從 Delta 2.0 開始聊聊我們需要怎樣的數據湖
- 2022 年 8 月 12 日
- 筆記
盤點行業內近期發生的大事,Delta 2.0 的開源是最讓人津津樂道的,尤其在 Databricks 官宣 delta2.0 時拋出了下面這張性能對比,頗有些引戰的味道。
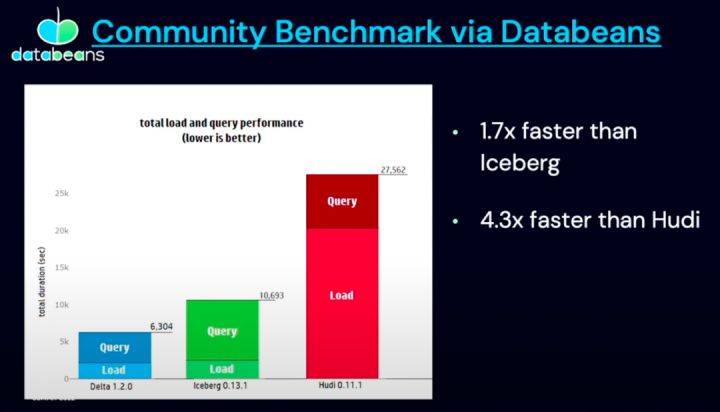
雖然 Databricks 的工程師反覆強調性能測試來自第三方 Databeans,並且他們沒有主動要求 Databeans 做這項測試,但如果全程看完 delta2.0 發布會,會發現在 delta2.0 即將開放的 key feature 中,特別列出了 Iceberg 到 Delta 的轉換功能,並且官方著重講到了 Adobe 從 Iceberg 遷移到 Delta2.0 的實踐,這就難免讓人浮想聯翩了。

過去兩年,我們團隊在新型數據湖技術的研究、探索和實踐上投入了大量精力,雖然我們主要投入的方向是 Iceberg,但 delta2.0 的開源,以及 Databricks 自身對 Iceberg 的重視,更加堅定了我們對數據湖,湖倉一體這個方向的信心,開源之爭,本質上是標準之爭,競爭會加速標準的確認和落地,而所有大數據的從業者都將從中獲益。
由於我們的工作更多將 Iceberg 當做一個底層依賴使用,在架構上具備解耦的可能,我們完全可以擁抱 Delta,所以這裡我想站在一個第三方立場上講講對 Lakehouse 這個方向,以及幾個主流開源產品的理解和思考,順帶也會簡單講講我們的工作,另外希望大家可以和我共同思考和探索下面這個問題:企業究竟需要怎樣的數據湖?
1 Table format 三強之爭
Table format 最早由 Iceberg 提出,目前已經成為行業共識的概念, table format 是什麼?簡單概括的話:
- Table format 定義了哪些文件構成一張表,這樣任何引擎都可以根據 table format 查詢和檢索數據;
- Table format 規範了數據和文件的分布方式,任何引擎寫入數據都要遵照這個標準,通過 format 定義的標準支援 ACID,模式演進等高階功能。
目前中國外同行將 delta、iceberg 和 hudi 作為數據湖 table format 的對標方案,我們先來聊聊 delta,iceberg,hudi 這三個開源數據湖的背景。
1.1 Delta
delta 是 databricks 公司在 2017 年立項、2018 年公布、2019 年開源的數據湖產品,可以看到 delta 立項時 databricks 已成立 4 年,經歷過幾次融資,並且在有條不紊地布局商業版圖,彼時 hadoop 發行版還不是公認難做的生意,delta 的誕生更像是 databricks 根據自身 spark 創始團隊的基因打造的核心競爭力,這樣也不難理解,為什麼 delta 1.0 幾乎不向其他引擎開放。
delta 的推出是為了解決傳統數據湖在事務處理,流計算,BI 分析上的不足,Databricks 用極強的講故事能力為 delta 打造了一個 lakehouse 的概念,時至今日,lakehouse 和湖倉一體的概念已經深入人心,甚至老對手 snowflake 也採納了這個概念,並且在官網中給出了更貼合自家產品的定義。在 2021 Gartener 資料庫領導力象限中,Databricks 和 snowflake 一起晉陞第一象限,lakehouse 也首次進入 hype cycle for data management,定位躍升期,依據 Gartner 的定義,lakehouse 技術距離完全成熟可能還有 3 – 5 年的時間。
按照 Databricks 的構想,delta1.0 作為 lakehouse 解決方案,可以讓數據湖更多,更快地作用於實時和 AI 場景,databricks 提出 delta 架構幫助用戶從 lambda 架構中解放出來,核心思想是數據湖既可以跑批,也可以跑流,流計算和批計算的流程和程式碼可以復用,這樣用戶沒有了維護 lambda 架構的負擔,當然計算引擎必須是 spark。遺憾的是 spark streaming 和 struct streaming 在中國用戶體量很小,絕大部分用戶對 delta1.0 是望梅止渴,對 spark 的深度綁定也一定程度上限制了 delta 社區的發展,給 iceberg 的崛起預埋了伏筆,截止 2022 Q1 社區活躍度的一個對比如下:

但另一方面,我們也絕不能忽略 Databricks 作為一家運營多年的商業公司,已有相當體量的付費用戶,再加上對 spark 社區的主導權,成熟的營銷和渠道能力,也許很容易重新建立開源上的優勢。
