遊戲業務安全實時計算集群:雲原生資源優化實踐
「毛東方,騰訊後台開發工程師,負責IEG-業務安全部的後台實時系統Kubernetes相關的開發與運營,目前主要致力於提高集群的資源利用率,減少機器成本。」
背景
隨著公司內部上雲的呼聲越來越高,越來越多的團隊已經完成業務上雲的進程。
然而,本人所在平台的應用部署上雲後,在資源管理方面依然出現了一系列的問題,這些問題或多或少都對成本優化或應用的服務品質造成了一定程度的影響。
a. 應用資源使用設置不合理
雲原生的資源管理方式要求應用在部署之前,提前設置好 CPU、記憶體、磁碟的最小和最大資源使用量,並且之後不能改動(除非重建所有實例),這要求應用在正式上線之前預估其資源需求。線上的資源需求可以通過壓測來模擬,但難免和實際情況有出入;此外應用上線之後,其資源使用會隨著業務、策略等的動態更新而發生變化,因此在創建之初設置的資源使用量並不能很好地反映實際的資源需求,容易造成資源浪費或資源不足。
b. 相同類型的 Pod,各項資源使用有差異
在實際運行過程中,我們發現即使是相同的 Pod,其 CPU、記憶體、磁碟、網路等監控指標也會有很大的差異,極端情況下會相差60%。有時會遇見大部分 Pod 的 CPU 利用率都很低,個別 Pod 的 CPU 利用率卻長期在90%以上,最穩妥的解決方式為擴容,但是這樣卻會造成資源的大量浪費。例如下圖為一段線上環境相同 Pod 的 CPU 利用率監控,可以看到不同的 Pod 其 CPU 使用也存在幾倍的差距。
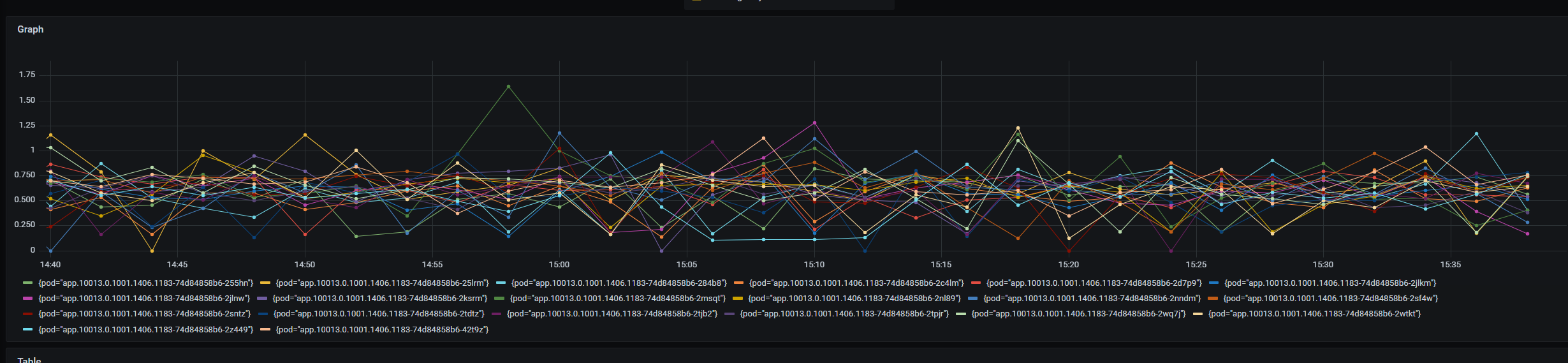
經過進一步分析,出現該現象的原因有以下幾點:
-
Pod 部署的節點性能不同 -
Pod 部署的節點各項資源的消耗不同 -
Pod 在細粒度的時間單位內,佔用的資源不均衡
