主流前沿的開源監控和報警系統Prometheus+Grafana入門之旅
Prometheus概述
定義
Prometheus 官網地址 //prometheus.io/
Prometheus 官網文檔地址 //prometheus.io/docs/introduction/overview/
Prometheus GitHub地址 //github.com/prometheus/prometheus
Prometheus是一個開源的系統監控和警報工具包,最初由SoundCloud開發的,社區活躍,2016年加入了雲原生計算基金會成為繼Kubernetes之後的第二個託管項目;普羅米修斯以時間序列數據的形式收集並存儲度量值;大部分模組由Go語言編寫的。最新版本v2.37.0
特性
- 多維數據模型,時間序列數據由指標名稱和鍵/值對標識。
- PromQL靈活的查詢語言。
- 不依賴於分散式存儲,單個節點自治。
- 時間序列收集通過拉模型基於HTTP。
- 基於網關實現採集監控指標數據的推送。
- 目標通過服務發現或靜態配置。
- 多種模式的圖形化和儀錶板支援。
- 支援分層和水平聯合。
組件
- Prometheus伺服器:用於抓取和存儲時間序列數據。
- Prometheus本身是一個以進程方式啟動,之後多進程和多執行緒實現監控數據收集,計算,查詢,更新,存儲的咋樣一個C/S模型運行模式。
- Prometheus採用的是time-series(時間序列)的方式以一種自定義的格式存儲在本地硬碟上。
- Prometheus的本地T-S(time-series)資料庫以每兩小時為間隔來分block(塊)存儲,每一個塊中又分為多個chunk文件,chunk文件是用來存放採集過來的T-S數據,metadata和索引文件(index)。
- index文件,是對metrics(Prometheus中一次K/V採集數據,叫做一個metric)和labels(標籤)進行索引,之後存儲在chunk中,chuunk是作為存儲的基本單位,index and metadata是作為子集。
- Prometheus平時是將採集過來的數據,先都存放在記憶體之中(Prometheus對記憶體的消耗還是不小的),以類似快取的方式,用於加快搜索和訪問
當出現宕機時,Prometheus有一種保護機制叫做WAL,可以將數據定期存入硬碟中,以chunk來表示,並在重新啟動時,用以恢復進入記憶體。
- 客戶端庫:編寫自定義收集器從其他系統提取指標,並將指標公開給普羅米修斯。
- Pushgateway:網關,支援短周期的監控指標推送。
- exporters:用於HAProxy, StatsD, Graphite等服務的特殊用途採集。
- alertmanager:處理各種警報支援工具。
架構
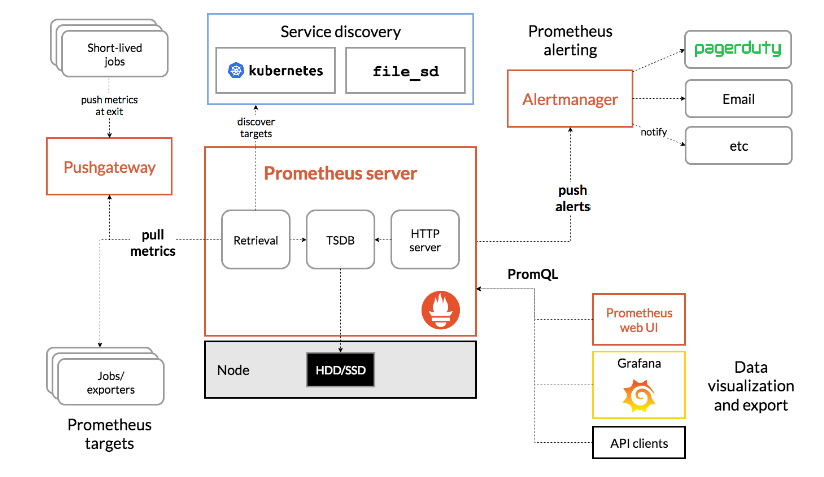
Prometheus可以通過exporters直接拉取監控指標,或者通過Pushgateway獲取短期任務推送監控數據,數據存儲在Prometheus服務端本地,基於存儲時間序列的數據上運行分析、聚合、生成警報。可以使用Grafana或其他API消費者對收集的數據進行可視化。普羅米修斯可以很好地記錄任何純數字的時間序列,它既適合以機器為中心的監視,也適合高度動態的面向服務的體系結構的監視,特別擅長於微服務和容器下多維數據收集和查詢。也適合對可靠性要求高場景,每個Prometheus伺服器都是獨立的,不依賴於網路存儲或其他遠程服務。
優勢
- 相比其他老款監控的不可被替代的巨大優勢,功能更加強大
- 監控數據的精細程度高,可以精確到1~5秒的採集精度,是其他監控系統無法企及的。
- 集群部署的速度,監控腳本的製作(指的是熟練之後)非常快速,大大縮短監控的搭建時間成本,周邊插件很豐富大多數都不需要自己開發了。
- 本身基於數學計算模型,大量的實用函數可以實現很複雜規則的業務邏輯監控(例如QPs的曲線彎曲凸起下跌的比例等等模糊概念)。
- 可以嵌入很多開源工具的內部進行監控數據更準時更可信(其他監控很難做到這一點)。
- 本身是開源的,更新速度快,bug修復快·支援N多種語言做本身和插件的二次開發。
- 圖形很高大上很美觀老闆特別喜歡看這種業務圖(主要是指跟 Grafana的結合)。
對運維要求
- 要求對作業系統有很深入紮實的了解,不能只是浮在表面。
- 對數據思維有一定的要求,因為它基本的內核就是數學公式。
- 對監控的經驗有很高的要求,很多時候,監控項需要很細的訂製。
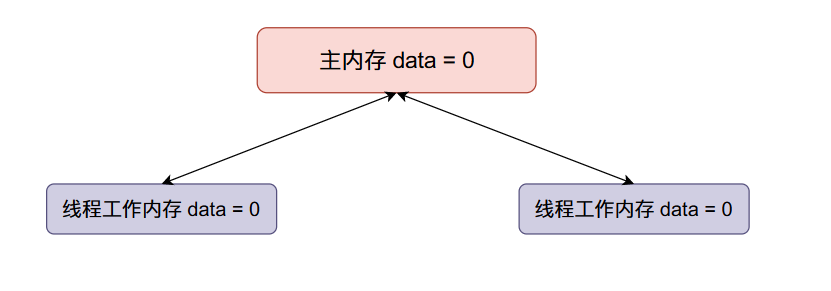
數據模型(DATA MODEL)
從根本上說,Prometheus將所有數據存儲為時間序列:帶有時間戳的數據流屬於同一度量標準和同一組標記維度。除了存儲的時間序列,Prometheus還可以生成臨時的派生時間序列作為查詢的結果。
- 度量名稱和標籤(Metric names and labels):每個時間序列由其度量名稱和可選的鍵值對(稱為標籤)唯一標識。
- 樣本(Samples):樣本構成實際的時間序列數據。每個樣本包括,float64值和毫秒精度的時間戳。
- 標記(Notation):給定一個度量名稱和一組標籤,時間序列經常使用以下符號來標識。
工作和實例(JOBS AND INSTANCES)
在Prometheus術語中,可以抓取的端點稱為實例,通常對應於單個進程。具有相同目的的實例集合,例如為了可伸縮性或可靠性而複製的進程,稱為作業。
例如一個有四個複製實例的API伺服器作業
- job:api-server
- instance 1:
1.2.3.4:5670 - instance 2:
1.2.3.4:5671 - instance 3:
5.6.7.8:5670 - instance 4:
5.6.7.8:5671
- instance 1:
自動生成標籤和時間序列,當Prometheus抓取目標時,它會自動在抓取的時間序列上附加一些標籤,用於識別被抓取的目標:
- job:配置的目標所屬的作業名稱。
- instance:被抓取的目標URL的
: 部分。
指標度量(metrics)
Prometheus監控中,對於採集過來的數據,統一成為metrics數據,metrics已經相信大家都已耳熟,當我們需要為某個系統某個服務做監控、做統計,就需要用到metrics。metrics是一種對採集數據的總稱(metrics並不代表某一種具體的數據格式,是一種對於度量計算單位的抽象)
Prometheus客戶端庫提供了四種核心度量類型;目前僅在客戶端庫(以支援針對特定類型的使用進行訂製的api)和連接協議中區分這些類型。Prometheus伺服器還沒有使用類型資訊,並將所有數據扁平化為無類型的時間序列;常見使用的就是counter、gauges和histogram
