什麼是謂詞下推,看這一篇就夠了
今天有個小夥伴問我,什麼是謂詞下推,然後我就開啟巴拉巴拉模式,說了好長一段時間,結果發現他還是懵的。
最後我概述給他一句話:所謂謂詞下推,就是將儘可能多的判斷更貼近數據源,以使查詢時能跳過無關的數據。用在SQL優化上來說,就是先過濾再做聚合等操作。
看到這裡的朋友可能就已經明白了什麼是謂詞下推,如果僅為了解有啥用,看到這裡就可以退出了,如果想告訴別人這是個啥(高大上)那且聽我細細道來。
要理解謂詞下推,應該從兩個方面來看,即謂詞和下推兩部分。
1.什麼是謂詞
predicate push down 翻譯為謂詞下推,這個翻譯很準確,明確的告訴了我們這個操作是一個什麼動作,但是為人詬病的是,什麼是謂詞,結合起來是什麼意思,就比較難以理解。
predicate push down 又可以叫做 Filter Push down,這個叫法準確的描述了動作,但沒有精準定位什麼能被稱之為Filter。全局來看,還是predicate push down較為準確。
predicate(謂詞)即條件表達式,在SQL中,謂詞就是返回boolean值即true和false的函數,或是隱式轉換為bool的函數。SQL中的謂詞主要有 LKIE、BETWEEN、IS NULL、IS NOT NULL、IN、EXISTS其結果為布爾值,即true或false。
謂詞的使用場景:在SELECT語句的WHERE子句或HAVING子句中,確定哪些行與特定查詢相關。 ps:並非所有謂詞都可以在HAVING子句中使用。
那麼反過來想,是不是在以上的場景中使用的,用來判斷true或false的就是謂詞呢?是的!
這樣是不是就可以很好的理解了什麼是謂詞。
2.什麼是下推
理解了什麼是謂詞後,我們再看看什麼是下推,哪裡被稱為下,哪裡被稱為上呢?看圖說話。

如圖,下是table_A和table_B,即數據源頭。
上是Result,即數據結果。
藍色部分是未採用謂詞下推運算過程,黃色部分是採用了謂詞下推的運算過程。
3.什麼是謂詞下推
看到這裡,我們可能已經理解了什麼是謂詞下推,基本的意思predicate pushdown 是將SQL語句中的部分語句( predicates 謂詞部分) 可以被 「pushed」 下推到數據源或者靠近數據源的部分。
根據上圖對比可以看出通過儘早過濾掉數據,這種處理方式能大大減少數據處理的量,降低資源消耗,在同樣的伺服器環境下,極大地減少了查詢/處理時間。
在Hive SQL和Spark SQL等一系列SQL ON Hadoop的解析語法樹時都在謂詞下推方面作出了優化,其實在使用SQL的過程,我們心中記住這是一種將過濾儘可能在靠近數據源(取數據)的時候完成的一種操作,是資料庫的一種經典的優化手段。
我們平時的SQL優化手段中,謂詞下推也是一種被頻繁使用的方式,簡潔且有效。
4.一些常見的應用
4.1傳統資料庫應用
在傳統資料庫的查詢系統中謂詞下推作為優化手段很早就出現了,謂詞下推的目的就是通過將一些過濾條件儘可能的在最底層執行可以減少每一層交互的數據量,從而提升性能。
例如下面這個例子:
select count(0) from A Join B on A.id = B.id
where A.a > 10 and B.b < 100;
通過查看執行計劃,可以看到,在處理Join操作之前需要首先對A和B執行TableScan操作,然後再進行Join,再執行過濾,最後計算聚合函數返回,但是如果把過濾條件A.a > 10和B.b < 100分別移到A表的TableScan和B表的TableScan的時候執行,可以大大降低Join操作的輸入數據。
優化後的語句如下:
select count(0) from (select * from A where a>10) A1
Join (
select * from B where b<100
)B1 on A1.id = B1.id;
4.2Hive中的謂詞下推
下面說說Hive中的謂詞下推(同樣適用於SparkSQL)
Hive中的Predicate Pushdown簡稱謂詞下推,簡而言之,就是在不影響結果的情況下,盡量將過濾條件提前執行。謂詞下推後,過濾條件在map端執行,減少了map端的輸出,降低了數據在集群上傳輸的量,節約了集群的資源,也提升了任務的性能。
具體配置項是hive.optimize.ppd,默認為true,即開啟謂詞下推。
PPD規則:
規則的邏輯描述如下:
During Join predicates cannot be pushed past Preserved Row tables( join條件過濾不能下推到保留行表中)
比如以下選擇,left join中左表s1為保留行表(先掃描s1表,即以左表為基表),所以on條件(join過濾條件)不能下推到s1中
select s1.key, s2.key from src s1 left join src s2 on s1.key > '2';