c. 多維度空閑資源碎片化嚴重
集群在運行一段時間後,隨著節點不斷上架下架,Pod 不斷擴縮容,會有越來越多的空閑資源分散在整個集群,並且這樣的閑散資源同時存在多個維度(例如節點 CPU 耗盡,但是記憶體還剩很多)。這樣的多維度閑散資源通常難以集中並下架,也會造成資源的浪費。
d. 突發流量洪峰導致資源不足
遊戲安全服務在正常運行時有著明顯的周期性,並且周期與周期之間峰值變化不大,一般情況下晚上九十點流量最高,後半夜流量最低。但是在某些突發情況下(突發性熱點、大型節假日等),服務的請求量會在短時間內大幅上漲,造成資源不足,影響服務正常運行產生告警。
e. 資源維度有限
原生的調度策略只會基於 CPU、記憶體、磁碟這三個維度判斷節點資源是否充足。然而實際情況下,磁碟 IO、網路 IO、連接數等維度同樣是決定業務是否正常運行的關鍵。因此資源維度的匱乏會對業務正常的保障造成影響。
## 現有解決方案
上述提到的問題在上雲的實踐過程中幾乎遇到,因此前人在遇到這些問題時已經提出了一些解決方案,具體如下:
-
HPA:基於業務實際運行的性能指標(一般為 CPU),自動變更 Pod 數量 -
反親和性:設置 Pod 反親和屬性,使得相同 Pod 盡量部署在不同節點,優化均衡性 -
在線離線混布:在同一集群混合部署在離線業務,離線業務在在線業務的低峰期擴容,提高低峰期利用率 -
Descheduler:定期掃描節點資源和部署情況,通過驅逐 Pod 平均節點負載以及均衡 Pod 部署 -
Dynamic Scheduler:基於節點實際負載調度 Pod,優先調度到低負載節點,優化均衡性 -
高低水位線:設置高低水位線,擴容時 Pod 優先調度到負載處於高低水位線之間的節點,縮容時優先縮容部署在低水位線下節點的 Pod
這些解決方案對上述問題的效果如下表:
| 解決方案 | 資源設置不合理 | 相同 Pod 資源使用有差異 | 多維度空閑資源碎片化 | 突發流量 | 資源維度有限 |
|---|---|---|---|---|---|
| HPA | × | × | × | √ | × |
| 反親和性 | × | √ | × | × | × |
| 在離線混布 | × | × | √ | × | × |
| Descheduler | × | √ | × | × | × |
| Dynamic Scheduler | × | √ | × | × | × |
| 高低水位線 | × | √ | √ | × | × |
從表中可以看出,上述解決方案只是解決了部分問題,沒有解決資源設置不合理、資源維度有限這兩個問題。此外,缺少一個整體的解決方案來對上述所有問題進行統一優化。因此,後文將分享一些本團隊對上述問題的解決方案。
## 優化方案
基於歷史監控的預測值 predicts 替代 requests
對於遊戲安全的實時計算業務,其資源使用往往具備明顯的周期性,並且周期之間變動不會太大,因此可以基於 Pod 的歷史監控數據預測未來的資源使用情況,並且準確度較高,以此解決資源設置不合理問題。
### 預測模型
預測模型旨在基於 Pod 的歷史多個周期監控數據,預測下個周期的資源使用數據(一般為基於歷史一個月預測未來一周)。主要有以下幾種預測方式:
| 方法 | 優點 | 缺點 |
|---|---|---|
| 直接使用歷史數據 | 1. 邏輯簡單 2. 可解釋性好 | 1. 準確率低 2. 相同類型 Pod 預測結果相同 |
| 周期因子法 | 1. 邏輯簡單 2. 可解釋性好 | 1. 只適合周期性場景 2. 無法預測趨勢 3. 對節假日、活動等特殊場景無法建模 |
