挑戰海量數據:基於Apache DolphinScheduler對千億級數據應用實踐
- 2022 年 10 月 11 日
- 筆記
- Apache DolphinScheduler
點亮 ⭐️ Star · 照亮開源之路
GitHub://github.com/apache/dolphinscheduler

精彩回顧
近期,初靈科技的大數據開發工程師鍾霈合在社區活動的線上 Meetup 上中,給大家分享了《基於 Apache DolphinScheduler 對千億級數據的應用實踐》主題演講。
我們對於千億級數據量的數據同步需求,進行分析和選型後,初靈科技最終決定使用DolphinScheduler進行任務調度,同時需要周期性調度 DataX、SparkSQL 等方式進行海量數據遷移。在日常大數據工作中,利用DolphinScheduler減少日常運維工作量。
講師介紹

鍾霈合
初靈科技 大數據開發工程師
演講大綱:
-
背景介紹
-
海量數據處理
-
應用場景
-
未來的規劃
背景介紹
01 自研任務調度
我們公司前期一直是用的自研的任務調度框架,隨著這個調度領域開源軟體的發展,湧現了很多像海豚調度這樣非常優秀的任務調度系統,而我們的需求已經到了必須要引入新的任務調度系統程度,來保證技術的更新迭代。
02 需求分析
1、支援多租戶的許可權控制
我們在日常工作中不止研發會進行任務的調度,其他的業務部門和廠商都可能會在DS上跑一些任務,如果沒有多租戶的許可權控制的話,那整個集群使用起來都會非常的混亂。
2、上手簡單,支援可視化任務管理
上手簡單,因為我們團隊內部在很多時候,開發會給到數倉/業務團隊去使用,如果任務調度上手非常困難,如果需要進行大量的配置或者編寫程式碼,相對成本就要高很多,相信在很多大數據團隊都會存在這個需求,並且有些項目需要快速迭代,所以對於選型的工具必然是上手簡單的。
3、支援對任務及節點狀態進行監控
我們對任務調度原生監控主要有兩點需求,第一是伺服器的監控,可以直接通過任務調度web頁面去看,第二是任務調度的監控,針對任務是否成功、執行時間等相關數據和狀態能夠一目了然。
4、支援較為方便的重跑、補數
我們數據有實時、周期和離線三部分的,數據特性產生了這個需求,比如對於每15分鐘或者每小時的數據任務,如果不能很好的支援重跑和補數的話,對我們影響還是比較大的。
5、支援高可用HA、彈性擴容、故障容錯
集群運維和故障管理方面也是需要支援的。
6、支援時間參數
有時候需要基於時間參數進行數據的ETL周期操作。
03 任務調度對比

Crontab
在Unix和類Unix系統中周期性地執行指令或腳本,用來在Linux上直接執行腳本,但只能用來運行腳本。
