作業系統學習筆記12 | 從生磁碟到文件
下面就是磁碟管理的第3層抽象,從磁碟到文件,上一講最後留下的盤塊號並不符合我們日常使用電腦的習慣,而文件才是我們使用電腦更為常用的方式。這一部分就來細說第3層抽象:生磁碟到文件。這部分將解釋如何從文件得到盤塊號。
參考資料:
-
課程:哈工大作業系統(本部分對應 L29 && L30)
磁碟管理共4層抽象,本部分為第3層,前兩層在 筆記11
-
課本:《作業系統原理、實現與實踐》-李治軍、劉宏偉
1. 第3層抽象描述:為什麼引入文件?
引入文件抽象的磁碟也稱,File-cooked disk,這正與上一講中的生磁碟 Raw disk 相對,也是比較有意思的一件事情。
前兩層抽象的建立已經讓人嘆為觀止,但是對於普通用戶而言,並不了解盤塊號這樣的專業名詞,所以引入更高一層的抽象:文件,這樣普通用戶操縱磁碟資訊時更為方便和舒適。
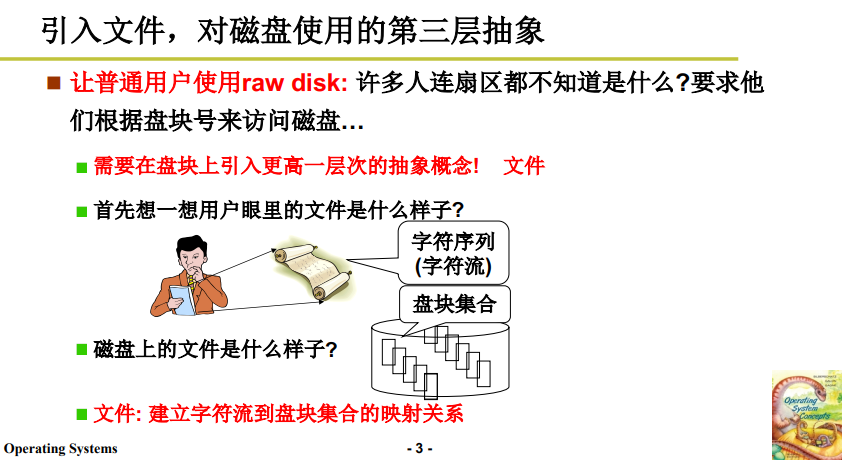
用戶眼中的文件是什麼樣子的?
- 在用戶眼中,文件本質是字元流;但這顯然是一個抽象的概念;
- 在電腦/作業系統眼中,文件作為數據只能存放在磁碟上。而磁碟是由盤塊組成的(作業系統視角),如下圖所示;
我們要做的事情就是 建立字元流到盤塊的映射關係。而文件抽象的初心是建立文件與盤塊號的聯繫,這意味著這層抽象中作業系統將從文件字元流中推算盤塊號。
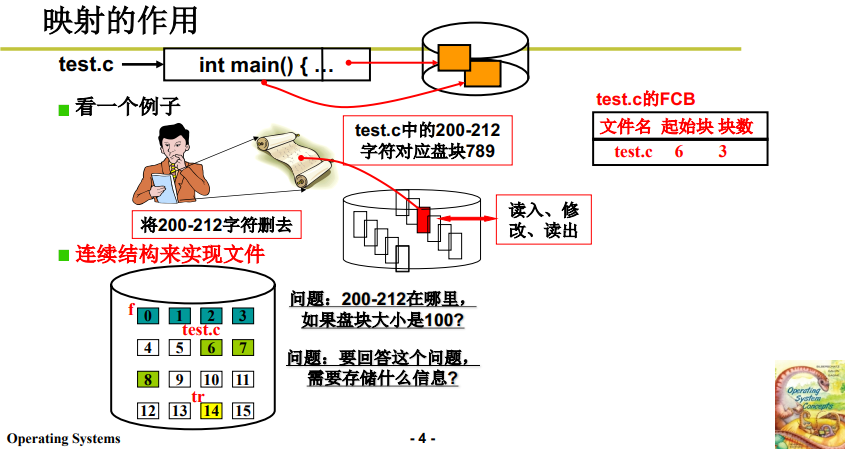
下面舉例說明一下上面提到的映射關係的作用:
-
對於一個 test.c 文件,我們想要刪掉其中的 200 ~ 212 行(這也是日常調試過程經常發生的事情)。
這一段在用戶眼中就是連續的字元流,而在OS眼中就對應磁碟的盤塊。
-
因此,從 作業系統/磁碟管理 的角度來講,刪除,首先需要讀出這一段程式碼,然後在記憶體中修改後再寫入磁碟。
- 找到這段字元對應的盤塊 (比如789);
- 按照上篇筆記的讀寫方式,通過電梯隊列將盤塊內容讀入記憶體緩衝區;
- 用戶進行刪除。
- 再通過電梯隊列將這段數據寫回到磁碟上,再讀取該位置磁碟數據時,就不會顯示這一段程式碼了。
這裡留一個坑:刪除了200~212行,對應磁碟盤塊就出現了空白,這段空白怎麼處理?
