全能成熟穩定開源分散式存儲Ceph破冰之旅-上
@
概述
定義
Ceph 最新官網文檔 //docs.ceph.com/en/latest
Ceph GitHub源碼地址 //github.com/ceph/ceph
Ceph是一個開源的、自我修復和自我管理的統一分散式存儲系統。目前最新版本為Quincy
ceph目前已得到眾多雲計算廠商的支援並被廣泛應用。RedHat及OpenStack kubernetes都可與Ceph整合以支援虛擬機鏡像的後端存儲。Ceph是統一存儲解決方案,根據場景劃分可以將Ceph分為三大塊,分別是對象存儲(兼容swift s3協議)、塊設備存儲和文件系統服務。在虛擬化領域裡,比較常用到的是Ceph的塊設備存儲,比如在OpenStack項目里,Ceph的塊設備存儲可以對接OpenStack的cinder後端存儲、Glance的鏡像存儲和虛擬機的數據存儲,比較直觀的是Ceph集群可以提供一個raw格式的塊存儲來作為虛擬機實例的硬碟;SDS 能將存儲軟體與硬體分隔開的存儲架構。
傳統存儲方式及問題
- 塊存儲:裸磁碟未被格式化的磁碟
- DAS(直連存儲,usb,硬碟插到電腦):scsi介面、介面數量有限、傳輸距離有限,scsi重新封裝為iscsi,iscsi在ip網路里跑,scsi協議寫數據到硬碟,加了個i可以在san的區域網路中傳輸。
- SAN(存儲區域網路):ip-san 網路(iscsi) 乙太網 fc-san網路 (fc協議) 光纖模組
- ceph rbd
- 文件系統存儲:共享目錄
- 集中式
- NAS:網路附加存儲 通過網路共享目錄
- nfs:unix nfs
- cifs:samba 網上鄰居
- FTP
- 分散式
- cephfs
- glusterfs:屬於紅帽,ceph也屬於紅帽
- moosefs
- server共享目錄,client掛載目錄使用
- hdfs:hadoop分散式文件系統
- 集中式
- 對象存儲:一般都是分散式存儲
- 非結構化數據:備份文件,上傳和下載文件。
- 結構化數據:資料庫 (購物,商品價格數量。有規律,一列一列的)
- 非結構化數據:多媒體(圖片 影片 音頻)
傳統存儲存在問題,存儲處理能力不足、存儲空間能力不足、單點問題。傳統存儲 DAS、NAS、SAN、RAID擴容問題不方便,將一堆磁碟,放在一個控制器里,縱向擴展scale up,擴容cpu、記憶體、硬碟可能更貴;分散式存儲 (性能是不如傳統存儲,比如資料庫) 無中心節點 普通伺服器存儲數據(硬碟,cpu,記憶體) ,但可以橫向擴展 scale out 擴伺服器,加節點 (節點可以橫向擴展,無中心節點,偏向軟體和人才要求 ) ,使用傳統存儲性價比很低,除非對特定性能有需求。
優勢
- 高擴展性:使用普通X86伺服器,支援10~1000台伺服器,支援TB到EB級的擴展。
- 高可靠性:沒有單點故障,多數據副本,自動管理,自動修復。
- 高性能:數據分布均衡。
生產遇到問題
- 擴容問題
Ceph中數據以PG為單位進行組織,因此當數據池中加入新的存儲單元(OSD)時,通過調整OSDMAP會帶來數據重平衡。正如提到的,如果涉及到多個OSD的擴容是可能導致可用PG中OSD小於min_size,從而發生PG不可用、IO阻塞的情況。為了盡量避免這種情況的出現,只能將擴容粒度變小,比如每次只擴容一個OSD或者一個機器、一個機櫃(主要取決於存儲隔離策略),但是這樣註定會帶來極大的運維工作量,甚至連擴容速度可能都趕不上數據增長速度。
- 數據遷移過程中的IO爭用問題
在頻繁數據遷移過程中帶來的IO爭用問題。當集群規模變大後,硬碟損壞、PG數量擴充可能會變得常態化。
- PG數量調整問題
在解決了數據遷移過程中的PG可用性問題和IO爭用問題後,提到的PG數量調整問題自然也就解決了。
- 集群利用率問題
存儲成本問題主要是講集群可用率問題,即Ceph集群規模增大後,偽隨機演算法導致了存儲資源分布不均衡,磁碟利用率方差過大的問題。
- 運維複雜度問題
Ceph本身是一個十分複雜的體系,要做到穩定運維非常看重團隊的實力。
架構
總體架構
Ceph在實現統一存儲,支援對象、塊和文件存儲。Ceph非常可靠,易於管理且免費。Ceph具有管理大量數據的能力和可伸縮性,支援數以千計的客戶端訪問pb到eb的數據。Ceph節點利用普通硬體和智慧守護進程,Ceph存儲集群容納大量節點,這些節點相互通訊以動態地複製和重分發數據。通過ceph面板或客戶端登錄到ceph集群後看到3個服務:RADOSGW、RBD、CEPH FS。
