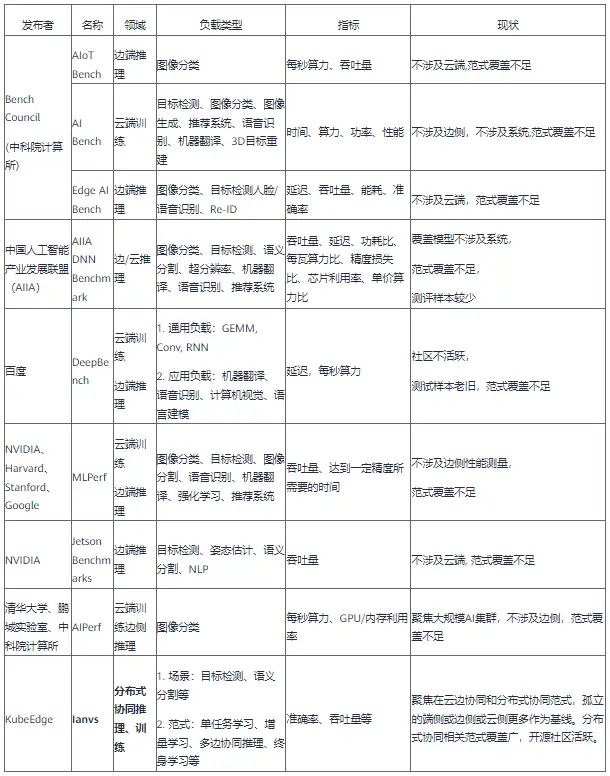
KubeEdge SIG AI發布首個分散式協同AI Benchmark調研
摘要:AI Benchmark旨在衡量AI模型的性能和效能。
本文分享自華為雲社區《KubeEdge SIG AI發布首個分散式協同AI Benchmark調研》,作者:KubeEdge SIG AI (成員:張揚,張子陽)。
人工智慧技術已經在我們生活中的方方面面為我們提供服務,尤其是在影像、影片、語音、推薦系統等方面帶來了突破性成果。AI Benchmark旨在衡量AI模型的性能和效能。KubeEdge SIG AI成員張揚和張子陽博士就AI Benchmark的困難與挑戰,以及新興的邊緣計算領域的分散式協同AI Benchmark發展現狀進行了分析總結。
AI Benchmark困難與挑戰
深度學習技術可以利用有限的數據逼近高維函數。但我們仍未掌握模型參數、系統配置對機器學習、深度學習演算法的學習動態的影響。目前AI Benchmark領域的困難與挑戰總結如下:
1. 學習動態難解釋:深度學習技術一定程度上是一個高維非凸優化問題,細微的變化會導致不同的優化路徑,嚴重依賴參數調整的經驗。
2. 成本高昂:在我們開啟一次訓練之後,我們必須完整的跑完整個訓練過程。完整訓練一次GPT-3模型的成本約7500萬人民幣。
3. 指標問題:在時間品質(Time to Quality, TTQ)指標上,時間品質嚴重依賴超參數的調整,同時需要解耦架構、系統和演算法評估模組;在每秒浮點運算次數(floating-point operations per second, FLOPS)上,有半精度浮點、單精度浮點、雙精度浮點、多精度浮點、混合浮點等浮點類型。
4. 需求衝突:主要問題為1.組件基準(component benchmarks)無法在模擬器上運行,2.微基準(Micro benchmarks)可負擔,但不能模擬學習動態。
5. 有效期問題:人工智慧模型的演變和變化往往會超過人工智慧基準。
6. 可拓展性問題:AI問題的規模是固定的,不可拓展。
7. 可重複性問題:基準測試要求測試是可復現的,神經網路的隨機性會影響基準測試的復現性。神經網路中的隨機性包括:隨機種子、模型初始化、數據增強、數據Shuffle、Dropout等等。
隨著邊側算力逐步強化,時代也正在見證邊緣AI往分散式協同AI的持續演變。分散式協同AI技術是指基於邊緣設備、邊緣伺服器、雲伺服器利用多節點分散式乃至多節點協同方式實現人工智慧系統的技術。除了以上問題外,如果考慮到分散式協同AI,還存在如邊側算力不足、雲邊網路不穩定、數據孤島等實際的約束和限制問題。
分散式協同AI Benchmark總覽
本章節首先總結當前學界與業界的分散式協同AI Benchmark,接下來對各個Benchmark展開簡單描述。
AIoT Bench
