剖析虛幻渲染體系(17)- 實時光線追蹤
- 17.1 本篇概述
- 17.2 光線追蹤基礎
- 17.3 光線追蹤技術
- 17.4 圖形API和GPU
- 17.5 UE光線追蹤
- 17.6 UE光線追蹤源碼分析
- 17.7 本篇總結
- 特別說明
- 參考文獻
17.1 本篇概述
17.1.1 本篇內容
UE的光線追蹤一直是童鞋們呼籲比較高的一篇,雖然多年前部落客已經在探究光線追蹤技術及UE4的實現闡述過,但內容較基礎和片面。那麼,此篇就針對UE的實時光線追蹤進行更加系統、全面、深入地分析。本篇主要闡述UE的以下內容:
- 光線追蹤的基本概念、技術。
- 光線追蹤的實現方案。
- 光線追蹤的優化、降噪技術。
- 光線追蹤涉及的圖形API、GPU結構。
- 光線追蹤的UE實現。
與傳統的掃描線或光柵化渲染方式不同,光線追蹤(Ray tracing)是三維電腦圖形學中的特殊渲染演算法,追蹤從攝像機發出的光線而不是光源發出的光線,通過這樣一項技術生成編排好的場景的數學模型顯現出來。

利用光線追蹤技術渲染出的照片級畫面。
與傳統方法的掃描線技術相比,這種方法有更好的光學效果,例如對於反射與折射有更準確的模擬效果,並且效率非常高,所以當追求高品質的效果時經常使用這種方法。
在物理學中,光線追跡可以用來計算光束在介質中傳播的情況。在介質中傳播時,光束可能會被介質吸收,改變傳播方向或者射出介質表面等。我們通過計算理想化的窄光束(光線)通過介質中的情形來解決這種複雜的情況。
在實際應用中,可以將各種電磁波或者微小粒子看成理想化的窄波束(即光線),基於這種假設,人們利用光線追跡來計算光線在介質中傳播的情況。光線追跡方法首先計算一條光線在被介質吸收,或者改變方向前,光線在介質中傳播的距離,方向以及到達的新位置,然後從這個新的位置產生出一條新的光線,使用同樣的處理方法,最終計算出一個完整的光線在介質中傳播的路徑。
17.1.2 光線追蹤和光柵化
光柵化渲染管線(Raster pipeline)是傳統的渲染管線流程,是以一個三角形為單元,將三角形變成像素的過程(下圖左),在目前影像API和顯示卡硬體有著廣泛的支援和應用。
光線追蹤渲染管線(Ray tracing pipeline)則是以一根光線為單元,描述光線與物體的求交和求交後計算的過程(下圖右)。和光柵化線性管線不同的是,光線追蹤的管線是可以通過遞歸調用來衍生出另一根光線,並且執行另一個管線實例。
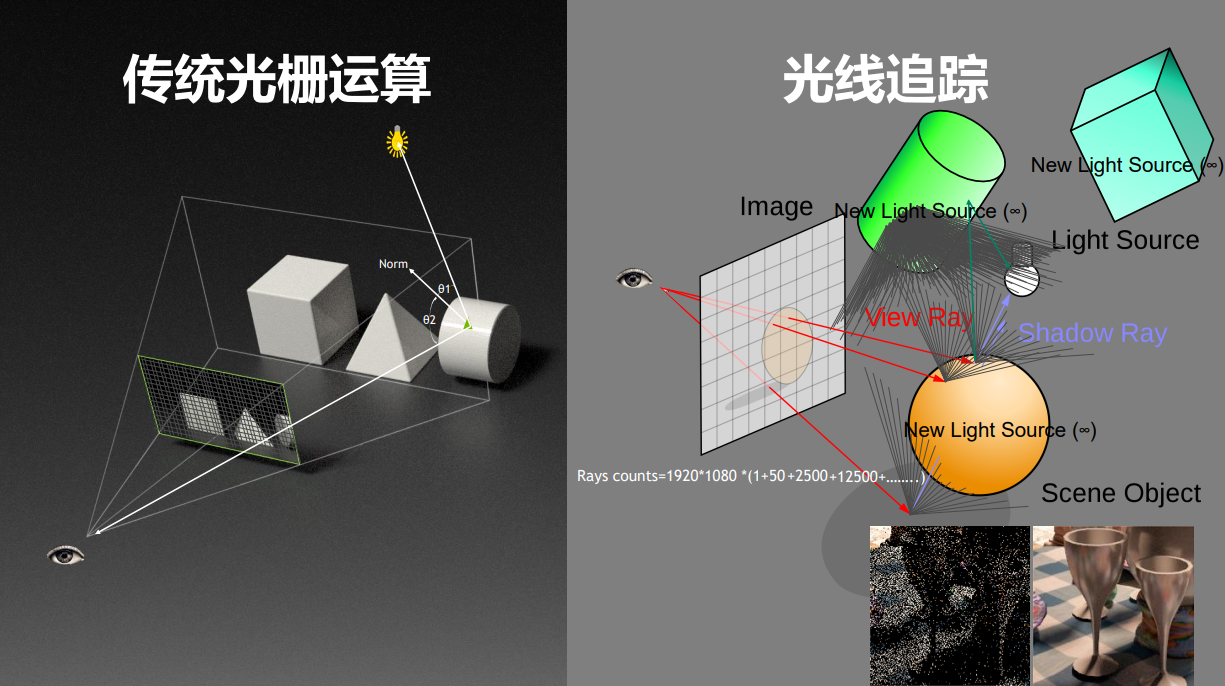
更詳細的對比表:
| 關鍵概念 | 光柵化 | 光線追蹤 |
|---|---|---|
| 基本問題 | 幾何體覆蓋了哪些像素? | 什麼物體對光線可見? |
| 關鍵操作 | 測試像素是否在三角形內 | 光線-三角形相交測試 |
| 如何流化工作 | 流化三角形(每個測試像素) | 流化光線(每條測試交點) |
| 低效率 | 每個像素對多個三角形著色(過繪製) | 每條光線對多個三角形相交測試 |
| 加速結構 | (層級)Z-Buffering | 層次包圍盒(BVH) |
| 劣勢 | 非一致性查詢難以實現 | 遍歷記憶體非常不一致 |
17.1.3 光線追蹤簡史
光線追蹤渲染技術從自然界中的光線簡化、光線投射演算法、光線追蹤演算法等一步步演變而來。
-
光線投射演算法(1968年)
由Arthur Appel提出用於渲染的光線投射演算法。光線投射的基礎就是從眼睛投射光線到物體上的每個點,查找阻擋光線的最近物體,也就是將影像當作一個屏風,每個點就是屏風上的一個正方形。
根據材質的特性以及場景中的光線效果,這個演算法可以確定物體的濃淡效果。其中一個簡單假設就是如果表面面向光線,那麼這個表面就會被照亮而不會處於陰影中。
光線投射超出掃描線渲染的一個重要優點是它能夠很容易地處理非平面的表面以及實體,如圓錐和球體等。如果一個數學表面與光線相交,那麼就可以用光線投射進行渲染。複雜的物體可以用實體造型技術構建,並且可以很容易地進行渲染。
-
經典光線追蹤演算法(1980年)
最先由Turner Whitted於 1979 年做出的突破性嘗試。以前的演算法從眼睛到場景投射光線,但是並不追蹤這些光線。而光線追蹤演算法則追蹤這些光線,並且每次與物體表面相交時,計算一次所有光源的貢獻量。

-
Cook隨機(分布)光線追蹤(1984年)
允許陰影光線到達區域燈光上的隨機點,允許鏡面光線在理想反射周圍受到鏡面擾動,在幀中的某個時間捕捉運動模糊。



-
Kajiya風格漫反射互反射(1986年)
路徑追蹤:拍攝每條光線並沿一系列互反射進行追蹤,提出渲染方程,保證在極限下給出正確答案。


-
光線追蹤API及硬體集成(2018年)
在早些年,NV就聯合Microsoft共同打造基於硬體的新一代光線追蹤渲染API及硬體。在2018年,他們共同發布了RTX(Ray tracing X)標準。Direct X 12支援了RTX,而NV的RTX系列顯示卡支援了RTX技術,從而宣告光線追蹤實時化的到來。

NV RTX演示影片截圖。
-
UE4集成光線追蹤(2019年)
UE於2019年4月發布了4.22版本,該版本最耀眼的新特性無疑是支援了光線追蹤技術,將助力廣大啟用UE的個人或團隊更加有效地渲染出照片級的畫面。

利用UE的光線追蹤技術渲染出的逼真畫面。


- UE5 Lumen集成硬體光線追蹤(2021年)
UE5的核心技術之一便是Lumen,實現了實時可信的全局光照效果,它支援軟體光線追蹤和硬體光線追蹤兩種模式。

UE的SSR(左)和光線追蹤反射(右)對比圖。

UE5的遠場的大規模GI效果。它支援硬體光線追蹤模式。
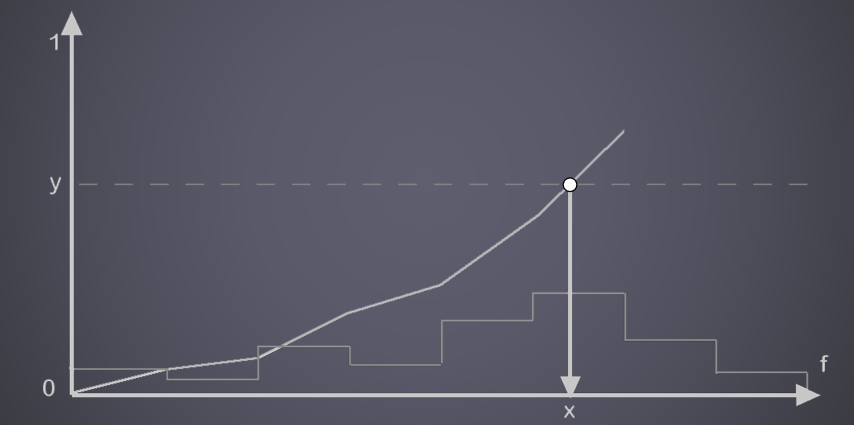
17.2 光線追蹤基礎
17.2.1 數學基礎
已知原點\(\vec{o}\)和方向\(\vec{d}\),則射線是半無限的直線:
\]
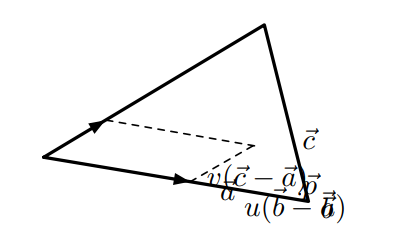
已經有3個頂點\(\vec{a}\)、\(\vec{b}\)、\(\vec{c}\),它們可以組成一個三角形,該三角形的法線可通過叉乘計算而得:
\]
射線和三角形的交點必須沿著射線,並且必須在三角形的平面內,因此必須滿足:\((\vec{p}-\vec{a})\cdot\vec{n} = 0\),結合射線公式,可計算出\(t\)值:
\]
以上公式需要處理一種特殊的情況,那就是\(\vec{d}\cdot\vec{n}=0\),即射線平行三角形的平面。如果計算的\(t\)值是負數,說明不在三角形內,可以拒絕該點。
給定任意的距離\(t\),可以很方便地通過射線的公式計算得到射線和三角形平面的交點。接下來,我們必須檢查該點是在三角形內還是在三角形外,可以通過計算質心坐標\((u, v)\)來實現這一點。質心坐標定義為:
\]
對應的圖例如下:
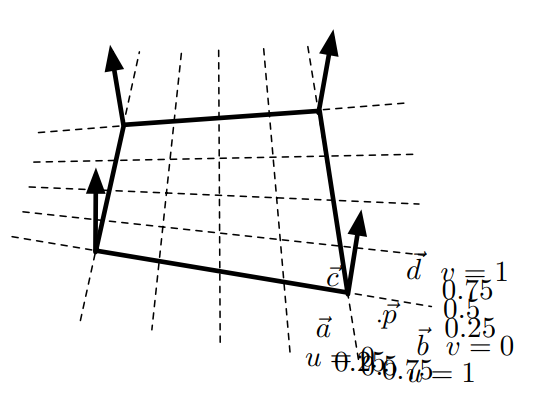
對於四邊形(雙線性面片),質心坐標更加複雜:
\]
對應圖例:
以上是針對四個頂點位於同一個平面的情況,但實際上,它們可能不在同一個平面,會產生兩個平面。

由兩個三角形近似的四邊形。
包圍盒(bounding box)對於加速複雜場景的光線追蹤非常有用。一般盒子由一個頂點和三個向量定義(下圖)。直接的相交測試將測試六個面中的每個面是否相交。通過僅需要測試面向射線原點的三個面,可以實現更快的測試。
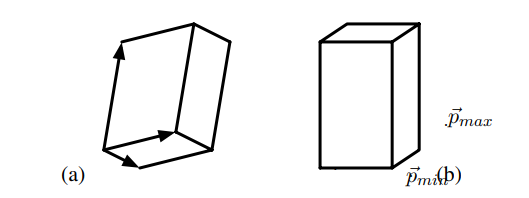
(a)具有一般方向的盒;(b) 軸對齊盒。
軸對齊的盒子可以更有效地進行交叉測試。軸對齊盒由xy、xz和yz平面中的每個平面中的兩個矩形組成。軸對齊盒由其最小和最大頂點\(\vec{p}_{min}\)和\(\vec{p}_{max}\)定義,如上圖(b)所示。我們可以將盒子視為三塊無限大空間板的交點。Smits描述了一種非常有效的射線交叉測試,利用IEEE浮點約定優雅而有效地處理0的除法,從而簡化了程式碼。
如果盒用作邊界盒,我們不需要知道最近的交點和法線,我們只需要知道光線是否與盒相交。
二次曲面(Quadrics)由圓盤、球體、圓柱體、圓錐體、橢球體、拋物面和雙曲面組成。
圓盤由其中心\(\vec{c}\)、法線\(\vec{n}\)和半徑\(r\)定義。尋找射線-圓盤交點與射線-三角形交點測試非常相似。我們首先計算射線-平面交點\(\vec{p}\),並檢查距離\(\vec{t}\)是否為正且小於之前的最近交點,如果\((\vec{p}-\vec{c})^2\le r^2\),則交點在圓盤上。圓盤在實際渲染中被大量使用,例如用於渲染粒子系統。
球體由其中心\(\vec{c}\)和半徑\(r\)定義。如果存在交點,則交點必須位於射線的某個位置,並且必須位於球體的表面上。為了找到交點,我們將射線方程代進球體方程\((\vec{p}-\vec{c})^2 = r^2\):
0 &=(\vec{p}-\vec{c})^{2}-r^{2} \\
&=\vec{p}^{2}-2(\vec{p} \cdot \vec{c})+\vec{c}^{2}-r^{2} \\
&=(\vec{o}+t \vec{d})^{2}-2(\vec{o}+t \vec{d}) \cdot \vec{c}+\vec{c}^{2}-r^{2} \\
&=\vec{o}^{2}+2 t(\vec{o} \cdot \vec{d})+t^{2} \vec{d}^{2}-2(\vec{o} \cdot \vec{c})-2 t(\vec{d} \cdot \vec{c})+\vec{c}^{2}-r^{2} \\
&=\vec{d}^{2} t^{2}+2 \vec{d} \cdot(\vec{o}-\vec{c}) t+(\vec{o}-\vec{c})^{2}-r^{2}
\end{aligned}
\]
\(t\)存在兩個解:\(t_1 = \cfrac{-B+D}{2A}\)和\(t_2 = \cfrac{-B-D}{2A}\),其中\(A = \vec{d}^2,B=2\vec{d}\cdot(\vec{o}-\vec{c}),C=(\vec{o}-\vec{c})^2-r^2,D=\sqrt{B^2-4AC}\)。對於判別式\(D\),存在3種情況:
- 如果\(D\)為負,則不存在(實)解,並且光線不會擊中球體。
- 如果\(D\)為零,則光線與球體相切,並且只有一個交點。
- 如果\(D\)為正,則存在兩個交點,最近的交點是具有最小非負值t的交點。
給定交點距離\(t\),我們可以計算出交點\(\vec{p}\),交點上的法線是\(\vec{n} = \vec{p} – \vec{c}\)。
還有其它形式的二次曲面,本文就不再解析,有興趣的同學可以自行尋找資料。
隱式曲面(Implicit surface)由函數\(f\)定義:曲面是點\(\vec{p}\)的集合,其中函數的值為0,\(f(\vec{p})=0\)。因此,為了找到射線-曲面交點,我們必須確定沿射線的(最近的)點\(\vec{p})\),其中\(f(\vec{p})\)為0:
\]
它可以使用例如Newton-Raphson迭代或其他迭代方法來完成,Sherstyuk描述了一種有效的演算法。交點處的曲面法線由該點處函數的梯度給出:
\]
還有NURBS曲面、細分曲面、位移曲面、盒體等,本文不再詳述。
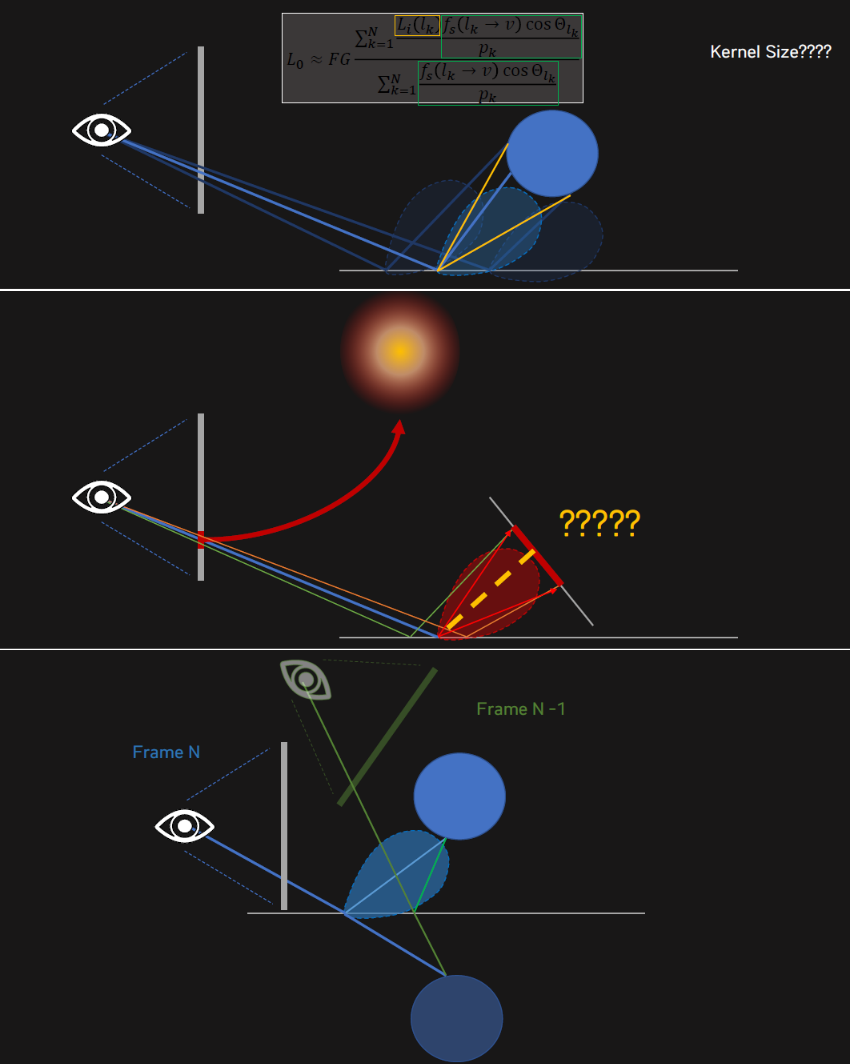
光線微分(Ray differential)儘管是光線的基本屬性,但用於光線追蹤還是相對較新的,對於包括紋理過濾和曲面細分在內的許多應用程式都很有用。光線微分描述了光線與其真實或虛擬「相鄰」光線之間的差異。如下圖所示,微分給出了每條射線所代表的光束大小的指示。

光線和光束。
Igehy的光線微分方法追蹤光線傳播、鏡面反射和折射時的光線微分。曲面交點處的曲率決定了在鏡面反射和折射後光線差及其相關光束的變化。例如,如果光線擊中高度彎曲的凸面,鏡面反射光線將具有較大的差異(表示高度發散的相鄰光線)。
下圖顯示了光線追蹤的鏡面反射。在左影像中,不計算光線微分,並且紋理濾波器寬度為零,因此產生鋸齒瑕疵。在右圖中,光線微分用於確定適當的紋理過濾器大小。為了清楚地顯示差異,影像的解析度非常低(200×200像素),每個像素僅拍攝一條反射光線,並關閉像素濾波。

反射:(a)不使用光線微分,(b) 使用。
Suykens和Willems將光線微分推廣到光澤和漫反射。對於漫反射或環境遮擋的分布光線追蹤,光線微分對應於半球的一部分。從同一點追蹤的光線越多,對端半球部分越小。如果半球分數(fraction)非常小,曲率相關微分(如鏡面反射)將佔主導地位。
17.2.2 浮點數
浮點數的實數必須近似,包含浮點數(Floating-point number)、定點數(Fixed-point number,亦即整數)、有理數(Rational number,齊次表示)。IEEE-754單精度的數據布局是:1位符號、8位指數(偏置)、23位分數(帶隱藏位的24位尾數),其圖例如下:

其表示的數值公式是:
\]
這是一種標準化格式,IEEE-754可表示的數字如下表:
| 序號 | 指數(Exponent) | 分數(Fraction) | 符號(Sign) | 值 |
|---|---|---|---|---|
| 1 | \(0 < e < 255\) | \(V = (-1)^s \ \times\ (1.f)\ \times\ 2^{e-127}\) | ||
| 2 | \(e = 0\) | \(f = 0\) | \(s = 0\) | \(V = 0\) |
| 3 | \(e = 0\) | \(f = 0\) | \(s = 1\) | \(V = -0\) |
| 4 | \(e = 0\) | \(f ≠ 0\) | \(V = (-1)^s \ \times\ (0.f)\ \times\ 2^{e-126}\) | |
| 5 | \(e = 255\) | \(f = 0\) | \(s = 0\) | \(V = +Inf\) |
| 6 | \(e = 255\) | \(f = 0\) | \(s = 1\) | \(V = -Inf\) |
| 7 | \(e = 255\) | \(f ≠ 0\) | \(V = NaN\) |
上表補充以下幾點說明:
- 注意序號1和4的區別。序號1表達的是普通的浮點值,而序號4表達的是兩個特殊的值:當\(s=0\)時,值是\((0.f)\ \times\ 2^{-126}\);當\(s=1\)時,值是\(-(0.f)\ \times\ 2^{-126}\)。
- 序號2和3值是相等的,但符號不一樣。
- 序號5、6、7代表的值分別是正無窮、負無窮、非法值(空值)。例如:
- 如果\(a>0\),則\(a/0=+Inf\)。
- 如果\(a<0\),則\(a/0=–Inf\)。
- \(0/0=Inf – Inf=±Inf·0=NaN\)。
涉及\(NaN\)、\(Inf\)的運算稱為無窮算術(Infinity Arithmetic,IA)。IA是魯棒性錯誤的潛在來源!\(+Inf\)和\(–Inf\)比較是正常的,但\(NaN\)比較卻無法預料:
-
NaN != NaN是true! -
涉及NaN的所有其他比較都是
false! -
下面兩個表達式不等價:
if (a > b) X(); else Y(); if (a <= b) Y(); else X();
但IA也提供了一個很好的功能,允許不必測試除零操作,從內循環(inner loop)中刪除測試分支,對SIMD程式碼有用。(儘管同樣的方法通常也適用於非IEEE CPU。)
IEEE-754的特殊表達方式,導致了不規則數字線——即距離零越遠,間距越大,指數k+1的數字範圍的間距是指數k的兩倍,從一個指數到另一個指數的等同於多個可表示數。(下圖)
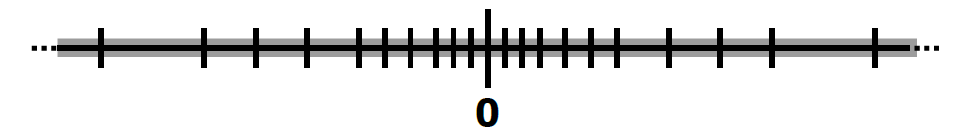
不規則間距的後果:
- \(–1020 + (1020 + 1) = 0\)
- \((–1020 + 1020 ) + 1 = 1\)
因此,會導致非結合律:\((a+b)+c \ne a+ (b+c)\),錯誤層出不窮!所有離散表示都有不可表示的點:
在浮點運算中,由於間距不規則,行為會根據位置而變化!
例如,Sutherland-Hodgman裁剪演算法(多邊形分割的演算法之一):

進入浮點錯誤:
ABCD相對於平面拆分:
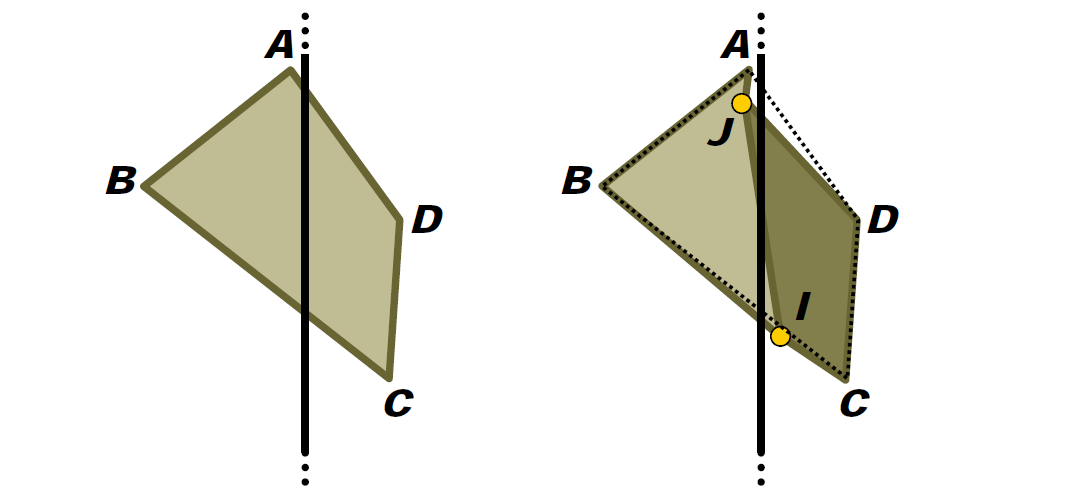
當然,可以用厚平面來解決:
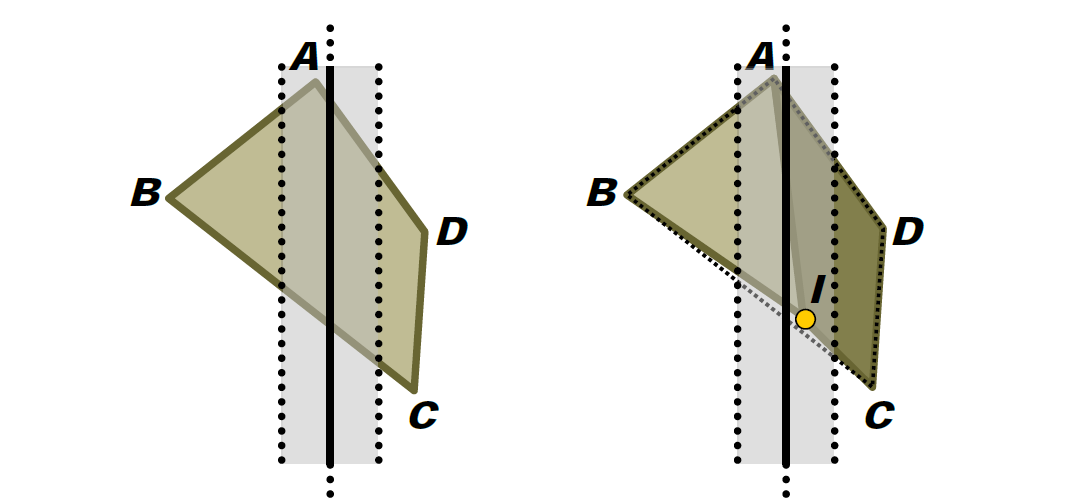
厚平面也有助於限制錯誤:
ABCD相對於厚平面拆分:
順序不一致導致的裂紋:

另一個示例是BSP樹魯棒性,存在以下方面的穩健性問題:
-
插入圖元。
-
查詢(碰撞檢測)。
-
同樣的問題也適用於:
- 所有空間分區方案!
- (k-d樹、網格、八叉樹、四叉樹…)。


實現穩健性的方法:保守插入圖元,考慮查詢和插入錯誤,然後可以忽略查詢問題。
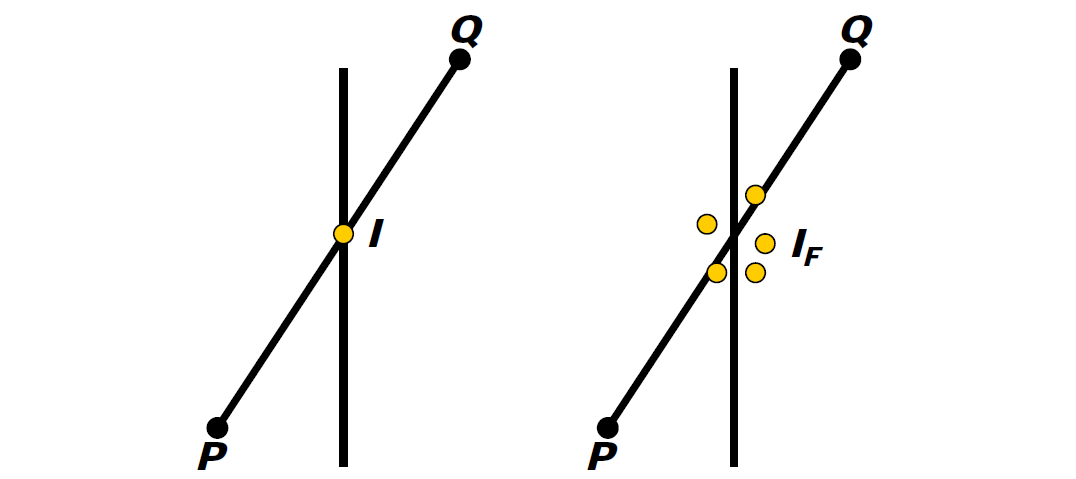
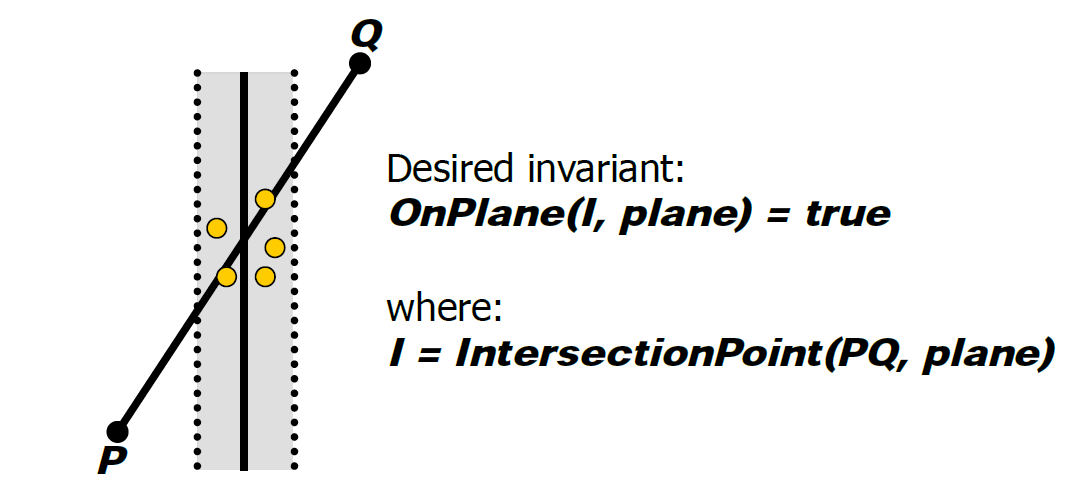
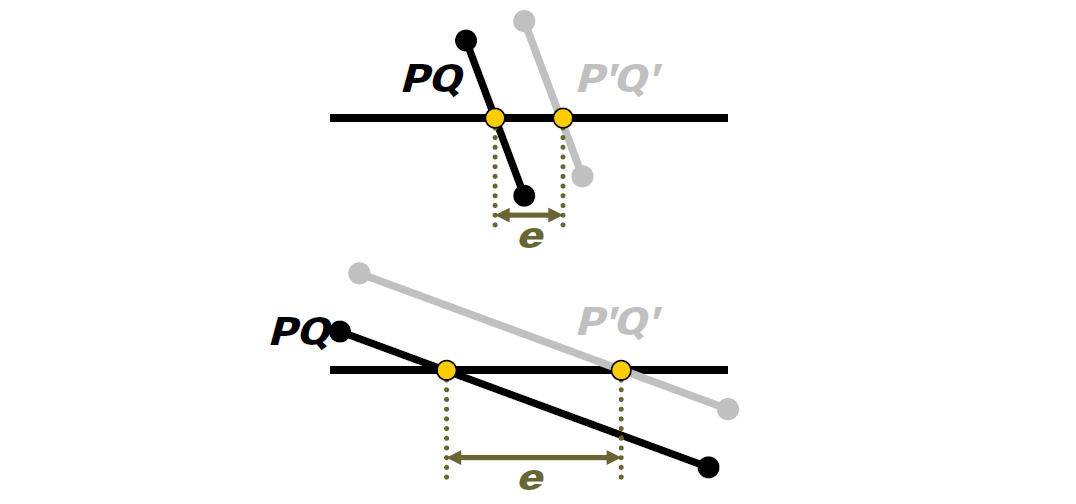
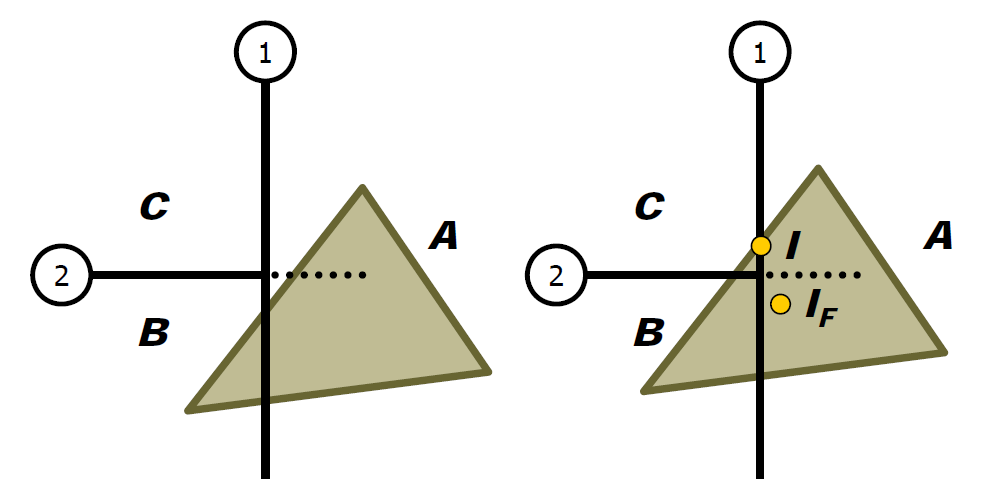
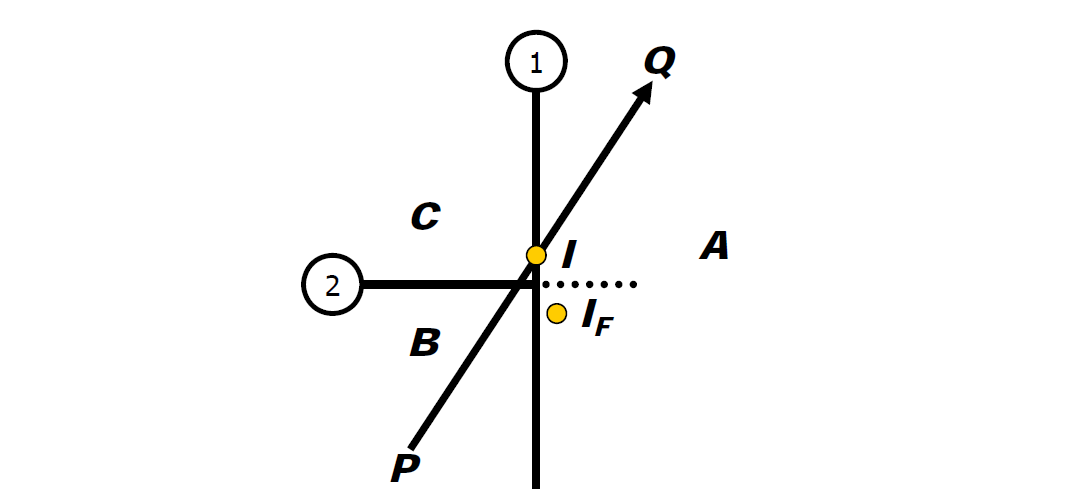
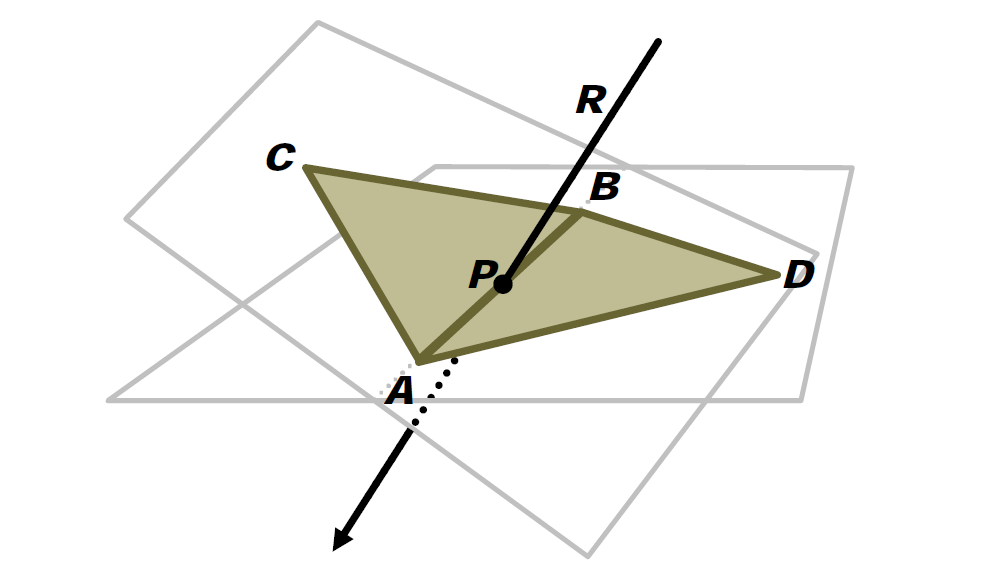
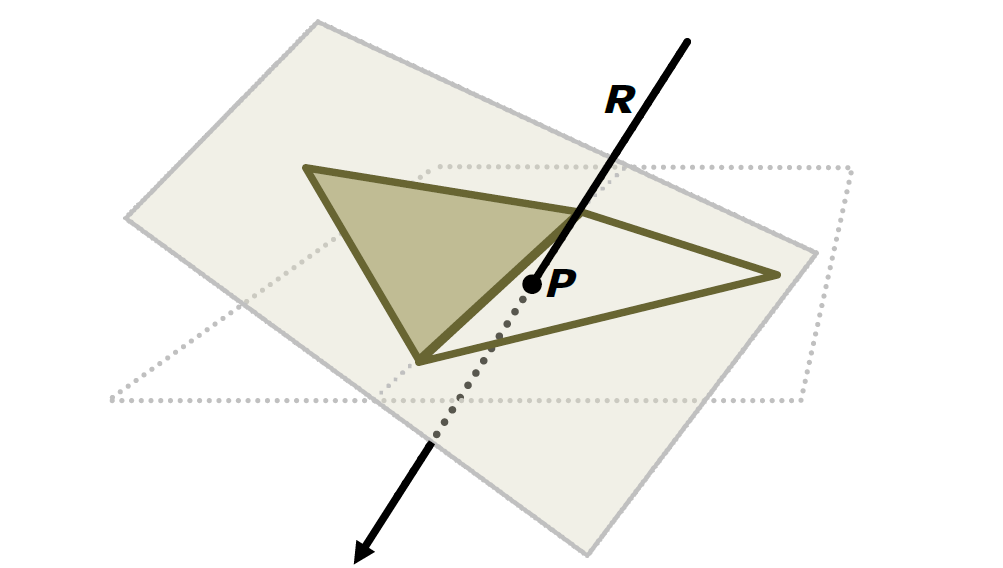
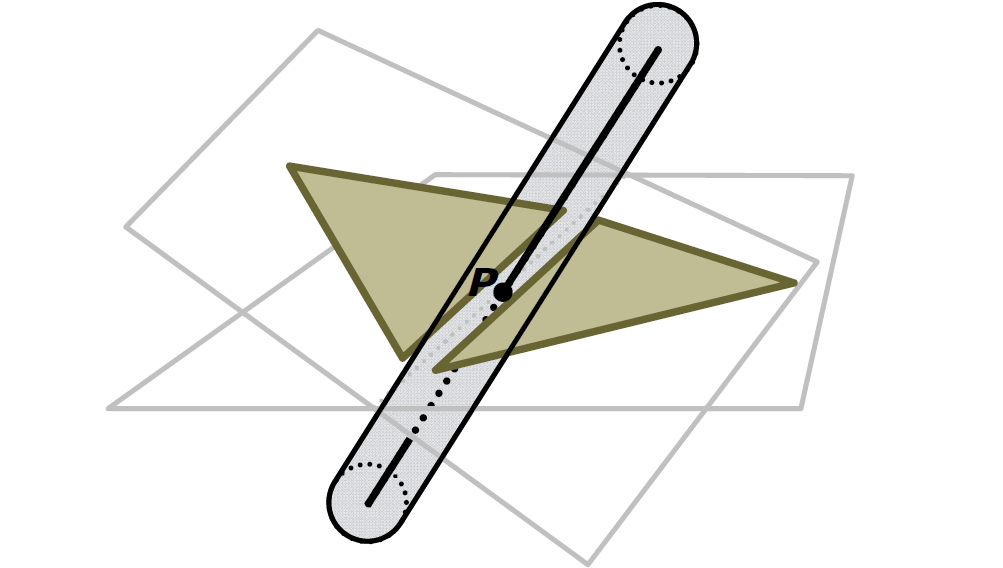
浮點值誤差的示例還有射線和三角形的檢測。常用方法:計算光線R與三角形T平面的交點P,測試P是否位於T的邊界內。然而,這是非魯棒性的!以下圖舉例:
R與一個平面相交:
R與另一平面相交:

穩健測試必須共享共享的邊緣AB的計算,直接在3D中執行測試,過程如下:
- R可表示為:\(R(t)=O + t\bold d\)。
- 然後,\(\bold d \cdot (OA \times OB)\)的符號表示AB的左邊還是右邊。
- 如果R在所有邊的左側,則R與CCW(反時針)三角形相交。
- 然後才計算P。
仍然存在錯誤,但可控。胖(fat)射線測試也很魯棒!
實現魯棒性的方法有:
- 正確公差(tolerance,也叫容差)的使用。
- 計算的共享。
- 胖(fat)圖元的使用。
公差比較包含以下幾種方式:
-
絕對公差。比較兩個浮點值是否相等:
if (Abs(x –y) <= EPSILON) (...)幾乎從未正確使用過!
EPSILON應該是什麼?通常使用任意小的數字!下一個可表示數的增量步長:十進位 十六進位 下一個可表示數 10.0 0x41200000 x + 0.000001 100.0 0x42C80000 x + 0.000008 1000.0 0x447A0000 x + 0.000061 10000.0 0x461C4000 x + 0.000977 100000.0 0x47C35000 x + 0.007813 1000000.0 0x49742400 x + 0.0625 10000000.0 0x4B189680 x + 1.0 上表可知,數值越大,所需的
EPSILON越大,對於之前我們常見的取EPSILON為0.001(或其它若干個0)的做法顯然是有問題的!例如Möller Trumbore射線和三角形的測試程式碼:#define EPSILON 0.000001 #define DOT(v1,v2) (v1[0]*v2[0] + v1[1]*v2[1] + v1[2]*v2[2]) (...) // if determinant is near zero, ray lies in plane of triangle det = DOT(edge1, pvec); (...) if (det > -EPSILON && det < EPSILON) // Abs(det) < EPSILON return 0;改用雙精度書寫,在不改變
EPSILON的情況下改變為float?DOT({10,10,10},{10,10,10})破壞測試! -
相對公差。比較兩個浮點值是否相等:
if (Abs(x–y) <= EPSILON * Max(Abs(x), Abs(y)) (...)EPSILON按輸入幅值縮放,但是考慮
Abs(x)<1.0、Abs(y)<1.0。 -
組合公差。比較兩個浮點值是否相等:
if (Abs(x –y) <= EPSILON * Max(1.0f, Abs(x), Abs(y)) (...)用
Abs(x)≤1.0、Abs(y)≤1.0進行絕對值測試,否則進行相對測試! -
整數測試。
警告:英特爾內部使用80位格式,除非另有說明。錯誤取決於生成的程式碼,在調試和發布時給出不同的結果。
接下來介紹精確算術(Exact arithmetic,半精確同樣)。
整數算術是精確的,只要沒有溢出(overflow),在+、–、和*下是封閉的,但對/不是,通常可以通過叉乘(cross multiplication)刪除除法。示例:C如何投影到AB上?

用浮點和整數的運算如下:
// float
float t = Dot(AC, AB) / Dot(AB, AB);
if (t >= 0.0f && t <= 1.0f)
... /* do something */
// integer
int tnum = Dot(AC, AB), tdenom = Dot(AB, AB);
if (tnum >= 0 && tnum <= tdenom)
... /* do something */
測試(Test)是布爾值,可以精確計算。構造(Construction)是非布爾型,無法精確執行。測試通常表示為行列式,例如:
u_{x} & u_{y} & u_{z} \\
v_{x} & v_{y} & v_{z} \\
w_{x} & w_{y} & w_{z}
\end{array}\right| \geq 0 \Leftrightarrow \mathbf{u} \cdot(\mathbf{v} \times \mathbf{w}) \geq 0
\]
使用擴展精度演算法(EPA)進行估算,EPA開銷昂貴,通過「浮點過濾器」限制EPA的使用,常用的濾波器是區間計算(Interval arithmetic)。區間計算的樣例:x = [1,3] = { x ∈R | 1 ≤ x ≤ 3 },其規則如下:
- [a,b] + [c,d] = [a+c, b+d]
- [a,b] – [c,d] = [a–d, b–c]
- [a,b] * [c,d] = [min(ac, ad, bc, bd), max(ac, ad, bc, bd)]
- [a,b] / [c,d] = [a, b] * [1/d, 1/c] for 0 ∉ [c, d]
區間計算的間隔必須向上/向下四捨五入到最接近的機器表示數,是可靠的計算。
17.2.3 隱式函數
球體追蹤是光線追蹤的諸多形式的其中一種,是隱式函數的理想選擇,不是光柵化或體素的替代品。很低效,但是很簡單,並且非常靈活。球體追蹤只需要4步:
-
構建視圖。
只需要兩個三角形和UV坐標。相關的程式碼如下:
vec2 screen_coordinates = gl_FragCoord.xy; screen_coordinates /= resolution; screen_coordinates = screen_coordinates - .5; screen_coordinates *= resolution/min(resolution.x, resolution.y); float field_of_view = 1.5; vec3 direction = vec3(screen_coordinates, field_of_view); direction = normalize(direction); -
追蹤光線。
追蹤的步驟和射線步長如下所示:

對應的程式碼:
vec2 origin = vec2(0.0); vec2 position = origin; float surface_threshold = 0.001; for(int i=0; i<128; i++) { float distance_to_surface = map(position); if(distance_to_surface < surface_threshold) break; position += direction * distance_to_surface; } float distance_to_scene = distance(origin, position); -
確定曲面的朝向。
在光線末端附近取樣,比較它們的偏導數,通過除以畢達哥拉斯定理的結果進行歸一化:
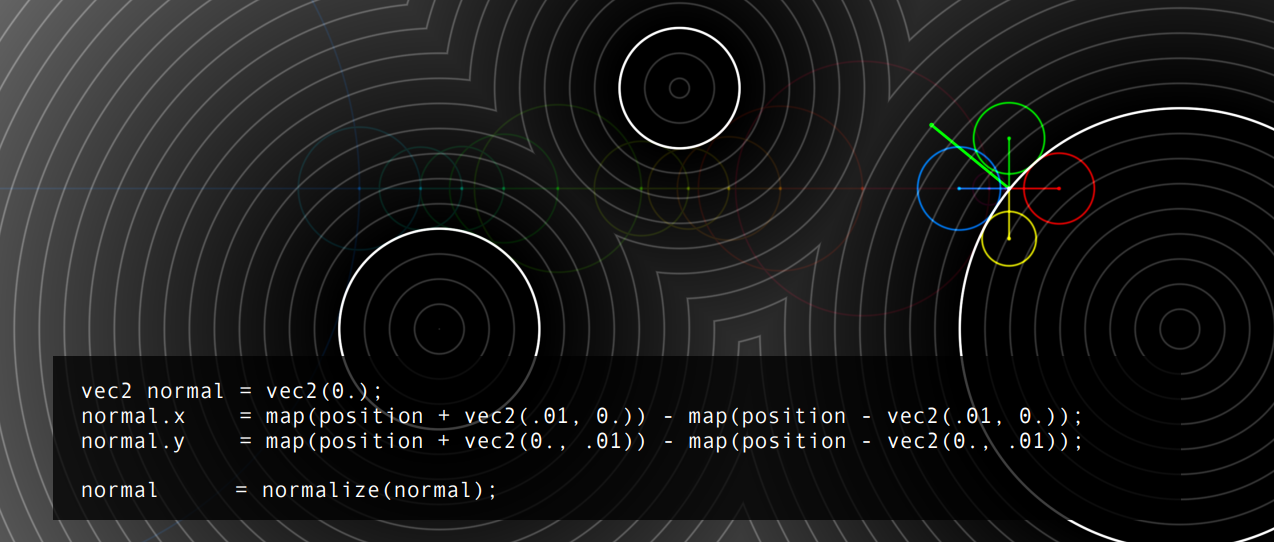
獲得了表面的法線:

法線可以從場中的任何位置取樣,而不僅僅是表面:

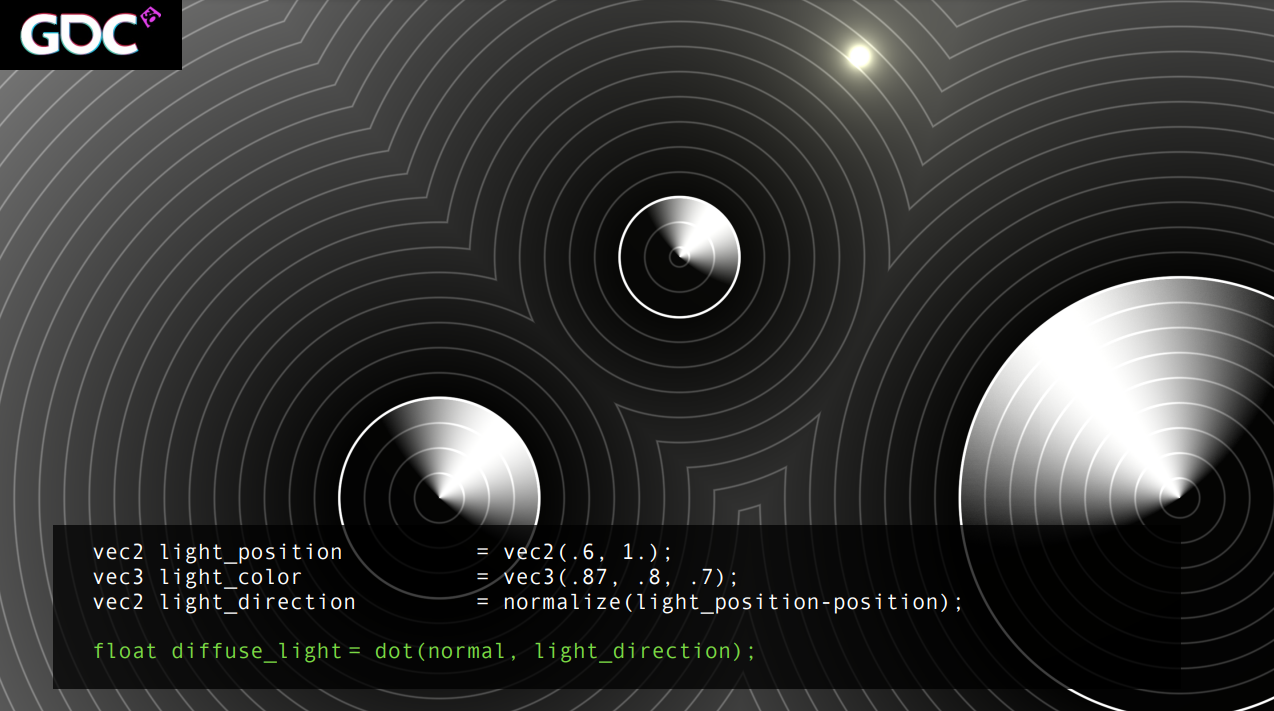
-
添加燈光。
增加光源的程式碼和效果如下:





通過以上幾個步驟,就可以實現複雜而有趣的場景(來自shadertoy):

顯式數據作為獨立值存儲在存儲器中,如網格頂點、紋理像素等…從存儲器中讀取數據。隱式數據的程式碼是數據,一切都是程式性的,通過計算訪問數據。

通過簡單的加減乘除和mod、min、max、noise等操作可以實現複雜、自然的模型:

關於距離和噪音,有一些事情需要注意。大多數情況下,需要很多步驟才能找到物體表面,這也是個問題。追蹤正弦曲線時,空間不是線性的。Mod和雜訊操作同樣如此(下圖)。


雜訊還會引起渲染瑕疵:

有人說你應該不惜一切代價避免雜訊,因為它會破壞渲染,其他人則不同意,下面是非雜訊和添加雜訊的場景對比:

17.2.4 取樣方式
在圖形學中,取樣是個有意思卻蘊含著豐富的技術,包含了各式各樣的方式。在光線追蹤中,常見的取樣有均勻、隨機、低差異序列、重要性等方式。
均勻取樣(Uniform Sampling)是不區分光源重要性的平均化取樣,生成的光線樣本在各個方向上概率都相同,並不會對燈光特殊對待,偏差與實際值通常會很大。蒙特卡洛取樣(Monte Carlo Sampling)著重考慮了光源方向的取樣,能突出光源對像素的貢獻量,但會造成光源貢獻量過度。重要性取樣(Importance Sampling)則加入概率密度函數pdf,通過縮小取樣結果,防止光源的貢獻量太大。
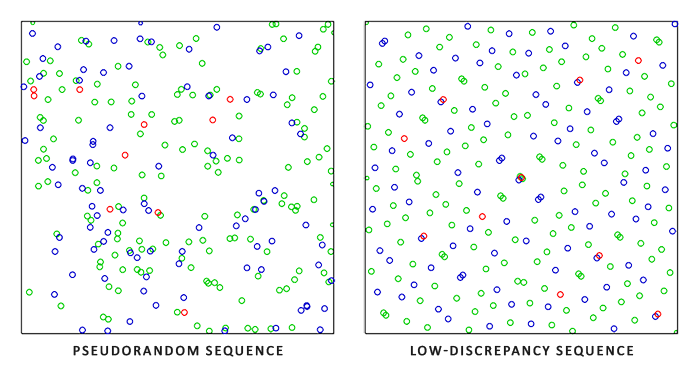
左:完全偽隨機序列生成的採用點;右:低差異序列生成的取樣點。可以看出右邊的更均勻。
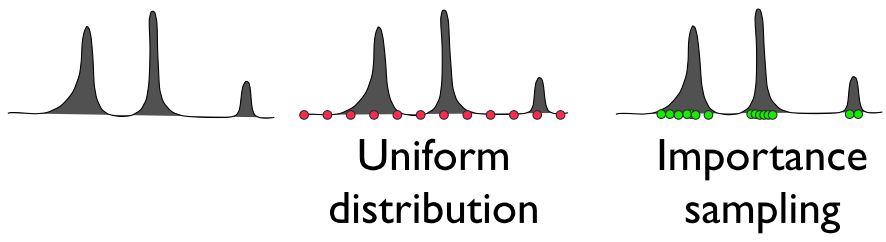
蒙特卡洛取樣使用隨機樣本來數值計算該積分。重要性取樣的思想是嘗試生成與具有類似形狀的被積函數的概率密度函數(PDF)成比例的隨機樣本。
UE在實現TAA時採用了Halton、Sobal等序列:

相比隨機取樣,Halton獲得的取樣序列更加均勻,且可以獲得沒有上限的樣本數(UE默認限制在8以內)。除此之外,還有Sobel、Niederreiter、Kronecker等低差異序列演算法,它們的比較如下圖:
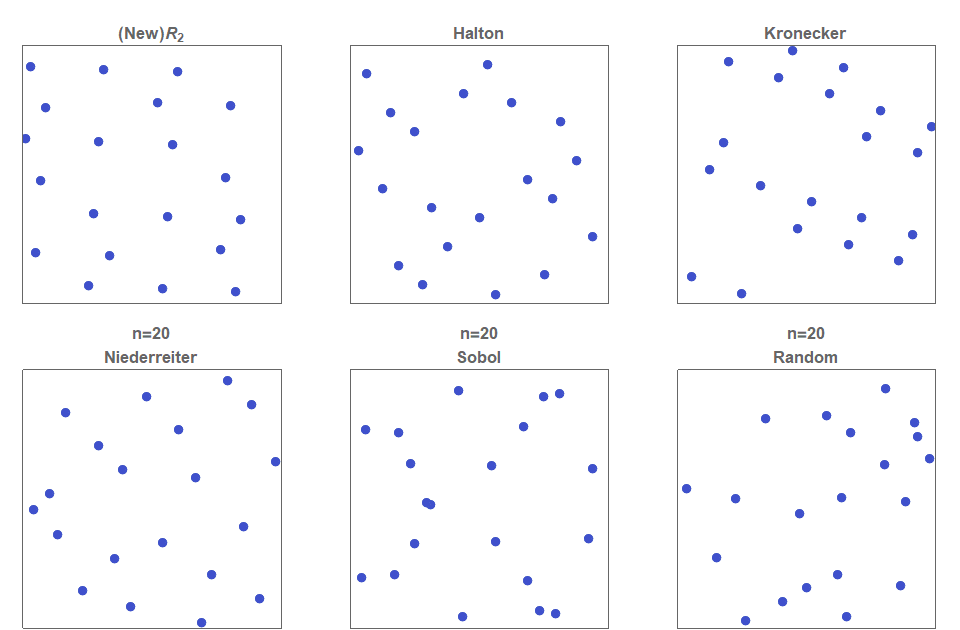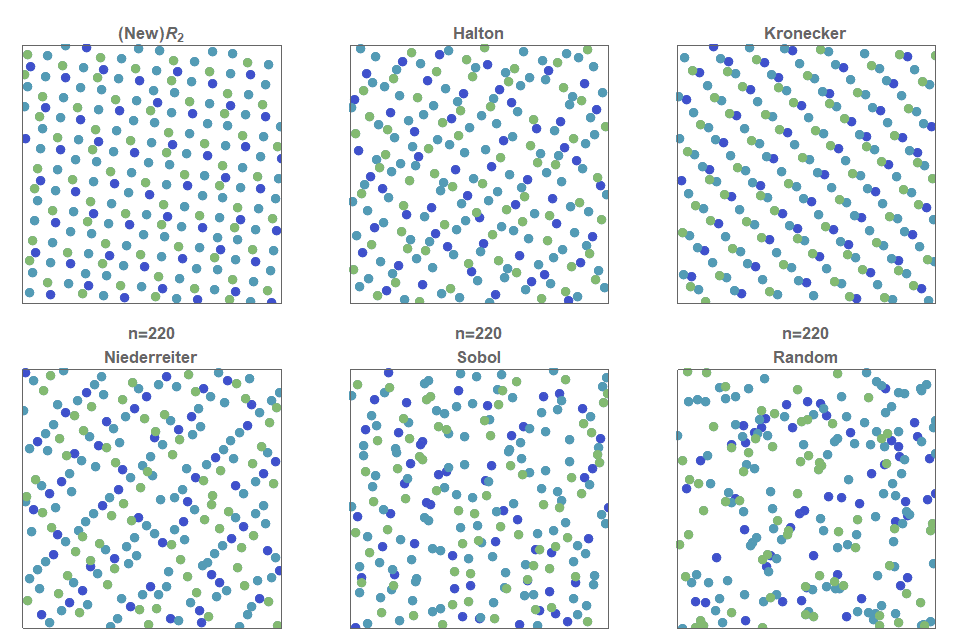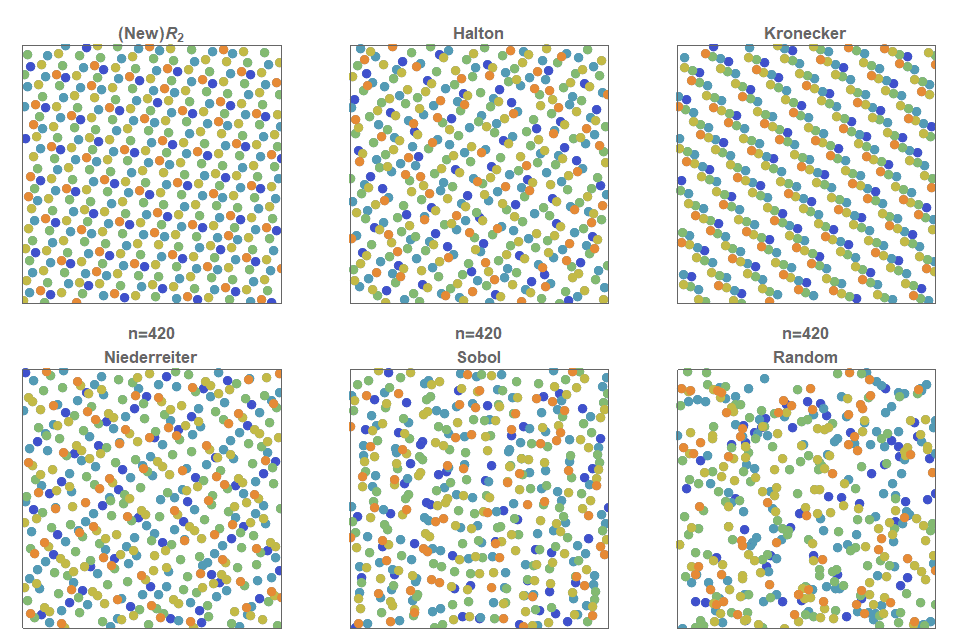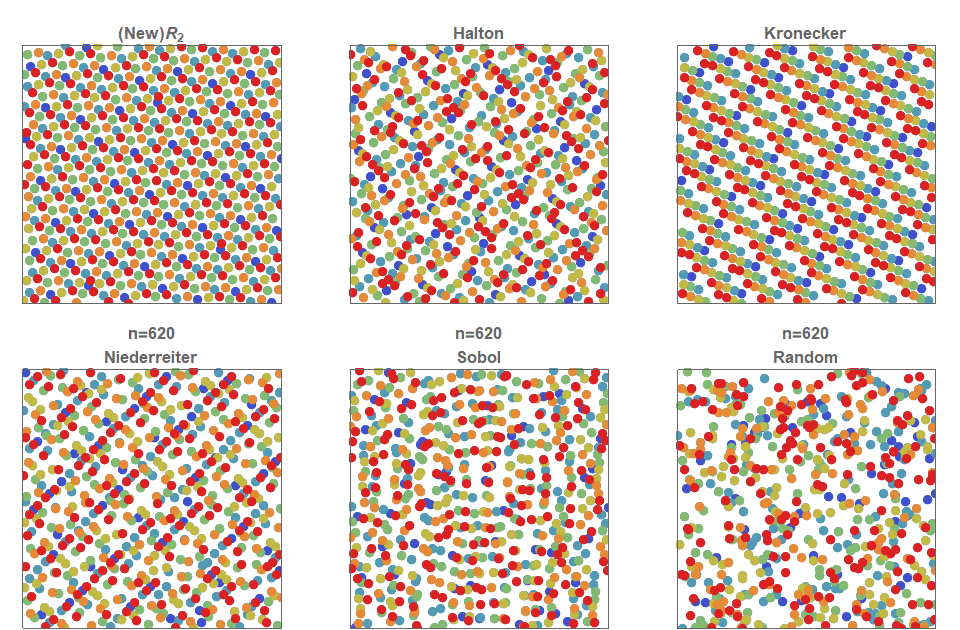
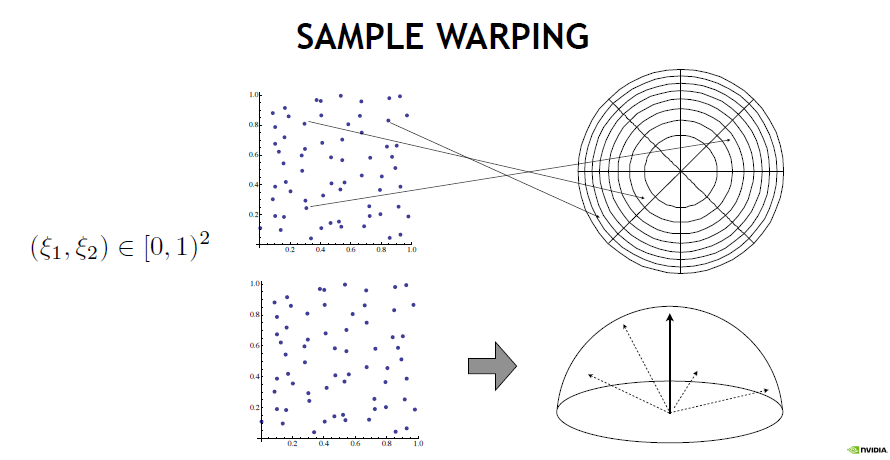
所有取樣技術都基於將隨機數從單位平方扭曲到其它域,再到半球、球體、球體周圍的圓錐體,再到圓盤。還可以根據BSDF的散射分布生成取樣,或選擇IBL光源的方向。有許許多多的取樣方式,但它們都是從0到1之間的值開始的,其中有一個很好的正交性:有「你開始的那些值是什麼」,然後有「你如何將它們扭曲到你想要取樣的東西的分布,以使用第二個蒙特卡羅估計」。
對應取樣方式,常用的有均勻、低差異序列、分層取樣、元素區間、藍噪點抖動等方式。低差異類似廣義分層,藍色噪點類似不同樣本之間的距離有多近。過程化模式可以使用任意數量的前綴,並且(某些)前綴分布均勻。

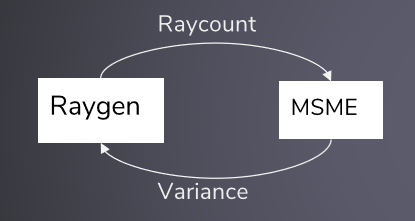
方差驅動的取樣——根據迄今為止採集的樣本,周期地估計每個像素的方差,在差異較大的地方多取樣,更好的做法是在方差/估計值較高的地方進行更多取樣,在色調映射等之後執行此操作。離線(品質驅動):一旦像素的方差足夠低,就停止處理它。實時(幀率驅動):在方差最大的地方採集更多樣本。計算樣本方差(樣本方差是對真實方差的估計):
float SampleVariance(float samples[], int n)
{
float sum = 0, sum_sq = 0;
for (int i=0; i<n; ++i)
{
sum += samples[i];
sum_sq += samples[i] * samples[i];
}
return sum_sq/(n*(n-1))) - sum*sum/((n-1)*n*n);
}
樣本方差只是一個估計值,大量的工作都是為了降噪,MC渲染自適應取樣和重建的最新進展。總體思路:在附近像素處加入樣本方差,可能根據輔助特徵(位置、法線等)的接近程度進行加權。高方差是個詛咒,一旦引入了一個高方差樣本,就會有大麻煩了,可以考慮對數據進行均勻取樣。
此外,對於不同粗糙度的表面,所需的光線數量和方向亦有所不同:
在計算陰影、AO等通道中,也使用了重要性取樣來生成光線,相同視覺品質需要的光線更少。重要性取樣過程中使用了半球、餘弦取樣、距離取樣:

從左到右:半球、半球+餘弦、半球+餘弦+距離。
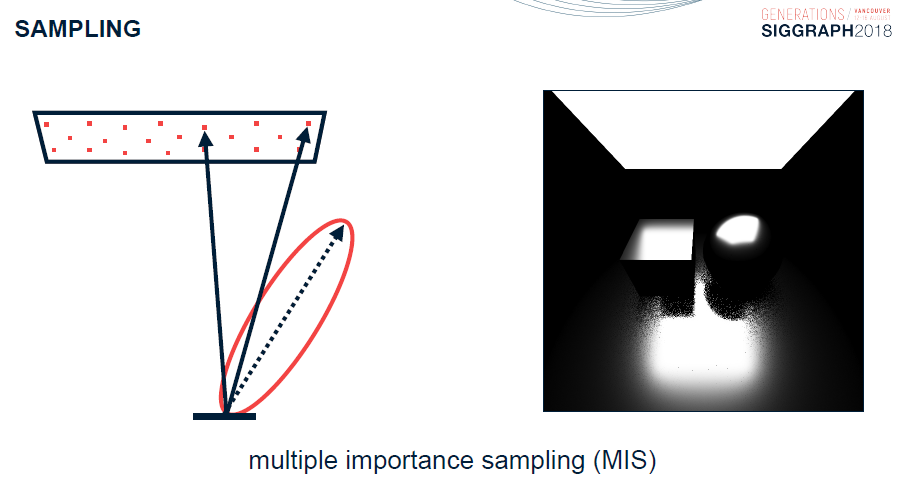
更進一步的,存在多重要性取樣(Multiple Important Sampling,MIS),以便同時考量光源、BRDF、PDF等因素的影響,對取樣的方向和位置等有所偏倚。

多重要性取樣公式:
\]
其中:\(n_k\)是從某個 PDF 中提取的樣本數\(p_k\),加權函數\(w_k\)採用可能生成樣本的所有不同方式,並且\(w_k\)可以通過冪啟發式計算:
\]
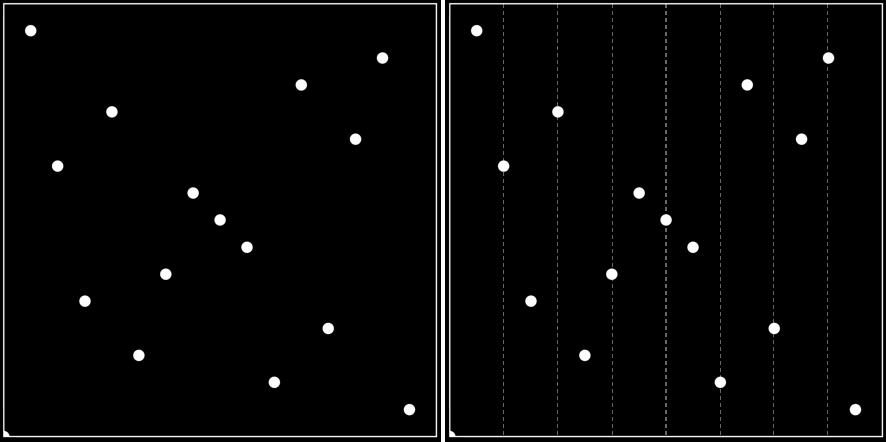
除了以上方式,還有方差、域扭曲、准隨機序列、低差異、分層等等取樣方式。准蒙特卡羅(QMC)的特點是確定性、低差異序列/集合(Halton、Hammersley、Larcher-Pillichshammer)比隨機的收斂速度更好,例如Sobol或(0-2)序列不需要知道樣本數量,奇妙的分層特性。
若是繼續拓廣之,可以以任意形狀任意數量的tap去取樣,如雙邊、藍雜訊、棋盤、星狀等,或者它們之間的結合:

為了避免階梯式瑕疵,Inside使用了隨機取樣(藍色噪點 + TRAA)。
雙邊上取樣的其中一種模式。
更有甚者,可以通過旋轉、升至更高維度以獲得更多樣本和低噪點:
總之,目前存在諸多取樣方式,目的都是為了讓光線追蹤更快地收斂到準確結果,從而降低噪點,提升渲染性能。
17.2.5 體素化
對於任意連續的函數\(f(x, y, z)\),隱式地將體積定義為\(f(x, y, z) > 0\),表面是\(f(x, y, z) = 0\)的水平集。
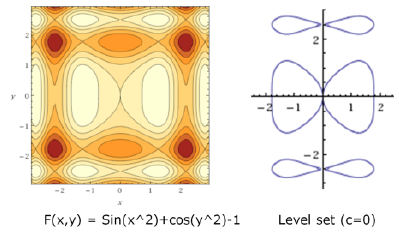
只需要一個連續的函數,任意的代數函數、有向距離場(CSG樹,在網格三線性取樣)、密度函數(在網格三線性取樣)。

使用密度(Density)要容易得多(局部更改),但在距離場上的一些有用操作(如放大、縮小體積、更高品質的漸變計算)上會失敗,可以將密度視為距離場,夾緊距離約為一個取樣單元格。
將隱式曲面或參數化網格體素化的過程:
1、在網格上取樣。
2、近似每個單元格中的表面。
3、確保表面與單元邊界對齊。
體素化的理想特徵是易於實現、局部獨立、平滑、自適應/適合LOD、最小化三角形條形、保留銳利和薄的特徵。
對於簡單的立方體,在每個網格單元的中心取樣\(f(x, y, z)\),在具有不同符號的單元格之間繪製一個面。
這種表達方式在體素化的理想特徵的優劣如下表:
| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| ++ | + | – | – | + | – | – |
步進立方體(Maring Cube):在每個單元格的角落取樣\(f(x, y, z)\),在三角形拓撲中使用角的符號,沿著邊緣在插值的0點處定位頂點。
這種表達方式在體素化的理想特徵的優劣如下表:
| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| + | + | + | – | – | – | – |
超體素(transvoxel)演算法:在每個單元格的角落取樣\(f(x, y, z)\),允許細分一次單元格的邊(以縫合相鄰的LOD級別),為三角形拓撲使用取樣點的符號,沿邊在插值的0點處定位頂點。

Transvoxel是一種允許行進立方體跨越不同LOD級別的方法。總共71種拓撲方式,用於處理任意邊組合的細分。
這種表達方式在體素化的理想特徵的優劣如下表:
| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| + | + | + | + | – | – | – |
雙重輪廓(Dual Contour):在每個單元格的角落取樣\(f(x, y, z)\),在每個邊交叉點位置取樣\(f'(x, y, z)\),在輪廓上的每個單元格內找到一個理想點,連接相鄰單元格的兩點(支援多個LOD解析度)。
這種表達方式在體素化的理想特徵的優劣如下表:
| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| – | – | + | + | + | + | ~ |
雙重行進立方體(Dual Marching Cube):在精細網格上取樣\(f(x, y, z)\),找出誤差最小的點(QEF),如果誤差 > $\varepsilon $,則在該點細分八叉樹。重複前面的步驟,直到索引的誤差 < \(\varepsilon\)。構造此八叉樹的拓撲對偶(topological dual),當成雙重輪廓曲面細分之。

這種表達方式在體素化的理想特徵的優劣如下表:
| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| – | – | + | + | + | + | + |
立方體行進正方體(Cubical Marching Square):構建一個帶有誤差細分的八叉樹(類似於DMC),對於任何體素(在任何八叉樹級別):展開體素,分別觀察每一側;使用行進立方體創建曲線,如果出現誤差,則進行細分;將兩邊摺疊在一起,形成三角形。

| 易於實現 | 局部獨立 | 平滑 | 自適應LOD | 最小化三角形 | 銳利 | 薄 |
|---|---|---|---|---|---|---|
| – | + | + | + | + | + | + |
Windborne的體素化概覽:\(F(x, y, z)\) = 合成的、軸對齊的密度網格,每個塊(chunk)都有重疊的特徵列表,在計算時,使用布爾運算累積到塊。

組合時,每個特徵都是一個層,每一層要麼減去,要麼疊加,Alpha混合密度:\(\alpha_a + \alpha_b (1-\alpha_a)\)。
除了組合,還有減去、疊加、並集、輪廓指示器、網格密度(可用於動態光照,如光流、AO)、暴露參數、利用特徵等等操作或應用。
17.2.6 有向距離場
有向距離場(SDF)是函數SDF(P)到P處最近表面的有符號距離,有解析距離函數和體積紋理兩種形式。
- 解析距離函數流行於場景demo中,巨大的著色器,很多數學知識,沒有數據。
- 體積紋理存儲距離函數,使用三線性過濾。遊戲Claybook將體積紋理與mip貼圖結合使用,世界SDF的解析度=1024x1024x512,格式=8位有符號,大小=586 MB(5 mip級別),[-4,+4]體素的距離,256個值/8個體素,1/32體素精度,每mip級別最大步進(世界空間)翻倍。
Claybook在GPU上生成世界SDF的步驟:
-
生成SDF筆刷網格。64x64x32的dispatch,4x4x4的執行緒組。
- 在分塊中心T處取樣刷子體積。如果SDF>光柵分塊邊界+4個體素,則剔除。如果接受,原子添加+存儲到GSM。
- 通過GSM中的筆刷循環。細胞中心C處的樣本[i],如果接受,存儲到網格(線性),局部+全局原子壓縮。
-
生成調度坐標。64x64x32的調度,4x4x4的執行緒組。
- 讀取刷子網格單元。
- 如果不是空的:原子加法(L+G)得到寫索引,將單元格坐標寫入緩衝區。
-
生成Mip掩碼。4x調度(mips),4x4x4的執行緒組。
- 分組:載入1個更寬的體素網格L-1鄰域,下取樣1=0掩碼並存儲到GSM。
- 將掩碼放大1個體素(3x3x3)。
- 掩碼=0則寫入網格單元坐標。
-
在8x8x8的tile中生成0級(稀疏)。間接調度,8×8的執行緒組。
- 分組:讀取網格單元坐標(SV_GroupId)。
- 從網格讀取筆刷並存儲到GSM。
- 通過GSM中的筆刷循環,取樣[i],執行exp平滑最小/最大操作。
- 將體素寫入WorldSDF的級別0。
-
生成mips(稀疏)。4倍間接調度(mips),8×8的執行緒組。
- 分組:載入更寬的L-1鄰域的4個體素。2x2x2下取樣(平均值)並在GSM中存儲為123123,+-4體素帶變成+-2體素階(band)。
- 分組:在GSM中運行3步eikonal方程(下圖),擴展階:2個體素變成4個體素。
- 存儲8x8x8鄰域的中心。


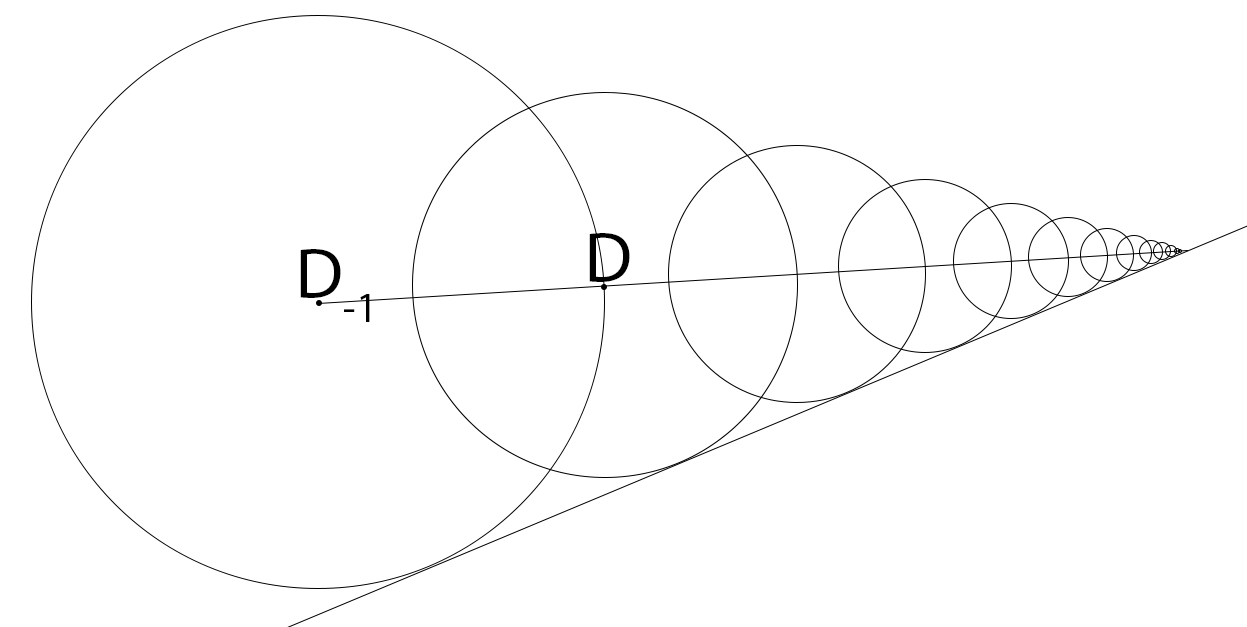
球體追蹤演算法:
- D = SDF(P)。
- P += ray * D。
- if (D < epsilon) break。
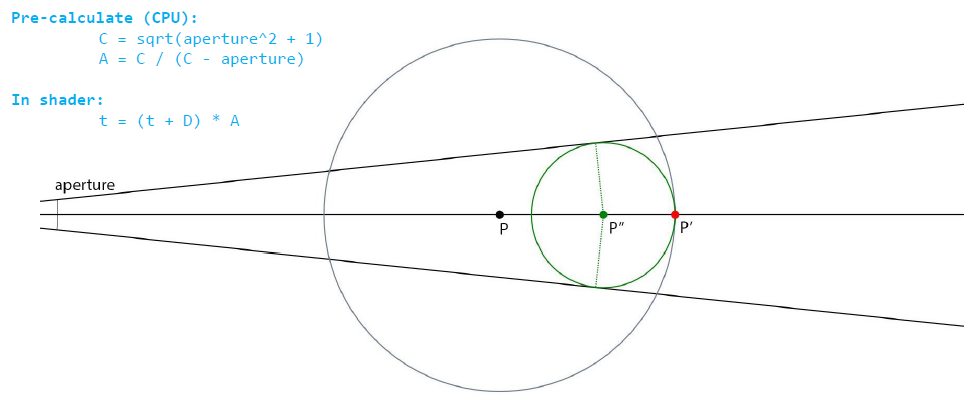
多層體紋理追蹤:
Loop
D = volume.SampleLevel(origin + ray*t, mip)
t += worldDistance(D, mip)
IF D == 1.0 -> mip += 2
IF D <= 0.25 -> mip -= 2; D -= halfVoxel
IF D < pixelConeWidth * t -> BREAK
// 如果曲面位於像素內邊界圓錐體內,則中斷,獲得完美的LOD!
最後一步:球體追蹤需要無限步才能收斂,假設我們碰到一個*面,三線性過濾=分段線性曲面,幾何級數,使用最後兩個樣本,Step=D/(1−(D−D−1))Step=D/(1−(D−D−1))。
錐體追蹤解析解:
粗糙錐體追蹤Prepass:
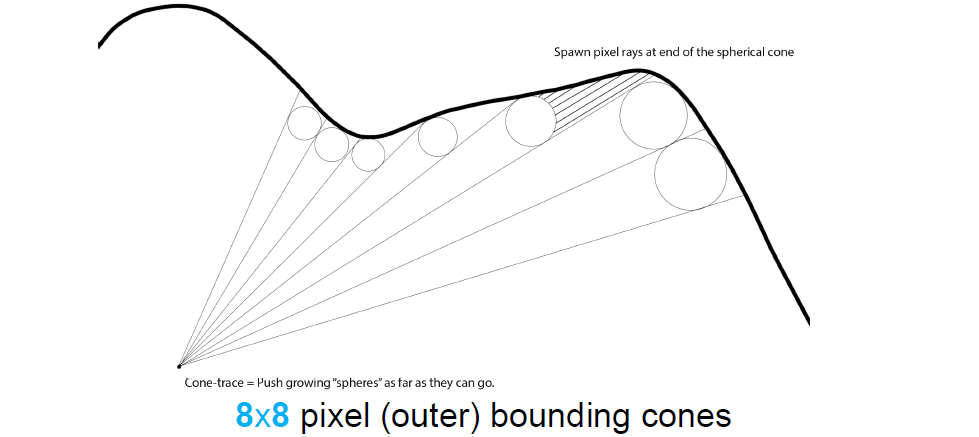
錐形追蹤可以跳過大面積的空白空間,大幅縮短步長,體積取樣更多快取局部性。Mip映射改善快取的局部性,Log8數據縮放:100%、12.5%、1.6%、0.2%…測量(1080p渲染),訪問8MB數據(512MB),99.85%的快取命中率。存在的問題有過步進(Overstepping)、載入平衡等,它們有各自的緩解方案。
17.3 光線追蹤技術
在幾何光學中,可以忽略光線的波動性而直接簡化成直線,從而研究光線的物理特性。同樣地,在電腦圖形學,也可以利用這一特點,以簡化光照著色過程。
此外,人類的眼睛接收到的光照資訊是有限的像素,大多數人的眼睛在5億像素左右。人類接收到的影像資訊可以分拆成5億個像素,也就是說,可以分拆成5億條非常微小的光線,以相反的方式去逆向追蹤這些光線,就可以檢測出這些光線對應的場景物體的資訊(位置、朝向、表明材質、光照顏色和亮度等等)。