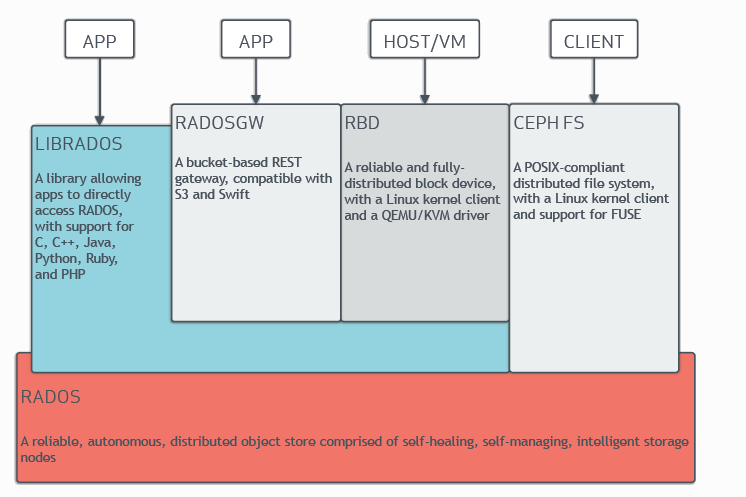
- RADOS GW:全稱是RADOS Gateway,顧名思義,是個網關。它提供對象存儲服務,像華為雲、騰訊雲網頁上花錢買到的對象存儲伺服器基本上就是它提供的。它將RADOS對象存儲服務封裝成了一個一個bucket,顧客能買到的就是bucket。注意GW本身沒有對象存儲功能,它只是基於RADOS,在RADOS基礎之上提供了一個簡單的命名空間隔離功能(bucket)。對象存儲功能完完全全是RADOS提供的。
- RBD: reliable block device。它提供塊存儲服務。雲伺服器系統盤在後台實際上是一個大文件,塊存儲相比普通硬碟的優勢是,它適合存儲超大文件。
- CEPH FS :它提供文件系統服務。說白了,通過網路連接FS就能創建文件夾、存放文件了。你可以把它理解成百度網盤。文件系統擅長處理和保存小文件。
- Ceph Storage Cluster:中文名是Ceph存儲集群,前面的三大服務的安裝需要基於Ceph存儲集群。一個Ceph存儲集群包括OSD設備、MON設備、librados介面。所以Ceph存儲集群包含的守護進程有osd進程、mon進程、ceph-manager進程。
- Ceph Cluster:在Ceph存儲集群中,去掉所有的OSD設備,剩下的部分就是Ceph集群。Ceph集群直接由cephadm bootstrap命令創建出來。
- LIBRADOS:是ceph服務中的基礎介面,以上的三大服務都是基於LIBRADOS中的一堆散碎介面封裝出來的。三大服務和LIBRADOS的關係就相當於系統命令和cpu指令集的關係。LIBRADOS存在的意義就是將RADOS中無數個細小的功能封裝成介面,供後續三大服務和客戶端的再封裝和使用
- RADOS:A reliable,automomous,distributed object storage.提取首字母就是RADOS。它是ceph最底層的功能模組,是一個無限可擴容的對象存儲服務,能將文件拆解成無數個對象(碎片)存放在硬碟中,大大提高了數據的穩定性。一個RADOS服務由OSD和Monitor兩個組件組成。OSD和Monitor都可以部署在1-n個硬碟中,這就是ceph分散式的由來,高擴展性的由來。
- OSD:Object Storage Device。是分散式存儲系統的基本單位,物理意義上對應一塊硬碟。這個服務包含作業系統(linux)和守護進程(OSD daemon)。所以一台伺服器上插了很多塊硬碟,就能創建很多個OSD。
- Monitor: 很多部落格和文檔里把它簡寫成Mon。它的功能是提供集群運行圖。用戶登錄ceph客戶端後,首先會連接Mon獲取集群運行圖,知道某某文件保存在哪些OSD上,隨後直接和這些OSD通訊,獲取文件。集群運行圖中包含很多資訊,包括:Monitor Map、OSD Map、PG Map、Crush演算法Map、MDS Map。由於用戶每次讀取文件,只是從Monitor中拿一個json,所以Monitor程式的壓力不是很大。ceph速度快,硬體開銷小,十分優秀。
- POOL:多個OSD組成的存儲池。ceph管理員可以將多個OSD組成一個池子,存儲池是軟體層面規划出來的的,物理上不真實存在。ceph在安裝的時候會自動生成一個default池。你可以根據自己的業務需求分配不同容量的存儲池。你也可以把機械硬碟划到一個存儲池而把所有SSD劃分到另一個存儲池。Pool中數據保存方式有多副本和糾刪碼兩種形式。多副本模式下,一個塊文件默認保存3分,放在不同的故障域中,可以吧多副本模式用raid1去類比。而糾刪碼更像是raid5,對cpu消耗稍大,但是節約磁碟空間,文件只有1份。
- MDS:元數據伺服器。負責提供CEPH FS文件系統的元數據。元數據記錄了目錄名、文件所有者、訪問模式等資訊。MDS設備只對Ceph FS服務。如果你不需要部署FS,則無需創建MDS。它存在的意義是保證用戶讀寫文件時才喚醒OSD,如果用戶只是ls看一下文件,則不會啟動OSD,這樣減輕ceph集群的壓力。
- 心跳:OSD和OSD之間會時刻檢查對方的心跳。OSD和Mon之間也會檢查心跳。以保證服務正常,網路通暢。一旦任何組件心跳異常,就會從集群中摘除。由其他組件繼續提供服務。