Bench Council發布的AIoT Bench是一個基準套件,AIoTBench專註於評估移動和嵌入式設備的推理能力,包含三個典型的重量級網路:ResNet50、InceptionV3、DenseNet121以及三個輕量級網路:SqueezeNet、MobileNetV2、MnasNet。每個模型都由三個流行的框架實現:Tensorflow Lite、Caffe2、Pytorch Mobile。對於Tensorflow Lite中的每個模型,還提供了三個量化版本:動態範圍量化(dynamic range quantization)、全整數量化(full integer quantization)、float16量化(float16 quantization)。

圖 1 AIotBench中使用模型的FLOPs、Parameters和準確率
在框架的選擇上,AIoTBench支援了三個流行和具有代表性的框架:Tensorflow Lite、Caffe2、Pytorch Mobile。
最後,在指標上,AIoTBench通過VIPS(Valid Images Per Second, 每秒有效影像)來反映得分。
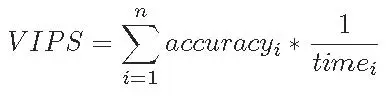
圖 2 AIotBench中VIPS計算
目前,Bench Council已經發布了Android版本的AIoTBench,它包含四個模組:
1. 配置模組:用戶可以配置模型文件的路徑和數據集的路徑。預處理參數由文件配置。我們在默認路徑中提供了數據集、準備的模型和相應的預處理配置。添加新型號很方便。用戶只需要i)準備模型文件並放入模型路徑,ii)在配置文件中添加該模型的預處理設置。
2. 預處理模組:讀取和預處理影像。
3. 預測模組:由於不同的框架有不同的推理API,AIoT Bench抽象了兩個介面,並為三個框架實現它們:Tensorflow Lite、Caffe2、Pytorch Mobile。prepare()介面負責載入和初始化模型,infer()介面負責執行模型推理。當用戶需要添加新的框架時,只需要根據新框架實現對應的兩個API介面即可。
4. 評分模組:記錄每次測試的準確性和推斷時間,並計算最終的AI基準測試分數。
AI Bench
AI Bench是Bench Council在2018年提出的適用於數據中心、HPC、邊緣和 AIoT 的綜合 AI 基準測試套件,提出了一種場景提取的基準測試方法論和企業級AI基準測試框架和套件。測試數據源有公共開源數據集和經過保密脫敏處理的合作機構的數據集。
AI Bench框架分為數據輸入、AI問題域、離線訓練、在線推理四個部分。
• 數據輸入(data input)模組:負責將數據輸入其他模組,支援結構化、半機構化、非結構化數據,例如表格、圖形、文本、影像、音頻、影片等等。同時,數據輸入模組集成了各種開源數據存儲系統,支援大規模數據生成和部署。
• AI問題域:AI Bench確定了最重要的AI問題領域,針對這些領域的AI演算法的具體實現作為組件基準(component benchmarks)。並對組件基準中最密集的計算單元實現為一組微基準(micro benchmarks)。組件基準和微基準可以自由組合,每個基準也都可以獨立運行。
• 離線訓練(offline training)和在線推理(online inference)模組:構建端到端(End-to-End)的應用程式基準。首先,離線訓練模組通過指定所需的基準ID、輸入數據和批量大小等執行參數,從AI問題域模組中選擇一個或多個組件基準。然後離線訓練模組訓練一個模型並將訓練好的模型提供給在線推理模組。在線推理模組將訓練好的模型載入到推理服務中,與關鍵路徑中的其他非AI模組協作,構建端到端應用程式基準。