Delta 是 Lakehouse 的解決方案,Databricks 也被當做 lakehouse 的代表,但是 delta 這個項目自身的定義卻經歷了一些變化,我關注到去年某個時間點之前, delta 定義為 open format,引擎中可以直接用 delta 替換 parquet。
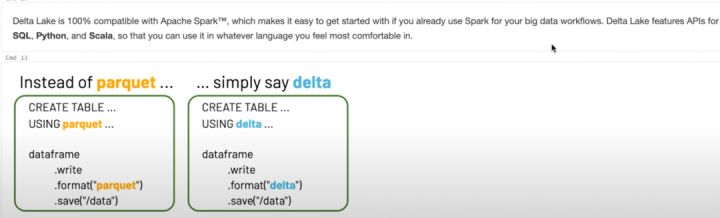
Format 的定義與 iceberg 的 table format 的定義非常相似,但在目前官網中,以及各種相關的分享和部落格中,再也見不到此類描述,目前 delta 被官方定義為 lakehouse storage framework,當然,無論 format 還是 framework,湯還是那個湯,只是菜譜更加豐滿了。
1.2 Iceberg
Iceberg 是由 Netflix 團隊研發並開源的數據湖 table format,創始人 Ryan Blue 是 spark,parquet,avro 的 PMC,在數據分析領域有非常豐富的經驗和人脈,co-fonder 中還有一位來自 Cloudera 的資深工程師,從時間線上看,iceberg 2018 年進入 apache 孵化,2020 年畢業,考慮到項目本身的研發周期,很難評判它和 delta 的時間先後,再加上創始人本身是活躍的 spark 貢獻者,兩個項目從一開始就高度相似。
從功能上看,套用知乎上的一句話:不能說非常相似,只能說一模一樣。從發展上看,iceberg 更加符合一個開源項目的氣質,早期這個項目更多是為了應對 Netflix 對大體量數據分析的需求,重點強調了以下的特性:
ACID 和 MVCC 的特性,讀數據時不會讀到寫入的不一致狀態:
- Data skipping,通過在 table format 這一層 skip 文件,在一些場景下 query 性能有較大提升
- Plan 時不像 hive 需要過多地依賴 namenode,對超大集群來說 plan 的性能有巨大提升
- 設計時更多考慮了 S3 上搭建 table format,讓 iceberg 成為數據湖上雲的一個很好選型
- Schema evolve 和 hidden partition,讓表的變更和維護變的更加輕鬆
創始人非常強調 iceberg 之於 hive 的優勢,並且切實戳中了開發者,尤其有上雲需求的用戶痛點,很多圈內人提出 iceberg 會成為下一代的 hive,iceberg 引擎平權的特性,進一步促進了外圍廠商的認同,目前公開資訊可以了解到 Cloudera 主推 iceberg;snowflake 上支援 iceberg 外表;starrocks 支援 iceberg 外表;Amazon Athena 可以使用 iceberg 表,與 delta 相比,iceberg 的出身更加純粹,被各家追捧也不奇怪,雖然 delta 2.0 也開始吸引 spark 之外的引擎開發者參與,但追趕目前 iceberg 的外圍生態還需要一定的時間。
我本人是在 2020 年接觸 iceberg,當時在為 flink 尋找比 hive 更好的數據湖方案,以解決 upsert, 以及批流場景開發和運維割裂的問題,當時 iceberg 和 hudi 都在孵化,delta 依然是 spark 的 delta,而 hudi 當時也是一個 spark lib,只有 iceberg 讓人眼前一亮,iceberg 也是最早支援 flink connector。
Iceberg 社區對 roadmap 一直很克制,任何對底層表格式的修改都慎之又慎,保障了對任何引擎都足夠友好,操作的可擴展性和 row-level api 則給開發者留足了想像空間,在引擎平權方面,iceberg 是獨樹一幟的,未來怎麼樣值得我們持續觀察。
1.3 Hudi
Hudi 開源和孵化的時間線與 iceberg 比較相近,回溯開源之初,hudi 的全稱是 hadoop upsert and incremental,核心功能是在 hadoop 上支援 upsert 和 incremental process,發展至今,hudi 已經不再局限於 hadoop 以及名字上的兩個功能,hudi 不強調自己的數據 format,經過幾次大的迭代,對自己的定義變地有些複雜,打開官網我們會看到這樣的描述:
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer while being optimized for lake engines and regular batch processing.
