數據科學手把手:碳中和下的二氧化碳排放分析 ⛵

💡 作者:韓信子@ShowMeAI
📘 數據分析實戰系列://www.showmeai.tech/tutorials/40
📘 本文地址://www.showmeai.tech/article-detail/322
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容
ShowMeAI在本篇內容中整理了一個數據科學學習的基本項目,我們會分析世界各地的二氧化碳排放量,我們可以看到二氧化碳排放的主要國家以及導致二氧化碳排放的不同來源。這也是『碳中和』大環境下大家關心的主題之一。

大家可以使用本地的jupyter notebook來運行我們下述程式碼,也可以使用 Google Colab 或 Kaggle notebook來運行。本項目使用的 🏆owid co2 data數據集,大家可以通過ShowMeAI的百度網盤下載獲取。
🏆 實戰數據集下載(百度網盤):公眾號『ShowMeAI研究中心』回復『實戰』,或者點擊 這裡 獲取本文 [23]碳中和背景下的二氧化碳排放數據分析 『owid co2 data數據集』
⭐ ShowMeAI官方GitHub://github.com/ShowMeAI-Hub
💡 數據處理

數據分析處理涉及的工具和技能,歡迎大家查閱ShowMeAI對應的教程和工具速查表,快學快用。
首先,我們將導入庫:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
讀取數據:
dataset = pd.read_csv('owid-co2-data.csv')
查看數據:
有兩個核心的函數可以幫助我們查看數據基本形態:
dataset.head() :顯示數據集的前5行。 如果您想查看更多行,調整括弧中數字即可。例如dataset.head(10)查看前10行
dataset.shape :顯示數據集的行數和列數
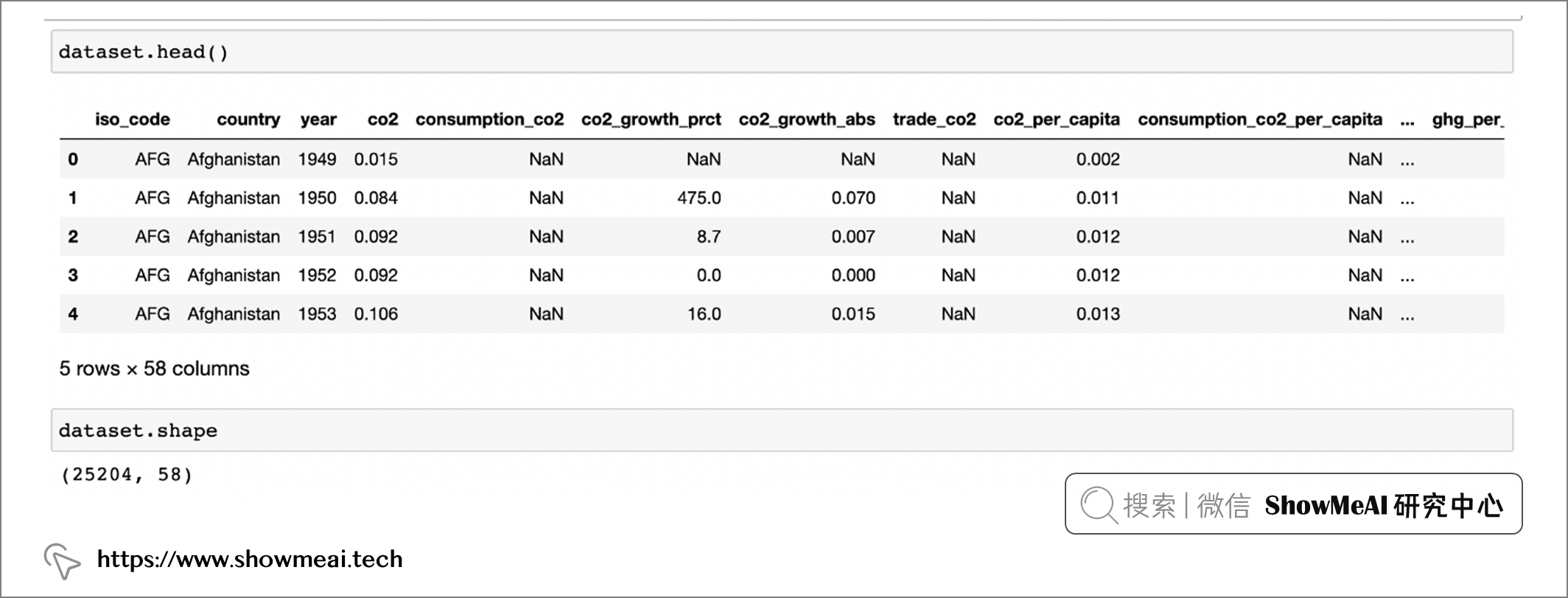
我們本次分析的數據集有 25204 行和 58 列。
刪除列:
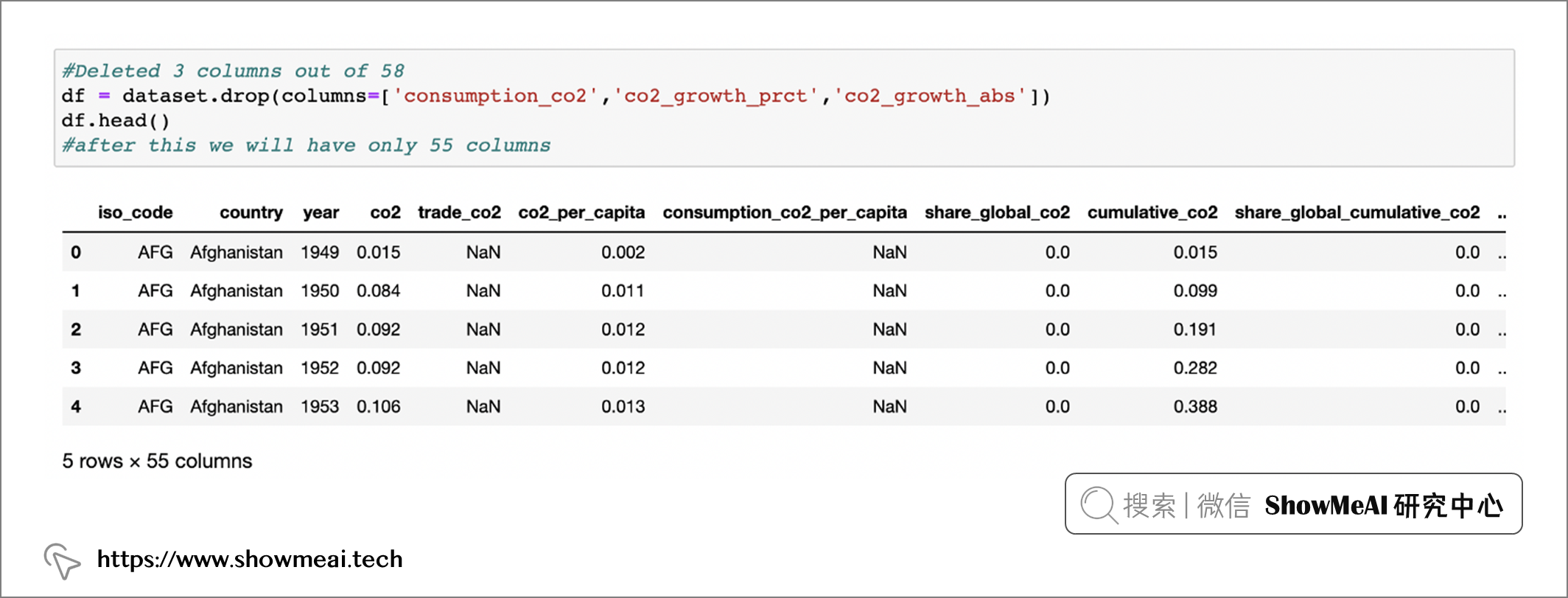
我們可以做一些數據處理,比如刪除一些數據分析中不適用的欄位/列。
