基於 Apache Hudi 和DBT 構建開放的Lakehouse
- 2022 年 8 月 21 日
- 筆記
本部落格的重點展示如何利用增量數據處理和執行欄位級更新來構建一個開放式 Lakehouse。 我們很高興地宣布,用戶現在可以使用 Apache Hudi + dbt 來構建開放Lakehouse。
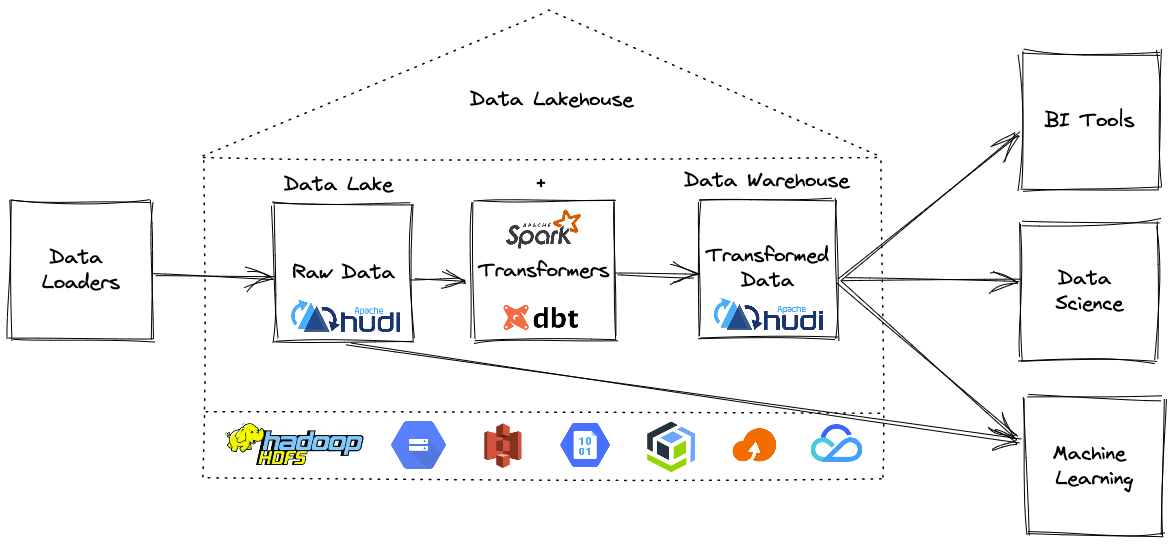
在深入了解細節之前,讓我們先澄清一下本部落格中使用的一些術語。
什麼是 Apache Hudi?
Apache Hudi 為Lakehouse帶來了 ACID 事務、記錄級更新/刪除和變更流。
Apache Hudi 是一個開源數據管理框架,用於簡化增量數據處理和數據管道開發。該框架更有效地管理數據生命周期等業務需求並提高數據品質。
什麼是dbt?
dbt(數據構建工具)是一種數據轉換工具,使數據分析師和工程師能夠在雲數據倉庫中轉換、測試和記錄數據。
dbt 使分析工程師能夠通過簡單地編寫select語句來轉換其倉庫中的數據。 dbt 處理將這些select語句轉換為表和視圖。
dbt 在 ELT(提取、載入、轉換)過程中執行 T——它不提取或載入數據,但它非常擅長轉換已經載入到倉庫中的數據。
什麼是Lakehouse?
Lakehouse 是一種新的開放式架構,它結合了數據湖和數據倉庫的最佳元素。 Lakehouses 是通過一種新的系統設計實現的:在開放格式的低成本雲存儲之上直接實施類似於數據倉庫中的事務管理和數據管理功能。如果必須在現代世界中重新設計數據倉庫,Lakehouse便是首選,因為現在可以使用廉價且高度可靠的存儲(以對象存儲的形式)。
換句話說,雖然數據湖歷來被視為添加到雲存儲文件夾中的一堆文件,但 Lakehouse 表支援事務、更新、刪除,在 Apache Hudi 的情況下,甚至支援索引或更改捕獲等類似資料庫的功能。
如何建造一個開放的Lakehouse?
現在我們知道什麼是Lakehouse了,所以讓我們建造一個開放的Lakehouse,你需要幾個組件:
- 支援 ACID 事務的開放表格式
- Apache Hudi(與 dbt 集成)
- Delta Lake(鎖定到 Databricks 運行時的專有功能)
- Apache Iceberg(目前未與 dbt 集成)
- 數據轉換工具
- 開源 dbt 是轉換層事實上的流行選擇
- 分散式數據處理引擎
- Apache Spark 是計算引擎事實上的流行選擇
- 雲儲存
- 可以選擇任何具有成本效益的雲存儲或 HDFS
- 選擇最心儀的查詢引擎
構建 Lakehouse需要一種方法來提取數據並將其載入為 Hudi 表格式,然後使用 dbt 就地轉換。
DBT 通過 dbt-spark 適配器包支援開箱即用的 Hudi。使用 dbt 創建建模數據集時,您可以選擇 Hudi 作為表的格式。
可以按照此頁面上的說明學習如何安裝和配置 dbt+hudi。
第 1 步:如何提取和載入原始數據集?