可以看出 hudi 想干很多事,並且給自己建立了像資料庫一樣的目標,這個目標的達成有很長的路要走。Hudi 在三個項目中最早提供 stream upsert 能力 ,如果不做二次開發,hudi 是開箱即用的數據湖 upsert 方案,並且 hudi 社區對開發者非常開放,和 iceberg 專註又謹慎的調性可謂兩個極端,但 hudi 大版本之間的變化很大,這個方面先壓下不表,有機會專門開個文章聊聊。
最早的時候 hudi 只有 spark 下的實現,為了支援 flink 在重構方面社區下了很大的功夫(delta 類似),這也是 2020 年沒有選擇 hudi 的最重要原因,在 hudi 的核心團隊創業成立 Onehouse 之後,hudi 的定位明顯和其他兩家產生了較大的分化,databricks 作為一家商業公司,delta 是他吸引流量的重要手段,商業化上再通過上層的數據開發,治理和 AI platform 變現,同理從公開資訊看, Ryan Blue 成立的 Tabular 也是在 iceberg 之上構建 platform,和 table format 涇渭分明。而 hudi 自身已經將自己拔到 platform 的高度,雖然功能上還距離很遠,但可以預見長期的 roadmap 會產生較大不同。
出於競爭的考慮,delta 和 iceberg 有的,hudi 可能都會跟進,所以 hudi 也可以作為 table format 來使用。當我們為企業做技術選型時,需要考慮是選擇一個純凈的 table format 整合到自己的 platform 中,還是選擇一個新的 platform 或者將 platform 融合。
2 Iceberg 背刺與 delta2.0 的反擊
現在下判斷,為時尚早。
如果一定要對比,我更加喜歡對比 delta 和 iceberg,因為 hudi 的願景和前兩個有較大的不同,換句話說,就 table format 而言,delta 和 iceberg 可能更懂要做什麼,就懂的層面兩講,iceberg 我認為更勝一籌。拿最近 delta 2.0 發布的內容來看,有興趣的同學可以去看下 Databricks 官方舉辦的 Data + AI summit 2022 的 相關分享。
發布會重點提及的功能總結如下:
- Data skipping via column stats:通過 format 級別的元數據做 data skipping
- Optimize ZOrder:這個應該是 delta 一直有的功能,只是在 2.0 中正式開源了
- Change data feed:支援 UPDATE/DELETE/MERGE INTO 下的 CDC 功能
- Column mapping:delta 也能像 iceberg 一樣模式演進了,功能上相差不大
- Full ACID guarantees on S3:在提交階段引入 DynamoDB,在 S3 上也能保障 ACID
- Flink、presto、trino connector:重點強調了 flink 和 trino,connector 和 delta 項目分開管理
- Delta standalone:我理解是提供了一層 format api,像 iceberg 一樣不用通過引擎也可以操作數據
