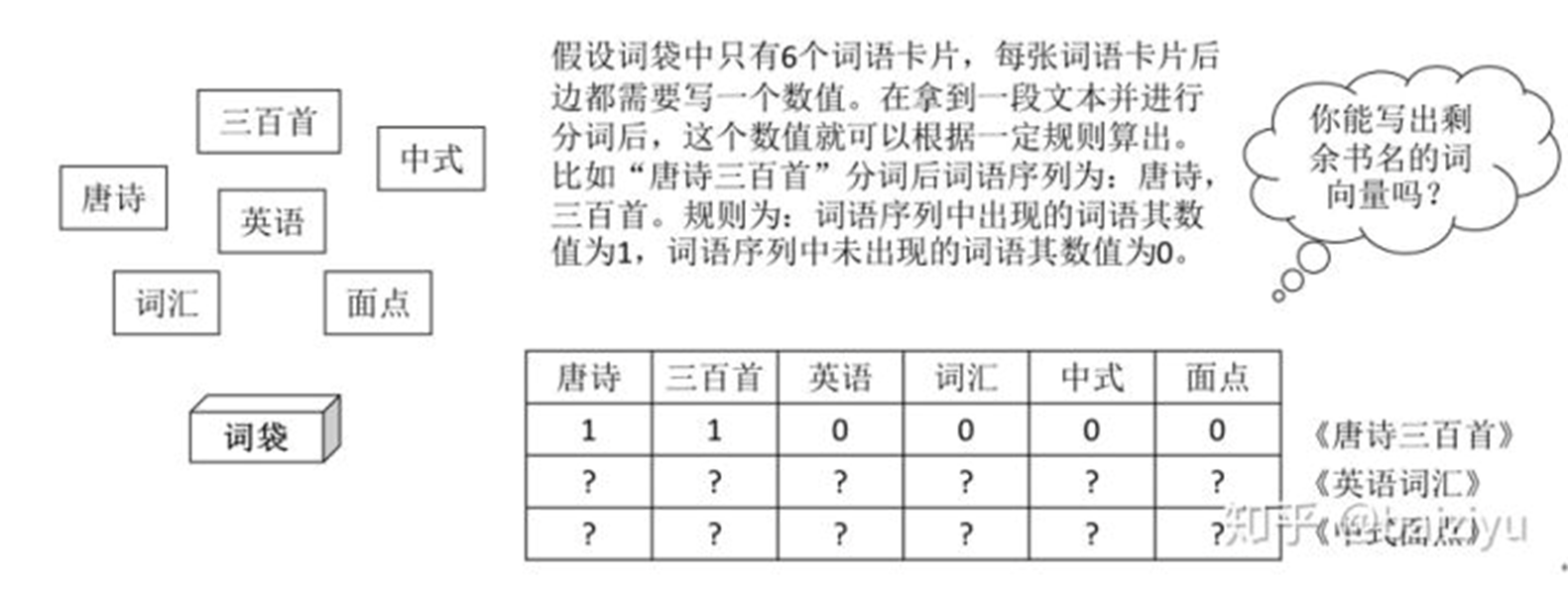
One-Hot表示法
One-Hot表示法的數值計算規則為:詞語序列中出現的詞語其數值為1,詞語序列中未出現的詞語其數值為0。用數學式子表達為:
1, \text { 文本含有詞項 } j \\
0, \text { 文本不含詞項 } j
\end{array} .\right.
\]
例1 已知有下邊的幾篇英文文本,請用詞袋模型One-Hot法向量化表示每篇文本。

從以上介紹可以看到,詞袋模型的One-Hot表示法考慮了都有哪些詞在文本中出現,用出現的詞語來表示文本的語義。
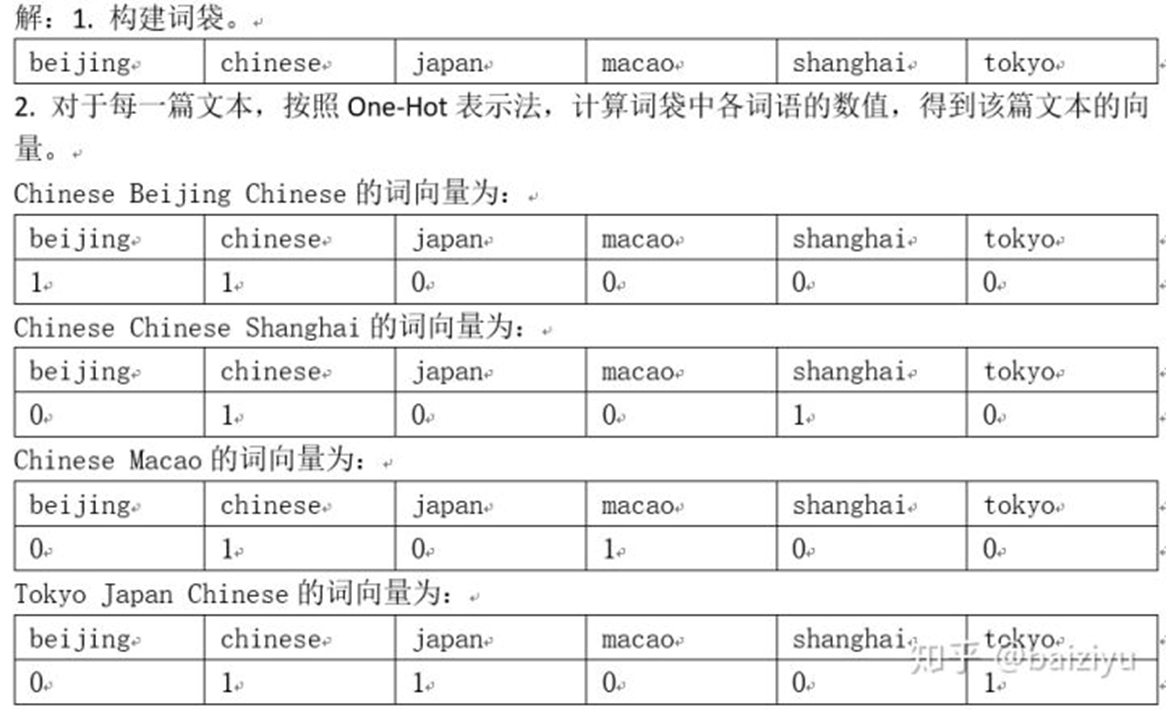
TF表示法
TF表示法的數值計算規則為:詞語序列中出現的詞語其數值為詞語在所在文本中的頻次,詞語序列中未出現的詞語其數值為0。用數學式子表達為:
\operatorname{count}\left(t_{j}\right) \text {, 文本含有詞項 } j \\
0, \text { 文本不含詞項 } j
\end{array}\right.
\]
其中,\(t\)表示詞語\(j\),\(count(t)\)表示詞語\(j\)在所在文本出現的次數。
從以上介紹可以看到,詞袋模型的TF表示法除了考慮都有哪些詞在文本中出現外,還考慮了詞語出現的頻次,用出現詞語的頻次來突出文本主題進而表示文本的語義。
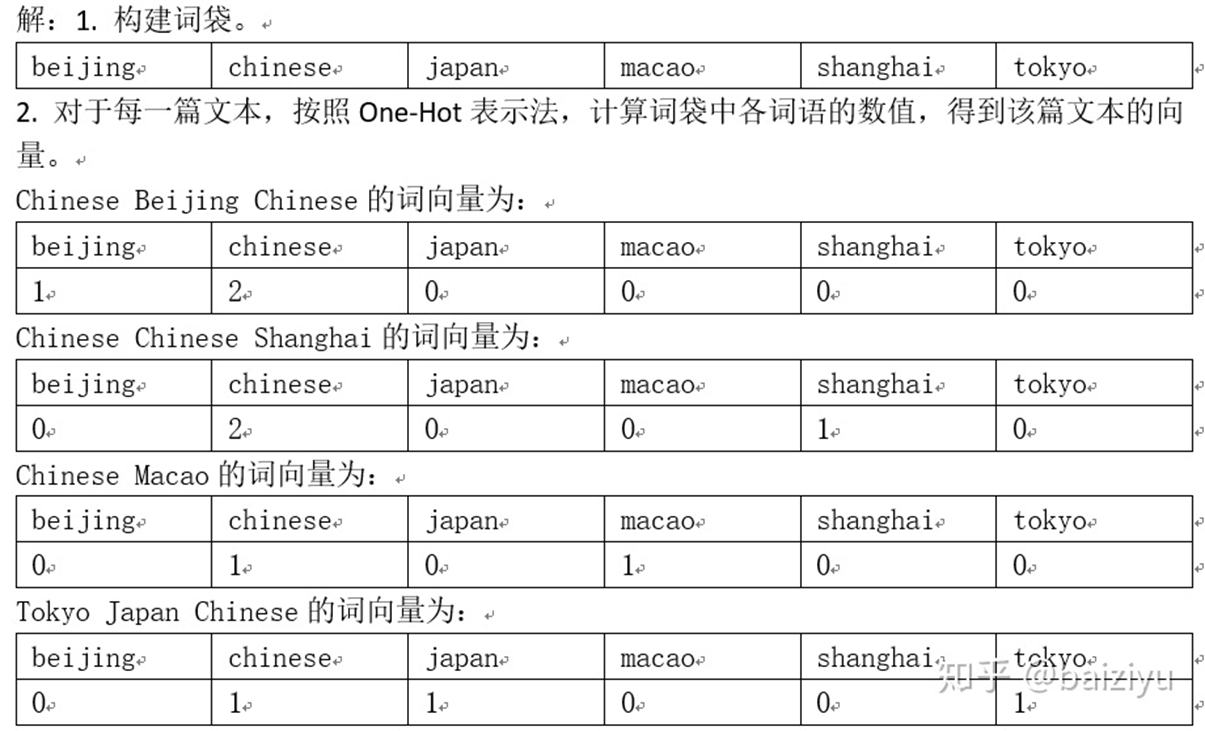
TF-IDF表示法
TF-IDF表示法的數值計算規則為:詞語序列中出現的詞語其數值為詞語在所在文本中的頻次乘以詞語的逆文檔頻率,詞語序列中未出現的詞語其數值為0。用數學式子表達為:
\operatorname{count}\left(t_{j}\right) \times i d f\left(t_{j}\right), \text { 文本含有詞項 } j \\
0, \text { 文本不含詞項 } j
\end{array}\right.
\]

例2 已知有下邊的幾篇英文文本,請用詞袋模型TF法向量化表示每篇文本。文本同例1

IDF值計算過程

非詞袋模型
詞袋(Bag Of Word)模型是最早的以詞語為基礎處理單元的文本項量化方法。該模型產生的向量與原來文本中單詞出現的順序沒有關係,而是詞典中每個單詞在文本中出現的頻率。該方法雖然簡單易行,但是存在如下三個方面的問題:維度災難,無法保留詞序資訊,存在語義鴻溝。
神經網路語言模型(Neural Network Language Model,NNLM)與傳統方法估算的不同在於直接通過一個神經網路結構對n元條件概率進行估計。
由於NNLM模型使用低維緊湊的詞向量對上下文進行表示,解決了詞袋模型帶來的數據稀疏、語義鴻溝等問題。
另一方面,在相似的上下文語境中,NNLM模型可以預測出相似的目標詞,而傳統模型無法做到這一點。
例如,如果在語料中A=「小狗在院子里趴著」出現1000次,B=「小貓在院子里趴著」出現1次。A和B的唯一區別就是狗和貓,兩個詞無論在語義還是語法上都相似。根據頻率來估算概率P(A)>>P(B),這顯然不合理。如果採用NNLM計算P(A)~P(B),因為NNLM模型採用低維的向量表示詞語,假定相似的詞其詞向量也相似。
Word2Vec是從大量文本語料中以無監督的方式學習語義知識的一種模型,它被大量地用在自然語言處理(NLP)中。
Word2Vec模型中,主要有Skip-Gram和CBOW兩種模型,從直觀上理解,Skip-Gram是給定input word來預測上下文。而CBOW是給定上下文,來預測input word。
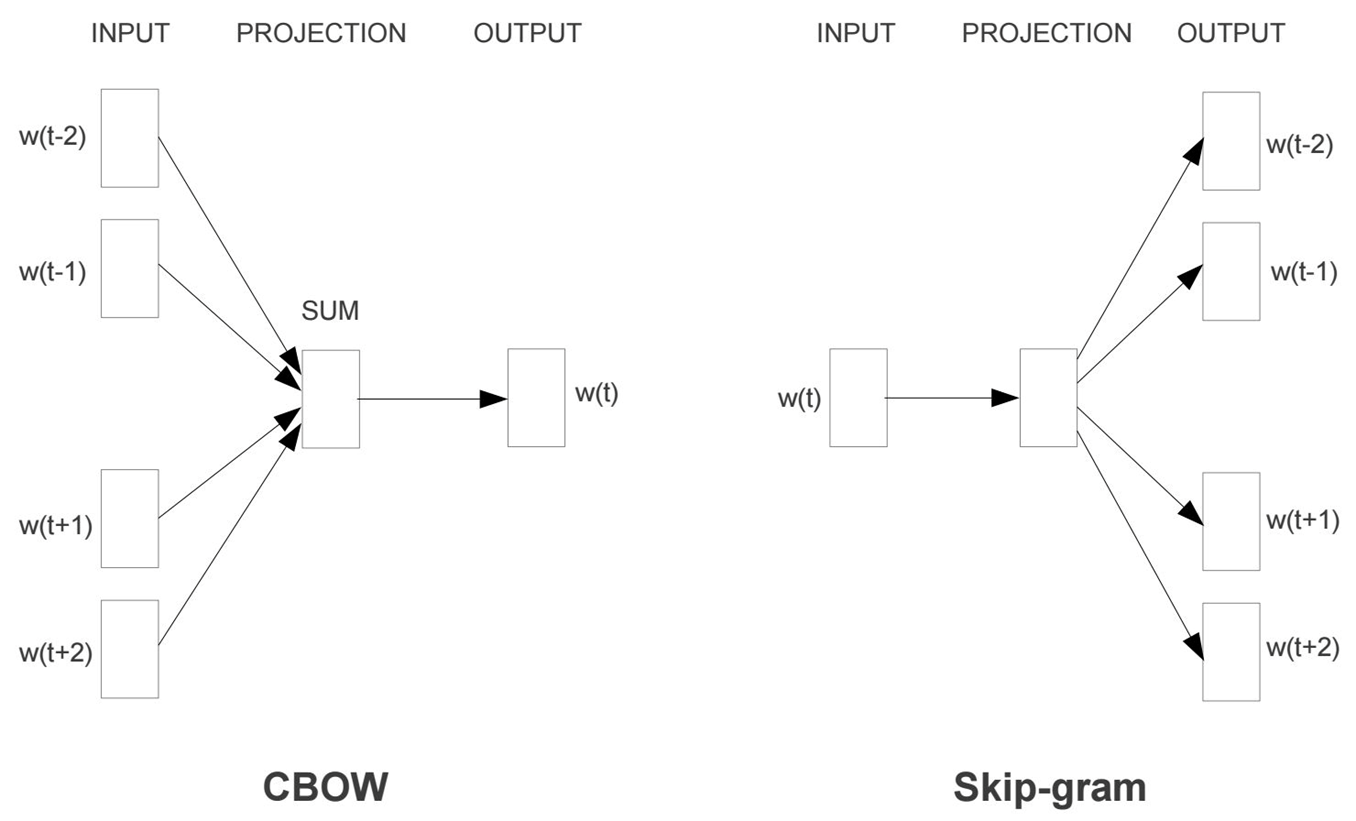
Word2Vec模型實際上分為了兩個部分,第一部分為建立模型,第二部分是通過模型獲取嵌入詞向量。Word2Vec的整個建模過程實際上與自編碼器(auto-encoder)的思想很相似,即先基於訓練數據構建一個神經網路,當這個模型訓練好以後,我們並不會用這個訓練好的模型處理新的任務,我們真正需要的是這個模型通過訓練數據所學得的參數,例如隱層的權重矩陣。
模型的輸出概率代表著到我們詞典中每個詞有多大可能性跟input word同時出現。舉個例子,如果我們向神經網路模型中輸入一個單詞「Soviet「,那麼最終模型的輸出概率中,像「Union」, 」Russia「這種相關詞的概率將遠高於像」watermelon「,」kangaroo「非相關詞的概率。因為」Union「,」Russia「在文本中更大可能在」Soviet「的窗口中出現。
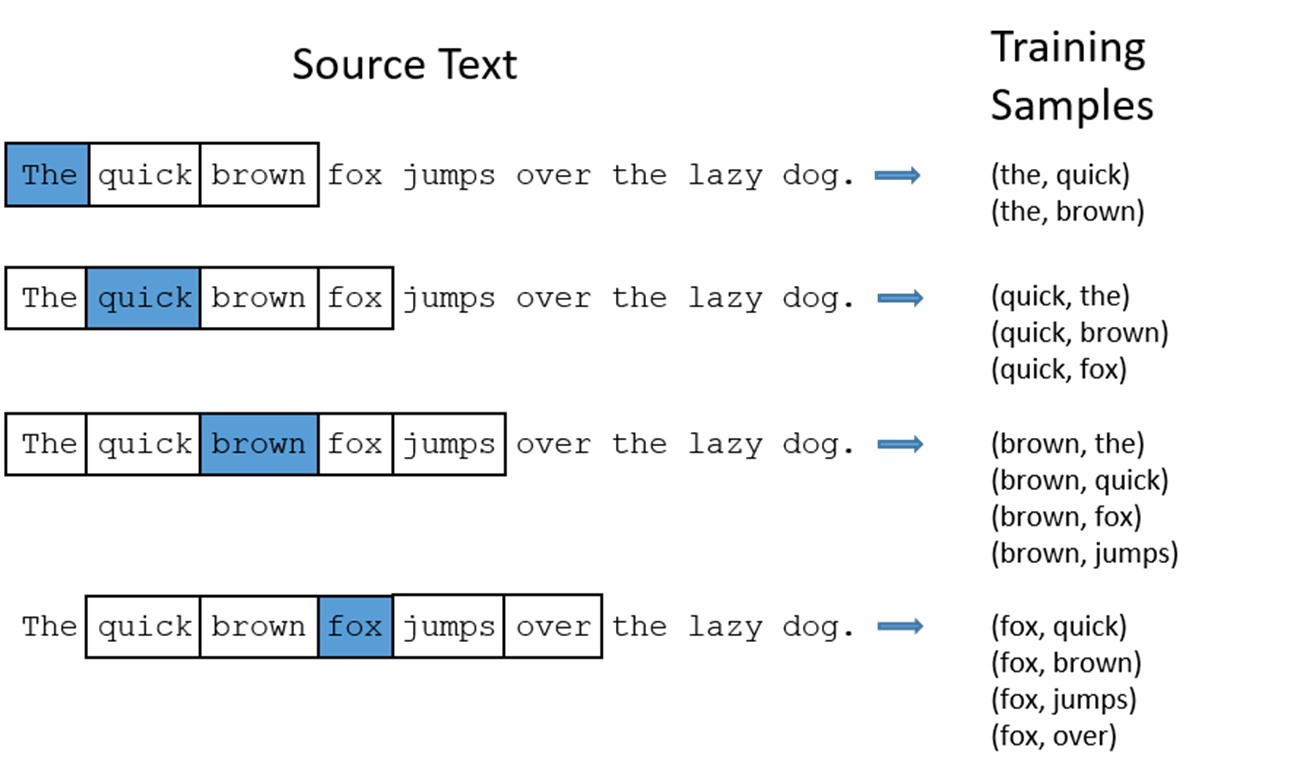
我們的模型將會從每對單詞出現的次數中習得統計結果。例如,我們的神經網路可能會得到更多類似(「Soviet「,」Union「)這樣的訓練樣本對,而對於(」Soviet「,」Sasquatch「)這樣的組合卻看到的很少。因此,當我們的模型完成訓練後,給定一個單詞」Soviet「作為輸入,輸出的結果中」Union「或者」Russia「要比」Sasquatch「被賦予更高的概率。
如果兩個不同的單詞有著非常相似的「上下文」(也就是窗口單詞很相似,比如「Kitty climbed the tree」和「Cat climbed the tree」),那麼通過我們的模型訓練,這兩個單詞的嵌入向量將非常相似。
那麼兩個單詞擁有相似的「上下文」到底是什麼含義呢?
比如對於同義詞「intelligent」和「smart」,我們覺得這兩個單詞應該擁有相同的「上下文」。而例如」engine「和」transmission「這樣相關的詞語,可能也擁有著相似的上下文。
實際上,這種方法實際上也可以幫助你進行詞幹化(stemming),例如,神經網路對」ant「和」ants」兩個單詞會習得相似的詞向量。
詞幹化(stemming)就是去除詞綴得到詞根的過程。
主題挖掘
LDA主題模型基本知識
文本挖掘背景知識
什麼是文本挖掘?
- 電腦通過高級數據挖掘和自然語言處理,對非結構化的文字進行機器學習。
- 文本數據挖掘包含但不局限以下幾點:
- 主題挖掘
- 文本分類
- 文本聚類
- 語義庫的搭建
在機器學習和自然語言處理等領域,主題挖掘是尋找是主題模型,主題模型是用來在一系列文檔中發現抽象主題的一種統計模型。
如果一篇文章有一個中心思想,那麼一些特定詞語會更頻繁的出現。簡單而言,主題挖掘就是要找到表達文章中心思想的主題詞。
從大量文字中找到主題是一個高度複雜的工作,不僅因為人的自然語言具有多層面特性,而且很難找到準確體現資料核心思想的詞語。
主題挖掘的現有方案如下:
- TF-IDF(Term Frequency–Inverse Document Frequency)
- 共現關係(co-occurrence)
- LDA(隱含狄利克雷分布Latent Dirichlet allocation)
但是這些演算法也存在一定的局限性:要麼是無法做到只提煉出重要主題,要麼是不具高度擴展性和高效性。
TF-IDF
TF-IDF(term frequency–inverse document frequency,詞頻-逆向文件頻率)是一種用於資訊檢索(information retrieval)與文本挖掘(text mining)的常用加權技術。
TF-IDF是一種統計方法,用以評估一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
TF-IDF的主要思想是:如果某個單詞在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。
- TF是詞頻(Term Frequency)
詞頻(TF)表示詞條(關鍵字)在文本中出現的頻率。
這個數字通常會被歸一化(一般是詞頻除以文章總詞數), 以防止它偏向長的文件。

