大數據技術之HBase原理與實戰歸納分享-下
@
整合Phoenix
定義
Phoenix 官網地址 //phoenix.apache.org/
Phoenix作為一款OLTP和Apache Hadoop的操作分析,是面向HBase的開源 SQL 皮膚,其通過 JDBC API 代替繁重的 HBase 客戶端 API來創建表,插入數據和查詢 HBase 數據。目前最新版本為5.1.2
Apache Phoenix通過結合兩者的優點,在Hadoop中為低延遲應用提供OLTP和操作分析,標準SQL和JDBC api的強大功能與完整的ACID事務功能,以及通過利用HBase作為其後備存儲,採用NoSQL使得讀寫數據更加靈活性。Apache Phoenix與其他Hadoop產品(如Spark、Hive、Pig、Flume和Map Reduce)完全集成。
為何要使用
官方原文:Doesn』t putting an extra layer between my application and HBase just slow things down?
Actually, no. Phoenix achieves as good or likely better performance than if you hand-coded it yourself (not to mention with a heck of a lot less code) by:
翻譯為在 Client 和 HBase 之間放一個 Phoenix 中間層不會減慢速度,因為用戶編寫的數據處理程式碼和 Phoenix 編寫的沒有區別(更不用說你寫的垃圾的多),不僅如此Phoenix 對於用戶輸入的 SQL 同樣會有大量的優化手段(就像 hive 自帶 sql 優化器一樣)。
Phoenix 在 5.0 版本默認提供有兩種客戶端使用(瘦客戶端和胖客戶端),在 5.1.2 版本安裝包中刪除了瘦客戶端,本文也不再使用瘦客戶端。而胖客戶端和用戶自己寫 HBase 的API 程式碼讀取數據之後進行數據處理是完全一樣的。
安裝
# 當前版本4.16.1可以運行在Apache HBase 1.3、1.4、1.5和1.6上;當前版本5.1.2可以運行在Apache HBase 2.1、2.2、2.3和2.4上。
# 由於前面Hbase是2.5版本,我們先嘗試下載phoenix最新版本使用
wget --no-check-certificate //dlcdn.apache.org/phoenix/phoenix-5.1.2/phoenix-hbase-2.4.0-5.1.2-bin.tar.gz
