麻了,程式碼改成多執行緒,竟有9大問題
前言
很多時候,我們為了提升介面的性能,會把之前單執行緒同步執行的程式碼,改成多執行緒非同步執行。
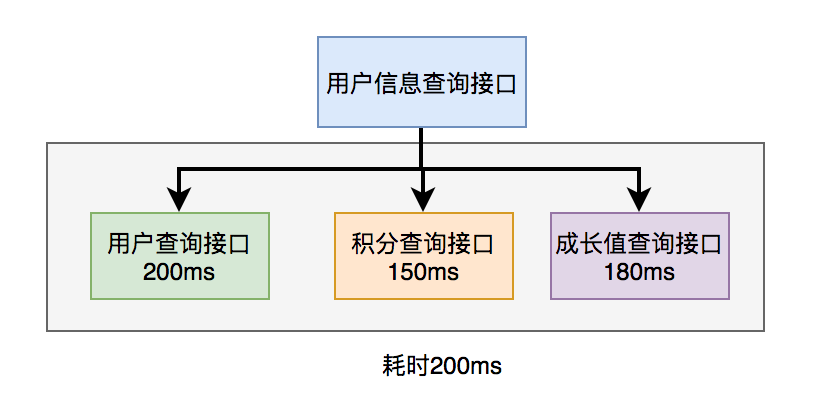
比如:查詢用戶資訊介面,需要返回用戶基本資訊、積分資訊、成長值資訊,而用戶、積分和成長值,需要調用不同的介面獲取數據。
如果查詢用戶資訊介面,同步調用三個介面獲取數據,會非常耗時。
這就非常有必要把三個介面調用,改成非同步調用,最後匯總結果。
再比如:註冊用戶介面,該介面主要包含:寫用戶表,分配許可權,配置用戶導航頁,發通知消息等功能。
該用戶註冊介面包含的業務邏輯比較多,如果在介面中同步執行這些程式碼,該介面響應時間會非常慢。
這時就需要把業務邏輯梳理一下,劃分:核心邏輯和非核心邏輯。這個例子中的核心邏輯是:寫用戶表和分配許可權,非核心邏輯是:配置用戶導航頁和發通知消息。
顯然核心邏輯必須在介面中同步執行,而非核心邏輯可以多執行緒非同步執行。
等等。
需要使用多執行緒的業務場景太多了,使用多執行緒非同步執行的好處不言而喻。
但我要說的是,如果多執行緒沒有使用好,它也會給我們帶來很多意想不到的問題,不信往後繼續看。
今天跟大家一起聊聊,程式碼改成多執行緒調用之後,帶來的9大問題。
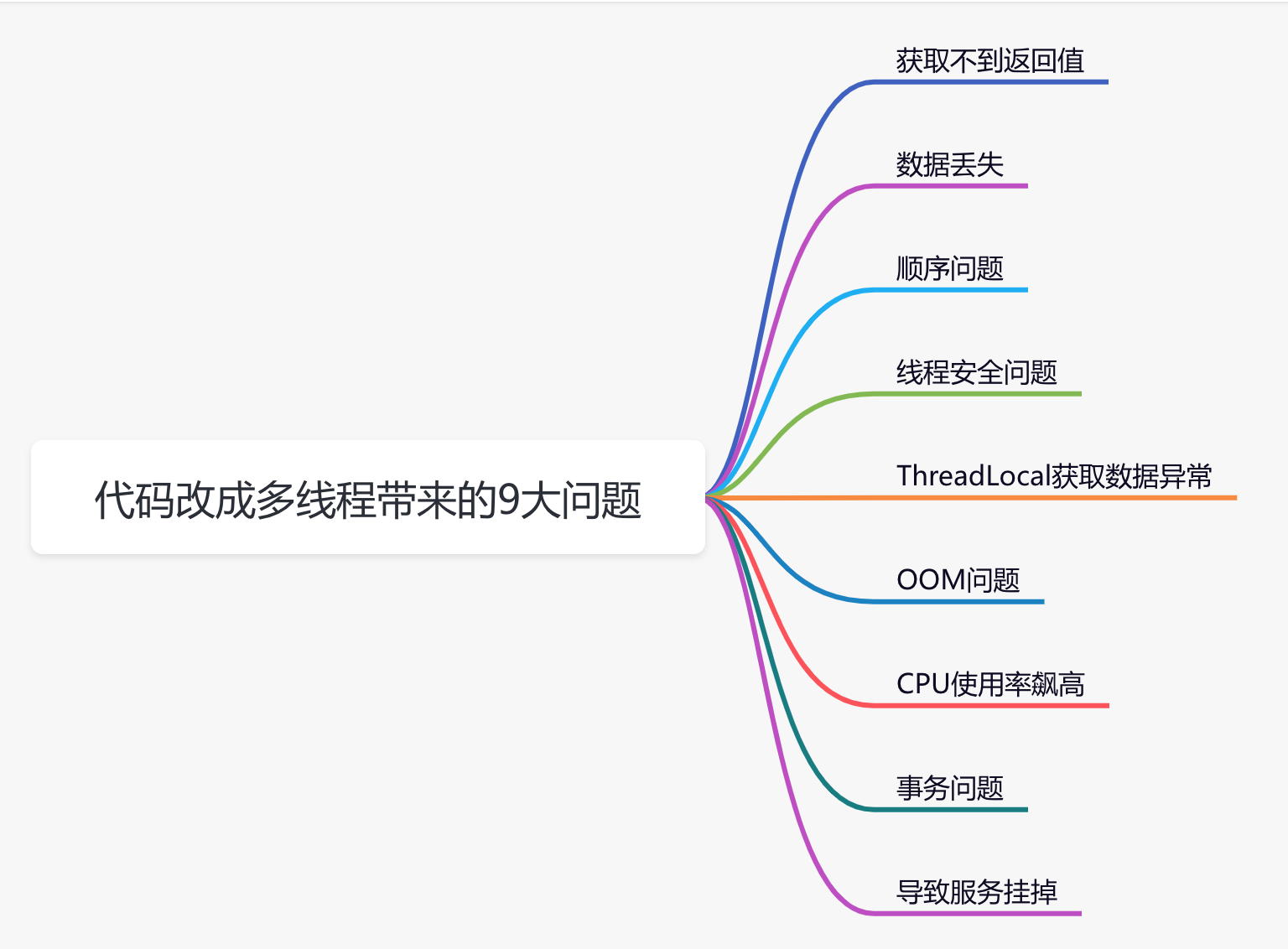
1.獲取不到返回值
如果你通過直接繼承Thread類,或者實現Runnable介面的方式去創建執行緒。