- IDF是逆向文件頻率(Inverse Document Frequency)
逆向文件頻率 (IDF) :某一特定詞語的IDF,可以由總文件數目除以包含該詞語的文件的數目,再將得到的商取對數得到。
如果包含詞條t的文檔越少, IDF越大,則說明詞條具有很好的類別區分能力。
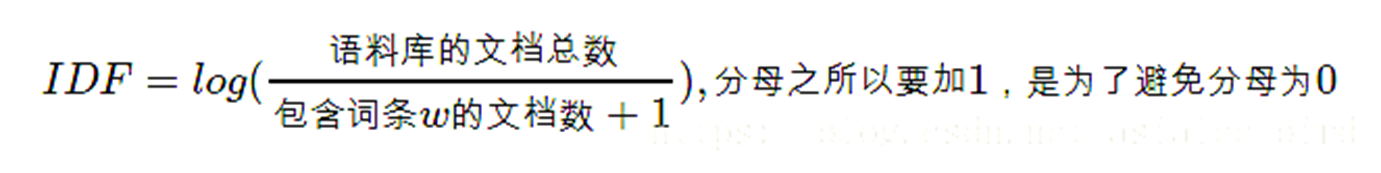
- TF-IDF實際上是:TF * IDF
某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
- TF-IDF應用
(1)搜索引擎;
(2)關鍵詞提取;
(3)文本相似性;
(4)文本摘要
Python如何實現TF-IDF演算法: NLTK、 Sklearn、 Jieba
Co-occurrence(共現關係)
共詞關係分析方法在網路研究中應用普遍,通常利用單元(如辭彙、人物和機構等)之間的共現關係構建共現矩陣,進而映射為共現關係網路並可視化,從而來揭示某領域的熱點與趨勢、結構與演化等。
在大規模語料中,若兩個詞經常共同出現(共現)在截取的同一單元(如一定詞語間隔/一句話/一篇文檔等)中,則認為這兩個詞在語義上是相互關聯的,而且,共現的頻率越高,其相互間的關聯越緊密。
兩個詞共同出現的次數越多,網路圖中兩個詞語節點連線越粗,也就是共現的次數為邊上的權值
其次,單個詞出現的次數越多,在網路圖中節點越大,若一個詞與許多詞均有聯繫,則這個詞會在網路圖的中心區域。
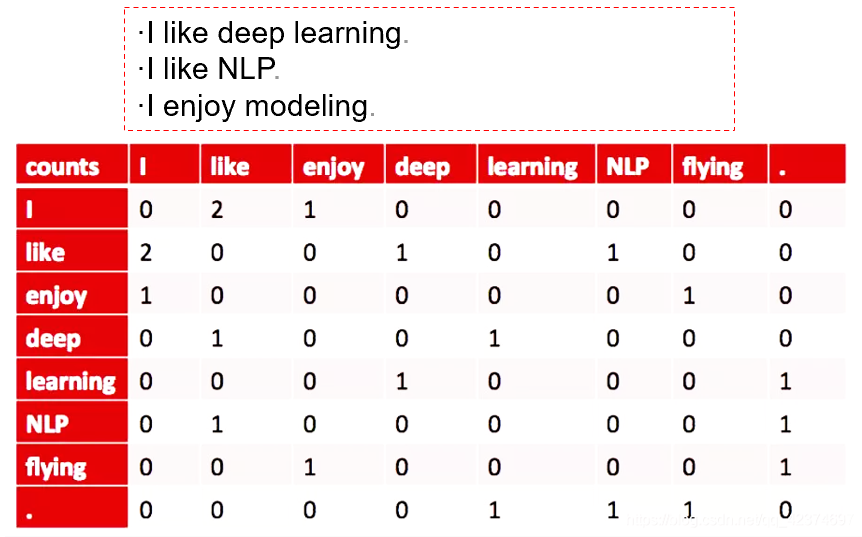
在文本挖掘中,有共現矩陣的概念,如下
案例:
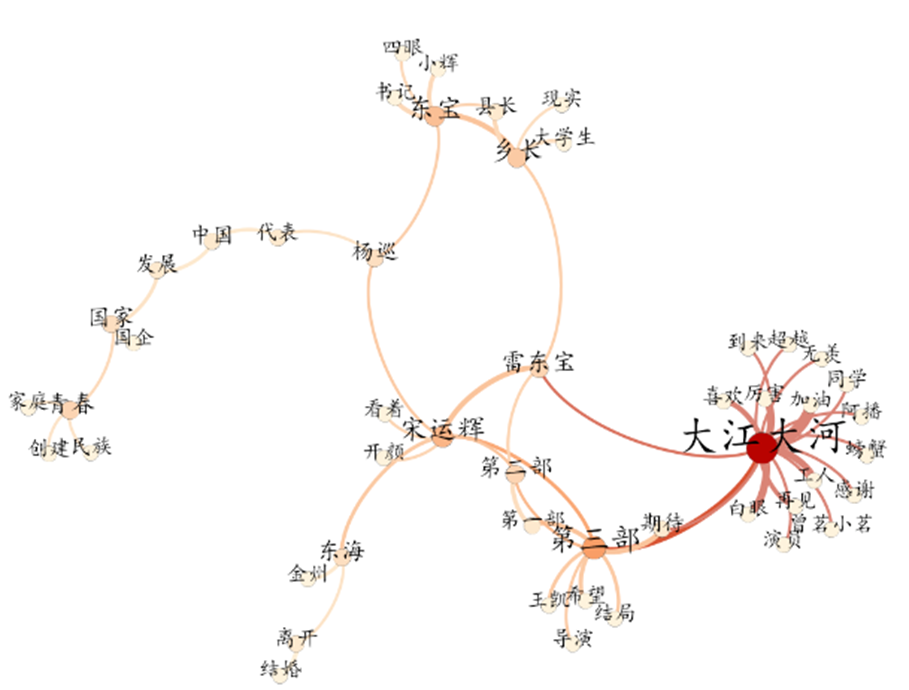
利用Python構建共現關係分析大江大河2彈幕數據

導入Gephi 製作網路圖
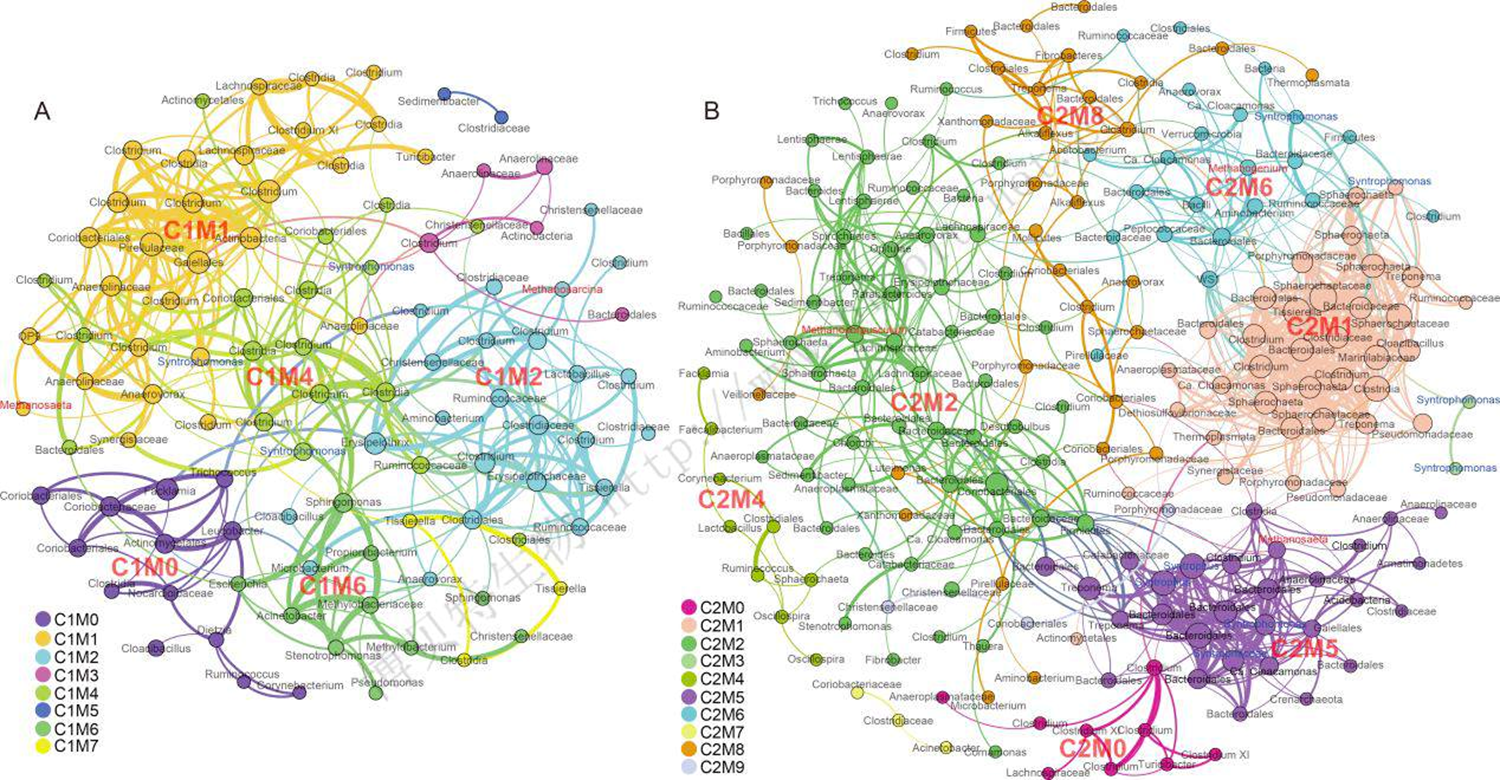
案例:利用共現關係分析微生物群落中菌群之間的生態學關係
什麼是LDA主題模型
介紹
- 關於LDA有兩種含義,一種是線性判別分析(Linear Discriminant Analysis),一種是概率主題模型:隱含狄利克雷分布(Latent Dirichlet Allocation,簡稱LDA),我們講後者。
- 按照wiki上的介紹,LDA由Blei, David M.、Ng, Andrew Y.、Jordan於2003年提出,是一種在PLSA基礎上改進的主題模型,它可以將文檔集中每篇文檔的主題以概率分布的形式給出,從而通過分析一些文檔抽取出它們的主題(分布)出來後,便可以根據主題(分布)進行主題聚類或文本分類。同時,它是一種典型的詞袋模型,即一篇文檔是由一組詞構成,詞與詞之間沒有先後順序的關係。
- 研表究明,漢字的序順並不定一能影閱響讀。比如當你看完這句話後,才發這現里的字,全是都亂的。
- 此外,一篇文檔可以包含多個主題,文檔中每一個詞都由其中的一個主題生成。
人類是怎麼生成文檔的呢?LDA的這三位作者在原始論文中給了一個簡單的例子。比如假設事先給定了這幾個主題:Arts、Budgets、Children、Education,然後通過學習訓練,獲取每個主題Topic對應的詞語。如下圖所示:
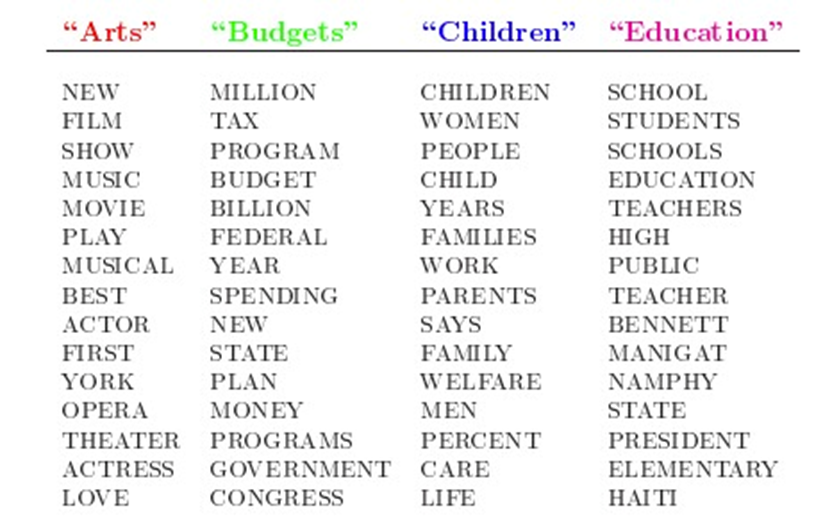
然後以一定的概率選取上述某個主題,再以一定的概率選取那個主題下的某個單詞,不斷的重複這兩步,最終生成如下圖所示的一篇文章(其中不同顏色的詞語分別對應上圖中不同主題下的詞):

