[演算法2-數組與字元串的查找與匹配] (.NET源碼學習)
- 2022 年 9 月 29 日
- 筆記
- .NET源碼學習, C#相關知識, 演算法&數據結構學習心得
[演算法2-數組與字元串的查找與匹配] (.NET源碼學習)
關鍵詞:1. 數組查找(演算法) 2. 字元串查找(演算法) 3. C#中的String(源碼) 4. 特性Attribute 與內在屬性(源碼) 5. 字元串的比較(底層原理) 6. C#中的StringComparsion(源碼) 7. 字元串與暫存池(底層原理)
【註:本人在寫文章時遇到認為有必要或想要展開的點就會將其併入文章中,避免事後遺忘。因此非主題內容可能會比較多,篇幅也可能比較大,各位學者在瀏覽時可以自行轉跳到感興趣的部分進行閱覽,存在相關問題或建議,歡迎留言指導,謝謝!】
查找,大體上可以分為兩類:數組查找、字元串查找。其中數組查找以二分為主;字元串查找以BK、BM、KMP三類演算法為主。由於二分在之前的文章中已經詳細敘述過,在此不再重複論述。故本文主要以有關字元串的查找為重點,附帶.NET關於String類型及相關底層邏輯的源碼分析為主,進行論述。
【# 請先閱讀注意事項】
【註:
(1)文章篇幅較長,可直接轉跳至想閱讀的部分。
(2)以下提到的複雜度僅為演算法本身,不計入演算法之外的部分(如,待排序數組的空間佔用)且時間複雜度為平均時間複雜度。
(3)除特殊標識外,測試環境與程式碼均為.NET 6/C# 10。
(4)默認情況下,所有解釋與用例的目標數據均為升序。
(5)默認情況下,圖片與文字的關係:圖片下方,是該幅圖片的解釋。
(6)文末「 [ # … ] 」的部分僅作補充說明,非主題(演算法)內容,該部分屬於 .NET 底層運行邏輯,有興趣可自行參閱。
(7)本文內容基本為本人理解所得,可能存在較多錯誤,歡迎指出並提出意見,謝謝。】
一、有關數組
(一) 二分查找及相關優化
關於二分的相關內容,在本人的這篇文章中(LC T668筆記 & 有關二分查找、第K小數、BFPRT演算法 – PaperHammer – 部落格園 (cnblogs.com))有較為詳細地論述,詳情請參閱。
在此,僅總結一下二分的要點:
1. 二分集合須保證有序。有序是二分的前提,在二分前須明確二分的對象,該對象必須具有有序性。
2. 確定搜索區間形式(閉區間、左閉右開、左開右閉)。不同區間形式,循環條件與最終返回值不同;同時也應用於不同的場景。
3. 盡量寫或想清楚所有的if…else…,清楚地展現出所有細節,避免不必要的紕漏與麻煩。
(二) 有關方法BinarySearch()的源碼
該方法的主要實現形式是雙指針或折半查找,詳細內容在本人之前的文章([數據結構1.2-線性表] 動態數組ArrayList(.NET源碼學習) – PaperHammer – 部落格園 (cnblogs.com))中,詳情請參閱。
二、有關字元串
(一) .NET中的String與C#中的string
1. C#是區分大小寫的語言,所以string與String理論上是不同的,但在編譯器的定義導航中,卻將這兩個類型均導航至同一個類——類String。
2. 據現有資料可知,String是.NET(以前稱為.NET Framework)中的類,string是C#中的類。在C#中使用string時,編譯器會將string自動映射到.NET中的String,同時調用的方法也是.NET中類String內部的方法。據該原理,使用String可以在一定程度上減少編譯器的工作量,但微軟官方不建議這樣,依舊建議使用string以符合相關規範。其他基本數據類型也是如此,如short映射Int16,int映射Int32,long映射Int64,double映射Double等。
3. 這樣做的原因個人猜測可能如下:.NET是一套底層運行規範,其需要對所有支援的語言定義一個通用的規則(CLS通用語言規範Common Language Specification)不同語言語法的不同,.NET通過CLS提供了公共的語法,不同語言經過IL的翻譯生成對應的.NET語法。如F#中的let賦值語句(let str = 「.NET」;;);VB中的String(Dim 變數名 As String = 「.NET」);加上現在C#中的string。它們都是基於.NET運行的,所以需要有一個總綱來規範化,使得每個語言具有獨特性的同時,可以實現相同或相近的功能。因此在.NET中定義了類String,無論時哪種語言,只要編譯時需要使用.NET,均須遵守其相關規範,將獨特的風格轉換為統一且通用的規範化表達。
4. 因此,String不是C#中的關鍵字,可以將其用作變數名。
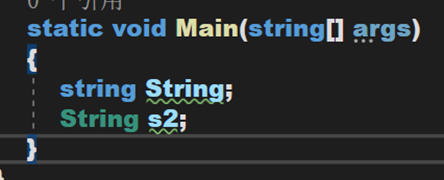
(二) 有關類String

String類位於命名空間System中,是一個公共密封類,繼承了許多介面,其中「著名的」有:IComparable用於字元串間的比較;IEnumerable用於迭代器的遍歷。其內部包含2個屬性,3個欄位,1個結構(體),3種運算符的重載方法,9個構造方法和一堆其他方法(真的太多了)。
1. 兩個屬性
首先是索引器,可以發現這是一個以int為索引,char為返回值的只讀索引器。對比其他數據類型的索引器,如之前文章提到的動態數組ArrayList

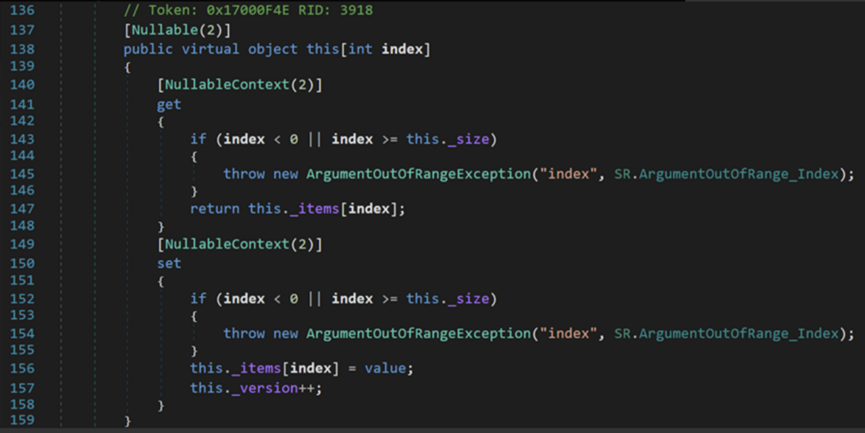
不難發現,String中的索引器只讀不能寫,因此經常頭昏會寫出這樣的程式碼:
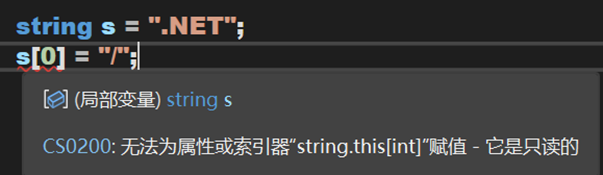
同時,String類中的索引器還是一個extern屬性,說明其支援在外部根據不同的需求重新定義新的索引器。

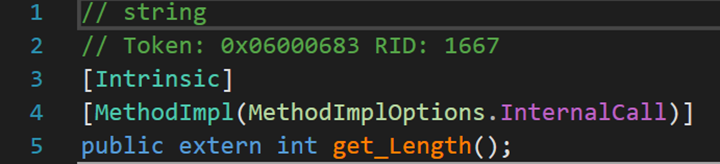
第二個數Length屬性,其內部包含了一個get_Length()方法,用於返回字元串的長度(調用的時候,不用在後面加括弧,且第一個字母大寫)。
可以看到,這裡都出現了Intrinsic和MethodImpl及其相關內容,這兩個內容會在文末進行補充說明。
2. 三個欄位
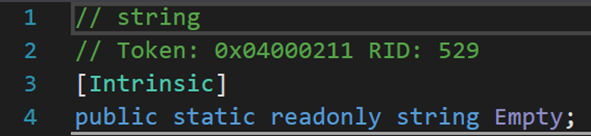
string.Empty用於初始化字元串為空。這裡對四種初始化方式:(省略前綴string)str = null;str = 「」;str = string.Empty;str = new()進行分析。
(1)對於str = null,理論上這種方式不能稱之為常規意義上的初始化,因為賦值為null並沒有在堆上分配,僅是在棧上分配了空間,依然不可直接使用,因為變數不引用記憶體中的任何對象。這種方式,相當於只定義了一個變數並未對其賦值,在使用前必須先賦值。
(2)對於str = 「」與str = string.Empty,其初始化並在記憶體空間堆與棧上都進行分配,將其賦值為空。其在基本用法和性能上並沒有較大差異。
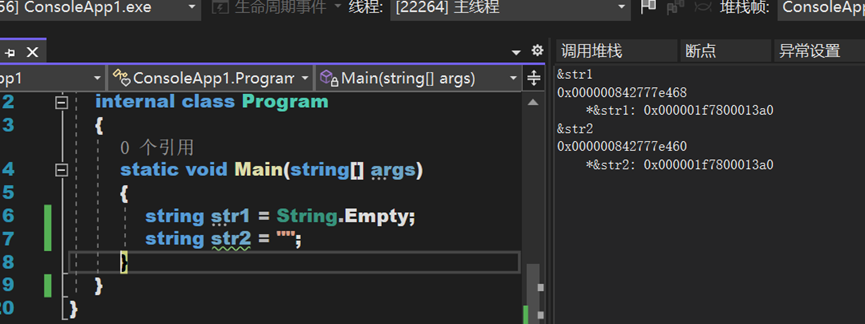
據測試後可知,即使已存在一個空字元串,用以上兩種方法繼續進行定義變數,均不會重新申請新的記憶體空間,而是每次去指向固定的靜態只讀記憶體區域。
據CLR中的相關資訊及本人的理解,二者僅僅在優化方面稍有差別,string.Empty是C#對””在語法級別的優化。也就是說,“”是通過CLR(Common Language Runtime公共語言運行庫)進行優化的,CLR會維護一個字元串池,以防在堆中創建重複的字元串。而string.Empty是一種C#語法級別的優化,是在C#編譯器將程式碼編譯為IL(即MSIL)時進行了優化,即所有對string類的靜態欄位Empty的訪問都會被指向同一引用,以節省記憶體空間。
還有兩外兩個欄位。這兩欄位從命名來看,一個變數存儲的是字元串的長度;另一個存儲的是第一個字元。有關二者的應用及更多內容,會在之後的某些方法中進一步解釋。

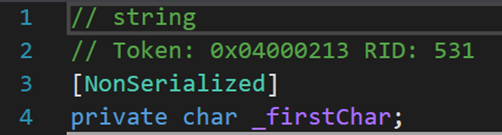
3. 一個結構(體)
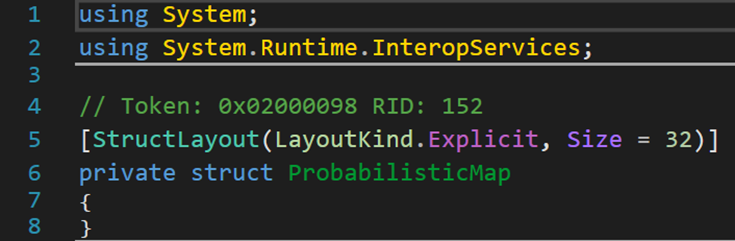

該結構體派生自類object下的類ValueType,從父類來看應該是用於存儲某些數據類型間的映射關係。(下方翻譯來自Microsoft Bing)

4. 三種運算符重載



首先是運算符「==」和「!=」。對於兩個字元串的比較,類String內部從新定義了比較規則,即重載了判斷運算符,使用判斷運算符就相當於調用類String內部的Equals()方法。因此,對於字元串而言,使用「==」和方法Equals()進行比較,是完全等價的。
一般地,對於運算符「==」和Equals()方法,在比較方式上還是有所差異。
(1)對於值類型和字元串,這兩種方式均只比較內容;
(2)對於除字元串以外的引用類型,運算符」==」比較的是在棧中的引用(是否指向同一個對象);方法Equals()比較的是在堆中的內容(是否是同一個對象的引用)。
但這樣就有一個問題,我們知道C#對於字元串有某些優化。一般地,內容相同的字元串不會開闢新的堆空間,而是指向儲存在暫存池(堆的一部分,Java中稱為常量池)中的對象。但以某些方式創建的字元串對象,並不會檢查暫存池,而是直接在堆中開闢新空間,導致內容相同的字元串,棧和堆的地址均不同。那麼這樣是否會導致判斷運算符和方法Equals()出現問題呢?有關該部分的詳細內容請轉到文末的 [# 有關字元串的比較與暫存池]
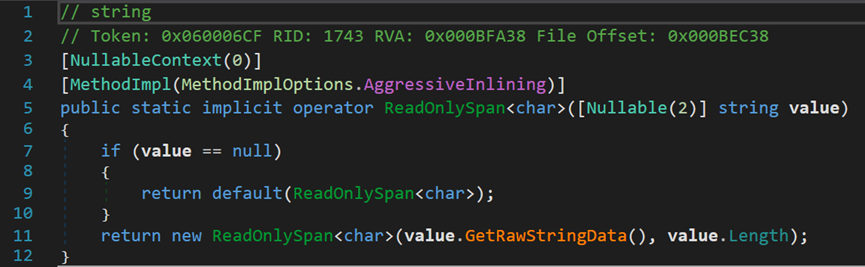
其次是ReadOnlySpan<T>。這是一種較為特殊的運算符重載,其中關鍵字implicit用於聲明隱式的自定義類型轉換運算符。它可以實現2個不同類型的隱式轉換,提高程式碼的可讀性。但是使用隱式轉換操作符之後,在編譯時會跳過異常檢查,所以在使用隱式轉換運算符前,應當在一定程度上確保其不會引發異常並且不會丟失資訊,否則在運行時會出現一些意外的問題。該隱式轉換,是將string類型轉換成ReadOnlySpan<char>類型。
先簡單介紹一下類型Span<T>
![]()
該類型被微軟官方稱為「新增的重要組成部分「,其主要作用是提供任意記憶體連續區域的類型安全與記憶體安全表示形式。即,此數據類型可以實現對任意記憶體的相鄰區域進行操作,無論相應記憶體是與託管對象相關聯,還是通過互操作由本機程式碼提供,亦或是位於堆棧上。解決了在不使用不安全程式碼(指針等直接對記憶體進行的操作)的情況下,實現了在記憶體上,對數據進行修改的操作。更多詳細資訊請參閱(C# – Span 全面介紹:探索 .NET 新增的重要組成部分 | Microsoft Docs)。
ReadOnlySpan<T>亦是如此,只是被附上了對內部元素只讀的屬性,以滿足字元串不可修改的基本性質。


其將傳入的字元串首字元作為指針的起始位置,length為字元串的長度,通過指針+偏移量的方式(類似於C++中通過指針ptr訪問數組第一個位置,ptr++實現向後偏移),實現對數據的訪問。
5. 九個構造方法