- Gauges
- 最簡單的度量指標,只有一個簡單的返回值,或者叫瞬間狀態,舉個例子:要監控硬碟容量或者記憶體的使用量,那麼就應該使用Gauges的metrics格式來度量。
- 因為硬碟的容量或者記憶體的使用量是隨著時間的推移,不過的瞬時變化這種變化沒有規律,當前是多少採集回來就是多少,既不能肯定是一直持續增長,也不能肯定是一直降低,這種就是Gauges使用類型的代表。
- Counter
- Counter計數器,從數據量0開始累積計算,在理想狀態下,只能是永遠的增長,不會降低(一些特殊情況另說).舉個例子:比如對用戶訪問量的取樣數據,產品被用戶訪問一次就是1,過了10分鐘後,累積到100過一天後,累積到20000一周後,積累到100000。
- Histograms
- Histogram統計數據的分布情況,比如最小值,最大值,中間值,還有中位數,75百分位,90百分位,95百分位,98百分位,99百分位,和99.9百分位的值(percentiles)。這是一種特殊的Metrics數據類型,代表的是一種近似的百分比估算數值。
- 可以通過Histogram類型(prometheus中,其實提供了一個基於histogram演算法的函數,可以直接使用)可以分別統計出,全部用戶的響應時間中~=0.05秒的量有多少 0 ~ 0.05秒的有多少, > 2秒的有多少 > 10 秒的有多少 = 1%多少處於速度極快的用戶,多少處於慢請求或者有問題的請求。
- Summary
- 與直方圖類似,摘要取樣觀察結果(通常是像請求持續時間和響應大小這樣的東西)。雖然它還提供了觀測的總數和所有觀測值的總和,但它在滑動時間窗口中計算可配置的分位數。
函數
Prometheus的查詢提供很多內置的函數,這些函數後續在實戰使用到再說,可以在使用查閱官網文檔說明,比如
- rate() 函數:就是是專門搭配counter類型數據使⽤的函數,它的功能是按照設置⼀個時間段,取counter在這個時間段中的平均每秒的增量。
- increase():increase 函數 在promethes中,是⽤來 針對Counter 這種持續增長的數值,截取其中⼀段時間的增量。
Prometheus部署
Docker部署
# 掛載配置文件方式部署,準備prometheus.yml文件,可以從二進位文件拷貝,默認配置無需修改,或者從github中獲取,這裡暴露埠我改為9080,本機已有9090的服務
docker run \
-p 9080:9090 \
-v /home/commons/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
# 掛載配置目錄方式部署
docker run \
-p 9090:9090 \
-v //home/commons/prometheus/config:/etc/prometheus \
prom/prometheus
查看docker容器進程

訪問//192.168.50.95:9080/ 出現prometheus的控制台頁面
二進位部署
# 下載最新版本v2.37.0的prometheus server
wget //github.com/prometheus/prometheus/releases/download/v2.37.0/prometheus-2.37.0.linux-amd64.tar.gz
# 解壓文件
tar -xvf prometheus-2.37.0.linux-amd64.tar.gz
# 進入目錄
cd prometheus-2.37.0.linux-amd64
# 後台運行prometheus server,可通過nohup &之類或後台運行管理工具如daemonize、screen
nohup ./prometheus > prometheus.log 2>&1 &
默認情況下無需修改prometheus根目錄下的prometheus.yml配置文件就可啟動
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# scrape_interval. 抓取采詳數據的時間間隔,默認每15秒去被監控機上采詳一次,這個就是我們所說的Prometheus的自定義數據採集頻率
# evaluation_interval. 監控數據規則的評估頻率,默認為15秒,這個參數是Prometheus多長時間會進行一次監控規則的評估,假如設置當記憶體使用量 > 70%時,發出報警,這麼一條rule(規則),那麼Prometheus會默認每15秒來執行一次這個規則,檢查記憶體的情況。
# Alertmanager configuration 這個是Alertmanager是Prometheus的一個用於管理和發出報警的插件
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
# 在這個Jobs 的名字下面,具體來定義,要被監控的節點,以及節點上具體的埠資訊等等,如果Prometheus配合,例如consul這種服務發現軟體,Prometheus的配置文件,就不在需要人工去手工定義出來,而是能自動發現集群中,有哪些新機器以及新機器上出現了哪些新服務可以被監控
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
訪問//192.168.5.52:9090/ 出現prometheus的控制台頁面,無帳號密碼驗證(如果希望加上驗證,可以使用apache httpass方式添加)
訪問//192.168.5.52:9090/ 出現prometheus的控制台頁面,無帳號密碼驗證(如果希望加上驗證,可以使用apache httpass方式添加)
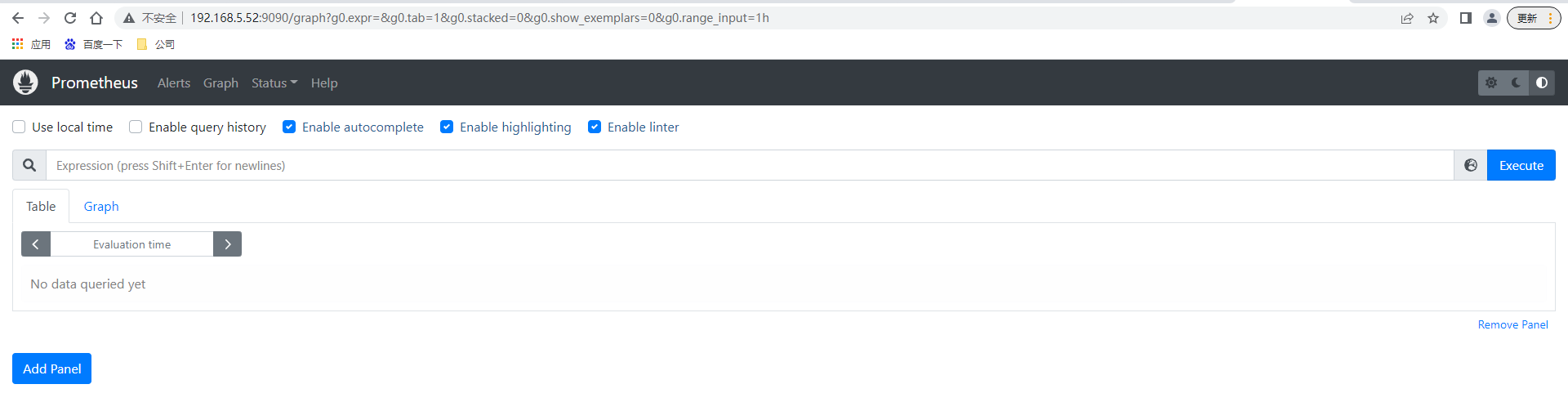
命令行支援參數可以查閱控制台頁面//192.168.5.52:9090/flags ,也可以直接通過控制台頁面查詢prometheus.yml的配置內容
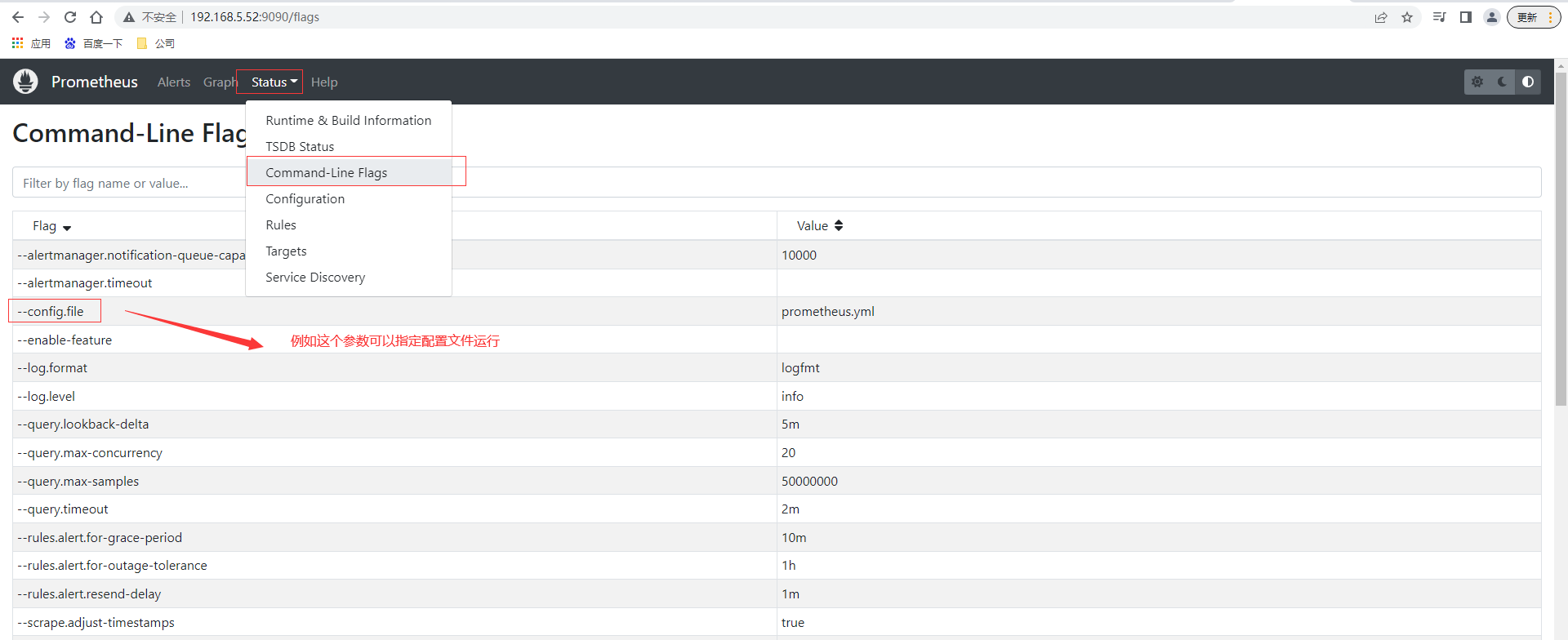
通過上面scrape_configs配置可以知道默認情況下配置了對prometheus的監控,查詢控制台頁面prometheus的實例節點也是UP狀態
prometheus數據存放在data目錄下,其中長串字母的是歷史數據保留,⽽當前近期數據實際上保留在記憶體中,並且按照⼀定間隔存放在 wal / ⽬錄中防⽌突然斷電或者重啟以⽤來恢復記憶體中的數據。
監控基礎
監控對運維重要性
- 運維是什麼?