| Prophet | 1. 預測準確率高 2. 綜合考慮趨勢項、周期項、節假日項 3. 可處理異常值和缺失值 | 1. 預測結果存在波動,魯棒性差 2. 複雜度高,計算速度慢 |
我們基於真實場景的數據進行了測試,輸入為歷史兩周的小時級別的 CPU 利用率,輸出為未來一周小時級別的 CPU 使用率,評價指標為 MAPE(Mean Absolute Percentage Error),具體結果見下圖。
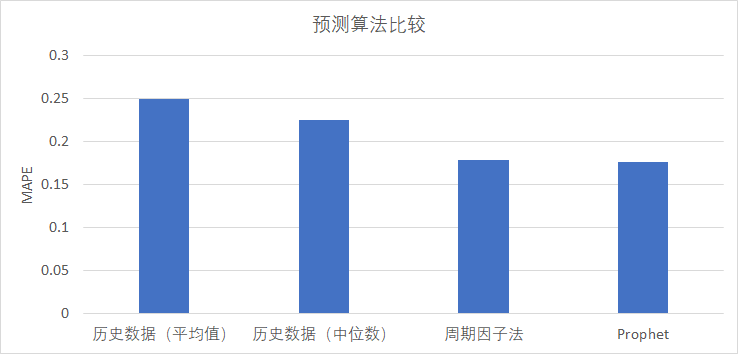
根據各演算法得出的預測結果比較見下圖:
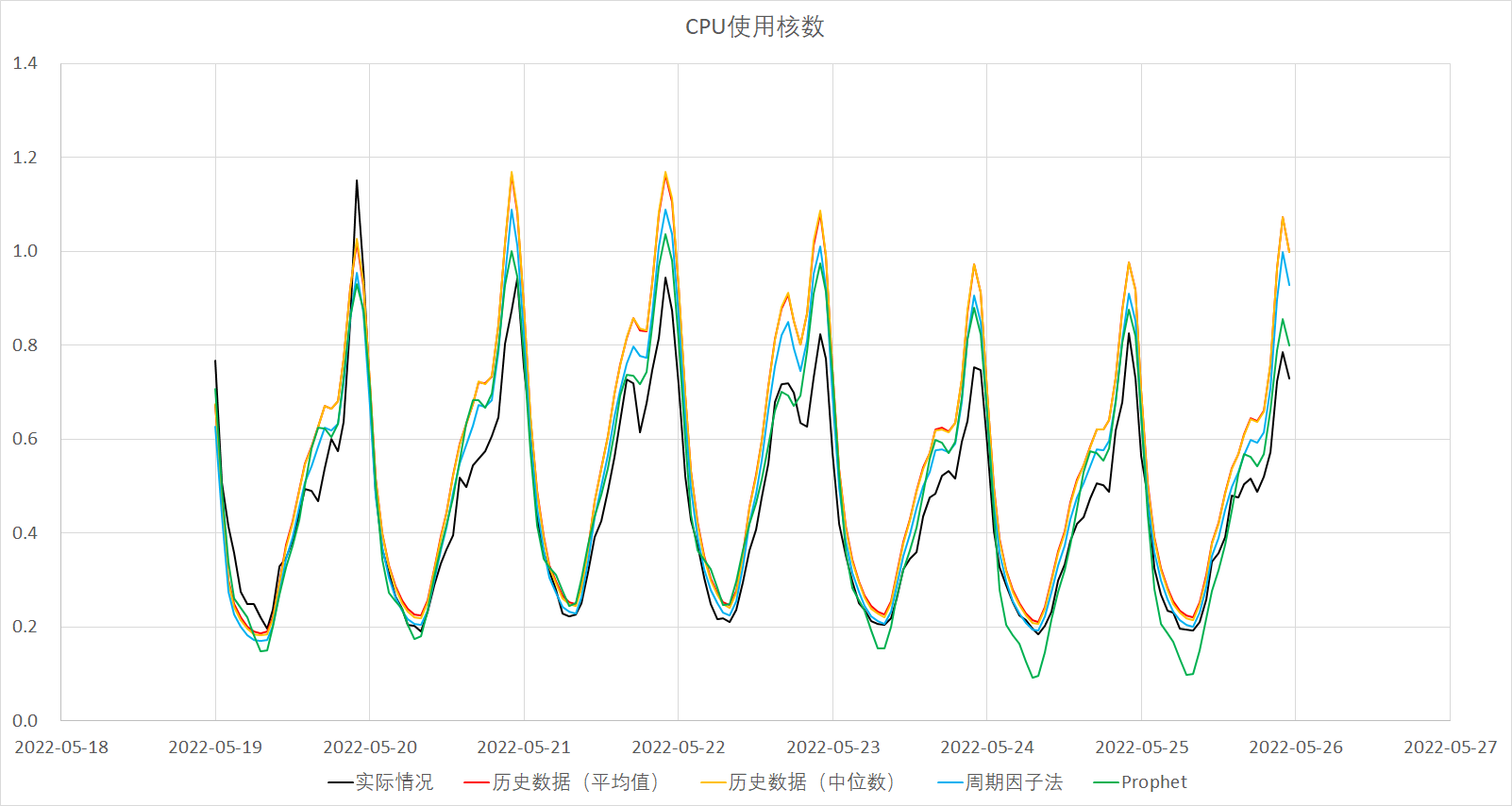
### 基於預測值調度 Pod
雲原生的調度方式是基於 requests 進行的,為了實現基於 predicts 調度,需要對調度器的功能進行擴展,這裡推薦雲原生提供的 Scheduling Framework,用插件化的方式添加用戶自定義的功能。
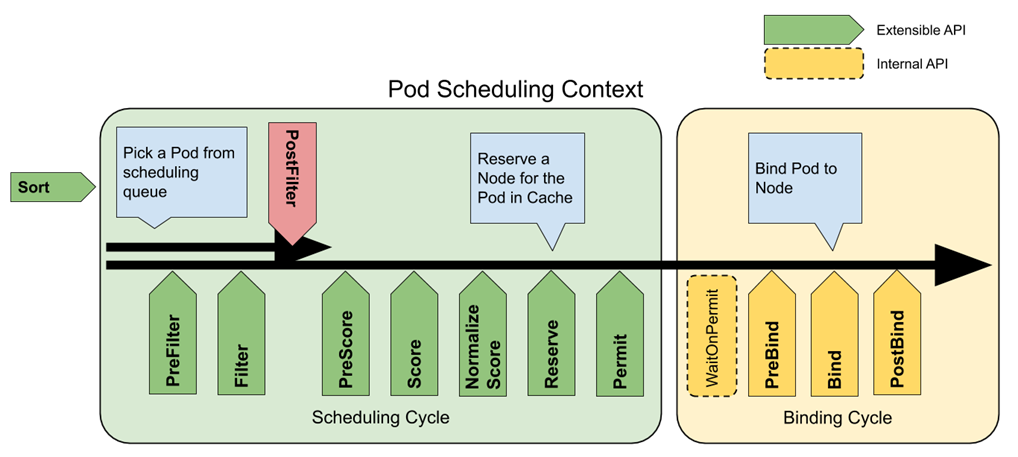
該框架將調度過程劃分成排序、過濾、評分、批准、綁定,共五個階段,具體功能如下:
-
排序:對調度隊列中的 Pod 進行排序 -
過濾:過濾掉不滿足 Pod 運行需求的節點 -
評分:對通過過濾階段的節點進行打分 -
批准:選取評分最高的節點,並判斷是否綁定 -
綁定:將 Pod 調度到最終選定的節點
上述每個階段都支援用戶添加自定義的插件。為了實現基於 predicts 調度,需要添加一個過濾插件,計算節點已綁定 Pod 的 predicts 和待調度的 Pod predicts 之和,並過濾掉不滿足資源需求的節點。