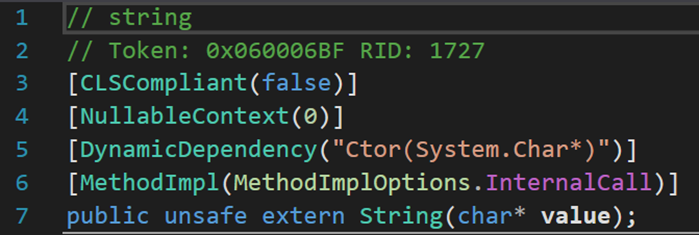
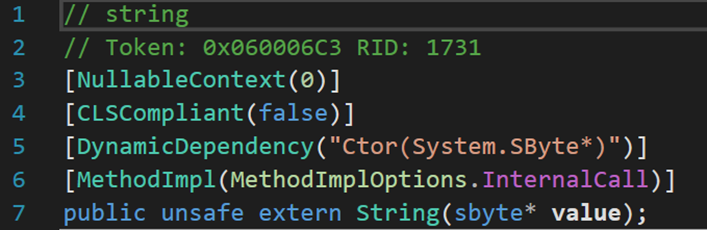

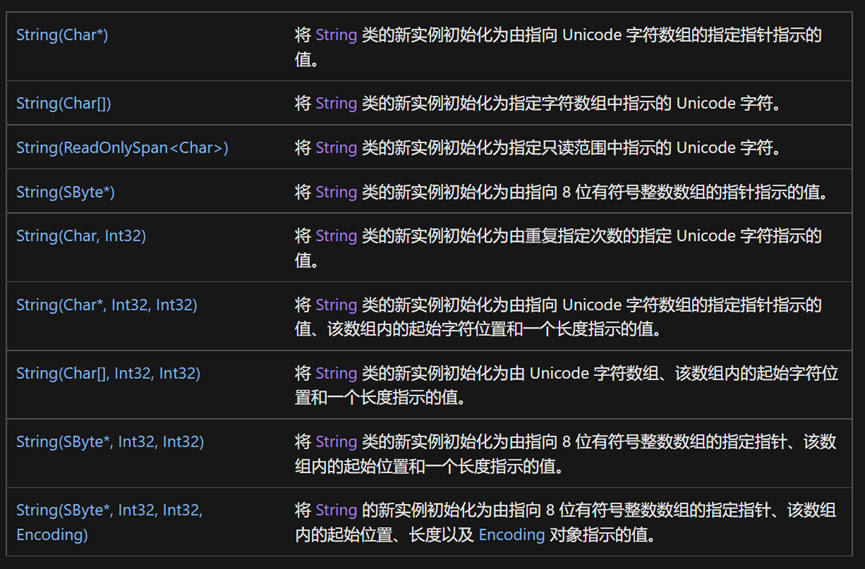
與其他類型的構造方法不同,這九個構造方法均為外部方法extern,需要從外部從新定義其實現形式。個人猜測,外部定義可能在.NET庫中。其功能均是將所給數據集,按照一定條件轉化為字元串。詳細資訊參考下表:
(三) 有關String的查找與匹配
1. BF演算法(Brute Force)
Brute Force,一種暴力匹配演算法,其思想是對於兩個字元串 s 與 ,在s(主串)中查找/匹配pat(模式串)。若s[i] == pat[j],則i++且j++;否則i++且j = 0。此時 i 即為模式串 pat 在主串 s 中第一次匹配的起始下標位置。
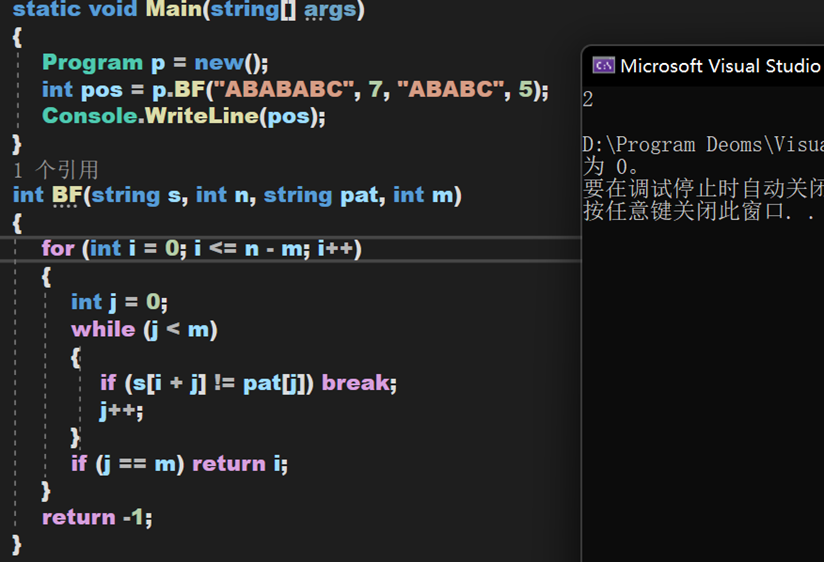
複雜度分析:
- 時間複雜度:O( nm )(最快O( n+ m ),pat 在 s 的開頭就匹配完成;最慢O( nm ),每次都是在 pat 的末尾匹配失敗)
- 空間複雜度:O( 1 )
我們找個題目測試一下其運行效率(題目:kmp演算法_牛客題霸_牛客網 (nowcoder.com))

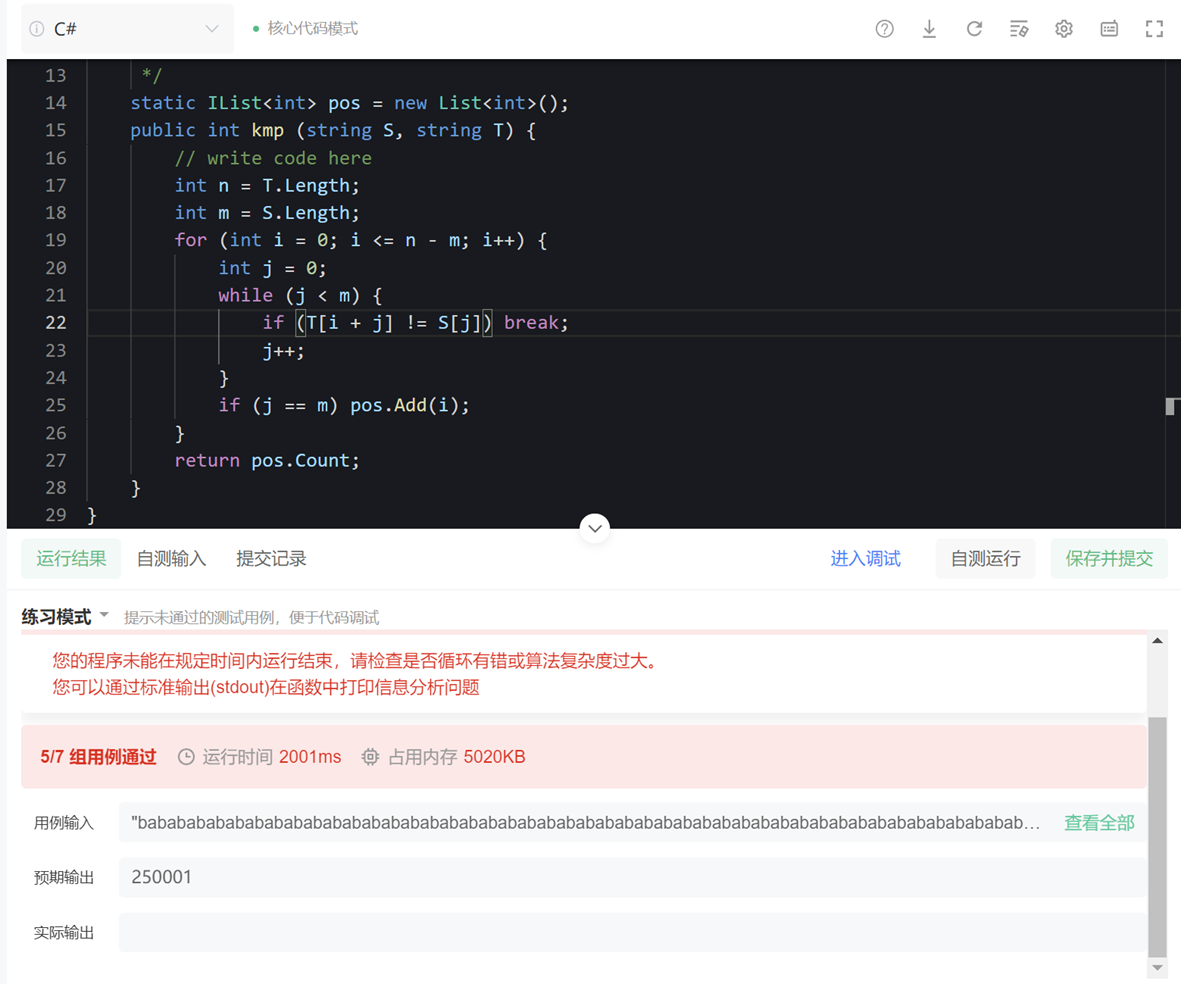
實測運行時間:
【註:由於牛客上的本題無法獲取該超時樣例,因此此處及之後選用某一衰減測試樣例進行實測計時,僅用於觀察演算法時間複雜度。樣例:主串字元全為 『A』,長度為500000;模式串字元全為 『A』,長度為100】

毫無疑問,對於這樣的時間複雜度, 105 及以上量級的數據是比較慢的。雖然理論上BF演算法時間複雜度較高,但其在實際開發中比較常用原因主要有以下2點:
(1)實際開發中,多數情況下主串與模式串長度不會很長。對於小規模數據,其時間複雜度並不能代表其執行時間,某些情況下,可能比其他優化後的演算法更快。因此,儘管理論最壞時間複雜度為 O( nm ),但從概率統計上看,多數情況下其效率還是可觀的。(打比賽另說)
(2)BF 演算法思想簡單,實現簡單。簡單意味著不容易出錯,出錯也很容易查找修改。工程應用中,在滿足性能的前提下,簡單是我們的首選。這也符合 KISS (Keep It Simple and Stupid) 設計原則。
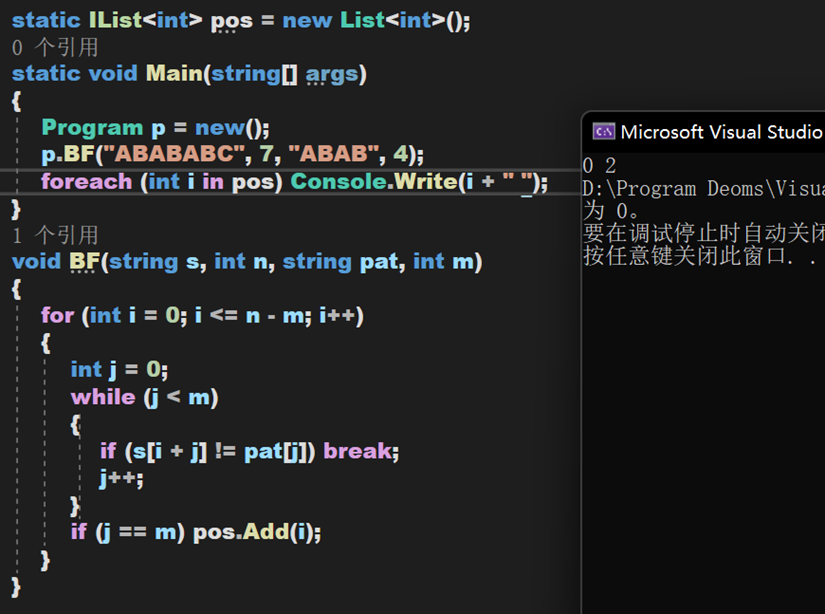
【思考】如果要返回所有匹配的字串首地址,該如何實現?
【參考如下】
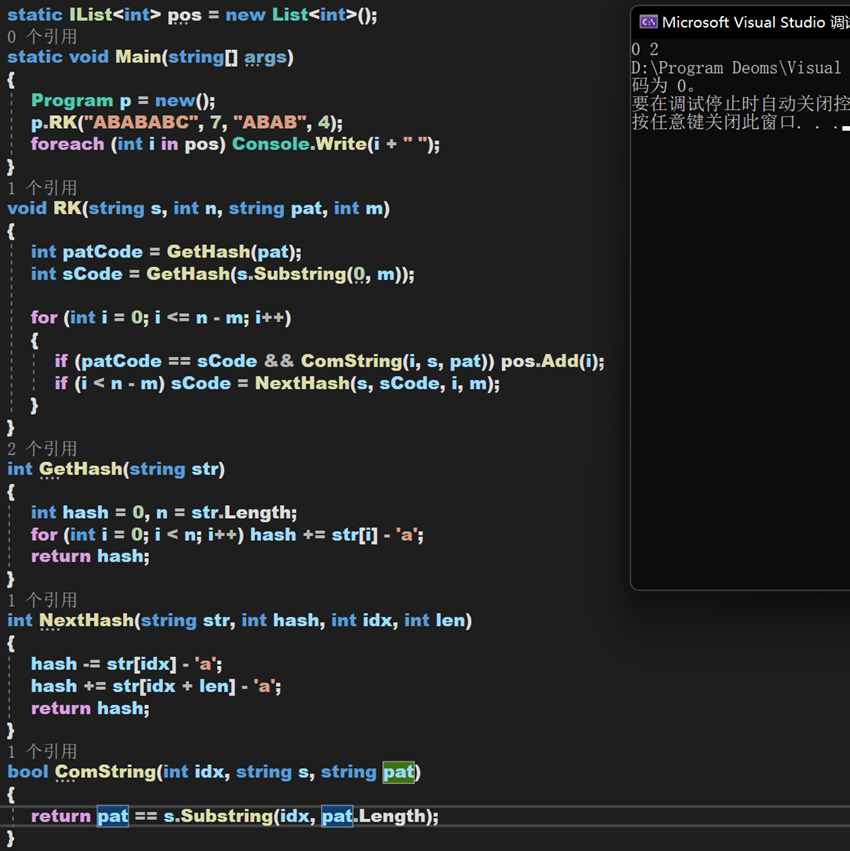
2. RK演算法(Rabin-Karp)
該演算法算是對BF演算法的優化,既然比較字元效率不高,那不如換一種比較對象。要轉換那就需要保證按照某種規則進行轉換,且轉換後需要保證唯一性。對於每個字元串,除了它本身外有一種一般情況下唯一的表示方式,哈希值。並且數字的比較效率要比字元高上不少;而且字元要一個一個比較,而哈希值可以代表一個串,所以比較的時候時間複雜度為 O( n )。
簡單來說其方法思想是,在主串中每次截取和模式串一樣長的字元串,獲取二者的哈希值進行比較。
【註:有關.NET/C#中的哈希及其衝突的問題,會在今後的文章的提到,以下均默認不會發生哈希衝突】
獲取哈希值有兩種方法:
(1)遍歷字串中每個字元。這樣就會有許多操作:截取、遍歷、計算。但反覆直接截取並沒有優化時間複雜度,反而在一定程度上增加了時間複雜度,因為截取字元串也是一個O(n)級的操作,因此總時間複雜度依舊是O(n2)級。我們好不容易將複雜度降低了一個量級,結果算個哈希又把量級升了回來,得不償失。
(2)滑動窗口。
根據滑動窗口的原理,獲取第一個串後,之後串的哈希值,可以根據移除前一個,加入後一個來實現,從而將O(n)的時間複雜度降為O(1)。具體實現如下:
複雜度分析:
現在,該演算法第一次計算t的哈希值時,時間複雜度為O( n );後續計算哈希值因為利用了滑窗的優化只有O( 1 );比較字元串的Equals()方法,一般地,可以視為O( 1 )。
- 總時間複雜度為O( n )
- 空間複雜度為O( 1 )
這裡解釋一下為什麼兩串求得的哈希值相同還要對字元串本身進行比較。當兩個串字元類型與數量相同時(如 「aaab」,」abaa」 )以這樣的方式進行哈希計算,會得出相同的值,但兩個字元串本身並不相同。這也是其缺點:不穩定,過於簡單的計算方式或較大的數據量很容易產生哈希衝突。同時,在極端情況下,如果存在大量哈希衝突(哈希值相同,字元串本身並不相同),每次都要比較主串某一部分與模式串,那麼RK演算法就會退化為BF演算法,時間複雜度重回 O( nm )。
同樣,再測一下剛才的題