那麼,恭喜你,你將沒法獲取該執行緒方法的返回值。
使用執行緒的場景有兩種:
- 不需要關注執行緒方法的返回值。
- 需要關注執行緒方法的返回值。
大部分業務場景是不需要關注執行緒方法返回值的,但如果我們有些業務需要關注執行緒方法的返回值該怎麼處理呢?
查詢用戶資訊介面,需要返回用戶基本資訊、積分資訊、成長值資訊,而用戶、積分和成長值,需要調用不同的介面獲取數據。
如下圖所示:
在Java8之前可以通過實現Callable介面,獲取執行緒返回結果。
Java8以後通過CompleteFuture類實現該功能。我們這裡以CompleteFuture為例:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}
溫馨提醒一下,這兩種方式別忘了使用執行緒池。示例中我用到了executor,表示自定義的執行緒池,為了防止高並發場景下,出現執行緒過多的問題。
此外,Fork/join框架也提供了執行任務並返回結果的能力。
2.數據丟失
我們還是以註冊用戶介面為例,該介面主要包含:寫用戶表,分配許可權,配置用戶導航頁,發通知消息等功能。
其中:寫用戶表和分配許可權功能,需要在一個事務中同步執行。而剩餘的配置用戶導航頁和發通知消息功能,使用多執行緒非同步執行。
表面上看起來沒問題。
但如果前面的寫用戶表和分配許可權功能成功了,用戶註冊介面就直接返回成功了。
但如果後面非同步執行的配置用戶導航頁,或發通知消息功能失敗了,怎麼辦?
