Redis核心設計原理(深入底層C源碼)
Redis 基本特性
1. 非關係型的鍵值對資料庫,可以根據鍵以O(1) 的時間複雜度取出或插入關聯值
2. Redis 的數據是存在記憶體中的
3. 鍵值對中鍵的類型可以是字元串,整型,浮點型等,且鍵是唯一的
4. 鍵值對中的值類型可以是string,hash,list,set,sorted set 等
5. Redis 內置了複製,磁碟持久化,LUA腳本,事務,SSL, ACLs,客戶端快取,客戶端代理等功能
6. 通過Redis哨兵和Redis Cluster 模式提供高可用性
Redis高性能的原因
1.圖示(換算時間:1s =1000 ms ,1ms=1000 us ,1us =1000 ns):

2.對於記憶體資料庫來說,本身數據就存在於記憶體里,避免了磁碟 I/O 的限制,無疑訪問速度會遠大於磁碟資料庫。
3.其次Redis,默認是採用一個執行緒執行指令任務的,既減少了執行緒上下文切換帶來的開銷,也避免並發問題。
4.而且Redis中有多種數據類型,每種數據類型的底層都由一種或多種數據結構來支援。正是因為有了這些數據結構,Redis 在存儲與讀取上的速度才不受阻礙。
深入底層C源碼分析Redis
1.Redis是基於鍵值對存儲數據的,像我們平時會使用的時候很容易覺得Redis的鍵值是多種數據類型的,其實不然,Redis的鍵值是String類型的,數據變成位元組流(byte)基於網路傳輸的過程,傳到Redis服務轉成SDS(Simple Dynamic String【簡單動態字元串】) String(Redis自定義的數據類型)。既然Redis是基於C語言寫的,那麼為什麼不用原生的?
//如果我們想存儲字元串:myname C: char data[]="myname\0"; //而C語言中對於字元串是默認採用\0作為結尾的 而對於Redis,它是面向多種語言的,對於傳過來的數據是不可控的: 如果傳輸的影片流或者音頻的流文件,大概率會出現"name\0orxxx"這種 那麼C語言只能讀到「name」這部分遇到「\0」,則會視為結束了。(這明顯是不合適,容易導致數據丟失) 故,Redis採用sds結構: struct sdshdr { int len; //存儲的長度 int free; //剩餘的空閑空間 char buf[]; //數據存儲的地方 }; 這種數據結構的好處是: 1.對於存儲數據的準確性更高了,依靠len欄位來標明準確數據的位置。【二進位安全的數據結構】 2.採用以空間換時間的方式,每次擴容的時候可以適當分配大一點的空間,記錄剩餘時間是否夠下一次的修改或者追加。(減少對象的銷毀與創建的步驟)【提供了記憶體預分配機制,避免了頻繁的記憶體分配】 3.會在數據末尾依舊採用\0作為結尾【兼容C語言的函數庫】
說明:
Redis自定義sdshdr數據結構具備三大特性:
【1】二進位安全的數據結構
【2】提供了記憶體預分配機制,避免了頻繁的記憶體分配
【3】兼容C語言的函數庫
2.String類型的數據結構
1)程式碼展示
//redis 3.2 以前 struct sdshdr { int len; int free; char buf[]; }; //redis 3.2 後 //redis\deps\hiredis\sds.h文件 typedef char *sds; //存在注釋:sdshdr5 is never used, we just access the flags byte directly.However is here to document the layout of type 5 SDS strings. //意思大概是:sdshdr5從未使用過,我們只是直接訪問標誌位元組。然而,這裡是為了記錄類型5 SDS字元串的布局 struct __attribute__ ((__packed__)) sdshdr5 { // 對應的字元串長度小於 1<<5 unsigned char flags; char buf[]; }; //__attribute__ ((packed)) 的作用就是告訴編譯器取消結構體在編譯過程的優化對齊,按照實際佔用位元組數進行對齊 struct __attribute__ ((__packed__)) sdshdr8 { // 對應的字元串長度小於 1<<8 uint8_t len; //目前字元串的長度 uint8_t alloc; //分配的記憶體總長度 unsigned char flags; //flag用3bit來標明類型,類型後續解釋,其餘5bit目前沒有使用 char buf[]; //柔性數組,以'\0'結尾 }; struct __attribute__ ((__packed__)) sdshdr16 { // 對應的字元串長度小於 1<<16 uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { // 對應的字元串長度小於 1<<32 uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { // 對應的字元串長度小於 1<<64 uint64_t len; uint64_t alloc; unsigned char flags; char buf[]; }; #define SDS_TYPE_5 0 #define SDS_TYPE_8 1 #define SDS_TYPE_16 2 #define SDS_TYPE_32 3 #define SDS_TYPE_64 4 static inline char sdsReqType(size_t string_size) { if (string_size < 1<<5) return SDS_TYPE_5; if (string_size < 1<<8) return SDS_TYPE_8; if (string_size < 1<<16) return SDS_TYPE_16; #if (LONG_MAX == LLONG_MAX) if (string_size < 1ll<<32) return SDS_TYPE_32; return SDS_TYPE_64; #else return SDS_TYPE_32; #endif }
2)發現說明
【1】為什麼要對原本的數據結構進行修改?(改版後的優化在哪裡)
因為int佔據4個位元組(8bit),也就是能存42億左右的,但是在我們實際上,存儲的數據大概率都是小數據,所以它存在浪費資源的嫌疑。
所以進行優化的思維就是根據不同的數據範圍,設置不同容量,如,uint8_t 表示佔據1位元組(8bit,在二進位中最大可以表示255),uint16_t 表示佔據2位元組(16bit,在二進位中最大可以表示65535)
【2】官網上說String類型限制大小512M,是怎麼限制的?