實測時間:

可以發現,RK演算法在一定程度上確實比純暴力得BF演算法效率要高,尤其是當主串長度越長時,提升越明顯。
【思考】假設有兩個以行為優先主序列二維矩陣,如果要返回所有匹配的字串首地址,該如何實現?
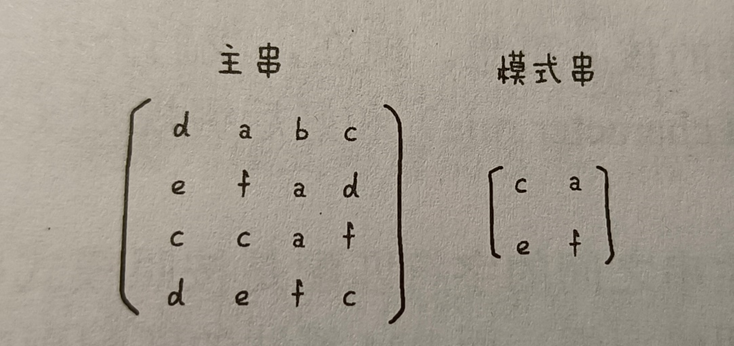
【參考如下】
RK演算法比較的是字元串的哈希值,那隻要獲取了對應位置的哈希值,進行比較即可。對於一維,在哈希值轉移時只需減去前一個、加上後一個;而二維的轉移需根據模式串的規格而定。
using System; using System.Collections; using System.Collections.Generic; using System.Linq; using System.Text; using System.Numerics; using System.Diagnostics; using System.Runtime.CompilerServices; namespace Common { internal class Program { static IList<int[]> pos = new List<int[]>(); static int m, n; static int p, q; static void Main(string[] args) { Program pg = new(); char[][] s = { new char[]{ 'c', 'a', 'b', 'c' }, new char[]{ 'e', 'f', 'a', 'd' }, new char[]{ 'c', 'c', 'a', 'f' }, new char[]{ 'd', 'e', 'f', 'c' } }; char[][] pat = { new char[]{ 'c', 'a' }, new char[]{ 'e', 'f' } }; m = s.Length; n = s[0].Length; p = pat.Length; q = pat[0].Length; pg.RK(s, pat); foreach (int[] arr in pos) Console.WriteLine("{ " + arr[0] + ", " + arr[1] + " }"); } void RK(char[][] s, char[][] pat) { int patCode = GetHash(pat, 0, 0); int sCode = GetHash(s, 0, 0); for (int row = 0; row <= m - p; row++) { for (int col = 0; col <= n - q; col++) { if (patCode == sCode && ComString(s, pat, row, col)) pos.Add(new int[] { row, col }); if (row < m - p || col < n - q) sCode = NextHash(s, sCode, row, col); } } } int GetHash(char[][] tmp, int row, int col) { int hash = 0; for (int i = row, cntR = 0; cntR < p; i++, cntR++) for (int j = col, cntC = 0; cntC < q; j++, cntC++) hash += tmp[i][j] - 'a'; return hash; } int NextHash(char[][] s, int hash, int row, int col) { if (row < m - p && col == n - q) return GetHash(s, row + 1, 0); for (int i = row, cntR = 0; cntR < p; i++, cntR++) { hash -= s[i][col] - 'a'; hash += s[i][col + q] - 'a'; } return hash; } bool ComString(char[][] s, char[][] pat, int row, int col) { for (int i = row, cntR = 0; cntR < p; i++, cntR++) for (int j = col, cntC = 0; cntC < q; j++, cntC++) if (s[i][j] != pat[cntR][cntC]) return false; return true; } } }
3. KMP演算法(Knuth-Morris-Pratt)
【參考文章:漫畫:什麼是KMP演算法?;KMP演算法—終於全部弄懂了_June·D的部落格-CSDN部落格】
回顧一下前兩種演算法效率不高的原因:在不匹配時,從待匹配串的起始位置重新全部開始匹配;反覆計算哈希值,且需要處理哈希衝突的問題。這兩種方式可以看作每次將字元串向後一位一位滑動。這樣的方式導致了中間存在大量無意義的比較,以及不得不完成的比較,使得效率低下。而KMP就針對這一點進行了優化,其核心在於:在匹配過程中,當不匹配時,對於已匹配好的部分,找到一種規律,將模式串一次性向後滑動很多位,從而提高效率。其中,記不匹配的字元為 「壞字元」,已匹配的部分為 「好前綴」。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 於是現在的問題就:如何制定滑動策略?
思考一個應用場景:在一篇文章中匹配某個字元串。那麼對於不同的主串,總是用同一個模式串去匹配。如果每針對一個新匹配的主串都要制定新的策略,那麼時間複雜度依舊是 n2 級,甚至超過該級數。因此,制定的滑動策略不應該依賴於主串,對於同一個模式串,應當嘗試製定同一個滑動策略。即,滑動的策略只與模式串有關。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 接下來進一步思考滑動策略的細節:不匹配時,應當滑動到哪裡?
舉個例子:
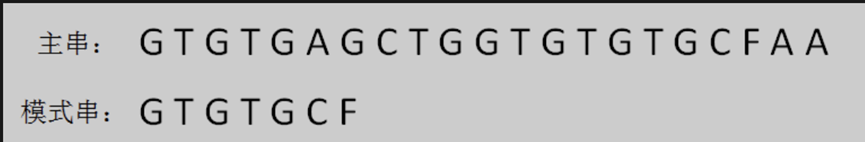
首先,把主串和模式串的首位對齊,從左到右對逐個字元進行比較。

第一輪,發現前5個字元都是匹配的,第6個字元不匹配,將其標記為壞字元 『A』。

【重難點】
可以發現,在好前綴 「GTGTG」 當中,主串的好前綴的後三個字元 「GTG」 和模式串的前三位字元 「GTG」 是相同的。我們分別把這兩部分記作可匹配後綴子串與可匹配前綴子串。在之後的比較中,這兩部分一定能夠匹配上。並且在這兩個部分匹配上之前,一定沒有其他可能使得模式串成功匹配的情況,這也為選擇最長的子串進行滑動提供了保障。因此,我們直接將模式串後移兩位,使得這兩部分對齊,並開始下一次比較,省去了中間的無效比較。
同理,如果在好前綴中如果存在多個可匹配後綴子串,那麼為了能省區更多的無效比較,我們選擇找到最長的子串進行滑動。因此,我們的滑動策略為:在主串的好前綴中,找到最長可匹配後綴子串;在模式串中,找到對應的最長可匹配前綴子串。
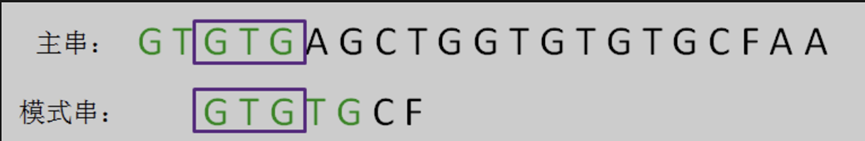
第二輪,我們直接把模式串向後移動兩位,讓兩個 「GTG」 對齊,繼續從剛才主串的壞字元 『A』 開始進行比較。

此時,主串的字元 『A』 仍然是壞字元,這時候的匹配前綴縮短成了 「GTG」。

按照第一輪的思路,我們來重新確定最長可匹配後綴子串和最長可匹配前綴子串。此時,剩下字元串 「G」。

第三輪,我們再次把模式串向後移動兩位,讓兩個「G」對齊,繼續從剛才主串的壞字元A開始進行比較。
……
小結:整體思路是,在主串的好前綴中尋找最長可匹配後綴子串(在好前綴中,從後往前找),在模式串中尋找對應的最長可匹配前綴子串(在已匹配串中,從前往後找),直接把兩者對齊,從而實現模式串的快速滑動。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 知道了退回到哪裡,現在的關鍵在於如何實現退回?【重難點】
我們肯定不能每次都從頭遍歷一遍去尋找前後綴子串。前文提到找到某種規律,在每次失配後,都不會從頭重新開始枚舉,而是根據這種規律,從某個特定的位置開始匹配;而對於模式串的每一位,都具有唯一的規律,這種規律可以幫助我們利用已有的數據不用從頭匹配,從而節約時間。
注意到,對於主串中的某一最長可匹配後綴子串,在當前狀態下是已經匹配上的。如果在模式串中找到了另一個合法的最長可匹配前綴子串,那我們就將其進行滑動。說明,如果可以滑動,那麼在模式串中,一定存在兩個不同起始位置的子串,且這兩個子串的內容是相同的。因此我們可以用這個資訊,在只依賴模式串的情況下完成規律的查找與構建。
數學化表達:對於模式串 t 的每個元素 t[j],都存在一個實數 k ,使得模式串 t 開頭的 k 個字元( t[ 0 ], t[ 1 ],…, t[ k-1 ] )依次與 t[ j ] 前面的 k 個字元( t[ j-k ], t[ j-k+1 ],…, t[ j-1 ] ) 相同(其中,字元 t[ j-k ] 最少從 t[ 1 ] 開始,須保證不重複,所以 k < j )。。如果這樣的 k 有多個,則取最大的一個,以此保證最長。模式串 t 中每個位置 j 的字元都適配這種規律,定義一個 next 數組存儲這種規律,即 next[ j ] = MAX{ k }。
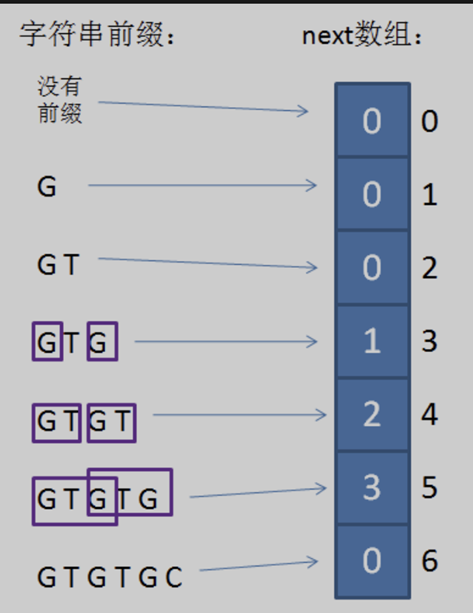
對於 next 數組,其索引表示當前比較的兩個字元的位置 『j』 ;索引對應值表示 k 。若當前字元為壞字元,則可以滑動 j – k 位,即下一次的比較位置。
(1) 當模式串的第一個字元和主串不匹配時,並不存在已匹配前綴子串,更不存在最長可匹配前綴子串,因此next數組下標是0,next[ 0 ]的元素值也是0。
(2) 如果已匹配前綴是 「G」、「GT」、「GTGTGC」,但其並不存在最長可匹配前綴子串,所以對應的next數組元素值(next[ 1 ],next[ 2 ],next[ 6 ])同樣是0。
(3) 對於好前綴 「GTG」,此時比較位置為索引 j = 3,從該位置向前找最長可匹配前綴子串;從開頭找最長可匹配後綴子串,得出最長可匹配前綴是 『G』,即 k = 1(此時滑動 j – k = 2 位)。因此,對應數組中的next[ 3 ],元素值是k = 1(即,下一次的比較位置)。以此類推,「GTGT」 對應 next[ 4 ],元素值是2;「GTGTG「 對應 next[ 5 ],元素值是3。
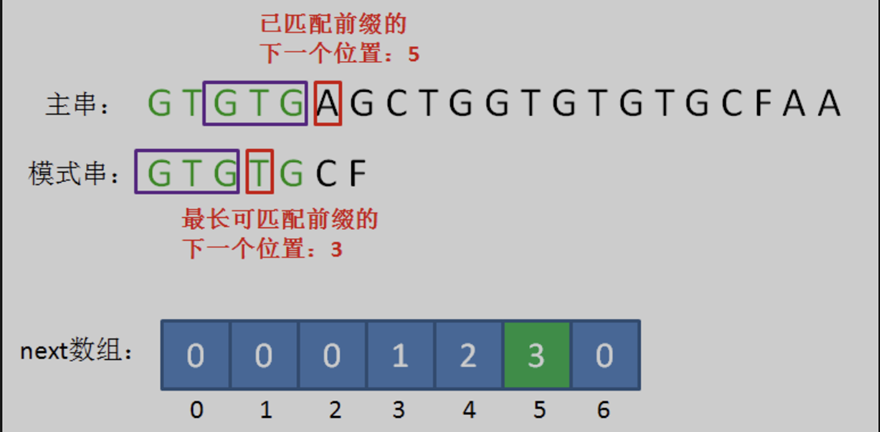
小結:用一個數組保存每個字元的資訊,當在該字元處不匹配時,通過數組保存的資訊,退回到相應位置。其中,數組的下標表示「當前比較兩個字元的位置 j」,元素的值則是「最長可匹配前綴子串的下一個位置 《=》 最長可匹配前綴子串的長度 《=》 MAX{ k }」。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 如何構建next數組?【重難點】
這個問題其實剛剛已經基本講述清楚了,現在按照例子再過一遍,掌握這個構建方法,就掌握了KMP的核心。
由於已匹配前後綴子串僅在模式串中查找,與主串無關。所以僅依據模式串,即可生成next數組。
最簡單的方法是從最長的前綴子串開始,把每一種可能情況都做一次判斷。假設模式串的長度是m,生成next數組所需的最大總判斷次數是1+2+3+4+……+m-2 次。
顯然,這種方法的效率非常低,整體近似 n2 的量級。因此,可以採用類似「動態規劃」的方法。首先next[ 0 ]和next[ 1 ]的值肯定是0,因為不存在前後綴字串;從next[ 2 ]開始,next數組的每一個元素都可以由上一個元素推導而來。
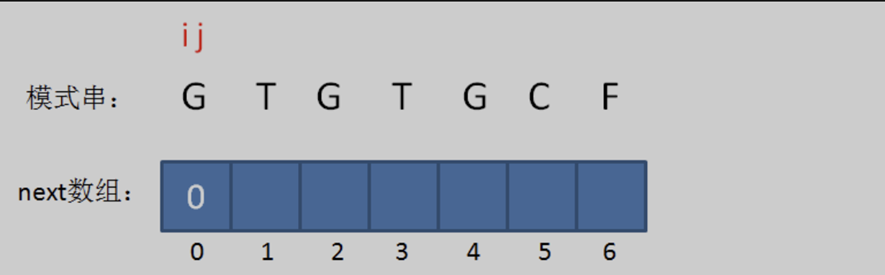
設置兩個變數i和j,其中i表示「當前比較兩字元的位置」,也就是待填充的數組下標;j表示「最長可匹配前綴子串的下一個位置」,即轉跳回來的下一次比較位置,也就是待填充的元素值。分析可知,此時最長可匹配前綴子串不存在,所以當 i = 0 時,j = 0,next[ 0 ] = 0。

