HDFS的讀寫流程——宏觀與微觀
HDFS的讀寫流程——宏觀與微觀
HDFS:分散式文件系統,負責存放數據
分散式文件系統:就是將我們的數據放到多台電腦上存儲。
寫數據:就是將客戶端上的數據上傳到HDFS
宏觀過程
-
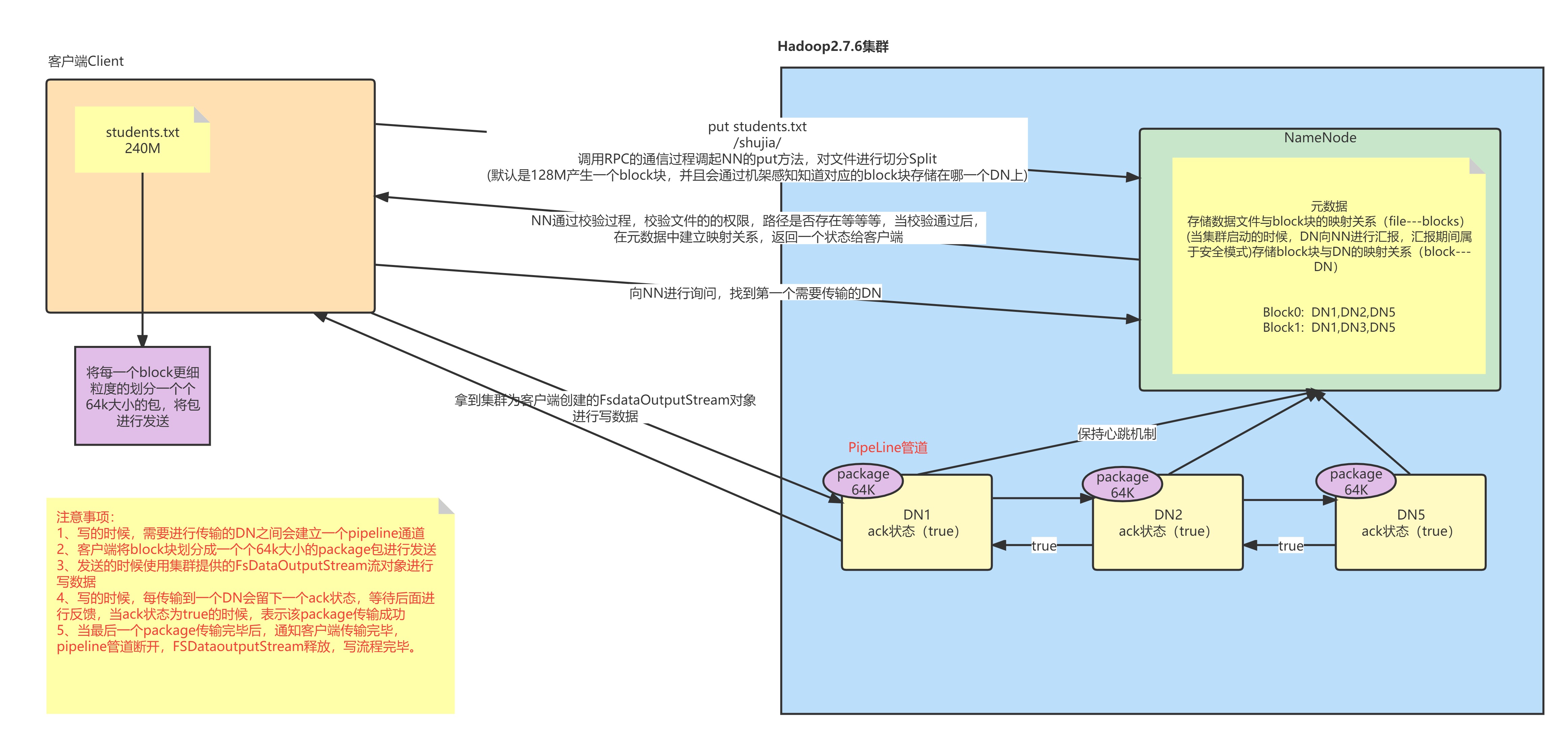
客戶端向HDFS發送讀寫數據請求
hdfs dfs -put student.txt /shujia/ 客戶端發送命令將student.txt文件上傳到/shujia/目錄下 -
Filesystem通過rpc調用namenode的put方法
- NN(NameNode)首先檢查是否有足夠的空間許可權等條件來創建這個文件,或者這個路徑是否已經存在,有許可權會針對這個文件創建一個空的Entry對象,並提示返回成功狀態給DFS。沒有許可權會直接拋出對應的異常,給與客戶端錯誤提示資訊
-
如果DFS接收到成功的狀態,會創建一個FSDataOutputStream的對象給客戶端使用
-
客戶端要向NN詢問第一個Block塊存放的位置(通過機架感知策略)
-
需要將客戶端與DN(DataNode)節點通過管道(pipeline)的方式建立連接,DN節點之間也是通過這種方式連接
-
客戶端會按照塊對文件進行切分,但是按照packet的方式來發送數據。默認一個packet的大小是64K,一個塊128M就有2048個packet