不支援多租戶許可權管理、平台管理、分發執行等功能,在我們公司中的應用是在一些特點伺服器跑一些臨時的腳本。
並且原生Crontab只支援分鐘級別的調度,不支援重跑。
Rundeck
Rundeck是一個基於Java和Grails的開源的運維自動化工具,提供了Web管理介面進行操作,同時提供命令行工具和WebAPI的訪問控制方式。
像Ansible之類的工具一樣,Rundeck能夠幫助開發和運維人員更好地管理各個節點。
分為企業版和免費版,免費版對於我們來說功能還是有點欠缺的。
Quartz
Quartz 是一款開源且豐富特性的任務調度庫,是基於Java實現的任務調度框架,能夠集成與任何的java應用。
需要使用Java程式語言編寫任務調度,這對於非研發團隊而言,是無法去推廣使用的。
xxl-job
是一款國產開發的輕量級分散式調度工具,但功能比海豚調度少。
其不依賴於大數據組件,而是依賴於MySQL,和海豚調度的依賴項是一樣的。
Elastic-Job
是基於Quartz 二次開發的彈性分散式任務調度系統,初衷是面向高並發且複雜的任務。
設計理念是無中心化的,通過ZooKeeper的選舉機制選舉出主伺服器,如果主伺服器掛了,會重新選舉新的主伺服器。
因此elasticjob具有良好的擴展性和可用性,但是使用和運維有一定的複雜度。
Azkaban
Azkaban也是一個輕量級的任務調度框架,但其缺點是可視化支援不好,任務必須通過打一個zip包來進行實現,不是很方便。
AirFlow
AirFlow是用Python寫的一款任務調度系統,介面很高大上,但不符合中國人的使用習慣。
需要使用Python進行DAG圖的繪製,無法做到低程式碼任務調度。
Oozie
是集成在Hadoop中的大數據任務調度框架,其對任務的編寫是需要通過xml語言進行的。
04 選擇DolphinScheduler的理由
1、部署簡單,Master、Worker各司其職,可線性擴展,不依賴於大數據集群
2、對任務及節點有直觀的監控,失敗還是成功能夠一目了然
3、任務類型支援多,DAG圖決定了可視化配置及可視化任務血緣
4、甘特圖和版本控制,對於大量任務來說,非常好用
5、能夠很好滿足工作需求
大數據平台架構
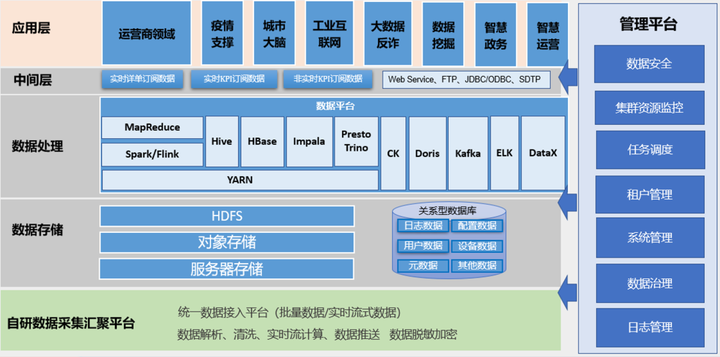
數據流圖
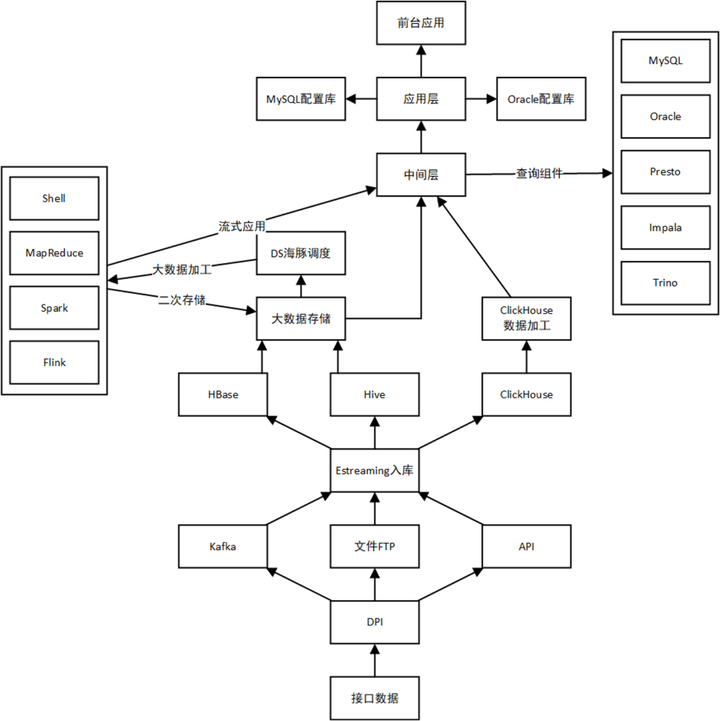
海量數據處理
01 數據需求
數據量:每天上千億條
欄位數:上百個欄位,String類型居多
數據流程:在數據倉庫中進行加工,加工完成的數據放入CK,應用直接查詢CK的數據
存儲周期:21天~60天
查詢響應:對於部分欄位需要秒級響應
02 數據同步選型

Sqoop