- 空白是文件系統處理的,文件系統會對其進行縮進和調整,然後體現在記憶體緩衝區中,文件關閉的時候會從緩衝區寫入磁碟。
- 文件系統下一篇筆記會講。
- 這個映射關係是由作業系統來維護的,對於上層用戶不可見,用戶層面的是文件字元流操作,而作業系統負責將字元流操作請求解析為盤塊號,接著以前2層封裝再向下執行。
- 這裡已經很接近我們日常使用電腦的真相了。
2. 映射表:文件存儲結構
上文提到,作業系統負責根據映射關係解析文件字元流,這種映射需要一個映射表。映射表需要根據文件在磁碟中的存儲結構來建立,下面介紹幾種基本的文件存儲結構及其映射表建立,我們也可以自行設計其他文件存儲結構及映射:
2.1 順序存儲結構
文件使用順序結構儲存在磁碟上,文件字元流被按照順序存放在連續的盤塊里。
比如 1~100 字元放在6號盤塊,101~200 字元就放在7號盤塊,以此類推。
順序結構的映射建立如下,如下圖下半部分所示:
-
已知字元數與盤塊的存儲關係;
如例子中的100個字元1個盤塊,這是作業系統內部的參數。
-
根據字元序號計算盤塊序號;
比如訪問第202字元,202/100 = 2,可知該字元被存放在該文件對應的第2個盤塊里(從0開始)。
-
文件的 FCB (File Control Block 文件控制塊)存儲該文件的起始塊號,結合盤塊序號就能知道對應的字元在那個盤塊;
起始塊號為6,6+2=8,符合事實。
映射建立後,讀寫磁碟所需的盤塊號就被映射表封裝成了文件字元流的修改。聯繫上一講的上層介面 盤塊號,繼續向下就實現了磁碟的訪問。
順序存儲結構也有不妥之處:
- 用順序存儲的結構適合文件的直接讀寫,不適合文件的動態增長,就像C語言數組,不方便插入元素。
- 當插入內容時,需要整體拷貝挪到另一片空閑空間,涉及整個文件的讀出和寫入,這開銷很大。
所以每種存儲結構的特點不同,我們需要根據文件的特性,來選擇/設計存儲結構。
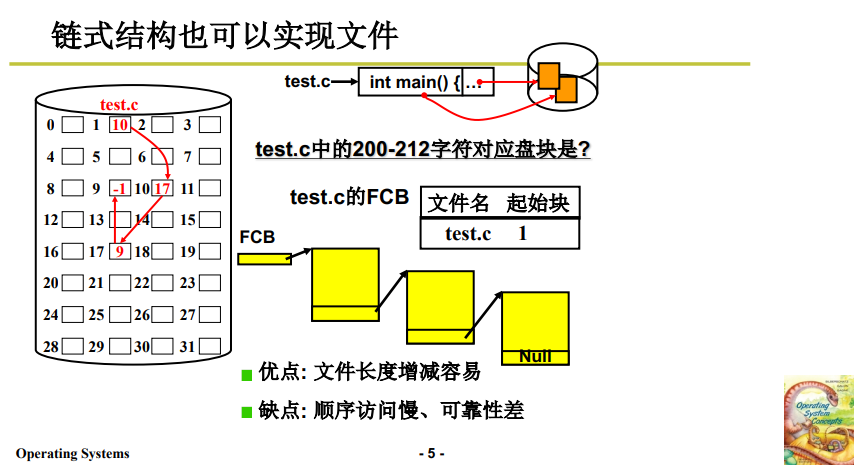
2.2 鏈式存儲結構
文件使用鏈式結構儲存在磁碟上,當前盤塊中存放下一塊盤塊的位置指針,實際上就是鏈表在磁碟中的表現形式。如下圖所示:
文件控制塊 FCB 中需要存放的主要映射資訊:第一個磁碟塊的盤塊號。