為了在大規模集群上輕鬆部署,框架提供了部署工具,提供了Ansible和Kuberneres的兩個自動化部署模板。Ansible主要提供的是在物理機或者虛擬機上的1+N複製模式,Kubernetes需要提前構件好集群,在Master節點上通過配置文件將配置下發至各個節點從而完成部署。
Edge AI Bench
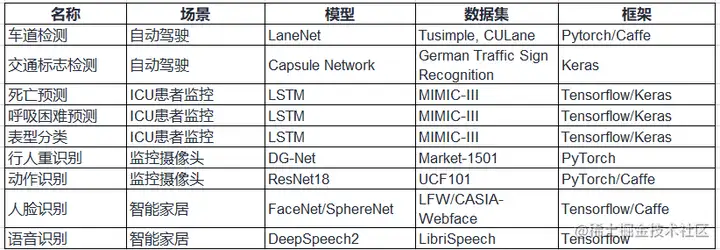
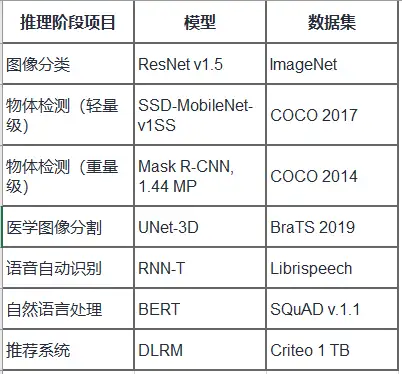
Edge AI Bench是一個基於場景的基準套件,是AI Bench場景基準的一部分,設置了4個典型的邊緣AI場景:自動駕駛、ICU患者監視器、智慧家居、智慧家居。Edge AI Bench提供了一個端到端的應用程式基準框架,包括訓練、驗證和推理階段。
Edge AI Bench涵蓋的場景、模型、數據集情況如下表所示。
AIIA DNN benchmark
AIIA DNN benchmark項目由中國人工智慧產業發展聯盟計算架構與晶片推進組發起。AIIA DNN benchmark項目是用於測試具有機器學習處理能力的加速器或處理器硬體、軟體以及服務的訓練和推理性能的開源基準平台。它能幫助人工智慧研究人員採用通用標準來衡量用於訓練或推理任務的人工智慧硬體、軟體的最佳性能。旨在客觀反映當前以提升深度學習處理能力的 AI 加速器現狀,為晶片企業提供第三方評測結果,幫助產品市場宣傳;同時為應用企業提供選型參考,幫助產品找到合適其應用場景的晶片。
AIIA DNN benchmark系統架構如下:

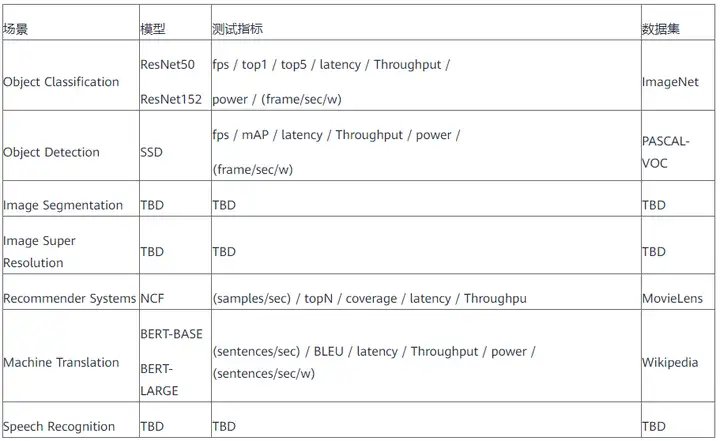
AIIA DNN benchmark依據行業應用,區分垂直應用場景對深度神經網路加速器/處理器展開基於真實應用場景的基準測試工作。

AIIA DNN benchmark評測場景與指標如下:
DeepBench
DeepBench 的主要目的是在不同硬體平台上對深度學習很重要的操作進行基準測試。儘管深度學習背後的基本計算很容易理解,但它們在實踐中的使用方式卻出奇的多樣化。例如,矩陣乘法可能是計算受限的、頻寬受限的或佔用受限的,這取決於被相乘的矩陣的大小和內核實現。由於每個深度學習模型都使用這些具有不同參數的操作,因此針對深度學習的硬體和軟體的優化空間很大且未指定。
DeepBench直接使用神經網路庫(cuDNN, MKL)對不同硬體上基本操作的性能進行基準測試。它不適用於為應用程式構建的深度學習框架或深度學習模型。
DeepBench 由一組基本操作(密集矩陣乘法GEMM、卷積Conv)以及一些循環神經網路RNN類型組成。DeepBench的測試包括七個硬體平台的訓練結果,NVIDIA 的 TitanX、M40、TitanX Pascal、TitanXp、1080 Ti、P100 和英特爾的 Knights Landing。推理結果包括三個伺服器平台,NVIDIA 的 TitanX Pascal、TitanXp 和 1080 Ti。三款移動設備 iPhone 6 和 7、RaspBerry Pi 3 的推理結果也包括在內。