組成部分
ceph存儲集群,提供了一個基於RADOS的無限可擴展的Ceph存儲集群,基於RADOS存儲可擴展的,可靠的存儲 pb級集群服務。Ceph存儲集群由多種守護進程組成:
- Ceph Monitor:維護集群映射的主副本,Ceph監控器集群可以確保在監控器守護進程發生故障時的高可用性。
- 存儲集群客戶端從Ceph Monitor檢索集群映射的副本。Ceph Monitor (Ceph -mon)維護集群狀態的映射,包括監視器映射、管理器映射、OSD映射、MDS映射和CRUSH映射。
- 這些映射是Ceph守護進程相互協調所需的關鍵集群狀態。監視器還負責管理守護進程和客戶機之間的身份驗證。
- 為了實現冗餘和高可用性,通常需要至少三個監視器。
- Ceph OSD Daemon:守護進程檢查自己的狀態和其他OSD的狀態,並向監視器報告。
- Ceph Manager守護進程(Ceph -mgr)負責跟蹤運行時指標和Ceph集群的當前狀態,包括存儲利用率、當前性能指標和系統負載。
- Ceph Manager守護進程還託管基於python的模組來管理和公開Ceph集群資訊,包括基於web的Ceph儀錶板和REST API。
- 高可用性通常需要至少兩個管理器。多個監視器實例之間就集群的狀態達成一致,利用Paxos演算法大多數的監視器原則來在監視器之間建立關於集群當前狀態的共識。
- Ceph Manager:充當監視、編製和插件模組的端點。
- 對象存儲守護進程(Ceph OSD, Ceph – OSD)負責存儲數據、處理數據複製、恢復、再平衡,並通過檢查其他Ceph OSD守護進程的心跳情況,向Ceph Monitors和manager提供一些監控資訊。
- 通常至少需要三個Ceph osd來實現冗餘和高可用性。
- Ceph Metadata Server:使用Ceph fs提供文件服務時,通過MDS (Ceph Metadata Server)管理文件元數據。
- Ceph元數據伺服器(MDS, Ceph – MDS)代表Ceph文件系統存儲元數據(例如,Ceph塊設備和Ceph對象存儲不使用MDS)。
- Ceph元數據伺服器使用POSIX文件系統用戶執行基本命令(如ls、find等),而不會給Ceph存儲集群帶來巨大的負擔。

CRUSH演算法
Ceph將數據作為對象存儲在邏輯存儲池中。Ceph使用CRUSH演算法計算出哪個放置組(PG)應該包含該對象,哪個OSD應該存儲該放置組。
CRUSH演算法使Ceph存儲集群能夠動態地擴展、平衡和恢復。存儲集群客戶端和每個Ceph OSD Daemon使用CRUSH演算法高效地計算數據位置資訊,而不是依賴於一個中央查找表。
Ceph的高級特性包括一個通過librados與Ceph存儲集群的本地介面,以及許多構建在librados之上的服務介面。
Ceph client和Ceph OSD Daemons都使用CRUSH演算法來高效地計算對象位置資訊,而不是依賴於一個中央查找表,提供了更好的數據管理機制,工作分配給集群中的所有客戶端和OSD守護進程來實現大規模擴展;CRUSH使用智慧數據複製來確保彈性更適合超規模存儲。
數據讀寫過程
- client創建cluster handler;
- client讀取配置文件;
- client連接上monitor,獲取集群map資訊;
- client讀寫io根據crshmap演算法請求對應的主osd數據節點。
- 主osd數據節點同時寫入另外兩個副本節點數據;
- 等待主節點以及另外兩個副本節點寫完數據狀態;
- 主節點及副本節點寫入狀態都成功後,返回給client,io寫入完成。【強一致性】
CLUSTER MAP
Ceph依賴於Ceph客戶端和Ceph OSD守護進程對集群拓撲的了解,包括5個地圖,統稱為「集群地圖」:
- The Monitor Map:包含每個監視器的集群fsid、位置、名稱地址和埠。表示當前的時代、地圖創建的時間以及最後一次更改的時間。要查看監視器映射,請執行ceph mon dump。
- OSD Map:包含集群fsid,當Map被創建和最後一次修改時,一個池列表,副本大小,PG號,一個OSD列表和它們的狀態(例如up, in)。可通過執行ceph OSD dump命令查看OSD地圖。