而s2表不是保留行,所以s2.key>2條件可以下推到s2表中:
select s1.key, s2.key from src s1 left join src s2 on s2.key > '2';
After Join predicates cannot be pushed past Null Supplying tables(where條件過濾不能下推到NULL補充表)
比如以下選擇left join的右表s2為NULL補充表所以,s1.key>2 where條件可以下推到s1:
select s1.key, s2.key from src s1 left join src s2 where s1.key > '2';
而以下選擇由於s2未NULL補充表所以s2.key>2過濾條件不能下推
select s1.key, s2.key from src s1 left join src s2 where s2.key > '2';
關於join和where,PPD採用的規則如下:
實驗結果表格形式:

總結如下:
-
對於Join(Inner Join)、Full outer Join,條件寫在on後面,還是where後面,性能上面沒有區別;
-
對於Left outer Join ,右側的表寫在on後面、左側的表寫在where後面,性能上有提高;
-
對於Right outer Join,左側的表寫在on後面、右側的表寫在where後面,性能上有提高;
-
當條件分散在兩個表時,謂詞下推可按上述結論2和3自由組合;
-
所謂下推,即謂詞過濾在map端執行;所謂不下推,即謂詞過濾在reduce端執行
注意:如果在表達式中含有不確定函數,整個表達式的謂詞將不會被pushed,例如
select a.* from a join b on a.id = b.id
where a.ds = '2022-08-15' and a.create_time = unix_timestamp();
因為unix_timestamp是不確定函數,在編譯的時候無法得知,所以,整個表達式不會被pushed,即ds='2022-08-15'也不會被提前過濾。類似的不確定函數還有rand()等。
4.3列式存儲中的謂詞下推
無論是行式存儲還是列式存儲,都可以在將過濾條件在讀取一條記錄之後執行以判斷該記錄是否需要返回給調用者,在ORC File和Parquet文件存儲格式中又利用該思想做了更進一步的優化。
以Parquet為例,優化的方法是對每一個Row Group的每一個Column Chunk在存儲的時候都計算對應的統計資訊,包括該Column Chunk的最大值、最小值和空值個數。通過這些統計值和該列的過濾條件可以判斷該Row Group是否需要掃描。另外Parquet未來還會增加諸如Bloom Filter和Index等優化數據,更加有效的完成謂詞下推。
在使用Parquet的時候可以通過如下兩種策略提升查詢性能:1、類似於關係資料庫的主鍵,對需要頻繁過濾的列設置為有序的,這樣在導入數據的時候會根據該列的順序存儲數據,這樣可以最大化的利用最大值、最小值實現謂詞下推。2、減小行組大小和頁大小,這樣增加跳過整個行組的可能性,但是此時需要權衡由於壓縮和編碼效率下降帶來的I/O負載。
ORC File也是類似的操作,具體在講解ORC File時詳細說明。
RF演算法中,用了謂詞下推思想。大小表進行broadcast hash join時,用小表的join列數據構建BloomFilter,廣播到大表的所有partition,使用該BloomFilter對大表join列數據進行過濾。最後將大表過濾後得到的數據與小表數據進行hashJoin。
這個過程如下圖:
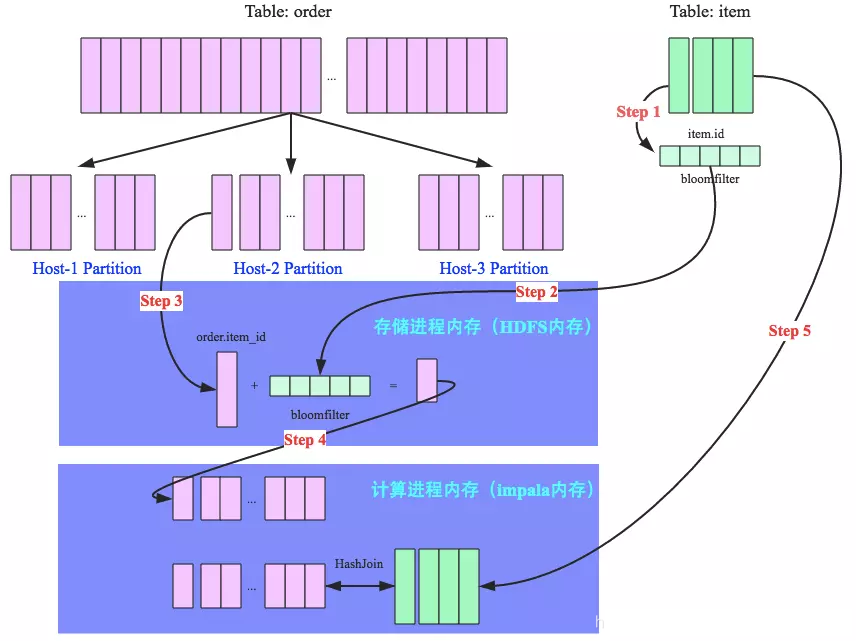
這樣的好處是:
- 在存儲層即過濾了大量大表無效數據,減少掃描無效數據列的同行其他列數據IO
- 減少存儲進程到計算進程傳輸的數據
- 減少hashjoin開銷
例如如下sql:
select item.name, order.* from order , item where order.item_id = item.id and item.category = 『book』
使用謂詞下推,會將表達式 item.category = 『book』下推到join條件order.item_id = item.id之前。
再往高大上的方面說,就是將過濾表達式下推到存儲層直接過濾數據,減少傳輸到計算層的數據量。
以上,就是完整的謂詞下推理解了。
參考資料:
//blog.csdn.net/strongyoung88/article/details/81156271
上一期:
Hive存儲格式之RCFile詳解,RCFile的過去現在未來
下期預告:Hive存儲格式之ORC File詳解
按例,我的個人公眾號:魯邊社,點擊關注
後台回復關鍵字 hive,隨機贈送一本魯邊備註版珍藏大數據書籍。