Sqoop是一款開源的工具,主要用於在Hadoop(Hive)與傳統的資料庫(mysql、postgresql…)間進行數據的傳遞,在DolphinScheduler上也集成了Sqoop的任務調度,但是對於從Hive到ClickHouse的需求,Sqoop是無法支援的。
Flink
通過DS調度Flink任務進行或者直接構建一套以Flink為主的實時流計算框架,對於這個需求,不僅要搭建一套計算框架,還要加上Kafka做消息隊列,除此之外有增加額外的資源開銷。
其次需要編寫程式,這對於後面的運維團隊是不方便的。
最後我們主要的場景是離線,單比較吞吐量的話,不如考慮使用Spark。
Spark&SparkSQL
在不考慮環境及資源的情況下,Spark確實是最優選擇,因為我們的數據加工也是用的SparkSQL,那現在的情況就是對於數據同步來說有兩種方式去做。
第一種是加工出來的數據不持久化存儲,直接通過網路IO往ClickHouse裡面去寫,這一種方式對於伺服器資源的開銷是最小的,但是其風險也是最大的,因為加工出來的數據不落盤,在數據同步或者是ClickHouse存儲中發現異常,就必須要進行重新加工,但是下面dws、dwd的數據是14天清理一次,所以不落盤這種方式就需要再進行考慮。
第二種方式是加工出來的數據放到Hive中,再使用SparkSQL進行同步,只是這種的話,需要耗費更多的Yarn資源量,所以在一期工程中,因為資源量的限制,我們並沒有使用SparkSQL來作為數據同步方案,但是在二期工程中,得到了擴容的集群是完全足夠的,我們就將數據加工和數據同步全部更換為了SparkSQL。
SeaTunnel
SeaTunnel是Spark和Flink上做了一層包裝,將自身的配置文件轉換為Spark和Flink的任務在Yarn上跑,實現的話也是通過各種配置文件去做。
對於這個場景來說,SeaTunnel需要耗費Yarn資源。
DataX
所以經過多方面的調研,最終選擇一期工程使用DataX來作為數據通過工具,並使用DolphinScheduler來進行周期調度。
03 ClickHouse優化
在搞定數據加工和數據同步架構之後,就需要進行ClickHouse的優化。
寫入本地表
在整個集群中最開始是用的Nginx負載均衡寫,這個過程中我們發現效果不理想,也嘗試了用分散式表寫,效果提升也不明顯,後面的話我們的解決方案就是調整寫入本地表,整個集群有多台設備,分別寫到各個CK節點的本地表,然後查詢的時候就查分散式表。
使用MergeTree表引擎家族
ClickHouse的一大核心就是MergeTree表引擎,社區也是將基於MergeTree表引擎的優化作為一個重點工作。