如下圖所示:
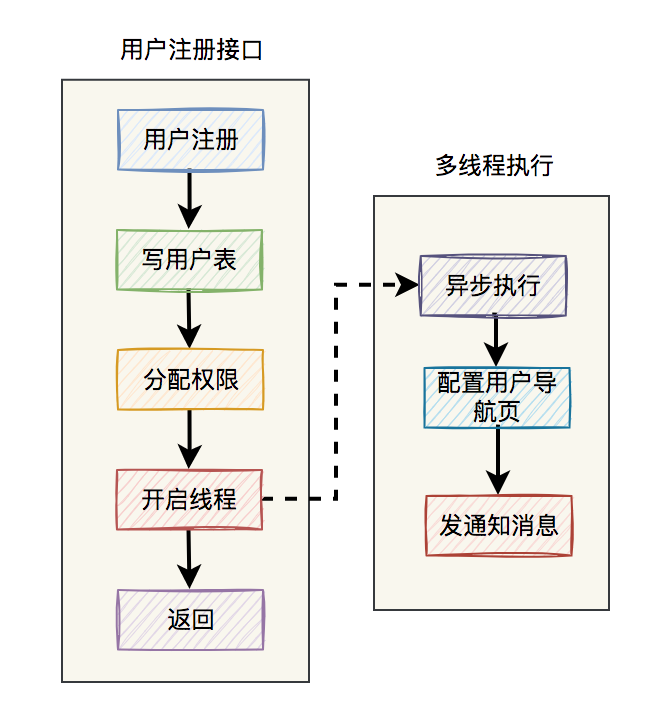
該介面前面明明已經提示用戶成功了,但結果後面又有一部分功能在多執行緒非同步執行中失敗了。
這時該如何處理呢?
沒錯,你可以做失敗重試。
但如果重試了一定的次數,還是沒有成功,這條請求數據該如何處理呢?如果不做任何處理,該數據是不是就丟掉了?
為了防止數據丟失,可以用如下方案:
- 使用mq非同步處理。在分配許可權之後,發送一條mq消息,到mq伺服器,然後在mq的消費者中使用多執行緒,去配置用戶導航頁和發通知消息。如果mq消費者中處理失敗了,可以自己重試。
- 使用job非同步處理。在分配許可權之後,往任務表中寫一條數據。然後有個job定時掃描該表,然後配置用戶導航頁和發通知消息。如果job處理某條數據失敗了,可以在表中記錄一個重試次數,然後不斷重試。但該方案有個缺點,就是實時性可能不太高。
3.順序問題
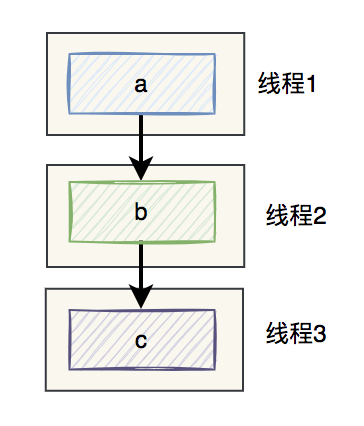
如果你使用了多執行緒,就必須接受一個非常現實的問題,即順序問題。
假如之前程式碼的執行順序是:a,b,c,改成多執行緒執行之後,程式碼的執行順序可能變成了:a,c,b。(這個跟cpu調度演算法有關)
例如:
public static void main(String[] args) {
Thread thread1 = new Thread(() -> System.out.println("a"));
Thread thread2 = new Thread(() -> System.out.println("b"));
Thread thread3 = new Thread(() -> System.out.println("c"));
thread1.start();
thread2.start();
thread3.start();
}
執行結果:
a
c
b
那麼,來自靈魂的一問:如何保證執行緒的順序呢?