//位於t_string.c文件中 //為什麼要限制,要知道512M已經是一個很大的值了(已經是一個bigkey了),在redis單執行緒操作中已經很容易阻塞執行緒 //故在追加命令appendCommand和設置命令setrangeCommand中都會進行校驗 static int checkStringLength(client *c, long long size) { if (size > 512*1024*1024) { addReplyError(c,"string exceeds maximum allowed size (512MB)"); return C_ERR; } return C_OK; }
3)分析是怎麼創建的
//在sds.c文件內 //sds在創建的時候,buf數組初始大小為:struct結構體大小 + 字元串的長度+1, +1是為了在字元串末尾添加一個\0。 //在完成字元串到字元數組的拷貝之後,會在字元串末尾加一個\0,這樣可以復用C語言的一些函數。 sds sdsnewlen(const void *init, size_t initlen) { void *sh; sds s; // 根據長度計算sds類型 char type = sdsReqType(initlen); if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; //為空時強制用sdshdr8 // 獲取結構體大小 int hdrlen = sdsHdrSize(type); unsigned char *fp; /* flags pointer. */ // 分配記憶體空間,初始大小為:struct結構體大小+字元串的長度+1,+1是為了在字元串末尾添加一個\0,兼容傳統C語言 sh = s_malloc(hdrlen+initlen+1); // sh在這裡指向了這個剛剛分配的記憶體地址 if (sh == NULL) return NULL; // 判斷是否是init階段 if (!init) //init 不為空的話,將sh這塊記憶體全部設置為0 memset(sh, 0, hdrlen+initlen+1); // 指向buf數組的指針 s = (char*)sh+hdrlen; //因為可以看到地址的順序是 len,alloc,flag,buf,目前s是指向buf,那麼後退1位,fp 正好指向了flag對應的地址 fp = ((unsigned char*)s)-1; // 類型選擇 switch(type) { case SDS_TYPE_5: { *fp = type | (initlen << SDS_TYPE_BITS); break; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } } //如果兩者都不為空,則init 這個對應的字元串,賦值給s if (initlen && init) memcpy(s, init, initlen); // 將字元串拷貝到buf數組 s[initlen] = '\0'; // 字元串末尾添加一個\0 return s; } // 獲取結構體大小 static inline int sdsHdrSize(char type) { switch(type&SDS_TYPE_MASK) { case SDS_TYPE_5: return sizeof(struct sdshdr5); case SDS_TYPE_8: return sizeof(struct sdshdr8); case SDS_TYPE_16: return sizeof(struct sdshdr16); case SDS_TYPE_32: return sizeof(struct sdshdr32); case SDS_TYPE_64: return sizeof(struct sdshdr64); } return 0; }
4)怎麼防止操作時緩衝區溢出
//先檢查 SDS 的空間是否滿足修改所需的要求 //如果不滿足要求的話,API 會自動將 SDS 的空間擴展到執行修改所需的大小 //最後才是返回,去執行實際的修改操作 sds sdscatlen(sds s, const void *t, size_t len) { size_t curlen = sdslen(s); //獲取s已經使用過的空間字元數 s = sdsMakeRoomFor(s,len); //擴大s的空閑空間 if (s == NULL) return NULL; memcpy(s+curlen, t, len); //拷貝數據 sdssetlen(s, curlen+len); //設置s的len s[curlen+len] = '\0'; //最後加上空字元串 return s; }
5)分析是怎麼擴容的
程式碼展示
// 擴容sds sds sdsMakeRoomFor(sds s, size_t addlen) { void *sh, *newsh; //獲取剩餘可用的空間 size_t avail = sdsavail(s); size_t len, newlen; char type, oldtype = s[-1] & SDS_TYPE_MASK; int hdrlen; //如果可用空間大於需要增加的長度,那麼直接返回 if (avail >= addlen) return s; //len 已使用長度 len = sdslen(s); //sh 回到指向了這個sds的起始位置。 sh = (char*)s-sdsHdrSize(oldtype); // newlen 代表最小需要的長度 newlen = (len+addlen); //Redis認為一旦被擴容了,那這個字元串被再次擴容的幾率就很大,所以會在此基礎上多加一些空間,防止頻繁擴容 if (newlen < SDS_MAX_PREALLOC) newlen *= 2; else newlen += SDS_MAX_PREALLOC; //獲取新長度的類型 type = sdsReqType(newlen); //如果是SDS_TYPE_5會被強行轉為SDS_TYPE_8 if (type == SDS_TYPE_5) type = SDS_TYPE_8; hdrlen = sdsHdrSize(type); if (oldtype==type) { //sh是開始地址,在開始地址的基礎上,分配更多的空間,邏輯如同初始化部分,hdrlen 是head的長度,即struct本身大小。後面newlen 是buf 大小, +1 是為了結束符號,sds 通常情況下是可以直接列印的 newsh = s_realloc(sh, hdrlen+newlen+1); if (newsh == NULL) { s_free(sh); return NULL; } s = (char*)newsh+hdrlen; } else { //如果類型發生變化,地址內容不可復用,所以找新的空間。 newsh = s_malloc(hdrlen+newlen+1); if (newsh == NULL) return NULL; //複製原來的str到新的sds 上面,newsh+hdrlen 等於sds buf 地址開始的位置,s 原buf的位置,len+1 把結束符號也複製進來 memcpy((char*)newsh+hdrlen, s, len+1); //釋放前面的記憶體空間 s_free(sh); //調整s開始的位置,即地址空間指向新的buf開始的位置 s = (char*)newsh+hdrlen; //-1 正好到了flag的位置 s[-1] = type; //分配len的值 sdssetlen(s, len); } sdssetalloc(s, newlen); //返回新的sds return s; } // 給len 設值 static inline size_t sdsavail(const sds s) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { return 0; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); return sh->alloc - sh->len; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); return sh->alloc - sh->len; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); return sh->alloc - sh->len; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); return sh->alloc - sh->len; } } return 0; } // 獲取當前sds,可用的長度。 