我們在CK中是使用的ReplicatedMergeTree作為數據表的本地表引擎,使用的ReplicatedReplacingMergeTree作為從MySQL遷移過來的數據字典的表引擎。
二級索引優化
第一個的優化點是二級索引的優化,我們把二級索引從minmax替換到了bloom_filter,並將索引粒度更改到了32768。
在二級索引方面的話我們嘗試過minmax、intHash64、halfMD5、farmHash64等,但是對於我們的數據而言的話,要麼就是查詢慢,要麼就是入數據慢,後來改為了bloom_filter之後寫入才平衡了。
小文件優化
在數據加工後,出現的小文件非常多,加工出來的小文件都是5M左右,所以在SparkSQL中添加了參數,重新加工的文件就是在60M~100M左右了。
set spark.sql.adaptive.enabled=true;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=256000000;
參數優化
CK的優化參數非常多,除了基礎的參數外,在二級索引調整為布隆過濾器後,寫入CK的parts就比原來多了,在這個時候調整CK的parts參數,使其可以正常運行,但是這個參數會稍微影響一下CK查詢的性能,對於我們來說,數據都放不進去,再查詢也就沒有用了。
parts_to_delay_insert:200000
此外還可以添加background_pool_size參數(我們沒有用)。
Zookeeper優化
對於ClickHouse多分片多副本集群模式來說,Zookeeper是最大的性能瓶頸點。
在不改動源碼的情況下,我們做了如下的優化:
-
調整MaxSessionTimeout參數,加大Zookeeper會話最大超時時間
-
在Zookeeper中將dataLogDir、dataDir目錄分離
-
單獨部署一套CK集群專供ClickHouse使用,磁碟選擇超過1T,然後給的是SSD盤
04 海量數據處理架構
一期技術架構
Hive數倉架構——Hive——SparkSQL——DataX——DataX Web——DolphinScheduler——ClickHouse
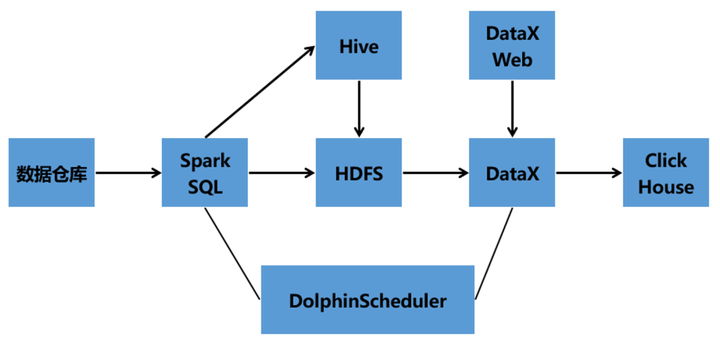
二期架構1
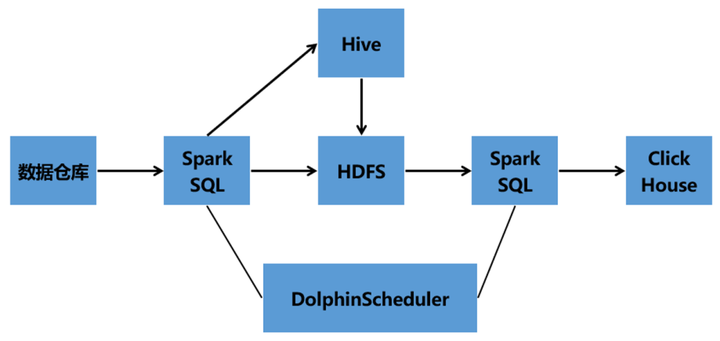
二期架構2
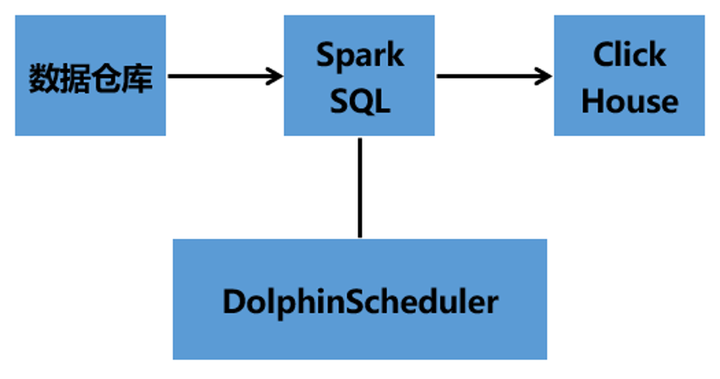
05 數據同步操作
DataX技術原理
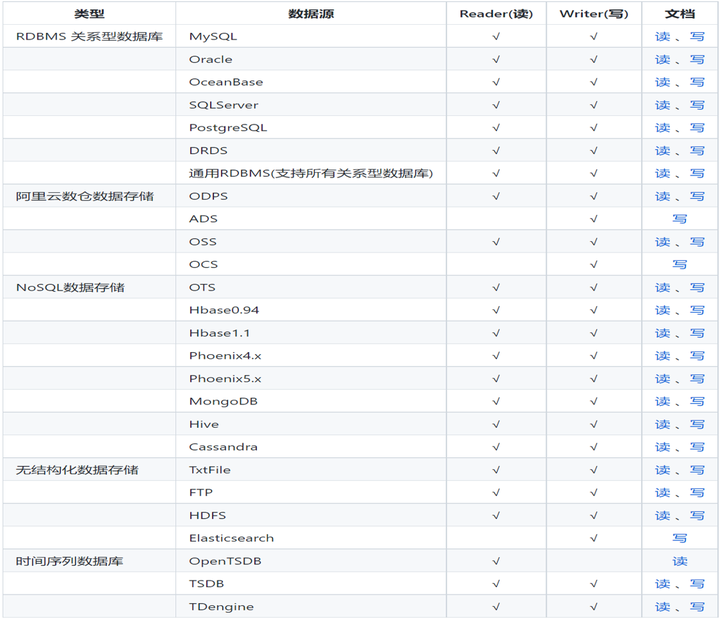
DataX 是阿里巴巴開源的一個異構數據源離線同步工具,致力於實現包括關係型資料庫(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各種異構數據源之間穩定高效的數據同步功能。