即執行緒啟動的順序是:a,b,c,執行的順序也是:a,b,c。
如下圖所示:
3.1 join
Thread類的join方法它會讓主執行緒等待子執行緒運行結束後,才能繼續運行。
列如:
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> System.out.println("a"));
Thread thread2 = new Thread(() -> System.out.println("b"));
Thread thread3 = new Thread(() -> System.out.println("c"));
thread1.start();
thread1.join();
thread2.start();
thread2.join();
thread3.start();
}
執行結果永遠都是:
a
b
c
3.2 newSingleThreadExecutor
我們可以使用JDK自帶的Excutors類的newSingleThreadExecutor方法,創建一個單執行緒的執行緒池。
例如:
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
Thread thread1 = new Thread(() -> System.out.println("a"));
Thread thread2 = new Thread(() -> System.out.println("b"));
Thread thread3 = new Thread(() -> System.out.println("c"));
executorService.submit(thread1);
executorService.submit(thread2);
executorService.submit(thread3);
executorService.shutdown();
}
執行結果永遠都是:
a
b
c
使用Excutors類的newSingleThreadExecutor方法創建的單執行緒的執行緒池,使用了LinkedBlockingQueue作為隊列,而此隊列按 FIFO(先進先出)排序元素。
添加到隊列的順序是a,b,c,則執行的順序也是a,b,c。
3.3 CountDownLatch
CountDownLatch是一個同步工具類,它允許一個或多個執行緒一直等待,直到其他執行緒執行完後再執行。
例如:
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch1 = new CountDownLatch(0);
CountDownLatch latch2 = new CountDownLatch(1);
CountDownLatch latch3 = new CountDownLatch(1);
Thread thread1 = new Thread(new TestRunnable(latch1, latch2, "a"));
Thread thread2 = new Thread(new TestRunnable(latch2, latch3, "b"));
Thread thread3 = new Thread(new TestRunnable(latch3, latch3, "c"));
thread1.start();
thread2.start();
thread3.start();
}
}
class TestRunnable implements Runnable {
private CountDownLatch latch1;
private CountDownLatch latch2;
private String message;
TestRunnable(CountDownLatch latch1, CountDownLatch latch2, String message) {
this.latch1 = latch1;
this.latch2 = latch2;
this.message = message;
}
@Override
public void run() {
try {
latch1.await();
System.out.println(message);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch2.countDown();
}
}
執行結果永遠都是:
a
b
c
此外,使用CompletableFuture的thenRun方法,也能多執行緒的執行順序,在這裡就不一一介紹了。
4.執行緒安全問題
既然使用了執行緒,伴隨而來的還會有執行緒安全問題。
假如現在有這樣一個需求:用多執行緒執行查詢方法,然後把執行結果添加到一個list集合中。
程式碼如下:
List<User> list = Lists.newArrayList();
dataList.stream()
.map(data -> CompletableFuture
.supplyAsync(() -> query(list, data), asyncExecutor)
));
CompletableFuture.allOf(futureArray).join();
使用CompletableFuture非同步多執行緒執行query方法:
public void query(List<User> list, UserEntity condition) {
User user = queryByCondition(condition);
if(Objects.isNull(user)) {
return;
}
list.add(user);
UserExtend userExtend = queryByOther(condition);
if(Objects.nonNull(userExtend)) {
user.setExtend(userExtend.getInfo());
}
}
在query方法中,將獲取的查詢結果添加到list集合中。
結果list會出現執行緒安全問題,有時候會少數據,當然也不一定是必現的。
這是因為ArrayList是非執行緒安全的,沒有使用synchronized等關鍵字修飾。
如何解決這個問題呢?