繼續向後移動當前比較的位置。此時存在字元串 「G「,由於只有一個字元,不滿足 k < j 的條件。因此,同樣不存在最長可匹配前綴子串,所以當 i = 1 時,j = 0,next[ 1 ] = 0。

此時的已匹配前綴是 「GT」,由於模式串當中 pat[ j ] != pat [ i-1 ],即』G』 != 『T』,最長可匹配前綴子串仍然不存在。所以當 i = 2 時,j = 0,next[ 2 ] = 0。

繼續後移。此時的可匹配前綴是 「GTG「,此時模式串中 pat [ j ] == pat [ i-1 ],即 『G『 = 』G『,最長可匹配前綴子串出現了,是 」G「。

所以當i=3時,j=1,next[ 3 ] = next[ 2 ] + 1 = 1。

繼續後移。此時的已匹配前綴是 「GTGT「,由於模式串中 pat [j] == pat [i-1],即 『T』 = 『T』,最長可匹配前綴子串又增加了一位,是 」GT「。
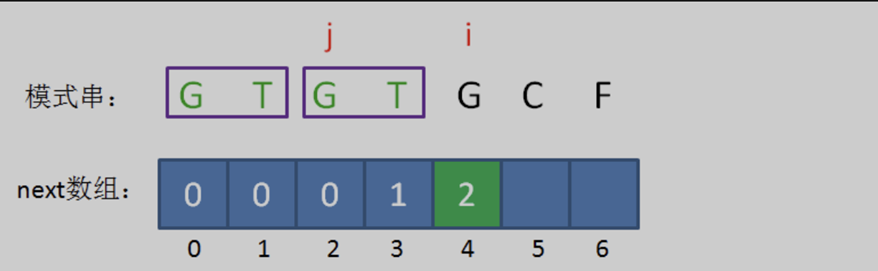
所以當i=4時,j=2,next[ 4 ] = next[ 3 ] + 1 = 2。
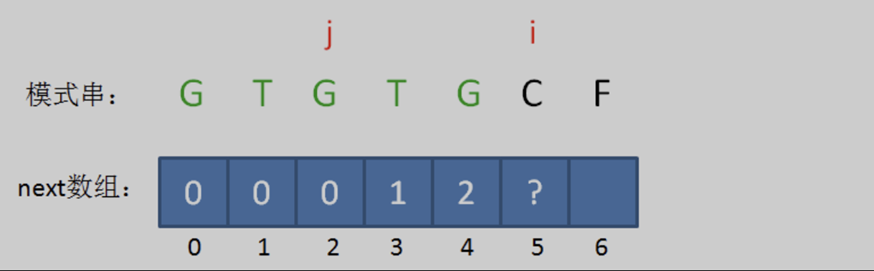
此時的已匹配前綴是 「GTGTG「,由於模式串當中 pat [ j ] == pat [ i-1 ],即 『G』 = 『G』,最長可匹配前綴子串又增加了一位,是 」GTG「。
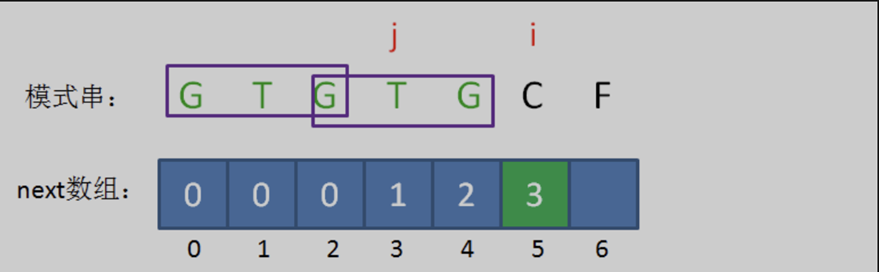
所以當i=5時,j=3,next[ 5 ] = next[ 4 ] + 1 = 3。

此時的已匹配前綴是 「GTGTGC「。此時,模式串中 pat [ j ] != pat [ i-1 ],即 『T』 != 『C』。此時無法從next[ 5 ]的值推導出next[ 6 ],而字元 『C』 的前面又有兩段重複的子串「GTG」。
【重難點】
我們要找的是最長公共前後綴子串,在之前的判斷中,我們已經獲得了兩組滿足條件的公共字串 「GT「 與 」GTG「。既然在當前 」GTG 「 找不到滿足的前綴,那就到上一個前綴 「GT」 去找。
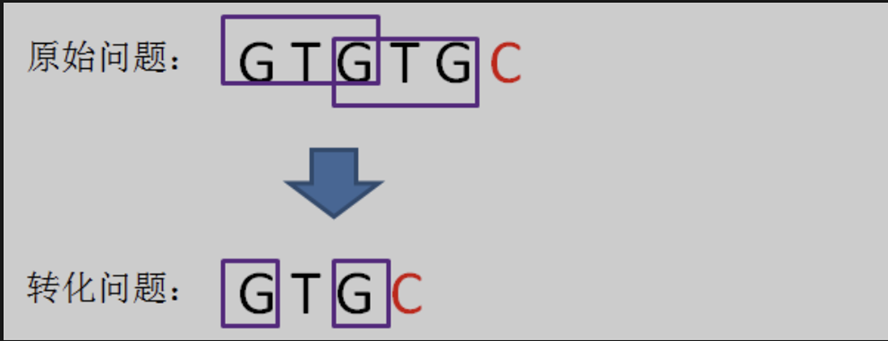
相當於把變數j回溯到了next[ j ],也就是j = 1的局面,在之前的前綴中尋找滿足的前後綴子串。
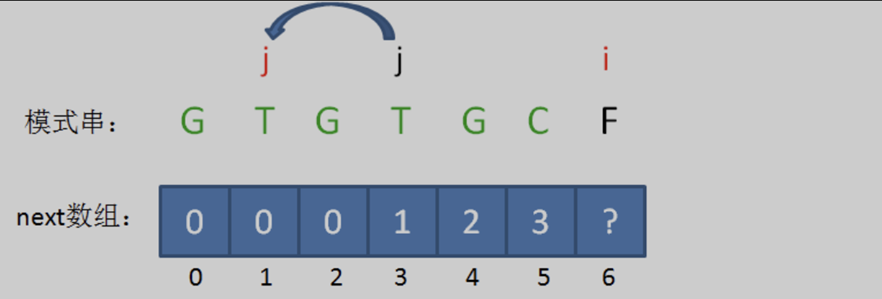
回溯後,情況仍然是 pat [ j ] != pat[ i-1 ],即 』T』 != 『C』。那就繼續回溯。
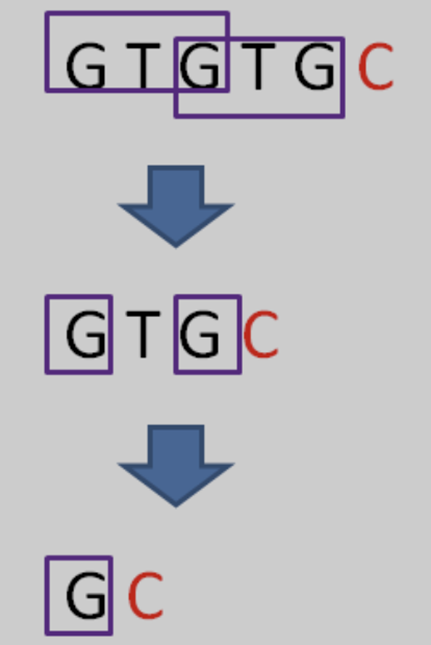
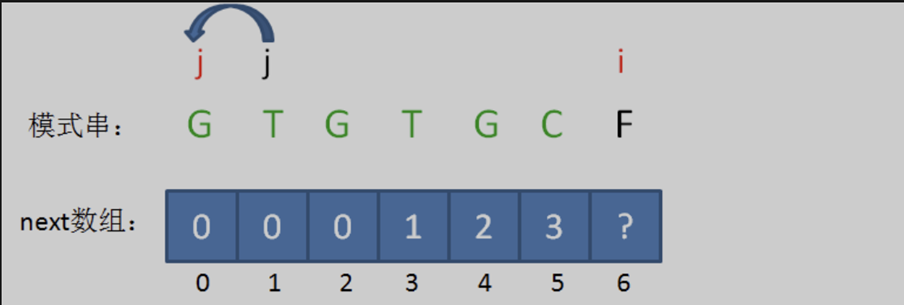
相當於再一次把變數 j 退回到了next[ j ],也就是 j = 0 的局面。
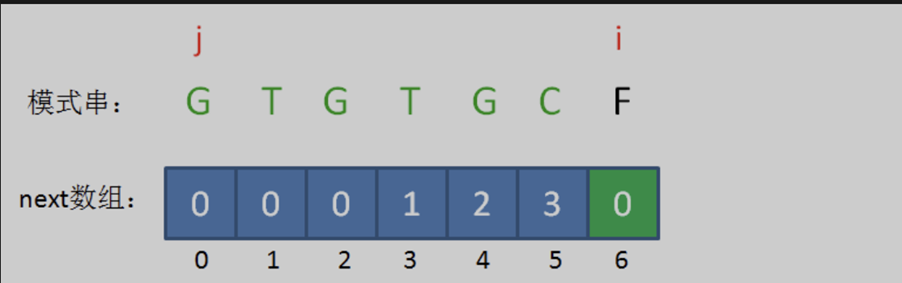
情況仍然是 pat [ j ] != pat[ i-1 ],即 『G』 != 『C』。j 已經不能再回溯了,所以得出結論:i=6時,j=0,next[ 6 ] = 0。
小結:
1. 對模式串預處理,生成next數組
1.1 從next[ 2 ]開始,利用動態規劃 + 雙指針推推出跳轉數組。
2. 進入主循環,遍歷主串
2.1. 比較主串和模式串的字元。
2.2. 如果發現壞字元,查詢next數組,得到匹配前綴所對應的最長可匹配前綴子串,移動模式串到對應位置。
2.3.如果當前字元匹配,繼續循環。

【註:有關 Line 88 行的分析,僅為個人推斷,可能錯在錯誤或解釋不清的地方,望各位有想法的大佬及學者留言評論,謝謝!】
- Line 88:為什麼要加這一句呢?如果是找第一次匹配的位置,那直接 return 結果就好。但是,我們需要找到模式串在主串中所有出現過的位置。這就使得我們需要保證,在找到一次匹配後,需要滑動到某一特定位置,再次開始匹配,且滑動後的位置需要保證不會漏掉任何一種情況。
據之前的分析,j = next[ j ] 表示將 j 回溯到上一個滿足的前綴子串的下一次比較位置; j 表示的是當前應滑動到的比較位置。同理 j = next[ j – 1 ] 的含義肯定也是回溯到某一位置上。那為什麼是 j – 1 呢?這裡個人推斷應該有如下兩個方面:
(1)越界問題。進入到這個 if 內部的前提是 j == m,而 next 數組的最大索引位 m – 1。因此,為了防止越界,傳入 next 中的值應當在 [0, m – 1] 之內。
(2)合理轉化。

這是當前的狀態,我們可以將當前 j 的位置補一個空白字元,其不與任何一個字元相匹配,因此需要回溯。那麼對於當前前綴子串 「ABA#」 其不存在對應的可匹配前後綴子串,根據上面的規則,需要在之前找到一組可匹配的前後綴子串,重新進行判斷。而如何滑動到之前的可匹配子串呢?我們可以把 j 的前一位視作當前的比較位置,假設該位置的字元是不匹配的,這樣就可以直接回溯到之前的可匹配子串的下一次比較位置。因此,此處位 j = next[ j – 1 ]。
複雜度分析:
現在,該演算法第一次計算t的哈希值時,時間複雜度為O(n);後續計算哈希值因為利用了滑窗的優化只有O(1);比較字元串的Equals()方法,一般地,可以視為O(1)。
- 總時間複雜度為O( m + n ),其中計算 next 數組的時間為 O( m );匹配時 時間為 O( n )。
- 空間複雜度為O( m ),使用了一個 next 數組,其中 m 為模式串的長度。
照例,測一下剛才的題

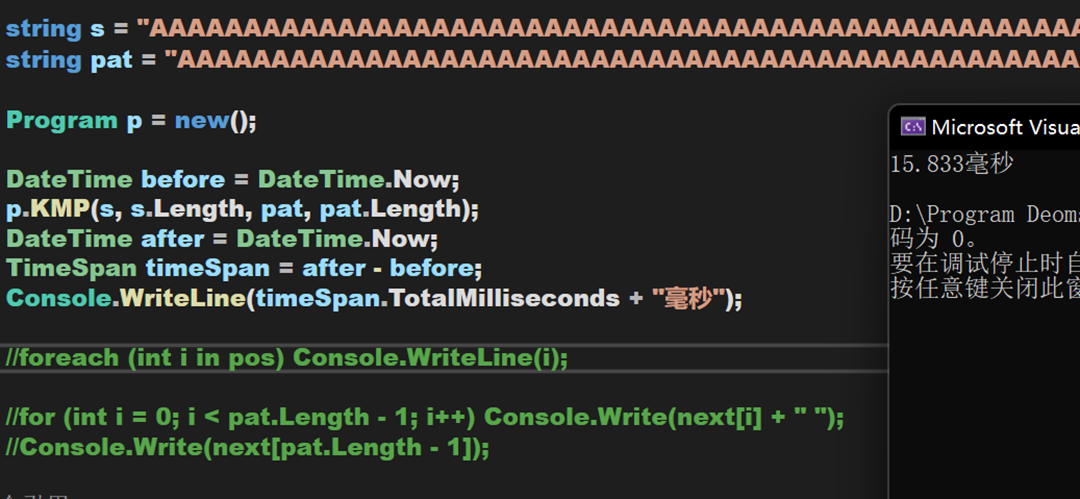
可以發現,即使面對很高數量級的數據,其效率是RK演算法的兩倍。
【注意:用此程式碼提交洛谷的題目(P3375 【模板】KMP字元串匹配 – 洛谷)會存在兩個點超時,另一位使用C#提交的Coder也發生了同樣的問題。推測可能是運行環境的原因,洛谷上的C#運行環境為C# MONO,其優化與相關底層邏輯並不如現行的 .NET 。力扣和牛客使用的運行環境分別是 .NET 6/C# 10 與 mcs5.4 ,因此一般不會出現卡語言的情況】

4. BM演算法(Boyer-Moore)
【參考文章:字元串匹配演算法:KMP與BM – AD_milk – 部落格園 (cnblogs.com) 參考書籍:《數據結構與演算法之美》】
雖然KMP比較出名,但在效率上有很多的演算法都比它要好,如BM演算法,其效率要比KMP好上3到4倍。當模式串長度較短時,二者效率基本相近;隨著模式串 pat 的長度增大,BM的優勢也逐漸凸顯出來。原因可能在於,BM屬於貪心演算法,適應於實際應用,同時,貪心也是思考問題最直接的方式;KMP是穩定演算法,中規中矩,按規矩辦事,不在乎特例。
首先拋出兩個定義:
(1)壞字元規則:指待匹配串和主串當中不匹配的字元,將主串的的該字元定義為壞字元。
BM演算法與我們平常接觸的字元串比較方法不同,它是按模式串從大到小的順序,倒著比的。這樣做也是有好處的,起碼直觀上是這樣感覺的,貪心也是憑感覺嘛。就像做選擇題,出卷老師為了讓你花的時間久一點,故意把正確答案放到C跟D上。所以根據統計規律聰明點的做法應該是先算C跟D。
舉個例子:

從模式串的末尾開始比較,當前主串的字元 『C』 與模式串的字元 』D』,將其定義為「壞字元」,有該字元存在,則無論之前匹不匹配,模式串均不可能在包含該壞字元的字串內被匹配。

俗話說:「三十六計走為上計「,既然你不滿足我那我就開溜,直接向後移動6位,從沒有壞字元的地方開始匹配。配著配著,發現又不滿足了,定義壞字元為 『T『 ,所以繼續後移。
據此我們可以發現一個規律:當不匹配時,設壞字元對應的模式串中的字元,在模式串中的下標為 si (相對下標)。若壞字元在模式串中存在,則把這個壞字元在模式串中的下標記為 xi;不存在,則把 xi 記為 -1。且這樣的壞字元在模式串中若存在多個,則總是選擇最靠後的一個下標,以此保證不會因滑動過多而略過某些情況。那麼,模式串向後滑動的位數 k = si – xi。圖解參閱如下:

(2) 好後綴規則:指待匹配串和主串當中相匹配的後綴。
利用壞字元規則,BM在最優情況下的時間複雜度為 O( n / m ),例如主串為 aaabaaabaaabaaab,模式串為 aaaa,每次均可向後滑動四位。但只有這一個規則還不夠,因為 k 可能為負數,如主串為 aaaaaaaaaaaa,模式串為 baaa。因此,我們又引入一個規則:好後綴規則。
依舊來舉例說明:

將已經匹配的 「BC」 稱為好後綴,記作 { u }。我們用它在模式串中尋找另一個與好後綴匹配的字元串 { u* }。

如果存在,則將模式串滑動到子串 { u* } 與好後綴 { u } 上下對齊的位置。

如果不存在,則直接滑動到好後綴 { u } 的後面。

此外,若在模式串中若存在多個與好後綴匹配的相同字元串或與好後綴的後綴字串相同的模式串中的前綴子串,則選擇最長且靠後的串並記為 { v },按規則滑動。
以上就是BM演算法的兩個核心規則,在使用中可以分別計算好使用兩用規則的滑動位數,取較大的一個 max( k1, k2 ),作為向後滑動的位數,這樣既能使得時間複雜度接近最優的O( n / m ),也能避免滑動位數出現負數的情況。
具體實現如下:
(1)對於壞字元規則的計算,如果每次都去遍歷那效率會很低,可以利用一個哈希表,存儲每個字元在模式串中的位置,如果有多個相同字元,則取下標最大的一個。如圖:


(2)對於好後綴規則,其核心在於:在模式串中查找與好後綴匹配的子串;在好後綴的所有後綴字串中,查找能與模式串前綴子串匹配的最長子串。
- 先來解決第一個問題,如何表示模式串中不同的後綴字串以及如何滑動到對應位置?
分析可知,後綴子串的最後一個字元的位置是固定且唯一的,因此只需通過後綴子串的長度即可進行唯一標識。然後引入一個數組suffix,數組下標表示後綴子串的長度(下標唯一且不變,子串最後一個字元的位置唯一且不變),對應數組值表示與其匹配的另一個子串的起始下標。如圖:

如果存在多個合法的子串,則取下標最大的一個。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 找完了模式串中的所有子串,還有一個問題:查找在好後綴的所有後綴子串中,能與模式串前綴子串匹配的最長的一個後綴子串(以下記為 「最長可匹配後綴子串」)
同樣,為了避免每次遍歷帶來的時間消耗問題,我們對其也進行預處理。因為已經用數組 suffix 記錄了滑動的規則,因此現在只需記錄是否需要滑動即可。定義一個bool類型的數組 prefix,記錄模式串的每個後綴子串是否能匹配模式串的前綴子串。如圖:
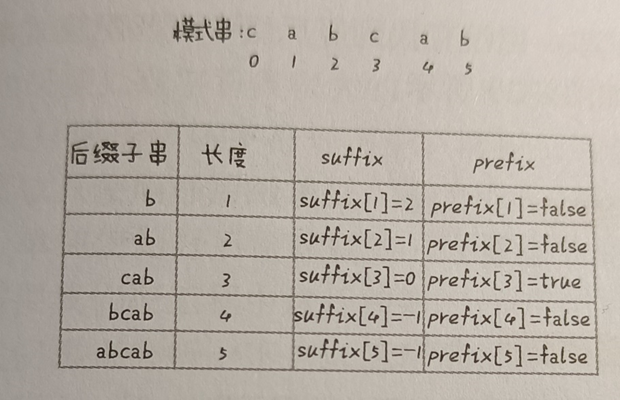
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 接下來,理解並推導一下這兩個數組的值
用模式串的前綴子串,即下標為 [ 0, i ] ( 0 <= i <= m – 2 )的子串,與整個模式串求公共後綴子串。若公共後綴字串的長度為 k ,在前綴子串中的起始下標為 j ,則記錄 suffix[ k ] = j 。若 j = 0,說明公共後綴子串是模式串的前子串,那就記錄prefix[ k ] = true。相當於將字元串分為兩部分,若存在兩部分完全相同,則記錄為 true。

—— —— —— —— —— —— —— —— —— —— —— —— —— ——
- 最後來看一下,如何根據這兩個數組計算出滑動的位數
設好後綴長度為 k,用好後綴 { u } 在數組 suffix 中查找可匹配子串。若 suffix[ k ] ≠ -1,說明存在可匹配字串,則將模式串往後移動 j – suffix[ k ] + 1 位,其中 j 表示壞字元對應模式串中的下標位置。如圖:
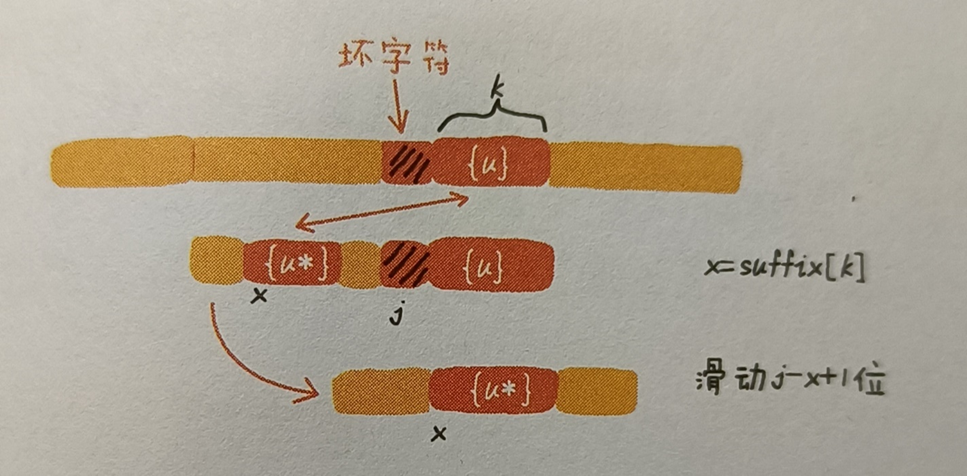
如果 suffix[ k ] = -1,說明模式串中不存在與好後綴匹配的子串。此時,使用好後綴的另一條規則:查找好後綴中,所有後綴子串中,能與模式串前綴子串匹配的,最長的那一個後綴子串。好後綴 pat[ j + 1, m – 1 ]的後綴子串 pat[ r, m – 1]( j + 2 <= r <= m – 1 )記作 { v },其長度 k = m – r。若 prefix[ k ] = true,表示長度為 k 的後綴子串,存在可匹配的前綴子串 { v* },則將模式串移動 r 位。如圖:
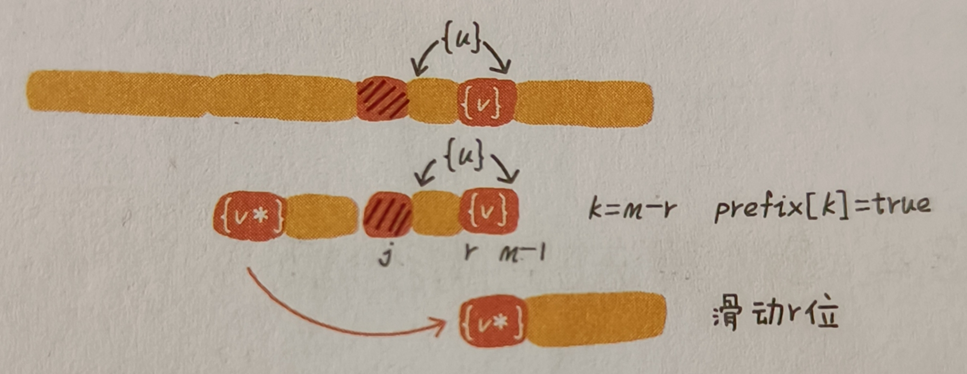
如果在模式串中沒有找到與好後綴可以匹配的前綴子串,也沒有找到好後綴中可匹配模式串中前綴子串的,後綴子串,則將整個模式串後移 m 位。如圖:

—— —— —— —— —— —— —— —— —— —— —— —— —— ——
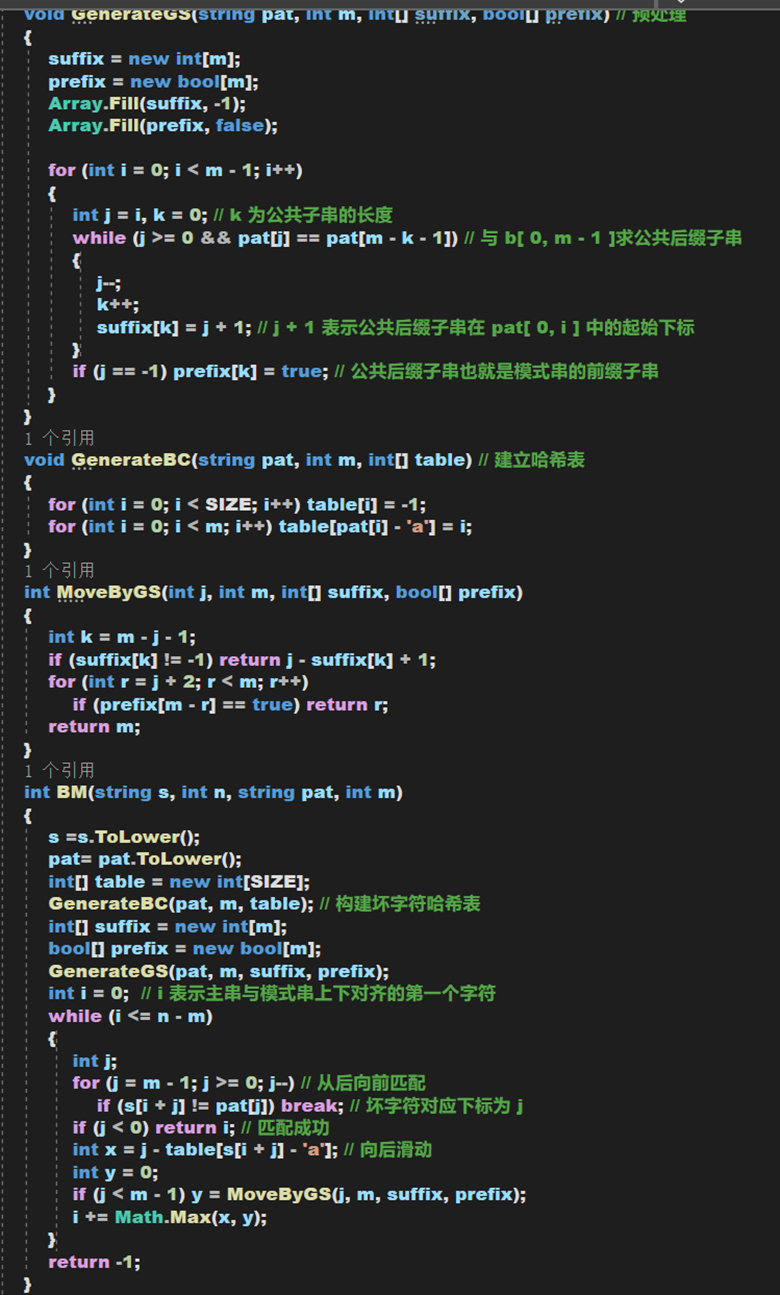
程式碼實現:【註:考慮到時間成本與篇幅問題,在此不做BM演算法的同意主串多次匹配問題,如有興趣歡迎自行研究,本人也可能會在今後放出可對同一主串多次匹配的程式碼】
複雜度分析:
- 時間複雜度為O( n ) 若模式串中包含大量重複字元,則計算兩個數組的時間將會達到 O( m2 ),但一般不會出現這樣的極端情況。
- 空間複雜度為O( m )
這就是一種極端情況,存在大量重複字元,導致其效率嚴重下降。
總結
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
至此,四種匹配方法全部介紹完畢,總結一下:
1. BF純暴力演算法,一位以為比較,遇到不匹配的從模式串開頭在此一位一位比較。時間複雜度較高,但簡潔明了思路清晰,因此在實際應用中最為常用。
2. RK演算法,基於BF的比較字元的思想,轉化為比較子串的哈希值。數值間的比較確實比字元比較快,而且利用滑窗的思想將計算哈希的時間複雜度將為 O( n ),但容易存在哈希衝突的問題,衝突後需要對 兩部分子串進行完整比較。計算哈希方式越簡單、字元串越長,衝突的概率越高,複雜度也會接近 O( n2 )。
3. KMP演算法,利用某一特殊的規律,減少在不匹配時向後退回的位數,以達到降低時間複雜度的目的。
4. BM演算法,結合貪心思想,進一步對KMP進行優化。但這兩種方法過於複雜,掌握很不容易。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
[附 BF演算法程式碼]
void BF(string s, int n, string pat, int m) { for (int i = 0; i <= n - m; i++) { int j = 0; while (j < m) { if (s[i + j] != pat[j]) break; j++; } if (j == m) pos.Add(i); } }
[附 RK演算法程式碼]
void RK(string s, int n, string pat, int m) { int patCode = GetHash(pat); int sCode = GetHash(s.Substring(0, m)); for (int i = 0; i <= n - m; i++) { if (patCode == sCode && ComString(i, s, pat)) pos.Add(i); if (i < n - m) sCode = NextHash(s, sCode, i, m); } } int GetHash(string str) { int hash = 0, n = str.Length; for (int i = 0; i < n; i++) hash += str[i] - 'a'; return hash; } int NextHash(string str, int hash, int idx, int len) { hash -= str[idx] - 'a'; hash += str[idx + len] - 'a'; return hash; } bool ComString(int idx, string s, string pat) { return pat == s.Substring(idx, pat.Length); }
[附 KMP演算法程式碼]
void KMP(string s, int n, string pat, int m) { next = GetNext(pat, m); int j = 0; for (int i = 0; i < n; i++) { while (j > 0 && s[i] != pat[j]) j = next[j]; if (s[i] == pat[j]) j++; if (j == m) { pos.Add(i - m + 1); j = next[j - 1]; } } } int[] GetNext(string pat, int m) { next = new int[m]; int j = 0; for (int i = 1; i < m; i++) { while (j != 0 && pat[j] != pat[i]) j = next[j]; if (pat[j] == pat[i]) j++; next[i] = j; } foreach (int i in next) Console.Write(i + " "); return next; }
[附 BM演算法程式碼]
static int SIZE = 26; void GenerateGS(string pat, int m, int[] suffix, bool[] prefix) // 預處理 { suffix = new int[m]; prefix = new bool[m]; Array.Fill(suffix, -1); Array.Fill(prefix, false); for (int i = 0; i < m - 1; i++) { int j = i, k = 0; // k 為公共子串的長度 while (j >= 0 && pat[j] == pat[m - k - 1]) // 與 b[ 0, m - 1 ]求公共後綴子串 { j--; k++; suffix[k] = j + 1; // j + 1 表示公共後綴子串在 pat[ 0, i ] 中的起始下標 } if (j == -1) prefix[k] = true; // 公共後綴子串也就是模式串的前綴子串 } } void GenerateBC(string pat, int m, int[] table) // 建立哈希表 { for (int i = 0; i < SIZE; i++) table[i] = -1; for (int i = 0; i < m; i++) table[pat[i] - 'a'] = i; } int MoveByGS(int j, int m, int[] suffix, bool[] prefix) { int k = m - j - 1; if (suffix[k] != -1) return j - suffix[k] + 1; for (int r = j + 2; r < m; r++) if (prefix[m - r] == true) return r; return m; } int BM(string s, int n, string pat, int m) { s = s.ToLower(); pat = pat.ToLower(); int[] table = new int[SIZE]; GenerateBC(pat, m, table); // 構建壞字元哈希表 int[] suffix = new int[m]; bool[] prefix = new bool[m]; GenerateGS(pat, m, suffix, prefix); int i = 0; // i 表示主串與模式串上下對齊的第一個字元 while (i <= n - m) { int j; for (j = m - 1; j >= 0; j--) // 從後向前匹配 if (s[i + j] != pat[j]) break; // 壞字元對應下標為 j if (j < 0) return i; // 匹配成功 int x = j - table[s[i + j] - 'a']; // 向後滑動 int y = 0; if (j < m - 1) y = MoveByGS(j, m, suffix, prefix); i += Math.Max(x, y); } return -1; }
[# 有關Intrinsic、Attribute與「內在屬性」]
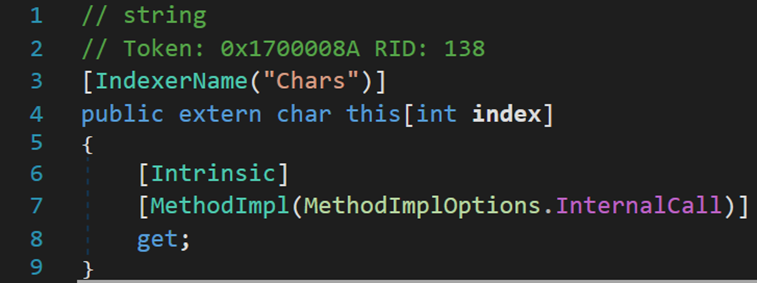
[Intrinsic] 被稱為內在屬性,我們把形如 [xxxx] 的表達式稱為內在屬性,如 [Serializable]、[IndexerName(“Chars”)]、[MethodImpl(MethodImplOptions.InternalCall)]等。