static inline void sdssetlen(sds s, size_t newlen) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { unsigned char *fp = ((unsigned char*)s)-1; *fp = (unsigned char)(SDS_TYPE_5 | (newlen << SDS_TYPE_BITS)); } break; case SDS_TYPE_8: SDS_HDR(8,s)->len = (uint8_t)newlen; break; case SDS_TYPE_16: SDS_HDR(16,s)->len = (uint16_t)newlen; break; case SDS_TYPE_32: SDS_HDR(32,s)->len = (uint32_t)newlen; break; case SDS_TYPE_64: SDS_HDR(64,s)->len = (uint64_t)newlen; break; } } // 獲取alloc的長度 /* sdsalloc() = sdsavail() + sdslen() */ static inline size_t sdsalloc(const sds s) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: return SDS_TYPE_5_LEN(flags); case SDS_TYPE_8: return SDS_HDR(8,s)->alloc; case SDS_TYPE_16: return SDS_HDR(16,s)->alloc; case SDS_TYPE_32: return SDS_HDR(32,s)->alloc; case SDS_TYPE_64: return SDS_HDR(64,s)->alloc; } return 0; } // 給 alloc 設值 static inline void sdssetalloc(sds s, size_t newlen) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: /* Nothing to do, this type has no total allocation info. */ break; case SDS_TYPE_8: SDS_HDR(8,s)->alloc = (uint8_t)newlen; break; case SDS_TYPE_16: SDS_HDR(16,s)->alloc = (uint16_t)newlen; break; case SDS_TYPE_32: SDS_HDR(32,s)->alloc = (uint32_t)newlen; break; case SDS_TYPE_64: SDS_HDR(64,s)->alloc = (uint64_t)newlen; break; } }
程式碼說明
【1】sds內部buf的擴容機制:新buf長度 = (原buf長度 + 添加buf長度)*2,如果buf長度大於1M後,每次擴容也只會增大1M
【2】對於類型改變的需要變換存儲空間。
3.RedisDb 數據結構
1)程式碼展示
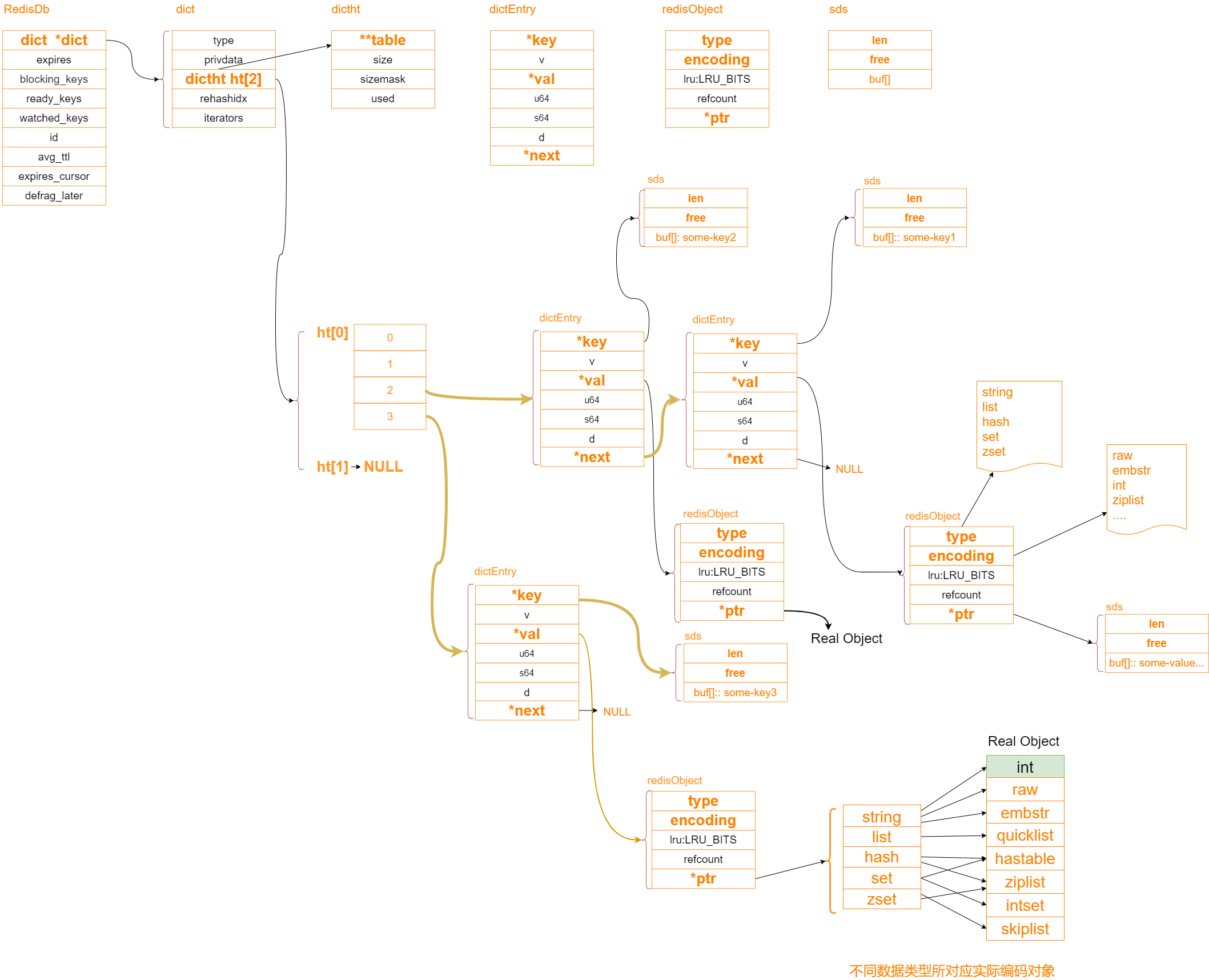
//位於server.h文件中 typedef struct redisDb { dict *dict; // 保存了當前資料庫的鍵空間 dict *expires; //鍵空間中所有鍵的過期時間 dict *blocking_keys; //客戶端等待數據的鍵(BLPOP) dict *ready_keys; //保存著處於阻塞狀態的鍵,value為NULL dict *watched_keys; //監視鍵的MULTI/EXEC CAS int id; //資料庫ID long long avg_ttl; //鍵的平均過期時間 unsigned long expires_cursor; //周期性刪除過期鍵的游標 list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */ } redisDb; //位於dict.h文件中 typedef struct dict { dictType *type; void *privdata; dictht ht[2]; // ht[0] , ht[1] =null //方便漸進的rehash擴容,dict的hashtable ,其中一個哈希表正常存儲數據,另一個哈希表為空,空哈希表在 rehash 時使用 long rehashidx; /* rehash 索引,當不在進行 rehash 時,值為 -1 */ unsigned long iterators; //當前正在運行的迭代器的數量 } dict; //位於dict.h文件中
/*這是我們的哈希表結構。每本字典都有兩個這樣的詞,實現增量重哈希,從舊錶到新表。* / typedef struct dictht { dictEntry **table; unsigned long size; // hashtable 容量 unsigned long sizemask; // size -1 unsigned long used; // hashtable 元素個數 used / size =1 } dictht; //位於dict.h文件中 typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; //位於server.h文件中 //redisObject對象 : string , list ,set ,hash ,zset ... typedef struct redisObject { unsigned type:4; // 4 bit, sting , hash unsigned encoding:4; // 4 bit unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or LFU data (least significant 8 bits frequency * and most significant 16 bits access time). * 24 bit * */ int refcount; // 4 byte void *ptr; // 8 byte 總空間: 4 bit + 4 bit + 24 bit + 4 byte + 8 byte = 16 byte } robj;
2)視圖展示
3)程式碼說明
【1】由上可知redisDb,主要都是將數據存儲在字典(dict)中,而且還是多個,固定存儲,過期維護等多個字典。
【2】dict字典結構,每個字典有兩個哈希表結構的原因是為了用於漸進式擴容,當某個哈希表結構過於龐大的時候(按照hashMap的思維,必定是需要對數組進行擴容,增大數組長度,將鏈表長度縮小,加快遍歷),其實它也需要進行擴容,但是再進行擴容操作的同時,容易出現阻塞執行緒的情況(如果時間太久),為此,dict中採用rehashidx標明是否正在處於擴容狀態,且ht[1]會生成一個新的哈希表結構,容量是之前的兩倍,然後把ht[0]中的數據按槽位一點一點的搬運過來【斷斷續續的操作,這樣就不會一直阻塞住執行緒】,新的數據也會落到ht[1]中,直到搬完。然後將ht[1]指針指向ht[0],然後自己再指向null,rehashidx變為0,就完成了擴容操作。
【3】dictEntry相當於hashMap中的節點(包含了key,value,和指向下個節點的指針),其中val會被進一步封裝成redisObject。
【4】redisObject中的type用於約束客戶端命令,如set操作,會判斷操作的值與操作的類型匹不匹配。encoding記錄了值在redis底層是怎麼樣的編碼形式。ptr指向記憶體的真實地址。
4)分析String類型的編碼
【1】會存在:int,raw,embstr三種。
【2】為什麼會有int,因為整型值最大固定是64bit,其實與指針*ptr佔據的大小一致,其實把數值存於這裡可以減少了對空間的開闢。程式碼展示:
//server.c文件中封裝了所有的客戶端命令 //發現set命令會執行setCommand方法【該方法位於t_string.c文件中】,直接看核心部分 void setCommand(client *c) { .... // 完成編碼 set: key value c->argv[2] = tryObjectEncoding(c->argv[2]); setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL); } //該方法位於object.c文件中 robj *tryObjectEncoding(robj *o) { long value; sds s = o->ptr; size_t len; /*確保這是一個字元串對象,我們在這個函數中編碼的唯一類型。其他類型使用編碼的記憶體高效表示,但由實現該類型的命令處理。