day48-JDBC和連接池04
JDBC和連接池04
10.資料庫連接池
10.1傳統連接弊端分析
- 傳統獲取Connection問題分析
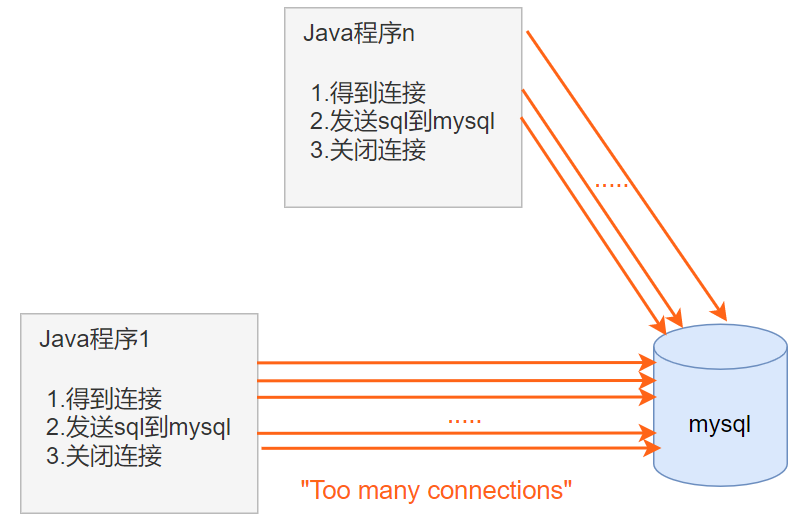
- 傳統的 JDBC 資料庫連接使用DriverManager來獲取,每次向資料庫建立連接的時候都要將Connection載入到記憶體中,再驗證IP地址,用戶名和密碼(約0.05s~1s時間)。需要資料庫連接的時候,就向資料庫要求一個,頻繁地進行資料庫連接操作將會佔用很多的系統資源,容易造成伺服器崩潰
- 每一次資料庫連接,使用完後都得斷開,如果程式出現異常而未能關閉,將導致資料庫記憶體泄漏,最終將導致重啟資料庫
- 傳統獲取連接的方式,不能控制創建的連接數量,如連接過多,也可能導致記憶體泄漏,MySQL崩潰
- 解決傳統開發中的資料庫連接問題,可以採用資料庫連接池技術(connection pool)

例子1
package li.jdbc.datasource;
import li.jdbc.utils.JDBCUtils;
import org.junit.Test;
import java.sql.Connection;
public class ConQuestion {
@Test
public void testCon(){
for (int i = 0; i < 5000; i++) {
//使用傳統的jdbc方式得到連接
Connection connection = JDBCUtils.getConnection();
//這裡做一些工作....
//不關閉連接資源,使其一直佔用
}
}
}
出現的異常:
java.lang.RuntimeException: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source rejected establishment of connection, message from server: "Too many connections"


例子2:
package li.jdbc.datasource;
import li.jdbc.utils.JDBCUtils;
import org.junit.Test;
import java.sql.Connection;
public class ConQuestion {
@Test
public void testCon(){
long start = System.currentTimeMillis();
System.out.println("開始連接...");
for (int i = 0; i < 5000; i++) {
//使用傳統的jdbc方式得到連接
Connection connection = JDBCUtils.getConnection();
//這裡做一些工作....