對 Iceberg 不太了解的同學,可以去看下 iceberg 官網,引用上文中的一句話,不能說非常相似,只能說一模一樣,而且大部分功能在 2 年前的 iceberg 中已經相當成熟了。
在發布會後段,Databricks 工程師重點介紹了:
- Adobe 公司從 iceberg 到 delta 的遷移實踐,對 iceberg 的重視可謂是寫在臉上了
- Delta 不只是 databricks 公司貢獻,2.0 中也 involve 了來自 flink,trino 社區的開發者,不過引擎開發者貢獻的部分單獨在一個 connector 項目,與 delta 的主體區分開,未來在引擎平權方面能不能做到或超越 iceberg,還需要觀察
- 引用第三方 Databeans 的測試,delta 2.0 性能比 iceberg 快 1.7 倍,比 hudi 快 4.3 倍
我們團隊也用 benchmark 工具對 delta2.0 和 iceberg 進行了對比,測試方案是在 trino 下測試 100 個 warehouse 的 tpch(測試工具實際是為測 stream lakehouse 量身訂製的 chbenchmark,下文也有提及),當我們採用 delta 和 iceberg 開源版本默認的參數,對比下來 delta 確實驚艷,平均響應時間 delta 比 iceberg 快 1.4 倍左右,但我們注意到默認參數中有兩個重要的區別:
- Trino 下 delta 和 iceberg 的默認壓縮演算法不同,trino 寫入 iceberg 默認的壓縮演算法是 ZSTD,而寫入 delta 默認的壓縮演算法是 SNAPPY,ZSTD 具有比 SNAPPY 更高的壓縮比,通過實際觀測 ZSTD 壓縮出來的文件大小只有 SNAPPY 大小的 60%,但是在查詢時 SNAPPY 對於 CPU 更友好,查詢效率更高;
- Delta 和 iceberg 默認 read-target-size 不同,delta 默認 32m,iceberg 默認 128m,plan 階段組裝更小的文件可以在執行計劃採用更多並發度,當然這會帶來更多資源消耗,從實踐上看 32m 的文件大小對響應時間敏感的數據分析而言或許是更好的選擇。
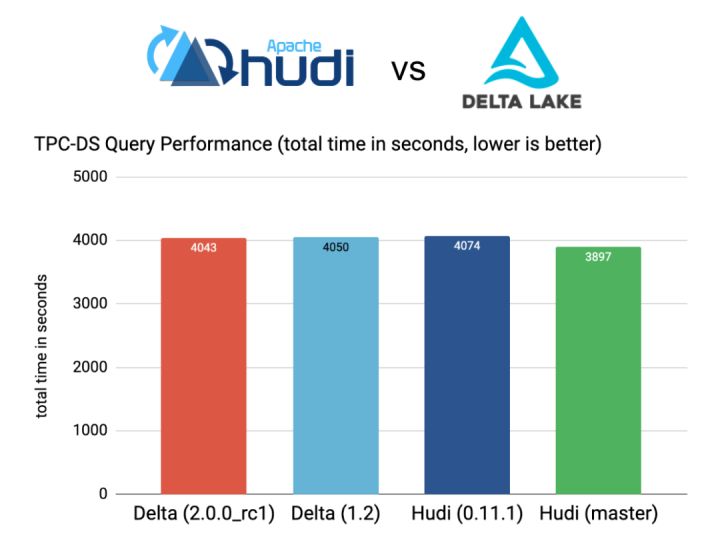
將 delta 和 iceberg 的壓縮演算法設置相同,read-target-size 設置為 32m,實測下來 tpch 平均響應時間不再有差別,從原理上看,排除佔比極低的元數據讀取和 plan 時間,在相同的配置下,benchmark 測試的主要是 parquet 這類文件格式的 IO 性能,沒有差異是比較合理的。後續 Onehouse 在性能測試上給出的 回擊 也佐證這一點:
作為一名相關從業者,Delta2.0 的完全開源是一件振奮人心的事,幾乎可以下結論,delta2.0 和 iceberg 重疊的功能,會成為數據湖 table format 的事實標準,在這個方向上提前投資的產品和開發者有可能更快地收穫果實。
至於誰更優秀?iceberg 的開放,專註和執行力讓人嘆服,delta 的影響力,商業資源和成熟度不可忽略。從功能和外圍生態看,iceberg 依然有至少 1-2 年的先發優勢,但是生長在 iceberg 上原汁原味的 Tablur 還沒影,delta 的平台背書本就超強,再向其他引擎開放了 connector 和 API 之後,相信開源的貢獻者和影響力也會同步跟進,期待 delta 社區在活躍度上可以迎頭趕上。