答:使用CopyOnWriteArrayList集合,代替普通的ArrayList集合,CopyOnWriteArrayList是一個執行緒安全的機會。
只需一行小小的改動即可:
List<User> list Lists.newCopyOnWriteArrayList();
溫馨的提醒一下,這裡創建集合的方式,用了google的collect包。
5.ThreadLocal獲取數據異常
我們都知道JDK為了解決執行緒安全問題,提供了一種用空間換時間的新思路:ThreadLocal。
它的核心思想是:共享變數在每個執行緒都有一個副本,每個執行緒操作的都是自己的副本,對另外的執行緒沒有影響。
例如:
@Service
public class ThreadLocalService {
private static final ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public void add() {
threadLocal.set(1);
doSamething();
Integer integer = threadLocal.get();
}
}
ThreadLocal在普通中執行緒中,的確能夠獲取正確的數據。
但在真實的業務場景中,一般很少用單獨的執行緒,絕大多數,都是用的執行緒池。
那麼,在執行緒池中如何獲取ThreadLocal對象生成的數據呢?
如果直接使用普通ThreadLocal,顯然是獲取不到正確數據的。
我們先試試InheritableThreadLocal,具體程式碼如下:
private static void fun1() {
InheritableThreadLocal<Integer> threadLocal = new InheritableThreadLocal<>();
threadLocal.set(6);
System.out.println("父執行緒獲取數據:" + threadLocal.get());
ExecutorService executorService = Executors.newSingleThreadExecutor();
threadLocal.set(6);
executorService.submit(() -> {
System.out.println("第一次從執行緒池中獲取數據:" + threadLocal.get());
});
threadLocal.set(7);
executorService.submit(() -> {
System.out.println("第二次從執行緒池中獲取數據:" + threadLocal.get());
});
}
執行結果:
父執行緒獲取數據:6
第一次從執行緒池中獲取數據:6
第二次從執行緒池中獲取數據:6
由於這個例子中使用了單例執行緒池,固定執行緒數是1。
第一次submit任務的時候,該執行緒池會自動創建一個執行緒。因為使用了InheritableThreadLocal,所以創建執行緒時,會調用它的init方法,將父執行緒中的inheritableThreadLocals數據複製到子執行緒中。所以我們看到,在主執行緒中將數據設置成6,第一次從執行緒池中獲取了正確的數據6。
之後,在主執行緒中又將數據改成7,但在第二次從執行緒池中獲取數據卻依然是6。
因為第二次submit任務的時候,執行緒池中已經有一個執行緒了,就直接拿過來複用,不會再重新創建執行緒了。所以不會再調用執行緒的init方法,所以第二次其實沒有獲取到最新的數據7,還是獲取的老數據6。
那麼,這該怎麼辦呢?