JDBCUtils.close(null,null,connection);//每次連接完都正常關閉連接資源
}
long end = System.currentTimeMillis();
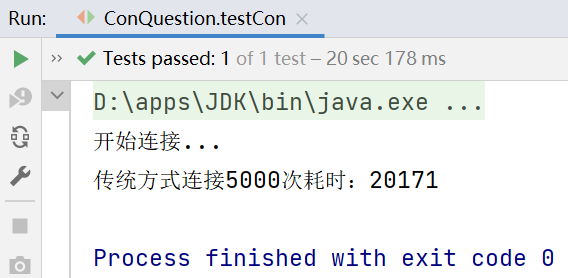
System.out.println("傳統方式連接5000次耗時:"+(end-start));//20171ms
}
}
每次連接完都正常關閉連接資源,可以看到5000次連接資料庫需要耗時20171ms

10.2資料庫連接池原理
- 資料庫連接池基本介紹
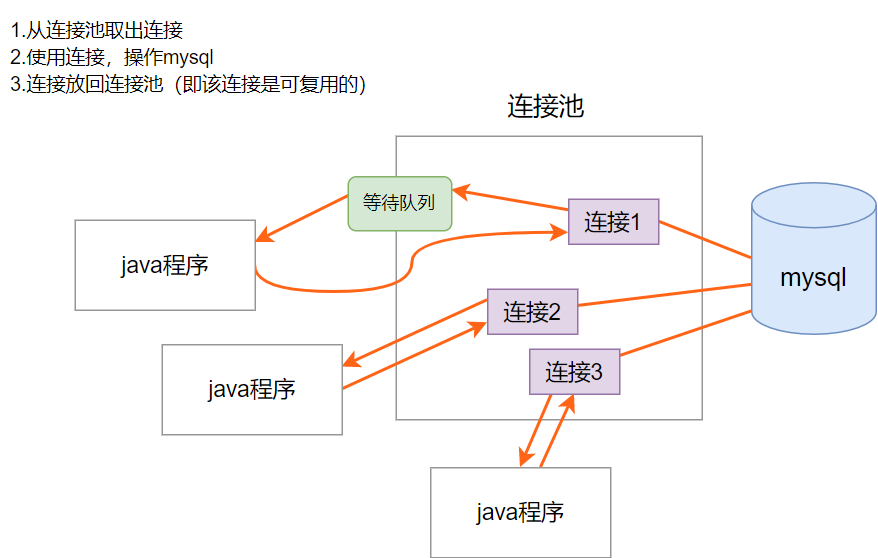
- 預先在緩衝池中放入一定數量的連接,當需要建立資料庫連接時,只需從「緩衝池」中取出一個,使用完畢之後再將連接放回連接池中。
- 資料庫連接池負責分配、管理和釋放資料庫連接,它允許應用程式重複使用一個現有的資料庫連接,而不是重新建立一個
- 當應用程式向連接池請求的連接數超過最大連接數量時,這些請求將被加入到等待隊列中
- 資料庫連接池種類
- JDBC的資料庫連接池使用javax.sql.DataSource來表示,DataSource只是一個介面,該介面通常由第三方提供實現 [提供相應的jar包]
- C3P0資料庫連接池,速度相對較慢,穩定性不錯(hibernate,spring)
- DBCP資料庫連接池,速度相對C3P0較快,但不穩定
- Proxool資料庫連接池,有監控連接池狀態的功能,穩定性較C3P0差一點
- BoneCP資料庫連接池,速度快
- Druid(德魯伊)是阿里提供的資料庫連接池,集DBCP、C3P0、Proxool優點於一身的資料庫連接池
10.3C3P0方式
10.3.1方式1-相關參數在程式中指定
使用程式碼實現c3p0資料庫連接池
首先在網上下載c3p0jar包,並將其複製到項目的lib文件夾中,右鍵選擇add as library

package li.jdbc.datasource;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.junit.Test;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
/**
* 演示c3p0的使用
*/
public class C3P0_ {
//方式1:相關參數在程式中指定,user,url,password等
@Test
public void testC3P0_01() throws Exception {
//1.創建一個數據源對象
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2.通過配置文件mysql.properties獲取相關的連接資訊
Properties properties = new Properties();
properties.load(new FileInputStream("src\\mysql.properties"));
//讀取相關的屬性值
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String url = properties.getProperty("url");
String driver = properties.getProperty("driver");
//給數據源 comboPooledDataSource設置相關的參數
//注意:連接管理 是由comboPooledDataSource來管理
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//設置初始化連接數
comboPooledDataSource.setInitialPoolSize(10);
//最大連接數--連接請求超過最大連接數據將進入等待隊列
comboPooledDataSource.setMaxPoolSize(50);
//測試連接池的效率
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = comboPooledDataSource.getConnection();//這個方法就是從DataSource 介面實現的
