收藏!攻克目標檢測難點秘籍二,非極大值抑制與回歸損失優化之路
- 2020 年 2 月 24 日
- 筆記
來源:AI演算法修鍊營
前面的話
在前面的秘籍一中,我們主要關注了模型加速之輕量化網路,對目標檢測模型的實時性難點進行了攻克。但是要想獲得較好的檢測性能,檢測演算法的細節處理也極為重要。
在眾多的細節處理中,先來介紹非極大值抑制、回歸損失函數這2個問題。本文主要介紹秘籍二:非極大值抑制與回歸損失的優化之路。
秘籍二. 非極大值抑制與回歸損失優化之路
當前的物體檢測演算法為了保證召回率,對於同一個真實物體往往會有多於1個的候選框輸出。由於多餘的候選框會影響檢測精度,因此需要利用NMS過濾掉重疊的候選框,得到最佳的預測輸出。
基本的NMS方法,利用得分高的邊框抑製得分低且重疊程度高的邊框。然而基本的NMS存在一些缺陷,簡單地過濾掉得分低且重疊度高的邊框可能會導致漏檢等問題。針對此問題陸續產生了一系列改進的方法,如Soft NMS、Softer NMS及IoU-Net等。
目標檢測主要的任務:1)對象是什麼?2)對象在哪裡?其中,對象是什麼主要分清楚對象的類別。而對象在哪裡,需要尋找這個對象在影像中的位置。回歸損失問題就是探討如何更好地學習對象在哪裡。當然最近anchor free的方法有很多,但是主流應用上目前還是基於anchor的方式。
對於有先驗框的目標檢測,位置是通過學習給定的先驗框和真實目標框的距離來進行預測。而這個距離的刻畫主要通過距離公式來度量,比如曼哈頓距離L1和歐式距離L2。
那麼利用歐式距離來計算存在什麼問題呢?繼續往下看,下面將詳細介紹。一起來看攻克目標檢測難點秘籍二:非極大值抑制和回歸損失優化之路。
1 NMS:非極大值抑制優化
為了保證物體檢測的召回率,在Faster RCNN或者SSD網路的計算輸出中,通常都會有不止一個候選框對應同一個真實物體。如下圖左圖是人臉檢測的候選框結果,每個邊界框有一個置信度得分(confidence score),如果不使用非極大值抑制,就會有多個候選框出現。右圖是使用非極大值抑制之後的結果,符合我們人臉檢測的預期結果。

非極大值抑制,顧名思義就是抑制不是極大值的邊框,這裡的抑制通常是直接去掉冗餘的邊框。這個過程涉及以下兩個量化指標。
- 預測得分:NMS假設一個邊框的預測得分越高,這個框就要被優先考慮,其他與其重疊超過一定程度的邊框要被捨棄,非極大值即是指得分的非極大值。
- IoU:在評價兩個邊框的重合程度時,NMS使用了IoU這個指標。如果兩個邊框的IoU超過一定閾值時,得分低的邊框會被捨棄。閾值通常會取0.5或者0.7。
NMS演算法輸入包含了所有預測框的得分、左上點坐標、右下點坐標一共5個預測量,以及一個設定的IoU閾值。演算法具體流程如下:
(1)按照得分,對所有邊框進行降序排列,記錄下排列的索引order,並新建一個列表keep,作為最終篩選後的邊框索引結果。
(2)將排序後的第一個邊框置為當前邊框,並將其保留到keep中,再求當前邊框與剩餘所有框的IoU。
(3)在order中,僅僅保留IoU小於設定閾值的索引,重複第(2)步,直到order中僅僅剩餘一個邊框,則將其保留到keep中,退出循環,NMS結束。
利用PyTorch,可以很方便地實現NMS模組。
def nms(self, bboxes, scores, thresh=0.5): x1 = bboxes[:,0] y1 = bboxes[:,1] x2 = bboxes[:,2] y2 = bboxes[:,3] areas = (x2-x1+1)*(y2-y1+1) _, order = scores.sort(0, descending=True) keep = [] while order.numel() > 0: if order.numel() == 1: i = order.item() keep.append(i) break else: i = order[0].item() keep.append(i) xx1 = x1[order[1:]].clamp(min=x1[i]) yy1 = y1[order[1:]].clamp(min=y1[i]) xx2 = x2[order[1:]].clamp(max=x2[i]) yy2 = y2[order[1:]].clamp(max=y2[i]) inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0) iou = inter / (areas[i]+areas[order[1:]]-inter) idx = (iou <= threshold).nonzero().squeeze() if idx.numel() == 0: break order = order[idx+1] return torch.LongTensor(keep)
NMS方法雖然簡單有效,但在更高的目標檢測需求下,也存在如下缺點:
- 將得分較低的邊框強制性地去掉,如果物體出現較為密集時,本身屬於兩個物體的邊框,其中得分較低的也有可能被抑制掉,降低了模型的召回率。
- 速度:NMS的實現存在較多的循環步驟,GPU的並行化實現不是特別容易,尤其是預測框較多時,耗時較多。
- 將得分作為衡量指標。NMS簡單地將得分作為一個邊框的置信度,但在一些情況下,得分高的邊框不一定位置更准。
- 閾值難以確定。過高的閾值容易出現大量誤檢,而過低的閾值則容易降低模型的召回率,超參很難確定。
1.1 Soft NMS:抑製得分
NMS方法雖有效過濾了重複框,但也容易將本屬於兩個物體框中得分低的框抑制掉,從而降低了召回率。造成這種現象的原因在於NMS的計算公式。

公式中Si代表了每個邊框的得分,M為當前得分最高的框,bi為剩餘框的某一個,Nt為設定的閾值,可以看到,當IoU大於Nt時,該邊框的得分直接置0,相當於被捨棄掉了,從而有可能造成邊框的漏檢。
而SoftNMS演算法對於IoU大於閾值的邊框,沒有將其得分直接置0,而是降低該邊框的得分,具體方法是:

從公式中可以看出,利用邊框的得分與IoU來確定新的邊框得分,如果當前邊框與邊框M的IoU超過設定閾值Nt時,邊框的得分呈線性的衰減。
但是,上式並不是一個連續的函數,當一個邊框與M的重疊IoU超過閾值Nt時,其得分會發生跳變,這種跳變會對檢測結果產生較大的波動。
因此還需要尋找一個更為穩定、連續的得分重置函數,最終Soft NMS給出了如下式所示的重置函數。