# 解壓 tar 包
tar -xvf phoenix-hbase-2.4.0-5.1.2-bin.tar.gz
# 複製 server 包並拷貝到各個節點的 hbase/lib
cp phoenix-hbase-2.4.0-5.1.2-bin/phoenix-server-hbase-2.4.0-5.1.2.jar hbase-2.5.0/lib/
scp hbase-2.5.0/lib/phoenix-server-hbase-2.4.0-5.1.2.jar hadoop2:/home/commons/hbase-2.5.0/lib/
scp hbase-2.5.0/lib/phoenix-server-hbase-2.4.0-5.1.2.jar hadoop3:/home/commons/hbase-2.5.0/lib/
# 三個節點上都配置環境變數
export PHOENIX_HOME=/home/commons/phoenix-hbase-2.4.0-5.1.2-bin
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
# 三個節點上都使環境變數生效
source /etc/profile
# 先停止
bin/stop-hbase.sh
# 啟動
bin/start-hbase.sh
# 進入phoenix根目錄
cd phoenix-hbase-2.4.0-5.1.2-bin
# 連接phoenix
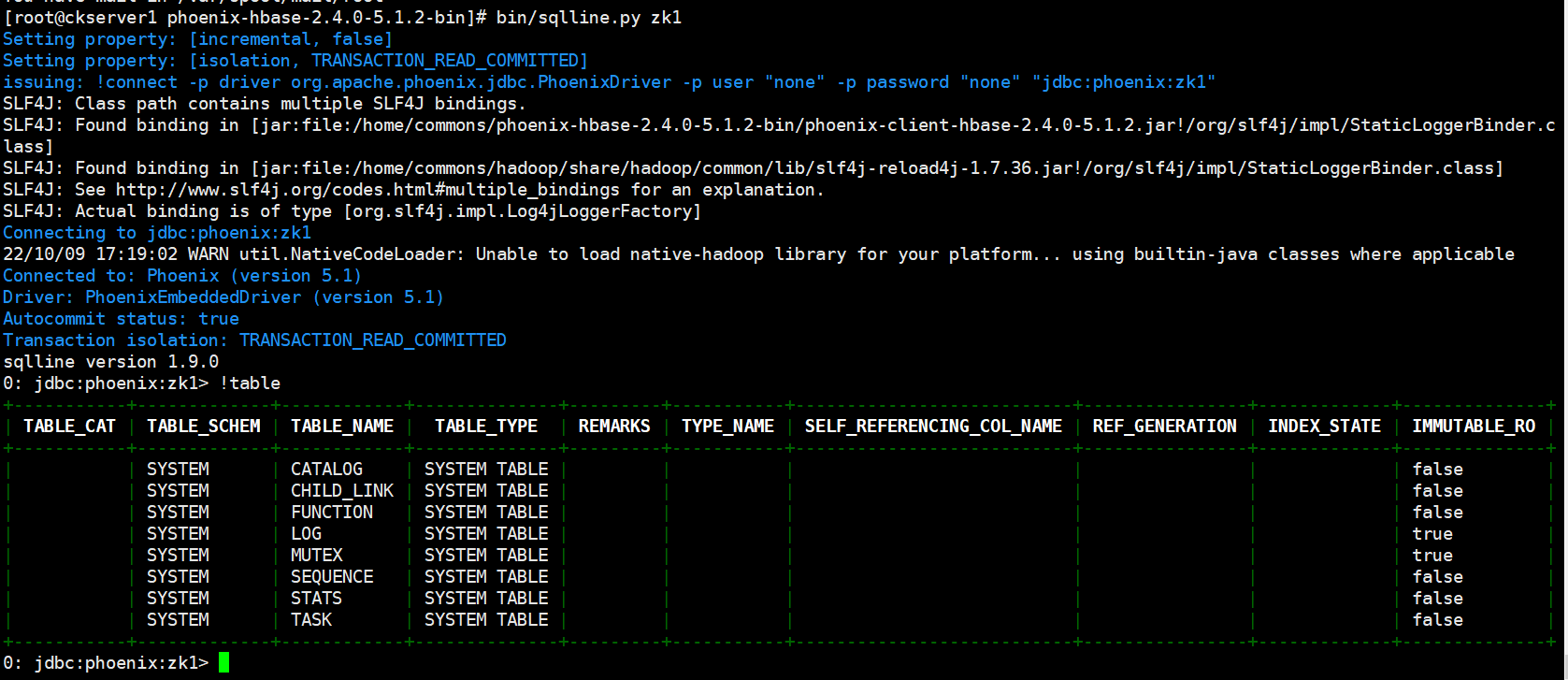
bin/sqlline.py zk1
# 顯示所有表
!table
!tables
# 退出
!quit
SHELL操作
# 創建表,直接指定單個列作為 RowKey
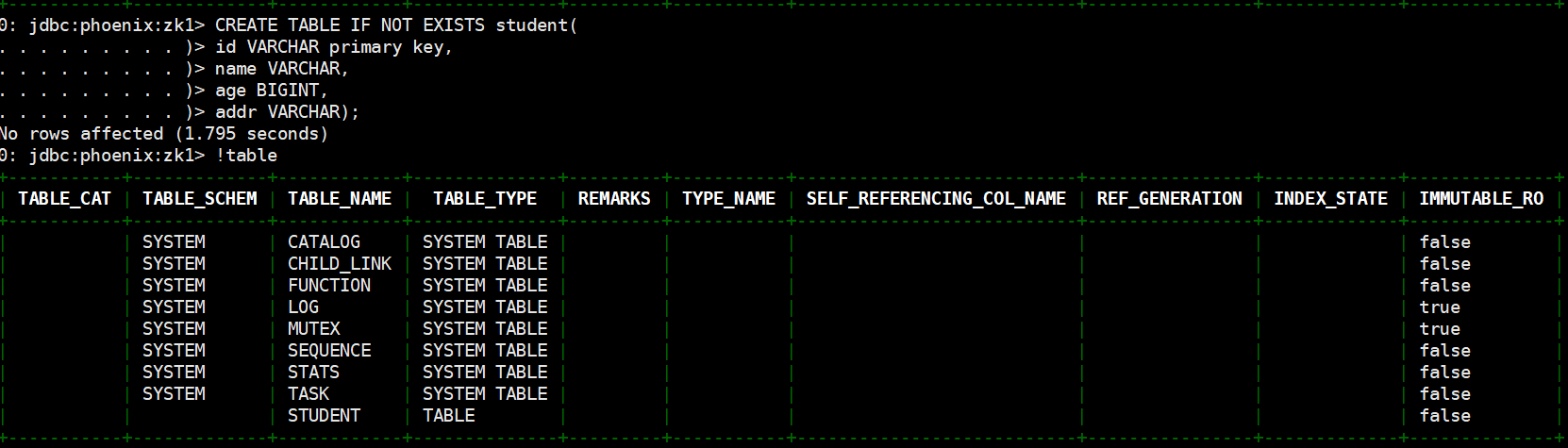
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
age BIGINT,
addr VARCHAR);