- PG Map:包含PG版本,它的時間戳,最後的OSD地圖epoch,完整的比率,以及每個放置組的詳細資訊,如PG ID, Up Set, Acting Set, PG的狀態(例如,active + clean),以及每個池的數據使用統計。
- CRUSH Map:包含存儲設備列表、故障域層次結構(例如,設備、主機、機架、行、房間等),以及存儲數據時遍歷層次結構的規則。查看CRUSH地圖,執行ceph osd getcrushmap -o {filename};然後執行crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}反編譯。可在文本編輯器中或使用cat查看反編譯的映射。
- MDS Map:包含當前MDS Map epoch、Map創建的時間和最後一次更改的時間。它還包含用於存儲元數據的池、元數據伺服器列表以及啟動和運行的元數據伺服器。執行ceph fs dump命令,查看MDS的map資訊。
每個映射維護其操作狀態更改的迭代歷史。Ceph Monitors維護集群映射的主副本,包括集群成員、狀態、更改和Ceph存儲集群的總體健康狀況。
部署
部署建議
Ceph存儲集群部署都要從設置每個Ceph節點、網路和Ceph存儲集群開始。一個Ceph存儲集群至少需要一個Ceph Monitor、Ceph Manager和Ceph OSD (Object Storage Daemon)。運行Ceph文件系統客戶端時也需要Ceph元數據伺服器。如果是在生產中使用Ceph,官方有提供硬體建議(CPU、RAM、記憶體、數據存儲、網路、故障最低硬體建議)和作業系統建議(Ceph的依賴性、平台),詳細可以查閱官方文檔。比如推薦若干條件
- 存儲集群採用全萬兆網路。
- 集群網路與公共網路分離。這也是ceph網路模型需求
- mon、mds與osd分離部署在不同機器上。
- osd使用SATA。
- 根據容量規劃集群
- 至強E5 2620 V3或以上cpu,64GB或更高記憶體。
- 集群主機分散部署,避免機櫃故障(電源、網路)
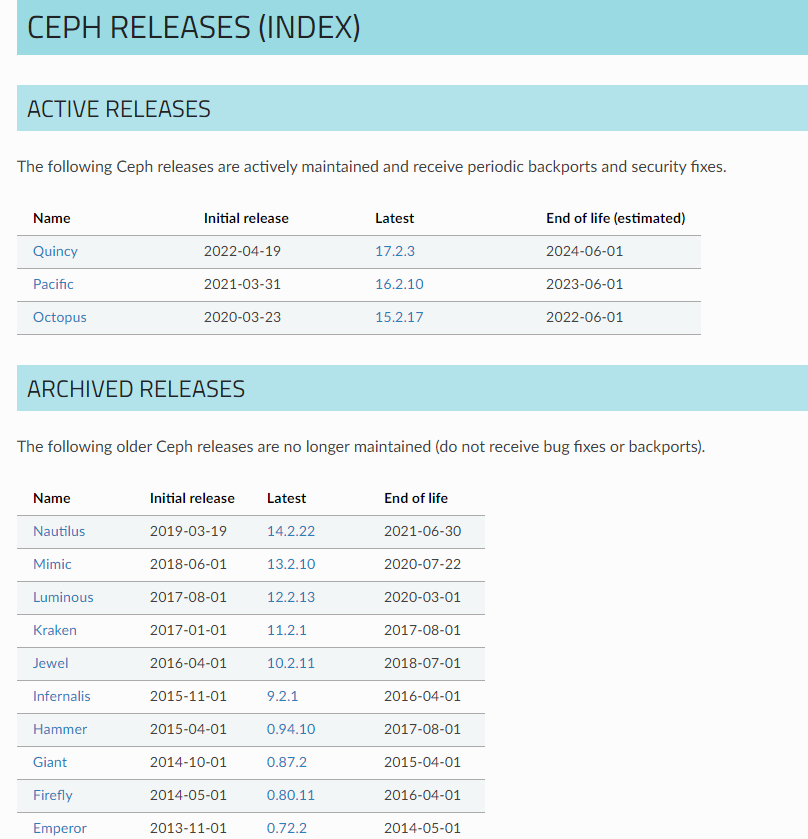
部署版本
Ceph官方發布版本號目前按照英文字母大寫開頭的單詞編排,有三個組成部分,生產使用要選擇x.2後面越大越好,代表解決問題越多越穩定。x.y.z. x表示發布周期(例如,13表示Mimic)。Y表示發布類型:
- x.0。Z -開發版本
- x.1。Z -發布候選版本(用於測試集群,勇敢的用戶)
- x.2。Z -穩定/bug修復版本(供用戶使用)
部署方式
由於ceph組件較多,手工安裝步驟較多,因此官方提供幾種不同的快速安裝Ceph的方法,推薦方法有如下兩種
- Cephadm:使用容器和systemd安裝和管理Ceph集群,並與CLI和儀錶板GUI緊密集成。
- cephadm只支援Octopus比其更新的版本。
- cephadm與新的業務流程API完全集成,並完全支援新的CLI和儀錶板特性來管理集群部署。
- cephadm需要容器支援(podman或docker)和Python 3。
- Rook:部署和管理運行在Kubernetes中的Ceph集群,同時通過Kubernetes api支援存儲資源管理和供應。推薦使用Rook在Kubernetes中運行Ceph,或者將現有的Ceph存儲集群連接到Kubernetes。
- Rook只支援Nautilus和Ceph的更新版本。
- Rook是在Kubernetes上運行Ceph的首選方法,或者是將Kubernetes集群連接到現有(外部)Ceph集群的首選方法。
- Rook支援新的編排器API,完全支援CLI和儀錶板中的新管理特性。
其他方法有,比較早使用或者目前已在使用大多數都應該使用的是Ceph-deploy方式:
- Ceph – Ansible:使用Ansible部署和管理Ceph集群。
- Ceph-ansible被廣泛使用。
- ceph-ansible並沒有與Nautlius和Octopus引入的新的編碼器api集成,這意味著新的管理功能和儀錶板集成是不可用的。
- Ceph-deploy:是一個用於快速部署集群的工具。
- Ceph-deploy不再被積極維護。它沒有在比Nautilus更新的Ceph上進行測試。不支援RHEL8、CentOS 8或更新的作業系統。
- Ceph使用Salt和cephadm安裝Ceph。
- 安裝Ceph 使用 Juju.