採用這種得分衰減的方式,對於某些得分很高的邊框來說,在後續的計算中還有可能被作為正確的檢測框,而不像NMS那樣「一棒子打死」,因此可以有效提升模型的召回率。
Soft NMS的計算複雜度與NMS相同,是一種更為通用的非極大值抑制方法,可以將NMS看做Soft NMS的二值化特例。
Soft NMS優缺點分析
優點:
1、Soft-NMS可以很方便地引入到object detection演算法中,不需要重新訓練原有的模型、程式碼容易實現,不增加計算量(計算量相比整個object detection演算法可忽略)。並且很容易集成到目前所有使用NMS的目標檢測演算法。
2、Soft-NMS在訓練中採用傳統的NMS方法,僅在推斷程式碼中實現soft-NMS。作者應該做過對比試驗,在訓練過程中採用soft-NMS沒有顯著提高。
3、NMS是Soft-NMS特殊形式,當得分重置函數採用二值化函數時,Soft-NMS和NMS是相同的。Soft-NMS演算法是一種更加通用的非最大抑制演算法。
缺點:
Soft-NMS也是一種貪心演算法,並不能保證找到全局最優的檢測框分數重置。除了以上這兩種分數重置函數,我們也可以考慮開發其他包含更多參數的分數重置函數,比如Gompertz函數等。但是它們在完成分數重置的過程中增加了額外的參數。
1.2 Softer NMS:加權平均
NMS與Soft NMS演算法都使用了預測分類置信度作為衡量指標,即假定分類置信度越高的邊框,其位置也更為精準。但很多情況下並非如此。
NMS時用到的score僅僅是分類置信度得分,不能反映Bounding box的定位精準度,既分類置信度和定位置信非正相關的,直接使用分類置信度作為NMS的衡量指標並非是最佳選擇。
NMS只能解決分類置信度和定位置信度都很高的,但是對其它三種類型:「分類置信度低-定位置信度低」,「分類置信度高-定位置信度低」,「分類置信度低-定位置信度高「都無法解決。
基於此現象,Softer NMS進一步改進了NMS的方法,新增加了一個定位置信度的預測,使得高分類置信度的邊框位置變得更加準確,從而有效提升了檢測的性能。
首先,為了更加全面地描述邊框預測,Softer NMS方法對預測邊框與真實物體做了兩個分布假設:1.真實物體的分布是狄拉克delta分布,即標準方差為0的高斯分布的極限。2.預測邊框的分布滿足高斯分布。
基於這兩個假設,Softer NMS提出了一種基於KL(Kullback-Leibler)散度的邊框回歸損失函數KL loss。KL散度是用來衡量兩個概率分布的非對稱性衡量,KL散度越接近於0,則兩個概率分布越相似。
具體到邊框上,KL Loss是最小化預測邊框的高斯分布與真實物體的狄克拉分布之間的KL散度。即預測邊框分布越接近於真實物體分布,損失越小。
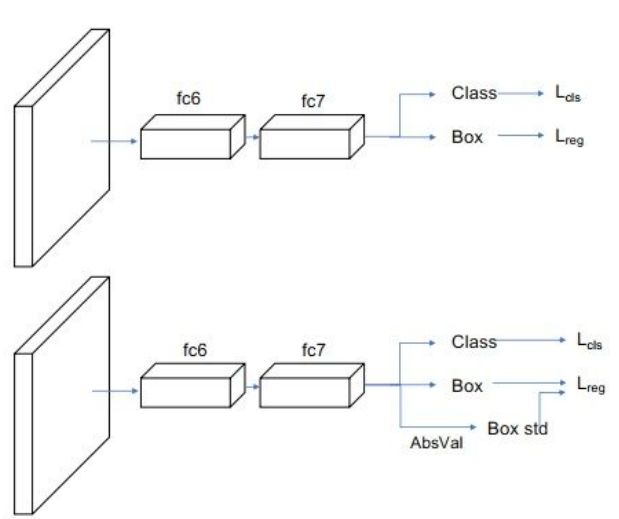
為了描述邊框的預測分布,除了預測位置之外,還需要預測邊框的標準差。Softer NMS在原Fast RCNN預測的基礎上,增加了一個標準差預測分支,從而形成邊框的高斯分布,與邊框的預測一起可以求得KL損失。
Softer NMS的實現過程,其實很簡單,預測的四個頂點坐標,分別對IoU>Nt的預測加權平均計算,得到新的4個坐標點。第i個box的x1計算公式如下(j表示所有IoU>Nt的box):

可以看出,Softer NMS對於IoU大於設定閾值的邊框坐標進行了加權平均,希望分類得分高的邊框能夠利用到周圍邊框的資訊,從而提升其位置的準確度。
1.3 IoU-Net:定位置信度
目標檢測的分類與定位通常被兩個分支預測。對於候選框的類別,模型給出了一個類別預測,可以作為分類置信度,然而對於定位而言,回歸模組通常只預測了一個邊框的轉換係數,而缺失了定位的置信度,即框的位置準不準,並沒有一個預測結果。
定位置信度的缺失也導致了在前面的NMS方法中,只能將分類的預測值作為邊框排序的依據,然而在某些場景下,分類預測值高的邊框不一定擁有與真實框最接近的位置,因此這種標準不平衡可能會導致更為準確的邊框被抑制掉。
基於此,曠視提出了IoU-Net,增加了一個預測候選框與真實物體之間的IoU分支,並基於此改善了NMS過程,進一步提升了檢測器的性能。

