吳恩達機器學習複習2:多重特徵、多重變數的梯度下降、梯度下降實踐Ⅰ:數據特徵縮放、梯度下降實踐Ⅱ:學習率、特徵和多項式回歸、正規方程法、向量化
- 2022 年 10 月 9 日
- 筆記
【多重特徵】
多變數線性回歸
可以有任何輸入變數的等式的表示方法

假設

使用矩陣乘法的定義,我們的多變數假設功能可以被簡潔地描述為
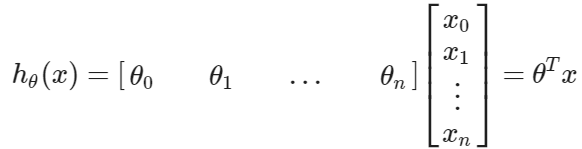
這是未來我們為訓練例子的準備的假設函數的向量化
【多重變數的梯度下降】
假設
參數
代價函數
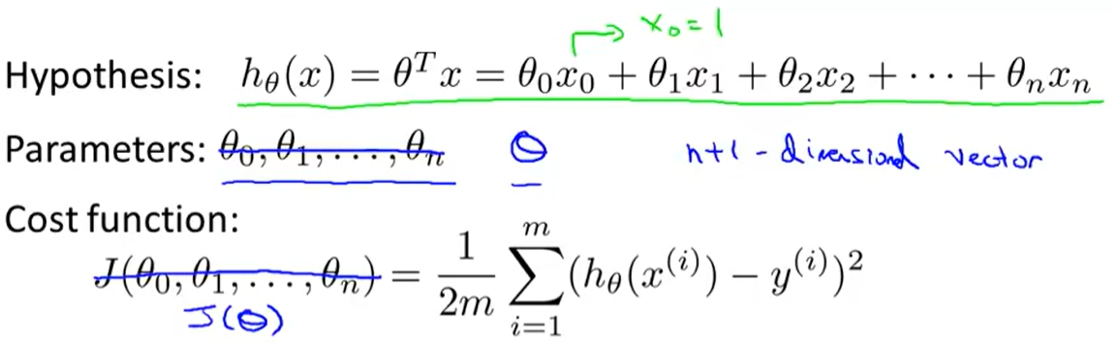


梯度下降的步驟
原來的演算法(n=1)
反覆做{
角度0 = 原角度0-學習率 *(1/m) 求和[ 假設函數值-實際函數值 ]
角度1 = 原角度1-學習率 *(1/m) 求和[(假設函數值-實際函數值)* 自變數 ]
}
新的演算法(n>=1)
反覆做{
角度j = 原角度1-學習率 *(1/m) 求和[(假設函數值-實際函數值)* 自變數 ]
}
【梯度下降實踐Ⅰ:數據特徵縮放】
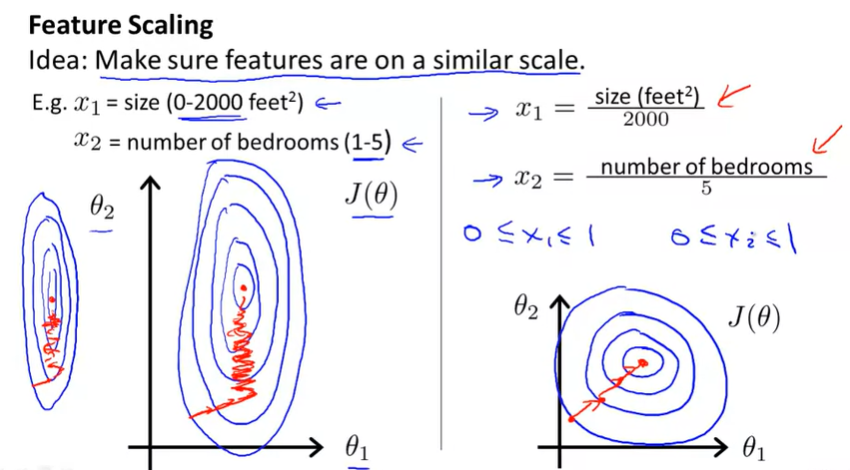
思想: 使得確定的特徵在一個相似的衡量尺度上
平均值歸一化
把x換成x-μ,使特徵接近大約零平均值

標準化
現在你知道了特徵放大,如果你運用這個簡單的技巧,它會讓梯度下降運行得更快,並且在更小的迭代步數里收斂。
把你的輸入值以粗略的相同的範圍,加速梯度下降
【梯度下降實踐Ⅱ:學習率】