DeepBench提供多種晶片的測試方法,共有以下5種類型:
1. NVIDIA Benchmarks:需指定MPI_PATH、CUDA_PATH、CUDNN_PATH、NCCL_PATH、GPU數量、精度類型等,通過編譯後,可以運行基準測試。
2. Baidu Benchmarks:需指定MPI_PATH、CUDA_PATH、BAIDU_ALLREDUCE_PATH、GPU數量等參數,之後使用mpirun運行Baidu All-Reduce基準測試。
3. Intel Benchmarks:需要指定Intel工具icc、mkl、mpi路徑,可以進行GEMM、Conv、ALL-Reduce等基準測試。
4. ARM Benchmarks:需要在64位ARM v8處理器上編譯和運行ARM Benchmarks,可以進行GEMM、Conv、稀疏GEMM基準測試。
5. AMD Benchmarks:需要支援ROCm的平台、rocBLAS、MIOpen等組件,可以進行Conv、RNN、GEMM基準測試。
MLPerf
MLPerf是一個由來自學術界、研究實驗室和行業的人工智慧領導者組成的聯盟。
MLPerf的訓練測試由八個不同的工作負載組成,涵蓋了各種各樣的用例,包括視覺、語言、推薦和強化學習。

MLPerf推理測試七種不同神經網路的七個不同用例。其中三個用例用於電腦視覺,一個用於推薦系統,兩個用於自然語言處理,一個用於醫學成像。
Jetson Benchmarks
Jetson Benchmarks是通過高性能推理將各種流行的DNN模型和ML框架部署到邊緣側Jetson設備中,以實時分類和對象檢測、姿勢估計、語義分割和自然語言處理(NLP)等任務作為工作負載,檢測邊緣側Jetson設備性能的基準測試工具。
針對各類Jetson設備,Jetson Benchmarks的腳本會自動運行如下配置的基準測試,並得到測試結果(FPS)
• Names : Input Image Resolution
• Inception V4 : 299×299
• ResNet-50 : 224×224
• OpenPose : 256×456
• VGG-19 : 224×224
• YOLO-V3 : 608×608
• Super Resolution : 481×321
AIPerf
AIPerf Benchmark由鵬城實驗室、清華大學等團隊聯合提出。AIPerf Benchmark基於微軟NNI開源框架,以自動化機器學習(AutoML)為負載,使用network morphism進行網路結構搜索和TPE進行超參搜索。
AIPerf官方提供四種數據集: Flowers、CIFAR-10、MNIST、ImageNet-2012 前三個數據集數據量小,直接調用相關腳本自動會完成下載、轉換(TFRecord格式)的過程。
AIPerf為了保證基準測試結果有效,要求測試需要滿足如下條件:
1. 測試運行時間應不少於1小時;
2. 測試的計算精度不低於FP-16;
3. 測試完成時所取得的最高正確率應大於70%;
AIPerf的工作流如下:
1. 用戶通過SSH登陸主節點,收集集群內Replica nodes的資訊並創建SLURM配置腳本
2. 主節點通過SLURM將工作負載分派到對應於請求和可用資源的Replica nodes中,分發的過程是並行且非同步的
3. 各個Replica nodes接收工作負載並執行架構搜索和模型訓練
4. Replica nodes上的CPU根據當前歷史模型列表搜索新架構,其中包含詳細的模型資訊和測試數據集的準確性,然後將候選架構存儲在緩衝區(如NFS)中以供後續訓練
5. Replica nodes上的AI加速器載入候選架構和數據集,利用數據並行性和HPO一起訓練,然後將結果存儲在歷史模型列表中
6. 一旦滿足條件(如達到用戶定義的時間),運行終止,根據記錄的指標計算最終結果後得出基準測試報告

圖 3 AIPerf工作流示意圖
KubeEdge-Ianvs
Ianvs是KubeEdge SIG AI孵化的開源分散式協同AI基準測試套件,幫助演算法開發者快速測試分散式協同AI演算法性能,促進更高效更有效的開發。藉助單機就可以完成分散式協同AI前期研發工作。項目地址://github.com/kubeedge/ianvs
Ianvs項目包括如下內容:
• 基於典型的分散式協同AI範式和應用,提供跨設備、邊緣節點、雲節點的端到端基準測試套件。
- 測試環境管理工具:在測試環境(演算法、系統配置)中支援CRUD操作等
- Test Cases管理工具:包括範式模板、模擬測試工具、基於超參數的輔助工具等
- 基準演示工具:生成排行榜和測試報告等
• 與其他組織和社區合作,例如在Kubeedge SIG AI中,建立全面的基準並開發相應的應用,包括但不限於如下內容:
- 數據集收集、重組和發布
- 形式化規範
- 舉辦競賽獲編碼活動
- 為商業用途維護解決方案排行榜或認證
Ianvs的目標用戶包括分散式協同AI演算法開發者和終端用戶。演算法開發者可以藉助Ianvs高效地構建和發布分散式協同AI解決方案;終端用戶則可以藉助Ianvs快速分析比較各分散式協同AI方案的效能。
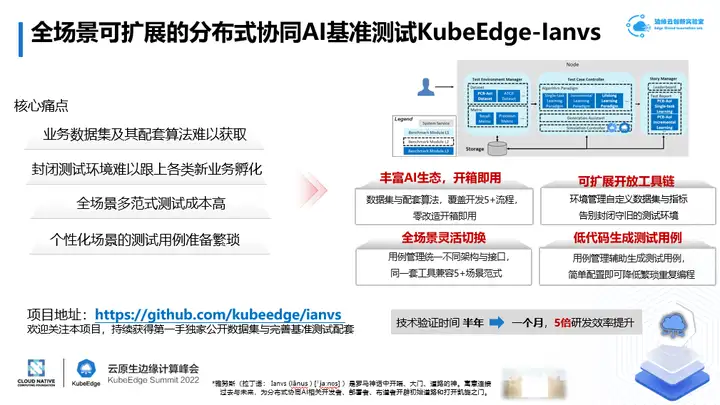
1、 針對業務數據集難以獲取,數據採集與處理成本高的痛點,ianvs提供豐富AI生態,做到開箱即用。ianvs開源數據集與5+配套演算法,覆蓋預處理、預訓練、訓練、推理、後處理全流程,零改造開箱即用。
2、 針對封閉測試環境難以跟上各類新業務孵化的痛點,ianvs提供可擴展開放工具鏈。測試環境管理實現自定義動態配置測試數據集、測試指標,告別封閉守舊的測試環境。
3、 針對全場景多範式測試成本高的痛點,ianvs提供全場景靈活切換。ianvs測試用例管理統一不同場景及其AI演算法架構與介面,能夠用一套工具同時兼容多種AI範式。
4、 針對個性化場景的測試用例準備繁瑣的痛點,ianvs提供低程式碼生成測試用例。ianvs測試用例管理基於網格搜索等輔助生成測試用例,比如一個配置文件即可實現多個超參測試,降低超參搜索時的繁瑣重複編程。
Ianvs同步發布一個新的工業質檢數據集PCB-AoI。PCB-AoI 數據集是首個面向印刷電路板AoI焊點表面缺陷的開源數據集,是開源分散式協同 AI 基準測試項目 KubeEdge-Ianvs 的一部分。工作組將PCB-AoI 公共數據集同時也放在 Kaggle和雲服務上方便開發者下載。