//System.out.println("連接成功");
connection.close();
}
long end = System.currentTimeMillis();
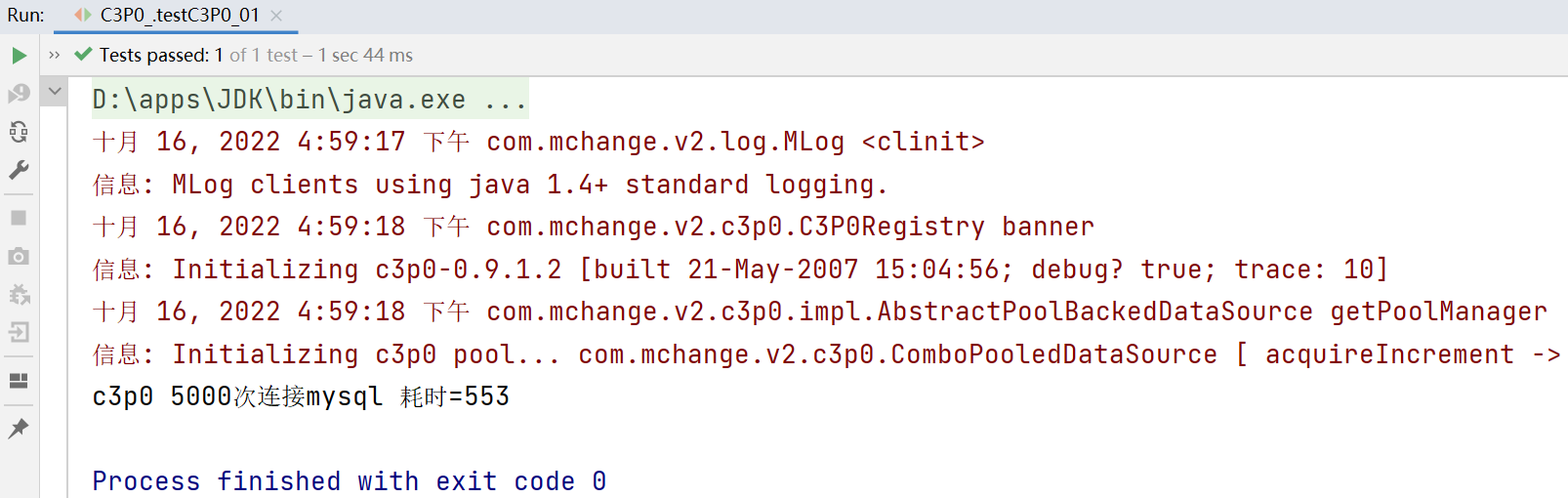
System.out.println("c3p0 5000次連接mysql 耗時=" + (end - start));
}
}
c3p0方式一:5000次的連接耗時553ms
10.3.2方式2-使用配置文件模板來完成
首先如10.3.1一樣將jar包加入到項目中
然後將c3p0提供的配置文件c3p0-config.xml複製到src目錄下,該文件指定了連接資料庫和連接池的相關參數
c3p0-config.xml:
<c3p0-config>
<!--數據源的名稱,代表連接池,名字是隨意的 -->
<named-config name="hello">
<!-- 驅動類 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<!-- url-->
<property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/hsp_db02</property>
<!-- 用戶名 -->
<property name="user">root</property>
<!-- 密碼 -->
<property name="password">123456</property>
<!-- 每次增長的連接數-->
<property name="acquireIncrement">5</property>
<!-- 初始的連接數 -->
<property name="initialPoolSize">10</property>
<!-- 最小連接數 -->
<property name="minPoolSize">5</property>
<!-- 最大連接數 -->
<property name="maxPoolSize">50</property>
<!-- 可連接的最多的命令對象數 -->
<property name="maxStatements">5</property>
<!-- 每個連接對象可連接的最多的命令對象數 -->
<property name="maxStatementsPerConnection">2</property>
</named-config>
</c3p0-config>
測試程式:
package li.jdbc.datasource;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.junit.Test;
import java.sql.Connection;
/**
* 演示c3p0的使用
*/
public class C3P0_ {
//方式2:使用配置文件模板來完成
//將c3p0提供的配置文件c3p0-config.xml複製到src目錄下
// 該文件指定了連接資料庫和連接池的相關參數
@Test
public void testC3P0_02() throws Exception {
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("hello");
//測試5000次連接誒mysql
long start = System.currentTimeMillis();
System.out.println("開始執行...");
for (int i = 0; i < 5000; i++) {
Connection connection = comboPooledDataSource.getConnection();
//System.out.println("連接成功");
connection.close();
}
long end = System.currentTimeMillis();
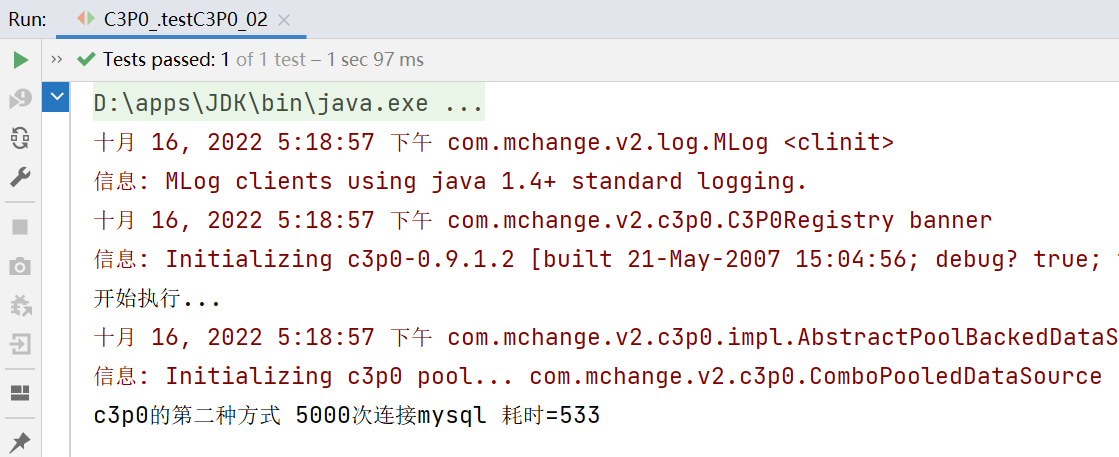