這是構建Lakehouse的第一步,這裡有很多選擇可以將數據載入到我們的開放Lakehouse中。可以使用 Hudi 的 Delta Streamer工具,因為所有攝取功能都是預先構建的,並在大規模生產中經過實戰測試。
Hudi 的 DeltaStreamer 在 ELT(提取、載入、轉換)過程中執行 EL——它非常擅長提取、載入和可選地轉換已經載入到 Lakehouse 中的數據。
第二步:如何用dbt項目配置Hudi?
要將 Hudi 與 dbt 項目一起使用,需要選擇文件格式為 Hudi。文件格式配置可以在特定模型中指定,也可以為 dbt_project.yml 文件中的所有模型指定:
models:
+file_format: hudi
或者
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
…
) }}
選擇 Hudi 作為 file_format 後,可以使用 dbt 創建物化數據集,這提供了 Hudi 表格式獨有的額外好處,例如欄位級更新/刪除。
第三步:如何增量讀取原始數據?
在我們學習如何構建增量物化視圖之前,讓我們快速了解一下,什麼是 dbt 中的物化?物化是在 Lakehouse 中持久化 dbt 模型的策略。 dbt 中內置了四種類型的物化:
- table
- view
- incremental
- ephemeral
在所有物化類型中,只有增量模型允許 dbt 自上次運行 dbt 以來將記錄插入或更新到表中,這釋放了 Hudi 的能力,我們將深入了解細節。
使用增量模型需要執行以下兩個步驟:
- 告訴 dbt 如何過濾增量執行的行
- 定義模型的唯一性約束(使用>= Hudi 0.10.1版本時需要)
如何在增量運行中應用過濾器?
dbt 提供了一個宏 is_incremental(),它對於專門為增量實現定義過濾器非常有用。
通常需要過濾「新」行,例如自上次 dbt 運行此模型以來已創建的行。查找此模型最近運行的時間戳的最佳方法是檢查目標表中的最新時間戳。 dbt 通過使用「{{ this }}」變數可以輕鬆查詢目標表。
{{
config(
materialized='incremental',
file_format='hudi',
)
}}
select
*
from raw_app_data.events
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where event_time > (select max(event_time) from {{ this }})
{% endif %}
如何定義唯一性約束?
unique_key 是數據集的主鍵,它確定記錄是否具有新值,是否應該更新/刪除或插入。
可以在模型頂部的配置塊中定義 unique_key。 這個 unique_key 將作為 Hudi 表上的主鍵(hoodie.datasource.write.recordkey.field)。
第 4 步:如何在編寫數據集時使用 upsert 功能?
dbt 在載入轉換後的數據集時提供了多種載入策略,例如:
- append(默認)
- insert_overwrite(可選)
- merge(可選,僅適用於 Hudi 和 Delta 格式)
默認情況下dbt 使用 append 策略,當在同一有效負載上多次執行 dbt run 命令時,可能會導致重複行。
當你選擇insert_overwrite策略時,dbt每次運行dbt都會覆蓋整個分區或者全表載入,這樣會造成不必要的開銷,而且非常昂貴。
除了所有現有的載入數據的策略外,使用增量物化時還可以使用Hudi獨佔合併策略。使用合併策略可以對Lakehouse執行欄位級更新/刪除,這既高效又經濟,因此可以獲得更新鮮的數據和更快的洞察力。
如何執行欄位級更新?
如果使用合併策略並指定了 unique_key,默認情況下dbt 將使用新值完全覆蓋匹配的行。
由於 Apache Spark 適配器支援合併策略,因此可以選擇將列名列表傳遞給 merge_update_columns 配置。在這種情況下dbt 將僅更新配置指定的列,並保留其他列的先前值。
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
merge_update_columns = ['msg', 'updated_ts'],
) }}
如何配置額外的Hudi自定義配置?
如果想指定額外的 Hudi 配置時,可以使用選項配置來做到這一點:
{{ config(
materialized='incremental',
file_format='hudi',
incremental_strategy='merge',
options={
'type': 'mor',
'primaryKey': 'id',
'precombineKey': 'ts',
},
unique_key='id',
partition_by='datestr',
pre_hook=["set spark.sql.datetime.java8API.enabled=false;"],
)
}}
總結
希望本篇博文可以助力基於Apache Hudi 與 dbt構建開放的 Lakehouse !