df = dataset.drop(columns=[ 'consumption co2','co2 growth _prect','co2 growth_abs' ])
df.head()
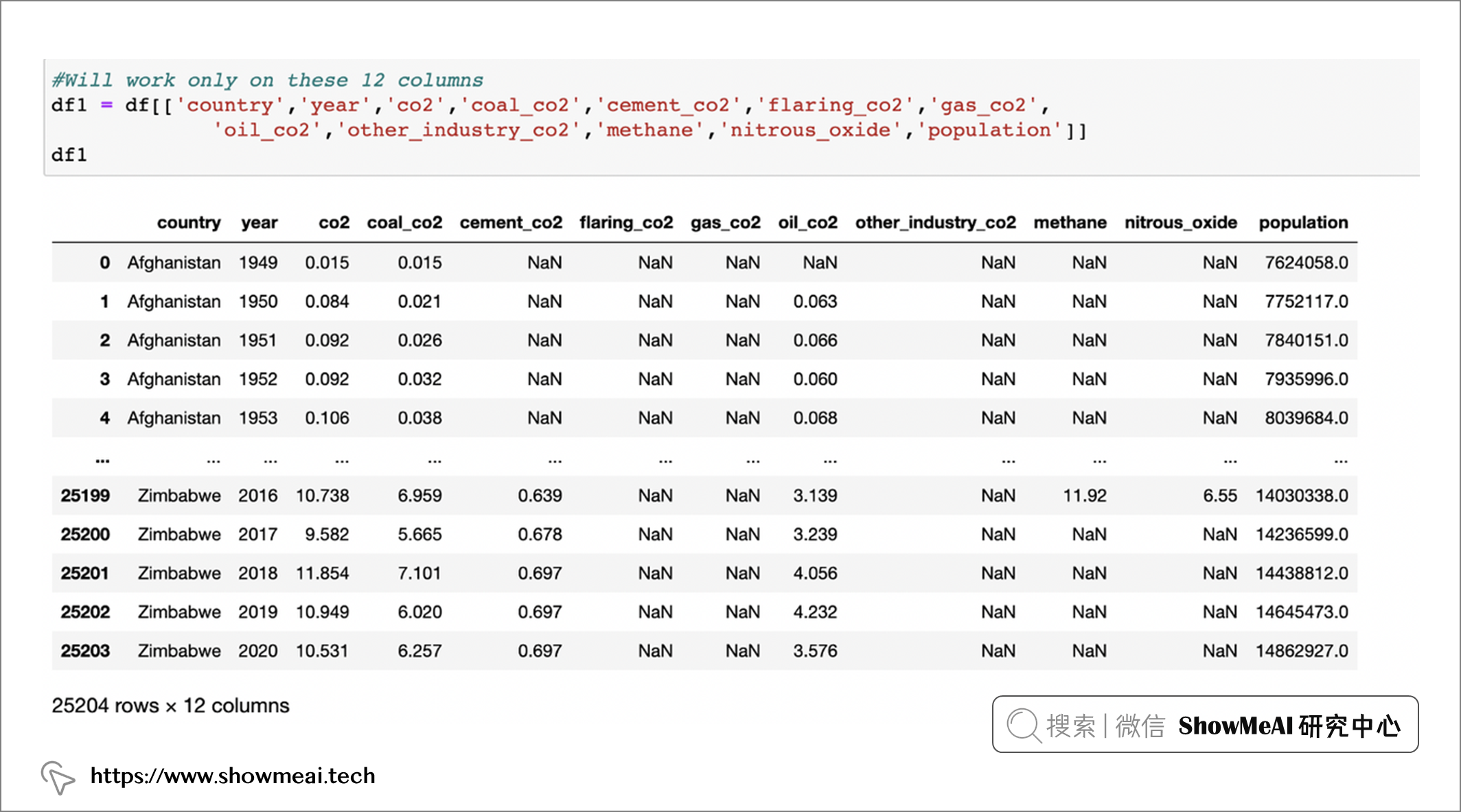
熟悉pandas的同學也知道,我們也可以直接通過欄位名選擇需要分析的欄位,如下程式碼所示:
df1 = df[['country', 'year','co2','coal_co2','cement _co2', 'flaring_co2','gas_co2','oil _co2', 'other industry co2','methane', 'nitrous_oxide', 'population' ]]
df1
我們可以通過pandas的條件選擇來選取數據子集:
final df = df1[df1['year' ]>1995]
final df
可以通過isin等函數來框定類別型欄位的取值,例如下述程式碼:
final_df = final_df[(final_df['country'].isin(['United States', 'Africa', 