《Java編程思想》讀書筆記(三)
- 2022 年 9 月 2 日
- 筆記
- 《Java編程思想》讀書筆記, JAVA
前言:三年之前就買了《Java編程思想》這本書,但是到現在為止都還沒有好好看過這本書,這次希望能夠堅持通讀完整本書並整理好自己的讀書筆記,上一篇文章是記錄的第十一章到第十六章的內容,這一次記錄的是第十七章到第十八章的內容,主要是集合和I/O內容太多,限於篇幅本文先記錄兩章內容,本文還是會把自己感興趣的知識點記錄一下,相關示例程式碼放在碼雲上了,碼雲地址://gitee.com/reminis_com/thinking-in-java
第十七章:容器深入研究
完整的容器分類法:這張圖是把工作中常用到的實現類和相關介面使用UML類圖辨識出來
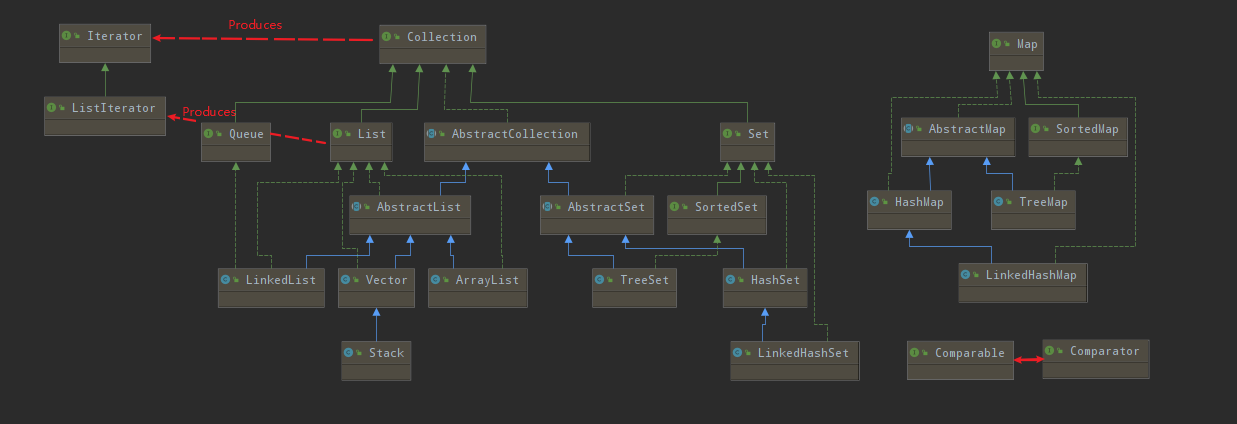
Java SE5新添加了:
- Queue介面及其實現PriorityQueue和各種風格的BlockingQueue
- ConcurrentMap介面及其實現ConcurrentHashMap,它們也是用於多執行緒機制的
- CopyOnWriteArrayList和CopyOnWriteArraySet,它們也是用於多執行緒機制的
- EnumSet和EnumMap,為使用enum而設計的Set和Map的特殊實現
Collection的功能方法
| 方法 | 描述 |
|---|---|
| boolean add(T e); | 確保容器持有具有泛型類型T的參數。如果沒有則將此參數添加進容器,則返回false |
| boolean addAll(Collection<? extends T> c); | 添加參數中的所有元素,只要添加了任意元素就返回true |
| void clear(); | 移除容器中的所有元素 |
| boolean contains(T e); | 如果容易已持有具有泛型類型T此參數,則返回true |
| boolean containsAll(Collection<?> c); | 如果容器持有參數中的所有元素,則返回true |
| boolean isEmpty(); | 容器中沒有元素時返回true |
| Iterator |
返回一個Iterator |
| boolean remove(Object o); | 如果參數在容器中,則移除此元素的一個實例。如果做了移除動作,則返回true |
| boolean removeAll(Collection<?> c); | 移除參數中的所有元素,只要有移除動作則返回true |
| boolean retainAll(Collection<?> c); | 只保存參數中的元素(相當於”交集”的概念),只要Collection發生了改變就返回true |
| int size(); | 返回容器中元素的數目 |
| Object[] toArray(); | 返回一個數組,該數組包含容器中的所有元素 |
| 返回一個數組,該數組包含容器中的所有元素。返回結果的運行時類型與參數數組a的類型相同,而不是單純的Object |
注意:Collection的方法中不包括隨機訪問所選擇元素的get()。因為Collection包含Set,而Set是自己維護內部順序的(這使得隨機訪問變得沒有意義)。因此,如果想檢查Collection中的元素,那就必須使用迭代器。
- UnsupportedOperationException:最常見的未獲支援的操作,都來源於背後由固定尺寸的數據結構支援的容器。當你用Arrays.asList()將數組轉為List時,就會得到這樣的容器。因為Arrays.asList()生成的List是基於一個固定大小的數組,僅支援那些不會改變數組大小的操作。任何會引起對底層數據結構的尺寸進行修改的方法都會產生一個UnsupportedOperationException異常。而Collections.unmodifiableList()會產生一個不可修改的列表。
Set和存儲順序
| 集合對象 | 描述 |
|---|---|
| Set(interface) | 存入Set的每個元素都必須是唯一的,因為Set不保存重複元素。加入Set的元素必須定義equals()方法以確保對象的唯一性。Set和Collection有完全一樣的介面。Set介面不保證維護元素的次序 |
| HashSet | 為了快速查找而設計的Set。存入HashSet的元素必須定義hashCode() |
| TreeSet | 保證次序的Set,底層為樹結構。使用它可以從Set中提取有序的序列。元素必須實現Comparable介面 |
| LinkedHashSet | 具有HashSet的查詢速度,且內部使用鏈表維護元素的順序(插入的次序),於是在使用迭代器遍歷Set時,結果會按元素的插入次序顯示。元素也必須定義hashCode()方法。 |
注意: 對於良好的編程風格而言,你在覆蓋equals()方法時,需要總是同時覆蓋hashCode()方法。
理解Map
Map也叫映射表(或者關聯數組),其基本思想是它維護的是鍵-值(對)關聯,因此你可以用鍵來查找值。
| Map | 描述 |
|---|---|
| HashMap | Map基於散列表的實現(它取代了Hashtable),插入和查詢」鍵值對「的開銷是固定的。可以通過構造器設置容量和負載因子,以調整容器的性能 |
| LinkedHashMap | 類似於HashMap,但是迭代遍歷它時,取得」鍵值對「的順序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一點,而在迭代訪問時反而更快,因為它使用鏈表維護內部次序 |
| TreeMap | 基於紅黑樹的實現。查看」鍵「或」鍵值對「時,它們會被排序(次序由Comparable或Comprator決定)。TreeMap的特點在於,所得到的結果是經過排序的。TreeMap是唯一帶有subMap()方法的Map,它可以返回一個子樹。 |
| WeakHashMap | 弱鍵(weak key)映射,需要釋放映射所指向的對象,這是為解決某類特殊問題而設計的。如果映射之外沒有引用指向某個」鍵「,則此」鍵「可以被垃圾回收器回收 |
| ConcurrentHashMap | 一種執行緒安全的Map,它不涉及同步加鎖。將在後面」並發「繼續討論 |
| IdentityHashMap | 使用 == 代替 equals()對」鍵「進行比較的散列映射。專為解決某類特殊問題而設計的。 |
注意:對Map中使用的鍵的要求與對Set的元素要求一樣。
SortedMap
使用SortedMap(TreeMap是其現階段的唯一實現),可以確保鍵處於排序狀態,這使得它具有額外的功能,這些功能由SortedMap介面中的下列方法提供:
- Comparator comparator(): 返回當前Map使用的Comparator;或者返回null,表示以自然方式排序
- T firstKey()返回Map中的第一個鍵
- T lastKey()返回Map中的最末一個鍵
- SortedMap subMap(fromKey, toKey)生成此Map的子集,範圍由formKey(包含)到toKey(不包含)的鍵確定
- SortedMap headMap(toKey)生成此Map的子集,由鍵小於toKey的所有鍵值對組成。
- SortedMap tailMap(fromKey)生成此Map的子集,由鍵大於或等於formKey的所有鍵值對組成。
在測試TreeMap的新增功能之前為了更好創建測試數據,自定義了CountingMapData這個類,它經過預初始化,並且都是唯一的Integer和String的Map,它可以具有任意尺寸。CountingMapData實現如下:
public class CountingMapData extends AbstractMap<Integer, String> {
private int size;