- 安裝Ceph via Puppet.
Cephadm部署
前置條件
cephadm不依賴於外部配置工具如Ansible、Rook和Salt。Cephadm管理Ceph集群的完整生命周期,cephadm先在單個節點上創建一個由一個監視器和一個管理器組成小型Ceph集群,後續cephadm使用業務流程介面擴展集群,添加所有主機並提供所有Ceph守護進程和服務。這些都通過Ceph命令行介面(CLI)或儀錶板(GUI)來執行。
- Python 3
- Systemd
- Podman或Docker用於運行容器(參考之前的文章部署)
- 時間同步(如chrony、NTP)
- LVM2用於發放存儲設備(yum install lvm2)
Python 3安裝步驟如下
# 官網下載
wget //www.python.org/ftp/python/3.10.6/Python-3.10.6.tgz
# 解壓
tar -xvf Python-3.10.6.tgz
# 創建安裝部署目錄
mkdir python3
# 進入目錄
cd Python-3.10.6
# 安裝依賴包
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make
# 如果需要openssl編譯安裝則選擇下面步驟
wget //www.openssl.org/source/openssl-1.1.1q.tar.gz --no-check-certificate
tar -xvf openssl-1.1.1q.tar.gz
mkdir /usr/local/openssl
cd openssl-1.1.1
./config --prefix=/usr/local/openssl
make
make installq
# 安裝python3
mkdir -p /home/commons/python3
ln -s /usr/local/openssl/lib/libssl.so.1.1 /usr/lib64/libssl.so.1.1
ln -s /usr/local/openssl/lib/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1
