帶你認識JDK8中超nice的Native Memory Tracking
摘要:從 OpenJDK8 起有了一個很 nice 的虛擬機內部功能: Native Memory Tracking (NMT)。
本文分享自華為雲社區《Native Memory Tracking 詳解(1):基礎介紹》,作者:畢昇小助手。
0.引言
我們經常會好奇,我啟動了一個 JVM,他到底會佔據多大的記憶體?他的記憶體都消耗在哪裡?為什麼 JVM 使用的記憶體比我設置的 -Xmx 大這麼多?我的記憶體設置參數是否合理?為什麼我的 JVM 記憶體一直緩慢增長?為什麼我的 JVM 會被 OOMKiller 等等,這都涉及到 JAVA 虛擬機對記憶體的一個使用情況,不如讓我們來一探其中究竟。
1.簡介
除去大家都熟悉的可以使用 -Xms、-Xmx 等參數設置的堆(Java Heap),JVM 還有所謂的非堆記憶體(Non-Heap Memory)。
可以通過一張圖來簡單看一下 Java 進程所使用的記憶體情況(簡略情況):
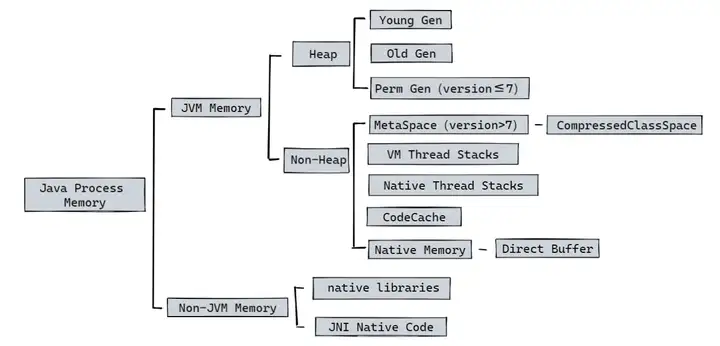
非堆記憶體包括方法區和Java虛擬機內部做處理或優化所需的記憶體。
- 方法區:在所有執行緒之間共享,存儲每個類的結構,如運行時常量池、欄位和方法數據,以及方法和構造函數的程式碼。方法區在邏輯上(虛擬機規範)是堆的一部分,但規範並不限定實現方法區的記憶體位置和編譯程式碼的管理策略,所以不同的 Java 虛擬機可能有不同的實現方式,此處我們僅討論 HotSpot。
- 除了方法區域外,Java 虛擬機實現可能需要記憶體用於內部的處理或優化。例如,JIT編譯器需要記憶體來存儲從Java虛擬機程式碼轉換的本機程式碼(儲存在CodeCache中),以獲得高性能。
從 OpenJDK8 起有了一個很 nice 的虛擬機內部功能: Native Memory Tracking (NMT) 。我們可以使用 NMT 來追蹤了解 JVM 的記憶體使用詳情(即上圖中的 JVM Memory 部分),幫助我們排查記憶體增長與記憶體泄漏相關的問題。
2.如何使用
2.1 開啟 NMT
默認情況下,NMT是處於關閉狀態的,我們可以通過設置 JVM 啟動參數來開啟:-XX:NativeMemoryTracking=[off | summary | detail]。
注意:啟用NMT會導致5% -10%的性能開銷。
NMT 使用選項如下表所示:

我們注意到,如果想使用 NMT 觀察 JVM 的記憶體使用情況,我們必須重啟 JVM 來設置XX:NativeMemoryTracking 的相關選項,但是重啟會使得我們丟失想要查看的現場,只能等到問題復現時才能繼續觀察。
筆者試圖通過一種不用重啟 JVM 的方式來開啟 NMT ,但是很遺憾目前沒有這樣的功能。
JVM 啟動後只有被標記為 manageable 的參數才可以動態修改或者說賦值,我們可以通過 JDK management interface (com.sun.management.HotSpotDiagnosticMXBean API) 或者 jinfo -flag 命令來進行動態修改的操作,讓我們看下所有可以被修改的參數值(JDK8):
java -XX:+PrintFlagsFinal | grep manageable intx CMSAbortablePrecleanWaitMillis = 100 {manageable} intx CMSTriggerInterval = -1 {manageable} intx CMSWaitDuration = 2000 {manageable} bool HeapDumpAfterFullGC = false {manageable} bool HeapDumpBeforeFullGC = false {manageable} bool HeapDumpOnOutOfMemoryError = false {manageable} ccstr HeapDumpPath = {manageable} uintx MaxHeapFreeRatio = 100 {manageable} uintx MinHeapFreeRatio = 0 {manageable} bool PrintClassHistogram = false {manageable} bool PrintClassHistogramAfterFullGC = false {manageable} bool PrintClassHistogramBeforeFullGC = false {manageable} bool PrintConcurrentLocks = false {manageable} bool PrintGC = false {manageable} bool PrintGCDateStamps = false {manageable} bool PrintGCDetails = false {manageable} bool PrintGCID = false {manageable} bool PrintGCTimeStamps = false {manageable}