System.out.println("c3p0的第二種方式 5000次連接mysql 耗時=" + (end - start));
}
}
c3p0的第二種方式 5000次連接mysql 耗時=533ms
10.4德魯伊連接池
首先將Druid的jar包複製到項目的lib文件夾中,點擊右鍵,選擇add as library

jar包在該網站可以下載 Central Repository: com/alibaba/druid (maven.org)
然後將提供的配置文件的druid.properties(文件名可以隨意)複製到src目錄下
druid.properties:
#key=value
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/hsp_02?rewriteBatchedStatements=true
#url=jdbc:mysql://localhost:3306/hsp_02
username=root
password=123456
#initial connection Size
initialSize=10
#min idle connecton size
minIdle=5
#max active connection size
maxActive=50
#max wait time (5000 mil seconds) 在等待隊列中的最大等待時間
maxWait=5000
測試程式:
package li.jdbc.datasource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import org.junit.Test;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
/**
* 測試德魯伊Druid的使用
*/
public class Druid_ {
@Test
public void testDruid() throws Exception {
//1.加入Druid包
//2.加入配置文件 druid.properties,將該文件複製到項目的src目錄下面
//3.創建Properties對象,讀取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
//4.創建一個指定參數的資料庫連接池,Druid連接池
DataSource dataSource =
DruidDataSourceFactory.createDataSource(properties);
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = dataSource.getConnection();
//System.out.println("連接成功!");
connection.close();
}
long end = System.currentTimeMillis();
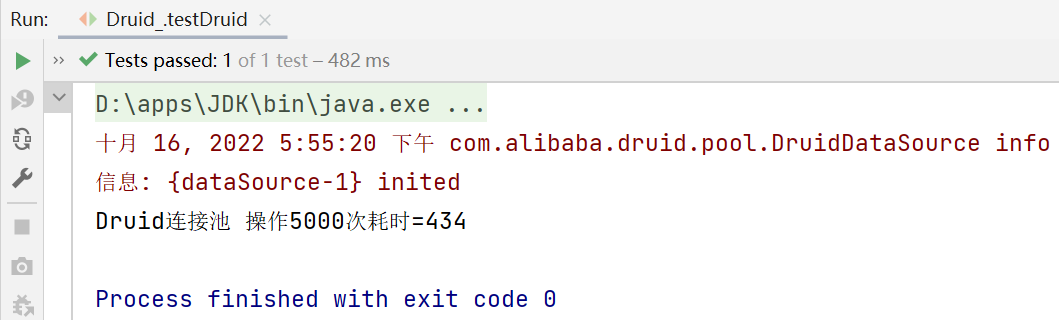
System.out.println("Druid連接池 操作5000次耗時="+(end-start));
}
}
德魯伊連接池操作5000次的總耗時為434ms
5000次連接池的時間和c3p0的時間差不多,但是當連接數量到50萬、500萬時差距就會很明顯,因此在實際開發中推薦使用Druid連接池。
10.4.1德魯伊工具類
將之前7.1的JDBCUtils工具類改為Druid(德魯伊)實現
通過德魯伊資料庫連接池獲取連接對象
工具類:JDBCUtilsByDruid
package li.jdbc.datasource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 基於Druid資料庫連接池的工具類
*/
public class JDBCUtilsByDruid {
private static DataSource ds;
//在靜態程式碼塊完成ds的初始化
//靜態程式碼塊在載入類的時候只會執行一次,因此數據源也只會初始化一次
static {