# 修改
./configure --prefix=/home/commons/python3
make
make install
# 建立軟鏈接
ln -s /home/commons/python3/bin/python3.10 /usr/local/bin/python3
ln -s /home/commons/python3/bin/python3.10 /usr/local/bin/pip3
ln -s /home/commons/python3/bin/python3.10 /usr/bin/python3
# 可以加入環境變數
vi ~/.bash_profile
export PYTHON_HOME=/home/commons/python3/
export PATH=$PYTHON_HOME/bin:$PATH
source ~/.bash_profile
# 查看版本
python3 --version

# 各自linux發行版的特定安裝方法,一些Linux發行版可能已經包含了最新的Ceph包。在這種情況下,您可以直接安裝cephadm。例如:
# Ubuntu:
apt install -y cephadm
# CentOS Stream
dnf search release-ceph
dnf install --assumeyes centos-release-ceph-quincy
dnf install --assumeyes cephadm
# Fedora:
dnf -y install cephadm
# openSUSE或SLES
zypper install -y cephadm
安裝CEPHADM
# 使用curl獲取獨立腳本的最新版本。
curl --silent --insecure --remote-name --location //github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
# 由於官方獲取不到,jsdelivr的地址
curl --silent --remote-name --location //cdn.jsdelivr.net/gh/ceph/ceph@quincy/src/cephadm/cephadm