當我們看到一篇文章後,往往喜歡推測這篇文章是如何生成的,我們可能會認為作者先確定這篇文章的幾個主題,然後圍繞這幾個主題遣詞造句,表達成文。
LDA就是要干這事:根據給定的一篇文檔,推測其主題分布。
通俗來說,可以假定認為人類是根據上述文檔生成過程寫成了各種各樣的文章,現在某小撮人想讓電腦利用LDA干一件事:你電腦給我推測分析網路上各篇文章分別都寫了些什麼主題,且各篇文章中各個主題出現的概率大小(主題分布)是什麼。
數學背景知識
在LDA模型中,一篇文檔生成的方式如下:
- 從狄利克雷分布中取樣生成文檔 i 的主題分布
- 從主題的多項式分布中取樣生成文檔i第 j 個詞的主題
- 從狄利克雷分布中取樣生成主題對應的詞語分布
- 從詞語的多項式分布中取樣最終生成詞語
其中,類似Beta分布是二項式分布的共軛先驗概率分布,而狄利克雷分布(Dirichlet分布)是多項式分布的共軛先驗概率分布。
這裡先簡單解釋下二項分布、多項分布、beta分布、Dirichlet 分布這4個分布。
- 二項分布(Binomial distribution),是從伯努利分布推進的。伯努利分布,又稱兩點分布或0-1分布,是一個離散型的隨機分布,其中的隨機變數只有兩類取值,非正即負{+,-}。
- 多項分布,是二項分布擴展到多維的情況。單次試驗中的隨機變數的取值不再是0-1的,而是有多種離散值可能(1,2,3…,k)。比如投擲6個面的骰子實驗,N次實驗結果服從K=6的多項分布。
- Beta分布,二項分布的共軛先驗分布。給定參數和,取值範圍為[0,1]的隨機變數 x 的概率密度函數。
- Dirichlet分布,是beta分布在高維度上的推廣,其密度函數形式跟beta分布的密度函數如出一轍。
貝葉斯派思考問題的固定模式:
先驗分布\(\pi(\theta)\) + 樣本資訊\(\chi\) \(\Rightarrow\)後驗分布\(\pi(\theta|x)\)
上述思考模式意味著,新觀察到的樣本資訊將修正人們以前對事物的認知。換言之,在得到新的樣本資訊之前,人們對的認知是先驗\(\pi(\theta)\)分布,在得到新的樣本資訊\(\chi\)後,人們對\(\theta\)的認知為 \(\pi(\theta|x)\)。
所觀測到的數據符合二項分布,參數的先驗分布和後驗分布都是Beta分布的情況,就是Beta-Binomial共軛。換言之,Beta分布是二項式分布的共軛先驗概率分布。
在貝葉斯概率理論中,如果後驗概率P(θ|x)和先驗概率p(θ)滿足同樣的分布律,那麼,先驗分布和後驗分布被叫做共軛分布,同時,先驗分布叫做似然函數的共軛先驗分布。
所觀測到的數據符合多項分布,參數的先驗分布和後驗分布都是Dirichlet 分布的情況,就是Dirichlet-Multinomial 共軛。換言之,至此已經證明了Dirichlet分布的確就是多項式分布的共軛先驗概率分布。
實現
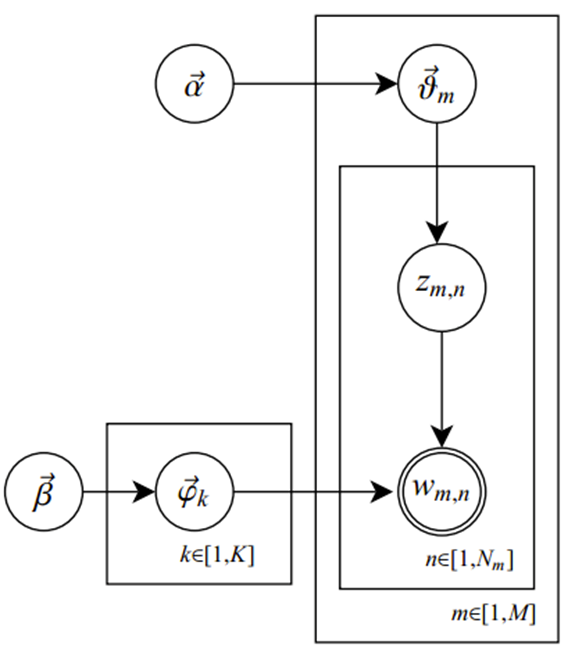
為了方便描述,首先定義一些變數:

圖模型為(圖中被塗色的w表示可觀測變數,N表示一篇文檔中總共N個單詞,M表示M篇文檔)
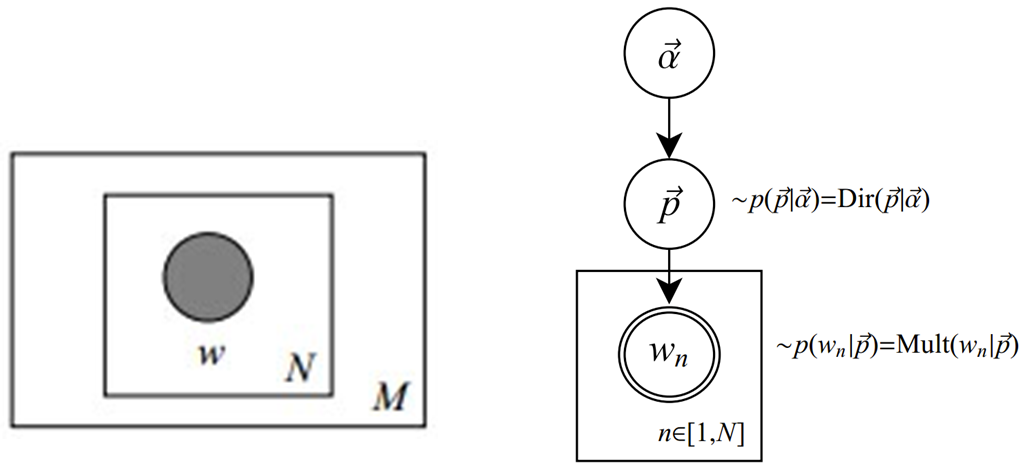
主題模型下生成文檔
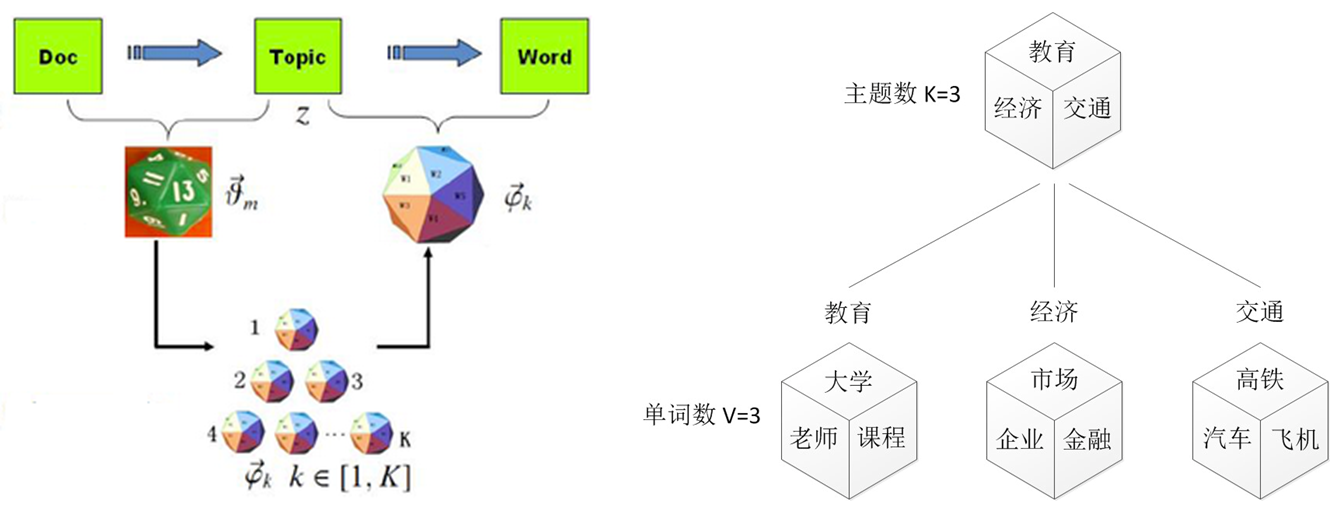
PLSA中,主題分布和詞分布是唯一確定的,能明確的指出主題分布可能就是{教育:0.5,經濟:0.3,交通:0.2},詞分布可能就是{大學:0.5,老師:0.3,課程:0.2}。
但在LDA中,主題分布和詞分布不再唯一確定不變,即無法確切給出。例如主題分布可能是{教育:0.5,經濟:0.3,交通:0.2},也可能是{教育:0.6,經濟:0.2,交通:0.2},到底是哪個我們不再確定(即不知道),因為它是隨機的可變化的。但再怎麼變化,也依然服從一定的分布,即主題分布跟詞分布由Dirichlet先驗隨機確定。
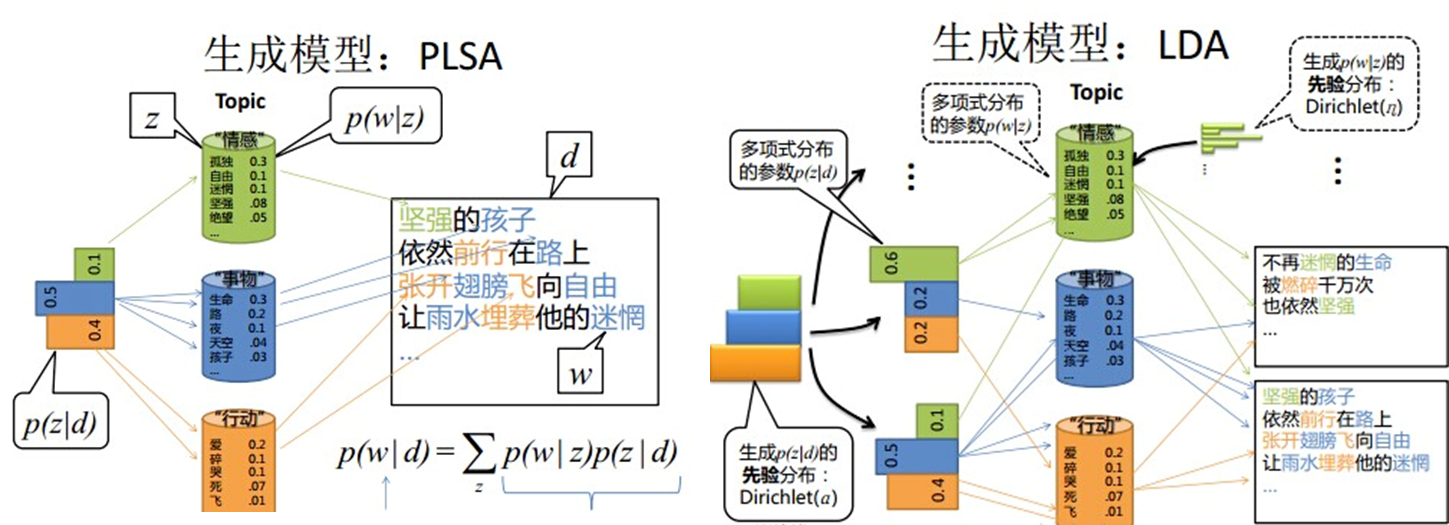
PLSA和LDA生成模型的比較
LDA生成文檔的過程中,先從dirichlet先驗中「隨機」抽取出主題分布,然後從主題分布中「隨機」抽取出主題,最後從確定後的主題對應的詞分布中「隨機」抽取出詞。
形式化LDA
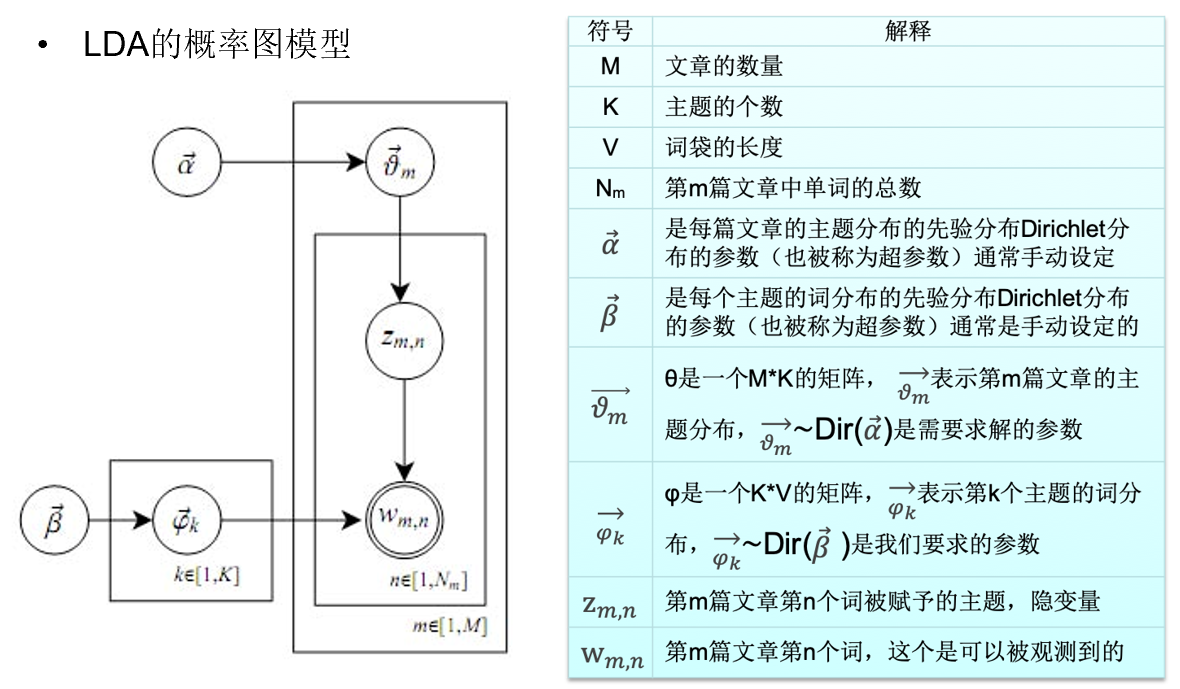
對於語料庫中的每篇文檔,LDA定義了如下生成過程(generative process):
(1)對每一篇文檔,從主題分布中抽取一個主題。
(2)從上述被抽到的主題所對應的單詞分布中抽取一個單詞。
(3)重複上述過程直至遍歷文檔中的每一個單詞。
LDA認為每篇文章是由多個主題混合而成的,而每個主題可以由多個詞的概率表徵。所以整個程式的輸入和輸出如下表所示。