* / serverAssertWithInfo(NULL,o,o->type == OBJ_STRING); // 只有類型為 原生sds類型 或者 embstr類型, 還有機會可以進一步編碼,否則直接返回 if (!sdsEncodedObject(o)) return o; // 如果其他地方有應用即當前對象為共享對象, 修改範圍將擴大,所以放棄編碼為整形操作 if (o->refcount > 1) return o; //判斷是否可以把該字元串轉化為一個長整型 len = sdslen(s); // 範圍是否在 整型值得表示範圍 , 0 - 2^64,最多不超過20 位 if (len <= 20 && string2l(s,len,&value)) { /* * 如果Redis的配置不要求運行LRU替換演算法,且轉成的long型數字的值又比較小 * (小於OBJ_SHARED_INTEGERS,在目前的實現中這個值是10000), * 那麼會使用共享數字對象來表示。之所以這裡的判斷跟LRU有關,是因為LRU演算法要求每個robj有不同的lru欄位值, * 所以用了LRU就不能共享robj。shared.integers是一個長度為10000的數組,裡面預存了10000個小的數字對象。 * 這些小數字對象都是 encoding = OBJ_ENCODING_INT的string robj對象。 * * */ // 沒有設置記憶體淘汰策略,且數字範圍在 快取整型得範圍內 if ((server.maxmemory == 0 || !(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) && value >= 0 && value < OBJ_SHARED_INTEGERS) { decrRefCount(o); // 不需要用額外得對象來存儲 incrRefCount(shared.integers[value]); return shared.integers[value]; // 共享對象 } else { // 如果前一步不能使用共享小對象來表示,那麼將原來的robj編碼成encoding = OBJ_ENCODING_INT,這時ptr欄位直接存成這個long型的值。 // 注意ptr欄位本來是一個void *指針(即存儲的是記憶體地址), // 因此在64位機器上有64位寬度,正好能存儲一個64位的long型值。這樣,除了robj本身之外,它就不再需要額外的記憶體空間來存儲字元串值。 if (o->encoding == OBJ_ENCODING_RAW) { sdsfree(o->ptr); // 釋放空間 o->encoding = OBJ_ENCODING_INT; // 用整形編碼 o->ptr = (void*) value; return o; } else if (o->encoding == OBJ_ENCODING_EMBSTR) { decrRefCount(o); return createStringObjectFromLongLongForValue(value); } } } // 數據長度 小於 OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44 的話, 用 embstr 進行編碼 if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) { robj *emb; if (o->encoding == OBJ_ENCODING_EMBSTR) return o; emb = createEmbeddedStringObject(s,sdslen(s)); decrRefCount(o); return emb; } trimStringObjectIfNeeded(o); /* Return the original object. */ return o; }
【3】為什麼會有embstr,程式碼展示
//CPU讀取數據的時候其實是會有一個快取行的概念(cache line,通常是64byte的空間),也就是一次性讀取的大小 //而redisObject數據大小為16 byte typedef struct redisObject { unsigned type:4; // 佔4 bit unsigned encoding:4; // 佔4 bit unsigned lru:LRU_BITS; // 佔24 bit int refcount; // 4 byte void *ptr; // 8 byte } robj; //總空間: 4 bit + 4 bit + 24 bit + 4 byte + 8 byte = 16 byte 所以讀取是會讀【redisObject 16 byte,及其後面的48byte的數據(但是用不到)】 為了節約CPU成本,可不可以在創建的時候,將數據就存在後面呢?(為什麼採用sdshdr8,因為最多存44個字元,sdshdr8可以容納128個,滿足條件,且消耗最小) struct __attribute__ ((__packed__)) sdshdr8 { // 對應的字元串長度小於 1<<8 uint8_t len; //佔據1byte,表示128個 uint8_t alloc; //佔據1byte unsigned char flags; //佔據1byte char buf[]; //以'\0'結尾,這個字元也會佔據1byte }; 所以如果把他們都存於一個64byte的記憶體中是不是讀取對象的時候順便可以把值也拿出來了,減少了一次IO。
【4】而raw便是表示:字元串將以簡單動態字元串(SDS)的形式存儲,需要兩次 malloc 分配記憶體,redisObject 對象頭和 SDS 對象在記憶體地址上一般是不連續的。
5)發現說明
【1】會有人疑問為什麼DB默認是16?
因為Redis的配置文件redis/redis.conf中的databases屬性默認是16。所以Redis啟動的時候默認會創建16個資料庫且拿資料庫索引為0的資料庫作為默認資料庫。這些都是可以通過配置調整的。
4.List 數據結構(Redis採用quicklist(雙端鏈表) 和 ziplist 作為List的底層實現)
1)介紹
【1】List是一個有序(按加入的時序排序)的數據結構,Redis採用quicklist(雙端鏈表) 和 ziplist 作為List的底層實現。以通過設置每個ziplist的最大容量,quicklist的數據壓縮範圍,提升數據存取效率。
//當值為正數時,表示quicklistNode節點上的ziplist的長度。比如當這個值為5時,每個quicklistNode節點的ziplist最多包含5個數據項 //當值為負數時,表示按照位元組數來限制quicklistNode節點上的ziplist的的長度,可選值為-1到-5,每個值的含義如下 //-1 ziplist節點最大為4kb //-2 ziplist節點最大為8kb //-3 ziplist節點最大為16kb //-4 ziplist節點最大為32kb //-5 ziplist節點最大為64kb list-max-ziplist-size -2 // 單個ziplist節點最大能存儲 8kb ,超過則進行分裂,將數據存儲在新的ziplist節點中 //對節點中間的數據進行壓縮,進一步節省記憶體 //0 特殊值,表示都不壓縮 //1 quicklist兩端各有1個節點不壓縮,中間的節點壓縮 //2 quicklist兩端各有2個節點不壓縮,中間的節點壓縮 //n quicklist兩端各有n個節點不壓縮,中間的節點壓縮 list-compress-depth 1 // 0 代表所有節點,都不進行壓縮,1, 代表從頭節點往後走一個,尾節點往前走一個不用壓縮,其他的全部壓縮,以此類推
2)ziplist 分析詳解
【1】介紹
1.ziplist是一個經過特殊編碼的雙向鏈表,它的設計目標就是為了提高存儲效率;
2.ziplist可以用於存儲字元串或整數,其中整數是按真正的二進位表示進行編碼的,而不是編碼成字元串序列。它能以O(1)的時間複雜度在表的兩端提供push和pop操作;
3.因為ziplist是一個記憶體連續的集合,所以ziplist遍歷只要通過當前節點的指針 加上 當前節點的長度 或 減去 上一節點的長度 ,即可得到下一個節點的數據或上一個節點的數據,這樣就省去的指針從而節省了存儲空間,又因為記憶體連續所以在數據讀取上的效率也遠高於普通的鏈表。
【2】程式碼展示
