分布事務和分散式鎖
分散式事務
1 兩階段提交
二階段提交協議(Two-phase Commit,即 2PC)是常用的分散式事務解決方案,即將事務的提交過程分為兩個階段來進行處理:準備階段和提交階段
階段 1:準備階段
- 協調者向所有參與者發送事務內容,詢問是否可以提交事務,並等待所有參與者答覆。
- 各參與者執行事務操作,將 undo 和 redo 資訊記入事務日誌中(但不提交事務)。
- 如參與者執行成功,給協調者回饋 yes,即可以提交;如執行失敗,給協調者回饋 no,即不可提交
階段 2:提交階段
- 如果協調者收到了參與者的失敗消息或者超時,直接給每個參與者發送回滾(rollback)消息;否則,發送提交(commit)消息。
- 參與者根據協調者的指令執行提交或者回滾操作,釋放所有事務處理過程中使用的鎖資源
2 三階段提交
三階段提交協議,是二階段提交協議的改進版本,與二階段提交不同的是,引入超時機制。同時在協調者和參與者中都引入超時機制
階段 1:canCommit
- 協調者向參與者發送 commit 請求,參與者如果可以提交就返回 yes 響應(參與者不執行事務操作),否則返回 no 響應:
- 協調者向所有參與者發出包含事務內容的 canCommit 請求,詢問是否可以提交事務,並等待所有參與者答覆
- 參與者收到 canCommit 請求後,如果認為可以執行事務操作,則回饋 yes 並進入預備狀態,否則回饋 no
階段 2:preCommit
- 協調者根據階段 1 canCommit 參與者的反應情況來決定是否可以進行基於事務的 preCommit 操作。根據響應情況,有以下兩種可能
- 情況 1:階段 1 所有參與者均回饋 yes,參與者預執行事務
- 協調者向所有參與者發出 preCommit 請求,進入準備階段
- 參與者收到 preCommit 請求後,執行事務操作,將 undo 和 redo 資訊記入事務日誌中(但不提交事務)
- 各參與者向協調者回饋 ack 響應或 no 響應,並等待最終指令
- 情況 2:階段 1 任何一個參與者回饋 no,或者等待協調者超時,無法收到所有參與者的回饋,即中斷事務
- 協調者向所有參與者發出 abort 請求
- 無論收到協調者發出的 abort 請求,或者在等待協調者請求過程中出現超時,參與者均會中斷事務
階段 3:do Commit
- 該階段進行真正的事務提交,分為以下三種情況
- 情況 1:階段 2 所有參與者均回饋 ack 響應,執行真正的事務提交
- 如果協調者處於工作狀態,則向所有參與者發出 do Commit 請求,參與者收到 do Commit 請求後,會正式執行事務提交,並釋放整個事務期間佔用的資源
- 各參與者向協調者回饋 ack 完成的消息,協調者收到所有參與者回饋的 ack 消息後,即完成事務提交
- 情況 2:階段 2 任何一個參與者回饋 no,或者等待超時後協調者尚無法收到所有參與者的回饋,即中斷事務
- 如果協調者處於工作狀態,向所有參與者發出 abort 請求,參與者使用階段 1 中的 undo 資訊執行回滾操作,並釋放整個事務期間佔用的資源
- 各參與者向協調者回饋 ack 完成的消息,協調者收到所有參與者回饋的 ack 消息後,即完成事務中斷
- 情況 3:協調者與參與者網路出現問題
- 參與者在協調者發出 do Commit 或 abort 請求等待超時,仍會繼續執行事務提交
3 TCC

- Try階段:需要做資源的檢查和預留。在扣錢場景下,Try 要做的事情是就是檢查賬戶可用餘額是否充足,再凍結賬戶的資金。Try 方法執行之後,帳號餘額雖然還是100,但是其中 30 元已經被凍結了,不能被其他事務使用
- Confirm階段: 扣減 Try 階段凍結的資金,Confirm 方法執行之後,帳號在一階段中凍結的 30 元已經被扣除,帳號 A 餘額變成 70 元
- Cancel階段:回滾的話,就需要在 Cancel 方法內釋放一階段 Try 凍結的 30 元,使帳號的回到初始狀態,100 元全部可用
4 saga
Saga是一個長活事務,可被分解成可以交錯運行的子事務集合,每個子事務有相應的執行模組和補償模組,當saga事務中的任意一個本地事務出錯了,可以通過調用相關事務對應的補償方法恢復,達到事務的最終一致性。

每個Saga由一系列sub-transaction Ti 組成
- 每個Ti 都有對應的補償動作Ci,補償動作用於撤銷Ti造成的結果
- 可以看到,和TCC 相比,Saga沒有「預留」動作,它的 Ti 就是直接提交到庫。