- 利用這個資訊可以找到文件的第一個磁碟塊;
- 每個磁碟塊中存放下一個盤塊號的指針,據此找到第二個磁碟塊……
- 這種鏈式存儲結構就很適合文件動態增長,插入只需要申請空閑盤塊寫入後插入鏈表即可。
- 同時,鏈式存儲結構的讀寫就會變得複雜,需要順序遍歷才能找到,不能像順序存儲結構那樣直接讀寫;並且,其中一個盤塊資訊丟失,就可能導致整個文件不可用。
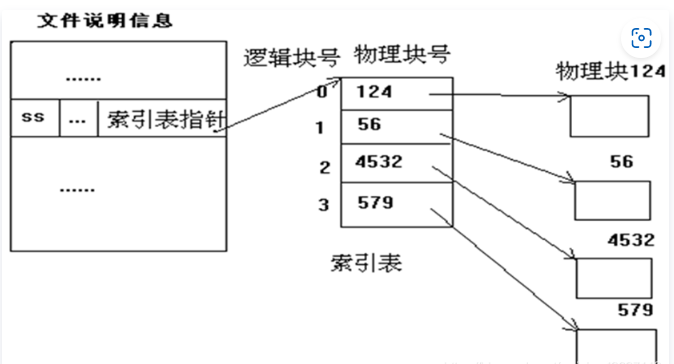
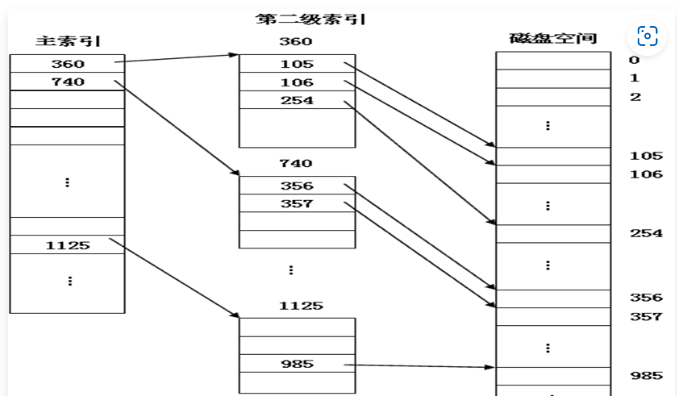
2.3 索引存儲結構
聯想前面鍵盤和顯示器中 Linux 0.11 文件的讀取方式,使用了一個 inode 的結構來存儲文件資訊並據此進行讀取,這顯然是一種索引結構。
文件使用索引結構儲存在磁碟上時,文件資訊可以存放在不連續的磁碟盤塊上,FCB 存儲索引表,索引表存儲盤塊號,如下圖所示(位置是19):
-
將文件字元流分割成多個邏輯塊,在磁碟上申請一些空閑物理盤塊(無需連續),將這些邏輯塊的內容存放進去;
-
用另外的磁碟塊(可能不止1個)建立索引表,按序存放各個邏輯塊對應的盤塊號;
就像記憶體管理的頁表一樣。
-
當訪問202號字元時(還是繼續上文例子):
- 首先我們計算出,這是該文件第2個盤塊(從0計數)上的內容;
- 根據文件的FCB中的索引表位置,查找索引表,對應盤塊號是1;
- 讀入盤塊1,就完成了202號字元的讀入。

- 索引存儲結構結合了順式存儲和鏈式存儲兩者的優點,支援動態增長、插入刪除;既能夠順序讀寫,也能夠隨機讀寫。能夠充分利用磁碟空間。
- 索引存儲結構的缺點就是引入了 索引表,建表和查表會帶來額外的開銷。但是這一問題可以通過存儲技術發展來得到解決。
2.4 多級索引結構
由於上述優點和可解決的缺點,實際作業系統 如 Linux 和 Unix,使用的文件存儲都是 基於 索引存儲 的 多級索引結構。如下圖所示:
-
如果是小型文件,inode 直接作為索引對應盤塊,此時類似於上文索引存儲;
-
如果是中等文件,建立一階間接索引,inode 放置索引表的位置;
-
如果是大型文件,則建立多階間接索引,此時可以表示非常大的文件;
inode 的理解:
- 文件數據存儲在盤塊里,還需要空間存儲文件本身的資訊,比如創建者、創建日期、大小、位置等;
- 這種儲存文件元資訊的區域就叫做inode,中文譯名為”索引節點”。是一個映射表。
- 參考資料:理解inode – 阮一峰的網路日誌,部落客我關注了很久,這篇博文寫得也很好。同時,這篇部落格講解了更深入的 inode 軟鏈接、硬鏈接等內容。
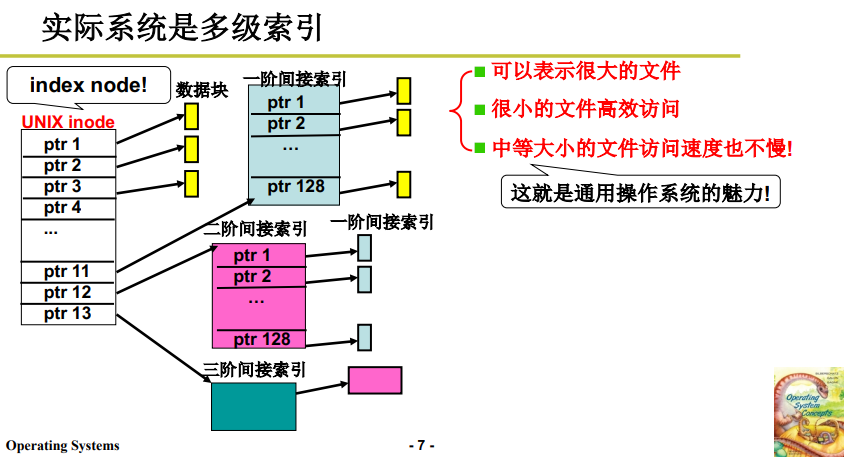
可見,如上圖這樣的索引架構:可以表示很大的文件,很小的文件高效訪問,中等大小的文件訪問速度也不慢。是一種比較優秀的綜合方案。
3. 程式碼實現:文件使用磁碟
這部分介紹文件層抽象使用磁碟的最核心程式碼。
其實這部分也可以聯繫 之前學習筆記10-鍵盤和滑鼠 的內容一起理解,在驅動外設時已經使用了文件抽象,因此其中的過程跟這裡很相似。
3.1 sys_write
用戶對文件的寫操作,在系統介面層面具體行動是調用write(),內核層功能程式碼sys_write()如下所示:
// 在fs/read_write.c中
int sys_write(int fd, const char* buf, int count)
{
struct file *file = current->filp[fd];
struct m_inode *inode = file->inode;
if(S_ISREG(inode->i_mode)){
// file 包含了前面缺少的字元流資訊
return file_write(inode, file, buf, count);
}
}
-
可見,sys_write 的參數: fd 為 文件描述符, buf 為 記憶體緩衝區, count 為 寫入記憶體的字元個數;盤塊號此時就被封裝了。
文件描述符見下文參考資料部分我的總結描述,簡言之就是使用 fd 找到對應文件。這部分在學習筆記10-顯示器與鍵盤中的2.3.1與2.3.2 、2.3.3 我也仔細分析過。
這裡老師可能是因為講過,所以講的很簡略。
-
file=current->filp[fd];如果對多進程影像還有點印象,current 就是當前進程的PCB,這裡的意思就是 PCB 中的一個數組 flip 的 fd 號位置處 存儲了一個文件。flip 數組的來源:是從子進程根據父進程創建時就拷貝過來的 (sys_fork),最原始的父進程從作業系統進程拷貝。通過 sys_open 建立從文件inode 到進程PCB的鏈;