3 新技術推廣的困局
作為一名基礎軟體工程師,自底向上倒逼需求是非常艱難的,想要業務團隊切換基礎軟體可能同時需要天時地利人和,而研究數據湖的同學相信在過去兩年推動業務時多少會遇到力不從心的局面,這裡我來分享一些我的理解。
我們將目前數據湖 Format 已經形成的標準能力做一個小結:
- 結構自由,用戶可以自由變更表結構,包括加列改列刪列,數據無需重寫
- 讀寫自由,通過 commit 原語保障 ACID,可以並發寫入和讀取,不會讀寫到不一致狀態
- 流批同源,除了批讀和批寫外,通過增量讀和流式攝取支援流計算
- 引擎平權,支援大部分用戶會用到的主流計算引擎,包括 flink、spark、trino 等
現在用戶使用數據湖,基本是在一個成熟的數據生產力平台中使用,代表有阿里 Dataworks,網易數帆有數平台,借用同事對網易大數據業務過去十年的發展實踐,大體分為三個階段:
- 大數據平台:能夠在 Hadoop 平台上開發工作流,支援基礎的數據開發和運維,有一定數據治理能力。
- 數據中台:將數據業務的更多共性需求抽象到中台層,圍繞業務主題域構建指標體系,並打通數據模型、數據開發運維、為業務構建許可權和品質評估體系,資產平台為業務提供更高階的數據治理能力。
- 3D 平台:我們從數據中台,升級到 Dataops,Datafusion,Dataproduct 的 3D 體系,3D 更加強調體系化和流程標準化,強調 CICD,強調多數據源融合。
在市面上除了阿里,數據生產力平台基本還是圍繞 Hadoop,Hive 的數據湖體系,或者雲端的對象存儲來構建,相比於 Delta,Iceberg 這類數據湖 Format,Hive 和對象存儲的結構不自由,讀寫不自由的問題基本已通過流程規範和上層規避克服掉了。在新數據湖技術興起階段,大家津津樂道的模式演進, ACID,對一個成熟的數據生產力平台以及它所面向的平台運維,數據消費者,分析師基本無感,而引擎平權的特性,hive 自己已經做到了最佳。
至於流批同源,在實踐中歸納起來有以下兩點:
- 用數據湖 CDC 替代消息隊列,理論上能夠帶來成本收益,但也會引入小文件問題;
- 數據湖 + 讀時合併,在一定程度上對 kudu,clickhouse,doris 等實時數倉方案形成替代方案。
總體來說,以上兩點是行業內討論最多的數據湖實踐,但這套技術在實踐上客觀說還不夠成熟,比如說用數據湖 CDC 替代 kafka,延遲降低到分鐘級別,先不說產品的適配成本,業務接受這種能力降級往往需要比成本優化更充分的理由,而且數據湖 CDC 還會引入小文件問題。對讀時合併這點,我們測試下來,用流式攝取方式往 iceberg 表寫入兩個小時,AP 的性能下降至少一半。當然 delta/iceberg 帶來的新功能不止於此,比如模式演進對特徵的場景非常有用,MERGE INTO 的語法對補數的場景非常有用,UPDETE/DELETE SQL 對國外 GDPR/CPAA 的執行是強需求,但這些特性比較細,往往只是對特定場景有吸引。