通過追蹤發現其派生於類Attribute。在分析該內在屬性前,先來看看什麼是 Attribute。
1. 類 Attritube
這裡要注意,屬性和特性的區別。在微軟翻譯器上,Arrtibute 被翻譯為屬性,這個翻譯在 C# 中並不準確。
- 屬性:又叫智慧欄位,是類的成員,是面向對象程式語言的一個基本概念,提供了安全和靈活的數據訪問封裝,不存儲數據。
- 特性:特性本質上是一個類,用來為目標元素提供附加資訊,並在運行時通過反射機制來獲取這些資訊以影響或控制應用程式運行時的行為。目標元素可以是程式集、類、構造函數、委託、枚舉、事件、欄位、介面、方法、可移植可執行文件模組、參數、屬性、返回值、結構或其他特性。
限於篇幅,在此就簡單描述一下這個類的基本資訊與功能。一般地,我們並不直接使用這個類,而是較多的使用其派生出的類
此處僅展示部分,派生的類有很多,每個類之下有不同的內容,其內容用於規定被修飾的對象應當怎樣做或只能怎樣做。如:AttributeUsage(AttributeTargets.Method) 。其中,AttributeTargets 用於指定對哪些程式元素使用;而 AttributeTargets.Method 表示被修飾的對象只能被方法體使用。
在 .NET 中,提供了三種預定義的特性:AttributeUsage、Conditional 與 Obsolete。
- AttributeUsage:描述了如何使用一個自定義特性類。
- Conditional:標記了一個條件方法,其執行依賴於指定的預處理標識符。它會引起方法調用的條件編譯,取決於指定的值,比如 Debug 或 Trace。
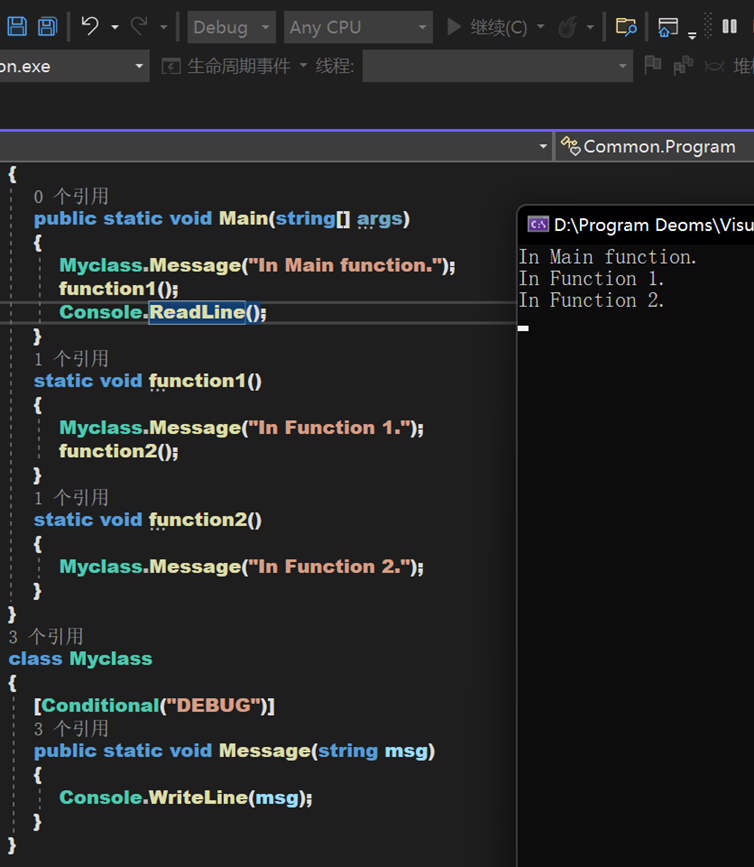
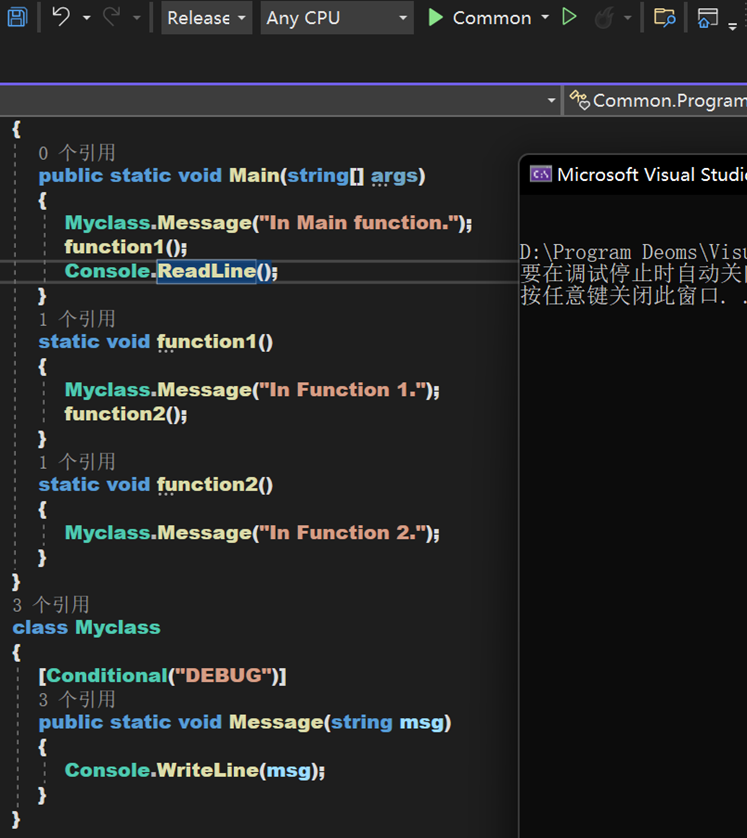
如,我們在方法上附加一個 Conditional 特性,使得其只在 DEGUB 模式下運行。
- Obsolete:用於標記不應被使用的程式實體。它可以讓通知編譯器丟棄某個特定的目標元素。如,當一個新方法被用在一個類中,但是仍然想要保留類中的舊方法,可以把它標記為 Obsolete(過時的)並輸出輸出資訊。
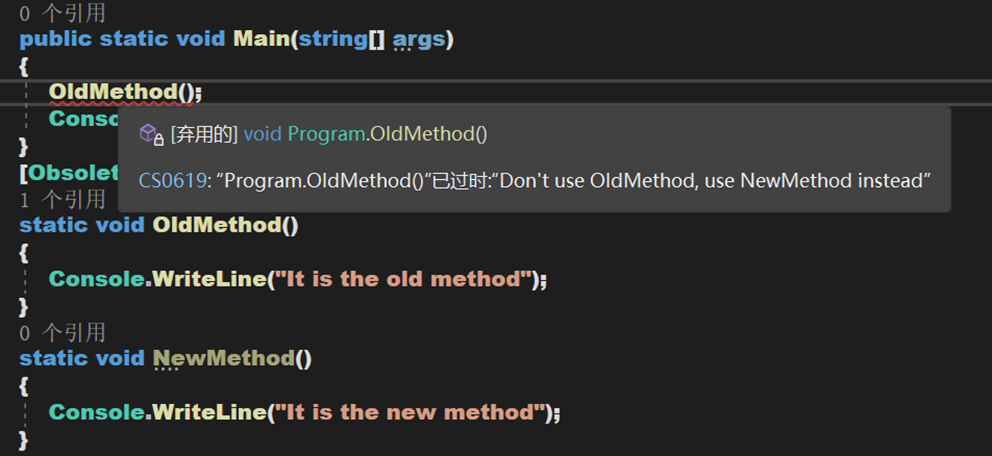
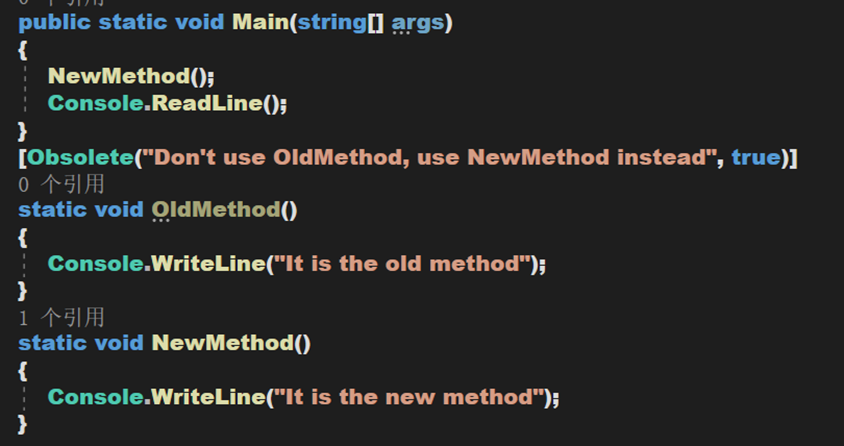
2. 類 IntrinsicAttribute
關於特性 Intrinsic,在 dotnet/corefx 中找到其相關注釋如下:

- Calls to methods or references to fields marked with this attribute may be replaced at ome call sites with jit intrinsic expansions. 微軟翻譯:某些調用站點中,對使用此屬性標記的方法的調用或對使用此屬性標記的欄位的引用可能會替換為 JIT擴展。說人話就是,被該屬性標記的方法或欄位,可能會被 JIT 替換/優化成功能相同的方法或欄位。
- Types marked with this attribute may be specially treated by the runtime/compiler. 微軟翻譯:運行時/編譯器可能會專門處理使用此屬性標記的類型。也就是說,被該內在屬性標記的對象確實會進行專門的處理。
舉個粗略的例子:JIT-optimizer 可以代替 Enum.HasFlag 在某些情況下進行簡單的按位比較,而在其他情況下則不然。為此,它需要將方法標識為 Enum.HasFlag ,檢查一些條件並將其替換為更優化的實現。雖然優化器可以通過名稱識別方法,但出於性能原因,最好在執行字元串比較之前通過簡單的標誌過濾掉方法,即在編譯階段就將要優化的部分識別出來,而不是將其交給優化器來進行識別工作。
下面,簡單解釋一下其運行流程:
- 關於方法的定義
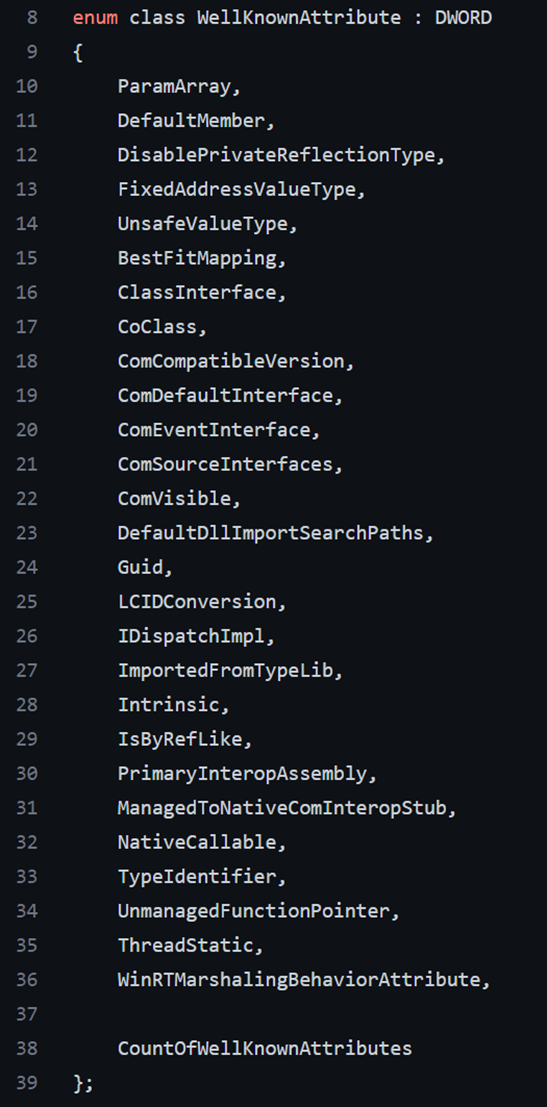
【註:訪問以下超鏈接可能需要已解析好的 DNS】
在 donet/coreclr/vm 下的 wellknownattributes.h 文件內,定義了一個枚舉類 WellKnownAttribute,其派生於 DWORD。
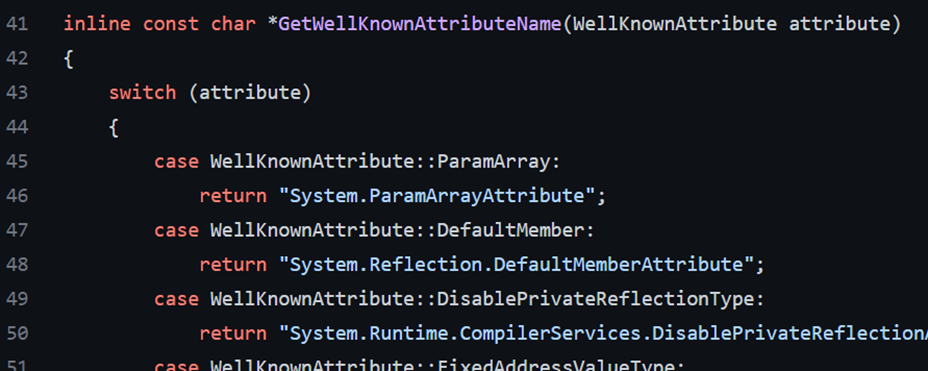
還定義了一個返回值為 char* 的常量方法體(注意,此處的語言並不是 C#,眾多周知,C#/.NET 的底基本上是用 C/C++ 編寫的,C# 並不支援 inline,也不能用 const 修飾方法體,不過 JIT 支援自動 inline 將IL轉成真正機器碼時,會自動將某些函數進行inline展開)