'Antartica','South Korea', 'Bangladesh', 'Canada', 'Germany', 'Brazil', 'Argentina','Japan', 'India', 'United Kingdom', 'Saudi Arabia', 'China', 'Australia','Russia']) & (final_df['co2'] > 0))]
final_df
檢查缺失值:
final_df.isnull().sum()
💡 數據分析&可視化
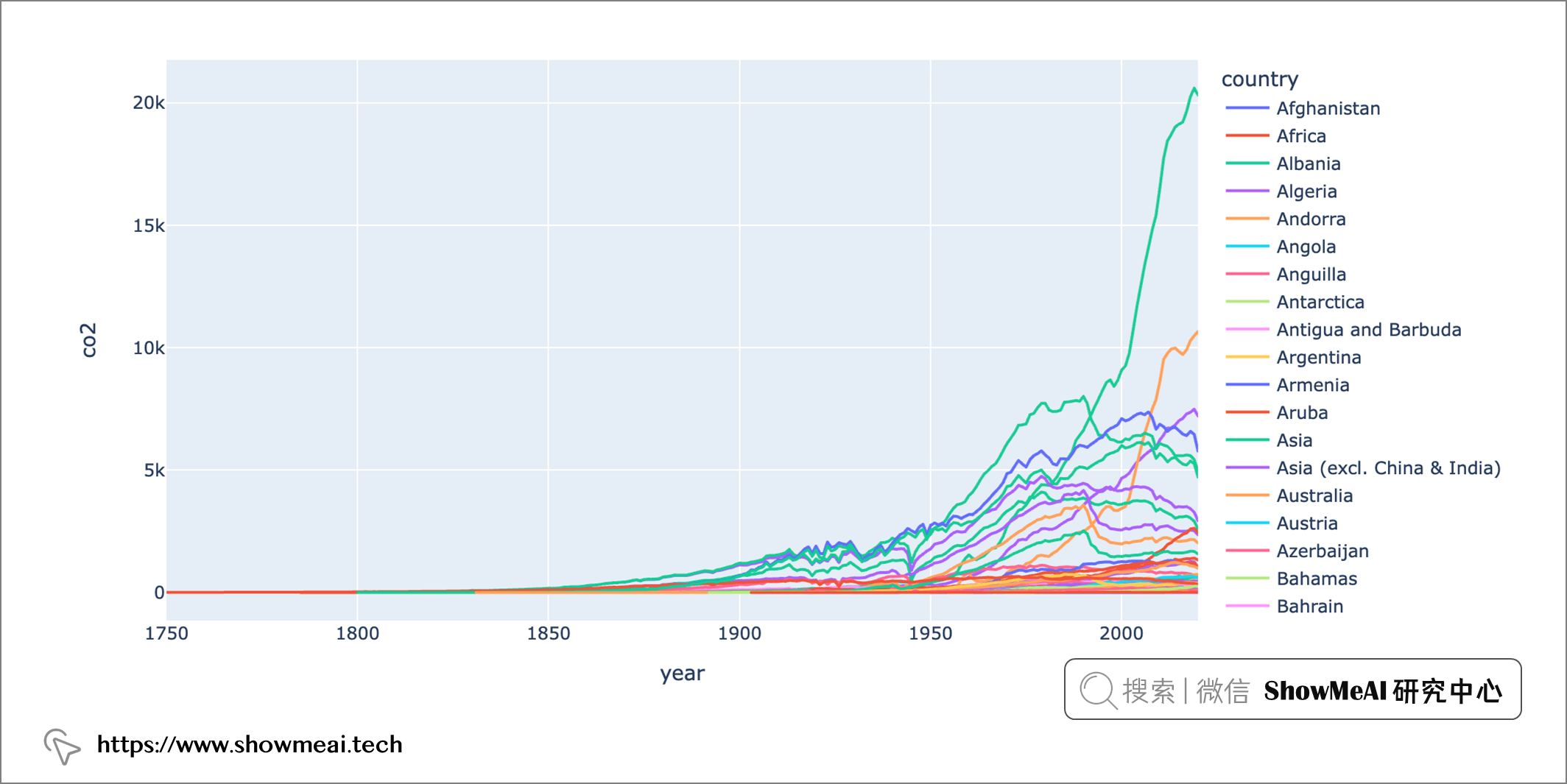
我們將根據我們的數據集繪製圖表並分析一些結果。 我們繪製一下隨時間線的co2排放趨勢圖:
px.line(dataset, x = 'year', y = 'co2', color='country')
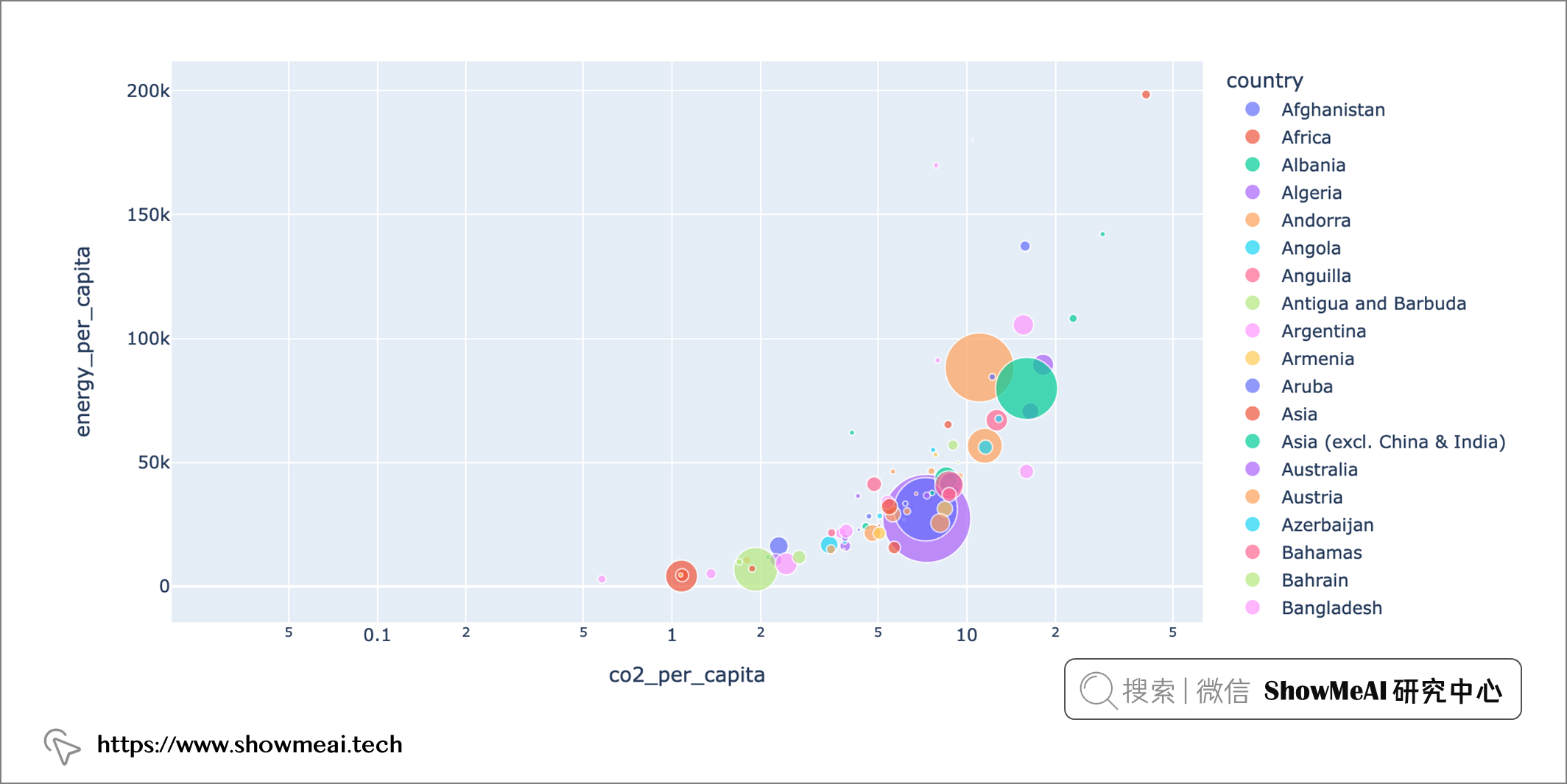
我們按照co2排放量為大小繪製散點圖,如下