# 在 phoenix 中,表名等會自動轉換為大寫,若要小寫,使用雙引號,如"us_population"。
# 指定多個列的聯合作為 RowKey
CREATE TABLE IF NOT EXISTS student1 (
id VARCHAR NOT NULL,
name VARCHAR NOT NULL,
age BIGINT,
addr VARCHAR
CONSTRAINT my_pk PRIMARY KEY (id, name));
註:Phoenix 中建表,會在 HBase 中創建一張對應的表。為了減少數據對磁碟空間的佔用,Phoenix 默認會對 HBase 中的列名做編碼處理。具體規則可參考官網鏈接://phoenix.apache.org/columnencoding.html,若不想對列名編碼,可在建表語句末尾加上 COLUMN_ENCODED_BYTES = 0;
# 插入數據
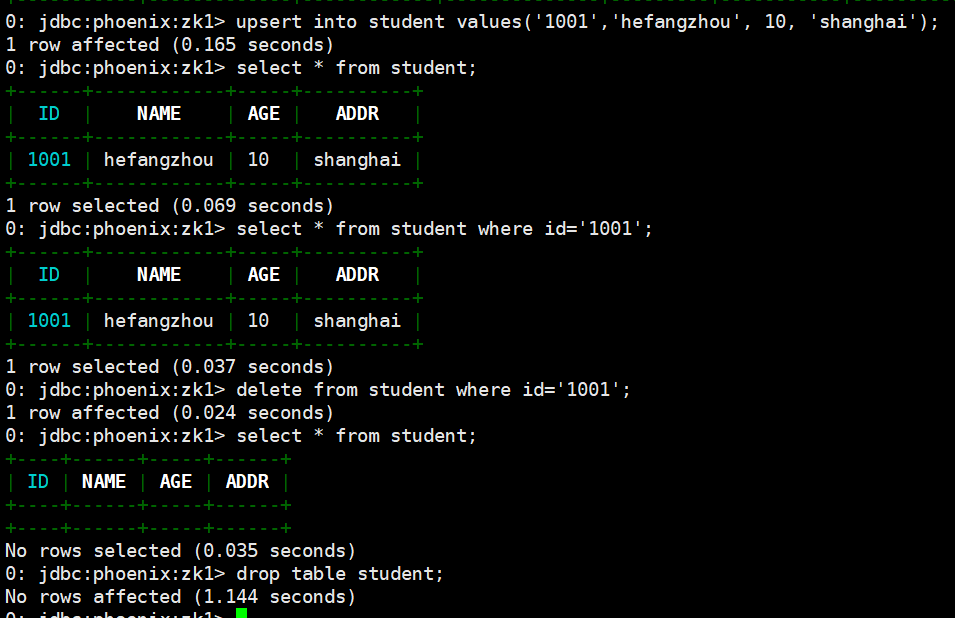
upsert into student values('1001','hefangzhou', 10, 'shanghai');
# 查詢記錄
select * from student;
select * from student where id='1001';
# 刪除記錄
delete from student where id='1001';
# 刪除表
drop table student;
表的映射
表的關係在默認情況下, HBase 中已存在的表,通過 Phoenix 是不可見的。如果要在 Phoenix 中操作 HBase 中已存在的表,可以在 Phoenix 中進行表的映射。映射方式有兩種:視圖映射和表映射。
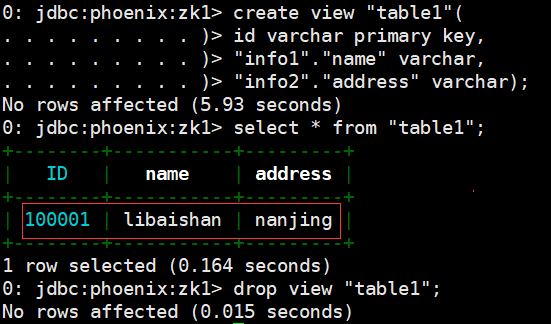
- 視圖映射:Phoenix 創建的視圖是只讀的,所以只能用來做查詢,無法通過視圖對數據進行修改等操作。在 phoenix 中創建關聯 table1 表的視圖
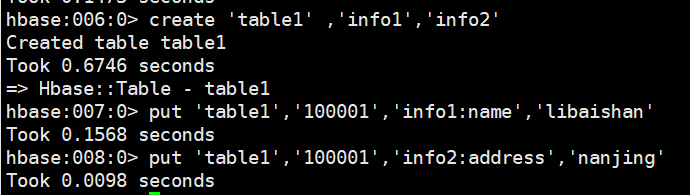
# HBase 中 table1 的表結構如下,兩個列族 info11、info12。先執行hbase shell
create 'table1' ,'info1','info2'
put 'table1','100001','info1:name','libaishan'