- 說白了就是管理伺服器,保證伺服器給線上產品提供穩定運行的服務環境。
- 監控是什麼?
- 說白了就是用一種形式去盯著觀察伺服器把伺服器的各種行為表現都顯示出來用以發現問題和不足。
- 報警是什麼?
- 監控和報警這兩個詞一定要分開說分開理解!監控是監控,報警是報警。監控是把行為表現展示出來,用來觀察的。報警則是當監控獲取的數據發生異常並且到達了某個臨界點的時候,採用各種途徑來通知用戶通知管理員通知運維人員甚至通知老闆。
- 很多時候總是把監控和報警混在一起說這是不正確的需要糾正,報警跟監控 嚴格來說 是需要分開對待的。
- 因為報警也有專門的報警系統。
- 報警系統包括⼏種主要的展現形式 : 簡訊報警,郵件報警,電話報警(語⾳播報), 通訊軟體。
- 不像監控系統 ⽐較成型的報警系統 ⽬前⼤多數都是收費的 商業化。
- 報警系統中 最重要的⼀個概念之⼀ 就是對報警閾值的理解,閾值(Trigger Value) ,是監控系統中 對數據到達某⼀個臨界值的定義;例如: 通過監控發現,當前某⼀台機器的CPU突然升⾼,到達了 99%的使⽤率,99 就是作為⼀次報警的 觸發閾值。
監控理論基礎
-
監控重要性
- 監控在企業中扮演著重要的監督者的⾓⾊,任何⼀個地⽅出現問題都需要及時的知道,很多情況下企業對某種類型的監控需要⾮常的敏感(採集的精度),例如⽤戶正常訪問這種業務級別的監控⼀旦出現了問題需要在秒級時間知道,(時間=錢)不然就是毀滅性的災難和損失由其是針對哪些⼤規模的企業。
-
監控運維基礎⼯作
- 基礎運維(系列第⼀階段)⼀線 主要扮演著 ⼀個處理⽇常任務,及時救⽕這樣的⾓⾊。
- 監控的搭建 和 數據採集的⼯作 很多時候 需要依賴於 運維開發的協助(開發 創新),不管是哪⼀種運維(哪怕你是運維架構師 運維專家)在緊急的時候 ⼈⼈都要扮演起 救⽕英雄的⾓⾊⽽救⽕ 指的是 及時的發現和解決線上出現的各種故障 問題那麼為了要做到 及時的發現問題,那麼⼀個好的完善的監控系統 就很⾃然的作為運維⼯作中的第⼀優先任務。
-
監控系統設計
- 評估系統的業務流程 業務種類 架構體系,各個企業的產品不同,業務⽅向不同,程式程式碼不同,系統架構更不同,對於各個地⽅的細節 都需要有⼀定程度的認知 才可以開起設計的源頭
- 分類出所需的監控項種類,⼀般可分為 : 業務級別監控 / 系統級別監控 / ⽹絡監控 / 程式程式碼監控/ ⽇志監控 / ⽤戶⾏為分析監控/ 其它種類監控⼤的分類 還有更多的細⼩分類。
-
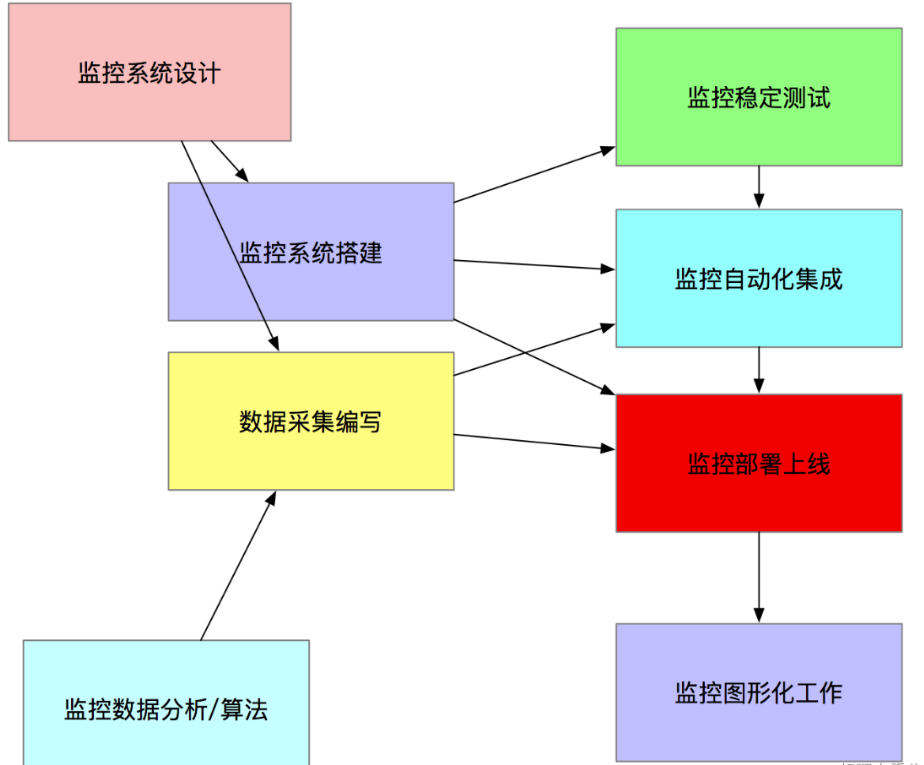
監控系統實施總體過程
- 監控系統搭建
- 單點服務端的搭建(prometheus)
- 單點客戶端的部署
- 單點客戶端伺服器測試
- 採集程式單點部署
- 採集程式批量部署
- 監控服務端HA / cloud
- 監控數據圖形化搭建(Grafana)
- 報警系統測試(如Pagerduty)
- 報警規則測試
- 監控+報警聯合測試
- 正式上線監控
- 數據採集編寫
