論文解讀(PairNorm)《PairNorm: Tackling Oversmoothing in GNNs》
論文資訊
論文標題:PairNorm: Tackling Oversmoothing in GNNs
論文作者:Lingxiao Zhao, Leman Akoglu
論文來源:2020,ICLR
論文地址:download
論文程式碼:download
1 Introduction
GNNs 的表現隨著層數的增加而有所下降,一定程度上歸結於 over-smoothing 問題,重複圖卷積操作會使得節點表示最終變得不可區分。為緩解過平滑問題提出了 PairNorm, 一種歸一化方法。
比較可惜的時,該論文在使用了 2022 年的 “Mask” 策略,可惜了實驗做的不咋好。
2 Understanding oversmoothing
Definition
$\tilde{\mathbf{A}}_{\mathrm{sym}}=\tilde{\mathbf{D}}^{-1 / 2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1 / 2}$
$\tilde{\mathbf{A}}_{\mathrm{rw}}=\tilde{\mathbf{D}}^{-1} \tilde{\mathbf{A}}$
2.1 The oversmoothing problem
2.1.1 Oversmoothing
GNN 性能下降的原因:
-
- 參數數量的增加;
- 梯度消失導致訓練困難;
- 圖卷積而造成的過平滑;
過平滑的考慮方法如下:當多次使用拉普拉斯平滑導致節點特徵收斂到一個平穩點。假設 $\mathbf{x}_{\cdot j} \in \mathbb{R}^{n}$ 表示 $\mathbf{X}$ 的第 $j $ 列,對於任意 $\mathbf{x}_{\cdot j} \in \mathbb{R}^{n}$:
$\begin{array}{l}\underset{k \rightarrow \infty}{\text{lim}} \quad \tilde{\mathbf{A}}_{\mathrm{sym}}^{k} \mathbf{x}_{\cdot j} =\boldsymbol{\pi}_{j}\\ \text { and } \quad \frac{\boldsymbol{\pi}_{j}}{\left\|\boldsymbol{\pi}_{j}\right\|_{1}}=\boldsymbol{\pi}\end{array}$
其中,標準化解 $\pi \in \mathbb{R}^{n}$ 滿足 $\boldsymbol{\pi}_{i}=\frac{\sqrt{\operatorname{deg}_{i}}}{\sum_{i} \sqrt{\operatorname{deg}_{i}}} \text{ for all } i \in[n]$。
Note:$\boldsymbol{\pi}$ 不依賴於節點特徵矩陣,而是一個單純依靠圖結構度的函數。
2.1.2 Its Measurement
本文提出兩種度量過平滑的方式:$\text{row-diff}$ 和 $\text{col-diff}$。
設 $\mathbf{H}^{(k)} \in \mathbb{R}^{n \times d}$ 為第 $k$ 個圖卷積後的節點表示矩陣,即 $\mathbf{H}^{(k)}=\tilde{\mathbf{A}}_{\mathrm{sym}}^{k} \mathbf{X}$。設 $\mathbf{h}_{i}^{(k)} \in \mathbb{R}^{d}$ 為 $\mathbf{H}^{(k)}$ 的第 $i$ 行,$\mathbf{h}_{. i}^{(k)} \in \mathbb{R}^{n}$ 為 $\mathbf{H}^{(k)}$ 的第 $i$ 列。
$\text{row-diff}( \left.\mathbf{H}^{(k)}\right)$ 和 $\text{col-diff}( \left.\mathbf{H}^{(k)}\right)$ 的定義如下:
${\large \operatorname{row}-\operatorname{diff}\left(\mathbf{H}^{(k)}\right) =\frac{1}{n^{2}} \sum\limits _{i, j \in[n]}\left\|\mathbf{h}_{i}^{(k)}-\mathbf{h}_{j}^{(k)}\right\|_{2}} \quad\quad\quad(2)$