robj *createZiplistObject(void) { unsigned char *zl = ziplistNew(); robj *o = createObject(OBJ_LIST,zl); o->encoding = OBJ_ENCODING_ZIPLIST; return o; } robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(*o)); o->type = type; o->encoding = OBJ_ENCODING_RAW; o->ptr = ptr; o->refcount = 1; if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; } else { o->lru = LRU_CLOCK(); // 獲取 24bit 當前時間秒數 } return o; } //以下為ziplist.c文件中 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //獲取ziplist的zlbytes的指針(ziplist 所佔空間位元組數) #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //獲取ziplist的zltail的指針 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //獲取ziplist的zllen的指針 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //ziplist頭大小 #define ZIPLIST_END_SIZE (sizeof(uint8_t)) // ziplist結束標誌位大小 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) // 獲取第一個元素的指針 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) // 獲取最後一個元素的指針 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) // 獲取結束標誌位指針 unsigned char *ziplistNew(void) { // 創建一個壓縮表 unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE; // zip頭加結束標識位數 unsigned char *zl = zmalloc(bytes); ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // 大小端轉換 ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); ZIPLIST_LENGTH(zl) = 0; // len賦值為0 zl[bytes-1] = ZIP_END; // 結束標誌位賦值 return zl; } /* * 壓縮列表節點 對應 上文中 Ziplist 中的 entry * zlentry每個節點由三部分組成:Previous entry len、encoding、data * prevlengh: 記錄上一個節點的長度,為了方便反向遍歷ziplist * encoding: 編碼,由於 ziplist 就是用來節省空間的,所以 ziplist 有多種編碼,用來表示不同長度的字元串或整數。 * data: 用於存儲 entry 真實的數據 * 結構體定義了7個欄位,主要還是為了滿足各種可變因素 */ typedef struct zlentry { unsigned int prevrawlensize; //prevrawlensize是描述prevrawlen的大小,有1位元組和5位元組兩種 unsigned int prevrawlen; //prevrawlen是前一個節點的長度, unsigned int lensize; //lensize為編碼len所需的位元組大小 unsigned int len; //len為當前節點長度 unsigned int headersize; //當前節點的header大小 unsigned char encoding; //節點的編碼方式 unsigned char *p; //指向節點的指針 } zlentry;
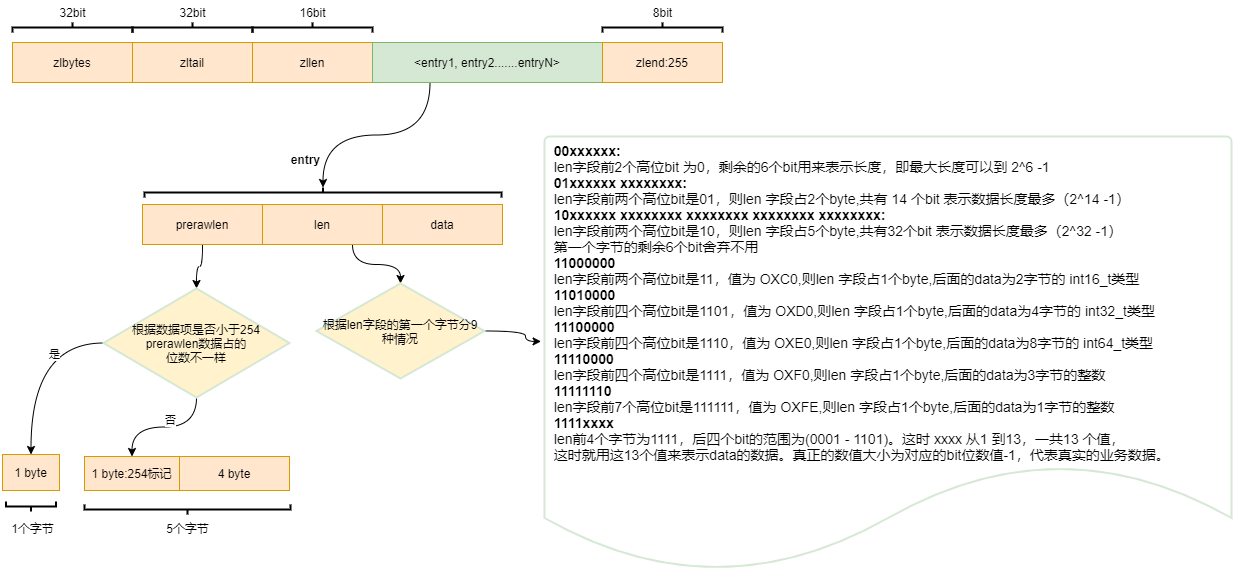
【3】圖示:
【4】圖示參數說明
zlbytes:32bit,表示ziplist佔用的位元組總數。
zltail: 32bit,表示ziplist表中最後一項(entry)在ziplist中的偏移位元組數。通過zltail我們可以很方便地找到最後一項,從而可以在ziplist尾端快速地執行push或pop操作
zlen: 16bit, 表示ziplist中數據項(entry)的個數。
entry:表示真正存放數據的數據項,長度不定
zlend: ziplist最後1個位元組,是一個結束標記,值固定等於255。
prerawlen: 前一個entry的數據長度。
len: entry中數據的長度
data: 真實數據存儲
【5】說明
1.Ziplist的設計結構,保障了空間的節省與查詢的高效,但是當出現zlentry增加或刪除時,Ziplist是不能直接在原有空間上進行修改,每一次變動都需要重新開闢空間去拷貝、修改。這樣的場景下Ziplist一旦內部元素過多,將會導致性能的急劇下滑。因此Redis 在實現上做了一層優化,當Ziplist過大時,會將其分割成多個Ziplist,然後再通過一個雙向鏈表將其串聯起來。
3)quicklist 分析詳解
【1】介紹
1.Redis quicklist是Redis 3.2版本以後針對鏈表和壓縮列表進行改造的一種數據結構,是 zipList 和 linkedList 的混合體,相對於鏈表它壓縮了記憶體,進一步的提高了效率。
【2】程式碼展示
robj *createQuicklistObject(void) { quicklist *l = quicklistCreate(); robj *o = createObject(OBJ_LIST,l); o->encoding = OBJ_ENCODING_QUICKLIST; return o; } //處於quicklist.c文件中 quicklist *quicklistCreate(void) { struct quicklist *quicklist; quicklist = zmalloc(sizeof(*quicklist)); quicklist->head = quicklist->tail = NULL; quicklist->len = 0; quicklist->count = 0; quicklist->compress = 0; quicklist->fill = -2; quicklist->bookmark_count = 0; return quicklist; } //處於quicklist.h文件中 //quicklist 是一個 40 位元組的結構(在 64 位系統上),描述了一個快速列表。 typedef struct quicklist { quicklistNode *head; //指向頭節點(左側第一個節點)的指針。 quicklistNode *tail; //指向尾節點(右側第一個節點)的指針。 unsigned long count; // 所有 quicklistNode 節點中所有的 entry 個數 unsigned long len; // quickListNode 節點個數,也就是 quickList 的長度 int fill : QL_FILL_BITS; //單個節點的填充因子,也就是 ziplist 的大小 unsigned int compress : QL_COMP_BITS; // 保存壓縮成都只,配置文件設置,64位作業系統占 16bit , 6 表示壓縮 unsigned int bookmark_count: QL_BM_BITS; quicklistBookmark bookmarks[]; } quicklist; //quicklistNode 是一個 32 位元組的結構,描述了一個快速列表的 ziplist。 typedef struct quicklistNode { struct quicklistNode *prev; // 雙向鏈表前驅節點 struct quicklistNode *next; // 雙向鏈表的後節點 unsigned char *zl; //數據指針。如果當前節點的數據沒有壓縮,那麼它指向一個ziplist結構;否則,它指向一個quicklistLZF結構。 unsigned int sz; // 壓縮列表 ziplist 的總長度 unsigned int count : 16; // 每個 ziplist 中 entry 的個數 unsigned int encoding : 2; // 表示是否採用了 LZF 壓縮 quickList 節點 1 表示壓縮過,2 表示沒有壓縮站 2bit 長度 unsigned int container : 2; // 表示是否開啟 ziplist 進行壓縮 unsigned int recompress : 1; // 表示該節點是否被壓縮過 unsigned int attempted_compress : 1; // 測試使用 unsigned int extra : 10; // 額外拓展位,占 10bit 長度 } quicklistNode; //當指定使用 lzf 壓縮演算法壓縮 ziplist entry 節點時,quicklistNode 結構的 zl 成員執行 quicklistLZF 結構 typedef struct quicklistLZF { unsigned int sz; //表示被LZF 壓縮後的 ziplist 的大小 char compressed[]; // 壓縮有的數據,柔性數組 } quicklistLZF;
【3】圖示:

【4】說明
1.通過控制ziplist 的大小,則很好的解決了超大ziplist 的拷貝情況下對性能的影響。每次改動只需要針對具體的小段ziplist 進行操作。
4)發現說明
【1】為什麼不採用兩個指針指向前後數據的方式,而是要採用複合的數據結構完成?