IoU-Net的基礎架構與原始的Faster RCNN類似,使用了FPN方法作為基礎特徵提取模組,然後經過RoI的Pooling得到固定大小的特徵圖,利用全連接網路完成最後的多任務預測。
同時,IoU-Net與Faster RCNN也有不同之處,主要有3點:
1. 在Head處增加了一個IoU預測的分支,與分類回歸分支並行。圖中的Jittered RoIs模組用於IoU分支的訓練。
2. 基於IoU分支的預測值,改善了NMS的處理過程。
3. 提出了PrRoI-Pooling(Precise RoI Pooling)方法,進一步提升了感興趣區域池化的精度。
IoU預測分支
IoU分支用於預測每一個候選框的定位置信度。需要注意的是,在訓練時IoU-Net通過自動生成候選框的方式來訓練IoU分支,而不是從RPN獲取。
具體來講,Jittered RoIs在訓練集的真實物體框上增加隨機擾動,生成了一系列候選框,並移除與真實物體框IoU小於0.5的邊框。實驗證明這種方法來訓練IoU分支可以帶來更高的性能與穩健性。IoU分支也可以方便地集成到當前的物體檢測演算法中。
在整個模型的聯合訓練時,IoU預測分支的訓練數據需要從每一批的輸入影像中單獨生成。此外,還需要對IoU分支的標籤進行歸一化,保證其分布在[-1,1]區間中。
基於定位置信度的NMS
由於IoU預測值可以作為邊框定位的置信度,因此可以利用其來改善NMS過程。IoU-Net利用IoU的預測值作為邊框排列的依據,並抑制掉與當前框IoU超過設定閾值的其他候選框。此外,在NMS過程中,IoU-Net還做了置信度的聚類,即對於匹配到同一真實物體的邊框,類別也需要擁有一致的預測值。具體做法是,在NMS過程中,當邊框A抑制邊框B時,通過下式來更新邊框A的分類置信度。

PrRoI-Pooling方法
RoI Align的方法,通過取樣的方法有效避免了量化操作,減小了RoIPooling的誤差,如圖下圖所示。但Align的方法也存在一個缺點,即對每一個區域都採取固定數量的取樣點,但區域有大有小,都採取同一個數量點,顯然不是最優的方法。
以此為出發點,IoU-Net提出了PrRoI Pooling方法,採用積分的方式實現了更為精準的感興趣區域池化,如下圖中的右圖所示。

與RoI Align只取樣4個點不同,PrRoI Pooling方法將整個區域看做是連續的,採用積分公式求解每一個區域的池化輸出值,區域內的每一個點(x, y)都可以通過雙線性插值的方法得到。這種方法還有一個好處是其反向傳播是連續可導的,因此避免了任何的量化過程。