-
客戶端通過pipeline管道使用FDSOutputStream對象將數據輸出
- 客戶端首先將一個packet包發送給node1,同時給予node1一個ack狀態
- node1接收數據後會將數據繼續傳遞給node2,同時給與node2一個ack狀態
- 同理,node2會傳給node3,同時給node3一個ack狀態
- node3將這個packet接收完成後會響應這個ack狀態,給node2說我的狀態為true。
- node2會響應node1,node2的ack狀態為true。
- node1會響應客戶端,node1的ack狀態為true
-
如果客戶端接收到成功的狀態,說明這個packet發送成功了。客戶端會一直發送,直到當前塊的所有packet發完。
-
如果客戶端接收到最後一個packet的成功狀態,說明當前block塊傳輸完成,管道就會撤銷,客戶端會將這個傳遞完成的消息給NN,然後詢問NN第二個塊的存放位置,依次類推。
-
當所有的block塊傳輸完成後,NN在Entry中存儲的所有File與Block與DN的映射關係都會關閉。
注意:客戶端與要存放block塊的DN節點進行連接,然後DN與它的副本節點建立管道連接。DataNode中的節點是可以相互通訊的,也就是說客戶端在DN1上保存block0,然後在DN4、DN6上保存這個塊的副本。那麼管道連接就是 客戶端–>DN1–>DN4–>DN6(雙向箭頭,這裡打不出來)
流程圖
微觀過程
在說微觀過程之前我們要考慮兩個問題:一是客戶端怎麼知道packet傳輸完畢的,二是如果在傳輸過程中packet丟了,例如斷電怎麼辦。
那麼如何保證packet發送的工程中不出錯呢
-
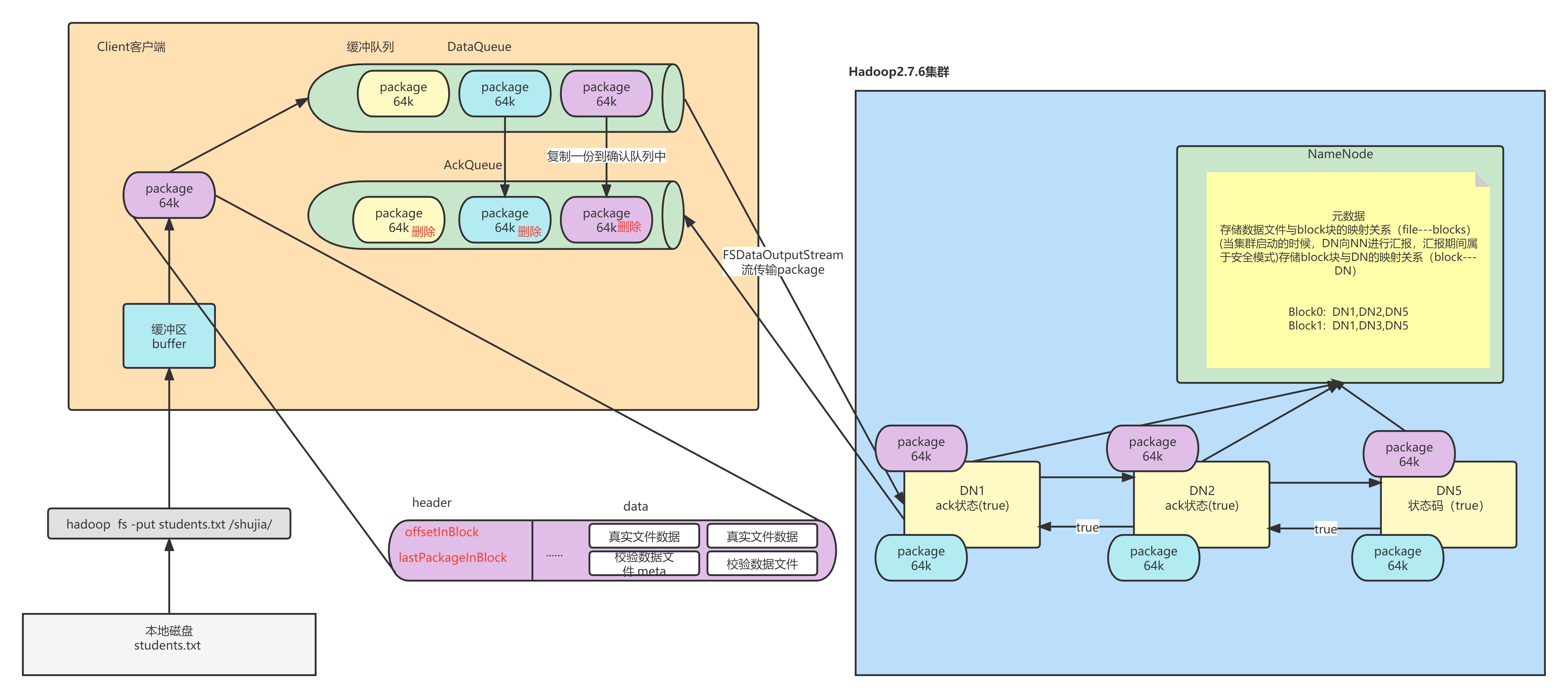
客戶端首先將自己的數據以流的方式讀取到快取中
-
然後將快取中的數據以chunk(512B)和checksum(4B)的方式放入到packet中(64K)
- chunk:checksum=128:1
- checksum:在數據處理和數據通訊領域中,用於校驗目的的一組數據項的和
- packet中的數據分為兩類:一類是實際數據包,一類是header包
-
一個數據包的組成結構
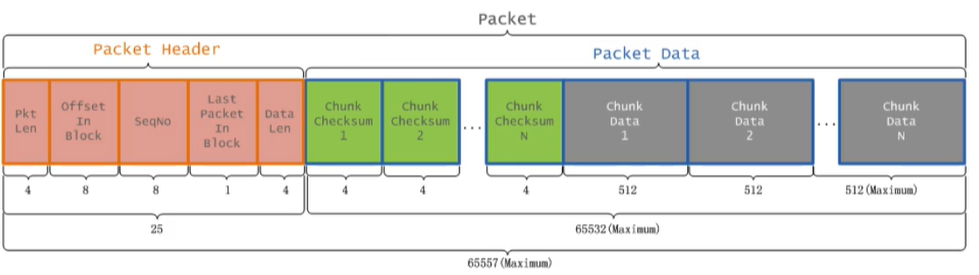
offsetInBlock:packet在block中的偏移量
LastPacketInBlock:是否是一個Block塊的最後一個packet,通過這個參數就可以解決前面的第一個問題
-