$\text{row-diff}$ 量化節點之間的成對距離,而 $\text{col-diff}$ 特徵之間的成對距離。
2.2 Studying oversmoothing with SGC
GCN 過平滑可能由於層數增加導致的性能下降,即添加更多的層導致更多的參數(添加的線性層 存在 $\mathbf{W}^{(k)}$)容易導致過擬合。同樣層數增加,容易存在反向傳播梯度的消失(應該指的是參數多)。
將層數增加影響過平滑和 使用參數導致過擬合即反向傳播梯度消失 解耦。本文使用 SGC ,一種簡化的 GCN :去除圖卷積層的所有投影參數和所有層間的非線性激活。SGC可寫為:
$\widehat{\boldsymbol{Y}}=\operatorname{softmax}\left(\tilde{\mathbf{A}}_{\mathrm{sym}}^{K} \mathbf{X} \mathbf{W}\right) \quad\quad\quad(4) $
Note:SGC有一個固定數量的參數,不依賴於圖卷積的數量(即層),也因此防止了過擬合和消失梯度問題的影響。
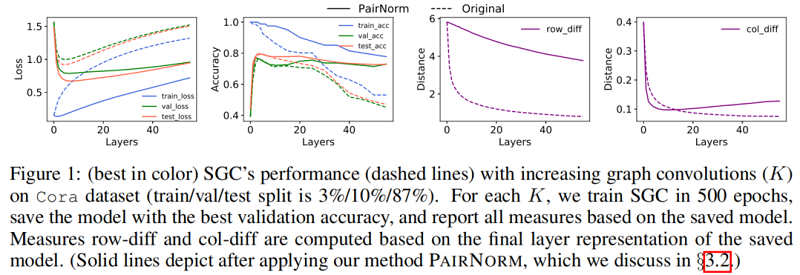
Figure 1 中的虛線說明了當增加層數( $K$ )時,SGC 在 Cora 數據集上的性能。訓練(交叉熵)損失隨著 $K$ 的增大而單調地增加,這可能是因為圖卷積將節點表示與它們的鄰居混合在一起,使它們變得不那麼容易區分(訓練變得更加困難)。另一方面,至多到 $K=4$,圖卷積(即平滑)提高了泛化能力,減少了訓練和驗證/測試損失之間的差距,之後,過平滑開始影響性能。$\text{row-diff}$ 和 $\text{col-diff}$ 都隨 $K$ 繼續單調遞減,為過平滑提供了支援證據。
3 Tackling oversmoothing
3.1 Proposed pairnorm
考慮圖正則化最小二乘(GRLS):設 $\overline{\mathbf{X}} \in \mathbb{R}^{n \times d}$ 是節點表示矩陣,其中 $\overline{\mathbf{x}}_{i} \in \mathbb{R}^{d}$ 表示 $\overline{\mathbf{X}}$ 的第 $i$ 行,GRLS 問題為:
$\underset{\overline{\mathbf{x}}}{\text{min}} \sum\limits _{i \in \mathcal{V}}\left\|\overline{\mathbf{x}}_{i}-\mathbf{x}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}+\sum\limits_{(i, j) \in \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}\quad\quad\quad(5)$
其中:
-
- $\left\|\mathbf{z}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}=\mathbf{z}_{i}^{T} \tilde{\mathbf{D}} \mathbf{z}_{i}$;
第一項可以看作是度加權最小二乘,第二個是一個圖正則化項,度量新特徵在圖結構上的變化。
優化問題的目標可認為是估計新的 「去噪」 特徵 $\overline{\mathbf{x}}_{i}$ 離輸入特徵 $\mathbf{x}_{i}$ 不遠,並且在圖結構上很平滑。
理想情況下,希望獲得對同一集群內的節點的平滑,但是避免平滑來自不同集群的節點。$\text{Eq.5}$ 中的目標通過圖正則化項只優化第一個目標。因此,當重複應用卷積時,它容易出現過平滑。為規避這個問題並同時實現這兩個目標,可以添加一個負項,如沒有邊連接對之間的距離之和如下:
$\underset{\overline{\mathbf{x}}}{\text{min}} \sum\limits _{i \in \mathcal{V}}\left\|\overline{\mathbf{x}}_{i}-\mathbf{x}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}+\sum\limits_{(i, j) \in \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}-\lambda \sum_{(i, j) \notin \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}\quad\quad\quad(6)$