很顯然,其中不包含 NativeMemoryTracking 。
2.2 使用 jcmd 訪問 NMT 數據
我們可以通過 jcmd 命令來很方便的查看 NMT 相關的數據:
jcmd VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
jcmd 操作 NMT 選項如下表所示:
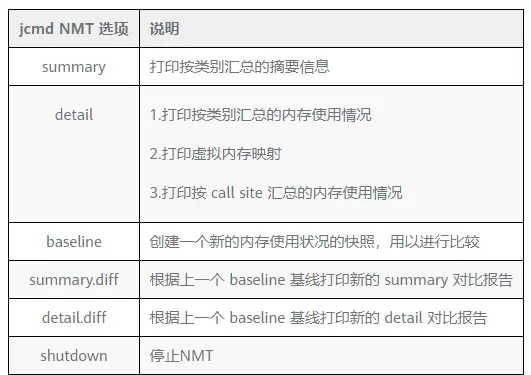
- NMT 默認列印的報告是 KB 來進行呈現的,為了滿足我們不同的需求,我們可以使用scale=MB | GB來更加直觀的列印數據。
- 創建 baseline 之後使用 diff 功能可以很直觀地對比出兩次 NMT 數據之間的差距。
看到 shutdown 選項,筆者本能的一激靈,既然我們可以通過 shutdown 來關閉 NMT ,那為什麼不能通過逆向 shutdown 功能來動態的開啟 NMT 呢?筆者找到 shutdown 相關源碼(以下都是基於 OpenJDK 8):
# hotspot/src/share/vm/services/nmtDCmd.cpp void NMTDCmd::execute(DCmdSource source, TRAPS) { // Check NMT state // native memory tracking has to be on if (MemTracker::tracking_level() == NMT_off) { output()->print_cr("Native memory tracking is not enabled"); return; } else if (MemTracker::tracking_level() == NMT_minimal) { output()->print_cr("Native memory tracking has been shutdown"); return; } ...... //執行 shutdown 操作 else if (_shutdown.value()) { MemTracker::shutdown(); output()->print_cr("Native memory tracking has been turned off"); } ...... } # hotspot/src/share/vm/services/memTracker.cpp // Shutdown can only be issued via JCmd, and NMT JCmd is serialized by lock void MemTracker::shutdown() { // We can only shutdown NMT to minimal tracking level if it is ever on. if (tracking_level () > NMT_minimal) { transition_to(NMT_minimal); } } # hotspot/src/share/vm/services/nmtCommon.hpp // Native memory tracking level //NMT的追蹤等級 enum NMT_TrackingLevel { NMT_unknown = 0xFF, NMT_off = 0x00, NMT_minimal = 0x01, NMT_summary = 0x02, NMT_detail = 0x03 };
遺憾的是通過源碼我們發現,shutdown 操作只是將 NMT 的追蹤等級 tracking_level 變成了 NMT_minimal 狀態(而並不是直接變成了 off 狀態),注意注釋:We can only shutdown NMT to minimal tracking level if it is ever on(即我們只能將NMT關閉到最低跟蹤級別,如果它曾經打開)。
這就導致了如果我們沒有開啟過 NMT ,那就沒辦法通過魔改 shutdown 操作逆向打開 NMT ,因為 NMT 追蹤的部分記憶體只在 JVM 啟動初始化的階段進行記錄(如在初始化堆記憶體分配的過程中通過 NMT_TrackingLevel level = MemTracker::tracking_level(); 來獲取 NMT 的追蹤等級,視等級來記錄記憶體使用情況),JVM 啟動之後再開啟 NMT 這部分記憶體的使用情況就無法記錄,所以目前來看,還是只能在重啟 JVM 後開啟 NMT。