1.採用雙指針的方式,那就必須賦予兩個指針pre和next,一個指針佔據了8byte,故兩個指針就需要消耗16byte。如果list存在大量數據,所以就需要消耗相當多的記憶體在指針方面(胖指針問題)。
2.採用雙鏈表的話數據可能會分的很散,因為指針就是採用不連續的存儲空間來存儲數據,容易造成大量的記憶體碎片。
3.採用quicklist 和 ziplist 混合,達到減少指針消耗的空間,其次連續的存儲空間讀取起來效率高於不連續的存儲空間,節省IO。
4.通過控制ziplist 的大小,則很好的解決了超大ziplist 的拷貝情況下對性能的影響。每次改動只需要針對具體的小段ziplist 進行操作。
5.Hash 數據結構
1)介紹
【1】Hash 數據結構底層實現為一個字典( dict ),也是RedisBb用來存儲K-V的數據結構,當數據量比較小,或者單個元素比較小時,底層用ziplist存儲,數據大小和元素數量閾值可以通過如下參數設置。
hash-max-ziplist-entries 512 // ziplist 元素個數超過 512 ,將改為hashtable編碼 hash-max-ziplist-value 64 // 單個元素大小超過 64 byte時,將改為hashtable編碼
2)發現說明
【1】為什麼數據量小的時候採用ziplist存儲?
1.ziplist使用緊湊的連續記憶體塊順序存儲數據,在list或者hash結構中,未使用listNode(24位元組)和dictEntry(24位元組)結構體來存儲元素項,因此會節省記憶體。
2.ziplist結構元素訪問採用的是後向遍歷(從後往前),因此在hash中可將熱點的key或者在list中將熱點的元素項放在最後,可以提升性能。
3.因為ziplist的記憶體結構中,僅僅只使用了額外的11個位元組來存儲ziplist的屬性,另外很重要的是ziplist使用後向遍歷,當list或者hash中的元素較多時,可以根據元素的冷熱性調整元素存儲順序。
4.而在dictht結構體中,存儲屬性需要32個位元組,其中元素dictEntry也是每個佔用24個位元組。
6.Set 數據結構
1)介紹
【1】Set 為無序的,自動去重的集合數據類型,Set 數據結構底層實現為一個value 為 null 的 字典( dict ),當數據可以用整形表示時,Set集合將被編碼為intset數據結構。
//在配置文件中設置 set-max-intset-entries 512 // intset 能存儲的最大元素個數,超過則用hashtable編碼
【2】兩個條件任意滿足時Set將用hashtable存儲數據。1, 元素個數大於 set-max-intset-entries , 2 , 元素無法用整形表示。
2)intset數據結構
//intset內部其實是一個數組(int8_t coentents[]數組),而且存儲數據的時候是有序的,因為在查找數據的時候是通過二分查找來實現的。 typedef struct intset { uint32_t encoding; // 編碼方式 uint32_t length; // 集合包含的元素數量 int8_t contents[]; // 保存元素的數組 } intset;
3)set存儲過程
// set添加元素的處理函數,在文件t_set.c中 //過程匯總 //檢查set是否存在不存在則創建一個set結合。 //根據傳入的set集合一個個進行添加,添加的時候需要進行記憶體壓縮。 //setTypeAdd執行set添加過程中會判斷是否進行編碼轉換。 void saddCommand(client *c) { robj *set; int j, added = 0; // 取出集合對象 set = lookupKeyWrite(c->db,c->argv[1]); // 對象不存在,創建一個新的,並將它關聯到資料庫 if (set == NULL) { set = setTypeCreate(c->argv[2]->ptr); dbAdd(c->db,c->argv[1],set); } // 對象存在,檢查類型 else { if (set->type != OBJ_SET) { addReply(c,shared.wrongtypeerr); return; } } // 將所有輸入元素添加到集合中 for (j = 2; j < c->argc; j++) { // set 類型 添加元素 if (setTypeAdd(set,c->argv[j]->ptr)) added++; } // 如果有至少一個元素被成功添加,那麼執行以下程式 if (added) { // 發送鍵修改訊號 signalModifiedKey(c,c->db,c->argv[1]); // 發送事件通知 notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[1],c->db->id); } // 將資料庫設為臟 server.dirty += added; // 返回添加元素的數量 addReplyLongLong(c,added); } //元素已經存在 直接返回 0 , 否則添加元素 返回 1 //過程匯總 //如果能夠轉成int的對象(isObjectRepresentableAsLongLong),那麼就用intset保存。 //如果用intset保存的時候,如果長度超過512(REDIS_SET_MAX_INTSET_ENTRIES)就轉為hashtable編碼。 //其他情況統一用hashtable進行存儲。 int setTypeAdd(robj *subject, sds value) { long long llval; // 字典 if (subject->encoding == OBJ_ENCODING_HT) { // 將 value 作為鍵, NULL 作為值,將元素添加到字典中 dict *ht = subject->ptr; dictEntry *de = dictAddRaw(ht,value,NULL); if (de) { dictSetKey(ht,de,sdsdup(value)); dictSetVal(ht,de,NULL); return 1; } } // intset else if (subject->encoding == OBJ_ENCODING_INTSET) { // 判斷是否可以用整形編碼,可以的話用intset 編碼 if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) { uint8_t success = 0; subject->ptr = intsetAdd(subject->ptr,llval,&success); if (success) { //如果元素個數超過 set-max-intset-entries[ 默認 512 ] 時,將轉化為 hashtable 數據結構 if (intsetLen(subject->ptr) > server.set_max_intset_entries) setTypeConvert(subject,OBJ_ENCODING_HT); return 1; } } else { //轉整形失敗,直接用hashtable存儲 setTypeConvert(subject,OBJ_ENCODING_HT); // 執行添加操作 serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK); return 1; } } else { // 未知編碼 serverPanic("Unknown set encoding"); } return 0; }
7.ZSet 數據結構
1)介紹
【1】ZSet 為有序的,自動去重的集合數據類型,ZSet 數據結構底層實現為 字典(dict) + 跳錶(skiplist) ,當數據比較少時,用ziplist編碼結構存儲。
zset-max-ziplist-entries 128 // 元素個數超過128 ,將用skiplist編碼 zset-max-ziplist-value 64 // 單個元素大小超過 64 byte, 將用 skiplist編碼
【2】數據比較少時,用ziplist編碼結構存儲的圖示:

2)skiplist 分析解析
【1】數據結構程式碼
// 創建zset 數據結構: 字典 + 跳錶 robj *createZsetObject(void) { zset *zs = zmalloc(sizeof(*zs)); robj *o; // dict用來查詢數據到分數的對應關係, 如 zscore 就可以直接根據 元素拿到分值 zs->dict = dictCreate(&zsetDictType,NULL); // skiplist用來根據分數查詢數據(可能是範圍查找) zs->zsl = zslCreate(); // 設置對象類型 o = createObject(OBJ_ZSET,zs); // 設置編碼類型 o->encoding = OBJ_ENCODING_SKIPLIST; return o; } //位於edis/src/server.h 中 #define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */ #define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */ typedef struct zskiplistNode { sds ele; //存儲字元串類型數據 redis3.0版本中使用robj類型表示,但是在redis4.0.1中直接使用sds類型表示 double score; //存儲排序的分值 struct zskiplistNode *backward; //指向上一個節點,用於zrevrange命令 struct zskiplistLevel { struct zskiplistNode *forward; //指向下一個節點 unsigned long span; //到達後一個節點的跨度(兩個相鄰節點span為1) } level[]; //該節點在各層的資訊,柔性數組成員 } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; // 跳躍表頭尾節點 unsigned long length; //節點個數 int level; //除頭結點外最大的層數 } zskiplist; typedef struct zset { dict *dict; zskiplist *zsl; } zset;