- saga 不保證 acid,只保持服務的基本可用和數據的最終一致性,事務隔離性差,要保證數據不被臟讀需要在業務上進行相應的邏輯處理。可以再業務層加入鎖隔離相關聯的操作
- Saga的執行順序有兩種:
- T1, T2, T3, …, Tn
- T1, T2, …, Tj, Cj,…, C2, C1,其中
0<j<n
- Saga定義了兩種恢復策略:
- backward recovery,向後恢復,補償所有已完成的事務,如果任一子事務失敗。即上面提到的第二種執行順序,其中j是發生錯誤的sub-transaction,這種做法的效果是撤銷掉之前所有成功的sub-transation,使得整個Saga的執行結果撤銷。
- forward recovery,向前恢復,重試失敗的事務,假設每個子事務最終都會成功。適用於必須要成功的場景,執行順序是類似於這樣的:T1, T2, …, Tj(失敗), Tj(重試),…, Tn,其中j是發生錯誤的sub-transaction。該情況下不需要 Ci。
5 seata
Seata 是一款開源的分散式事務解決方案,致力於提供高性能和簡單易用 的分散式事務服務。Seata 將為用戶提供了 AT、TCC、SAGA 和 XA 事 務模式,為用戶打造一站式的分散式解決方案(AT模式是阿里首推的模式)
AT模式(阿里分散式框架seata)
一階段:提交
- 在一階段,Seata 會攔截「業務 SQL」,首先解析SQL語義,找到「業務 SQL」要更新的業務數據,在業務數據被更新前,將其保存成「before image」,然後執行「業務 SQL」更新業務數據,在業務數據更新之後,再將其保存成「after image」,最後生成行鎖。以上操作全部在一個資料庫事務內完成,這樣保證了一階段操作的原子性
二階段提交或回滾
- 二階段如果是提交的話,因為「業務 SQL」在一階段已經提交至資料庫, 所以 Seata 框架只需將一階段保存的快照數據和行鎖刪掉,完成數據清理即可
- 二階段如果是回滾的話,Seata 就需要回滾一階段已經執行的「業務 SQL」,還原業務數據
- 回滾方式便是用「before image」還原業務數據;但在還原前要首先要校驗臟寫,對比「資料庫當前業務數據」和 「after image」,如果兩份數據完全一致就說明沒有臟寫,可以還原業務數據,如果不一致就說明有臟寫,出現臟寫就需要轉人工處理
6 事務消息
- 本地消息事務表 + 消息隊列
- 1 在同一個事務中完成訂單數據和單獨的消息表入庫
- 通過 cancal 將增量消息放入消息隊列
- 主動執行緒輪詢查詢增量消息放入消息隊列,增量可以通過快取已發送過的消息表最大ID篩選
- 2 消費者消費過後,標記事務消息的成功與失敗
- 1 在同一個事務中完成訂單數據和單獨的消息表入庫
- 本地消息事務表 + 消息隊列 + kafka 事務API。initTransactions 和 commitTransaction 範圍需要大於包括資料庫的事務操作範圍
- 在同一個資料庫事務中完成訂單數據和單獨的消息表入庫(處理中)
- 資料庫事務提交後,成功再提交 kafka 事務 commitTransaction。失敗則 abortTransaction
- 事務消息的補償,為防止隊列消息投遞失敗。定期查詢狀態是處理中的事務表消息,重新投遞
- 消費者消費過後,標記事務消息的成功與失敗
// 初始化事務,需要注意確保transation.id屬性被分配
void initTransactions();
// 開啟事務
void beginTransaction() throws ProducerFencedException;
// 為Consumer提供的在事務內Commit Offsets的操作
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
// 提交事務
void commitTransaction() throws ProducerFencedException;
// 放棄事務,類似於回滾事務的操作
void abortTransaction() throws ProducerFencedException;
- RocketMQ事務消息也是類似kafka,但是更加完善,採用了2PC(兩階段提交)+ 補償機制(事務狀態回查)的思想來實現了提交事務消息,同時增加一個補償邏輯來處理二階段超時或者失敗的消息
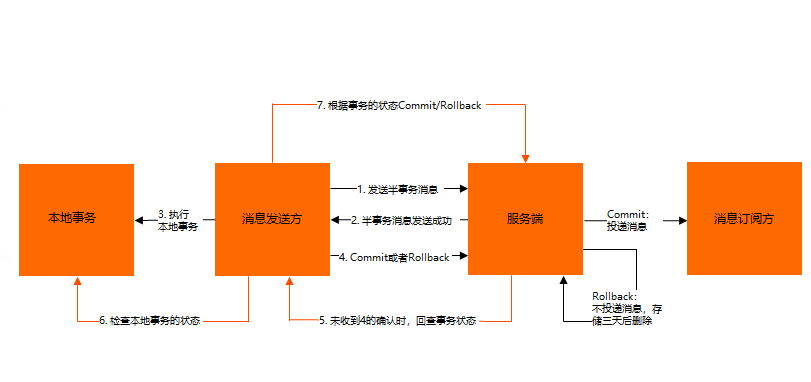
- 正常事務消息的發送及提交
- a、 生產者發送half消息到Broker服務端(半消息)半消息是一種特殊的消息類型,該狀態的消息暫時不能被Consumer消費