兩年來我們跟不少同行做實踐上的交流,大家大體上遇到的都是這樣的問題:業務吸引不夠,相比替代方案好像沒有帶來質的提升;產品適配意願不強,三個項目都很牛,但似乎看不到能給產品帶來什麼實質的好處,又怕站錯邊選錯路;疊加經濟形勢下行,業務風險偏好降低,對新技術也沒那麼上心了。
所以當我們真正把新的數據湖技術應用到產品和實踐中,不妨先自頂向下地思考這個問題:企業究竟需要怎樣的數據湖?
4 企業需要怎樣的數據湖?
這個問題其實 Databricks 已經給了我們答案,Delta 用一套數據湖存儲,將批計算和流計算融合,將傳統數倉在數據分析上的優勢,數據湖在 AI,數據科學上的優勢結合起來,基於 Lakehouse 這個存儲底座,實現數據業務的全場景覆蓋。總結為一點,Delta 給 Databricks 帶來的價值是用一套基礎數據湖軟體,實現全場景覆蓋。
那麼這套方法論適用於其他企業嗎?我認為答案是肯定的,但是要稍作修改,首先 Databricks 公司做這個項目比較早,並且是作為一個戰略型項目來做,它的產品,上層建築一定是同步跟進的,這也讓他的整套 platform 受益於 Lakehouse 非常簡潔,而大部分企業用戶歷史負擔要重很多,產品適配牽一髮動全身。
另一方面,中國基本上實時計算用 Flink,這裡不評價 Flink 和 Spark 哪個更好,現實是絕大多數企業不會綁定一個計算引擎,這也是為什麼引擎平權對數據湖極為重要,重要到 Delta 也不得不妥協,不同引擎的應用可以吸收各家優勢,但會帶來產品割裂的問題,主流大數據平台的供應商大多把實時計算作為一個單獨的產品入口,當然這背後的原因不光是引擎的問題 ,最重要的依然是存儲方案的不統一。產品割裂在大數據方法論的迭代中被更加放大,比如在數據中台中,指標系統,數據模型,數據品質,數據資產這一套中台模組基本是圍繞離線場景打造,而在強調 CICD 的 Dataops 中,流計算的需求和場景因為存儲和計算的不統一更加難以被納入考量。
這個狀況的直接結果是實時數倉,流計算對應的場景和需求在大數據平台的方法論迭代中被邊緣化,用戶無法在實時場景下體驗到數據安全,數據品質,數據治理帶來的收益,變本加厲的是,很多既需要實時也需要離線的場景下,用戶需要維護流表和批表兩套模型,兩套程式碼,並且時刻警惕語義和模型的二義性。
了解了 Lakehouse 意義,立足於現實,以網易數帆為例,新的數據湖技術應當幫助 dataops 拓展邊界,讓數據開發和運維,數據治理的整套體系囊括實時和 AI 的場景,流批一體的數據湖肩負著為業務實現去 lambda 的架構,產品的交互和體驗應當更加簡潔和高效,讓演算法分析師,數據科學家,對時效性更加敏感的風控等場景也能按照 Dataops 的標準和規範快速上手,可以用數據治理的方法論優化成本。
聊到這裡,可能會覺得越來越抽象,我們來舉一個數據分析的 lambda 架構:
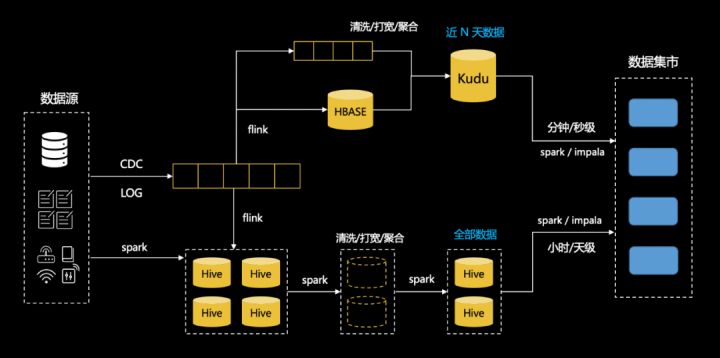
場景中用 Hive 做批表,kafka 做流表,整個離線遵循數據中台和 Dataops 的方法論,實時場景下需要用戶構建同步到 hbase 的流計算任務,需要用戶實現 join hbase 維表的流計算任務,把數據寫到支援實時更新的 kudu 中,最後由業務根據實時和離線的需要選擇查詢 kudu 表還是 hive 表,在此之前,用戶需要分別在數據模型中建表,使用 kudu 的工具建表,並且自己處理兩個系統的差異。在這個架構中,用戶遭受了割裂的體驗,並且需要在上層做很多工作。