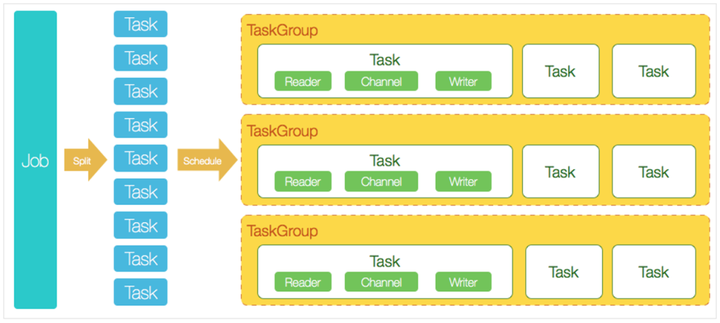
DataX在使用上比較簡單,兩部分一個Reader和一個Writer,在配置上面的話主要也是針對這兩部分進行配置。
DataX支援的插件非常多,除了官方已經打進包裡面直接可以使用的插件,還可以自己從Github上面下載源碼進行Maven編譯,像ClickHouse、Starrocks的writer插件都需要這麼去做。
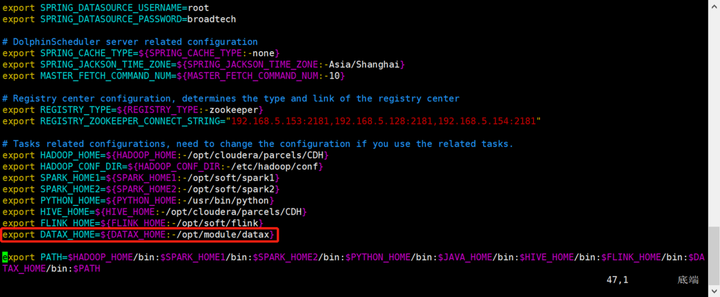
06 DataX在DS中的應用
使用DataX需要在dolphinscheduler_env.sh文件中去指定datax的路徑。
export DATAX_HOME=${DATAX_HOME:-/opt/module/datax}
之後DataX可以有三種方式去使用。
第一種方式的使用「自定義模板」,然後在自定義模板中去編寫DataX的json語句:

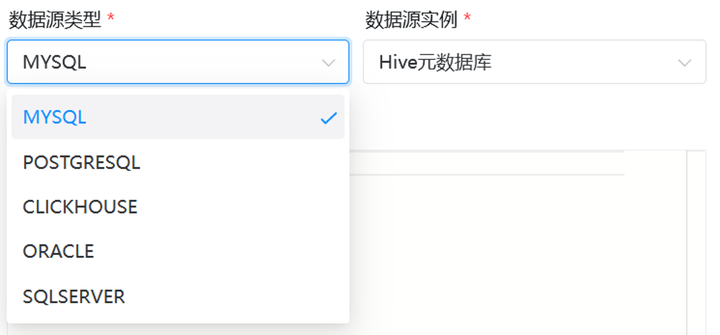
第二種方式是通過DS自帶的選型,然後編寫SQL去使用DataX,在DS中可以通過可視化介面配置的插件有_MySQL、PostgreSQL、ClickHouse、Oracle、SQLServer:_
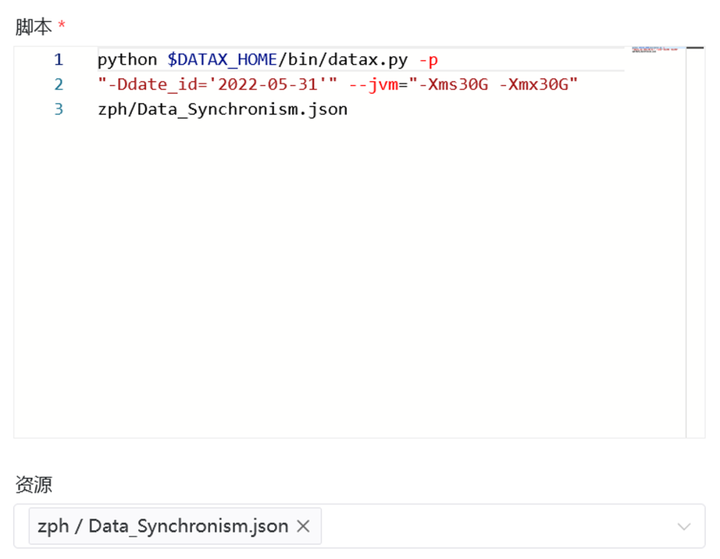
第三種方式是在DS中建立shell任務,然後通過shell去調用部署在伺服器上的DataX腳本,並且要把腳本放到DS的資源中心裏面:
第一種方式對我們來說是最方便也是適配性最強的方式,第二種和第三種的話就要根據情況去使用了。
07 DataX的使用
在DataX內部對每個Channel會有嚴格的速度控制,分兩種,一種是控制每秒同步的記錄數,另外一種是每秒同步的位元組數,默認的速度限制是1MB/s, 可以根據具體硬體情況設置這個byte速度或者record速度,一般設置byte速度。
我們的channel的話是根據每個任務的數據量條數、大小進行多次調優後得出的,這個要根據自己的數據情況進行適配,我的任務最大的一個數據量配置的是總的record限速是300M/s,單個channel的record限速是10M/s。
{
但是channel並不是越大越好,過分大反而會影響伺服器的性能,會經常的報GC,一報GC的話,性能就會下降。
一般我們的伺服器,配置了上面的參數後,一個任務沒事,如果多個DataX任務同時在一台伺服器上跑的話並且JVM設置得過小的話,一般5分鐘會報一次GC。