至於提供 shutdown 功能的原因,應該就是讓用戶在開啟 NMT 功能之後如果想要關閉,不用再次重啟 JVM 進程。shutdown 會清理虛擬記憶體用來追蹤的數據結構,並停止一些追蹤的操作(如記錄 malloc 記憶體的分配)來降低開啟 NMT 帶來的性能耗損,並且通過源碼可以發現 tracking_level 變成 NMT_minimal 狀態後也不會再執行 jcmd VM.native_memory 命令相關的操作。
2.3 虛擬機退出時獲取 NMT 數據
除了在虛擬機運行時獲取 NMT 數據,我們還可以通過兩個參數:-XX:+UnlockDiagnosticVMOptions和-XX:+PrintNMTStatistics ,來獲取虛擬機退出時記憶體使用情況的數據(輸出數據的詳細程度取決於你設定的跟蹤級別,如 summary/detail 等)。
-XX:+UnlockDiagnosticVMOptions:解鎖用於診斷 JVM 的選項,默認關閉。
-XX:+PrintNMTStatistics:當啟用 NMT 時,在虛擬機退出時列印記憶體使用情況,默認關閉,需要開啟前置參數 -XX:+UnlockDiagnosticVMOptions 才能正常使用。
3.NMT 記憶體 & OS 記憶體概念差異性
我們可以做一個簡單的測試,使用如下參數啟動 JVM :
-Xmx1G -Xms1G -XX:+UseG1GC -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=256m -XX:ReservedCodeCacheSize=256M -XX:NativeMemoryTracking=detail
然後使用 NMT 查看記憶體使用情況(因各環境資源參數不一樣,部分未明確設置數據可能由虛擬機根據資源自行計算得出,以下數據僅供參考):
jcmd VM.native_memory detail
NMT 會輸出如下日誌:
Native Memory Tracking: Total: reserved=2813709KB, committed=1497485KB - Java Heap (reserved=1048576KB, committed=1048576KB) (mmap: reserved=1048576KB, committed=1048576KB) - Class (reserved=1056899KB, committed=4995KB) (classes #442) (malloc=131KB #259) (mmap: reserved=1056768KB, committed=4864KB) - Thread (reserved=258568KB, committed=258568KB) (thread #127) (stack: reserved=258048KB, committed=258048KB) (malloc=390KB #711) (arena=130KB #234) - Code (reserved=266273KB, committed=4001KB) (malloc=33KB #309) (mmap: reserved=266240KB, committed=3968KB) - GC (reserved=164403KB, committed=164403KB) (malloc=92723KB #6540) (mmap: reserved=71680KB, committed=71680KB) - Compiler (reserved=152KB, committed=152KB) (malloc=4KB #36) (arena=148KB #21) - Internal (reserved=14859KB, committed=14859KB) (malloc=14827KB #3632) (mmap: reserved=32KB, committed=32KB) - Symbol (reserved=1423KB, committed=1423KB) (malloc=936KB #111) (arena=488KB #1) - Native Memory Tracking (reserved=330KB, committed=330KB) (malloc=118KB #1641) (tracking overhead=211KB) - Arena Chunk (reserved=178KB, committed=178KB) (malloc=178KB) - Unknown (reserved=2048KB, committed=0KB) (mmap: reserved=2048KB, committed=0KB) ......
