大數據管理系統架構Hadoop
Hadoop 起源於Google Lab開發的Google File System (GFS)存儲系統和MapReduce數據處理框架。2008年,Hadoop成了Apache上的頂級項目,發展到今天,Hadoop已經成了主流的大數據處理平台,與Spark、HBase、Hive、Zookeeper等項目一同構成了大數據分析和處理的生態系統。Hadoop是一個由超過60個子系統構成的系統集合。實際使用的時候,企業通過訂製Hadoop生態系統(即選擇相應的子系統)完成其實際大數據管理需求。Hadoop生態系統由兩大核心子系統構成∶HDFS分散式文件系統和MapReduce數據處理系統。
HDFS分散式文件系統
HDFS是一個可擴展的分散式文件系統,它為海量的數據提供可靠的存儲。HDFS的架構是構建在一組特定的節點上,其中包括一個NameNode 節點和數個DataNode 節點。NameNode 主要負責管理文件系統名稱空間和控制外部客戶機的訪問,它對整個分散式文件系統進行總控制,記錄數據分布存儲的狀態資訊。DataNode則使用本地文件系統來實現HDFS的讀寫操作。每個DataNode都保存整個系統數據中的一小部分,通過心跳協議定期向NameNode報告該節點存儲的數據塊的狀況。為了保證系統的可靠性,在DataNode發生宕機時不致文件丟失,HDFS會為文件創建複製塊, 用戶可以指定複製塊的數目, 默認情況下, 每個數據塊擁有額外兩個複製塊, 其中一個存儲在與該數據塊同一機架的不同節點上, 而另一複製塊存儲在不同機架的某個節點上。
所有對HDFS文件系統的訪問都需要先與NameNode通訊來獲取文件分布的狀態資訊,再與相應的DataNode節點通訊來進行文件的讀寫。由於NameNode處於整個集群的中心地位,當NameNode節點發生故障時整個HDFS 集群都會崩潰,因此HDFS中還包含了一個Secondary NameNode,它與NameNode之間保持周期通訊,定期保存NameNode上元數據的快照,當NameNode發生故障而變得不可用時,Secondary NameNode 可以作為備用節點頂替NameNode,使集群快速恢復正常工作狀態。
NameNode的單點特性制約了HDFS的擴展性,當文件系統中保存的文件過多時NameNode會成為整個集群的性能瓶頸。因此在Hadoop 2.0 中,HDFS Federation被提出,它使用多個NameNode分管不同的目錄,使得HDFS具有橫向擴展的能力。
MapReduce 數據處理系統
MapReduce是位於HDFS文件系統上一層的計算引擎,它由JobTracker 和 TaskTracker 組成。JobTracker是運行在 Hadoop 集群主節點上的重要進程,負責MapReduce的整體任務調度。同NameNode 一樣,JobTracker在集群中也具有唯一性。TaskTracker進程則運行在集群中的每個子節點上,負責管理各自節點上的任務分配。
當外部客戶機向MapReduce引擎提交計算作業時,JobTracker將作業切分成一個個小的子任務,並根據就近原則,把每個子任務分配到保存了相應數據的子節點上,並由子節點上的TaskTracker負責各自子任務的執行,並定期向JobTracker發送心跳來彙報任務執行狀態。
Hadoop 2.0對MapReduce的架構加以改造,對JobTracker所負擔的任務分配和資源管理兩大職責進行分離,在原本的底層HDFS文件系統和MapReduce計算框架之間加入了新一代架構設計——YARN。
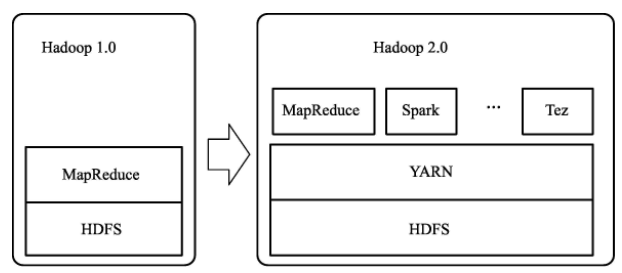
YARN 是一個通用的資源管理系統,為上層的計算框架提供統一的資源管理和調度。 NodeManager 運行於每個子節點上, 對不同的節點進行自管理,任務分配的職責也從原本的JobTracker中獨立出來,由ApplicationMaster來負責,並在NodeManager控制的資源容器中運行。應用程式負責向資源管理器索要適當的資源容器, 運行任務以及跟蹤應用程式執行狀態。
YARN 新架構採用的責任下放思路使得 Hadoop 2.0擁有更高的擴展性,資源的動態分配也極大提升了集群資源利用率。不僅如此,ApplicationMaster的加入使得用戶可以將自己的編程模型運行於Hadoop 集群上,加強了系統的兼容性和可用性,HDFS和MapReduce是Hadoop生態系統中的核心組件,提供基本的大數據存儲和處理能力,以上述兩個核心組件為基礎,Hadoop 社區陸續開發出一系列子系統完成其他大數據管理需求,這些子系統和HDFS、MapReduce一起共同構成了Hadoop生態系統。下圖顯示了HortonWorks公司發布的Hadoop生態系統的系統架構。
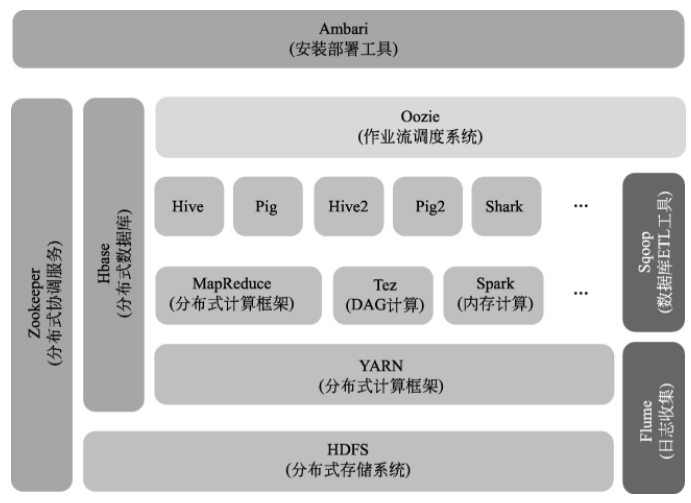
綜上概括,Hadoop生態系統為用戶提供的是一套可以用來組裝自己的個性化數據管理系統的工具,用戶根據自己的數據特徵和應用需求,對一系列的部件進行有機地組裝和部署,就能得到一個完整可用的管理平台。傳統資料庫軟體採用的理念在大數據時代已經不再適用,大數據處理對系統架構的靈活性、數據處理伸縮性、數據處理效率提出了更高的要求。Hadoop 生態系統是開源社區對大數據挑戰的解決方案,為大數據管理系統的後續發展奠定了良好的基礎。