【2】追蹤添加函數
//在server.c發現跳錶的添加函數為zaddCommand //去t_zset.c文件查看流程 void zaddCommand(client *c) { zaddGenericCommand(c,ZADD_NONE); } void zaddGenericCommand(client *c, int flags) { static char *nanerr = "resulting score is not a number (NaN)"; robj *key = c->argv[1]; robj *zobj; sds ele; double score = 0, *scores = NULL; int j, elements; int scoreidx = 0; /* The following vars are used in order to track what the command actually * did during the execution, to reply to the client and to trigger the * notification of keyspace change. */ int added = 0; //新添加元素的數量 int updated = 0; //更新分數的元素數量 int processed = 0; //被處理的元素數量 /* Parse options. At the end 'scoreidx' is set to the argument position * of the score of the first score-element pair. */ scoreidx = 2; // 輸入參數解析 while(scoreidx < c->argc) { char *opt = c->argv[scoreidx]->ptr; if (!strcasecmp(opt,"nx")) flags |= ZADD_NX; else if (!strcasecmp(opt,"xx")) flags |= ZADD_XX; else if (!strcasecmp(opt,"ch")) flags |= ZADD_CH; else if (!strcasecmp(opt,"incr")) flags |= ZADD_INCR; else break; scoreidx++; } /* Turn options into simple to check vars. */ int incr = (flags & ZADD_INCR) != 0; int nx = (flags & ZADD_NX) != 0; int xx = (flags & ZADD_XX) != 0; int ch = (flags & ZADD_CH) != 0; /* After the options, we expect to have an even number of args, since * we expect any number of score-element pairs. */ elements = c->argc-scoreidx; if (elements % 2 || !elements) { addReply(c,shared.syntaxerr); return; } elements /= 2; /* Now this holds the number of score-element pairs. */ /* Check for incompatible options. */ if (nx && xx) { addReplyError(c, "XX and NX options at the same time are not compatible"); return; } if (incr && elements > 1) { addReplyError(c, "INCR option supports a single increment-element pair"); return; } /* Start parsing all the scores, we need to emit any syntax error * before executing additions to the sorted set, as the command should * either execute fully or nothing at all. */ scores = zmalloc(sizeof(double)*elements); for (j = 0; j < elements; j++) { if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL) != C_OK) goto cleanup; } /* Lookup the key and create the sorted set if does not exist. 查詢對應的 key 在對應的 db 即 hash table 中,是否存在 */ zobj = lookupKeyWrite(c->db,key); if (zobj == NULL) { if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */ // 如果 zset_max_ziplist_entries ==0 // // 或者 zadd 元素的長度 > zset_max_ziplist_value // // 則直接創建 skiplist 數據結構 // // 否則創建ziplist 壓縮列表數據結構 if (server.zset_max_ziplist_entries == 0 || server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)) { zobj = createZsetObject(); } else { zobj = createZsetZiplistObject(); } // 關聯對象到db dbAdd(c->db,key,zobj); } else { if (zobj->type != OBJ_ZSET) { addReply(c,shared.wrongtypeerr); goto cleanup; } } // 處理所有元素 for (j = 0; j < elements; j++) { double newscore; // 分值 score = scores[j]; int retflags = flags; // 元素 ele = c->argv[scoreidx+1+j*2]->ptr; // 往 zobj 添加元素 int retval = zsetAdd(zobj, score, ele, &retflags, &newscore); if (retval == 0) { addReplyError(c,nanerr); goto cleanup; } if (retflags & ZADD_ADDED) added++; if (retflags & ZADD_UPDATED) updated++; if (!(retflags & ZADD_NOP)) processed++; score = newscore; } server.dirty += (added+updated); reply_to_client: if (incr) { /* ZINCRBY or INCR option. */ if (processed) addReplyDouble(c,score); else addReplyNull(c); } else { /* ZADD. */ addReplyLongLong(c,ch ? added+updated : added); } cleanup: zfree(scores); if (added || updated) { signalModifiedKey(c,c->db,key); notifyKeyspaceEvent(NOTIFY_ZSET, incr ? "zincr" : "zadd", key, c->db->id); } } // 創建zset 數據結構: 字典 + 跳錶 robj *createZsetObject(void) { zset *zs = zmalloc(sizeof(*zs)); robj *o; // dict用來查詢數據到分數的對應關係, 如 zscore 就可以直接根據 元素拿到分值 zs->dict = dictCreate(&zsetDictType,NULL); // skiplist用來根據分數查詢數據(可能是範圍查找) zs->zsl = zslCreate(); // 設置對象類型 o = createObject(OBJ_ZSET,zs); // 設置編碼類型 o->encoding = OBJ_ENCODING_SKIPLIST; return o; } // 創建zset 數據結構: ZipList robj *createZsetZiplistObject(void) { unsigned char *zl = ziplistNew(); robj *o = createObject(OBJ_ZSET,zl); o->encoding = OBJ_ENCODING_ZIPLIST; return o; } int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) { /* Turn options into simple to check vars. 