其中,定義了當傳入特性為 Attribute 的情況,返回這個命名空間。
- VM 解析它並設置 IsJitIntrinsic 方法的標誌為真(
methodtablebuilder.cpp)

- 此標誌用於在方法屬性(
jitinterface.cpp)中設置另一個標誌

- 此標誌用於過濾掉明顯不是內在的方法(
importer.cpp)

- impIntrinsic然後利用 lookupNamedIntrinsic 識別(主要是通過名稱)真正(不僅僅是可能)應該優化的方法;
- 畢竟,importer可以根據方法進行優化。例如,優化 Enum.HasFlag( importer.cpp )

以上是根據現有的遠古資料推斷出的運行方式,因為資料實在有限,本人目前對 CLR 了解並不是很深,如果存在錯誤或其他見解還請留言!
[# 有關MethodImpl]
還是這個例子,有了剛才的分析,那很快得出結論:MethodImpl 也是一個內在屬性。其中,Impl 是 implement 的縮寫,直譯為「實現」。
(1)作用:字面翻譯可以初步得出,這是一個對方法進行特定優化的特性,優化的方式是內部調用。
(2)作用域:可以在方法以及構造函數上使用。可以影響 JIT 編譯器的行為。
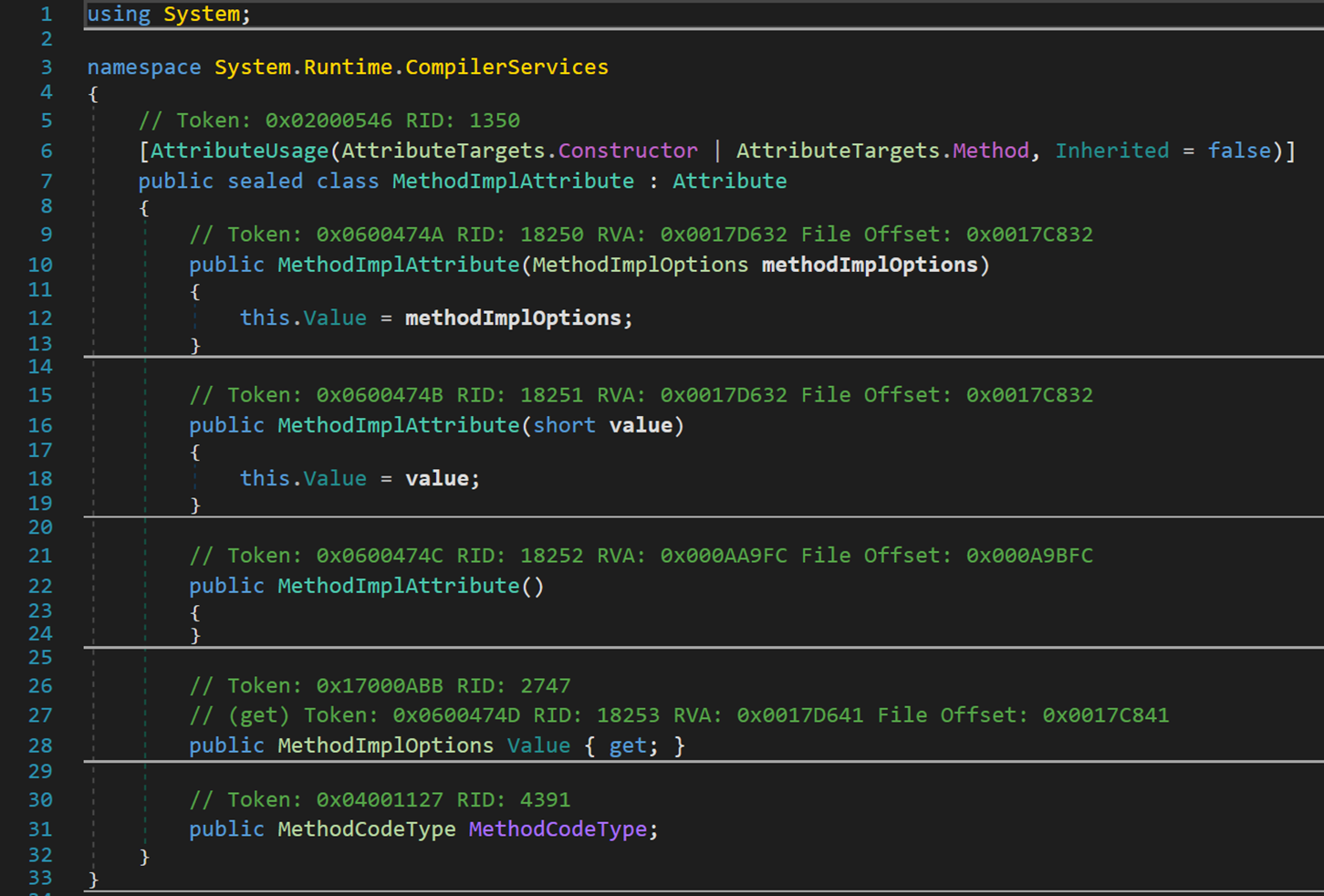
- Line 10、16:兩個構造函數,讀入傳進來的具體優化機制。
- Line 28:一個只讀屬性,用於存儲具體的優化機制。
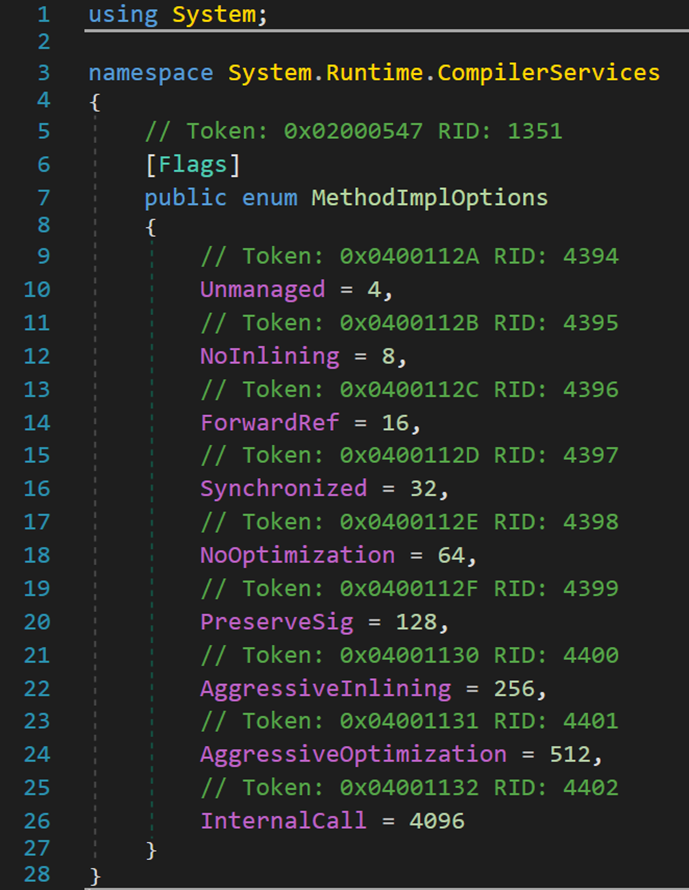
其中的枚舉值與功能對應參見下圖:

- Line 31:用於存儲並標記不同的運行環境(IL、Native、OPTIL、Runtime)。

[# 有關字元串的比較與暫存池]
1. 字元串的比較 與 StringComparsion
String類里的字元串比較方法,面對簡單的比較時,直接使用關係運算符(「==」,「<=」,」>=「);面對較為複雜的比較操作時,會調用在類CompareInfo下的Compare()方法。
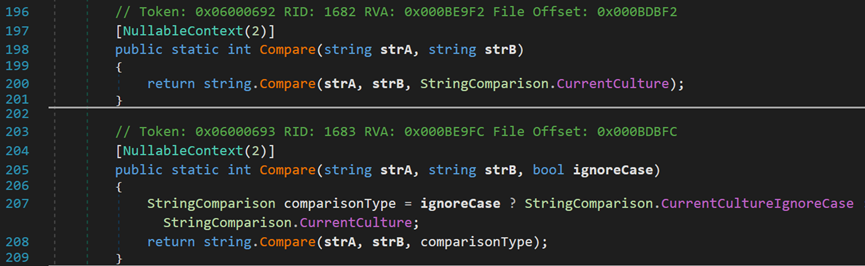
首先來看最簡單也是最常用的Compare()方法。兩個字元串的直接比較、帶有自定義比較器的字元串比較。
這兩個方法均會進入到String內部的一個重載方法中,如下圖所示:
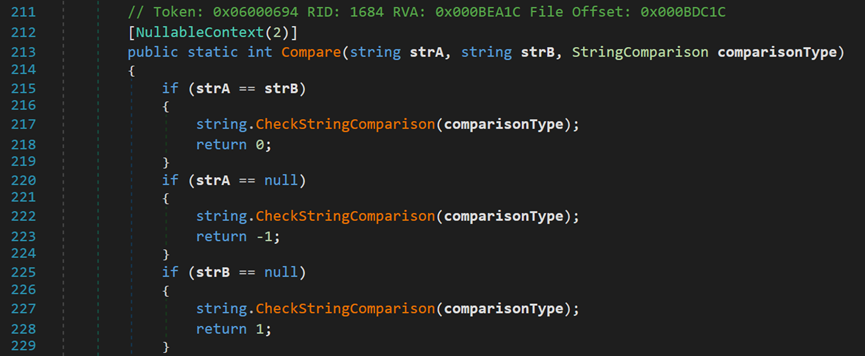
- Line 213:strA與strB為待比較的兩個字元串;comparisonType為比較器類型。
- Line 215~229:直接利用關係運算符,只判斷是否相等。對於關係運算符,默認情況下,判斷字元串大小規則如下:
(1)比較長度,長度越長字元串值越大。
(2)長度相同,依次比較每個字元,按照ASCII碼大小進行比較,字元ASCII碼越大,則字元串值越大。
【註:Comapre()方法的比較規則與關係運算符不同】