put 'table1','100001','info2:address','nanjing'
# Phoenix shell執行視圖創建,先執行bin/sqlline.py zk1
create view "table1"(
id varchar primary key,
"info1"."name" varchar,
"info2"."address" varchar);
select * from "table1";
# 刪除視圖
drop view "table1";
- 視圖映射:在 Pheonix 創建表去映射 HBase 中已經存在的表,是可以修改刪除 HBase 中已經存在的數據的。而且,刪除 Phoenix 中的表,那麼 HBase 中被映射的表也會被刪除。註:進行表映射時,不能使用列名編碼,需將 column_encoded_bytes 設為 0。
create table "table2"(
id varchar primary key,
"info1"."name" varchar,
"info2"."address" varchar)
column_encoded_bytes=0;
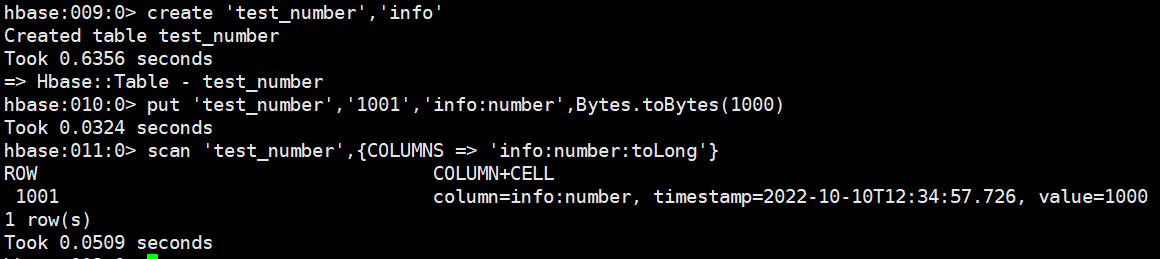
- 數字類型說明:HBase 中的數字,底層存儲為補碼,而 Phoenix 中的數字,底層存儲為在補碼的基礎上,將符號位反轉。故當在 Phoenix 中建表去映射 HBase 中已存在的表,當 HBase 中有數字類型的欄位時,會出現解析錯誤的現象。
# Hbase 操作示例
create 'test_number','info'
put 'test_number','1001','info:number',Bytes.toBytes(1000)
scan 'test_number',{COLUMNS => 'info:number:toLong'}
# phoenix 操作示例
create view "test_number"(id varchar primary key,"info"."number" bigint);
select * from "test_number";
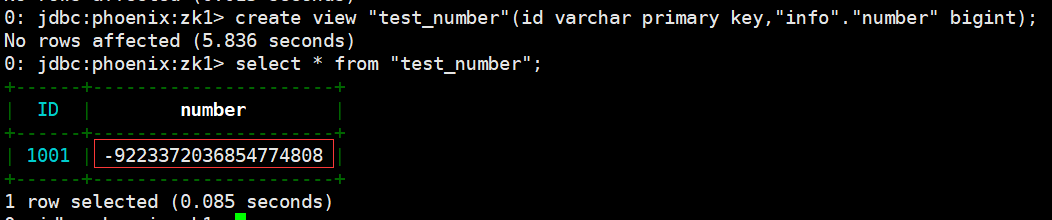
解決上述問題的方案有以下兩種:
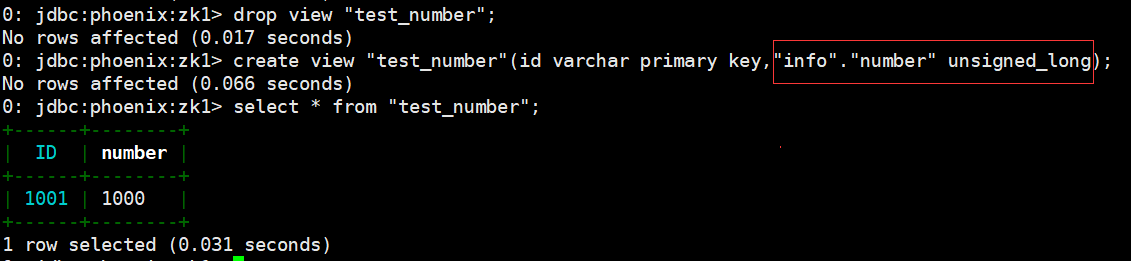