private static String[] chars = ("A B C D E F G H I J K L M N O P Q R S T " +
"U V W X Y Z").split(" ");
public CountingMapData(int size) {
if (size < 0) {
this.size = 0;
}
this.size = size;
}
public static class Entry implements Map.Entry<Integer, String> {
int index;
public Entry(int index) {
this.index = index;
}
@Override
public boolean equals(Object obj) {
return Integer.valueOf(index).equals(obj);
}
@Override
public int hashCode() {
return Integer.valueOf(index).hashCode();
}
@Override
public Integer getKey() {
return index;
}
@Override
public String getValue() {
return chars[index % chars.length] + index / chars.length;
}
@Override
public String setValue(String value) {
throw new UnsupportedOperationException();
}
}
@Override
public Set<Map.Entry<Integer, String>> entrySet() {
// LinkedHashSet維護了初始化順序
Set<Map.Entry<Integer, String>> entries = new LinkedHashSet<>();
for (int i = 0; i < size; i++) {
entries.add(new Entry(i));
}
return entries;
}
public static void main(String[] args) {
System.out.println(new CountingMapData(100));
}
}
下面的例子演示了TreeMap新增的功能:
public class SortedMapDemo {
/**
* 演示 TreeMap 新增的功能
*/
public static void main(String[] args) {
TreeMap<Integer, String> sortedMap = new TreeMap<>(
new CountingMapData(10));
System.out.println(sortedMap);
Integer firstKey = sortedMap.firstKey();
System.out.println(firstKey);
Integer lastKey = sortedMap.lastKey();
System.out.println(lastKey);
Iterator<Integer> iterator = sortedMap.keySet().iterator();
for (int i = 0; i <= 6; i++) {
if (i == 3) {
firstKey = iterator.next();
}
if (i == 6) {
lastKey = iterator.next();
} else {
iterator.next();
}
}
System.out.println(firstKey);
System.out.println(lastKey);
System.out.println(sortedMap.subMap(firstKey, lastKey));
System.out.println(sortedMap.headMap(lastKey));
System.out.println(sortedMap.tailMap(firstKey));
}
}
運行結果如下圖:
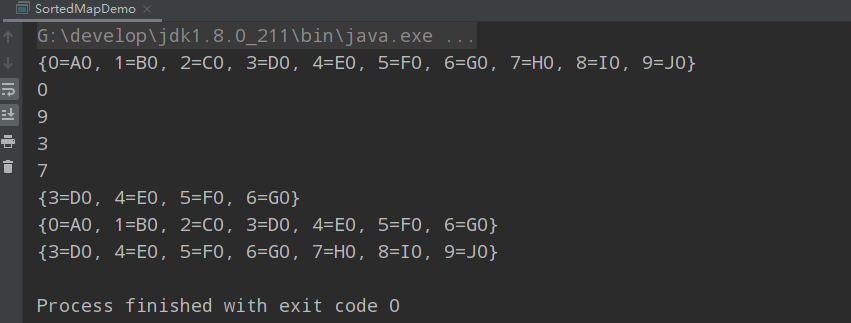
此外,鍵值對是按照鍵的次序排列的。TreeMap中的次序是由意義的,因為」位置「的概念才有意義,所以才能取得第一個和最後一個元素,並且可以提取Map的子集。
LinkedHashMap
為了提高速度,LinkedHashMap散列化所有元素,但是在遍歷鍵值對時,卻又以鍵值對的插入順序返回鍵值對。此外,可以在構造器中設定LinkedHashMap,使之採用最近最少用(LRU)演算法,於是沒有被訪問過的(可看作需要被刪除的)元素,就會出現在隊列的前面。對於需要定期清理元素以節省空間的程式的來說,此功能使得程式容易實現。下面這個簡單的例子演示了LinkedHashMap的這兩種特點:
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer, String> linkedHashMap = new LinkedHashMap<>(
new CountingMapData(9)
);
System.out.println(linkedHashMap);
// LRU順序
linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.putAll(new CountingMapData(9));
System.out.println(linkedHashMap);
for (int i = 0; i < 6; i++) {
linkedHashMap.get(i);
}
System.out.println(linkedHashMap);
linkedHashMap.get(0);
System.out.println(linkedHashMap);
}
}
執行結果如下:
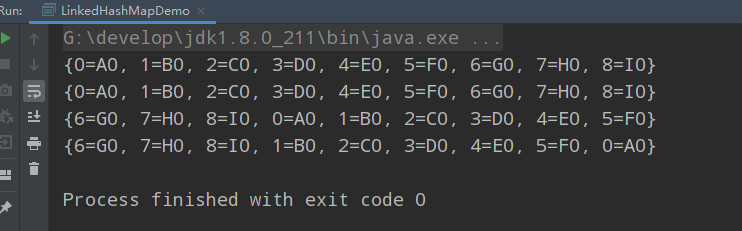
從輸出中可以看到,鍵值對是以插入的順序進行遍歷的,甚至LRU演算法版本也是如此。但是在LRU版本中,在(只)訪問過前面6個元素後,最後三個元素移動到了隊列前面,然後在訪問一次元素」0「時,它就被移動到隊列後端了。
散列與散列碼
正確的equals()方法必須滿足系列5個條件:
- 自反性:對任意x,x.equals(x)一定返回true
- 對稱性:對任意的x和y,如果y.equals(x)為true,則x.equals(y)也返回true
- 傳遞性:對任意的x、y、z,如果x.equals(y)返回true,y.equals(z)返回true,則x.equals(z)一定返回true
- 一致性:對任意x和y,如果對象中用於等價比較的資訊沒有改變,那麼無論調用x.equals(y)多少次,返回的結果都應該保持一致,要麼一直是true,要麼一直是false。
- 對於任何不是null的x,x.equals(null)一定返回false。
注意:Object默認的equals()方式只是比較對象的地址,如果要使用自己的類作為HashMap的鍵,必須同時重載equlas()和hashCode()方法。
理解hashCode():首先,使用散列的目的在於:想要使用一個對象來查找另一個對象。
為速度而散列:散列的價值在於速度,散列使得查詢得以快速進行。由於瓶頸位於鍵的查詢速度,因此解決方案之一就是鍵的排序狀態,然後使用Collections.binarySearch()進行查詢。
散列則更進一步,它將鍵保存在某處,以便很快能夠找到。存儲一組元素最快的數據結構是數組,所以使用它來表示鍵的資訊(請小心留意,我是說鍵的資訊,而不是鍵本身)。但是因為數組不能調整容量,因此就有一個問題:我們希望在Map中保存不確定數量的值,但是如果鍵的數量被數組的容量限制了,該怎麼辦呢?
