分散式系統中的主從複製基本原理
分散式系統中的主從複製基本原理
複製指在多台機器上保存相同數據的副本,通過數據的複製,人們希望達到以下目的:
- 使用戶使用物理上離他們更近的的數據,降低訪問延遲。
- 部分組件出現故障,系統仍然可以繼續工作,提高可用性。
- 擴展至多台機器以令他們同時提供數據訪問服務,提高讀吞吐量。
本文只討論一些簡單情況:數據規模比較小,每台機器都可以存儲數據集的完整副本;只考慮簡單的故障問題;不考慮多主節點和無主節點架構。
1. 主從複製的基本工作原理
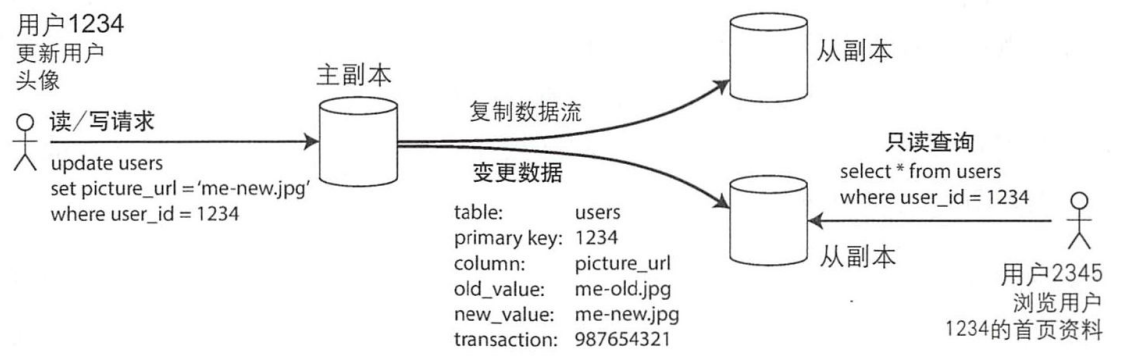
- 指定一個節點為主節點,客戶寫資料庫時首先寫到主節點。
- 其他節點為從節點,主節點將數據寫到本地後將數據更改以日誌的形式發送給所有從節點。每個從節點獲得日誌後將其應用到本地的,且嚴格保持與主節點相同的寫入順序。
- 客戶端從資料庫讀數據時,可以在主節點或從節點上執行查詢。只有主節點可以接受寫請求,所有節點都可以接受讀請求。
複製技術廣泛應用於各種關係型資料庫、非關係型資料庫、分散式消息隊列、網路文件系統等等。
2. 同步複製與非同步複製
對於關係型資料庫,複製通常是同步或非同步可選的的。對於其它系統通常是只能選擇其中一個。
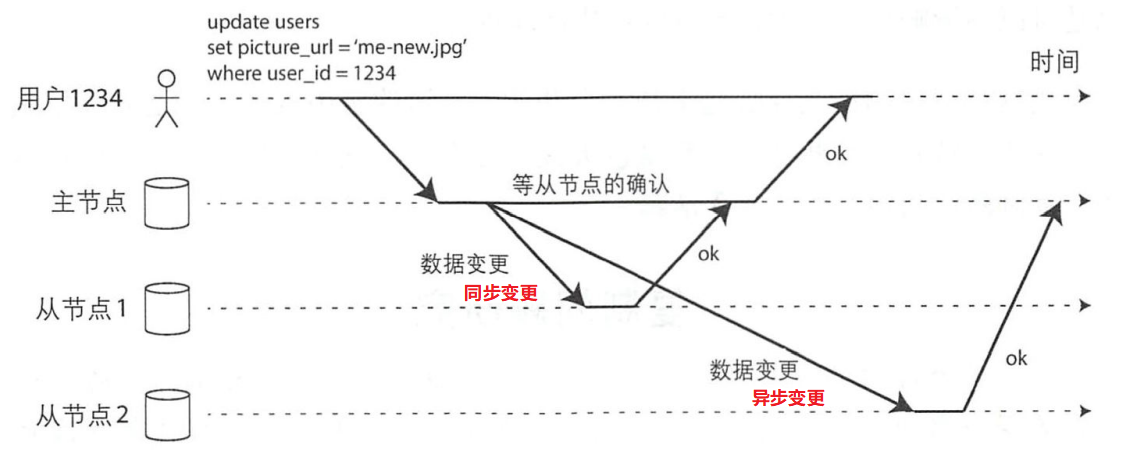
上圖中表達了向從節點1同步變更,向從節點2非同步變更。
2.1 從節點失效:追趕式恢復
從節點的失效恢複比較簡單,只需要通過中斷前記錄的最後一個執行事務的事務號,向主節點請求從這個事務到當前中間執行的所有操作,然後追趕上主節點的進度即可。
2.2 主節點失效:節點切換
當主節點失效,我們要做的是將其中一個從節點提升為主節點,令他行使主節點的職責。這個過程可以手動切換,也可以自動進行,自動進行的步驟如下:
- 確認主節點失效。一般使用心跳+超時的機制。節點之間互相發送心跳消息來確認對方是否存活,超過一段時間未收到心跳消息回復則認為該節點已下線。
- 選舉新的主節點。可以通過共識選舉的方式確定新的主節點,也可以由之前選定的某控制節點來指定新的主節點。主要原則在於讓新的主節點和原主節點最為相似。