總體上,IoU-Net提出了一個IoU的預測分支,解決了NMS過程中分類置信度與定位置信度之間的不一致,可以與當前的物體檢測框架一起端到端地訓練,在幾乎不影響前向速度的前提下,有效提升了物體檢測的精度。
2 回歸損失函數優化
正如前面講到的,對於有先驗框的目標檢測,位置是通過學習給定的先驗框和真實目標框的距離來進行預測。而這個距離的刻畫主要通過距離公式來度量,比如曼哈頓距離L1和歐式距離L2。
利用常見的L1和L2距離公式來刻畫IoU存在缺陷,主要原因還是距離度量將各個點孤立來進行,而IoU刻畫的是整體的重合度問題。在這個問題基礎上,IoU系列損失函數被提出來了。
2.1 IoU
由於L1和L2距離損失沒有很好的刻畫目標檢測的最終指標IoU,有學者提出,能否直接用IoU來進行優化呢?
IoU就是我們所說的交並比,是目標檢測中最常用的指標,在anchor-based的方法中,他的作用不僅用來確定正樣本和負樣本,還可以用來評價輸出框(predict box)和ground-truth的距離。
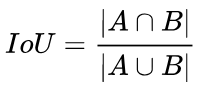
IoU可以反映預測檢測框與真實檢測框的檢測效果。還有一個很好的特性就是尺度不變性,也就是對尺度不敏感(scale invariant), 在regression任務中,判斷predict box和gt的距離最直接的指標就是IoU。(滿足非負性;同一性;對稱性;三角不等性)
def Iou(box1, box2, wh=False): if wh == False: xmin1, ymin1, xmax1, ymax1 = box1 xmin2, ymin2, xmax2, ymax2 = box2 else: xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0) xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0) xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0) xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0) # 獲取矩形框交集對應的左上角和右下角的坐標(intersection) xx1 = np.max([xmin1, xmin2]) yy1 = np.max([ymin1, ymin2]) xx2 = np.min([xmax1, xmax2]) yy2 = np.min([ymax1, ymax2]) # 計算兩個矩形框面積 area1 = (xmax1-xmin1) * (ymax1-ymin1) area2 = (xmax2-xmin2) * (ymax2-ymin2) inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1])) #計算交集面積 iou = inter_area / (area1+area2-inter_area+1e-6) #計算交並比 return iou
IOU作為損失函數會出現的問題:
1.如果兩個框沒有相交,根據定義,IoU=0,不能反映兩者的距離大小(重合度)。同時因為loss=0,沒有梯度回傳,無法進行學習訓練。
2.IoU無法精確的反映兩者的重合度大小。如下圖所示,三種情況IoU都相等,但看得出來他們的重合度是不一樣的,左邊的圖回歸的效果最好,右邊的最差。

2.2 GIoU
考慮到以上IOU的問題,有學者提出了GIoU:

上面公式的意思是:先計算兩個框的最小閉包區域面積 (通俗理解:同時包含了預測框和真實框的最小框的面積),再計算出IoU,再計算閉包區域中不屬於兩個框的區域占閉包區域的比重,最後用IoU減去這個比重得到GIoU。

引入CAUB項可以看出,即使兩個目標沒有並集,那麼GIoU的值也會是-|C(AUB)|/|C|,而兩個目標如果距離的越來越遠,這個值大小也會越來越大。因此加入了這一項之後緩解了IoU損失中目標框和預測框無交集,梯度為0而導致的無法優化問題。
GIoU主要特點
- GIoU對尺度scale不敏感
- GIoU是IoU的下界,在兩個框無線重合的情況下,IoU=GIoU。IoU取值[0,1],但GIoU有對稱區間,取值範圍[-1,1]。在兩者重合的時候取最大值1,在兩者無交集且無限遠的時候取最小值-1,因此GIoU是一個非常好的距離度量指標。
- 與IoU只關注重疊區域不同,GIoU不僅關注重疊區域,還關注其他的非重合區域,能更好的反映兩者的重合度。
def Giou(rec1,rec2): #分別是第一個矩形左右上下的坐標 x1,x2,y1,y2 = rec1 x3,x4,y3,y4 = rec2 iou = Iou(rec1,rec2) area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4)) area_1 = (x2-x1)*(y1-y2) area_2 = (x4-x3)*(y3-y4) sum_area = area_1 + area_2 w1 = x2 - x1 #第一個矩形的寬 w2 = x4 - x3 #第二個矩形的寬 h1 = y1 - y2 h2 = y3 - y4 W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的寬 H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高 Area = W*H #交叉的面積 add_area = sum_area - Area #兩矩形並集的面積 end_area = (area_C - add_area)/area_C #閉包區域中不屬於兩個框的區域占閉包區域的比重 giou = iou - end_area return giou
GIoU的改進使得預測框和真實框即使無重疊也可以優化,然而其依然存在著兩個問題:1)對於預測框和真實框在水平或者豎直情況下,不管其距離遠近,其GIoU的計算值幾乎相同,接近於0。2)對於預測框包含住真實框的情況下,GIoU退化為IoU,在這種情況下,無法找到最合適的預測框。
基於IoU和GIoU存在的問題,論文《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》作者提出了兩個問題:
第一:直接最小化anchor框與目標框之間的歸一化距離是否可行,以達到更快的收斂速度。
第二:如何使回歸在與目標框有重疊甚至包含時更準確、更快。
文中提出了目標檢測中回歸框主要考慮的三要素:重疊區域,中心距離和寬高比。作者提出了DIoU和CIoU損失,提高了目標檢測的精度。
2.3 DIoU
DIoU要比GIou更加符合目標框回歸的機制,將目標與anchor之間的距離,重疊率以及尺度都考慮進去,使得目標框回歸變得更加穩定,不會像IoU和GIoU一樣出現訓練過程中發散等問題。