px.scatter(dataset[dataset['year']==2019], x="co2_per_capita", y="energy_per_capita", size="co2", color="country", hover_name="country", log_x=True, size_max=60)
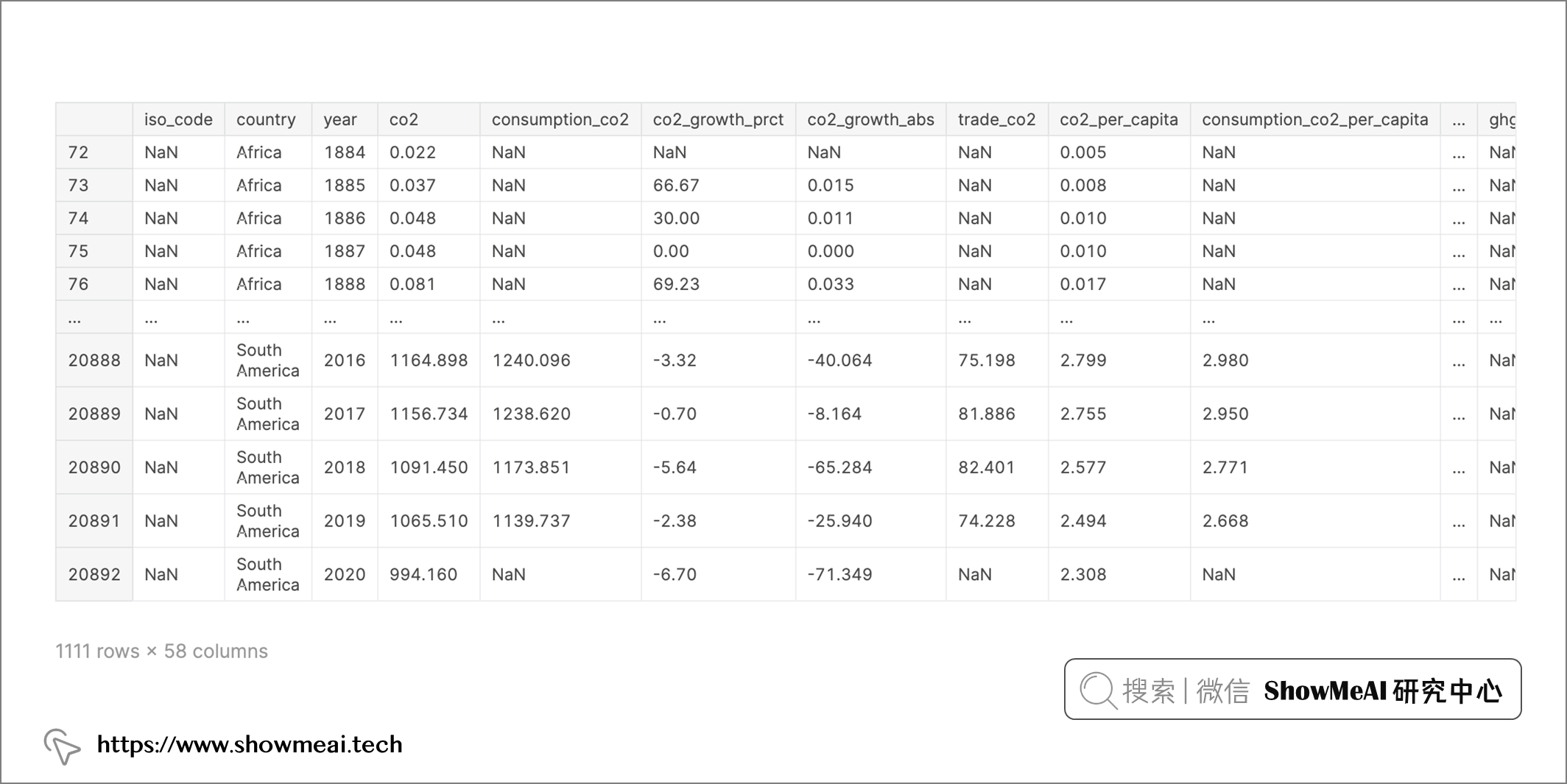
選出各大洲的數據
continent_data = dataset[(dataset['country'].isin(['Europe', 'Africa', 'North America', 'South America', 'Oceania', 'Asia'])) & (dataset['co2'] > 0)]
continent_data
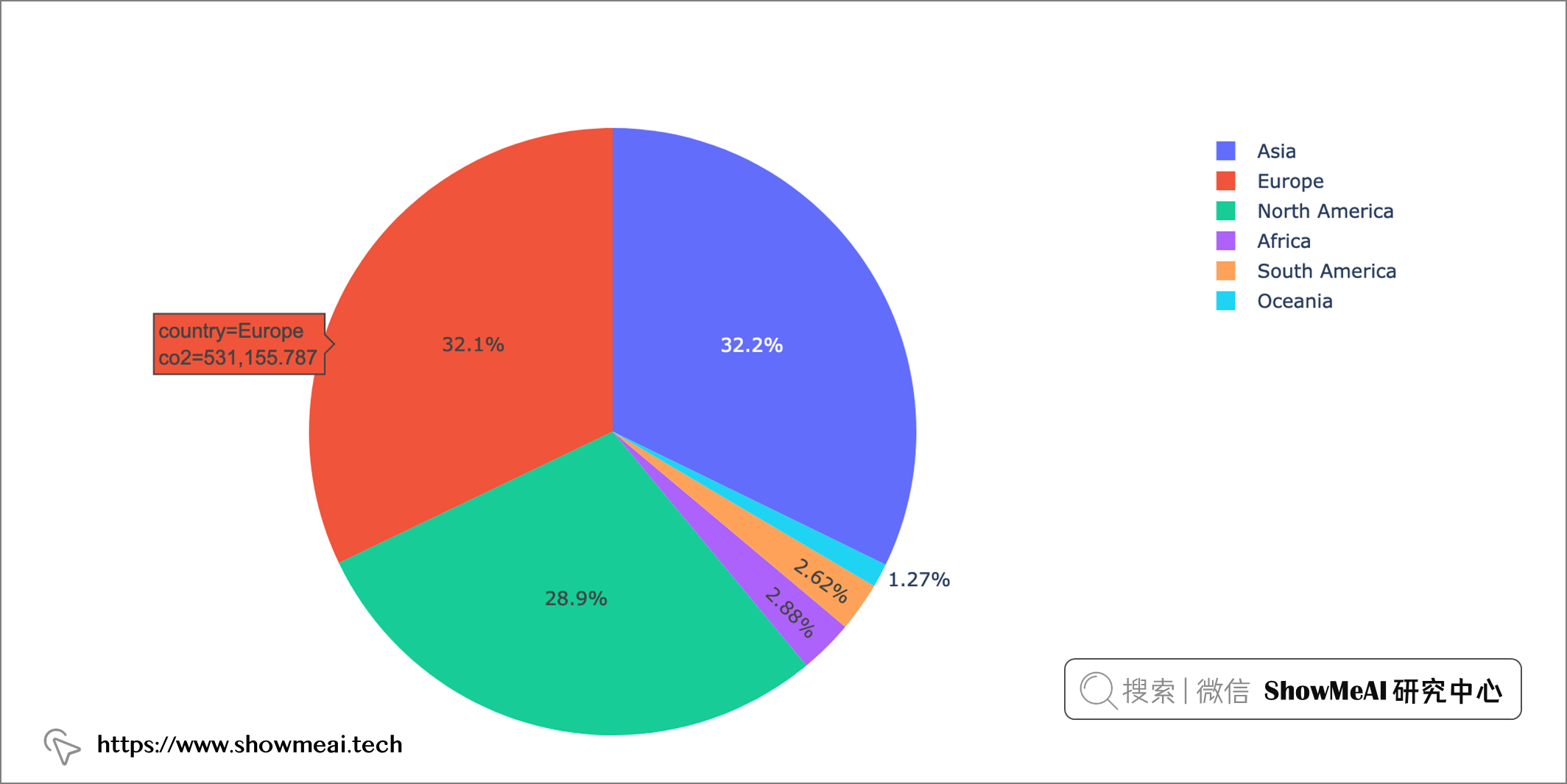
從各大洲來看的佔比情況如下
px.pie(continent_data, names='country', values='co2')
下面,我們將根據國家和 Co2 列繪製餅圖,看看哪些國家的 Co2 排放量最高。
px.pie(final_df, names='country', values='co2')