- Phoenix 種提供了 unsigned_int,unsigned_long 等無符號類型,其對數字的編碼解碼方式和 HBase 是相同的,如果無需考慮負數,那在 Phoenix 中建表時採用無符號類型是最合適的選擇。
- phoenix 演示:
drop view "test_number";
create view "test_number"(id varchar primary key,"info"."number" unsigned_long);
select * from "test_number";
- 如需考慮負數的情況,則可通過 Phoenix 自定義函數,將數字類型的最高位,即符號位反轉即可,自定義函數可參考如下接://phoenix.apache.org/udf.html。
簡易JDBC示例
這裡演示一個標準的 JDBC 連接操作,實際開發中會直接使用別的框架內嵌的Phoenix 連接,添加maven 依賴
<dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-client-hbase-2.4</artifactId> <version>5.1.2</version> </dependency>
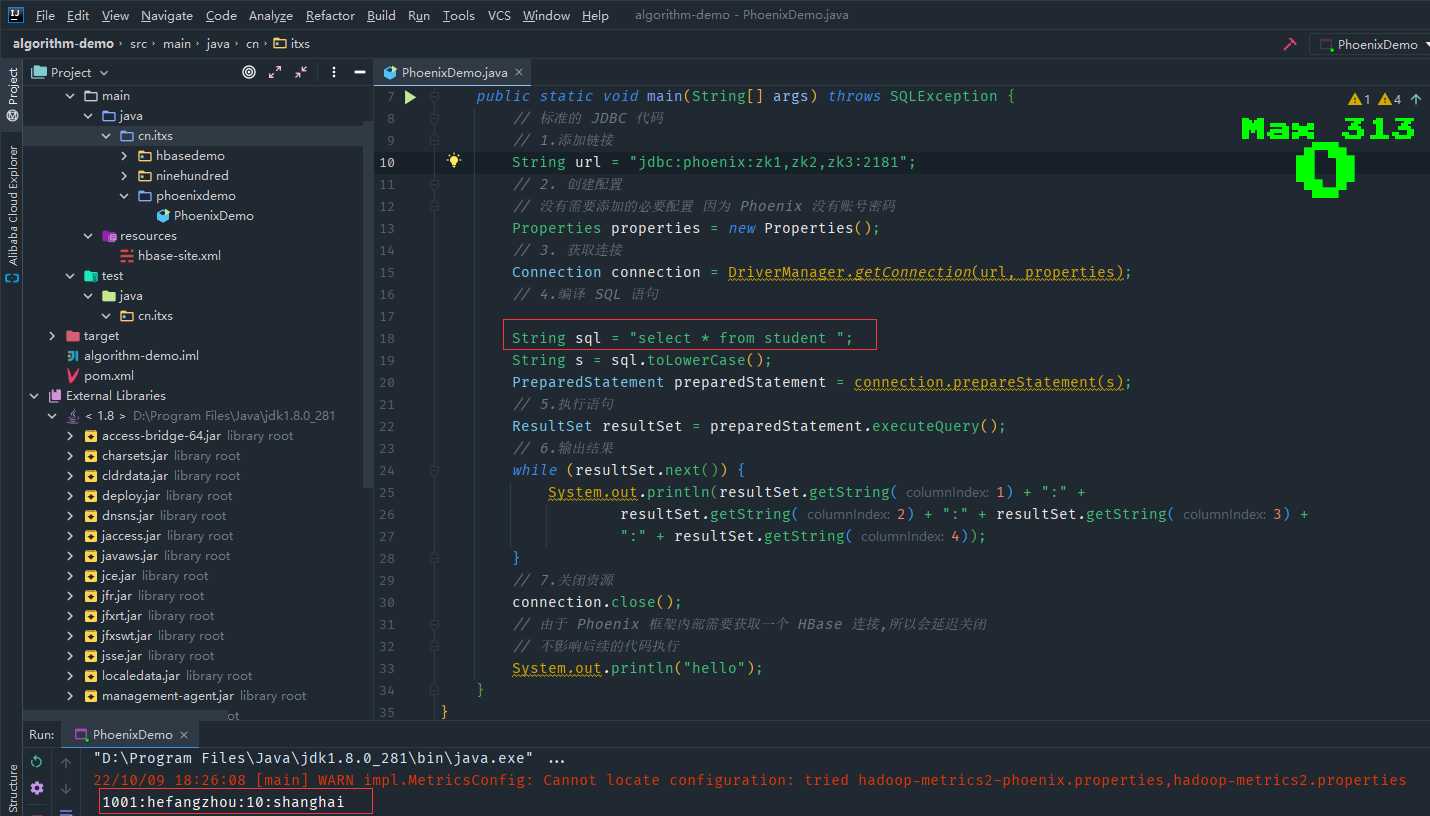
重新執行phoenix shell操作關於student表創建和插入數據,測試程式碼PhoenixDemo.java
package cn.itxs.phoenixdemo;
import java.sql.*;
import java.util.Properties;
public class PhoenixDemo {
public static void main(String[] args) throws SQLException {
// 標準的 JDBC 程式碼
// 1.添加鏈接
String url = "jdbc:phoenix:zk1,zk2,zk3:2181";
// 2. 創建配置
// 沒有需要添加的必要配置 因為 Phoenix 沒有帳號密碼
Properties properties = new Properties();
// 3. 獲取連接
Connection connection = DriverManager.getConnection(url, properties);