PCB-AoI數據集由KubeEdge SIG AI 來自中國電信和瑞斯康達的成員發布。在這個數據集中,收集了 230 多個板,影像數量增加到 1200 多個。具體來說,數據集包括兩部分,即訓練集和測試集。訓練集包括 173 個板,而測試集包括 60 個板。也就是說,就 PCB 板而言,train-test 比率約為 3:1。進行了數據增強,將影像方面的訓練測試比率提高到 1211:60(約 20:1)。 train_data 和 test_data 的兩個目錄都包含索引文件,用於關聯原始影像和注釋標籤。
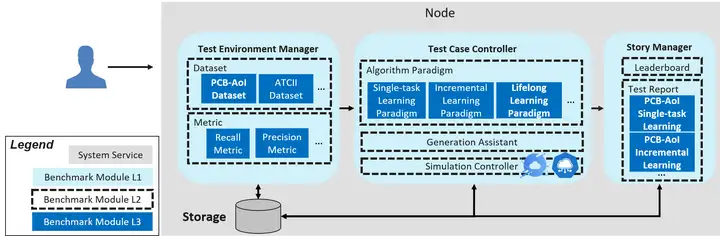
Ianvs只需一台機器即可運行,架構圖如上圖所示,關鍵組件包括:
• Test Environment Manager:為全局使用服務的測試環境的CRUD
• Test Case Controller:管理控制各個Test Case運行時的行為,比如生成和刪除實例
- GenerationAssistant:根據一定的規則或約束,例如參數的範圍,幫助用戶生成測試用例
- SimulationController:控制分散式協同AI的模擬過程,包括模擬容器實例的生成和刪除。Note:在v0.5之前的早期版本不包括模擬工具。
• Story Manager:測試用例的輸出管理和展示,包括排行榜和測試報告生成
KubeEdge-Ianvs項目規劃路標如下圖:
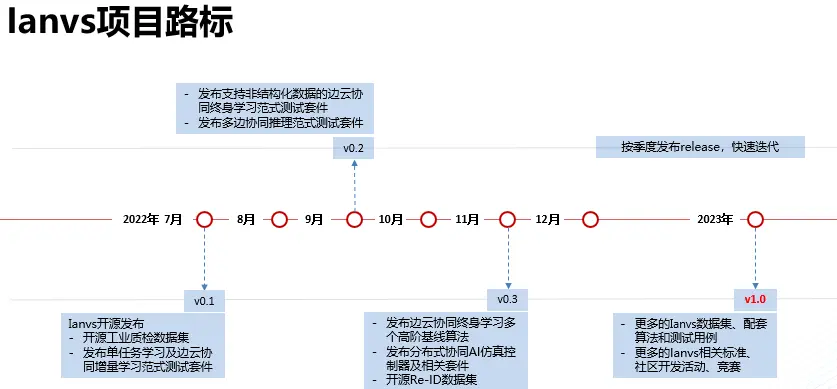
也歡迎關注Ianvs項目,持續獲得第一手獨家公開數據集與完善基準測試配套。社區也持續募集在Ianvs項目上的合作夥伴,共同孵化開源項目、研究報告及行業標準等。開源項目GitHub地址://github.com/kubeedge/ianvs
參考文獻
AIoT Bench //www.benchcouncil.org/aibench/aiotbench/index.html
AI Bench //www.benchcouncil.org/aibench/index.html
Edge AI Bench //www.benchcouncil.org/aibench/edge-aibench/index.html
AIIA DNN Benchmark //aiiaorg.cn/benchmark/zh/index.html
DeepBench //github.com/baidu-research/DeepBench
MLPerf //www.nvidia.com/en-us/data-center/resources/mlperf-benchmarks/
Jetson Benchmarks //developer.nvidia.com/embedded/jetson-benchmarks
AIPerf //github.com/AI-HPC-Research-Team/AIPerf
Kubeedge-Ianvs //ianvs.readthedocs.io/en/latest/index.html