根據剛才的調控,明顯一個DataX任務中的channel數是增多了的,這就表示佔用的記憶體也會增加,因為DataX作為數據交換通道,在記憶體中會快取較多的數據。
在DataX中會有一個Buffer作為臨時的記憶體交換的快取區,而且在Reader和Writer中,也會存在一些Buffer用來快取數據,JVM報GC的話主要也是在這上面報,所以我們需要根據配置調整JVM的參數。
一般我的任務參數會用DS的參數進行控制,如下所示,一般設置為4G~16G,這個的話得根據硬體的性能來決定。
$DATAX_HOME:/opt/beh/core/datax/pybin/datax.py –jvm=”-Xms8G -Xms8G” -p”-Da=1″
將記憶體和CPU調優做了之後,再往下就是對Reader和Writer的基礎配置,比如說HDFS路徑、Kerberos相關、欄位的映射關係、CK的庫表等等。
最後一部分就是我們在使用的時候,發現即使對CK做了優化,還是會報parts過多的錯誤,經過排查,DataX的ClickHouse Writer是通過JDBC遠程連接到ClickHouse資料庫,然後利用ClickHouse暴露的insert介面將數據insert into到ClickHouse。根據ClickHouse特性,每一次的insert into都是一個parts,所以不能一條數據就insert一次,必須大批量的插入ClickHouse,這也是官方推薦的。
所以我們對DataX的batchSize進行了優化,優化參數如下:
"batchSize": 100000,
應用場景
01 元數據備份
使用DS周期性備份Hive元數據、CDH元數據、HDP元數據、DS自己的元數據,並將其上傳到HDFS中進行保存。
02 任務調度
對Shell、SparkSQL、Spark、DataX、Flink等任務進行調度,目前的工作點主要是分為新加任務和老任務遷移。
新加任務的話就是新項目的任務我們會推動業務部門及其餘研發中心將任務上到DS調度平台,老任務遷移的話阻力比較大,就是把之前的離線、流式和shell任務給遷移到DS上,遷移的過程中將一些老舊的MR程式碼改為Spark或者Flink後放到DS上來跑。
03 甘特圖

04 數據清理
主要就是針對部分數據有存放周期的,需要周期對Hive、HDFS,還有一些伺服器上的日誌進行周期清理。
未來的規劃
1、從某一個任務調度系統往DS進行任務遷移的工具,半自動化,幫助推進DS的在調度領域的應用。
2、DS集群部署、升級工具,減少運維工作量。
3、從訂製化監控轉變為插件式監控,從高程式碼到低程式碼的轉變,時監控告警更加靈活,及早發現節點、工作流、資料庫、任務等的問題。
4、二次開發,增加只讀場景、回收站功能,增多判斷條件及功能,資源批量上傳等,助力大數據。