答案就是:數組並不保存鍵本身,而是通過鍵對象產生一個數字,將其作為數組的下標,這個數字就是散列碼,由定義在Object中的,且可能由你的類覆蓋的hashCode()方法(也叫散列函數)生成。
為解決數組容量固定的問題,不通的鍵可以產生相同的下標。也就是說可能會有衝突,因此,數組多大就不重要了,任何鍵總能在數組中找到它的位置。
於是查詢一個值的過程首先就是計算散列碼,然後使用散列碼查詢數組,如果能夠保證沒有衝突(如果值的數量是固定的,那麼就有可能),那可就有了一個完美的散列函數,但是這種情況只是特例。通常,衝突由外部鏈接處理:數組並不直接保存值,而是保存值的list。然後對list中的值使用equals()進行線性的查詢。這部分的查詢自然會很慢,但是,如果散列函數好的話,數組的每個位置就只有比較少的值。因此,不是查詢整個list,而是快速跳到數組的某個位置,只對很少的元素進行比較。這便是HashMap會如此快的原因。
由於散列表中的」槽位「(slot)通常稱為(bucket),因此我們將表示實際散列表的數組命名為bucket。為使散列均勻分布,桶的數量通常使用質數(事實證明:質數實際上並不是散列桶的理想容量,近來,經廣泛的測試,,Java的散列函數都使用2的整數次冪。對現代的處理器來說,除法與求餘數是最慢的操作。使用2的整數次方長度的散列表,可用掩碼代替除法,因為get()是使用最多的操作,求餘數的%操作是其開銷最大的部分, 而使用2的整數次方可以消除此開銷)。
對於put()方法,hashCode()將針對鍵而被調用,並且其結果將被強制轉換為正數。為了使產生的數字適合bucket數組的大小,取模操作符將按照該數組的尺寸取模,如果數組的某個位置是null,這表示還沒有元素被散列至此,所以為了保存剛散列到該定位的對象,需要創建一個新的LinkedList。一般的過程是,查看當前位置的list是都有相同的元素,如果有,則將舊的值賦給oldValue,然後用新的值取代舊的值。標記found用來跟蹤是否找到(相同的)舊的鍵值對,如果沒有,則將新的鍵值對添加到list的末尾。
覆蓋hashCode()
在明白了如何散列之後,編寫自己的hashCode()方法就更有意義了。設計hashCode()時最重要的因素就是:無論何時,對同一個對象調用hashCode()都應該生成同樣的值。如果在將一個對象用put()添加進HashMap時產生一個hashCode()值,而用get()取出時卻產生了另一個hashCode()值,那麼就無法重新獲得該對象了。所以,如果你的hashCode()方法依賴於對象中易變的數據,用戶就要當心了,因為此數據發生變化時,hashCode()就會生成一個不通的散列碼,相當於產生了一個不同的鍵。此外,也不應該使hashCode()依賴於具有唯一性的對象資訊,尤其是使用this的值,這隻能產生很糟糕的hashCode()。因為這樣做無法生成一個新的鍵,使之與put()中原始的鍵值對中的鍵相同。
選擇介面的不同實現
容器之間的區別通常歸結為由什麼在背後「支援」它們。也就是說,所使用的介面是由什麼樣的數據結構實現的,例如,因為ArrayList和LinkedList都實現了List介面,所以無論選擇哪個,基本的List操作都是相同的。然而,ArrayList底層由數組支援;而LinkedList是由雙向鏈表實現的,其中的每個對象包含數據的同時還包含指向鏈表中前一個與後一個元素的引用。因此,如果要經常在表中插人或刪除元素,LinkedList比較合適(LinkedList還有建立在 AbstractSequentialList基礎上的其他功能),否則,應該使用速度更快的ArrayList。
再舉個例子,Set可被實現為TreeSet、HashSet或LinkedHashSet。每一種都有不同的行為 HashSet是最常用的,查詢速度最快;LinkedHashSet保持元素插入的次序;TreeSet基於 TreMap,生成一個總是處於排序狀態的Set。你可以根據所需的行為來選擇不同的介面實現。
第十八章:Java I/O系統
對程式語言的設計者而言,創建一個好的輸入/輸出(I/O)系統是一項艱難的任務。
- File類既能代表一個特定文件的名稱,又能代表一個目錄下一組文件的名稱。下面展示了如何使用「目錄過濾器」顯示我們符合條件的File對象
// Args: "D.*\.java"
public class DirList {
public static void main(String[] args) {
File path = new File("G:\\demo");
String[] list;
// File的list()方法會為此目錄對象下的每個文件名調用accept(),來判斷該文件是否包含在內,判斷結果由accept()返回的布爾值表示
if (args.length == 0) {
list = path.list();
} else {
list = path.list(new DirFilter(args[0]));
}
// 按照字母排序
Arrays.sort(list, String.CASE_INSENSITIVE_ORDER);
for (String dirItem : list) {
System.out.println(dirItem);
}
}
}
class DirFilter implements FilenameFilter {
private Pattern pattern;
public DirFilter(String regex) {
this.pattern = Pattern.compile(regex);
}
@Override
public boolean accept(File dir, String name) {
return pattern.matcher(name).matches();
}
}
/* Output:
DirectoryDemo.java
DirList.java
DirList2.java
DirList3.java
*///:~
- File類不僅僅只代表存在的文件或目錄,也可以用File對象來創建新的目錄或尚不存在的整個目錄路徑。我們還可以查看文件的特性(如:大小,最後修改日期,讀/寫),檢查某個File對象代表的是一個文件還是一個目錄,並可以刪除文件。下面展示了File類的一些其它方法:
// {Args: MakeDirectoriesTest}
public class MakeDirectories {
private static void usage() {
System.err.println(
"Usage:MakeDirectories path1 ...\n" +
"Creates each path\n" +
"Usage:MakeDirectories -d path1 ...\n" +
"Deletes each path\n" +
"Usage:MakeDirectories -r path1 path2\n" +
"Renames from path1 to path2");
System.exit(1);
}
private static void fileData(File f) {
System.out.println(
"絕對路徑: " + f.getAbsolutePath() +
"\n 可讀: " + f.canRead() +
"\n 可寫: " + f.canWrite() +
"\n 文件名稱: " + f.getName() +
"\n 上級目錄: " + f.getParent() +
"\n 文件路徑: " + f.getPath() +
"\n 文件大小: " + f.length() +
"\n 最後修改時間: " + f.lastModified());
if(f.isFile()) {
System.out.println("這是一個文件");
} else if(f.isDirectory()) {