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src\\druid.properties"));
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//編寫getConnection方法
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
//關閉連接(注意:在資料庫連接池技術中,close不是真的關閉連接,而是將Connection對象放回連接池中)
public static void close(ResultSet resultSet, Statement statemenat, Connection connection) {
try {
if (resultSet != null) {
resultSet.close();
}
if (statemenat != null) {
statemenat.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
測試程式:JDBCUtilsByDruid_Use
package li.jdbc.datasource;
import org.junit.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Date;
public class JDBCUtilsByDruid_Use {
@Test
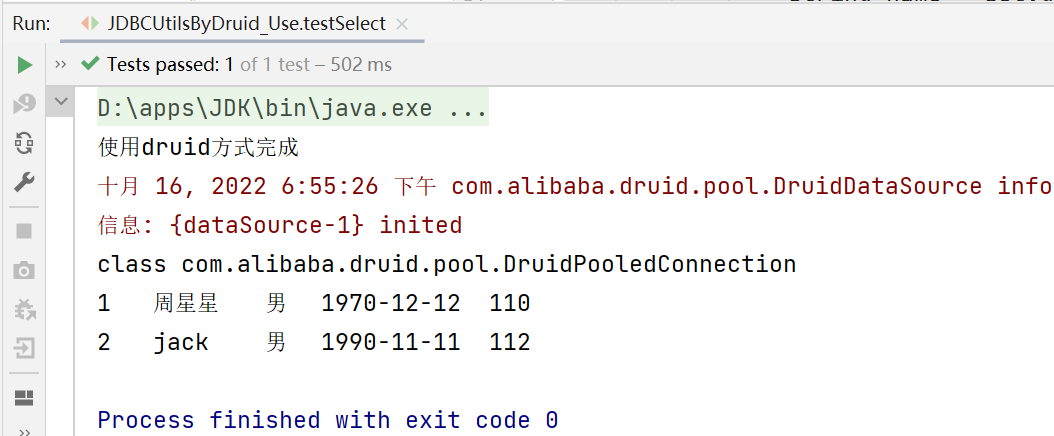
public void testSelect() {
System.out.println("使用druid方式完成");
//1.得到連接
Connection connection = null;
//2.組織一個sql語句
String sql = "Select * from actor where id >=?";
//3.創建PreparedStatement對象
PreparedStatement preparedStatement = null;
ResultSet set = null;
try {
connection = JDBCUtilsByDruid.getConnection();
/**
* Connection是個介面,是由sun公司定義的規範,根據Connection的實現類不同,close方法也不同
* mysql的廠商的實現類是直接把連接關閉,Alibaba的實現是將引用的連接放回到連接池等待下一次引用
* 因此在Druid中的close方法並不是真正地關閉連接
*/
System.out.println(connection.getClass());//運行類型 class com.alibaba.druid.pool.DruidPooledConnection
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1);//給?號賦值
//執行sql,得到結果集
set = preparedStatement.executeQuery();
//遍歷該結果集
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");
String sex = set.getString("sex");
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
System.out.println(id + "\t" + name + "\t" + sex + "\t" + borndate + "\t" + phone);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//關閉資源(不是真的關閉連接,而是將Connection對象放回連接池中)
JDBCUtilsByDruid.close(set, preparedStatement, connection);
}
}
}
注意:
Connection是個介面,是由sun公司定義的規範,根據Connection的實現類不同,close方法也不同