### 支援多維度資源
針對業務安全現有的服務,除了 CPU、記憶體和磁碟大小外,磁碟 IO、網路 IO 對於業務運行也非常重要。所以在收集 Pod 監控數據時,額外收集了這兩個維度的數據,在調度時也會計算在內。同時如果業務有其他額外的資源維度,也可以很方便的擴展。這樣解決了資源維度有限的問題。
### 整體編排
資源均衡性是解決相同 Pod 資源使用有差異的重要方法,這裡的資源均衡性要考慮多個維度的資源均衡性。如果僅僅在 Pod 需要調度時才考慮均衡性,那麼在 Pod 調度之後,隨著集群整體的部署情況變動,均衡性也會被破壞。因此,為了實現集群整體長期的資源均衡性,需要定期對集群整體進行重新規劃編排。這樣的整體編排同時也可以解決多維度空閑資源碎片化問題。整體編排主要分為兩個步驟:
-
基於 Pod predicts 計算出資源均衡的部署方案,使用儘可能少的節點滿足當前 Pod 的資源需求; -
將計算出的部署方案應用到集群;
### 部署方案計算
部署方案主要需要實現兩個目標:
-
壓縮多個維度的資源 -
在節點層面均衡分布多個維度的資源
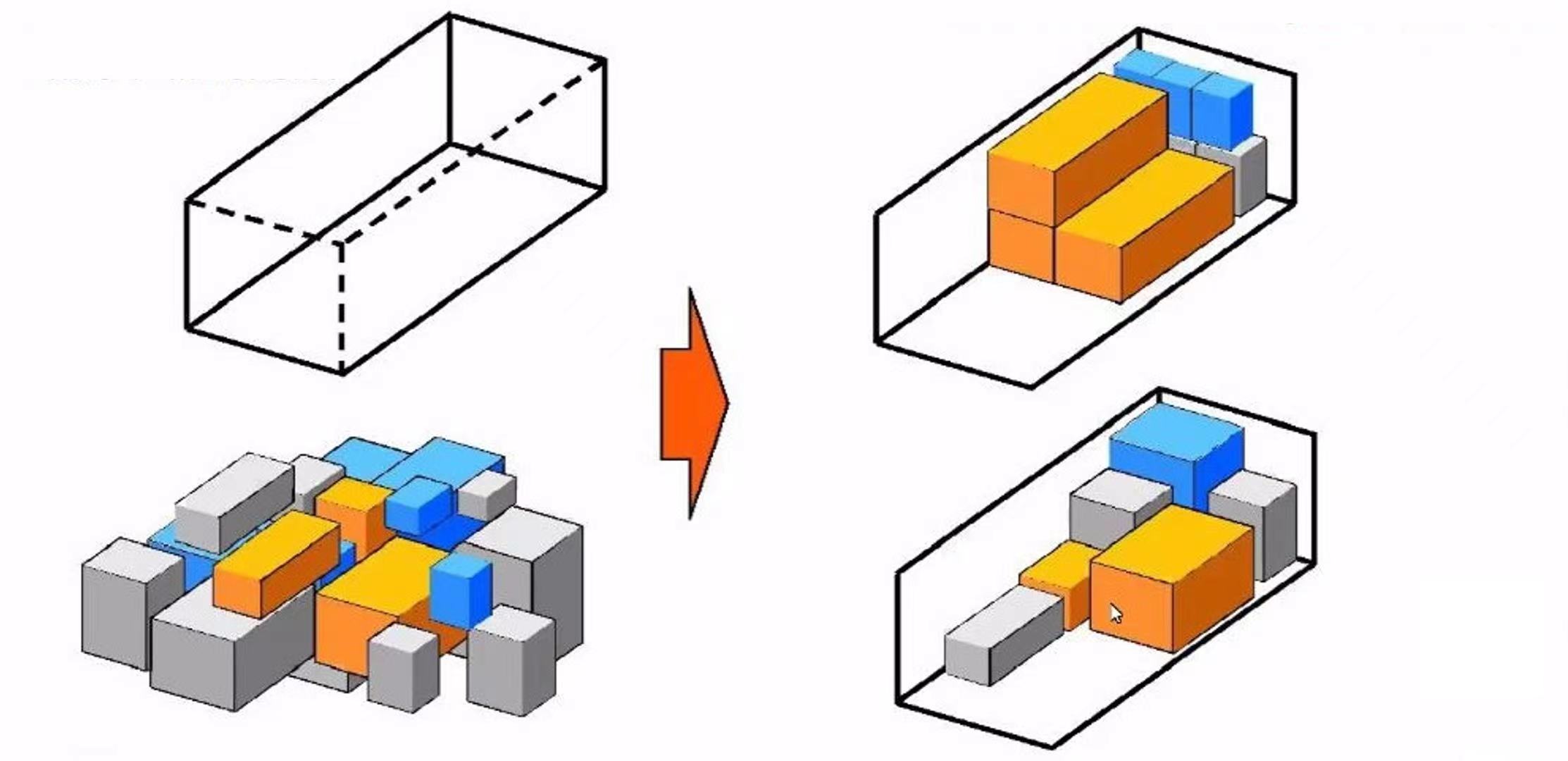
上述目標抽象來講即為一個多維裝箱問題,同時要求在裝箱的同時維護多維度的均衡。對於這一類問題,主要有以下幾種演算法解決:
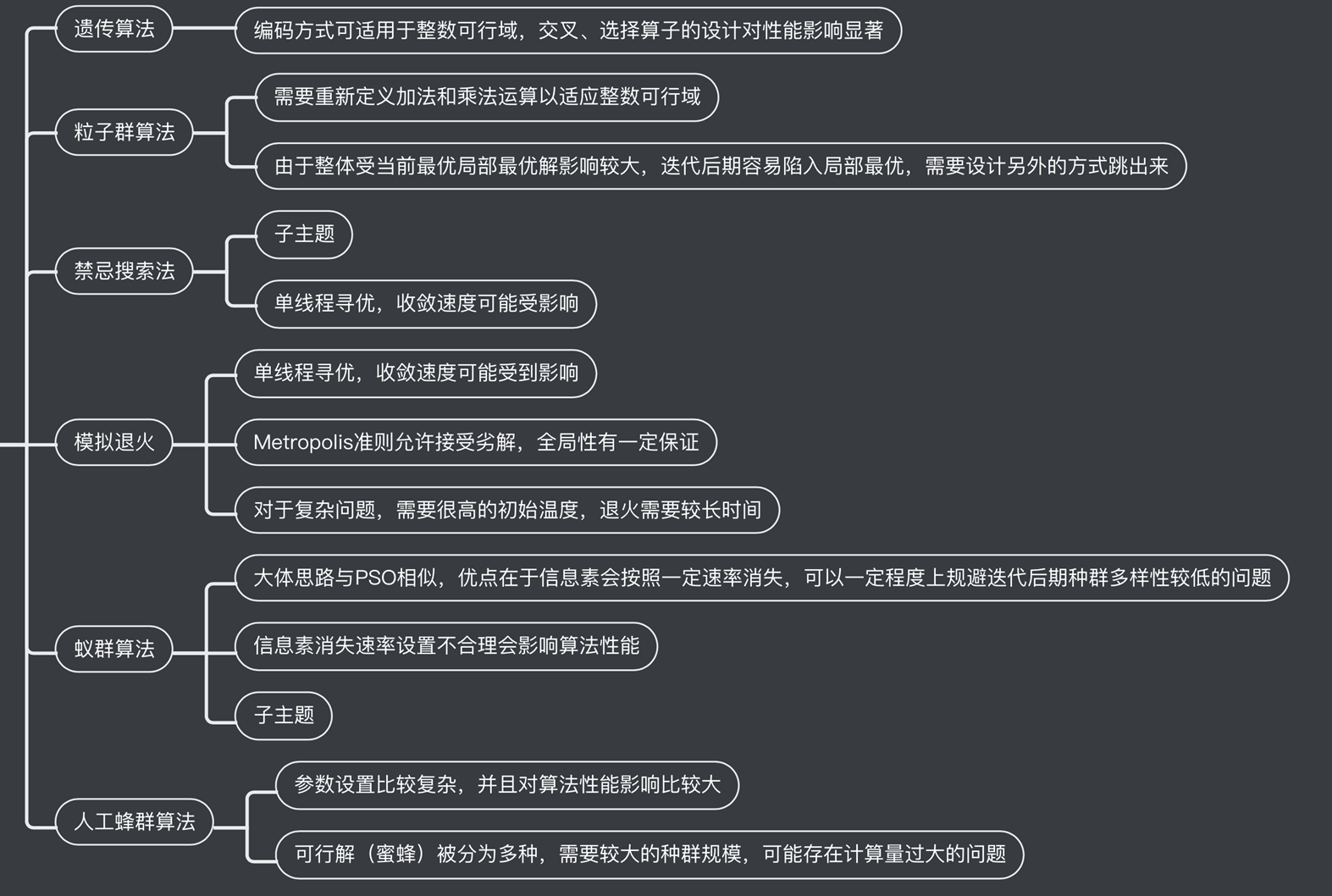
多維裝箱問題的一個難點是求解容易陷入到局部最優解,另外集群中的 Pod 數量一般上萬,對於裝箱問題來講規模較大,因此綜合考慮,決定採用遺傳演算法(GA)來求解最佳部署方案,因為其具有能跳出局部最優解的特性,同時相對來講對於大規模求解有著更好的性能。
對於遺傳演算法,多維裝箱問題的可行解可以被設計成一個染色體。
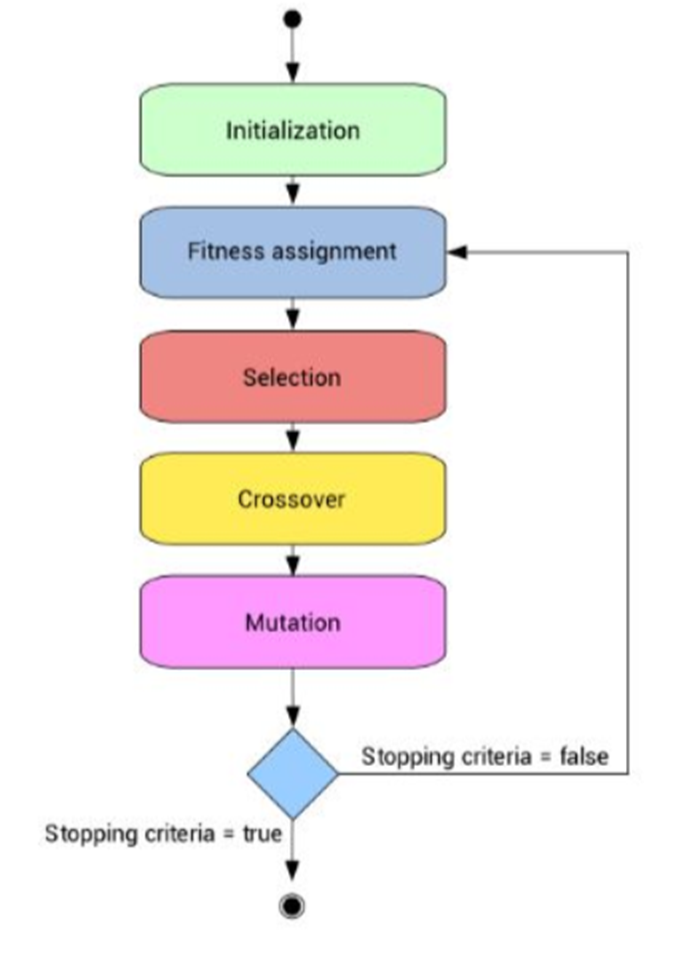
演算法整體流程大致如下:
以我們線上環境的重慶集群為例,當前集群使用了69個節點,在計算部署方案之後,只需要使用27個節點即可滿足所有 Pod 的運行,機器成本下降**61%**。並且為了保證服務品質,計算部署方案時節點各維度資源的最高利用率設置為不超過80%,因此有進一步壓縮的可能。同時各資源維度也實現了較好的均衡性,下圖以 CPU、記憶體為例,展示部署方案中資源的均衡性。
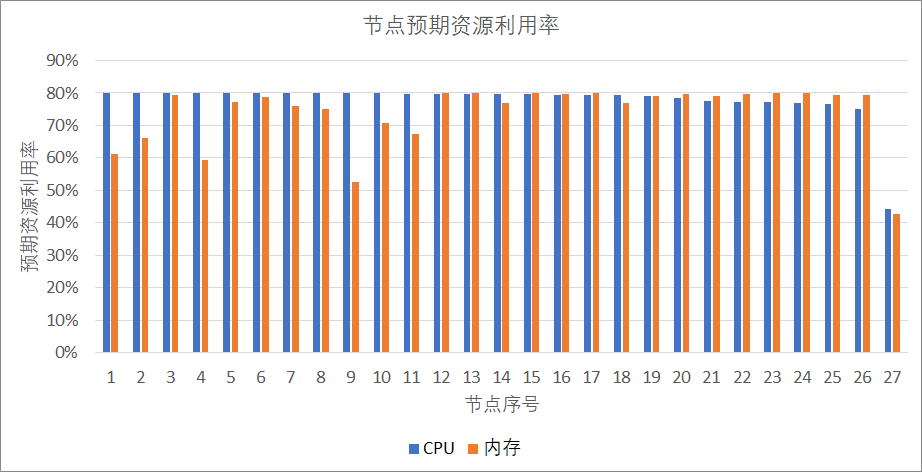
從圖中可看出,除了最後一個節點沒有布滿,其他節點都接近我們的目標80%利用率。記憶體方面,大部分節點也都在60%-80%的區間內。
### 部署方案應用
部署方案旨在使用最少的節點容納當前所有 Pod,將資源使用儘可能壓縮。這樣會將節點分成兩部分:
-
熱節點:在方案中部署 Pod 的節點 -
冷節點:在方案中被騰出空間的空閑節點,可下架或用於冗餘
對於大型集群而言,實施部署方案是一個耗時較長的過程,在這期間原先的 Pod 會有變動,例如擴縮容。對於縮容,只是會使原本壓縮的資源使用沒有那麼緊密;對於擴容或者新業務部署,我們需要預留一批節點資源來容納這些新創建的 Pod。這裡建議實際使用時先評估未來的使用量,然後從冷節點中把這部分預留資源劃分出來,剩餘的冷節點禁止新的 Pod 調度上去,這樣在部署方案應用之後,可以避免上一步騰出來的空閑節點被新產生的 Pod 佔用,從而無法直接下架。
除此之外,將部署方案實際應用到節點還面臨兩大挑戰:
-
如何將 Pod 調度到方案指定的節點 -
調度 Pod 時如何保證不影響業務正常運行
#### 調度
和之前相似,要想控制 Pod 的調度結果,也需要對 K8s 調度器進行功能擴展。此處仍然推薦使用雲原生提供的 Scheduling Framework 實現,具體不在贅述。此處實現需要分別添加一個過濾插件和評分插件:
-
過濾:根據待調度 Pod 的部署方案,過濾掉已有足夠 Pod 數量的節點 -
評分:增加熱節點的評分,降低冷節點評分,使 Pod 優先調度到熱節點
#### 保證業務正常運行
應用部署方案難免會對集群中的部分 Pod 進行重建,而這裡的核心目標除了實現部署方案,還需要保證不影響業務的正常運行。不影響業務正常運行的一個重要前提是服務網格的改造,這方面的內容已經在IEG-大規模遊戲安全實時計算服務的上雲實踐 的3.2節做了簡單介紹,這裡不再贅述。
此外,為了保證調度不影響業務的正常運行,需要根據業務的不同類型實施不同的調度策略。
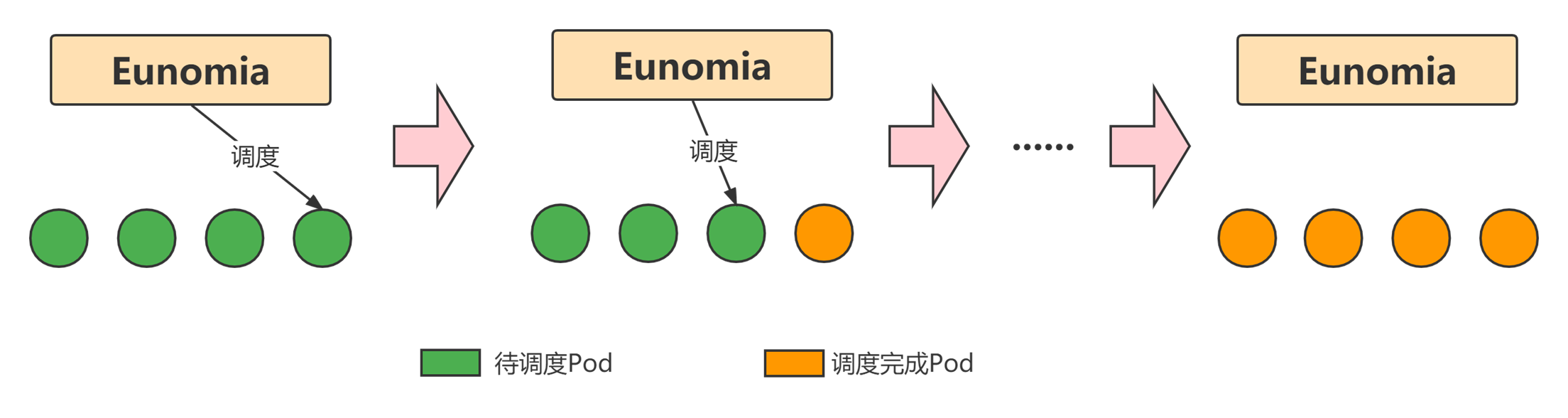
## 無狀態服務
無狀態服務指 Pod 即使立即停止也對當前業務沒有影響。針對這一類型服務,需要保證的是同一時刻有指定比例的 Pod 正常提供服務。這可以通過設置就緒探針和存活探針實現,同時要求業務側支援灰度,確保開始調度下一批 Pod 時,新啟動的 Pod 已經可以正常提供服務。
## 弱狀態服務
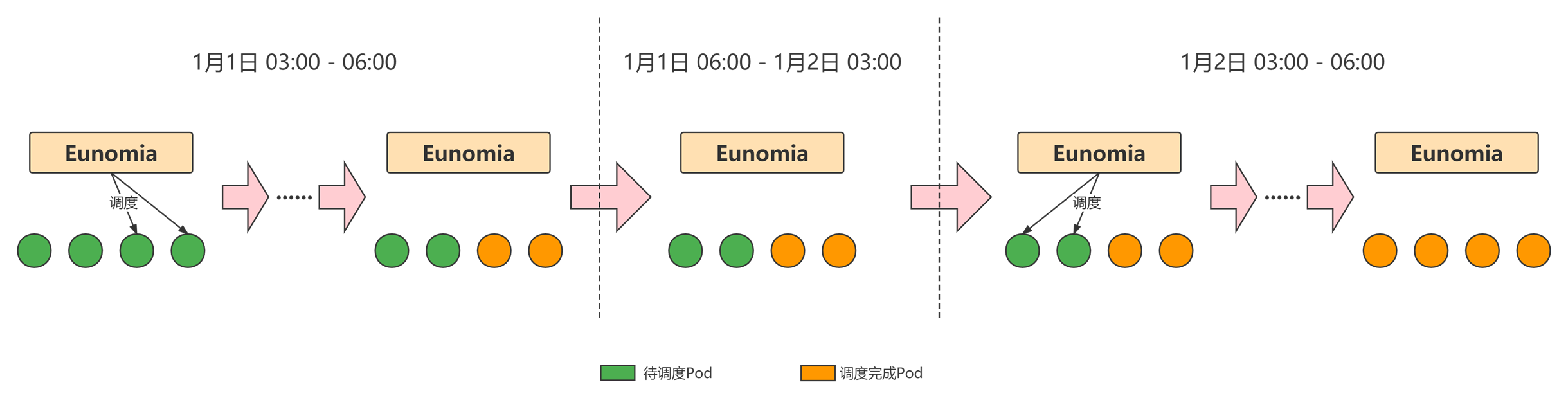
弱狀態服務指 Pod 立即停止對當前業務有一定影響,但不致命。對於該種服務,可以通過在服務訪問量較小的時段調度(例如凌晨3-6點)來進一步優化。
## 強狀態服務
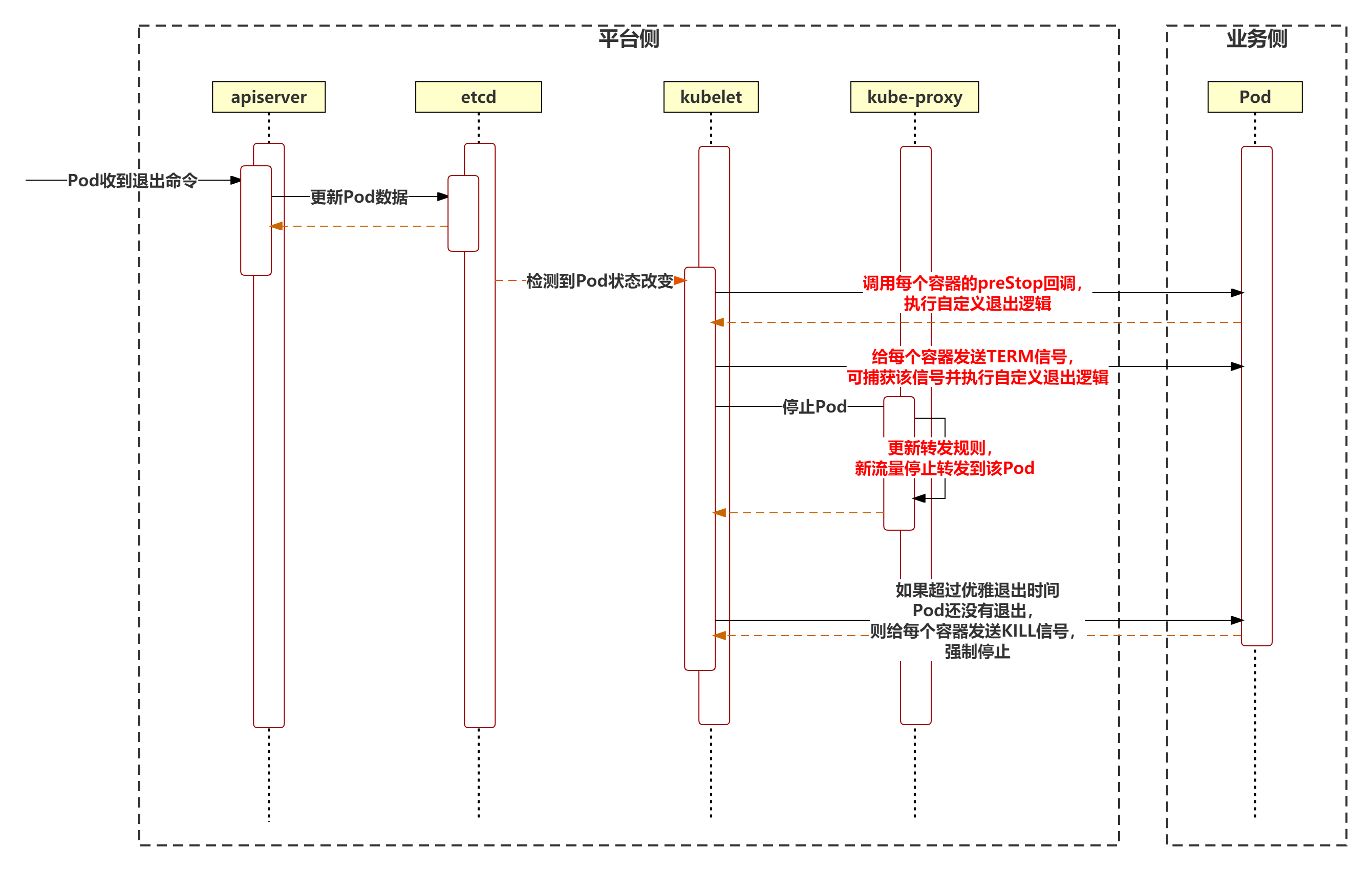
強狀態服務指 Pod 立即停止對當前業務有影響,並且致命。此類服務的停止比較複雜,需要平台側和業務側協同合作。其中業務側需要設置 Pod Prestop 回調,且需要捕獲並處理退出時收到的 TERM 訊號,對當前請求進行收尾並退出。平台側則需要切斷轉發到該 Pod 的流量,避免有新的請求發送到該 Pod。具體流程如下:
## 容災恢復
基於 Pod 預測值調度存在以下風險:
-
Pod 可能因為資源過度壓縮,無法正常提供服務 -
突發性流量高峰可能使 Pod 資源使用超過 predicts
針對第一種情況,可以給 Pod 設置存活探針,監控 Pod 的健康狀態。如果 Pod 頻繁出現不健康,則需要進一步查看原因,是否有其他關鍵資源維度或者需要調整節點預期的資源利用率。
針對第二種情況,需要設置告警監控集群節點狀態,告警觸發時自動調用介面刷新 Pod predicts 並驅逐低優先順序的 Pod,保證高優先順序的 Pod 正常運行。這樣可以有效避免突發流量影響業務服務品質。
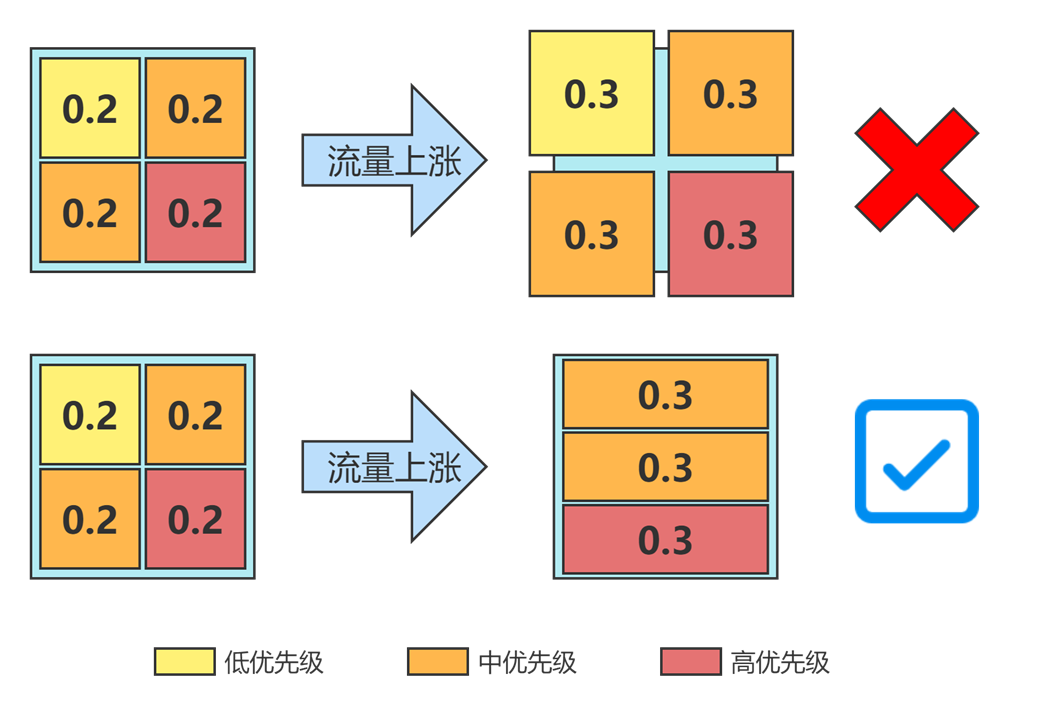
## 低負載節點裁撤
前文提到通過整體編排解決多維度空閑資源碎片化問題,但是整體編排的整個流程耗時比較長,無法快速地回收資源。在實際生產環境中,針對一些可預見的流量高峰期(例如國慶),業務會提前擴容,這要求新節點資源的添加;流量峰值過後,業務會再縮容,這時之前添加的節點資源就會空閑出來,但是這些空閑資源並不能直接回收,因為縮容並不能精準縮容之前擴容出的 Pod,並且在新節點上架期間,老的 Pod 也會被調度上去。因此業務縮容過後經常出現的情況是直接添加的節點負載很低,但是上面有少量業務 Pod 還在運行。
對於這種情況,如果採用之前的整體編排方案去解決難免有大炮打蚊子的嫌疑,因此我們採用了另一套更簡單直接的解決方案:
-
篩選出低負載節點; -
將上面的 Pod 驅逐,該步驟也需要在不影響業務服務品質的前提下進行; -
正式下架節點,完成成本的削減。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!