- shell / python / awk / lua (Nginx 安全控制,功能分類)/ php / perl/ go,作為監控數據採集, ⾸推 shell + python , 如果說 數據採集選取的模式 對性能/後台/界⾯ 不依賴, 那麼shell速度最快 成本最低。
- ⼀次性採集和後台採集。
- 監控數據分析/演算法
- 監控的數據分析和演算法 其實⾮常依賴 運維架構師對Linux作業系統的各種底層知識的掌握
- 監控穩定測試
- 穩定性測試 就是通過⼀段時間的單點部署觀察 對線上有沒有任何影響
- 監控自動化
- 如監控客戶端的批量部署,監控服務端的HA再安裝,監控項⽬的修改,監控項⽬的監控集群變化的自動化, Puppet(配置⽂件部署),Jenkins(CI 持續集成部署) , CMDB(配置管理資料庫)
- 監控圖形化
- 採集的數據 和 準備好的監控演算法,最終需要⼀個好的圖形展⽰ 才能發揮最好的作⽤
- 監控系統搭建

監控面臨問題
- 監控自動化依然不夠
- 很少能和CMDB完善的結合起來
- 監控依然需要大量人工
- 監控的準確性和真實性 提⾼的緩慢
- 監控工具和方案的制定較為潦草
- 對監控本身的重視程度依然有待提高
Prometheus部署
數據採集
概述
Prometheus主要有兩種方式採集:pull 主動拉取的形式和push 被動推送的形式。
pull : 指的是客戶端(被監控機器)先安裝各類已有exporters(由社區組織或企業開發的監控客戶端插件)在系統上之後,exporters以守護進程的模式運行,並開始採集數據,exporter本身也是一個http_server可以對http請求作出響應返回數據,Prometheus用pull這種主動拉取的方式(HTTP get)去訪問每個節點上exporter並採集回需要的數據。
push: 指的是在客戶端(或服務端)安裝官方提供的pushgateway插件,然後使用我們運維自行開發的各種腳本,把監控數據組織成K/V的形式metrics形式,發送給pushgateway之後pushgateway會在推送給Prometheus,這種是一種被動的數據採集模式。
exporter的使用
官網提供提供多種獨立常用的exporter,這些exporter分別使用不同的開發語言開發
- prometheus
- alertmanager
- blackbox_exporter
- consul_exporter
- graphite_exporter
- haproxy_exporter
- memcached_exporter
- mysqld_exporter
- node_exporter
- pushgateway
- statsd_exporter
比如最常用的 node_exporter就非常強大,幾乎可以把Linux系統中和系統自身相關的監控數據全抓出來(很多參數)
# 下載最新版本v1.4.0node_exporter
wget //github.com/prometheus/node_exporter/releases/download/v1.4.0-rc.0/node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