System.out.println("這是一個目錄");
}
}
public static void main(String[] args) {
if(args.length < 1) {
usage();
}
if(args[0].equals("-r")) {
if(args.length != 3) {
usage();
}
File old = new File(args[1]), rname = new File(args[2]);
old.renameTo(rname);
fileData(old);
fileData(rname);
return; // Exit main
}
int count = 0;
boolean del = false;
if(args[0].equals("-d")) {
count++;
del = true;
}
count--;
while(++count < args.length) {
File f = new File(args[count]);
if(f.exists()) {
System.out.println(f + " exists");
if(del) {
System.out.println("deleting..." + f);
f.delete();
}
}
else { // Doesn't exist
if(!del) {
f.mkdirs();
System.out.println("created " + f);
}
}
fileData(f);
}
}
}
運行結果如下圖:
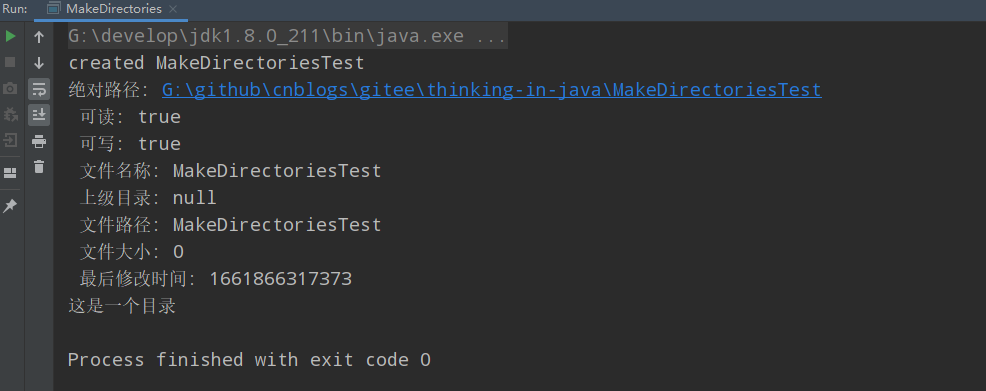
輸入和輸出
程式語言的I/O類庫中常使用流這個抽象概念,它代表任何有能力產出數據的數據源對象或者是有能力接收數據的接收端對象。「流」屏蔽了實際的I/O設備中處理數據的細節。Java類庫中的I/O類分成輸入和輸出兩部分,可以在JDK文檔里的類層次結構中查看到。通過繼承,任何自Inputstream或Reader派生而來的類都含有名為read()的基本方法,用於讀取單個位元組或者位元組數組。同樣,任何自OutputStream或Writer派生而來的類都含有名為write()的基本方法,用於寫單個位元組或者位元組數組。但是,我們通常不會用到這些方法,它們之所以存在是因為別的類可以使用它們,以便提供更有用的介面。因此,我們很少使用單一的類來創建流對象,而是通過疊合多個對象來提供所期望的功能(這是裝飾器設計模式,你將在本節中看到它)。實際上,Java中「流」類庫讓人迷惑的主要原因就在於∶創建單一的結果流,卻需要創建多個對象。
在Java1.0中,類庫的設計者首先限定與輸入有關的所有類都應該從InputStream繼承,而與輸出有關的類都應該從OutputStream繼承。但Java 1.1對基本的I/O流類庫進行了重大的修改。當我們初次看見Reader和Writer類時,可能會以為這是兩個用來替代InputStream和OutputStreamt的類;但實際上並非如此。儘管一些原始的「流」類庫不再被使用(如果使用它們,則會收到編譯器的警告資訊),但是ImputStream 和OutputStreamt在以面向位元組形式的I/O中仍可以提供極有價值的功能,Reader和Writer則提供兼容Unicode與面向字元的I/O功能。另外∶
1)Java 1.1向InputStream和OutputStreamt繼承層次結構中添加了一些新類,所以顯然這兩個類是不會被取代的。
2)有時我們必須把來自於「位元組」層次結構中的類和「字元」層次結構中的類結合起來使用。為了實現這個目的,要用到「適配器」(adapter)類∶InputStreamReader可以把InputStream轉換為Reader,而OutputStreamWriter可以把OutputStream轉換為Writer。
設計Reader和Writer繼承層次結構主要是為了國際化。老的I/O流繼承層次結構僅支援8位位元組流,並且不能很好地處理16位的Unicode字元。由於Unicode用於字元國際化(Java本身的char也是16位的Unicode),所以添加Reader和Writer繼承層次結構就是為了在所有的I/O操作中都支援Unicode。另外,新類庫的設計使得它的操作比舊類庫更快。
我們有必要按照功能對這些類進行分類:
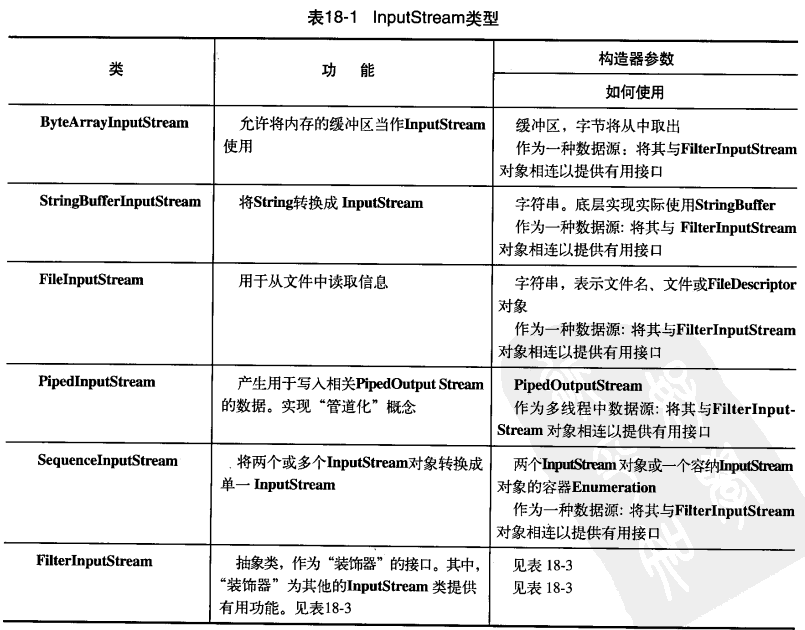
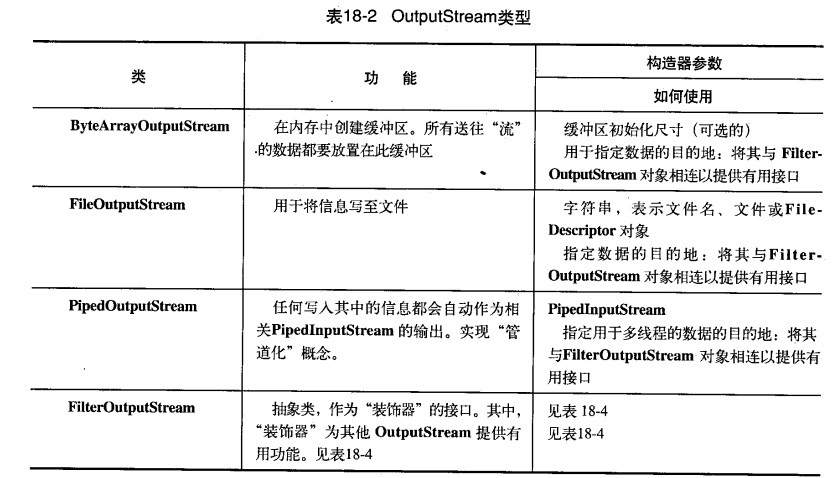
數據的來源和去處
幾乎所有原始的Java I/O流類都有相應的Reader和Writer類來提供天然的Unicode操作。然而在某些場合,面向位元組的InputStream和OutputStream才是正確的解決方案;特別是java.util.zip類庫就是面向位元組的而不是面向字元的。因此,最明智的做法是盡量嘗試使用Reader 和Writer,一旦程式程式碼無法成功編譯,我們就會發現自己不得不使用面向位元組類庫。


自我獨立的類:RandomAccessFile
RandomAccessFile適用於由大小已知的記錄組成的文件,所以我們可以使用seek()將記錄從一處轉移到另一處,然後讀取或者修改記錄。文件中記錄的大小不一定都相同,只要我們能夠確定那些記錄有多大以及它們在文件中的位置即可。
最初,我們可能難以相信RandomAccessFile不是InputStream或者OutputStream繼承層次結構中的一部分。除了實現了DataInput和DataOutput介面(DataInputStream和DataOutputStream 也實現了這兩個介面)之外,它和這兩個繼承層次結構沒有任何關聯。它甚至不使用InputStream和OutputStream類中已有的任何功能。它是一個完全獨立的類,從頭開始編寫其所有的方法(大多數都是本地的)。這麼做是因為RandomAccessFlle擁有和別的I/O類型本質不同的行為,因為我們可以在一個文件內向前和向後移動。在任何情況下,它都是自我獨立的,直接從Object派生而來。
從本質上來說,RandomAccessFile的工作方式類似於把DatalnputStream和DataOutStream 組合起來使用,還添加了一些方法。其中方法getFilePointer()用於查找當前所處的文件位置,seek()用於在文件內移至新的位置,length()用於判斷文件的最大尺寸。另外,其構造器還需要第二個參數(和C中的fopen()相同)用來指示我們只是「隨機讀」(r)還是「既讀又寫」(rw)。它並不支援只寫文件,這表明RandomAccessFile若是從DatalnputStream繼承而來也可能會運行得很好。
只有RandonAccessFile支援搜尋方法,並且只適用於文件。BufferedInputStream卻能允許標註(mark0)位置(其值存儲於內部某個簡單變數內)和重新設定位置(reset)),但這些功能很有限,不是非常有用。
在JDK1.4中,RandomAccessFile的大多數功能(但不是全部)由nio存儲映射文件所取代。
public class UsingRandomAccessFile {
private static String file = "rtest.dat";
private static void display() throws IOException {
RandomAccessFile rf = new RandomAccessFile(file, "r");
for (int i = 0; i < 7; i++) {
System.out.println("Value " + i + ": " + rf.readDouble() );
}
System.out.println(rf.readUTF());
rf.close();
}
public static void main(String[] args) throws IOException {