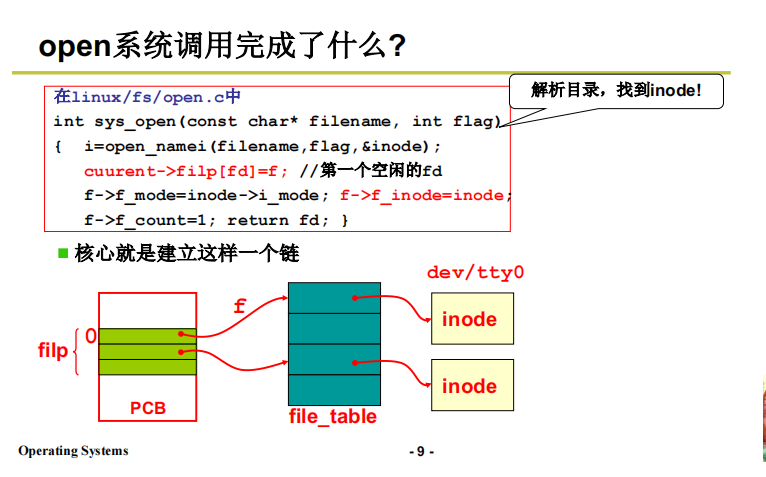
上圖摘自我的筆記10,這個鏈本部分的配圖也有。
-
struct m_inode *inode = file->inode;獲得 inode(文件本身的資訊); -
接下來根據 字元流file 和 inode 換算 盤塊號,調用 file_wirte;

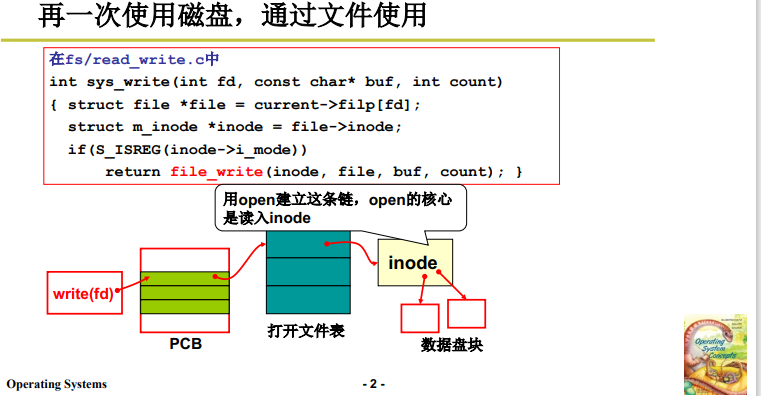
3.2 file_write
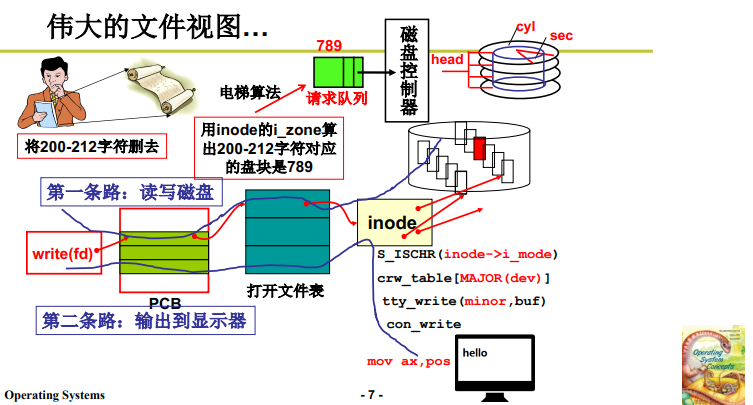
這部分程式碼實現 人訪問文件的影像 向 生磁碟讀寫數據的影像的轉換;也就是這裡的程式碼實現本文第1部分思路的實現。
如下圖,我們要修改200~212字元,下面的參數意義就是:
-
file_write(inode,file,buf,count); -
inode 表示文件索引塊(索引結構), file 是 200,buf 是 記憶體緩衝區位置,count 是 12;
-
根據這些資訊,就可以找到相關盤塊,放入電梯隊列,進行訪問。
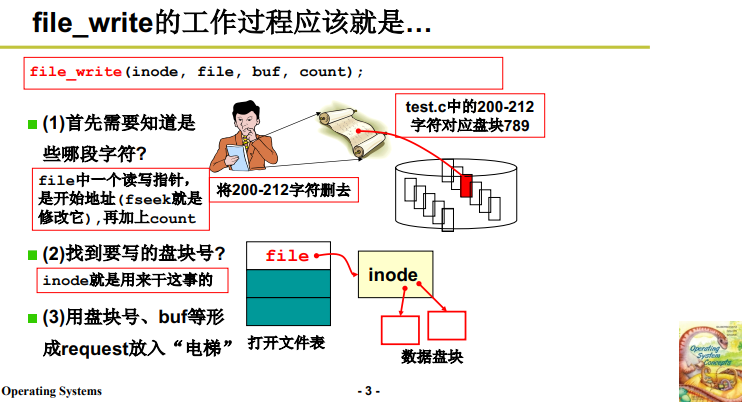
file_write 的 工作過程:
-
首先要根據 file 找到 200 ,這個目標字元流的開始位置。
- fseek 調整 file 中的讀寫指針(文件的當前讀寫位置);
這個讀寫指針是字元流形式的一個具體表現,剛打開時讀寫指針,隨著讀寫,讀寫指針後移,也就形成了字元流的影像。
- 並根據 count 找到 文件讀寫 對應的字元流;
-
接著 根據對應的字元流 計算找到盤塊號;
根據字元流上的讀寫位置 算出邏輯塊號(也就是相對位置) ,由 inode 找到物理盤塊號(也對於基址);具體調用了 create_block 來計算,見 3.3 部分。
-
接下來的故事其實就很順利了,與上一篇筆記接到一起:
- 接上第2層抽象,用盤塊號、buf等形成的 進程請求 request 放入電梯隊列。