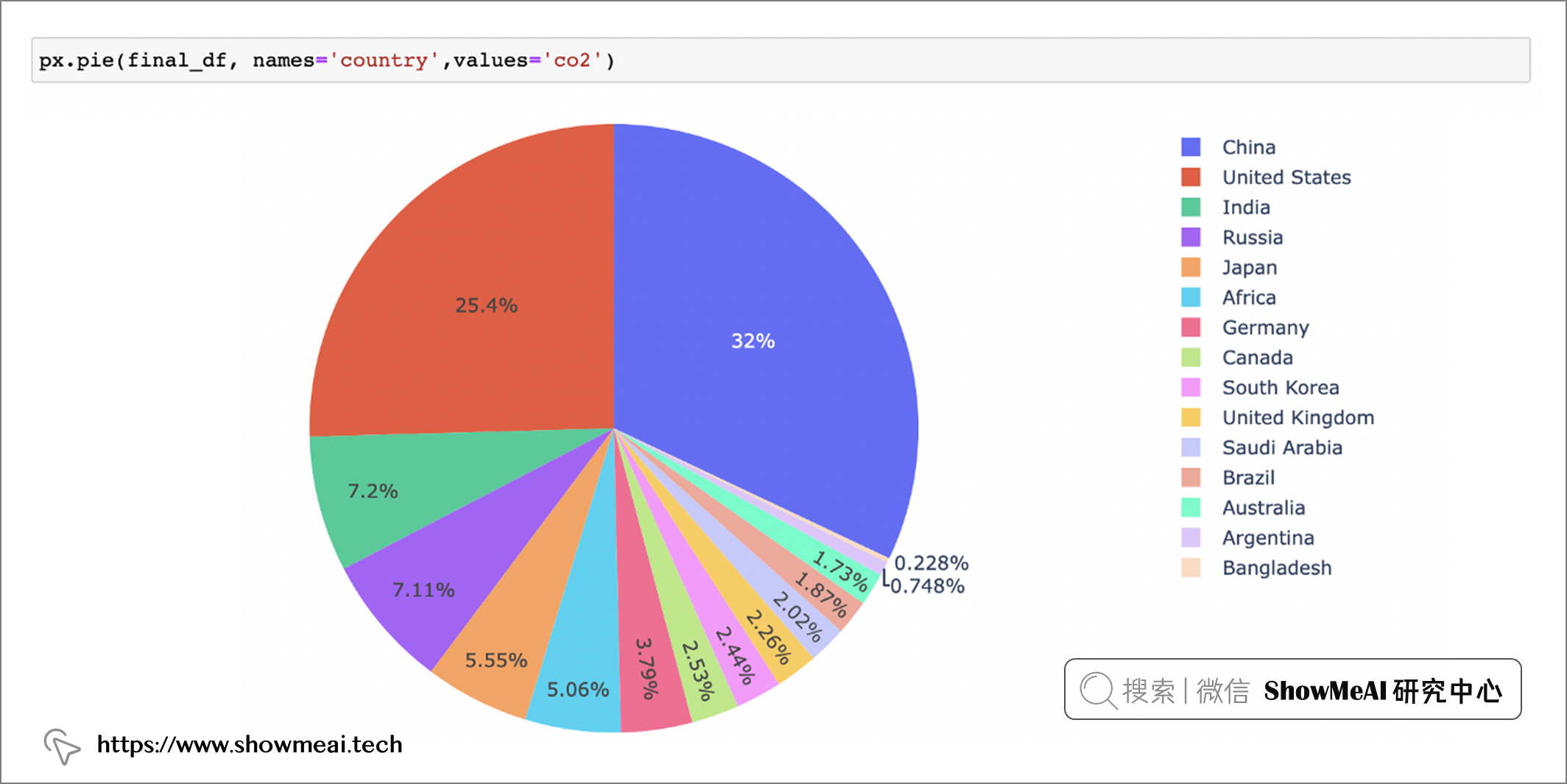
我們可以看到中國、美國、印度都是主要的co2排放大國。如果我們根據二氧化碳的來源進一步分析並僅看 2020 年,那麼我們將得到以下結果:
final df 2020 = final _df[(final_df[ 'year' ]==2020) ]
final df 2020
final df 2020[['country','coal_co2','cement_co2','flaring _co2','gas_co2', 'oil _co2','other_ industry co2']].plot(x='country', kind='bar',figsize=(9,5),width=0.9)
plt.title(『'2020 CO2 consumption')
plt.xlabel('Countries' )
plt.ylabel('CO2 measured in million tonnes')
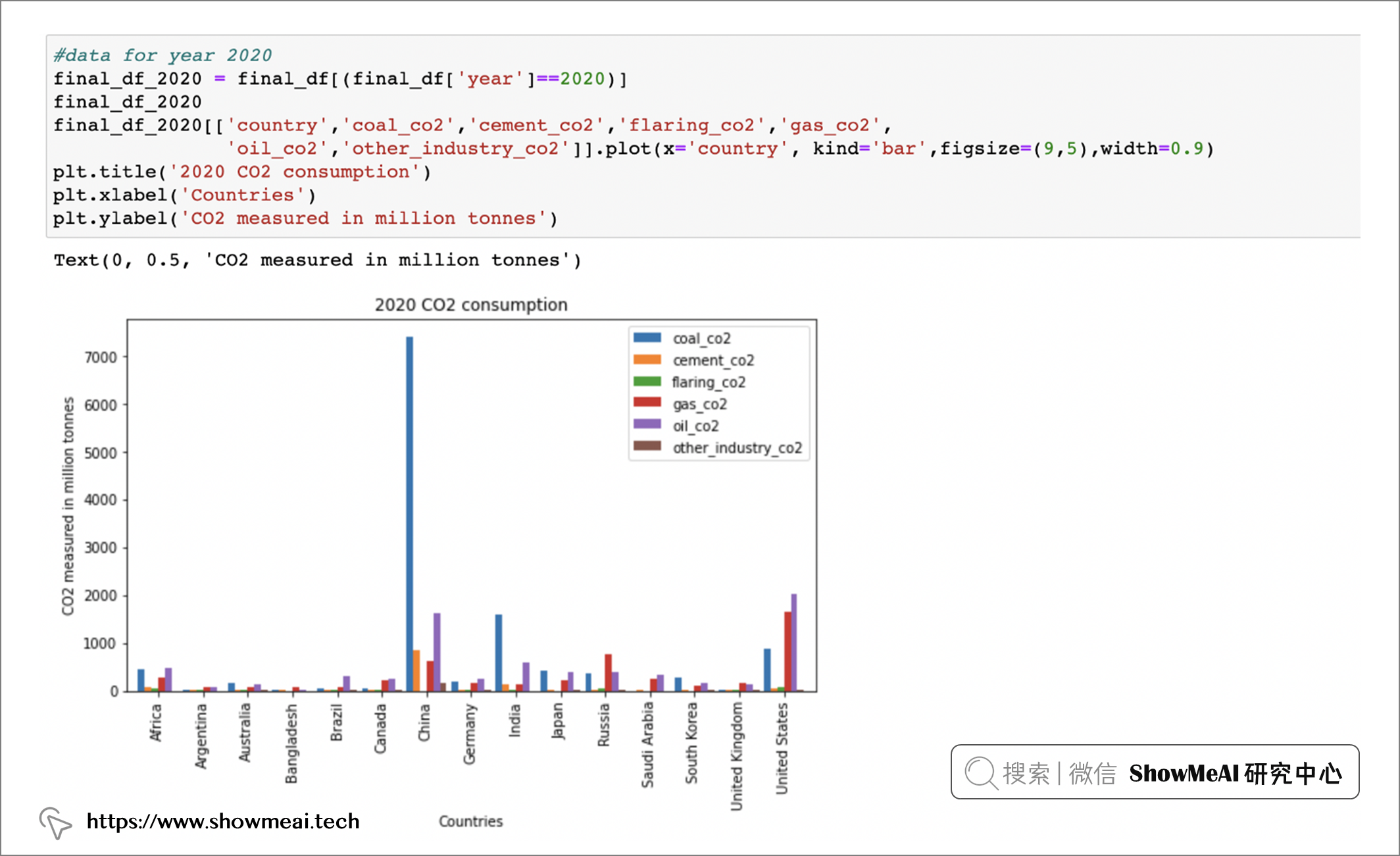