大家可能會發現 NMT 所追蹤的記憶體(即 JVM 中的 Reserved、Committed)與作業系統 OS (此處指Linux)的記憶體概念存在一定的差異性。
首先按我們理解的作業系統的概念:
作業系統對記憶體的分配管理典型地分為兩個階段:保留(reserve)和提交(commit)。保留階段告知系統從某一地址開始到後面的dwSize大小的連續虛擬記憶體需要供程式使用,進程其他分配記憶體的操作不得使用這段記憶體;提交階段將虛擬地址映射到對應的真實物理記憶體中,這樣這塊記憶體就可以正常使用 [1]。
如果使用 top 或者 smem 等命令查看剛才啟動的 JVM 進程會發現:
top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 36257 dou+ 20 0 10.8g 54200 17668 S 99.7 0.0 13:04.15 java
此時疑問就產生了,為什麼 NMT 中的 committed ,即日誌詳情中 Total: reserved=2813709KB, committed=1497485KB 中的 1497485KB 與 top 中 RES 的大小54200KB 存在如此大的差異?
使用 man 查看 top 中 RES 的概念(不同版本 Linux 可能不同):
RES -- Resident Memory Size (KiB) A subset of the virtual address space (VIRT) representing the non-swapped physical memory a task is currently using. It is also the sum of the RSan, RSfd and RSsh fields. It can include private anonymous pages, private pages mapped to files (including program images and shared libraries) plus shared anonymous pages. All such memory is backed by the swap file represented separately under SWAP. Lastly, this field may also include shared file-backed pages which, when modified, act as a dedicated swap file and thus will never impact SWAP.
RES 表示任務當前使用的非交換物理記憶體(此時未發生swap),那按對作業系統 commit 提交記憶體的理解,這兩者貌似應該對上,為何現在差距那麼大呢?
筆者一開始猜測是 JVM 的 uncommit 機制(如 JEP 346[2],支援 G1 在空閑時自動將 Java 堆記憶體返回給作業系統,BiSheng JDK 對此做了增強與改進[3])造成的,JVM 在 uncommit 將記憶體返還給 OS 之後,NMT 沒有除去返還的記憶體導致統計錯誤。
但是在翻閱了源碼之後發現,G1 在 shrink 縮容的時候,通常調用鏈路如下:
G1CollectedHeap::shrink ->
G1CollectedHeap::shrink_helper ->
HeapRegionManager::shrink_by ->
HeapRegionManager::uncommit_regions ->
G1PageBasedVirtualSpace::uncommit ->
G1PageBasedVirtualSpace::uncommit_internal ->
os::uncommit_memory
忽略細節,uncommit 會在最後調用 os::uncommit_memory ,查看 os::uncommit_memory 源碼:
bool os::uncommit_memory(char* addr, size_t bytes) { bool res; if (MemTracker::tracking_level() > NMT_minimal) { Tracker tkr = MemTracker::get_virtual_memory_uncommit_tracker(); res = pd_uncommit_memory(addr, bytes); if (res) { tkr.record((address)addr, bytes); } } else { res = pd_uncommit_memory(addr, bytes); } return res; }
可以發現在返還 OS 記憶體之後,MemTracker 是進行了統計的,所以此處的誤差不是由 uncommit 機製造成的。
既然如此,那又是由什麼原因造成的呢?筆者在追蹤 JVM 的記憶體分配邏輯時發現了一些端倪,此處以Code Cache(存放 JVM 生成的 native code、JIT編譯、JNI 等都會編譯程式碼到 native code,其中 JIT 生成的 native code 佔用了 Code Cache 的絕大部分空間)的初始化分配為例,其大致調用鏈路為下:
InitializeJVM ->
Thread::vreate_vm ->
init_globals ->
codeCache_init ->
CodeCache::initialize ->
CodeHeap::reserve ->
VirtualSpace::initialize ->
VirtualSpace::initialize_with_granularity ->
VirtualSpace::expand_by ->
os::commit_memory
查看 os::commit_memory 相關源碼:
bool os::commit_memory(char* addr, size_t size, size_t alignment_hint, bool executable) { bool res = os::pd_commit_memory(addr, size, alignment_hint, executable); if (res) { MemTracker::record_virtual_memory_commit((address)addr, size, CALLER_PC); } return res; }
我們發現 MemTracker 在此記錄了 commit 的記憶體供 NMT 用以統計計算,繼續查看 os::pd_commit_memory 源碼,可以發現其調用了 os::Linux::commit_memory_impl 函數。
查看 os::Linux::commit_memory_impl 源碼:
int os::Linux::commit_memory_impl(char* addr, size_t size, bool exec) { int prot = exec ? PROT_READ|PROT_WRITE|PROT_EXEC : PROT_READ|PROT_WRITE; uintptr_t res = (uintptr_t) ::mmap(addr, size, prot, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0); if (res != (uintptr_t) MAP_FAILED) { if (UseNUMAInterleaving) { numa_make_global(addr, size); } return 0; } int err = errno; // save errno from mmap() call above if (!recoverable_mmap_error(err)) { warn_fail_commit_memory(addr, size, exec, err); vm_exit_out_of_memory(size, OOM_MMAP_ERROR, "committing reserved memory."); } return err; }
問題的原因就在 uintptr_t res = (uintptr_t) ::mmap(addr, size, prot, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0); 這段程式碼上。
我們發現,此時申請記憶體執行的是 mmap 函數,並且傳遞的 port 參數是 PROT_READ|PROT_WRITE|PROT_EXEC 或 PROT_READ|PROT_WRITE ,使用 man 查看 mmap ,其中相關描述為:
The prot argument describes the desired memory protection of the mapping (and must not conflict with the open mode of the file). It is either PROT_NONE or the bitwise OR of one or more of the following flags: PROT_EXEC Pages may be executed. PROT_READ Pages may be read. PROT_WRITE Pages may be written. PROT_NONE Pages may not be accessed.