debug除錯:使得梯度下降正確工作
如何選擇除錯率?
找到你希望用來最小化代價函數的theta值
x軸代表梯度下降的迭代次數

迭代100次後得到一個theta,又得出一個代價函數J(theta)。

當梯度下降不能正常工作時
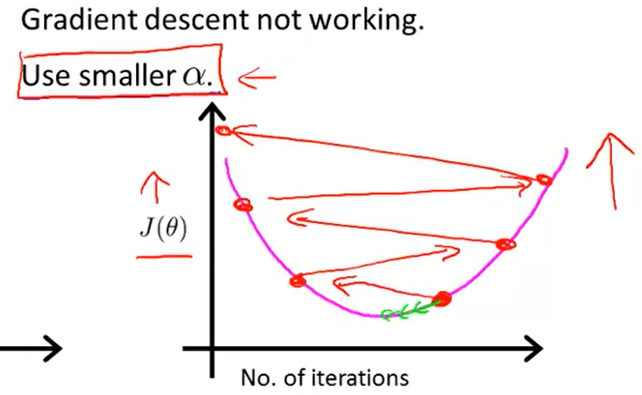
有關學習率選擇與梯度下降影像的選擇題
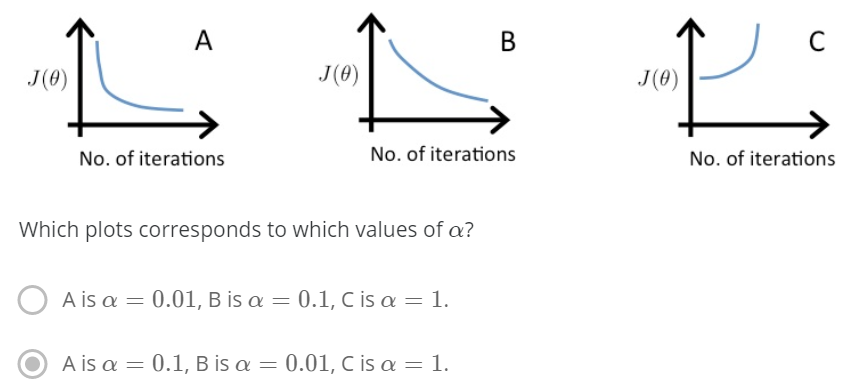
在圖C中,代價函數值在增加,說明學習率太高了
A和B都收斂到一個代價函數的最優點,但是B收斂太慢了,說明學習率太低

總結:
學習率太小:收斂慢
學習率太大:代價函數隨迭代次數增加而增加,甚至不收斂
{為梯度下降除錯}
畫一個該梯度下降的迭代次數與代價函數值的圖
如果代價函數甚至增加了,你可能需要減小學習率啦
{自動收斂測試}
如果代價函數每次都比E(10的-3次方)減少得還要慢,說明是收斂的
然而實際上很難選擇門檻值
【特徵和多項式回歸】
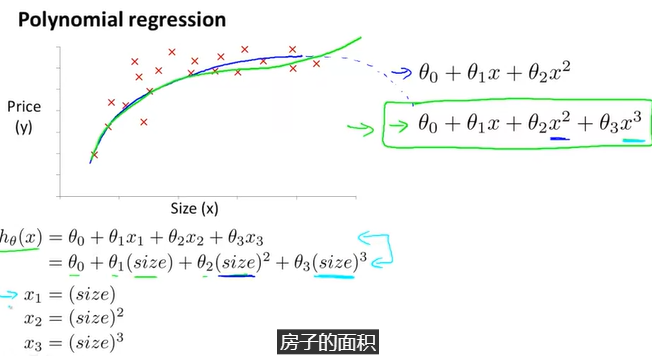
提高特徵和假設函數的形式,以一系列不同的方式
{多項式回歸}
我們的假設函數不需要是線性,如果能和數據擬合得很好的話
我們可以改變行為或我們假設函數的曲線,通過製造一個二次的、三次的或平方根函數(或任何形式)
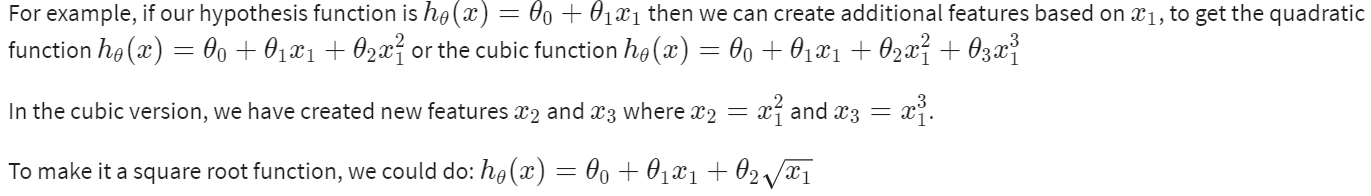
注意:如果你以這種方式選擇特徵,那麼特徵縮放就變得很重要了!
【正規方程法】
在正規方程法的方法中,通過對theta j求導,最小化代價函數,然後把它們設為0.
這讓我們得以不用迭代就能找到最優化值。

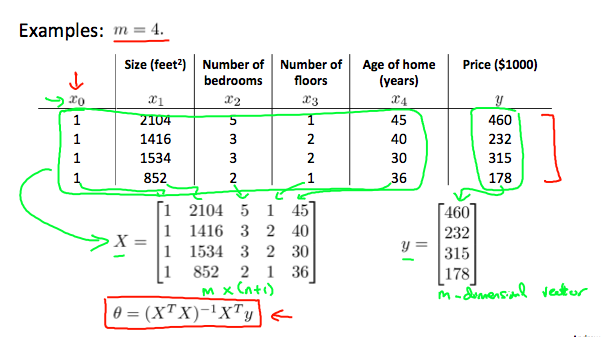
不需要用正規方程法做特徵縮放
*梯度下降法和正規方程法的比較

用正規方程法計算轉置有O(n^3)的複雜度
所以如果我們有更大數量的特徵,那麼用正規方程法就會很慢。
實際上,當n超過1萬時,從正規解法到迭代過程會有一個很好的時間。

正規方程的不可逆
在matlab里執行正規方程時,我們一般用pinv功能,它能返回theta值(即使X^TX不可逆的時候)
常見的原因是:
1.冗餘的特徵,有兩個特徵是相關的(儘管不是線性獨立)
2.太多的特徵了。在本例中,刪除一些特徵或使用歸一化
解決方法:
1.刪除互相線性獨立的一個特徵
2.如果特徵太多了,刪除一個或多個特徵
【向量化】
向量化的例子
h(x)=sum(theta_j*x_j)=theta^T*x



%matlab %未向量化執行法 prediction=0.0; for j=1:n+1; prediction=prediction+theta(j)*x(j) end; double prediction =0.0; for(int j = 0;j<=n;j++) prediction+=theta[j]*x[j]; %向量化執行方法 prediction=theta'*x; double prediction=theta.transpose()*x;