- 再接上第1層抽象,磁碟中斷時從電梯隊列中取出請求,解算出CHS,通過 outb 指令,發到磁碟控制器,控制對應的磁碟地址進行讀寫。
而 file_write 就是上面幾步的頂層程式碼,每一步調用函數來完成:
-
第一大部分:得到目標字元流位置;
- 通過對目標讀寫位置pos 進行處理,找到文件的讀寫位置;
- 記錄在 f_pos 中;
-
第二大部分:根據字元流計算盤塊號;(核心)
-
create_block,核心程式碼,計算盤塊號 / 扇區號(左移);
-
bread,展開就是 make_request,向磁碟發出請求,放入電梯隊列後阻塞;
make_request,見第2層抽象解釋。
-
-
第三大部分:寫 完成,對 pos 做相應處理;
- 這裡的例子是磁碟寫,所以寫操作完成後,應當增加pos,相當於向後移動,形成字元流。
-
具體見程式碼注釋:
int file_write(struct m_inode *inode, struct file *filp, char *buf, int count)
{
// pos 代表當前位置
off_t pos;
//1.得到字元流的讀寫位置,也就是200
if(filp->f_flags&O_APPEND){
//如果是追加,pos從文末開始,i_size就是文件大小。
pos=inode->i_size;
}
else{
//如果不是,就從上一次讀寫的位置繼續。
pos=filp->f_pos;
}
.....
//2. 下面是核心程式碼,根據讀寫位置找到盤塊號。
while(i<count)
{
//算出對應的塊
block=create_block(inode, pos/BLOCK_SIZE);//起始位置和偏移量
//發送請求,放入電梯隊列,bread展開就是 make_request。
bh=bread(inode->i_dev, block);//放入電梯隊列後阻塞
//3.修改pos
//寫入數據後,修改 pos
int c=pos%BLOCK_SIZE; char *p=c+bh->b_data;
// pos指向文件的讀寫位置(字元流的末尾位置)
bh->b_dirt=1; c=BLOCK_SIZE-c; pos+=c;
...