企業需要的數據湖,應當能夠幫助業務解決割裂的問題,用數據湖實現 ETL 、data pipeline 以及 olap 全流程,實現下面的效果:
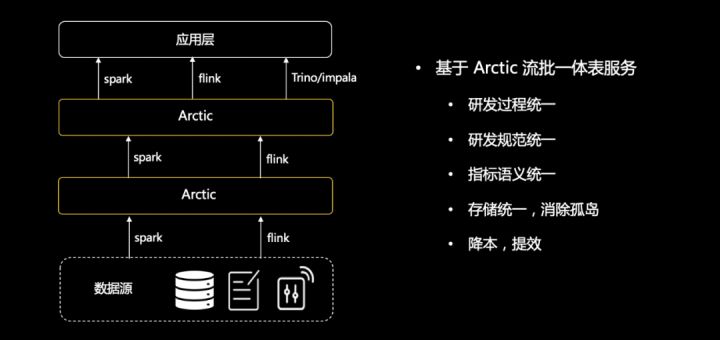
因為實時和離線使用了一套模型,在理論上已經可以將中台和 dataops 的很多能力應用到實時場景中,比如數據品質,當然這個過程中還需要在細節上做出更多的創新。核心的一點,數據湖技術的應用和推廣不應當立足在某個或某些特定功能之上,應當結合數據平台的方法論全局來看,讓數據分析、AI、流計算各個場景各個環節都能從中受益。
5 我們的工作
在這樣的目標驅動下,過去兩年我們團隊開發了 Arctic 這個項目,並且在 7 月底默默開源了。
首先,我們的工作不是另起爐灶,做一個跟 delta/iceberg 競爭的產品,這不符合企業的需求,Arctic 是立足於開源數據湖 Format 之上的服務,如前文所說,目前我們基於 iceberg。
其次,我們的目標要將 Dataops 的邊界拓展到流計算,所以 Arctic 會為用戶提供更加優化的流的能力,包括 stream upsert,CDC,生產可用的讀時合併技術,提供分鐘級別新鮮度的數據分析能力,用一句話概括,Arctic 是適配多引擎的流式湖倉服務:
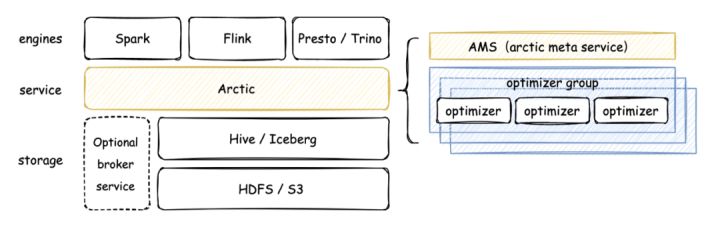
通過 Arctic 的幾個核心特性可以看出我們是怎麼聚焦於拓展大數據平台的邊界。
- Arctic 具備持續自優化的能力(self-optimized)
- 提供 hive 或 iceberg 兩種兼容模式,可以把一張 Arctic 表當成開源的 hive 表或 iceberg 表來使用,用戶永遠不用擔心 iceberg 的新功能用不上,也不用擔憂老業務的 hive 表不能使用 Arctic 功能
- 支援多引擎並發寫入,並且保障主鍵場景下的數據一致性,流和批各寫各的,arctic 會解決相同主鍵寫入的數據衝突
-
提供實時數據湖的標準化 metrics 和管理工具,並且向平台提供 thrift API
Arctic 作為服務可以去適配不同的數據湖 Format,這樣產品無需擔心數據湖技術的選型問題,持續自優化的能力讓數據分析即插即用,平替實時數倉,兼容模式則可以讓產品在選型上更加沒有後顧之憂,實踐中可以針對性的設計升級和灰度方案,並發衝突解決和一致性讓數據流管理變的簡單。性能也是 Arctic 非常關注的點,尤其在讀時合併方面,我們做了大量工作,面向流式湖倉性能測試工具我們做出了針對性的方案,這塊的工作今年晚些時候我們也會向大家開放,簡單來說,我們使用 HTAP 的 chbenchmark 思路,tpcc 持續寫入的數據通過 FlinkCDC 流式寫入 arctic 和 hudi,benchmark 的測試結果用 tpch 來衡量,測試的對象是 olap 場景下的讀時合併性能,arctic 和 hudi 的數據新鮮度都設置為 1 分鐘,目前 arctic 開源版本測試結果如下(數值越小性能越好):
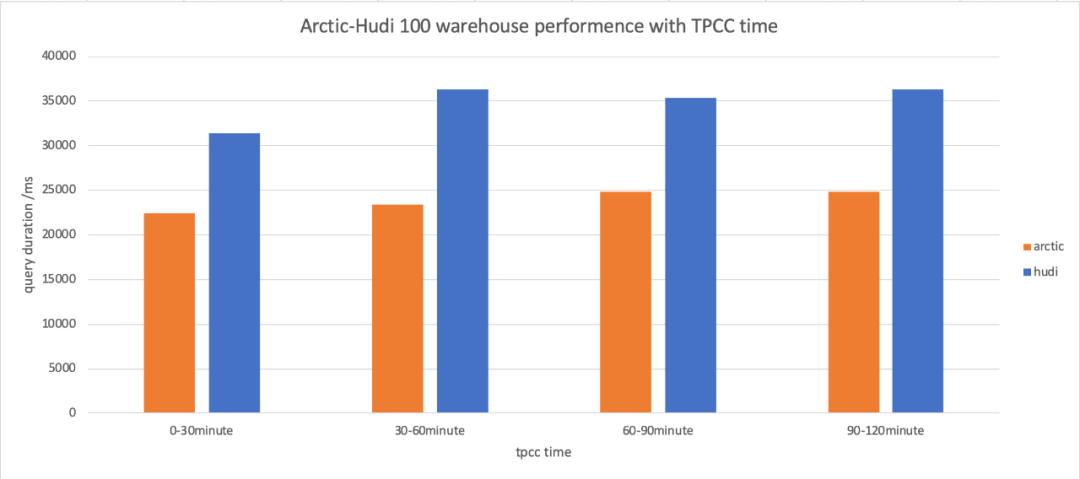