每個主題規則文件.twords如下格式所示
案例分析
「埃航空難」的主題圖譜構建及分析
王晰巍,張柳,黃博,韋雅楠.基於LDA的微博用戶主題圖譜構建及實證研究——以「埃航空難」為例[J].數據分析與知識發現,2020,4(10):47-57.
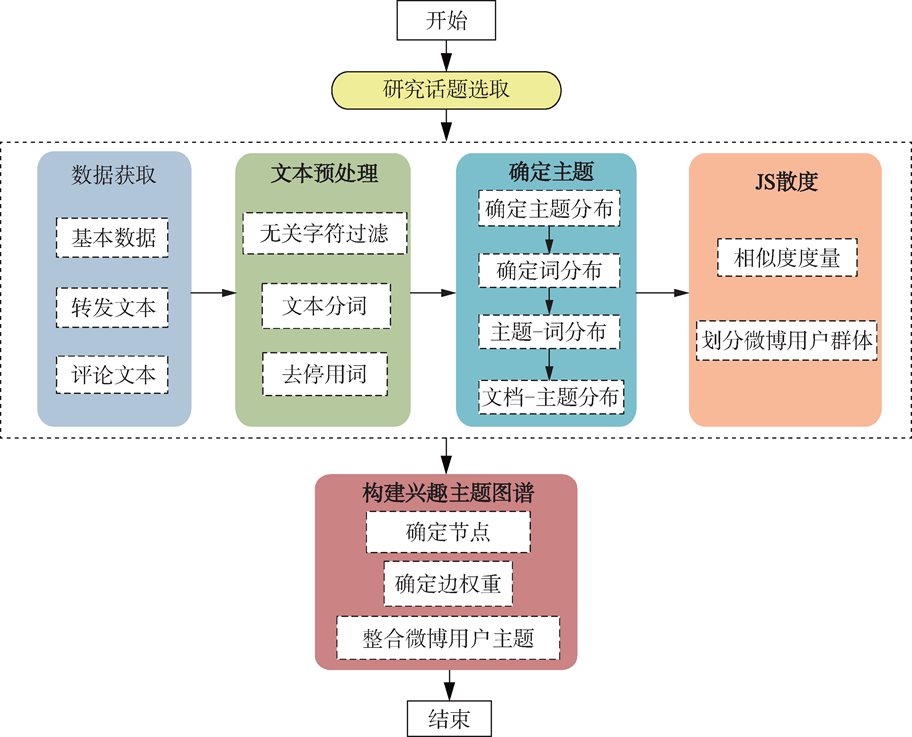
數據獲取與文本預處理
第一步,採用網路爬蟲方式採集用戶數據,獲取字 段包括用戶 ID、用戶名、用戶個人資料相關欄位、轉發評論文本及時間等資訊。
數據採集時間段參考百度指數,如圖 2 所示,「埃航空難」的活躍期以 2019 年 3 月 10 日為起始 點、2019 年 6 月 20 日為終結點,從而最大限度地保證 數據的有效性,最終獲得微博數據 34 325 條。
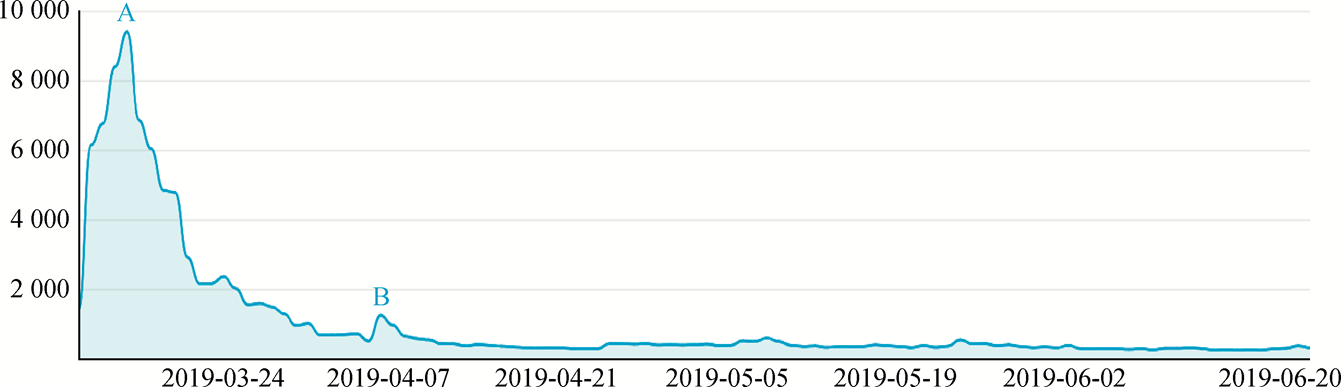
確定主題
選用 gensim 中的類實例化 LDA 主題模型,對處理後的文本進行分類訓練。
困惑度的局部極小值點出現在主題數為 7 時,最佳主題數為7。
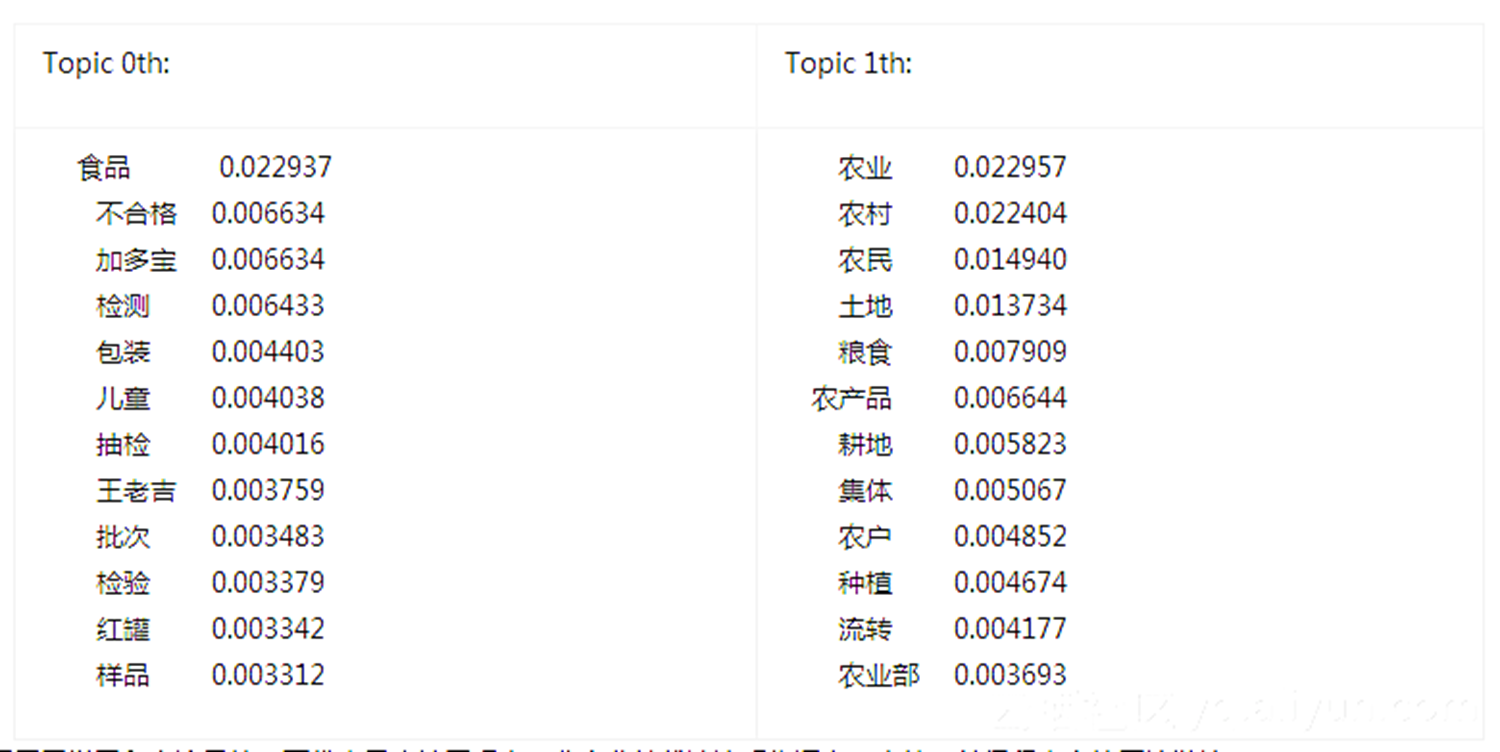
表:主題高頻詞分布

隨機微博用戶的「文檔-主題」分布
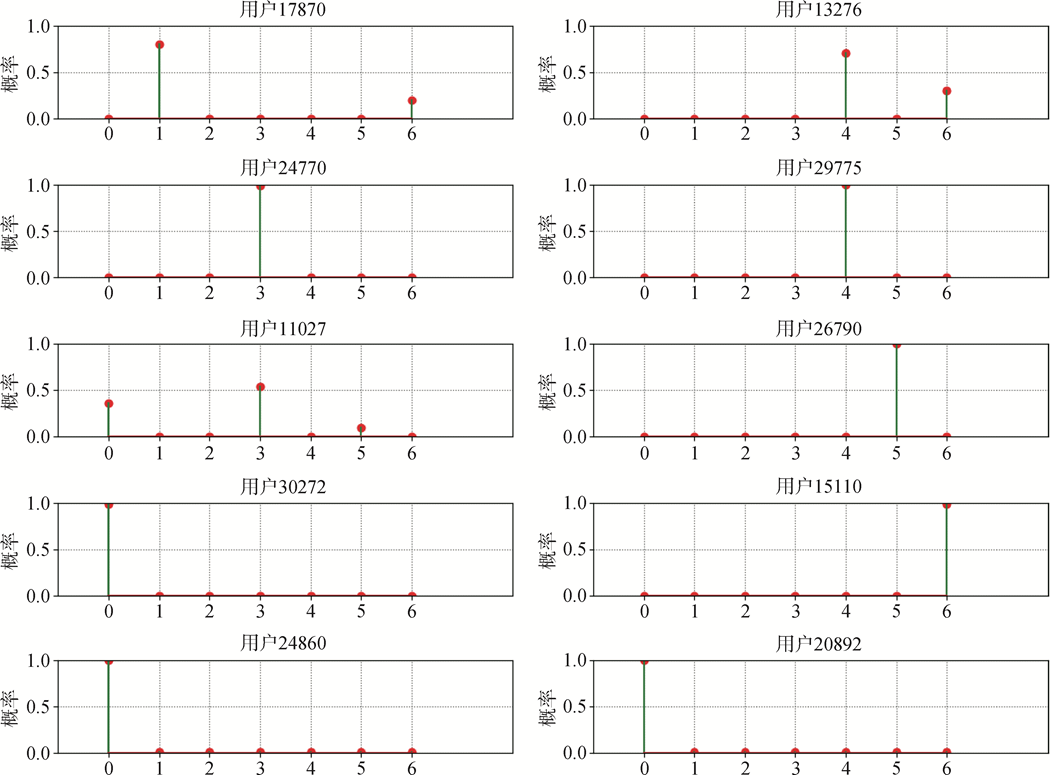
「埃航空難」微博用戶主題圖譜
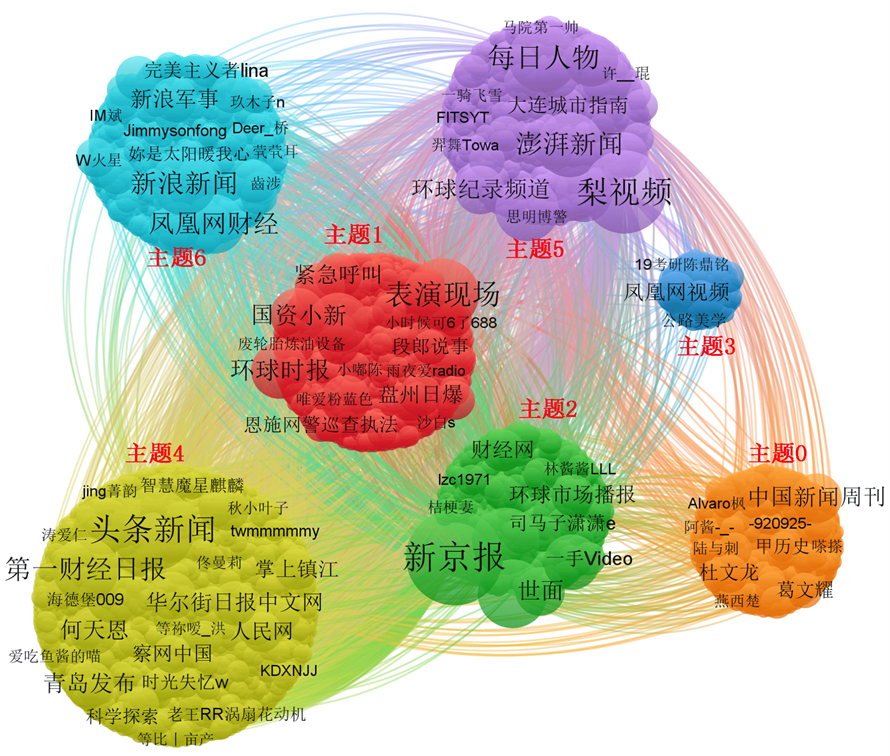
主題 3 用戶節點分布及意見領袖識別