光線追蹤技術就是利用以上的物理原理衍生出來。將眼睛抽象成攝像機,視網膜抽象成顯示器幕,5億個像素簡化成螢幕像素,從攝像機位置與螢幕的每個像素連成一條射線,去追蹤這些射線與場景物體交點的光照資訊。當然,實際的光線追蹤演算法會更加複雜,光線追蹤的偽程式碼:
for each pixel do
compute ray for that pixel
for each object in scene do
if ray intersects object and intersection is nearest so far then
record intersection distance and object color
set pixel color to nearest object color (if any)
每個像素都會發出一條光線,該演算法計算出哪個物體首先被光線擊中,以及光線擊中物體的確切點。這個點被稱為第一個交點,演算法在這裡做了兩件事:
-
估計交點處的入射光。要估計入射光在第一個交點處的樣子,演算法需要考慮該光從何處反射或折射。
-
將入射光的資訊與被擊中物體的資訊相結合。關於每個對象的特定資訊很重要,因為對象並不都具有相同的屬性——它們以不同的方式吸收、反射和折射光:
- 不同的吸收方式導致物體具有不同的顏色(例如,葉子是綠色的,因為它吸收了除綠光以外的所有光)。
- 不同的反射率會導致一些物體發出鏡面反射,而其他物體會向各個方向散射光線。
- 不同的折射率導致某些物體(如水)比其他物體更扭曲光線。
通常,為了估計第一交叉點處的入射光,演算法必須將該光線追蹤蹤到第二交叉點(因為擊中物體的光可能已被另一物體反射),甚至更遠。有時發出的光線不會擊中任何東西,這就是第一種邊緣情況,我們可以通過測量光線傳播的距離來輕鬆覆蓋,這樣我們就可以對傳播太遠的光線進行額外的處理。第二種邊緣情況涵蓋了相反的情況:光線可能會反彈太多,從而減慢演算法速度,或者無限次,導致無限循環。該演算法追蹤光線在每一步後被追蹤的次數,並在一定次數的反射後終止。我們可以證明這樣做是合理的,因為現實世界中的每個物體都會吸收一些光,甚至是鏡子。這意味著光線每次被反射時都會失去能量(變得更弱),直到它變得太弱而無法察覺。因此,即使我們可以,追蹤光線任意次數也沒有意義。
與傳統的光柵化渲染技術相比,光線追蹤的演算法過程還是比較明晰的。以視點為起點,向場景發射N條光線,然後根據碰撞點的材質進行BXDF、BRDF的運算,然後再進行漫反射、鏡面反射或者折射,如此遞歸循環直到光線逃離場景或者到達最大反射次數,最後對N條光線進行蒙特卡洛積分即可獲得結果。
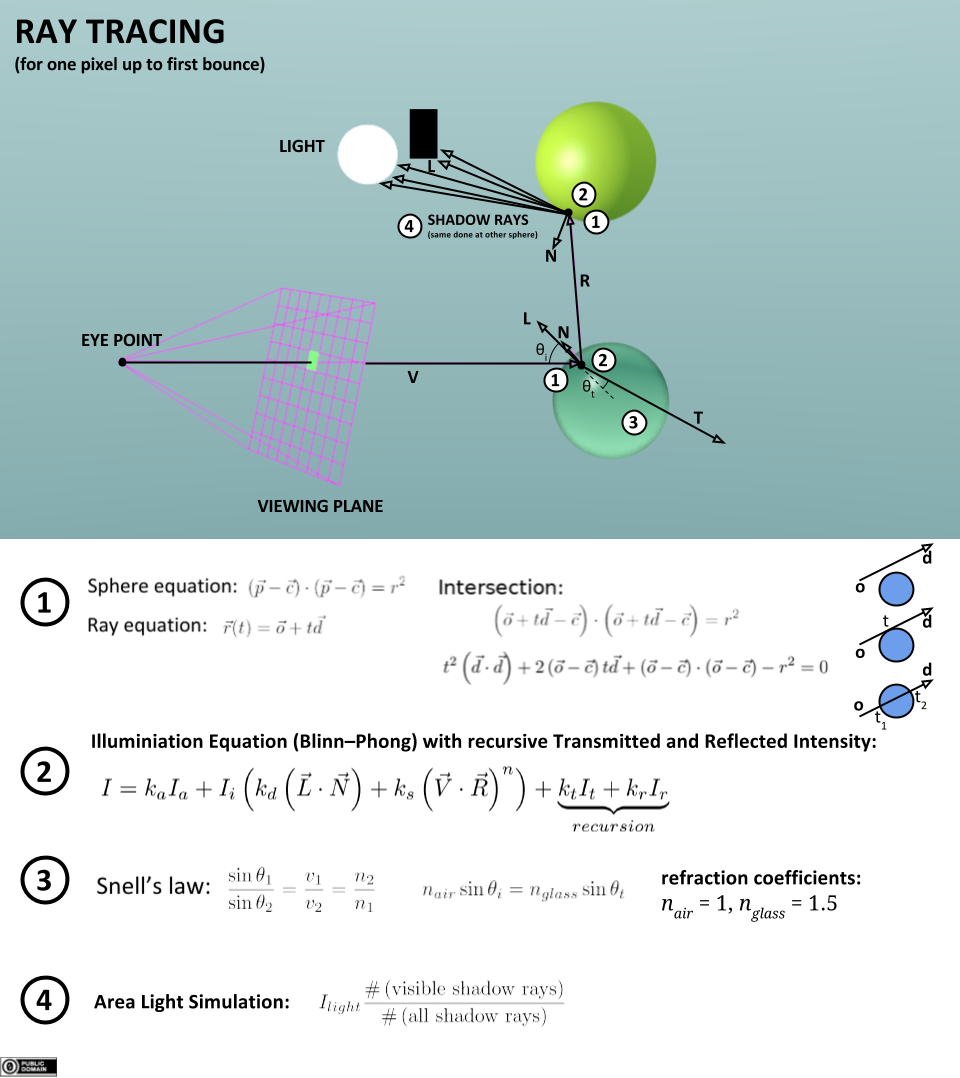
結合上圖,可以將光線追蹤的演算法過程抽象成以下偽程式碼:
遍歷螢幕的每個像素 {
創建從視點通過該像素的光線
初始化 最近T 為 無限大,最近物體 為 空值
遍歷場景中的每個物體 {
如果光線與物體相交 {
如果交點處的 t 比 最近T 小 {
設置 最近T 為交點的 t 值
設置 最近物體 為該物體
}
}
}
如果 最近物體 為 空值{
用背景色填充該像素
} 否則 {
對每個光源射出一條光線來檢測是否處在陰影中
如果表面是反射面,生成反射光,並遞歸
如果表面透明,生成折射光,並遞歸
使用 最近物體 和 最近T 來計算著色函數
以著色函數的結果填充該像素
}
}
上述偽程式碼中涉及的著色函數可採用任意光照模型,可以是Lambert、Phong、Blinn-Phong、BRDF、BTDF、BSDF、BSSRDF等等。若是更近一步,用電腦語言形式的偽程式碼描述,則光線追蹤的計算過程如下:
-- 遍歷影像的所有像素
function traceImage (scene):
for each pixel (i,j) in image S = PointInPixel
P = CameraOrigin
d = (S - P) / || S – P||
I(i,j) = traceRay(scene, P, d)
end for
end function
-- 追蹤光線
function traceRay(scene, P, d):
(t, N, mtrl) ← scene.intersect (P, d)
Q ← ray (P, d) evaluated at t
I = shade(mtrl, scene, Q, N, d)
R = reflectDirection(N, -d)
I ← I + mtrl.kr ∗ traceRay(scene, Q, R) -- 遞歸追蹤反射光線
-- 區別進入介質的光和從介質出來的光
if ray is entering object then
n_i = index_of_air
n_t = mtrl.index
else n_i = mtrl.index
n_i = mtrl.index
n_t = index_of_air
end if
if (mtrl.k_t > 0 and notTIR (n_i, n_t, N, -d)) then
T = refractDirection (n_i, n_t, N, -d)
I ← I + mtrl.kt ∗ traceRay(scene, Q, T) -- 遞歸追蹤折射光線
end if
return I
end function
-- 計算所有光源對像素的貢獻量(包含陰影)
function shade(mtrl, scene, Q, N, d):
I ← mtrl.ke + mtrl. ka * scene->Ia
for each light source l do:
atten = l -> distanceAttenuation( Q ) * l -> shadowAttenuation( scene, Q )
I ← I + atten*(diffuse term + spec term)
end for
return I
end function
-- 此處只計算點光源的陰影,不適用其它類型光源的陰影
function PointLight::shadowAttenuation(scene, P)
d = (l.position - P).normalize()
(t, N, mtrl) ← scene.intersect(P, d)
Q ← ray(t)
if Q is before the light source then:
atten = 0
else
atten = 1
end if
return atten
end function
上述distanceAttenuation的介面中,通常還涉及到BRDF的光照積分,但是在實時渲染領域,要對每個相交點做一次積分是幾乎不可能的。於是可以引入蒙特卡洛積分和重要性取樣(可參看《由淺入深學習PBR的原理及實現》的章節5.4.2.1 蒙特卡洛(Monte Carlo)積分和重要性取樣(Importance sampling)),以局部取樣估算整體光照積分。
當然,引入這個方法,如果取樣數量不夠多,會造成光照貢獻量與實際值偏差依然會很大,形成噪點。隨著取樣數量的增加,局部估算越來越接近實際光照積分,噪點逐漸消失(下圖)。

從左到右分別對應的每個象素取樣為1、16、256、4096、65536。

在每個像素內部,可以使用偏移來生成追蹤像素,從而獲得更準確且帶抗鋸齒的渲染效果。
結合了蒙特卡羅積分和重要性取樣的光線追蹤技術,也被稱為路徑追蹤(Path tracing)。
17.3.1 光線追蹤方式
17.3.1.1 遞歸光線追蹤
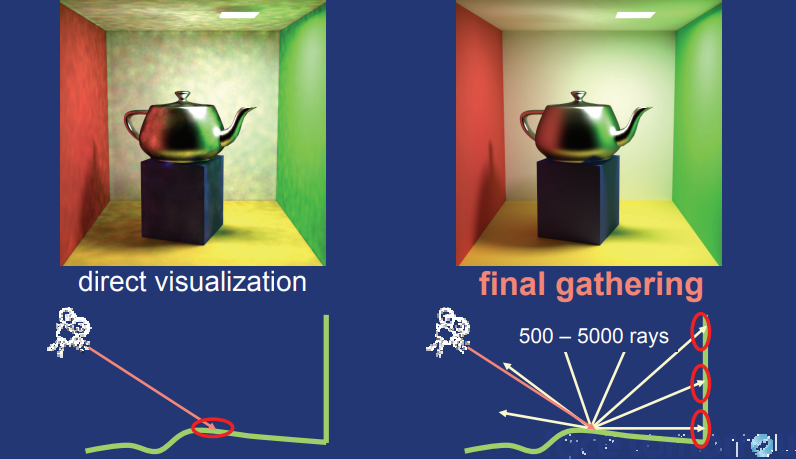
當光線擊中具有鏡面反射或折射的表面時,計算那裡的顏色可能需要追蹤更多光線——分別稱為反射光線和折射光線。這些光線可能會擊中其他鏡面反射表面,導致更多光線被追蹤,由此有了術語——遞歸光線追蹤(Recursive ray tracing)。下圖顯示了反射光線的遞歸「樹」,這種技術也被稱為經典光線追蹤或惠特式光線追蹤,因為它是由特納·惠特於1980年引入的。
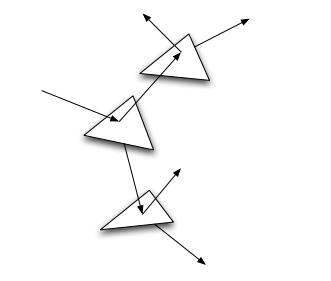
遞歸式的光線追蹤通常在最後階段需要一個最終收集(Final gathering)——從粗略的GI解決方案中讀取輻射度(Radiosity)或光子映射。
17.3.1.2 蒙特卡洛光線追蹤
蒙特卡洛光線追蹤(Monte Carlo ray tracing)也稱為隨機光線追蹤(Stochastic Ray Tracing),其中光線原點、方向或時間使用隨機數計算。蒙特卡羅射線追蹤通常分為兩類:分布光線追蹤(Distribution ray tracing)和路徑追蹤(Path tracing)。
分布光線追蹤從每個曲面點向取樣區域燈光、光澤和漫反射以及許多其他效果發射多條光線。下圖顯示了用於分布光線追蹤的反射和折射光線樹。如圖所示,分布光線追蹤在經過幾次反射後,光線數量易於爆炸;為了避免這種情況,通常在幾級反射後減少光線的數量。使用分布光線追蹤,很容易確保反射點處光線方向的良好分布,例如通過分層方向。

用於分布光線追蹤的反射和折射樹。
路徑追蹤是分布光線追蹤的一種變體,其中每個點僅發射一條反射和折射光線,避免了光線數量的爆炸,但簡單的實現會導致非常明顯噪點的影像。為了補償這一點,通過每個像素追蹤許多可見性光線。路徑追蹤的一個優點是,由於每個像素拍攝許多可見性光線,因此可以以很少的額外成本合併景深和運動模糊等相機效果。
另一方面,與分布光線追蹤相比,更難確保反射光線的良好分布(例如通過分層)。簡而言之,分布光線追蹤會在光線樹中向更深的位置發射最多光線,而路徑追蹤會發射最多可見性光線。
17.3.2 場景加速結構
光線追蹤涉及的數據結構包含邊界體積層次結構(Bounding Volume Hierarchy,BVH)、無棧邊界體積層次結構(Stackless Bounding Volume Hierarchy,SBVH)、KD樹、邊界區間層次(Bounding Interval Hierarchy,BIH)等。

堆棧和無棧數據結構和記憶體布局對比圖。
測試相同場景採用不同數據結構的時間曲線如下:
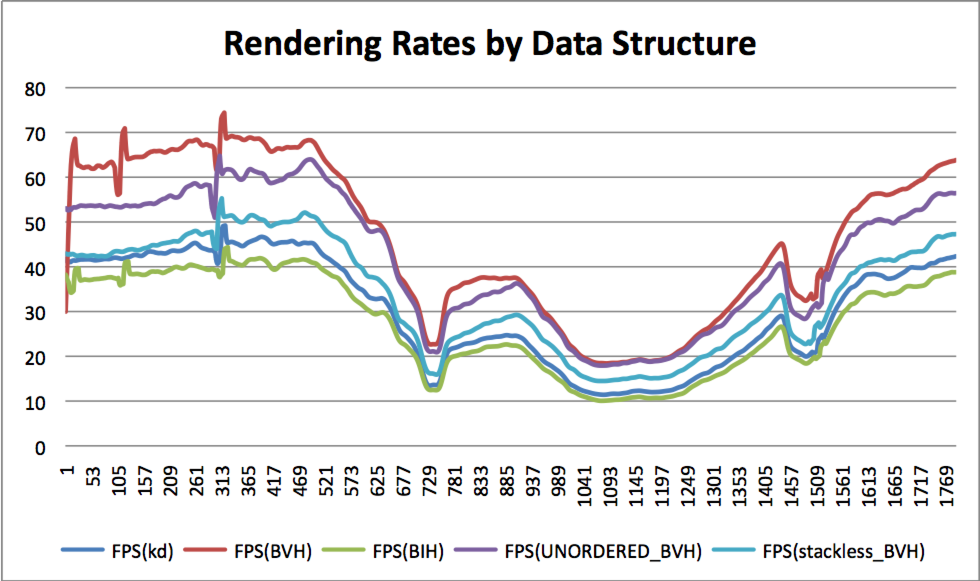
BVH優勢是可以矢量化測試,更好地處理空白空間,堆棧不是瓶頸。
17.3.2.1 BVH
對於複雜場景,測試每一個對象與每一條光線的交集將是毫無希望的低效。因此,我們將對象組織成一個層次結構,以便快速拒絕大部分對象。
加速度數據結構最重要的特徵是構造時間、記憶體使用和光線遍歷時間。根據應用,可能會對這些特性中的每一個給予不同的強調。對於影像序列的渲染(例如,用於互動式視覺化或用於電影的「快照」渲染),還需要選擇可以隨著增量幾何變化而有效更新的加速數據結構。
有一系列令人困惑的加速度數據結構:邊界體積層次結構、均勻網格、層次網格、BSP樹、kd樹、八叉樹、5D原點方向樹、邊界區間層次結構等。在這裡,我們將僅詳細描述一種加速度數據結構,即邊界體積層次。
光線追蹤場景使用了大量的射線檢測,需要一種高效的場景加速結構。在實時光線追蹤中,使用最廣的的加速結構是層次包圍盒(Bounding volume hierarchy,BVH)。BVH將對象及其邊界體積組織成一棵樹,樹的根是包含整個場景的邊界體積,最常用的邊界體積是軸對齊框,因為這樣的框易於計算和組合。
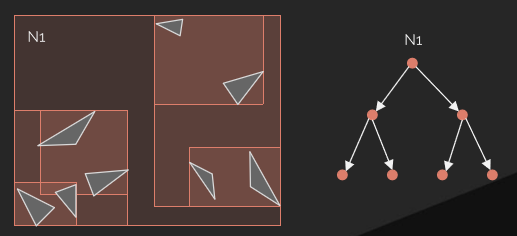
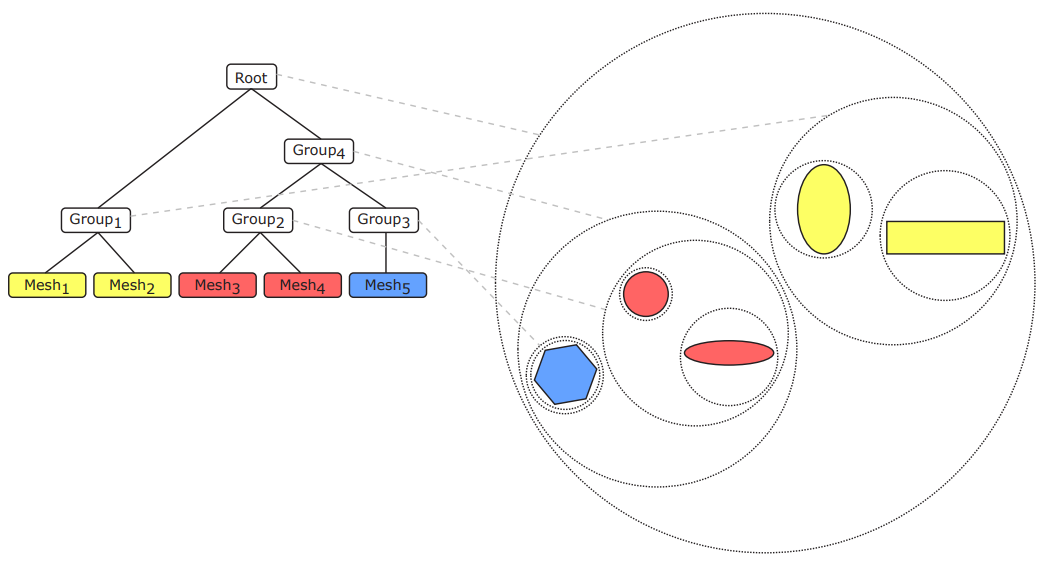
BVH樹的示例。
例如,茶壺場景的BVH具有五層邊界框,頂層由整個場景的單個邊界框組成,下一層包含兩個茶壺和正方形的邊界框。每個茶壺由四部分組成:壺身、壺蓋、壺柄和壺嘴,每個零件都有一個邊界框,茶壺主體由八個貝塞爾面片組成,每個面片都有自己的邊界框。對於曲面細分的Bezier面片,每組四邊形可以有一個邊界框,用於有效的光線相交測試。
可以直接使用場景建模層次,如茶壺場景示例。另一種策略是分割幾何體,使每個部分的表面積近似相等。
當光線需要與場景中的對象進行交集測試時,第一步是檢查與整個場景的邊界框的交集。如果光線擊中邊界框,將測試子對象的邊界框,依此類推。當到達層次結構的某個葉時,必須對該葉表示的對象進行交集測試。
這些加速度數據結構中沒有一個始終比另一個更快。對於給定場景,哪一個是最佳的取決於場景特徵,以及重點是快速構建、快速更新、快速光線遍歷還是緊湊記憶體使用。
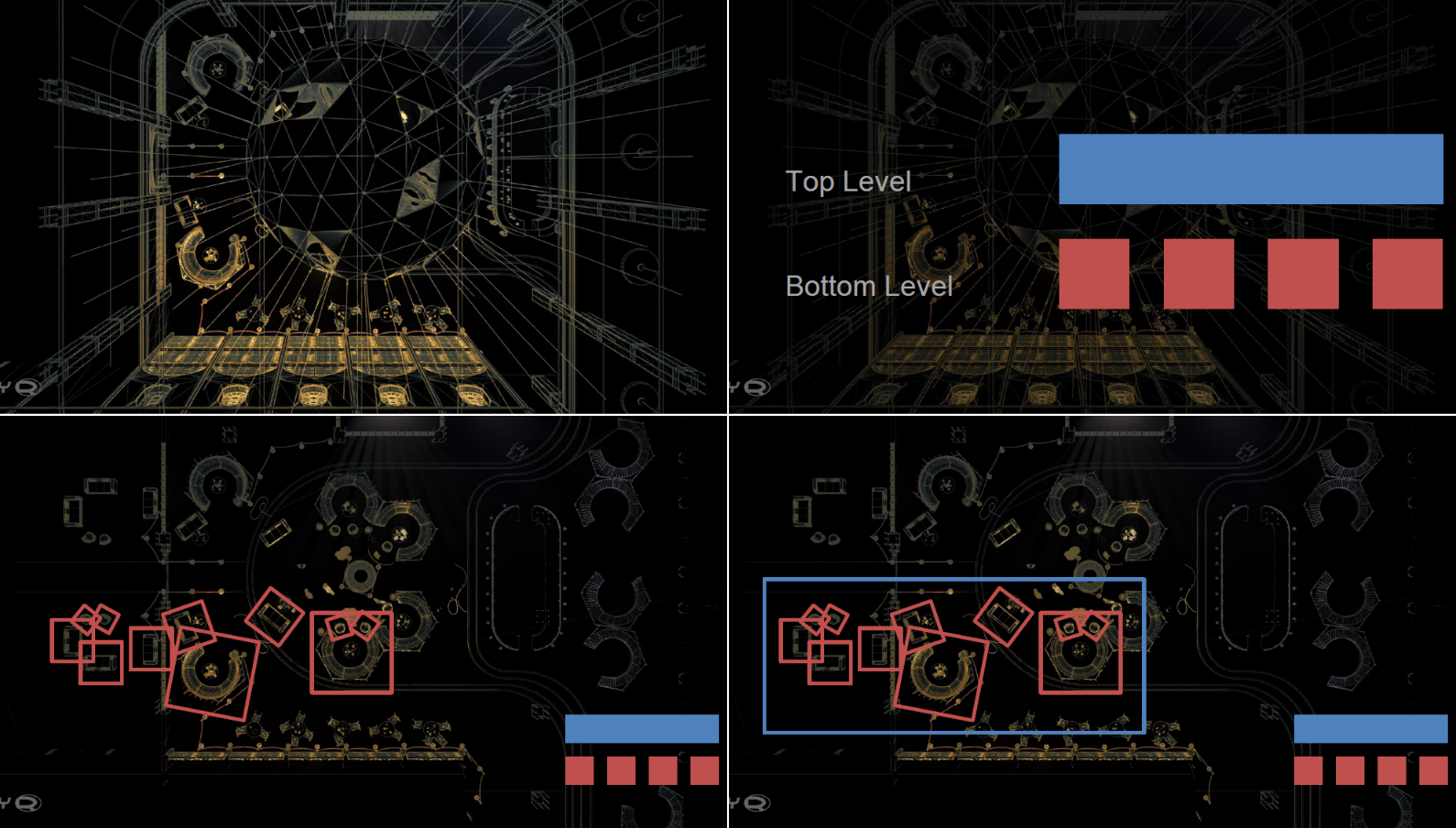
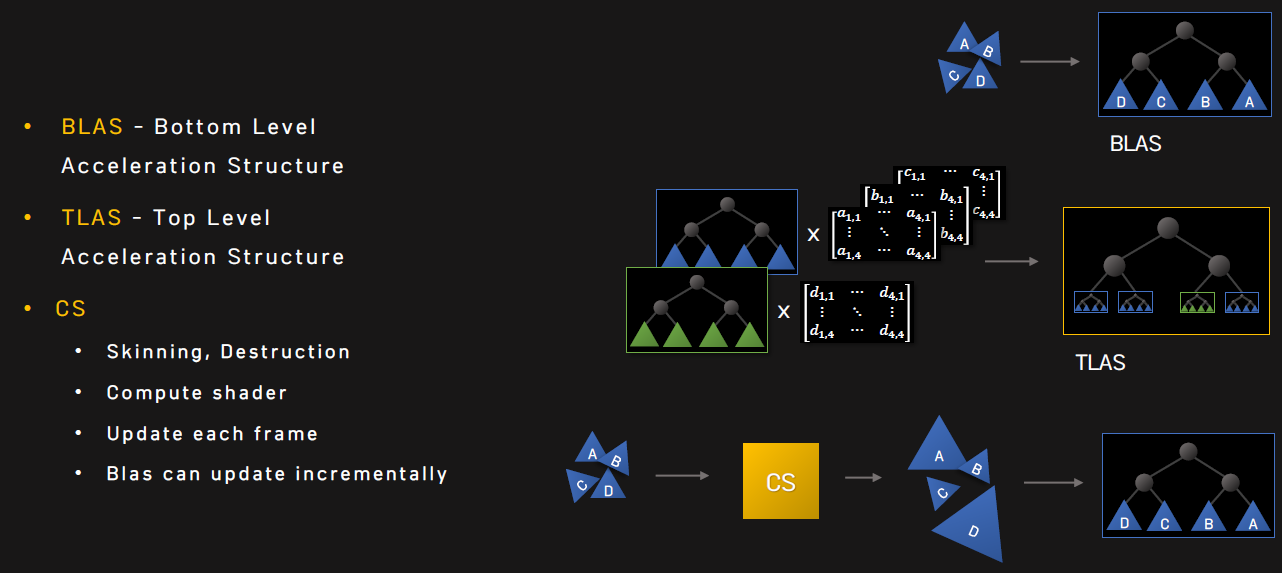
坦克世界在實現光線追蹤的部分特性(如軟陰影)時,分為CPU側和GPU側邏輯。其中CPU側包含兩級加速結構:
- BLAS(底層加速結構)BVH。適用於所有坦克模型,在網格載入期間構造一次並上傳到GPU,網格中的硬蒙皮部分拆分為多個靜態BVH,跳過軟蒙皮部分。
- TLAS(頂層加速結構)BVH。多執行緒,使用Intel Embree和Intel TBB,重建每幀並上傳到GPU。

TLAS BVH(左)和BLAS BVH(右)可視化。
實時光線追蹤中的基於可見性的演算法和加速結構圖例如下:
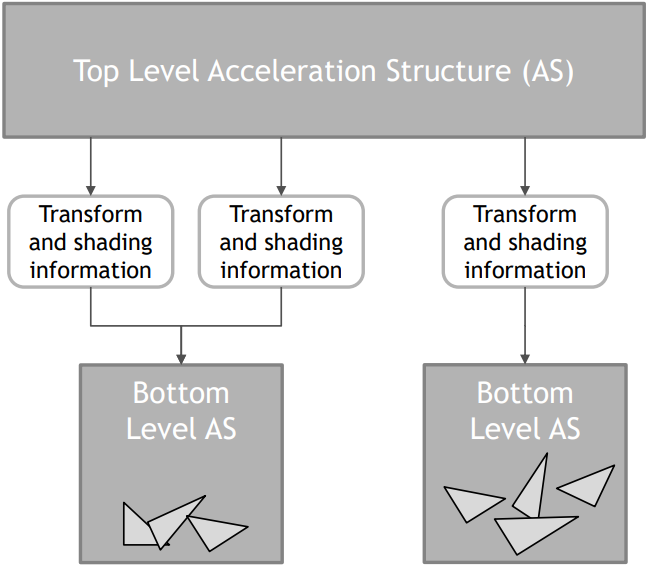
加速結構的雙層加速結構,不透明(實現定義的)數據結構,高效的構建和更新:
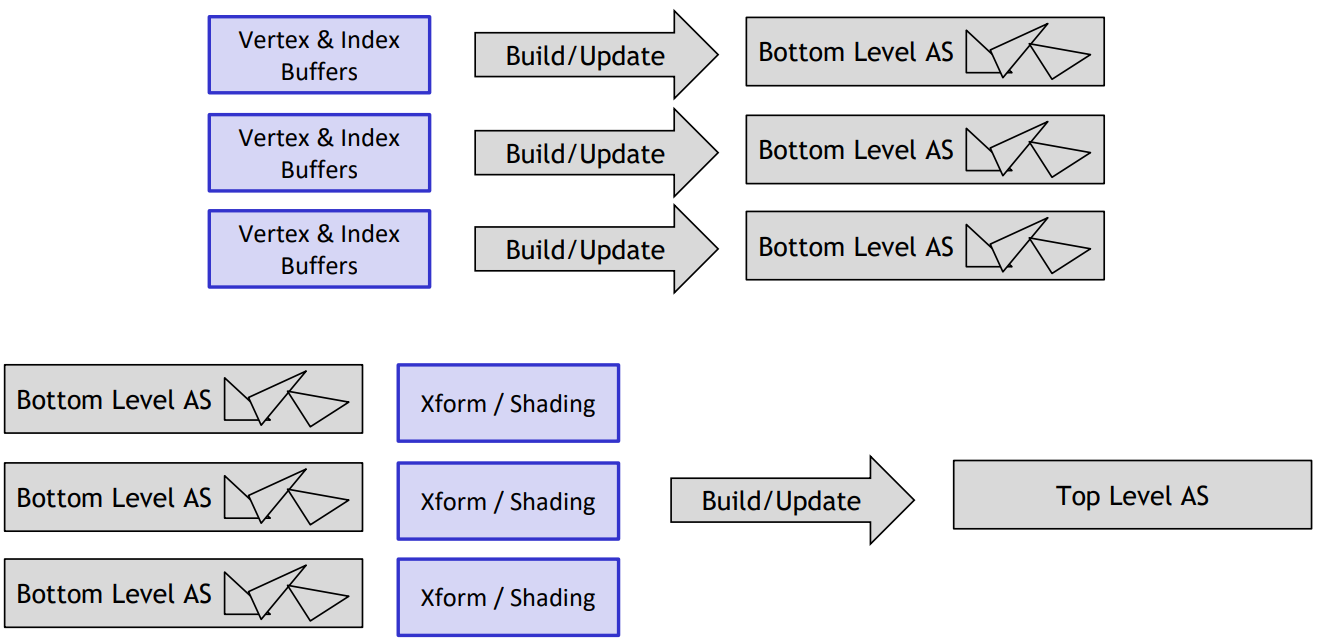
RTX構建、更新、使用加速結構示意圖:
17.3.2.2 KD-Tree
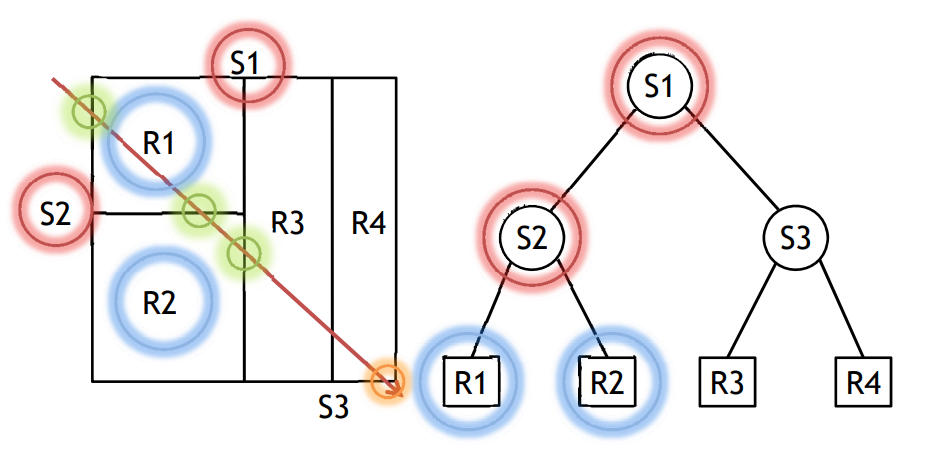
通過KD-Tree結構體可以避免棧遍歷,下圖是一個示例場景在拆分平面後構成的一個樹形結構:
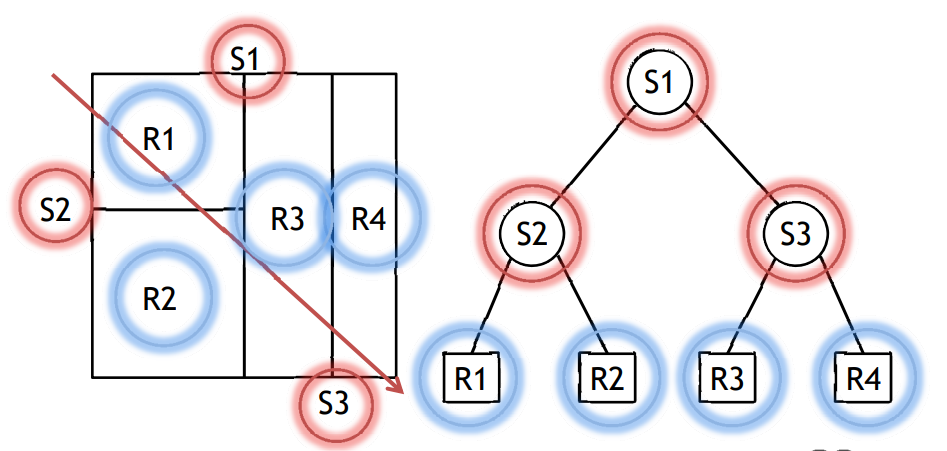
遍歷時,通過樹形結構可以快速檢測到相交物體避免棧遍歷:
Highly Parallel Fast KD-tree Construction for Interactive Ray Tracing of Dynamic Scenes提出了一種高度並行、線性可伸縮的kd樹構造技術,用於動態幾何的光線追蹤。其使用與高性能演算法(如MLRTA或截頭體追蹤)兼容的傳統kd樹,提供了卓越的構建速度,為渲染階段保持了合理的kd樹品質。該演算法從每幀開始構建kd樹,因此不需要運動/變形或運動約束的先驗知識。對於具有200K動態三角形、1024×1024解析度和陰影和紋理的模型,實現了7-12fps的幾乎實時性能。
使用高品質的kd樹對於實現互動式光線追蹤性能至關重要。因此,目標是儘可能快地構建kd樹,以最小化其品質退化。典型的kd樹構造以自頂向下的方式進行,通過使用以下任務序列將當前節點遞歸地拆分為兩個子節點。
1、在某些位置生成分裂平面候選。
2、在每個位置使用SAH評估成本函數。
3、選擇最佳候選(成本最低),並將其拆分為兩個子節點。
4、跳過幾何圖形,將其分配給子節點。
5、遞歸重複。
該文著眼於前三個階段。在快速估計SAH期間,使用三角形AABB作為三角形的代理。成本函數是分段線性的,因此只需要在位於當前節點內的AABB邊界處進行評估,這些位置也稱為拆分候選位置。
在第2個步驟,對於大量幾何圖元,由於其積分形式,成本函數可以在離散化設置中計算。為了克服演算法複雜性,使用概念上類似的技術,儘管此方法適用於大型和小型對象。不在每個容器中存儲對象引用,而是用一個對象計數器替換一個可變大小的列表(或數組)。構建這樣的結構需要對幾何體進行單一且廉價的通道,而不是排序。
最初,針對點提出了裝箱演算法(鴿子洞排序、桶排序)。其思想是將1D間隔分割為給定數量的大小相等的容器,形成規則網格。對象所屬的bin索引可以直接從其位置計算。使用一個單一的線性傳遞幾何體,可以計算箱中的三角形數量,並更新箱的候選分割值(最接近箱邊界),如下圖所示。當一個三角形表示為一個點時,如果演算法在整個三角形範圍內工作,則更新該點所在的箱,或更新與該三角形重疊的每個箱。該數據隨後用於非常不精確的快速SAH近似。
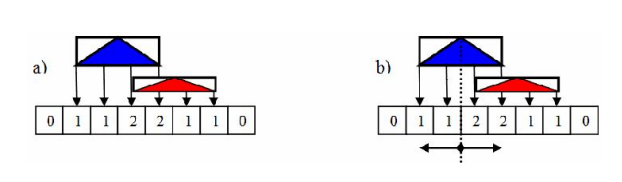
(a) 傳統的裝箱演算法;(b)使用該演算法評估SAH。
最小-最大裝箱演算法的思想是追蹤每個三角形AABB在兩組單獨的裝箱中的開始和結束位置(下圖)。每個箱子只是一個櫃檯,對於每個圖元的AABB,在第一個集合(AABB開始的地方)和第二個集合(AAABB結束的地方)中只更新一個bin。因此,完全消除了對容器總數的依賴。演算法的這一特性對於初始聚類任務至關重要,且使用最小-最大裝箱演算法估計SAH。
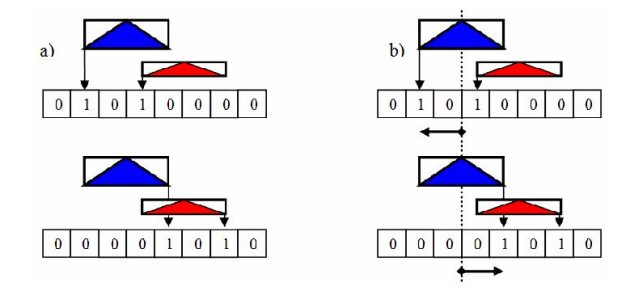
(a) 最小-最大裝箱演算法;(b)使用該演算法評估SAH。
該方法易於擴展到多執行緒並行構造kd樹,並行運行任務需要將整個任務劃分為分配給執行緒的較小部分(作業)。
一種簡單的方法是在每個步驟中利用數據並行性。事實上,當每個執行緒被賦予相等數量的圖元時,裝箱和幾何拆分過程完美地並行運行。記憶體管理也很簡單:每個執行緒都有自己的上述池集,適用於大量圖元。另一種方法是每個執行緒構建子樹,需要對幾何體進行某種初始分解。然而,迄今為止的初始分解是按順序進行的,實際上,這個階段也可使用並行解決方案。
最簡單的分解是在可用執行緒之間均勻分布圖元,如4個執行緒中的每個執行緒處理場景中1M個三角形中的250K個三角形。儘管具有良好的記憶體局部性,但這種幾何分解具有明顯的缺點,即不同執行緒構建的Kd樹將在空間上重疊,沒有已知的方法可以合併重疊的kd樹,而使用光線遍歷多個樹會導致渲染速度減慢。空間分割而不是幾何分割導致不重疊的kd樹很容易合併為一棵樹。常規的空間分區會導致負載平衡不良。因此,並行處理空間區域需要使用幾何分布資訊進行區域選擇。
該文使用了混合併行化方案,對數據進行並行初始分解(聚類),以創建獨立處理的作業。
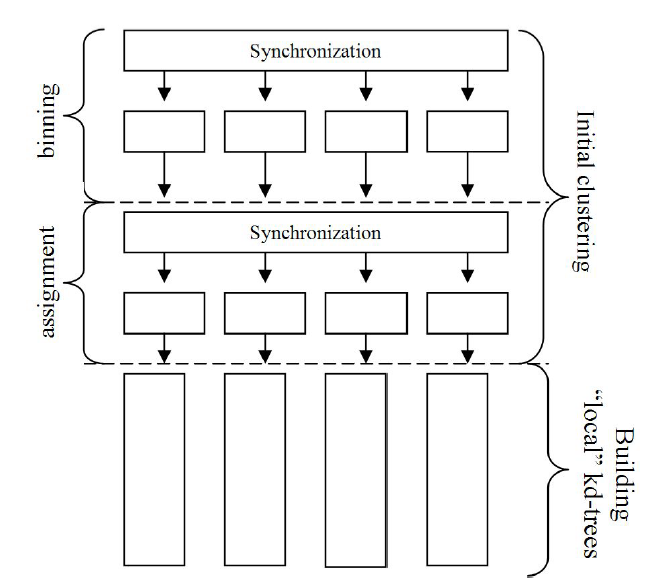
且使用了初始聚類平衡分解:
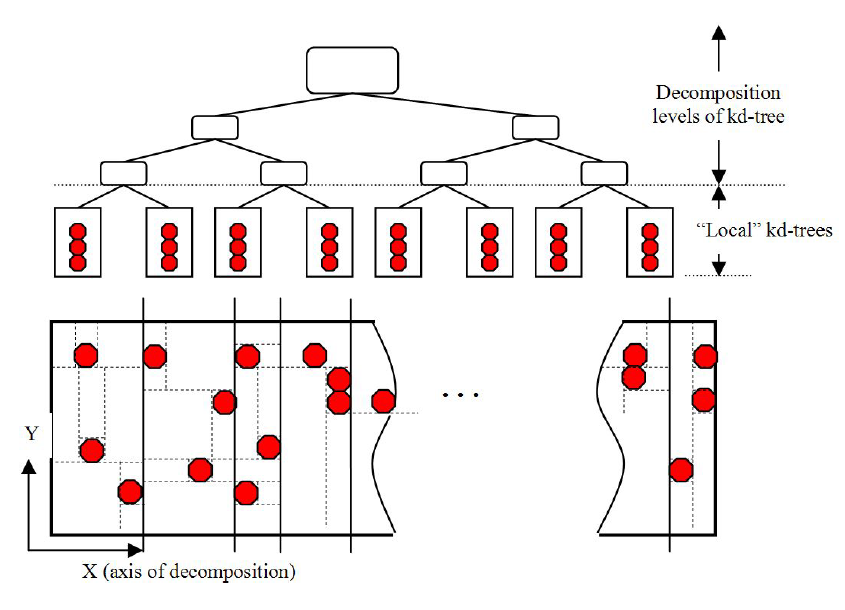
使用優化後的KD-Tree,在不同的場景的加速比如下圖:
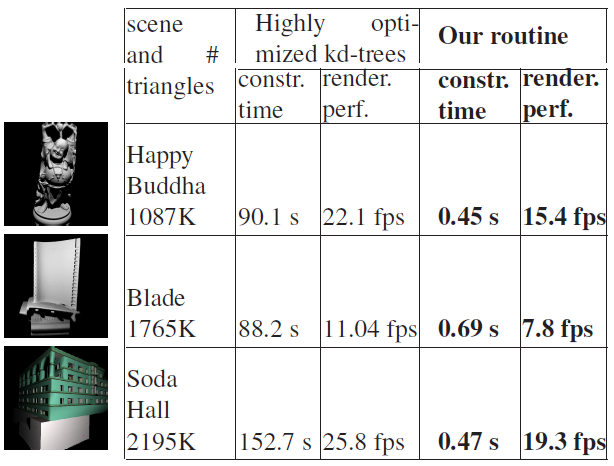
由此可見,KD-Tree的構建實際大幅度提升,但渲染性能有所下降。
17.3.3 光線追蹤陰影
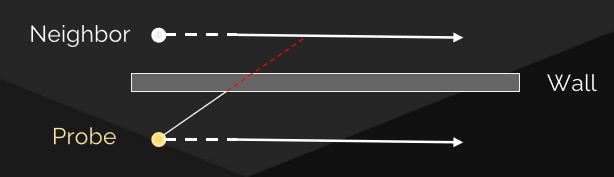
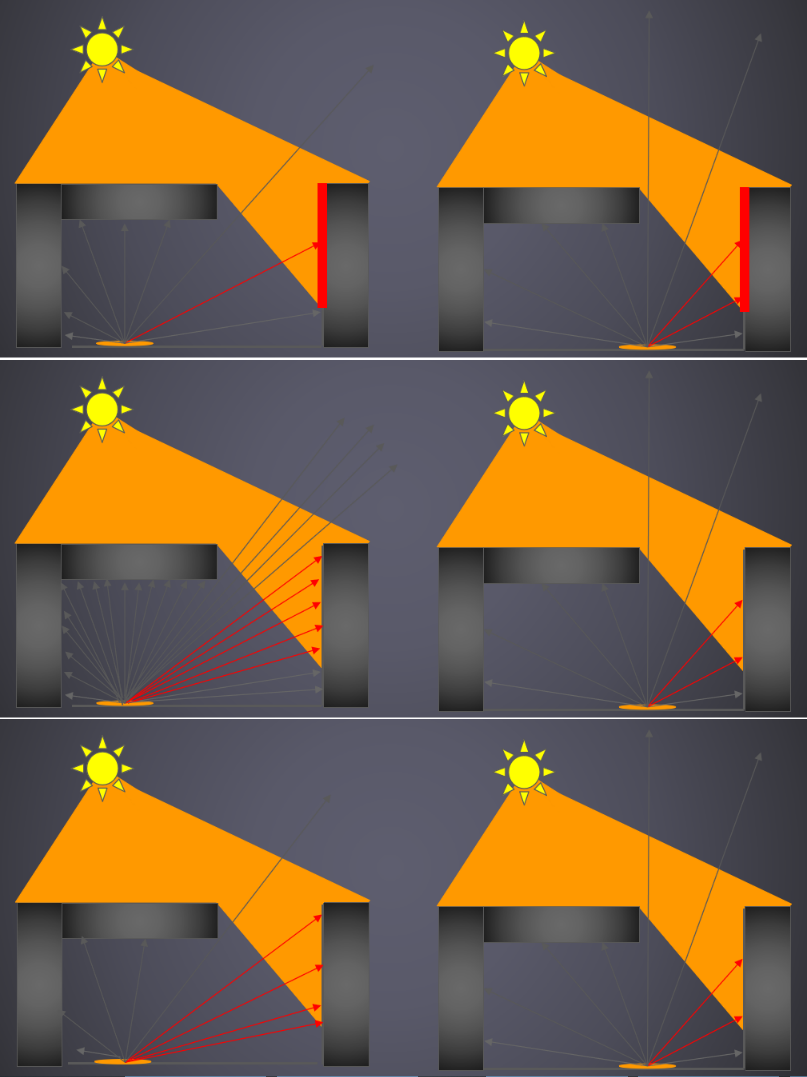
光線追蹤的第一個附加用途是陰影計算:我們可以通過追蹤從點到光源的光線來確定點是否處於陰影中。如果光線沿途擊中不透明對象,則該對象處於陰影中;如果沒有,它將照亮。當計算不透明陰影的光線對象交點時,我們只關心命中或不命中;不是交點和法線。對於點光源和聚光燈,我們追蹤曲面點和光源位置之間的光線。對於定向光源,我們沿著光的方向追蹤來自表面點的平行光線。
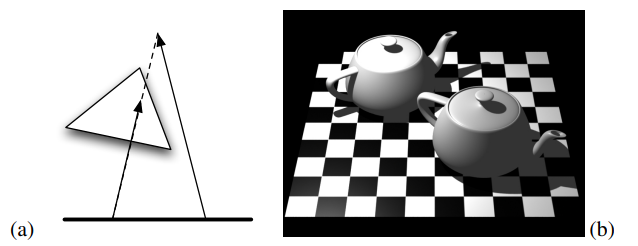
(a)陰影射線;(b)帶有光線追蹤陰影的茶壺。
如果對象是不透明的,任何命中都足以確定陰影。但是如果物體是半透明的(例如彩色玻璃),我們需要獲得點和光源之間所有相交表面的透射顏色,然後通過乘以每個顏色分量來合成透射顏色。
區域光源導致柔和陰影,完全陰影和完全照明之間的區域稱為半影。軟陰影可以通過向區域光源表面上的隨機點發射陰影光線來計算。下圖(a)顯示了從三個表面點到三角形區域光源的陰影光線,一些光線擊中物體;圖(b)顯示了熟悉的茶壺場景中的軟陰影。在該影像中,光源是球形的,軟陰影是通過分布光線追蹤計算的。

(a) 將光線投影到區域光源。(b) 有柔和陰影的茶壺。
在表面和光源之間發射光線:
- 如果光線擊中任何東西,則什麼都不做(區域被陰影和未照明)。
- 如果光線到達光線而沒有擊中任何物體,則照亮該像素。
不是為每個表面點發射一條光線,而是發射多條光線。每個光線的行為與硬陰影情況相同,平均每個像素的所有光線的結果:
- 如果所有光線都被遮擋,則表面完全被遮擋。
- 如果所有光線到達光源,則表面將完全照亮。
- 如果一些光線被遮擋,一些光線到達光線,則表面處於半影區域。
如果區域中的光源為燈光,則將光線分布在從表面可見的光源的橫截面上。要使用無限遠的平行光近似日光,請從表面選擇一個光線錐:為了表示完全晴朗的一天,圓錐體的立體角為零;為了表示多雲的日光,立體角變大。正在估計到達表面點的入射光,要獲得良好的估計,樣本應均勻覆蓋域。

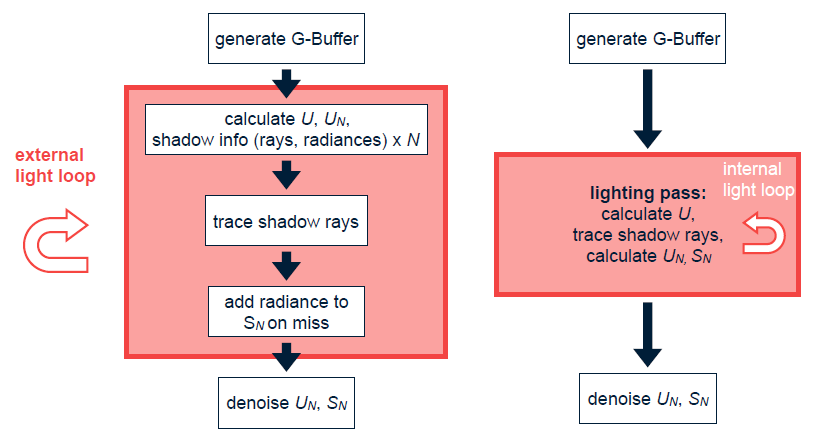
需要大量光線來精確取樣軟陰影,但此過程盡量保證GBuffer的連續性,避免多餘的光線。對於大多數影像,從一個像素到其相鄰像素,表面屬性變化很小。因此,從G緩衝區的一個像素髮送的光線很可能與從相鄰像素髮送的相同光線擊中同一對象。當然有一種方法可以利用這個事實來減少光線計數,但保持視覺精度?
可以嘗試交錯取樣(Interleaved Sampling),以利用來自相鄰像素的陰影光線數據。在幀緩衝區上分塊\(N^2\)個光線方向的正方形2D數組,基於網格發射陰影光線,得到的影像具有臨界特性,即對於影像的任何NxN區域,表示整個$數組。因此,使用方框濾波器從影像中去除雜訊。每個輸出像素是N2個相鄰輸入像素的平均值,必須處理影像中的不連續性。
傳統的邊界體積層次結構可以跳過許多光線三角形命中測試,需要在GPU上重建層次結構,對於動態對象,樹遍曆本身就很慢。
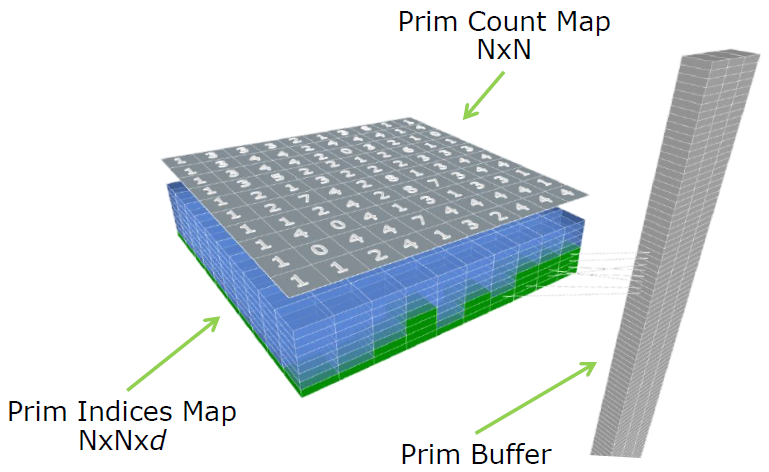
存儲用於光線跟追蹤的圖元,而無需構建邊界體積層次!對於陰影貼圖,存儲來自光源的深度,簡單而連貫的查找。同樣地存儲圖元,一個深層圖元圖,逐紋素存儲一組正面三角形。深度圖元圖繪製(N x N x d)包含3個資源:
- 圖元數量圖(Prim Count Map):紋理中有多少個三角形,使用一個原子來計算相交的三角形。
- 圖元索引圖(Prim index Map):圖元緩衝區中三角形的索引。
- 圖元緩衝區(Prim Buffer):後變換的三角形。
d夠大嗎?可視化佔用率——黑色表示空的,白色表示滿了,紅色則超出限制,對於一個已知的模型,很容易做到這一點。

GS向PS輸出3個頂點和SV_PrimitiveID:
[maxvertexcount(3)]
void Primitive_Map_GS( triangle GS_Input IN[3], uint uPrimID : SV_PrimitiveID, inout TriangleStream<PS_Input> Triangles )
{
PS_Input O;
[unroll]
for( int i = 0; i < 3; ++i )
{
O.f3PositionWS0 = IN[0].f3PositionWS; // 3 WS Vertices of Primitive
O.f3PositionWS1 = IN[1].f3PositionWS;
O.f3PositionWS2 = IN[2].f3PositionWS;
O.f4PositionCS = IN[i].f4PositionCS; // SV_Position
O.uPrimID = uPrimID; // SV_PrimitiveID
Triangles.Append( O );
}
Triangles.RestartStrip();
}
PS哈希了使用SV_PrimitiveID的繪製調用ID(著色器常量),以生成圖元的索引/地址。
float Primitive_Map_PS( PS_Input IN ) : SV_TARGET
{
// Hash draw call ID with primitive ID
uint PrimIndex = g_DrawCallOffset + IN.uPrimID;
// Write out the WS positions to prim buffer
g_PrimBuffer[PrimIndex].f3PositionWS0 = IN.f3PositionWS0;
g_PrimBuffer[PrimIndex].f3PositionWS1 = IN.f3PositionWS1;
g_PrimBuffer[PrimIndex].f3PositionWS2 = IN.f3PositionWS2;
// Increment current primitive counter uint CurrentIndexCounter;
InterlockedAdd( g_IndexCounterMap[uint2( IN.f4PositionCS.xy )], 1, CurrentIndexCounter );
// Write out the primitive index
g_IndexMap[uint3( IN.f4PositionCS.xy, CurrentIndexCounter)] = PrimIndex; return 0;
}
需要使用保守的光柵來捕捉所有與紋素接觸的圖元,可以在軟體或硬體中完成。硬體保守光柵化——光柵化三角形接觸的每個像素,在DirectX 12和11.3中啟用:D3D12_RASTERIZER_DESC、D3D11_RASTERIZER_DESC2。
軟體保守光柵化——使用GS在裁減空間中展開三角形,生成AABB以剪裁PS中的三角形,參見GPU Gems 2-第42章。
光線追蹤時,計算圖元坐標(與陰影貼圖一樣),遍歷圖元索引數組,對於每個索引,取一個三角形進行射線檢測。
float Ray_Test( float2 MapCoord, float3 f3Origin, float3 f3Dir, out float BlockerDistance )
{
uint uCounter = tIndexCounterMap.Load( int3( MapCoord, 0 ), int2( 0, 0 ) ).x;
[branch]
if( uCounter > 0 )
{
for( uint i = 0; i < uCounter; i++ )
{
uint uPrimIndex = tIndexMap.Load( int4( MapCoord, i, 0 ), int2( 0, 0 ) ).x;
float3 v0, v1, v2;
Load_Prim( uPrimIndex, v0, v1, v2 );
// See 「Fast, Minimum Storage Ray / Triangle Intersection「
// by Tomas Möller & Ben Trumbore
[branch]
if( Ray_Hit_Triangle( f3Origin, f3Dir, v0, v1, v2, BlockerDistance ) != 0.0f )
{
return 1.0f;
}
}
}
return 0.0f;
}

左:3k x 3k的陰影圖;右:3k x 3k的陰影圖 + 1K x 1K x 64的PM。
為了抗鋸齒,使用額外的光線可行嗎?開銷太大了!可使用簡單技巧——應用螢幕空間AA技術(如FXAA、MLAA等)。
混合方法——將光線追蹤陰影與傳統的軟陰影相結合,使用先進的過濾技術,如CHS或PCS,使用阻擋體距離計算lerp係數,當阻擋體距離->0時,光線追蹤結果普遍存在。插值因子可視化:
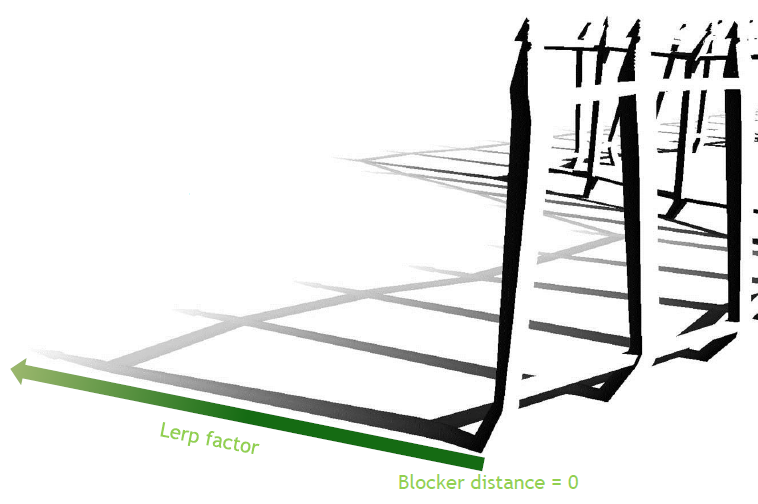
L = saturate( BD / WSS * PHS )
L: Lerp factor
BD: Blocker distance (from ray origin)
WSS: World space scale – chosen based upon model
PHS: Desired percentage of hard shadow
FS = lerp( RTS, PCSS, L )
FS: Final shadow result
RTS: Ray traced shadow result (0 or 1)
PCSS: PCSS+ shadow result (0 to 1)
使用收縮半影過濾,否則,光線追蹤結果將無法完全包含軟陰影結果,將導致在兩個系統之間執行lerp時出現問題。

效果對比:

不同圖元複雜度的效果、消耗及性能如下:

目前僅限於單一光源,不能擴大到適用於整個場景,存儲將成為限制因素,但最適合最接近的模型:當前的焦點模型、最近級聯的內容。總之,解決傳統的陰影貼圖問題,AA光線追蹤硬陰影的性能非常好,混合陰影結合了這兩個世界的優點,無需重新編寫引擎,遊戲速度足夠快!
在2017年,坦克世界就已經通過各種優化手段在DirectX 11及以上的圖形平台實現了光線追蹤陰影。他們實現了實時光線追蹤物理正確的軟陰影,不需要硬體RT Core,使用了用於構建BVH的Intel Embree,使得坦克世界成為第一款在D3D11中使用實時RT陰影的遊戲。

坦克世界開啟(左)和關閉(右)光線追蹤軟陰影的對比圖。
在實現光線追蹤軟陰影時,分為CPU側和GPU側邏輯。其中CPU側包含兩級加速結構:
- BLAS(底層加速結構)BVH。適用於所有坦克模型,在網格載入期間構造一次並上傳到GPU,網格中的硬蒙皮部分拆分為多個靜態BVH,跳過軟蒙皮部分。
- TLAS(頂層加速結構)BVH。多執行緒,使用Intel Embree和Intel TBB,重建每幀並上傳到GPU。
CPU BVH佔CPU幀時間的2.5%,使用TBB執行緒,SSE 4.2(比原始WoT內部BVH builder快5.5倍),每幀更新高達約5mb的GPU數據,高達72mb的靜態GPU數據。下圖是CPU側的各個階段消耗:

GPU側執行像素著色或計算著色:
- 基於均勻錐分布的時間射線抖動。
- BVH遍歷和射線三角形交點。
- 時間積累。
- 降噪器(基於SVGF)。
- 時間抗鋸齒(TAA)。
下圖是GPU側的各個階段消耗:
 )
)
坦克世界對光線追蹤陰影進行了優化:RT陰影只能由坦克投射,不支援alpha測試的幾何體,BLAS使用LOD,每像素只發射1根射線。如果出現以下情形之一,則不追蹤光線的像素:
NdotL <= 0。- 如果像素已被陰影貼圖遮擋。
- 距離攝像機300米以上。
利用此法實現的實時光線追蹤陰影的性能參數如下:
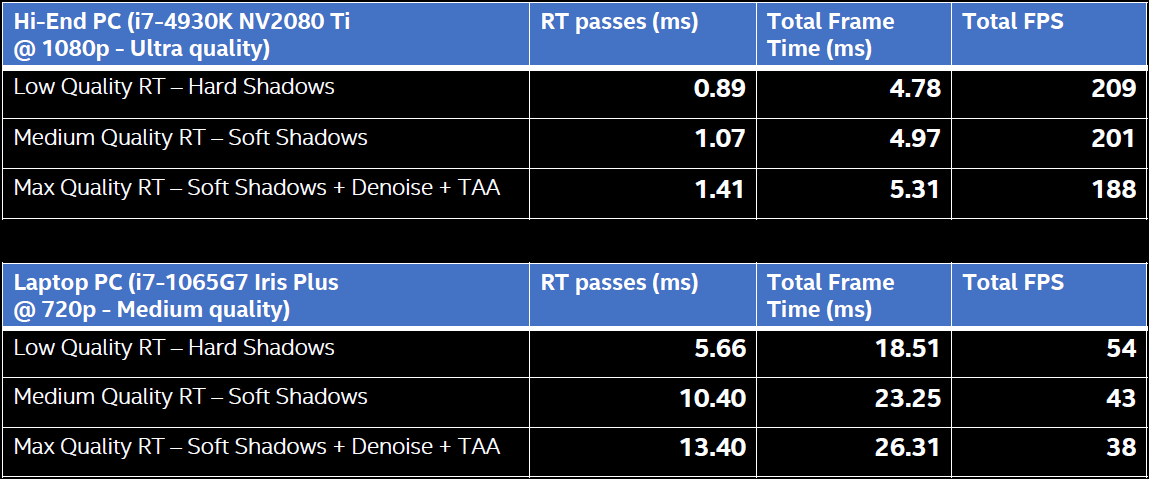
Northlight Engine實現的光線追蹤陰影和常規的Shadow Map陰影對比如下:

1080p上的每像素單根光線只耗費小於4ms,下圖是每像素單根光線的局部放大圖:

Claybook使用了軟陰影球體追蹤,用柔和的半影擴大陰影,沿光線步進SDF近似最大圓錐體覆蓋率,Demoscene圓錐體覆蓋近似:
c = min(c, light_size * SDF(P) / time);
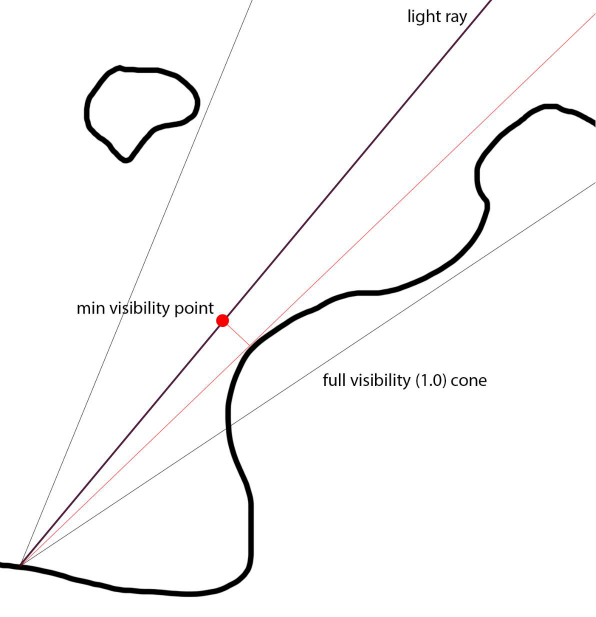
並且對軟陰影進行了改進,即三角測量最近距離,Demoscene=單個樣本(最小),三角測量cur和prev樣本,更少條帶。抖動陰影光線,UE4時間累積,隱藏剩餘的帶狀瑕疵,較寬的內半影。
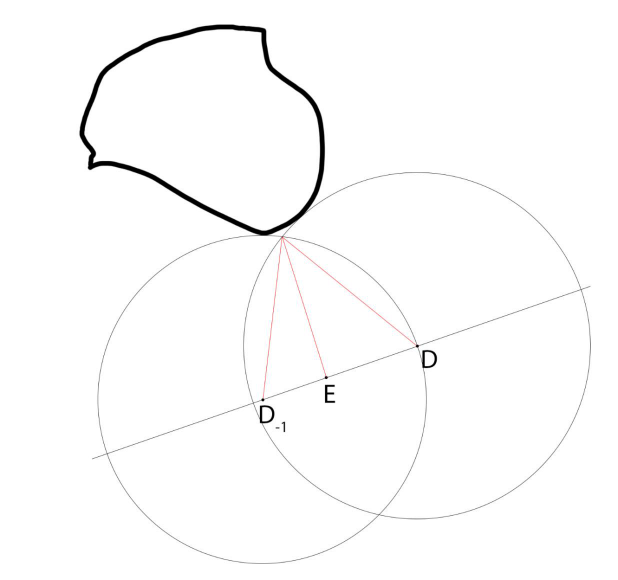
改進前後對比:

以往的LTC並不能處理遮擋的光照,但更真實的光影應該具備:

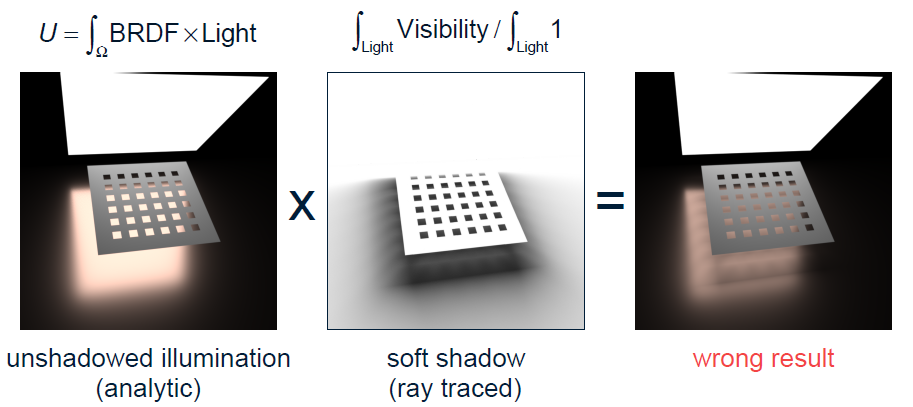
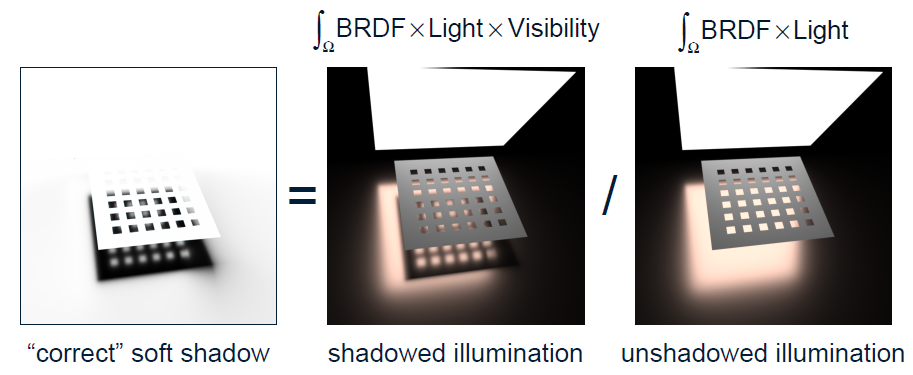
之前有文獻提出了僅光線追蹤的軟陰影,做法是平均可見性:

但如果使用BRDF獲得直接光,再乘以光線追蹤的平均可見性的軟陰影,將得到錯誤的結果:
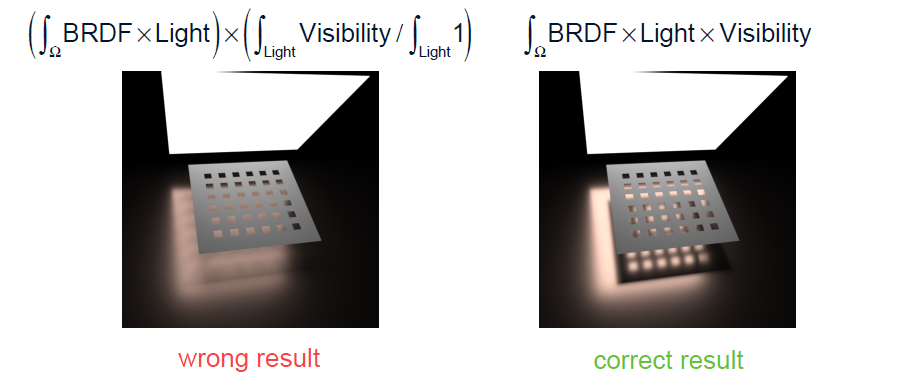
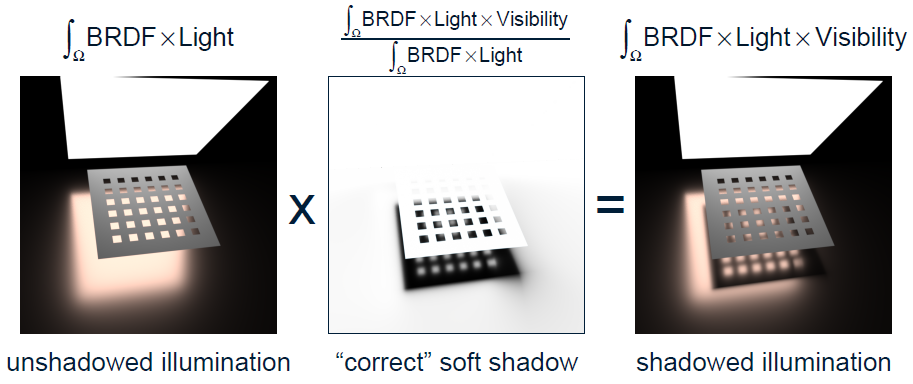
正確的做法應該如下圖右邊所示:
也可以採用隨機化的方式,但必須強制BRDF的所有項都是隨機化的:

隨機化的結果是過多噪點和過於模糊:

所以僅光線追蹤的軟陰影和完全隨機化的兩種方案都將獲得錯誤或不良的結果。正確的軟陰影演算法應該如下所示:
從數學上講,我們可以看到事情顯然是正確的:\(a·b/a=b\):
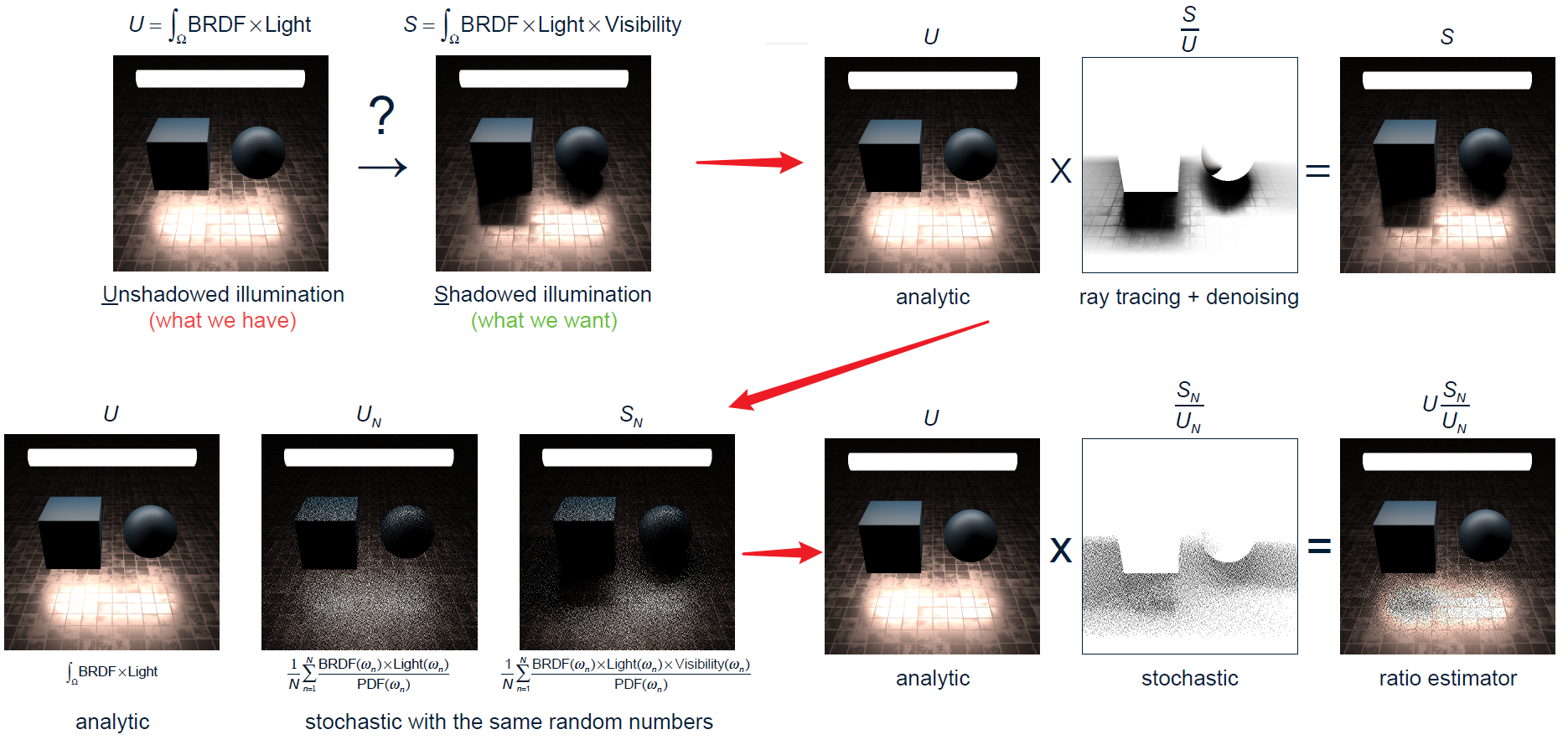
對應的正確隨機化公式:
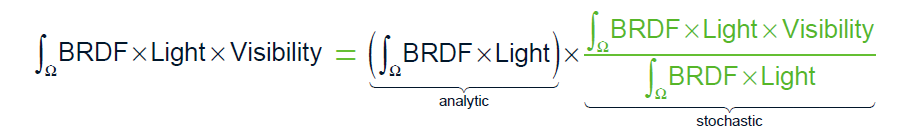
更加準確的方法推導如下:
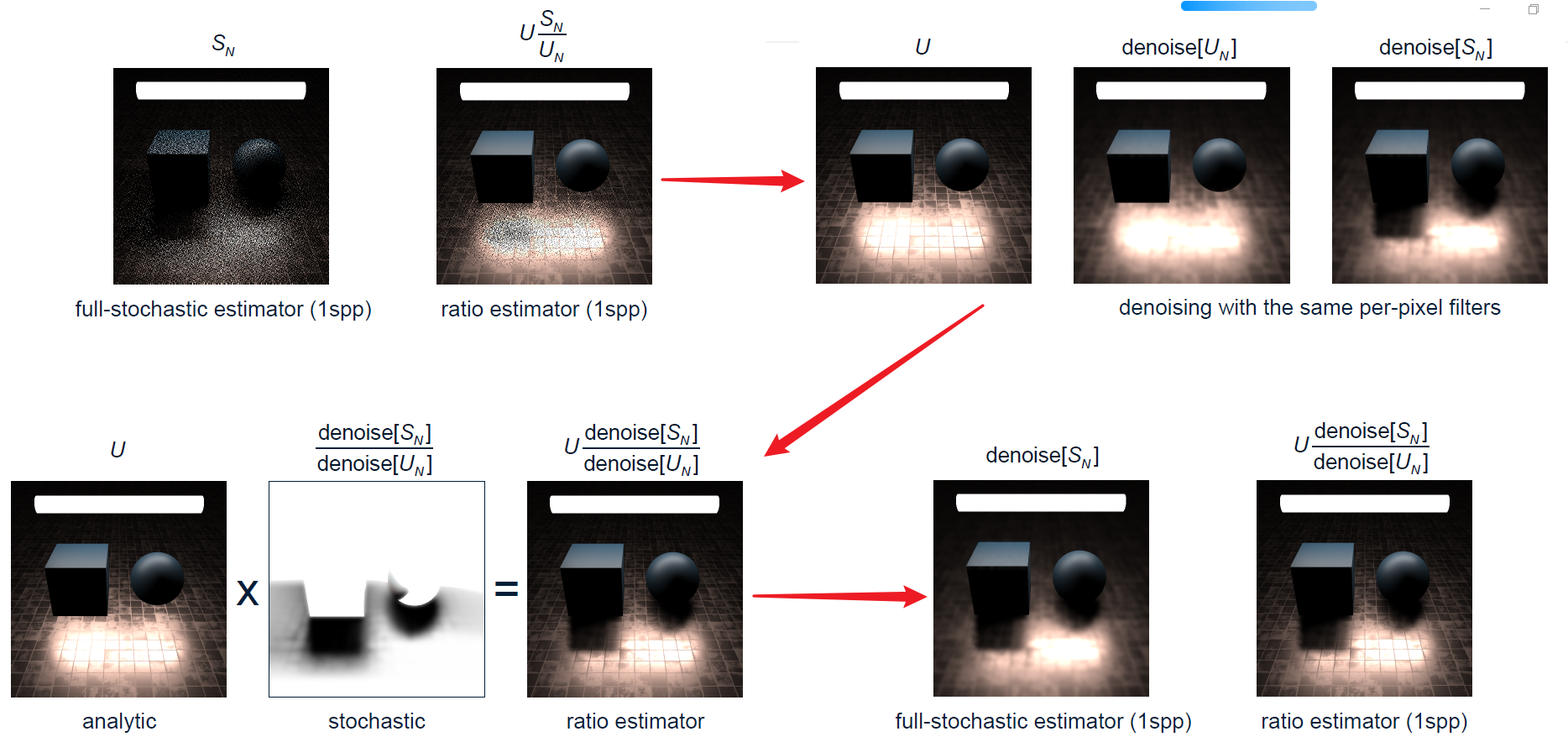
正確降噪的各個頻率的函數如下:
降噪圖例:

在取樣方面,使用了多重要性取樣:
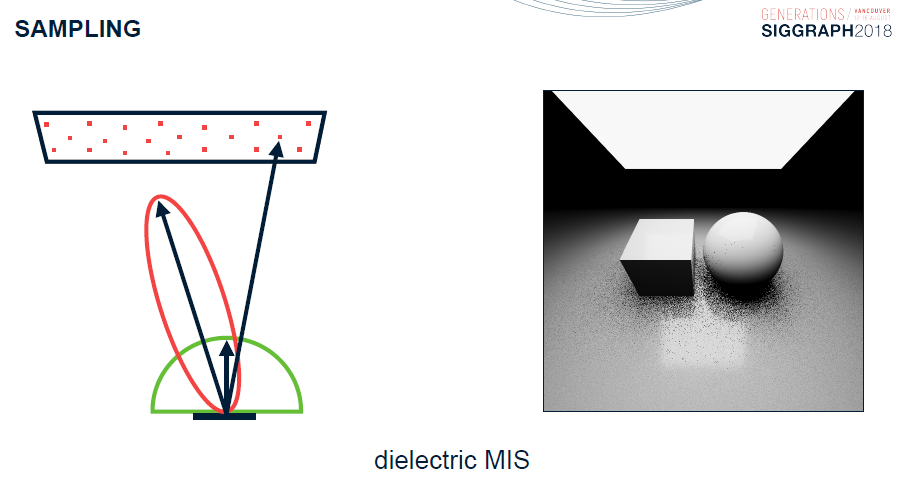
對於電介質(非金屬),使用了電解質多重要性取樣:
最終效果對比:

渲染通道和流程如下:
總之,比率估計器:無雜訊有偏分析+無偏雜訊隨機,作為穩健雜訊估計的總變化(非方差),由分析著色驅動的陰影多重要性取樣。實時光線追蹤GPU的注意事項包含活動狀態、延遲和佔用率、多重要性取樣的分支、波前與內聯,混合的光線+光柵圖形示例。
17.3.4 光線追蹤AO
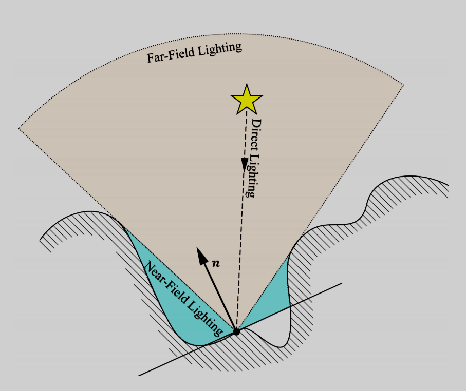
環境遮擋可以被認為是由非常大面積的光源(即每個點上方的整個半球)進行的照明,類似於陰天的室外照明。下圖(a)顯示了來自兩個表面點的環境遮擋光線。在左側點,大部分光線擊中對象,因此遮擋較高;在正確的點上,幾乎沒有光線擊中對象,因此幾乎沒有遮擋。圖(b)顯示了茶壺場景中的環境遮擋。此圖顯示純環境遮擋;當然,可以與表面顏色、紋理等相結合。

Northlight Engine實現的SSAO和光線追蹤AO的對比圖如下:

在不同的rpp(每像素光線數量)上,光線追蹤AO效果也有所不同:

Claybook在表面法線方向構造圓錐體,加上隨機變化+時間累積,AO射線使用低SDF mip,更好的GPU快取位置和更少的頻寬,軟遠程AO。Claybook也使用UE4的SSAO,小規模的環境遮擋。

上:SSAO;下:SSAO + RTAO。
17.3.5 光線追蹤反射
當光線擊中完美鏡面反射表面時,它是否以與入射角相同的角度反射,基本物理定律最早由歐幾里德在公元前3世紀編纂。在現實世界中,反射對象很常見,不僅僅是金屬球!
對於光線追蹤反射,從反射表面發射一條額外光線,反射光線的方向使用反射定律從入射光線方向計算。光線照射場景中的對象時,使用與直接可見表面相同的照明計算對該表面進行著色。

間接光的光澤反射可以通過在光澤反射分布的方向內發射光線來計算。對於給定的入射方向和一對隨機數,反射模型提供反射方向。下圖顯示了兩個茶壺中的光澤反射,使用Ward(各向同性)光澤反射模型計算反射。

類似地,可以通過圍繞折射方向分布光線來計算光澤折射,可以產生輕微磨砂玻璃的外觀。
SSR和光線追蹤反射也有明顯的區別,SSR無法反射物體背面和螢幕以外的集合體,而光線追蹤反射沒有此限制:

Northlight Engine實現的光線追蹤反射的各分量和合成效果如下:


對於不同的亮度,採用了不同的rpp,其中對亮度較高的像素採用更多的光線,且使用了抑制因子,最後結合陰影圖做優化。其組合過程圖例如下:




17.3.6 光線追蹤折射
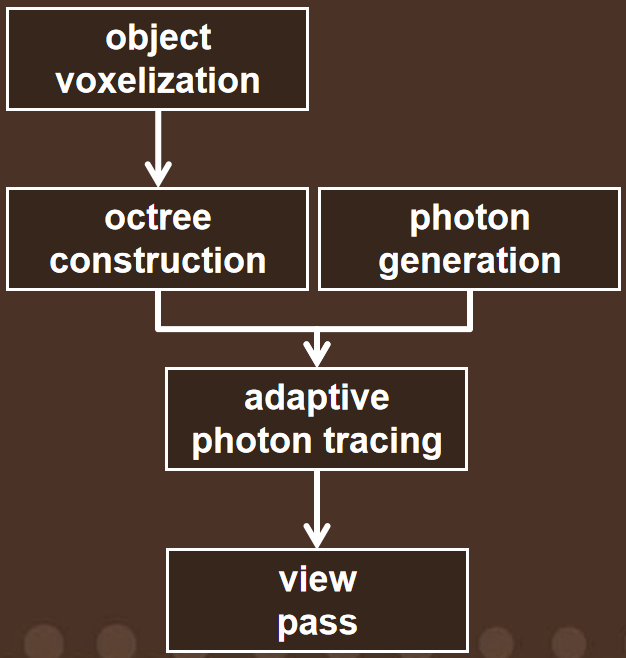
早在Siggraph 2008,周昆團隊就已經在研究基於光線追蹤的折射效果,實現了令人瞠目結舌的折射、反射、焦散、多重摺射、陰影、色散等等效果(下圖),該成果發表成論文Interactive Relighting of Dynamic Refractive Objects。

其實現流程主要是將物體體素化,生成八叉樹結構體來加速遍歷,然後採用自適應光子追蹤,從而實現高效且逼真的光線追蹤效果。
體素化的過程將三角形網格轉換為體積數據:
體素化使用GPU Gems III[Crane 07]的技術,僅在表面附近添加了超取樣,添加高斯平滑。
八叉樹構建時,使用密集3D數組代替稀疏樹,考慮折射率和消光係數,構造類似於mipmap。

生成光子時,在邊界框上生成光子,在折射對象的表面上生成光子,周圍體積必須為空,需要陰影貼圖來完成遮蔽。
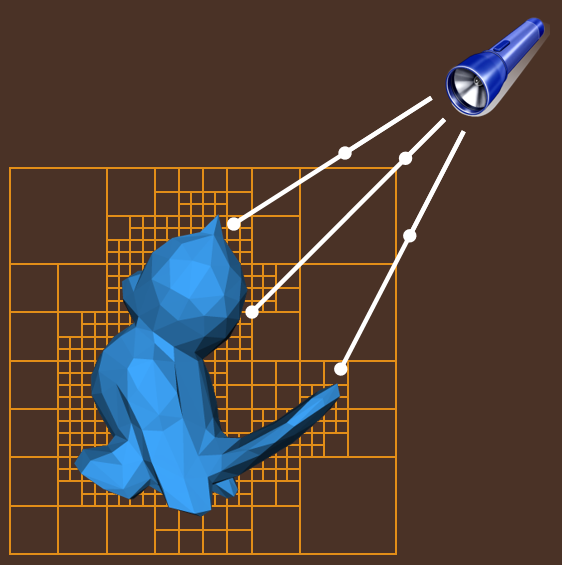
將輻射直接存入體素,為每個光子步驟使用線段:

然後根據表面積的大小使用不同精度的數據(即八叉樹的不同節點數據):
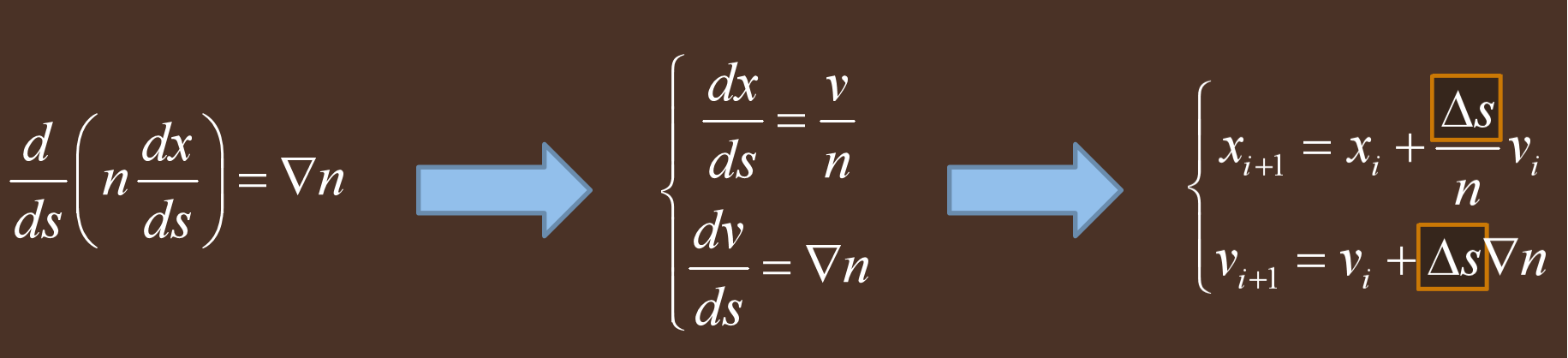

不同追蹤技術的效果對比:

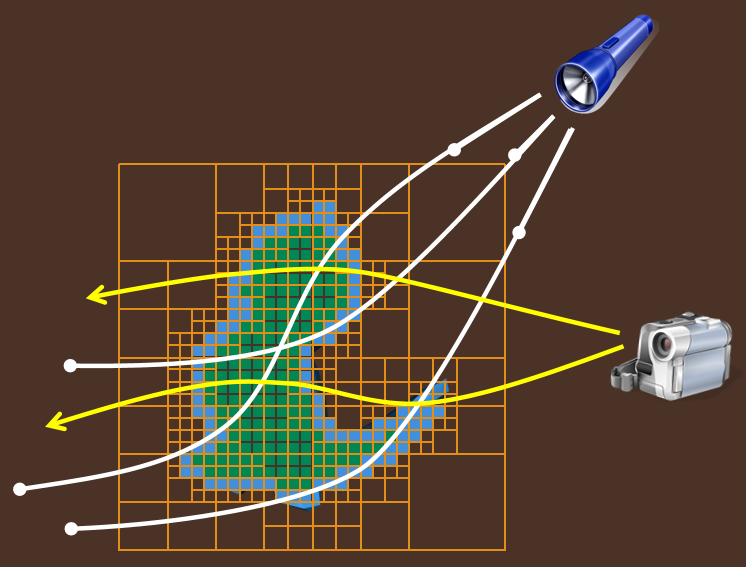
在view pass中,曲線觀察光線的軌跡,聚集光輝,考慮散射、衰減。同時忽略八叉樹,原因是影像對步長敏感,性能已經足夠好。
在2008年前後,採用128 x 128 x 128體積解析度、1024 x 1024初始光子、640 x 480影像解析度,使用NVIDIA GeForce 8800 Ultra渲染,可達到2到7fps。
17.3.7 光線追蹤間接漫反射
Ward等人使用寬分布光線追蹤來計算間接漫射光。反射光線的分布覆蓋了每個點上方的整個半球,具有餘弦加權分布,因此在朝向極點的方向上追蹤的光線多於赤道附近的方向(下圖)。在該影像中,沒有環境光源;陰影區域中的任何光都是由於間接光的漫反射。請特別注意,白色棋盤格是如何在茶壺底部反射的,以及右茶壺上的壺嘴是如何將光線投射到茶壺主體的附近部分的。這種效果通常被稱為顏色溢出(儘管在這種情況下「顏色」是白色),並可以用附近對象的顏色對錶面著色。

Northlight Engine在實現間接漫反射上,與AO類似,有許多非相干光線,GI存儲在稀疏網格體積中。基於靜態幾何圖形和靜態燈光集計算的輻照度,動態幾何體可以接收光,但不影響計算的輻照度,動態幾何沒有貢獻,三線性取樣創建階梯樣式,薄幾何體會導致光照泄漏,通過取樣餘弦分布上的輻射來收集照明,考慮丟失的幾何圖形(下圖)。
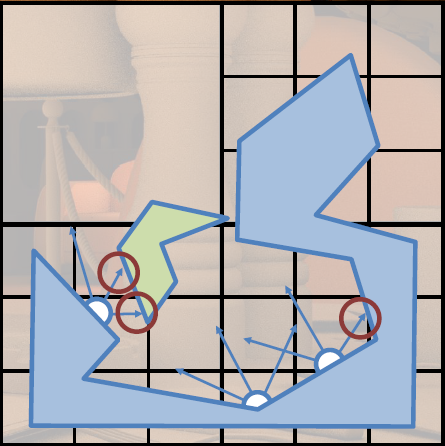
直接取樣和AO、光線追蹤收集的效果如下:


17.3.8 光線追蹤半透明
真正的透明度不是alpha混合!在現實光學中,當光穿過半透明物體時,一些光被吸收,一些光不被吸收。從表面的背面發射光線,像反射光線一樣的陰影,順序獨立。

當陰影光線擊中透明對象時,它將繼續朝向燈光。撞擊透明對象的陰影光線應進行著色並重新發射,就像它是非陰影光線一樣。陰影光線將穿過表面的完全透明區域,陰影光線從半透明對象獲取顏色。

除了以上特性,光線追蹤還可以實現互反射(Interreflection)、溢色、焦散、色散、DOF、運動模糊、複雜半透明、體積光霧、參與介質等等效果。

透過霧照在球體上的聚光燈。請注意,由於參與介質中的附加散射,聚光燈照明分布的形狀和球體陰影清晰可見。
17.3.9 降噪技術
降噪技術只用於BRDF的可見項(光照項採用解析近似):
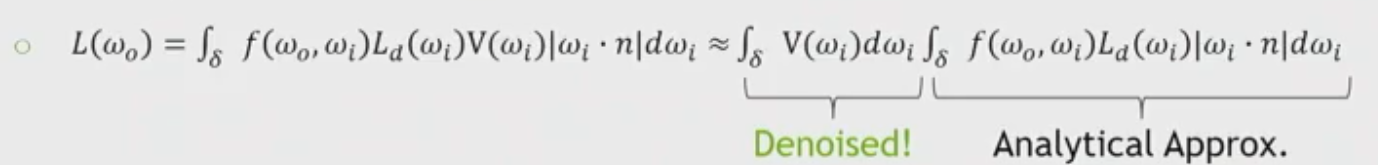
在實時光線追蹤領域,降噪演算法有很多,諸如使用引導的模糊內核的濾波,機器學習驅動濾波器或重要取樣,通過更好的准隨機序列(如藍色雜訊和時空積累)改進取樣方案以及近似技術,嘗試用某種空間結構來量化結果(如探針、輻照度快取)。
-
濾波(Filtering)技術。有Gaussian、Bilateral、À-Trous、Guided以及Median,這些方法常用於過濾蒙特卡洛追蹤的模糊照片。特別是由特性緩衝區(如延遲渲染的GBuffer)和特殊緩衝區(如first-bounce data, reprojected path length, view position)驅動的引導濾波器已被廣泛使用。
-
取樣(Sampling)技術。有TAA、Spatio-Temporal Filter、SVGF(Spatio-Temporal Variance Guided Filter)、Adaptive SVGF (A-SVGF)、BMFR(Blockwise Multi-Order Feature Regression)、ReSTIR(Spatiotemporal Importance Resampling for Many-Light Ray Tracing)等技術。
-
近似(approximation )技術。常用於嘗試微調路徑追蹤器的不同方面的行為。
-
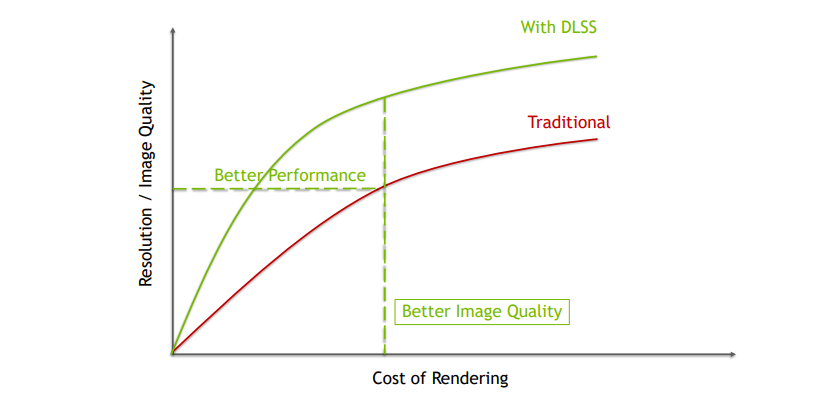
深度學習降噪技術。常見的有DLSS、OIDN、Optix等。Intel和NVIDIA等行業領先企業贊助了基於機器學習的降噪器的研究,Intel Open Image Denoise和NVIDIA Optix Autoencoder都使用降噪自動編碼器對影像進行降噪,取得了巨大成功。NVIDIA的深度學習超級取樣(DLSS 2.0)也被用於升級光線追蹤應用程式,如Minecraft RTX、Remedy Entertainment的控制等,目的是通過將原始影像的一部分上取樣到原生解析度來降低計算成本。深度學習超取樣(DLSS)是一种放大技術,它使用小的顏色緩衝區和方向圖將輸出解析度乘以2-4倍,是由NVIDIA預先批准的開發人員專用的,因此目前無法公開使用,也就是說,有其他替代方案,如 DirectML’s SuperResolution Sample。
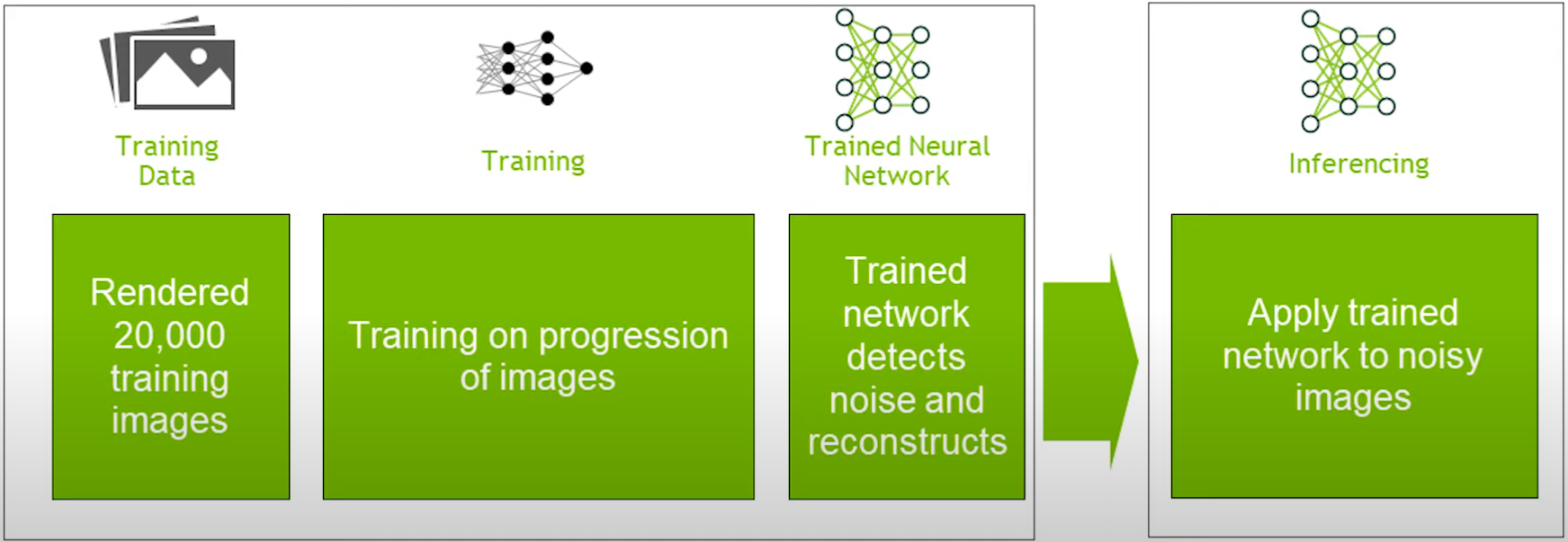
NVIDIA基於AI的降噪架構圖。

下面抽取部分重要的降噪技術來剖析。
17.3.9.1 SVGF / A-SVGF
時空方差引導濾波器(SVGF)[Schied 2017]是一種降噪器,使用時空重投影以及特徵緩衝器(如法線、深度和方差計算)驅動雙邊濾波器模糊高方差區域。
SVGF將噪點輸入轉換為完整影像,通常需要10毫秒才能運行,因此將其集成到實時光線追蹤器中可能沒有好處。深度學習過濾器可能在更短的時間內完成類似的任務。然而,該技術非常擅長重建最終影像,尤其是調整版本(A-SVGF,自適應SVGF)。NVIDIA聲稱,與之前的互動式重建濾波器相比,提供了大約10倍的時間穩定結果,匹配參考影像的效果更好5-47%(根據SSIM),並且在1920×1080解析度的現代圖形硬體上僅運行10毫秒(15%以內誤差)。
自適應時空方差引導濾波(A-SVGF)[Schied等人2018]是一種較新的技術,在SVGF基礎上進行了改進,消除了閃爍等問題,通過自適應地重用根據時間特徵(如編碼在矩緩衝器中的方差、視角等的變化)在空間上重新投影的先前樣本,並使用快速雙邊濾波器對其進行濾波,改進了SVGF。因此,與基於歷史長度累積樣本不同,矩緩衝區充當替代色調,使用方差的變化來驅動舊樣本和新樣本的比例,從而減少重影。雖然SVGF僅使用矩緩衝器來驅動模糊,但A-SVGF將其用於濾波和累積步驟。
雖然引入力矩緩衝區有助於消除時間延遲,但並不能完全消除時間延遲。具有大量累積樣本的區域和新區域之間可能存在亮度差異。這在光線追蹤場景的較暗區域(如室內)中尤其明顯。為了緩解這種情況,最好在場景的黑暗區域使用2 spp,而不是使用每像素1個取樣(1 spp)。
Quake 2 RTX使用A-SVGF作為其去噪解決方案。
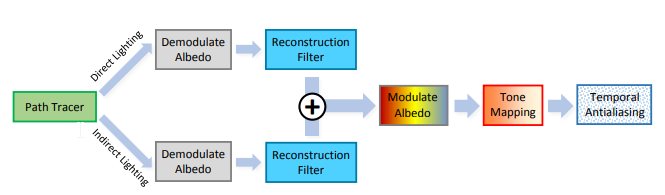
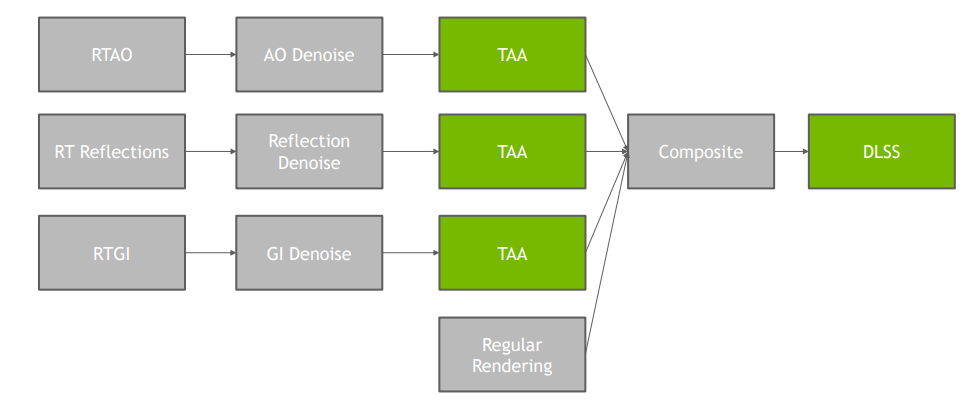
路徑追蹤器/光線追蹤器提供直接和間接照明,經過重建濾波器並被合併。然後,對結果應用色調映射和TAA(可以替換為色調映射+DLSS)。
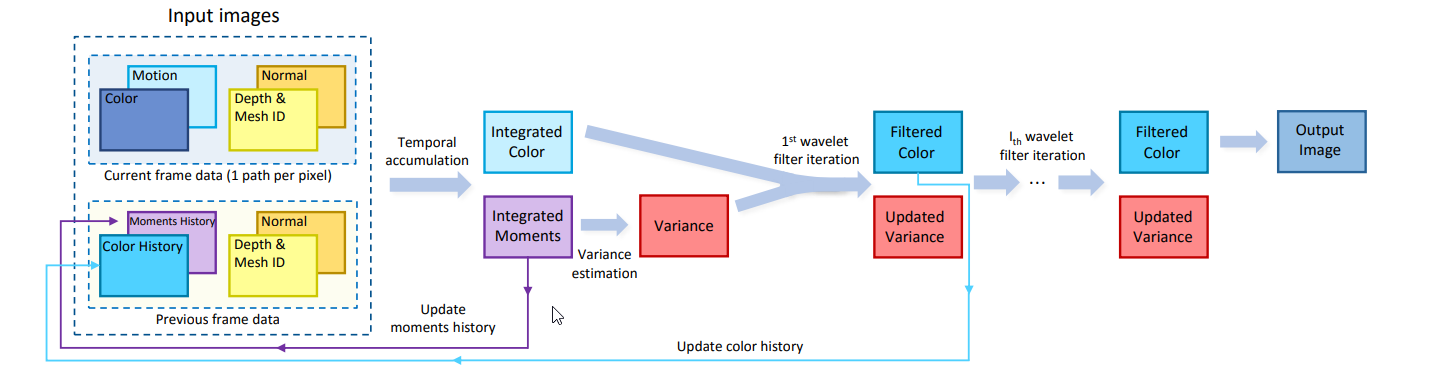 g)
g)
如上圖所示,重建濾波器使用時間累積來確定積分顏色/矩,並使用方差估計來獲得濾波後的顏色。意味著我們需要歷史緩衝區(來自先前的幀重建),需要光柵化來提供法線、反照率、深度、運動矢量和網格id。
Minecraft RTX使用特殊形式的SVGF,添加了輻照度快取,使用光線長度更好地驅動反射,並對透射表面(如水)進行分割渲染。SVGF雖然非常有效,但確實引入了在遊戲中可能注意到的時間延遲。
17.3.9.2 ReSTIR
多光線追蹤的時空重要性重取樣(ReSTIR)[Bitterli等人2020]試圖將實時降噪器的時空重投影步驟移到渲染的早期,重用來自相鄰取樣概率的統計數據。本質上是一篇早期論文的結合,討論了重取樣重要性取樣,並添加了時空去噪器引入的思想。
ReSTIR將可用於NVIDIA的RTXDI SDK。已被NV實現在UE的分支中,源碼在//github.com/NvRTX/UnrealEngine/tree/NvRTX_Caustics-4.27。詳細的原理參見Spatiotemporal Reservoir Resampling (ReSTIR) – Theory and Basic Implementation。
17.3.9.3 DLSS
在DLSS面世之前,NV已經有AI超取樣:

DLSS利用AI的學習能力,將低解析度的輸入畫面,上取樣成高清(接近原生解析度)的畫面:


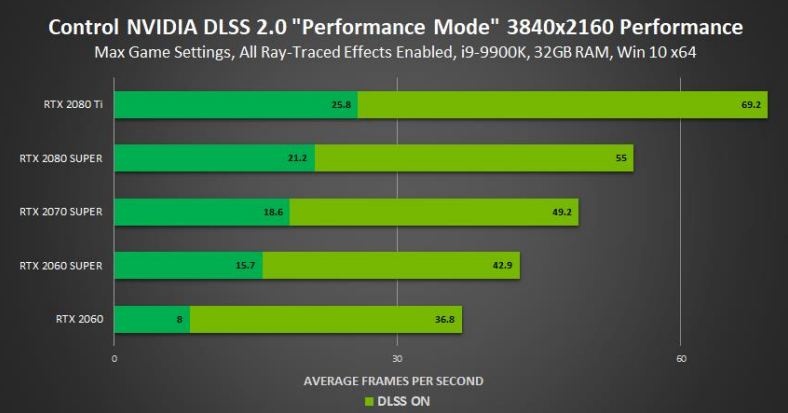
利用DLSS2.0將1080P上取樣到4K比原生4K有了巨大的性能提升(2x到5x):
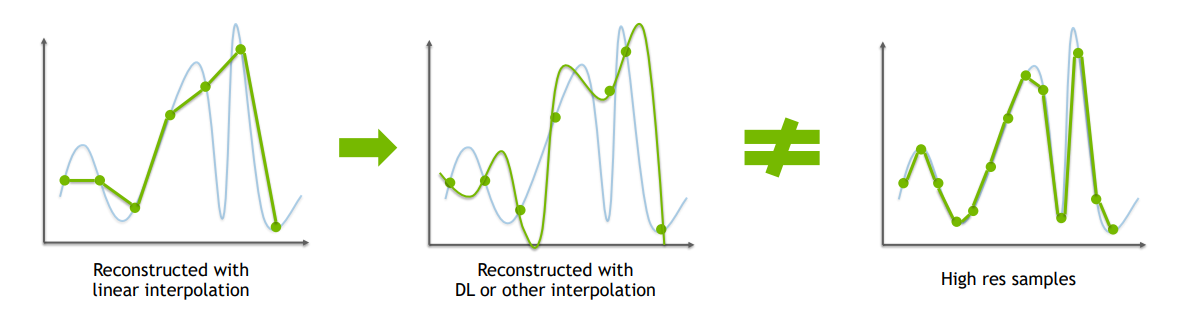
傳統初級的抗鋸齒演算法是通過插值低解析度像素重建高解析度影像,常見的選擇是雙線性、雙三次、lanczos,對比感知銳化,深度神經網路可以根據先驗或訓練數據在現有像素的基礎上產生幻覺(hallucination)。它們與原生高解析度影像相比,生成的影像缺少細節。由於幻覺,影像可能與原生渲染不一致,且時間不穩定:

進一步的演算法,如TAAU等使用鄰域截取,對高頻訊號、新出現的訊號重建後方差大,從而導致摩爾紋、閃爍、模糊、重影等瑕疵:

實時超解析度的挑戰是:對於單幀方法,模糊影像品質,與原生渲染現不一致,時間不穩定;對於多幀方法,用於檢測和糾正跨幀變化的啟發式方法,啟發式的局限性導致模糊、時間不穩定和重影。
在重建訊號時,和傳統的抗鋸齒等演算法不同,DLSS 2.0是基於DL(深度學習)的多幀重建,使用從成千上萬的高品質影像中訓練的神經網路,神經網路比手工製作的啟發式更強大,使用來自多幀的樣本進行更高品質的重建,從而獲得更為精準的重建訊號(下圖)。

左:原始的高頻訊號;中:非DL技術的重建,和原始訊號方差大;右:DLSS重建方法,更加精準貼合原始訊號。
DLSS 2.0在相同的渲染消耗下,獲得更佳的解析度和影像品質:
以下是1080P+TAA、540P+DLSS 2.0、540P+TAAU的畫面對比:

如果遊戲引擎需要集成DLSS,其步驟概覽如下:

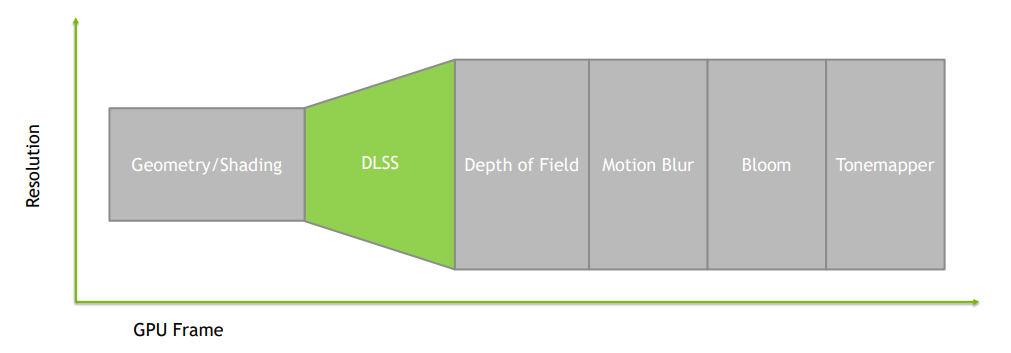
Geometry/Shading階段,因為TAA被DLSS取代,依賴TAA的去噪器需要改進降噪器或在降噪後添加專用的TAA通道:
DL Upsampling需要輸入以下資訊,通過NGX SDK處理成降噪和抗鋸齒後的畫面:

Post(後處理)階段採用放大後的解析度渲染,引擎需要處理與幾何體和著色不同的後處理解析度:
值得一提的是,DLSS的主要研發者是閆令琪的師弟文刀秋二——跟部落客一樣是個熱愛攝影的人 。
。
17.3.9.4 降噪實現
理想的降噪器結合了最新技術論文中的想法,圖例和步驟如下所示:

1、Prepass
計算場景的NDC空間速度,寫入常見的G-Buffer附件,如反照率、法線等。可能還需要這些緩衝區的第一次反彈版本,將需要基於光線追蹤的prepass ,而不是基於光柵的prepass 。

在降噪之前,重要的是使用某種通用通道(G通道)對材質資訊進行編碼,如法線、反照率、深度/位置、對象ID、粗糙度/金屬度等。此外,訪問速度可以將以前的取樣轉換到當前位置。可以通過確定渲染的每個頂點的先前和當前NDC空間坐標位置,並取兩者的差來計算速度緩衝區。
\]
因此,需要對象的前一幀modelViewProjection矩陣,以及該對象的動畫頂點速度,即當前和先前動畫取樣之間的位置差。

// NDC space velocity
float3 ndc = inPosition.xyz / inPosition.w;
float3 ndcPrev = inPositionPrev.xyz / inPositionPrev.w;
outVelocity = ndc.xy - ndcPrev.xy;
可以進一步使用此概念,例如使用運動矢量進行第一次反彈光澤反射,使用陰影運動矢量在對象移動時進行更好的陰影重投影,甚至使用雙運動矢量進行遮擋。[Zeng等人,2021]
2、Ray Trace
使用[Kuznetsov等人2018年][Hasselgren等人2020年]的人工智慧自適應取樣和樣本映射,以更好地確定哪些區域應接收更多樣本,通常是高光/陰影,以幫助避免鹽巴/胡椒(salt/peppering)等瑕疵,並隨時間保持亮度。將鏡面反射和全局照明寫入單獨附件的分離降噪器比較理想,因為反射降噪將更好地處理第一次反彈數據,全局照明、環境遮擋、陰影可以基於較少的數據使用更簡單的時空累積。
3、Accumulation(累積)
儘可能頻繁地使用時空重投影,對於朗伯數據(如全局照明/環境遮擋)更容易實現,而對於鏡面反射數據(如反射)則更難實現。為了獲得更好的結果,使用啟發式數據(如法線/反照率/對象ID)將之前的樣本轉換為當前位置,以及第一次反彈數據(如視圖方向、第一次反彈法線、反射率等)。然後,任何成功的重投影都可以用於重要性樣本[Bitterli等人2020],或將其輻射編碼到輻射歷史緩衝區[Schied等人2018]。
時空重投影是重複使用來自前一幀的數據,將其空間重投影到當前幀。將以前的取樣轉換為當前幀需要首先在視圖空間中找到以前幀數據的坐標,可以通過添加速度緩衝區來完成。通過比較此螢幕空間坐標的當前位置/法線/對象ID/等與其上一個坐標之間的差異,可以判斷對象是否已被遮擋,現在是否在視圖中,或者重用以前的取樣。

在執行時空重投影時,具有描述給定樣本必須累積的時間的緩衝區非常有價值,即歷史緩衝區。它可以用於驅動濾波器在具有較少累積樣本的區域中模糊更強,或者用於估計當前影像的方差(較高的歷史將意味著較小的方差)。
outHistoryLength = successfulReprojection ? prevHistoryLength + 1.0 : 0.0;
然後,歷史長度可以用作累積因子\(\alpha\),即當前取樣對最終輻射的貢獻因子。
outColor = lerp(colorPrevious, colorCurrent, accumulationFactor);
雖然歷史緩衝區是一個有用的東西,但有更好的方法來確定累積因子,而不是成功重投影的比率,我們可以使用統計分析來防止時間延遲。
4、Statistical Analysis(統計分析)
估計當前光線追蹤影像的方差,計算亮度/速度的方差變化,並使用其驅動時空重投影和濾波。嘗試使用該差異資訊拒絕螢火蟲(fireflies,即異常亮點)。
\]
方差是訊號平均值(均值)的平方差。我們可以取當前訊號的平均值,然後用3×3高斯核(本質上是張量),然後取兩者的差。
\]
const float radius = 2; // 5x5 kernel
float2 sigmaVariancePair = float2(0.0, 0.0);
float sampCount = 0.0;
for (int y = -radius; y <= radius; ++y)
{
for (int x = -radius; x <= radius; ++x)
{
// Sample current point data with current uv
int2 p = ipos + int2(xx, yy);
float4 curColor = tColor.Load(p);
// Determine the average brightness of this sample
// Using International Telecommunications Union's ITU BT.601 encoding params
float samp = luminance(curColor);
float sampSquared = samp * samp;
sigmaVariancePair += float2(samp, sampSquared);
sampCount += 1.0;
}
}
sigmaVariancePair /= sampCount;
float variance = max(0.0, sigmaVariancePair.y - sigmaVariancePair.x * sigmaVariancePair.x);
Christoph Schied在A-SVGF中將空間方差估計為邊緣避免guassian濾波器(類似於A-trous引導濾波器)的組合,並在回饋迴路中使用它來驅動時空重投影期間的累積因子。除了管理累積,估計方差還可以讓我們在時間上降低過濾器的權重,[Olejnik等人2020]使用類似於A-SVGF的泊松圓盤過濾器,以更好地渲染接觸陰影。
/**
* Variance Estimation
* Copyright (c) 2018, Christoph Schied
* All rights reserved.
* Slightly simplified for this example:
*/
// Setup
float weightSum = 1.0;
int radius = 3; // ⚪ 7x7 Gaussian Kernel
float2 moment = tMomentPrev.Load(ipos).rg;
float4 c = tColor.Load(ipos);
float histlen = tHistoryLength, ipos, 0).r;
for (int yy = -radius; yy <= radius; ++yy)
{
for (int xx = -radius; xx <= radius; ++xx)
{
// We already have the center data
if (xx != 0 && yy != 0) { continue; }
// Sample current point data with current uv
int2 p = ipos + int2(xx, yy);
float4 curColor = tColor.Load(p);
float curDepth = tDepth.Load(p).x;
float3 curNormal = tNormal.Load(p).xyz;
// Determine the average brightness of this sample
// Using International Telecommunications Union's ITU BT.601 encoding params
float l = luminance(curColor.rgb);
float weightDepth = abs(curDepth - depth.x) / (depth.y * length(float2(xx, yy)) + 1.0e-2);
float weightNormal = pow(max(0, dot(curNormal, normal)), 128.0);
uint curMeshID = floatBitsToUint(tMeshID, p, 0).r);
float w = exp(-weightDepth) * weightNormal * (meshID == curMeshID ? 1.0 : 0.0);
if (isnan(w))
w = 0.0;
weightSum += w;
moment += float2(l, l * l) * w;
c.rgb += curColor.rgb * w;
}
}
moment /= weightSum;
c.rgb /= weightSum;
varianceSpatial = (1.0 + 2.0 * (1.0 - histlen)) * max(0.0, moment.y - moment.x * moment.x);
outFragColor = float4(c.rgb, (1.0 + 3.0 * (1.0 - histlen)) * max(0.0, moment.y - moment.x * moment.x));
螢火蟲抑制(Firefly Rejection)可以通過多種方式進行,從調整光線追蹤期間的取樣方式,到使用過濾技術或關於輸出輻射亮度的huristics。
// 增加每次彈跳的粗糙度
////twitter.com/YuriyODonnell/status/1199253959086612480
////cg.ivd.kit.edu/publications/p2013/PSR_Kaplanyan_2013/PSR_Kaplanyan_2013.pdf
////jcgt.org/published/0007/04/01/paper.pdf
float oldRoughness = payload.roughness;
payload.roughness = min(1.0, payload.roughness + roughnessBias);
roughnessBias += oldRoughness * 0.75f;
// 截取拒絕
// Ray Tracing Gems Chapter 17
float3 fireflyRejectionClamp(float3 radiance, float3 maxRadiance)
{
return min(radiance, maxRadiance);
}
// 方差拒絕
// Ray Tracing Gems Chapter 25
float3 fireflyRejectionVariance(float3 radiance, float3 variance, float3 shortMean, float3 dev)
{
float3 dev = sqrt(max(1.0e-5, variance));
float3 highThreshold = 0.1 + shortMean + dev * 8.0;
float3 overflow = max(0.0, radiance - highThreshold);
return radiance - overflow;
}
5、Filtering(過濾)
可以使用À-Trous雙邊濾波器快速完成,根據想要的模糊強度重複此步驟3到5次,每次將步長減小2的冪(因此,在3次迭代的情況下,順序為4、2、1)。或者,可以使用降噪自動編碼器,該編碼器速度較慢,但可以產生更好的過濾結果。然後,該結果可以輸入一個超級取樣自動編碼器,該編碼器可以上取樣結果,類似於NVIDIA的DLSS 2.0。
À-Trous避免了以略微抖動的模式取樣,以覆蓋比3×3或5×5高斯核通常可能的更寬的半徑,同時具有重複多次的能力,並避免由於不同輸入的數量而在邊緣模糊。可以結合以下方法進行:
- 根據抖動模式進行子取樣,從而進一步減少模糊內核中的取樣數。
- 使用更多資訊驅動模糊,如表面粗糙度[Abdollah shamshir saz 2018]、近似鏡面BRDF瓣[Tokuyoshi 2015]、陰影半影[Liu等人2019]等。
6、History Blit(歷史拷貝)
寫入當前預處理數據,如反照率、深度等,以便重新投影下一幀。
NVIDIA發布了一個使用ReSTIR的類似降噪器的示例實現[Wyman等人2021]。下圖是NV的AI降噪,可利用1取樣高噪點圖,通過降噪演算法,獲得良好的降噪結果。


上:1次取樣的原始噪點圖;下:開啟了降噪處理的畫面。

頂部影像中的環境遮擋使用每像素一條光線進行光線追蹤,然後進行降噪。縮放影像從左至右顯示:基準真相、螢幕空間環境遮擋、光線追蹤環境遮擋。其中光線追蹤環境遮擋每幀每像素一個樣本,並從每像素一樣本進行降噪。降噪影像不會捕獲所有較小的接觸陰影,但仍然比螢幕空間環境遮擋更接近基準真相。(NVIDIA提供)
所有這些類型的演算法都依賴於重用數據,因此,當重用數據不可用時,例如在快速移動的對象、高度複雜的幾何體或歷史資訊很少的區域,每個方法的品質都會下降。有一些方法可以利用一些快取數據來幫助避免這種情況,例如使用輻照度快取來獲得更好的默認顏色,如Minecraft RTX。
對於反射,時空重投影也非常困難,因此通常情況下,降噪器將依賴於第一次反彈數據,其中反射表面的法線、位置數據等基於第一次反射,而不是原始表面。
降噪可以通過時空重投影重新使用以前的樣本——自適應地重新取樣輻射或統計資訊以進行重要性取樣,並使用快速高斯/雙邊濾波器等濾波器或人工智慧技術(如去噪自動編碼器和通過超取樣進行放大),幫助彌合低樣本/像素影像與基準真相之間的差距。
雖然降噪並不完美,因為時間技術可能會引入輻射滯後,並且任何濾波器都會由於試圖模糊原始影像而導致銳度損失,但引導濾波器可以幫助保持銳度,並且自適應取樣或增加每幀像素的樣本數可以使去噪影像和地面真實影像之間的差異可以忽略不計。儘管如此,每像素取樣率更高是無法替代的,因此使用不同的每像素取樣(spp)計數來試驗這些技術。
一個健壯的降噪器應該考慮使用所有這些技術,但取決於應用程式的權衡和需求。最近的研究側重於通過改進取樣方案和使用快取資訊重新取樣像素,將降噪移到渲染的早期,而之前的研究則側重於過濾、機器學習中的自動編碼器、重要性取樣以及當前在商業遊戲和渲染器中生產的實時方法。
UE大量綜合使用了濾波、取樣的若干種技術(雙邊濾波、空間卷積、時間卷積、隨機取樣、訊號和頻率等等),而不僅僅限於光線追蹤,還用於包含SSGI、SSR、SSAO等螢幕空間技術。下圖是UE的SSGI在經過時間累積之後,可以看到畫面的噪點更少且不明顯了:

17.3.9.5 降噪文獻
降噪是未來值得深究的課題和領域,希望童鞋們有志參與其中,現推薦部分降噪相關的樣例、論文、演講和文獻:
-
Samples
-
Dihara Wijetunga (@diharaw94) released a blog post that discusses denoising different aspects of a hybrid renderer.
-
NVIDIA released their Real-Time Denoiser for limited review. You can sign up to view it here.
-
Interactive Path Tracing and Reconstruction of Sparse Volumes uses a machine learning denoiser to denoise volumes with adaptive sampling.
-
Peter Kristof of Microsoft made a really robust DirectX Ray Tracing Ambient Occlusion example with a robust implementation of SVGF here.
-
The Apple Metal Team released an example of using Metal Performance Shaders, Temporal Anti-Aliasing (MPSTAA), and SVGF (MPSSVGF) to denoise a ray traced scene.
-
AMD’s FidelityFX SSSR features spatio-temporal reprojection to denoise screen space reflections. Here’s their Github. AMD also released several denoisers for reflections and shadows on thisGithub Repo.
-
NVIDIA has released an SDK to itegrate Deep Learning Super Sampling here. AMD’s Fidelity FX Super resolution is also available for developers to integrate into their applications.
-
Ingo Wald (@IngoWald)) released a Optix course which showcases how to use the Optix denoiser here.
-
Christof Shied (@c_schied) and Alexey Panteleev (@more_fps) of NVIDIA wrote the denoiser for Quake 2 RTX which is on Github here.
-
Microsoft’s DirectML Super Resolution Example, while not NVIDIA Deep Learning Super Sampling 2.0 (DLSS 2.0), is similar in that both perform upscaling.
-
Xiaoxu Meng released the source of their Neural Bilateral Grid paper here.
-
released a number of open source denoisers for shadows and reflections in raster based rendering here.
-
In the University of Pennsylvania’s CIS565 course, a number of students, teaching assistants, and former students made awesome projects that implement the latest in denoising research:
- CUDA SVGF by Zheyuan Xie, Yan Dong, and Weiqi Chen
- Blockwise Multi-Order Feature Regression for Real-Time Path Tracing Reconstruction (BMFR) by Jiangping Xu, Gangzheng Tong, and Tianming Xu
- Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder by Dewang Sultania & Vaibhav Arcot implemented with Pytorch.
- ReSTIR in DirectX 12 by Sydney Miller, Sireesha Putcha, Thy Tran.
- ReSTIR in DirectX 12 by Jilin Liu (@Jilin18043110), Keyi Yu, and Li Zheng.
- ReSTIR in Vulkan by Xuanyi Zhou, Xuecheng Sun, Jiarui Yan.
-
-
Talks
- Chris Wyman’s High Performance Graphics 2020 talk on ReSTIR is available here.
- Eric Haines (@pointinpolygon) released Ray Tracing Essentials Part 7: Denoising for Ray Tracing, a great introduction to denoising.
- Tomasz Stachowiak (@h3r2tic) et al. designed the Pica Pica renderer, an amazing reference hybrid renderer featured in Ray Tracing gems. Their talk is available here.
- Ray Tracing in Games with NVIDIA RTX (Presented by NVIDIA)
-
Articles
- Kostas Anagnostou (@KostasAAA) wrote an article describing a method of handling global illumination denoising inspired in part by Metro Exodus.
- Ray Tracing Filtering
- Machine Learning Denoising
- Real-Time_Rendering_4th-Real-Time_Ray_Tracing
- Ray Tracing Denoising
- DirectML’s SuperResolution Sample
- Spatiotemporal Variance-Guided Filtering
- TURING RTX RAY TRACING 與 DLSS
- DLSS 2.0 – IMAGE RECONSTRUCTION FOR REAL-TIME RENDERING WITH DEEP LEARNING
- Spatiotemporal Reservoir Resampling (ReSTIR) – Theory and Basic Implementation
17.3.10 光線追蹤優化
光線追蹤的實際場景可能很複雜:數千個光源,超過記憶體容量的紋理,超過記憶體容量的幾何圖形(以鑲嵌形式),非常複雜的可編程著色器,用於位移、照明和反射。
17.3.10.1 光源優化
在光源方面,直接照明的主要消耗通常是陰影。如果使用陰影貼圖,則必須為每個光源渲染和管理陰影貼圖。如果使用光線追蹤,並且我們必須為每個光源追蹤至少一條陰影光線,則渲染時間將長得無法接受。幸運的是,可以通過基於潛在照明對光源進行排序來處理來自許多光源的陰影。有些光源太遠,照明太暗,因此可以非常粗略地近似。在每個表面點處,計算每個光源的直接照明,然後根據照明強度對燈光進行排序,最後對要計算陰影的燈光、要計算無陰影的燈光和要跳過的燈光進行概率選擇。
17.3.10.2 紋理優化
在紋理方面,當渲染影像所需的紋理超過可用記憶體時,必須按需從磁碟讀取紋理,僅以所需解析度讀取紋理,並將紋理快取在記憶體中。
可以使用紋理Mipmap和紋理分塊。分塊紋理以便將相鄰像素組一起從磁碟讀取到存儲器,下圖顯示了平鋪紋理MIP貼圖的三個級別。在本例中,每個分塊包含16×16像素。最粗糙的MIP貼圖級別(級別0-3)可以壓縮到單個塊中(此處未顯示),MIP映射級別4由單個塊組成,下一層有2×2個分塊(每個分塊中仍有16×16個像素),下一層有4×4個分塊,依此類推。

此外,還可以使用多解析度紋理分塊快取。多解析度紋理分塊快取的紋理訪問對於直接可見幾何體的渲染具有高度一致性,快取大小為總紋理大小的1%就足夠了。當光線微分用於為紋理查找選擇適當的MIP貼圖級別時,觀察到光線追蹤的類似結果,選擇紋理像素與射線束橫截面大小大致相同的級別。非相干光線具有較寬的光線束,因此將選擇粗略的MIP貼圖級別。更精細的MIP圖級別將僅由具有窄射線束的射線訪問;幸運的是,這些光線是相干的,因此生成的紋理快取查找也將是相干的。
17.3.10.3 幾何優化
對於複雜場景,可以使用實例化、光線重新排序和著色快取(Ray reordering and shading caching)、幾何替身( stand-ins)、多解析度曲面細分等技術。
在光線重新排序和著色快取方面,Toro渲染器對光線進行了重新排序,以增加幾何相干性,使得光線追蹤大於電腦主記憶體的場景成為可能。對射線重新排序要求每個射線的影像貢獻是線性的,這種要求對於真實的物理反射是正確的,但對於電影製作中使用的非常藝術化的可編程著色器通常不是正確的。Razor項目受到用於掃描線渲染的REYES演算法的啟發,一次性對曲面點的整個網格進行著色,並存儲著色結果中與視圖無關的部分。如果以下某些光線擊中同一曲面面片,則可以重複使用著色結果。
幾何替身的預計算是一個相當長的過程,但一旦完成,就可以互動式地對場景進行光線追蹤。
對於多解析度曲面細分,在實際應用中,對曲線、Bezier面片、NURBS曲面、細分曲面和任何具有位移的曲面進行細分,而不是用數值方法計算光線曲面交點是有利的。這些曲面被分割為大小可控的較小曲面面片,對應於紋理的分塊。直接可見曲面面片的鑲嵌率應取決於觀察距離和曲面曲率,還可選擇地取決於觀察角度。對於反射或陰影,我們通常可以使用更粗糙的曲面細分。下圖顯示了曲面面片的五個細分的示例,最精細的細分率為14×11,較粗的層次由最精細細分的頂點子集組成,最粗糙的細分只是面片的四個角,可以將不同級別的細分視為細分幾何體的MIP貼圖。
曲面面片的多解析度細分示例:14×11、7×6、4×3、2×2和1個四邊形。
Pharr和Hanrahan快取了置換曲面的曲面細分幾何體,但沒有利用多解析度曲面細分。根據需要以所需的解析度細分曲面面片(然後在適當的情況下置換頂點),並將細分存儲在快取中。由於細分的大小相差很大,快取可以存儲比精細細分多得多的粗細分。
對於射線相交測試,可以選擇四邊形與射線束橫截面大小大致相同的細分。對精細和中等鑲嵌的訪問通常是非常一致的,對粗細分的訪問相當不一致,但粗細分的快取容量很大,而且這些細分無論如何都很快重新計算。精細細分僅用於直接可見的幾何體、平面的鏡面反射和折射以及光線原點附近的漫反射和環境遮擋光線,對於所有其他光線,光線束較寬,並使用中等和粗糙曲面細分。(類似不同粗糙度對應不同紋理的Mipmap等級!)
17.3.10.4 並行計算
光線追蹤似乎非常適合併行加速:每個像素的計算獨立於所有其他像素,導致人們普遍認為光線追蹤是「令人尷尬的平行」。但是,只有當場景數據適合主記憶體時,這才是成立的!如果場景較大,則必須非常小心地維護和利用數據訪問一致性,安排執行順序以使後續光線趨向於遍歷相同的幾何體並訪問相同的紋理,從而確保良好的快取行為。此舉非常值得,可提升快取命中率。
現代CPU有SIMD指令(英特爾上的SSE、IBM/Motorola上的AltiVec、AMD上的3dNow),可以並行執行四種操作。利用這些指令對平行於一個三角形的四條射線進行交叉測試。如果光線是相干的,將提供良好的加速,對於可見性光線,典型的加速比約為3.5倍。
利用SIMD指令的另一種方法是對平行的四個三角形進行一條射線的交叉測試。如果三角形是相干的(就像它們來自細分曲面上的相鄰位置一樣),會提供良好的加速,並且不需要光線是相干的。SIMD指令的另一個用途是平行交叉測試軸對齊包圍盒的所有三個平面。
17.3.10.5 GPU加速
PowerVR、RTX等系列GPU已經新增了光線追蹤的硬體單元,從而加速了實時光線追蹤的到來。此外,在GPU內如何提升光線、紋理等數據的一致性也是提升光線追蹤的首要問題。PowerVR內置了一致性引擎,用來收集和處理相關性高的光線(下圖)。

此外,GPU需要考慮SIMD、SIMT、連貫性、記憶體合併、核心佔用、管線瓶頸、同步方式甚至物理溫度(防止降頻)等,更多可參閱:Parallel Architectures。
在實現時,需要注意或使用自相交、數據精度、面片(patch)相交、載入均衡、多相交、LOD等問題或技巧。更多可參閱:
17.3.11 綜合技術
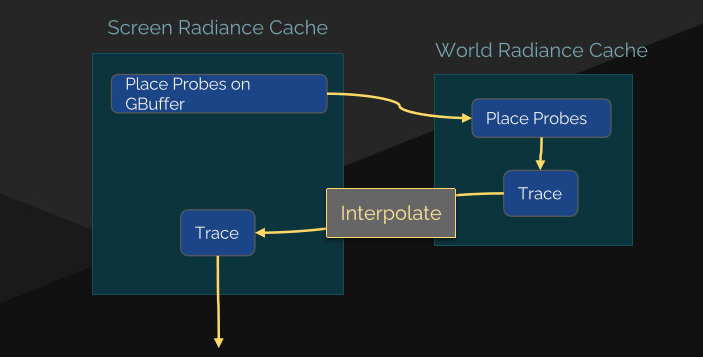
17.3.11.1 Lumen GI
以往的實時研究有輻照度場(Irradiance Fields)、螢幕空間降噪器(Screen Space Denoiser)等方式。而UE5的Lumen使用了螢幕空間降噪器(Screen Space Denoiser)。
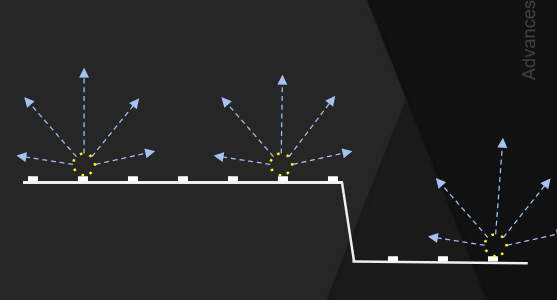
下取樣入射輻射,入射光是相干的,而幾何法線不是,以全解析度積分BRDF上的輸入照明:

在輻射快取空間中過濾,而不是螢幕空間(下圖左)。首先要進行更好的取樣——重要的是對入射光進行取樣(下圖中)。穩定的遠距離照明和世界空間輻射快取(下圖右)。
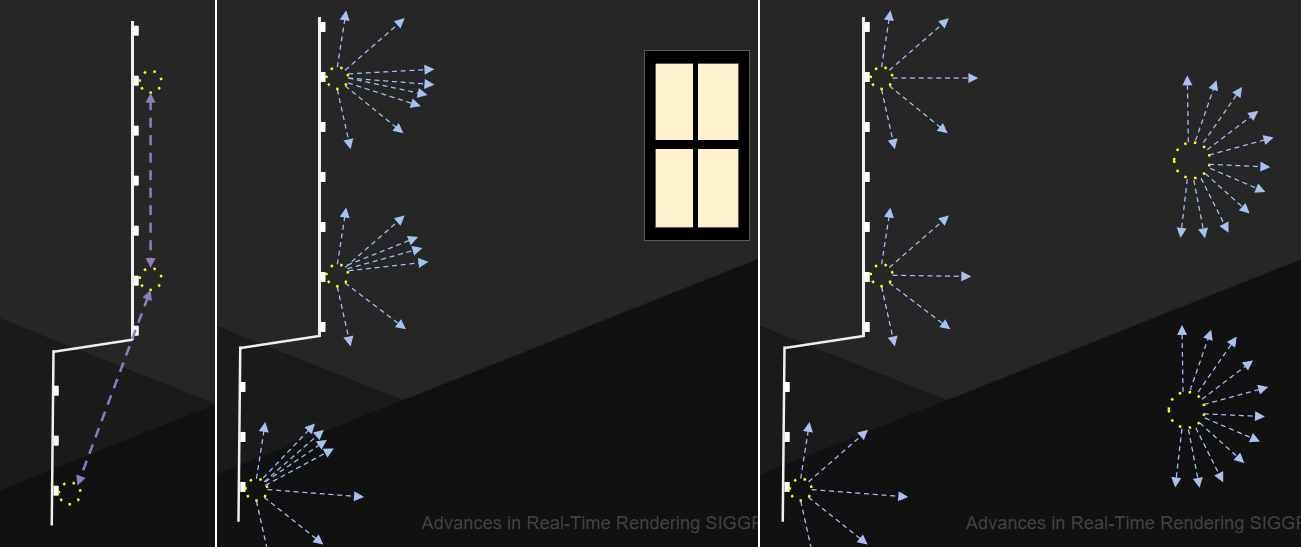
最終收集管線:
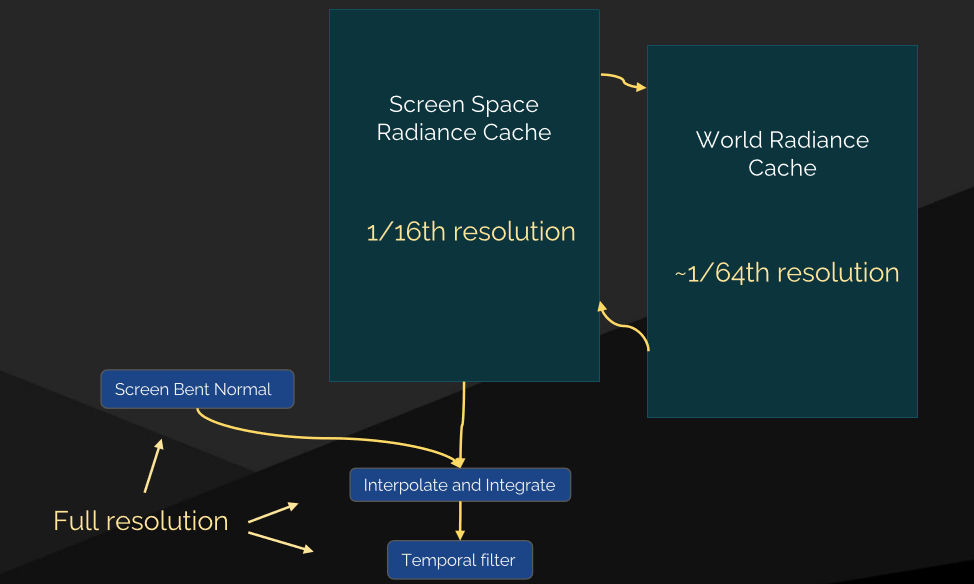
其中螢幕空間的輻照率快取可以細分成以下階段:
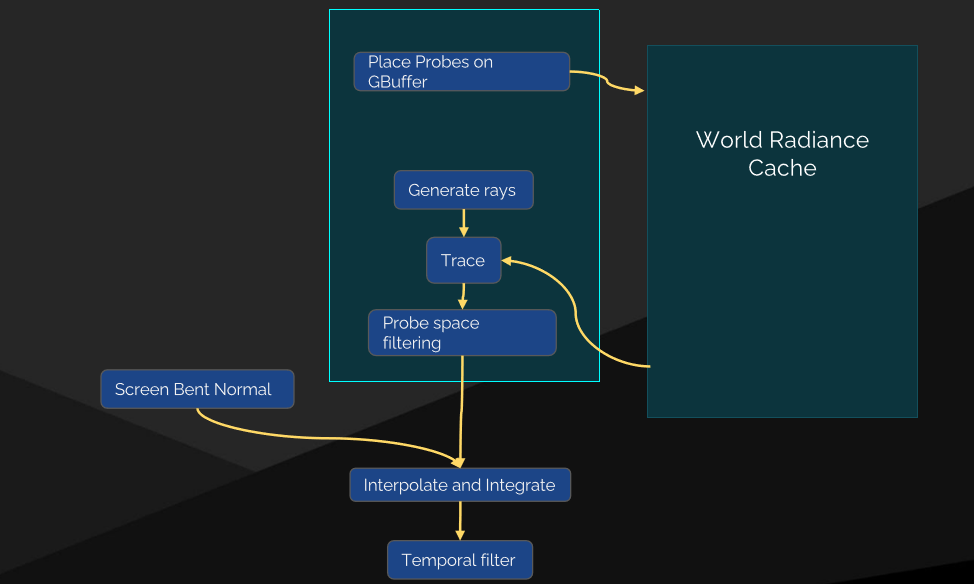
螢幕探針結構體:帶邊框的八面體圖集,通常每個探針8×8個,均勻分布的世界空間方向,鄰域有相同的方向,二維圖集中的輻射率和交點距離:

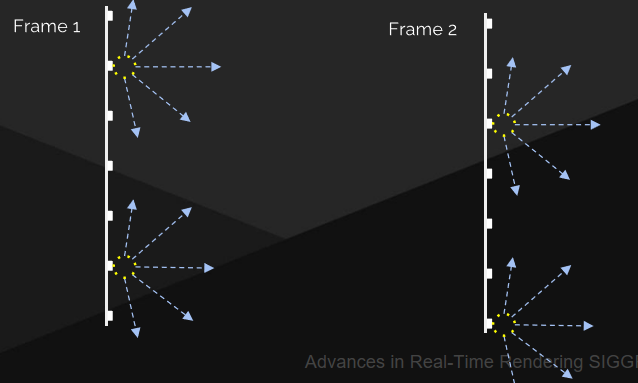
螢幕探針放置:分層細化的自適應布局[Křivánek等人2007],迭代插值失敗的地方,最終級別的地板填充(Flood fill)。

採用自適應取樣——實時性需要上限,不希望在處理自適應探針時遇到額外障礙,將自適應探針放在圖集底部:
螢幕探針抖動——時間抖動放置網格和方向,直接放置在像素上,沒有泄露,螢幕單元格內的遮擋差異必須通過時間過濾來隱藏:
面距離加權,防止前台未命中泄漏到後台,插值中的抖動偏移,只要還在同一個面上,在空間上分布探針之間的差異,通過擴展TAA 3×3的鄰域達到時間穩定最終照明。
還使用了重要性取樣——對於入射輻射率\(L_i(l)\),重投射最後一幀的螢幕探針的輻射率!不需要做昂貴的搜索,光線已按位置和方向索引,回退到世界空間探針上。對於BRDF,從將使用此螢幕探針的像素累積,更好的是,希望取樣與入射輻射率\(L_i(l)\)和BRDF的乘積成比例。
結構重要性取樣(Structured Importance Sampling)——將少量樣本分配給概率密度函數(PDF)的層次結構區域,實現良好的全局分層,樣本放置需要離線演算法。
完美地映射到八面體mip四叉樹!

集成到管線中——向追蹤執行緒添加間接路徑,存儲RayCoord、MipLevel,追蹤後,將TraceRadiance組合進均勻的探針布局,以進行最終集成:

光線生成演算法——計算每個八面體紋理的BRDF的PDF x 光照的PDF,從均勻分布的探針射線方向開始,需要固定的輸出光線計數——保持追蹤執行緒飽和。按PDF對光線進行排序,對於PDF低於剔除閾值的每3條光線,超級取樣以匹配高PDF光線。

改進的點是不允許光照PDF來剔除光線,光照PDF為近似值,BRDF為精確值,藉助空間過濾可以更積極地進行剔除,具有較高BRDF閾值的剔除,在空間過濾過程中減少剔除光線的權重,修復角落變暗的問題。

重要性取樣回顧:使用最後一幀的光照和遠距離光照引導此幀的光線,將射線捆綁到探針中可以提供更智慧的取樣。
接下來聊空間過濾的技術。
輻射快取空間中的過濾:廉價的大空間濾波,探針空間為32×32,螢幕空間為482×482,可以忽略空間鄰域之間的發現差異,僅深度加權。從鄰域收集輻射率——從相鄰探針中匹配的八面體單元收集,誤差權重——重投影的相鄰射線擊中的角度誤差,過濾遠處的燈光,保留局部陰影。
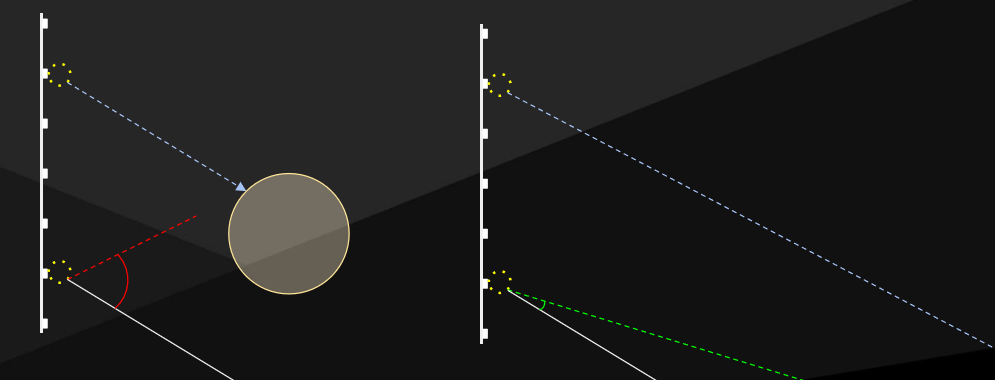
對於平坦表面的效果是良好的,但對於幾何接觸的地方,存在漏光的問題:

保持接觸陰影——角度誤差偏向遠光等於泄漏,遠距離光沒有視差,永遠不會被拒絕。解決方案是在重投影之前,將鄰域的命中距離截取到自己的距離。

接下來聊世界空間的輻射快取。
遠距離光存在問題,微亮特徵的噪點隨著距離的增加而增加,長而不連貫的追蹤是緩慢的,遠處的燈光正在緩慢變化——快取的機會,附近螢幕探針的冗餘操作,解決方案是對遠距離輻射進行單獨取樣。用於遠距離照明的世界空間輻射快取(The Tomorrow Children [McLaren 2015]的技術),自世界空間以來的穩定誤差——易於隱藏,就像體積光照圖一樣。
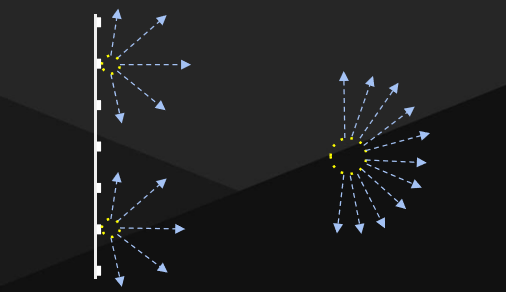
管線集成——在螢幕探針周圍放置,然後追蹤計算輻射,插值以解決螢幕探測光線的遠距離照明。
世界探針射線必須跳過插值足跡以避免自光照:
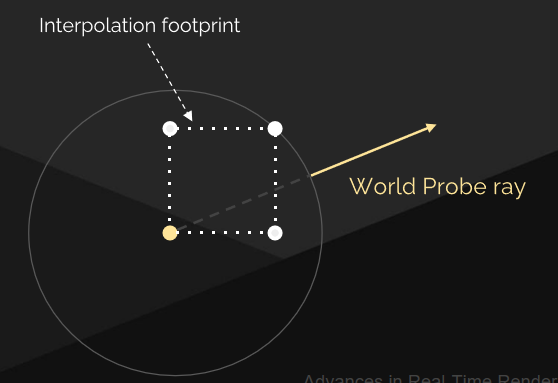
螢幕探針光線必須覆蓋插值足跡+跳過距離:
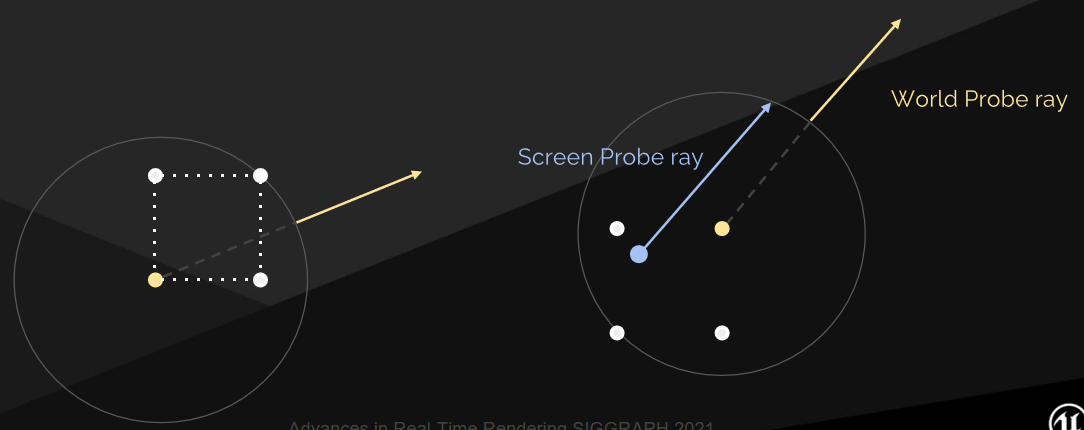
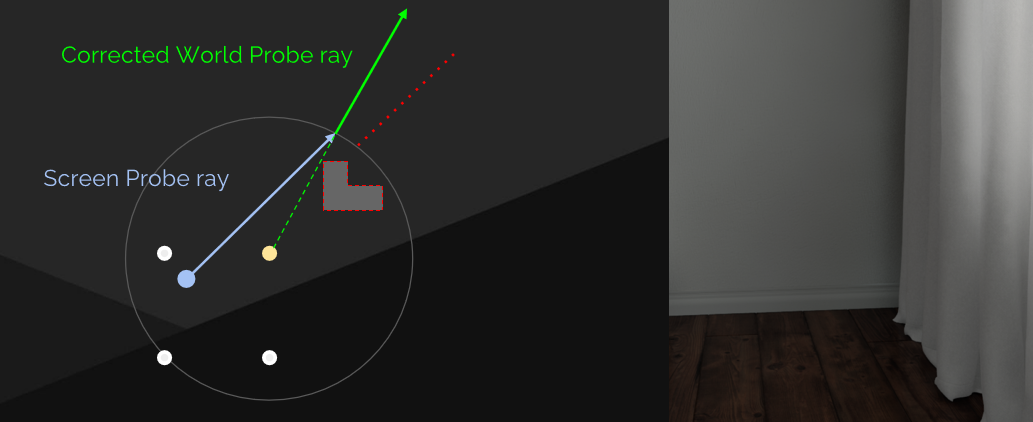
還存在漏光的問題,世界探針的輻射應該被遮擋,但不是因為視差不正確。
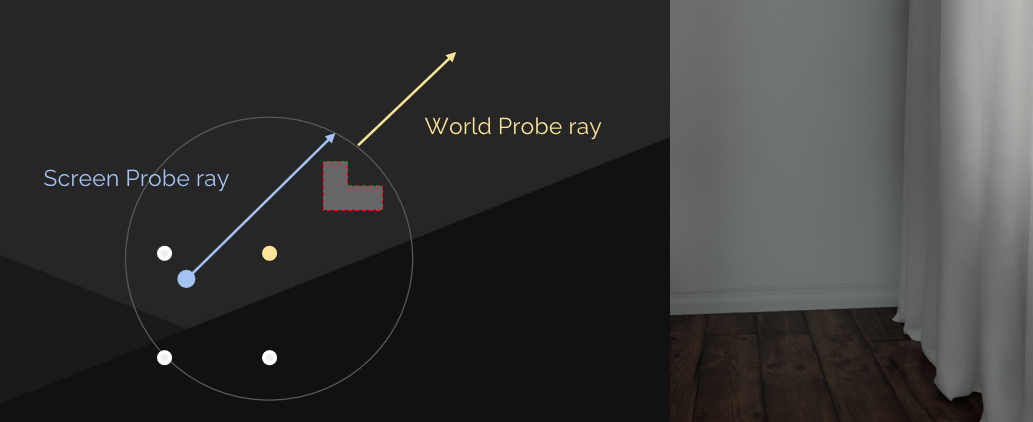
解決方案是簡單的球面視差,重投影螢幕探針光線與世界探針球相交。
稀疏覆蓋——以攝影機為中心的3d clipmap網格將探針索引存儲到圖集中,Clipmap分布保持有限的螢幕大小。

八面體探針圖集存儲輻射、追蹤距離,通常每個探針為32×32的輻射率:

放置和快取——標記將在後面的clipmap間接中插入的任何位置,對於每個標記的世界探針:重用上一幀的追蹤,或分配新的探針索引,重新追蹤快取命中的子集以傳播光照更改。
依然存在的問題是高度可變的成本,快速的攝像機移動和不連續需要追蹤許多未經快取的探針。解決方案是全解析度探針的固定預算,快取未命中的其它探針追蹤的解析度較低,跳過照明更新的其它探針追蹤。
BRDF的重要取樣的做法是從螢幕探針累積BRDF,切塊(Dice )探針追蹤分塊,根據BRDF生成追蹤分塊解析度。超取樣近的相機,高達64×64的有效解析度,4096條追蹤!非常穩定的遠距離照明。
探針之間的空間過濾——再次拒絕鄰域交點,問題是不能假設相互可見性。理想情況下,通過探測深度重新追蹤相鄰射線路徑,單次遮擋試驗效果良好,幾乎免費——重複使用探針深度。

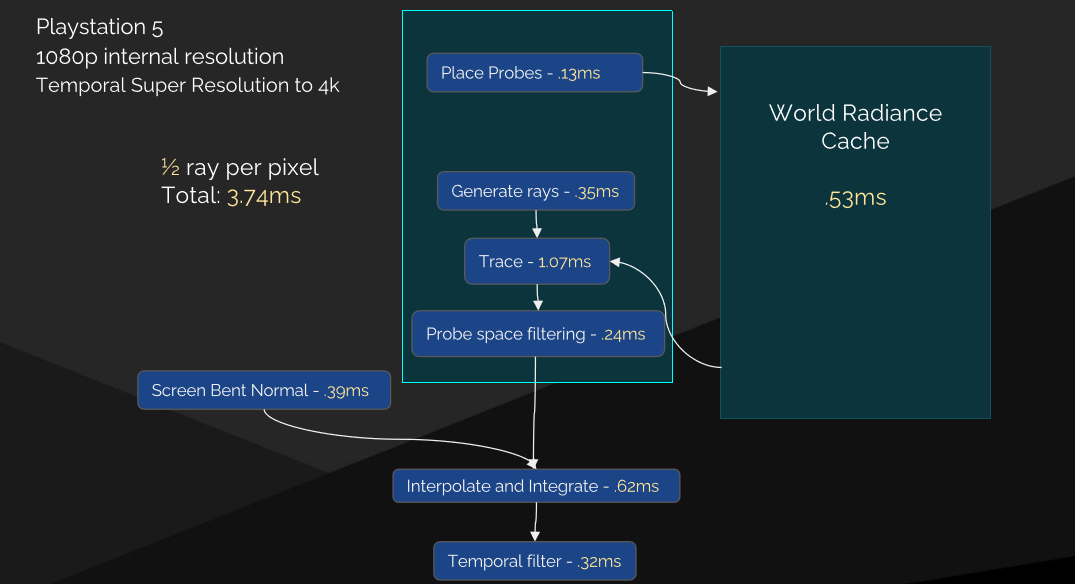
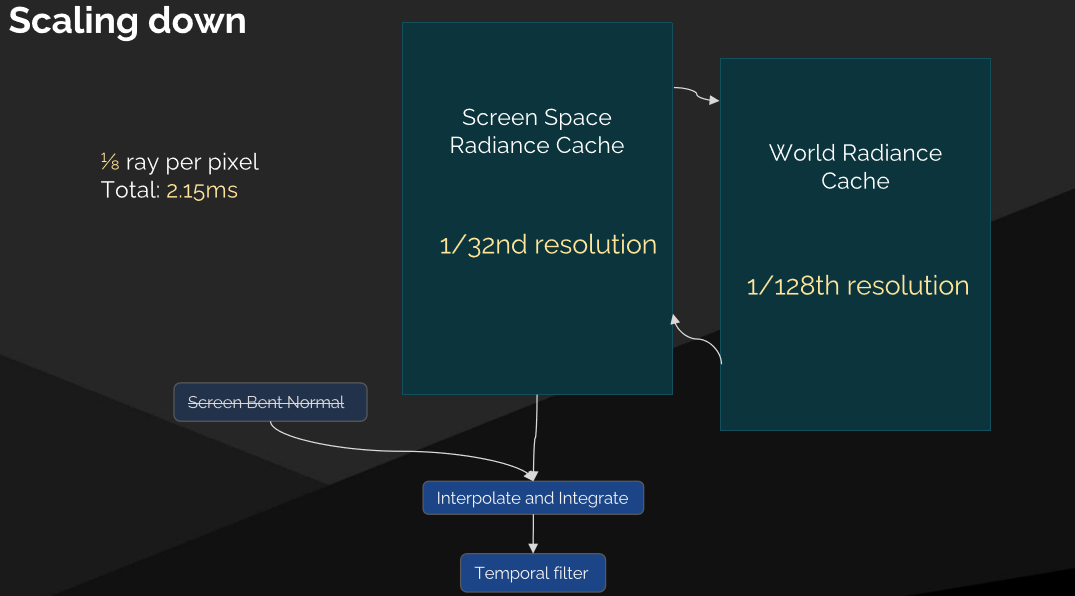
世界空間輻射快取還用於引導螢幕探針重要性取樣、頭髮、半透明、多反彈。
回到積分,現在已經在螢幕空間的輻射快取中以較低的解析度計算了入射輻射,需要以全解析度進行積分,以獲得所有的幾何細節。

重要性取樣BRDF會導致不一致的獲取,8spp*4相鄰探針方向查找,可以使用mips(過濾重要性取樣),但會導致自光照,尤其是在直接照明區域周圍。將探針輻射轉換為三階球諧函數:SH是按螢幕探針計算的,全解析度像素一致地載入SH,SH低成本高品質積分。

對於高粗糙度下的光線追蹤反射,在漫反射上聚集。重用螢幕探針——從GGX生成方向,取樣探針輻射,自動利用已完成的探針取樣和過濾!下取樣追蹤會丟失接觸陰影。使用全解析度彎曲法線——使用快速螢幕追蹤進行計算,與螢幕探針之間的距離耦合的追蹤距離,約16像素。與螢幕空間輻射快取積分——將螢幕探針GI視為遠場輻照度,全解析度彎曲法線表示場的數量,基於水的間接照明,多重反彈似給出場輻照度。

接著使用時間過濾——抖動探針位置需要可靠的時間過濾,使用深度剔除,結果穩定,但對光線變化的反應也很慢。追蹤過程中追蹤命中速度和命中深度,屬於快速移動對象的投影面積。當追蹤擊中快速移動的對象時,切換到快速更新模式,降低時間過濾,提高空間過濾。

最終收集性能:

未來的工作是降噪品質、高動態場景中的時間穩定性、將螢幕空間輻射快取應用於Lumen的表面快取以實現多反彈GI。
Radiance Cache只是Lumen的一小部分技術,Lumen還涉及表面快取、軟體射線追蹤、硬體光線追蹤、反射、透明GI等內容。關於Lumen的源碼剖析可參見:剖析虛幻渲染體系(06)- UE5特輯Part 2(Lumen和其它)。
17.3.11.2 Surfel GI
Surfel即表面元素(Surface Element),一個surfel由位置、半徑和法線定義,並近似了給定位置附近表面的一個小鄰域(下圖)。
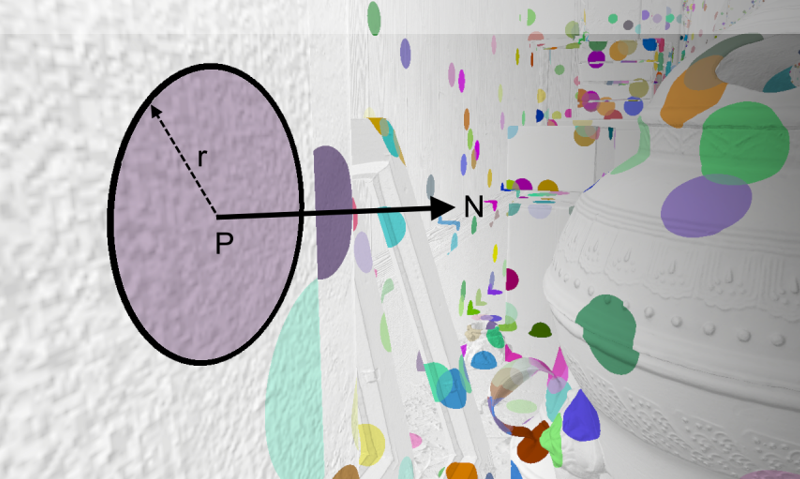
從GBuffer中生成面元,當幾何圖形進入視圖時填充螢幕,在世界空間中持久存在,累積和快取輻照度。迭代螢幕空間填充,將螢幕拆分為16×16塊,找到覆蓋率最低的tile,應用面元覆蓋率和追蹤權重,如果tile超過隨機閾值,則生成surfel。

除了支援剛體,還支援蒙皮骨骼的面元化。由於所有東西都假設是動態的,所以蒙皮幾何體和移動幾何體都與解決方案的其餘部分交互,就像靜態幾何體一樣。

面元根據螢幕空間投影進行縮放,生成演算法確保覆蓋範圍在任何距離,由非線性加速度結構支撐。

所有東西都有固定大小的緩衝區,可預測的預算,固定數量的面元,固定的加速度結構,回收未使用的面元。
讓相關的面元保持活躍,最後一次見到時追蹤,如果在間隙檢測期間看到,則重置,位置更新期間增加。啟發式基於激活的面元總數、自從見過的時間、距離、覆蓋率。下圖是距離啟發式:
為了應用光照,對每個像素:查找表面網格單元,從單元格里取N個面元,累積表面輻照度,按距離和法線加權,如果輻照度權重<1,則添加加權的平均單元格的輻照度。存在光照溢出的問題,使用徑向高斯深度來解決:

修復前後對比:

積分輻照度圖示:
修正指數移動平均估值器[BarréBrisebois2019],追蹤短期均值和方差估計值,使用短期估計器調整混合因子,能夠快速響應變化,同時收斂到低噪點。基於短期方差的偏差光線計數,使用射線計數通知相對置信度的多尺度均值估計器,回饋迴路對變化和變化做出快速反應,在穩定的情況下保持光線計數小。
累積漫反射輻照度,假設是蘭伯特BRDF,通過對餘弦葉進行重要取樣來生成光線:
採用了光線引導:
每個surfel在其半球上生成一個移動平均6×6亮度圖,存儲在單個4K紋理中(可支援所有surfel的7×7),每個紋理8位+每個紋理單個16位縮放,規範化每幀函數。
有了重要性取樣變數,函數的每個離散部分都將根據其值按比例選取,還有它的概率密度函數,也就是函數在那個位置的值。
利用附近的面元數據,允許surfel查找相鄰surfel的輻射,結構化加速,使用與surfel VPL相同的權重、Mahalanobis距離、深度函數。
輻照度共享前後對比:

還可以使用BF5方法對光線進行排序,按位置和方向排列的箱射線,12位表示空間,4位表示方向,空間散列的單元定位,射線方向定向,計算箱子總計數和偏移量,根據光線索引和以前計算的面元偏移對光線重新排序。
多光源取樣使用了重要性取樣(隨機光源分割、儲備取樣)。隨機光源切割是小樣本快速收斂,需要預先構建的數據結構,取樣可能開銷很大。
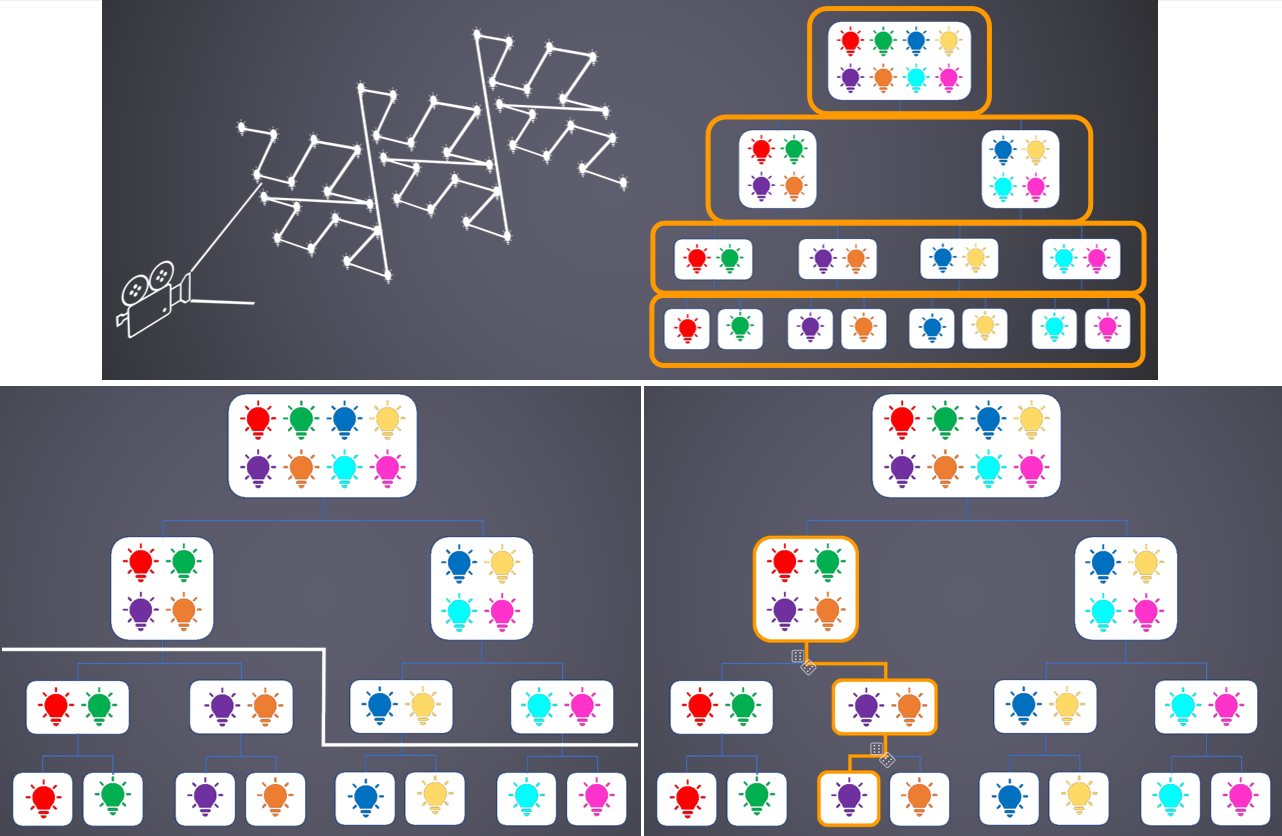
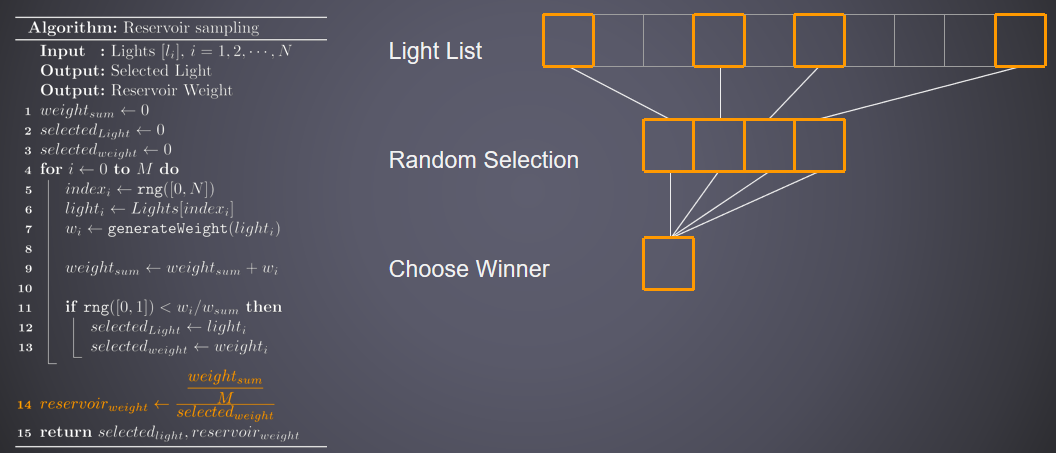
蓄水池取樣(Reservoir Sampling)示意圖:
光線追蹤探針示意圖:
透明對象需要大螢幕支援,例如不透明對象,Clipmap是滿足需求的最佳選擇:保持近距離的細節,支援大規模場景,具有低記憶體成本的稀疏探針放置,LOD的變速率更新。
計算更新方向和距離,複製移位後有效的探針數據,用更高級別的探針初始化新創建的探針。
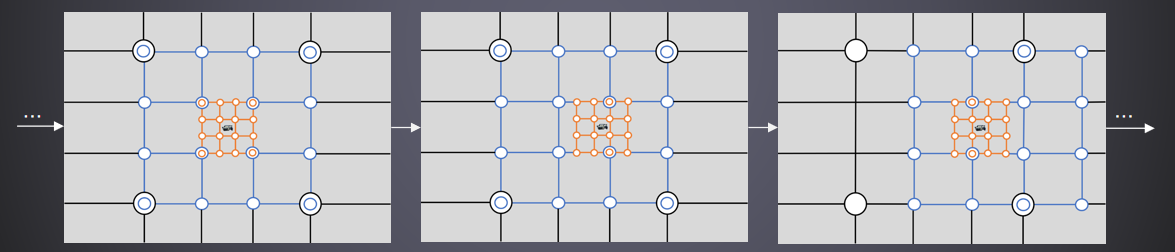
4級clipmap的放置示意圖:

Clipmap取樣過程如下:
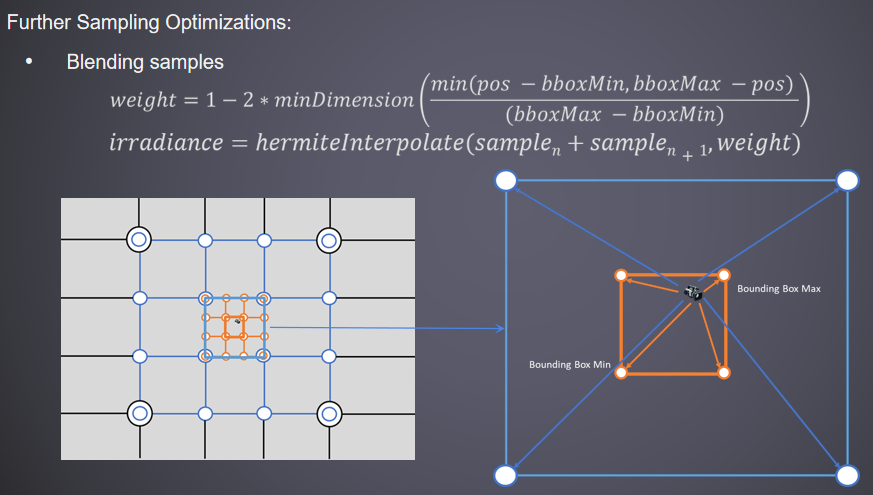
進一步的取樣優化是使用藍色雜訊梯度抖動取樣。

一幀概覽:
- 持續的。位置更新,回收利用,網格分配,射線排序,光線追蹤,Clipmap更新,探針追蹤。
- 創建。幾何法線重建,空隙填充,射線排序,光線追蹤,寫入持久存儲,寫入探針體積。
- 過濾。空間降噪,時間降噪。
- 應用。注入新的創建,應用照明(以四分之一區域解析度運行),照明上取樣,Clipmap取樣。
17.3.11.3 收集與合成
過濾通常被認為是取平均值的過程,用於產生模糊像素的相鄰像素的加權平均值,我們稱這種方法為聚集(也稱收集,Gathering),許多像素被聚集在一起以產生一個輸出。Northlight Engine在幾何體交點上取樣照明,最終的光線追蹤各分量和組合效果如下:


總之,通過DXR輕鬆訪問最先進的GPU光線追蹤,性能正在達到目標,易於不適合光柵化的原型化演算法,可與現有低頻結構相結合。

Claybook在光線追蹤的各項時間消耗如下表:

SDF到網格的轉換使用雙通道近似,多個三角形指向同一個粒子,首先需要生成粒子。輸出用於PBD模擬器的線性粒子數組(表面)和三角形渲染的索引緩衝區。使用單個間接繪製調用繪製的所有網格。轉成粒子使用64x64x64的dispatch、4x4x4的執行緒組,過程如下:
- 分組:將\(6^3\)個SDF鄰域載入到GSM。
- 讀取\(2^3\)個GSM的鄰域,如果在邊緣內/外找到:
- 將P移動到表面(梯度下降)。
- 分配粒子id(L+G原子)。
- 將P寫入數組[id]。
- 將粒子id寫入643643網格。
轉成三角形使用64x64x64的dispatch、4x4x4的執行緒組,過程如下:
- 分組:將\(63^3\)個SDF鄰域載入到GSM。
- 讀取\(2^3\)GSM的鄰域,如果找到XYZ邊緣:
- 每個XYZ邊分配2倍三角形(L+G原子)。
- 從643643的id網格讀取3倍的粒子id。
- 將三角形寫入索引緩衝區(3倍的粒子id)。
非同步計算:
- 將幀拆分為3個非同步段。
- 重疊UE4的GBuffer和陰影級聯。
- 重疊UE4的速度渲染和深度解壓縮。
- 重疊UE4的照明和後處理。
- 工作立即提交。
- 計算隊列等待柵欄啟動(x3)。
- 主隊列等待柵欄繼續(x3)。
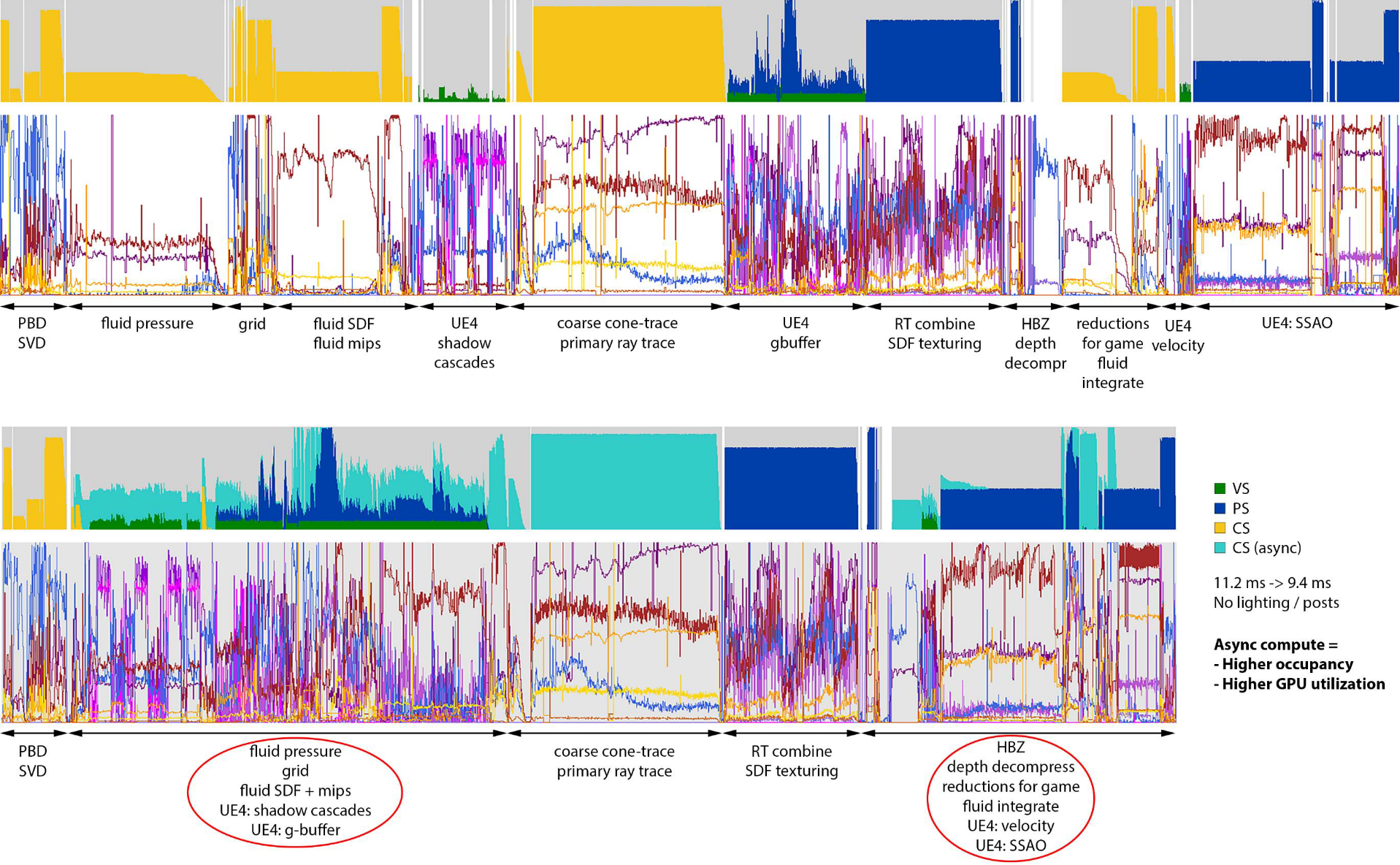
非同步計算可以讓fps提升19%+。
集成到UE4渲染器:
- GBuffer組合。
- 全螢幕PS組合光線追蹤數據。
- 取樣材質貼圖(自定義gather4過濾)。
- 寫入UE4的GBuffer+深度緩衝區(SV_Depth)。
- 陰影遮蔽(shadow mask)組合。
- 全螢幕PS到球體追蹤陰影。
- 寫入UE4陰影遮罩緩衝區(使用alpha混合)。
UE4 RHI訂製:
- 在不進行隱式同步的情況下設置渲染目標。
- 可以對重疊深度/顏色進行解壓縮。
- 可以將繪製重疊到多個RT(下圖)。
- 清除RT/buffer而不進行隱式同步。
- 缺少非同步計算功能。
- 緩衝區/紋理複製並清除。
- 計算著色器索引緩衝區寫入。

此外,Claybook額外訂製了UE4 RHI,使用GPU->CPU緩衝區回讀,UE4僅支援2d紋理回讀而不停頓,其它readback API會讓整個GPU陷入停頓,緩衝區可以有原始視圖和類型化視圖,寬原始寫入等於高效填充窄類型緩衝區。
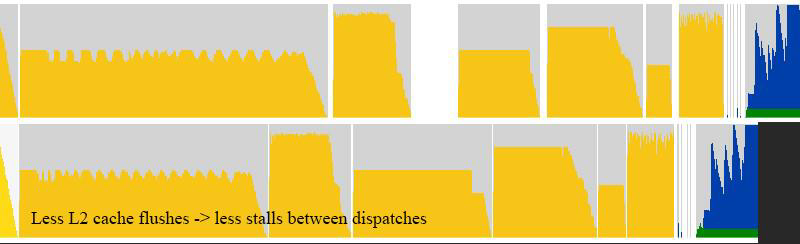
其它的UE4優化:允許間接分派/提取的重疊,允許清除和複製操作重疊,允許不同RT的繪製重疊,減少GPU快取刷新和停頓(下圖),優化的暫存緩衝區,快速清晰的改進。優化屏障和柵欄,優化紋理數組子資源屏障,更好的3d紋理GPU分塊模式,改進的部分2d/3d紋理更新,5倍更快的直方圖+眼睛適應著色器,4倍更快的離線CPU SDF生成器(烘焙)。
物理數據存儲在一個大的原始緩衝區中,寬載入4/Store4指令(16位元組),位壓縮:粒子位置:16位範數、粒子速度:fp16、粒子標誌(活動、碰撞等)的位欄位,基準工具://github.com/sebbbi/perftest。
Groupshared記憶體是一個巨大的性能利器,SDF生成、網格生成、物理,重複載入相同數據時使用。標量載入是AMD在性能上的一大勝利,用例:常量索引原始緩衝區載入,用例:基於SV_GroupID的原始緩衝區載入,存儲到SGPR的負載獲得更好的佔用率。
17.3.11.4 光子映射
光子映射綜合來看,分為兩個Pass:
-
Pass 1:光子追蹤。粗略的GI解決方案。
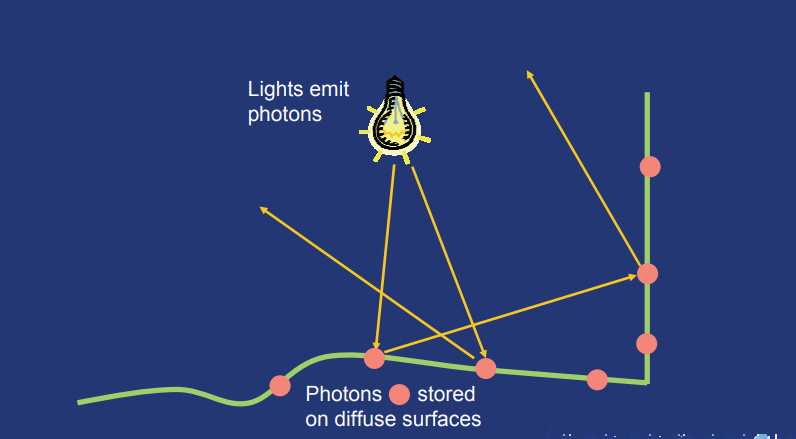
-
Pass 2:光線追蹤。影像渲染。


光子追蹤過程的目的是計算漫反射表面上的間接照明,是通過從光源發射光子、在場景中追蹤光子並將其存儲在漫反射表面來實現的。
從光源發射的光子應具有對應於光源發射功率分布的分布,以確保發射的光子攜帶相同的通量,即我們不會在低功率光子上浪費計算資源。
來自漫射點光源的光子從該點以均勻分布的隨機方向發射。來自平行光的光子都沿同一方向發射,但來自場景外部的原點。來自漫反射正方形光源的光子從正方形上的隨機位置發射,方向限於半球。發射方向從餘弦分布中選擇:在平行於正方形平面的方向上發射光子的概率為零,在垂直於正方形的方向上的發射概率最高。
通常,光源可以具有任何形狀和發射特性——發射光的強度隨原點和方向而變化。例如,燈泡具有非平凡的形狀,從其發出的光的強度隨位置和方向而變化。光子發射應遵循此變化,因此通常,發射概率根據光源表面上的位置和方向而變化。下圖顯示了這些不同類型光源的發射:
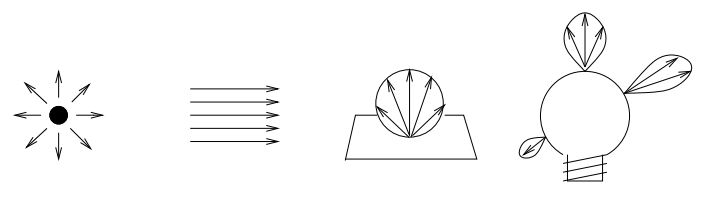
光源發光:點光源、定向光源、方形光源、普通光源。
光源的功率必須分布在從光源發射的光子之間。如果光源的功率為\(P_{light}\)且發射光子的數量為\(n_e\),則每個發射光子的功率是:
\]
下面給出了漫射點光源光子發射的簡單示例的偽程式碼:

為了進一步減少計算的間接照明(在渲染期間)的變化,希望儘可能均勻地發射光子。例如,可以使用分層或者低差異准隨機取樣。
在具有稀疏幾何體的場景中,許多發射的光子不會擊中任何對象,發射這些光子將浪費很大時間。為了優化發射,可以使用投影圖(Projection map)。投影圖只是從光源看到的幾何圖形的圖,由許多小單元格(cell)組成。如果在該方向上有幾何圖形,則單元格為「開」,如果沒有,則為「關」。例如,投影貼圖是點光源的場景的球形投影,是平行光的場景的平面投影。為了簡化投影,可以方便地圍繞每個對象或對象簇投影邊界球體。此舉也大大加快了投影圖的計算,因為不必檢查場景中的每個幾何元素。投影圖最重要的方面是,它給出了從光源發射光子所需方向的保守估計。如果估計不是保守的(例如,可以先用幾個光子對場景進行取樣),可能會丟失重要的效果,例如焦散。
使用投影圖發射光子非常簡單。可以在包含對象的單元格上循環,並向單元格所表示的方向發射隨機光子。然而,這種方法可能會導致稍微有偏差的結果,因為光子圖可能在訪問所有單元格之前「已滿」。另一種方法是生成隨機方向,並檢查對應於該方向的單元是否有任何對象(如果沒有,則應嘗試新的隨機方向)。這種方法通常效果良好,但在稀疏場景中可能代價高昂。對於稀疏場景,最好為具有對象的單元隨機生成光子。一種簡單的方法是選擇具有對象的隨機單元,然後為該單元的發射光子選擇隨機方向。在所有情況下,都必須根據投影圖中的活動單元格數量和發射的光子數量來縮放存儲光子的能量。因此需要修改光子能力的公式:
\]
投影圖的另一個重要優化是識別具有鏡面反射特性的對象(即可以生成焦散的對象)。如後所述,焦散是單獨生成的,由於鏡面反射對象通常稀疏分布,因此使用焦散投影圖非常有益。
場景中的光子路徑:(a)兩次漫反射後被吸收;(b)鏡面反射後轉為兩次漫反射;(c)兩次鏡面透射後被吸收。
光子發射後,將使用光子追蹤在場景中進行追蹤(也稱為「光線追蹤」、「反向光線追蹤」、「正向光線追蹤」和「反向路徑追蹤」)。光子追蹤的工作方式與光線追蹤完全相同,只是光子傳播通量,而光線收集輻射。這是一個重要的區別,因為光子與材質的相互作用可能不同於射線的相互作用。一個值得注意的例子是折射,其中根據相對摺射率改變輻射亮度的情況不會發生在光子上。
當光子擊中物體時,它可以被反射、透射或吸收——根據表面的材質參數概率而定。用於確定交互類型的技術稱為俄羅斯輪盤賭——擲骰子,決定光子是否應該存活並被允許執行另一個光子追蹤步驟。
光子僅存儲在它們撞擊漫反射表面(或更準確地說,非特殊表面)的位置。原因是,在鏡面反射表面上存儲光子不會提供任何有用的資訊:從鏡面反射方向具有匹配入射光子的概率為零,因此,如果我們想要渲染精確的鏡面反射,最好的方法是使用標準光線追蹤沿鏡面方向追蹤光線。對於所有其他光子-表面相互作用,數據存儲在全局數據結構(光子圖)中。注意,每個發射的光子可以沿其路徑存儲多次。此外,有關光子的資訊存儲在其被吸收的表面(如果該表面是漫反射的)。
對於每個光子-表面相互作用,存儲位置、入射光子功率和入射方向(實際還會為每個光子數據集保留了一個標記空間,該標記在光子圖中的排序和查找過程中使用)。
struct Photon
{
float x,y,z; // position
char p[4]; // power packed as 4 chars
char phi, theta; // compressed incident direction
short flag; // flag used in kdtree
};
再次考慮上圖中的簡單場景,(a)顯示了該場景的傳統光線追蹤影像(直接照明和鏡面反射和透射),(b)顯示了為該場景生成的光子圖中的光子,玻璃球下光子的高濃度是由玻璃球聚焦光子引起的。
數據存儲還可以擴展到參與介質,以及多重散射、各向異性散射和非均勻介質。
光子僅在光子追蹤過程中生成,在渲染過程中,光子圖是一種靜態數據結構,用於計算場景中許多點處的入射通量和反射輻射的估計。為此,需要在光子圖中定位最近的光子。這是一個非常頻繁的操作,因此需要在渲染過程之前優化光子圖,以便儘可能快地找到最近的光子。
首先,我們需要選擇一個好的數據結構來表示光子圖。數據結構應緊湊,同時允許快速最近鄰搜索。它還應該能夠處理高度不均勻的分布——在焦散光子貼圖中非常常見。處理這些需求的自然候選者是平衡kd樹。用於平衡光子圖的偽程式碼:

光子映射方法的一個基本組成部分是計算任何給定方向上任何非鏡面反射表面點處的輻射估計的能力。光子輻射亮度估算可由經典的BRDF推導而成:
L_{r}(x, \vec{\omega})=\int_{\Omega_{x}} f_{r}\left(x, \vec{\omega}^{\prime}, \vec{\omega}\right) L_{i}\left(x, \vec{\omega}^{\prime}\right)\left|\vec{n}_{x} \cdot \vec{\omega}^{\prime}\right| d \omega_{i}^{\prime}, \\
L_{i}\left(x, \vec{\omega}^{\prime}\right)=\cfrac{d^{2} \Phi_{i}\left(x, \vec{\omega}^{\prime}\right)}{\cos \theta_{i} d \omega_{i}^{\prime} d A_{i}}, \\
L_{r}(x, \vec{\omega})=\int_{\Omega_{x}} f_{r}\left(x, \vec{\omega}^{\prime}, \vec{\omega}\right) \cfrac{d^{2} \Phi_{i}\left(x, \vec{\omega}^{\prime}\right)}{\cos \theta_{i} d \omega_{i}^{\prime} d A_{i}}\left|\vec{n}_{x} \cdot \vec{\omega}^{\prime}\right| d \omega_{i}^{\prime} \\
=\int_{\Omega_{x}} f_{r}\left(x, \vec{\omega}^{\prime}, \vec{\omega}\right) \cfrac{d^{2} \Phi_{i}\left(x, \vec{\omega}^{\prime}\right)}{d A_{i}} . \\
L_{r}(x, \vec{\omega}) \approx \sum_{p=1}^{n} f_{r}\left(x, \vec{\omega}_{p}, \vec{\omega}\right) \cfrac{\Delta \Phi_{p}\left(x, \vec{\omega}_{p}\right)}{\Delta A} .
\end{array}
\]
這個過程可以想像為圍繞\(x\)展開一個球體,直到它包含\(n\)個光子(見下圖),然後使用這\(n\)個光子來估計輻射亮度。
使用光子圖中最近的光子估計輻射亮度。
上圖使用了球體,通過假設曲面在\(x\)周圍局部平坦,我們可以通過將球體投影到曲面上並使用所得圓的面積來計算該面積(即上圖中的陰影區域),等於:
\]
其中\(r\)是球體的半徑,即\(x\)和每個光子之間的最大距離。使用光子圖計算表面處反射輻射的公式變成了以下等式:
\]
該估計基於許多假設,精度取決於光子圖和公式中使用的光子數。由於球體用於定位光子,因此很容易在估計中包括錯誤的光子,特別是在物體的角和銳邊。邊和角也會導致面積估計錯誤。發生這些誤差的區域的大小在很大程度上取決於光子圖和估計中的光子數量。隨著估算和光子圖中使用更多光子,公式變得更精確。如果我們忽略由於位置、方向和通量表示的有限精度而導致的誤差,那麼我們可以達到極限並將光子數量增加到無窮大。將給出了以下有趣的結果,其中\(N\)是光子圖中的光子數:
\]
該公式適用於位於表面局部平坦部分上的所有點\(x\),其中BRDF不包含狄拉克\(δ\)函數(不包括完美鏡面反射)。上面等式中的原理是,不僅將使用無限量的光子來表示模型內的通量,而且還將使用無限數量的光子來估計輻射,並且估計中的光子將位於無窮小的球體內。不同的無限度由項\(N_α\)控制,其中\(α∈]0,1[\),確保了估計中的光子數量將無限小於光子圖中的光子數。
上述公式意味著我們可以通過使用足夠的光子獲得任意好的輻射估計!在基於有限元的方法中,獲得任意精度更為複雜,因為誤差取決於網格的解析度、輻射的方向表示的解析度和光模擬的精度。
上圖顯示了定位最近的光子如何類似於圍繞x展開球體並使用該球體內的光子。在此過程中,可以使用球體以外的其他體積。人們可以使用立方體,圓柱體或圓盤。這可能有助於獲得定位最近光子更快的演算法,或者在選擇光子時可能更準確。如果使用不同的體積,則∆等式中的A應替換為體積與在x處接觸表面的切面之間的交點面積。
球體具有明顯的優點,即投影面積和距離計算非常簡單,因此計算效率高。通過將球體沿x處表面法線方向壓縮(如下圖所示),將球體修改為圓盤(橢球體),可以獲得更精確的體積。使用圓盤的優點是,在邊緣和拐角處的估計中使用更少的「假光子」。例如,在房間的邊緣效果非常好,因為可以防止牆壁上的光子泄漏到地板上。然而,仍然存在的一個問題是,面積估計可能是錯誤的,或者光子可能泄漏到它們不屬於的區域。這個問題主要通過使用過濾來解決。

使用球體(左)和圓盤(右)來定位光子。
如果光子圖中的光子數太低,則輻射亮度估計在邊緣處變得模糊。當光子圖用於估計分布射線追蹤器的間接照明時,這種偽影可能令人滿意,但在輻射估計表示焦散的情況下,這種偽影是不需要的。焦散通常具有銳利的邊緣,在不需要太多光子的情況下保留這些邊緣會很好。
為了減少邊緣的模糊量,對輻射估計進行濾波。濾波背後的思想是增加接近感興趣點x的光子的權重。由於我們使用球體來定位光子,因此自然會假設濾波器應該是三維的。然而,光子存儲在二維表面上。面積估計也基於光子位於表面的假設。因此,我們需要在光子定義的區域上歸一化的2d濾波器(類似於影像過濾器)。
過濾焦散可以使用兩個徑向對稱過濾器:錐形過濾器、高斯過濾器及專用微分過濾器(differential filter)。前面兩個過濾器是老調重彈了,下面重點說說微分過濾器。
基於微分檢查的過濾器的思想是在估計過程中檢測邊緣附近的區域,並在這些區域中使用更少的光子。這樣,我們可能會在估計中得到一些雜訊,但通常比模糊邊緣更好。基於以下觀察修改輻射估計:在邊緣附近向估計添加光子時,估計的變化將是單調的。也就是說,如果我們剛好在焦散線之外,並且我們開始將光子添加到估計中(通過增加包含光子的以x為中心的球體的大小),那麼可以觀察到,隨著我們添加更多光子,估計值正在增加;反之亦然,當我們在焦散中時。基於此觀察,可以將微分檢查添加到估計中-如果我們觀察到隨著更多光子的添加,估計值不斷增加或減少,則停止添加光子並使用可用的估計值。
定位最近的光子需要一種高效的演算法,下面是其中一種的偽程式碼:

對於該搜索演算法,需要提供初始最大搜索半徑。選擇好的半徑可以很好地減少搜索,減少測試的光子數量。另一方面,太小的最大半徑將在光子圖估計中引入噪點。可以基於誤差度量或場景的大小來選擇半徑,誤差度量例如可以考慮所存儲光子的平均能量,並根據該平均能量計算最大半徑,假設輻射估計中存在一些允許誤差。
可以添加一些額外的優化,例如,將最大堆的構建延遲到找到所需光子數的時間,在所請求的光子數量較大時特別有用。也可以初始最大搜索半徑被設置為非常低的值,如果該值太低,則使用更高的最大半徑執行另一次搜索。搜索常式的另一個更改是使用前面描述的磁碟檢查,有助於避免不正確的顏色溢出,並且在不使用收集步驟且光子直接可視化的情況下特別有用。
接下來就是渲染部分了。
使用分布光線追蹤來渲染最終影像,其中通過對多個樣本估計求平均來計算像素輻射亮度,每個樣本包括從眼睛通過一個像素追蹤光線進入場景。可將照光拆分為直接光、鏡面和光澤反射、焦散、多重漫反射以及參與介質等部分。它們和傳統的PBR比較類似,本文就忽略研討之。

光子映射的效果圖。
Unbiased Photon Gathering for Light Transport Simulation提出了一種新的光子收集方法,以有效地實現光子映射的無偏倚渲染。不像經典光子映射那樣將收集的光子收集到估計的密度中,而是單獨處理每個光子,並將相應的光子路徑與生成聚集點的眼睛子路徑連接,從而創建無偏路徑樣本。通過以嚴格和無偏的方式評估所有相關項來計算此類路徑樣本的蒙特卡洛估計,從而形成一種獨立的無偏取樣技術。該文進一步開發了一組多重要性取樣(MIS)權重,允許文中方法與雙向路徑追蹤(BDPT)進行最佳組合,從而產生一種無偏渲染演算法,該演算法可以有效地處理各種光路,並與以前的演算法相比較。實驗證明了該方法的有效性和魯棒性。

隨機漸進光子映射(SPPM)、統一路徑取樣/頂點連接和合併(UPS/VCM)和該文的無偏光子採集與雙向路徑追蹤(UPG+BDPT)在渲染1小時後的比較。SPPM利用偏置光子映射來產生低方差結果,代價是過度模糊銳利特徵。UPS/VCM從BDPT中獲得額外的好處,但頂點合併部分仍有偏差。文中的方法既無偏又穩健,產生了與參考最相似的結果。請注意,左插圖設置為曝光1=64,以使HDR陰影細節可見。
17.3.11.5 綜合實現
當前階段,光柵化仍然比光線追蹤「快」,而光線追蹤可以比光柵化更好地處理某些效果,如反射、軟陰影、全局照明等。目前通常採用混合射線追蹤,例如僅反射使用光線追蹤而光柵化其他所有內容(包括主光線)。主流的GPU已基本支援光柵化、計算、光線追蹤甚至深度學習等管線混合計算:

確定遊戲開發人員在集成到現有遊戲引擎基礎設施時必須解決的問題,因為遊戲引擎是為GPU設計和優化的,包含藝術資源和材質著色器。
傳統的渲染管線如下圖上所示,其中藍色部分和間接光無關,可以忽略。下圖下的紅色是和間接光相關的階段。
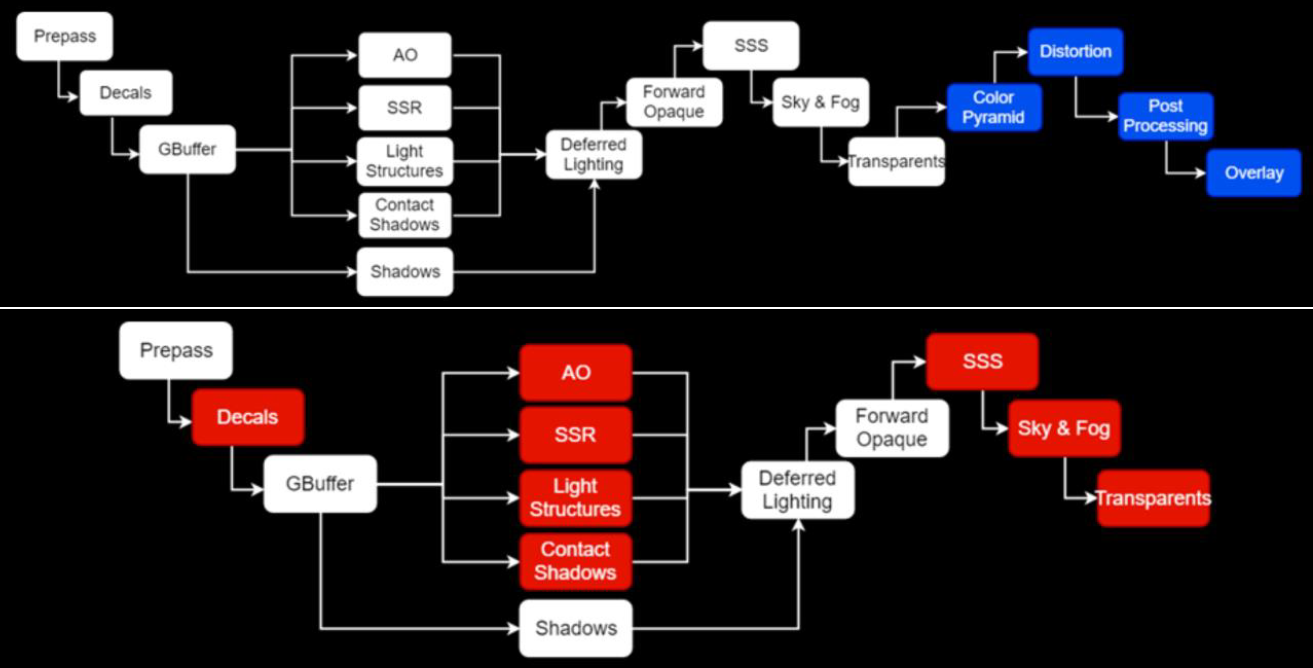
對於下圖的黃色步驟,解決方案是多次反彈或近似。接下來要看的是透明度,它似乎是光線追蹤的一個很好的候選者,對嗎?
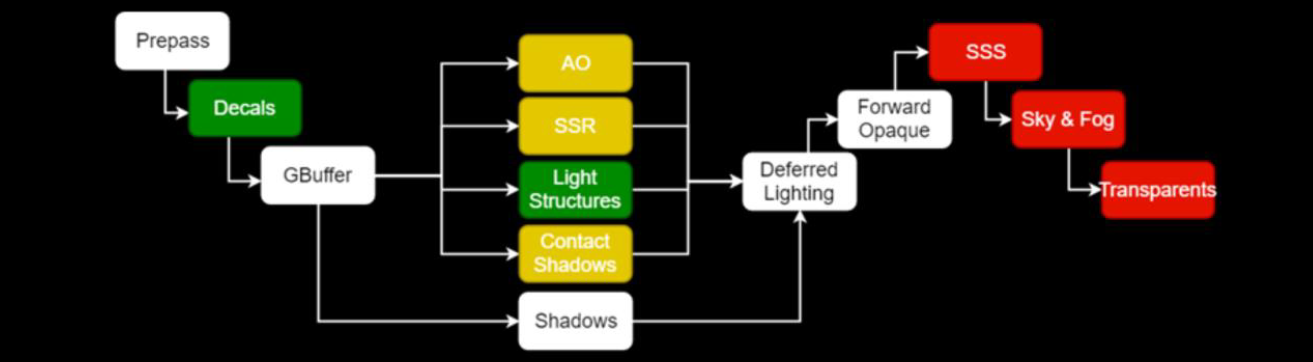
事實證明,螢幕空間照明問題同樣適用於透明材質(多維性、性能、過濾)。當前已經在探索SSS的體積解決方案,但沒有正確的SSS體積解決方案。混合渲染管線的流程如下:
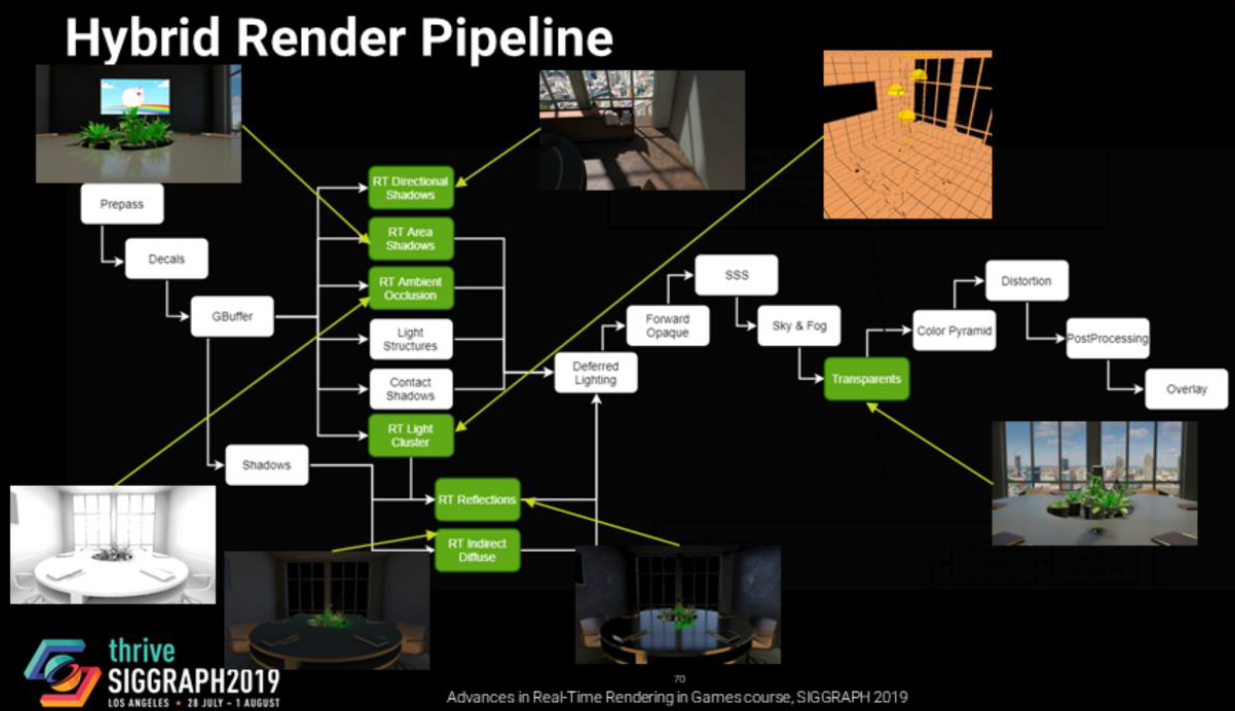
對於非直接光照,分裂和近似Karis 2013有助於減少方差,藍色是預先計算的,使用光柵化或光線追蹤進行評估。

在RTX的渲染流程如下:
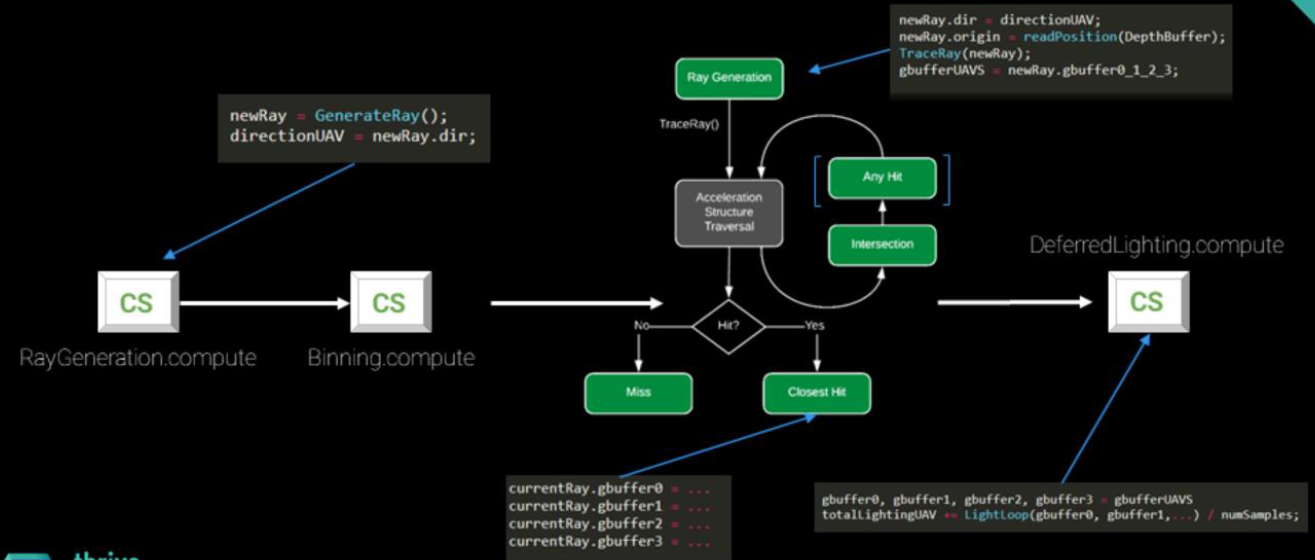
隨機化的區域光渲染流程如下:
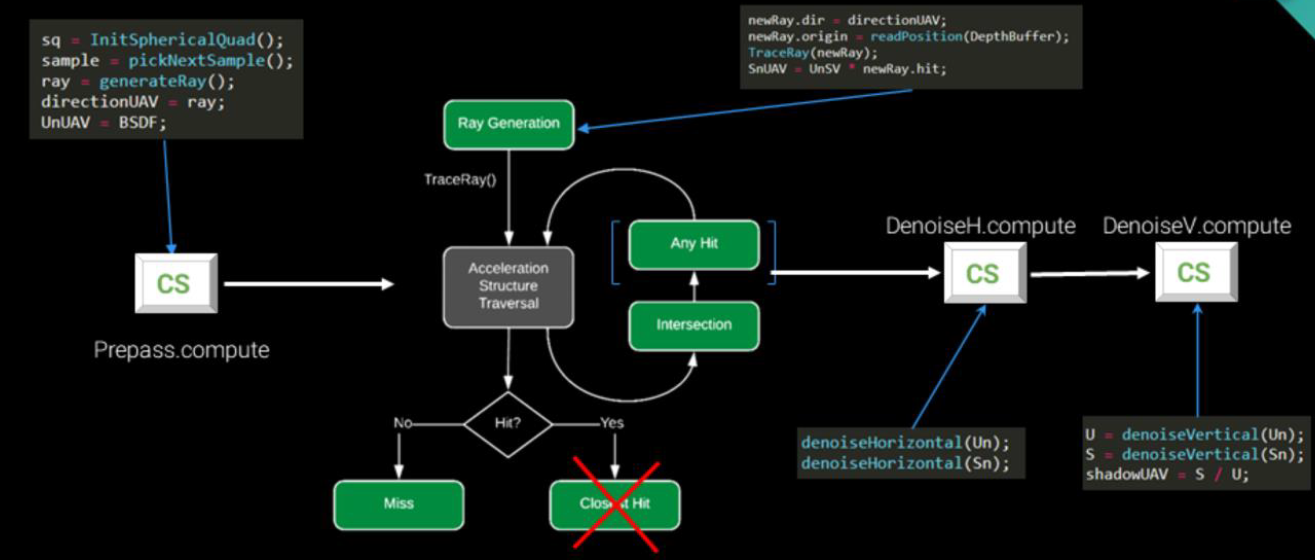
Battlefield V的光線追蹤包含了GPU光線追蹤管線、DXR的引擎集成、GPU性能等。

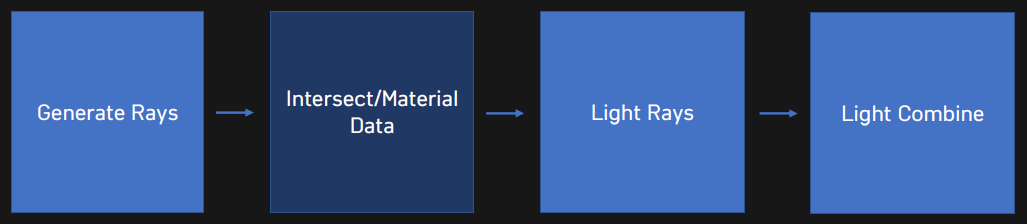
簡單光線追蹤管線:
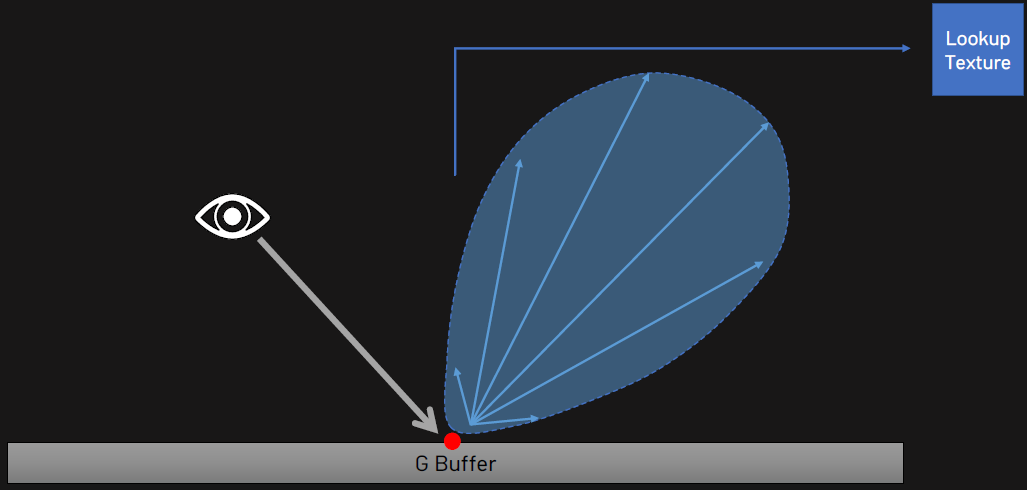
生成管線階段,讀取GBuffer的紋理,使用隨機光柵化來生成光線:
float4 light(MaterialData surfaceInfo , float3 rayDir)
{
foreach (light : pointLights)
radiance += calcPoint(surfaceInfo, rayDir, light);
foreach (light : spotLights)
radiance += calcSpot(surfaceInfo, rayDir, light);
foreach (light : reflectionVolumes)
radiance += calcReflVol(surfaceInfo, rayDir, light);
(...)
}
然而這種簡單的光線追蹤管線渲染出來的畫質存在噪點、低效、光線貢獻較少等問題:

可以改進管線,在生成射線時加入可變速率追蹤:

可變速率追蹤的過程如下:
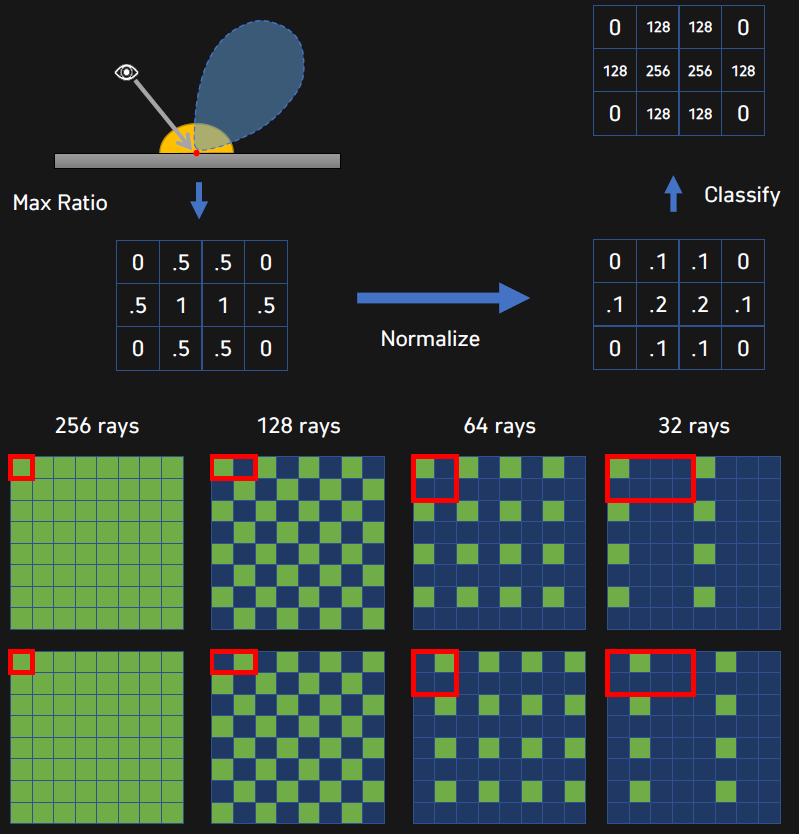
可變速率追蹤使得水上、掠射角有更多光線。但依然存在問題:

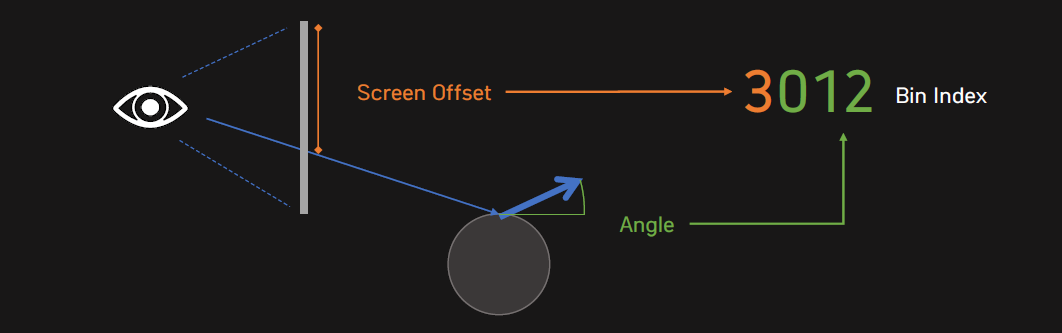
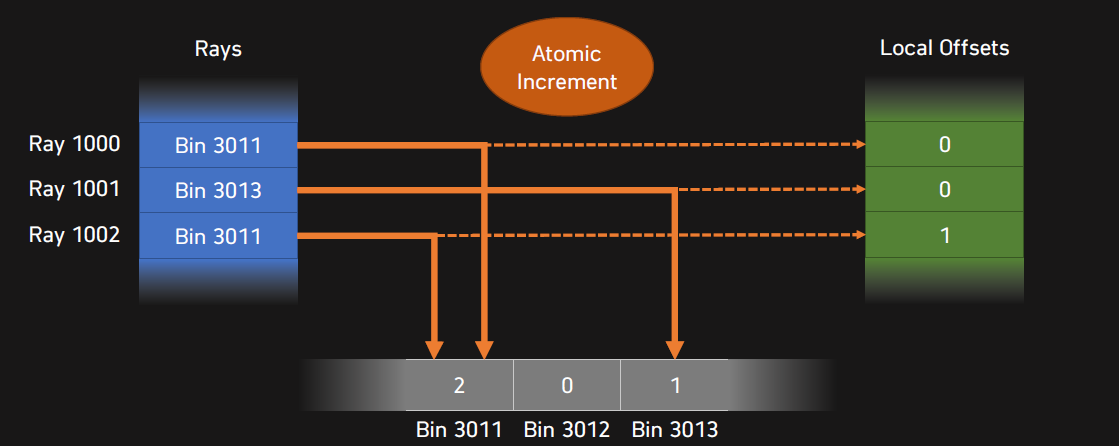
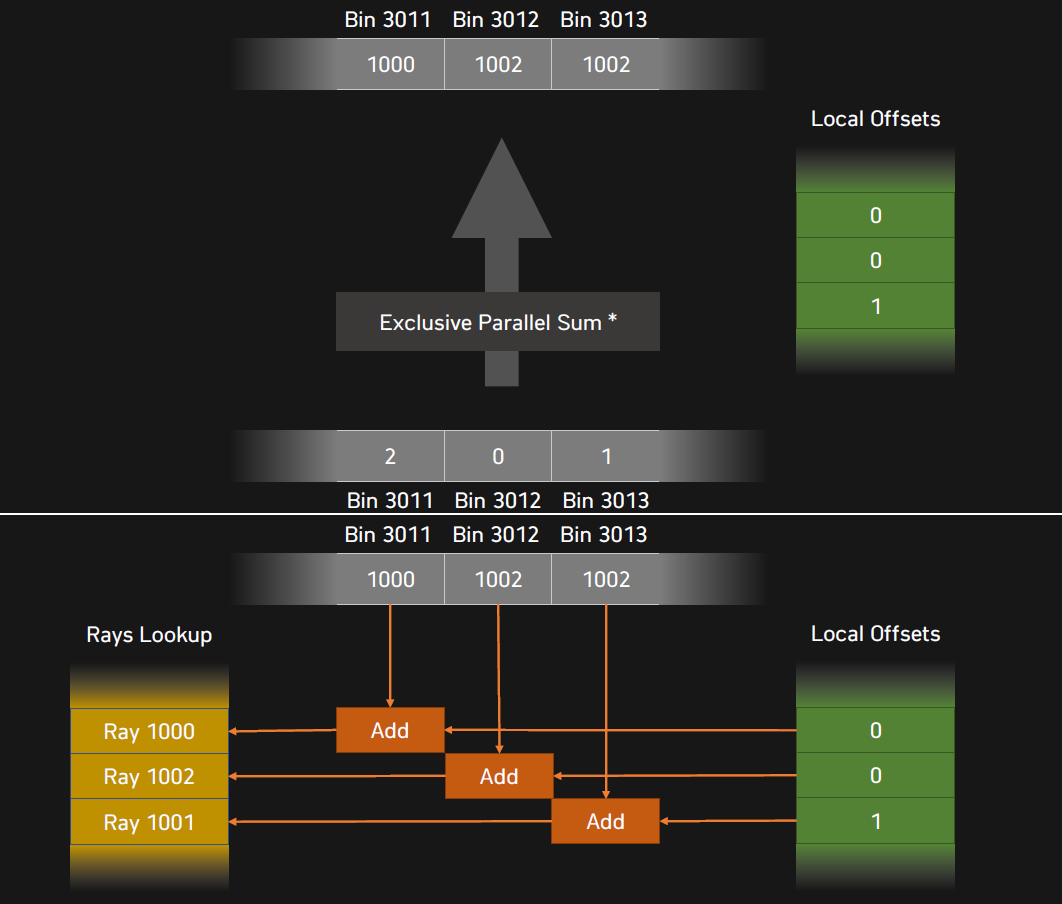
可以加入Ray Binning(光線箱化),將螢幕偏移和角度作為bin的索引。

依次可以加入SSR混合(SSR Hybridization)、碎片整理(Defrag)、逐單元格光源列表光照、降噪(BRDF降噪、時間降噪)等優化。

SSR Hybridization的過程和結果。
逐單元格光源列表光照。
BRDF降噪過程。
最終形成的新管線和時間消耗如下:

渲染效果:

DXR基礎:
DXR的性能優化包含減少實例數、使用剔除啟發法、接受(一些)小瑕疵。剔除啟發法假設遠處的物體並不重要,除了橋樑、建築等大型物體物,需要一些測量。投影球體包圍盒,如果θθ小於某個閾值,則剔除:
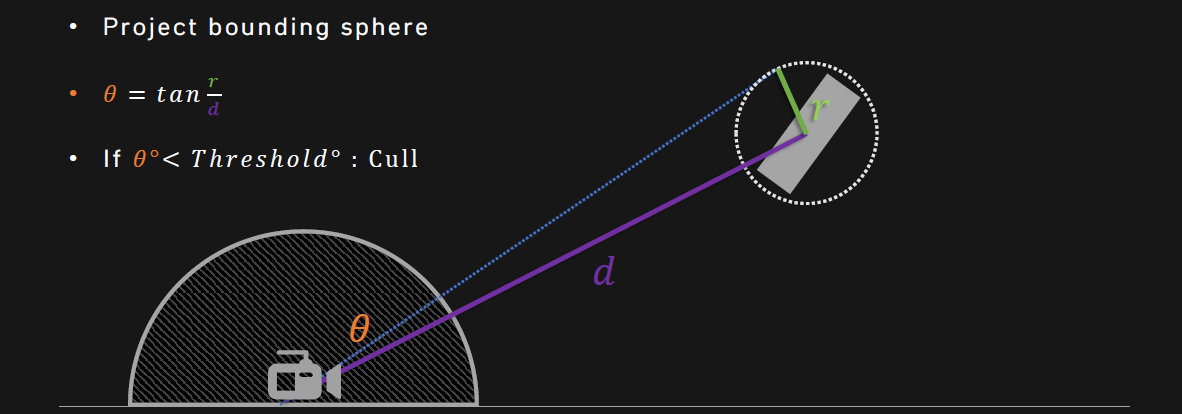
不同閾值的效果:

剔除結果是:使用4度剔除,每幀5000->400 BLAS、20000->2800個TLAS實例的重建,TLAS+BLAS構建(GPU)從64毫秒降到14.5毫秒,但引入了偶爾跳變及物體丟失等瑕疵。
BLAS更新依舊開銷大,可以採用以下方法優化:
- 錯開完整和增量BLAS重建。在完全重建之前N幀增量。
- 使用D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_BUILD。
- 避免重複重建。檢查CS輸入(骨骼矩陣),400 -> 50,將BLAS更新與GFX重疊,如Gbuffer、陰影圖。
TLAS+BLASGPU構建耗時從14.5毫秒降低到1.15毫秒,RayGen(GPU)從0.71毫秒降低0.81毫秒(使用交錯重建+標誌)。
不透明物體應該總是使用ClosestHit著色器,僅對Alpha tested物體使用Any Hit著色器,對蒙皮、破壞使用計算著色器。
射線有效載荷(RAY PAYLOAD)在ray交點出返回,與Gbuffer RTV的格式相同,包含材質數據、法線、基礎色、平滑度等。
struct GbufferPayloadPacked
{
uint data0; // R10G10B10A2_UNORM
uint data1; // R8G8B8A8_SRGB
uint data2; // R8G8B8A8_UNORM
uint data3; // R11G11B10_FLOAT
float hitT; // Ray length
};
還可以驗證正確性,即光柵化輸出,向場景中發射主要光線,將有效載荷與Gbuffer進行比較,如果是非零輸出,則有bug!需要修正錯誤。

Embree是Intel開發的光線追蹤開源庫,其核心特點是:
- 主要針對專業渲染應用程式。
- 高度優化的光線追蹤內核(1.5x 6x加速)。
- 提供豐富的功能和靈活性。
- 支援最新的CPU和ISA(如英特爾®AVX 512)。
- Windows、macOS10.x和Linux支援。
- 易於集成到應用程式中的API。
- Apache 2.0許可下的開源。
它的技術上的特點是:
- 使用最新的光線追蹤演算法。
- 高品質的BVH構建,使用英特爾®TBB進行了良好的並行化。
- 寬BVH,單射線遍歷,混合射線遍歷…
- 硬體方面的優化實現。
- 儘可能矢量化,以利用SIMD和其他特殊指令。
- 減少最內部循環中的指令依賴鏈。
- 為常見情況實施快速路徑。
- 針對快取使用、記憶體訪問模式等優化數據結構…
Embree支援的特性如下所示:
其系統概覽如下:

它已成功在World Of Tank等遊戲中應用。
利用GPU硬體加速的光線追蹤步驟和圖例如下:
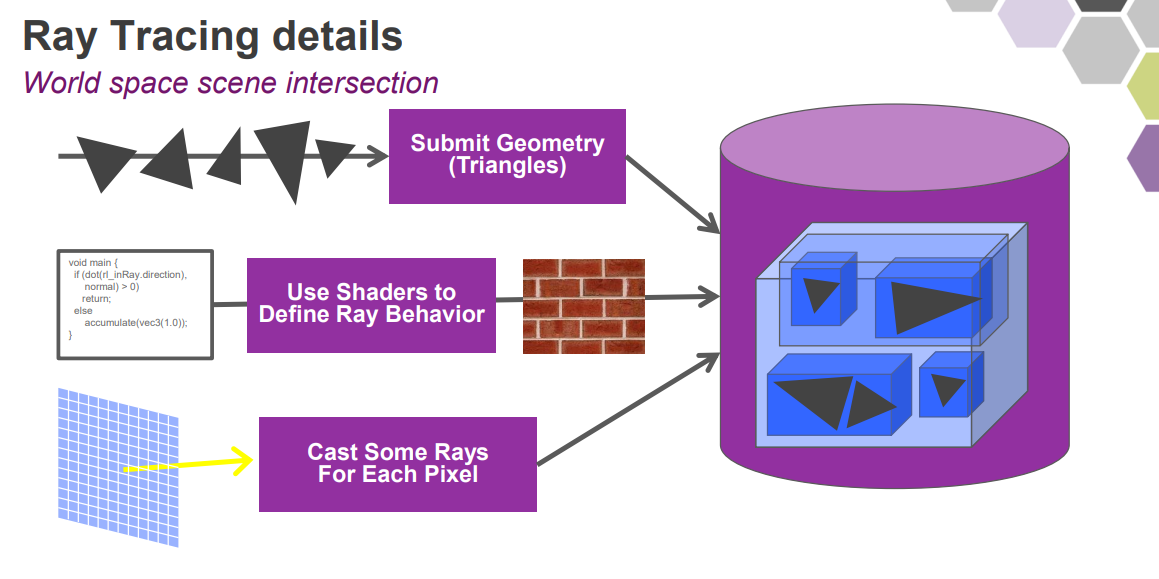
基於現代光柵化遊戲引擎的光線追蹤實現流程如下:
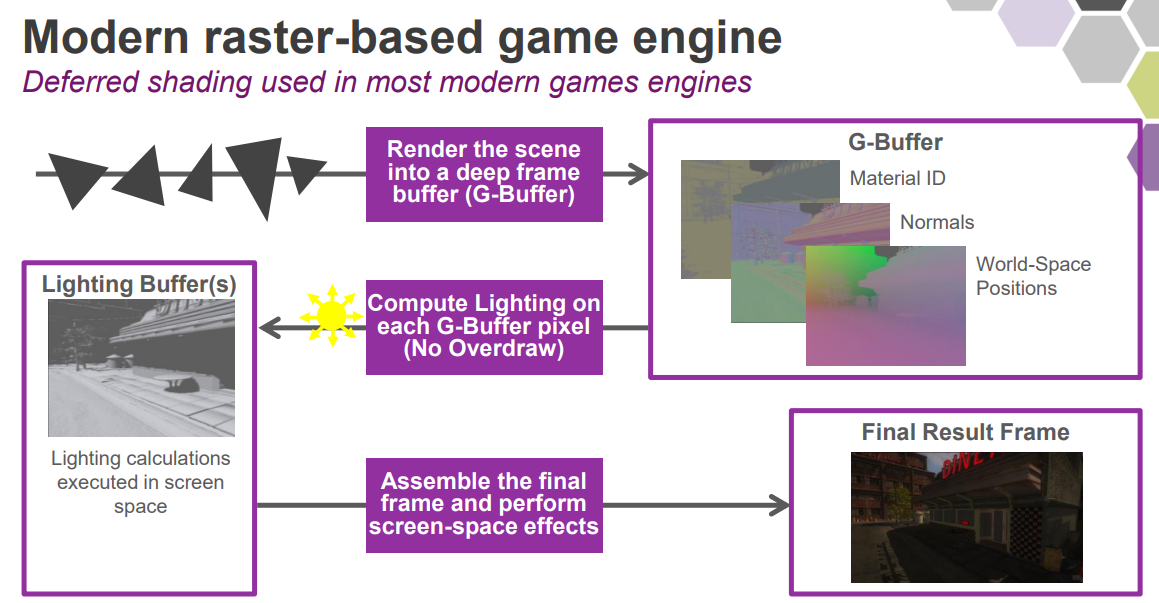
結合GBuffer資訊之後,由此產生了混合渲染管線:

下面是光柵化和光線追蹤的效果對比圖:

在2021年11月,Imagination Tech發布了IMG CXT系列及其突出功能:PowerVR Photon架構,提供超高效的混合光線追蹤,可提供7nm、5nm甚至3nm製程設計。其特性包括基於貼圖的延遲渲染、Imagination專用影像壓縮、超寬ALU、超標量ALU處理、廣泛的非同步機制、基於韌體的GPU、去中心化的多核等硬核技術。其中該架構添加了並發非同步光線追蹤,意味著CXT GPU現在可以有多達五種不同的任務類型在GPU內並發執行:幾何、片段/像素、計算、2D和光線追蹤。

上圖中可以看到IMG CXT GPU的高級視圖。GPU的主要組件包括:
- 統一著色集群(USC):GPU的計算核心,是一個多執行緒可編程SIMT處理器,可同時處理像素數據、幾何數據、計算數據以及2D/拷貝內務任務。對於GPU配置,更多USC等於更高的計算性能。
- 紋理處理單元(TPU):以高度優化的邏輯處理紋理定址、取樣和過濾。更多的紋理單元意味著更高的視覺複雜度、更高的刷新率和更高的顯示解析度支援。
- 光柵/幾何塊:一組固定功能單元,可在USC處理之前/之後對數據進行後處理和預處理,包括剔除、剪裁、分塊、壓縮、解壓縮、迭代等。
- 頂級(CXT RT3):包括三級快取、AXI匯流排介面和韌體處理器。
- 光線加速集群(RAC):一個新的專用塊,用於有效處理所有光線追蹤處理階段。此外,與之前的IMG B系列相比,CXT在單個核心單元中包含的ALU、TPU和幾何性能增加了50%。

與B系列GPU類似,CXT GPU也具有多核能力,可擴展到四個核。在上述「超越桌面」配置中,設計還包括額外的可選IP塊:
- NNA:我們的神經網路加速單元提供高功率、高性能和高效優化的神經網路處理。這些單元可以與IMG CXT GPU協同工作,並在具有多達八個核心的多核配置中提供多達100個頂級AI性能(如上圖所示)。
- OCM:片上共享存儲器,可用於在IMG CXT GPU和NNA單元之間高效交換數據。OCM還可以用於與其他IP塊的交互,方法是將數據保持在晶片上,以實現最高吞吐量、最低延遲和最佳功率效率。
- EPP:想像力的乙太網分組處理器(EPP)IP是一系列可擴展的多埠IEEE 802.3多千兆乙太網交換機和路由器解決方案。經過硅驗證,IP專門設計用於滿足高性能託管和非託管多埠交換機和路由器的苛刻通訊要求,非常適合汽車行業和其他網路處理市場。在此處所示的設計中,EPP將實現GPU組和/或數據存儲單元之間的高速連接,甚至允許影片壓縮遊戲流的直接流傳輸。
從3D的早期開始,傳統的渲染就使用光柵化進行,即使用三角形網格構建對象的幾何體,然後「著色」以創建其外觀。然而,通過光柵化,世界的照明方式只能近似。光線追蹤是不同的,它模擬了光在真實世界中的工作方式,其中光子從光源發射並在場景周圍反彈,直到到達觀看者的眼睛。光線追蹤將光線從觀察者(螢幕)發送到場景、對象上,並從那裡發送到光源。當燈光與對象交互時,它會被對象阻擋、反射或折射,這取決於其材質屬性,從而創建陰影和反射,甚至是螢幕外對象。一旦光線射入場景,照明過程自然發生,意味著開發人員不必花費時間創建「假」照明效果。這種優雅的照明場景方法有助於提供更逼真的圖形,改善遊戲和視覺應用程式,同時簡化內容創建者的照明過程。
根據不同的級別,存在6種光線追蹤級別系統(Ray Tracing Levels System,RTLS):

對於Level 2,添加長方體/三角形測試器:
對於級別3,是全硬體的BVH遍歷:

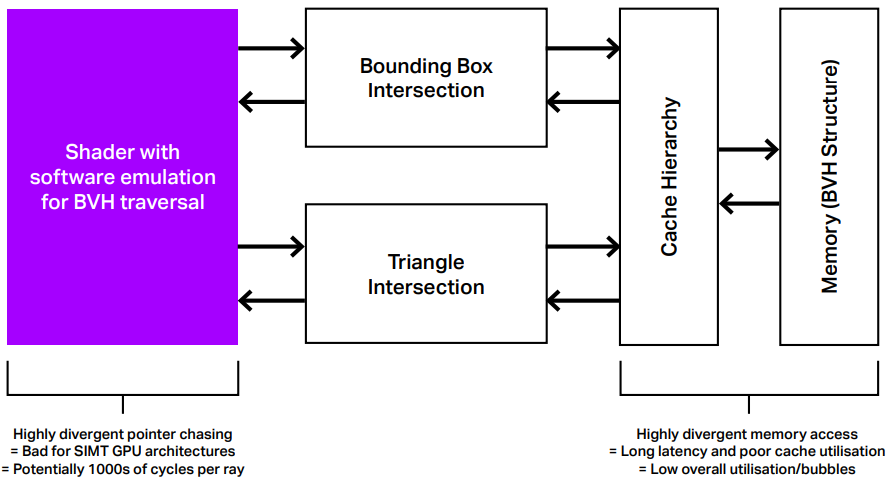
對於PowerVR Photon,支援Level 4 RTLS。PowerVR Photon體系架構旨在實現智慧手機功率和頻寬預算中的光線追蹤,還允許將這種效率擴展到移動以外的市場。光線追蹤的核心問題是缺乏一致性,因為射線可以、也會引入隨機方向,會與傳統GPU中設計的並行性相衝突。解決此問題的最佳解決方案是關注工作負載,為此,引入了一致性收集單元。
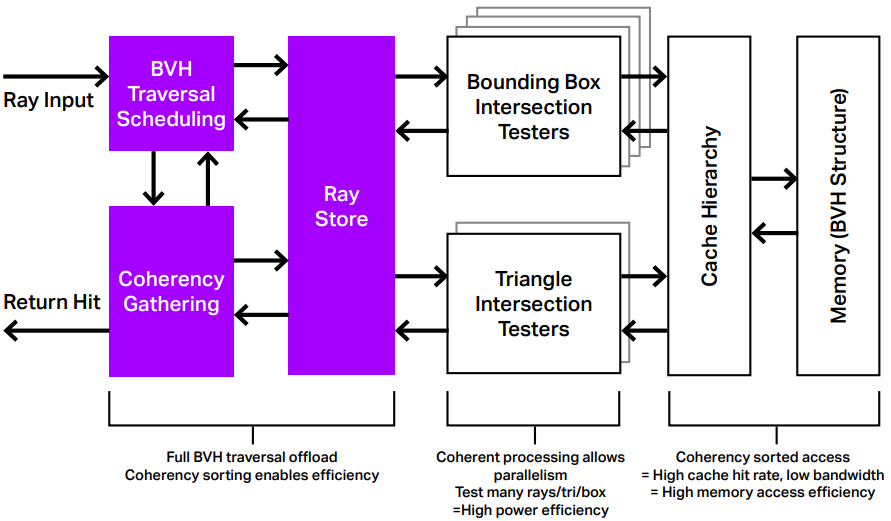
有了這個單元,BVH行走仍然是完全卸載的,但它現在變成了一個調度問題。可以存儲許多射線,然後相干單元將射線分組成類似的包或束,例如,通過BVH加速結構的類似路徑的射線——這些被稱為「相干」。雖然它們從一條射線到下一條射線可能是非相干的,但在多條射線上求平均值時,總是可以利用相似性和相關性,這正是PowerVR Photon體系結構所做的。
在PowerVR Photon中,光線被分組成處理包,不僅在處理中,而且在存儲器訪問中都將實現高效率。這種排序給了我們另一個好處:與MIMD架構不同,返回到GPU內部常見的高效處理方法:許多單元都做相同的事情。
因此,可以利用並行性,因為不只是針對一個方框檢查一條光線,可以針對同一方框檢查多條光線。此舉帶來了顯著的效率提高,並減少了對快取和記憶體子系統的壓力。對於三角形交點也是如此:可以同時針對多個三角形檢查光線。
因此,Photon架構有四個基本好處:
- 從ALU管線完整卸載BVH遍歷和箱/三測試。
- 一致性收集,確保光線處理變得並行。
- 一致性收集,確保數據重用率高,並顯著降低對快取和記憶體子系統的壓力。
- 由於有許多光線在運行,所以可以將ALU陰影工作和光線追蹤解耦,從而使延遲吸收(latency absorption)變得有效。
下表是不同的級別和對應設計的特性支援情況:
| Level 2 | Level 3 | Level 4 | |
|---|---|---|---|
| Example implementations | 2020 game console designs | 2021 desktop designs | PowerVR CXT |
| ALU Offloading | Partial | Full | Full |
| HW Box Testers | Y | Y | Y |
| HW Triangle Testers | Y | Y | Y |
| HW BVH Processing | N | Y | Y |
| HW Coherency Sort | N | N | Y |
| Cache Hit Rate | Low | Low/Medium | High |
| Memory Latency Tolerance | Low | Low | High |
| Processing Efficiency | Low(SIMT utilisation) | Low(MIMD) | High |
| Mobile Power Budget | N | N | Y |
PowerVR早在1996年就開創了基於分塊的延遲渲染(TBDR)。TBDR的重點是處理效率和頻寬。基於分塊的渲染通過在渲染之前將所有三角形幾何體排序到螢幕空間平鋪區域中來實現。這不同於即時模式渲染(IMR),其中每個三角形都被變換並立即繪製。對所有幾何體進行排序,然後按螢幕空間分塊區域(通常為16×16或32×32像素)進行渲染的好處是,可以僅使用用於深度/模板緩衝區和顏色緩衝區的片上記憶體來完成分塊區域的渲染。IMR將所有這些頻寬推離晶片,並依賴快取命中來減少頻寬,但由於幾何體提交在螢幕空間中的空間不一致,這種快取方法通常會失敗,導致高頻寬、延遲敏感性和低功率效率。
因此,通過首先對幾何體進行排序,快取命中率實際上變為100%。此外,深度和模板緩衝區通常只使用一次,因此可以丟棄。使用GBuffer和MRT渲染,許多MRT「顏色」目標僅用於中間暫存數據,只需要將一個顏色緩衝區寫入記憶體。使用TBDR,所有這些都可以在晶片上完成,節省記憶體佔用和大量頻寬。TBDR在處理抗鋸齒方面也具有顯著優勢。由於過取樣緩衝區僅存在於片上存儲器中,因此僅寫入下取樣顏色目標,再次節省了記憶體佔用和頻寬。
PowerVR Photon光線追蹤體系結構在許多方面與PowerVR TBDR體系結構相同,因為還進行了空間排序,只是將光線分成沿類似路徑通過BVH的包,而不是在2D螢幕空間中。這裡的好處與一致性排序類似——顯著的快取效率和減少的頻寬,同時處理保持SIMD/SIMT性質,確保邏輯和整體處理的高功率效率。
PowerVR Photon體系結構在PowerVR GPU中添加了一個新塊,稱為光線加速集簇(RAC),負責PowerVR GPU上的所有光線追蹤活動,包括整個過程:從發射光線(從著色器/內核)到將命中(或未命中)結果返回給ALU進行處理。
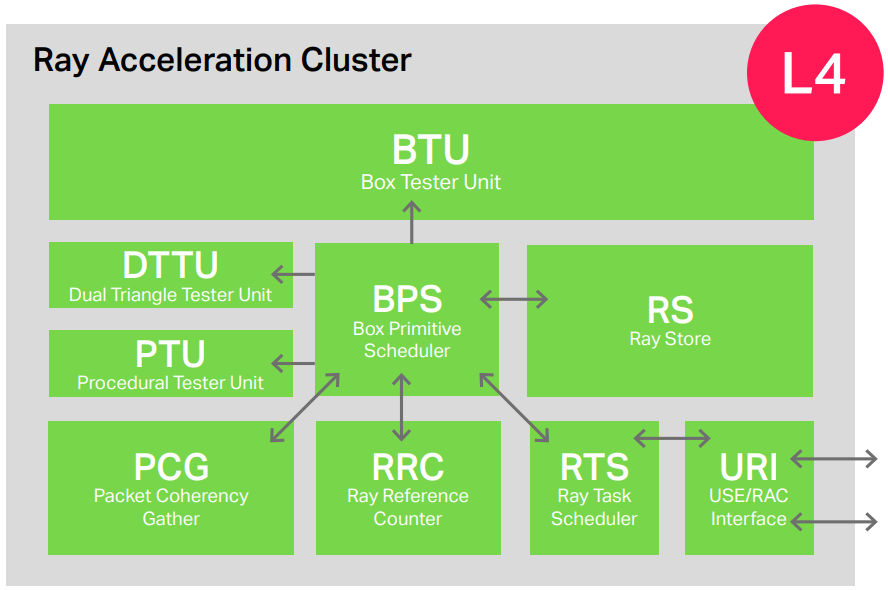
當光線由圖形著色器或計算內核程式生成並處理結果時,RAC與GPU的ALU引擎緊密耦合。雖然這些裝置與交換射線和命中/未命中資訊密切相關,但它們在技術上完全「解耦」,意味著兩個裝置同時運行,以實現最高的效率和利用率。RAC有效地處理整個BVH遍歷,包括計算非常密集的盒/射線和三角形射線交叉,以及效率優化,如相干排序。RAC與當前光線追蹤API公開的所有模式和功能完全兼容,包括Khronos Vulkan®擴展和Microsoft DirectX光線追蹤。
RAC是一個可擴展單元,支援多個性能點(例如,RAC的1x、0.5x、0.25x)以及多核可擴展性(2x及以上),其中多個RAC可以放置在ALU單元旁邊。在當前的PowerVR GPU設計中,RAC由兩個128寬的ALU單元共享,從而提高了RAC、ALU和紋理處理單元(TPU)的利用率。具有調度邏輯和其他固定功能支援的RAC、兩個ALU和兩個TPU單元的組合稱為可擴展處理單元(SPU)。這些構成了構建CXT GPU系列的基本單元,從每個GPU核心一個到四個SPU單元,然後由於分散多核系統,可以進一步擴展。
下表總結了不同級別及對執行效率的影響,以及由此產生的對功率、性能和頻寬的影響。
| GPU Block Ray Tracing Task | Level 1 RTLS | Level 2 RTLS | Level 3 RTLS | Level 4 RTLS |
|---|---|---|---|---|
| ALU Loading | Full | High | Low | Low |
| ALU Efficiency | Low | Low | Medium | High |
| Box/Tri Testers | N/A | Medium | High | Full |
| BVH Walking | Yes | Yes | Yes | Yes |
| Coherency | No | No | No | Yes |
| Cache Hits | Low | Low | Low/Medium | High |
| Bandwidth Usage | High | High | Medium | Low |
| Power Efficiency | Very Low | Low | Medium | High |
光線查詢也稱為Microsoft DirectX光線追蹤(DXR)下的內聯光線追蹤,非常容易理解,因為本質上任何著色器或內核(計算)都可以發出光線查詢,該查詢將啟動整個光線追蹤過程。在該系統中,生成的命中/未命中資訊返回到必須處理它的同一著色器/內核。因此,光線追蹤非常簡單,根據DXR名稱樣式,它實際上是一個內聯過程。
一個簡單的例子就是陰影光線。在這裡,場景被渲染為正常,但現在在片段/像素著色器中,光線朝光源發射,當光源被擊中時,我們知道當前像素被照亮,可以在著色器中執行正確的程式碼。如果擊中場景中的任何其他對象,可以知道它在陰影中,並且再次,可以在著色器中執行正確的程式碼。在該方案中,反射將更加困難,因為當反射對象被擊中時,必須觸發大量複雜度,以確定如何為該反射對象渲染正確的顏色,而這一切都必須在原始投射著色器中處理。
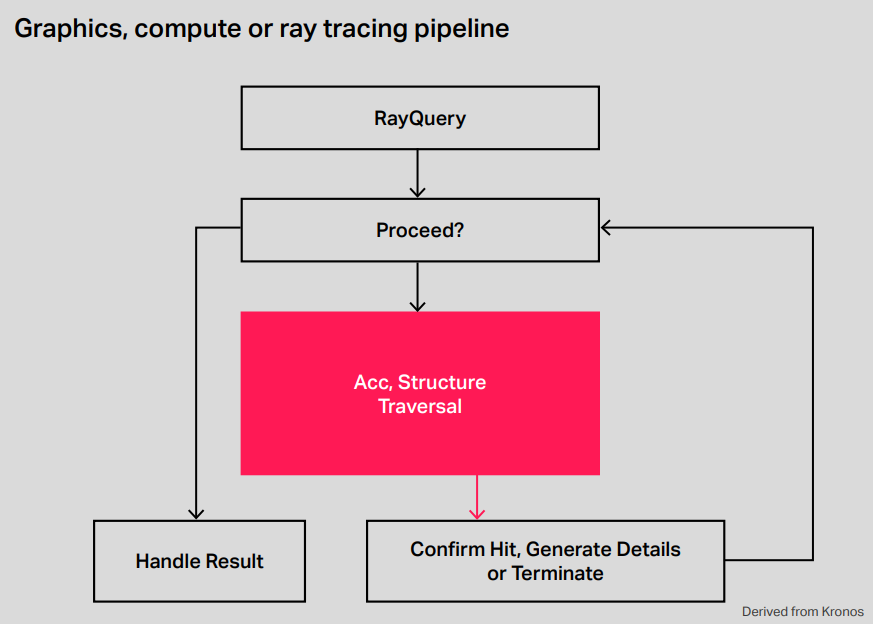
對於大多數初始渲染演算法,將推薦使用光線查詢,更容易添加到現有遊戲引擎中,並且也可能在實現中提供更可預測的性能。

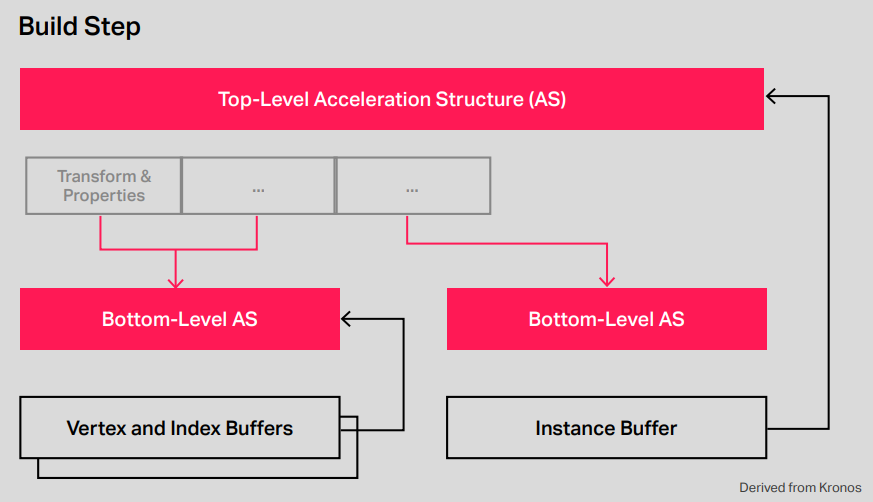
PowerVR Photon參考了加速結構和邊界體積層次結構,用來剔除光線盒和光線三角形測試數量的高級結構,如下所示:

如圖所示,邊界體積層次結構提供了一種加速機制,可以系統地檢查邊界框,如果遺漏了一個框,我們知道可以忽略該級別下的所有框/三角形。這使得它成為一種加速結構,將射線測試過程儘可能減少到最小。這種結構以及在其創建中使用的品質和啟發式方法,將對硬體的效率產生重大影響,因為最佳結構可以比簡單、構造差的結構更有效地減少工作量。因此,API公開了生成此加速結構的快速和慢速方法。
快速構建演算法對於被動畫化並在幀與幀之間廣泛變化以保持高幀速率的對象至關重要。對於靜態對象,應在載入時(甚至在開發期間離線)使用慢速構建方法,靜態對象將在其整個生命周期中使用,因此應儘可能優化。它們由兩個元素組成,一個頂層加速結構(TLAS)和多個底層加速結構(BLAS)。上面描述的更多的是BLAS,因為它包含一個對象的加速度結構,例如示例中的兔子,而TLAS由多個BLAS結構組成。
構建加速結構的步驟如下所示:
在進入RAC之前,GPU內部需要各種其他處理步驟,對於使用光線查詢的混合渲染工作負載,可以總結如下:
應用程式通過發出API調用來渲染場景,這些API調用由GPU驅動程式在記憶體中構造命令緩衝區和數據結構(紋理、著色器、緩衝區)來處理。驅動程式還將啟動硬體,可能會將其從節能模式中喚醒,或者只是標記有更多的工作可供處理。此觸發觸發嵌入式韌體處理器,該處理器將處理所有內部活動管理,並確保所有作業遵守設置的優先順序。
典型的首先要做的是啟動幾何處理,意味著繪製調用將成為GPU內的任務,每個任務都在GPU內進行調度,並旨在在USC內保留所需的資源進行處理。然後將提取頂點/幾何體數據,當數據可用時,任務變為活動狀態並執行著色器程式。這將生成輸出幾何圖形,然後輸出幾何圖形將命中一系列固定功能塊,如剔除、剪裁、平鋪和幾何圖形壓縮,然後將中間參數數據寫入記憶體。
該參數數據是每個分片的幾何體鏈接列表,在每個分片中都可能可見,從而使基於分塊的延遲渲染髮揮其魔力。所有這些工作都是處理的第一階段,通常將其稱為幾何階段或分塊加速器(TA)階段。此階段與下一個渲染階段同時運行。

基於分塊的延遲渲染架構中的3D處理從HSR開始。所有的3D處理都是一塊一塊地完成的,意味著使用參數數據鏈表結構獲取位置數據。對於分塊深度/模板內的所有幾何數據,執行測試,在標記緩衝區內生成可見性列表,該列表指示每個像素的可見對象。一旦處理了所有幾何體,就有了按像素標記的可見性列表,從邏輯上講,它是一個單一的不透明對象(因為它後面的所有東西都將被隱藏/移除),並且在不透明對象前面有幾個Alpha混合層。
然後按正確的深度順序開始渲染,並按每個著色器進行排序,每個著色器代表一個任務。任務處理意味著,首先,調度器在USC內保留所需的資源進行處理,然後在任務變為活動狀態並執行正確的著色器程式指令之前預取任務和數據。如果任務中的著色器程式包含光線查詢調用,則將在此處觸發RAC。
對於具有光線查詢調用的著色器,該任務不僅將請求USC資源,還將請求RAC資源。當著色器使用USC/ray介面(URI)將所需的光線資訊發射到RAC時,執行實際光線追蹤,並且該資訊存儲在光線存儲中。
與紋理操作類似,在將所需光線資訊傳輸到RAC之後,USC將將任務置於非計劃等待狀態,意味著在RAC執行其工作時,USC會開始處理其他任務/作業。可以想像,所有這些工作都是大規模並行的,因為不僅僅處理一個片段/工作項或射線,而是在每個任務(warp)中並行處理多個執行緒。硬體還將執行許多此類任務,以確保延遲吸收和高利用率。RAC將有效地存儲許多需要處理的射線。
此時,光線參考計數器會追蹤每條光線,該計數器會隨著所需的每次測試而增加。根據加速度結構,這些測試從一開始,隨著更多的盒子相交而增加,從而觸發更多的盒子測試。射線處理在相干組中進行,意味著分組相干收集塊將掃描射線,以構建相干地穿過結構的射線分組。當數據包填滿時,它們將被執行,根據需要運行射線穿過盒子和/或三角形和/或基本測試儀。此處理通過專用加速結構快取(ASC)運行,確保數據也在數據包中重複使用。
當然,ASC只是一個快取級別。進一步的快取將在整個GPU記憶體層次結構中發生,包括最大的SLC快取級別,甚至可能是SoC級別的系統級快取。當該處理完成時,射線參考計數器(RRC)將隨著測試的調度和完成而遞增和遞減,直到當參考計數達到零並且射線的結果準備就緒時,處理結束。
此時,一條或多條光線將被調度為將控制權返回給USC進行進一步的著色器處理,意味著USC任務將恢復。然後,USC可以通過URI從為所有處理保留了資源的光線存儲讀取生成的光線數據。
在這個階段,著色器的處理將繼續正常進行,直到通過執行具有和不具有光線查詢的著色器/內核的混合來完全繪製分塊。在此過程中,其他固定功能塊(如紋理處理單元)將用於執行著色器。
重要的是要認識到,此時的執行是許多任務的混合:幾何體將在處理,計算任務可能在運行,RAC將追蹤光線並查找命中/未命中,而著色器核心將執行程式碼作為所有這些操作的一部分。2D和內務任務也可以用於複製數據或生成MIPMAP。對於如此多樣的作業,目標是在所有處理單元中獲得最大效率,並確保任何處理任務和記憶體訪問的延遲通過處理其他獨立任務完全隱藏。
一旦分塊完成,將觸發像素後端,將完成的分塊寫入記憶體,可能使用想像影像壓縮(IMGIC)幀緩衝區壓縮。
光線追蹤時隱藏的一致性
雖然光線追蹤在本質上是「令人尷尬的平行」,但實時光線追蹤之所以花了這麼長時間才變得實用,原因之一是,儘管存在並行性,但它通常是發散的和非相干的。可以從下圖中加以理解。
在現實世界中,材質具有不同的屬性——有些是平滑的,但大多數是粗糙的——因此,對於真實曲面,光線不會以相同的方式反射,而是在不同的方向上反彈。結果是發散,例如光線從一個像素反彈到下一個像素,光線沿不同方向傳播。因此,光線將沿著不同的路徑穿過BVH框,從而導致不同的記憶體訪問,從邏輯上講,沿不同方向傳播的光線也將與不同的三角形相交,從而觸發不同的著色器程式,從而導致著色器執行的差異。
發散對GPU是不利的,因為儘管它們非常擅長處理高度並行的工作負載,但它們的SIMD架構只有在這些工作負載一致且相似的情況下才有意義。如果每個像素都想做一些不同的事情,那麼GPU所依賴的高執行和頻寬效率的技巧就會失敗。意味著最終會採用暴力方法(即使用大量ALU和光線追蹤單元),需要在處理流程難以有效使用它們時進行補償(即儘管理論上的峰值吞吐量很高,但在實際使用中,低利用率會導致低吞吐量)。
然而,雖然從一個像素到下一個像素的光線可能是發散的,但並不意味著在四處反彈的光線束之間沒有「相干」。同樣,這在下圖中得到了最好的說明。下面的反射形狀顯示了從該對象反射的光線中隱藏的相干。例如,你可以看到穿黃色衣服的人被多次反射,意味著這些光線進入同一方向,實際上是相干的。更重要的是,如果我們能將這些光線分組,它們將沿著類似的路徑通過BVH,為我們提供高速快取命中率和數據重用率。它們也將最終命中並與相同的三角形相交,並且可能還執行相同或類似的著色器程式,從而在傳統的並行GPU ALU管線中提供高效率。

大約10年前,多通道光柵化達到了臨界點,對於藝術家來說,迭代時間長,工作流程笨拙,從可視性角度渲染瑕疵近似值,預烘焙和快取照明通常有效…直到它不起作用,無法按預期準確模擬光照傳輸。採用路徑追蹤——處理一切的統一光照傳輸演算法,圖元包含曲面、頭髮、體積測量…反射包含所有類型的BSDF、BSSRDF…燈光包含點光源、區域光源、環境圖光源…
方差的概念和公式:
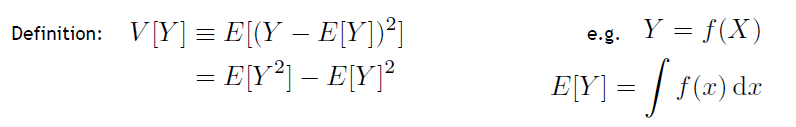
所有取樣技術都基於將隨機數從單位平方扭曲到其它域,再到半球、球體、球體周圍的圓錐體,再到圓盤。還可以根據BSDF的散射分布生成取樣,或選擇IBL光源的方向。有許許多多的取樣方式,但它們都是從0到1之間的值開始的,其中有一個很好的正交性:有「你開始的那些值是什麼」,然後有「你如何將它們扭曲到你想要取樣的東西的分布,以使用第二個蒙特卡羅估計」。
對應取樣方式,常用的有均勻、低差異序列、分層取樣、元素區間、藍噪點抖動等方式。低差異類似廣義分層,藍色噪點類似不同樣本之間的距離有多近。過程化模式可以使用任意數量的前綴,並且(某些)前綴分布均勻。
方差驅動的取樣——根據迄今為止採集的樣本,周期地估計每個像素的方差,在差異較大的地方多取樣,更好的做法是在方差/估計值較高的地方進行更多取樣,在色調映射等之後執行此操作。離線(品質驅動):一旦像素的方差足夠低,就停止處理它。實時(幀率驅動):在方差最大的地方採集更多樣本。計算樣本方差(重要提示:樣本方差是對真實方差的估計):
float SampleVariance(float samples[], int n)
{
float sum = 0, sum_sq = 0;
for (int i=0; i<n; ++i)
{
sum += samples[i];
sum_sq += samples[i] * samples[i];
}
return sum_sq/(n*(n-1))) - sum*sum/((n-1)*n*n);
}
樣本方差只是一個估計值,大量的工作都是為了降噪,MC渲染自適應取樣和重建的最新進展。總體思路:在附近像素處加入樣本方差,可能根據輔助特徵(位置、法線等)的接近程度進行加權。高方差是個詛咒,一旦引入了一個高方差樣本,就會有大麻煩了,例如考慮對數據進行均勻取樣:
1 & x<.999 \\
100 & \text { otherwise }
\end{array}\right.
\]
6個樣本:(1, 1, 1, 1, 1, 100 ) ≈ 17.5,再取6個樣本:(1, 1, 1, 1, 1, 100, 1, 1, 1, 1, 1, 1 ) ≈ 9.25,回想一下,方差隨樣本數呈線性下降…面對這種高方差樣本,最hack但也最有效的方式是clamp,如下圖所示:

更複雜的選擇是基於密度的異常值剔除,保存所有樣本,分析並過濾異常值。根據亮度將樣本分成幾個單獨的影像,然後根據統計分析重新加權。

光線追蹤從離線到實時的幾個重要方面:
- 明智地選擇光線。採用蒙地卡羅積分法、方差、重要性取樣、多重重要性取樣。
- 仔細選擇你的(非)隨機數。域扭曲、准隨機序列、低差異、分層。
- 把你的射線預算花在最有用的地方。自適應取樣。
- 理解並防止錯誤。強度夾緊、路徑正則化。
蒙特卡羅快速回顧:

准蒙特卡羅(QMC):確定性、低差異序列/集合(Halton、Hammersley、Larcher-Pillichshammer)比隨機的收斂速度更好,例如Sobol或(0-2)序列不需要知道樣本數量,奇妙的分層特性。
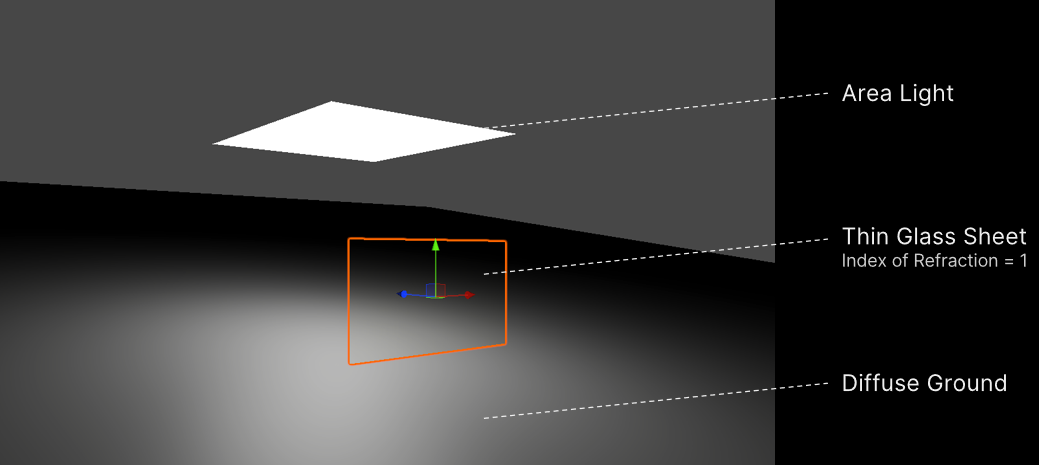
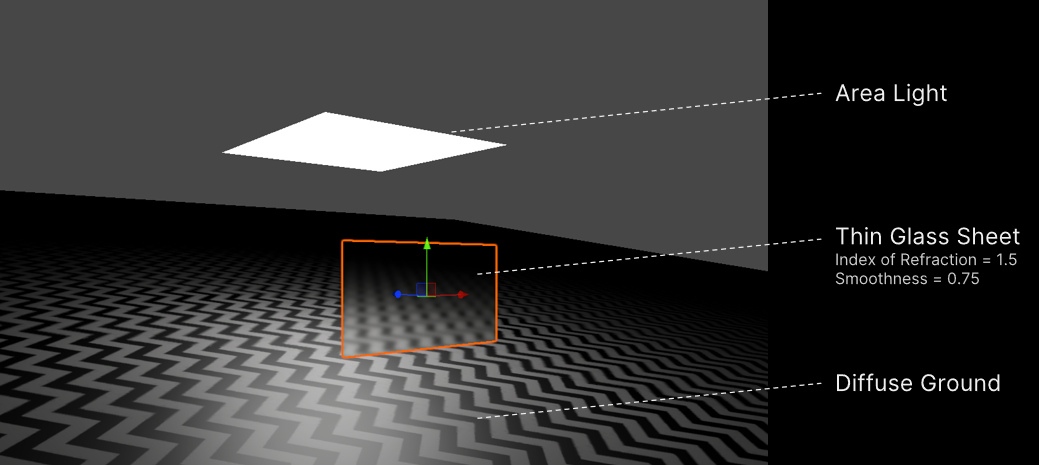
下圖中有一個大面積的光在傾斜,漫反射地面上。相機正前方是一片薄玻璃片,折射率為1(因此完全透射)。這將是一個相當常見的場景的調試版本,其中場景的大部分(如果不是全部的話)都在一個窗口後面。
因為對光線有一個固定的分裂因子,索引也很容易追蹤:對於每個光取樣計算,可以使用樣本i到i+3。如果每個照明位置都與對應位置非常不同,就像康奈爾盒子的情況一樣,不會有太大的區別(但考慮到屬性或我們的順序,至少會同樣好)。然而,如果位置更相似(甚至完全相同)。。。
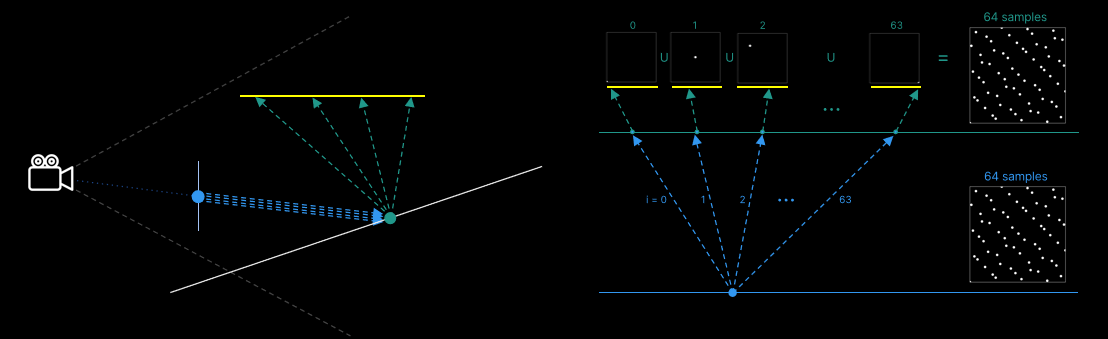
在地面上使用64個相機直接可見的光源樣本。
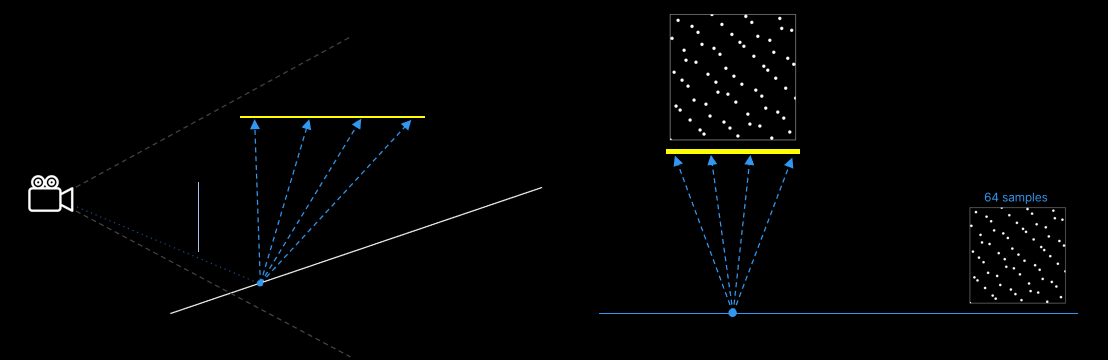
下圖是一個稍微不同的場景,使取樣預算更容易測試。場景中的薄玻璃片更粗糙,為了更好地欣賞這種粗糙的效果,對地面進行紋理處理。
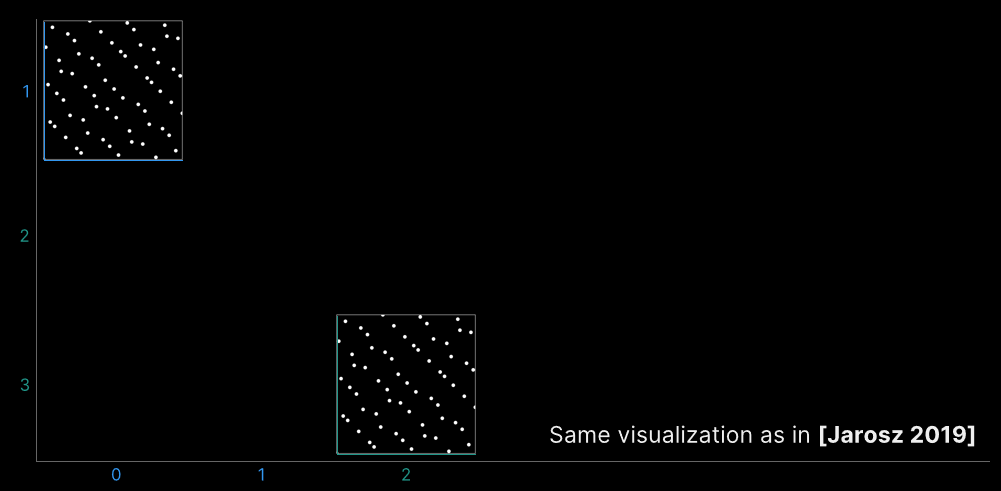
若使用之前一樣的取樣方式,由粗糙玻璃產生的BSDF射線的相干度當然不如以前,由此獲得了下圖那樣更加毛躁的影像:

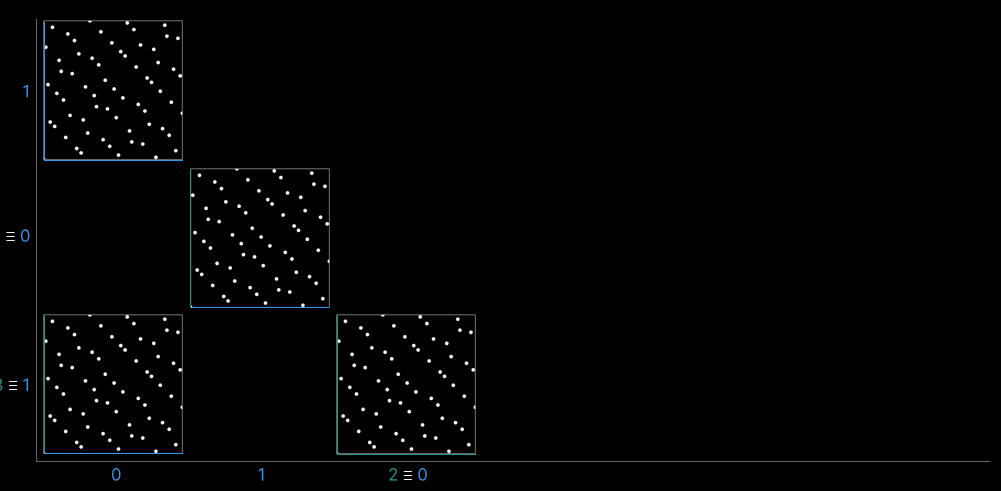
由此遇到了一個像素之間相關性很差的情況,4D序列中的一些維度在一個像素內的相關性很差。為此,需要查看4D點的不同2D投影,遵循Jarosz等人在正交陣列論文中使用的可視化約定:可以在軸上看到對應於每個維度的索引,在數組的每個單元格中,將顯示相應的2D切片,是尺寸(0,1)和(2,3)的2D切片,是在取樣常式中使用的切片,它們其實是一樣的。
現在看看下圖的「診斷」切片,(0,3)和(1,2)也是相同的。剩下的(0,2)和(1,3)相當於(0,0)和(1,1)。。。
實際上,需要使用高緯度的Sobol序列。有許多可能的Sobol序列,[Grünschloß]和[Joe 2008]的Sobol序列優化了低維2D投影的分層特性,用於低樣本數量:
雖然樣本數量少,但任何維度配對都會產生非常好的結果!在之前的各種填充嘗試中,我們注意到的問題已經消失了。
如果上升維度,可以找到品質明顯最差的2D切片,以確保對被積函數的最重要部分使用最低維度:
額外的改進包括將Owen指令應用於所有維度,它有助於打破序列特徵的對齊模式,並提高收斂速度。由於不是一個快速的過程(特別是對於實時),可以預計算並存儲大量樣本,這也是HDRP中的操作,256D中有256個點。
錦上添花的做法是增加螢幕空間的藍色噪點:
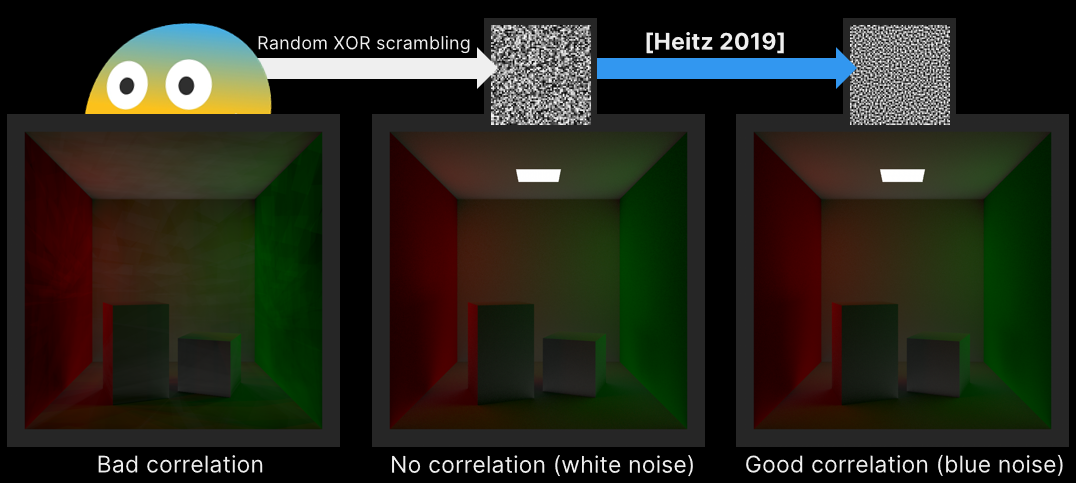
白噪點和藍噪點的對比:

當進入高維時,同時考慮所有維度,避免考慮遞歸的低維積分(即使這樣開始更自然)。實時(預計算)選擇序列是一種低差異取樣器,將蒙特卡羅方差作為藍色雜訊分布在螢幕空間[Heitz 2019],漸進式多抖動樣本序列[Christensen 2018]。近期在高維集合方面值得注意的工作是蒙特卡羅渲染的正交數組取樣[Jarosz 2019],實時路徑跟追蹤的未來是實時重構光照傳輸[Wyman 2020]。
T-ReX: Interactive Global Illumination ofMassive Models on HeterogeneousComputing Resources也提到了利用混合渲染管線的思路,即CPU用幾何表達來計算包含完整細節的直接光,而GPU用稀疏體素八叉樹為結構的體積表達來計算近似的間接光(下圖)。其中直接光和非直接光存在數據轉換和傳輸,而幾何表達和體素表達沒有。

下圖則分別顯示了原始網格、近似體積、用原始網格和近似體積計算而得的光照效果(黃色圈表示用體積計算的間接光)。

該文將光線分為C-Ray和G-Ray。其中C-Ray(下圖藍色)對幾何細節更敏感,用於生成高頻視覺效果,一次光線和在完美鏡面材質上反射的二次光線。

而G-Ray(下圖深紫色和橙黃色)對幾何細節不太敏感,用於生成低頻視覺效果,除C-Ray以外的任何射線(例如收集射線、陰影射線)
在數據結構方面,CPU使用HCCMesh,而GPU使用ASVO:
HCCMesh是用來處理C-Ray的高品質幾何結構,隨機可訪問壓縮(壓縮比7:1~20:1),支援高性能解壓縮。
而ASVO是增強稀疏體素八叉樹(Augmented SparseVoxel Octree),是G-Ray的GPU側體積表示,在GPU中高效遍歷,近似幾何&光子映射。ASVO可以提高解析度,保存遮擋點陣圖,用作LOD表示——可表示材質、逐節點上的法線。

ASVO採用兩級結構:頂層ASVO始終載入在GPU記憶體上(如300MB),底層ASVO按需非同步載入,以進行漸進渲染。採用遮擋點陣圖前後的對比如下:

整體渲染流程如下:
1、GPU側利用體素追蹤光子,將光子資訊存儲到ASVO中。
2、CPU側利用HCCMesh追蹤C-Ray,完成後(只是部落客推測)同步到GPU側。
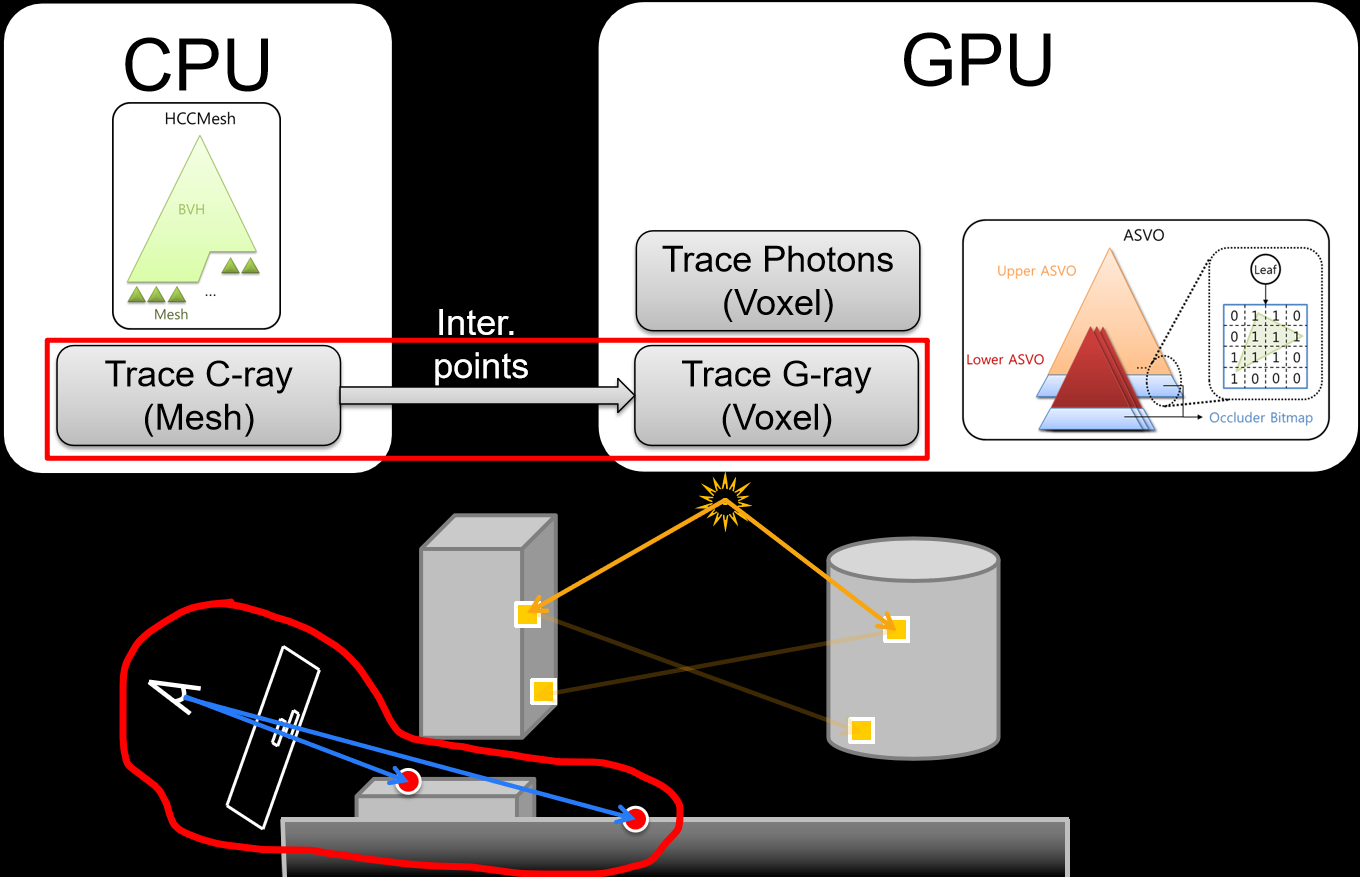
3、GPU側利用體素追蹤G-Ray,將結果存儲到光子資訊中。

4、GPU側利用ASVO的兩級結構中的光子資訊著色,生成最終的光照結果。
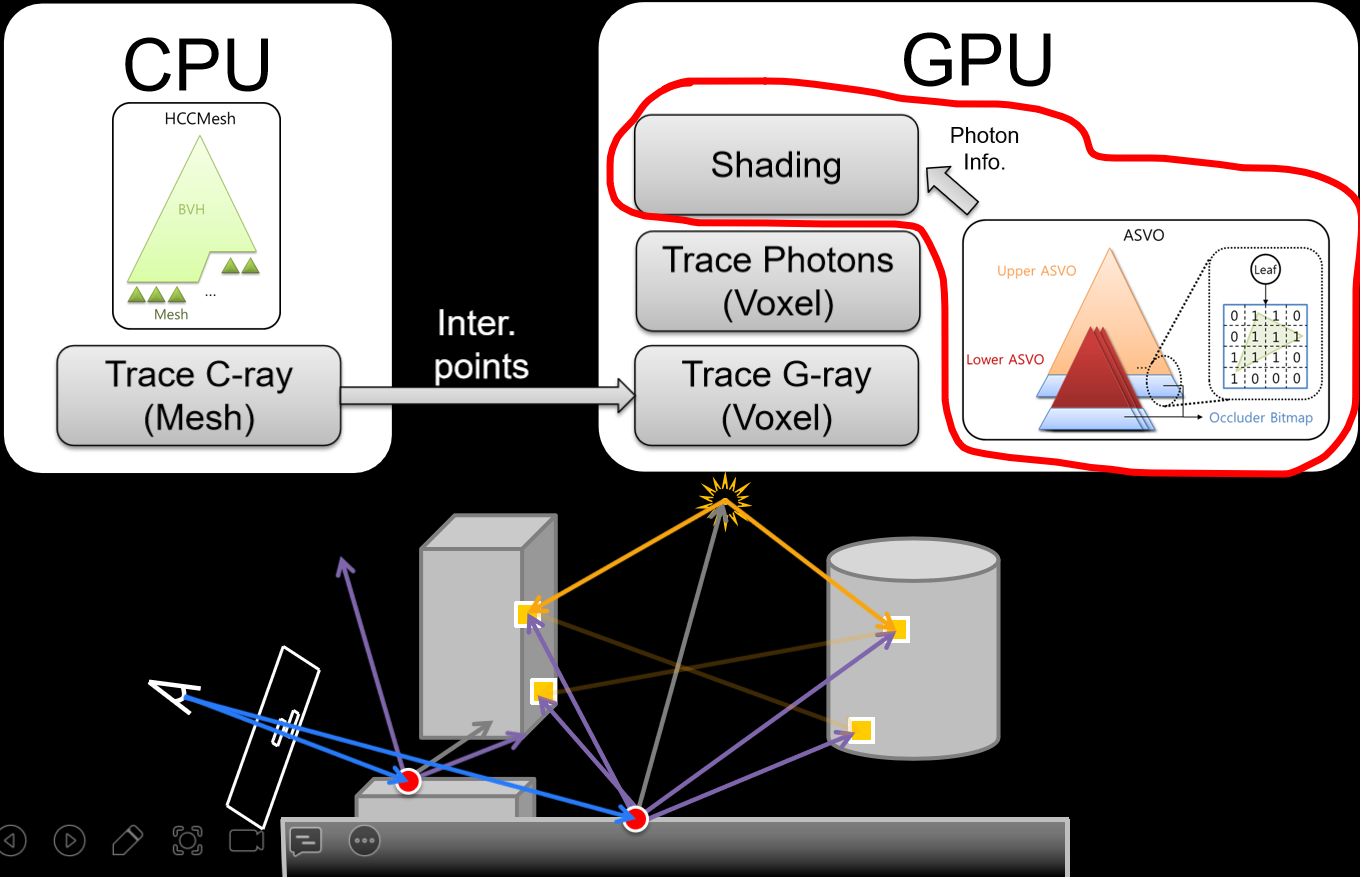
此方法提出了一種用於大規模模型全局照明的集成漸進渲染框架,使用解耦表示——CPU中的HCCMeshes和GPU中的ASVOs,用於處理大規模模型,降低昂貴的傳輸成本,實現CPU和GPU的高利用率。限制是體積表示法存在偏倚和不一致,跨越的空間大於其幾何模型。

Scalable Real time Global Illumination for Large Scenes講述了用於大規模場景的可擴展的實時GI解決方案。其解決方案是場景的體素表示(如體素圓錐體追蹤),相機周圍的初始體素化照明場景儘可能好,儘可能快,如碰撞幾何、實體的較低LOD、高度圖數據,來自螢幕GBuffer的回饋體素化燈光場景,可見光輻照度volmap(體積圖)部分地在每一幀重新計算,使用真實的強力光線投射(無光)。
輻照度圖:將輻照度存儲在相機周圍的嵌套體積貼圖中(3d clipmap),每個級聯為約64x32x64,單元格大小為\(0.45m \cdot 3^i\)(或在低端設備上為\(0.9m \cdot 3^i\),i是級聯索引),選擇了HL2環境立方體基,正交基,但GPU對樣本非常友好,可以很容易地更改為其它基。
基本場景參數化:將場景存儲在相機周圍的嵌套體積貼圖(3d clipmap)中,每個級聯為128x64x128,單元大小為\(0.25m \cdot 3^i\)(或在低端設備上為\(0.5m \cdot 3^i\),i是級聯索引),要麼存儲完全照明的結果,要麼存儲兩個體積紋理中的照明+反照率。
Sponza場景參數化:

初始場景填充:當相機移動時,「以環形方式」填充新的體素(類似於紋理包裹),用高度貼圖數據和碰撞幾何體(頂點著色)或實體的低級LOD填充新的體素,然後立即用太陽光、間接光輻照度和該區域最重要的光照亮這個新的體素。
場景回饋循環:在中等設置下,場景不斷更新,隨機選擇32k GBuffer像素,對於每個隨機選擇的GBuffer像素,使用它的反照率、法線和位置以及直接光和間接輻照度貼圖來照亮它,使用移動平均更新這個新的發光顏色的體素化場景表示。這提供了回饋循環,因為使用重照明GBuffer像素更新場景體素,使用當前輻照度體積圖更新它們,並用當前場景體素更新輻照度體積圖。它不僅提供多次反彈,還解決了體素化問題(牆比2個體素薄,精度高),此外,環境探針(在渲染時)提供了「主」攝影機無法捕捉到的更多數據。
輻照度貼圖初始化:當攝像機移動時,我們填充新的紋理(探針),對於更精細的級聯,從更粗糙的級聯複製數據,對於「場景相交」和最粗糙的級聯貼圖,追蹤64條光線以獲得更好的初始近似,用magic(「不是真正計算的」)值來標記它們的時間收斂權重,所以一旦它們變得可見,它們就會被重新激活。
輻照度圖-計算循環:在輻照度體積圖中隨機選擇幾百個可見的「探針」(位置),選擇的概率取決於「探測」的可見性和探測的收斂因子(上次變化的程度),對於選定的「探針」,在場景中投射1024到2048條光線(取決於設置),用移動平均法累積結果。
輻照度圖-計算隊列:為了快速收斂,在輻照度圖中為不同的「探針」設置不同的隊列非常重要,第一次看到,從未計算過要儘快計算,即使品質較低。使用256條射線,但隊列中有4096個探針,不相交的場景探針不參與光照傳輸,但仍然需要為動態對象、體積測量和粒子計算它們。使用1024條射線,隊列大小只有64到128個探針。
初始化光照-雞和蛋問題:當攝像機傳送時,它周圍的所有級聯都是無效的,所以不能用輻照度(第二次反彈)來照亮初始場景,也不能計算沒有初始場景的初始輻照度。分兩次完成:體素化場景,僅使用直射光照亮,計算天光和第二次反彈的輻照度,然後重新縮放場景,很少發生(剪影)。
使用輻照度貼圖進行渲染:選擇最好的級聯,根據法線符號,從六個輻照度體積貼圖紋理中抽取三個進行取樣(請參見HL2 Ambient Cube)。在邊界上,將其與下一個級聯混合,延遲通道和向前通道(以及體積光照)也一樣。
另外,使用凸面偏移過濾來解決光照泄漏:

對於室內的過暗問題,添加「孔/窗」體積(永遠不會用體素填充)來解決:

總之,此法產生的GI具有多次反彈的一致間接照明,可調品質,從低端PC到超高端硬體支援,但不影響遊戲性,可擴展的細節大小,以及光線追蹤品質。動態的(在某種程度上),炸毀一堵牆,摧毀一棟建築,光照可以照進,建造圍牆產生反射和間接陰影,快速迭代。
17.4 圖形API和GPU
本章將闡述目前市面上的幾種流行圖形API對光線追蹤支援的現狀和技術。
17.4.1 DirectX RayTracing(DXR)
DirectX RayTracing(DXR)是DirectX 12引入的用以支援硬體光線追蹤的圖形API特性集。在最高級別,DXR為DirectX 12 API引入了四個新概念:
- 加速結構是一個對象,它以最適合GPU遍歷的格式表示全3D環境。表示為兩級層次結構,該結構提供了GPU的優化光線遍歷,以及應用程式對動態對象的有效修改。
DispatchRays是一種新的命令列表方法,是將光線追蹤到場景中的起點,也是遊戲將DXR工作負載提交給GPU的方式。- 光線追蹤管線狀態是當今圖形和計算管線狀態對象的精神伴侶,它封裝了光線追蹤著色器和與光線追蹤工作負載相關的其他狀態。
- 一組新的HLSL著色器類型,包括光線生成、最近命中、任何命中和未命中著色器。它們指定了DXR工作負載在計算上實際執行的操作。調用DispatchRays時,將運行光線生成著色器。使用HLSL中新的TraceRay內部函數,光線生成著色器將光線追蹤到場景中。根據光線在場景中的位置,可以在交叉點調用多個命中或未命中著色器中的一個,以允許遊戲為每個對象指定其自己的著色器和紋理集,從而產生唯一的材質。

光線追蹤在GPU內部的處理流程圖。
在DX12的全新圖形API中,加入了可編程的光線追蹤渲染管線(上圖)。和傳統光柵化管線一樣,光線追蹤的管線有固定的邏輯,也有可編程的部分。新管線中新增了5種著色器(Shader),分別是:
- Ray Generation:用於生成射線。在此shader中可以調用TraceRay()遞歸追蹤光線。所有光線追蹤工作的起點,從Host啟動的執行緒的簡單二維網格,追蹤光線,寫入最終輸出。
- Intersection:當TraceRay()內檢測到光線與物體相交時,會調用此shaderr,以便使用者檢測此相交的物體是否特殊的圖元(球體、細分表面或其它圖元類型)。使用應用程式定義的圖元計算光線交點,內置光線三角形交點。
- Any Hit:當TraceRay()內檢測到光線與物體相交時,會調用此shader,以便使用者檢測此相交的物體是否特殊的圖元(球體、細分表面或其它圖元類型)。在找到交點後調用,以任意順序調用多個交點。
- Closest Hit和Miss:當TraceRay()遍歷完整個場景後,會根據光線相交與否調用這兩個Shader。Cloesit Hit可以執行像素著色處理,如材質、紋理查找、光照計算等。Cloesit Hit和Miss都可以繼續遞歸調用TraceRay()。Closest Hit在光線的最近交點上調用,可以讀取屬性和追蹤光線以修改有效載荷。Miss如果未找到並接受命中,則調用,可以追蹤射線並修改射線有效載荷。
下面是以上部分shader的應用示例,以便更好說明它們的用途:
// 追蹤光線時使用的數據負載,可自定義需要的數據。
struct Payload
{
float4 color;
float hitDistance;
};
// 追蹤的加速結構,表示了場景的幾何體。
RaytracingAccelerationStructure scene : register(t5);
[shader("raygeneration")]
void RayGenMain()
{
// 獲取已調度二維工作項網格內的位置(通常映射到像素,因此可以表示像素坐標)。
uint2 launchIndex = DispatchRaysIndex();
// 定義一條射線,由原點、方向和間隔t組成。
RayDesc ray;
ray.Origin = SceneConstants.cameraPosition.
ray.Direction = computeRayDirection( launchIndex ); // 計算光線方向(非內建函數,實現忽略)
ray.TMin = 0;
ray.TMax = 100000;
Payload payload;
// 使用我們定義的有效載荷類型追蹤射線,由此觸發的著色器必須在相同的有效負載類型上運行。
TraceRay( scene, 0 /*flags*/, 0xFF /*mask*/, 0 /*hit group offset*/,
1 /*hit group index multiplier*/, 0 /*miss shader index*/, ray, payload );
outputTexture[launchIndex.xy] = payload.color;
}
// 屬性包含命中資訊,並由相交著色器填充。對於內置三角形相交著色器,屬性始終由命中點的重心坐標組成。
struct Attributes
{
float2 barys;
};
[shader("closesthit")]
void ClosestHitMain( inout Payload payload, in Attributes attr )
{
// 讀取相交屬性並將結果寫入有效負載。
payload.color = float4( attr.barys.x, attr.barys.y, 1 - attr.barys.x - attr.barys.y, 1 );
// 演示一個新的HLSL指令:沿當前光線的查詢距離。
payload.hitDistance = RayTCurrent();
}
AnyHit和ClosetHit運行機制和區別示意圖:
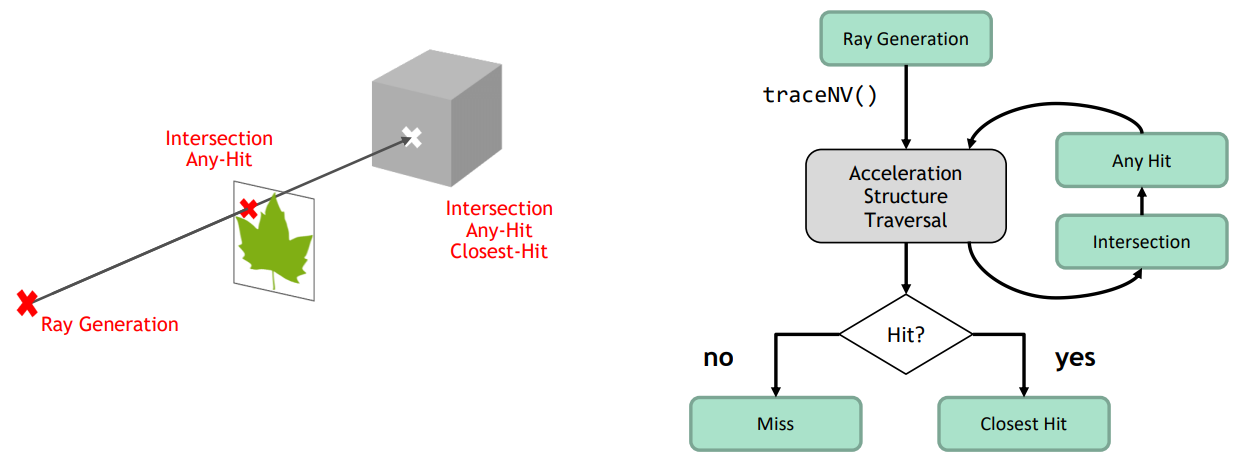
射線可以附帶有效載荷——亦即應用程式定義的結構,用於在生成光線的命中階段和著色器階段之間傳遞數據,用於將最終交點資訊返回到光線生成著色器:
射線還可以有屬性——應用程式定義的結構,用於將交點資訊從交集著色器傳遞到命中著色器:
DXR被設計為允許實現獨立地處理射線,包括各種類型的著色器,它們只能看到單條輸入光線,不能看到或依賴運行中的其他光線的處理順序。某些著色器類型可以在給定調用過程中生成多條光線(如果需要),可以查看光線處理的結果。無論如何,運行中生成的光線永遠不會相互依賴。這種光線獨立性打開了平行性的可能性。為了在執行期間利用這一點,典型的實現將在調度和其他任務之間進行平衡。
執行的調度部分是硬連接的(hard-wired),或者至少以可針對硬體訂製的不透明方式實現。通常會使用排序工作等策略,以最大化執行緒之間的一致性,從API的角度來看,光線調度是內置功能。
光線追蹤中的其他任務是固定功能和完全或部分可編程工作的組合,其中最大的固定功能任務是遍歷由應用程式提供的幾何結構構建的加速結構,目的是有效地找到潛在的射線交點,固定函數也支援三角形相交。著色器可編程性體現在生成射線、確定隱式幾何圖形的交點(與「固定函數三角形交點」選項相反)、處理光線交點(如曲面著色)或未命中。該應用程式還可以高度控制在任何給定情況下從著色器池中運行哪些著色器,以及每個著色器調用可以訪問的紋理等資源的靈活性。
下圖展示了硬體光線追蹤體系涉及的概念、加速結構、記憶體布局以及運行機制:
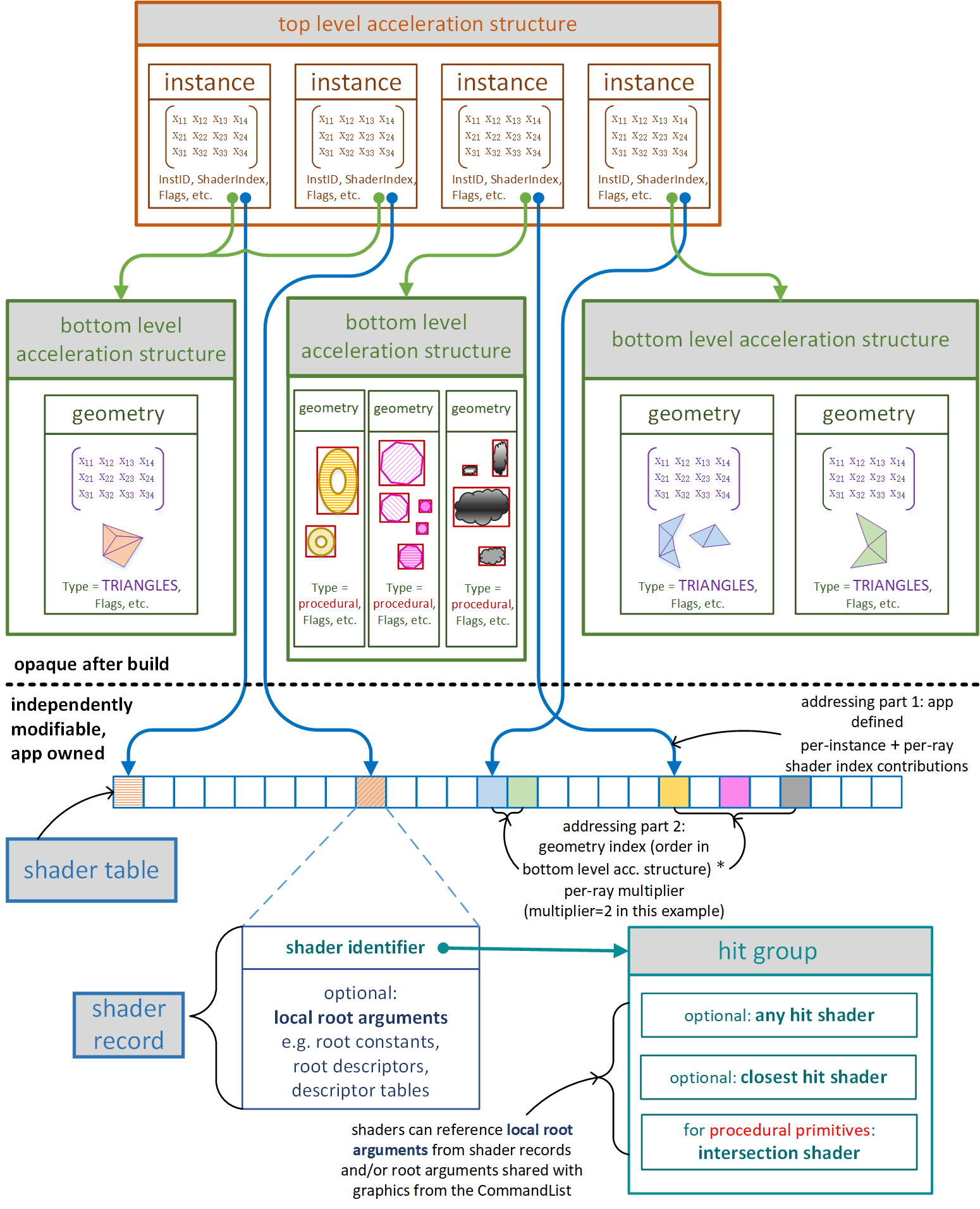
上圖中涉及到加速結構(Acceleration Structure),其作用是保存場景的所有幾何物體資訊,在GPU內提供物體遍歷、相交測試、光線構造等等的極限加速演算法,使得光線追蹤達到實時渲染級別,可以在應用程式通過BuildRaytracingAccelerationStructure()介面構建。
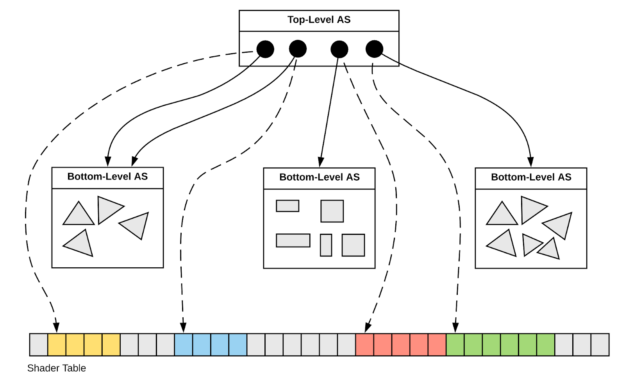
如上圖,對於場景中的每個幾何體,在GPU內部都存在兩個級別的加速結構:
- 底層加速結構(Bottom-Level Acceleration Structure,BLAS)從輸入的圖元資訊構建而成,如三角形、四邊形。
- 頂層加速結構(Top-Level Acceleration Structure,TLAS)從底層加速結構創建而來,相當於是底層加速結構的實例,保存了底層結構的變換矩陣和shader偏移。
應用程式可以通過BuildRaytracingAccelerationStructure()中的D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAGS標記使得加速結構變成可更新的,或更新可更新的加速結構。在光線追蹤性能方面,可更新加速結構(在更新之前和之後)不會像從頭構建靜態加速結構那樣最佳,然而更新將比從頭構建加速結構更快。
Shader綁定表(Shader Binding Table,SBT)描述了shader與場景的哪個物體關聯,也包含了shader中涉及的所有資源(紋理、buffer、常量等)。
在GPU底層,Shader映射表是一個等尺寸的記錄體(record),每個記錄體關聯著帶著一組資源的shader(或相交組,Hit group)。通常每個幾何體存在一個記錄體。
由上圖可見,每個記錄體由shader編號起始,隨後存著CBV、UAV、常量、描述表等shader資源。這種雙層架構的好處是將資源和實例化分離,加速實例創建和初始化,降低頻寬和顯示記憶體佔用。
SBT針對典型光線追蹤器的命中組記錄布局,具有兩種光線類型,渲染具有兩個實例的場景,其中一個實例具有兩種幾何體。結合下圖舉個例子,每個命中組記錄為32位元組,步長為64位元組。當追蹤光線時,\(R_{stride}=2\),並且\(R_{offset}\)對於主光線為0,對於遮擋光線為1。
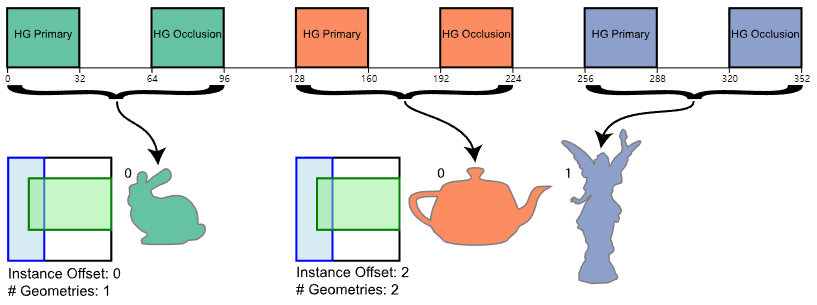
更詳細深入的SBT機制參見:The RTX Shader Binding Table Three Ways。
DXR的TraceRay運行流程如下:
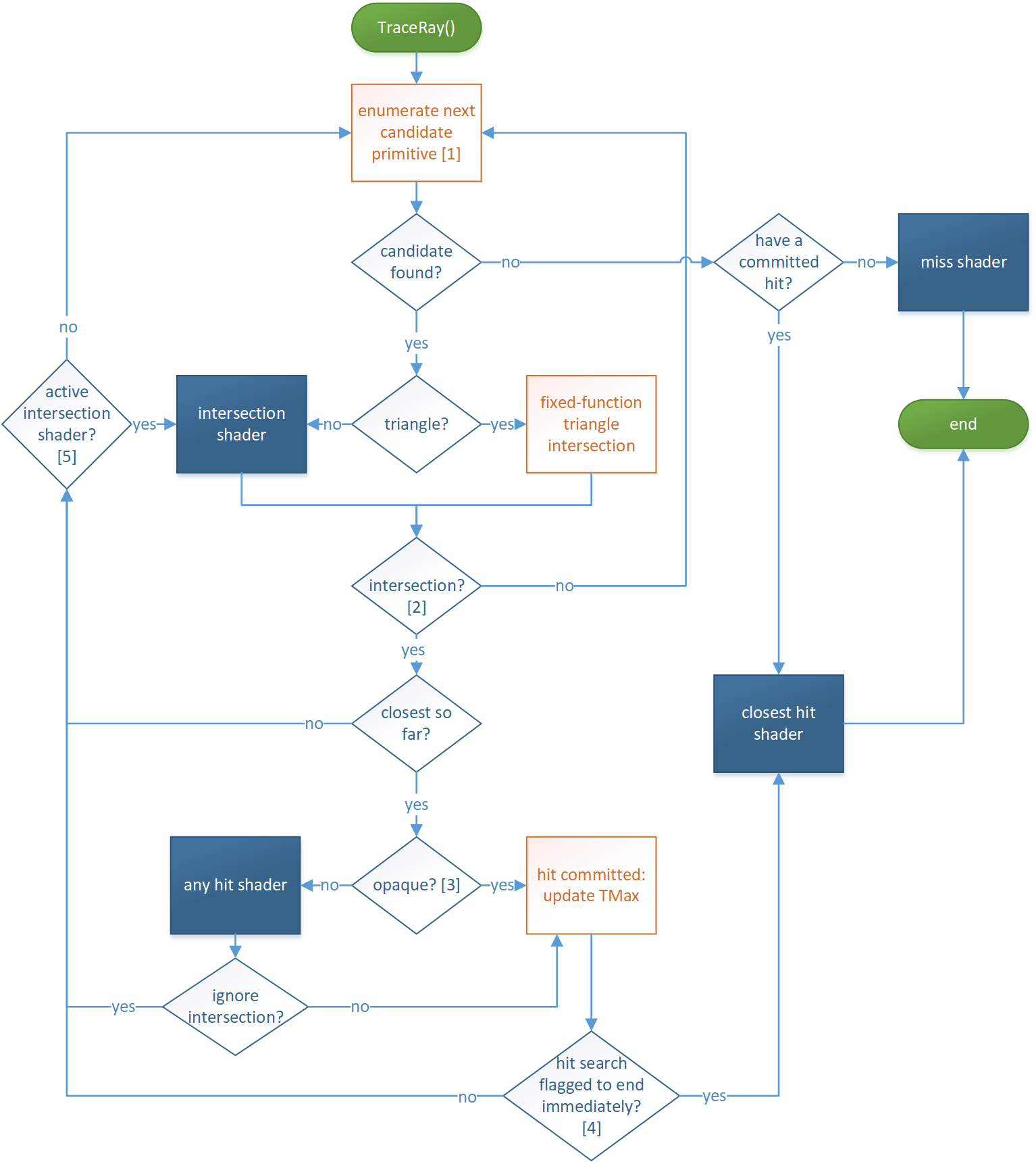
上圖中:
[1] 此階段搜索加速結構,以枚舉可能與射線相交的圖元,保守地:如果圖元與射線相交且在當前射線範圍內,則保證最終將枚舉。如果基本體未與光線相交或在當前光線範圍之外,則可以枚舉或不枚舉該基本體。請注意,提交命中時會更新TMax。
[2] 如果交集著色器正在運行並調用ReportHit(),則後續邏輯將處理交集,然後通過[5]返回交集著色器。
[3] 不透明度是通過檢查交點的幾何圖形和實例標誌以及光線標誌來確定的。此外,如果沒有任何命中著色器,幾何體將被視為不透明。
[4] 如果設置了RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH光線標誌,或者設置了名為AcceptHitAndEndSearch()的任何命中著色器,將中止在AcceptHitandSearch()調用點執行任何命中著色器。由於至少提交了此命中,因此迄今為止最接近的命中都會在其上運行最近的命中著色器(並且未通過RAY_FLAG_SKIP_CLOSEST_HIT_SHADER禁用)。
[5] 如果相交的圖元不是三角形,則相交著色器仍處於活動狀態並繼續執行,因為它可能包含對ReportHit()的更多調用。
DXR還支援內聯管線追蹤模式,調用TraceRayInline()執行,是TraceRay()的變體,它的運行流程圖如下:
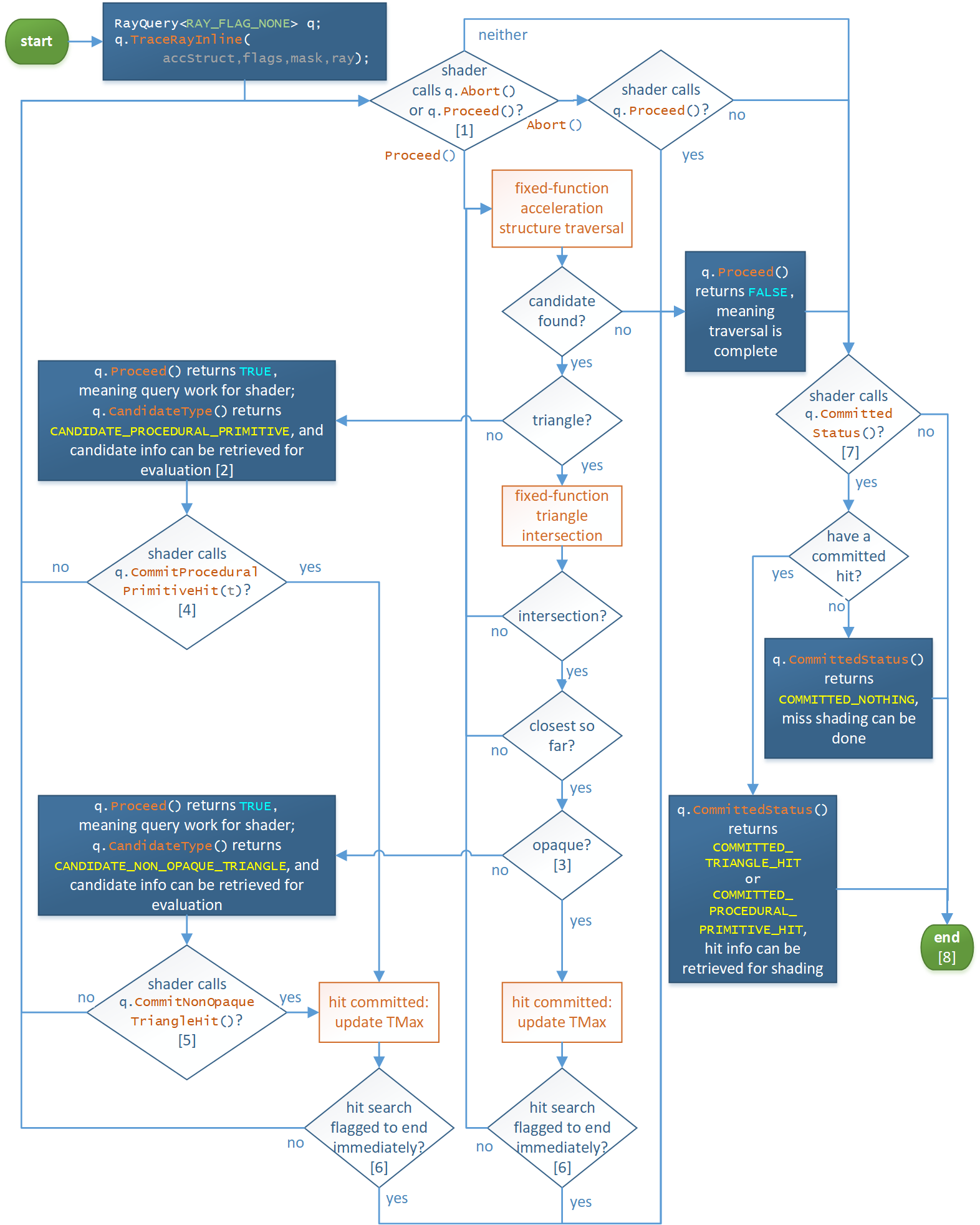
DXIL庫和狀態對象示例:
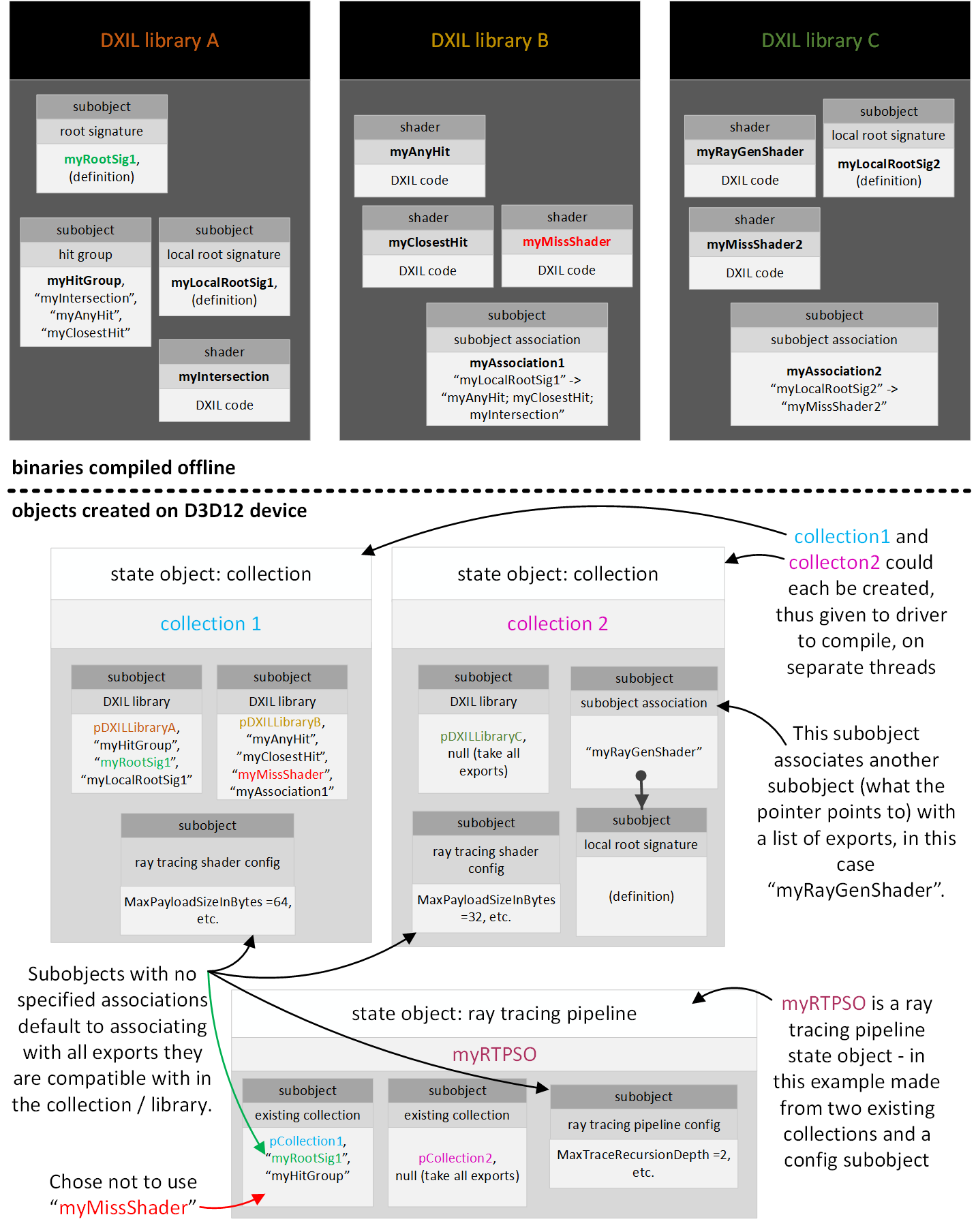
PIX作為Microsoft的老牌且強大的圖形調試軟體,在DXR發布之初就支援了對它的調試。利用PIX可方便調試各類調用棧、渲染狀態及資源等資訊。

使用DXR的步驟如下:
- 第一步是構建加速結構,它在兩級層次結構中運行。在結構的底層,應用程式指定了一組幾何圖形,基本上是頂點和索引緩衝區,表示世界上不同的對象。在結構的頂層,應用程式指定了一個實例描述列表,其中包含對特定幾何體的引用,以及一些附加的每個實例數據,如變換矩陣,這些數據可以以類似於當前遊戲執行動態對象更新的方式逐幀更新。它們一起允許有效地遍歷多個複雜幾何圖形。
兩個幾何體的實例,每個幾何體都有自己的變換矩陣。
- 第二步是創建光線追蹤管線狀態。如今大多數遊戲為了提高效率而將它們的繪製調用批處理在一起,例如首先渲染所有金屬對象,然後渲染所有塑料對象。但由於無法準確預測特定光線將擊中的材質,因此光線追蹤不可能進行這樣的批處理。相反,光線追蹤管線狀態允許指定多組光線追蹤著色器和紋理資源。例如,與對象A的任何光線交點都應使用著色器P和紋理X,而與對象B的交點應使用著色器Q和紋理Y,使得應用程式可以讓光線交點使用它們所擊中的材質的正確紋理運行正確的著色器程式碼。
- 第三步是調用
DispatchRays,它調用光線生成著色器。在該著色器中,應用程式調用TraceRay內在函數,觸發加速結構的遍歷,並最終執行適當的命中或未命中著色器。此外,還可以從命中和未命中著色器中調用TraceRay,允許光線遞歸或多重反彈效果。

場景中光線遞歸的說明
注意,由於光線追蹤管線省略了圖形管線的許多固定功能單元,如輸入彙編程式和輸出合併器,因此由應用程式指定如何解釋幾何體。為著色器提供了執行此操作所需的最小屬性集,即基本體中交點的重心坐標。最終,這種靈活性是DXR的一大優勢,允許多種技術,而不需要強制要求特定格式或構造。
所有與光線追蹤相關的GPU工作都通過應用程式調度的命令列表和隊列進行調度。因此,光線追蹤與其他工作(如光柵化或計算)緊密集成,並且可以通過多執行緒應用程式有效地排隊。光線追蹤著色器作為工作項網格進行調度,類似於計算著色器,允許實現利用GPU的大規模並行處理吞吐量,並根據給定硬體的情況執行工作項的低級別調度。
應用程式保留在必要時顯式同步GPU工作和資源的責任,就像光柵化和計算一樣,允許開發人員優化光線追蹤、光柵化、計算工作和記憶體傳輸之間的最大重疊量。光線追蹤和其他調度類型共享所有資源,如紋理、緩衝區和常量,從光線追蹤著色器訪問資源不需要轉換、複製或映射。保存光線追蹤特定數據的資源,如加速結構和著色器表,以及記憶體分配或傳輸不會隱式發生,著色器編譯是顯式的,完全受應用程式控制。著色器可以單獨編譯,也可以成批編譯,如果需要,可以跨多個CPU執行緒並行編譯。
17.4.2 Vulkan RayTracing
Vulkan光線追蹤和DirectX相似,包含新增的Shader類型、加速結構等。
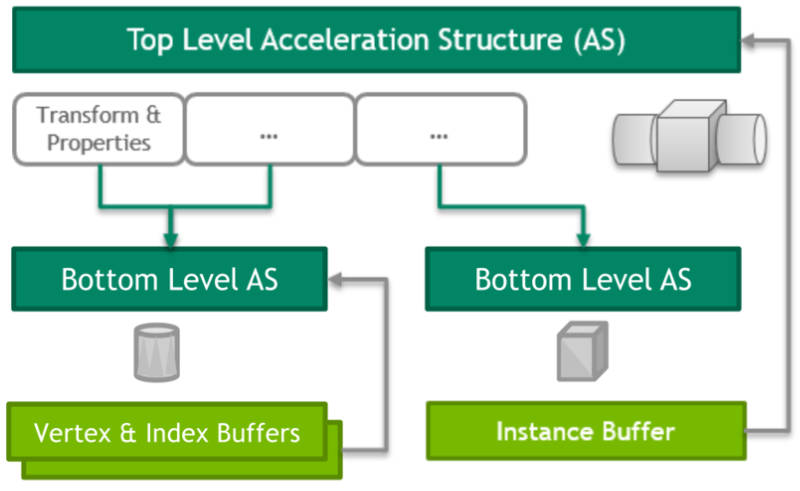
Vulkan的兩層加速結構示意圖。

Vulkan光線追蹤的shader流程。
此外,Vulkan光線追蹤是依靠Vulkan的諸多擴展實現的:
// Vulkan extension specifications
VK_KHR_acceleration_structure
VK_KHR_ray_tracing_pipeline
VK_KHR_ray_query
VK_KHR_pipeline_library
VK_KHR_deferred_host_operations
// SPIR-V extensions specifications
SPV_KHR_ray_tracing
SPV_KHR_ray_query
// GLSL extensions specifications
GLSL_EXT_ray_tracing
GLSL_EXT_ray_query
GLSL_EXT_ray_flags_primitive_culling
主要的類型:
- VkPhysicalDeviceAccelerationStructureFeaturesKHR:描述可由實現支援的加速結構特徵的結構。
- VkPhysicalDeviceRayQueryFeaturesKHR:描述可由實現支援的光線查詢功能的結構。
- VkPhysicalDeviceRayTracingPipelineFeaturesKHR:描述可由實現支援的光線追蹤功能的結構。
- VkPhysicalDeviceAccelerationStructurePropertiesKHR:用於加速結構的物理設備的屬性。
- VkPhysicalDeviceRayTracingPipelinePropertiesKHR:用於光線追蹤的物理設備的屬性。
其它特殊的類型:
-
VK_KHR_deferred_host_operations:允許將高消耗的驅動程式操作卸載到應用程式管理的CPU執行緒池,以便在後台執行緒上完成或跨多個內核並行化任務,可用於光線追蹤管線編譯或基於CPU的加速結構構建。

VkDeferredOperationKHR對象封裝了延遲命令的執行狀態,在其整個生命周期中將處於兩種狀態之一(完成或掛起)。
-
VK_KHR_pipeline_library:提供了一組可鏈接到管線中的著色器的能力,在增量構建光線追蹤管線時非常有用。

主機(Host)加速結構構建提供了利用閑置CPU提高性能的機會,考慮一個遊戲中的假設情景(下圖左),加速結構構造和更新在設備上實現,但應用程式有相當多的CPU空閑時間。將這些操作移動到主機允許CPU執行與前一幀渲染並行的下一幀加速結構,可以提高吞吐量,即使CPU需要更多的掛鐘時間來執行相同的任務(下圖右)。
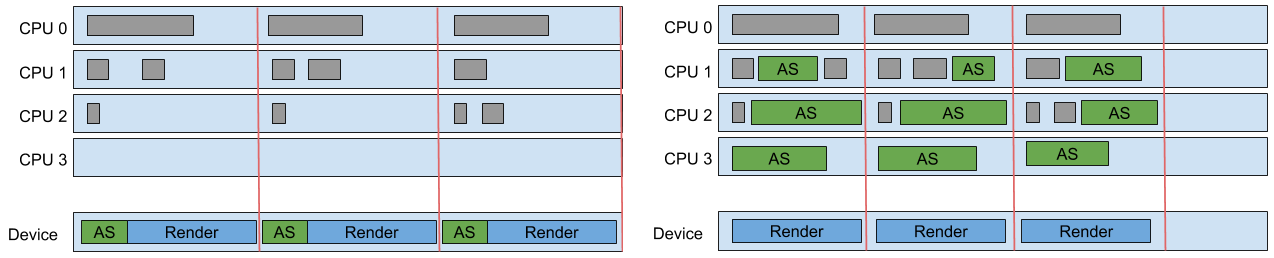
在Vulkan中,根據加速結構追蹤光線需要經過多個邏輯階段,從而在如何追蹤光線方面具有一定的靈活性。交點候選者最初純粹基於其幾何特性找到——是否存在沿光線與加速結構中描述的幾何對象的交點?
相交測試在Vulkan中是無縫的(watertight),意味著對於加速度結構中描述的單個幾何對象,光線不能通過三角形之間的間隙泄漏,並且不能報告同一位置不同三角形的多次命中。此舉並不能保證鄰接的相鄰對象,但意味著單個模型中不會有洞或者過度著色。
一旦找到候選點,在確定交點之前會進行一系列剔除操作,這些剔除操作基於用於遍歷的標誌和加速結構的屬性丟棄候選。剩餘的不透明三角形候選被確認為有效交點,而AABB和非不透明三角形需要著色器程式碼以編程方式確定是否發生命中。
遍歷繼續,直到找到所有可能的候選,並確認或丟棄,並確定最近的命中,也可以使遍歷提前結束,以避免不必要的處理。此舉可用於檢測遮擋,或在某些情況下用作優化。
追蹤光線和獲得遍歷結果可以通過Vulkan中的兩種機制之一完成:光線追蹤管線和光線查詢(下圖):
- 光線查詢提供了對任何著色器階段中光線遍歷邏輯的直接訪問,允許將它們插入現有著色器中,並增強這些著色器表達的效果。
- 光線追蹤管線提供了一種帶有動態著色器選擇的專用光線追蹤機制,使場景和可編程交集邏輯中使用的材質具有極大的靈活性。
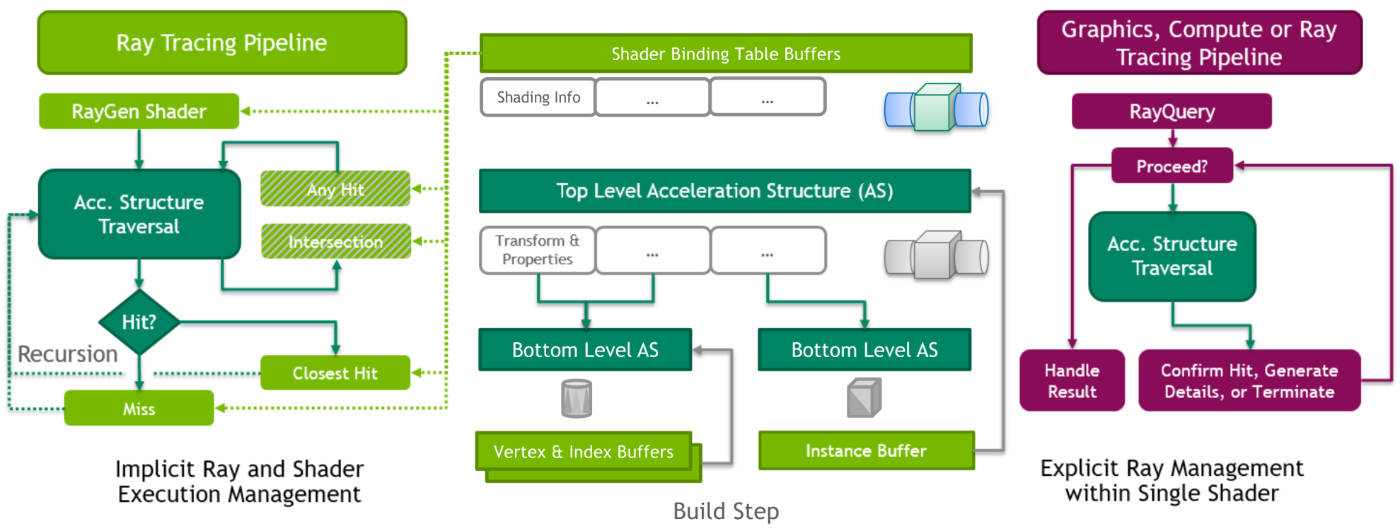
光線查詢可用於執行光線遍歷,並在任何著色器階段返回結果。除了需要加速結構之外,光線查詢僅使用一組新的著色器指令執行。光線查詢使用要查詢的加速結構、確定遍歷屬性的光線標誌、剔除遮罩和被追蹤光線的幾何描述進行初始化。在遍歷過程中,著色器可以訪問潛在交點和提交交點的屬性,以及光線查詢本身的屬性,從而能夠根據幾何體的相交、相交方式和位置進行複雜決策(下圖)。
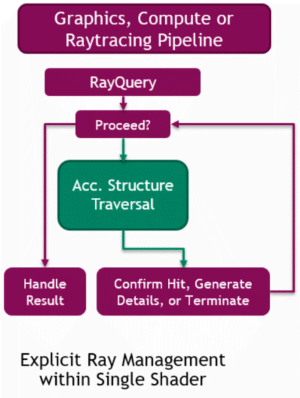
更詳細的教程:NVIDIA Vulkan Ray Tracing Tutorial,示例程式碼:Ray Tracing In Vulkan。
Vulkan光線追蹤效果示例。
17.4.3 Metal RayTracing
Metal光線追蹤的流程如下:
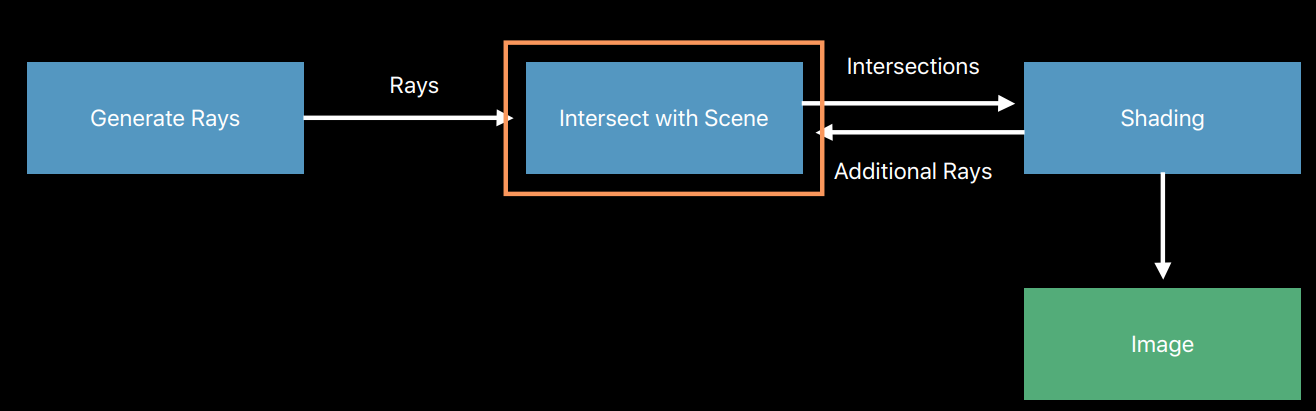
Metal性能著色器使用高性能相交器(MPSRayIntersector)解決了相交消耗高的問題,可加速GPU上的光線三角形相交測試,其接受通過Metal緩衝區的光線,並返回沿每個光線穿過金屬緩衝區最近的交點(對於主光線)或任何交點(對於陰影光線)。Metal性能著色器構建了一種稱為加速結構的數據結構,用於優化計算交點。Metal性能著色器從描述場景中三角形的頂點構建加速結構。若要搜索交點,可向交點提供加速度結構。
MPSRayIntersector在加速結構支援下的檢測交點過程的示意圖:
在頂點緩衝區中的三角形上構建加速結構(可在GPU上構建),將加速結構傳遞到MPSRayIntersector。

有了加速結構和交點檢測器,流程變成了如下圖所示:
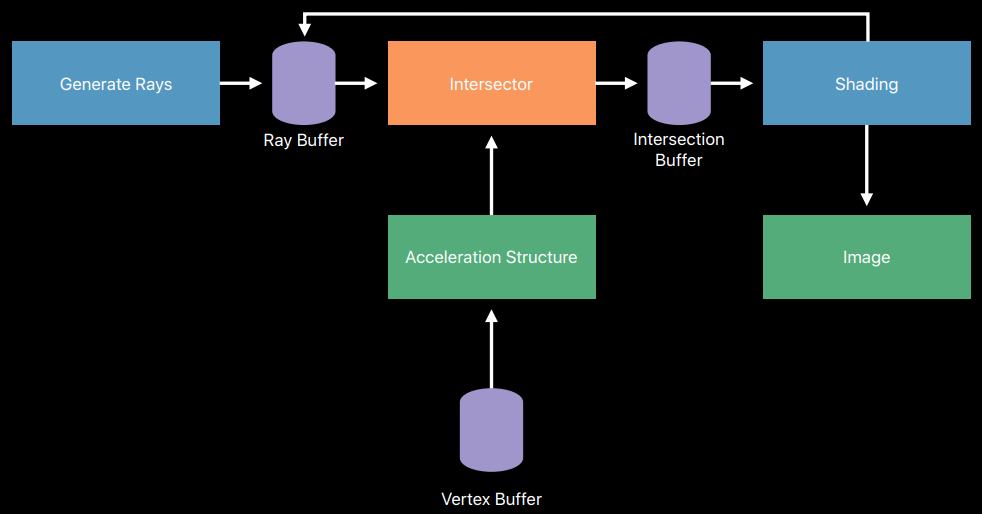
對於動態物體,啟用了Refit機制,比從頭開始建造要快得多,在GPU上運行,無法添加或刪除幾何體,可能會降低加速結構品質。

對於兩級加速結構,場景示例和數據結構如下:
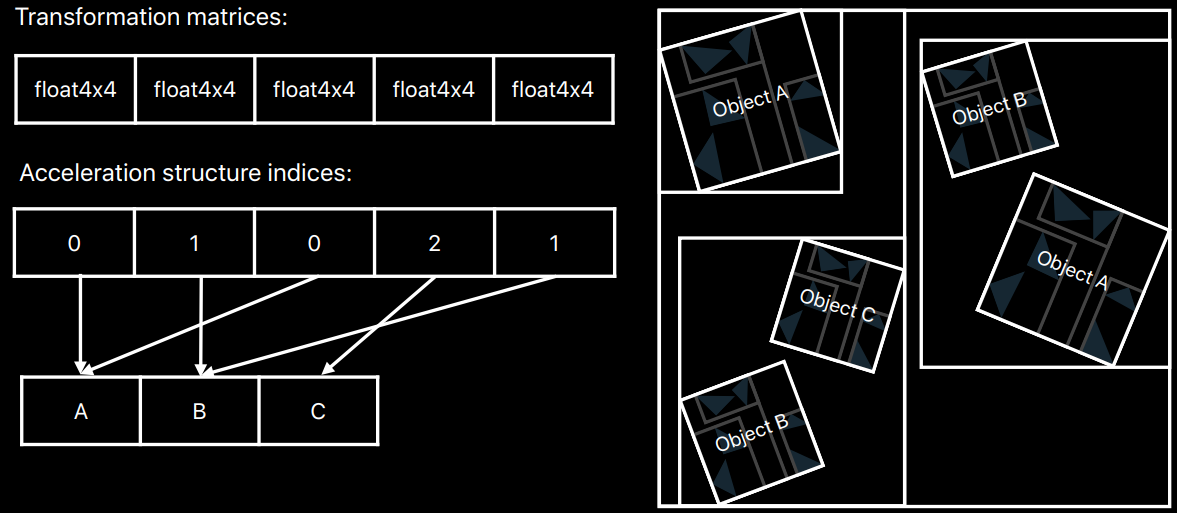
在降噪方面,輸入有本幀和上一幀的噪點影像、深度、法線和運動向量,結果降噪器處理後,輸出降噪影像:
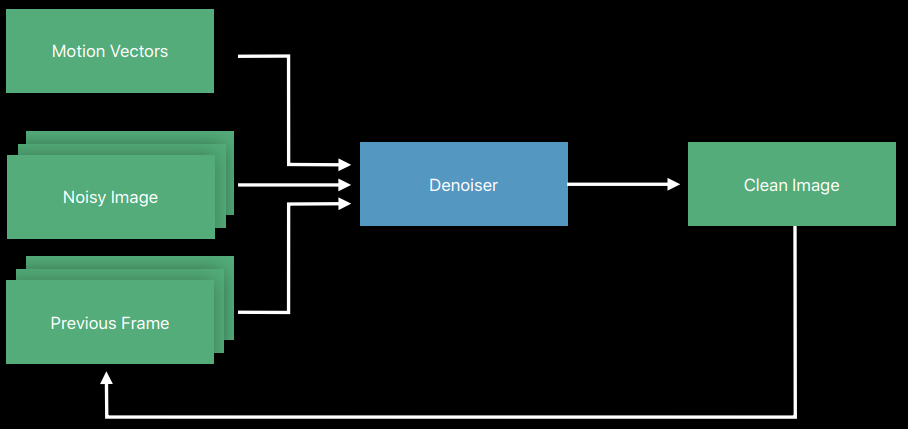
降噪演算法採用了MPSSVGF,高品質的SVGF降噪演算法,MPSSVGFDenoiser協調降噪過程,低級別控制:
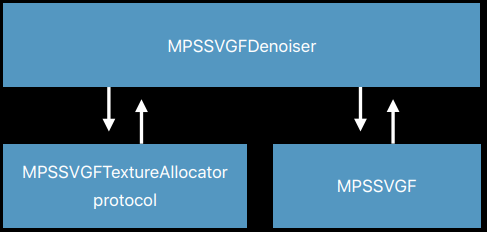
在渲染過程中,和其他友商一樣,採用了混合渲染管線:
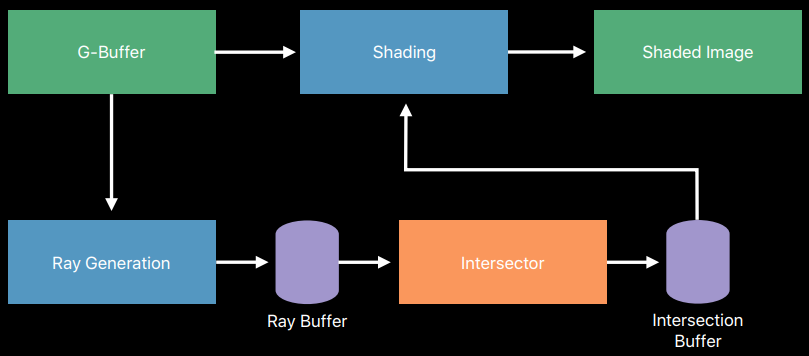
在生成光線時,Metal按指定的順序處理光線,塊狀線性布局可以提高光線一致性,提升快取命中率,從而提高性能:
在計算陰影、AO等過程中,也使用了重要性取樣來生成光線,相同視覺品質需要的光線更少。重要性取樣過程中使用了半球、餘弦取樣、距離取樣:

從左到右:半球、半球+餘弦、半球+餘弦+距離。
為了降低噪點,使用了Halton、Sobol等低差異序列,相鄰像素取樣方向不同,可以對所有像素使用相同的低差異取樣
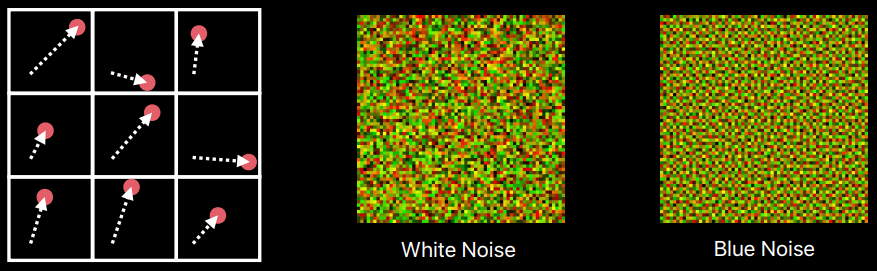
對於GI,渲染流程如下:
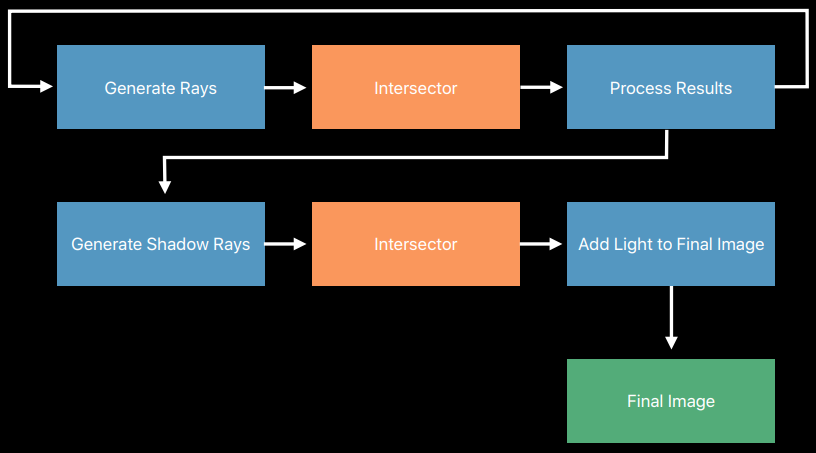
Metal的優化技巧有:
-
減少頻寬佔用。合併負載和存儲,儘可能使用較小的數據類型,分裂結構。反直覺——使用自己的原點和方向緩衝區,避免載入/存儲不需要的結構成員。
-
減少暫存器壓力。同時追蹤存活的變數數量和大小,不要保留結構數據,小心循環計數器和函數調用。
-
消除非活動光線。如離開場景,不再攜帶足夠能量的光線,無法產生可測量的影響,透明表面的全內反射。經過多次迭代之後,最終存活的光線只有23%:

執行緒組變得很少使用,射線相交器仍必須處理非活動射線,控制流語句以剔除非活動光線。可以壓實(Compaction)光線——僅將活動光線添加到下一個光線緩衝區,執行緒組得到充分利用,也適用於陰影光線。
緩衝區索引不再映射到恆定像素位置,需要追蹤每個光線的像素坐標。
此外,Metal還支援交叉分塊(Interleaved Tiling),用於多個GPU:

較小的分塊在GPU上更均勻地分布渲染,偽隨機分配避免與場景相關,相同的GPU在每幀渲染相同的塊。
 ng)
ng)




 ng)
ng)分塊分配時,為每個分塊分配一個隨機數,與閾值比較以選擇GPU。
數據傳輸的流程如下:

Metal的光線追蹤場景通常遵循以下步驟:
1、將主光線從相機投射到場景,並在最近的交點處計算陰影。也就是說,距離攝影機最近的點,光線擊中幾何體。
2、將陰影光線從交點投射到光源。如果陰影光線由於相交幾何體而未到達光源,則交點處於陰影中。
3、在隨機方向上從交點投射次光線以模擬光反彈。在次級光線與幾何體相交的位置添加照明貢獻。
Metal光線追蹤的相關示例程式碼:
- Accelerating ray tracing using Metal
- Rendering reflections in real time using ray tracing
- Control the Ray Tracing Process Using Intersection Queries
- Accelerating ray tracing and motion blur using Metal
17.4.4 Ray tracing X(RTX)
NV作為世界級的圖形學界的探索先鋒隊,在光線追蹤方面有著深入的研發,最終抽象成技術標準RTX平台。
隨著DirectX 12的DXR和Vulkan的支援,使得支援硬體級的光線追蹤技術漸漸普及。NV最先在Turing架構的GPU支援了RTX技術:
由上圖可見,最上層是用戶層(MDL和USD),包含了深度學習和普通應用開發;中間層是圖形API層,支援RTX的有OptiX、DXR、Vulkan,OpenGL並不支援RTX;最底層就是RTX平台,它又包含了4個部分:傳統的光柵化器、光線追蹤(RT Core)、CUDA計算器、AI核心。
當然,除了Turing架構的GPU,還有PASCAL、VOLTA、TURING RTX等架構的眾多款GPU支援RTX技術。(下圖)

下圖是若干款支援RTX技術的GPU運行同一個Demo(Battlefield)的性能對比:
此外,對於光線追蹤,每種光線追蹤的特性都會有不同的負載:
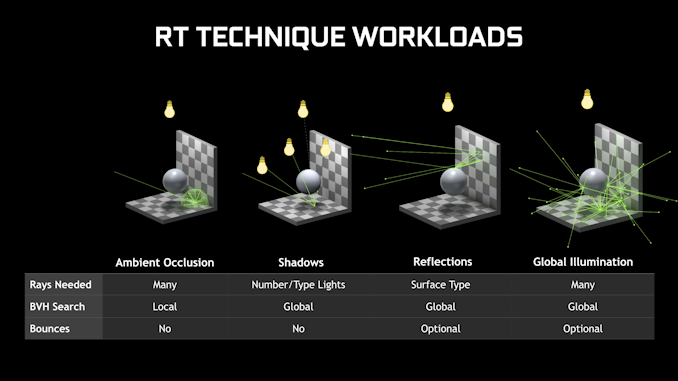
上圖涉及的BVH(Bounding volume hierarchy)是層次包圍盒,是一種加速場景物體查找的演算法和結構體。
對於開發者,需要根據品質等級,做好各類指標預選項,以便程式能夠良好地運行在各個畫質級別的設備中。
TURING RTX的三大核心功能如下:

圖靈還引入了新的工作流和效能測試標準:

利用RT Core和Tensor Core(DLSS),可以大幅提升渲染性能,縮減總時長:

NVIDIA Ampere體系架構GPU系列的最新成員GA102和GA104,GA102和GA104是新NVIDIA 「GA10x」級Ampere架構GPU的一部分,GA10x GPU基於革命性的NVIDIA Turing GPU架構。
GeForce RTX 3090是GeForce RTX系列中性能最高的GPU,專為8K HDR遊戲設計。憑藉10496個CUDA內核、24GB GDDR6X記憶體和新的DLSS 8K模式,它可以在8K@60fps。GeForce RTX 3080的性能是GeForce RTX 2080的兩倍,實現了GPU有史以來最大的一代飛躍,GeForce RTX 3070的性能可與NVIDIA上一代旗艦GPU GeForce RTX 2080 Ti相媲美,GA10x GPU中新增的HDMI 2.1和AV1解碼功能允許用戶使用HDR以8K的速度傳輸內容。
NVIDIA A40 GPU是數據中心在性能和多工作負載能力方面的一次革命性飛躍,它將一流的專業圖形與強大的計算和AI加速相結合,以應對當今的設計、創意和科學挑戰。A40具有與RTX A6000相同的內核數量和記憶體大小,將為下一代虛擬工作站和基於伺服器的工作負載提供動力。NVIDIA A40的能效比上一代高出2倍,它為專業人士帶來了光線追蹤渲染、模擬、虛擬製作等最先進的功能。