- 重新配置系統使主節點生效。我們需要做一些配置讓新的主節點切實生效,例如讓所有客戶端將請求路由到新的主節點上;在原主節點再次上線之後令他降級為從節點。
上述過程中存在許多變數:
-
如果使用的是非同步複製,且失效之前新主節點沒收到原主節點的所有數據,且選舉之後原主節點很快重新上線。接下來新的主節點很可能收到來自原主節點的衝突的寫請求,因為原主節點尚未搞明白身份的變化。
常見的解決方案是,原主節點上未完成複製的寫請求就此丟棄。
-
在故障情況下,可能出現兩個節點都認為自己是主節點,這種情況非常危險並且難以處理。
-
難以設置恰好的超時時間來判定主節點失效,過長可能導致恢復時間太長,過短可能導致很多不必要的主節點切換。
3. 複製日誌的實現
3.1 基於語句的複製
最簡單的方法,主節點將每個寫請求轉發給從節點。這樣做很合理也不複雜,但有一些不適用的場景:
- 任何調用非確定函數的語句,比如
NOW()獲取當前時間,RAND()獲取一個隨機數。 - 語句中使用了自增列,或依賴於資料庫的現有數據。那麼副本必須按完全相同的順序執行。
- 有副作用的語句,如觸發器,存儲過程,用戶自定義函數等。
3.2 基於預寫日誌WAL傳輸
主節點可以將它的 WAL 日誌傳輸給從節點,從節點依次構造數據副本。
這樣做缺點在於複製方案強依賴於存儲引擎的實現方式(實質上是 WAL 的實現方式)。
3.3 基於行的邏輯日誌複製
我們也可以令複製和存儲引擎採用不同的日誌格式,讓複製和存儲邏輯剝離。
關係型資料庫的邏輯日誌往往是以下這樣的實現:
- 對於行插入,日誌包含新值。
- 對於行刪除,日誌唯一標識已刪除的行,通常是依賴主鍵。
- 對於行更新,日誌唯一標識需要更新的行和他們的新值。
如果事務涉及多行的修改,則會產生多個這樣的日誌記錄,並在後面跟著一條記錄來指出事務已經提交。例如 MySQL 的 binlog 是這樣實現的。
3.4 基於觸發器的複製
前面的複製方法都是資料庫提供的,我們也可以自己實現一個觸發器,來自己實現複製的邏輯。


