並發刺客(False Sharing)——並發程式的隱藏殺手
並發刺客(False Sharing)——並發程式的隱藏殺手
前言
前段時間在各種社交平台「雪糕刺客」這個詞比較火,簡單的來說就是雪糕的價格非常高!其實在並發程式當中也有一個刺客,如果在寫並發程式的時候不注意不小心,這個刺客很可能會拖累我們的並發程式,讓我們並發程式執行的效率變低,讓並發程式付出很大的代價,這和「雪糕刺客」當中的「刺客」的含義是一致的。這個並發程式當中的刺客就是——假共享(False Sharing)。
假共享(False Sharing)
快取行
當CPU從更慢級別的快取讀取數據的時候(三級Cache會從記憶體當中讀取數據,二級快取會從三級快取當中讀取數據,一級快取會從二級快取當中讀取數據,快取級別越低執行速度越快),CPU並不是一個位元組一個位元組的讀取的,而是一次會讀取一塊數據,然後將這個數據快取到CPU當中,而這一塊數據就叫做快取行。有一種快取行的大小就是64位元組,那麼我們為什麼會做這種優化呢?這是因為局部性原理,所謂局部性原理簡單說來就是,當時使用一個數據的時候,它附近的數據在未來的一段時間你也很可能用到,比如說我們遍曆數組,我們通常從前往後進行遍歷,比如我們數組當中的數據大小是8個位元組,如果我們的快取行是64個位元組的話,那麼一個快取行就可以快取8個數據,那麼我們在遍歷第一個數據的時候將這8個數據載入進入快取行,那麼我們在遍歷未來7個數據的時候都不需要再從記憶體當中拿數據,直接從快取當中拿就行,這就可以節約程式執行的時間。
假共享
當兩個執行緒在CPU上兩個不同的核心上執行程式碼的時候,如果這兩個執行緒使用了同一個快取行C,而且對這個快取行當中兩個不同的變數進行寫操作,比如執行緒A對變數a進行寫操作,執行緒B對變數b進行寫操作。而由於快取一致性(Cache coherence)協議的存在,如果其中A執行緒對快取行C中變數a進行了寫操作的話,為了保證各個CPU核心的數據一致(也就是說兩個CPU核心看到了a的值是一樣的,因為a的值已經發生變化了,需要讓另外的CPU核心知道,不然另外的CPU核心使用的就是舊的值,那麼程式結果就不對了),其他核心的這個快取行就會失效,如果他還想使用這個快取行的話就需要重新三級Cache載入,如果數據不存在三級Cache當中的話,就會從記憶體當中載入,而這個重新載入的過程就會很拖累程式的執行效率,而事實上執行緒A寫的是變數a,執行緒B寫的是變數b,他們並沒有真正的有共享的數據,只是他們需要的數據在同一個快取行當中,因此稱這種現象叫做假共享(False Sharing)。
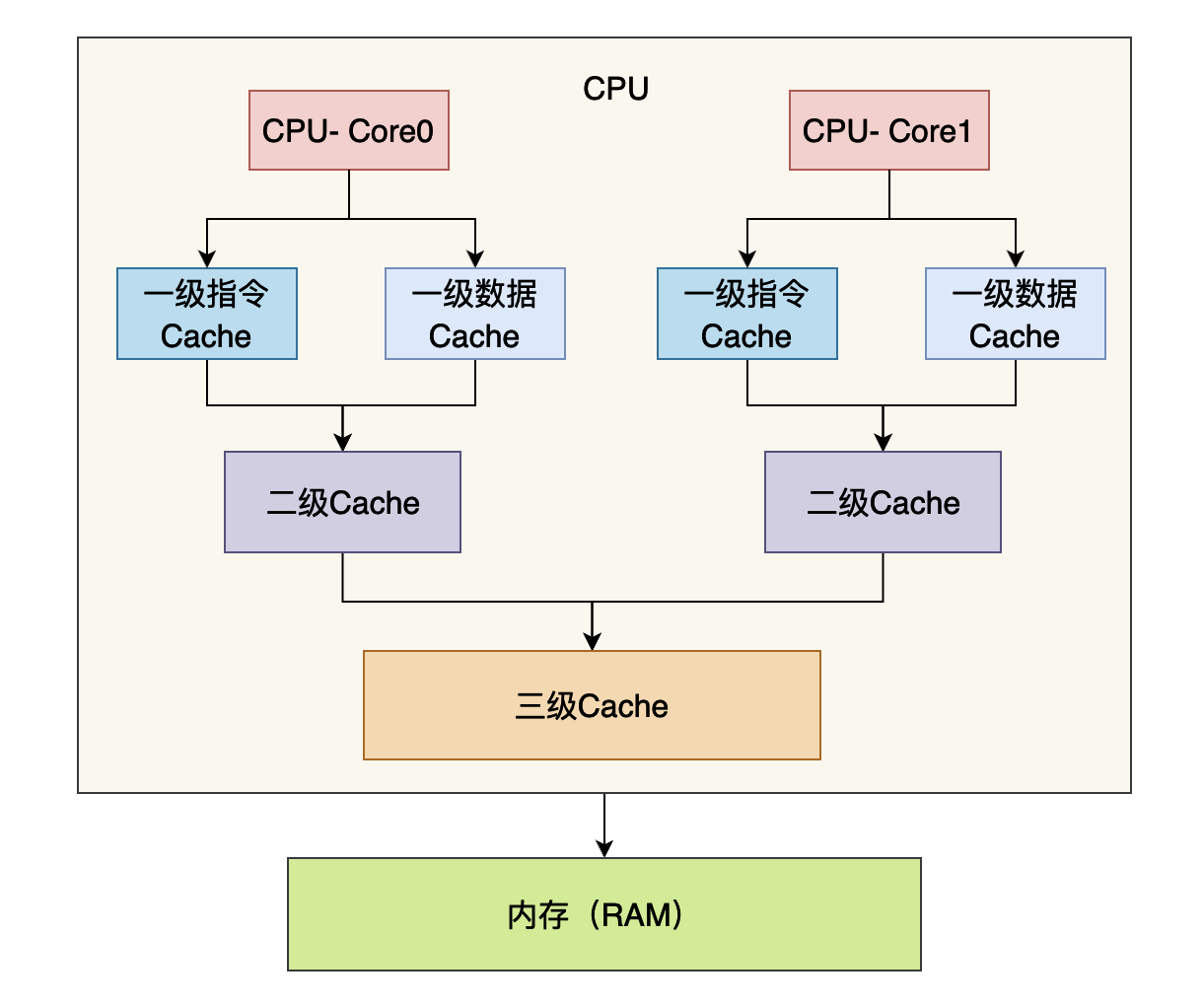
上面我們談到了,當快取行失效的時候會從三級Cache或者記憶體當中載入,而多個不同的CPU核心是共享三級Cache的(上圖當中已經顯示出來了),其中一個CPU核心更新了數據,會把數據刷新到三級Cache或者記憶體當中,因此這個時候其他的CPU核心去載入數據的時候就是新值了。
上面談到的關於CPU的快取一致性(Cache coherence)的內容還是比較少的,如果你想深入了解快取一致性(Cache coherence)和快取一致性協議可以仔細去看這篇文章。
我們再來舉一個更加具體的例子:
假設在記憶體當中,變數a和變數b都佔四個位元組,而且他們的記憶體地址是連續且相鄰的,現在有兩個執行緒A和B,執行緒A要不斷的對變數a進行+1操作,執行緒B需要不斷的對變數進行+1操作,現在這個兩個數據所在的快取行已經被快取到三級快取了。
- 執行緒A從三級快取當中將數據載入到二級快取和一級快取然後在CPU- Core0當中執行程式碼,執行緒B從三級快取將數據載入到二級快取和一級快取然後在CPU- Core1當中執行程式碼。
- 執行緒A不斷的執行a += 1,因為執行緒B快取的快取行當中包含數據a,執行緒A在修改a的值之後,就會在匯流排上發送消息,讓其他處理器當中含有變數a的快取行失效,在處理器將快取行失效之後,就會在匯流排上發送消息,表示快取行已經失效,執行緒A所在的CPU- Core0收到消息之後將更新後的數據刷新到三級Cache。