在本文中,沒有提出了一個全新的圖卷積運算元,而是提出了一個通用的、有效的 「修補程式」,稱為 PAIRNORM,它可以應用於具有過平滑潛力的任何形式的圖卷積。
設 $\tilde{\mathbf{X}}$(圖卷積的輸出)和 $\dot{\mathbf{X}}$ 分別為 PAIRNORM 的輸入和輸出。觀察到圖卷積 $\tilde{\mathbf{X}}=\tilde{\mathbf{A}}_{\text {sym }} \mathbf{X}$ 的輸出實現了第一個目標 度加權,PAIRNORM 作為一個標準化層,在 $\tilde{\mathbf{X}}$ 上工作,以實現第二個目標,即保持未連接的對表示更遠。具體來說,PAIRNORM 將 $\tilde{\mathbf{X}}$ 歸一化,使總成對平方距離 $\operatorname{TPSD}(\dot{\mathbf{X}}):=\sum\limits_{i, j \in[n]}\left\|\dot{\mathbf{x}}_{i}-\dot{\mathbf{x}}_{j}\right\|_{2}^{2} $ 和 $\operatorname{TPSD}(\mathbf{X} )$ 一樣:
實踐中,不需要時刻關注 $\operatorname{TPSD}(\mathbf{X} )$ 的值,只需要在所有層使得 $\operatorname{TPSD}(\mathbf{X} )$ 保持一個恆定的常量 $C$。
同樣地,規範化可以通過一個兩步的方法來完成,其中 $\operatorname{TPSD}$ 被重寫為
$\operatorname{TPSD}(\tilde{\mathbf{X}})=\sum\limits_{i, j \in[n]}\left\|\tilde{\mathbf{x}}_{i}-\tilde{\mathbf{x}}_{j}\right\|_{2}^{2}=2 n^{2}\left(\frac{1}{n} \sum\limits_{i=1}^{n}\left\|\tilde{\mathbf{x}}_{i}\right\|_{2}^{2}-\left\|\frac{1}{n} \sum\limits_{i=1}^{n} \tilde{\mathbf{x}}_{i}\right\|_{2}^{2}\right) \quad\quad\quad(8)$
$\text{Eq.8}$ 的第一項 表示節點表示的均方長度,第二項描述了節點表示的均值的平方長度。
為簡化 $\text{Eq.8}$ 的計算,令每個 $\tilde{\mathbf{x}}_{i}$ 減去行均值 $\tilde{\mathbf{x}}_{i}^{c}=\tilde{\mathbf{x}}_{i}-\frac{1}{n} \sum\limits _{i}^{n} \tilde{\mathbf{x}}_{i}$,其中 $\tilde{\mathbf{x}}_{i}^{c}$ 表示中心表示。這種移動不會影響 $\operatorname{TPSD}$,並且驅動了項 $\left\|\frac{1}{n} \sum\limits _{i=1}^{n} \tilde{\mathbf{x}}_{i}\right\|_{2}^{2} $ 趨近 $0$。那麼,計算 $\operatorname{TPSD}(\tilde{\mathbf{X}}) $ 可歸結為計算 $\tilde{\mathbf{X}}^{c}$ 的 $F$ 範數的平方,並有 $\mathcal{O}(n d)$:
$\operatorname{TPSD}(\tilde{\mathbf{X}})=\operatorname{TPSD}\left(\tilde{\mathbf{X}}^{c}\right)=2 n\left\|\tilde{\mathbf{X}}^{c}\right\|_{F}^{2} \quad\quad\quad(9)$
$\text{Eq.9}$ 可以寫成一個兩步的、中心和規模的歸一化過程:
$\tilde{\mathbf{x}}_{i}^{c}=\tilde{\mathbf{x}}_{i}-\frac{1}{n} \sum\limits _{i=1}^{n} \tilde{\mathbf{x}}_{i} \quad\quad\text{(Center)}\quad(10)$