# 解壓
tar -xvf node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
# 進入目錄
cd node_exporter-1.4.0-rc.0.linux-amd64
# 啟動node_exporter
nohup ./node_exporter > node_exporter.log 2>&1 &
node_exporter默認工作在9100埠,可以響應Prometheus_server發過來的HTTP_GET請求,也可以響應其它方式的HTTP_GET請求,測試下請求
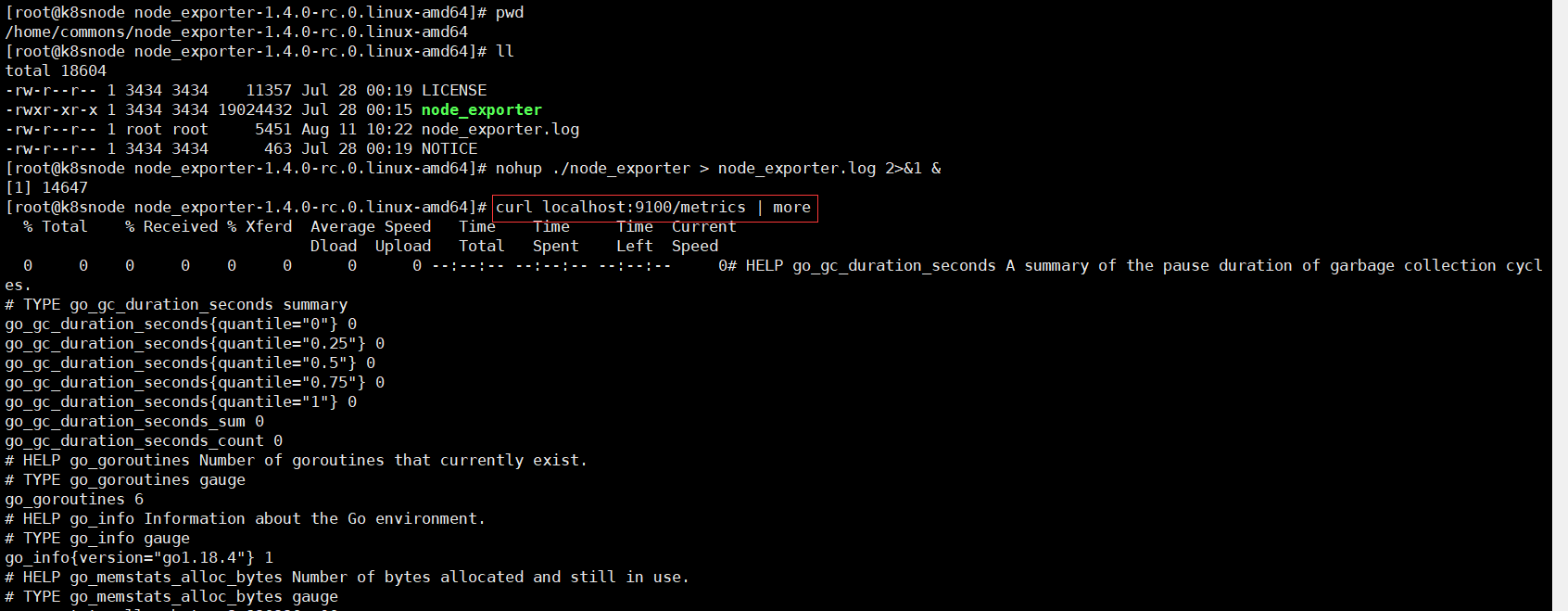
執行curl之後,可以看到node_exporter返回了大量的metrics類型的K/V數據,這些返回的K/V數據,其中的Key名稱,可以直接複製到Prometheus的查詢命令行來查看結果。將剛才node_exporter部署節點的通過文件配置發現的加入Prometheus的監控中,在Prometheus的prometheus.yml配置文件內scrape_configs配置節點中增加job_name: “node_exporter”的配置資訊
scrape_configs:
- job_name: "node_exporter"
static_configs:
# targets可以並行寫入多個節點,用逗號隔開,機器名或者IP+埠號,埠號:通常用的就是exporter的埠,這裡9100其實是node_exporter的默認埠
- targets: ["192.168.50.95:9100"]
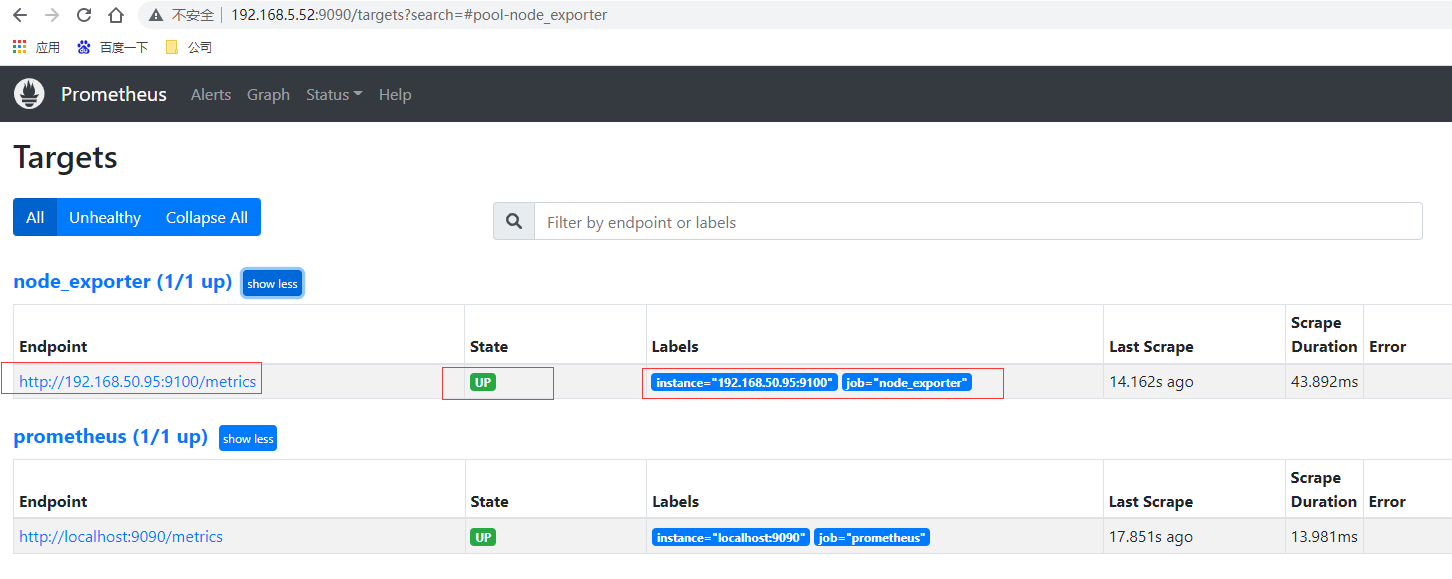
重新啟動prometheus,prometheus就可以通過配置文件識別監控的節點,持續開始採集數據。查看監控目標頁面已經有加進來的node_exporter節點了
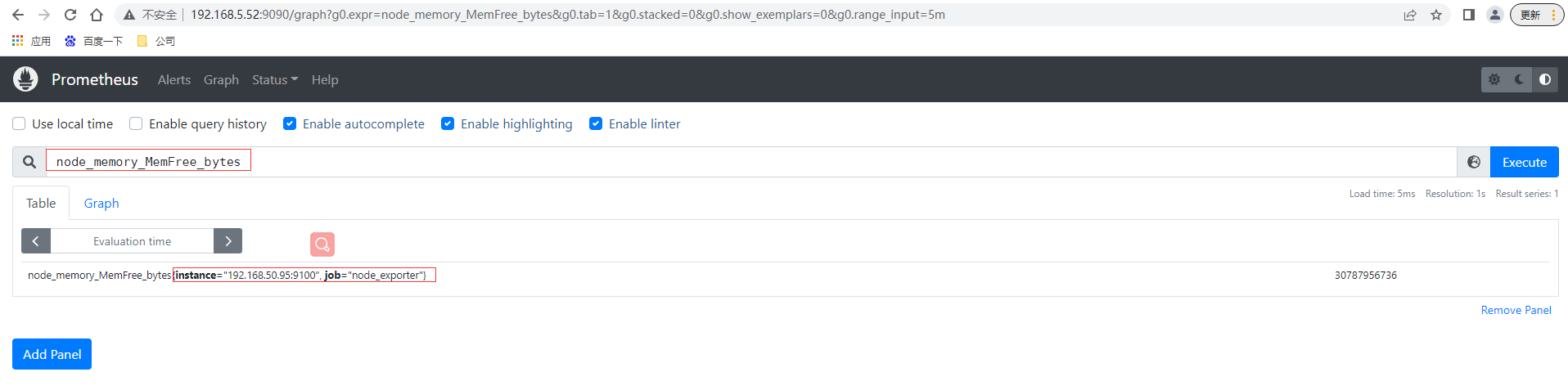
# 先通過http請求查看剛部署的node_exporter節點的記憶體資訊
curl localhost:9100/metrics | grep node_memory_MemFree

本⾝node_exporter提供的 keys 實在太多了 (因為 都是從Linux系統中的底層各種挖掘數據回來),找到key為node_memory_MemFree_bytes後直接複製在prometheus的Graph頁面中查看,已經可以看到查詢的數據
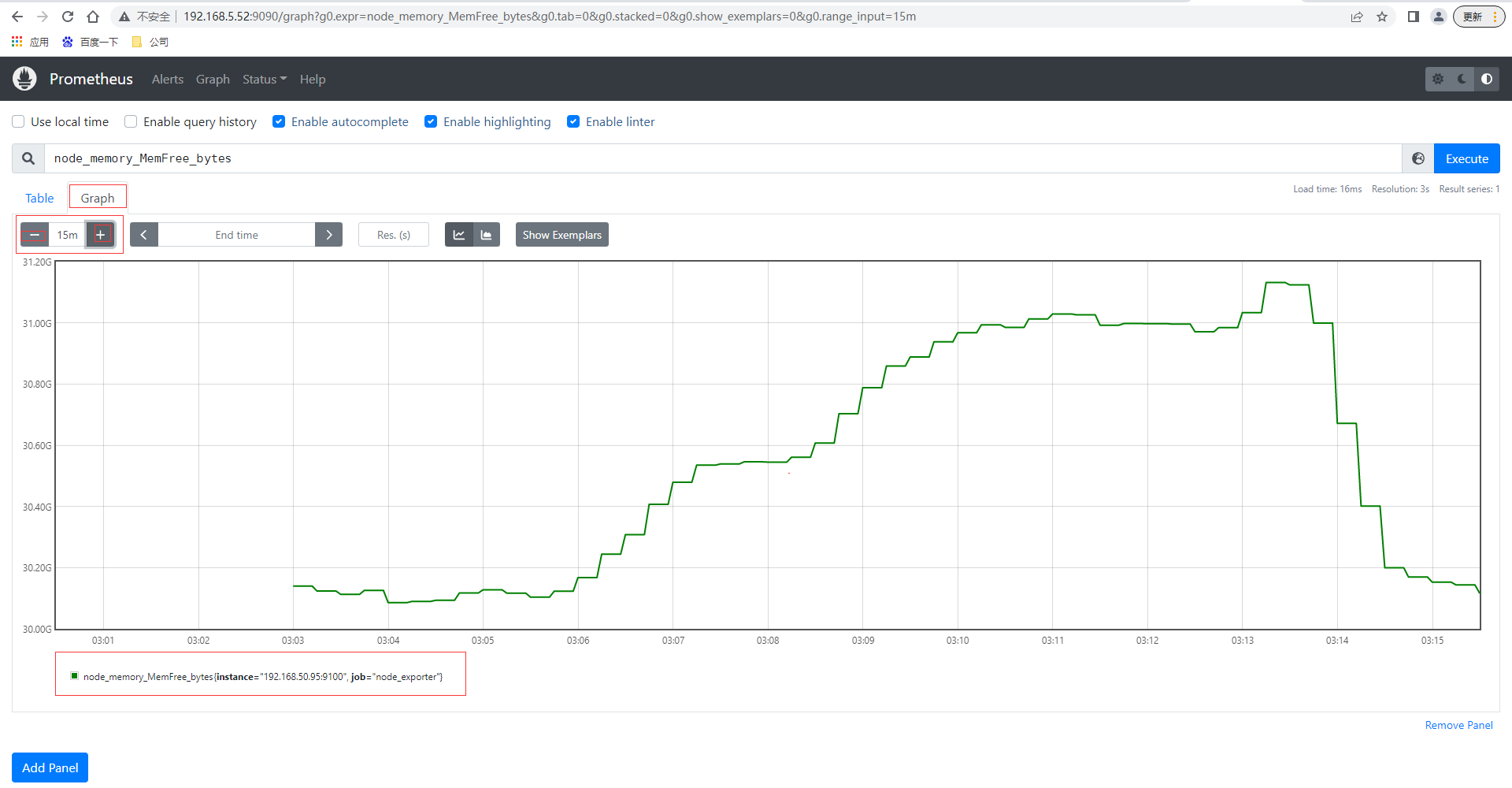
還可以切換到圖查看最近15分鐘的數據曲線趨勢圖
pushgateway使用
部署