表:主題3中用戶度中心度(TOP10)
春秋時期社會發展的主題挖掘與演變分析
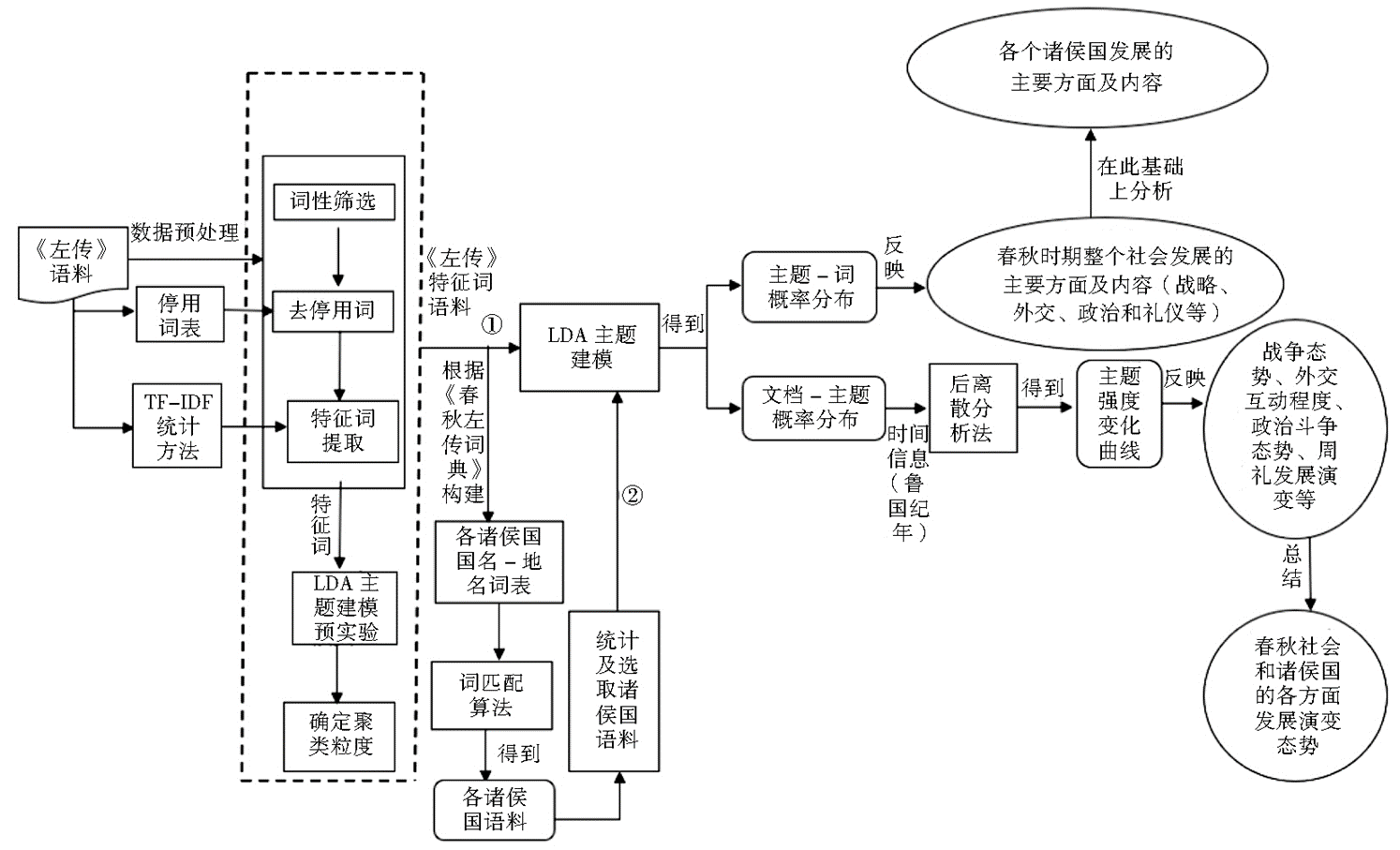
何琳,喬粵,劉雪琪.春秋時期社會發展的主題挖掘與演變分析——以《左傳》為例[J].圖書情報工作,2020,64(07):30-38.
《左傳》是先秦時期的重要典籍,是中國第一部編年體史書。它以《春秋》的記事為綱,以時間先後為序,記敘了上起魯隱公元年(公元前 722 年),下迄魯哀公二十七年(公元前 467 年),共 255 年的歷史,記錄了春秋時期 100 多個諸侯國政治、經濟、軍事、外交和文 化方面的重要事件和重要人物,是研究中國先秦歷史和春秋時期社會發展的重要文化材料。
利用LDA主題模型和自然語言處理技術,可以打破《 左傳》線性的編年體記載順序,通過不同的主題維度展現春秋時期整個社會以及不同諸侯國在戰爭、政治及外交等方面的發展變遷,實現對春秋時期社會發展的定量分析。
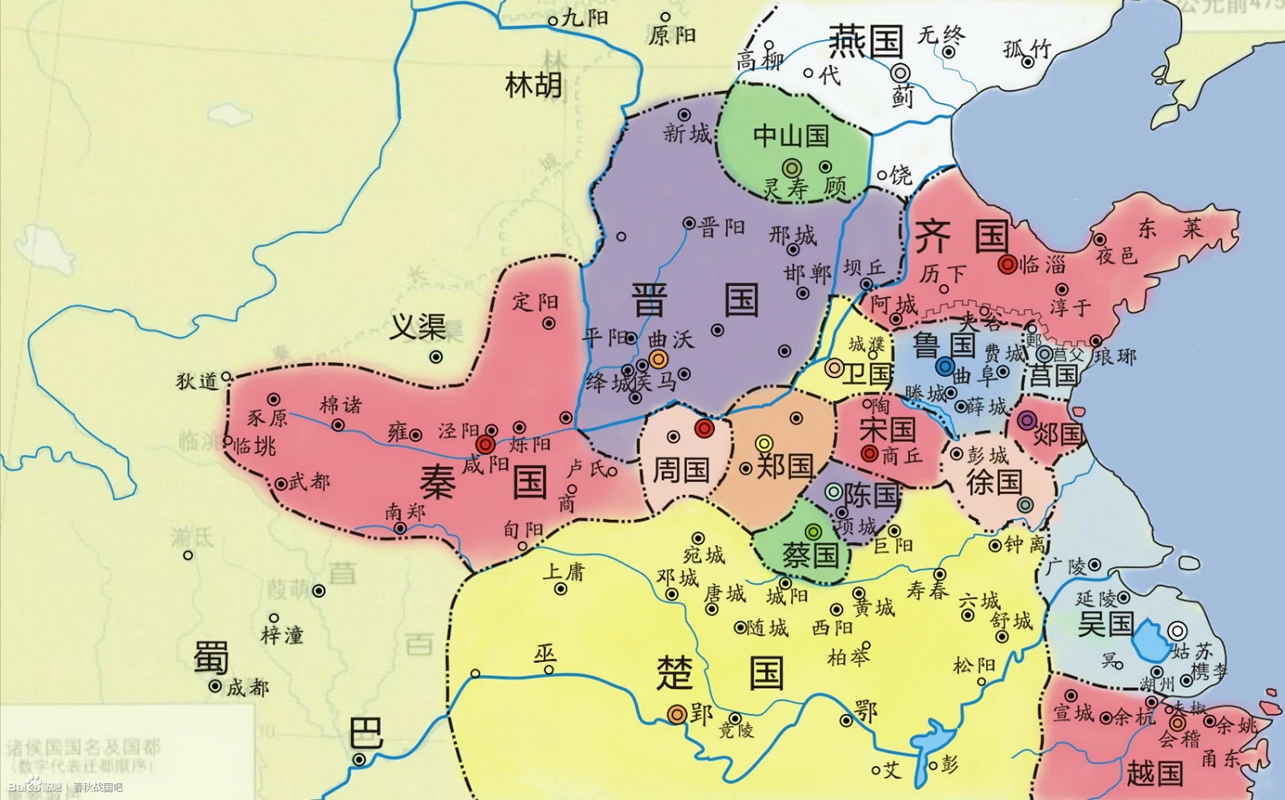
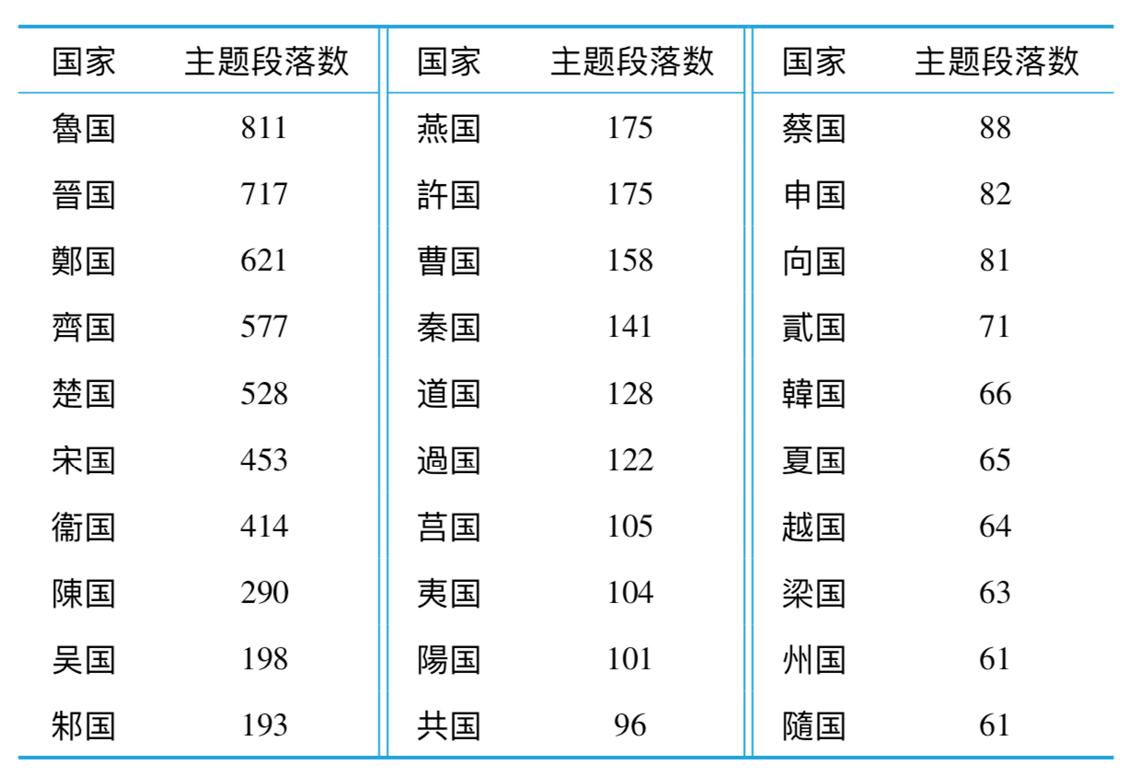
不同諸侯國文本主題段落分布數量
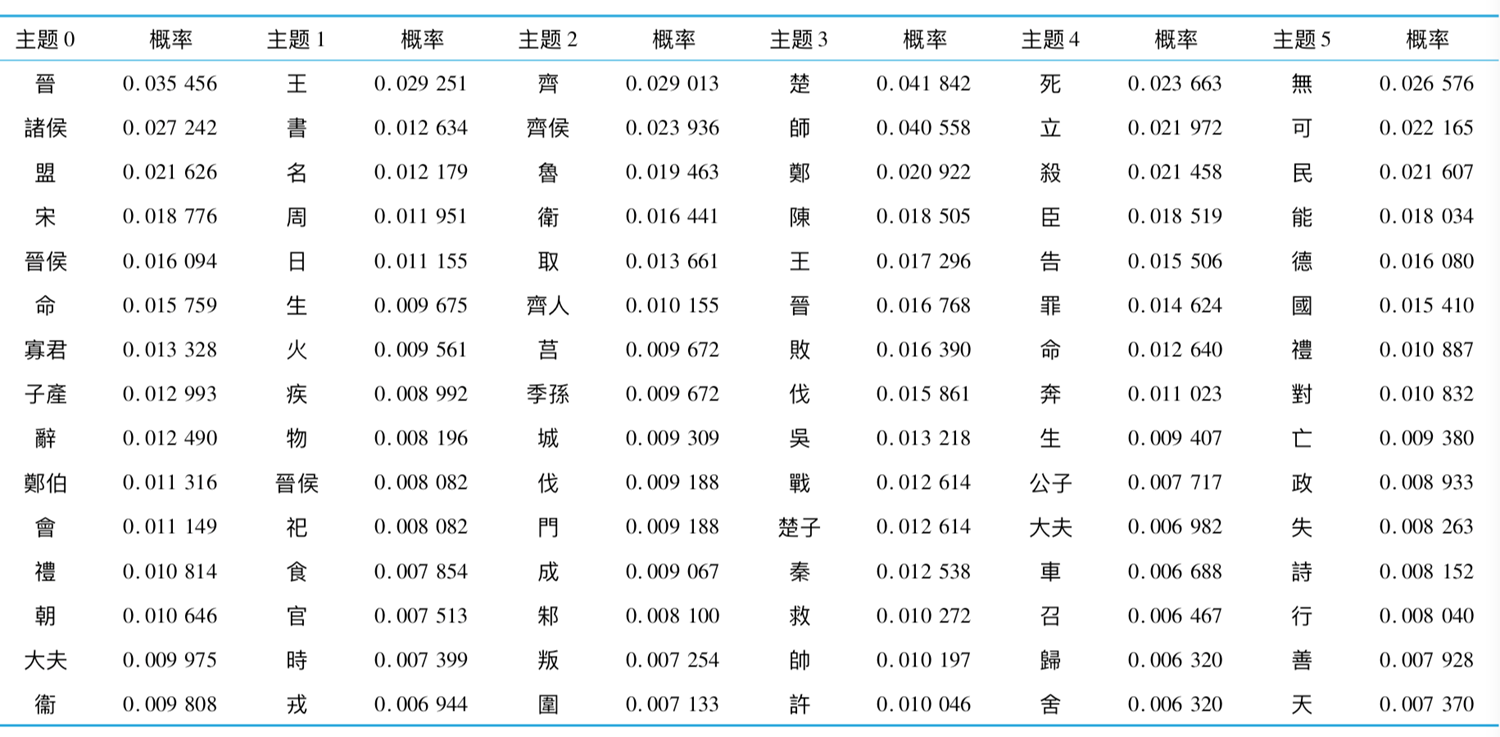
《左傳》主題-詞概率分布
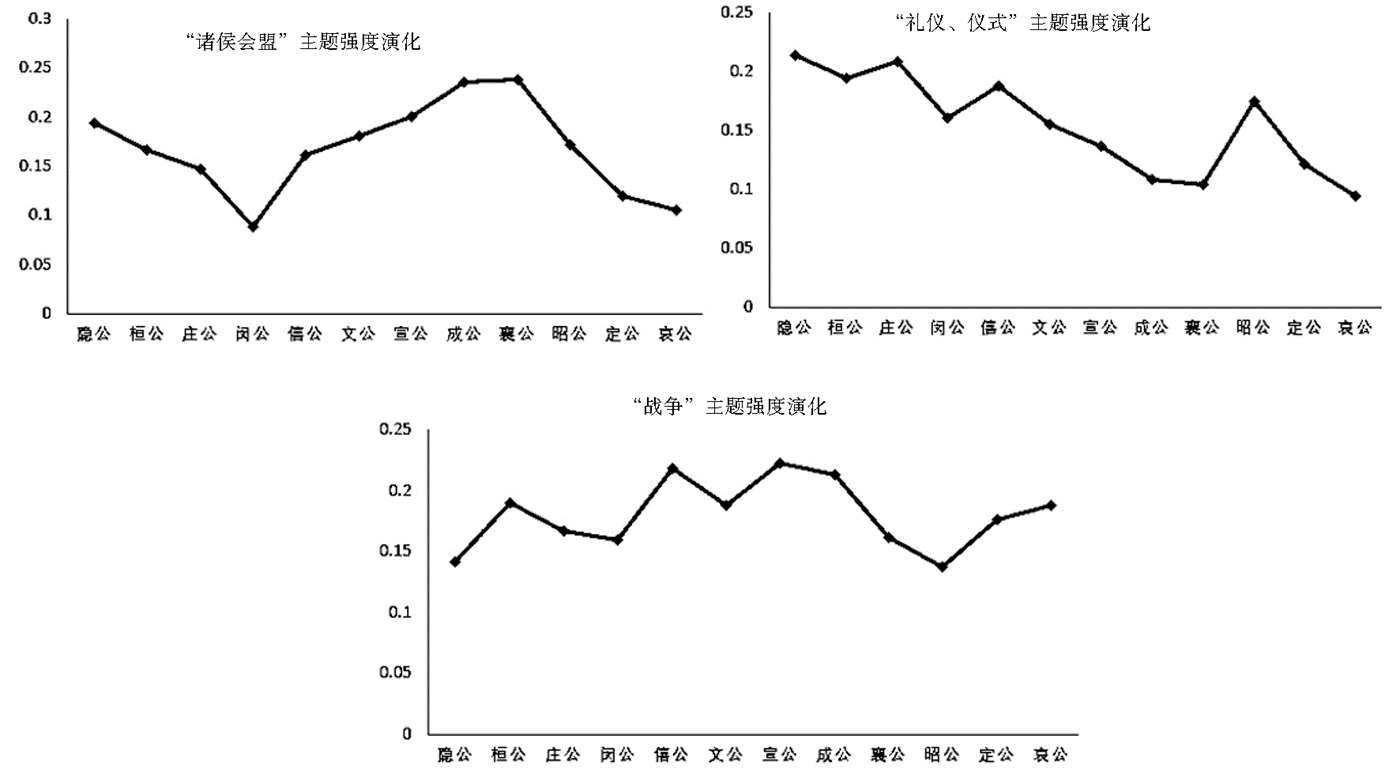
部分主題的主題強度演化
魯國主題-詞分布