由此我們可以看出,JVM 中所謂的 commit 記憶體,只是將記憶體 mmaped 映射為可讀可寫可執行的狀態!而在 Linux 中,在分配記憶體時又是 lazy allocation 的機制,只有在進程真正訪問時才分配真實的物理記憶體。所以 NMT 中所統計的 committed 並不是對應的真實的物理記憶體,自然與 RES 等統計方式無法對應起來。
所以 JVM 為我們提供了一個參數 -XX:+AlwaysPreTouch,使我們可以在啟動之初就按照記憶體頁粒度都訪問一遍 Heap,強製為其分配物理記憶體以減少運行時再分配記憶體造成的延遲(但是相應的會影響 JVM 進程初始化啟動的時間),查看相關程式碼:
void os::pretouch_memory(char* start, char* end) { for (volatile char *p = start; p < end; p += os::vm_page_size()) { *p = 0; } }
讓我們來驗證下,開啟 -XX:+AlwaysPreTouch 前後的效果。
NMT 的 heap 地址範圍:
Virtual memory map: [0x00000000c0000000 - 0x0000000100000000] reserved 1048576KB for Java Heap from [0x0000ffff93ea36d8] ReservedHeapSpace::ReservedHeapSpace(unsigned long, unsigned long, bool, char*)+0xb8 [0x0000ffff93e67f68] Universe::reserve_heap(unsigned long, unsigned long)+0x2d0 [0x0000ffff93898f28] G1CollectedHeap::initialize()+0x188 [0x0000ffff93e68594] Universe::initialize_heap()+0x15c [0x00000000c0000000 - 0x0000000100000000] committed 1048576KB from [0x0000ffff938bbe8c] G1PageBasedVirtualSpace::commit_internal(unsigned long, unsigned long)+0x14c [0x0000ffff938bc08c] G1PageBasedVirtualSpace::commit(unsigned long, unsigned long)+0x11c [0x0000ffff938bf774] G1RegionsLargerThanCommitSizeMapper::commit_regions(unsigned int, unsigned long)+0x5c [0x0000ffff93943f54] HeapRegionManager::commit_regions(unsigned int, unsigned long)+0x7c
對應該地址的/proc/{pid}/smaps:
//開啟前 //開啟後 c0000000-100080000 rw-p 00000000 00:00 0 c0000000-100080000 rw-p 00000000 00:00 0 Size: 1049088 kB Size: 1049088 kB KernelPageSize: 4 kB KernelPageSize: 4 kB MMUPageSize: 4 kB MMUPageSize: 4 kB Rss: 792 kB Rss: 1049088 kB Pss: 792 kB Pss: 1049088 kB Shared_Clean: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Clean: 0 kB Private_Dirty: 792 kB Private_Dirty: 1049088 kB Referenced: 792 kB Referenced: 1048520 kB Anonymous: 792 kB Anonymous: 1049088 kB LazyFree: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB ShmemPmdMapped: 0 kB Shared_Hugetlb: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB Swap: 0 kB SwapPss: 0 kB SwapPss: 0 kB Locked: 0 kB Locked: 0 kB VmFlags: rd wr mr mw me ac VmFlags: rd wr mr mw me ac
對應的/proc/{pid}/status:
//開啟前 //開啟後 ... ... VmHWM: 54136 kB VmHWM: 1179476 kB VmRSS: 54136 kB VmRSS: 1179476 kB ... ... VmSwap: 0 kB VmSwap: 0 kB ...