- 這個時候執行緒B所在的CPU-Core1當中含有a的快取行已經失效,因為變數b和變數a在同一個快取行,現在執行緒B想對變數b進行加一操作,但是在一級和二級快取當中已經沒有了,它需要三級快取當中載入這個快取行,如果三級快取當中沒有就需要去記憶體當中載入。
- 仔細分析上面的過程你就會發現執行緒B並沒有對變數a有什麼操作,但是它需要的快取行就失效了,雖然和執行緒B共享需要同一個內容的快取行,但是他們之間並沒有真正共享數據,所以這種現象叫做假共享。
Java程式碼復現假共享
復現假共享
下面是兩個執行緒不斷對兩個變數執行++操作的程式碼:
class Data {
public volatile long a;
public volatile long b;
}
public class FalseSharing {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
long start = System.currentTimeMillis();
Thread A = new Thread(() -> {
for (int i = 0; i < 500_000_000; i++) {
data.a += 1;
}
}, "A");
Thread B = new Thread(() -> {
for (int i = 0; i < 500_000_000; i++) {
data.b += 1;
}
}, "B");
A.start();
B.start();
A.join();
B.join();
long end = System.currentTimeMillis();
System.out.println("花費時間為:" + (end - start));
System.out.println(data.a);
System.out.println(data.b);
}
}
上面的程式碼比較簡單,這裡就不進行說明了,上面的程式碼在我的筆記型電腦上的執行時間大約是17秒。
上面的程式碼變數a和變數b在記憶體當中的位置是相鄰的,他們在被CPU載入之後會在同一個快取行當中,因此會存在假共享的問題,程式的執行時間會變長。
下面的程式碼是優化過後的程式碼,在變數a前面和後面分別加入56個位元組的數據,再加上a的8個位元組(long類型是8個位元組),這樣a前後加上a的數據有64個位元組,而現在主流的快取行是64個位元組,夠一個快取行的大小,因為數據a和數據b就不會在同一個快取行當中,因此就不會存在假共享的問題了。而下面的程式碼在我筆記型電腦當中執行的時間大約為5秒。這就足以看出假共享會對程式的執行帶來多大影響了。
class Data {
public volatile long a1, a2, a3, a4, a5, a6, a7;
public volatile long a;
public volatile long b1, b2, b3, b4, b5, b6, b7;
public volatile long b;
}
public class FalseSharing {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
long start = System.currentTimeMillis();
Thread A = new Thread(() -> {
for (int i = 0; i < 500_000_000; i++) {
data.a += 1;
}
}, "A");
Thread B = new Thread(() -> {
for (int i = 0; i < 500_000_000; i++) {
data.b += 1;
}
}, "B");
A.start();