mysql的廠商的實現類是直接把連接關閉,Alibaba的實現是將引用的連接放回到連接池等待下一次引用
因此在Druid中的close方法並不是真正地關閉連接,而是將Connection對象放回連接池中
10.5Apache-DBUtils
10.5.1resultSet問題
先分析一個問題
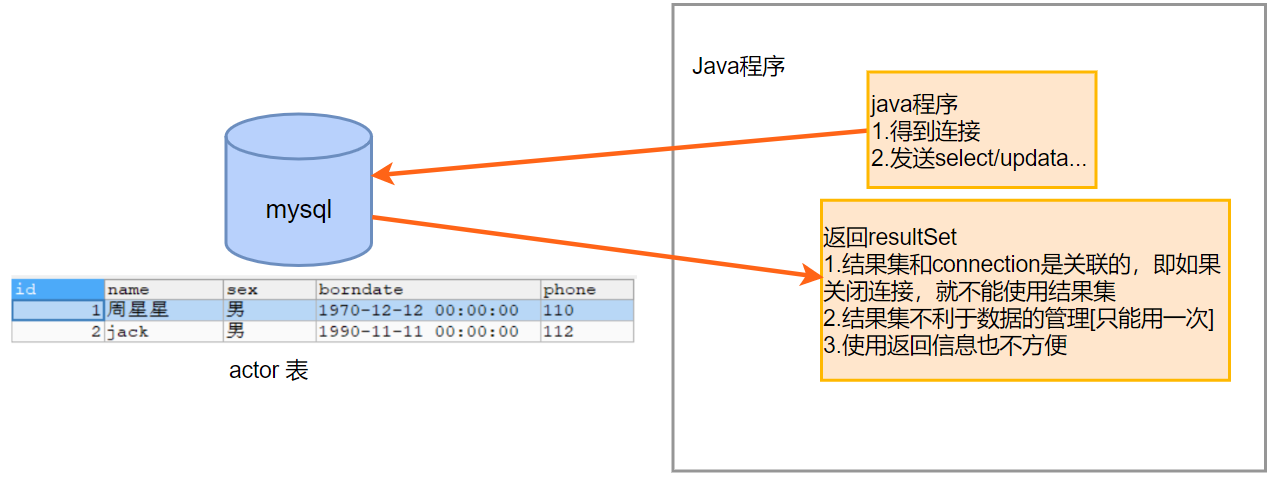
在之前的程式中,執行sql語句後返回的結果集存在如下問題:
-
關閉connection後,resultSet結果集無法使用
如果要使用結果集,就不能關閉連接,不能關閉連接,就會反過來影響別的程式去連接資料庫,就會對多並發程式造成很大的影響
-
resultSet不利於數據的管理
如果其它的方法或者程式想要使用結果集,也需要一直保持連接,影響其他程式對資料庫的連接
-
使用返回資訊也不方便
解決方法:
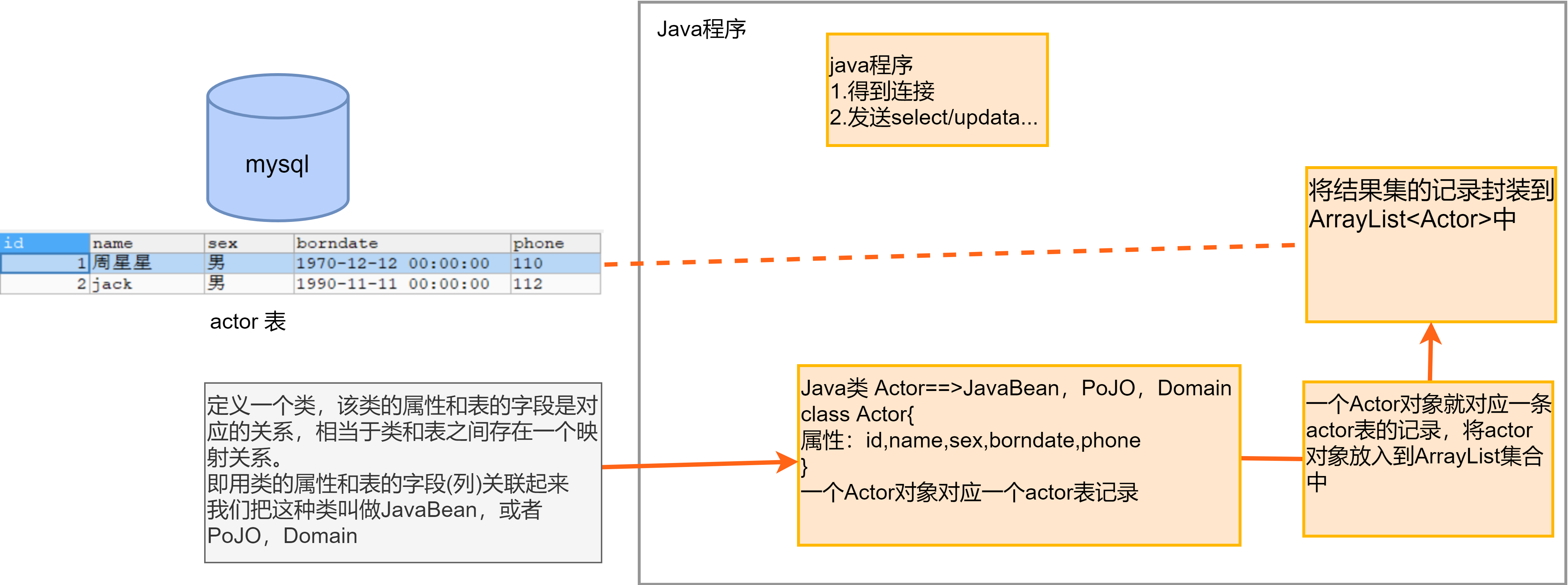
定義一個類,該類的屬性和表的欄位是對應關係/映射關係,即用類的屬性和表的欄位(列)關聯起來
我們把這種類叫做JavaBean,或者POJO,Domain。
一個Actor對象就對應一條actor表的記錄,將Actor對象放入到ArrayList集合中(將結果集的記錄封裝到ArrayList中)

10.5.2土方法完成封裝
Actor類(JavaBean):
package li.jdbc.datasource;
import java.util.Date;
/**
* Actor對象和actor表的記錄對應
*/
public class Actor {//JavaBean/POJO/Domain
private Integer id;
private String name;
private String sex;
private Date borndate;
private String phone;
public Actor() {//一定要給一個無參構造器[反射需要]
}
public Actor(Integer id, String name, String sex, Date borndate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.borndate = borndate;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBorndate() {
return borndate;
}
public void setBorndate(Date borndate) {
this.borndate = borndate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "\nActor{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", borndate=" + borndate +
", phone='" + phone + '\'' +
'}';
}
}
測試程式:
package li.jdbc.datasource;
import org.junit.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Date;
public class JDBCUtilsByDruid_Use {
//使用土方法嘗試解決ResultSet問題==封裝=>ArrayList
@Test
public void testSelectToArrayList() {//也可以設置返回值
System.out.println("使用druid方式完成");
//1.得到連接
Connection connection = null;
//2.組織一個sql語句
String sql = "Select * from actor where id >=?";
//3.創建PreparedStatement對象
PreparedStatement preparedStatement = null;
ResultSet set = null;