楚國主題 – 詞分布

三國共同主題強度變化
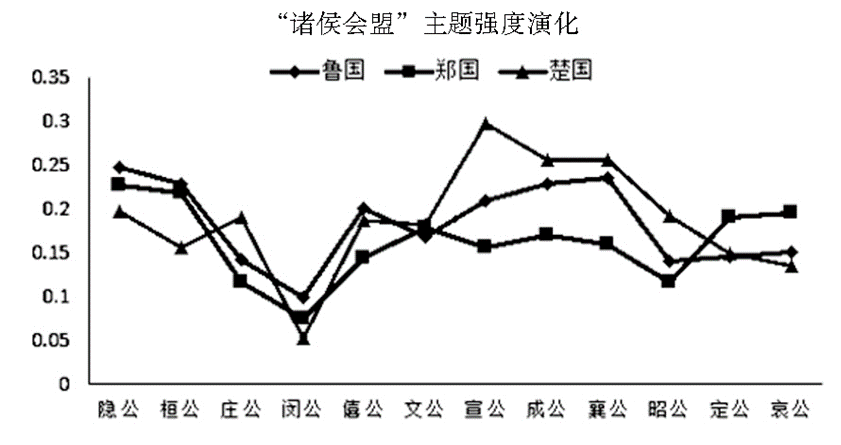
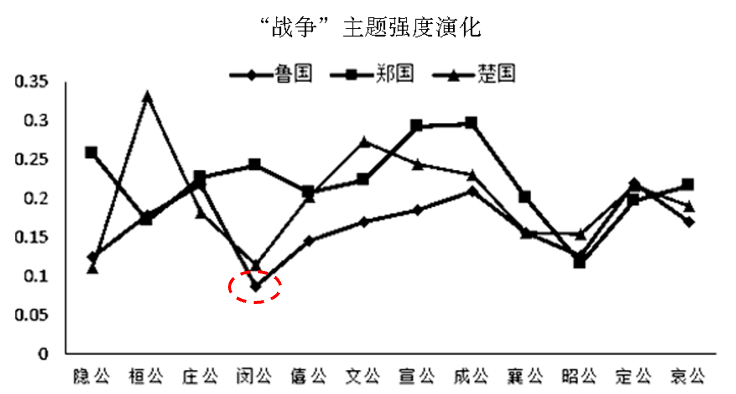
單個國家特有主題強度變化
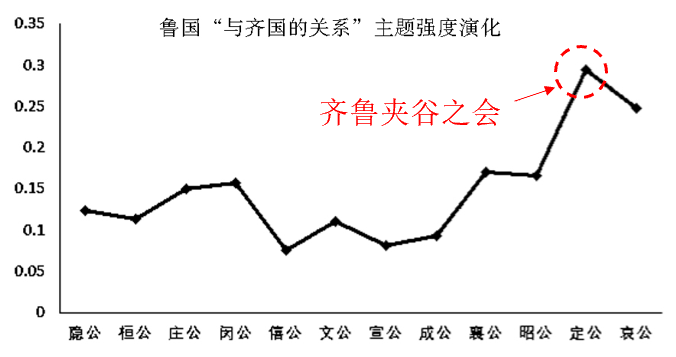
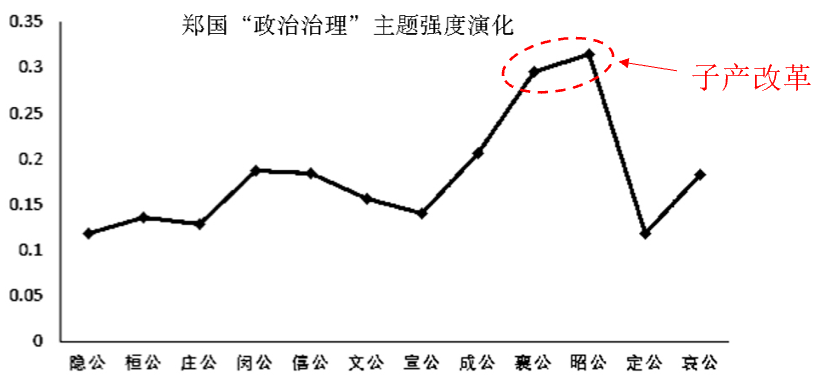
文本情感分析
情感分析的背景知識
互聯網(如部落格和論壇)上產生了大量的用戶參與的、對於諸如人物、事件、產品等有價值的評論資訊。這些評論資訊表達了人們的各種情感色彩和情感傾向性,如喜、怒、哀、樂和批評、讚揚等。
潛在的用戶可以通過瀏覽這些主觀色彩的評論來了解大眾輿論對於某一事件或產品的看法。
什麼是情感分析?
情感分析(Sentiment analysis),又稱傾向性分析,意見抽取(Opinion extraction),意見挖掘(Opinion mining),情感挖掘(Sentiment mining),主觀分析(Subjectivity analysis),它是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。
如從評論文本中分析用戶對「數位相機」的「變焦、價格、大小、重量、閃光、易用性」等屬性的情感傾向。
正面與負面評價?
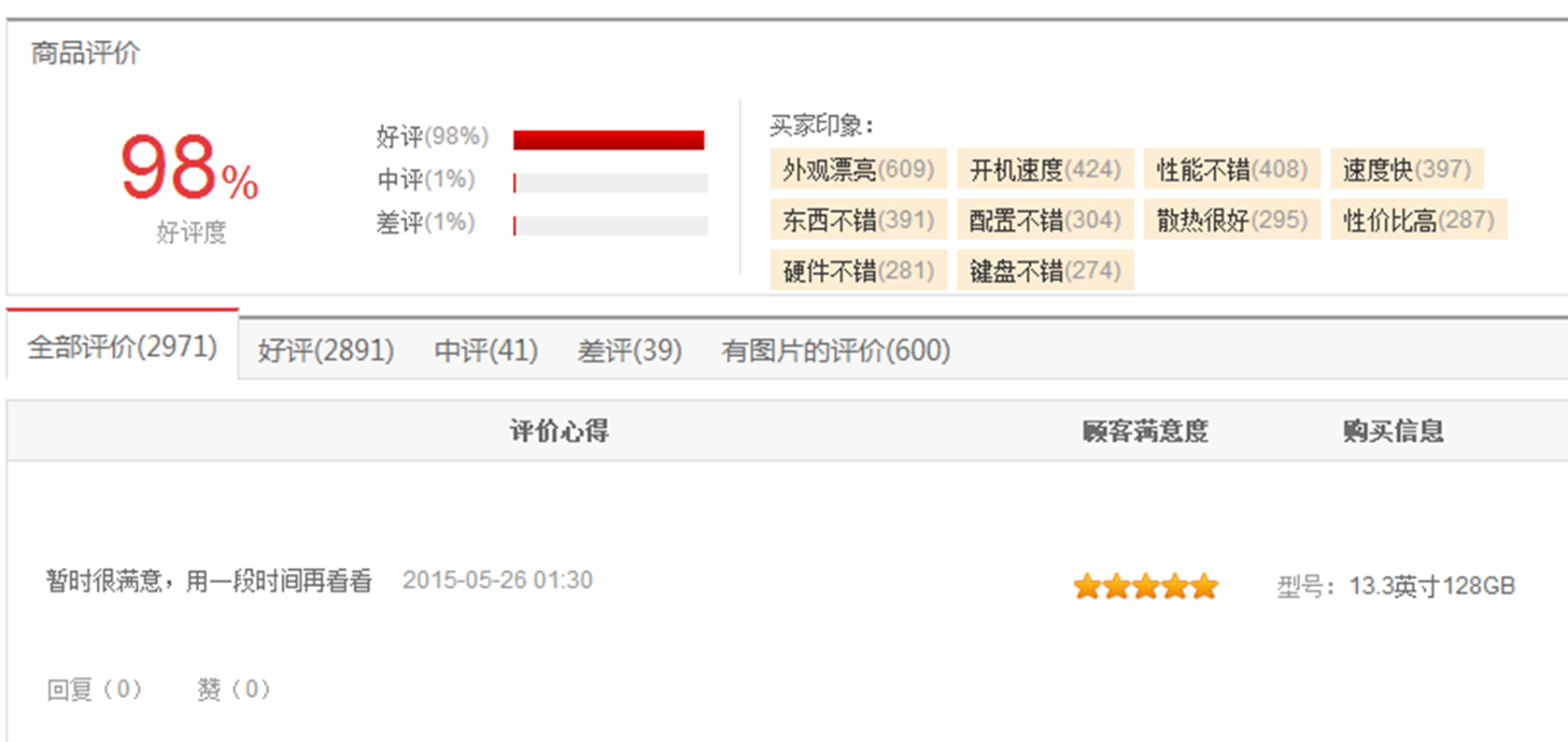
電影評論
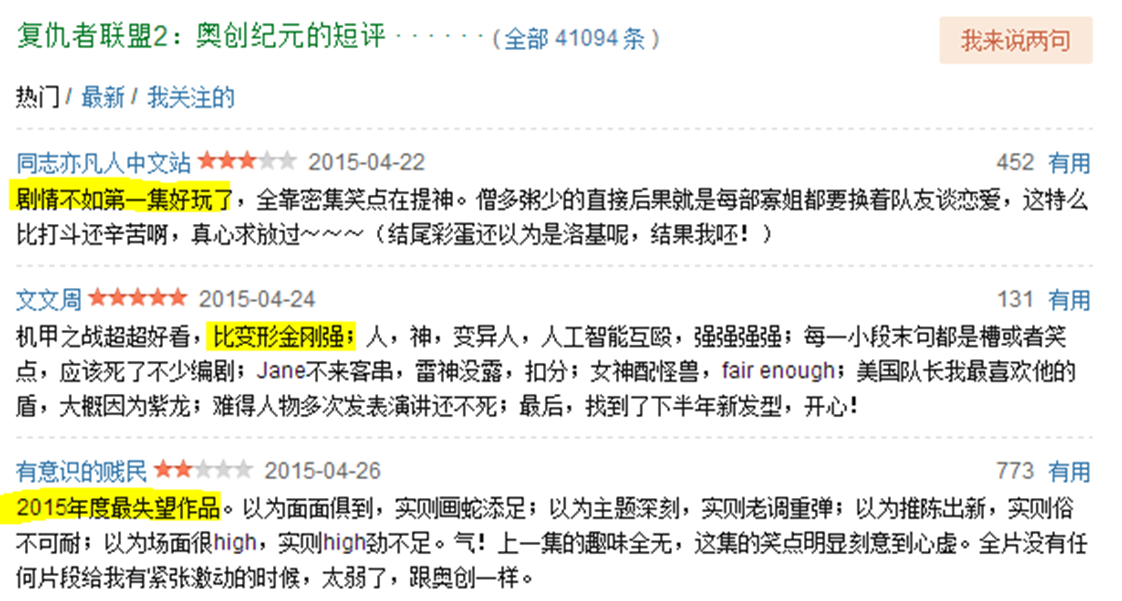
輿情分析
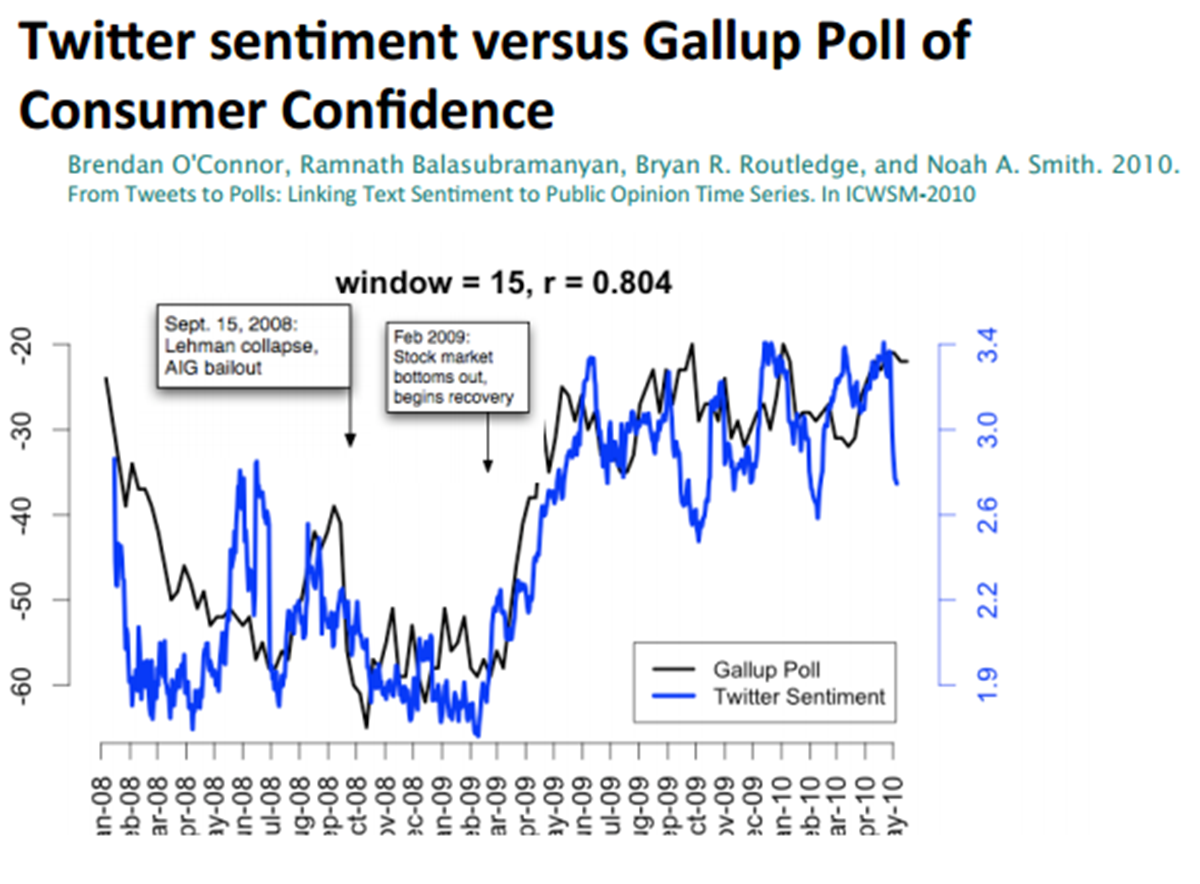
使用twitter預測股市
情感分析領域的主題詞共現圖
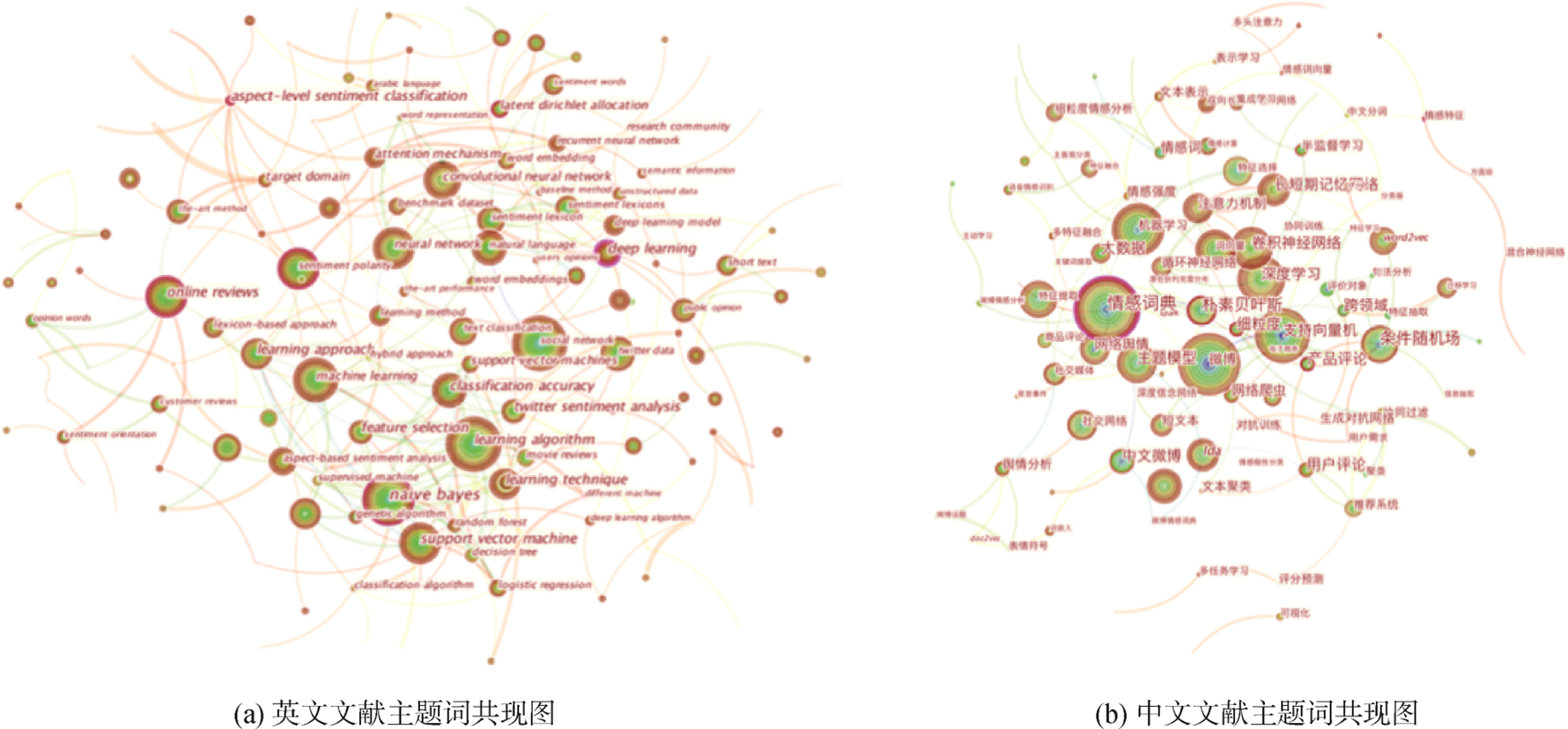
情感分析的應用領域
| 應用 | 英文文獻 | 中文文獻 |
|---|---|---|
| 社交媒體 | Twitter、微博、Facebook、公眾意見、預測、危機、政治、健康、疾病、諷刺檢測 | 微博、Twitter、輿情分析、預測、觀點分析 |
| 在線評論 | 商品評論、消費者評論、用戶評論、電影評論、酒店評論、旅遊評論 | 商品評論、用戶評論、電影評論、彈幕 |
| 商業投資 | 股票市場、股票價格、投資者情緒 | 股票預測、股票市場、投資者情緒、行為金融 |
| 其他 | 新聞文章、阿拉伯語、遷移學習、跨領域、跨語言 | 新聞、維吾爾語、新詞發現、遷移學習、跨領域、多模態、跨語言 |
情感分析的目的
情感分析主要目的是識別用戶對事物或人的看法、態度。參與主體主要包括:
(1)Holder (source)** of attitude:觀點持有者
(2)Target (aspect) of attitude:評價對象
(3)Type of attitude:評價觀點
set of types:Like, love, hate, value, desire, etc.
simple weighted polarity: positive, negative, neutral
Text containing the attitude:評價文本,一般是句子或整篇文檔
文本情感分析存在的問題和挑戰
(1)領域依賴。是指文本情感分析的模型對某一領域的文本數據非常有效,但是將其應用於其他領域的時候,會使得分類模型的性能嚴重下降。
(2)情感語義理解。由於自然語言情感表達的複雜性,使得電腦能夠精確理解文本中的情感語義,就必須藉助自然語言理解技術,難度較大。
(3)特徵提取。現有的文本情感分析使用的提取特徵的方法能達到的精度還有限,如何有效地表達語句作者情感的特徵,是尚待研究的。
(4)樣本標註。雖然針對產品評論的情感分析,可以通過用戶對該產品的打分來進行標註,但是絕大部分情感分析領域,有監督的機器學習情感分析方法,無法在訓練階段或者精確的標註樣本,而人工進行標註的話,則非常困難,因此樣本標註也是一個待解決的挑戰。
情感分析的難易程度
- Simplest task: Is the attitude of this text positive or negative?
- 最簡單的任務:這個文本的態度是積極還是消極?
- More complex: Rank the attitude of this text from 1 to 5
- 更複雜。將此文的態度從1到5排序
- Advanced: Detect the target, source, or complex attitude types
- 高級的。檢測目標、來源或複雜的態度類型
情感分析的分類
按文本類型劃分
按照處理文本的類別不同,分為基於新聞評論的情感分析和基於產品評論的情感分析。
前者處理的文本主要是新聞評論,如情感句「他堅定地認為台灣是中國不可分割的一部分」,表明了觀點持有者「他」對於事件「台灣歸屬問題」的立場;
後者處理的主要是網路在線的產品評論文本,如「Iphone6s的外觀很時尚」,表明了對評價對象「Iphone6s的外觀」的評價「時尚」是褒義的。
按方法劃分
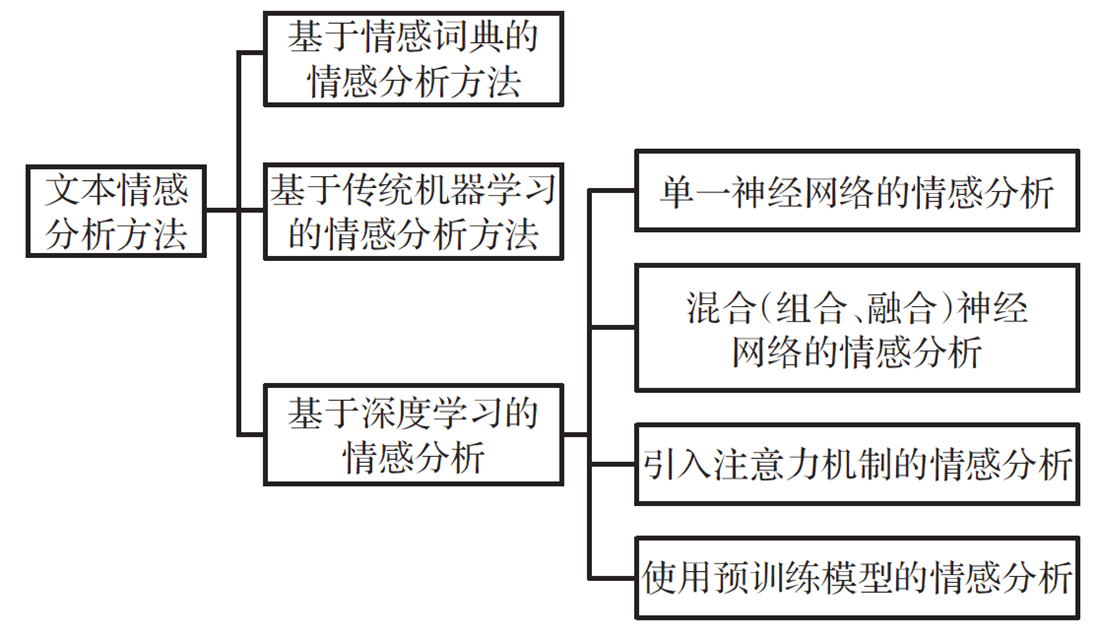
根據使用的不同方法,將情感分析方法分為:
- 基於情感詞典的情感分析方法
- 基於傳統機器學習的情感分析方法
- 基於深度學習的情感分析方法
基於情感詞典的情感分析方法
基於情感詞典的方法,是指根據不同情感詞典所提供的情感詞的情感極性,來實現不同粒度下的情感極性劃分。具體步驟如下:
- 將文本輸入,通過對數據的預處理(包含去噪、去除無效字元等);
- 分詞,並將情感詞典中的不同類型和程度的詞語放入模型中進行訓練;
- 根據情感判斷規則將情感類型輸出。
關鍵問題:構建情感詞典(閱讀大量資料和現有詞典、總結含有情感傾向的詞語、標註詞語的情感極性和強度)
英文情感詞典:General Inquirer、SentiWordNet、Opinion Lexicon和MPQA等
中文情感詞典:有知網詞典HowNet、台灣大學的NTUSD、大連理工大學的中文情感辭彙本體庫
方法優勢:易於分析和理解
方法劣勢:對詞典依賴程度高,詞語的多義性、上下文語義關係
情感分析的粒度
- 文檔級情感分析。是指以文檔為單位進行分類,該分析是將整個文檔看作一個整體來進行情感分類,並判斷該文檔表達的是正面的、中立的還是負面的情感。
- 句子級情感分析。是指以句子為單位進行分類,判斷一個句子所表達的情感是正面的、中立的還是負面的。句子級情感分析和句子的主客觀判斷有非常大的聯繫。句子的主客觀判斷的目的是區分一個句子是主觀句還是客觀句,但並不是只有主觀句才表達觀點或者看法,客觀句里有時也隱藏著情感。
- 方面級情感分析。早期也叫作特徵級情感分析,它首先識別出觀點的目標(通常是一個實體),然後將其分成幾個方面,挖掘出人們在不同方面對該實體的情感喜好。
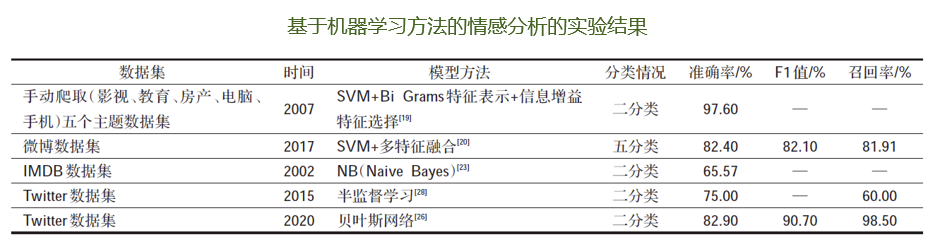
基於傳統機器學習的情感分析方法
基於機器學習的情感分析方法,是指通過大量有標註的或無標註的語料,使用統計機器學習演算法,抽取特徵,最後在進行情感分析輸出結果。
此類方法分為三類:有監督(KNN、樸素貝葉斯、SVM)、半監督(對未標記的文本進行特徵提取)和無監督(根據文本間的相似性對未標記的文本進行分類)的方法。
此類方法的關鍵在於情感特徵的提取以及分類器的組合選擇。
缺點:在對文本內容進行情感分析時並未充分利用上下文語境資訊,可能影響準確性。
基於深度學習的情感分析方法
此類方法可分為:
- 單一神經網路的情感分析方法(CNN, RNN, LSTM)
- 混合(組合、融合)神經網路的情感分析方法
- 引入注意力機制的情感分析
- 使用預訓練模型的情感分析
| 方法 | 英文文獻 | 中文文獻 |
|---|---|---|
| 基於情感詞典與規則的方法 | 情感詞典、語義相似度、關聯規則等 | 領域情感詞典、依存句法分析、語義規則、語義相似度、本體等 |
| 基於機器學習的方法 | 支援向量機、樸素貝葉斯、邏輯回歸、LDA 主題模型、隨機森林、決策樹、遺傳演算法、集成學習、最大熵等 | 支援向量機、LDA主題模型、條件隨機場、樸素貝葉斯、協同過濾、集成學習、隨機森林、最大熵、K-Means 等 |
| 基於深度學習的方法 | 卷積神經網路、長短期記憶網路、注意力機制、循環神經網路、雙向長短期記憶網路等 | 卷積神經網路、注意力機制、長短期記憶網路、雙向長短期記憶網路、循環神經網路、遞歸神經網路、生成對抗網路等 |
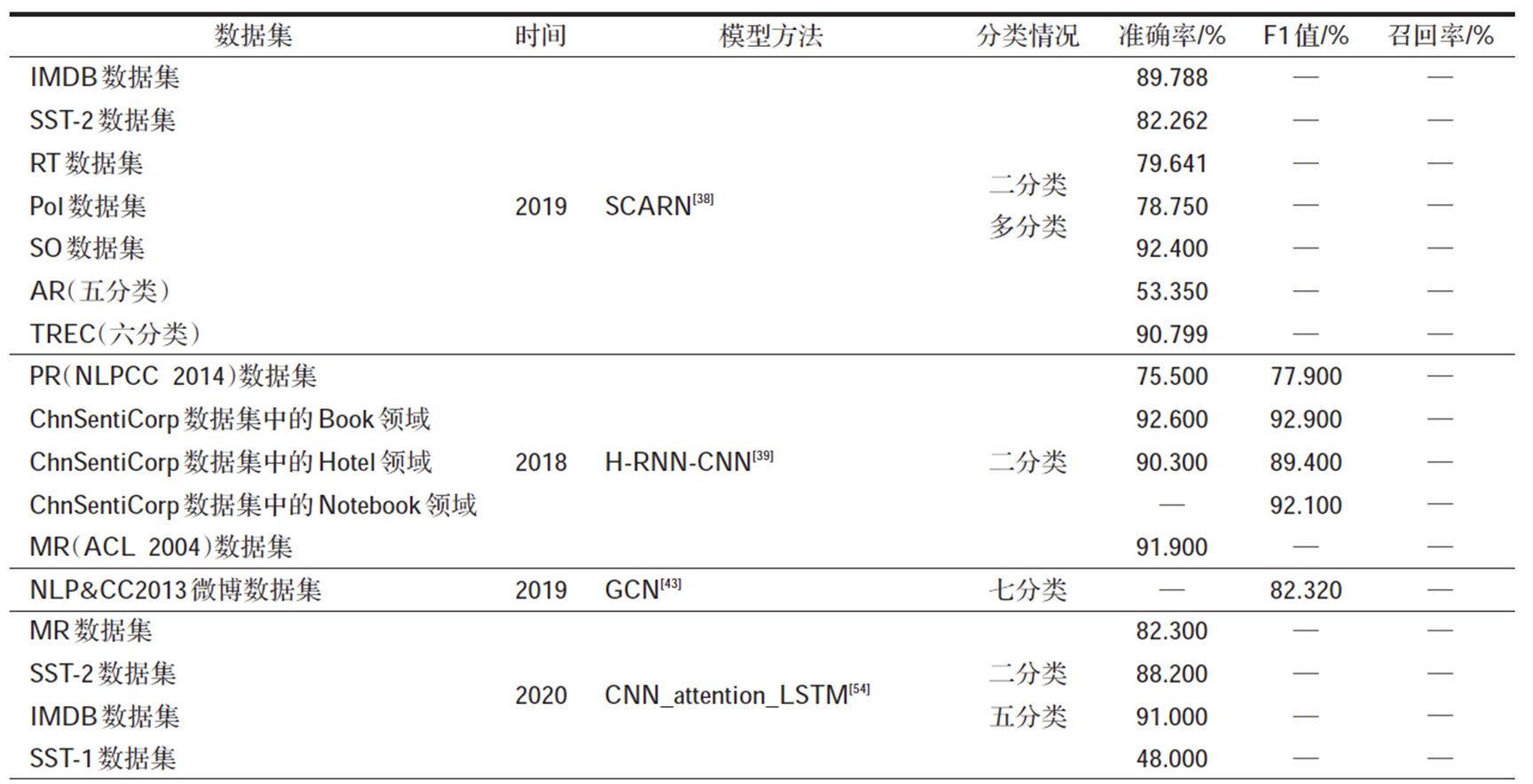
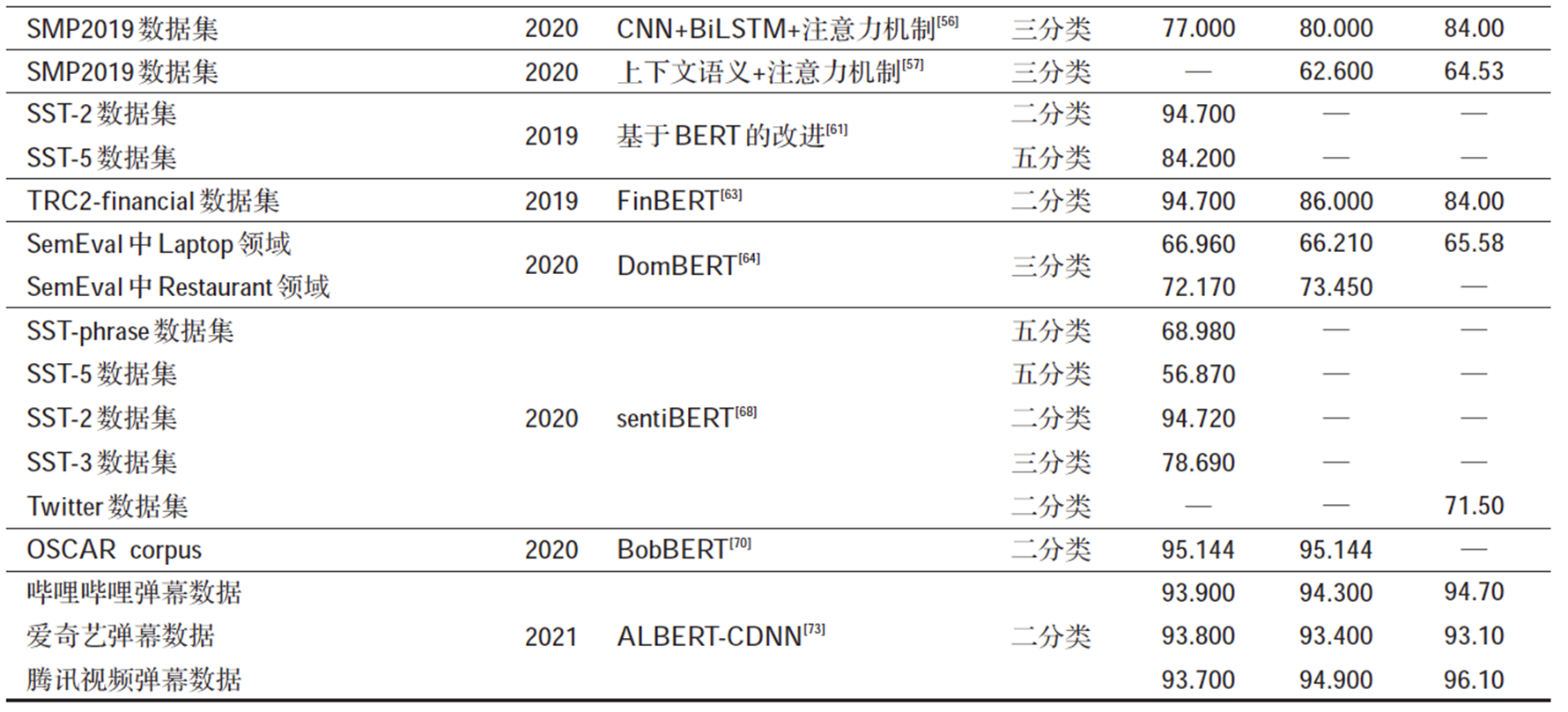
基於深度學習方法的情感分析中的實驗結果
文本情感分析方法對比
| 方法 | 優點 | 缺點 |
|---|---|---|
| 基於情感詞典的情感分析方法 | 基於情感詞典的方法能有效反映文本的結構特徵,易於理解,在情感詞數量充足時情感分類效果明顯 | 基於情感詞典的方法沒有突破情感詞典的限制,要對情感詞典不斷擴充,使得文本情感判斷的準確率不高 |
| 基於傳統機器學習的情感分析方法 | 基於傳統機器學習的方法能夠根據對情感特徵的選取以及情感分類器的組合對文本的情感進行分類 | 這一類方法存在不能充分利用上下文文本的語境資訊,影響分類準確性;數據量大時完成分類任務的效率和品質低的問題 |
| 基於深度學習的情感分析方法 | 能充分利用上下文文本的語境資訊;能主動學習文本特徵,保留文本中詞語的順序資訊,從而提取到相關詞語的語義資訊,來實現文本的情感分類;通過深層網路模型學習數據中的關鍵資訊,來反映數據的特徵,從而提升學習的性能;通過和傳統方法相比,使用語言模型預訓練的方法充分利用了大規模的單語語料,可以對一詞多義進行建模,有效緩解對模型結構的依賴問題 | 基於深度學習的方法需要大量數據支撐,不適合小規模數據集;演算法訓練時間取決於神經網路的深度和複雜度,一般花費時間較長;對深層網路的內部結構、理論知識、網路結構等不了解也是對研究人員的一項挑戰 |
情感分析的一般框架