- b、Broker服務端將消息持久化之後,給生產者響應消息寫入結果(ACK響應);
- c、生產者根據發送結果執行本地事務邏輯(如果寫入失敗,此時half消息對業務不可見,本地邏輯不執行);
- d、生產者根據本地事務執行結果向Broker服務端提交二次確認(Commit 或是 Rollback),Broker服務端收到 Commit 狀態則將半事務消息標記為可投遞,訂閱方最終將收到該消息;Broker服務端收到 Rollback 狀態則刪除半事務消息,訂閱方將不會接收該消息
- 事務消息的補償流程
- a、在網路閃斷或者是應用重啟的情況下,可能導致生產者發送的二次確認消息未能到達Broker服務端,經過固定時間後,Broker服務端將會對沒有Commit/Rollback的事務消息(pending狀態的消息)進行「回查」;
- b、生產者收到回查消息後,檢查回查消息對應的本地事務執行的最終結果;
- c、生產者根據本地事務狀態,再次提交二次確認給Broker,然後Broker重新對半事務消息Commit或者Rollback
- 正常事務消息的發送及提交

分散式鎖
1 redis 的實現方案
- 1:set ex | px nx
- 鎖可以自動過期
- 加鎖和加失效時間兩是原子性操作
- 缺點:如果需要回滾刪除鎖,易出現 bug 引起誤刪其他執行緒加上的鎖
- 缺點:鎖過期釋放了,業務還沒執行完,無法延遲過期時間
- 2:set ex | px nx 。value 是當前執行緒獨有的唯一隨機值,需要校驗 value 再刪除
- 鎖可以自動過期
- 加鎖和加失效時間是原子性的操作
- 可防止鎖被別的執行緒誤刪
- 缺點:鎖過期釋放了,業務還沒執行完,無法延遲過期時間
- 3: redission
- Redisson 可以解決 鎖過期釋放,業務沒執行完的問題
- 只要執行緒一加鎖成功,就會啟動一個watch dog看門狗,它是一個後台執行緒,會每隔10秒檢查一下,如果執行緒1還持有鎖,那麼就會不斷的延長鎖key的生存時間。因此,Redisson就是使用Redisson解決了鎖過期釋放,業務沒執行完問題
- 4:Redlock
- redis 如果是單 master 的,執行緒 A 在Redis的master節點上拿到了鎖,但是加鎖的key還沒同步到slave節點。恰好這時,master節點發生故障,一個slave節點就會升級為master節點。執行緒 B 就可以獲取同個key的鎖啦,但執行緒 A 也已經拿到鎖了,鎖的安全性就沒了
- 多個Redis master部署,以保證它們不會同時宕掉。並且這些master節點是完全相互獨立的,相互之間不存在數據同步
- 然後在多台 Redis master 同時請求加鎖,但加鎖 redis 機器超過一半。並且加鎖使用的時間小於鎖的有效期,則加鎖成功。
2 資料庫的實現方案
- 單點故障:資料庫可以多搞個資料庫備份
- 沒有失效時間:每次加鎖時,插入一個期待的有效時間
- A:定時任務,隔一段時間清理時間失效鎖
- B:下次加鎖時則先判斷當前時間是否大於鎖的有效時間,以此判斷鎖是否失效
- 不可重入:在數據加鎖時加入一個冪等唯一值欄位,下次獲取時,先判斷這個欄位是否一致,一致則說明是當前操作重入操作
3 zookeeper
- zookeeper 臨時順序節點:臨時節點的生命周期和客戶端會話綁定。也就是說,如果客戶端會話失效,那麼這個節點就會自動被清除掉(可解決分散式鎖的自動失效)。另外,在臨時節點下面不能創建子節點
- zookeeper 監視器:zookeeper創建一個節點時,會註冊一個該節點的監視器,當節點狀態發生改變時,watch會被觸發,zooKeeper將會向客戶端發送一條通知
- zookeeper 分散式鎖原理
- 創建臨時有序節點,每個執行緒均能創建節點成功,但是其序號不同,只有序號最小的可以擁有鎖,其它執行緒只需要監聽比自己序號小的節點狀態即可
- 1: 在指定的節點下創建一個鎖目錄lock
- 2: 執行緒 X 進來獲取鎖在lock目錄下,並創建臨時有序節點
- 3: 執行緒 X 獲取lock目錄下所有子節點,並獲取比自己小的兄弟節點,如果不存在比自己小的節點,說明當前執行緒序號最小,順利獲取鎖
- 4: 此時執行緒Y進來創建臨時節點並獲取兄弟節點,判斷自己是否為最小序號節點,發現不是,於是設置監聽(watch)比自己小的節點(這裡是為了發生上面說的羊群效應)
- 5: 執行緒X執行完邏輯,刪除自己的節點,執行緒Y監聽到節點有變化,進一步判斷自己是已經是最小節點,順利獲取鎖