#安裝cephadm,ceph需要python3和epel源;在執行安裝步驟有時會報錯無效的gpg密鑰,可以將ceph.repo文件中gpgcheck參數改成0,表示不適用密鑰驗證
vi /etc/yum.repos.d/ceph.repo
# 使cephadm腳本可執行
chmod +x cephadm
# 在cephadm腳本import ssl後面加入下面語句
ssl._create_default_https_context = ssl._create_unverified_context
# 驗證cephadm命令是否可用
./cephadm --help
# 其實到這一步,cephadm就已經能夠部署集群了,但是沒有安裝全部功能,也沒有把命令安裝成作業系統命令,添加ceph指定版本的系統包鏡像源,這裡我們安裝octopus版。本地apt或yum庫中會多出一些鏡像地址。
#使用cephadm腳本生成需要的yum源(可以替換為中國源提高下載速度) 可選
sed -i 's#download.ceph.com#mirrors.aliyun.com/ceph#' /etc/yum.repos.d/ceph.repo #可選
rpm --import '//download.ceph.com/keys/release.asc' #可選
# 添加倉庫
./cephadm add-repo --release octopus
# cephadm 安裝
./cephadm install
which cephadm
引導新的集群
cephadm bootstrap --mon-ip 192.168.5.53
執行上面後在Pulling container image步驟會需要一段時間,出現下面的返回後表示安裝成功,可看到儀錶盤訪問地址
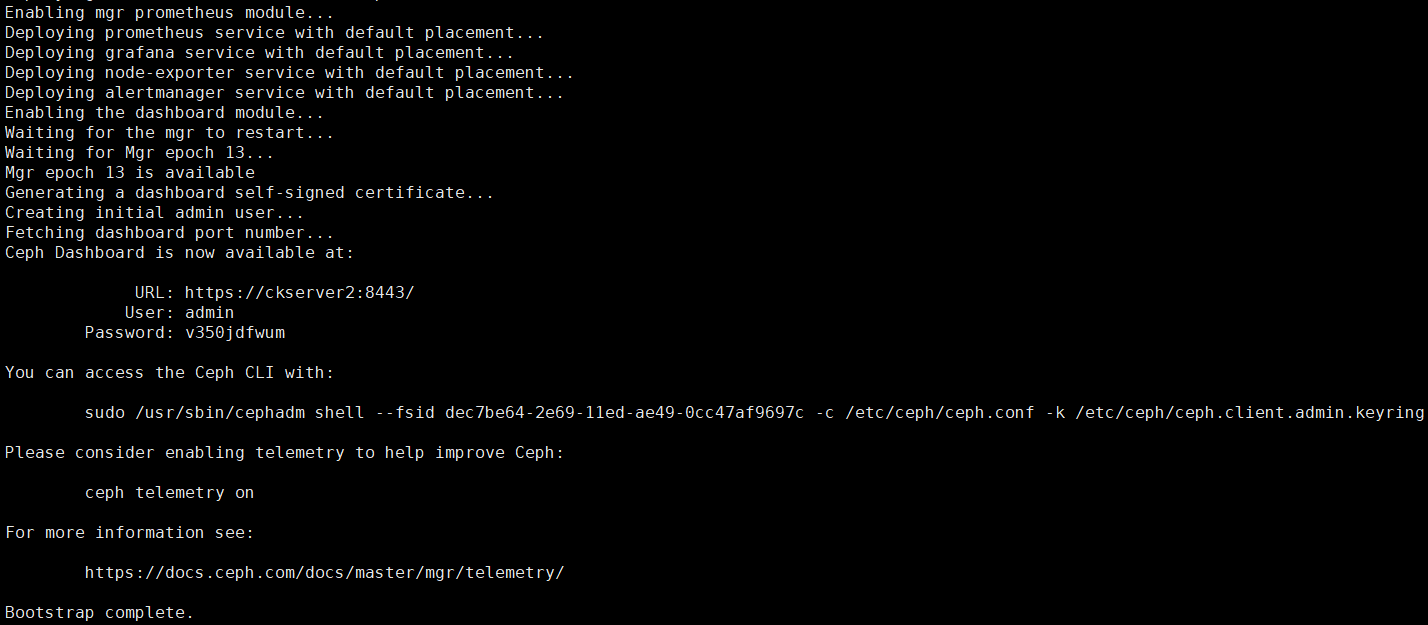
bootstrap完成後伺服器若干docker容器運行,prometheus+grafana作為監控系統,alertmanager提供告警功能(集群有異常會發送郵件或簡訊),node-exporter將主機暴露給ceph集群,讓別的伺服器直連訪問OSD;ceph-mon容器提供Monitor守護進程,為集群提供集群運行圖;ceph-mgr其實是ceph manager守護進程,為集群提供librados介面;ceph-crash是Crush演算法容器;查看拉取鏡像和啟動的容器如下:
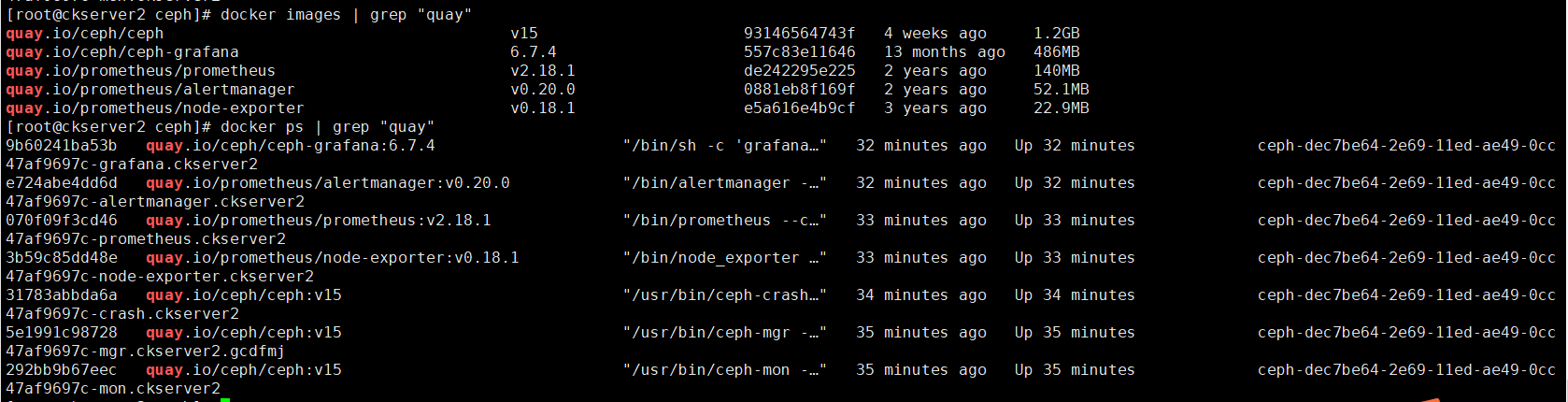
一個ceph集群算是創建出來了,ceph集群包括了Mon進程+librados介面;只要我們再安裝OSD,一個完全的Ceph存儲集群就創建好了;目前這個ceph沒有存儲的功能,僅僅是個管理器。訪問//ckserver2:8443/ ,輸入用戶密碼後,先修改密碼然後再登錄
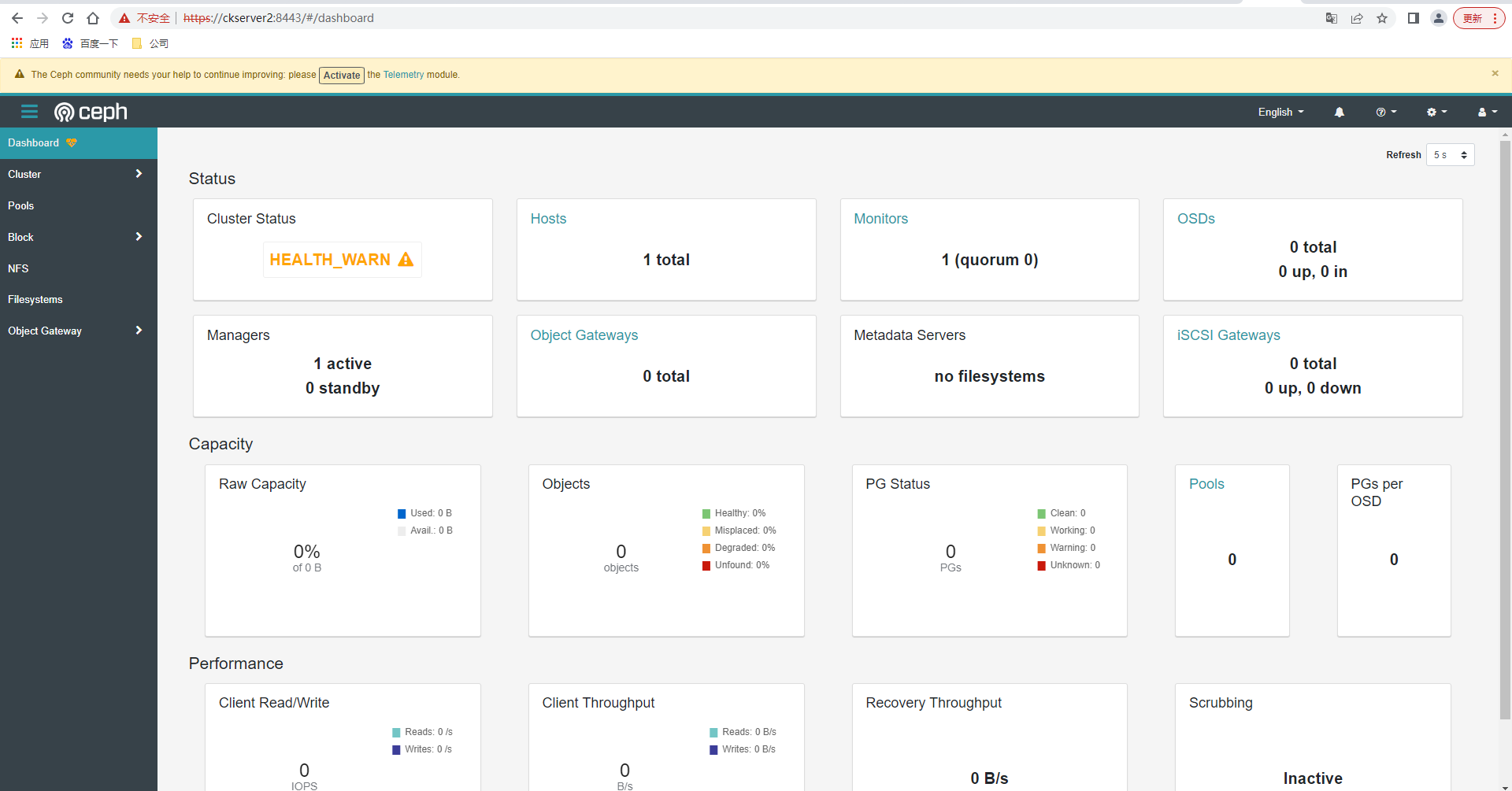
# (注)如果儀錶盤(dashboard)密碼忘了,可以使用以下命令重置密碼
ceph dashboard ac-user-set-password admin redhat
安裝命令
# 使用ceph命令第一種方法:cephadm安裝需要切換shell才可以使用ceph命令
cephadm shell
ceph -s
ceph -s
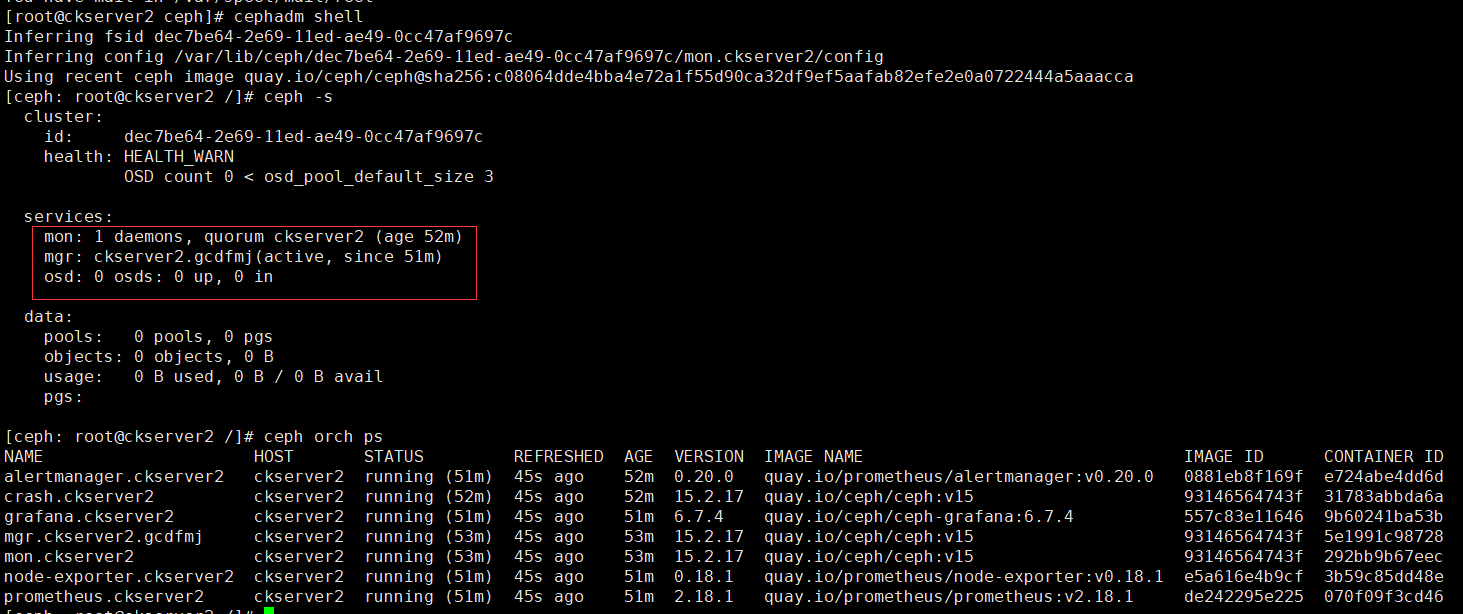
# 使用ceph命令第二種方法:要執行ceph命令,也可以運行如下命令:
cephadm shell -- ceph -s
# 使用ceph命令第三種方法:可以安裝ceph-common包,其中包含所有ceph命令,包括ceph、rbd、mount。ceph(用於掛載cepphfs文件系統),等等:。也即是如果沒有安裝ceph工具包,那麼需要先執行cephadm shell命令,再執行ceph操作
cephadm add-repo --release quincy
cephadm install ceph-common
# 檢驗ceph命令在主機上安裝成功
ceph -v
# 檢驗主機上的ceph命令能成功連接集群,獲取集群狀態
ceph status
典型的Ceph集群在不同的主機上有3到5個監視器守護進程。如果集群中有5個或更多節點,建議部署5個監視器。
# 首先在新主機的根用戶authorized_keys文件中安裝集群的公共SSH密鑰
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
本篇先到此,待續…….
**本人部落格網站 **IT小神 www.itxiaoshen.com