RandomAccessFile rf = new RandomAccessFile(file, "rw");
for (int i = 0; i < 7; i++) {
rf.writeDouble(i*1.414);
}
rf.writeUTF("The end of the file");
rf.close();
display();
rf = new RandomAccessFile(file, "rw");
rf.seek(5*8);
rf.writeDouble(47.0001);
rf.close();
display();
}
}
display()方法打開了一個文件,並以double值的形式顯示了其中的七個元素。在main()中,首先創建了文件,然後打開並修改了它。因為double總是8位元組長,所以為了用seek()查找第5個雙精度值,你只需用5*8來產生查找位置。
正如先前所指,RandomAccessFile除了實現Datalnput和DataOutput介面之外,有效地與I/O繼承層次結構的其他部分實現了分離。因為它不支援裝飾,所以不能將其與InputStream及OutputStream子類的任何部分組合起來。我們必須假定RandomAccessFile已經被正確緩衝,因為我們不能為它添加這樣的功能。
可以自行選擇的是第二個構造器參數∶我們可指定以「只讀」(r)方式或「讀寫」(rw)方式打開一個RandomAccessFile文件。
你可能會考慮使用「記憶體映射文件」來代替RandomAccessFile。
I/O流的典型使用方式
緩衝輸入文件
如果想要打開一個文件用於字元輸入,可以使用以String或File對象作為文件名的FlleInputReader。為了提高速度,我們希望對那個文件進行緩衝,那麼我們將所產生的引用傳給一個BufferedReader構造器。由於BufferedReader也提供readLine()方法,所以這是我們的最終對象和進行讀取的介面。當readLine()將返回null時,你就達到了文件的末尾。
public class BufferInputFile {
/**
* 讀取文件
*/
public static String read(String filename) throws IOException {
BufferedReader in = new BufferedReader(new FileReader(filename));
String s;
// 字元串sb用來累計文件的全部內容(包括必須添加的換行符,因為readline已將它們刪掉)
StringBuilder sb = new StringBuilder();
while ((s = in.readLine()) != null) {
sb.append(s + "\n");
}
// 最後,調用close()關閉文件
in.close();
return sb.toString();
}
public static void main(String[] args) throws IOException {
System.out.println(read("src/io/BufferInputFile.java"));
}
}
從記憶體輸入
在下面的示例中,BufferedInputFile.read()讀入的Stirng結果被用來創建一個StringReader。然後調用read()每次讀取一個字元,並把它發送到控制台。
public class MemoryInput {
public static void main(String[] args) throws IOException {
StringReader in = new StringReader(BufferInputFile.read("src/io/MemoryInput.java"));
int c;
// 注意read()方法是以int形式返回下一個位元組,因此必須類型轉換為char才能正確列印
while ((c = in.read()) != -1) {
System.out.print((char)c);
}
in.close();
}
}
格式化的記憶體輸入
要讀取格式化數據,可以使用DatalnputStream,它是一個面向位元組的I/O類(不是面向字元的)。因此我們必須使用InputStream類而不是Reader類。當然,我們可以用InputStream以位元組的形式讀取任何數據(例如一個文件),不過,在這裡使用的是字元串。
public class FormatMemoryInput {
public static void main(String[] args) throws IOException {
DataInputStream in = null;
try {
in = new DataInputStream(new ByteArrayInputStream(
BufferInputFile.read("src/io/FormatMemoryInput.java").getBytes()));
while (true) {
System.out.print((char) in.readByte());
}
} catch (EOFException e) {
System.err.println("End of stream");
} finally {
if (Objects.nonNull(in)) {
in.close();
}
}
}
}
必須為ByteArrayInputStream提供位元組數組,為了產生該數組String包含了一個可以實現此項工作的getBytes()方法。所產生的ByteArrayInputStrem是一個適合傳遞給DatalnputStream的InputStream。如果我們從DataImputStream用readByte()一次一個位元組地讀取字元,那麼任何位元組的值都是合法的結果,因此返回值不能用來檢測輸入是否結束。相反,我們可以使用available()方法查看還有多少可供存取的字元。下面這個例子演示了怎樣一次一個位元組地讀取文件∶
public class TestEOFE {
public static void main(String[] args) throws IOException {
DataInputStream in = new DataInputStream(new ByteArrayInputStream(
BufferInputFile.read("src/io/TestEOFE.java").getBytes()));
while (in.available() != 0) {
System.out.print((char) in.readByte());
}
}
}
注意,available()的工作方式會隨著所讀取的媒介類型的不同而有所不同;字面意思就是「在沒有阻塞的情況下所能讀取的位元組數」。對於文件,這意味著整個文件;但是對於不同類型的流,可能就不是這樣的,因此要謹慎使用。
我們也可以通過捕獲異常來檢測輸入的末尾。但是,使用異常進行流控制,被認為是對異常特性的錯誤使用。
文件讀寫的實用工具
一個很常見的程式化任務就是讀取文件到記憶體,修改,然後再寫出。下面的TextFile類包含的static方法可以像簡單字元串那樣讀寫文本文件,並且我們可以創建一個TextFile對象,他用一個ArrayList來保存文件的若干行(如此,當我們操縱文件內容時,就可以使用ArrayList的所有功能)。
package io;
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.TreeSet;
/**
* @author Mr.Sun
* @date 2022年08月31日 22:24
*
* 文件讀寫的實用工具
*/
