訂製化JDK升級引發的離奇事件
1、背景
由於Oracle對外宣稱Oracle JDK停止免費用於商用。公司法務部門評估之後擔心後續會惹上光司,於是就開始了JDK升級-將所有服務Oracle修改為OpenJDK。上周開始微服務JDK升級原本只不過是一個基礎組件的升級,由於沒有涉及業務程式碼的變更覺得問題不大。但怎麼也想不到開始升級之後便陸陸續續出現服務不斷重啟的異常想像。這到底是咋了?
2、問題暴露
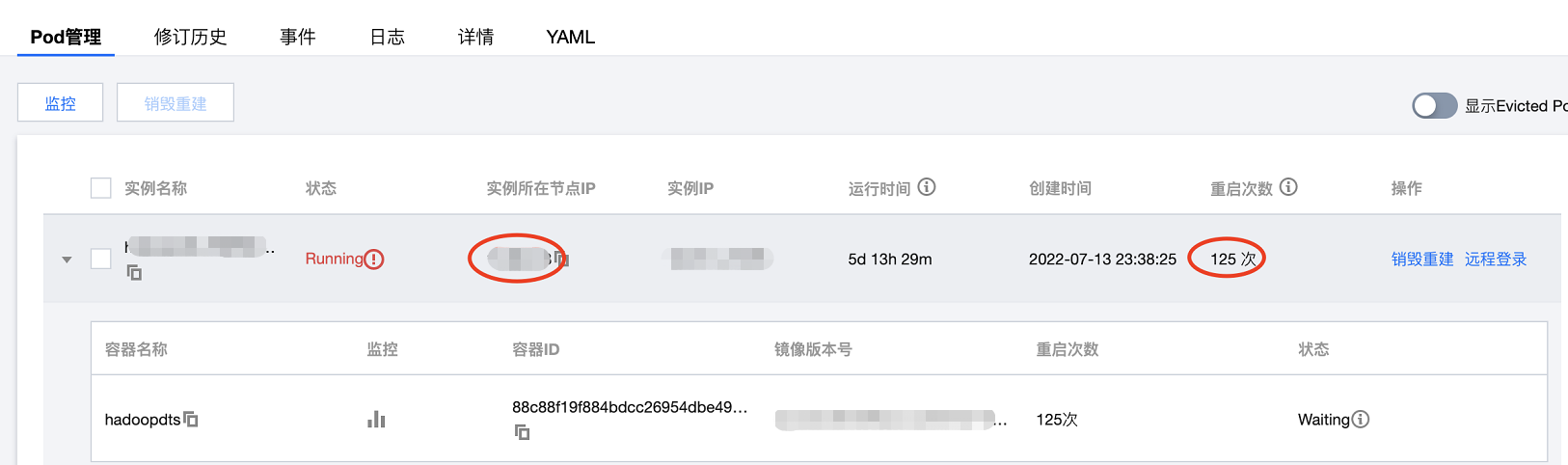
升級鏡像之後,java服務頻繁重啟,服務對外的介面處於半不可用狀態,具體表現為介面請求失敗率5-10%(該介面對應數據看板主要是內部人員使用,之所以沒有第一時間進行止損)
3、異常排查
本次升級除了更新基礎JDK鏡像,既沒有業務程式碼的變更也沒有修改配置,到底是什麼原因導致的呢?
帶著十分困惑的心情,我和團隊開啟了漫長的異常排查之旅。
1) 當時出現服務重啟,第一感覺是啟動耗時長導致探測介面超時超過一定閾值導致重啟。
於是在發生異常重啟的第1個小時內,我把探測超時由30s調大為60s,發現沒有效果,於是又調大到90s, 可惜還是不奏效,服務還是出現一直重啟的想像。
2)接下來是懷疑pod所在的宿主機會不會是記憶體不足導致的呢?於是登陸宿主機查看記憶體
$ free -m

總記憶體128g, 可用記憶體有60g以上,宿主機的物理記憶體是足夠的。
3)主機記憶體也是正常的,不知道JVM的監控是否有明顯的異常提示呢?