顯然從圖中可以看出,最右邊的圖是最理想的預測框情況,然而IoU或者GIoU計算的這三者的值是相等的,所以GIoU的刻畫還是無法找到一些最優情況。因此作者提出了DIoU。

其中,

,

分別代表了預測框和真實框的中心點,且

代表的是計算兩個中心點間的歐式距離。

代表的是能夠同時包含預測框和真實框的最小閉包區域的對角線距離。

通過上述的改進,DIoU既保留了GIoU的一些保留特性,同時其又帶來了幾個優勢:
1. DIoU能直接優化預測框和真實框的距離,比GIoU更快。
2. DIoU緩解了GIoU在預測框和真實框在水平或者豎直情況下|C-AUB|接近於0的問題。
作者在文中還提到了對NMS進行改進,提出將中心距離也作為其中的一個變數來選擇最好的預測框。

DIoU主要特點
- 與GIoU loss類似,DIoU loss在與目標框不重疊時,仍然可以為邊界框提供移動方向。
- DIoU loss可以直接最小化兩個目標框的距離,因此比GIoU loss收斂快得多。
- 對於包含兩個框在水平方向和垂直方向上這種情況,DIoU損失可以使回歸非常快,而GIoU損失幾乎退化為IoU損失。
- DIoU還可以替換普通的IoU評價策略,應用於NMS中,使得NMS得到的結果更加合理和有效。
2.4 CIOU
論文作者在提出了DIoU的基礎上,回答了一個問題,即一個好的回歸框損失應該考慮哪幾個點?作者給出了答案,三個要素:重疊區域,中心點的距離,寬高比。
DIoU考慮了重疊區域和中心點距離問題,還剩下寬高比沒考慮,因此後續提出了CIoU損失。



上述CIoU主要是在DIoU的基礎上,加入了寬和高的比值,將第三個要素寬高比也加入進來,具體的,多了和這兩個參數。其中是用來平衡比例的係數,是用來衡量Anchor框和目標框之間的比例一致性。
因為實際中寬和高都是非常小的值,在進行求梯度的時候要注意防止梯度爆炸的問題。具體的,一般都會對原始的,分別處以原影像的長寬。所以直接將設為常數1,這樣不會導致梯度的方向改變,雖然值變了,但這可以加快收斂。
實驗分析
試驗數據集:採用PASCAL VOC和COCO數據集進行評測。
網路模型:採用了單階段的SSD和YOLOV3以及雙階段的FasterRCNN網路。
評價指標:AP = (AP50 + AP55+ : : : + AP95) / 10 ,IoU閾值從0.5,0.55到0.95總共10個值的平均。AP75 ([email protected])是IoU閾值為0.75時的值。


將上述提出的DIoU和CIoU應用到上述的單階段網路,可以看出,相比較而言,改進的損失都有了一定的提升。特別是閾值為0.75的時候更加的明顯。

對於FasterRCNN來看,DIoU和CIoU都有一定的提升,且CIoU提升比較大。
程式碼復現參考
https://github.com/JaryHuang/awesome_SSD_FPN_GIoU
https://github.com/Zzh-tju/DIoU-darknet
參考:
1.深度學習之PyTorch物體檢測實戰 董洪義
2.https://zhuanlan.zhihu.com/p/94799295
3.https://blog.csdn.net/qiu931110/article/details/103330107
4.論文原文:https://arxiv.org/pdf/1911.08287.pdf
-END-