public class TextFile extends ArrayList<String> {
/**
* 讀取單個文件
*
* @param filename 文件名稱
* @return 文件內容
*/
public static String read(String filename) {
StringBuilder sb = new StringBuilder();
try {
BufferedReader in = new BufferedReader(new FileReader(
new File(filename).getAbsoluteFile()));
try {
String s;
while ((s = in.readLine()) != null) {
sb.append(s);
sb.append("\n");
}
} finally {
in.close();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return sb.toString();
}
/**
* 向文件中寫內容
*
* @param filename 文件名稱
* @param text 內容
*/
public static void write(String filename, String text) {
try {
PrintWriter out = new PrintWriter(new File(filename).getAbsoluteFile());
try {
out.print(text);
} finally {
out.close();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 讀取文件,由任何正則表達式拆分
*
* @param filename 文件名稱
* @param splitter 分隔符
*/
public TextFile(String filename, String splitter) {
super(Arrays.asList(read(filename).split(splitter)));
// 正則表達式split() 通常在第一個位置留下一個空字元串
if (get(0).equals("")) {
remove(0);
}
}
public TextFile(String filename) {
this(filename, "\n");
}
public void write(String filename) {
try {
PrintWriter out = new PrintWriter(new File(filename).getAbsoluteFile());
try {
for (String item : this) {
out.println(item);
}
} finally {
out.close();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
String filename = "src/io/TextFile.java";
String file = read(filename);
write("test.txt", file);
TextFile text = new TextFile("test.txt");
text.write("test2.txt");
// 拆分為單詞的唯一排序列表
TreeSet<String> words = new TreeSet<>(
new TextFile(filename, "\\W+"));
// 顯示大寫的單詞
System.out.println(words.headSet("a"));
}
}
運行結果如下:

read()將每行添加到StringBuffer,並且為每行加上換行符,因為在讀的過程中換行符會被去除掉。接著返回一個包含整個文件的字元串。write()打開文本並將其寫入文件,在這兩個方法完成時,都要記著調用close()關閉文件。注意,在任意打開文件的程式碼在finaly子句中,作為防衛措施都添加了對文件的close()方法調用,以保證文件將會被正確關閉。
- 讀取二進位文件,這個工具與TextFile類似,因為它簡化了讀取二進位文件的過程:
package io;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
/**
* @author Mr.Sun
* @date 2022年09月02日 10:24
*
* 讀取二進位文件
*/
public class BinaryFile {
public static byte[] read(File bfile) throws IOException {
BufferedInputStream in = new BufferedInputStream(new FileInputStream(bfile));
try {
byte[] data = new byte[in.available()];
in.read(data);
return data;
} finally {
in.close();
}
}
public static byte[] read(String bfile) throws IOException {
return read(new File(bfile).getAbsoluteFile());
}
}
其中一個重載方法接受File參數,第二個重載方法接受表示文件名的String參數,這兩個方法都返回產生的byte[]數組,available()方法被用來產生恰當的數組尺寸,並且read()方法的特定的重載版本填充了這個數組。
新I/O
JDK 1.4的java.nio.*包中引入了新的Java I/O類庫,其目的在於提供速度。實際上,舊的I/O包已經使用nio重新實現過,以便充分利用這種速度提高,因此,即使我們不顯示地用nio編寫程式碼,也能從中受益。
速度的提高來自於所使用的結構更接近於作業系統執行I/O的方式∶通道和緩衝器。我們可以把它想像成一個煤礦,通道是一個包含煤層(數據)的礦藏,而緩衝器則是派送到礦藏的卡車。卡車載滿煤炭而歸,我們再從卡車上獲得煤炭。也就是說,我們並沒有直接和通道交互;我們只是和緩衝器交互,並把緩衝器派送到通道。通道要麼從緩衝器獲得數據,要麼向緩衝器發送數據。
唯一直接與通道交互的緩衝器是ByteBuffer————也就是說,可以存儲未加工位元組的緩衝器。當我們查詢JDK文檔中的java.nio.ByteBuffer時,會發現它是相當基礎的類∶通過告知分配多少存儲空間來創建一個ByteBuffer對象,並且還有一個方法選擇集,用於以原始的位元組形式或基本數據類型輸出和讀取數據。但是,沒辦法輸出或讀取對象,即使是字元串對象也不行。這種處理雖然很低級,但卻正好,因為這是大多數作業系統中更有效的映射方式。
舊I/O類庫中有三個類被修改了,用以產生FileChannel。這三個被修改的類是FilelnputStream、FileOutputStream以及用於既讀又寫的RandomAccessFile。注意這些是位元組操縱流,與低層的nio性質一致。Reader和Writer這種字元模式類不能用於產生通道;但是javanio.channels.Channels類提供了實用方法,用以在通道中產生Reader和Writer。
下面的簡單實例演示了上面三種類型的流,用以產生可寫的、可讀可寫的及可讀的通道。
public class GetChannel {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
FileChannel fc = new FileOutputStream("data.txt").getChannel();
fc.write(ByteBuffer.wrap("Some text ".getBytes()));
fc.close();