5、集成API網關功能,對協議適配、服務管理、限流熔斷、認證授權、介面請求等進行一站式操作。
我的分享就到這裡,感謝!感興趣的朋友可以進入社區跟我討論,添加社區小助手即可拉入中國區用戶組~
最後非常歡迎大家加入 DolphinScheduler 大家庭,融入開源世界!
我們鼓勵任何形式的參與社區,最終成為 Committer 或 PMC,如:
-
將遇到的問題通過 GitHub 上 issue 的形式回饋出來。
-
回答別人遇到的 issue 問題。
-
幫助完善文檔。
-
幫助項目增加測試用例。
-
為程式碼添加註釋。
-
提交修復 Bug 或者 Feature 的 PR。
-
發表應用案例實踐、調度流程分析或者與調度相關的技術文章。
-
幫助推廣 DolphinScheduler,參與技術大會或者 meetup 的分享等。
歡迎加入貢獻的隊伍,加入開源從提交第一個 PR 開始。
- 比如添加程式碼注釋或找到帶有 」easy to fix」 標記或一些非常簡單的 issue(拼寫錯誤等) 等等,先通過第一個簡單的 PR 熟悉提交流程。
註:貢獻不僅僅限於 PR 哈,對促進項目發展的都是貢獻。
相信參與 DolphinScheduler,一定會讓您從開源中受益!
參與貢獻
隨著中國開源的迅猛崛起,Apache DolphinScheduler 社區迎來蓬勃發展,為了做更好用、易用的調度,真誠歡迎熱愛開源的夥伴加入到開源社區中來,為中國開源崛起獻上一份自己的力量,讓本土開源走向全球。
參與 DolphinScheduler 社區有非常多的參與貢獻的方式,包括:
貢獻第一個PR(文檔、程式碼) 我們也希望是簡單的,第一個PR用於熟悉提交的流程和社區協作以及感受社區的友好度。
社區匯總了以下適合新手的問題列表://github.com/apache/dolphinscheduler/issues/5689
非新手問題列表://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A”volunteer+wanted”
如何參與貢獻鏈接://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
來吧,DolphinScheduler開源社區需要您的參與,為中國開源崛起添磚加瓦吧,哪怕只是小小的一塊瓦,匯聚起來的力量也是巨大的。
參與開源可以近距離與各路高手切磋,迅速提升自己的技能,如果您想參與貢獻,我們有個貢獻者種子孵化群,可以添加社區小助手微信(Leonard-ds) ,手把手教會您( 貢獻者不分水平高低,有問必答,關鍵是有一顆願意貢獻的心 )。
添加小助手微信時請說明想參與貢獻。
來吧,開源社區非常期待您的參與。