如果字元串不相等且沒有任何一個字元串為null,則進入之後的判斷。通過對傳入的比較規則comparsinType進行不同的處理。
再分析這些枚舉項的作用前,先解釋一下幾個概念:
(1)區域性:字面意思,某一區域所具有的性質。
(2)當前區域性:當前系統所在的區域所執行的規則。
(3)固定區域性:不依賴於任何區域性(固定的),可以理解為公共區域性,任何情況下無論身在何處都遵守該規則。一般地,這個屬於國際通用標準。
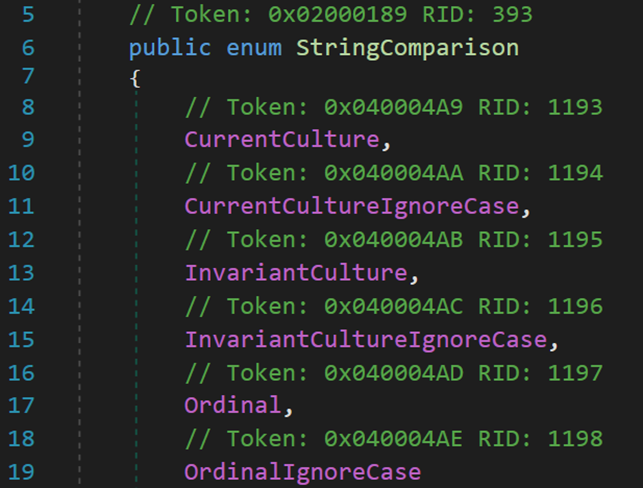
對於枚舉集StringComparsion內部包含6個屬性,每個屬性的值用十六進位表示,從0到5,用於調用不同的比較器,存在的意義是對字元串的比較進行優化。如,當比較的字元串存在大小寫字母,但不需要區分大小寫時,使用轉換的方式統一大小寫會造成一定的性能消耗,此時就可使用該枚舉集中的屬性進行標記,以提升性能。
- Line 9:CurrentCulture屬性,使用區分區域性的排序規則和當前區域性比較字元串。即,在當前的區域資訊下進行比較。這是String.Compare在沒有指定StringComparison的時候,進行的默認比較方式。對於當前的區域資訊,指的是當前所使用的官方字典。不同地區的字典規則不同,因此會造成同一個比較結果不同的情況,舉例如下:
其中 Thread 在這裡的作用是,當調用該方法時,啟動一個具有特殊屬性的執行緒,執行緒有效性直到方法結束。在該執行緒生命期內,所有關於該執行緒的屬性都將被強制應用。
在瑞典官方字典中,某些我們熟知的字元存在不同的含義,對應值也不同。
- Line 13:InvaiantCulture屬性,在任何系統中的(即,不同的culture)比較都將得到相同的結果。即,忽略地域性的影響,使用國際通用的默認字典進行比較。
- Line 17:Ordinal屬性,按照 ASCII 碼的數值進行比較。
- Line 11、15、19:忽略大小寫字元的差異.
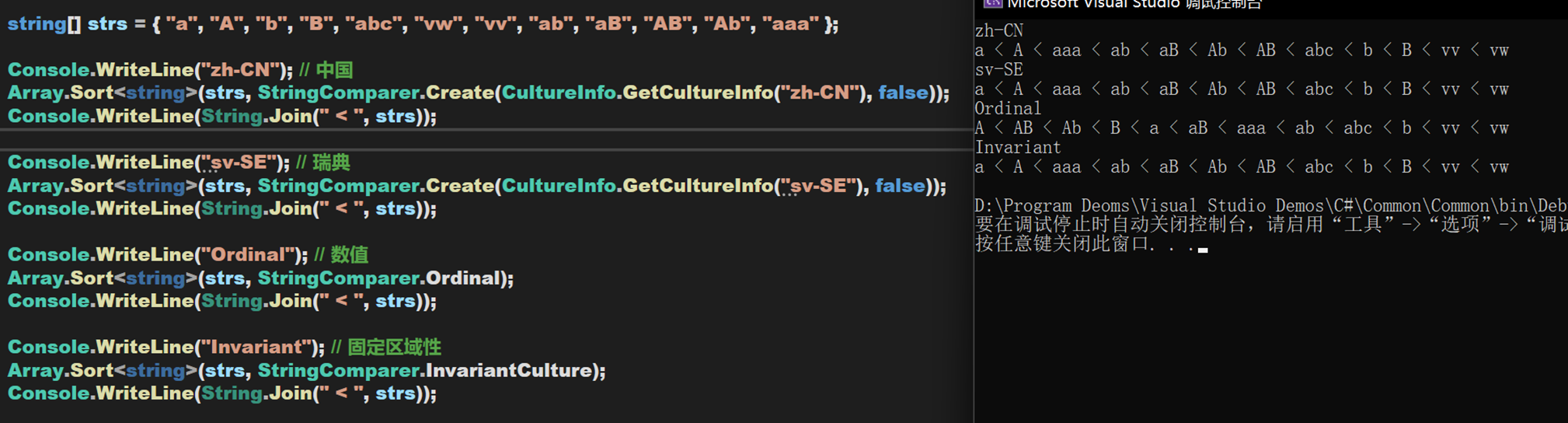
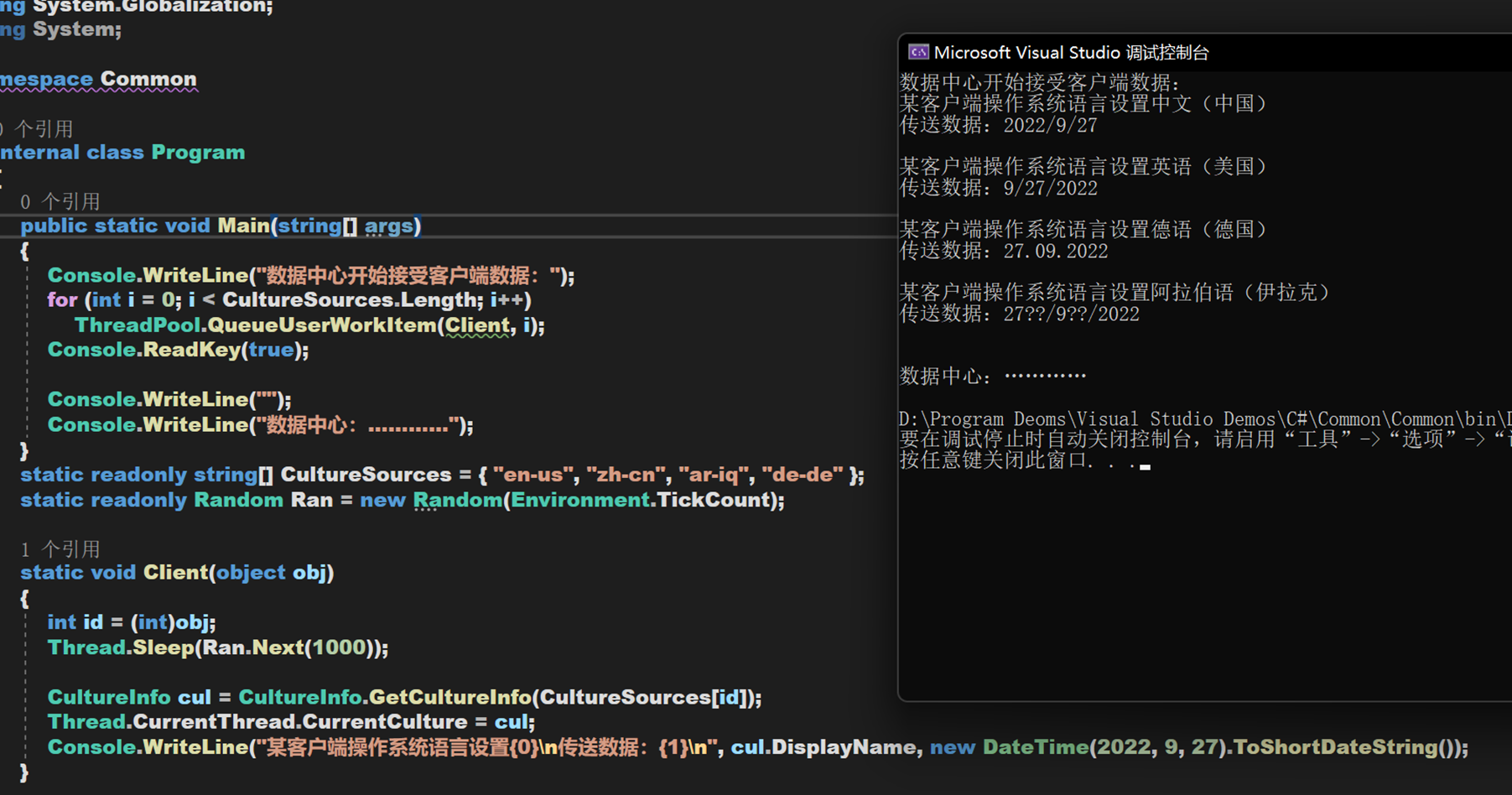
小結一下,經過多次嘗試,發現大多數國家應該都是遵守國際比較標準的,只是在格式上可能會有所不同。支援多種CultureInfo使得 .NET 在跨區域上更加人性化,因為這可以使同一個數據適應不同地區和文化,滿足處於不同地區和文化的用戶,但前提是數據給「人」看。如果這些數據用於電腦之間的傳輸,給「機器」看,這樣的多文化處理反而不妥,會造成同一個數據的不同展現形式,尤其是讀寫兩方的文化地區不同時,數據可能根本無法被正常讀取或者產生潛在bug,因此這裡,這也正是InvariantCulture的用武之地。強制規定一個國際通用標準,就像 .NET 中的 CLR 一樣,指定了一個規範。
2. 字元串的記憶體分配與字元串暫存池
這個暫存池有好多稱法:常量池,緩衝池等。.NET/C# 在編譯階段就能確定相同的字元串,在運行期間使用的都是相同的實例。暫存池的引入避免分配大量的字元串對象造成的過多的記憶體空間浪費。本次主要解決以下三個問題:對於所有的初始化方式,是否都會進行判斷,將多個相同字元串的引用指向暫存池的一個實例?對於存在運算的字元串,在編譯階段是否會進行判斷,將運算結果相同字元串的引用指向暫存池?為什麼要針對字元串專門建立一個暫存池這樣的機制,而值類型和其他引用類型沒有這樣的機制?同時,String 提供了一個方法 IsInterned() 來判斷字元串是否在暫存池中,如果存在則返回其引用;不存在返回 null,可以利用這個方法具體分析每種情況。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
下面來解決兩個問題:
(1)對於所有的初始化方式,是否都會進行判斷,將相同引用指向暫存池?
(2)對於存在運算的字元串,在編譯階段是否會進行判斷,將運算結果相同字元串的引用指向暫存池?
- 直接完整初始化
即,直接對字元串變數進行完整賦值。種植情況,毫無疑問是遵循字元串暫存池檢查的。
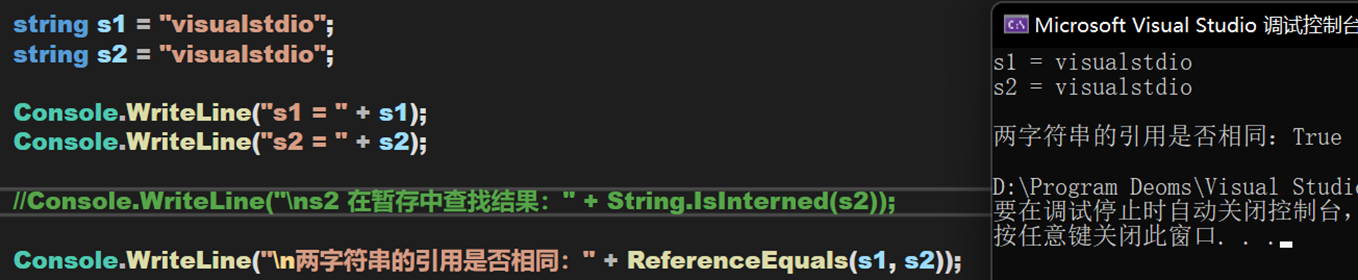
- 用運算符 『+』 連接

和 Java 一樣,對於字元串在編譯期間具有字元串優化機制,會在運行前計算出完整的字元串。
- 用 String.Join 連接

對於方法的運算,需要在運行時才能完成。而變數指向的引用是在編譯階段確定的,s2 這種方式,在編譯階段無法得出結果,因此只能先開闢一個新的記憶體,在運行時確定其值。

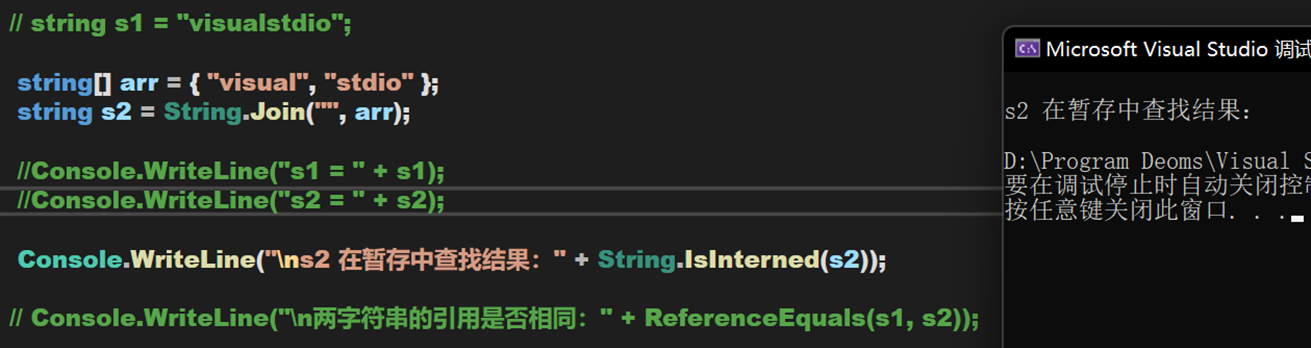
並且,無法再暫存池中查找到 s2 的引用,據此推斷在編譯階段不能確定值得字元串不會被寫入暫存池。
- StringBuilder 構建


同理,對於 StringBuilder 的構建,依舊無法在編譯階段確定其值,也就沒有寫入暫存池。
- 佔位符


由於佔位符需要調用方法體,因此無法在編譯階段確定 s2 的值。
- 字元串的內插
先簡單介紹一下什麼是字元串內插。由於佔位符需要我們在字元串中先用數字標記位置,再到字元串結束後寫下對應的值,過程較為繁瑣,因此引入內插操作。

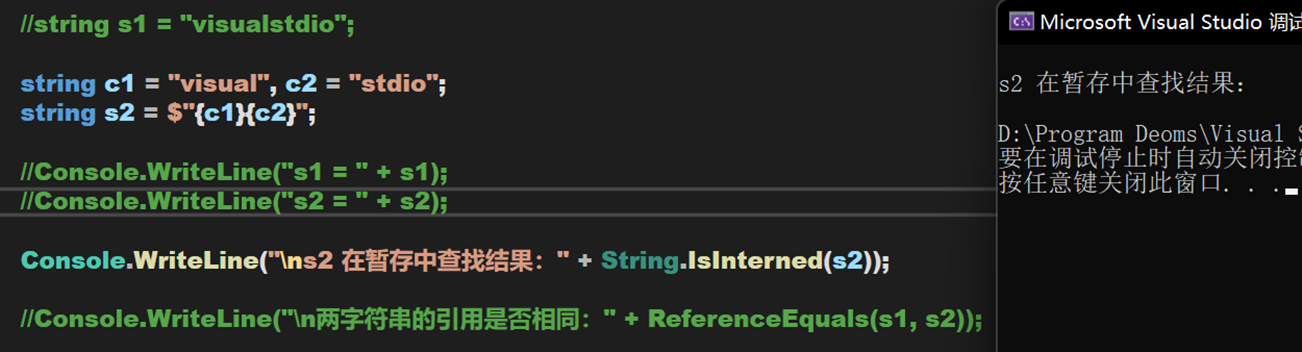
使用符號 『$』 代表被標記的字元串將實行內插操作。可看到,雖然內插操作看似不執行方法體,但依舊不指向暫存池中的對象,說明內插操作的值是在運行階段完成的。
不過,對於此處 s2 的定義方式,當 c1 與 c2 是常量時,其在編譯階段即可被確定,會被寫入暫存池。

小結
對於暫存池的寫入,在此得出的結論是:
(1)只有在編譯階段可以確定的字元串,才會被查找或寫入暫存池中。如何判斷一個字元串是在編譯階段被確定的?只需要在之前加上關鍵字 const 即可,報錯則表示不能在編譯階段確定。
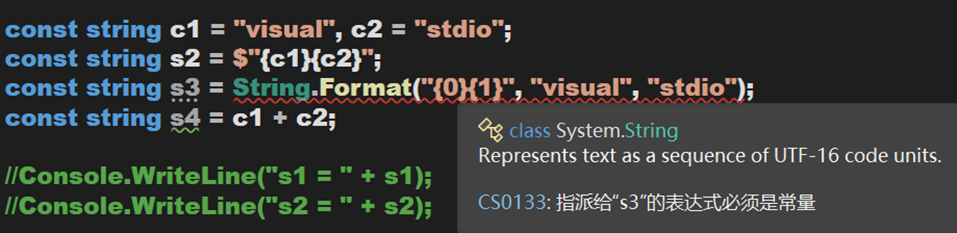
(2)除了直接完整初始化和使用運算符這兩種方式以外(註:不排除有其他方式),其餘方式均不會再暫存池中進行查找或寫入。
(3)對於存在於暫存池中的字元串,即使之後不會再被使用,也不會被 GC 回收。
(4)若不想要讓字元串池化。可加上特性標記 [assembly: CompilationRelaxations(CompilationRelaxations.NoStringInterning)]。即使加上後也不會被 GC 回收。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
下面解決剩下的問題:為什麼要針對字元串專門建立一個暫存池這樣的機制,而值類型和其他引用類型沒有這樣的機制?
結合資料,個人推斷,應該是因為字元串的不可變性。
(1)字元串是引用類型,在創建時不斷地在堆上開闢新空間,會佔用較高記憶體,產生較大的消耗。而值類型是在棧上存儲,相比於堆來說,不是那麼消耗記憶體。
(2)字元串的不可變性,使得其在確定之後就不可更改。此處的不可更改指的是,只要賦值,該值就會一直保留在記憶體中直到程式結束。為了避免出現大量重複對象,而創建大量重複實例佔用大量記憶體的問題,引入了暫存機制。而其他引用類型不具有不可變性,一般地可以在運行時隨意修改,相對而言不需要這樣的暫存機制。