情感資訊抽取
情感資訊抽取是情感分析的最底層的任務,它旨在抽取情感評論文本中有意義的資訊單元。
其目的在於將無結構化的情感文本轉化為電腦容易識別和處理的結構化文本,繼而供情感分析上層的研究和應用服務。
評價詞語的抽取和判別
評價詞語又稱極性詞、情感詞,特指帶有情感傾向性的詞語。評價詞語在情感文本中處於舉足輕重的地位。
主要有基於語料庫的方法和基於詞典的方法。
基於語料庫的方法:評價詞語抽取和判別主要是利用大語料庫的統計特性,觀察一些現象來挖掘語料庫中的評價詞語並判斷極性;
基於詞典的方法:評價詞語抽取及判別方法主要是使用詞典中的詞語之間的詞義聯繫來挖掘評價詞語。
評價對象的抽取
評價對象是指某段評論中所討論的主題,具體表現為評論文本中評價詞語所修飾的對象,如新聞評論中的某個事件/話題或者產品評論中某種產品的屬性(如「螢幕」)等。
基於規則/模板的方法:規則的制定通常要基於一系列的語言分析與預處理過程,如詞性標註、命名實體識別、句法分析等;
將評價對象看作產品屬性的一種表現形式(如對數位相機領域而言,「相機的大小」是數位相機的一個屬性,而「相機滑蓋」是數位相機的一個組成部分),繼而考察候選評價對象與領域指示詞(如「整體-部分」關係,指示詞「has」)之間的關聯度來獲取真正的評價對象。
觀點持有者抽取
觀點持有者的抽取在基於新聞評論的情感分析中顯得尤為重要,它是觀點/評論的隸屬者,如新聞評論句「中國政府堅定不移的認為台灣是中國領土不可分割的一部分」中的「中國政府」。
-
命名實體識別技術
-
序列標註
-
知識圖譜
組合評價單元的抽取
單獨的評價詞語存在一定的歧義性,如評價詞語「高」在以下 3 個句子中的使用:
Sen 1:Mac的價格真高.
Sen 2:華為手機的性價比相當高.
Sen 3:姚明有2米多高.
- 主觀表達式的抽取。表示情感文本單元主觀性的詞語或片語。
- 評價短語的抽取。評價短語表現為一組連續出現的片語,不同於主觀表達式,該片語往往是由程度副詞和評價詞語組合而成,如「very good」等。情感極性、修飾成分。
- 評價搭配的抽取。表現為二元對〈評價對象,評價詞語〉,如情感句「這件衣服價格很高」中的「價格-很高」。
情感資訊分類
情感資訊分類則利用底層情感資訊抽取的結果將情感文本單元分為若干類別,供用戶查看,如分為褒、貶兩類或者其他更細緻的情感類別(如喜、怒、哀、樂等).
按照不同的分類目的,可分為主客觀分析和褒貶分析;
按照不同的分類粒度,可分為詞語級、短語級、篇章級等多種情感分類任務。
情感資訊的分類任務可大致分為兩種:
一種是主、客觀資訊的二元分類;
另一種是主觀資訊的情感分類,包括最常見的褒貶二元分類以及更細緻的多元分類。
1)主客觀資訊分類;
2)主觀資訊情感分類;
3)觀點分類與挖掘
4)情感資訊檢索與歸納
主客觀資訊分類
情感文本中夾雜著少量客觀資訊而影響情感分析的品質,需將情感文本中的主觀資訊和客觀資訊進行分離。由於情感文本單元表現格式比較自由,區分主、客觀文本單元的特徵並不明顯,在很多情況下,情感文本的主客觀識別比主觀文本的情感分類更有難度。
情感資訊檢索與歸納
情感資訊抽取和分類後呈現的結果並不是用戶所能直接使用的。情感分析技術與用戶的交互主要集中於情感資訊檢索和情感資訊歸納兩項任務上。
情感資訊檢索旨在為用戶檢索出主題相關,且包含情感資訊的文檔;
情感資訊歸納則針對大量主題相關的情感文檔,自動分析和歸納整理出情感分析結果提供給用戶參考,以節省用戶翻閱相關文檔的時間。
情感分析的評測與資源
情感分析的評測
為了推動情感分析技術的發展,中國外的很多研究機構紛紛組織了一些公共評測。
- TREC;2006,部落格
- NTCIR;2006,新聞
- COAE;2008
情感分析的資源
(1) 康奈爾(Cornell)大學提供的影評數據集,電影評論
(2) 伊利諾伊大學芝加哥分校提供的產品領域的評論語料:主要包括從亞馬遜和 Cnet 下載的 5 種電子產品的網路評論;
(3) Wiebe 等人所開發的 MPQA(multiple-perspective QA)庫:包含 535 篇不同視角的新聞評論
(4) 麻省理工學院的 Barzilay 等人構建的多角度餐館評論語料;
(5) 中國科學院計算技術研究所提供的較大規模的中文酒店評論語料
情感分析的數據集
| 數據集名稱 | 數據集介紹 | 下載地址 |
|---|---|---|
| sentiment140 | 包含160 萬不同產品或品牌的推文,數據集標籤劃分為0(消極)和4(積極) | //help.sentiment140.com/site-functionality |
| IMDB影評數據集 | 包含50 000 個對電影評論的樣本值,該數據集分為正負兩個極性 | //www.cs.cornell.edu/people/pabo/movie-review-data/ |
| Twitter US Airline Sentiment數據集 | 包含美國各大航空公司14 640 條推文,分為正面、負面和中性 | //www.kaggle.com/crowdflower/twitter-airline-sentiment |
| weibo_senti_100k | 包含約12 萬條新浪微博,正負向約各6 萬條 | //github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/simplifyweibo_4_moods/intro.ipynb |
| 酒店評論數據集 | 包含10 000 條酒店評論,分為正面、負面和中性 | //www.datatang.com/data/11936 |
| 外賣評論數據集 | 包含某外賣平台正向4 000 條評論和負向8 000 條評論 | //github.com/SophonPlus/ChineseNlpCorpus/tree/master/ |
| SE-ABSA15 數據集 | 包含筆記型電腦、餐館和酒店3 類評論,含有方面標註 | //metashare.ilsp.gr:8080/ |
情感分析的詞典資源
(1) GI(general inquirer)評價詞詞典收集了 1 914 個褒義詞和 2 293 個貶義詞,並為每個詞語按照極性、強度、詞性等打上不同的標籤;
(2) NTU 評價詞詞典(繁體中文).該詞典由台灣大學收集,含有 2 812 個褒義詞與 8 276 個貶義詞;
(3) 主觀詞詞典,來自 OpinionFinder 系統。該詞典含有8 221 個主觀詞,並為每個詞語標註了詞性、詞性還原以及情感極性;
(4) HowNet 評價詞詞典,該詞典包含 9 193 個中文評價詞語/短語,9 142 個英文評價詞語/短語,並被分為褒貶兩類
| 情感詞典名稱 | 情感詞典介紹 | 下載地址 |
|---|---|---|
| SentiWordNet | 包含正、負以及中性三種情感極性 | //sentiwordnet.isti.cnr.it/ |
| NTUSD | 包含8 276 個貶義詞和2 812 個褒義詞 | //academiasinicanlplab.github.io/ |
| How Net | 包含9 142 個英文評價詞語和9 193 個中文評價詞語,詞語分為正負兩種極性 | //www.keenage.com/html/e_index.html |
| WordNet | 包含五種情感極性 | //wordnet.princeton.edu/download |
| Sentiment Lexicon | 包含2 006 個褒義辭彙和4 783 個貶義辭彙 | //www.cs.uic.edu/~liub/FBS/sentiment-analysis.html |
| 中文情感辭彙本體庫 | 包含詞語詞性種類、情感類別、情感強度級性等內容,將情感分為7 大類21 小類 | //ir.dlut.edu.cn/zyxz/qgbtk.htm |
情感分析的應用與案例
基於snownlp的情感分析
SnowNLP是一個python寫的類庫,主要用於處理中文文本,可實現分詞、詞性標註、情感分析、漢字轉拼音、繁體轉簡體、關鍵詞提取以及文本摘要等等。
SnowNLP 本身使用的語料是電商網站評論,其他場景的效果可能不理想。