答:使用TransmittableThreadLocal,它並非JDK自帶的類,而是阿里巴巴開源jar包中的類。
可以通過如下pom文件引入該jar包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.11.0</version>
<scope>compile</scope>
</dependency>
程式碼調整如下:
private static void fun2() throws Exception {
TransmittableThreadLocal<Integer> threadLocal = new TransmittableThreadLocal<>();
threadLocal.set(6);
System.out.println("父執行緒獲取數據:" + threadLocal.get());
ExecutorService ttlExecutorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(1));
threadLocal.set(6);
ttlExecutorService.submit(() -> {
System.out.println("第一次從執行緒池中獲取數據:" + threadLocal.get());
});
threadLocal.set(7);
ttlExecutorService.submit(() -> {
System.out.println("第二次從執行緒池中獲取數據:" + threadLocal.get());
});
}
執行結果:
父執行緒獲取數據:6
第一次從執行緒池中獲取數據:6
第二次從執行緒池中獲取數據:7
我們看到,使用了TransmittableThreadLocal之後,第二次從執行緒中也能正確獲取最新的數據7了。
nice。
如果你仔細觀察這個例子,你可能會發現,程式碼中除了使用TransmittableThreadLocal類之外,還使用了TtlExecutors.getTtlExecutorService方法,去創建ExecutorService對象。
這是非常重要的地方,如果沒有這一步,TransmittableThreadLocal在執行緒池中共享數據將不會起作用。
創建ExecutorService對象,底層的submit方法會TtlRunnable或TtlCallable對象。
以TtlRunnable類為例,它實現了Runnable介面,同時還實現了它的run方法:
public void run() {
Map<TransmittableThreadLocal<?>, Object> copied = (Map)this.copiedRef.get();
if (copied != null && (!this.releaseTtlValueReferenceAfterRun || this.copiedRef.compareAndSet(copied, (Object)null))) {
Map backup = TransmittableThreadLocal.backupAndSetToCopied(copied);
try {
this.runnable.run();
} finally {
TransmittableThreadLocal.restoreBackup(backup);
}
} else {
throw new IllegalStateException("TTL value reference is released after run!");
}
}
這段程式碼的主要邏輯如下:
- 把當時的ThreadLocal做個備份,然後將父類的ThreadLocal拷貝過來。
- 執行真正的run方法,可以獲取到父類最新的ThreadLocal數據。
- 從備份的數據中,恢復當時的ThreadLocal數據。
如果你想進一步了解ThreadLocal的工作原理,可以看看我的另一篇文章《ThreadLocal奪命11連問》
6.OOM問題
眾所周知,使用多執行緒可以提升程式碼執行效率,但也不是絕對的。
對於一些耗時的操作,使用多執行緒,確實可以提升程式碼執行效率。
但執行緒不是創建越多越好,如果執行緒創建多了,也可能會導致OOM異常。
例如:
Caused by:
java.lang.OutOfMemoryError: unable to create new native thread
在JVM中創建一個執行緒,默認需要佔用1M的記憶體空間。
如果創建了過多的執行緒,必然會導致記憶體空間不足,從而出現OOM異常。
除此之外,如果使用執行緒池的話,特別是使用固定大小執行緒池,即使用Executors.newFixedThreadPool方法創建的執行緒池。
該執行緒池的核心執行緒數和最大執行緒數是一樣的,是一個固定值,而存放消息的隊列是LinkedBlockingQueue。
該隊列的最大容量是Integer.MAX_VALUE,也就是說如果使用固定大小執行緒池,存放了太多的任務,有可能也會導致OOM異常。
java.lang.OutOfMemeryError:Java heap space
7.CPU使用率飆高
不知道你有沒有做過excel數據導入功能,需要將一批excel的數據導入到系統中。
每條數據都有些業務邏輯,如果單執行緒導入所有的數據,導入效率會非常低。
於是改成了多執行緒導入。
如果excel中有大量的數據,很可能會出現CPU使用率飆高的問題。
我們都知道,如果程式碼出現死循環,cpu使用率會飈的很多高。因為程式碼一直在某個執行緒中循環,沒法切換到其他執行緒,cpu一直被佔用著,所以會導致cpu使用率一直高居不下。
而多執行緒導入大量的數據,雖說沒有死循環程式碼,但由於多個執行緒一直在不停的處理數據,導致佔用了cpu很長的時間。
也會出現cpu使用率很高的問題。
那麼,如何解決這個問題呢?
答:使用Thread.sleep休眠一下。
在執行緒中處理完一條數據,休眠10毫秒。
當然CPU使用率飆高的原因很多,多執行緒處理數據和死循環只是其中兩種,還有比如:頻繁GC、正則匹配、頻繁序列化和反序列化等。
後面我會寫一篇介紹CPU使用率飆高的原因的專題文章,感興趣的小夥伴,可以關注一下我後續的文章。
8.事務問題
在實際項目開發中,多執行緒的使用場景還是挺多的。如果spring事務用在多執行緒場景中,會有問題嗎?