Ampere GA10x體系結構具有巨大的飛躍。
GA102的關鍵特性有2倍FP32處理、第二代RT Core、第三代Tensor Core、GDDR6X和GDDR6記憶體、PCIe Gen 4等。
與之前的NVIDIA GPU一樣,GA102由圖形處理集群(Graphics Processing Cluster,GPC)、紋理處理集群(Texture Processing Cluster,TPC)、流式多處理器(Streaming Multiprocessor,SM)、光柵操作器(Raster Operator,ROP)和記憶體控制器組成。完整的GA102 GPU包含7個GPC、42個TPC和84個SM。
GPC是主要的高級硬體塊,所有關鍵圖形處理單元都位於GPC內部。每個GPC都包括一個專用的光柵引擎,現在還包括兩個ROP分區(每個分區包含八個ROP單元),是NVIDIA Ampere Architecture GA10x GPU的一個新功能。GPC包括六個TPC,每個TPC包括兩個SM和一個PolyMorph引擎。
GA102 GPU還具有168個FP64單元(每個SM兩個),FP64 TFLOP速率是FP32操作TFLOP速率的1/64。包括少量的FP64硬體單元,以確保任何帶有FP64程式碼的程式都能正確運行,包括FP64 Tensor Core程式碼。
GA10x GPU中的每個SM包含128個CUDA核、四個第三代Tensor核、一個256 KB的暫存器文件、四個紋理單元、一個第二代光線追蹤核和128 KB的L1/共享記憶體,這些記憶體可以根據計算或圖形工作負載的需要配置為不同的容量。GA102的記憶體子系統由12個32位記憶體控制器組成(共384位),512 KB的二級快取與每個32位記憶體控制器配對,在完整的GA102 GPU上總容量為6144 KB。
Ampere架構還對ROP執行了優化。在以前的NVIDIA GPU中,ROP綁定到記憶體控制器和二級快取。從GA10x GPU開始,ROP是GPC的一部分,通過增加ROP的總數和消除掃描轉換前端和光柵操作後端之間的吞吐量不匹配來提高光柵操作的性能。每個GPC有7個GPC和16個ROP單元,完整的GA102 GPU由112個ROP組成,而不是先前在384位記憶體介面GPU(如前一代TU102)中可用的96個ROP。此方法可改進多取樣抗鋸齒、像素填充率和混合性能。
在SM架構方面,圖靈SM是NVIDIA的第一個SM體系結構,包括用於光線追蹤操作的專用內核。Volta GPU引入了張量核,Turing包括增強的第二代張量核。Turing和Volta SMs支援的另一項創新是並行執行FP32和INT32操作。GA10x SM改進了上述所有功能,同時還添加了許多強大的新功能。與以前的GPU一樣,GA10x SM被劃分為四個處理塊(或分區),每個處理塊都有一個64 KB的暫存器文件、一個L0指令快取、一個warp調度程式、一個調度單元以及一組數學和其他單元。這四個分區共享一個128 KB的一級數據快取/共享記憶體子系統。與每個分區包含兩個第二代張量核、總共八個張量核的TU102 SM不同,新的GA10x SM每個分區包含一個第三代張量核,總共四個張量核,每個GA10x張量核的功能是圖靈張量核的兩倍。與Turing相比,GA10x SM的一級數據快取和共享記憶體的組合容量要大33%。對於圖形工作負載,快取分區容量是圖靈的兩倍,從32KB增加到64KB。

GA10x Streaming Multiprocessor (SM) 。
GA10x SM繼續支援圖靈支援的雙速FP16(HFMA)操作。與TU102、TU104和TU106圖靈GPU類似,標準FP16操作由GA10x GPU中的張量核處理。FP32吞吐量的比較X因子如下表:
| Turing | GA10x | |
|---|---|---|
| FP32 | 1X | 2X |
| FP16 | 2X | 2X |
如前所述,與前一代圖靈體系結構一樣,GA10x具有用於共享記憶體、一級數據快取和紋理快取的統一體系結構。這種統一設計可以根據工作負載進行重新配置,以便根據需要為L1或共享記憶體分配更多記憶體。一級數據快取容量已增加到每個SM 128 KB。在計算模式下,GA10x SM將支援以下配置:
- 128 KB L1 + 0 KB Shared Memory
- 120 KB L1 + 8 KB Shared Memory
- 112 KB L1 + 16 KB Shared Memory
- 96 KB L1 + 32 KB Shared Memory
- 64 KB L1 + 64 KB Shared Memory
- 28 KB L1 + 100 KB Shared Memory
Ampere架構的RT Core比Turing的RT Core的射線/三角形相交測試速度提高了一倍:
GA10x GPU通過一種新功能增強了先前NVIDIA GPU的非同步計算功能,該功能允許在每個GA10x GPU SM中同時處理RT Core和圖形或RT Core和計算工作負載。GA10x SM可以同時處理兩個計算工作負載,並且不像以前的GPU代那樣僅限於同時計算和圖形,允許基於計算的降噪演算法等場景與基於RT Core的光線追蹤工作同時運行。

相比Turing架構,NVIDIA Ampere體系結構在渲染同一遊戲中的同一幀時,可大大提高性能:
上:基於圖靈的RTX 2080超級GPU渲染Wolfenstein的一幀:僅使用著色器核心(CUDA核心)、著色器核心+RT核心和著色器核心+RT核心+張量核心的Youngblood。請注意,在添加不同的RTX處理內核時,幀時間逐漸減少。
下:基於安培體系結構的RTX 3080 GPU渲染一幀Wolfenstein:Youngblood僅使用著色器核心(CUDA核心)、著色器核心+RT核心和著色器核心+RT核心+張量核心。
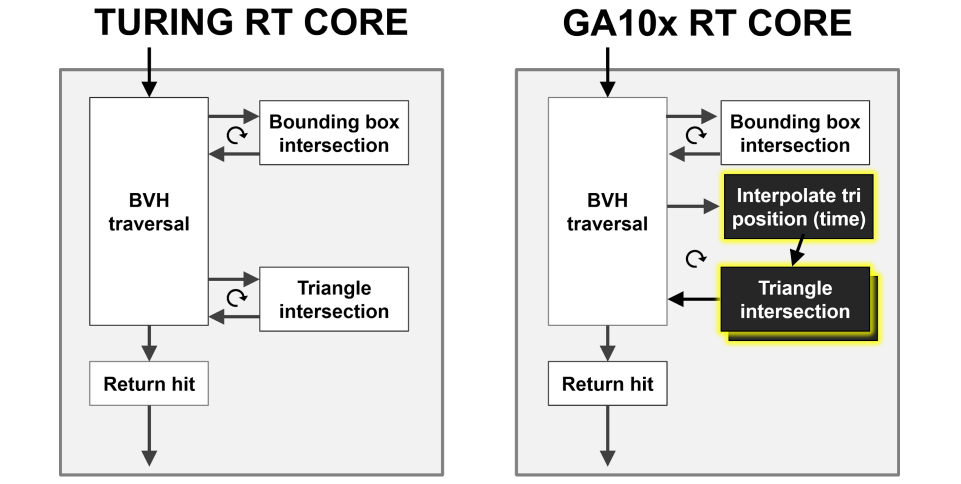
GA10x RT Core使光線/三角形相交測試速率比Turing RT Core提高了一倍,還添加了一個新的插值三角形位置加速單元,以協助光線追蹤運動模糊操作。
在啟用稀疏性的情況下,GeForce RTX 3080提供的FP16 Tensor堆芯操作峰值吞吐量是GeForce RTX 2080 Super的2.7倍,後者具有密集的Tensor堆芯操作:
細粒度結構化稀疏性使用四取二非零模式修剪訓練權重,然後是微調非零權重的簡單通用方法。對權重進行壓縮,使數據佔用和頻寬減少2倍,稀疏張量核心操作通過跳過零使數學吞吐量加倍。(下圖)
下圖顯示了GDDR6(左)和GDDR6X(右)之間的數據眼(data eye)比較,通過GDDR6X介面可以以GDDR6的一半頻率傳輸相同數量的數據,或者,在給定的工作頻率下,GDDR6X可以使有效頻寬比GDDR6增加一倍。
GDDR6X使用PAM4信令提高了性能和效率。
為了解決PAM4信令帶來的信噪比挑戰,開發了一種名為MTA(最大傳輸消除,見下圖)的新編碼方案,以限制高速訊號的轉移。MTA可防止訊號從最高電平轉換到最低電平,反之亦然,從而提高介面信噪比。它是通過在編碼管腳上傳輸的位元組中為每個管腳分配一部分數據突發(時間交錯),然後使用明智選擇的碼字將數據突發的剩餘部分映射到沒有最大轉換的序列來實現的。此外,還引入了新的介面培訓、自適應和均衡方案。最後,封裝和PCB設計需要仔細規劃和全面的訊號和電源完整性分析,以實現更高的數據速率。

在傳統的存儲模型中,遊戲數據從硬碟讀取,然後從系統記憶體和CPU傳輸,然後再傳輸到GPU,使得IO常常成為遊戲的性能瓶頸:
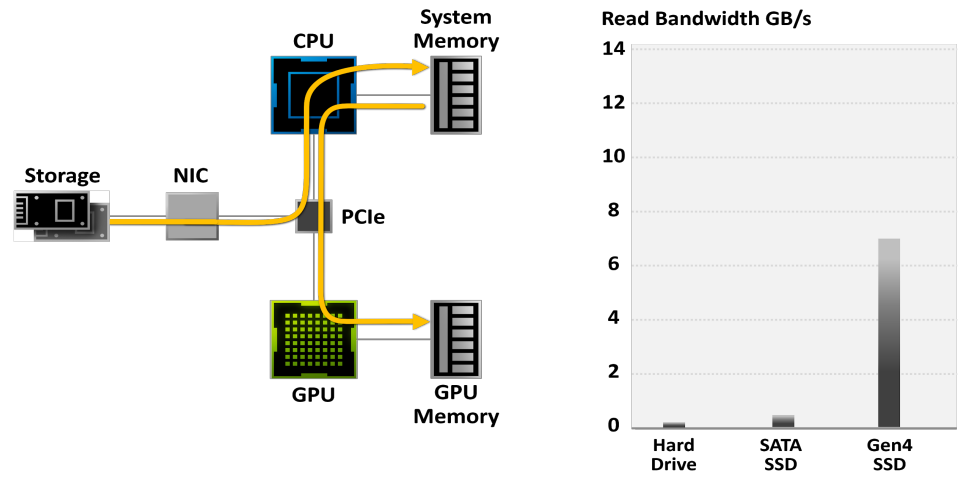
使用傳統的存儲模型,遊戲解壓縮可以消耗Threadripper CPU上的所有24個內核。現代遊戲引擎已經超過了傳統存儲API的能力。需要新一代的輸入/輸出體系結構。數據傳輸速率為灰色條,所需CPU內核為黑色/藍色塊。需要壓縮數據,但CPU無法跟上:
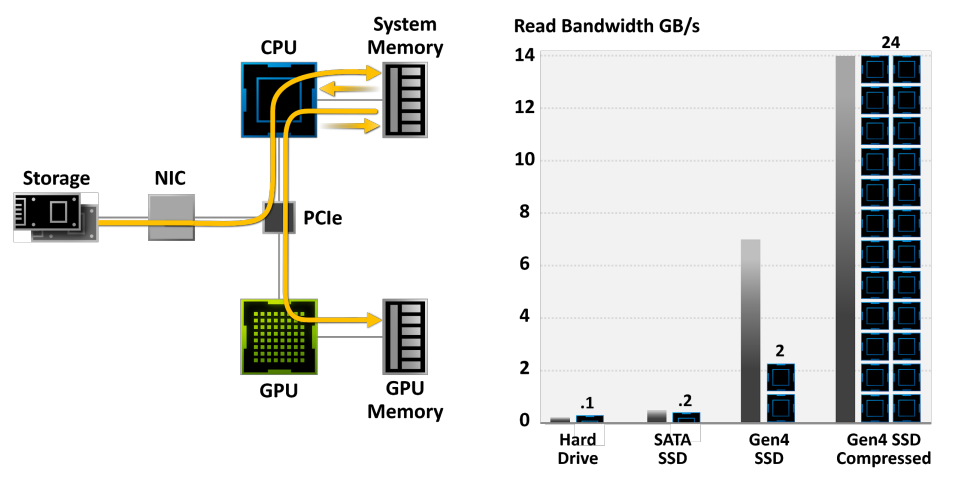
NVIDIA RTX IO插入Microsoft即將推出的DirectStorage API,這是一種新一代存儲體系結構,專為配備最先進NVMe SSD的遊戲PC和現代遊戲所需的複雜工作負載而設計。總之,專門為遊戲訂製的流線型和並行化API可以顯著減少IO開銷,並最大限度地提高從NVMe SSD到支援RTX IO的GPU的性能/頻寬。具體而言,NVIDIA RTX IO帶來了基於GPU的無損解壓縮,允許通過DirectStorage進行的讀取保持壓縮,並傳送到GPU進行解壓縮。此技術可消除CPU的負載,以更高效、更壓縮的形式將數據從存儲器移動到GPU,並將I/O性能提高了兩倍。
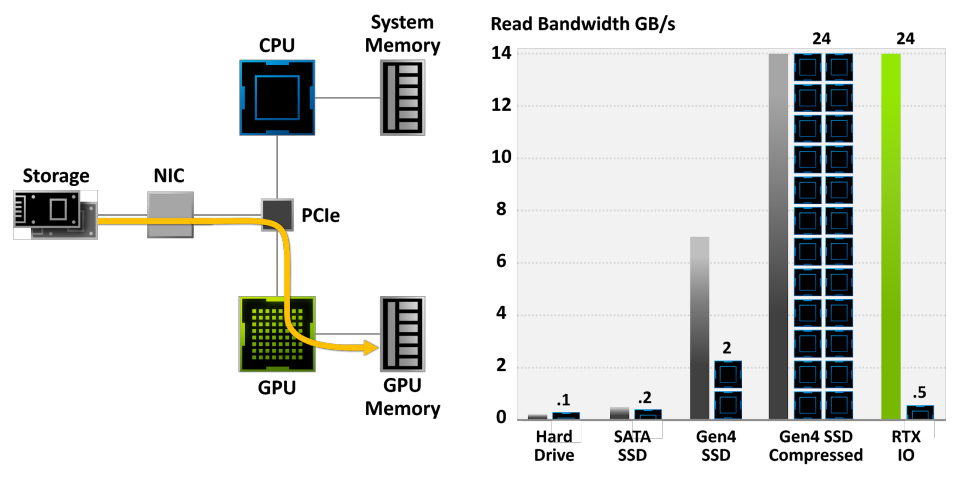
RTX IO提供100倍的吞吐量,20倍的CPU利用率。數據傳輸速率為灰色和綠色條,所需CPU內核為黑色/藍色塊。
關卡載入時間比較。負載測試在24核Threadripper 3960x平台上運行,原型Gen4 NVMe m.2 SSD,alpha軟體。
17.4.5 Radeon Rays / ProRender
Radeon Rays是AMD的高效、高性能光線交點檢測加速庫,如Radeon ProRender所示。它支援一系列用例,包括用於遊戲開發工作流的互動式燈光烘焙和實時間接聲音模擬。特性具體有:
-
支援DirectX 12和Vulkan。
-
自定義AABB,GPU BVH加速,幾何體更新而不完全重建。
-
全譜渲染。

-
AI加速。
-
便於調試的日誌記錄機制、驗證源程式碼更改的測試集。
-
基於MIT的開源。

Radeon Rays用於計算照明快取,採用了混合全局照明解決方案,照明快取使用層次結構,在螢幕空間追蹤光線,作為最後手段的世界空間光線追蹤,BVH流數據。Radeon ProRender是一種快速的GPU加速全局照明渲染器,遊戲內容創建加速有潛力,提供開發人員SDK(C API)、創作者插件。


Radeon ProRender部分特性。

Radeon ProRender渲染樣例。
Radeon ProRender利用新的OpenCL硬體加速渲染的函數,性能的提升取決於場景,具有更複雜著色器的場景通常從硬體加速光線追蹤中獲益較少。下圖是一些簡單的基準場景,使用AMD Radeon測試了硬體加速開關RX 6800 XT圖形卡。
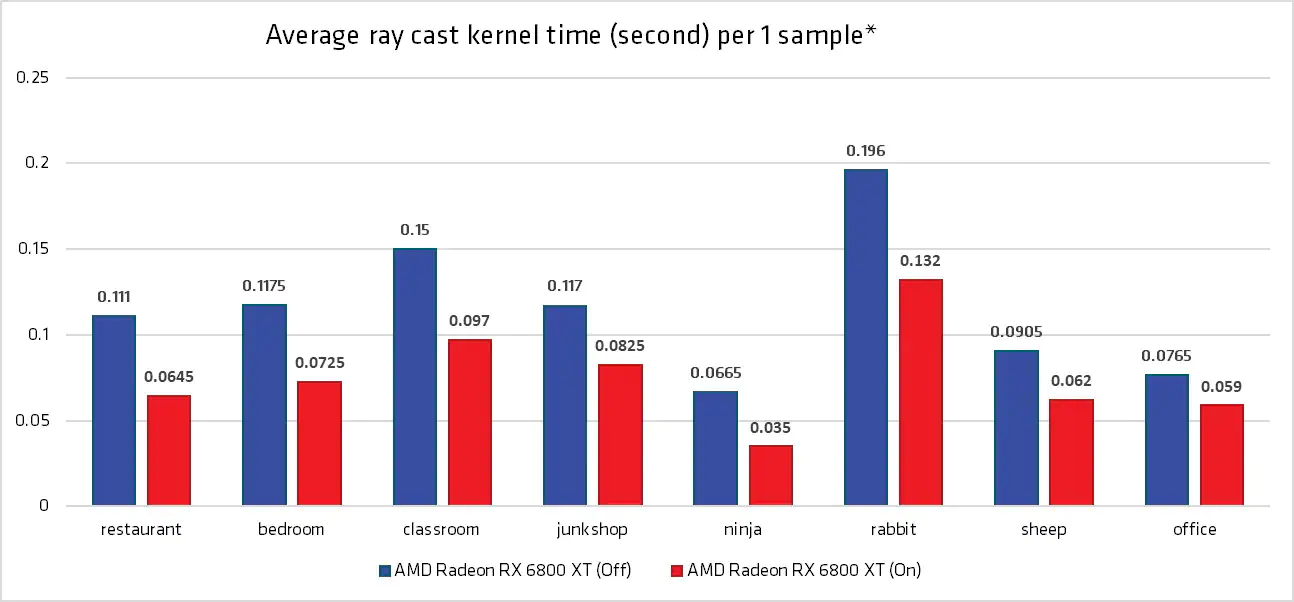
在GPU硬體方面,ZEN 2微體系結構的高級特性包含:
- 從ZEN到ZEN 2的IPC提高了15%。
- 2倍運算快取容量。
- 重新優化的L1I 快取(L1指令快取)。
- 第三代地址生成單元。
- 2倍FP數據路徑寬度。
- 2倍L3容量。
- 提高分支預測準確度。
- 硬體優化的安全緩解措施。
- 通過客戶模式執行陷阱(GMET)實現安全虛擬化。
- 改善SMT公平性(對於ALU和AGU調度器)。
- 改進的寫入組合緩衝區。
「RENOIR」8核處理器流程圖如下:
「MATISSE」16核處理器流程圖如下:
「CASTLE PEAK」 64核處理器流程圖如下:
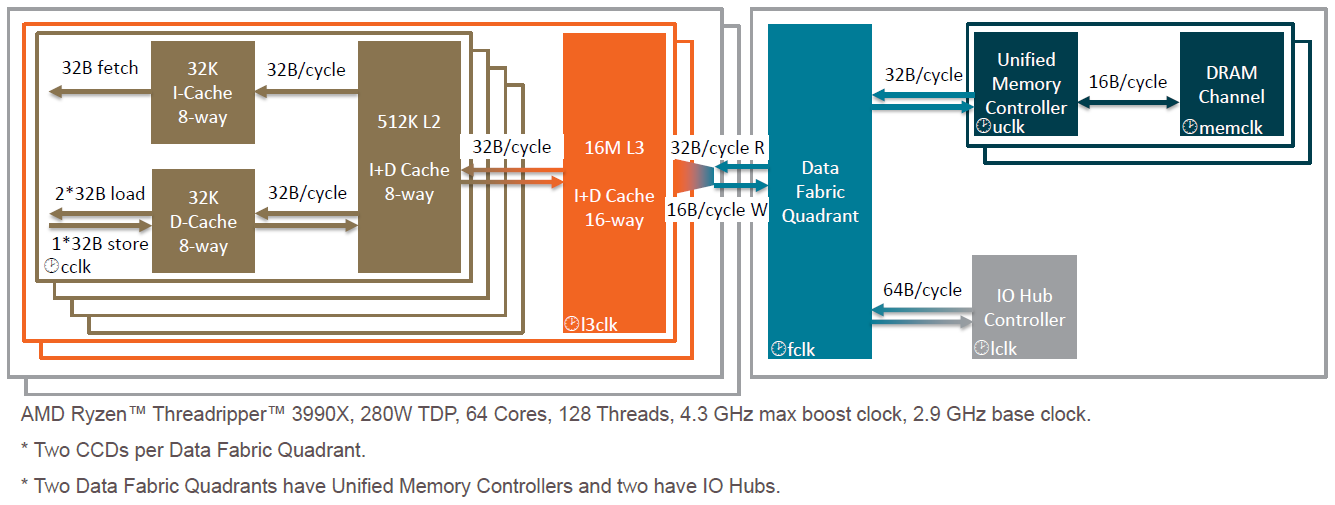
指令集演化歷程如下:
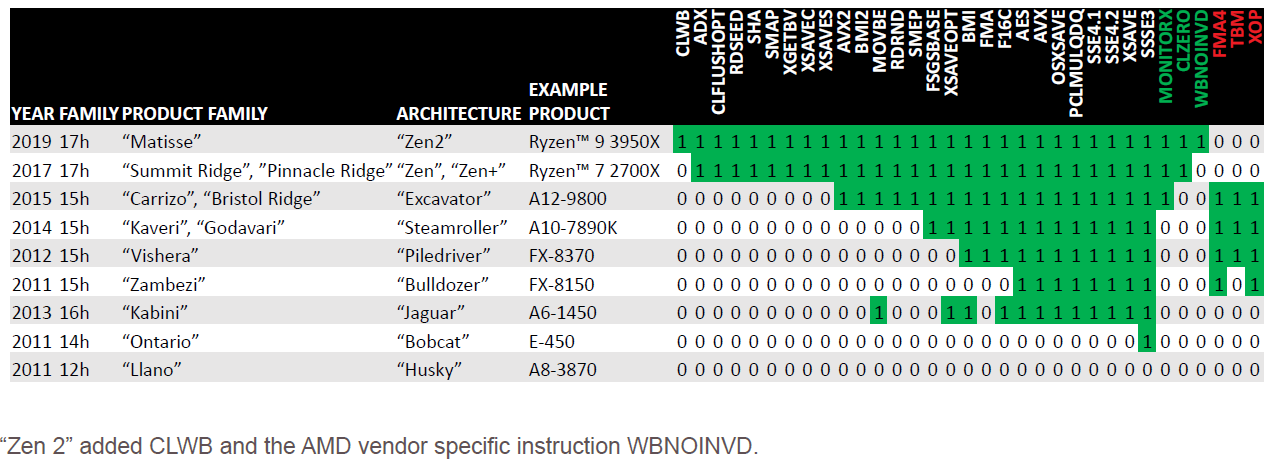
支援軟體預取級別指令:
- 將快取行從指定的記憶體地址載入到由位置引用T0、T1、T2或NTA指定的數據快取級別。
- 如果檢測到記憶體故障,則不會啟動匯流排周期,指令被視為NOP。
- 預取電平T0/T1/T2在「Zen」和「Zen 2」微體系結構中的處理方式相同。
- 用預取NTA表示的非臨時快取填充提示減少了僅使用一次的數據的快取污染。它不適用於小型數據集的快取阻塞。用預取NTA填充到二級快取中的行被標記為更快地從二級快取移出,並且當從二級高速快取移出時,不會插入三級快取。
- 本指令的操作取決於實施。預取填充和逐出策略可能因其他處理器供應商或微體系結構代而異。

各種指令的快取延遲如下表:

重裝(refill)支援三種模式:在相同的CCX內、從局部DRAM、從其它CCX。(下圖)
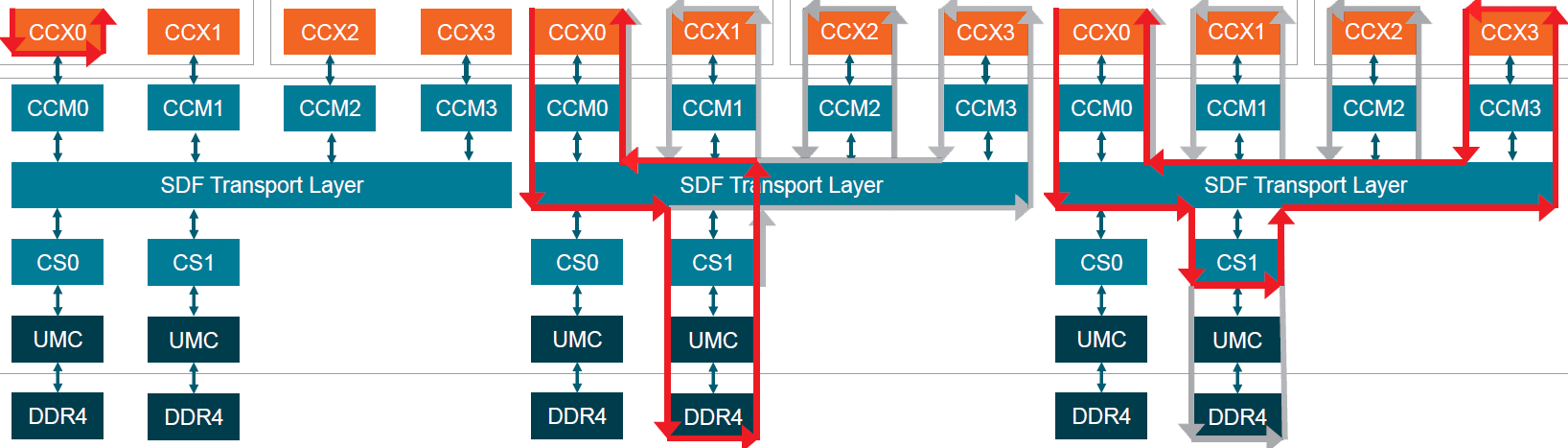
AMD Instinct MI200 Graphics Compute Die (GCD)如下所示:

MI200多晶片模組(AMD Instinct™ MI250/MI250X),其包括如圖所示的兩個圖形計算裸片(GCD)。
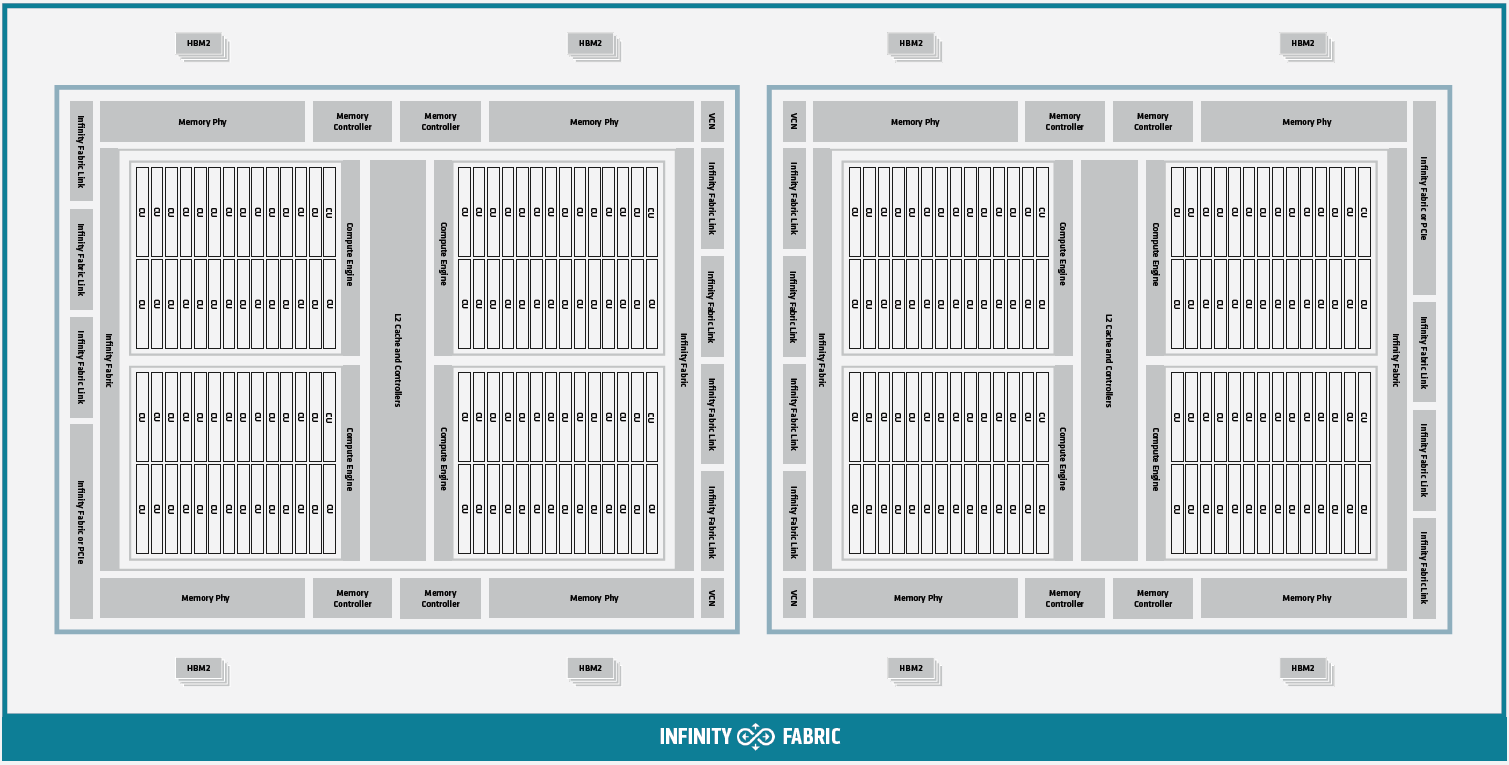
flagship HPC節點結構圖:
HPC/ML節點結構:
ML優化後的節點結構圖:

AMD的開源ROCm堆棧包括開發人員為科學計算和機器學習構建高性能應用程式所需的工具:

17.4.6 PowerVR
在2014年前後,ImageTech在PowerVR GR6500的系列GPU晶片中集成了光線追蹤的相關單元:光線數據管理、場景加速結構生成、光線追蹤單元及快取加速等。

PowerVR Graphics Wizard硬體架構,新增了光線追蹤相關的單元和處理。
Wizard的3個獨特功能:固定功能射線盒和射線三角形測試器,一致性驅動的任務形成與調度,流式場景層次生成器。相干引擎(Coherency Engine)可以讓我們同時處理下圖所示的所有光線:
下圖是其渲染效果:

PowerVR並行的是光線而非像素:
光線採用了AABB測試,受「Fast Ray-Axis Aligned Bounding Box Overlap Tests with Plucker Coordinates」 ( Jeffrey Mahovsky and Brian Wyvill)的啟發。6條線構成了AABB的輪廓,光線原點和每個邊向量的6個平面,平面法線和光線方向向量的點積,6個符號必須匹配且為負值。測試流程如下:
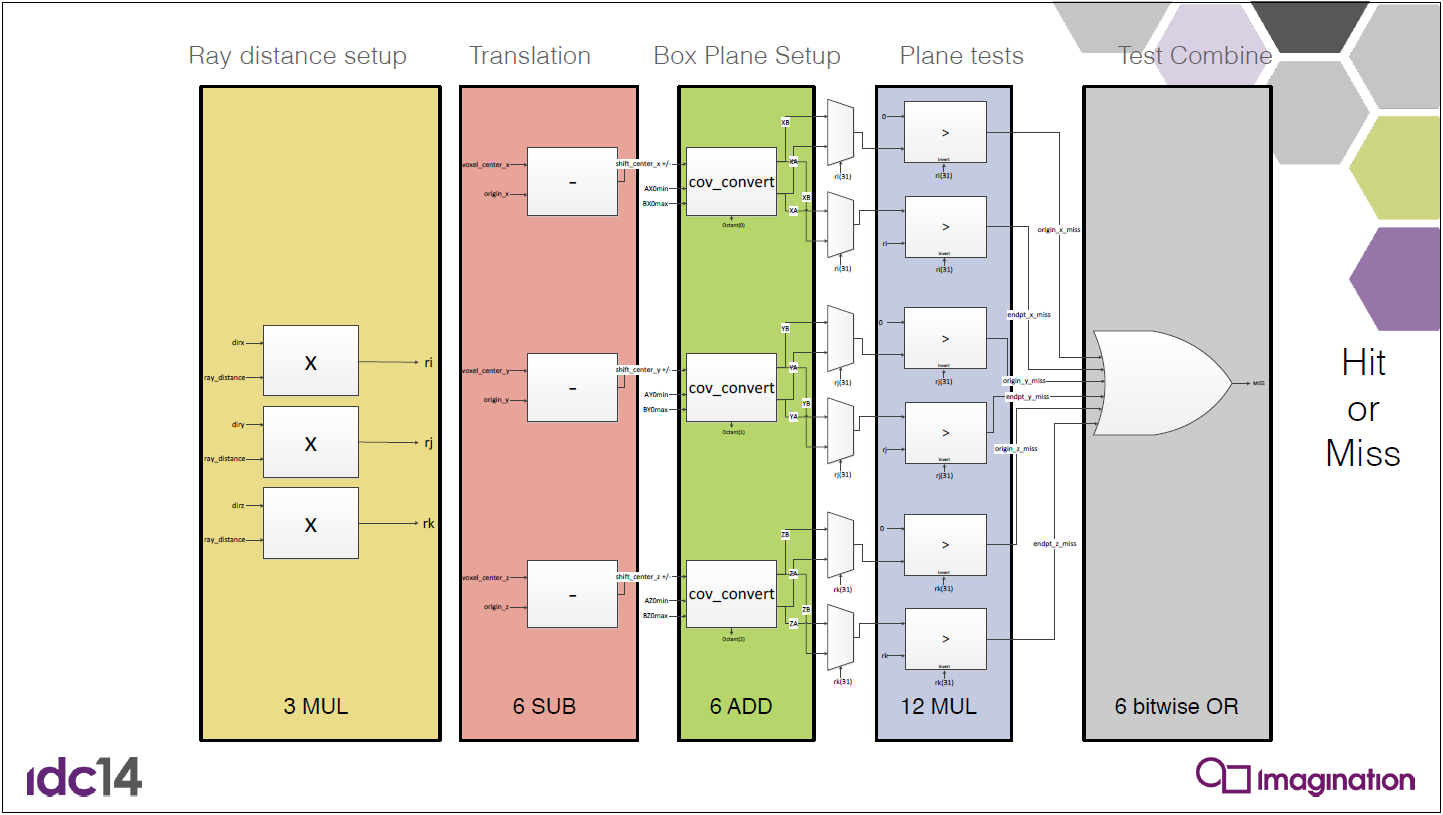
USC指令組打包,下圖顯示了26條指令(如果使用壓縮數據格式,則為32條):

此功能的面積減少了44倍:
光線追蹤單元和相干引擎的架構如下所示:

升序虛擬記憶體地址包含了AABB塊、頂點塊、變種等,大約100M,用於1百萬個三角形,包括可變三角形:
下圖是流式場景層次生成器的效果和樹形結構:

採用了一致性隊列:

自動查找一致性路徑:

場景層次生成器如下所示:
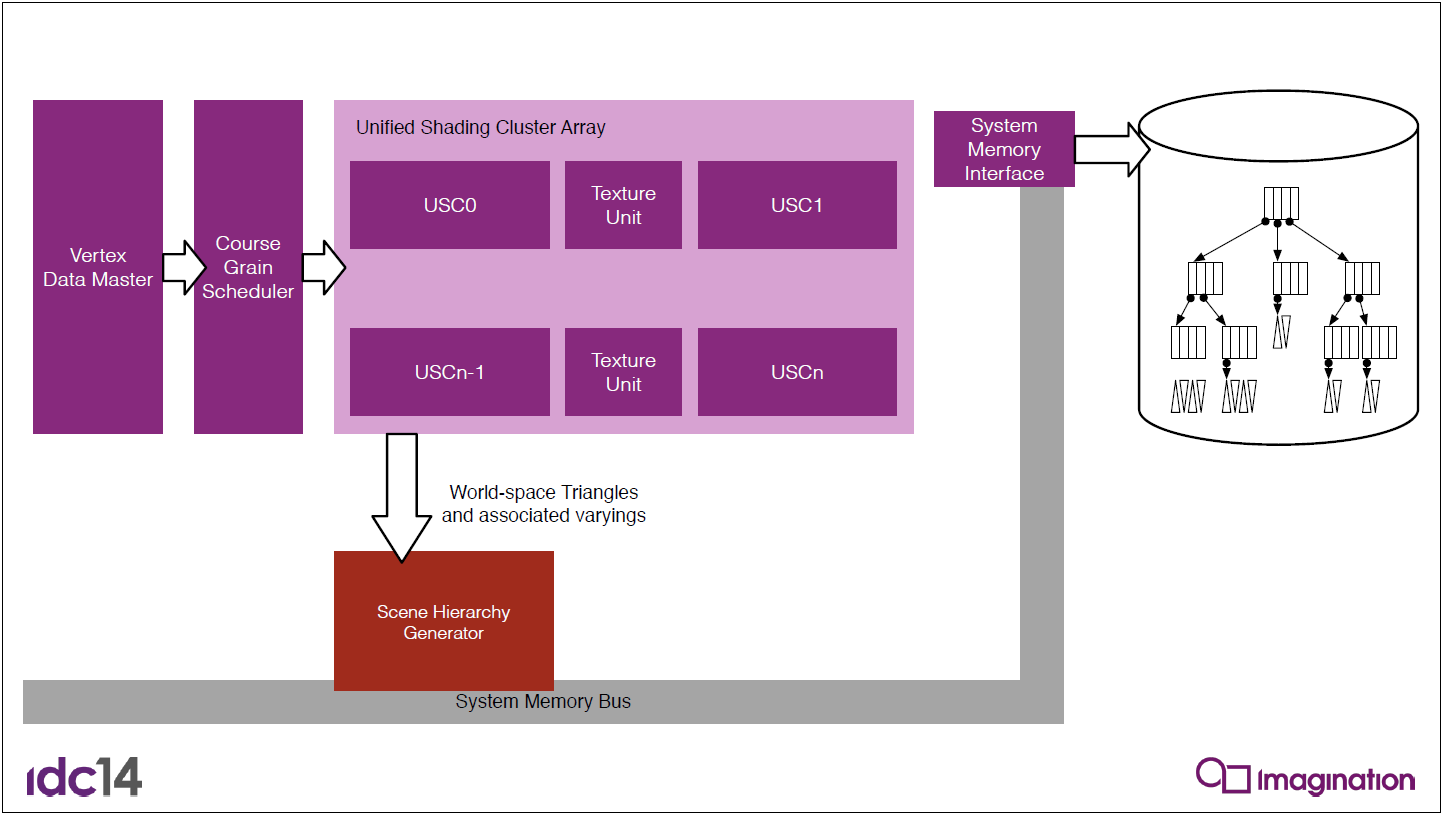
限制:場景由三角形表示——與今天相同,BVH採用經過優化的定義格式進行實現和遍歷,三角形順序通常必須遵循空間相干流,需要近似的場景比例估計,幾何體著色器不與光線追蹤管線內聯。
加強的點在於:著色群集工作負荷不高於頂點著色器,只需處理在世界空間中實際移動的幾何體,唯一演算法僅將工作集約束到內部暫存器,單遍操作:與頂點著色器執行一致,很好地處理「長而瘦的三角形」問題,流式寫入外部存儲器,由於構建演算法,無損壓縮輸出格式,緊湊邏輯。
基於稀疏的log2八叉樹層次結構:

整體執行流程如下:
經過一些三角形處理之後的情形如下:
組裝父節點之後:
一個級別的父節點組裝後如下所示:
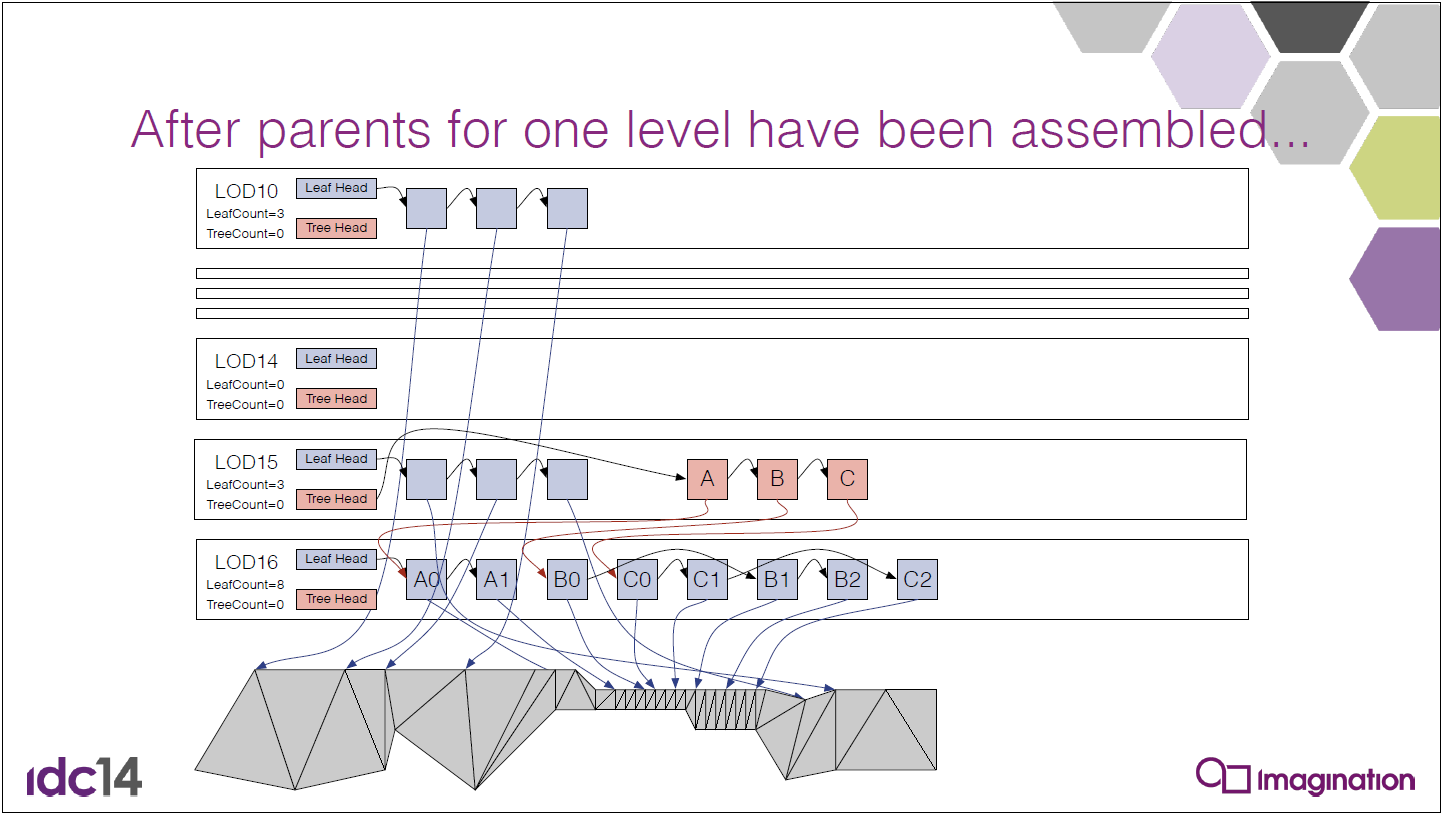
光線追蹤硬體架構各個部件的性能如下:

PowerVR光線追蹤具有硬體中的場景層次生成器(SHG),SHG生成邊界體層次結構數據結構,該數據結構被設計為大大提高檢測哪些三角形與哪些光線相交的效率。使用蠻力方法將需要使用世界上的每個三角形測試每一條光線,過於昂貴而無法實時執行。下圖是基於PowerVR GPU的實時光線追蹤流程圖:
作為對比,以下分別是NV和AMD的實時光線追蹤架構圖:

17.5 UE光線追蹤
本章先闡述UE在集成和實現光線追蹤時的經驗、教訓、優化技術等內容。
17.5.1 UE光線追蹤集成
17.5.1.1 光線追蹤概述
在實時應用程式(如遊戲)中使用光線追蹤具有挑戰性,光線追蹤演算法的許多步驟成本高昂,包括邊界體積層次結構(BVH)構造、BVH遍歷和光線/原始相交測試。此外,通常應用於光線追蹤技術的隨機取樣通常需要每像素數百到數千個樣本來產生收斂影像,遠遠超出了現代實時渲染技術的計算預算幾個數量級。此外,直到最近,實時圖形API還沒有光線追蹤支援,使得當前遊戲中的光線追蹤集成具有挑戰性。2018年,隨著DirectX 12和Vulkan中光線追蹤支援的宣布,這一情況發生了變化。
早在2018年,NVIDIA的Edward Liu(文刀秋二)和Epic Games的Juan Cañada等人將基於RTX的硬體光線追蹤集成進了UE:
- 採用了DirectX光線追蹤(DXR)並將其集成到UE4中,可以重用已有的材質著色器程式碼。
- 利用NVIDIA Turing架構中的RT內核進行硬體加速BVH遍歷和光線/三角形相交測試。
- 發明了用於高品質隨機渲染效果的新型重建濾波器,包括軟陰影、光澤反射、漫反射全局照明、環境遮擋和半透明,每個像素只有一個輸入樣本。
硬體加速和軟體創新的結合賦予開發者能夠創建兩個基於實時電影品質光線追蹤的應用程式,例如「反射」(Lucasfilm)和「光速」(Porsche)。
在大型應用程式(如虛幻引擎)中集成光線追蹤框架是一項具有挑戰性的任務,實際上是UE4發布以來最大的架構變化之一。在將光線追蹤集成到UE4中時,他們的目標如下:
- 性能:是UE4的一個關鍵因素,因此光線追蹤功能應符合用戶的期望。一個有助於性能的決定是,G-Buffer是使用已有的基於光柵化的技術計算的。除此之外,追蹤光線以計算特定的過程,例如反射或區域光陰影。
- 兼容性:光線追蹤過程的輸出必須與現有UE4的著色和後處理管線兼容。
- 著色一致性:UE4使用的著色模型必須通過光線追蹤精確實現,以產生與UE4中現有著色一致的著色結果。具體而言,嚴格遵循現有著色程式碼中的相同數學,對UE4提供的各種著色模型進行BRDF評估、重要性取樣和BRDF概率分布函數評估。
- 最小化中斷:現有UE4用戶應發現集成易於理解和擴展,因此,必須遵循UE設計範式。
- 多平台支援:雖然最初UE4中的實時光線追蹤完全基於DXR,但UE4的多平台特性要求他們設計新系統,使其能夠最終移植到其他未來解決方案,而無需進行重大重構。
集成過程最具挑戰性的是:性能、API、延遲著色光線中的集成、渲染硬體介面(RHI)中所需的更改、將用戶從每個硬體平台的細節中抽象出來的薄層、著色器API的更改、可伸縮性等。
在實驗性UE4實現中,擴展了渲染硬體介面(RHI),其抽象靈感來自NVIDIA OptiX API,但稍微簡化了。該抽象由三種對象類型組成:rtScene、rtObject和rtGeometry。rtScene由RTObject組成,它們實際上是實例,每個都指向rtGeometry。rtScene封裝TLAS,而rtGeometry封裝BLAS。rtGeometry和指向給定RTGeometrics的任何rtObject都可以由多個部分組成,所有部分都屬於相同的UE4基本體對象(靜態網格或骨架網格),因此共享相同的索引和頂點緩衝區,但可能使用不同的(材質)命中著色器。rtGeometry本身沒有關聯的命中著色器。我們在rtObject部分設置命中著色器及其參數。
引擎材質著色器系統和RHI也進行了擴展,以支援DXR中的新光線追蹤著色器類型:Ray Generation、Closest Hit、Any Hit、Intersection和Miss。除了Closest Hit和Any Hit著色器外,還擴展了引擎,以支援使用現有的頂點著色器(VS)和像素著色器(PS)。利用了一個Microsoft DirectX編譯器的擴展開源實用程式,提供了一種從VS和PS的預編譯DXIL表示生成Closest Hit和Any Hit著色器的機制。該實用程式將VS程式碼、輸入彙編階段的輸入布局(包括頂點和索引緩衝區格式和跨距)以及PS程式碼作為輸入。給定該輸入,它可以生成最佳程式碼,執行索引緩衝區提取、頂點屬性提取、格式轉換和VS評估(對於三角形中的三個頂點中的每一個),然後使用命中時的重心坐標對VS輸出進行插值,其結果作為輸入提供給PS。該工具還能夠生成最小的任意命中著色器以執行alpha測試,允許引擎中的渲染程式碼繼續使用頂點和像素著色器,就像它們將被用於光柵化G緩衝區一樣,並像往常一樣設置它們的著色器參數。
在UE集成光線追蹤的其中重要的一環是註冊各種引擎圖元的幾何體。為了註冊用於加速結構構造的幾何體,必須確保UE4中的各種圖元具有為它們創建的RHI級的rtGeometry和rtObject,通常需要確定創建rtGeometry和rtObject的正確範圍。對於大多數圖元,可以在與頂點和索引緩衝區幾何體相同的範圍內創建rtGeometry。對於靜態三角形網格,則很簡單;但對於其他基本體,可能會涉及更多,例如,粒子系統、景觀(地形)基本體和骨架網格(即蒙皮幾何體,可能使用變形目標或布料模擬)需要特殊處理。在UE4中,開發組人員利用了現有的GPUSkinCache——一個基於計算著色器的系統,它在每一幀執行蒙皮到臨時GPU緩衝區,這些緩衝區可以用作光柵化過程、加速結構更新和命中著色器的輸入。還需要注意的是,每個骨架網格實例都需要自己單獨的BLAS;因此,在這種情況下,骨架網格的每個實例都需要單獨的rtGeometry,並且不可能像靜態網格那樣實例化或共享這些實例。
另一個重要環節是更新場景的光線追蹤表示(representation)。每一幀,UE4渲染器執行其渲染循環體,在其中執行多個過程,例如光柵化G緩衝區、應用直接照明或後處理。開發組人員修改了該循環以更新用於光線追蹤目的的場景表示,該表示在最低級別由著色器綁定表、相關記憶體緩衝區和資源描述符以及加速結構組成。
從高級渲染器的角度來看,第一步涉及確保場景中所有對象的著色器參數都是最新的。為此,利用了現有的基本過程渲染邏輯,通常用於光柵化延遲著色渲染器中的G緩衝區。主要的區別在於,對於光線追蹤,必須在場景中的所有對象上執行此循環,而不僅僅是相機截頭體內部和潛在可見的對象,基於遮擋剔除結果。第二個區別是,第一個實現使用了前向著色渲染器的VS和PS,而不是使用延遲著色G緩衝區渲染的VS或PS,因為當著色命中反射時,看起來像是一種自然匹配。第三個區別是,必須更新多個光線類型的著色器參數,在某些情況下,使用稍微不同的著色器。
17.5.1.2 光線追蹤vs光柵化
在大型場景中,更新所有對象的著色器參數可能會花費大量CPU時間。為了避免它,應該致力於傳統上所稱的保留模式渲染(retained mode rendering)。即時模式渲染下,CPU在每一幀重新提交許多相同的命令以一個接一個地繪製相同的對象,而在保留模式渲染中,每一幀執行的工作只需要更新場景持久表示中自最後一幀以來發生的任何變化。保留模式渲染更適合光線追蹤,因為與光柵化不同,在光線追蹤中,需要關於整個場景的全局資訊。因此,NVIDIA RTX支援的所有GPU光線追蹤API(OptiX、DirectX光線追蹤和Vulkan光線追蹤)都支援保留模式渲染。然而,當今大多數實時渲染引擎仍然是圍繞著自OpenGL以來過去二十年中使用的光柵化API的局限性設計的。因此,渲染器被編寫為在每一幀重新執行所有著色器參數設置和繪圖程式碼,理想情況下,只需渲染從相機可見的對象。雖然這種方法對於用來演示實時光線追蹤的小場景效果很好,但它無法擴展到巨大的世界。出於這個原因,UE4渲染團隊開始了一個改造高級渲染器的項目,旨在實現更高效的保留模式渲染方法。
光線追蹤和光柵化渲染之間的第二個區別是,必須從VS和PS程式碼中構建命中著色器,這些程式碼為光線追蹤目的稍微訂製。最初的方法基於UE4中用於前向著色的程式碼,只是跳過了依賴於與螢幕空間緩衝區關聯的資訊的任何邏輯,意味著使用訪問螢幕空間緩衝區的節點的材質在光線追蹤中無法正常工作,在組合光柵化和光線追蹤時應避免使用此類材質。雖然最初的實現使用基於UE4前向渲染著色器的命中著色器,隨著時間的推移,開發組重構了著色器程式碼,使得命中著色器看起來更接近延遲著色中用於G緩衝區渲染的著色器。在此新模式中,所有動態照明都在光線生成著色器中執行,而不是在命中著色器中執行。此舉減少了hit著色器的大小和複雜性,避免了在hit著色器中執行嵌套的TraceRay()調用,並允許我們修改光線追蹤著色的照明程式碼,迭代時間大大減少,因為不必等待重建數千個材質像素著色器。除此之外,還優化了VS程式碼,確保在命中(origin + t * direction)時使用射線資訊計算的位置,從而避免了與VS中位置相關的記憶體負載和計算。此外,在可能的情況下,將計算從VS移動到PS,例如在計算變換法線和切線時。總的來說,將VS程式碼減少到主要用於數據獲取和格式轉換。
第三個差異是更新多種光線類型的參數,意味著在某些情況下,如果其中一種光線類型需要一組完全獨立的VS和PS,必須多次循環場景中的所有對象。然而,在某些情況中,能夠顯著減少額外光線類型的開銷。例如,能夠通過允許RHI抽象同時提交多個光線類型的著色器參數來處理兩種最常見光線類型(材質求值和Any Hit陰影)的更新,這些類型可以使用具有兼容著色器參數的命中著色器。這一要求由DirectX編譯器實用程式保證,該實用程式將VS和PS對轉換為命中著色器,因為它確保了Closest Hit著色器和Any Hit著色器的VS和PS參數布局相同(因為兩者都是從相同的VS與PS對生成的)。考慮到這一點,以及「Any Hit Shadow」光線類型只是使用與材質評估光線類型相同的Any Hit著色器,並結合空的(null)Closest Hit著色器,因此對於兩種光線類型使用相同的著色器綁定表記錄數據,但使用不同的著色器標識符是很簡單的。
在填充著色器綁定表記錄的過程中,開發組還注意在關聯的rtObject中記錄它們的偏移量。需要將此資訊提供給TLAS構建操作,因為DXR實現使用該資訊來決定要執行哪些命中著色器以及使用哪些參數。除了更新所有著色器參數,開發組還必須更新與每個rtObject關聯的實例變換和標誌,這在更新著色器參數之前在單獨的循環中完成,實例級標誌允許控制掩蔽和背面剔除邏輯。在UE4中使用掩蔽位來實現對照明通道的支援,以允許藝術家將特定的燈光集限制為僅與特定的對象集交互。背面剔除位用於確保光柵化和光線追蹤結果在視覺上匹配(剔除對光柵化而言有利於性能,但對光線追蹤不一定成立)。
更新所有光線追蹤著色器參數、rtObject變換以及剔除和掩蔽位後,包含命中著色器的著色器綁定表已準備就緒,所有rtObject都知道其相應的著色器綁定表格記錄。此時,將進入下一步,即調度任何底層加速結構的構建或更新,以及TLAS的重建。在實驗實現中,該步驟還處理與加速結構相關聯的延遲記憶體分配。該階段的一個重要優化是確保BLAS更新後所需的任何資源轉換屏障都將延遲到TLAS構建之前執行,而不是在每次BLAS更新之後立即執行。延遲很重要,因為每個轉換屏障都是GPU上的同步步驟。將轉換合併到命令緩衝區中的單個點可以避免冗餘同步,否則會導致GPU頻繁空閑。通過合併轉換,在所有BLAS更新之後執行一次同步,並允許多個BLAS更新(可能針對許多小三角形網格)在GPU上運行時重疊。
對Miss著色器的使用是有限的,儘管在RHI級別暴露了Miss著色器,但開發組從未在RHI的引擎端使用它們。開發組依賴RHI實現預先初始化一組相同的默認未命中著色器(每種光線類型一個),它只是將有效載荷中的HitT值初始化為特定的負值,以指示光線未命中任何東西。
17.5.1.3 Tier
在創建兩個高端光線追蹤演示的過程中積累了經驗之後,開發組能夠進行一次大規模的重構,可以使程式碼從特定於項目的程式碼過渡到能夠很好地滿足所有UE4用戶需求的程式碼。該階段的最終目標之一是將UE4渲染系統從即時模式移動到保留模式,此舉可帶來更高的效率,因為只有在給定幀發生變化的對象才能有效更新。由於光柵化管線的限制,UE4最初是按照即時模式風格編寫的。然而,這種風格對於光線追蹤大型場景來說是一個嚴重的限制,因為它總是更新每幀的所有對象,即使大多數情況下只有一小部分發生了更改。因此,轉向保留模式樣式是這一階段的關鍵成就之一。為了實現將來在任何平台上集成光線追蹤的最終目標,開發組將需求劃分為不同的層次,以了解支援每個功能需要什麼,以及當存在更先進的硬體時,如何在不犧牲功能的情況下面對任何特定設備的限制。
Tier 1描述了集成基本光線追蹤功能所需的最低功能級別,類似於現有的光線追蹤API,如Radeon光線或Metal性能著色器。輸入是包含光線資訊(原點、方向)的緩衝區,著色器輸出是包含相交結果的緩衝區。該層中沒有內置的TraceRay內部函數,也沒有任何可用的命中著色器。Tier 1非常適合於實現簡單的光線追蹤效果,如不透明陰影或環境遮擋,但超出這些效果具有挑戰性,需要對程式碼進行複雜更改,從而引入限制並難以實現良好的執行效率。
Tier 2支援ray generation著色器,該著色器可以調用TraceRay內部函數,其輸出在追蹤調用後立即可用。此級別的功能還支援動態著色器調度,該調度使用RTPSO和著色器綁定表進行抽象。Tier 2不支援遞歸光線追蹤,因此無法從命中著色器生成新光線。在階段1中,開發組發現在實踐中並不是一個很大的限制,它具有減少命中著色器的大小和複雜性的積極副作用。Tier 2使得在UE4中實現光線追蹤集成中定義的大多數目標成為可能。因此,UE4光線追蹤管線的設計是在假設Tier 2能力的情況下完成的。
Tier 3嚴格遵循DXR規範,支援所有Tier 2功能和具有預定義最大深度的遞歸調用,還支援追蹤ray generation著色器之外的其他著色器類型的光線,以及高級功能,例如可自定義的加速結構遍歷。Tier 3是當時(2018前後)功能最強大的一組功能,它支援以模組化方式集成離線渲染的高級光線追蹤功能,例如光子映射和輻照度快取。UE4中的光線追蹤集成設計為在硬體支援時使用Tier 3功能。
17.5.1.4 光源和降噪
除了從UE4中的光線追蹤集成中吸取的經驗教訓,初始實驗階段對於探索實時光線追蹤的可能性至關重要。開發組從鏡面反射和硬陰影開始,接著添加降噪以近似有限光線預算中的光澤反射和區域光陰影,然後添加環境光遮擋、漫反射全局照明和半透明。
基於光柵化的渲染器(離線和實時)通常將渲染方程拆分為多段光路,並分別處理每個段。例如,為螢幕空間反射執行一個單獨的過程,為直接照明執行另一個過程。此法在光線追蹤渲染器中不太常用,尤其是離線路徑追蹤器——它通過累積數十、數百或數千條光路進行渲染。一些光線追蹤渲染器使用技術來改進收斂性或交互性,例如虛擬點光源(即時輻射度)、路徑空間濾波和大量降噪演算法。
Zimmer等人將整個光線樹拆分為單獨的緩衝區,並在合成最終幀之前對每個緩衝區應用降噪濾波器。在UE的場景中,開發組遵循類似的方法,在嘗試求解渲染方程時分割出現的光路,並對來自不同光線類型(例如陰影、反射和漫反射光線)的結果應用自定義過濾器。對於每個效果,每像素使用少量光線,並積極地對它們進行降噪,以彌補樣本數量不足。利用局部屬性來提高降噪品質(例如光源的大小或有光澤的BRDF波瓣的形狀),並結合結果生成接近離線渲染器生成的影像。開發組稱這種技術為分區光路濾波(Partitioned Light Path Filtering)。
在光線追蹤的演示中,使用線性變換餘弦(LTC)方法計算區域光的照明評估,該方法提供了照明項的無方差估計,但不包括可見性。為了渲染區域燈光的陰影,開發組使用光線追蹤來收集可見性項的雜訊估計,然後將高級影像重建演算法應用於結果。最後,在照明結果的基礎上合成降噪可見性項。在數學上,可以寫成渲染方程的以下分割和近似:
L\left(\omega_{o}\right) &=\int_{s^{2}} L_{d}\left(\omega_{i}\right) V\left(\omega_{i}\right) f\left(\omega_{o}, \omega_{i}\right)\left|\cos \theta_{i}\right| d \omega_{i} \\
& \approx \int_{s^{2}} V\left(\omega_{i}\right) d \omega_{i} \int_{s^{2}} L_{d}\left(\omega_{i}\right) f\left(\omega_{o}, \omega_{i}\right)\left|\cos \theta_{i}\right| d \omega_{i}
\end{aligned}
\]
其中:
- \(L\left(\omega_{o}\right)\)是沿\(\omega_{o}\)方向離開表面的輻射亮度;
- \(V\left(\omega_{i}\right)\)是方向\(\omega_{i}\)上的二元可見性項;
- 表面特性\(f\)是BRDF(雙向反射分布函數);
- \(L_i\left(\omega_{i}\right)\)是沿\(\omega_{i}\)方向的入射光;
- \(\theta_i\)是表面法線與入射光方向之間的角度為,其中\(|\cos \theta_i|\) 考量了由於該角度引起的幾何衰減。
對於漫反射曲面,該近似具有可忽略的偏差,通常用於陰影圖技術。對於光澤表面上具有遮擋的區域光陰影,可以使用Heitz等人的比率估計器獲得更精確的結果。相反,在「光速」(Porsche)演示中,開發組直接使用光線追蹤反射加降噪來處理具有遮擋資訊的鏡面區域光陰影。
17.5.1.5 陰影
為了獲得具有大半影的高品質光線追蹤區域光陰影,通常每個像素需要數百個可見性樣本,以獲得無明顯噪點的估計。所需的光線數量取決於光源的大小以及場景中遮光器的位置和大小。對於實時渲染,有更嚴格的光線預算,數百條光線遠遠超出了性能預算。「反射」(Lucasfilm)和「光速」(Porsche)演示使用了每個光源每像素一個樣本,對於這個數量的樣本,結果包含大量的雜訊。開發組應用了一個先進的去噪濾波器來重建一個接近基準真相的無噪影像。
開發組設計了一種專用於半影區域光陰影的降噪演算法,陰影降噪器具有空間分量和時間分量,空間分量的靈感來自最近基於局部遮擋的頻率分析的高效濾波器的工作,例如,Yan等人的軸對齊軟陰影濾波(axis-aligned filtering for soft shadows)和剪切濾波器(sheared filter)。降噪器知道光源的相關資訊,例如光源的大小、形狀和方向、光源離接收器的距離,以及陰影光線的照射距離。降噪器使用該資訊來嘗試推導出每個像素的最佳空間濾波器足印。足印是各向異性的,每個像素具有不同的方向,下圖顯示了各向異性空間核的近似可視化。內核形狀沿半影方向延伸,從而在降噪後獲得高品質影像。降噪器的時間分量將每個像素的有效取樣數增加到8–16左右。如果啟用時間濾波器,則方差是輕微的時間延遲,但按照Salvi的建議執行時間截取以減少延遲。

陰影降噪器中使用的濾波器內核的可視化(綠色)。注意它是如何各向異性的,並沿著每個半影的方向延伸。
假設降噪器使用每個光源的資訊,必須分別降噪每個光源投射的陰影,以至於降噪成本與場景中光源的數量成線性關係。然而,降噪結果的品質高於開發組嘗試對多個光源使用公共濾光器的品質,因此在光線追蹤的兩個演示選擇了每個光源一個濾光器。
下圖中的輸入影像採用每像素一條陰影光線進行渲染,以模擬汽車頂部巨大矩形光源投射的軟照明。在這樣的取樣率下,得到的影像非常明顯的噪點。開發組的空間降噪器消除了大部分噪點,但仍存在一些偽影。結合時間和空間降噪分量,結果接近於以每像素2048條光線渲染的基準真相影像。

(a)降噪器工作在每像素一條陰影光線渲染的雜訊輸入上。(b) 只有降噪器的空間分量,仍然存在一些低頻偽影。(c) 時空降噪器進一步改進了結果,並且(d)它與基準真相非常匹配。
對於中等大小的光源,空間降噪器可產生高品質的結果。在「反射」(Lucasfilm)演示中,僅空間降噪就足以產生陰影品質結果。對於在「光速」(Porsche)演示中使用的巨型光源類型,純空間降噪結果不符合品質標準。因此,還在「光速」(Porsche)演示中使用了時間分量降噪器,以輕微的時間延遲為代價提高了重建品質。
17.5.1.6 反射
真實反射是基於光線追蹤渲染的另一個關鍵承諾。當前基於光柵化的技術,如螢幕空間反射(SSR),經常會受到螢幕外內容中的偽影的影響。其他技術,如預計算光源探針,無法很好地擴展到動態場景,也無法精確模擬光澤反射中存在的所有特徵,如沿表面法線方向拉伸和接觸硬化。此外,光線追蹤可以說是處理任意形狀表面上的多次反彈反射的最有效方法。下圖展示了「反射」(Lucasfilm)演示中使用光線追蹤反射產生的效果類型,注意Phasma盔甲各部分之間的多彈孔相互反射。

使用光線追蹤渲染的Phasma上的反射。注意盔甲各部分之間的精確相互反射,以及用降噪器重建的輕微光澤反射。
雖然光線追蹤使支援任意曲面上的動態反射變得更容易,即使對於螢幕外內容,但計算反射反彈的命中點處的著色和照明成本很高。為了降低反射命中點的材質評估成本,開發組提供了使用不同的藝術家簡化材質進行光線追蹤反射著色的選項。這種材質簡化對最終感知品質影響很小,因為反射對象通常在凸反射器上最小化,去除材質中的微觀細節通常在視覺上不明顯,但對性能有利。下圖比較了主視圖中多個紋理貼圖中具有豐富微觀細節的常規複雜材質(左)和反射命中著色中使用的簡化版本(右)。

左:具有完整微觀細節的原始Phasma材質;右:用於對反射光線命中點進行著色的簡化材質。
在光澤反射的降噪方面,使用光線追蹤獲得完全平滑的鏡面反射是很好的,但在現實世界中,大多數鏡面反射曲面都不是鏡像。它們的表面通常具有不同程度的粗糙度和凹凸。根據粗糙度和入射輻射亮度,使用光線追蹤,通常會使用數百到數千個樣本隨機取樣材質的局部BRDF。這樣做對於實時渲染是不切實際的。
開發組實現了一種自適應多彈跳機制來驅動反射光線的生成。反射反彈射線的發射由撞擊表面的粗糙度控制,因此撞擊粗糙度較高的幾何體的射線會更早被終止。平均而言,開發組只為每個像素指定了兩條反射光線,用於兩次反射反彈,因此對於每個可見著色點,只有一個BRDF樣本。結果非常明顯的噪點,開發組再次應用複雜的降噪濾波器來重建接近基準真相的光澤反射。
開發組設計了一種降噪演算法,只對反射的入射輻射項有效。光澤反射是入射輻射項L和陰影點周圍半球上的BRDF \(f\)的乘積的積分,將乘積的積分分離為兩個積分的近似乘積:
\]
它簡化了降噪任務,僅對入射輻射項應用降噪\(\int_{S^{2}} L\left(\omega_{i}\right) d \omega_{i}\),BRDF積分可以分離和預積分,是預集成光照探針的常見近似。此外,反射反照率也包含在BRDF中,因此通過僅過濾輻射項,不必擔心過度模糊紋理細節。
濾波器堆棧具有時間和空間分量。對於空間部分,開發組推導了螢幕空間中的各向異性形狀核,該核在局部陰影點處遵守BRDF分布。根據命中距離、表面粗糙度和法線,通過將BRDF波瓣投影回螢幕空間來估計核,得到的內核具有不同的內核大小和每個像素的方向,如下圖所示。

基於BRDF的反射濾波器內核的可視化。
基於BRDF的過濾器內核的另一個值得注意的特性是,它可以通過僅從鏡像表面進行過濾來產生中等粗糙的光滑表面,如下圖所示。過濾器從1 spp輸入產生令人信服的結果,與16384 spp的基準真相渲染結果非常匹配,參考下圖中和下圖下。

上:反射空間濾波器的輸入,如果它只是一個完美的鏡像反射影像;中:左圖的反射空間濾波器的輸出應用於鏡面反射影像,模擬了0.15的GGX平方粗糙度,它產生了光澤反射的所有預期特徵,如沿法線方向的接觸硬化和延伸;下:使用無偏隨機BRDF取樣(每像素數千條射線)渲染的GGX平方粗糙度為0.15。
該空間濾波器可以忠實地重建具有中等粗糙度(GGX平方粗糙度小於約0.25)的光滑表面。對於更高的粗糙度值,採用有偏隨機BRDF取樣,如Stachowiak等人,並將時間分量與空間分量相結合,以獲得更好的降噪品質。
反射表面上的時間重投影需要反射對象的運動矢量,可能很難獲得。之前,Stachowiak等人使用反射虛擬深度來重建平面反射器內反射物體的攝像機移動引起的運動矢量。然而,這種方法對於曲面反射器(curved reflector)不太有效。Hirvonen等人提出了一種新方法,將每個局部像素鄰域建模為薄透鏡,然後使用薄透鏡方程推導反射物體的運動矢量,它適用於曲面反射器,開發組使用這種方法計算時間濾波器中的運動矢量。
線性變換餘弦(LTC)是一種在分析上為任意粗糙度生成真實區域光陰影的技術,但它不處理遮擋。由於反射解決方案產生了每像素一個樣本的合理光澤反射,因此可以使用它直接評估面光源材質著色的鏡面反射分量。開發組沒有使用LTC,而是簡單地將面光源視為發射對象,在反射命中點對其進行著色,然後應用降噪濾波器重建包括遮擋資訊的鏡面著色。下圖顯示了兩種方法的比較。

場景地板是一個純鏡面,GGX平方粗糙度為0.17。(a)使用LTC計算兩個區域燈光的照明。當LTC產生正確的高光時,本應遮擋部分高光的汽車反射消失,使汽車看起來不接觸地板。(b) 對於光線追蹤反射,請注意光線追蹤如何處理來自汽車的正確遮擋,同時也從兩個區域燈光產生看似合理的光澤高光。
17.5.1.7 全局光照
為了追求照片真實感,「反射」(Lucasfilm)和「光速」(Porsche)演示使用光線追蹤計算間接照明,以提高渲染影像的真實感。但在兩個演示中使用的技術略有不同。「反射」(Lucasfilm)使用光線追蹤從預計算的體積光照貼圖中獲取輻照度資訊,以計算動態角色上的間接照明。「光速」(Porsche)使用了一種更為暴力的方法,直接使用來自G-Buffer的兩次間接漫反射光線進行路徑追蹤。它們都使用了下一事件估計(next event estimation)來加速收斂。
對於AO,環境光遮擋提供了一種近似的全局照明,該照明具有物理靈感且藝術家可控。將照明與遮擋分離會破壞物理正確性,但會提供可測量的效率。環境遮擋直接應用了幾十年來一直在電影中使用的相同的、有良好記錄的演算法——以餘弦半球分布發射多條光線,以候選點的著色法線為中心,生成了一個螢幕空間遮擋遮罩,該遮罩全局衰減照明貢獻。
雖然虛幻引擎支援螢幕空間環境遮擋(SSAO),但其存在明顯的缺陷——對視錐體的依賴導致邊界處的暗角(vignetting),並且不能準確捕獲主要平行於觀察方向的薄遮擋。此外,視錐體外的遮擋物無法對SSAO產生影響。然而,使用DXR,使得我們可以捕獲與視錐體無關的方向遮擋。
UE還使用了來自光照貼圖的間接漫反射。對於「反射」(Lucasfilm),需要一種能夠提供有效顏色滲出的環境遮擋技術。開發組實現了一個間接漫反射過程作為參考比較。對於該演算法,以與傳統環境遮擋類似的方式,從候選G-Buffer樣本中投射光線的餘弦半球分布。不記錄hit-miss因素,而是記錄了可視光線擊中發射器時的BRDF加權結果。正如預期的那樣,獲得有意義的結果所需的射線數量是難以解決的,但它們為更近似的技術提供了基準線。
開發組摒棄暴力計算,而採用了UE的光照映射解決方案,以提供近似的間接貢獻,將體積光照貼圖中的評估替換為環境遮擋光線的發射提供了一個合理的間接結果。與傳統環境遮擋演算法的加權可見性過程相比,生成的輻照度過程更容易降噪。對比影像如下所示。

全球照明技術比較。上:螢幕空間環境遮擋;中:燈光貼圖的間接漫反射;下:用於參考的一次彈跳的路徑追蹤。
除了使用預計算的光照貼圖渲染間接漫射照明,開發組還開發了一種路徑追蹤解決方案,進一步改進了全局照明效果。在對雜訊輻照度應用重建濾波器之前,我們使用路徑追蹤和下一事件估計來渲染一次反彈間接漫射照明,提供了比之前更準確的顏色滲出。
Mehta等人提出了用於漫反射間接照明的軸對齊濾波器,開發組使用了類似的降噪器。對於「光速」(保時捷)演示,降噪更具挑戰性。由於使用的是無需任何預計算的暴力路徑追蹤,因此將基於Mehta等人的空間濾波器與時間濾波器相結合,以獲得所需的品質。對於「反射」(Lucasfilm)演示,由於從附近的光照貼圖紋理元素中提取,因此使用時間抗鋸齒結合空間濾波器提供了足夠好的品質。
開發組僅對照明的間接漫反射分量應用去噪器,以避免過度模糊紋理細節、陰影或鏡面高光,因為它們在其他專用降噪器中單獨過濾。對於空間濾波器,應用了Mehta等人提出的具有從命中距離導出的足跡的世界空間空間核。根據命中距離調整濾波器大小避免了間接照明中細節的過度模糊,並使間接陰影等特徵更清晰。當與時間濾波器相結合時,它還根據像素累積了多少重投影樣本來減少空間內核佔用。對於具有更多時間累積樣本的像素,開發組應用了更小的空間濾波器足跡,從而使結果更接近於基準真相。下圖顯示了使用恆定半徑進行過濾與基於射線命中距離和時間取樣計數調整過濾器半徑的比較。顯然,使用適配的濾波器足跡在接觸區域提供了更好的精細細節。

同樣的想法也有助於光線追蹤環境遮擋降噪。下圖(a)具有恆定世界空間半徑的去噪光線追蹤環境遮擋,下圖(b)使用命中距離和時間樣本計數引導的自適應核半徑的降雜訊環境遮擋。
再次清楚的是,使用自適應濾波器大小導致在降噪環境遮擋中更好地保留接觸細節。
17.5.1.8 半透明
「光速」(保時捷)演示帶來了許多新挑戰,最明顯的最初挑戰是渲染玻璃,傳統的實時半透明渲染方法與延遲渲染演算法相衝突。通常,開發人員需要在單獨的前向通道中渲染半透明幾何體,並在主延遲渲染上合成結果。可應用於延遲渲染的技術通常不適用於半透明幾何體,從而造成不兼容,使得半透明和不透明幾何體的集成變得困難。
幸運的是,光線追蹤提供了表示半透明的自然框架。使用光線追蹤,半透明幾何體可以以統一幾何體提交的方式輕鬆與延遲渲染結合。它提供了任意的半透明深度複雜性以及正確模擬折射和吸收的能力。
開發組在虛幻引擎中實現的光線追蹤半透明使用了與光線追蹤反射類似的單獨光線追蹤通道。事實上,大多數著色器程式碼在這兩個通道之間共享。然而,兩者的行為方式有一些細微的差別。
第一種差異是使用提前光線終止(early-ray termination),以防止光線能量接近零時不必要地穿越場景;例如,如果移動得更遠,其貢獻可以忽略不計。
另一個差異在於,半透明光線追蹤的最大光線長度可防止碰撞已完全著色並存儲在相應像素的不透明幾何體。但是,如果執行折射,則半透明命中可能會導致任意方向上的新光線,並且該新光線或其後代可能會命中需要著色的不透明幾何體。在對此類不透明命中執行任何照明之前,將不透明命中點重新投影到螢幕緩衝區,如果在該重新投影步驟之後找到有效數據,則使用它們。這個簡單的技巧允許我們利用在G-Buffer中對不透明幾何體執行所有光線追蹤照明和降噪時獲得的更高視覺品質。此法可能適用於某些有限的折射量,但由於在這種情況下使用錯誤的入射方向計算鏡面照明,結果可能不正確。
反射過程的另一個關鍵區別是半透明光線在擊中後續介面後遞歸生成反射光線的能力。由於語言中缺乏對遞歸的支援,使用HLSL實現這一點並不完全簡單。通過遞歸,並不意味著追蹤來自命中著色器的光線的能力,而是簡單HLSL函數調用自身的能力。這在HLSL中是不允許的,但在實現一種削減式光線追蹤演算法時是可取的。為了解決HLSL的這個限制,開發組將相同的程式碼實例化為兩個名稱不同的函數,有效地將相關函數程式碼移動到一個單獨的文件中,並將該文件包含兩次,由每次設置函數名的預處理器宏包圍,導致相同函數的兩個不同實例具有不同的名稱。然後,讓兩個函數實例化中的一個調用另一個,從而允許有效地使用一個級別的硬編碼限制進行遞歸。由此產生的實現允許半透明路徑,具有可選的折射,其中沿著路徑的每個命中可以追蹤「遞歸」反射光線以及陰影光線。沿著該路徑從半透明曲面追蹤的反射可能會反彈到選定的次數。然而,如果在這些反彈中的任何一次,半透明曲面被擊中,則不允許追蹤其他遞歸反射光線。
將符合比爾-朗伯定律(Beer-Lambert)的均勻體積吸收添加到半透明通道中,以模擬厚玻璃並近似基底(substrate)。為了正確建模均勻有界體積,在幾何體上放置了附加約束。光線遍歷被修改為顯式追蹤正面和背面多邊形,以克服相交、非多邊形幾何體的問題。改進後的視覺真實感被認為不值得為「光速」(保時捷)演示增加的成本,也沒有應用在其最終版本中。
最近引入了用於光線追蹤加速的專用硬體,並在圖形API中添加了光線追蹤支援,這鼓勵開發組創新並嘗試一種新的混合渲染方式,將光柵化和光線追蹤相結合,發明了創新的重建過濾器,用於渲染隨機效果,如光澤反射、軟陰影、環境遮擋和漫反射間接照明,每個像素只有一條路徑,使這些昂貴的效果更適合實時使用。
此外,Practical Solutions for Ray Tracing Content Compatibility in Unreal Engine 4詳細闡述了利用光線追蹤和光柵化混合管線實現了多層半透明和樹葉的技術、過程及優化。(下圖)

17.5.2 Fortnite光線追蹤
17.5.2.1 概述
2020年初,虛幻引擎光線追蹤正在從測試階段過渡到生產階段,工程團隊決定在具有挑戰性的條件下進行戰鬥測試。Fortnite非常適合這項任務,不僅因為其規模巨大,還因為它具有許多其他特性,使得很難實現遊戲中的光線追蹤。也就是說,內容創建管線定義得很好,將其更改為包含光線追蹤不是一個選項。此外,內容更新經常發生,因此不可能調整參數以使特定版本看起來很好,但任何修改都應該相對永久,並且在未來的更新中表現正確。
該項目的主要目標是在Fortnite中發布光線追蹤,以改善遊戲的視覺效果,並使用UE4光線追蹤技術進行戰鬥驗證。從技術角度來看,最初的目標是在具有8核CPU(i7-7000系列或同等產品)和NVIDIA 2080 Ti圖形卡的系統上運行遊戲,並滿足以下要求:
- 幀速率:60 FPS。
- 解析度:1080p。
- 光線追蹤效果:陰影、環境遮擋和反射。
項目期間發生的改進有助於實現更宏偉的目標。光線追蹤反射、全局照明和降噪方面的新發展,加上NVIDIA深度學習超取樣(DLSS)的集成,使得可以針對更高解析度和更複雜的照明效果,如光線追蹤全局照明(RTGI)。
從藝術和內容創作的角度來看,團隊的目標並不是要在外觀上做出巨大的改變,但目標是在關鍵照明效果上實現特定的改進,通過移除螢幕空間效果引入的一些人瑕疵,使視覺效果更加愉悅。Fortnite是一款非真實感遊戲,目的是避免光線追蹤和光柵化看起來太不一樣的體驗。
從性能方面來看,初始測試表明,啟用光線追蹤時,CPU和GPU都遠未達到初始性能目標。在目標硬體上運行時,CPU時間平均約為每幀24毫秒,有些峰值超過30毫秒。GPU性能也遠未達到目標。雖然一些場景足夠快,但其他具有更複雜照明的場景在30-40毫秒/幀範圍內。具有許多動態幾何結構(例如樹)的一些反面案例在每幀100ms的量級上非常慢。
除了性能,還有其他一些領域提出了有趣的挑戰,例如內容創建管線。Fortnite管理著大量以極高頻率更新的資產,不可能在光線追蹤中更改資產以使其看起來更好,因為內容團隊的過載是不可接受的。例如,為了提高光線追蹤反射的性能,團隊考慮添加一個fag來設置對象是否投射反射光線。然而,經過進一步評估,很明顯,這種解決方案不會擴大規模。對於所有現有和未來的內容,任何改進都必須自動運行良好。
17.5.2.2 反射
Fortnite第15季的發行是Epic第一次在遊戲中使用光線追蹤反射的效果。雖然之前的用例需要實時性能,但目標與遊戲完全不同。在NVIDIA 2080 Ti上,Fortnite光線追蹤目標在1080p(4K,帶DLSS)下至少為60赫茲。為了達到這一目標,必須進行一些優化和犧牲。團隊做了一個專門針對遊戲的實驗性光線追蹤反射實現。它共享了原始反射著色器的主要思想,但去掉了大多數高端渲染功能,如多彈跳反射、反射中的半透明材質、基於物理的透明塗層等。下圖顯示了具有螢幕空間反射和無反射的新光線追蹤反射模式的比較。

演算法概述:虛幻引擎反射管線使用排序的延遲材質評估方案(下圖)。首先,基於G緩衝區數據生成反射光線,然後追蹤到最接近的曲面及其關聯的材質ID。然後按材質ID/著色器對命中點進行排序。最後,排序的命中點用於調度另一個光線追蹤過程,該過程使用全光線追蹤管線狀態對象(RTPSO)執行材質評估和照明。
A(Trace Rays) –> B(Sort Hits by Material)
B –> C(Evaluate Materials)
C –> D(Lighting)
該排序管線的目標是提高材質著色器執行一致性(SIMD效率)。因為反射光線是隨機化的,所以螢幕空間中靠近的像素通常會生成光線,這些光線擊中相距很遠的表面,從而增加了它們使用不同材質的可能性。如果不同材質的命中點最終出現在相同的GPU Wave中,性能將與唯一材質的數量大致成比例下降。雖然理論上,高級光線追蹤API(如DirectX光線追蹤)允許自動排序以避免此性能問題,但實際上,當時可用的驅動程式或硬體均未實現此優化。如後所述,在應用程式級別實現顯式排序顯著提高了性能。
使用基於G緩衝區數據的GGX分布取樣生成反射射線。為了節省GPU時間,使用粗糙度閾值來決定是否可以使用簡單的反射環境貼圖查找來代替追蹤光線。閾值映射到Fortnite圖形選項中的反射品質參數——中、高和史詩品質預設選擇了0.35、0.55和0.75。所有粗糙度超過0.75的表面都被剔除,因為與視覺改善相比,性能成本太高。還存在一個特殊的低預設,禁用除水以外的所有對象的光線追蹤反射。下圖顯示了這些品質預設及其GPU性能的可視化。
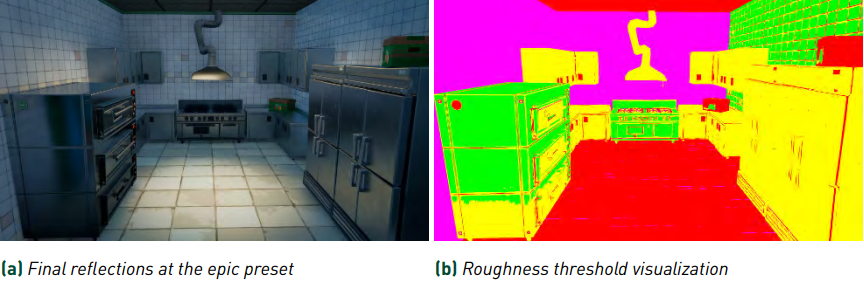
不同粗糙度閾值水平和相應GPU性能的可視化。綠色:中等反射品質預設,粗糙度<0.35,0.7毫秒。黃色:高預設,粗糙率<0.55,1.28毫秒。紅色:epic預設,粗糙程度<0.75,1.72毫秒。品紅色:粗糙度>0.75的剔除表面,2.09毫秒。基於1920×1080解析度下NVIDIA RTX 3090的計時。
因為Fortnite內容在設計時沒有考慮光線追蹤反射技術,所以大多數資產都是為螢幕空間反射而掌握的,這些反射使用純鏡像光線,因此看起來非常銳利。簡單的粗糙度閾值用於從大多數表面中剔除螢幕空間反射,這些表面看起來粗糙/漫射。不幸的是,這意味著基於物理的光線追蹤反射在大多數情況下都顯得相當遲鈍。由於遊戲中的內容太多,手動調整所有材質不是一個選項。如下程式碼所示,實現了一個自動解決方案,在GGX取樣過程中偏置表面粗糙度,使表面略微發亮:
float ApplySmoothBias(float Roughness , float SmoothBias)
{
// SmoothStep -類似於粗糙度值低於SmoothBias的函數,否則為原始粗糙度。.
float X = saturate(Roughness / SmoothBias);
return Roughness * X * X * (3.0 - 2.0 * X);
}
如下圖所示,該重映射函數將粗糙度值推到某個閾值以下接近零,但保留較高值不變。此特定功能旨在保留材質粗糙度貼圖貢獻,而無需剪裁,同時在整個粗糙度範圍內保持平滑。Fortnite中使用了0.5的偏差值,是理想外觀和物理精度之間的良好折衷。作為一個小小的獎勵,GPU性能在某些場景中略有改善,因為鏡面反射光線自然更連貫(使其追蹤速度更快)。
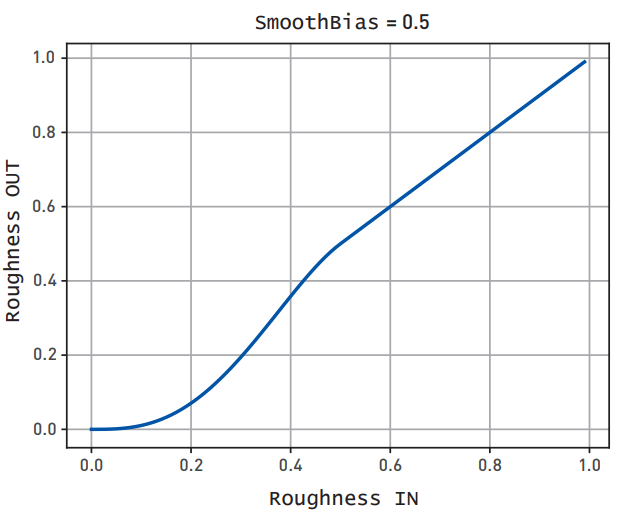
下圖比較了通過改變平滑度偏差值產生的視覺結果。