縮放後,數據保持中心化 $\left\|\sum\limits _{i=1}^{n} \dot{\mathbf{x}}_{i}\right\|_{2}^{2}=0$ 。在 $\text{Eq.11}$ 中,$s$ 是一個超參數,它決定了 $C$。具體來說,
$\operatorname{TPSD}(\dot{\mathbf{X}})=2 n\|\dot{\mathbf{X}}\|_{F}^{2}=2 n \sum\limits_{i}\left\|s \cdot \frac{\tilde{\mathbf{x}}_{i}^{c}}{\sqrt{\frac{1}{n} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}}}\right\|_{2}^{2}=2 n \frac{s^{2}}{\frac{1}{n} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}=2 n^{2} s^{2} \quad(12)$
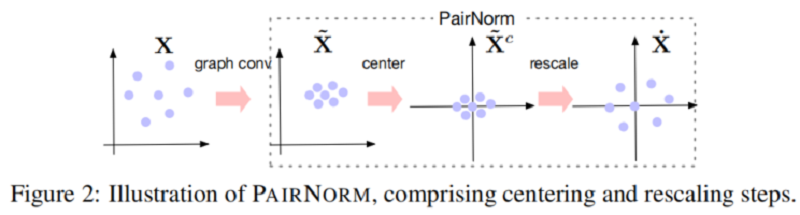
然後,$\dot{\mathbf{X}}:=\operatorname{PAIRNORM}(\tilde{\mathbf{X}})$ 擁有行均值為 $0$ (Center),和恆定的總成對平方距離 $C=2 n^{2} s^{2}$。在 Figure 2 中給出了一對範數的說明。PAIRNORM 的輸出被輸入到下一個卷積層。
本文還推導出 PAIRNORM 的變體,即通過替換 $\text{Eq.11}$ 的 $\sum\limits _{i=1}^{n}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2} $ 為 $n\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}$ ,本文稱之為 PAIRNORM-SI ,此時所有的節點都有相同的 $L_{2}$ 範數 $s$ 。
在實踐中,發現 PAIRNORM 和 PAIRNORM-SI 對 SGC 都很有效,而 PAIRNORM-SI 對 GCN 和 GAT 提供了更好和更穩定的結果。GCN 和 GAT 需要更嚴格的歸一化的原因可能是因為它們有更多的參數,更容易發生過擬合。在所有實驗中,對SGC採用PAIRNORM,對 GCN 和 GAT 採用 PAIRNORM-SI。
Figure 1 中的實線顯示了 SGC 性能, 與 「vanilla」 版本相比,隨著層數的增加,我們在每個圖卷積層之後使用 PAIRNORM。類似地,Figure 3 用於 GCN 和 GAT(在每個圖卷積激活後應用PAIRNORM-SI)。請注意,PAIRNORM 的性能衰減要慢得多。

雖然 PAIRNORM 使更深層次的模型對過度平滑更穩健,但總體測試精度沒有提高似乎很奇怪。事實上,文獻中經常使用的基準圖數據集需要不超過 $4$ 層,之後性能就會下降(即使是緩慢的)。
3.2 A case where deeper GNNs are beneficial
假設 $\mathcal{M} \subseteq \mathcal{V}_{u}$ 代表特徵缺失子集,其中 $\forall m \in \mathcal{M}$,$\mathbf{x}_{m}=\emptyset $。本文設置 $p=|\mathcal{M}| /\left|\mathcal{V}_{u}\right|$ 代表缺失比例。將這種任務的變體稱為具有缺失向量的半監督節點分類(SSNC-MV)。直觀的說,需要更多的傳播步驟才能恢復這些節點有效的特徵表示。
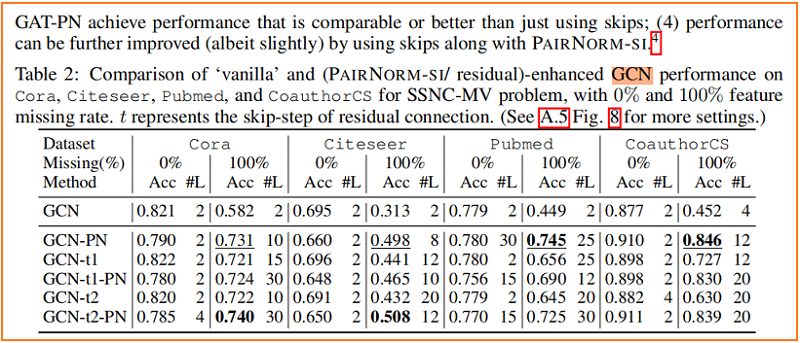
Figure 4 顯示了隨著層數的增加,SGC、GCN 和 GAT 模型在 Cora 上的性能變化,其中我們從所有未標記的節點中刪除特徵向量,即 $p=1$。與沒有PAIRNORM 的模型相比,具有 PAIRNORM 的模型獲得了更高的測試精度,它們通常會達到更多的層數。

4 Experiments
在本節中,我們設計了廣泛的實驗來評估在SSNC-MV設置下的SGC、GCN和GAT模型的有效性。
4.1 Experiment setup

4.2 Experiment results
節點分類


5 Conclusion
提出了一種有效防止過平滑問題的 成對範數 ,一種新的歸一化層,提高了深度 GNNs 對過平滑的魯棒性。