pushgateway 是另⼀種采⽤被動推送的⽅式(⽽不是exporter主動獲取)獲取監控數據的prometheus 插件,它是可以單獨運⾏在 任何節點上的插件(並不⼀定要在被監控客戶端),然後通過⽤戶⾃定義開發腳本把需要監控的數據發送給pushgateway,然後pushgateway再把數據推送給prometheus server。
pushgateway的安裝以及運行和配置,pushgateway 跟 prometheus和 exporter ⼀樣。
# 下載最新版本v1.4.0node_exporter
wget //github.com/prometheus/pushgateway/releases/download/v1.4.3/pushgateway-1.4.3.linux-amd64.tar.gz
# 解壓
tar -xvf pushgateway-1.4.3.linux-amd64.tar.gz
# 進入目錄
cd pushgateway-1.4.3.linux-amd64/
# 啟動pushgateway
nohup ./pushgateway > pushgateway.log 2>&1 &
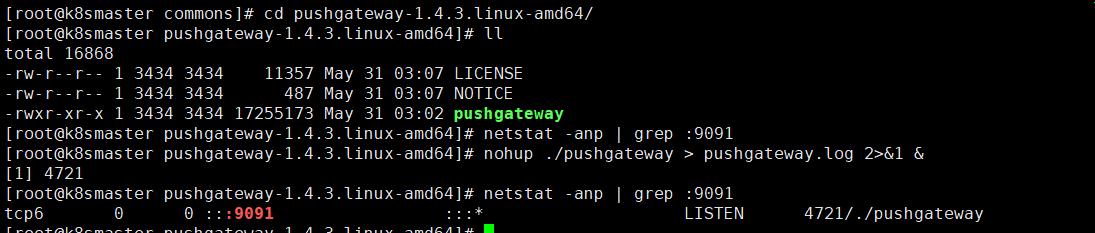
從上面可以看到pushgateway默認的埠為9091,接下來 在prometheus.yml 配置⽂件中, 單獨定義⼀個job配置target 指向到pushgateway運⾏所在的機器名和pushgateway運⾏的埠即可
- job_name: "pushgateway"
static_configs:
# targets可以並行寫入多個節點,用逗號隔開,機器名或者IP+埠號,埠號:通常用的就是pushgateway的埠,這裡9091其實是pushgateway的默認埠
- targets: ["192.168.50.94:9091"]
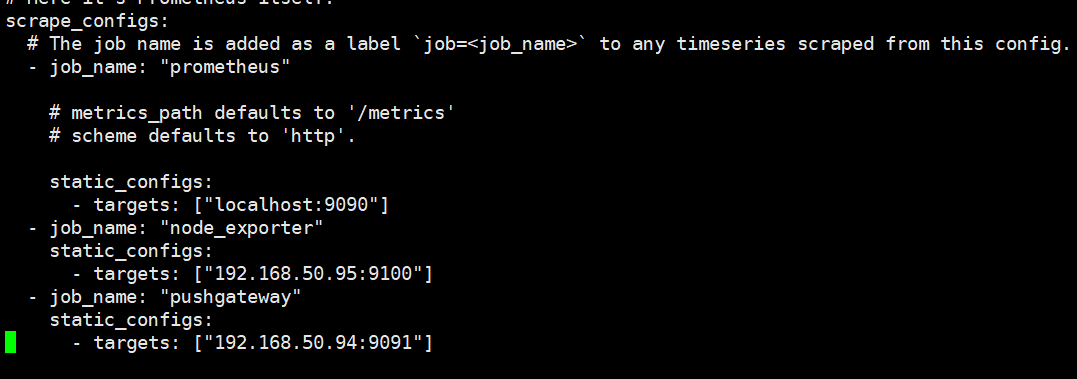
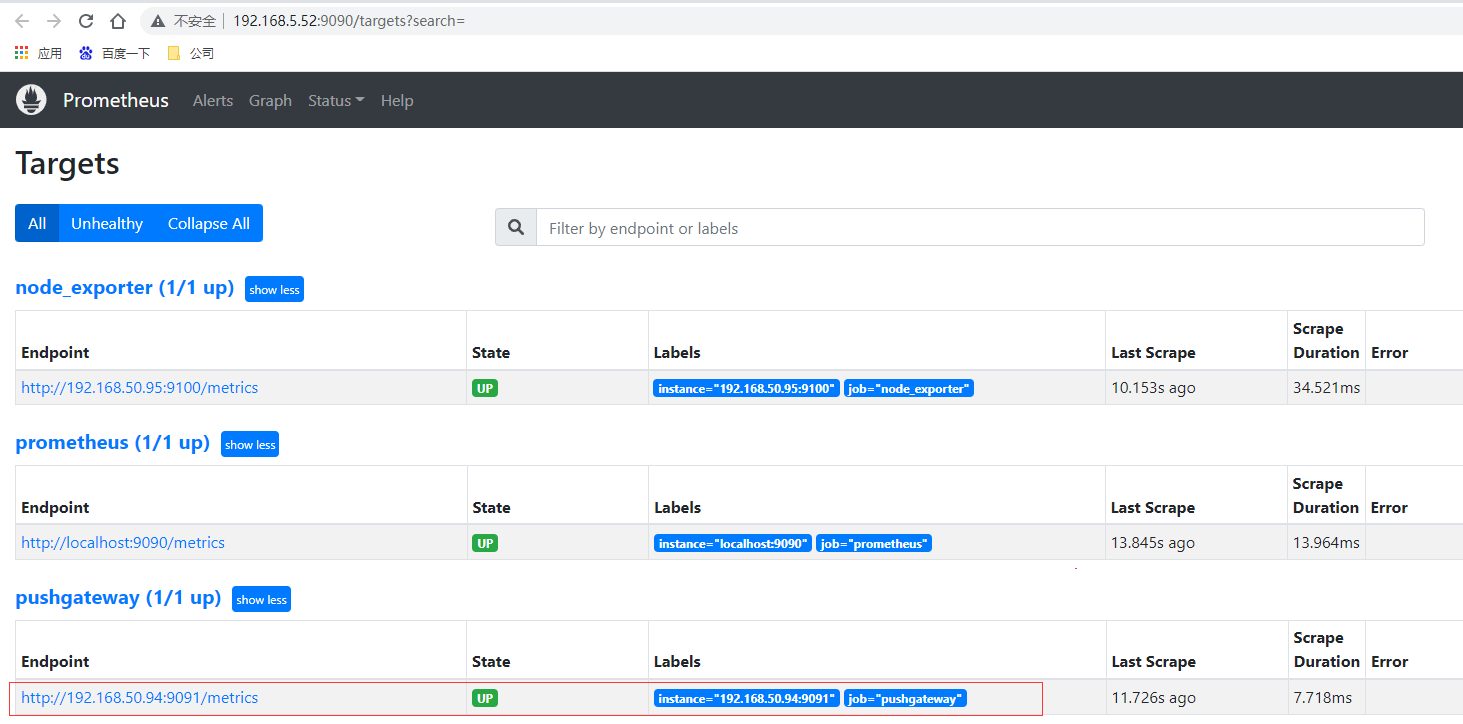
重新啟動prometheus,查看監控目標頁面已經有加進來的pushgateway節點了
腳本測試
pushgateway 本⾝是沒有任何抓取監控數據的功能的 它只是被動的等待推送過來,pushgateway 編程腳本的寫法,這裡使⽤shell 編寫的 pushgateway腳本⽤於抓取 TCP waiting_connection 瞬時數量,編寫monitor.sh如下
#!/bin/bash
instance_name=`hostname -f | cut -d'.' -f1` #本機機器名變數於之後的 標籤
if [ $instance_name == "localhost" ];then # 要求機器名不能是localhost不然標籤就沒有區分了
echo "Must FQDN hostname"
exit 1
fi
# For waitting connections
label="count_netstat_wait_connections" # 定義個新的 key