// 4.編譯 SQL 語句
String sql = "select * from student ";
String s = sql.toLowerCase();
PreparedStatement preparedStatement = connection.prepareStatement(s);
// 5.執行語句
ResultSet resultSet = preparedStatement.executeQuery();
// 6.輸出結果
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + ":" +
resultSet.getString(2) + ":" + resultSet.getString(3) +
":" + resultSet.getString(4));
}
// 7.關閉資源
connection.close();
// 由於 Phoenix 框架內部需要獲取一個 HBase 連接,所以會延遲關閉
// 不影響後續的程式碼執行
System.out.println("hello");
}
}
運行程式,列印出前面phoenix shell插入的數據
二級索引
二級索引配置文件
添加如下配置到 HBase 的 HRegionserver 節點的 hbase-site.xml,之後重啟Hbase集群
<!-- phoenix regionserver 配置參數-->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
全局索引
Global Index 是默認的索引格式,創建全局索引時,會在 HBase 中建立一張新表。也就是說索引數據和數據表是存放在不同的表中的,因此全局索引適用於多讀少寫的業務場景。
寫數據的時候會消耗大量開銷,因為索引表也要更新,而索引表是分布在不同的數據節點上的,跨節點的數據傳輸帶來了較大的性能消耗。在讀數據的時候 Phoenix 會選擇索引表來降低查詢消耗的時間。
創建單個欄位的全局索引。
# 創建索引語法
CREATE INDEX my_index ON my_table (my_col);
# 例如
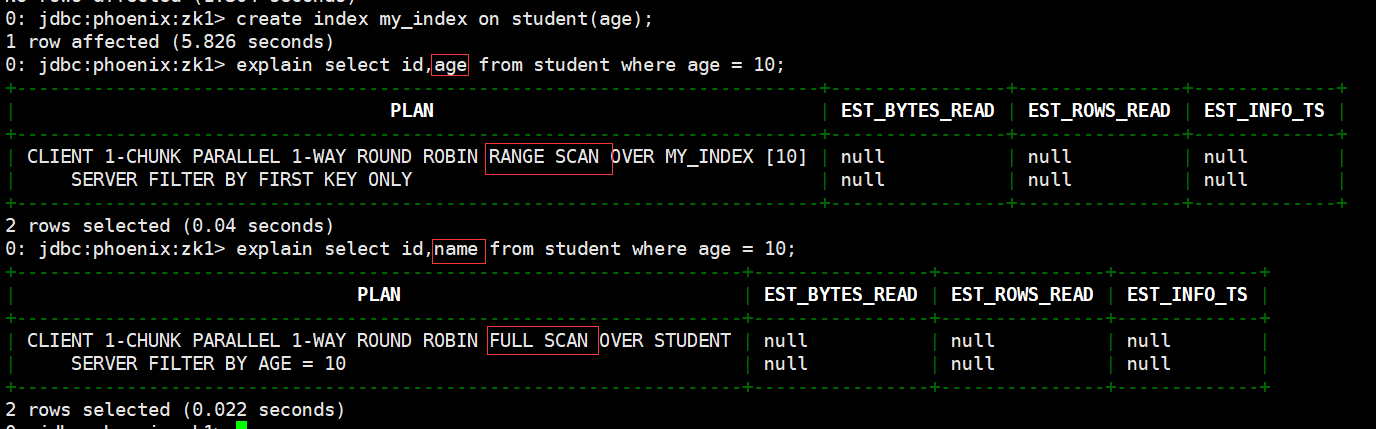
create index my_index on student(age);