上面的結果中,我們可以看到,三個主要的 Co2 來源是 coal_co2、oil_co2 和 gas_co2。 我們針對這三個主要來源做一點繪圖分析,結果會更清晰:
final_df_2020[(['country','coal_co2','gas_co2','o0il_co2')].plot(x='country', kind='bar' ,figsize=(9,5),width=0.9)
plt.title('2020 CO2 consumption')
plt.xlabel('Countries')
plt.ylabel('CO2 measured in million tonnes')
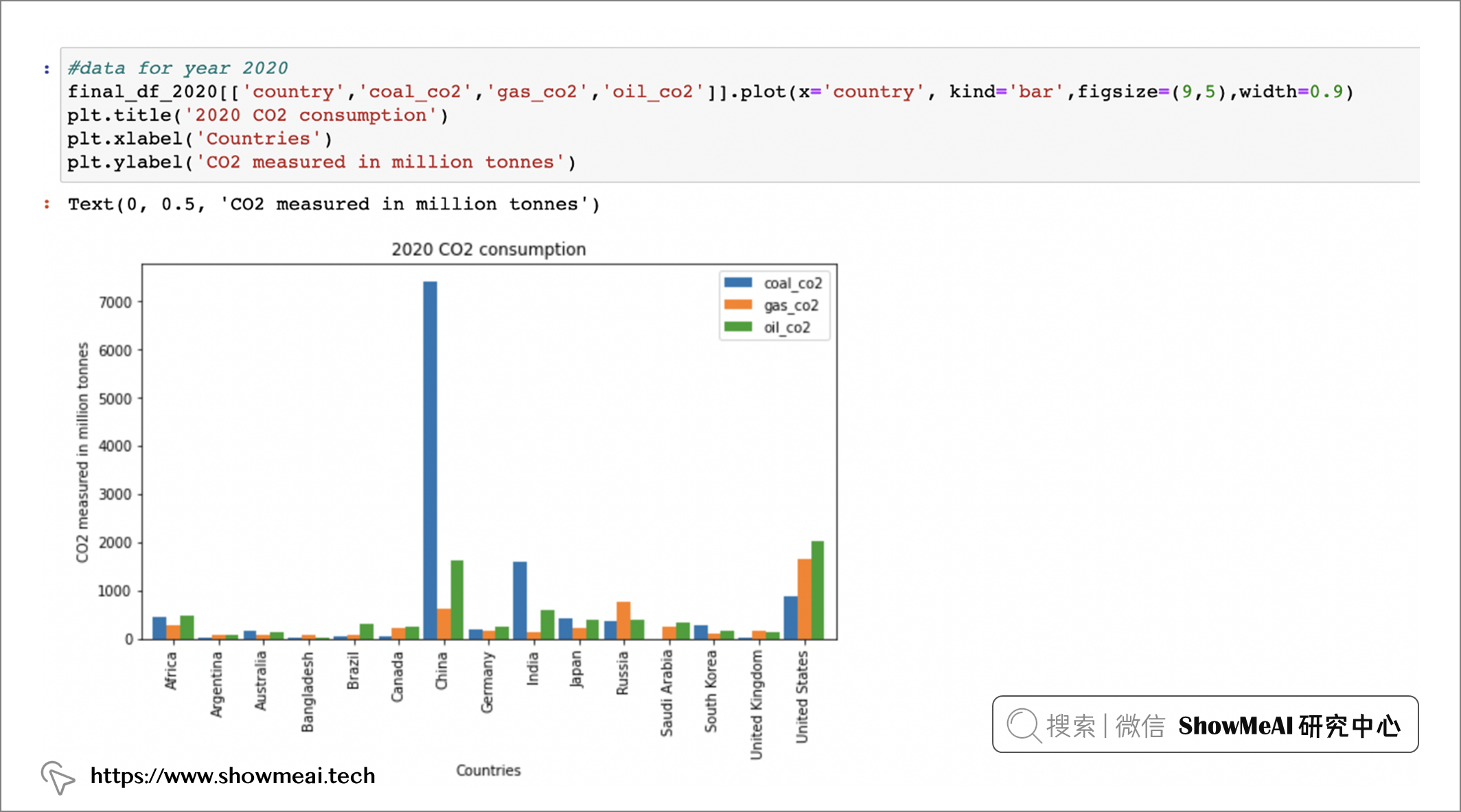
如果我們選定美國進行進一步分析:
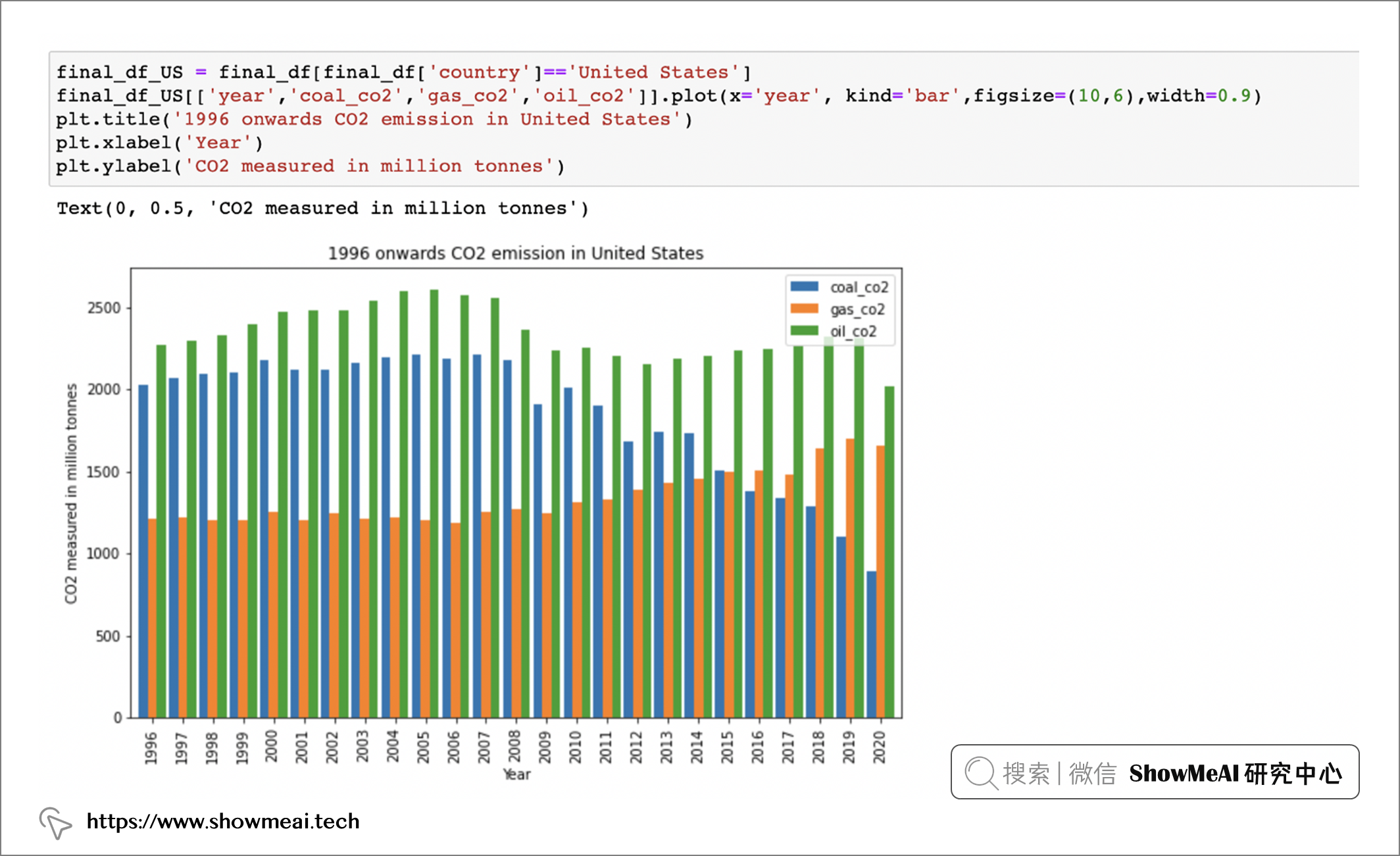
final_df_US = final_df[(final_df['country']=='United States']
final_df_US[['year','coal_co2','gas_co2','0il_co2']].plot(x='year', kind='bar',figsize=(10,6),width=0.9)
plt.title('1996 onwards CO2 emission in United States')
plt.xlabel('Year' )
plt.ylabel(『'CO2 measured in million tonnes')
圖例顯示,在美國,coal_co2 和 oil_co2 隨著時間的推移而減少,但 gas_co2 多年來一直在增加。
💡 總結
全球氣候是全世界都很關心的主題,本篇內容是 Co2 排放的一些簡單分析和可視化,大家可以基於上述數據與欄位做進一步分析。全球變暖是一個大問題,每個國家都在共同努力,營造更好的環境。
參考資料
- 📘 圖解數據分析:從入門到精通系列教程://www.showmeai.tech/tutorials/33
- 📘 數據科學工具庫速查表 | Pandas 速查表://www.showmeai.tech/article-detail/101
- 📘 數據科學工具庫速查表 | Seaborn 速查表://www.showmeai.tech/article-detail/105