# 定義1個新的數值 netstat中 wait 的數量,通過Linux命令⾏ 就簡單的獲取到了需要監控的數據 TCP_WAIT數
count_netstat_wait_connections=`netstat -an | grep -i wait | wc -l`
echo "$label : $count_netstat_wait_connections"
# 把 key & value 推送給 pushgatway
echo "$label $count_netstat_wait_connections" | curl --data-binary
@- //192.168.50.94:9091/metrics/job/pushgateway/instance/$instance_name
如果是每分鐘推送一次則可以結合crontab,如* * * * * sh /home/commons/script/monitor.sh,如果是短於一分鐘也可以shell腳本通過循環使用sleep實現;再到頁面上查看剛才自定義的key,已經有採集到數據。
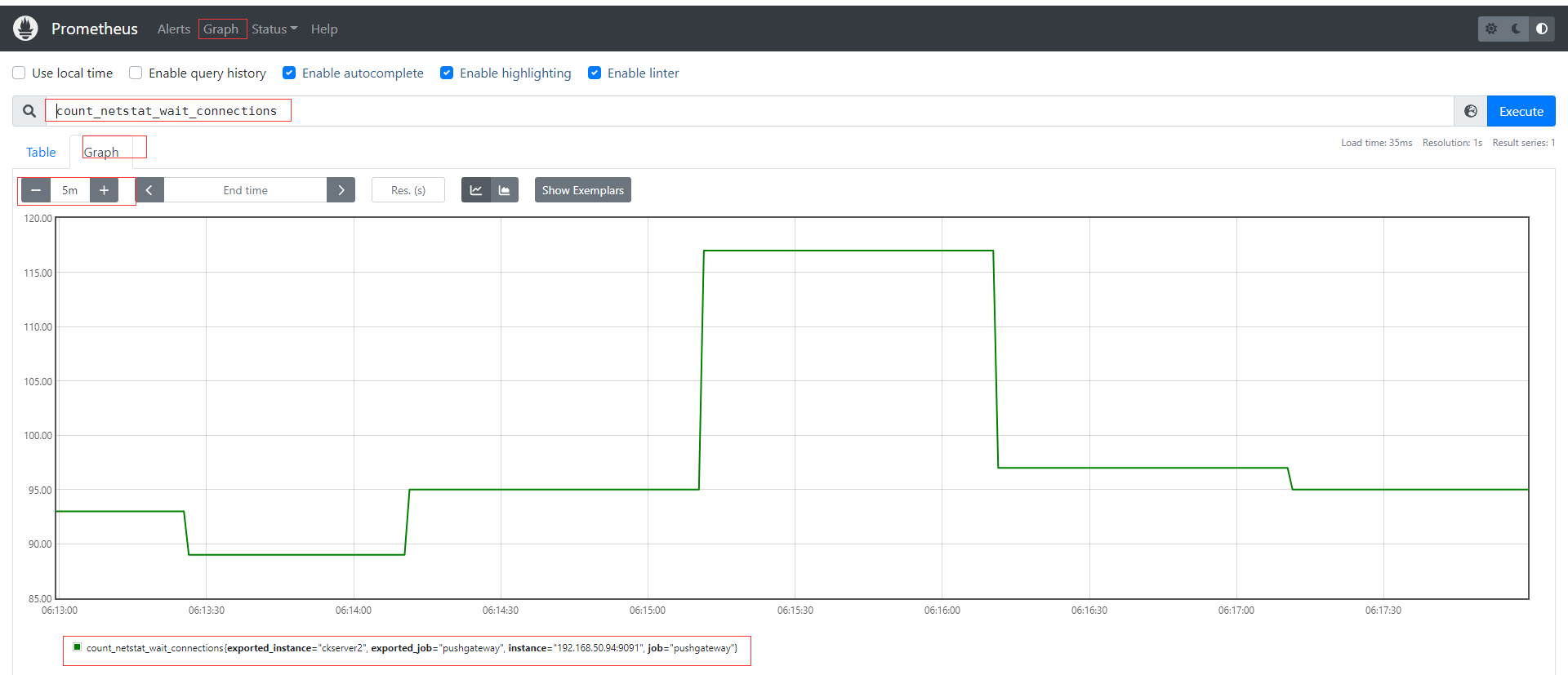
其他種類的監控數據我們都可以通過類似的形式直接寫腳本發送實現自定義採集。
優缺點
pushgateway這種⾃定義的採集⽅式⾮常的快速⽽且極其靈活⼏乎不收到任何約束,⾮常希望 使⽤pushgateway來獲取監控數據的,各類的exporters雖然玲琅滿⽬⽽且默認提供的數據很多了已經,⼀般情況下企業中只安裝 node_exporter 和 DB_exporter兩個,其他種類的 監控數據傾向於全部使⽤pushgateway的⽅式採集 (要的就是快速~ 靈活~)。官網在最佳實踐章節也有說明何時使用pushgateway,Pushgateway是一個中介服務,它允許你從無法抓取的工作中推送指標。
- pushgateway 會形成⼀個單點瓶頸,假如好多個腳本同時發送給 ⼀個pushgateway的進程如果這個進程沒了,那麼監控數據也就沒了。
- pushgateway 並不能對發送過來的腳本採集數據進⾏更智慧的判斷,假如腳本中間採集出問題了那麼有問題的數據pushgateway⼀樣照單全收發送給Prometheus。
CPU使用率監控示例
# 通過node_cpu關鍵字查看關於cpu的監控項
curl localhost:9100/metrics | grep node_cpu
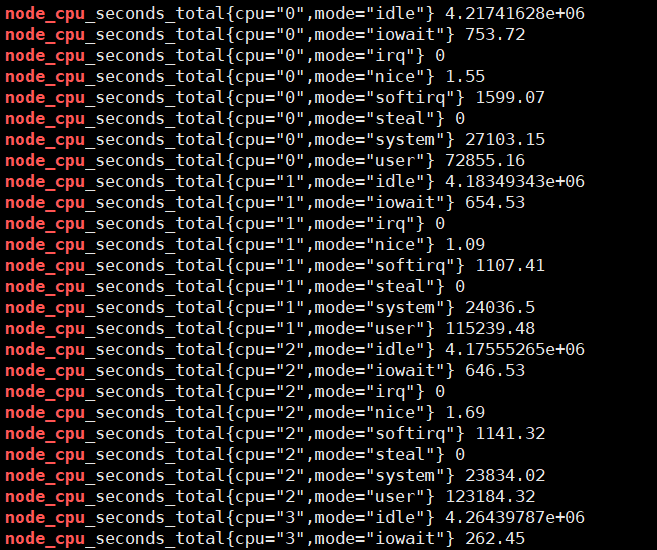
輸入查詢之後,可以看到結果,這個值是CPU各個核各個狀態下從開機開始一直累積下來的CPU使用時間的累計值,但我們理解的CPU應該是使用率,類似百分50%和80%這樣的數據才更好理解。
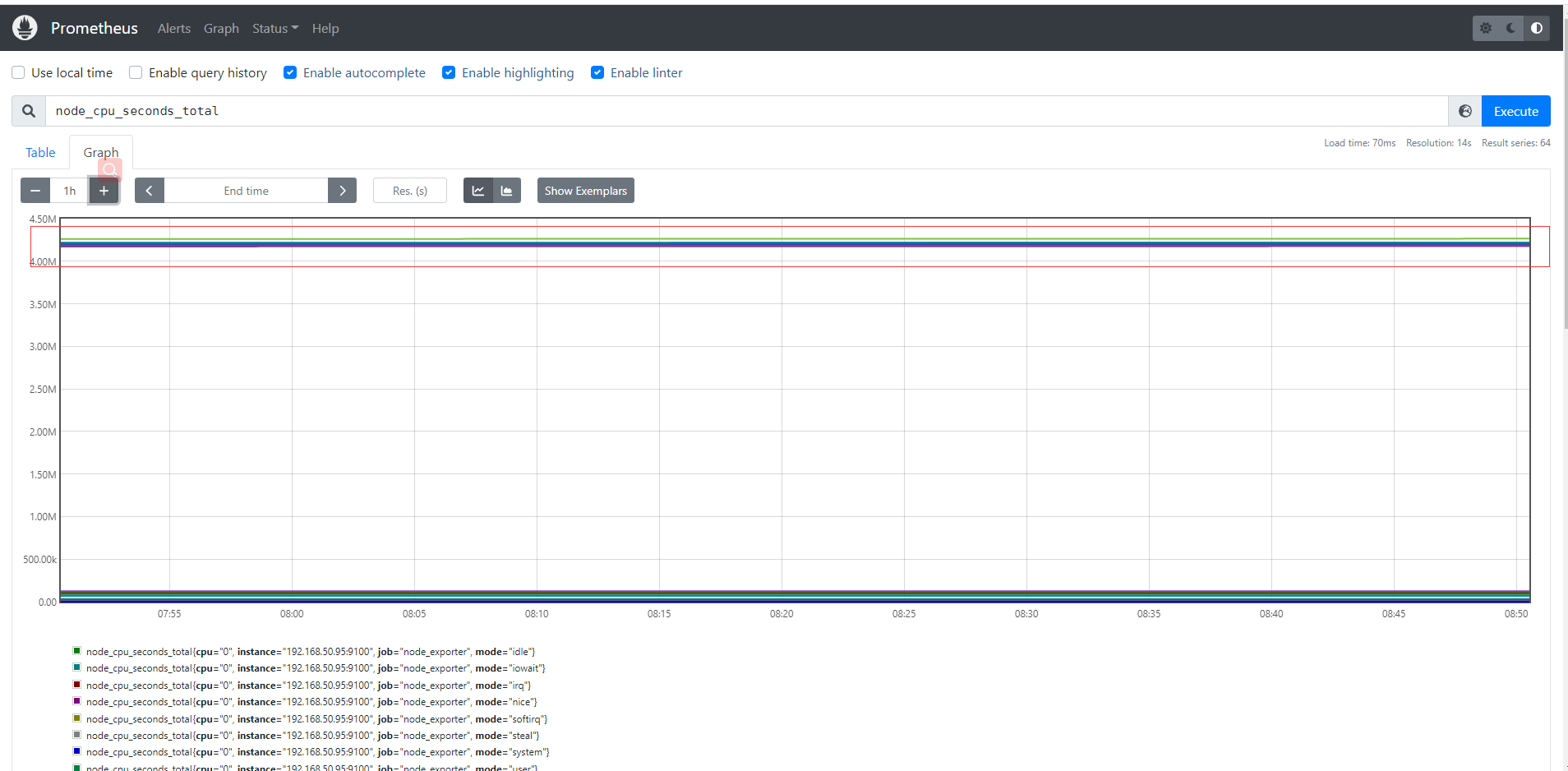