# 查看二級索引是否有效,可以使用 explain 執行計劃,有二級索引之後會變成範圍掃描.
explain select id,age from student where age = 10;
# 如果想查詢的欄位不是索引欄位的話索引表不會被使用,也就是說不會帶來查詢速度的提升。
explain select id,name from student where age = 10;
# 刪除索引語法
DROP INDEX my_index ON my_table
# 例如
drop index my_index on student;
若想解決上述問題,可採用如下方案:
- 使用包含索引
- 使用本地索引
包含索引
包含索引(covered index)創建攜帶其他欄位的全局索引(本質還是全局索引)
# 包含索引語法如下
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
# 先刪除之前的索引:
drop index my_index on student1;
#創建包含索引
create index my_index on student(age) include (name);
# 使用執行計劃查看效果,結果顯示已走了RANGE SACN
explain select id,name from student where age = 10;

本地索引(local index)
本地索引(local index) 適用於寫操作頻繁的場景。索引數據和數據表的數據是存放在同一張表中(且是同一個 Region),避免了在寫操作的時候往不同伺服器的索引表中寫索引帶來的額外開銷。
# 本地索引語法如下,my_column 可以是多個。
CREATE LOCAL INDEX my_index ON my_table (my_column);
# 本地索引會將所有的資訊存在一個影子列族中,雖然讀取的時候也是範圍掃描,但是沒有全局索引快,優點在於不用寫多個表了。
# 刪除之前的索引
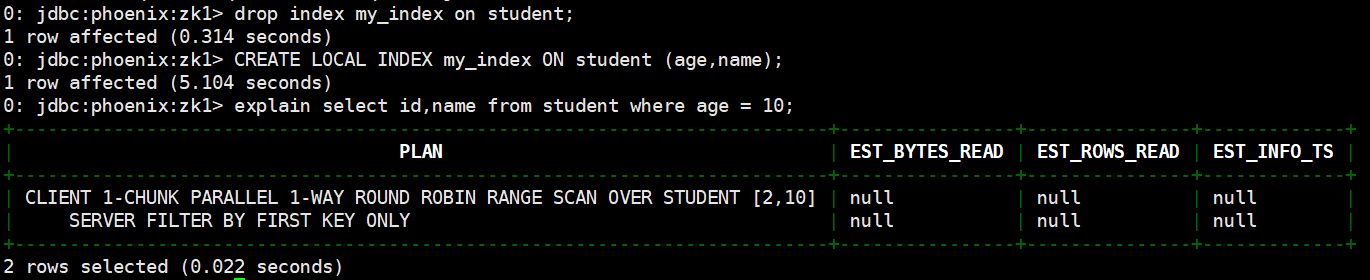
drop index my_index on student;
# 創建本地索引
CREATE LOCAL INDEX my_index ON student (age,name);
# 使用執行計劃
explain select id,name from student where age = 10;
HBase與 Hive 的集成
使用場景
如果大量的數據已經存放在 HBase 上面,需要對已經存在的數據進行數據分析處理,那麼 Phoenix 並不適合做特別複雜的 SQL 處理,此時可以使用 hive 映射 HBase 的表格,之後寫 HQL 進行分析處理。
集成方法
在 hive-site.xml 中添加 zookeeper 的屬性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
示例
接下來先建立 Hive 表,關聯 HBase 表,插入數據到 Hive 表的同時能夠影響 HBase 表
- 在 Hive 中創建表同時關聯 HBase
CREATE TABLE hive_emp(
empno INT,