// 在文件末尾追加點數據
fc = new RandomAccessFile("data.txt", "rw").getChannel();
// 移動到文件結尾
fc.position(fc.size());
fc.write(ByteBuffer.wrap("Some more".getBytes()));
fc.close();
// 讀取文件
fc = new FileInputStream("data.txt").getChannel();
ByteBuffer buff = ByteBuffer.allocate(BSIZE);
fc.read(buff);
buff.flip();
while (buff.hasRemaining()) {
System.out.print((char) buff.get());
}
}
}
對於這裡所展示的任何流類,getChannel()將會產生一個FileChannel。通道是一種相當基礎的東西∶可以向它傳送用於讀寫的ByteBuffer,並且可以鎖定文件的某些區域用於獨佔式訪問。
將位元組存放於ByteBuffer的方法之一是∶使用一種”put”方法直接對它們進行填充,填入一個或多個位元組,或基本數據類型的值。不過,正如所見,也可以使用warp()方法將已存在的位元組數組「包裝」到ByteBuffer中。一旦如此,就不再複製底層的數組,而是把它作為所產生的ByteBuffer的存儲器,我們稱之為數組支援的ByteBuffer。
data.txt文件用RandomAccessFile被再次打開。注意我們可以在文件內隨處移動FlleChannel;在這裡,我們把它移到最後,以便附加其他的寫操作。
對於只讀訪問,我們必須顯式地使用靜態的allocate()方法來分配ByteBuffer。nio的目標就是快速移動大量數據,因此ByteBuffer的大小就顯得尤為重要————實際上,這裡使用的1K可能比我們通常要使用的小一點(必須通過實際運行應用程式來找到最佳尺寸)。
甚至達到更高的速度也有可能,方法就是使用allocateDirect()而不是allocate(),以產生一個與作業系統有更高耦合性的「直接」緩衝器。但是,這種分配的開支會更大,並且具體實現也隨作業系統的不同而不同,因此必須再次實際運行應用程式來查看直接緩衝是否可以使我們獲得速度上的優勢。
一旦調用read()來告知FileChannel向ByteBuffer存儲位元組,就必須調用緩衝器上的flip(),讓它做好讓別人讀取位元組的準備(是的,這似乎有一點拙劣,但是請記住,它是很拙劣的,但卻適用於獲取最大速度)。如果我們打算使用緩衝器執行進一步的read()操作,我們也必須得調用clear()來為每個read()做好準備。這在下面這個簡單文件複製程式中可以看到∶
// {Args: src/io/ChannelCopy.java test.txt}
public class ChannelCopy {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.out.println("arguments: sourcefile destfile");
System.exit(1);
}
FileChannel in = new FileInputStream(args[0]).getChannel(),
out = new FileOutputStream(args[1]).getChannel();
ByteBuffer buffer = ByteBuffer.allocate(BSIZE);
while(in.read(buffer) != -1) {
// 為寫做準備
buffer.flip();
out.write(buffer);
// 為讀做準備
buffer.clear();
}
}
}
可以看到,打開一個FileChannel以用於讀,而打開另一個以用於寫。ByteBuffer被分配了空間,當FileChannel.read(返回-1時(一個分界符,毋庸置疑,它源於Unix和C),表示我們已經到達了輸入的末尾。每次read()操作之後,就會將數據輸入到緩衝器中,flip()則是準備緩衝器以便它的資訊可以由write()提取。write()操作之後,資訊仍在緩衝器中,接著clear()操作則對所有的內部指針重新安排,以便緩衝器在另一個read()操作期間能夠做好接受數據的準備。
緩衝器的細節
如果想把一個位元組數組寫到文件中去,那麼就應該使用ByteBuffer.wrap()方法把位元組數組包裝起來,然後用getChannel()方法在FileOutputStream上打開一個通道,接著將來自於ByteBuffer的數據寫到FileChannel中。
注意∶ByteBuffer是將數據移進移出通道的唯一方式,並且我們只能創建一個獨立的基本類型緩衝器,或者使用「as」方法從ByteBuffer中獲得。也就是說,我們不能把基本類型的緩衝器轉換成ByteBuffer。然而,由於我們可以經由視圖緩衝器將基本類型數據移進移出ByteBuffer,所以這也就不是什麼真正的限制了。
Buffer由數據和可以高效地訪問及操縱這些數據的四個索引組成,這四個索引是∶mark (標記),position(位置),limit(界限)和capacity(容量)。下面是用於設置和複位索引以及查詢它們的值的方法。

壓縮
Java I/O類庫中的類支援讀寫壓縮格式的數據流。你可以用它們對其他的I/O類進行封裝,以提供壓縮功能。
這些類不是從Reader和Writer類派生而來的,而是屬於InputStream和OutputStream繼承層次結構的一部分。這樣做是因為壓縮類庫是按位元組式而不是字元方式處理的。不過有時我們可能會被迫要混合使用兩種類型的數據流(注意我們可以使用InputStreamReader和OutputStreamWriter 在兩種類型間方便地進行轉換)。

儘管存在許多種壓縮演算法,但是ZIP和GZIP可能是最常用的,因此我們可以很容易使用多種可讀寫這些格式的工具來操作我們的壓縮數據。
使用GZIP進行簡單壓縮
GZIP介面非常簡單,因此如果我們只想對單個數據流(而不是一系列互異數據)進行壓縮,那麼它可能是比較適合的選擇。下面是對單個文件進行壓縮的例子:
// {args: io/src/GZIPcompress.java}
public class GZIPcompress {
public static void main(String[] args) throws IOException {
if(args.length == 0) {
System.out.println(
"Usage: \nGZIPcompress file\n" +
"\tUses GZIP compression to compress " +
"the file to test.gz");
System.exit(1);
}
BufferedReader in = new BufferedReader(new FileReader(args[0]));
BufferedOutputStream out = new BufferedOutputStream(
new GZIPOutputStream(new FileOutputStream("test.gz")));
System.out.println("Writing file");
int c;
while((c = in.read()) != -1)
out.write(c);
in.close();
out.close();
System.out.println("Reading file");
BufferedReader in2 = new BufferedReader(
new InputStreamReader(new GZIPInputStream(
new FileInputStream("test.gz"))));
String s;