//一塊一塊地拷貝用戶字元, 並且釋放寫出
while(c-->0) *(p++)=get_fs_byte(buf++);
brelse(bh);
}
filp->f_pos=pos;
}

3.3 create_block
計算盤塊號,這是第3層文件抽象的核心工作。
- 調用 create_block 的這段程式碼:
while(i<count){
//create=1的_bmap,沒有映射時創建映射
block=create_block(inode, pos/BLOCK_SIZE);
bh=bread(inode->i_dev, block);
...
-
create_block 調用了 _bmap,旨在建立 2.4 部分的多級索引結構/映射表。
強調:block 是邏輯塊,課程此處不夠清晰。block – 7是因為第7塊存儲在一重間接的指向的第0個索引表,以此類推
-
當 block < 7 ,對應小文件部分,0-6塊: 直接數據塊;
此時新申請數據塊時,就在 inode 中新批一塊來存放序號。
-
當 7 <= block < 512,建立一階間接索引,注意這裡的數據大小換算關係;
- 索引表中一個盤塊號的存儲需要 2 個位元組,2 個位元組 16 位;
- 索引表本身存儲需要 1 個盤塊。
- 1 個盤塊 = 2 個扇區 = 1 K = 1024 Byte
- ∴ 一個索引錶盤塊可以放 1024 /2 = 512 個盤塊號
- 當 盤塊 block < 512 時,一階索引完全就夠用了。
此時再申請新的數據塊時,邏輯塊號需要放到一階索引表的下一位(順序);
我在學習這部分時感覺不是很直觀,下圖表述一間接索引的情況較好:
-
很顯然,當 block >=512,索引表也需要建立二級索引表,因此引入多階間接索引。
-


int _bmap(m_inode *inode, int block, int create)
{
if(block<7){
if(create&&!inode->i_zone[block]){
// 新申請一個數據塊,返回它的塊號放在i_zone[block]中
//這樣0~6的inode就是直接索引數據
inode->i_zone[block]=new_block(inode->i_dev);
inode->i_ctime=CURRENT_TIME;
inode->i_dirt=1;
}
// 0~6 部分建表完成。
return inode->i_zone[block];
}
//
block-=7;
if(block<512){ //一個盤塊號2個位元組
bh=bread(inode->i_dev,inode->i_zone[7]);
return (bh->b_data)[block];
}
...
到這裡從文件到盤塊的映射表建立完成,接下來就會回到 file_write 中繼續 bread 向磁碟發出請求,接入前2層抽象。

3.4 inode抽象意義的理解
-
上面3.3 中 inode 可以作為映射表,從文件對應盤塊號;
-
inode 還可以視為 文件的抽象存在:
-
如果是普通文件,需要根據 inode 裡面的映射表來建立磁碟號到字元流直接的映射;
struct d_inode{ unsigned short i_mode;... unsigned short i_zone[9]; }//(0-6):直接數據塊,(7):一重間接索引,(8):二重間接索引 -
如果是特殊文件如設備文件,不需要inode去完成映射,inode存放主設備號、從設備號:
// 讀入記憶體後的inode,並不是設備文件和普通文件的該結構體不同 struct m_inode{ //前幾項和d_inode一樣! //文件的類型和屬性 //i_mode 存放 設備文件和普通文件的標誌位。 unsigned short i_mode; ... //指向文件內容數據塊 unsigned short i_zone[9]; //多個進程共享的打開這個inode,有的進程等待… struct task_struct *i_wait; unsigned short i_count; unsigned char i_lock; unsigned char i_dirt; ... }