ArrayList<Actor> list = new ArrayList<>();//創建ArrayList對象,存放actor對象
try {
connection = JDBCUtilsByDruid.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1);//給?號賦值
//執行sql,得到結果集
set = preparedStatement.executeQuery();
//遍歷該結果集
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");
String sex = set.getString("sex");
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
//把得到的當前 resultSet的一條記錄,封裝到一個Actor對象中,並放入arraylist集合
list.add(new Actor(id,name,sex,borndate,phone));
}
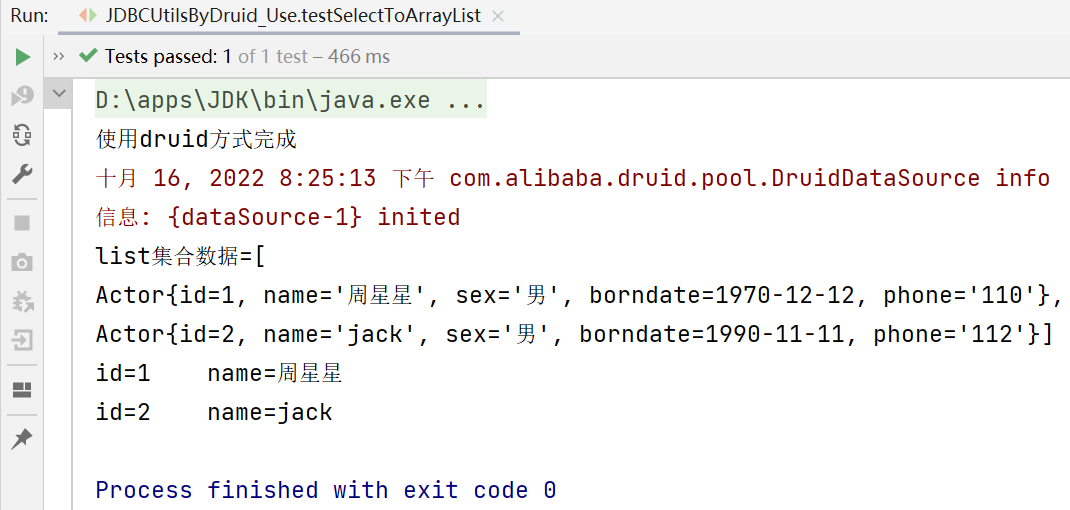
System.out.println("list集合數據="+list);
//or
for (Actor actor:list) {
System.out.println("id="+actor.getId()+"\t"+"name="+actor.getName());
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//關閉資源(不是真的關閉連接,而是將Connection對象放回連接池中)
JDBCUtilsByDruid.close(set, preparedStatement, connection);
}
//因為ArrayList 和 connection 沒有任何關聯,所以該集合可以復用
//return list;
}
}

10.5.3Apache-DBUtils
-
基本介紹
commons-dbutils是Apache組織提供的一個開源 JDBC工具類庫,它是對 JDBC的封裝,使用dbutils能極大簡化 JDBC編碼的工作量。
-
DbUtils類
- QueryRunner類:該類封裝了SQL的執行,是執行緒安全的。可以實現增、刪、改、查、批處理
- 使用QueryRunner類實現查詢
- ResultSetHandler介面:該介面用於處理 java.sql.ResultSet,將數據按要求轉換為另一種形式
| 方法 | 解釋 |
|---|---|
| ArrayHandler | 將結果集中的第一行數據轉成對象數組 |
| ArrayListHandler | 把結果集中的每一行數據都轉成一個數組,再存放到List中 |
| BeanHandler | 將結果集中的第一行數據封裝到一個對應的JavaBean實例中 |
| BeanListHandler | 將結果集中的每一行數據都封裝到一個對應的JavaBean實例中,再存放到List中 |
| ColumnListHandler | 將結果集中某一列的數據存放到List中 |
| KeyedHandler(name) | 將結果集中的每行數據都封裝到Map中,再把這些map再存放到一個map里,其key為指定的key |
| MapHandler | 將結果集中的第一行數據封裝到一個Map里,key是列名,value就是對應的值 |
| MapListHandler | 將結果集中的每一行數據都封裝到一個Map里,然後再存放到List |
DBUtils的jar包下載可以去官網下載
應用實例
使用DBUtils+資料庫連接池(德魯伊)方式,完成對錶actor的crud操作

首先將DBUtils的jar包添加到項目的libs文件夾下面,右鍵選擇add as library
Actor類詳見10.5.2
DBUtils_USE:
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
public class DBUtils_USE {