測試方案、環境和配置會在 Arctic 的官網中公開,同時我們將在 8 月 11 號的分享中公布更多 benchmark 的細節,感興趣的同學,或者對測試結果有疑問,歡迎參加我們的發布會了解更多資訊。
雖然我們在 table format 之上,引擎之下做了很多優化工作,但 Arctic 不會魔改 format 的內部實現, Arctic 依賴的都是社區發布的 release 包,未來 Arctic 也將堅持這一點,並通過 format 兼容的特性為用戶帶來最佳的方案。
我們在 2022 年 8 月 11 日在線上舉辦了一個簡單的發布會(點擊即可觀看Arctic開源發布會),我花 30 分鐘左右的時間講了講 Arctic 的目標、特性、規劃,以及可以給開源用戶帶來的價值。從調性上看,Arctic 作為基礎軟體會是一個完全開源的項目,相關商業化(如果有)會由另外的團隊推進,未來條件允許的情況下我們也會積極推動項目向基金會的孵化。
如果你對 Arctic 的定位、功能,或者任何與他相關的部分感興趣,歡迎觀看我們的直播或錄播。
6 總結
Delta2.0 的發布,標誌著數據湖 table format 標準開始走向明確,delta、iceberg 和 hudi 的競爭變得白熱化的同時,企業以及相關的供應商應當開始認真考慮怎樣引入數據湖 table format 技術,給平台用戶帶來 Lakehouse 的最佳實踐。
Lakehouse 給企業帶來的價值,應當是用一套數據湖底座,拓展數據平台的邊界,改善產品、數據孤島和流程規範割裂帶來的低效和成本浪費,首先要做的,是將圍繞傳統離線數倉打造的數據中台,或者衍生的 Dataops 方法論,拓展到實時場景,未來的數據產品方法論,在 Lakehouse 以及相關技術的推動下,相信會向流批融合的大方向上大步前進。
但是企業和開發者需要理解,開源的數據湖 Format 不等價於 Lakehouse,包括創造出 Lakehouse 這個概念的 Databricks 自己,也從未將 Delta 與 Lakehouse 劃等號,如何幫助企業構建 lakehouse,是我們此次開源 Arctic 項目的意義,Arctic 目前的定位是流式湖倉服務,流式強調向實時能力的拓展,服務則強調管理,標準化度量,以及其他可以抽象到基礎軟體中的 lakehouse 能力。以 Arctic 持續自優化的功能舉例:
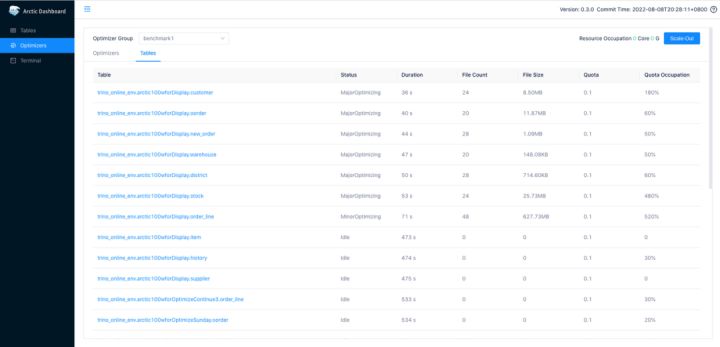
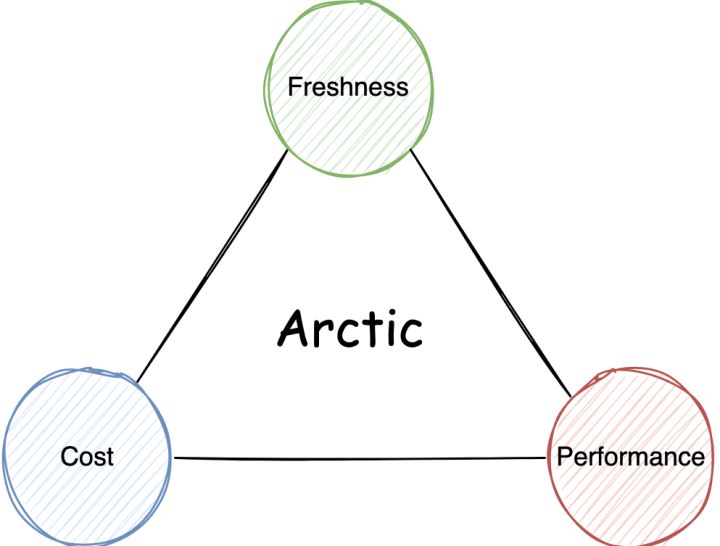
Arctic 為管理員和開發者提供了持續優化的度量和管理工具,以幫助用戶實現時效性,存儲和計算成本的測量,標定和規劃。進一步說,在以數據湖構建的離線場景中,成本和性能呈非常線性的關係,當性能或容量不足時,SRE 只需要考慮加多少機器。而當我們將數據湖的能力拓展到實時場景,成本,性能和數據新鮮度的關係將呈現更為複雜和微妙的狀態,Arcitic 的服務和管理功能,將為用戶和上層平台理清這一層三角關係:
作者簡介
馬進,網易數帆大數據實時計算技術專家、湖倉一體項目負責人,負責網易集團分散式資料庫,數據傳輸平台,實時計算平台,實時數據湖等項目,長期從事中間件、大數據基礎設施方面的研究和實踐,目前帶領團隊聚焦於流批一體、湖倉一體的平台方案和技術演進,及流式湖倉服務 Arctic 項目開源。