Prometheus對linux CPU的採集,並不是直接給我們返回一個現成的CPU百分比,而是返回Linux中很底層的cpu時間片,累積數值的咋樣一個數據(我們平時用慣了top/uptime這種簡便的方式看CPU使用率,根本沒有深入理解所謂的CPU使用率在Linux中到底怎麼回事),CPU使用時間包括CPU用戶態使用時間,系統/內核態使用時間,nice值分配使用時間,空閑時間,中斷時間等等。各個CPU狀態的時間單位解如下:

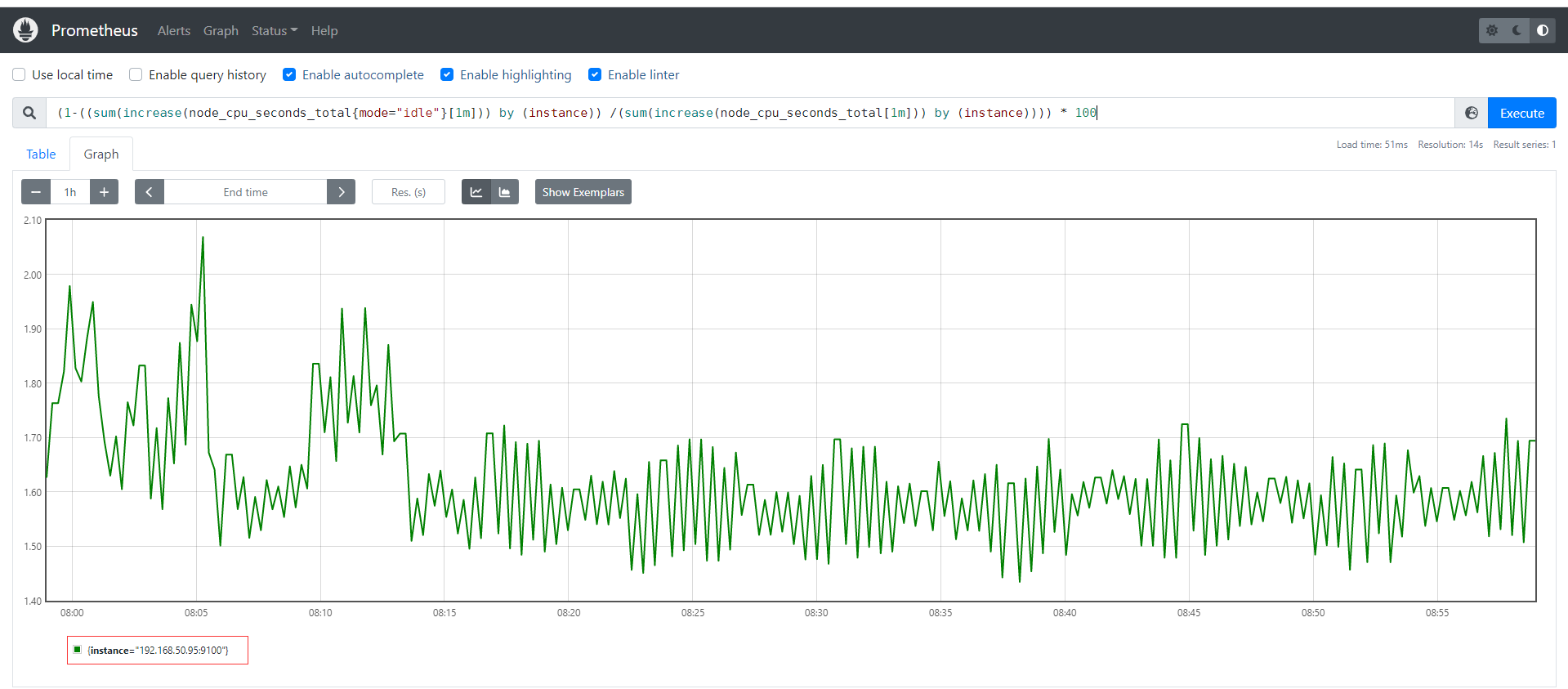
# 編寫數學公式如下,所以說需要理解底層原理和Prometheus對於數學的支援
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) /(sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100
Grafana部署
定義
Grafana 官網文檔地址 //grafana.com/docs/grafana/latest/?pg=oss-graf&plcmt=resources
Grafana GitHub地址 //github.com/grafana/grafana
Grafana 是⼀款近⼏年新興的開源數據繪圖⼯具平台默認⽀持如下這麼多種數據源作為輸⼊,無論它們存儲在哪裡都可以查詢、可視化、警告和理解您的指標,Grafana可以通過漂亮、靈活的儀錶板創建、探索和共享所有的數據。最新版本為9.0.7,由於Grafana有告警功能,因此可以直接Grafana來替換prometheus自身提供的告警系統,這也是目前各大企業最青睞可視化產品和最佳實踐。
部署
# 下載最新版本v9.0.7的grafana
wget //dl.grafana.com/enterprise/release/grafana-enterprise-9.0.7.linux-amd64.tar.gz
# 解壓文件
tar -xvf grafana-enterprise-9.0.7.linux-amd64.tar.gz
# 進入目錄
cd grafana-9.0.7
# 後台運行grafana-server,可通過nohup &之類或後台運行管理工具如daemonize、screen
nohup ./grafana-server > grafana-server.log 2>&1 &
訪問grafana默認埠3000,//192.168.5.52:3000/ 輸入用戶名密碼admin/admin ,下一步需要修改密碼後進入主頁面如下
配置數據源
選擇左側面板下面按鈕,然後選擇數據源,類型為prometheus,輸入url即可
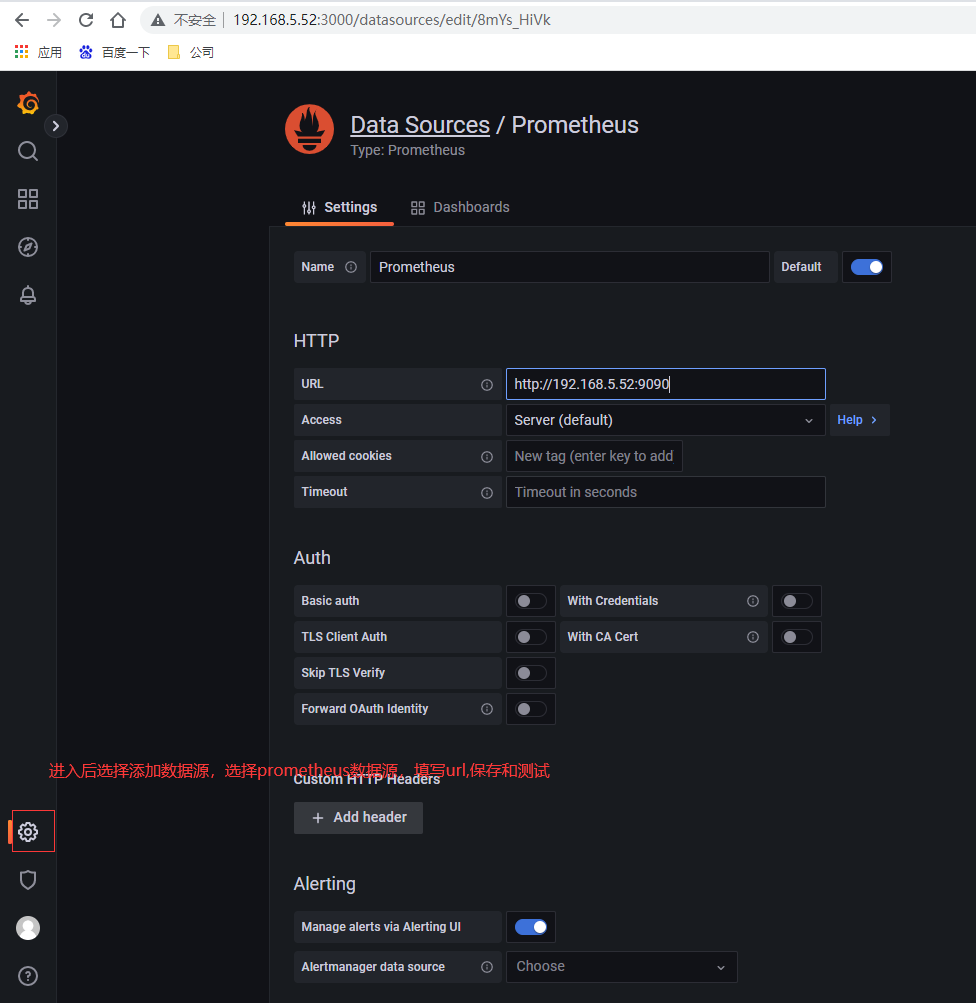
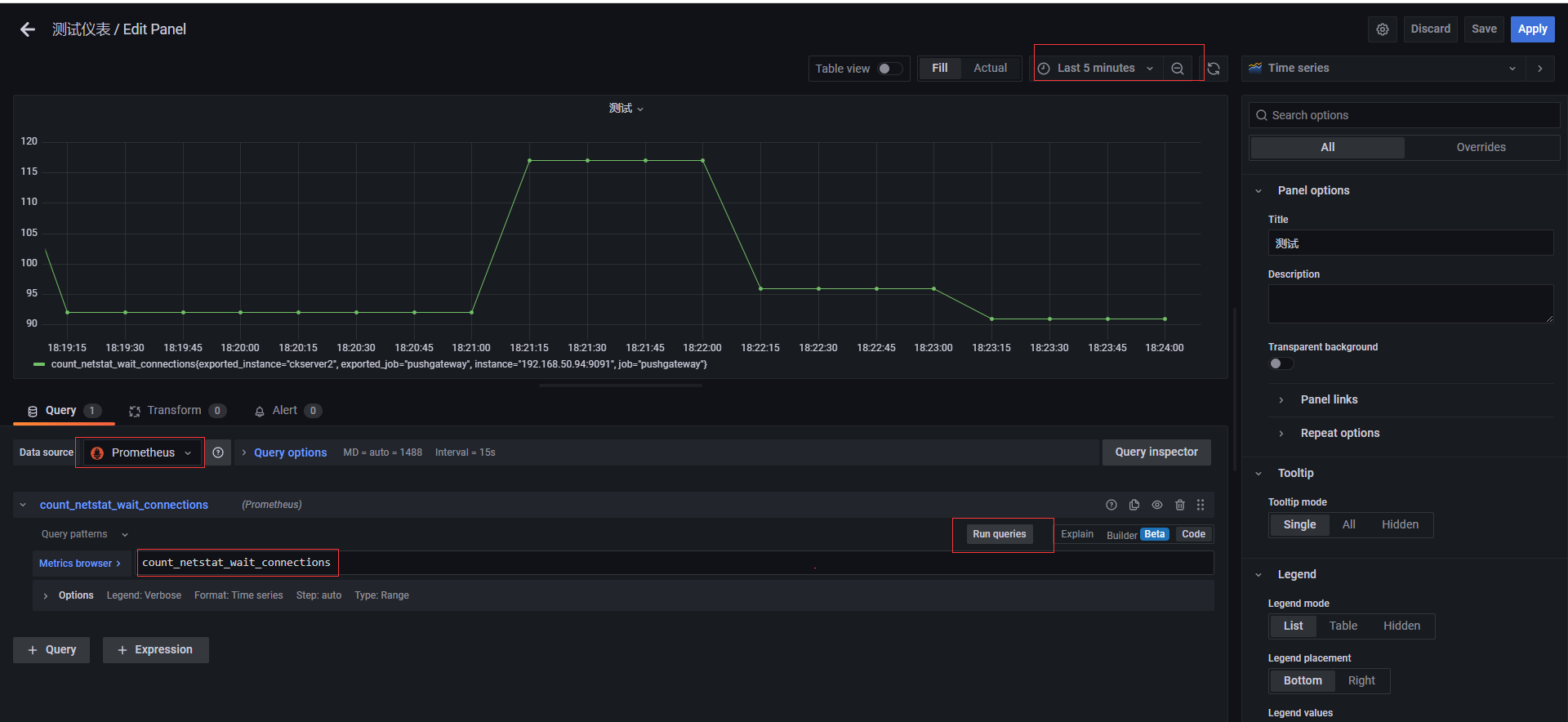
創建測試Graph
創建一個dashboards,編輯儀錶盤,添加圖,選擇數據源,選擇原始查詢方式,填入前面自定義收集指標count_netstat_wait_connections,運行查詢之後,選擇最近5分鐘的數據,簡單圖就出來了
**本人部落格網站 **IT小神 www.itxiaoshen.com