我們生成packet的速度肯定比我們將packet發送到DN上的速度要快,那麼客戶端就會產生很多的packet包,這時客戶端會將多餘的packet放入緩衝隊列DataQueue。然後調用FSDataOutputStream的對象從緩衝隊列調取packet寫入DN。在取出的時候會將packet複製一份放入AckQueue,這類似於另一個緩衝隊列。當客戶端接收到packet寫入完成的資訊後(ack=true)會刪除AckQueue緩衝區的對應packet。這樣即使斷電,正在傳輸中的packet丟失,由於AckQueue中對應的packet沒有刪除,說明這個packet沒有傳輸成功,就會重新傳輸這個包,這樣就解決了我們前面提到的第二個問題。


讀數據
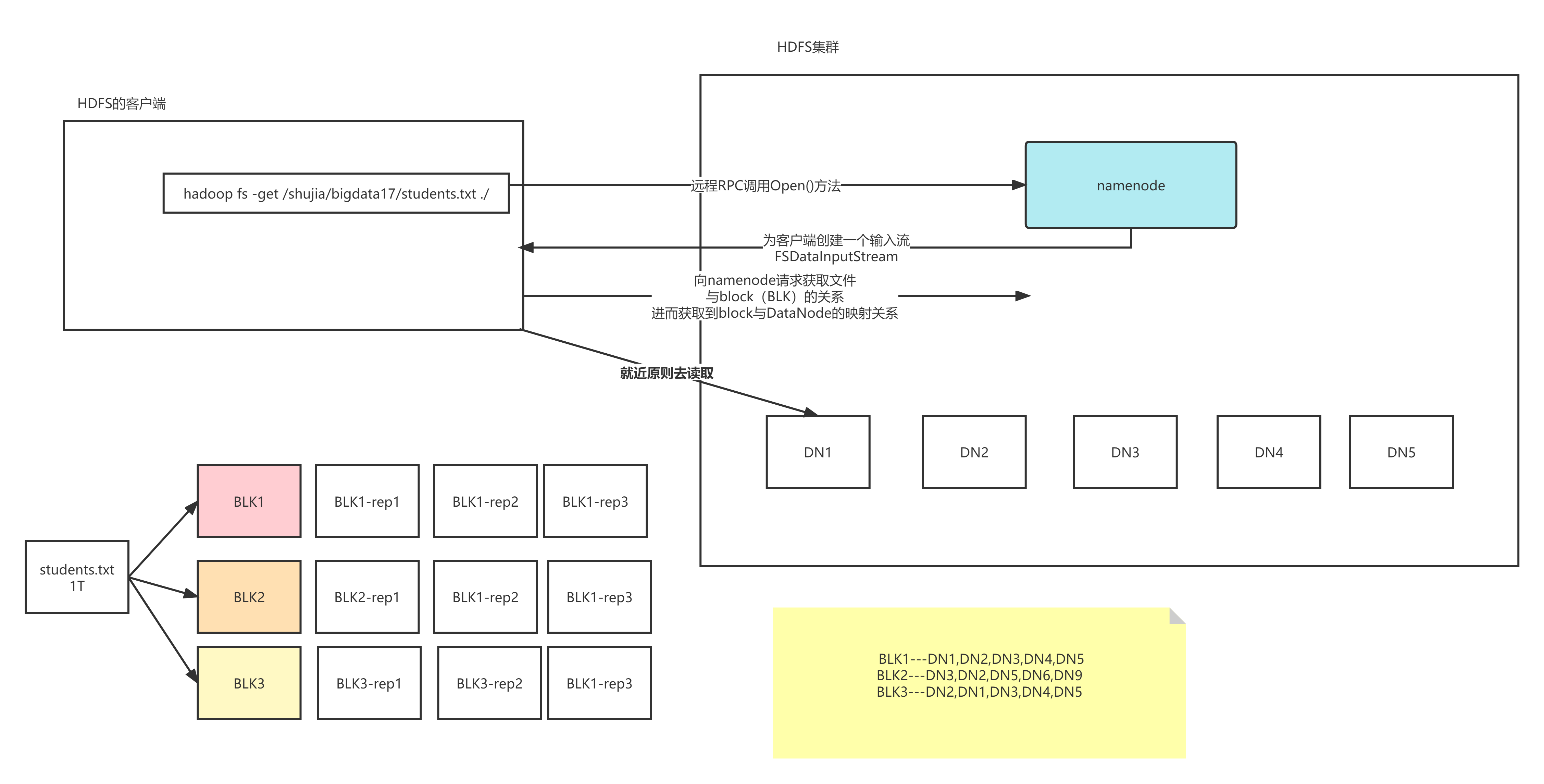
前面的都是從客戶端往DN寫數據,現在討論讀數據的過程
- 首先客戶端發送請求到DFS,申請讀某一個文件
- DFS去NN查找這個文件的元數據資訊
- DFS創建FSDataInputStream對象,客戶端通過這個對象讀取數據
- 客戶端獲取文件的第一個block塊資訊,返回DN1 DN2 DN4
- 客戶端直接就近原則選擇存放塊的DN1
- 依次類推其他block塊的資訊,知道最後一個塊,將所有的block塊合併成一個文件
- 關閉FSDataInputStream
流程圖