-
-
下面就可以根據 inode 區分文件的屬性和類型:
int sys_open(const char* filename, int flag) { if(S_ISCHR(inode->i_mode)) //字元設備,設備文件 { // 由於是設備文件,zone數組不再用於映射表,用於設備號存儲 if(MAJOR(inode->i_zone[0])==4) current->tty=MINOR(inode->i_zone[0]); } ... } // emm 此處解釋一下上面程式碼的 MAJOR 和 MINOR // MAJOR 取高位元組 #define MAJOR(a)(((unsigned)(a))>>8)) // MINOR 取低位元組 #define MINOR(a)((a)&0xff)

理解到這裡,整個文件視圖就可以建立了。
3.x 參考資料
本部分用於記錄一些需要拓展而不想佔用正文篇幅的資料。
-
fd,File Descriptor,文件描述符:
-
這一點在學習筆記10 的 sys_open 處有所提及。
-
簡稱 fd,是系統調用介面 open 的返回值,當應用程式請求內核 打開/新建 一個文件時,就會調用 open 執行 sys_open;
-
fd 本質上就是一個非負整數,讀寫文件也是需要使用這個文件描述符來指定待讀寫的文件的。
-
4. 簡單總結
4.1 文件視圖/整體流程
首先,用戶要操作文件,分為兩條路:
-
第一條:讀寫普通磁碟數據文件。
根據 系統介面層的 fd 找到文件表,再讀取對應的 inode,據此接入3層抽象,順利讀取磁碟;
如果C語言基礎不好,對於用戶在應用層的文件操作不熟練,我再提一下:
-
fd = open("test.c"); read(fd,...);可見,整體流程是:路徑名或文件名->inode (fd)->盤塊號->放入電梯隊列,取出時解算CHS->out發到磁碟控制器驅動電磁效應讀寫數據。
-
第3層抽象解釋的是 read 這一句,即已知 fd 如何找到文件位置;拿到對應的 inode 接入已經掌握的抽象層進行讀取。
-
目前缺乏的就是 從文件名test.c 到 fd 和 inode 的聯繫,這是第4層抽象。
注意:如何找到下圖文件表?如何打開文件(open那一句程式碼)?
- 這就是下一篇筆記會講到的第4層抽象。
- 到文件表是進程PCB與 文件表 的鏈接,打開文件是建立文件名與 inode 的來鏈接;
-
-
第二條:讀寫設備文件
這裡前面學習筆記10也詳細介紹過了,inode不再用於映射,而是用於操作函數的選擇,根據不同的函數最後向設備控制器發送對應指令。
4.2 實驗8介紹
實驗 8 要實現一個 proc 文件,實現的效果是:輸入 cat /proc/psinfo,打出如下圖所示的進程情況:
Linux0.11中 這些進程資訊存放在 PCB 中,也就是說,並不在磁碟上,而 cat 命令要打開一個文件。所以要從PCB中取出相關資訊 先放到記憶體中再讀寫放到磁碟文件中(見下圖 cat 的一些程式,作用是持續列印,知道文件中沒有資訊)。
要實現這樣的效果,還是沿著 4.1 中的思路,不過要將 該文件的 i_mode 設置為 proc 設備(S_ISPROC(inode -> i_mode); 接下來調用 proc_read() 從 PCB 中的 task_struct 中取出數據拷貝給 buffer 記憶體緩衝區。
執行讀記憶體的相關操作,就實現了要求的效果。
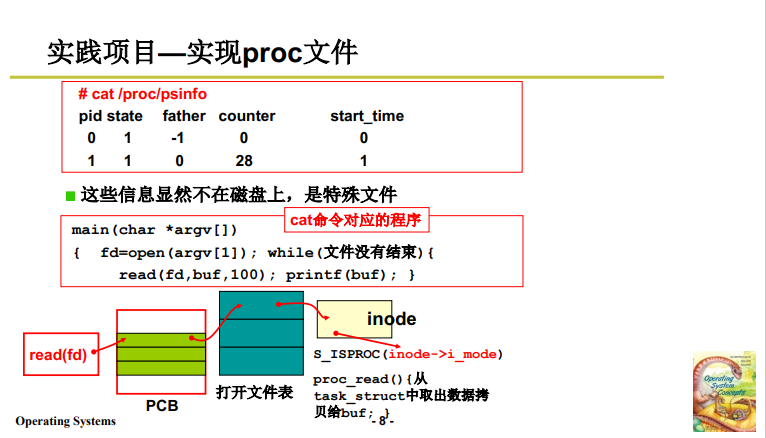
具體實現程式碼框架如下圖所示:
- 初始化時 mknod 創建設備,設備設計為 S_IFPROC 設備。
- sys_read 中對文件類型 即 i_mode 進行判斷,如果是,那就 proc_read.
- 從 PCB 中取出相關資訊放到記憶體上,傳到用戶態記憶體;
- 修改 pos 指針,將這些資訊不斷傳遞,形成字元流。