可選參數解析 */ int incr = (*flags & ZADD_INCR) != 0; int nx = (*flags & ZADD_NX) != 0; int xx = (*flags & ZADD_XX) != 0; *flags = 0; /* We'll return our response flags. */ double curscore; /* NaN as input is an error regardless of all the other parameters. 數值判斷 */ if (isnan(score)) { *flags = ZADD_NAN; return 0; } /* Update the sorted set according to its encoding. 數據類型為ziplist 的情況 */ if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { unsigned char *eptr; if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) { /* NX? Return, same element already exists. */ if (nx) { *flags |= ZADD_NOP; return 1; } /* Prepare the score for the increment if needed. */ if (incr) { score += curscore; if (isnan(score)) { *flags |= ZADD_NAN; return 0; } if (newscore) *newscore = score; } /* Remove and re-insert when score changed. 元素 score 有變化,則刪除老節點,重新插入 */ if (score != curscore) { zobj->ptr = zzlDelete(zobj->ptr,eptr); zobj->ptr = zzlInsert(zobj->ptr,ele,score); *flags |= ZADD_UPDATED; } return 1; } else if (!xx) { /* Optimize: check if the element is too large or the list * becomes too long *before* executing zzlInsert. */ zobj->ptr = zzlInsert(zobj->ptr,ele,score); if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries || sdslen(ele) > server.zset_max_ziplist_value) // 元素個數 或者 單個元素大小超過閾值 任意條件滿足就轉化為skiplist zsetConvert(zobj,OBJ_ENCODING_SKIPLIST); if (newscore) *newscore = score; *flags |= ZADD_ADDED; return 1; } else { *flags |= ZADD_NOP; return 1; } // 數據類型為 跳錶的情況 } else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) { // 獲取值指針 zset *zs = zobj->ptr; zskiplistNode *znode; dictEntry *de; // O(1) 的時間複雜度,獲取到元素 de = dictFind(zs->dict,ele); if (de != NULL) { /* NX? Return, same element already exists. NX 互斥 */ if (nx) { *flags |= ZADD_NOP; return 1; } // 當前分值 curscore = *(double*)dictGetVal(de); /* Prepare the score for the increment if needed. */ // 遞增 if (incr) { score += curscore; if (isnan(score)) { *flags |= ZADD_NAN; return 0; } if (newscore) *newscore = score; } /* Remove and re-insert when score changes. 分值不同的場景 */ if (score != curscore) { znode = zslUpdateScore(zs->zsl,curscore,ele,score); /* Note that we did not removed the original element from * the hash table representing the sorted set, so we just * update the score. * hash 表中不需要移除元素, 修改分值就可以了 * * */ dictGetVal(de) = &znode->score; /* Update score ptr. */ *flags |= ZADD_UPDATED; } return 1; // 元素不存在 } else if (!xx) { ele = sdsdup(ele); // 插入新元素 znode = zslInsert(zs->zsl,score,ele); serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK); *flags |= ZADD_ADDED; if (newscore) *newscore = score; return 1; } else { *flags |= ZADD_NOP; return 1; } } else { serverPanic("Unknown sorted set encoding"); } return 0; /* Never reached. */ } // 往跳錶中 新增元素 zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; unsigned int rank[ZSKIPLIST_MAXLEVEL]; int i, level; // 數值判斷 serverAssert(!isnan(score)); x = zsl->header; // 遍歷所有層高 ,尋找插入點: 高位 -> 低位 for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position 存儲排位, 便於更新 */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || // 找到第一個比新分值大的節點,前面一個位置即是插入點 (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) //相同分值則按字典序排序 { rank[i] += x->level[i].span; // 累加排位分值 x = x->level[i].forward; } update[i] = x; // 每一層的拐點 } /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. * * */ level = zslRandomLevel(); // 冪次定律, 隨機生成層高 ,越高的層出現概率越低 if (level > zsl->level) { // 隨機層高大於當前的最大層高,則初始化新的層高 for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; //header 最層都是跳錶的長度 } zsl->level = level; } x = zslCreateNode(level,score,ele); // 創建新的節點 for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; // 插入新節點 update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here 更新 span 資訊 */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; } /* increment span for untouched levels 新加入節點, 更新頂層 span */ for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; } // 更新後退指針 和尾指針 x->backward = (update[0] == zsl->header) ? NULL : update[0]; if (x->level[0].forward) x->level[0].forward->backward = x; else zsl->tail = x; zsl->length++; return x; } //返回一個隨機的層數,不是level的索引是層數 int zslRandomLevel(void) { int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) //有1/4的概率加入到上一層中 level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; }
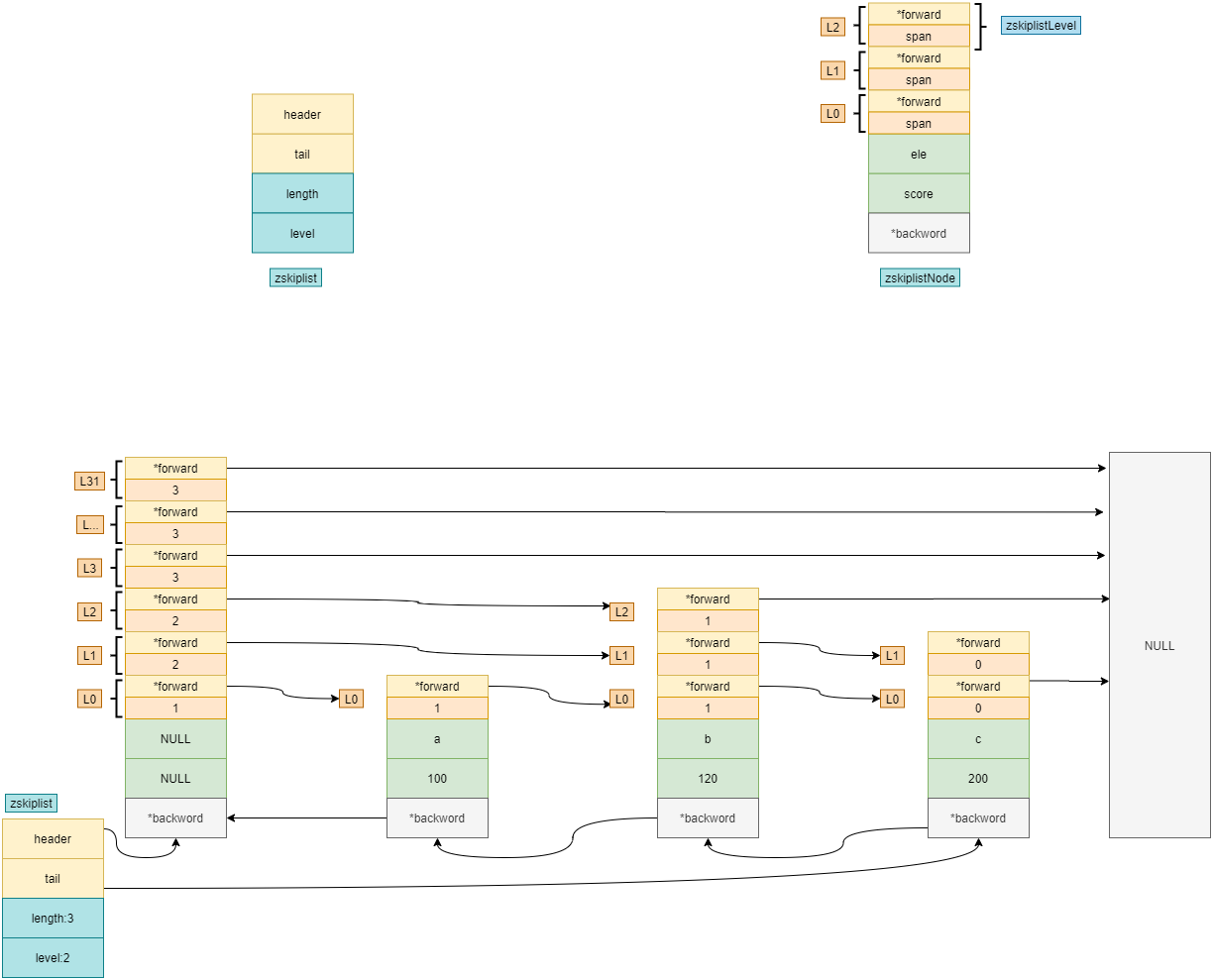
【3】示圖展示
【4】示圖說明
1.默認會構造一個不存數據的擁有32層高度的頭結點,而每加一個結點,會自身去概率生成層數(概率為1/4),這樣就可以通過頭結點快速查找數據了。