開啟參數後的 top:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 85376 dou+ 20 0 10.8g 1.1g 17784 S 99.7 0.4 14:56.31 java
觀察對比我們可以發現,開啟 AlwaysPreTouch 參數後,NMT 統計的 commited 已經與 top 中的 RES 差不多了,之所以不完全相同是因為該參數只能 Pre-touch 分配 Java heap 的物理記憶體,至於其他的非 heap 的記憶體,還是受到 lazy allocation 機制的影響。
同理我們可以簡單看下 JVM 的 reserve 機制:
# hotspot/src/share/vm/runtime/os.cpp char* os::reserve_memory(size_t bytes, char* addr, size_t alignment_hint, MEMFLAGS flags) { char* result = pd_reserve_memory(bytes, addr, alignment_hint); if (result != NULL) { MemTracker::record_virtual_memory_reserve((address)result, bytes, CALLER_PC); MemTracker::record_virtual_memory_type((address)result, flags); } return result; } # hotspot/src/os/linux/vm/os_linux.cpp char* os::pd_reserve_memory(size_t bytes, char* requested_addr, size_t alignment_hint) { return anon_mmap(requested_addr, bytes, (requested_addr != NULL)); } static char* anon_mmap(char* requested_addr, size_t bytes, bool fixed) { ...... addr = (char*)::mmap(requested_addr, bytes, PROT_NONE, flags, -1, 0); ...... }
reserve 通過 mmap(requested_addr, bytes, PROT_NONE, flags, -1, 0); 來將記憶體映射為 PROT_NONE,這樣其他的 mmap/malloc 等就不能調用使用,從而達到了 guard memory 或者說 guard pages 的目的。
OpenJDK 社區其實也注意到了 NMT 記憶體與 OS 記憶體差異性的問題,所以社區也提出了相應的 Enhancement 來增強功能:
1.JDK-8249666[4] :
- 目前 NMT 將分配的記憶體顯示為 Reserved 或 Committed。而在 top 或 pmap 的輸出中,首次使用(即 touch)之前 Reserved 和 Committed 的記憶體都將顯示為 Virtual memory。只有在記憶體頁(通常是4k)首次寫入後,它才會消耗物理記憶體,並出現在 top/pmap 輸出的 「常駐記憶體」(即 RSS)中。
- 當前NMT輸出的主要問題是,它無法區分已 touch 和未 touch 的 Committed 記憶體。
- 該 Enhancement 提出可以使用 mincore() [5]來查找 NMT 的 Committed 中 RSS 的部分,mincore() 系統調用讓一個進程能夠確定一塊虛擬記憶體區域中的分頁是否駐留在物理記憶體中。mincore()已在JDK-8191369 NMT:增強執行緒堆棧跟蹤中實現,需要將其擴展到所有其他類型的記憶體中(如 Java 堆)。
- 遺憾的是該 Enhancement 至今仍是 Unresolved 狀態。
2.JDK-8191369[6] :
- 1 中提到的 NMT:增強執行緒堆棧跟蹤。使用 mincore() 來追蹤駐留在物理記憶體中的執行緒堆棧的大小,用以解決執行緒堆棧追蹤時有時會誇大記憶體使用情況的痛點。
- 該 Enhancement 已經在 JDK11 中實現。
參考
- //weread.qq.com/web/reader/53032310717f44515302749k37632cd021737693cfc7149
- //openjdk.java.net/jeps/346
- //gitee.com/openeuler/bishengjdk-8/wikis/G1GCå å伸缩ç¹æ§ä»ç»?sort_id=3340035
- //bugs.openjdk.org/browse/JDK-8249666
- //man7.org/linux/man-pages/man2/mincore.2.html
- //bugs.openjdk.org/browse/JDK-8191369