empname string,
deptno INT
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,info:empname,info:deptno"
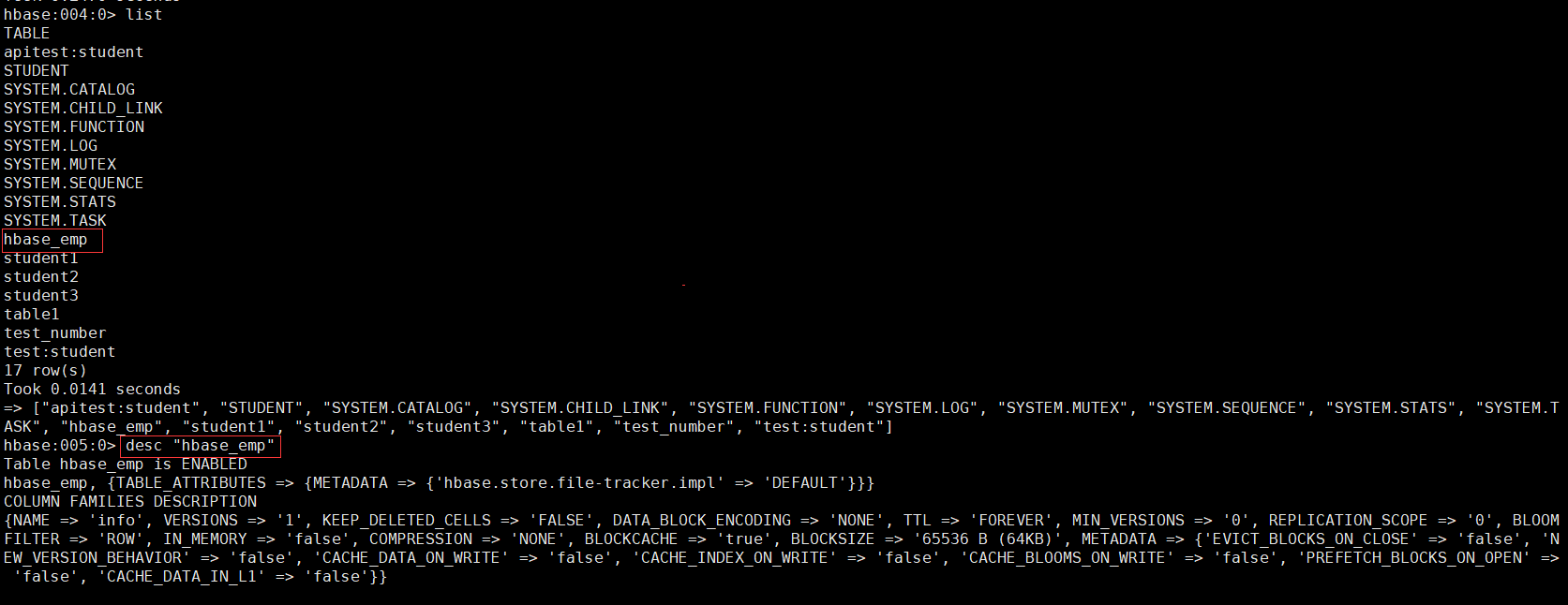
) TBLPROPERTIES ("hbase.table.name" = "hbase_emp");
完成之後,可以分別進入 Hive 和 HBase 查看,都生成了對應的表。
- 在 Hive 中創建臨時中間表,用於 load 文件中的數據。(不能將數據直接 load 進 Hive 所關聯 HBase 的那張表中)
CREATE TABLE emp_mid( empno int, ename string, deptno int)row format delimited fields terminated by ' ';
- 新建導入數據文件emp.txt。
1001 zhangsan 1001002 lisi 1001003 hangong 1001004 xieren 1011005 lili 1011006 guojia 102
- 往Hive 中間表emp_mid中 load 數據
load data local inpath '/home/commons/data/emp.txt' into table emp_mid;
- 通過 insert 命令將中間表中的數據導入到 Hive 關聯 Hbase 的那張表中。
insert into table hive_emp select * from emp_mid;
- 查看 Hive 以及關聯的 HBase 表中是否已經成功的同步插入了數據。
# Hive表中查看數據select * from hive_emp;

# HBase表中查看數據scan 'hbase_emp'
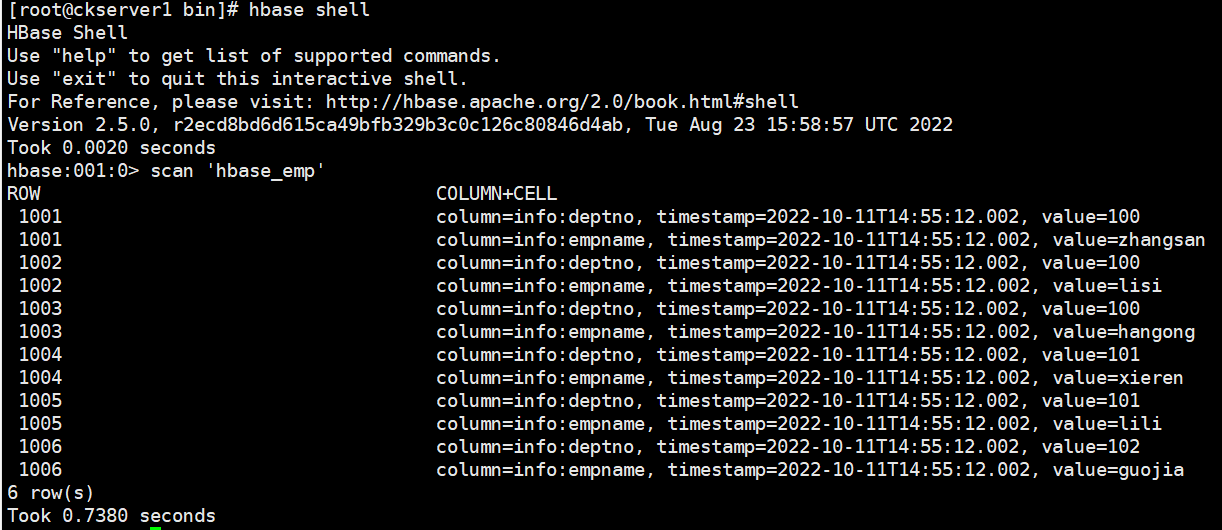
整合已有HBase表示例
上個示例中在 HBase 中已存儲了表 hbase_emp,接著我們在 Hive 中創建一個外部表hive_emp_external來關聯 HBase 中的 hbase_emp 這張表,使之可以藉助 Hive 來分析 HBase 這張表中的數據。
- 在 Hive 中創建外部表hive_emp_external
CREATE EXTERNAL TABLE hive_emp_external( empno INT, empname string, deptno INT) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( "hbase.columns.mapping" = ":key,info:empname,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp");
- 關聯後就可以使用 Hive 函數進行一些分析操作了
select deptno,count(empname) from hive_emp_external group by deptno;

**本人部落格網站 **IT小神 www.itxiaoshen.com