//使用Apache-DBUtils工具類 + Druid 完成對錶的crud操作
@Test
public void testQueryMany() throws SQLException {//返回結果是多行的情況
//1.得到連接(Druid)
Connection connection = JDBCUtilsByDruid.getConnection();
//2.使用DBUtils類和介面(先引入相關的jar,加入到本地的project)
//3.創建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//4.然後就可以執行相關的方法,返回ArrayList結果集
//String sql = "Select * from actor where id >=?";
//注意 :sql語句也可以查詢部分的列,沒有查詢的屬性就在actor對象中置空
String sql = "Select id,name from actor where id >=?";
/**
* (1) query方法就是執行sql語句,得到resultSet--封裝到-->Arraylist集合中
* (2) 然後返回集合
* (3) connection就是連接
* (4) sql:執行的sql語句
* (5) new BeanListHandler<>(Actor.class): 將resultSet->Actor對象->封裝到ArrayList
* 底層使用反射機制,去獲取 Actor的屬性,然後進行封裝
* (6) 1 就是給sql語句中的?賦值,可以有多個值,因為是可變參數
* (7) 底層得到的resultSet,會在query關閉,同時也會關閉PreparedStatement對象
*/
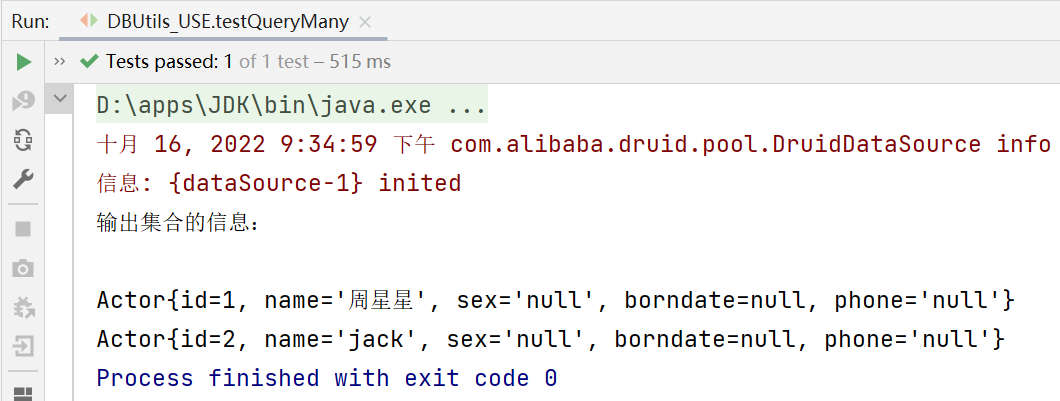
List<Actor> list =
queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("輸出集合的資訊:");
for (Actor actor : list) {
System.out.print(actor);
}
//釋放資源
JDBCUtilsByDruid.close(null, null, connection);
}
}
10.5.4ApDBUtils源碼分析
在上述10.5.3程式碼中,在List<Actor> list = queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);語句旁打上斷點,點擊debug,點擊step into

游標跳轉到如下方法:
public <T> T query(Connection conn, String sql, ResultSetHandler<T> rsh,
Object... params) throws SQLException {
PreparedStatement stmt = null;//定義PreparedStatement對象
ResultSet rs = null;//接收返回的resultSet
T result = null;//返回ArrayList
try {
stmt = this.prepareStatement(conn, sql);//創建PreparedStatement
this.fillStatement(stmt, params);//對SQL語句進行?賦值
rs = this.wrap(stmt.executeQuery());//執行SQL,返回resultSet
result = rsh.handle(rs);//將返回的resultSet-->封裝到ArrayList中[使用反射,對傳入的class對象進行處理]
} catch (SQLException e) {
this.rethrow(e, sql, params);
} finally {
try {
close(rs);//關閉resultSet
} finally {
close(stmt);//關閉preparedStatement
}
}
return result;//返回ArrayList
}