17.5.2.3 材質
虛幻引擎使用專門的輕量級管線狀態對象進行初始反射光線追蹤。它由一個ray generation著色器、一個微小的miss著色器和一個用於場景中所有幾何體的公共微小closest-hit著色器組成。如下所示,該著色器的目標是在不產生任何著色開銷的情況下,尋找最接近的交點。
struct FDeferredMaterialPayload
{
float HitT; // Ray hit depth or -1 on miss
uint SortKey; // Material ID
uint PixelCoord; // X in low 16 bits, Y in high 16 bits
};
[shader("closesthit")]
DeferredMaterialCHS(FDeferredMaterialPayload Payload, FDefaultAttributes Attributes)
{
Payload.SortKey = GetHitGroupUserData(); // Material ID
Payload.HitT = RayTCurrent();
}
材質ID收集過程的結果以64×64分塊順序寫入延遲材質有效負載緩衝區,用於後續排序。
反射光線命中點使用計算著色器按材質ID排序,在64×64像素螢幕空間分塊(4096個總像素)中執行排序,光線不是執行完全排序,而是按每個分塊合併到桶中。桶的數量是塊中的總像素數除以預期執行緒組大小,例如4096像素/32執行緒=128個桶。整個場景中可能有更多不同的材質(平均Fortnite RTPSO中大約有500種材質),但給定的分塊不太可能包含所有材質。如果一個分塊中有128種以上的不同材質,則無論如何都不可能將它們分類為完全一致的組。除了減少材質ID→ 桶ID映射中發生碰撞的可能性之外,增加箱(bin)的數量並不會有太大的改善。實際上,通過增加桶的數量並不能提高效率。
bin是作為單個計算著色器過程進行的,每個分開一個執行緒組,使用組共享記憶體存儲中間結果。這裡使用了一種簡單的裝箱演算法:
(1)從延遲材質緩衝區載入元素。
(2)使用原子計算每個分揀桶的元素數量。
(3)在計數上建立一個預求和,以計算排序索引。
(4)將元素寫回相同的延遲材質緩衝,以進行材質評估。
請注意,原始光線調度索引必須在整個管線中保留,並由命中著色器從光線有效載荷結構中讀取(DispatchRaysIndex() 內在屬性可能無法在原始(未排序)光線生成著色器之外使用)。
如下面兩圖所示,排序方案非常有效地減少了著色器執行差異。使用排序時,典型Fortnite幀中的大多數Wave包含單個材質著色器。儘管有效,但注意GPU性能影響非常依賴於場景。對於大多數光線自然照射到同一材質或天空的情況,由於排序開銷,可能不會有性能改進,甚至會有輕微的減速。然而,對於具有許多高粗糙度曲面的複雜場景,加速比可能高達3倍,Fortnite的平均性能改善約為1.6倍。分類用於除水以外的所有事物的參考,來自水的反射光線高度相干,通常會射向天空,因此分類幾乎沒有什麼好處。

射線排序提高SIMD執行效率的可視化。深藍色區域屬於完全不需要材質著色器的波(射入天空或被粗糙度閾值剔除的光線),較亮的顏色顯示包含1(淺藍色)和8+(深紅色)不同著色器的波。

1920×1080解析度下NVIDIA RTX 3090的排序性能比較。
「材質評估」步驟從在初始光線生成階段寫入的緩衝區載入光線參數,但縮短光線以僅覆蓋先前命中的三角形周圍的一小段。然後使用TraceRay調用完整材質著色器。儘管追蹤第二條射線有額外成本,但在整體反射管線中,這種方法明顯快於原始的TraceRay。
虛幻引擎使用平台特定的API直接啟動closest-hit著色器,儘可能不產生遍歷成本。在PC上的一個可行的替代路徑是使用DXR可調用著色器進行所有closest-hit著色,同時使用any-hit著色器進行alpha遮罩評估。這帶來了一組權衡,例如需要所有光線生成著色器通過有效載荷顯式地將命中參數傳遞給可調用著色器。最終,縮短光線方法是當時性能和簡單性之間的良好折衷。
光線追蹤時,儘可能避免any-hit著色器處理是重要的性能優化。不幸的是,典型的遊戲場景確實包含Alpha遮罩材質,這些材質在反射中必須看起來正確。在實踐中,絕大多數反射光線傾向於擊中完全不透明的材質或alpha遮罩材質的不透明部分,例如樹葉遮罩紋理的實心部分。使得可以在closest-hit著色器中評估不透明度,並將不透明度狀態寫入光線有效載荷。然後,所有初始光線追蹤都可以使用RAY_FLAG_FORCE_OPAQUE,光線生成著色器可以決定是否需要在不使用FORCE_ OPAQUE標記的情況下追蹤「全脂」(full-fat)光線,如下所示。
TraceRay(TLAS, RAY_FLAG_FORCE_OPAQUE , ..., Payload);
if (GBuffer.Roughness <= Threshold && Payload.IsTransparent())
{
TraceRay(TLAS, RAY_FLAG_NONE , ..., Payload);
}
Fortnite使用了0.1的進攻性任意命中粗糙度閾值,意味著Alpha遮罩材質(如植被)在粗糙表面上的反射中完全不透明。如下圖所示,只有近乎完美的反射鏡才能顯示正確的Alpha剪紙(cutout)。雖然是品質讓步,但在實踐中,它對Fortnite非常有效。此優化的性能改進取決於場景,但在Fortnite中平均測量到大約1.2倍的加速,有些場景接近2倍。FORCE_OPAQUE的好處很容易抵消在典型幀中回溯某些光線的成本。

任何命中材質評估的可視化。綠色區域顯示命中不透明幾何體或alpha遮罩材質的不透明部分的反射光線(由最近的命中著色器報告),黃色區域顯示由於粗糙度閾值而跳過非不透明光線追蹤的位置,紅色區域顯示追蹤非不透明光線的位置。NVIDIA RTX 3090在1920×1080解析度下的性能為1.8毫秒,不進行不透明光線優化,為2.4毫秒。
17.5.2.4 光照
虛幻引擎光線追蹤效果中的直接照明評估主要分為光線生成和未命中著色器。只有發射和間接照明來自最近的命中著色器,因為它可能涉及從紋理或燈光貼圖讀取。光線生成著色器包含具有基於柵格的剔除和光源形狀取樣的光源循環,始終使用光線追蹤(而不是陰影貼圖)計算反射中光源的陰影,在未命中著色器中計算光輻照度。如果光源不使用陰影,則通過設置TMin=TMax和InstanceInclusionMask=0,光源仍會通過公共追蹤光線路徑,並強制未命中,類似於啟動可調用著色器,但避免了光線生成著色器中的額外轉換。以這種方式使用未命中著色器可以精簡光線生成著色器程式碼,並導致更好的佔用率,從而提高所有目標平台的性能。
這種設計還提高了照明期間的SIMD效率,因為一個波中的光線可能會擊中不同的材質。在材質評估期間,執行會發散,但在照明時會重新會聚。材質分類並不能完全解決發散問題,因為不可能總是完美的填充波,只會留下部分波。
在光線生成著色器中保留所有照明計算允許較小的最近命中著色器,此舉有益於多方面,從迭代速度到程式碼模組化和遊戲修補程式大小。虛幻引擎為所有光線追蹤效果使用一組通用的材質命中著色器和一個主材質光線有效載荷結構,如下程式碼所示。在光柵圖形管線中,存在類似於前向和延遲著色的權衡,其中G-Buffer在不同渲染階段之間提供不透明介面,並允許解耦/熱交換(decoupled/hot-swappable)演算法。然而,這是以大G-Buffer存儲器佔用或更大的射線有效載荷結構為代價的。
struct FPackedMaterialClosestHitPayload
{
float HitT // 4 bytes
uint PackedRayCone; // 4 bytes
float MipBias; // 4 bytes
uint RadianceAndNormal[3]; // 12 bytes
uint BaseColorAndOpacity[2]; // 8 bytes
uint MetallicAndSpecularAndRoughness; // 4 bytes
uint IorAndShadingModelIDAndBlendingModeAndFlags; // 4 bytes
uint PackedIndirectIrradiance[2]; // 8 bytes
uint PackedCustomData; // 4 bytes
uint WorldTangentAndAnisotropy[2]; // 8 bytes
uint PackedPixelCoord; // 4 bytes
}; // 64 bytes total
除了優化材質評估成本,還需要平衡照明反射表面的成本。Fortnite廣闊的世界創造了大量燈光可能會影響表面的場景,由於曲面通常接近於受到多達256個光源(反射中支援的最大光源)的影響,因此我們需要一種策略,僅選擇有意義地影響曲面的光源。我們選擇的方法使用世界對齊、以攝影機為中心的3D網格來執行光源剔除。
Fortnite的大世界需要在單元格(cell)大小上進行權衡:大的單元格損害了剔除效率,但由於所需的覆蓋面積,小的單元格不實用。一個折衷方案是,單元格的大小根據與攝像機的距離呈指數增長。為了允許單元在網格中一起移動,對每個軸單獨應用縮放。在攝像機附近產生了適度的\(8米^3\)(2×2×2)的單元格,而在離攝像機100米的地方仍然有離散的單元格。進一步的調整簡化了數學,使前兩層單元格保持相同大小。下圖顯示了網格的二維布局,下面程式碼顯示了用於計算世界空間中任意位置的單元地址的HLSL著色器程式碼。

光柵格的2D切片,顯示四個最接近的單元格環。
int3 ComputeCell(float3 WorldPosition)
{
float3 Position = WorldPos - View.WorldViewOrigin;
Position /= CellScale;
// Use symmetry about the viewer.
float3 Region = sign(Position);
Position = abs(Position);
// Logarithmic steps with the closest cells being 2x2x2 scale units
Position = max(Position , 2.0f);
Position = min(log2(Position) - 1.0f, (CellCount/2 - 1));
Position = floor(Position);
Position += 0.5f; // Move the edge to the center.
Position *= Region; // Map it back to quadrants.
// Remap [-CellCount/2, CellCount/2] to [0, CellCount].
Position += (CellCount / 2.0f);
// Clamp to within the volume.
Position = min(Position , (CellCount - 0.5f));
Position = max(Position , 0.0f);
return int3(Position);
}
如下圖所示,光源剔除數據的最終表示在GPU上實現為三級結構。網格是最頂層的結構,每個網格單元存儲128位,每個網格單元格編碼多達11個索引的列表,每個索引10位,或者將計數和偏移量編碼到輔助緩衝器中。對於緊湊格式,此輔助緩衝區保存包含過多光源的單元格的索引。最低級別是索引所指的光源數據參數的結構化緩衝區。下面程式碼顯示了如何檢索網格單元的索引,網格結構和輔助緩衝區都是由計算著色器針對網格剔除光源生成的。
int GetLightIndex(int3 Cell, int LightNum)
{
int LightIndex = -1; // Initialized to invalid
const uint4 LightCellData = LightCullingVolume[Cell];
// Whether the light data is inlined in the cell
const bool bPacked = (LightCellData.x & (1 << 31)) > 0;
const uint LightCount = bPacked ? (LightCellData.w >> 20) & 0x3ff : LightCellData.x;
if (bPacked)
{
// Packed lights store 3 lights per 32-bit quantity.
uint Shift = (LightNum % 3) * 10;
uint PackedLightIndices = LightCellData[LightNum / 3];
uint UnpackedLightIndex = (PackedLightIndices >> Shift) & 0x3ff;
if (LightNum < LightCount)
{
LightIndex = UnpackedLightIndex;
}
}
else
{
// Non-packed lights use an external buffer
// with the offset in the cell data.
if (LightNum < LightCount)
{
LightIndex = LightIndices[LightCellData.y + LightNum];
}
}
return LightIndex;
}
17.5.2.5 全局光照
在Fortnite中,全局照明不是光線追蹤的初始要求。最初在虛幻引擎4.22中作為實驗演算法發布,強力全局照明不適用於要求實時性能的應用。相反,蠻力演算法僅適用於互動式和電影幀速率,原始演算法在虛幻引擎4.24中被重新表述為「最終收集」演算法。持續的開發、嚴格的照明約束以及降噪和放大帶來的實質性品質改進導致採用最終收集方法作為Fortnite的潛在實時全局照明解決方案。下圖顯示了遊戲中獲得的GI視覺效果。

Fortnite的Risky Reels,在應用光線追蹤全局照明之前和之後的對比,請注意從草地到格柵的反彈照明。
實驗蠻力演算法使用蒙特卡羅積分來求解渲染方程的漫反射分量。與其他光線追蹤通道一樣,全局照明通道從G-Buffer開始,其中根據光柵化深度緩衝區位置的世界空間法線生成漫反射光線。以這種方式,蠻力演算法的行為非常類似於環境遮擋演算法。但是,全局照明演算法不是投射可見性光線以列表化天空遮擋,而是投射更昂貴的光線,通過調用最近的命中著色器來評估次曲面材質資訊。
除了昂貴的最接近命中著色器評估外,該演算法還必須將直接照明應用於次級曲面。全局照明演算法使用下一事件估計(Next event estimation,NEE),而不是應用傳統的光源循環。下一事件估計(NEE)是選擇具有一定概率的候選光的隨機過程。首個處理過程稱為光源選擇,根據某種選擇概率決定要取樣的光。第二個過程類似於傳統的光照取樣,對光源的出射方向進行取樣。NEE過程構造陰影光線,以測試陰影點相對於選定光照的可見性。如果可見性光線成功連接到光源,將記錄漫反射照明評估。
NEE產生的每光線成本比傳統光照循環小,因為它僅評估候選光源總數的子集。儘管NEE通常被認為是每次調用選擇一個光源,但可以調用另一個輔助隨機過程來繪製多個NEE樣本。繪製多個樣本具有降低每射線方差的效果,同時也降低了構造昂貴操作評估射線的成本。每個材質評估射線繪製兩個NEE樣本在實踐中效果良好。如下程式碼示例。
float3 CalcNextEventEstimation(float3 ShadingPoint, inout FPayload Payload, inout FRandomSampleGenerator RNG, uint SampleCount)
{
float3 ExitantRadiance = 0;
for (uint NeeSample = 0; NeeSample < SampleCount; ++NeeSample)
{
uint LightIndex;
float SelectionPdf;
SelectLight(RNG, LightIndex , SelectionPdf);
float3 Direction;
float Distance;
float SamplePdf;
SampleLight(LightIndex , RNG, Direction , Distance , SamplePdf);
RayDesc Ray = CreateRay(ShadingPoint , Direction , Distance);
bool bIsHit = TraceVisibilityRay(TLAS, Ray);
if ( !bIsHit )
{
float3 Radiance = CalcDiffuseLighting(LightIndex , Ray, Payload);
float3 Pdf = SelectionPdf * SamplePdf;
ExitantRadiance += Radiance / Pdf;
}
}
ExitantRadiance /= SampleCount;
return ExitantRadiance;
}
根據藝術家允許的最大反彈次數,蠻力演算法可以從次級曲面釋放另一條漫反射光線,並重複該過程以擴展路徑鏈。隨後的反彈可能會提前終止,並由俄羅斯輪盤賭(Russian roulette)流程管理。
以這種方式計算的全局照明與路徑追蹤積分器非常匹配。然而,與路徑追蹤積分器一樣,該過程需要大量樣本才能收斂。強大的降噪核有助於生成平滑的最終結果,但實踐發現,根據照明條件和整體環境,每像素16到64個樣本對於足夠的品質仍然是必要的。此種做法有問題,因為每幀投射多個材質評估光線會快速將演算法推到實時交互幀率之外,並且僅適用於電影的耗損。下圖顯示了蠻力全局照明在Fortnite開發級別的應用。

開發測試環境中的蠻力全局照明技術,以螢幕解析度=50的每像素兩個樣本進行渲染。請注意,黃色從附近的牆壁溢色到灌木上。
為了保持強力積分器的良好性能,2019年9月對演算法進行了修改,以24 Hz的電影幀速率為Archviz內部渲染樣本[4]渲染漫反射。
加速蠻力演算法的關鍵洞察涉及將昂貴的材質評估射線轉換為相對便宜的可見性射線。為此,Fortnite開發組對連續幀上的材質評估光線進行時間切片。調用蠻力積分器,但每個像素只有一個樣本,並使用之前的幀模擬數據進行累積,就像實際激發了每個像素所需的樣本數一樣。累積先前幀數據需要樣本重投影,並且可能導致嚴重的重影瑕疵,特別是當先前幀的模擬數據不再有效時。為了幫助協調與累積先前幀數據相關的差異,選擇使用主路徑重新連接來重用先前追蹤的路徑,以前的路徑數據快取在稱為聚集點(gather point)的中間結構中,每個聚集點編碼次曲面的位置,以及記錄的輻照度和路徑創建概率密度函數(PDF)。像素的世界位置也被快取,並用於對照重投影標準進行測試,以便在後續幀中重用。聚集點緩衝區被解釋為環形緩衝區(circular buffer),其中緩衝區長度由演算法的每像素取樣數決定。以類似於Bekaert等人的方式,發射次級可見性光線,以測試成功的路徑重新連接。要正確執行此操作,需要從先前模擬中的活動著色點同時攜帶激發輻射和聚集點創建的概率密度。與下一個事件估計類似,成功的路徑重新連接事件記錄聚集點處的漫射照明。
漫反射光線的波作為每幀的一個單獨通道被調度。此通道的執行流程與蠻力演算法類似,但將照明數據記錄到輔助聚集點緩衝區。「聚集點緩衝區」記錄隨機光評估中的次級表面位置和漫射激發輻射,以及模擬中生成聚集點的概率密度。還提供了原始創建點,以便拒絕不滿足在當前幀中重用的足夠標準的聚集點。根據這些數據,可以將路徑重新連接事件投射到這些點,併合並快取的照明評估。使用與光線追蹤反射相同的排序延遲材質評估管線加速聚集點過程。(參見下面程式碼)
struct FGatherSample
{
float3 CreationPoint;
float3 Position;
float3 Irradiance;
float Pdf;
};
struct FGatherPoint
{
float3 CreationPoint;
float3 Position;
uint2 Irradiance;
};
uint2 PackIrradiance(FGatherSample GatherSample)
{
float3 Irradiance = ClampToHalfFloatRange(GatherSample.Irradiance);
float Pdf = GatherSample.Pdf;
uint2 Packed = (uint2)0;
Packed.x = f32tof16(Irradiance.x) | (f32tof16(Irradiance.y) << 16);
Packed.y = f32tof16(Irradiance.z) | (f32tof16(Pdf) << 16);
return Packed;
}
FGatherPoint CreateGatherPoint(FGatherSample GatherSample)
{
FGatherPoint GatherPoint;
GatherPoint.CreationPoint = GatherSample.CreationPoint;
GatherPoint.Position = GatherSample.Position;
GatherPoint.Irradiance = PackIrradiance(GatherSample);
return GatherPoint;
}
創建聚集點後,將執行最終聚集通道。最終聚集通道循環通過與當前像素關聯的所有聚集點,並將其重新投影到活動幀。成功重新投影的聚集點是路徑重新連接的候選點。將發射可見性光線,以潛在地將著色點的世界位置連接到聚集點的世界定位。如果路徑重新連接嘗試成功,著色點將記錄聚集點的漫反射照明。開發組發現,仍然需要大約16個路徑重聯事件才能獲得良好的定性結果。下面兩圖分別給出了兩種全局照明方法的視覺和運行時比較。

來自兩種全局照明演算法的結果。上圖:暴力法;底部:最終聚集方法。為了清晰起見,每個結果以螢幕百分比=100呈現,並以每像素一個樣本(左)和每像素16個樣本(右)顯示。為了可視化的目的,影像已被照亮。
| SPP | Brute Force (ms) | Final Gather (ms) |
|---|---|---|
| 1 | 19.78 | 11.63 |
| 2 | 46.95 | 13.39 |
| 4 | 121.33 | 13.49 |
| 8 | 259.48 | 15.86 |
| 16 | 556.31 | 20.15 |
最終聚集演算法僅限於擴散互反射的一次反彈。通過允許在給定事件創建隨機聚集點,該技術可以擴展到多個彈跳,但為了簡單起見,開發組選擇了一次彈跳。由於人為限制彈跳計數具有更低的運行時間成本和更低的方差的影響,考慮到該技術的一般成本,是一個適當的折衷方案。不幸的是,重投影和路徑重連失敗會導致比蠻力法收斂速度慢。當經歷顯著的相機或對象運動時,是可能發生的。
17.5.2.6 可行性
光線追蹤全局照明開發在UE 4.24發布後不久暫停。隨著虛幻引擎5技術進入全面開發,擴展一種最終將與新的方案競爭的演算法不再有意義。
然而,NVIDIA深度學習超級取樣(DLSS)等技術開始了新的討論。早期的測試Fortnite級別的實驗表明,在DLSS處於性能模式的情況下,可以以大約每秒50幀的速度運行整個光線追蹤著色器套件!光線追蹤陰影、環境遮擋、反射、天光和全局照明演算法接近發布的預期預算。最初是非常令人興奮的,但生產地圖仍然要複雜得多。特別是對於全局照明,原始隨機光選擇方法無法處理Fortnite的大量活動光源數量。即使對光源選擇進行了必要的改進,顯著的樣本噪點(主要是內部照明)也使得最終聚集演算法難以採用。
正如在生產中發生的那樣,其他功能目標也在開發過程中發生了變化。最值得注意的決定之一是,除了太陽(平行光)之外,所有光源都省略了光線追蹤陰影。如果光線追蹤陰影僅包含在太陽中,也可以對全局照明應用類似的排除規則。當然,這也限制了外部環境的反彈照明,但如果將全局照明限制為太陽,可以解決光源選擇方面的演算法效率低下的問題。其他潛在的取樣問題,如來自大面積燈光的照明,也消失了。通過將下一個事件估計樣本調整為1,避免了發射第二條陰影射線的成本,並獲得了額外的節省。由於特徵集被顯著剔除,採用光線追蹤全局照明實際上似乎是可行的。
儘管剔除了大量演算法要求,但由於剩餘的性能和取樣問題,為Fortnite部署最終聚集演算法仍然具有挑戰性。很明顯,開發組需要以更粗糙的決議來運作,以保持預算,預計該項目將需要半解析度或更小的操作。不幸的是,開發組發現在較小的解析度下運行通常需要更多的重新連接事件來幫助降低噪點。這樣做不符合開發組的臨時戰略;然而,隨著時間延遲的增加,成功重新連接事件的可能性降低。對於像Fortnite這樣快速發展的遊戲來說,對時間歷史的整體依賴被證明是困難的。
開發組開始試驗聚集點重投影和路徑重連接的擴展策略,使用隨時間變化(time-varying)的攝像機投影改進了簡單的基於世界的採集點數據重投影,以提高快速移動攝像機運動的穩定性。雖然最終聚集演算法的第一個實現利用了聚集點的時間路徑重投影,但預計空間和時間重用對於增加每個像素的有效樣本是必要的。該領域的先前實驗已經失敗,正如Bekaert等人之前提出的那樣,儘管最終結果中觀察到誤差減少,但使用規則鄰域重建內顯示出強烈令人反感的結構化雜訊。
由於還必須解決一般的降噪問題,該領域的進一步實驗停止了。開發組之前的全局照明降噪器在全解析度下運行良好,但在較低解析度下渲染時會迅速退化。值得慶幸的是,NVIDIA提供了時空方差引導濾波(SVGF),SVGF被證明是全局照明演算法的遊戲規則改變者,比Fortnite開發組的集成降噪器能更好地容忍下取樣、雜訊影像。SVGF很容易接受新的空間路徑重新連接策略中存在的結構化雜訊,並在增加每個像素的總體有效樣本的同時產生非常令人滿意的結果。不幸的是,開發組的SVGF實現在嘗試升級到所需解析度時顯示出具有高反照率表面的溢色瑕疵(下圖)。

Fortnite』s Misty Meadows在應用光線追蹤全局照明之前和之後對比圖,注意紅色從屋頂溢出到建築物上。
雖然這種情況並不頻繁,但在感興趣的汗砂點中普遍存在(下圖),需要解決。面對艱難的最後期限,開發組選擇實現上取樣預通道,這樣G-Buffer關聯不會干擾過濾器。如果在另一個項目中使用SVGF,開發組打算在未來解決這一過高的成本。

Fortnite』s Sweaty Sands在應用光線追蹤全局照明之前和之後對照圖。共享鄰域樣本創建了強結構化偽影,但SVGF仍然能夠重建平滑結果,同時也抑制了時間瑕疵。
下表左給出了最終聚集演算法迭代改進的最終分解,下表右給出了每次通過的最終成本分解。將全局照明限制為定向光顯示了避免光選擇時的顯著成本節約。DLSS允許該方法在分數尺度上工作,應用另一個顯著的加速。通過將照明限制到下一個事件估計樣本來實現中等速度增益。當使用SVGF應用我們的空間重新連接策略時,重新引入成本以保持時間穩定性。SVGF在半解析度和四分之一解析度方面提供了令人滿意的結果,這推動了我們的高品質和低品質設置。

17.5.2.7 CPU優化
- GPU緩衝區管理
在分析啟用光線追蹤時的CPU成本時,開發組很快注意到D3D12數據緩衝區管理程式碼需要改進。由於網格數據流,Fortnite在遊戲過程中花費了大量時間創建和銷毀加速結構數據緩衝區。
一種簡單的優化方法是從專用堆中分配所有這些資源,而不是使用單個提交或放置的資源,因為加速結構緩衝器必須保持在D3D12光線追蹤RAYTRACING_ACCELERATION_STRUCTURE狀態,而劃痕緩衝器保持在UNORDERED_ACCESS狀態。這意味著不需要狀態轉換,也不需要每個緩衝器的狀態追蹤。由於較小的對齊開銷,這種調整也節省了大量記憶體(D3D12中放置的資源需要64K對齊,但大多數緩衝區要小得多)。
開發組必須確保在遊戲過程中不會創建提交的資源,因為這可能會導致巨大的CPU峰值(有時超過100毫秒)。UE4的D3D12後端中的緩衝池方案進行了調整,以支援頂層和底層加速結構數據所需的大量分配(最大分配大小增加)。讀回緩衝區用於獲取壓縮資訊,並作為專用堆中的放置資源進行池化和子分配。
另一個問題是,幾乎所有靜態底層加速結構(BLAS)緩衝區都是臨時以全尺寸創建的,然後進行壓縮。壓縮要求讀回最終BLAS大小,並將其複製到新的壓縮加速結構緩衝區中,會導致大量碎片和記憶體浪費。由於時間限制,開發組沒有為Fortnite實現池碎片整理,但後來為虛幻引擎5完成了。
- 動態光線追蹤幾何
另一個CPU瓶頸是在更新BLAS數據之前收集和更新場景中的所有動態網格。為每個網格運行計算著色器,以生成該幀的動態頂點數據。該臨時頂點數據隨後用於更新/調整BLAS。在單個幀中可能會啟動數百個調度和構建操作。每個調度可能使用不同的計算著色器和輸出頂點緩衝區,從而在生成命令列表時造成大量CPU開銷,這種性能開銷來自切換著色器、狀態以及綁定不同的著色器參數。
開發組首先通過按著色器對所有動態幾何體更新請求進行排序來優化此過程,但還不足夠,額外的開銷來自切換每個網格的緩衝區和執行內部資源狀態轉換。大多數動態網格(如角色或可變形對象)需要在每幀更新,因此更新的頂點數據不必持久存儲,這允許我們使用瞬態每幀緩衝區,每個網格內具有簡單的線性子分配,最小化狀態追蹤成本。每個計算著色器調度寫入緩衝區的不同部分,因此,調度之間不需要無序訪問視圖(UAV)屏障。最後,將動態幾何體更新命令列表的生成與BLAS更新命令列表並行化,以隱藏驚人的BuildRaytracingAccelerationStructure的CPU成本。
- 構建著色器綁定表
最大的CPU成本(到目前為止)是為每個場景和光線追蹤管線狀態對象構建光線追蹤著色器綁定表(SBT)。虛幻引擎不使用持久著色器資源描述符表,因此必須手動收集所有資源綁定,並將其複製到每個幀的單個共享描述符堆中。
為了降低複製所有網格的所有描述符的成本,開發組引入了幾種級別的快取。最大的收益來自於使用相同的著色器和資源消除重複的SBT條目(例如應用於不同網格或同一網格的多個實例的相同材質)。虛幻引擎將著色器資源綁定分組到高級表(統一緩衝區,Uniform Buffer),典型的著色器引用其中的三個或四個(視圖、頂點工廠、材質等),每個統一緩衝區依次可能包含對紋理、緩衝區、取樣器等的引用。我們可以通過簡單地查看高級統一緩衝區而不檢視其內容來快取SBT記錄。
添加了較低級別的快取以消除描述符堆中的實際資源描述符數據的重複,主要用於消除取樣器描述符的重複,因為單個D3D12取樣器堆只能有2048個條目,並且一次只能綁定一個取樣器。D3D12 CopyDescriptors調用的成本與描述符哈希和哈希表查找/插入的成本大致相同(或大於)。
最後,開發組對SBT記錄構建進行了並行化,但發現添加工作執行緒帶來的改進很快就減少了。由於仍然希望使用描述符重複數據消除,每個工作執行緒需要使用自己的本地描述符快取,以避免同步開銷,然後,全局描述符堆空間由每個工作程式使用原子以塊的形式分配。此法降低了快取效率並增加了使用的描述符堆槽的總數,4或5個工作執行緒是並行SBT生成的最佳點。
- 幾何體裁剪
用於加速CPU和GPU渲染時間的一種簡單但有效的技術是,如果實例與當前幀無關,則完全跳過它們。光線追蹤時,場景中的每個對象都會影響攝影機看到的內容。然而,在現實生活中,許多對象的貢獻可以忽略不計。最初,開發組嘗試剔除相機後面的幾何體,這些幾何體放置在距離閾值更遠的位置。然而,這個解決方案被放棄了,因為當具有大覆蓋率的對象在一幀中被拒絕並在下一幀中接受時,它會產生跳變瑕疵。解決方案是更改剔除標準,以將實例的邊界球體的投影面積也考慮在內,並僅在其足夠小時丟棄。這個簡單的改變消除了跳變,同時大大提高了速度。平均而言,每幀的增益為2-3毫秒。
- DLSS
NVIDIA DLSS技術的集成有助於提高性能,使啟用光線追蹤全局照明成為可能,並在更高解析度下啟用光線追蹤運行遊戲。為集成DLSS而進行的引擎更改現在在公共UE4程式碼庫中可用,而UE4的DLSS插件現在在虛幻引擎商店中可用。
總之,光線追蹤在Fortnite第15季(2020年9月)發布,實現了比Fortnite團隊最初設定的目標更為雄心勃勃的目標。儘管該項目在許多層面上都具有挑戰性,但最終取得了成功。啟用光線追蹤後,不僅遊戲看起來更好,而且所有改進現在都是UE4公共程式碼庫的一部分。
實時光線追蹤中存在許多需要更多工作的開放問題,包括具有大量動態幾何體的場景,這些幾何體必須在每幀更新,需要多次反彈散射的複雜光傳輸,以及具有大量動態光的場景。這些問題很難解決,需要電腦圖形學界多年的努力。Epic Games的工程團隊將繼續改進為該項目開發的技術,以及路線圖上的其他新方法,目標是使光線追蹤成為任何類型遊戲或實時圖形應用的可行解決方案。
17.6 UE光線追蹤源碼分析
本篇以UE 5.0.3作為分析的源碼版本,如果需要同步看源碼的童鞋注意了。
17.6.1 UE光線追蹤總覽
在分析UE的光線追蹤的源碼之前,先放一張UE4的渲染管線總覽圖(來自UE官方影片教學,點擊可放大):
如上圖所示,光線追蹤和光柵化相結合,即所謂的混合渲染管線。其中,與光線追蹤相關的模組或特性有陰影、AO、GI、反射、半透明、體積材質等。
在UE 5.0.3版本中,【C++側】和光線追蹤相關的有:
-
Shared
- RayTracingBuiltInResources.h
- RayTracingDefinitions.h
- RayTracingTypes.h
-
D3D12RHI
- D3D12RayTracing.h
- D3D12RayTracing.cpp
- D3D12RayTracingRootSignature.h
-
Engine
- RayTracingInstance.h
- RayTracingInstance.cpp
- RayTracingSkinnedGeometry.cpp
-
RenderCore
- RayGenShaderUtils.h
- BuiltInRayTracingShaders.h
- RayTracingGeometryManager.h
- BuiltInRayTracingShaders.cpp
- RayTracingGeometryManager.cpp
-
Lumen
- LumenHardwareRayTracingCommon.h
- LumenHardwareRayTracingCommon.cpp
- LumenHardwareRayTracingMaterials.cpp
- LumenRadianceCacheHardwareRayTracing.cpp
- LumenReflectionHardwareRayTracing.cpp
- LumenSceneDirectLightingHardwareRayTracing.cpp
- LumenScreenProbeHardwareRayTracing.cpp
- LumenTranslucencyVolumeHardwareRayTracing.cpp
-
RayTracing
- RayTracingAmbientOcclusion.cpp
- RayTracingBarycentrics.cpp
- RayTracingDeferredMaterials.cpp
- RayTracingDeferredMaterials.h
- RayTracingDeferredReflections.cpp
- RayTracingDynamicGeometry.cpp
- RayTracingGlobalIllumination.cpp
- RayTracingIESLightProfiles.cpp
- RayTracingIESLightProfiles.h
- RayTracingInstanceBufferUtil.cpp
- RayTracingInstanceBufferUtil.h
- RayTracingInstanceCulling.cpp
- RayTracingInstanceCulling.h
- RayTracingLighting.h
- RayTracingLighting.cpp
- RayTracingMaterialHitShaders.cpp
- RayTracingMaterialHitShaders.h
- RaytracingOptions.h
- RayTracingPrimaryRays.cpp
- RayTracingReflections.cpp
- RayTracingReflections.h
- RayTracingScene.h
- RayTracingScene.cpp
- RayTracingShadows.cpp
- RayTracingSkyLight.h
- RayTracingSkyLight.cpp
- RayTracingTranslucency.cpp
- RayTracingDynamicGeometryCollection.h
-
VulkanRHI
- VulkanRayTracing.h
- VulkanRayTracing.cpp
【Shader側】和光線追蹤相關的有:
-
RayTracing
- GenerateSkyLightVisibilityRaysCS.usf
- RayGenUtils.ush
- RayTracingAmbientOcclusionRGS.usf
- RayTracingBarycentrics.usf
- RayTracingBuiltInShaders.usf
- RayTracingCalcInterpolants.ush
- RayTracingCommon.ush
- RayTracingCreateGatherPointsRGS.usf
- RayTracingDeferredMaterials.usf
- RayTracingDeferredMaterials.ush
- RayTracingDeferredReflections.usf
- RayTracingDeferredReflections.ush
- RayTracingDeferredShadingCommon.ush
- RayTracingDirectionalLight.ush
- RayTracingDiskLight.ush
- RayTracingDispatchDesc.usf
- RayTracingDynamicMesh.usf
- RayTracingFinalGatherRGS.usf
- RayTracingGatherPoints.ush
- RayTracingGlobalIlluminationRGS.usf
- RayTracingHitGroupCommon.ush
- RayTracingInstanceBufferUtil.usf
- RayTracingLightCullingCommon.ush
- RayTracingLightingCommon.ush
- RayTracingLightingMS.usf
- RayTracingMaterialDefaultHitShaders.usf
- RayTracingMaterialHitShaders.usf
- RayTracingOcclusionRGS.usf
- RayTracingPointLight.ush
- RayTracingPrimaryRays.usf
- RayTracingRectLight.ush
- RayTracingRectLightRGS.usf
- RayTracingReflectionEnvironment.ush
- RayTracingReflectionResolve.usf
- RayTracingReflections.usf
- RayTracingReflectionsCommon.ush
- RayTracingReflectionsGenerateRaysCS.usf
- RayTracingSkyLightCommon.ush
- RayTracingSkyLightEvaluation.ush
- RayTracingSkyLightRGS.usf
- RayTracingSphereLight.ush
- RayTracingSpotLight.ush
- SkyLightVisibilityRaysData.ush
- TraceRayInline.ush
- TraceRayInlineCommon.ush
- TraceRayInlineVulkan.ush
- VFXTraceRay.ush
-
Lumen
- LumenProbeHierarchyBuildProbeArray.usf
- LumenRadiosityHardwareRayTracing.usf
- LumenHardwareRayTracingCommon.ush
- LumenHardwareRayTracingMaterials.usf
- LumenHardwareRayTracingPayloadCommon.ush
- LumenHardwareRayTracingPipeline.usf
- LumenHardwareRayTracingPipelineCommon.ush
- LumenHardwareRayTracingPlatformCommon.ush
- LumenRadianceCacheHardwareRayTracing.usf
- LumenReflectionHardwareRayTracing.usf
- LumenSceneDirectLightingHardwareRayTracing.usf
- LumenScreenProbeHardwareRayTracing.usf
- LumenTranslucencyVolumeHardwareRayTracing.usf
- LumenVisualizeHardwareRayTracing.usf
-
HairStrands
-
HairStrandsRaytracing.ush
-
HairStrandsRaytracingGeometry.usf
-
HairStrandsVoxelPageRayMarching.usf
-
涉及面比較廣,無法對所有特性進行剖析,只能抽取部分重要的特性分析之。
17.6.2 UE光線追蹤基礎
從源碼可看出,UE5支援D3D12和Vulkan兩個圖形平台的光線追蹤。
17.6.2.1 RHI Raytracing
RHI層抽象出了部分和具體圖形平台無關的類型和介面,以便為上層提供統一的訪問方式。RHI層有關光線追蹤的主要類型和介面如下:
// RHI.h
// 此平台是否可以構建加速結構並使用完整光線追蹤管線或內聯光線追蹤(光線查詢)。
inline RHI_API bool RHISupportsRayTracing(const FStaticShaderPlatform Platform);
// 此平台是否可以編譯光線追蹤著色器(無論項目設置如何)。
inline RHI_API bool RHISupportsRayTracingShaders(const FStaticShaderPlatform Platform);
// 此平台是否可以編譯具有內聯光線追蹤功能的著色器。
inline RHI_API bool RHISupportsInlineRayTracing(const FStaticShaderPlatform Platform);
// RHI是否支援當前硬體上的光線追蹤(加速結構構建和新的光線追蹤特定著色器類型)。
extern RHI_API bool GRHISupportsRayTracing;
// RHI是否支援光線追蹤raygen、miss和hit著色器(即完整的光線追蹤管線)。
extern RHI_API bool GRHISupportsRayTracingShaders;
// RHI是否支援向現有RT PSO添加新著色器。
extern RHI_API bool GRHISupportsRayTracingPSOAdditions;
// RHI是否支援間接光線追蹤調度命令。
extern RHI_API bool GRHISupportsRayTracingDispatchIndirect;
// RHI是否支援非同步構建光線追蹤加速結構。
extern RHI_API bool GRHISupportsRayTracingAsyncBuildAccelerationStructure;
// RHI是否支援AMD Hit Token擴展。
extern RHI_API bool GRHISupportsRayTracingAMDHitToken;
// RHI是否支援計算著色器中的內聯光線追蹤,而不支援完整的光線追蹤管線。
extern RHI_API bool GRHISupportsInlineRayTracing;
// 光線追蹤加速結構所需的對齊。
extern RHI_API uint32 GRHIRayTracingAccelerationStructureAlignment;
// 光線追蹤劃痕緩衝區所需的對齊。
extern RHI_API uint32 GRHIRayTracingScratchBufferAlignment;
// 光線追蹤著色器綁定表緩衝區需要對齊。
extern RHI_API uint32 GRHIRayTracingShaderTableAlignment;
// 光線追蹤實例緩衝區中單個元素的大小。這定義了實例的結構化緩衝區所需的步幅和對齊。
extern RHI_API uint32 GRHIRayTracingInstanceDescriptorSize;
// 轉換資訊.
struct FRHITransitionInfo : public FRHISubresourceRange
{
union
{
class FRHIResource* Resource = nullptr;
class FRHITexture* Texture;
class FRHIBuffer* Buffer;
class FRHIUnorderedAccessView* UAV;
// 光線追蹤加速結構.
class FRHIRayTracingAccelerationStructure* BVH;
};
(...)
};
// RHICommandList.h
// 光線追蹤著色器綁定.
struct FRayTracingShaderBindings
{
FRHITexture* Textures[64] = {};
FRHIShaderResourceView* SRVs[64] = {};
FRHIUniformBuffer* UniformBuffers[16] = {};
FRHISamplerState* Samplers[16] = {};
FRHIUnorderedAccessView* UAVs[16] = {};
};
// 光線追蹤局部著色器綁定.
struct FRayTracingLocalShaderBindings
{
uint32 InstanceIndex = 0;
uint32 SegmentIndex = 0;
uint32 ShaderSlot = 0;
uint32 ShaderIndexInPipeline = 0;
uint32 UserData = 0;
uint16 NumUniformBuffers = 0;
uint16 LooseParameterDataSize = 0;
FRHIUniformBuffer** UniformBuffers = nullptr;
uint8* LooseParameterData = nullptr;
};
// RayTracingCommon.ush中聲明的FBasicRayData的C++計數器部分.
struct FBasicRayData
{
float Origin[3];
uint32 Mask;
float Direction[3];
float TFar;
};
// RayTracingCommon.ush中聲明的FIntersectionPayload的C++計數器部分.
struct FIntersectionPayload
{
float HitT; // 射線方向上從射線原點到交點的距離。如果是負數則表示未命中。
uint32 PrimitiveIndex; // 底層加速結構實例內幾何體中圖元的索引。未命中則是未定義狀態。
uint32 InstanceIndex; // 頂層結構中當前實例的索引。未命中則是未定義狀態。
float Barycentrics[2]; // 交點的原始重心坐標。未命中則是未定義狀態。
};
// 光線追蹤幾何體更新資訊.
struct FRHIRayTracingGeometryUpdateInfo
{
FRHIRayTracingGeometry* DestGeometry;
FRHIRayTracingGeometry* SrcGeometry;
};
struct FRHIResourceUpdateInfo
{
enum EUpdateType
{
UT_Buffer,
UT_BufferSRV,
UT_BufferFormatSRV,
UT_RayTracingGeometry, // 從中間幾何體接管底層資源
UT_Num
};
EUpdateType Type;
union
{
FRHIBufferUpdateInfo Buffer;
FRHIShaderResourceViewUpdateInfo BufferSRV;
FRHIRayTracingGeometryUpdateInfo RayTracingGeometry; // 光線追蹤幾何體更新資訊.
};
(...)
};
// 定義光線追蹤相關的命令
FRHICOMMAND_MACRO(FRHICommandCopyBufferRegions)
{
(...)
};
struct FRHICommandBindAccelerationStructureMemory final : public FRHICommand<FRHICommandBindAccelerationStructureMemory>
{
(...)
};
struct FRHICommandBuildAccelerationStructure final : public FRHICommand<FRHICommandBuildAccelerationStructure>
{
(...)
};
FRHICOMMAND_MACRO(FRHICommandClearRayTracingBindings)
{
FRHIRayTracingScene* Scene;
(...)
};
struct FRHICommandBuildAccelerationStructures final : public FRHICommand<FRHICommandBuildAccelerationStructures>
{
(...)
};
FRHICOMMAND_MACRO(FRHICommandRayTraceOcclusion)
{
(...)
};
FRHICOMMAND_MACRO(FRHICommandRayTraceIntersection)
{
(...)
};
FRHICOMMAND_MACRO(FRHICommandRayTraceDispatch)
{
(...)
};
FRHICOMMAND_MACRO(FRHICommandSetRayTracingBindings)
{
(...)
};
class FRHIComputeCommandList : public FRHICommandListBase
{
public:
// 構建加速結構和記憶體.
void BuildAccelerationStructure(FRHIRayTracingGeometry* Geometry);
void BuildAccelerationStructures(const TArrayView<const FRayTracingGeometryBuildParams> Params);
void BuildAccelerationStructures(const TArrayView<const FRayTracingGeometryBuildParams> Params, const FRHIBufferRange& ScratchBufferRange);
void BuildAccelerationStructure(const FRayTracingSceneBuildParams& SceneBuildParams);
void BindAccelerationStructureMemory(FRHIRayTracingScene* Scene, FRHIBuffer* Buffer, uint32 BufferOffset);
(...)
};
class RHI_API FRHICommandList : public FRHIComputeCommandList
{
public:
// 光線追蹤非直接調度
void RayTraceDispatchIndirect(FRayTracingPipelineState* Pipeline, FRHIRayTracingShader* RayGenShader, FRHIRayTracingScene* Scene, const FRayTracingShaderBindings& GlobalResourceBindings, FRHIBuffer* ArgumentBuffer, uint32 ArgumentOffset);
void RayTraceOcclusion(FRHIRayTracingScene* Scene, ...);
void RayTraceIntersection(FRHIRayTracingScene* Scene, ...);
void SetRayTracingHitGroup(FRHIRayTracingScene* Scene, ...);
void SetRayTracingCallableShader(FRHIRayTracingScene* Scene, ...);
void SetRayTracingMissShader(FRHIRayTracingScene* Scene, ...);
void ClearRayTracingBindings(FRHIRayTracingScene* Scene);
(...)
};
template <uint32 MaxNumUpdates>
struct TRHIResourceUpdateBatcher
{
void QueueUpdateRequest(FRHIRayTracingGeometry* DestGeometry, FRHIRayTracingGeometry* SrcGeometry);
(...)
};
// DynamicRHI.h
// FDynamicRHI和光線追蹤相關的介面。
class RHI_API FDynamicRHI
{
public:
virtual FRayTracingAccelerationStructureSize RHICalcRayTracingSceneSize(uint32 MaxInstances, ERayTracingAccelerationStructureFlags Flags);
virtual FRayTracingAccelerationStructureSize RHICalcRayTracingGeometrySize(const FRayTracingGeometryInitializer& Initializer);
virtual FRayTracingGeometryRHIRef RHICreateRayTracingGeometry(const FRayTracingGeometryInitializer& Initializer);
virtual FRayTracingSceneRHIRef RHICreateRayTracingScene(const FRayTracingSceneInitializer& Initializer);
virtual FRayTracingSceneRHIRef RHICreateRayTracingScene(FRayTracingSceneInitializer2 Initializer);
virtual FRayTracingShaderRHIRef RHICreateRayTracingShader(TArrayView<const uint8> Code, const FSHAHash& Hash, EShaderFrequency ShaderFrequency);
virtual FRayTracingPipelineStateRHIRef RHICreateRayTracingPipelineState(const FRayTracingPipelineStateInitializer& Initializer);
virtual void RHITransferRayTracingGeometryUnderlyingResource(FRHIRayTracingGeometry* DestGeometry, FRHIRayTracingGeometry* SrcGeometry);
(...)
};
// 和光線追蹤相關的全局介面.
TRefCountPtr<FRHIRayTracingPipelineState> RHICreateRayTracingPipelineState(const FRayTracingPipelineStateInitializer& Initializer);
FRayTracingAccelerationStructureSize RHICalcRayTracingSceneSize(uint32 MaxInstances, ERayTracingAccelerationStructureFlags Flags);
FRayTracingAccelerationStructureSize RHICalcRayTracingGeometrySize(const FRayTracingGeometryInitializer& Initializer);
FRayTracingGeometryRHIRef RHICreateRayTracingGeometry(const FRayTracingGeometryInitializer& Initializer);
FRayTracingSceneRHIRef RHICreateRayTracingScene(FRayTracingSceneInitializer2 Initializer);
FRayTracingShaderRHIRef RHICreateRayTracingShader(TArrayView<const uint8> Code, const FSHAHash& Hash, EShaderFrequency ShaderFrequency);
// RHIResources.h
// 光線追蹤Shader
class FRHIRayTracingShader : public FRHIShader
{
(...)
};
// 光線生成Shader
class FRHIRayGenShader : public FRHIRayTracingShader
{
(...)
};
// 光線未命中Shader
class FRHIRayMissShader : public FRHIRayTracingShader
{
(...)
};
// 光線可調用Shader
class FRHIRayCallableShader : public FRHIRayTracingShader
{
(...)
};
// 光線命中組shader
class FRHIRayHitGroupShader : public FRHIRayTracingShader
{
(...)
};
// 光線追蹤管線狀態.
class FRHIRayTracingPipelineState : public FRHIResource
{
(...)
};
// 部分類型定義.
typedef TRefCountPtr<FRHIRayTracingShader> FRayTracingShaderRHIRef;
typedef TRefCountPtr<FRHIRayTracingPipelineState> FRayTracingPipelineStateRHIRef;
// 光線追蹤實例標記.
enum class ERayTracingInstanceFlags : uint8
{
None = 0,
TriangleCullDisable = 1 << 1, // 沒有背面剔除。三角形從兩側可見。
TriangleCullReverse = 1 << 2, // 如果三角形頂點從光線原點逆時針旋轉,則使三角形朝前。
ForceOpaque = 1 << 3, // 禁用此實例的任何命中著色器調用。
ForceNonOpaque = 1 << 4, // 強制任何命中著色器調用,即使實例中的幾何體被標記為不透明。
};
// 光線追蹤場景中網格的一個或多個實例的高級描述符。此描述符覆蓋的所有實例將共享著色器綁定,但可能具有不同的變換和用戶數據。
struct FRayTracingGeometryInstance
{
// 關聯的幾何體RHI地址.
TRefCountPtr<FRHIRayTracingGeometry> GeometryRHI = nullptr;
// 存儲GPU轉換的可選緩衝區。用於代替CPU端轉換數據。
FShaderResourceViewRHIRef GPUTransformsSRV = nullptr;
// 單個物理網格可以使用不同的變換和用戶數據在場景中多次複製。所有副本共享相同的著色器綁定表條目,因此將具有相同的材質和著色器資源。
TArrayView<const FMatrix> Transforms;
// 實例在場景數據的偏移.
TArrayView<const uint32> InstanceSceneDataOffsets;
// 保守的實例數。如果使用GPU變換,則某些實際實例可能會處於非活動狀態。如果使用CPU轉換數據,則必須小於或等於轉換視圖中的條目數。如果GPUTransformsSRV為非空,則必須小於或等於它中的條目數。
uint32 NumTransforms = 0;
// 每個幾何體副本可以接收用戶提供的整數,該整數可用於檢索額外的著色器參數或自定義外觀。
uint32 DefaultUserData = 0;
TArrayView<const uint32> UserData;
// 每個幾何體副本可以有一個位,使其單獨停用(從TLA中刪除,同時保持命中組索引)。用於剔除。
TArrayView<const uint32> ActivationMask;
// 將根據著色器程式碼中提供給TraceRay()的掩碼進行測試。如果具有光線遮罩的實例遮罩的二進位和為零,則該實例被視為不相交/不可見。
uint8 Mask = 0xFF;
// 用於控制三角形背面剔除、是否允許任何命中著色器等的標誌。
ERayTracingInstanceFlags Flags = ERayTracingInstanceFlags::None;
};
// 光線追蹤幾何體類型.
enum ERayTracingGeometryType
{
// 具有固定函數光線交點的索引或非索引三角形列表。頂點緩衝區必須包含頂點位置,如VET_Float3。頂點步長必須至少為12位元組,但可能更大,以支援自定義逐頂點數據. 可以為索引三角形列表提供索引緩衝器, 否則假設隱式三角形列表。
RTGT_Triangles,
// 需要交集著色器的自定義基本體類型。程式幾何體的頂點緩衝區每個圖元必須包含一個AABB,如{float3 MinXYZ,float3 maxyz}。頂點跨距必須至少為24位元組,但可以更大,以支援自定義每圖元數據, 索引緩衝區不能用於程式幾何體。
RTGT_Procedural,
};
// 光線追蹤幾何體初始化類型.
enum class ERayTracingGeometryInitializerType
{
Rendering, // 完全初始化RayTracingGeometry對象:創建基礎緩衝區並初始化著色器參數。
StreamingDestination, // 不創建基礎緩衝區或著色器參數, 由流傳輸系統用作流傳輸到的對象。
StreamingSource, // 創建緩衝區,但不創建著色器參數, 用於流系統中的中間對象。
};
// 光線追蹤幾何體分段(子模型).
struct FRayTracingGeometrySegment
{
DECLARE_TYPE_LAYOUT(FRayTracingGeometrySegment, NonVirtual);
public:
// 頂點數據.
LAYOUT_FIELD_INITIALIZED(FBufferRHIRef, VertexBuffer, nullptr);
LAYOUT_FIELD_INITIALIZED(EVertexElementType, VertexBufferElementType, VET_Float3);
LAYOUT_FIELD_INITIALIZED(uint32, VertexBufferOffset, 0); // 頂點緩衝區基址的偏移量(位元組)。
LAYOUT_FIELD_INITIALIZED(uint32, VertexBufferStride, 12);
LAYOUT_FIELD_INITIALIZED(uint32, MaxVertices, 0);
// 此分段的圖元範圍.
LAYOUT_FIELD_INITIALIZED(uint32, FirstPrimitive, 0);
LAYOUT_FIELD_INITIALIZED(uint32, NumPrimitives, 0);
LAYOUT_FIELD_INITIALIZED(bool, bForceOpaque, false);
LAYOUT_FIELD_INITIALIZED(bool, bAllowDuplicateAnyHitShaderInvocation, true);
LAYOUT_FIELD_INITIALIZED(bool, bEnabled, true);
};
// 光線追蹤幾何初始化器.
struct FRayTracingGeometryInitializer
{
public:
LAYOUT_FIELD_INITIALIZED(FBufferRHIRef, IndexBuffer, nullptr);
LAYOUT_FIELD_INITIALIZED(uint32, IndexBufferOffset, 0);
LAYOUT_FIELD_INITIALIZED(ERayTracingGeometryType, GeometryType, RTGT_Triangles);
LAYOUT_FIELD_INITIALIZED(uint32, TotalPrimitiveCount, 0);
LAYOUT_FIELD(TMemoryImageArray<FRayTracingGeometrySegment>, Segments);
LAYOUT_FIELD_INITIALIZED(FResourceArrayInterface*, OfflineData, nullptr);
LAYOUT_FIELD_INITIALIZED(FRHIRayTracingGeometry*, SourceGeometry, nullptr);
LAYOUT_FIELD_INITIALIZED(bool, bFastBuild, false);
LAYOUT_FIELD_INITIALIZED(bool, bAllowUpdate, false);
LAYOUT_FIELD_INITIALIZED(bool, bAllowCompaction, true);
LAYOUT_FIELD_INITIALIZED(ERayTracingGeometryInitializerType, Type, ERayTracingGeometryInitializerType::Rendering);
};
// 光線追蹤場景生命周期.
enum ERayTracingSceneLifetime
{
RTSL_SingleFrame, // 場景只能在創建時的幀中使用。
// RTSL_MultiFrame, // 場景可以構建一次,並在任何數量的後續幀中使用(當前未實現)。
};
// 光線追蹤加速結構標記.
enum class ERayTracingAccelerationStructureFlags
{
None = 0,
AllowUpdate = 1 << 0,
AllowCompaction = 1 << 1,
FastTrace = 1 << 2,
FastBuild = 1 << 3,
MinimizeMemory = 1 << 4,
};
// 光線追蹤場景初始化器.
struct FRayTracingSceneInitializer
{
TArrayView<FRayTracingGeometryInstance> Instances;
uint32 ShaderSlotsPerGeometrySegment = 1;
uint32 NumCallableShaderSlots = 0;
uint32 NumMissShaderSlots = 1;
ERayTracingSceneLifetime Lifetime = RTSL_SingleFrame;
};
// 光線追蹤場景初始化器2.
struct FRayTracingSceneInitializer2
{
TArray<TRefCountPtr<FRHIRayTracingGeometry>> ReferencedGeometries;
TArray<FRHIRayTracingGeometry*> PerInstanceGeometries;
TArray<uint32> BaseInstancePrefixSum;
TArray<uint32> SegmentPrefixSum;
uint32 NumNativeInstances = 0;
uint32 NumTotalSegments = 0;
uint32 ShaderSlotsPerGeometrySegment = 1;
uint32 NumCallableShaderSlots = 0;
uint32 NumMissShaderSlots = 1;
ERayTracingSceneLifetime Lifetime = RTSL_SingleFrame;
};
// 光線追蹤加速結構尺寸.
struct FRayTracingAccelerationStructureSize
{
uint64 ResultSize = 0;
uint64 BuildScratchSize = 0;
uint64 UpdateScratchSize = 0;
};
// 光線追蹤加速結構
class FRHIRayTracingAccelerationStructure : public FRHIResource
{
public:
FRHIRayTracingAccelerationStructure() : FRHIResource(RRT_RayTracingAccelerationStructure) {}
};
// 底層光線追蹤加速結構(包含三角形)。
class FRHIRayTracingGeometry : public FRHIRayTracingAccelerationStructure
{
public:
virtual FRayTracingAccelerationStructureAddress GetAccelerationStructureAddress(uint64 GPUIndex) const = 0;
virtual void SetInitializer(const FRayTracingGeometryInitializer& Initializer) = 0;
(...)
protected:
FRayTracingAccelerationStructureSize SizeInfo = {};
FRayTracingGeometryInitializer Initializer = {};
ERayTracingGeometryInitializerType InitializedType = ERayTracingGeometryInitializerType::Rendering;
};
typedef TRefCountPtr<FRHIRayTracingGeometry> FRayTracingGeometryRHIRef;
// 頂層光線追蹤加速結構(包含網格實例).
class FRHIRayTracingScene : public FRHIRayTracingAccelerationStructure
{
public:
virtual const FRayTracingSceneInitializer2& GetInitializer() const = 0;
// 返回與此場景關聯的RHI特定系統參數的緩衝區視圖, 可能需要訪問使用光線查詢的著色器中的光線追蹤幾何體數據。如果當前RHI不需要此緩衝區,則返回NULL。
virtual FRHIShaderResourceView* GetMetadataBufferSRV() const;
};
typedef TRefCountPtr<FRHIRayTracingScene> FRayTracingSceneRHIRef;
// 光線追蹤管線狀態簽名
class FRayTracingPipelineStateSignature
{
public:
uint32 MaxPayloadSizeInBytes = 24; // sizeof FDefaultPayload declared in RayTracingCommon.ush
bool bAllowHitGroupIndexing = true;
bool operator==(const FRayTracingPipelineStateSignature& rhs) const;
friend uint32 GetTypeHash(const FRayTracingPipelineStateSignature& Initializer);
uint64 GetHitGroupHash();
uint64 GetRayGenHash();
uint64 GetRayMissHash();
uint64 GetCallableHash();
(...)
};
// 光線追蹤管線狀態初始值設定項.
class FRayTracingPipelineStateInitializer : public FRayTracingPipelineStateSignature
{
public:
// 部分光線追蹤管線可用於運行時非同步著色器編譯,但不用於渲染。創建部分管線時,可以為任何階段提供任意數量的著色器,但必須總共存在至少一個著色器(不允許完全空的管線)。
bool bPartial = false;
// 光線追蹤管線可以通過從現有基礎導出來創建。基本管線將通過向其中添加新的著色器來擴展,可能會節省大量CPU時間。在運行時依賴於GRHISupportsRayTracingPSOAdditions支援(如果不支援基本管線,則忽略它)。
FRayTracingPipelineStateRHIRef BasePipeline;
(...)
private:
uint64 ComputeShaderTableHash(const TArrayView<FRHIRayTracingShader*>& ShaderTable, uint64 InitialHash = 5699878132332235837ull);
// 著色器表.
TArrayView<FRHIRayTracingShader*> RayGenTable;
TArrayView<FRHIRayTracingShader*> MissTable;
TArrayView<FRHIRayTracingShader*> HitGroupTable;
TArrayView<FRHIRayTracingShader*> CallableTable;
};
17.6.2.2 D3D12 Raytracing
D3D12光線追蹤相關的核心類型和說明如下:
// D3D12RHIPrivate.h
// 表示各種RTPSO屬性的結構(如果未知,則為0),可用於報告性能特徵、按佔用率對著色器排序等。
struct FD3D12RayTracingPipelineInfo
{
// 基於佔用率或其他特定於平台的啟發式方法估計RTPSO組。0預計表現最差,9預計表現最好。
uint32 PerformanceGroup = 0;
uint32 NumVGPR = 0;
uint32 NumSGPR = 0;
uint32 StackSize = 0;
uint32 ScratchSize = 0;
};
// FD3D12DynamicRHI和光線追蹤有關的介面.
class FD3D12DynamicRHI : public FDynamicRHI
{
(...)
// 計算光線追蹤場景尺寸.
virtual FRayTracingAccelerationStructureSize RHICalcRayTracingSceneSize(uint32 MaxInstances, ERayTracingAccelerationStructureFlags Flags) final override;
// 計算光線追蹤幾何體大小.
virtual FRayTracingAccelerationStructureSize RHICalcRayTracingGeometrySize(const FRayTracingGeometryInitializer& Initializer) final override;
// 創建光線追蹤幾何體.
virtual FRayTracingGeometryRHIRef RHICreateRayTracingGeometry(const FRayTracingGeometryInitializer& Initializer) final override;
// 創建光線追蹤場景.
virtual FRayTracingSceneRHIRef RHICreateRayTracingScene(const FRayTracingSceneInitializer& Initializer) final override;
virtual FRayTracingSceneRHIRef RHICreateRayTracingScene(FRayTracingSceneInitializer2 Initializer) final override;
// 創建光線追蹤shader.
virtual FRayTracingShaderRHIRef RHICreateRayTracingShader(TArrayView<const uint8> Code, const FSHAHash& Hash, EShaderFrequency ShaderFrequency) final override;
// 創建光線追蹤管線狀態.
virtual FRayTracingPipelineStateRHIRef RHICreateRayTracingPipelineState(const FRayTracingPipelineStateInitializer& Initializer) final override;
// 創建光線追蹤幾何體底層資源.
virtual void RHITransferRayTracingGeometryUnderlyingResource(FRHIRayTracingGeometry* DestGeometry, FRHIRayTracingGeometry* SrcGeometry) final override;
(...)
};
// RayTracingBuiltInResources.h
struct FHitGroupSystemRootConstants
{
// 配置由位域組成:
// uint IndexStride : 8; // 可以只有1位以標明是16還是32位.
// uint VertexStride : 8; // 可以只有2位以標明是float3還是half2格式.
// uint Unused : 16;
UINT_TYPE Config;
UINT_TYPE IndexBufferOffsetInBytes; // HitGroupSystemIndexBuffer的偏移.
UINT_TYPE UserData; // 分配給hit組的用戶提供常數
UINT_TYPE BaseInstanceIndex; // 屬於當前批次的第一個幾何體實例的索引。可用於在光線追蹤著色器中模擬SV_InstanceID.
(...)
};
// D3D12RayTracing.h
// 始終綁定到所有命中著色器的內置本地根參數.
struct FHitGroupSystemParameters
{
D3D12_GPU_VIRTUAL_ADDRESS IndexBuffer;
D3D12_GPU_VIRTUAL_ADDRESS VertexBuffer;
FHitGroupSystemRootConstants RootConstants;
};
// D3D12光線追蹤幾何體
class FD3D12RayTracingGeometry : public FRHIRayTracingGeometry, public FD3D12AdapterChild, public FD3D12ShaderResourceRenameListener, public FNoncopyable
{
public:
// 設置FHitGroupSystemParameters.
void SetupHitGroupSystemParameters(uint32 InGPUIndex);
// 轉換緩衝區.
void TransitionBuffers(FD3D12CommandContext& CommandContext);
// 更新持久數據.
void UpdateResidency(FD3D12CommandContext& CommandContext);
// 壓縮加速結構.
void CompactAccelerationStructure(FD3D12CommandContext& CommandContext, uint32 InGPUIndex, uint64 InSizeAfterCompaction);
// 創建加速結構構建描述體.
void CreateAccelerationStructureBuildDesc(FD3D12CommandContext& CommandContext, EAccelerationStructureBuildMode BuildMode, D3D12_GPU_VIRTUAL_ADDRESS ScratchBufferAddress, D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_DESC& OutDesc, TArrayView<D3D12_RAYTRACING_GEOMETRY_DESC>& OutGeometryDescs) const;
// 釋放底層資源.
void ReleaseUnderlyingResource();
(...)
// 標記加速結構是否被修改
bool bIsAccelerationStructureDirty[MAX_NUM_GPUS] = {};
// 加速結構緩衝區.
TRefCountPtr<FD3D12Buffer> AccelerationStructureBuffers[MAX_NUM_GPUS];
bool bRegisteredAsRenameListener[MAX_NUM_GPUS];
bool bHasPendingCompactionRequests[MAX_NUM_GPUS];
// 逐幾何體分段命中著色器參數
TArray<FHitGroupSystemParameters> HitGroupSystemParameters[MAX_NUM_GPUS];
// 幾何圖形描述數組,每段一個(單段幾何圖形是常見情況). 它只引用CPU可訪問的結構(沒有GPU資源), 稍後用作BuildAccelerationStructure()的模板。
TArray<D3D12_RAYTRACING_GEOMETRY_DESC, TInlineAllocator<1>> GeometryDescs;
uint64 AccelerationStructureCompactedSize = 0;
(...)
};
// D3D12光線追蹤場景
class FD3D12RayTracingScene : public FRHIRayTracingScene, public FD3D12AdapterChild, public FNoncopyable
{
public:
// 光線追蹤著色器綁定可以並行處理。每個並發工作執行緒都有自己的專用描述符快取實例,以避免爭用或鎖定。(Fortnite團隊)實踐證明,擴展超過5個匯流排程不會產生任何加速.
static constexpr uint32 MaxBindingWorkers = 5; // RHI thread + 4 parallel workers.
// 緩衝區操作.
void BindBuffer(FRHIBuffer* Buffer, uint32 BufferOffset);
void ReleaseBuffer();
// 構建加速結構.
void BuildAccelerationStructure(FD3D12CommandContext& CommandContext, FD3D12Buffer* ScratchBuffer, uint32 ScratchBufferOffset, FD3D12Buffer* InstanceBuffer, uint32 InstanceBufferOffset);
// SRV
FShaderResourceViewRHIRef ShaderResourceView;
// 加速結構數據.
TRefCountPtr<FD3D12Buffer> AccelerationStructureBuffers[MAX_NUM_GPUS];
uint32 BufferOffset = 0;
D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS BuildInputs = {};
FRayTracingAccelerationStructureSize SizeInfo = {};
// 初始化數據.
const FRayTracingSceneInitializer2 Initializer;
// 實例數據.
TResourceArray<D3D12_RAYTRACING_INSTANCE_DESC, 16> Instances;
TArray<uint32> PerInstanceNumTransforms;
// Scene keeps track of child acceleration structure buffers to ensure
// they are resident when any ray tracing work is dispatched.
TArray<FD3D12ResidencyHandle*> GeometryResidencyHandles[MAX_NUM_GPUS];
// 更新持久數據.
void UpdateResidency(FD3D12CommandContext& CommandContext);
// 所有場景實例幾何體中每個幾何體段的命中組參數數組。作為HitGroupSystemParametersCache[SegmentPrefixSum[InstanceIndex]+SegmentIndex]訪問。僅用於GPU 0(輔助GPU採用慢速路徑)。
TArray<FHitGroupSystemParameters> HitGroupSystemParametersCache;
// 查找光線追蹤著色器表.
FD3D12RayTracingShaderTable* FindOrCreateShaderTable(const FD3D12RayTracingPipelineState* Pipeline, FD3D12Device* Device);
FD3D12RayTracingShaderTable* FindExistingShaderTable(const FD3D12RayTracingPipelineState* Pipeline, FD3D12Device* Device) const;
// 光線追蹤著色器表.
TMap<const FD3D12RayTracingPipelineState*, FD3D12RayTracingShaderTable*> ShaderTables[MAX_NUM_GPUS];
(...)
};
// 管理所有掛起的BLAS壓縮請求.
class FD3D12RayTracingCompactionRequestHandler : FD3D12DeviceChild
{
public:
void RequestCompact(FD3D12RayTracingGeometry* InRTGeometry);
bool ReleaseRequest(FD3D12RayTracingGeometry* InRTGeometry);
void Update(FD3D12CommandContext& InCommandContext);
(...)
};
17.6.2.3 Vulkan Raytracing
Vulkan光線追蹤相關的核心類型和說明如下:
// VulkanRaytracing.h
// 聲明光線追蹤入口點
namespace VulkanDynamicAPI
{
ENUM_VK_ENTRYPOINTS_RAYTRACING(DECLARE_VK_ENTRYPOINTS);
}
// Vulkan光線追蹤平台相關介面。
class FVulkanRayTracingPlatform
{
public:
static void GetDeviceExtensions(EGpuVendorId VendorId, TArray<const ANSICHAR*>& OutExtensions);
static void EnablePhysicalDeviceFeatureExtensions(VkDeviceCreateInfo& DeviceInfo, FVulkanDevice& Device);
static bool LoadVulkanInstanceFunctions(VkInstance inInstance);
};
// Vulkan光線追蹤分配
struct FVkRtAllocation
{
VkDevice Device = VK_NULL_HANDLE;
VkDeviceMemory Memory = VK_NULL_HANDLE;
VkBuffer Buffer = VK_NULL_HANDLE;
};
// Vulkan光線追蹤分配器
class FVulkanRayTracingAllocator
{
public:
static void Allocate(FVulkanDevice* Device, VkDeviceSize Size, VkBufferUsageFlags UsageFlags, VkMemoryPropertyFlags MemoryFlags, FVkRtAllocation& Result);
static void Free(FVkRtAllocation& Allocation);
};
// Vulkan光線追蹤TLAS.
struct FVkRtTLASBuildData
{
VkAccelerationStructureGeometryKHR Geometry;
VkAccelerationStructureBuildGeometryInfoKHR GeometryInfo;
VkAccelerationStructureBuildSizesInfoKHR SizesInfo;
};
// Vulkan光線追蹤BLAS.
struct FVkRtBLASBuildData
{
TArray<VkAccelerationStructureGeometryKHR, TInlineAllocator<1>> Segments;
TArray<VkAccelerationStructureBuildRangeInfoKHR, TInlineAllocator<1>> Ranges;
VkAccelerationStructureBuildGeometryInfoKHR GeometryInfo;
VkAccelerationStructureBuildSizesInfoKHR SizesInfo;
};
// Vulkan光線追蹤幾何體.
class FVulkanRayTracingGeometry : public FRHIRayTracingGeometry
{
public:
virtual FRayTracingAccelerationStructureAddress GetAccelerationStructureAddress(uint64 GPUIndex) const final override;
virtual void SetInitializer(const FRayTracingGeometryInitializer& Initializer) final override;
void Swap(FVulkanRayTracingGeometry& Other);
void BuildAccelerationStructure(FVulkanCommandListContext& CommandContext, EAccelerationStructureBuildMode BuildMode);
private:
FVulkanDevice* const Device = nullptr;
VkAccelerationStructureKHR Handle = VK_NULL_HANDLE;
VkDeviceAddress Address = 0;
TRefCountPtr<FVulkanResourceMultiBuffer> AccelerationStructureBuffer;
TRefCountPtr<FVulkanResourceMultiBuffer> ScratchBuffer;
};
// Vulkan光線追蹤場景.
class FVulkanRayTracingScene : public FRHIRayTracingScene
{
public:
void BindBuffer(FRHIBuffer* InBuffer, uint32 InBufferOffset);
void BuildAccelerationStructure(FVulkanCommandListContext& CommandContext, FVulkanResourceMultiBuffer* ScratchBuffer, uint32 ScratchOffset, FVulkanResourceMultiBuffer* InstanceBuffer, uint32 InstanceOffset);
FRayTracingAccelerationStructureSize SizeInfo;
private:
FVulkanDevice* const Device = nullptr;
const FRayTracingSceneInitializer2 Initializer;
TRefCountPtr<FVulkanResourceMultiBuffer> InstanceBuffer;
// 原生TLAS句柄由Vulkan RHI中的SRV對象擁有。D3D12和其他RHI允許在任何時候從任何GPU地址創建TLAS SRV,並且不需要它們進行構建或更新等操作。FVulkanRayTracingScene無法直接擁有VkaAccelerationStructureKHR,因為需要使用瞬態資源分配器分配TLAS記憶體,並且場景對象的生存期可能與緩衝區的生存期不同。可以創建多個VkaAccelerationStructureKHR,指向同一緩衝區。
TRefCountPtr<FVulkanShaderResourceView> AccelerationStructureView;
TRefCountPtr<FVulkanResourceMultiBuffer> AccelerationStructureBuffer;
// 包含每個實例索引和頂點緩衝區綁定數據的緩衝區.
TRefCountPtr<FVulkanResourceMultiBuffer> PerInstanceGeometryParameterBuffer;
TRefCountPtr<FVulkanShaderResourceView> PerInstanceGeometryParameterSRV;
void BuildPerInstanceGeometryParameterBuffer();
};
// Vulkan光線追蹤管線狀態.
class FVulkanRayTracingPipelineState : public FRHIRayTracingPipelineState
{
private:
FVulkanRayTracingLayout* Layout = nullptr;
VkPipeline Pipeline = VK_NULL_HANDLE;
FVkRtAllocation RayGenShaderBindingTable;
FVkRtAllocation MissShaderBindingTable;
FVkRtAllocation HitShaderBindingTable;
};
// Vulkan光線追蹤基礎管線. 用來處理遮擋.
class FVulkanBasicRaytracingPipeline
{
private:
FVulkanRayTracingPipelineState* Occlusion = nullptr;
};
17.6.3 UE光線追蹤渲染流程
要分析UE的光線追蹤的渲染流程,還得搬出我們最熟悉的FDeferredShadingSceneRenderer::Render。下面僅列出主流程中和光線追蹤相關的步驟:
// DeferredShadingRenderer.cpp
void FDeferredShadingSceneRenderer::Render(FRDGBuilder& GraphBuilder)
{
(...)
// 更新圖元的GPU場景資訊.
Scene->UpdateAllPrimitiveSceneInfos(GraphBuilder, true);
#if RHI_RAYTRACING
(...)
if (CurrentMode != Scene->CachedRayTracingMeshCommandsMode || bNaniteCoarseMeshStreamingModeChanged)
{
// 如果更改為路徑追蹤渲染或從路徑追蹤渲染更改,則需要刷新快取的光線追蹤網格命令,因為它們包含有關當前綁定著色器的數據。這種操作有點昂貴,但只在模式之間轉換時發生一次,應該是罕見的。
Scene->CachedRayTracingMeshCommandsMode = CurrentMode;
Scene->RefreshRayTracingMeshCommandCache();
}
(...)
#endif
(...)
#if RHI_RAYTRACING
FRayTracingScene& RayTracingScene = Scene->RayTracingScene;
// 重置內部數組,但不釋放任何資源。
RayTracingScene.Reset();
(...)
// 為渲染此幀準備場景。收集網格實例、著色器、資源、參數等,並構建光線追蹤加速結構.
GatherRayTracingWorldInstancesForView(GraphBuilder, ReferenceView, RayTracingScene);
#endif
(...)
RenderPrePass(GraphBuilder, ...);
(...)
#if RHI_RAYTRACING
bool bRayTracingSceneReady = false;
#endif
(...)
#if RHI_RAYTRACING
// 非同步加速結構構建可能與BasePass重疊.
FRDGBufferRef DynamicGeometryScratchBuffer;
DispatchRayTracingWorldUpdates(GraphBuilder, DynamicGeometryScratchBuffer);
#endif
RenderBasePass(GraphBuilder, ...);
(...)
// Shadows, lumen and fog after base pass
if (!bHasRayTracedOverlay)
{
(...)
RenderShadowDepthMaps(GraphBuilder, ...);
(...)
#if RHI_RAYTRACING
// 如果需要硬體光線追蹤陰影,Lumen場景照明要求光線追蹤場景準備就緒
if (Lumen::UseHardwareRayTracedSceneLighting(ViewFamily))
{
WaitForRayTracingScene(GraphBuilder, DynamicGeometryScratchBuffer);
bRayTracingSceneReady = true;
}
#endif
(...)
}
(...)
#if RHI_RAYTRACING
// 如果Lumen沒有強制較早的光線追蹤場景同步,則必須在此處等待。
if (!bRayTracingSceneReady)
{
WaitForRayTracingScene(GraphBuilder, DynamicGeometryScratchBuffer);
bRayTracingSceneReady = true;
}
#endif
if (bRenderDeferredLighting)
{
(...)
#if RHI_RAYTRACING
// 渲染抖動的LOD過渡遮罩.
RenderDitheredLODFadingOutMask(GraphBuilder, Views[0], SceneTextures.Depth.Target);
#endif
(...)
// 渲染光源.
RenderLights(GraphBuilder, ...);
(...)
#if RHI_RAYTRACING
// 渲染光線追蹤的天空光並組合.
RenderRayTracingSkyLight(GraphBuilder, ...);
CompositeRayTracingSkyLight(GraphBuilder, ...);
#endif
}
(...)
// 半透明
if (!bHasRayTracedOverlay && TranslucencyViewsToRender != ETranslucencyView::None)
{
(...)
#if RHI_RAYTRACING
// 渲染光線追蹤半透明.
RenderRayTracingTranslucency(GraphBuilder, SceneTextures.Color);
EnumRemoveFlags(TranslucencyViewsToRender, ETranslucencyView::RayTracing);
#endif
(...)
// 渲染非光線追蹤半透明.
RenderTranslucency(GraphBuilder, ...);
(...)
}
(...)
#if RHI_RAYTRACING
// 路徑追蹤
RenderPathTracing(GraphBuilder, View, ...);
#endif
(...)
// 後處理.
AddPostProcessingPasses(GraphBuilder, View, ...);
(...)
#if RHI_RAYTRACING
// 釋放光線追蹤資源.
ReleaseRaytracingResources(GraphBuilder, Views, Scene->RayTracingScene);
#endif
(...)
}
按傳統慣例,是時候來一發流程圖了:
A(Scene->UpdateAllPrimitiveSceneInfos) –> B(Scene->RefreshRayTracingMeshCommandCache)
B –> C(GatherRayTracingWorldInstancesForView)
C –> D(RenderPrePass)
D –> E(DispatchRayTracingWorldUpdates)
E –> F(RenderBasePass)
F –> F1(RenderShadowDepthMaps)
F1 –> G(WaitForRayTracingScene)
G –> H(RenderDitheredLODFadingOutMask)
H –> I(RenderLights)
I –> J(RenderRayTracingSkyLight)
J –> K(CompositeRayTracingSkyLight)
K –> L(RenderRayTracingTranslucency)
L –> M(RenderTranslucency)
M –> N(RenderPathTracing)
N –> O(AddPostProcessingPasses)
O –> P(ReleaseRaytracingResources)
對應RenderDoc的截幀如下:
由於RenderDoc無法截取硬體光線追蹤的詳情,部落客本想通過Windows PIX截幀,但發現PIX有BUG(也可能是驅動或UE的),無法正常截取UE5.0.3,截幀數據非常不完整:
如果想在UE5中啟用PIX截幀調試,可參閱:

光線追蹤相關的步驟簡要說明如下:
-
GatherRayTracingWorldInstancesForView:
- 通過RayTracingCollector收集view中可用於光線追蹤的物體,會區分動態和靜態物體。
-
DispatchRayTracingWorldUpdates:
- 獲取scene的RayTracingSkinnedGeometryUpdateQueue,通過GraphBuilder提交。
- GRayTracingGeometryManager處理光線追蹤物體的加速結構構建請求。
- GRayTracingGeometryManager強制構建RayTracingScene.GeometriesToBuild。
- 創建動態幾何體緩衝區。
- 向GraphBuilder增加RayTracingScene Pass。
-
WaitForRayTracingScene:
- 調用SetupRayTracingPipelineStates以設置光線追蹤管線狀態。
- 如果場景有任何內聯光線追蹤物體,則調用SetupLumenHardwareRayTracingHitGroupBuffer以支援Lumen硬體光線追蹤加速。
- 向GraphBuilder添加WaitForRayTracingScene Pass:
- 利用TaskGraph等待ReferenceView.RayTracingMaterialBindingsTask處理完成。執行於Local渲染執行緒。
- 處理ReferenceView.RayTracingMaterialBindings,嘗試合併它們。
- 調用RHICmdList.SetRayTracingHitGroups,以設置光線追蹤命中組。
- 處理Lumen光線追蹤硬體加速。
- 調用SetupRayTracingLightingMissShader以設置未命中著色器。
- 處理GPU資源轉換。
-
RenderLights:
- 如果光源是光線追蹤模式,且啟用了光線追蹤陰影,則調用RenderRayTracingShadows執行光線追蹤陰影計算。
- 對光線追蹤陰影執行降噪(如果啟用)。
-
RenderRayTracingSkyLight:
- GenerateSkyLightVisibilityRays生成天空光可見光線。
- 根據上一步驟生成的天空光可見光線構建加速結構。
- 向GraphBuilder添加SkyLightRayTracing的Pass。
- 對天空光的追蹤結果執行降噪。
-
CompositeRayTracingSkyLight:
- 將天空光線追蹤蹤降噪後的結果組合到場景顏色中。
-
RenderRayTracingTranslucency:
- 遍歷每個view,對存在半透明光線追蹤物體的view調用RenderRayTracingPrimaryRaysView,以繪製半透明物體的光照結果。
- 將半透明紋理結合到場景顏色中。
-
RenderPathTracing:
-
檢測view的狀態是否改變,如果是,則置之前的追蹤結果為無效,並重現開始路徑追蹤。
-
向GraphBuilder添加路徑追蹤的Pass。
- 如果反彈此處大於0,則調用RHICmdList.RayTraceDispatchIndirect。
- 否則,調用RHICmdList.RayTraceDispatch。
-
如果需要降噪,則對路徑追蹤結果執行降噪。
-
執行全螢幕繪製,以顯示路徑追蹤結果。
-
-
ReleaseRaytracingResources:
- 向GraphBuilder添加釋放光線追蹤資源的Pass,釋放的資源包含光線追蹤場景、次表面、光照數據等。
主要的流程和步驟已經闡述完畢。下面小節將對部分重要的特性進行剖析。
17.6.4 UE光線追蹤光影
17.6.4.1 RenderLights
光線追蹤光影的渲染過程集成在了FDeferredShadingSceneRenderer::RenderLights中:
// LightRendering.cpp
void FDeferredShadingSceneRenderer::RenderLights(FRDGBuilder& GraphBuilder, ...)
{
(...)
// 非合批光源,處理RHI預處理陰影遮罩紋理PreprocessedShadowMaskTextures。
if (RHI_RAYTRACING && bDoShadowBatching)
{
(...)
// 分配PreprocessedShadowMaskTextures
if (!View.bStatePrevViewInfoIsReadOnly)
{
View.ViewState->PrevFrameViewInfo.ShadowHistories.Empty();
View.ViewState->PrevFrameViewInfo.ShadowHistories.Reserve(SortedLights.Num());
}
PreprocessedShadowMaskTextures.SetNum(SortedLights.Num());
(...)
}
(...)
for (int32 LightIndex = UnbatchedLightStart; LightIndex < SortedLights.Num(); LightIndex++)
{
(...)
// 確定此燈光是否還沒有預處理陰影,如果需要,執行批處理以攤銷成本.
if (RHI_RAYTRACING && bWantsBatchedShadow && (PreprocessedShadowMaskTextures.Num() == 0 || !PreprocessedShadowMaskTextures[LightIndex - UnbatchedLightStart]))
{
(...)
// 處理降噪批次.
const auto QuickOffDenoisingBatch = [&]
{
(...)
TStaticArray<IScreenSpaceDenoiser::FShadowVisibilityOutputs, IScreenSpaceDenoiser::kMaxBatchSize> Outputs;
// 降噪陰影遮罩紋理.
DenoiserToUse->DenoiseShadowVisibilityMasks(GraphBuilder, View, ...);
for (int32 i = 0; i < InputParameterCount; i++)
{
const FLightSceneInfo* LocalLightSceneInfo = DenoisingQueue[i].LightSceneInfo;
int32 LocalLightIndex = LightIndices[i];
FRDGTextureRef& RefDestination = PreprocessedShadowMaskTextures[LocalLightIndex - UnbatchedLightStart];
check(RefDestination == nullptr);
RefDestination = Outputs[i].Mask;
DenoisingQueue[i].LightSceneInfo = nullptr;
}
};
// 光線追蹤需要的光線陰影,並快速關閉降噪批次。
for (int32 LightBatchIndex = LightIndex; LightBatchIndex < SortedLights.Num(); LightBatchIndex++)
{
const FSortedLightSceneInfo& BatchSortedLightInfo = SortedLights[LightBatchIndex];
const FLightSceneInfo& BatchLightSceneInfo = *BatchSortedLightInfo.LightSceneInfo;
// 降噪器不支援紋理矩形光源的重要性取樣。
const bool bBatchDrawShadows = BatchSortedLightInfo.SortKey.Fields.bShadowed;
(...)
// 如果降噪器不支援此光線追蹤配置,則不值得進行批處理並增加記憶體壓力。
if (bRequiresDenoiser && DenoiserRequirements != IScreenSpaceDenoiser::EShadowRequirements::PenumbraAndClosestOccluder)
{
continue;
}
(...)
// 執行光線追蹤陰影.
FRDGTextureUAV* RayHitDistanceUAV = GraphBuilder.CreateUAV(FRDGTextureUAVDesc(RayDistanceTexture));
{
// 光線追蹤不透明幾何體投射到髮絲幾何體上的陰影. 注意:此輸出不需要降噪器,因為髮絲具有幾何雜訊,因此很難降噪.
RenderRayTracingShadows(GraphBuilder, SceneTextureParameters, View, BatchLightSceneInfo, BatchRayTracingConfig, DenoiserRequirements, LightingChannelsTexture, RayTracingShadowMaskUAV, RayHitDistanceUAV, SubPixelRayTracingShadowMaskUAV);
(...)
}
bool bBatchFull = false;
// 將光線追蹤從排隊取出以對陰影降噪。
if (bRequiresDenoiser)
{
for (int32 i = 0; i < IScreenSpaceDenoiser::kMaxBatchSize; i++)
{
if (DenoisingQueue[i].LightSceneInfo == nullptr)
{
DenoisingQueue[i].LightSceneInfo = &BatchLightSceneInfo;
DenoisingQueue[i].RayTracingConfig = RayTracingConfig;
DenoisingQueue[i].InputTextures.Mask = RayTracingShadowMaskTexture;
DenoisingQueue[i].InputTextures.ClosestOccluder = RayDistanceTexture;
LightIndices[i] = LightBatchIndex;
// 如果此燈類型的隊列已滿,則快速批處理。
if ((i + 1) == MaxDenoisingBatchSize)
{
QuickOffDenoisingBatch();
bBatchFull = true;
}
break;
}
else
{
check((i - 1) < IScreenSpaceDenoiser::kMaxBatchSize);
}
}
}
else // 不需要降噪, 直接存到處理預處理陰影遮罩紋理數組中.
{
PreprocessedShadowMaskTextures[LightBatchIndex - UnbatchedLightStart] = RayTracingShadowMaskTexture;
}
// 如果填充的降噪批次或達到最大光批次,則終止批次.
ProcessShadows++;
if (bBatchFull || ProcessShadows == MaxRTShadowBatchSize)
{
break;
}
}
// 確保處理所有降噪隊列。
if (DenoisingQueue[0].LightSceneInfo)
{
QuickOffDenoisingBatch();
}
}
(...)
}
(...)
}
對光線追蹤陰影補充以下幾點說明:
-
不同類型的光源開啟光線追蹤陰影的條件有所不同:
// LightRendering.cpp // 根據不同類型的光源判斷是否可以開啟光線追蹤陰影。 static bool ShouldRenderRayTracingShadowsForLightType(ELightComponentType LightType) { switch(LightType) { case LightType_Directional: return !!CVarRayTracingShadowsDirectionalLight.GetValueOnRenderThread(); case LightType_Point: return !!CVarRayTracingShadowsPointLight.GetValueOnRenderThread(); case LightType_Spot: return !!CVarRayTracingShadowsSpotLight.GetValueOnRenderThread(); case LightType_Rect: return !!CVarRayTracingShadowsRectLight.GetValueOnRenderThread(); default: return true; } } // 判斷是否可以渲染光線追蹤陰影。 bool ShouldRenderRayTracingShadows() { const bool bIsStereo = GEngine->StereoRenderingDevice.IsValid() && GEngine->StereoRenderingDevice->IsStereoEnabled(); const bool bHairStrands = IsHairStrandsEnabled(EHairStrandsShaderType::Strands); return ShouldRenderRayTracingEffect((CVarRayTracingOcclusion.GetValueOnRenderThread() > 0) && !(bIsStereo && bHairStrands), ERayTracingPipelineCompatibilityFlags::FullPipeline, nullptr); } // 判斷光源場景代表是否可開啟光線追蹤陰影。 bool ShouldRenderRayTracingShadowsForLight(const FLightSceneProxy& LightProxy) { const bool bShadowRayTracingAllowed = ShouldRenderRayTracingEffect(true, ERayTracingPipelineCompatibilityFlags::FullPipeline, nullptr); return (LightProxy.CastsRaytracedShadow() == ECastRayTracedShadow::Enabled || (ShouldRenderRayTracingShadows() && LightProxy.CastsRaytracedShadow() == ECastRayTracedShadow::UseProjectSetting)) && ShouldRenderRayTracingShadowsForLightType((ELightComponentType)LightProxy.GetLightType()) && bShadowRayTracingAllowed; } // 判斷光源資訊是否可開啟光線追蹤陰影。 bool ShouldRenderRayTracingShadowsForLight(const FLightSceneInfoCompact& LightInfo) { const bool bShadowRayTracingAllowed = ShouldRenderRayTracingEffect(true, ERayTracingPipelineCompatibilityFlags::FullPipeline, nullptr); return (LightInfo.CastRaytracedShadow == ECastRayTracedShadow::Enabled || (ShouldRenderRayTracingShadows() && LightInfo.CastRaytracedShadow == ECastRayTracedShadow::UseProjectSetting)) && ShouldRenderRayTracingShadowsForLightType((ELightComponentType)LightInfo.LightType) && bShadowRayTracingAllowed; } -
陰影降噪時會進行合批,以減少批次和狀態切換,提升效率。
-
並非所有陰影都需要降噪。陰影降噪的條件包含:
-
光源類型滿足特定條件:矩形光源、角度大於0的平行光或半徑大於0的點光源或聚光燈。
static bool LightRequiresDenosier(const FLightSceneInfo& LightSceneInfo) { ELightComponentType LightType = ELightComponentType(LightSceneInfo.Proxy->GetLightType()); if (LightType == LightType_Directional) { return LightSceneInfo.Proxy->GetLightSourceAngle() > 0; } else if (LightType == LightType_Point || LightType == LightType_Spot) { return LightSceneInfo.Proxy->GetSourceRadius() > 0; } else if (LightType == LightType_Rect) { return true; } return false; } -
陰影需求類型是IScreenSpaceDenoiser::EShadowRequirements::PenumbraAndClosestOccluder。
-
不是帶有重要性取樣的紋理矩形光源類型。
-
17.6.4.2 RenderRayTracingShadows
本小節闡述光線追蹤陰影的具體過程。
// RayTracingShadows.cpp
void FDeferredShadingSceneRenderer::RenderRayTracingShadows(FRDGBuilder& GraphBuilder, ...)
#if RHI_RAYTRACING
{
FLightSceneProxy* LightSceneProxy = LightSceneInfo.Proxy;
(...)
// 陰影遮擋的光線生成Pass。
{
(...)
// 填充FOcclusionRGS參數。
FOcclusionRGS::FParameters* PassParameters = GraphBuilder.AllocParameters<FOcclusionRGS::FParameters>();
PassParameters->RWOcclusionMaskUAV = OutShadowMaskUAV;
PassParameters->RWRayDistanceUAV = OutRayHitDistanceUAV;
PassParameters->RWSubPixelOcclusionMaskUAV = SubPixelRayTracingShadowMaskUAV;
PassParameters->SamplesPerPixel = RayTracingConfig.RayCountPerPixel;
PassParameters->NormalBias = GetRaytracingMaxNormalBias();
PassParameters->LightingChannelMask = LightSceneProxy->GetLightingChannelMask();
(...)
// FOcclusionRGS的shader。
TShaderMapRef<FOcclusionRGS> RayGenerationShader(GetGlobalShaderMap(FeatureLevel), PermutationVector);
// 清理無用的RDG資源。
ClearUnusedGraphResources(RayGenerationShader, PassParameters);
(...)
// 增加RayTracedShadow的通道。
GraphBuilder.AddPass(
RDG_EVENT_NAME("RayTracedShadow (spp=%d) %dx%d", RayTracingConfig.RayCountPerPixel, Resolution.X, Resolution.Y),
PassParameters,
// Pass標記是Compute。
ERDGPassFlags::Compute,
[this, &View, RayGenerationShader, PassParameters, Resolution](FRHIRayTracingCommandList& RHICmdList)
{
FRayTracingShaderBindingsWriter GlobalResources;
SetShaderParameters(GlobalResources, RayGenerationShader, *PassParameters);
FRHIRayTracingScene* RayTracingSceneRHI = View.GetRayTracingSceneChecked();
// 啟用光線追蹤材質.
if (GRayTracingShadowsEnableMaterials)
{
// 向RHI派發光線追蹤命令.
RHICmdList.RayTraceDispatch(View.RayTracingMaterialPipeline, RayGenerationShader.GetRayTracingShader(), RayTracingSceneRHI, GlobalResources, Resolution.X, Resolution.Y);
}
// 不啟用光線追蹤材質.
else
{
// 初始化光線追蹤管線狀態.
FRayTracingPipelineStateInitializer Initializer;
Initializer.MaxPayloadSizeInBytes = RAY_TRACING_MAX_ALLOWED_PAYLOAD_SIZE;
FRHIRayTracingShader* RayGenShaderTable[] = { RayGenerationShader.GetRayTracingShader() };
Initializer.SetRayGenShaderTable(RayGenShaderTable);
FRHIRayTracingShader* HitGroupTable[] = { View.ShaderMap->GetShader<FOpaqueShadowHitGroup>().GetRayTracingShader() };
Initializer.SetHitGroupTable(HitGroupTable);
// 禁用SBT索引,以便對場景中的所有幾何體使用相同的命中著色器。
Initializer.bAllowHitGroupIndexing = false;
FRayTracingPipelineState* Pipeline = PipelineStateCache::GetAndOrCreateRayTracingPipelineState(RHICmdList, Initializer);
// 向RHI派發光線追蹤命令.
RHICmdList.RayTraceDispatch(Pipeline, RayGenerationShader.GetRayTracingShader(), RayTracingSceneRHI, GlobalResources, Resolution.X, Resolution.Y);
}
});
}
}
光線追蹤陰影的著色器是FOcclusionRGS,其對應的shader文件是RayTracingOcclusionRGS.usf。下面對其進行分析:
// RayTracingOcclusionRGS.usf
RAY_TRACING_ENTRY_RAYGEN(OcclusionRGS)
{
uint2 PixelCoord = DispatchRaysIndex().xy + View.ViewRectMin.xy + PixelOffset;
FOcclusionResult Occlusion = InitOcclusionResult();
FOcclusionResult HairOcclusion = InitOcclusionResult();
const uint RequestedSamplePerPixel = ENABLE_MULTIPLE_SAMPLES_PER_PIXEL ? SamplesPerPixel : 1;
uint LocalSamplesPerPixel = RequestedSamplePerPixel;
if (all(PixelCoord >= LightScissor.xy) && all(PixelCoord <= LightScissor.zw)) // 確保不越界
{
// 隨機序列.
RandomSequence RandSequence;
uint LinearIndex = CalcLinearIndex(PixelCoord);
RandomSequence_Initialize(RandSequence, LinearIndex, View.StateFrameIndex);
FLightShaderParameters LightParameters = GetRootLightShaderParameters(PrimaryView.PreViewTranslation);
// 獲取GBuffer數據.
float2 InvBufferSize = View.BufferSizeAndInvSize.zw;
float2 BufferUV = (float2(PixelCoord) + 0.5) * InvBufferSize;
float3 WorldNormal = 0;
uint ShadingModelID = SHADINGMODELID_UNLIT;
(...)
// 屏蔽掉無限遠的深度值.
float DeviceZ = SceneDepthTexture.Load(int3(PixelCoord, 0)).r;
const bool bIsDepthValid = SceneDepthTexture.Load(int3(PixelCoord, 0)).r > 0.0;
const bool bIsValidPixel = ShadingModelID != SHADINGMODELID_UNLIT && bIsDepthValid;
const uint LightChannel = GetSceneLightingChannel(PixelCoord);
const bool bTraceRay = bIsValidPixel && (LightChannel & LightingChannelMask) != 0;
if (!bTraceRay)
{
LocalSamplesPerPixel = 0;
}
(...)
// 計算遮擋.
Occlusion = ComputeOcclusion(PixelCoord, ShadingModelID, RAY_TRACING_MASK_SHADOW | RAY_TRACING_MASK_THIN_SHADOW, DeviceZ, WorldNormal, LightParameters, TransmissionProfileParams, LocalSamplesPerPixel);
(...)
}
(...)
// 計算遮擋到陰影.
const float Shadow = OcclusionToShadow(Occlusion, LocalSamplesPerPixel);
// 根據不同的降噪輸出維度, 保存不同的結果.
if (DIM_DENOISER_OUTPUT == 2)
{
RWOcclusionMaskUAV[PixelCoord] = float4(Shadow, Occlusion.ClosestRayDistance, 0, Occlusion.TransmissionDistance);
}
else if (DIM_DENOISER_OUTPUT == 1)
{
float AvgHitDistance = -1.0;
if (Occlusion.HitCount > 0.0)
{
AvgHitDistance = Occlusion.SumRayDistance / Occlusion.HitCount;
}
else if (Occlusion.RayCount > 0.0)
{
AvgHitDistance = 1.0e27;
}
RWOcclusionMaskUAV[PixelCoord] = float4(Shadow, Occlusion.TransmissionDistance, Shadow, Occlusion.TransmissionDistance);
RWRayDistanceUAV[PixelCoord] = AvgHitDistance;
}
else
{
const float ShadowFadeFraction = 1;
float SSSTransmission = Occlusion.TransmissionDistance;
// 0為陰影,1為非陰影,除非寫入SceneColor,否則不需要RETURN_COLOR.
float FadedShadow = lerp(1.0f, Square(Shadow), ShadowFadeFraction);
float FadedSSSShadow = lerp(1.0f, Square(SSSTransmission), ShadowFadeFraction);
// 通道指定記錄在ShadowRendering.cpp(尋找光衰減信道分配).
float4 OutColor;
if (LIGHT_TYPE == LIGHT_TYPE_DIRECTIONAL)
{
OutColor = EncodeLightAttenuation(half4(FadedShadow, FadedSSSShadow, 1.0, FadedSSSShadow));
}
else
{
OutColor = EncodeLightAttenuation(half4(FadedShadow, FadedSSSShadow, FadedShadow, FadedSSSShadow));
}
RWOcclusionMaskUAV[PixelCoord] = OutColor;
}
}
上述涉及了幾個重要的函數,繼續分析之:
// 遮擋變成陰影,就是可見樣本/總樣本。
float OcclusionToShadow(FOcclusionResult In, uint LocalSamplesPerPixel)
{
return (LocalSamplesPerPixel > 0) ? In.Visibility / LocalSamplesPerPixel : In.Visibility;
}
// 計算光線遮擋.
FOcclusionResult ComputeOcclusion(...)
{
FOcclusionResult Out = InitOcclusionResult();
const float3 WorldPosition = ReconstructWorldPositionFromDeviceZ(PixelCoord, DeviceZ);
(...)
uint TimeSeed = View.StateFrameIndex;
// 根據不同的樣本數量進行可見性測試.
#if ENABLE_MULTIPLE_SAMPLES_PER_PIXEL
LOOP for (uint SampleIndex = 0; SampleIndex < LocalSamplesPerPixel; ++SampleIndex)
#else
do if (LocalSamplesPerPixel > 0)
#endif
{
// 處理隨機序列.
RandomSequence RandSequence;
#if ENABLE_MULTIPLE_SAMPLES_PER_PIXEL
RandomSequence_Initialize(RandSequence, PixelCoord, SampleIndex, TimeSeed, LocalSamplesPerPixel);
#else
RandomSequence_Initialize(RandSequence, PixelCoord, 0, TimeSeed, 1);
#endif
float2 RandSample = RandomSequence_GenerateSample2D(RandSequence);
// 生成光線.
RayDesc Ray;
bool bIsValidRay = GenerateOcclusionRay(LightParameters, ...);
uint Stencil = SceneStencilTexture.Load(int3(PixelCoord, 0)) STENCIL_COMPONENT_SWIZZLE;
bool bDitheredLODFadingOut = Stencil & 1;
(...)
BRANCH
if (!bIsValidRay && (DIM_DENOISER_OUTPUT == 0))
{
// 降噪器仍然必須追蹤無效的光線,以獲得正確的最近命中距離.
continue;
}
else if (bApplyNormalCulling && dot(WorldNormal, Ray.Direction) <= 0.0)
{
continue;
}
// 衰減檢測.
if (LightParameters.InvRadius > 0.0)
{
const float MaxAttenuationDistance = 1.0 / LightParameters.InvRadius;
if (Ray.TMax > MaxAttenuationDistance)
{
continue;
}
}
uint RayFlags = 0;
// 如果不在雙面陰影投射模式中使用,則啟用背面剔除。
if (bTwoSidedGeometry != 1)
{
RayFlags |= RAY_FLAG_CULL_BACK_FACING_TRIANGLES;
}
(...)
uint RayFlagsForOpaque = bAcceptFirstHit != 0 ? RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH : 0;
// 追蹤可見光線.
FMinimalPayload MinimalPayload = TraceVisibilityRay(TLAS, RayFlags | RayFlagsForOpaque, RaytracingMask, PixelCoord, Ray);
(...)
Out.RayCount += 1.0;
// 有命中物體.
if (MinimalPayload.IsHit())
{
float HitT = MinimalPayload.HitT;
Out.ClosestRayDistance = (Out.ClosestRayDistance == DENOISER_INVALID_HIT_DISTANCE) || (HitT < Out.ClosestRayDistance) ? HitT : Out.ClosestRayDistance;
Out.SumRayDistance += HitT;
Out.HitCount += 1.0;
if (ShadingModelID == SHADINGMODELID_SUBSURFACE || ShadingModelID == SHADINGMODELID_HAIR)
{
(...)
}
}
// 未命中物體.
else
{
Out.ClosestRayDistance = (Out.ClosestRayDistance == DENOISER_INVALID_HIT_DISTANCE) ? DENOISER_MISS_HIT_DISTANCE : Out.ClosestRayDistance;
Out.TransmissionDistance += 1.0;
Out.Visibility += 1.0;
}
}
(...)
// 輸出結果.
if (ENABLE_TRANSMISSION && LocalSamplesPerPixel > 0 && ShadingModelID == SHADINGMODELID_SUBSURFACE_PROFILE)
{
(...)
}
else if (ShadingModelID == SHADINGMODELID_SUBSURFACE || ShadingModelID == SHADINGMODELID_HAIR)
{
(...)
}
else
{
Out.TransmissionDistance = (LocalSamplesPerPixel > 0) ? Out.Visibility / LocalSamplesPerPixel : Out.Visibility;
}
return Out;
}
下面對生成隨機序列、生成光線、追蹤可見光線進行分析:
// PathTracingRandomSequence.ush
// 生成二維隨機序列。
float2 RandomSequence_GenerateSample2D(inout RandomSequence RandSequence)
{
float2 Result;
// 純隨機.
#if RANDSEQ == RANDSEQ_PURERANDOM
Result.x = Rand(RandSequence.SampleSeed);
Result.y = Rand(RandSequence.SampleSeed);
// Halton隨機序列.
#elif RANDSEQ == RANDSEQ_HALTON
Result.x = Halton(RandSequence.SampleIndex, Prime512(RandSequence.SampleSeed + 0));
Result.y = Halton(RandSequence.SampleIndex, Prime512(RandSequence.SampleSeed + 1));
RandSequence.SampleSeed += 2;
// Sobol隨機序列.
#elif RANDSEQ == RANDSEQ_OWENSOBOL
Result = SobolSampler(RandSequence.SampleIndex, RandSequence.SampleSeed).xy;
#endif
return Result;
}
// RayTracingDirectionalLight.ush
// 生成平行光遮擋光線.
void GenerateDirectionalLightOcclusionRay(...)
{
// 繪製隨機變數並在單位圓盤上選擇一個點.
float2 BufferSize = View.BufferSizeAndInvSize.xy;
float2 DiskUV = UniformSampleDiskConcentric(RandSample) * LightParameters.SourceRadius;
// 在單位球體上按用戶定義的半徑排列燈光方向.
float3 LightDirection = LightParameters.Direction;
float3 N = LightDirection;
float3 dPdu = float3(1, 0, 0);
if (dot(N, dPdu) != 0)
{
dPdu = cross(N, dPdu);
}
else
{
dPdu = cross(N, float3(0, 1, 0));
}
float3 dPdv = cross(dPdu, N);
LightDirection += dPdu * DiskUV.x + dPdv * DiskUV.y;
RayOrigin = WorldPosition;
RayDirection = normalize(LightDirection);
RayTMin = 0.0;
RayTMax = 1.0e27;
}
// RayTracingPointLight.ush
// 生成點光源遮擋光線.
bool GeneratePointLightOcclusionRay(...)
{
float3 LightDirection = LightParameters.Position - WorldPosition;
float RayLength = length(LightDirection);
LightDirection /= RayLength;
// 定義光線時應用法線擾動.
RayOrigin = WorldPosition;
RayDirection = LightDirection;
RayTMin = 0.0;
RayTMax = RayLength;
return true;
}
// RayTracingSphereLight.ush
// 用區域取樣生成球體光源遮擋光線.
bool GenerateSphereLightOcclusionRayWithAreaSampling(...)
{
float4 Result = UniformSampleSphere(RandSample);
float3 LightNormal = Result.xyz;
float3 LightPosition = LightParameters.Position + LightNormal * LightParameters.SourceRadius;
float3 LightDirection = LightPosition - WorldPosition;
float RayLength = length(LightDirection);
LightDirection /= RayLength;
RayOrigin = WorldPosition;
RayDirection = LightDirection;
RayTMin = 0.0;
RayTMax = RayLength;
float SolidAnglePdf = Result.w * saturate(dot(LightNormal, -LightDirection)) / (RayLength * RayLength);
RayPdf = SolidAnglePdf;
return true;
}
// 用立體角取樣生成球體光源遮擋光線.
bool GenerateSphereLightOcclusionRayWithSolidAngleSampling(...)
{
(...)
// 確定著色點是否包含在球體燈光中.
float3 LightDirection = LightParameters.Position - WorldPosition;
float RayLength2 = dot(LightDirection, LightDirection);
float Radius2 = LightParameters.SourceRadius * LightParameters.SourceRadius;
BRANCH
if (RayLength2 <= Radius2)
{
return GenerateSphereLightOcclusionRayWithAreaSampling(...);
}
// 圍繞與z軸對齊的圓錐體均勻取樣.
float SinThetaMax2 = Radius2 / RayLength2;
float4 DirAndPdf = UniformSampleConeConcentricRobust(RandSample, SinThetaMax2);
float CosTheta = DirAndPdf.z;
float SinTheta2 = 1.0 - CosTheta * CosTheta;
RayOrigin = WorldPosition;
// 將光線方向投影到世界空間,使z軸與光照方向對齊.
float RayLength = sqrt(RayLength2);
LightDirection *= rcp(RayLength + 1e-4);
RayDirection = TangentToWorld(DirAndPdf.xyz, LightDirection);
RayTMin = 0.0;
// 裁剪到與球體最近交點的長度.
RayTMax = RayLength * (CosTheta - sqrt(max(SinThetaMax2 - SinTheta2, 0.0)));
RayPdf = DirAndPdf.w;
return true;
}
// RayTracingOcclusionRGS.usf
// 生成遮擋光線.
bool GenerateOcclusionRay(...)
{
// 根據不同光源類型生成光線.
#if LIGHT_TYPE == LIGHT_TYPE_DIRECTIONAL
{
GenerateDirectionalLightOcclusionRay(...);
}
#elif LIGHT_TYPE == LIGHT_TYPE_POINT
{
if (LightParameters.SourceRadius == 0)
{
return GeneratePointLightOcclusionRay(...);
}
else
{
float RayPdf;
return GenerateSphereLightOcclusionRayWithSolidAngleSampling(...);
}
}
#elif LIGHT_TYPE == LIGHT_TYPE_SPOT
{
return GenerateSpotLightOcclusionRay(...);
}
#elif LIGHT_TYPE == LIGHT_TYPE_RECT
{
float RayPdf = 0.0;
return GenerateRectLightOcclusionRay(..);
}
#endif
return true;
}
// RayTracingCommon.ush
void TraceVisibilityRayPacked(inout FPackedMaterialClosestHitPayload PackedPayload, ...)
{
const uint RayContributionToHitGroupIndex = RAY_TRACING_SHADER_SLOT_SHADOW;
const uint MultiplierForGeometryContributionToShaderIndex = RAY_TRACING_NUM_SHADER_SLOTS;
const uint MissShaderIndex = 0;
// 通過啟用最小有效載荷模式,忽略所有其他有效載荷資訊,意味著這些功能不需要有效載荷輸入.
PackedPayload.SetMinimalPayloadMode();
PackedPayload.HitT = 0;
PackedPayload.SetPixelCoord(PixelCoord);
// 追蹤光線(圖形API內建函數).
TraceRay(TLAS, RayFlags, InstanceInclusionMask, RayContributionToHitGroupIndex, MultiplierForGeometryContributionToShaderIndex, MissShaderIndex, Ray, PackedPayload);
}
FMinimalPayload TraceVisibilityRay(in RaytracingAccelerationStructure TLAS, ...)
{
FPackedMaterialClosestHitPayload PackedPayload = (FPackedMaterialClosestHitPayload)0;
if ((PayloadFlags & RAY_TRACING_PAYLOAD_INPUT_FLAG_IGNORE_TRANSLUCENT) != 0)
{
PackedPayload.SetIgnoreTranslucentMaterials();
}
// 追蹤可見性光線.
TraceVisibilityRayPacked(PackedPayload, TLAS, RayFlags, InstanceInclusionMask, PixelCoord, Ray);
// 解壓負載.
FMinimalPayload MinimalPayload = (FMinimalPayload)0;
// 理論上,由於FPackedMaterialClosestHitPayload源自FminiMallPayLoad,因此不需要此解包setp,但編譯器目前不喜歡它們之間的直接轉換。此外,如果將來HitT以不同的方式打包,並且FMinimalPayload不是直接從中繼承的,則需要更改。
MinimalPayload.HitT = PackedPayload.HitT;
return MinimalPayload;
}
以上可知,追蹤陰影的過程比較複雜,下面直接畫個流程圖,以便更加清晰明了:
A(OcclusionRGS) –> B(ComputeOcclusion)
B –> B1(RandomSequence_GenerateSample2D)
B1 –> |RANDSEQ_PURERANDOM| B1_1(Rand)
B1_1 –> B2(GenerateOcclusionRay)
B1 –> |RANDSEQ_HALTON| B1_2(Halton)
B1_2 –> B2(GenerateOcclusionRay)
B1 –> |RANDSEQ_OWENSOBOL| B1_3(SobolSampler)
B1_3 –> B2(GenerateOcclusionRay)
B2 –> |LIGHT_TYPE_DIRECTIONAL| B2_1(GenerateDirectionalLightOcclusionRay)
B2_1 –> B3(TraceVisibilityRay)
B2 –> |LIGHT_TYPE_POINT| B2_2(GeneratePointLightOcclusionRay)
B2_2 –> B3(TraceVisibilityRay)
B2 –> |LIGHT_TYPE_SPOT| B2_3(GenerateSpotLightOcclusionRay)
B2_3 –> B3(TraceVisibilityRay)
B2 –> |LIGHT_TYPE_RECT| B2_4(GenerateSpotLightOcclusionRay)
B2_4 –> B3(TraceVisibilityRay)
B3 –> B3_1(TraceVisibilityRayPacked)
B3_1 –> B3_2(TraceRay)
B3_2 –> C(OcclusionToShadow)
C –> D(EncodeLightAttenuation)
17.6.4.3 光線追蹤陰影降噪
光線追蹤陰影的降噪器根據不同的降噪類型而定:
// LightRendering.cpp
(...)
const int32 DenoiserMode = CVarShadowUseDenoiser.GetValueOnRenderThread();
const IScreenSpaceDenoiser* DefaultDenoiser = IScreenSpaceDenoiser::GetDefaultDenoiser();
const IScreenSpaceDenoiser* DenoiserToUse = DenoiserMode == 1 ? DefaultDenoiser : GScreenSpaceDenoiser;
(...)
const auto QuickOffDenoisingBatch = [&]
{
(...)
// 執行降噪處理。
DenoiserToUse->DenoiseShadowVisibilityMasks(GraphBuilder, View, &View.PrevViewInfo, SceneTextureParameters, DenoisingQueue, InputParameterCount, Outputs);
(...)
};
(...)
由此可知,有兩種陰影降噪器:IScreenSpaceDenoiser::GetDefaultDenoiser()和GScreenSpaceDenoiser。不過部落客搜索了整個UE工程,發現它們其實都是同一個類型:IScreenSpaceDenoiser,下面對它進行分析:
// ScreenSpaceDenoise.cpp
class FDefaultScreenSpaceDenoiser : public IScreenSpaceDenoiser
{
public:
virtual void DenoiseShadowVisibilityMasks(FRDGBuilder& GraphBuilder, const FViewInfo& View, ...) const
{
// 設置渲染紋理.
FViewInfoPooledRenderTargets ViewInfoPooledRenderTargets;
SetupSceneViewInfoPooledRenderTargets(View, &ViewInfoPooledRenderTargets);
FSSDSignalTextures InputSignal;
// 設置降噪數據.
DECLARE_FSSD_CONSTANT_PIXEL_DENSITY_SETTINGS(SSDShadowVisibilityMasksEffectName);
Settings.SignalProcessing = ESignalProcessing::ShadowVisibilityMask;
(...)
// 批處理ID.
for (int32 BatchedSignalId = 0; BatchedSignalId < InputParameterCount; BatchedSignalId++)
{
Settings.MaxInputSPP = FMath::Max(Settings.MaxInputSPP, InputParameters[BatchedSignalId].RayTracingConfig.RayCountPerPixel);
}
// 降噪歷史數據.
TStaticArray<FScreenSpaceDenoiserHistory*, IScreenSpaceDenoiser::kMaxBatchSize> PrevHistories;
TStaticArray<FScreenSpaceDenoiserHistory*, IScreenSpaceDenoiser::kMaxBatchSize> NewHistories;
for (int32 BatchedSignalId = 0; BatchedSignalId < InputParameterCount; BatchedSignalId++)
{
(...)
}
(...)
FSSDSignalTextures SignalOutput;
// 恆定像素密度下的訊號降噪.
DenoiseSignalAtConstantPixelDensity(GraphBuilder, View, SceneTextures, ViewInfoPooledRenderTargets, InputSignal, Settings, PrevHistories, NewHistories, &SignalOutput);
// 保存輸出數據.
for (int32 BatchedSignalId = 0; BatchedSignalId < InputParameterCount; BatchedSignalId++)
{
Outputs[BatchedSignalId].Mask = SignalOutput.Textures[BatchedSignalId];
}
}
};
以上程式碼涉及的DenoiseSignalAtConstantPixelDensity非常複雜,下面簡單地闡述其主要步驟:
static void DenoiseSignalAtConstantPixelDensity(FRDGBuilder& GraphBuilder, const FViewInfo& View, ...)
{
(...)
// 創建內部降噪緩衝區的描述符和緩衝區.
bool bHasReconstructionLayoutDifferentFromHistory = false;
TStaticArray<FRDGTextureDesc, kMaxBufferProcessingCount> InjestDescs;
TStaticArray<FRDGTextureDesc, kMaxBufferProcessingCount> ReconstructionDescs;
TStaticArray<FRDGTextureDesc, kMaxBufferProcessingCount> HistoryDescs;
(...)
// 設置公共著色器參數.
FSSDCommonParameters CommonParameters;
{
Denoiser::SetupCommonShaderParameters(View, SceneTextures, ...);
(...)
}
// 設置所有元數據以進行空間卷積。
FSSDConvolutionMetaData ConvolutionMetaData;
if (Settings.SignalProcessing == ESignalProcessing::ShadowVisibilityMask)
{
for (int32 BatchedSignalId = 0; BatchedSignalId < Settings.SignalBatchSize; BatchedSignalId++)
{
FLightSceneProxy* LightSceneProxy = Settings.LightSceneInfo[BatchedSignalId]->Proxy;
(...)
ConvolutionMetaData.LightPositionAndRadius[BatchedSignalId] = FVector4f(TranslatedWorldPosition, Parameters.SourceRadius);
ConvolutionMetaData.LightDirectionAndLength[BatchedSignalId] = FVector4f(Parameters.Direction, Parameters.SourceLength);
GET_SCALAR_ARRAY_ELEMENT(ConvolutionMetaData.HitDistanceToWorldBluringRadius, BatchedSignalId) =
FMath::Tan(0.5 * FMath::DegreesToRadians(LightSceneProxy->GetLightSourceAngle()) * LightSceneProxy->GetShadowSourceAngleFactor());
GET_SCALAR_ARRAY_ELEMENT(ConvolutionMetaData.LightType, BatchedSignalId) = LightSceneProxy->GetLightType();
}
}
// 壓縮元數據以實現更低的記憶體頻寬、半解析度的一致記憶體訪問和更低的VGPR佔用空間.
ECompressedMetadataLayout CompressedMetadataLayout = GetSignalCompressedMetadata(Settings.SignalProcessing);
if (CompressedMetadataLayout == ECompressedMetadataLayout::FedDepthAndShadingModelID)
{
CommonParameters.CompressedMetadata[0] = Settings.CompressedDepthTexture;
CommonParameters.CompressedMetadata[1] = Settings.CompressedShadingModelTexture;
}
else if (CompressedMetadataLayout != ECompressedMetadataLayout::Disabled)
{
(...)
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD CompressMetadata %dx%d", ...);
}
FSSDSignalTextures SignalHistory = InputSignal;
// 在重建過程中預計算重建過程的某些值.
if (SignalUsesInjestion(Settings.SignalProcessing))
{
(...)
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD Injest(MultiSPP=%i)", ...);
SignalHistory = NewSignalOutput;
}
// 使用比率估計器進行空間重建,以在歷史剔除中更精確.
if (Settings.bEnableReconstruction)
{
(...)
TShaderMapRef<FSSDSpatialAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD Reconstruction(MaxSamples=%i Scissor=%ix%i%s%s)", ...);
SignalHistory = NewSignalOutput;
}
// 空間預卷積.
for (int32 PreConvolutionId = 0; PreConvolutionId < Settings.PreConvolutionCount; PreConvolutionId++)
{
(...)
TShaderMapRef<FSSDSpatialAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD PreConvolution(MaxSamples=%d Spread=%f)", ...);
SignalHistory = NewSignalOutput;
}
(...)
// 時間Pass.
// 注意:即使沒有ViewState,也總是這樣做,因為它已經不是降噪品質的理想情況,因此並不真正關心性能,並且重建可能具有與時間累積輸出不同的布局。
if (bHasReconstructionLayoutDifferentFromHistory || Settings.bUseTemporalAccumulation)
{
FSSDSignalTextures RejectionPreConvolutionSignal;
// 時間拒絕可能利用可分離的預卷積.
if (SignalUsesRejectionPreConvolution(Settings.SignalProcessing))
{
(...)
TShaderMapRef<FSSDSpatialAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD RejectionPreConvolution(MaxSamples=5)"), ...);
}
(...)
TShaderMapRef<FSSDTemporalAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
(...)
// 設置訊號的前一幀歷史緩衝區.
for (int32 BatchedSignalId = 0; BatchedSignalId < Settings.SignalBatchSize; BatchedSignalId++)
{
FScreenSpaceDenoiserHistory* PrevFrameHistory = PrevFilteringHistory[BatchedSignalId] ? PrevFilteringHistory[BatchedSignalId] : &DummyPrevFrameHistory;
(...)
PassParameters->HistoryBufferScissorUVMinMax[BatchedSignalId] = FVector4f(
float(PrevFrameHistory->Scissor.Min.X + 0.5f) / float(PrevFrameBufferExtent.X),
float(PrevFrameHistory->Scissor.Min.Y + 0.5f) / float(PrevFrameBufferExtent.Y),
float(PrevFrameHistory->Scissor.Max.X - 0.5f) / float(PrevFrameBufferExtent.X),
float(PrevFrameHistory->Scissor.Max.Y - 0.5f) / float(PrevFrameBufferExtent.Y));
PrevFrameHistory->SafeRelease();
}
// 手動清除未使用的資源,以找出著色器在下一幀中實際需要什麼.
{
ClearUnusedGraphResources(ComputeShader, PassParameters);
(...)
for (int32 i = 0; i < kCompressedMetadataTextures; i++)
bExtractCompressedMetadata[i] = PassParameters->PrevCompressedMetadata[i] != nullptr;
}
// 增加時間累積通道.
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("SSD TemporalAccumulation%s", ...);
SignalHistory = SignalOutput;
}
// 空間過濾器,更快地收斂歷史.
int32 MaxPostFilterSampleCount = FMath::Clamp(Settings.HistoryConvolutionSampleCount, 1, kStackowiakMaxSampleCountPerSet);
if (MaxPostFilterSampleCount > 1)
{
(...)
TShaderMapRef<FSSDSpatialAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD HistoryConvolution(MaxSamples=%i)", ...);
SignalHistory = SignalOutput;
}
(...)
// 最終卷積/輸出校正
if (SignalUsesFinalConvolution(Settings.SignalProcessing))
{
(...)
TShaderMapRef<FSSDSpatialAccumulationCS> ComputeShader(View.ShaderMap, PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("SSD SpatialAccumulation(Final)"), ...);
}
else
{
*OutputSignal = SignalHistory;
}
}
以上可知,螢幕空間降噪(SSD)過程非常複雜,涉及諸多Pass:壓縮元數據、注入、重建、預卷積、拒絕預卷積、時間累積、歷史卷積、空間累積等。限於篇幅,下面選取時間累積進行分析:
// SSDTemporalAccumulation.usf
void TemporallyAccumulate(...)
{
(...)
// 取樣當前幀數據.
FSSDCompressedSceneInfos CompressedRefSceneMetadata = SampleCompressedSceneMetadata(SceneBufferUV, BufferUVToBufferPixelCoord(SceneBufferUV));
(...)
// 重新投影到上一幀.
float3 HistoryScreenPosition = float3(DenoiserBufferUVToScreenPosition(SceneBufferUV), DeviceZ);
bool bIsDynamicPixel = false;
float4 ThisClip = float4(HistoryScreenPosition, 1);
float4 PrevClip = mul(ThisClip, View.ClipToPrevClip);
float3 PrevScreen = PrevClip.xyz * rcp(PrevClip.w);
float3 Velocity = HistoryScreenPosition - PrevScreen;
float4 EncodedVelocity = GBufferVelocityTexture.SampleLevel(GlobalPointClampedSampler, SceneBufferUV, 0);
bIsDynamicPixel = EncodedVelocity.x > 0.0;
if (bIsDynamicPixel)
{
Velocity = DecodeVelocityFromTexture(EncodedVelocity);
}
HistoryScreenPosition -= Velocity;
// 取樣多路復用訊號.
FSSDSignalArray CurrentFrameSamples;
FSSDSignalFrequencyArray CurrentFrameFrequencies;
SampleMultiplexedSignals(SignalInput_Textures_0, SignalInput_Textures_1, ...);
// 取樣歷史緩衝區.
FSSDSignalArray HistorySamples = CreateSignalArrayFromScalarValue(0.0);
{
float2 HistoryBufferUV = HistoryScreenPosition.xy * ScreenPosToHistoryBufferUV.xy + ScreenPosToHistoryBufferUV.zw;
float2 ClampedHistoryBufferUV = clamp(HistoryBufferUV, HistoryBufferUVMinMax.xy, HistoryBufferUVMinMax.zw);
bool bIsPreviousFrameOffscreen = any(HistoryBufferUV != ClampedHistoryBufferUV);
BRANCH
if (!bIsPreviousFrameOffscreen)
{
FSSDKernelConfig KernelConfig = CreateKernelConfig();
// 內核的編譯時配置.
KernelConfig.SampleSet = CONFIG_HISTORY_KERNEL;
KernelConfig.bSampleKernelCenter = true;
(...)
// 在進行歷史記錄的雙邊拒絕時允許有一點錯誤,以容忍每幀TAA抖動.
KernelConfig.WorldBluringDistanceMultiplier = max(CONFIG_BILATERAL_DISTANCE_MULTIPLIER, 3.0);
// 設置雙邊預設.
SetBilateralPreset(CONFIG_HISTORY_BILATERAL_PRESET, KernelConfig);
// 內核的SGPR配置.
KernelConfig.BufferSizeAndInvSize = HistoryBufferSizeAndInvSize;
KernelConfig.BufferBilinearUVMinMax = HistoryBufferUVMinMax;
(...)
// 內核的VGPR配置.
KernelConfig.BufferUV = HistoryBufferUV + BufferUVBilinearCorrection;
KernelConfig.bIsDynamicPixel = bIsDynamicPixel;
(...)
// 計算隨機訊號.
KernelConfig.Randoms[0] = InterleavedGradientNoise(SceneBufferUV * BufferUVToOutputPixelPosition, View.StateFrameIndexMod8);
FSSDSignalAccumulatorArray SignalAccumulators = CreateSignalAccumulatorArray();
FSSDCompressedSignalAccumulatorArray UnusedCompressedAccumulators = CreateUninitialisedCompressedAccumulatorArray();
// 累積內核.
AccumulateKernel(KernelConfig, PrevHistory_Textures_0, ...);
// 從累加器導出歷史樣本.
for (uint BatchedSignalId = 0; BatchedSignalId < CONFIG_SIGNAL_BATCH_SIZE; BatchedSignalId++)
{
(...)
}
(...)
// 拒絕歷史. (跟上面類似, 忽略)
#if (CONFIG_HISTORY_REJECTION == HISTORY_REJECTION_MINMAX_BOUNDARIES || CONFIG_HISTORY_REJECTION == HISTORY_REJECTION_VAR_BOUNDARIES)
{
(...)
}
// 屏蔽應該輸出的內容,以確保編譯器編譯出最終不需要的所有內容。
uint MultiplexCount = 1;
FSSDSignalArray OutputSamples = CreateSignalArrayFromScalarValue(0.0);
FSSDSignalFrequencyArray OutputFrequencies = CreateInvalidSignalFrequencyArray();
{
MultiplexCount = CONFIG_SIGNAL_BATCH_SIZE;
for (uint BatchedSignalId = 0; BatchedSignalId < MultiplexCount; BatchedSignalId++)
{
OutputSamples.Array[BatchedSignalId] = HistorySamples.Array[BatchedSignalId];
OutputFrequencies.Array[BatchedSignalId] = CurrentFrameFrequencies.Array[BatchedSignalId];
}
}
// 不需要保持DispatchThreadId,而SceneBufferUV處於最高VGPR峰值,因為內核的中心。
uint2 OutputPixelPostion = BufferUVToBufferPixelCoord(SceneBufferUV);
if (all(OutputPixelPostion < ViewportMax))
{
OutputMultiplexedSignal(SignalHistoryOutput_UAVs_0, ...);
}
}
上述的降噪過程和6.6.1 Temporal Super Resolution、7.4.8.2 SSGI降噪比較相似,綜合使用了濾波、取樣的若干種技術(雙邊濾波、空間卷積、時間卷積、隨機取樣、訊號和頻率等等)。
17.6.5 UE光線追蹤天空光
啟用Cast Ray Traced Shadow並指定 Source Type時,天空照明支援軟環境陰影。天光捕捉關卡的距離部分,並將其作為光源應用於場景中。

17.6.5.1 RenderRayTracingSkyLight
RenderRayTracingSkyLight是渲染天空光的主邏輯,其C++側邏輯如下:
// RaytracingSkylight.cpp
void FDeferredShadingSceneRenderer::RenderRayTracingSkyLight(FRDGBuilder& GraphBuilder, ...)
{
(...)
// 填充天空光參數
if (!SetupSkyLightParameters(GraphBuilder, Scene, Views[0], bShouldRenderRayTracingSkyLight, &SkylightParameters, &SkyLightData))
{
(...)
return;
}
(...)
// 如果解耦取樣生成, 則單獨生成天空光可見光線.
if (CVarRayTracingSkyLightDecoupleSampleGeneration.GetValueOnRenderThread() == 1)
{
GenerateSkyLightVisibilityRays(GraphBuilder, Views[0], SkylightParameters, SkyLightData, SkyLightVisibilityRaysBuffer, SkyLightVisibilityRaysDimensions);
}
(...)
for (FViewInfo& View : Views)
{
(...)
TShaderMapRef<FRayTracingSkyLightRGS> RayGenerationShader(GetGlobalShaderMap(FeatureLevel), PermutationVector);
(...)
GraphBuilder.AddPass(RDG_EVENT_NAME("SkyLightRayTracing %dx%d", ...)
{
FRayTracingShaderBindingsWriter GlobalResources;
SetShaderParameters(GlobalResources, RayGenerationShader, *PassParameters);
FRayTracingPipelineState* Pipeline = View.RayTracingMaterialPipeline;
if (CVarRayTracingSkyLightEnableMaterials.GetValueOnRenderThread() == 0)
{
FRayTracingPipelineStateInitializer Initializer;
Initializer.MaxPayloadSizeInBytes = RAY_TRACING_MAX_ALLOWED_PAYLOAD_SIZE;
// 著色器表.
FRHIRayTracingShader* RayGenShaderTable[] = { RayGenerationShader.GetRayTracingShader() };
Initializer.SetRayGenShaderTable(RayGenShaderTable);
// 命中組.
FRHIRayTracingShader* HitGroupTable[] = { View.ShaderMap->GetShader<FOpaqueShadowHitGroup>().GetRayTracingShader() };
Initializer.SetHitGroupTable(HitGroupTable);
Initializer.bAllowHitGroupIndexing = false;
Pipeline = PipelineStateCache::GetAndOrCreateRayTracingPipelineState(RHICmdList, Initializer);
}
FRHIRayTracingScene* RayTracingSceneRHI = View.GetRayTracingSceneChecked();
// 派發光線追蹤.
RHICmdList.RayTraceDispatch(Pipeline, RayGenerationShader.GetRayTracingShader(), RayTracingSceneRHI, GlobalResources, RayTracingResolution.X, RayTracingResolution.Y);
});
// 降噪.
if (GRayTracingSkyLightDenoiser != 0)
{
// 使用默認降噪器(即螢幕空間降噪器)
const IScreenSpaceDenoiser* DefaultDenoiser = IScreenSpaceDenoiser::GetDefaultDenoiser();
const IScreenSpaceDenoiser* DenoiserToUse = DefaultDenoiser;
(...)
IScreenSpaceDenoiser::FDiffuseIndirectOutputs DenoiserOutputs = DenoiserToUse->DenoiseSkyLight(GraphBuilder, ...);
}
(...)
}
}
降噪過程和陰影一樣,之後就不再闡述。下面分析其使用的shader程式碼:
// RayTracing\RayTracingSkyLightRGS.usf
RAY_TRACING_ENTRY_RAYGEN(SkyLightRGS)
{
(...)
// 獲取GBuffer數據.
FScreenSpaceData ScreenSpaceData = GetScreenSpaceData(UV);
FGBufferData GBufferData = GetGBufferDataFromSceneTexturesLoad(PixelCoord);
float DeviceZ = SceneDepthTexture.Load(int3(PixelCoord, 0)).r;
float3 WorldPosition;
float3 CameraDirection;
ReconstructWorldPositionAndCameraDirectionFromDeviceZ(PixelCoord, DeviceZ, WorldPosition, CameraDirection);
float3 WorldNormal = GBufferData.WorldNormal;
float3 Albedo = GBufferData.DiffuseColor;
(...)
// 遮罩無限遠的深度值
bool IsFiniteDepth = DeviceZ > 0.0;
bool bTraceRay = (IsFiniteDepth && GBufferData.ShadingModelID != SHADINGMODELID_UNLIT);
uint SamplesPerPixel = SkyLight.SamplesPerPixel;
if (!bTraceRay)
{
SamplesPerPixel = 0;
}
// 評估表面點處的天空光
const bool bGBufferSampleOrigin = true;
const bool bDecoupleSampleGeneration = DECOUPLE_SAMPLE_GENERATION != 0;
float3 ExitantRadiance;
float3 DiffuseExitantRadiance;
float AmbientOcclusion;
float HitDistance;
// 估算天空光.
SkyLightEvaluate(DispatchThreadId, ...);
// 預除以反照率,在合成中恢復.
DiffuseExitantRadiance.r = Albedo.r > 0.0 ? DiffuseExitantRadiance.r / Albedo.r : DiffuseExitantRadiance.r;
DiffuseExitantRadiance.g = Albedo.g > 0.0 ? DiffuseExitantRadiance.g / Albedo.g : DiffuseExitantRadiance.g;
DiffuseExitantRadiance.b = Albedo.b > 0.0 ? DiffuseExitantRadiance.b / Albedo.b : DiffuseExitantRadiance.b;
DiffuseExitantRadiance.rgb *= View.PreExposure;
RWSkyOcclusionMaskUAV[DispatchThreadId] = float4(ClampToHalfFloatRange(DiffuseExitantRadiance.rgb), AmbientOcclusion);
RWSkyOcclusionRayDistanceUAV[DispatchThreadId] = float2(HitDistance, SamplesPerPixel);
}
下面分析SkyLightEvaluate:
// RayTracingSkyLightEvaluation.ush
void SkyLightEvaluate(...)
{
// 初始化數據.
float3 CurrentWorldNormal = WorldNormal;
(...)
// 在策略之間分割樣本,除非天空光pdf由於MIS(多重要性取樣)而為0(意味著恆定貼圖).
const float SkyLightSamplingStrategyPdf = SkyLight_Estimate() > 0 ? 0.5 : 0.0;
// 迭代到請求的樣本計數.
for (uint SampleIndex = 0; SampleIndex < SamplesPerPixel; ++SampleIndex)
{
RayDesc Ray;
float RayWeight;
if (bDecoupleSampleGeneration)
{
// 從預計算的可見性光線緩衝區中獲取當前取樣的可見性光線
const uint SkyLightVisibilityRayIndex = GetSkyLightVisibilityRayTiledIndex(SampleCoord, SampleIndex, SkyLightVisibilityRaysDimensions.xy);
FSkyLightVisibilityRays SkyLightVisibilityRay = SkyLightVisibilityRays[SkyLightVisibilityRayIndex];
Ray.Origin = WorldPosition;
Ray.Direction = SkyLightVisibilityRay.DirectionAndPdf.xyz;
Ray.TMin = 0.0;
Ray.TMax = SkyLight.MaxRayDistance;
RayWeight = SkyLightVisibilityRay.DirectionAndPdf.w;
}
else // 非解耦樣本生成模式.
{
RandomSequence RandSequence;
RandomSequence_Initialize(RandSequence, PixelCoord, SampleIndex, View.StateFrameIndex, SamplesPerPixel);
// 確定天光或朗伯光線.
float2 RandSample = RandomSequence_GenerateSample2D(RandSequence);
// 為當前取樣生成可見性光線.
float SkyLightPdf = 0;
float CosinePdf = 0;
BRANCH
if (RandSample.x < SkyLightSamplingStrategyPdf)
{
RandSample.x /= SkyLightSamplingStrategyPdf;
// 取樣光源.
FSkyLightSample SkySample = SkyLight_SampleLight(RandSample);
Ray.Direction = SkySample.Direction;
SkyLightPdf = SkySample.Pdf;
CosinePdf = saturate(dot(CurrentWorldNormal, Ray.Direction)) / PI;
}
else
{
RandSample.x = (RandSample.x - SkyLightSamplingStrategyPdf) / (1.0 - SkyLightSamplingStrategyPdf);
// 餘弦取樣半球.
float4 CosSample = CosineSampleHemisphere(RandSample, CurrentWorldNormal);
Ray.Direction = CosSample.xyz;
CosinePdf = CosSample.w;
// 計算pdf.
SkyLightPdf = SkyLight_EvalLight(Ray.Direction).w;
}
Ray.Origin = WorldPosition;
Ray.TMin = 0.0;
Ray.TMax = SkyLight.MaxRayDistance;
// MIS / pdf
RayWeight = 1.0 / lerp(CosinePdf, SkyLightPdf, SkyLightSamplingStrategyPdf);
}
(...)
// 基於取樣世界位置是否來自GBuffer,應用深度偏移.
float NoL = dot(CurrentWorldNormal, Ray.Direction);
if (NoL > 0.0)
{
if (bGBufferSampleOrigin)
{
ApplyCameraRelativeDepthBias(Ray, PixelCoord, DeviceZ, CurrentWorldNormal, SkyLight.MaxNormalBias);
}
else
{
ApplyPositionBias(Ray, CurrentWorldNormal, SkyLight.MaxNormalBias);
}
}
else
{
ApplyPositionBias(Ray, -CurrentWorldNormal, SkyLight.MaxNormalBias);
}
NoL = saturate(NoL);
(...)
// 追蹤一條可見性光線.
FMinimalPayload MinimalPayload = TraceVisibilityRay(TLAS, RayFlags, InstanceInclusionMask, PixelCoord, Ray);
(...)
if (MinimalPayload.IsHit()) // 如果命中了物體, 說明該光線不能觸達到天空盒.
{
RayDistance += MinimalPayload.HitT;
HitCount += 1.0;
}
else // 沒有命中物體, 則說明該光線命中了天空盒.
{
BentNormal += Ray.Direction;
// 估算材質.
const half3 N = WorldNormal;
const half3 V = -ViewDirection;
const half3 L = Ray.Direction;
FDirectLighting LightingSample;
if (GBufferData.ShadingModelID == SHADINGMODELID_HAIR)
{
(...)
}
else
{
FShadowTerms ShadowTerms = { 0.0, 0.0, 0.0, InitHairTransmittanceData() };
// 計算BxDF
LightingSample = EvaluateBxDF(GBufferData, N, V, L, NoL, ShadowTerms);
}
float3 Brdf = LightingSample.Diffuse + LightingSample.Transmission + LightingSample.Specular;
// 計算天空光.
float3 IncomingRadiance = SkyLight_EvalLight(Ray.Direction).xyz;
ExitantRadiance += IncomingRadiance * Brdf * RayWeight;
float3 DiffuseThroughput = LightingSample.Diffuse;
if (SkyLight.bTransmission)
{
DiffuseThroughput += LightingSample.Transmission;
}
DiffuseExitantRadiance += IncomingRadiance * DiffuseThroughput * RayWeight;
}
} // for
// 樣本數的平均值
if (SamplesPerPixel > 0)
{
const float SamplesPerPixelInv = rcp(SamplesPerPixel);
ExitantRadiance *= SamplesPerPixelInv;
DiffuseExitantRadiance *= SamplesPerPixelInv;
AmbientOcclusion = HitCount * SamplesPerPixelInv;
}
(...)
// 如果碰撞到任何遮擋幾何體,則計算碰撞距離.
if (HitCount > 0.0)
{
HitDistance = RayDistance / HitCount;
}
(...)
}
上述程式碼調用了兩次SkyLight_EvalLight,第一次為了計算天空光的pdf,第二次為了計算輻射率。SkyLight_EvalLight的解析如下:
// MonteCarlo.ush
// 逆向的等面積球面映射.
// Based on: [Clarberg 2008, "Fast Equal-Area Mapping of the (Hemi)Sphere using SIMD"]
float2 InverseEquiAreaSphericalMapping(float3 Direction)
{
float3 AbsDir = abs(Direction);
float R = sqrt(1 - AbsDir.z);
float Epsilon = 5.42101086243e-20;
float x = min(AbsDir.x, AbsDir.y) / (max(AbsDir.x, AbsDir.y) + Epsilon);
// Coefficients for 6th degree minimax approximation of atan(x)*2/pi, x=[0,1].
const float t1 = 0.406758566246788489601959989e-5f;
const float t2 = 0.636226545274016134946890922156f;
const float t3 = 0.61572017898280213493197203466e-2f;
const float t4 = -0.247333733281268944196501420480f;
const float t5 = 0.881770664775316294736387951347e-1f;
const float t6 = 0.419038818029165735901852432784e-1f;
const float t7 = -0.251390972343483509333252996350e-1f;
// Polynomial approximation of atan(x)*2/pi
float Phi = t6 + t7 * x;
Phi = t5 + Phi * x;
Phi = t4 + Phi * x;
Phi = t3 + Phi * x;
Phi = t2 + Phi * x;
Phi = t1 + Phi * x;
Phi = (AbsDir.x < AbsDir.y) ? 1 - Phi : Phi;
float2 UV = float2(R - Phi * R, Phi * R);
UV = (Direction.z < 0) ? 1 - UV.yx : UV;
UV = asfloat(asuint(UV) ^ (asuint(Direction.xy) & 0x80000000u));
return UV * 0.5 + 0.5;
}
// RayTracingSkyLightCommon.ush
float4 SkyLight_EvalLight(float3 Dir)
{
// 利用逆向的等面積球面映射算出天空光的UV,並取樣出天空光紋理的顏色.
float2 UV = InverseEquiAreaSphericalMapping(Dir.yzx);
float4 Result = SkylightTexture.SampleLevel(SkylightTextureSampler, UV, 0);
float3 Radiance = Result.xyz;
// 計算pdf.
#if USE_HIERARCHICAL_IMPORTANCE_SAMPLING
float Pdf = Result.w > 0 ? Result.w / (4 * PI * SkylightPdf.Load(int3(0, 0, SkylightMipCount - 1))) : 0.0;
#else
float Pdf = 1.0 / (4.0 * PI);
#endif
return float4(Radiance, Pdf);
}
17.6.5.2 CompositeRayTracingSkyLight
CompositeRayTracingSkyLight是組合RenderRayTracingSkyLight計算的結果到場景顏色中,其C++側邏輯如下:
// RaytracingSkylight.cpp
void FDeferredShadingSceneRenderer::CompositeRayTracingSkyLight(FRDGBuilder& GraphBuilder, ...)
{
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
const FViewInfo& View = Views[ViewIndex];
(...)
GraphBuilder.AddPass(RDG_EVENT_NAME("GlobalIlluminationComposite"), ...)
{
// VS和PS實例.
TShaderMapRef<FPostProcessVS> VertexShader(View.ShaderMap);
TShaderMapRef<FCompositeSkyLightPS> PixelShader(View.ShaderMap);
(...)
// 疊加性(Additive)混合模式.
GraphicsPSOInit.BlendState = TStaticBlendState<CW_RGB, BO_Add, BF_One, BF_One>::GetRHI();
(...)
DrawRectangle(RHICmdList, ...);
});
}
}
下面直接進入PS使用的shader程式碼:
// CompositeSkyLightPS.usf
void CompositeSkyLightPS(in noperspective float2 UV : TEXCOORD0, out float4 OutColor : SV_Target0)
{
// 獲取GBuffer數據.
FGBufferData GBufferData = GetGBufferDataFromSceneTextures(UV);
float3 Albedo = GBufferData.StoredBaseColor - GBufferData.StoredBaseColor * GBufferData.Metallic;
// 從天空光紋理取樣出數據.
float4 SkyLight = SkyLightTexture.Sample(SkyLightTextureSampler, UV);
// 降噪後應用反照率
SkyLight.rgb *= Albedo;
OutColor = SkyLight;
}
17.6.6 UE光線追蹤GI
17.6.6.1 UE光線追蹤GI開啟條件
UE 5.0.3的標準光線追蹤GI已被Lumen硬體光線追蹤取代(下圖),而Lumen的全局光照支援兩種光線追蹤模式:軟體光線追蹤(需要在項目設置中開啟Generate Mesh Distance Fields)和硬體光線追蹤(需要在項目設置中開啟Support Hardware Ray Tracing)。後面只分析Lumen硬體光線追蹤。

其中決定是否使用Lumen GI的程式碼如下:
void FDeferredShadingSceneRenderer::Render(FRDGBuilder& GraphBuilder)
{
(...)
InitViews(...);
// 計算並提交渲染器的整個依賴拓撲的最終狀態。
CommitFinalPipelineState();
(...)
}
void FDeferredShadingSceneRenderer::CommitFinalPipelineState()
{
(...)
CommitIndirectLightingState();
(...)
}
// IndirectLightRendering.cpp
bool ShouldRenderLumenDiffuseGI(const FScene* Scene, const FSceneView& View, bool bSkipTracingDataCheck, bool bSkipProjectCheck)
{
// 是否可啟用Lumen特性.
return Lumen::IsLumenFeatureAllowedForView(Scene, View, bSkipTracingDataCheck, bSkipProjectCheck)
// 動態全局光照方法是否Lumen
&& View.FinalPostProcessSettings.DynamicGlobalIlluminationMethod == EDynamicGlobalIlluminationMethod::Lumen
// 控制台變數是否開啟.
&& CVarLumenGlobalIllumination.GetValueOnAnyThread()
// 視圖家族的GI標記是否開啟.
&& View.Family->EngineShowFlags.GlobalIllumination
&& View.Family->EngineShowFlags.LumenGlobalIllumination
// 是否使用硬體光線追蹤探針收集或者支援軟體光線追蹤.
&& (bSkipTracingDataCheck || Lumen::UseHardwareRayTracedScreenProbeGather() || Lumen::IsSoftwareRayTracingSupported());
}
void FDeferredShadingSceneRenderer::CommitIndirectLightingState()
{
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
const FViewInfo& View = Views[ViewIndex];
TPipelineState<FPerViewPipelineState>& ViewPipelineState = ViewPipelineStates[ViewIndex];
EDiffuseIndirectMethod DiffuseIndirectMethod = EDiffuseIndirectMethod::Disabled;
EAmbientOcclusionMethod AmbientOcclusionMethod = EAmbientOcclusionMethod::Disabled;
EReflectionsMethod ReflectionsMethod = EReflectionsMethod::Disabled;
IScreenSpaceDenoiser::EMode DiffuseIndirectDenoiser = IScreenSpaceDenoiser::EMode::Disabled;
bool bUseLumenProbeHierarchy = false;
// 檢測是否使用Lumen GI.
if (ShouldRenderLumenDiffuseGI(Scene, View))
{
DiffuseIndirectMethod = EDiffuseIndirectMethod::Lumen;
bUseLumenProbeHierarchy = CVarLumenProbeHierarchy.GetValueOnRenderThread() != 0;
}
else if (ScreenSpaceRayTracing::IsScreenSpaceDiffuseIndirectSupported(View))
(...)
}
}
UseHardwareRayTracedScreenProbeGather程式碼如下:
// LumenScreenProbeHardwareRayTracing.cpp
bool UseHardwareRayTracedScreenProbeGather()
{
#if RHI_RAYTRACING
// 光線追蹤是否開啟.
return IsRayTracingEnabled()
// 是否使用硬體光線追蹤.
&& Lumen::UseHardwareRayTracing()
// Lumen的螢幕探針收集硬體光線追蹤的控制台變數不為0
&& (CVarLumenScreenProbeGatherHardwareRayTracing.GetValueOnAnyThread() != 0);
#else
return false;
#endif
}
17.6.6.2 RenderDiffuseIndirectAndAmbientOcclusion
一旦滿足所有條件,則Lumen的硬體光線追蹤GI會在RenderBasePass和RenderLights之間調用RenderDiffuseIndirectAndAmbientOcclusion渲染相關GI:
void FDeferredShadingSceneRenderer::Render(FRDGBuilder& GraphBuilder)
{
(...)
RenderBasePass(...);
(...)
RenderDiffuseIndirectAndAmbientOcclusion(GraphBuilder, ...);
(...)
RenderLights(...);
(...)
}
下面進入RenderDiffuseIndirectAndAmbientOcclusion分析和Lumen GI相關的邏輯:
// IndirectLightRendering.cpp
void FDeferredShadingSceneRenderer::RenderDiffuseIndirectAndAmbientOcclusion(FRDGBuilder& GraphBuilder, ...)
{
(...)
for (FViewInfo& View : Views)
{
const FPerViewPipelineState& ViewPipelineState = GetViewPipelineState(View);
(...)
else if (ViewPipelineState.DiffuseIndirectMethod == EDiffuseIndirectMethod::Lumen)
{
FLumenMeshSDFGridParameters MeshSDFGridParameters;
LumenRadianceCache::FRadianceCacheInterpolationParameters RadianceCacheParameters;
// 渲染Lumen螢幕探針收集.
DenoiserOutputs = RenderLumenScreenProbeGather(GraphBuilder, ...);
if (ViewPipelineState.ReflectionsMethod == EReflectionsMethod::Lumen)
{
DenoiserOutputs.Textures[2] = RenderLumenReflections(GraphBuilder, View, ...);
}
// Lumen需要它自己的深度歷史,因為像半透明速度這樣的東西會寫入深度.
StoreLumenDepthHistory(GraphBuilder, SceneTextures, View);
if (!DenoiserOutputs.Textures[2])
{
DenoiserOutputs.Textures[2] = DenoiserOutputs.Textures[1];
}
}
(...)
// 將漫反射間接和環境光遮擋應用於場景顏色。
if (... ViewPipelineState.DiffuseIndirectMethod == EDiffuseIndirectMethod::Lumen ...)
{
FDiffuseIndirectCompositePS::FParameters* PassParameters = GraphBuilder.AllocParameters<FDiffuseIndirectCompositePS::FParameters>();
(...)
else if (ViewPipelineState.DiffuseIndirectMethod == EDiffuseIndirectMethod::Lumen)
{
PermutationVector.Set<FDiffuseIndirectCompositePS::FApplyDiffuseIndirectDim>(4);
PermutationVector.Set<FDiffuseIndirectCompositePS::FScreenBentNormal>(ScreenBentNormalParameters.UseScreenBentNormal != 0);
DiffuseIndirectSampling = TEXT("ScreenProbeGather");
}
(...)
FPixelShaderUtils::AddFullscreenPass(GraphBuilder, View.ShaderMap,RDG_EVENT_NAME("DiffuseIndirectComposite(DiffuseIndirect=%s%s%s%s) %dx%d", ...);
}
(...)
} // for
}
17.6.6.3 RenderLumenScreenProbeGather
下面對RenderLumenScreenProbeGather的硬體光線追蹤部分進行分析:
// LumenScreenProbeGather.cpp
FSSDSignalTextures FDeferredShadingSceneRenderer::RenderLumenScreenProbeGather(FRDGBuilder& GraphBuilder, ...)
{
(...)
if (GLumenIrradianceFieldGather != 0)
{
return RenderLumenIrradianceFieldGather(GraphBuilder, SceneTextures, FrameTemporaries, View);
}
(...)
auto ComputeShader = View.ShaderMap->GetShader<FScreenProbeDownsampleDepthUniformCS>(0);
// 增加全局探針下取樣的Pass.
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("UniformPlacement DownsampleFactor=%u", ScreenProbeParameters.ScreenProbeDownsampleFactor), ...);
(...)
if (ScreenProbeParameters.MaxNumAdaptiveProbes > 0 && AdaptiveProbeMinDownsampleFactor < ScreenProbeParameters.ScreenProbeDownsampleFactor)
{
uint32 PlacementDownsampleFactor = ScreenProbeParameters.ScreenProbeDownsampleFactor;
do
{
PlacementDownsampleFactor /= 2;
FScreenProbeAdaptivePlacementCS::FParameters* PassParameters = GraphBuilder.AllocParameters<FScreenProbeAdaptivePlacementCS::FParameters>();
(...)
auto ComputeShader = View.ShaderMap->GetShader<FScreenProbeAdaptivePlacementCS>(0);
// 增加自適應探針放置的Pass.
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("AdaptivePlacement DownsampleFactor=%u", PlacementDownsampleFactor), ...);
}
while (PlacementDownsampleFactor > AdaptiveProbeMinDownsampleFactor);
}
(...)
auto ComputeShader = View.ShaderMap->GetShader<FSetupAdaptiveProbeIndirectArgsCS>(0);
// 設置自適應探索非直接參數的Pass.
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("SetupAdaptiveProbeIndirectArgs"), ...);
(...)
// 生成BRDF的pdf.
GenerateBRDF_PDF(GraphBuilder, View, SceneTextures, BRDFProbabilityDensityFunction, BRDFProbabilityDensityFunctionSH, ScreenProbeParameters);
(...)
if (LumenScreenProbeGather::UseRadianceCache(View))
{
(...)
// 渲染輻射率快取.
RenderRadianceCache(GraphBuilder, ...);
(...)
}
// 生成重要性取樣的光線.
if (LumenScreenProbeGather::UseImportanceSampling(View))
{
GenerateImportanceSamplingRays(GraphBuilder, View, ...);
}
(...)
// 追蹤螢幕探針.
TraceScreenProbes(GraphBuilder, Scene, ...);
FScreenProbeGatherParameters GatherParameters;
// 過濾螢幕探針.
FilterScreenProbes(GraphBuilder, View, SceneTextures, ScreenProbeParameters, GatherParameters);
(...)
// 在螢幕空間探針中插值並集成.
InterpolateAndIntegrate(GraphBuilder, ...);
(...)
// 降噪.
if (GLumenScreenProbeTemporalFilter)
{
if (GLumenScreenProbeUseHistoryNeighborhoodClamp)
{
(...)
auto ComputeShader = View.ShaderMap->GetShader<FGenerateCompressedGBuffer>(0);
// 生成壓縮的GBuffer數據.
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("GenerateCompressedGBuffer"), ...);
(...)
// 對非直接探針層級進行降噪.
DenoiserOutputs = IScreenSpaceDenoiser::DenoiseIndirectProbeHierarchy(GraphBuilder, View, ...);
bLumenUseDenoiserComposite = true;
}
else
{
// 更新歷史螢幕探針收集.
UpdateHistoryScreenProbeGather(GraphBuilder, View, ...);
DenoiserOutputs.Textures[0] = DiffuseIndirect;
DenoiserOutputs.Textures[1] = RoughSpecularIndirect;
}
}
(...)
return DenoiserOutputs;
}
17.6.6.4 TraceScreenProbes
從上可知,Lumen的GI使用了螢幕空間的光照探針,其中和硬體光線追蹤相關的是TraceScreenProbes,其它和軟體光線追蹤應該是一樣。下面就只分析TraceScreenProbes:
// LumenScreenProbeTracing.cpp
void TraceScreenProbes(FRDGBuilder& GraphBuilder, const FScene* Scene, ...)
{
(...)
// 清理追蹤結果.
auto ComputeShader = View.ShaderMap->GetShader<FClearTracesCS>(0);
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("ClearTraces %ux%u", ...);
(...)
// 追蹤螢幕空間的探針.
auto ComputeShader = View.ShaderMap->GetShader<FScreenProbeTraceScreenTexturesCS>(PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("TraceScreen(%s)", ...);
(...)
// 是否使用硬體光線追蹤.
const bool bUseHardwareRayTracing = Lumen::UseHardwareRayTracedScreenProbeGather();
if (bUseHardwareRayTracing)
{
FCompactedTraceParameters CompactedTraceParameters = CompactTraces(GraphBuilder, View, ...);
// 硬體追蹤螢幕探針.
RenderHardwareRayTracingScreenProbe(GraphBuilder, Scene, ...);
}
else
{
// 軟體追蹤螢幕探針.
(...)
}
(...)
// 螢幕空間追蹤體素, 也分硬體和軟體模式.
PermutationVector.Set< FScreenProbeTraceVoxelsCS::FTraceVoxels>(!bUseHardwareRayTracing && Lumen::UseGlobalSDFTracing(*View.Family));
auto ComputeShader = View.ShaderMap->GetShader<FScreenProbeTraceVoxelsCS>(PermutationVector);
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("%s%s", ...);
}
17.6.6.5 RenderHardwareRayTracingScreenProbe
從上得知如果是硬體光線追蹤模式,則會進入RenderHardwareRayTracingScreenProbe:
// LumenScreenProbeHardwareRayTracing.cpp
void RenderHardwareRayTracingScreenProbe(FRDGBuilder& GraphBuilder, const FScene* Scene, ...)
{
(...)
// 轉換光線分配器
TShaderRef<FConvertRayAllocatorCS> ComputeShader = View.ShaderMap->GetShader<FConvertRayAllocatorCS>();
FComputeShaderUtils::AddPass(GraphBuilder,RDG_EVENT_NAME("FConvertRayAllocatorCS"), ...);
(...)
// 【近場(near-field)】、提取表面快取和材質id的默認追蹤.
PermutationVector.Set<FLumenScreenProbeGatherHardwareRayTracingRGS::FEnableNearFieldTracing>(true);
PermutationVector.Set<FLumenScreenProbeGatherHardwareRayTracingRGS::FEnableFarFieldTracing>(false);
if (bInlineRayTracing)
{
DispatchComputeShader(GraphBuilder, Scene, ...);
}
else
{
DispatchRayGenShader(GraphBuilder, Scene, ...);
}
(...)
// 使用【遠場】進行螢幕探針採集
if (bUseFarFieldForScreenProbeGather)
{
// 硬體壓縮光線, 以提升快取一致性和命中率, 提升效率.
LumenHWRTCompactRays(GraphBuilder, Scene, ...);
(...)
PermutationVector.Set<FLumenScreenProbeGatherHardwareRayTracingRGS::FEnableNearFieldTracing>(false);
PermutationVector.Set<FLumenScreenProbeGatherHardwareRayTracingRGS::FEnableFarFieldTracing>(true);
if (bInlineRayTracing)
{
DispatchComputeShader(GraphBuilder, Scene, ...);
}
else
{
DispatchRayGenShader(GraphBuilder, Scene, ...);
}
}
}
以上需要執行兩次光線追蹤,第一次是追蹤近場(Near Field),第二次是追蹤遠場(Far Field)。追蹤時支援兩種模式:使用Compute Shader的內聯模式和使用Ray Generate的硬體模式。下面分析它們的區別,先分析Compute Shader模式:
// LumenScreenProbeHardwareRayTracing.cpp
void DispatchComputeShader(FRDGBuilder& GraphBuilder, const FScene* Scene, ...)
{
(...)
TShaderRef<FLumenScreenProbeGatherHardwareRayTracingCS> ComputeShader = ...;
(...)
GraphBuilder.AddPass(RDG_EVENT_NAME("HardwareInlineRayTracing %s %s", ..., ERDGPassFlags::Compute,
[PassParameters, &View, ComputeShader, DispatchResolution](FRHIRayTracingCommandList& RHICmdList)
{
(...)
if (IsHardwareRayTracingScreenProbeGatherIndirectDispatch())
{
// 非直接模式,注意參數是PassParameters->CommonParameters.HardwareRayTracingIndirectArgs
DispatchIndirectComputeShader(RHICmdList, ComputeShader.GetShader(), PassParameters->CommonParameters.HardwareRayTracingIndirectArgs->GetIndirectRHICallBuffer(), 0);
}
else
{
(...)
// 直接模式.
DispatchComputeShader(RHICmdList, ComputeShader.GetShader(), GroupCount.X, GroupCount.Y, 1);
}
(...)
}
);
}
以上可知,CS模式又支援非直接和直接兩種,注意它們雖然使用同一個shader,但PassParameters的參數不一樣!非直接的開啟條件如下:
// LumenScreenProbeHardwareRayTracing.cpp
bool IsHardwareRayTracingReflectionsIndirectDispatch()
{
return GRHISupportsRayTracingDispatchIndirect && (CVarLumenReflectionsHardwareRayTracingIndirect.GetValueOnRenderThread() == 1);
}
// WindowsD3D12Device.cpp
if (D3D12Caps5.RaytracingTier >= D3D12_RAYTRACING_TIER_1_1)
{
GRHISupportsRayTracingDispatchIndirect = true;
}
也就是說需要D3D12光線追蹤Tier 1.1以上(其它圖形API暫不支援)以及相關控制台變數為1才開啟。
相關說明可參見DX 12光線追蹤說明文檔:DispatchRays和 ExecuteIndirect。
非直接模式相當於非同步模式,可以提升GPU的並行度,通常效率更高。
17.6.6.6 LumenScreenProbeGatherHardwareRayTracing
下面繼續分析使用Ray Generation的硬體模式:
void DispatchRayGenShader(FRDGBuilder& GraphBuilder, const FScene* Scene, ...)
{
(...)
// 生成非直接參數.
DispatchLumenScreenProbeGatherHardwareRayTracingIndirectArgs(...);
// 設置螢幕追蹤參數.
SetLumenHardwareRayTracingScreenProbeParameters(...);
(...)
TShaderRef<FLumenScreenProbeGatherHardwareRayTracingRGS> RayGenerationShader = ...;
(...)
GraphBuilder.AddPass(RDG_EVENT_NAME("HardwareRayTracing %s %s", ...
{
(...)
// 非直接模式
if (IsHardwareRayTracingScreenProbeGatherIndirectDispatch())
{
RHICmdList.RayTraceDispatchIndirect(Pipeline, ...);
}
// 直接模式.
else
{
RHICmdList.RayTraceDispatch(Pipeline, ...);
}
}
);
}
以上可知,硬體光線追蹤也支援非直接和直接模式,如果支援非直接,則優先用之。下面分析FLumenScreenProbeGatherHardwareRayTracingRGS的shader:
// LumenScreenProbeHardwareRayTracing.usf
LUMEN_HARDWARE_RAY_TRACING_ENTRY(LumenScreenProbeGatherHardwareRayTracing)
{
// 計算執行緒組和執行緒id.
uint ThreadIndex = DispatchThreadIndex.x;
uint GroupIndex = DispatchThreadIndex.y;
#if DIM_INDIRECT_DISPATCH
uint Iteration = 0;
uint DispatchedThreads = RayAllocator[0];
#else
uint DispatchedThreads = ThreadCount * GroupCount;
uint IterationCount = (RayAllocator[0] + DispatchedThreads - 1) / DispatchedThreads;
// 直接模式則需要用for循環來實現迭代多條光線.
for (uint Iteration = 0; Iteration < IterationCount; ++Iteration)
#endif
{
uint RayIndex = Iteration * DispatchedThreads + GroupIndex * ThreadCount + ThreadIndex;
if (RayIndex >= RayAllocator[0])
{
return;
}
// 獲取追蹤數據.
#if (DIM_LIGHTING_MODE == LIGHTING_MODE_HIT_LIGHTING) || ENABLE_FAR_FIELD_TRACING
FTraceData TraceData = UnpackTraceData(RWRetraceDataPackedBuffer[RayIndex]);
uint RayId = TraceData.RayId;
#else
uint RayId = RayIndex;
#endif
(...)
// 創建追蹤光照上下文.
FRayTracedLightingContext Context = CreateRayTracedLightingContext(TLAS, ...);
(...)
// 執行小誤差追蹤.
FRayTracedLightingResult Result = EpsilonTrace(Ray, Context);
// 如果沒有命中物體
if (!Result.bIsHit)
{
Ray.TMin = max(Ray.TMin, AvoidSelfIntersectionTraceDistance);
Ray.TMax = Ray.TMin;
// 通過近場的球體包圍盒裁剪TMax
if (length(Ray.Origin - LWCHackToFloat(PrimaryView.WorldCameraOrigin)) < MaxTraceDistance)
{
float2 Hit = RayIntersectSphere(Ray.Origin, Ray.Direction, float4(LWCHackToFloat(PrimaryView.WorldCameraOrigin), MaxTraceDistance));
Ray.TMax = (Hit.x > 0) ? Hit.x : ((Hit.y > 0) ? Hit.y : Ray.TMin);
}
// 處理輻射度快取命中.
bool bIsRadianceCacheHit = false;
#if DIM_RADIANCE_CACHE
{
float ClipmapDitherRandom = InterleavedGradientNoise(ScreenTileCoord, View.StateFrameIndexMod8);
FRadianceCacheCoverage Coverage = GetRadianceCacheCoverage(Ray.Origin, Ray.Direction, ClipmapDitherRandom);
if (Coverage.bValid)
{
Ray.TMax = min(Ray.TMax, Coverage.MinTraceDistanceBeforeInterpolation);
bIsRadianceCacheHit = true;
}
}
#endif
// 設置遠場上下文特例化.
Context.FarFieldMaxTraceDistance = FarFieldMaxTraceDistance;
Context.FarFieldReferencePos = FarFieldReferencePos;
#if DIM_LIGHTING_MODE == LIGHTING_MODE_SURFACE_CACHE
Result = TraceAndCalculateRayTracedLightingFromSurfaceCache(Ray, Context);
#if DIM_PACK_TRACE_DATA
RWRetraceDataPackedBuffer[RayIndex] = PackTraceData(CreateTraceData(RayId, ...));
#endif
#endif
}
// 寫入最終光照結果.
#if DIM_WRITE_FINAL_LIGHTING
bool bMoving = false;
if (Result.bIsHit)
{
float3 HitWorldPosition = Ray.Origin + Ray.Direction * Result.TraceHitDistance;
bMoving = IsTraceMoving(...);
}
RWTraceRadiance[ScreenProbeTraceCoord] = Result.Radiance * View.PreExposure;
RWTraceHit[ScreenProbeTraceCoord] = EncodeProbeRayDistance(...);
#endif
}
}
下面進入光線追蹤的調用棧:
// LumenScreenProbeHardwareRayTracing.usf
FRayTracedLightingResult EpsilonTrace(RayDesc Ray, inout FRayTracedLightingContext Context)
{
FRayTracedLightingResult Result = CreateRayTracedLightingResult();
#if ENABLE_NEAR_FIELD_TRACING
uint OriginalCullingMode = Context.CullingMode;
Context.CullingMode = RAY_FLAG_CULL_BACK_FACING_TRIANGLES;
Ray.TMax = AvoidSelfIntersectionTraceDistance;
if (Ray.TMax > Ray.TMin)
{
// 第一次追蹤: 啟用背面剔除的短距離,以避免在追蹤幾何體與GBuffer中的幾何體不匹配的情況下自相交(Nanite、光線追蹤LOD等).
#if DIM_LIGHTING_MODE == LIGHTING_FROM_SURFACE_CACHE
{
Result = TraceAndCalculateRayTracedLightingFromSurfaceCache(Ray, Context);
}
#else
{
Result = TraceAndCalculateRayTracedLighting(Ray, Context, DIM_LIGHTING_MODE);
}
#endif
}
Context.CullingMode = OriginalCullingMode;
#endif
return Result;
}
以上的TraceAndCalculateRayTracedLighting和TraceAndCalculateRayTracedLighting會進入複雜的Luman Card追蹤和取樣邏輯,此文就不繼續分析了,可以參看6.5.6 Lumen場景光照和6.5.7 Lumen非直接光照。
此外,UE硬體光線追蹤的反射、AO、半透明等特性也雜糅在Lumen當中,形成了相輔相成、耦合性較高且極其複雜的渲染體系,從而呈現出精彩紛呈的電影級別的實時渲染畫質。
17.7 本篇總結
本篇主要闡述了UE的硬體光線追蹤的渲染流程和主要演算法,使得讀者對此模組有著大致的理解,至於更多技術細節和原理,需要讀者自己去研讀UE源碼發掘。
正如毛星雲(再次惋惜、緬懷以及RIP)在實時光線追蹤(real-time ray tracing)技術還有哪些未攻克的難題?中提及的,實時渲染領域還存在諸多懸而未決的問題:
- 渲染問題。如透明、部分覆蓋、粒子、全局光照等。
- 性能問題。包含一致性、調度、解耦、取樣、降噪等。
- 體系問題。如驅動、硬體、OS、圖形API、應用程式等。
但即便如此,基於硬體光線追蹤的渲染體系技術肯定是不久將來的主流,值得我們深入探究和挖掘。
希望童鞋們能夠踏實地紮根於圖形渲染技術,力爭做到客觀公正、實事求是、以德服人、以技服人(反面教材——【豬門馬保國】),一起提升中國圖形渲染技術的綜合實力,縮小國際之間的差距。共勉。
特別說明
- 感謝所有參考文獻的作者,部分圖片來自參考文獻和網路,侵刪。
- 本系列文章為筆者原創,只發表在部落格園上,歡迎分享本文鏈接,但未經同意,不允許轉載!
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
參考文獻
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- 探究光線追蹤技術及UE4的實現
- 由淺入深學習PBR的原理和實現
- Numerical Robustness for Geometric Calculations
- 6 Years of Optimizing World of Tanks: Making the Game a Great Experience on All Systems from Laptops to High End PCs
- The Latest Graphics Technology in Remedy’s Northlight Engine
- Advanced Graphics Techniques Tutorial: GPU-Based Clay Simulation and Ray-Tracing Tech in ‘Claybook’
- Interactive Relighting of Dynamic Refractive Objects
- Math for Game Programmers: Voxel Surfing
- Leveraging Real-Time Ray Tracing to build a Hybrid Game Engine
- Implicit Function Ray Tracing
- High Quality Rendering using Ray Tracing and Photon Mapping
- Stochastic ray tracing
- General-Purpose Computation on Graphics Hardware
- Introduction to PowerVR Ray Tracing
- PowerVR Graphics – Latest Developments and Future Plans
- It Just Works: Ray-Traced Reflections in “Battlefield V”
- Highly Parallel Fast KD-tree Construction for Interactive Ray Tracing of Dynamic Scenes
- Embree
- Intel® oneAPI Rendering Toolkit
- Rendering Technology in ‘Agents of Mayhem’
- Practical Techniques for Ray Tracing in Games
- Imagination-PowerVR Photon Architecture
- Photon Architecture White Paper
- Radiance Caching for real-time Global Illumination
- Real-Time Ray Tracing of Correct Soft Shadows
- [Adopting lessons from offline ray tracing to real-time ray tracing for practical pipelines](//advances.realtimerendering.com/s2018/Pharr – Advances in RTR – Real-time Ray Tracing.pdf)
- [Global Illumination Based on Surfels](//advances.realtimerendering.com/s2021/SIGGRAPH Advances 2021 – Surfel GI.pptx)
- Hybrid Ray-Traced Shadows
- [From Ray to Path Tracing: Navigating through Dimensions](//advances.realtimerendering.com/s2020/Turquin – From Ray to Path Tracing – SIGGRAPH 2020 Presentation.pptx)
- T-ReX: Interactive Global Illumination ofMassive Models on HeterogeneousComputing Resources
- Unbiased Photon Gathering for Light Transport Simulation
- When Fuzzy is Good: Advances in Filtering Techniques
- Scalable Real time Global Illumination for Large Scenes
- Announcing Microsoft DirectX Raytracing!
- Ray Tracing Denoising
- DirectML’s SuperResolution Sample
- Spatiotemporal Variance-Guided Filtering
- TURING RTX RAY TRACING 與 DLSS
- DLSS 2.0 – IMAGE RECONSTRUCTION FOR REAL-TIME RENDERING WITH DEEP LEARNING
- DLSS 2.0 – 重新定義AI渲染
- Spatiotemporal Reservoir Resampling (ReSTIR) – Theory and Basic Implementation
- Ray Tracing in Games with NVIDIA RTX (Presented by NVIDIA)
- Introduction to NVIDIA RTX and DirectX Ray Tracing
- Real-Time_Rendering_4th-Real-Time_Ray_Tracing
- RTX Technology
- NVIDIA Vulkan Ray Tracing Tutorial
- Ray Tracing In Vulkan
- Ray Tracing with Metal
- Metal for Accelerating Ray Tracing
- Accelerating ray tracing using Metal
- AMD Radeon™ Rays
- AMD Radeon ProRender
- Radeon ProRender and Radeon Rays in a Gaming Rendering Workflow
- AMD RYZEN™ PROCESSOR SOFTWARE OPTIMIZATION
- AMD CDNA™ 2 ARCHITECTURE
- Hardware-Accelerated Ray Tracing in AMD Radeon™ ProRender 2.0
- Ray Tracing Resources Page
- Ray Tracing Essentials
- Implementing GGX BRDF in Arnold with Multiple Importance Sampling
- NVIDIA RTX: Enabling Ray Tracing in Vulkan
- The RTX Shader Binding Table Three Ways
- SHINING A LIGHT ON RAY TRACING
- Parallel Architectures
- PBRT: Photorealistic Rendering and the Ray-Tracing Algorithm
- Ray Tracing Gems
- Ray Tracing Gems II
- Cinematic Rendering in UE4 with Real-Time Ray Tracing and Denoising
- UE Rendering Pipeline
- NVIDIA DLSS Plugin For Unreal Engine
- Practical Solutions for Ray Tracing Content Compatibility in Unreal Engine 4
- 實時光線追蹤(real-time ray tracing)技術還有哪些未攻克的難題?
- PIX GPU Captures
- PIX for Windows
- NVIDIA Development Tools Solutions – ERR_NVGPUCTRPERM: Permission issue with Performance Counters
- Tips & Tricks: How the Pros Use PIX to Make Their Games Better on Xbox and Windows
- Hardware Ray Tracing
- Hardware Ray Tracing Tips and Tricks
- Hardware Ray Tracing and Path Tracer Features Properties
- DirectX Raytracing (DXR) Functional Spec
- Lumen Technical Details