while((s = in2.readLine()) != null)
System.out.println(s);
}
}
壓縮類的使用非常直觀——直接將輸出流封裝成GZIPOutputStream或ZipOutputStream,並將輸入流封裝成GZIPInputStream或ZipInputStream即可。其他全部操作就是通常的I/O讀寫。這個例子把面向字元的流和面向位元組的流混合了起來;輸入(in)用Reader類,而GZIPOutputStream的構造器只能接受OutputStream對象,不能接受Writer對象。在打開文件時,GZIPImputStream就會被轉換成Reader。
使用Zip進行多文件保存
支援Zip格式的Java庫更加全面。利用該庫可以方便地保存多個文件,它甚至有一個獨立的類,使得讀取Zip文件更加方便。這個類庫使用的是標準Zip格式,所以能與當前那些可通過網際網路下載的壓縮工具很好地協作。下面這個例子具有與前例相同的形式,但它能根據需要來處理任意多個命令行參數。另外,它顯示了用Checksum類來計算和校驗文件的校驗和的方法。一共有兩種Checksum類型∶Adler32(它快一些)和CRC32(慢一些,但更準確)。
package io;
import java.io.*;
import java.util.Enumeration;
import java.util.zip.*;
/**
* @author Mr.Sun
* @date 2022年09月02日 11:21
*
* 使用zip進行多文件保存
* {args: src/io/ZipCompress.java}
*/
public class ZipCompress {
public static void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("test.zip");
CheckedOutputStream cos = new CheckedOutputStream(fos, new Adler32());
ZipOutputStream zos = new ZipOutputStream(cos);
BufferedOutputStream out = new BufferedOutputStream(zos);
// 只有setComment(),沒有getComment()
zos.setComment("A test of Java Zipping");
for(String arg : args) {
System.out.println("Writing file " + arg);
BufferedReader in = new BufferedReader(new FileReader(arg));
zos.putNextEntry(new ZipEntry(arg));
int c;
while((c = in.read()) != -1)
out.write(c);
in.close();
out.flush();
}
out.close();
// 校驗和僅在文件關閉後有效!
System.out.println("Checksum: " + cos.getChecksum().getValue());
// 現在提取文件
System.out.println("Reading file");
FileInputStream fi = new FileInputStream("test.zip");
CheckedInputStream cis = new CheckedInputStream(fi, new Adler32());
ZipInputStream in2 = new ZipInputStream(cis);
BufferedInputStream bis = new BufferedInputStream(in2);
ZipEntry ze;
while((ze = in2.getNextEntry()) != null) {
System.out.println("Reading file " + ze);
int x;
while((x = bis.read()) != -1) {
System.out.write(x);
}
}
if(args.length == 1) {
System.out.println("Checksum: " + cis.getChecksum().getValue());
}
bis.close();
// Alternative way to open and read Zip files:
ZipFile zf = new ZipFile("test.zip");
Enumeration e = zf.entries();
while(e.hasMoreElements()) {
ZipEntry ze2 = (ZipEntry)e.nextElement();
System.out.println("File: " + ze2);
}
}
}
對於每一個要加入壓縮檔案的文件,都必須調用putNextEntry(),並將其傳遞給一個ZipEntry對象。ZipEntry對象包含了一個功能很廣泛的介面,允許你獲取和設置Zip文件內該特定項上所有可利用的數據∶名字、壓縮的和未壓縮的文件大小、日期、CRC校驗和、額外欄位數據、注釋、壓縮方法以及它是否是一個目錄入口等等。然而,儘管Zip格式提供了設置密碼的方法,但Java的Zip類庫並不提供這方面的支援。雖然CheckedInputStream和CheckedOutputStream 都支援Adler32和CRC32兩種類型的校驗和,但是ZipEntry類只有一個支援CRC的介面。雖然這是一個底層Zip格式的限制,但卻限制了人們不能使用速度更快的Adler32。
為了能夠解壓縮文件,ZipInputStream提供了一個getNextEntry()方法返回下一個ZipEntry (如果存在的話)。解壓縮文件有一個更簡便的方法————利用ZipFile對象讀取文件。該對象有一個entries()方法用來向ZipEntries返回一個Enumeration(枚舉)。
為了讀取校驗和,必須擁有對與之相關聯的Checksum對象的訪問許可權。在這裡保留了指向CheckedOutputStream和CheckedInputStream對象的引用。但是,也可以只保留一個指向Checksum對象的引用。
Zip流中有一個令人困惑的方法setComment()。正如前面ZipCompress.java中所示,我們可以在寫文件時寫注釋,但卻沒有任何方法恢復ZipInputStream內的注釋。似乎只能通過ZipEntry,才能以逐條方式完全支援注釋的獲取。
當然,GZIP或Zip庫的使用並不僅僅局限於文件——它可以壓縮任何東西,包括需要通過網路發送的數據。
Java檔案文件
Zip格式也被應用於JAR(Java ARchive,Java檔案文件)文件格式中。這種文件格式就像Zip 一樣,可以將一組文件壓縮到單個壓縮文件中。同Java中其他任何東西一樣,JAR文件也是跨平台的,所以不必擔心跨平台的問題。聲音和影像文件可以像類文件一樣被包含在其中。
JAR文件非常有用,尤其是在涉及網際網路應用的時候。如果不採用JAR文件,Web瀏覽器在下載構成一個應用的所有文件時必須重複多次請求Web伺服器;而且所有這些文件都是未經壓縮的。如果將所有這些文件合併到一個JAR文件中,只需向遠程伺服器發出一次請求即可。同時,由於採用了壓縮技術,可以使傳輸時間更短。另外,出於安全的考慮,JAR文件中的每個條目都可以加上數字化簽名。
第十七章到第十八章的內容就在這裡告一段落了,其實關於I/O書中還介紹了有關進程式控制制、對象序列化和XML等相關詳細內容,想要了解更多關於Java I/O基礎知識的讀者建議查閱《Java編程思想》原書籍,雖然該書可能的確不適合入門的同學,但是對於有經驗的同學將它作為詞典來鞏固基礎知識還是有必要的。