例如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
new Thread(() -> {
roleService.doOtherThing();
}).start();
}
}
@Service
public class RoleService {
@Transactional
public void doOtherThing() {
System.out.println("保存role表數據");
}
}
從上面的例子中,我們可以看到事務方法add中,調用了事務方法doOtherThing,但是事務方法doOtherThing是在另外一個執行緒中調用的。
這樣會導致兩個方法不在同一個執行緒中,獲取到的資料庫連接不一樣,從而是兩個不同的事務。如果想doOtherThing方法中拋了異常,add方法也回滾是不可能的。
如果看過spring事務源碼的朋友,可能會知道spring的事務是通過資料庫連接來實現的。當前執行緒中保存了一個map,key是數據源,value是資料庫連接。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
我們說的同一個事務,其實是指同一個資料庫連接,只有擁有同一個資料庫連接才能同時提交和回滾。如果在不同的執行緒,拿到的資料庫連接肯定是不一樣的,所以是不同的事務。
所以不要在事務中開啟另外的執行緒,去處理業務邏輯,這樣會導致事務失效。
9.導致服務掛掉
使用多執行緒會導致服務掛掉,這不是危言聳聽,而是確有其事。
假設現在有這樣一種業務場景:在mq的消費者中需要調用訂單查詢介面,查到數據之後,寫入業務表中。
本來是沒啥問題的。
突然有一天,mq生產者跑了一個批量數據處理的job,導致mq伺服器上堆積了大量的消息。
此時,mq消費者的處理速度,遠遠跟不上mq消息的生產速度,導致的結果是出現了大量的消息堆積,對用戶有很大的影響。
為了解決這個問題,mq消費者改成多執行緒處理,直接使用了執行緒池,並且最大執行緒數配置成了20。
這樣調整之後,消息堆積問題確實得到了解決。
但帶來了另外一個更嚴重的問題:訂單查詢介面並發量太大了,有點扛不住壓力,導致部分節點的服務直接掛掉。
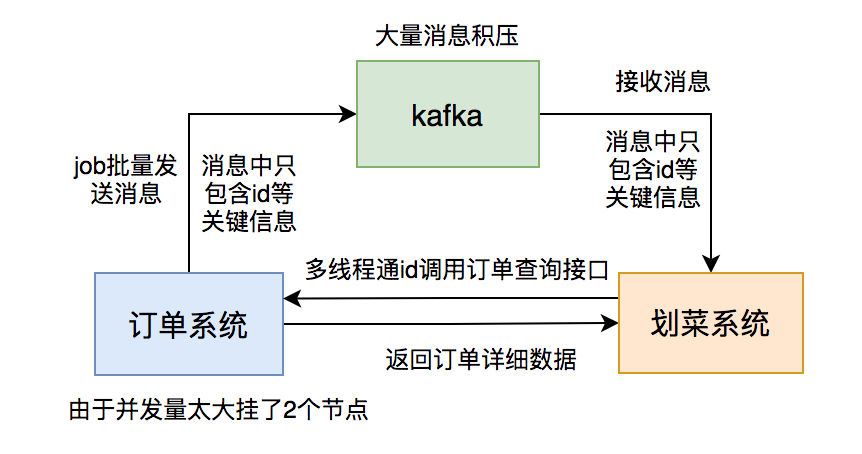
為了解決問題,不得不臨時加服務節點。
在mq的消費者中使用多執行緒,調用介面時,一定要評估好介面能夠承受的最大訪問量,防止因為壓力過大,而導致服務掛掉的問題。
最後說一句(求關注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發的話,幫忙掃描下發二維碼關注一下,您的支援是我堅持寫作最大的動力。
求一鍵三連:點贊、轉發、在看。
關注公眾號:【蘇三說技術】,在公眾號中回復:面試、程式碼神器、開發手冊、時間管理有超贊的粉絲福利,另外回復:加群,可以跟很多BAT大廠的前輩交流和學習。