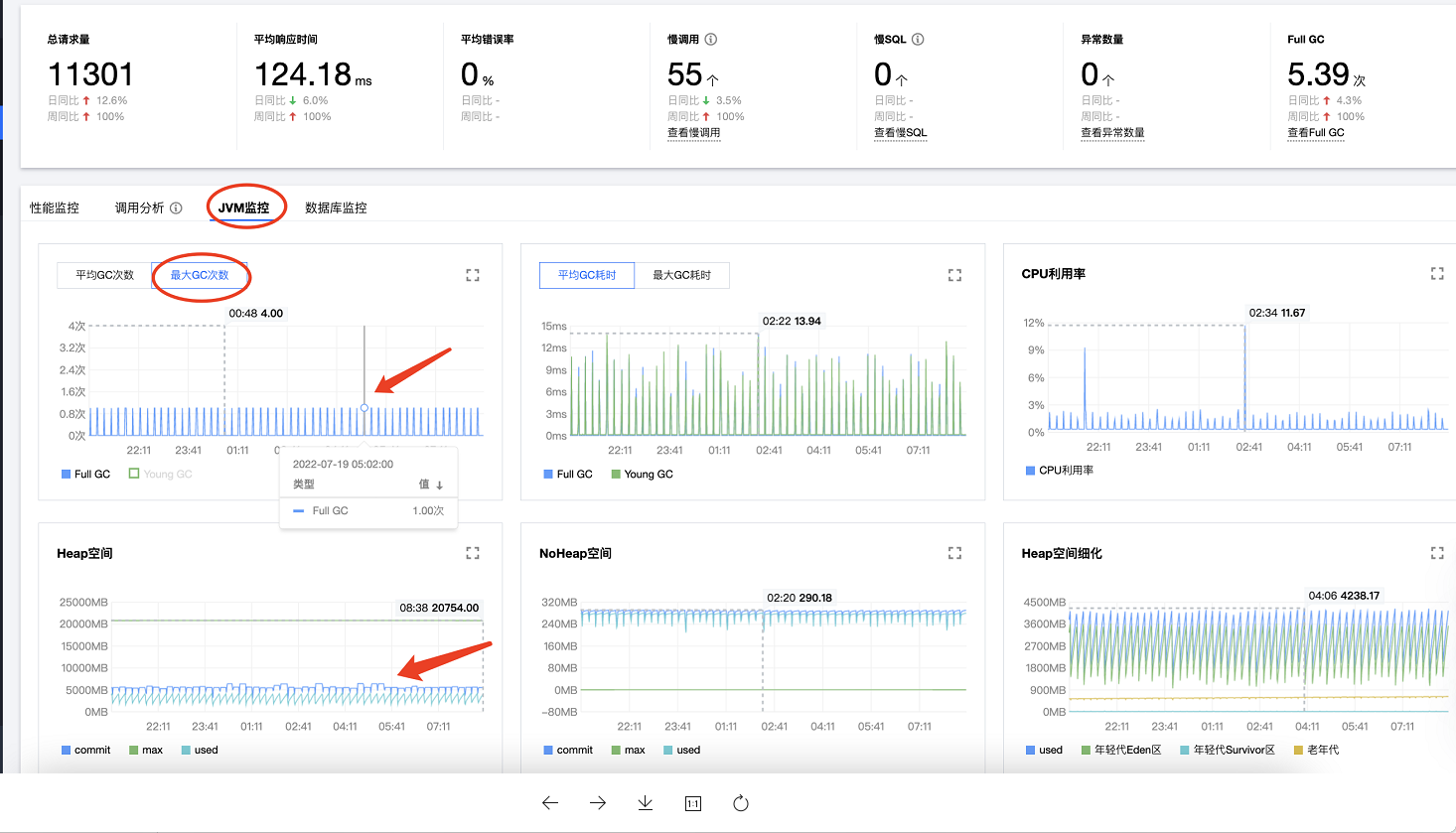
到這個時候,距離升級已經過去2小時了。於是打開業務jvm的heap和gc次數監控看板,發現full gc還是比較規律的,沒有明細的異常資訊。
此時距離升級已經過去將近3小時了。實在找不到任何頭緒了,難道只能回滾了嗎?
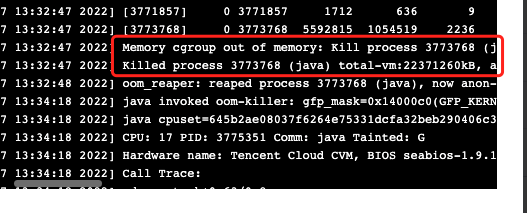
4)最後的最後,我們想到檢查系統級別日誌看看是否有異常提示,結果終於發現OOM的錯誤日誌。
dmesg -T
結論:
到這裡問題已經比較明顯了,pod內部的Java服務異常申請記憶體超過記憶體上限(該pod配置的的記憶體limit值是4g)觸發了系統的killer保護進程將pod進程kill掉。
4、根因定位
雖然定位到是OOM原因導致的,但是為什麼升級了JDK就導致OOM呢?
經過jinfo命令查看JVM啟動參數終於發現根本原因。原來服務反覆OOM被kill掉是因為「-XX:MaxHeapSize」參數失效導致Java進程使用默認值32g(物理機的1/4)超出了pod分配的limit上限8g。那為什麼「-XX:MaxHeapSize」參數失效呢?那是因為新鏡像給JAVA_OPS進行默認賦值,覆蓋了之前啟動參數JAVA_OPS的值。想要解決這個問題,需要取消OpenJDK鏡像對於JAVA_OPS的默認賦值。
jinfo -flags 1


再次確認MaxHeapSize的默認值,通過執行以下命令可以看到MaxHeapSize默認值確實是系統總記憶體的1/4。
java -XX:+PrintFlagsFinal -version | grep MaxHeapSize
5、總結復盤
結合本次發布引起的異常做一次復盤,主要包含問題發生和修復完成的時間點以及故障原因分析與優化措施。見如下表格:


