HOSMEL:一種面向中文的可熱插拔模組化實體鏈接工具包
HOSMEL: A Hot-Swappable Modularized Entity Linking Toolkit for Chinese
ACL 2022
論文地址://aclanthology.org/2022.acl-demo.21.pdf
程式碼地址://github.com/THUDM/HOSMEL
動機
我們需要標註一個新數據集,比如將關係作為問題回答的附加特性的數據集,並在新數據集上重新訓練EL模型。這種標註和模型重新訓練是非常昂貴和低效的,這就提出了一個自然的問題:我們能否開發一種有效的EL工具,可以很容易地適應下游任務?
所提出方法的特性
-
低耦合的模組。我們將提及過濾、提及檢測和實體消歧按實體的每個屬性模組化,保證每個模組可以單獨訓練和自由組合。
-
增量開發。這種解耦設計將每個步驟的模組變成一個可熱插拔模組,可以在不重新訓練整個模型的情況下靈活地添加之前沒有考慮的新特性。
-
使用靈活(三種使用模式)。我們開發了相應的中文EL工具包。為了靈活使用,我們發布了三種使用方法。第一個是直接調用API或訪問web應用程式的現成版本。第二個版本是部分版本,用於那些希望包含部分版本作為改進模型召回的前步驟的用戶。第三個版本是一個易於更改的版本,支援添加額外的特性或使用自定義數據進行訓練。
-
流可視化。解耦設計還提供了一種更易於解釋的方式來可視化每個模組的結果,這為用戶工程師提供了一種更輕鬆的體驗,以決定用於優化最佳結果的有用功能。
該方法的優勢
- 與SOTA模型相比,輕量級的HOSMEL訓練時間減少4-5倍。與EntQA相比,存儲佔用率降低了78%。
- 與EntQA相比,用更少的數據量可以訓練出更好的模型。
- 我們另外評估了HOSMEL的熱插拔能力,發現當添加新的特徵關係時,HOSMEL可以快速更新,並進一步提高3.71-5.02%的準確率。
具體介紹
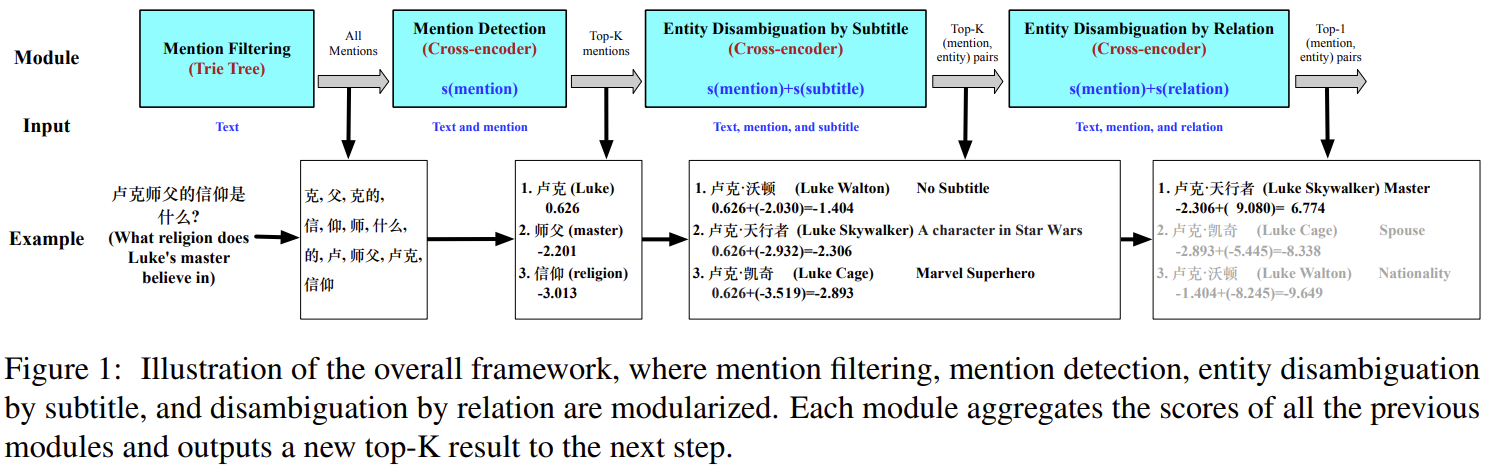
該方法具體可以分為四個部分組成:提及過濾、提及檢測、通過小標題實體消岐、通過關係實體消岐。
提及過濾
通過使用字典樹來獲得所有可能的提及(這些提及是通過使用的標題和別名進行收集)。對於提及內容與實體名稱或別名不完全相同的數據集,用戶可以將此Trie樹更改為其他更合適的方法,如bi-encoder(Zhang et al., 2021c)。
提及檢測
提及檢測從上一步返回的所有可能提及中確定最重要的提及數。將文本d和分別和每一個提及m進行拼接:\(d;[SEP]m_{i}\),然後輸入到MacBert中,然後對模型輸出的CLS向量執行MLP(多層感知機)操作,最終使用概率的對數作為實體的分數,並輸出top-k個提及及分數傳遞給下一步。
實體消岐
根據屬性進行消岐
實體消除歧義是為檢測到的提及從知識庫中尋找正確的實體。為了消除實體候選的歧義,我們以相同的方式將輸入文本和提及與每種類型的屬性獨立匹配。例如,對於一個給定的文本d,提及\(m_{i}\),屬性類型t,我們首先拼接得到:\(d;[SEP];m_{i};a_{ij}^{t}\)(\(a_{ij}^{t}\)表示類型t的第j個屬性),然後將其拼接輸入到MacBert中。同樣CLS後接一個MLP。最終對於給定的文本d和第i個提及\(m_{i}\),我們可以得到屬性\(a_{ij}^{t}\)的概率。我們對概率取對數,並從所有的屬性中取最大的分數。這裡不好理解,舉個例子:
文本:盧克師⽗的信仰是什麼?
提及過濾:
輸入:盧克師⽗的信仰是什麼?
中間層:Trie字典樹
輸出:克, ⽗, 克的, 信, 仰, 師, 什麼, 的, 盧, 師⽗, 盧克, 信仰
提及檢測:
輸入:(前面都加了一個是)
[CLS]盧克師⽗的信仰是什麼?[SEP]是盧克[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]是盧[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]是克的[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]是的[SEP]
標籤:0
中間層:MacBert-取出CLS-MLP-獲得概率對數
輸出:盧克
屬性實體消岐:
輸入:
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克是A character in Star Wars[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克是Marvel Superhero[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克是xxx[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克是xxxx[SEP]
標籤:0
中間層:MacBert-取出CLS-MLP-獲得概率對數
輸出:盧克.天行者
我們返回top-K排名(提到,實體)對到下一步。(注意到訓練策略中描述的是實例需要包括輸入文本和四個候選提及,其中一個被標記為ground truth)
根據關係進行消岐
這裡論文應該漏了這一部分。和屬性實體消岐其實差不多。舉個例子:
關係實體消岐:
輸入:
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克的是師父[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克的是x[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克的是xx[SEP]
[CLS]盧克師⽗的信仰是什麼?[SEP]盧克的是xxx[SEP]
標籤:0
中間層:MacBert-取出CLS-MLP-獲得概率對數
輸出:盧克.天行者
需要注意,分數是累加的。
這裡看下數據處理程式碼:
# coding=utf-8
from pprint import pprint
#
example = {
"sentence": "《白蛇》中的女性舞蹈家孫麗坤因編演舞劇《白蛇傳》傾倒眾生,也因其出色的才貌與風流人生在「文化大革命」中獲罪,由「天上人間」自由來去的「白娘子」淪落為連上廁所都被嚴格看守的階下囚,成為眾人唾棄的「反革命美女蛇」,落難後的孫麗坤與一個從小就迷戀她的「假小子」舞迷徐群珊在窗內與窗外的偶遇,引發了一段特殊歷史時期愛恨糾葛的傳奇故事",
"mention": "", "target0": "一個", "target1": "遇", "target2": "戀她", "target3": "白蛇",
"Label": 3}
# example = {"sentence":"《angel kiss》是一款ios系統手機遊戲,操作簡單,卡牌豐富","mention":"angel","target0":"Leona Lewis的歌曲","target1":"著名企業企宣","target2":"Sarah McLachlan歌曲","target3":"天使之吻—— IOS遊戲","Label":3}
# exmaple = {"sentence": "馮慧專業是什麼方向?", "Label": 0, "mention": "馮慧的", "target0": "專業方向", "target1": "出生日期", "target2": "職稱", "target3": "中文名"}
first_sentences = [example["sentence"]]*4
question_header = example["mention"]+"是"
ending_names = ["target0","target1","target2","target3"]
second_sentences = [question_header+example[end] for end in ending_names]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('xxx', use_fast=True)
tokenized = tokenizer(first_sentences,second_sentences,truncation=True,max_length=128)
tokenized['label'] = example['label']
pprint(tokenized)
訓練策略
訓練數據按照多項選擇題答案的設定進行組織。
- 用於訓練提及檢測模型的數據實例需要包括輸入文本和四個候選提及,其中一個被標記為ground truth。
- 而通過副標題等屬性訓練實體消歧模型時,需要包括輸入文本、要鏈接的內容以及四個帶有ground truth標籤的候選副標題。
- 針對於關係的實體消岐呢?論文里沒有介紹,估計和屬性的實體消岐構建方法類似。
使用方法
- 隨時可用的版本:是適用於需要將輸入文本鏈接至一般中文開放域知識庫的用戶

- 在線演示:對於這個準備使用的版本,我們還提供了一個實時演示來觀察管道中每個步驟的輸出,包括提及過濾、提及檢測、通過副標題消除實體歧義,以及通過關係消除歧義。此外,它還提供了可點擊的鏈接,以進一步觀察實體XLore。這對於喜歡可視化前端網頁的用戶來說是很有用的。

- 部分版本:部分版本是為那些有興趣在他們的下游模型中完成EL流程的用戶準備的,或者使用我們的部分版本來從XLore中檢索實體候選版本,而不是整個版本。在這個場景中,我們公開了每個管道步驟,供用戶根據他們的需要確定在哪裡停止。例如,如果用戶只想使用提及過濾、提及檢測和通過字幕消除歧義,他們可以使用以下腳本:

- 容易改變版本:正如我們在圖2中所說明的那樣,使用實體關係等特定特性可能有利於下游任務的EL。我們為有這種需求的用戶提供了一個訓練腳本和一個示例模型使用實現。為了添加新的特徵,HOSMEL要求用戶:(1)將他們的訓練數據格式化為我們的格式,(2)複製樣本關係用法,並在其中重寫generatePair方法來檢索所需的特徵。如果用戶喜歡將XLore更改為其他KBs,他們只需要重建Trie樹。更多的使用細節請查看開源的程式碼和README文檔。
實驗結果
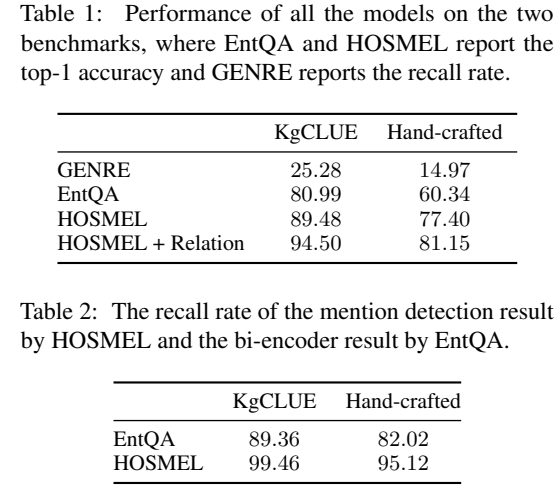
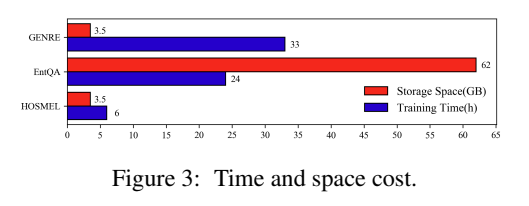
可能有部分理解有錯誤,具體細節還是去看看源程式碼。