SnowNLP 使用自定義語料進行模型訓練。
from snownlp import sentiment
sentiment.train('./train/neg60000.txt','./train/pos60000.txt')
sentiment.save('weibo.marshal')
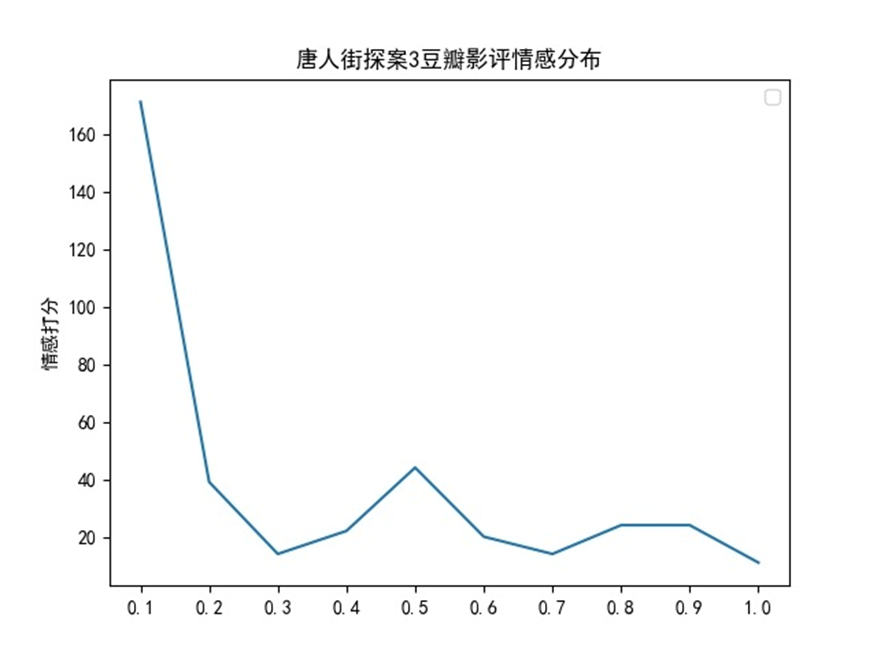
某餐廳評論的情感分析
- 導入數據
- 分析第一條評論
- 分析第二條評論
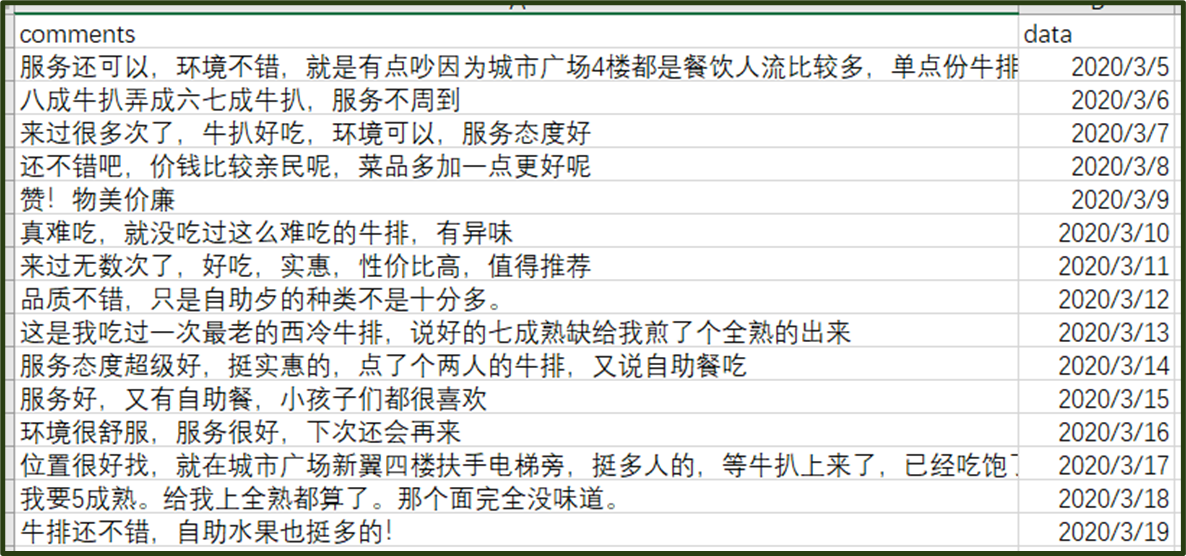
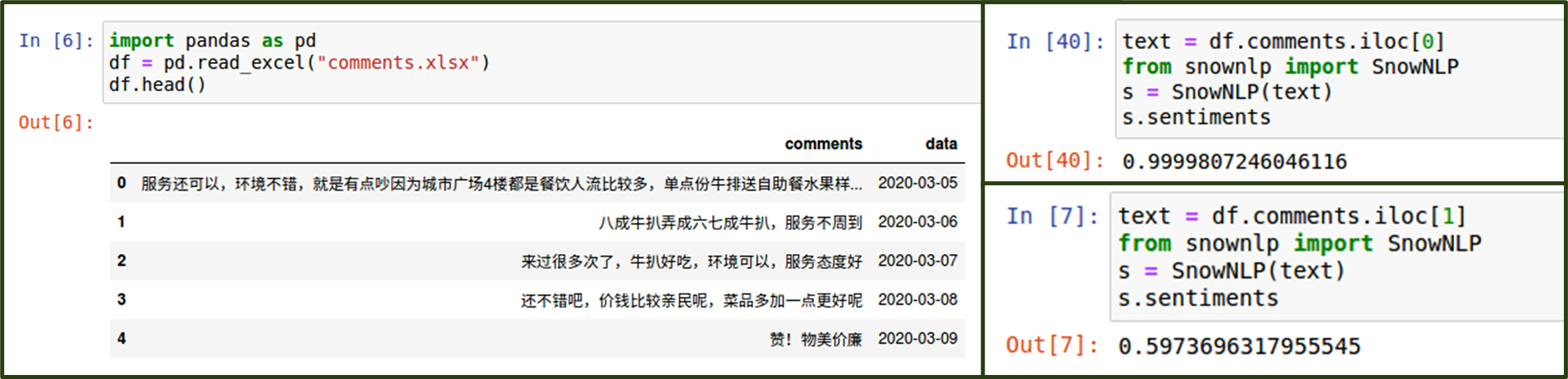
批量處理所有評論
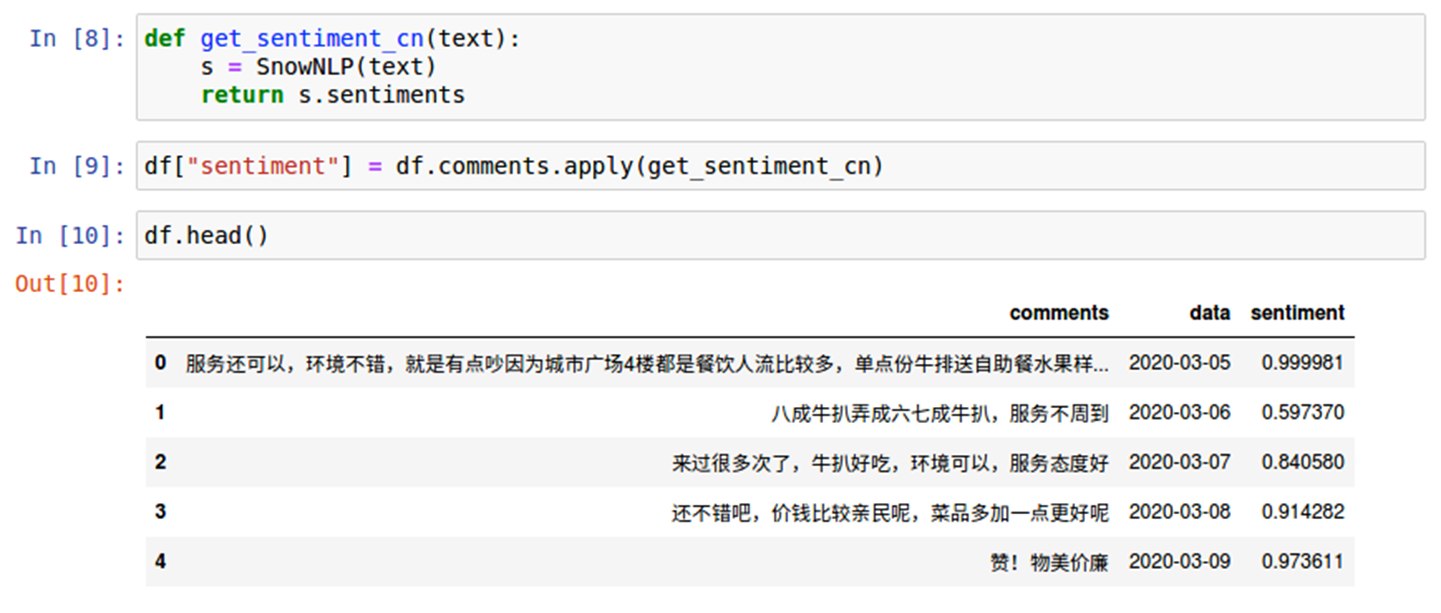
通過mean()函數可以知道評論的平均值。

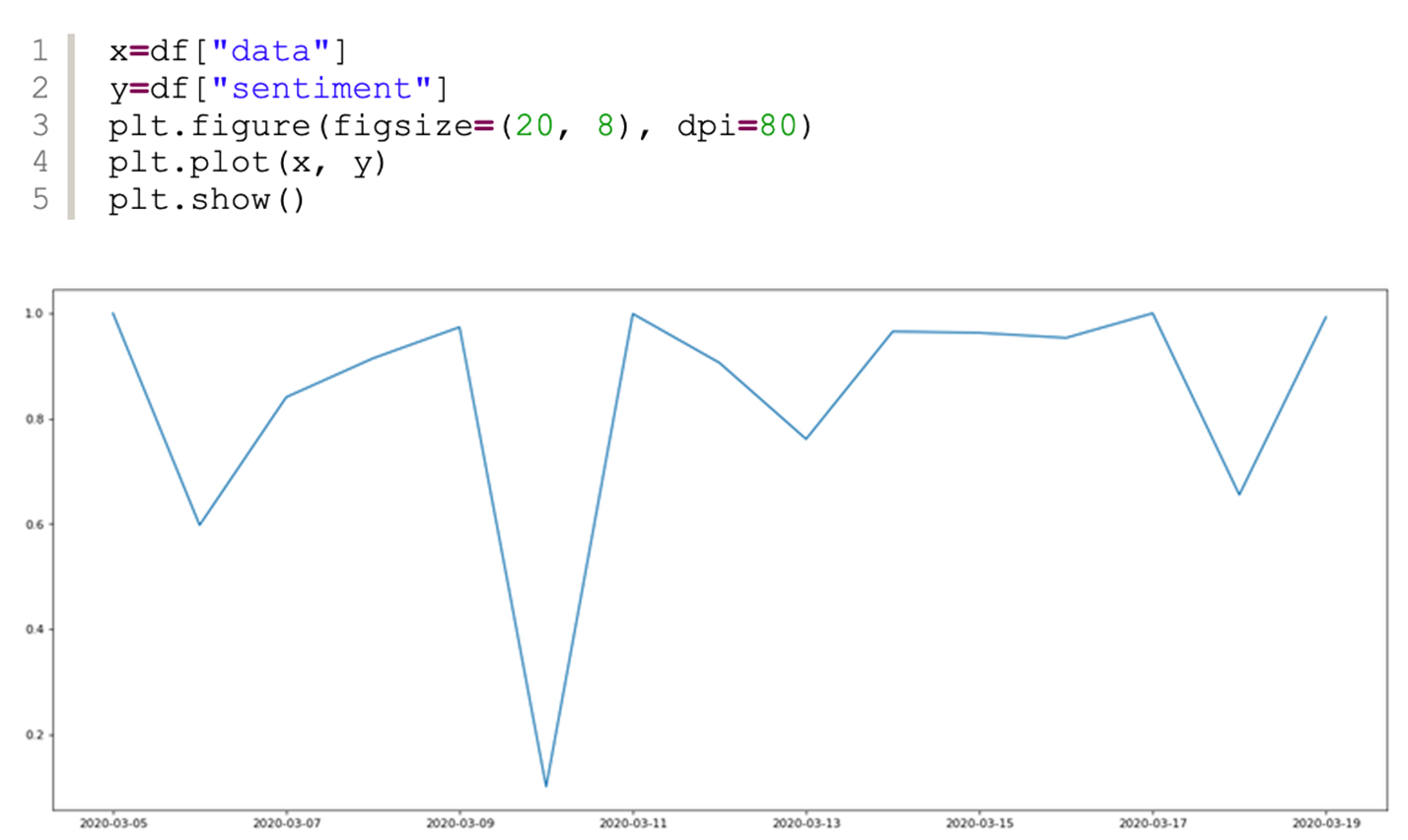
藉助matplotlib畫出時間的趨勢圖
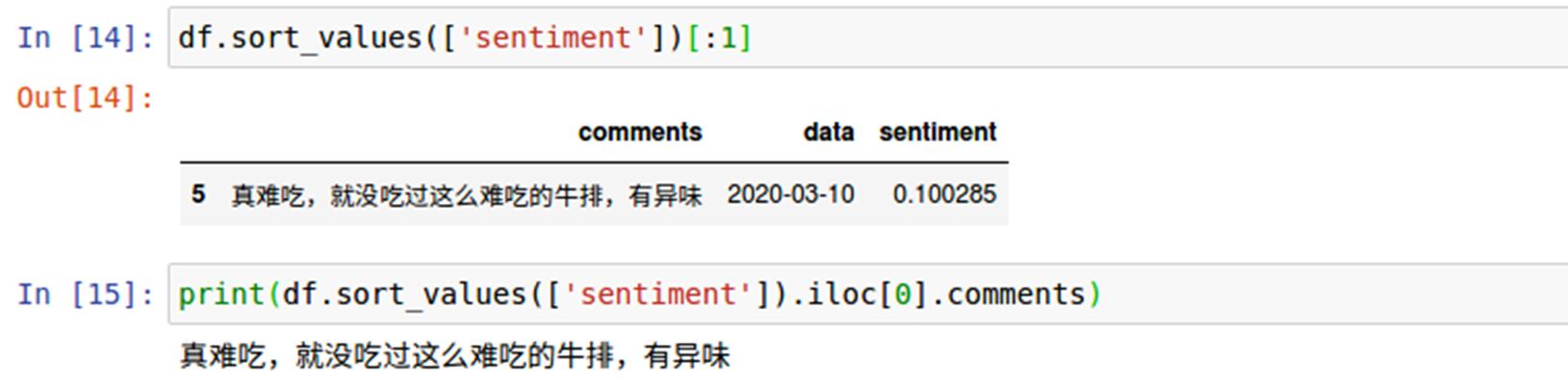
通過排序,找到情感分析得分倒數第一位的評論,並將內容列印出來:
原創作者:孤飛-部落格園
原文鏈接://www.cnblogs.com/ranxi169/p/16804615.html