B.start();
A.join();
B.join();
long end = System.currentTimeMillis();
System.out.println("花費時間為:" + (end - start));
System.out.println(data.a);
System.out.println(data.b);
}
}
JDK解決假共享
為了解決假共享的問題,JDK為我們提供了一個註解@Contened解決假共享的問題。
import sun.misc.Contended;
class Data {
// public volatile long a1, a2, a3, a4, a5, a6, a7;
@Contended
public volatile long a;
// public volatile long b1, b2, b3, b4, b5, b6, b7;
@Contended
public volatile long b;
}
public class FalseSharing {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
long start = System.currentTimeMillis();
Thread A = new Thread(() -> {
for (long i = 0; i < 500_000_000; i++) {
data.a += 1;
}
}, "A");
Thread B = new Thread(() -> {
for (long i = 0; i < 500_000_000; i++) {
data.b += 1;
}
}, "B");
A.start();
B.start();
A.join();
B.join();
long end = System.currentTimeMillis();
System.out.println("花費時間為:" + (end - start));
System.out.println(data.a);
System.out.println(data.b);
}
}
上面程式碼的執行時間也是5秒左右,和之前我們自己在變數的左右兩邊插入變數的效果是一樣的,但是JDK提供的這個介面和我們自己實現的還是有所區別的。(注意:上面的程式碼是在JDK1.8下執行的,如果要想@Contended註解生效,你還需要在JVM參數上加入-XX:-RestrictContended,這樣上面的程式碼才能生效否則是不能夠生效的)
-
在我們自己解決假共享的程式碼當中,是在變數
a的左右兩邊加入56個位元組的其他變數,讓他和變數b不在同一個快取行當中。 -
在JDK給我們提供的註解
@Contended,是在被加註解的欄位的右邊加入一定數量的空位元組,默認加入128空位元組,那麼變數a和變數b之間的記憶體地址大一點,最終不在同一個快取行當中。這個位元組數量可以使用JVM參數-XX:ContendedPaddingWidth=64,進行控制,比如這個是64個位元組。 -
除此之外
@Contended註解還能夠將變數進行分組:
class Data {
@Contended("a")
public volatile long a;
@Contended("bc")
public volatile long b;
@Contended("bc")
public volatile long c;
}
在解析註解的時候會讓同一組的變數在記憶體當中的位置相鄰,不同的組之間會有一定數量的空位元組,配置方式還是跟上面一樣,默認每組之間空位元組的數量為128。
比如上面的變數在記憶體當中的邏輯布局詳細布局如下:

OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 20 0a 06 00 (00100000 00001010 00000110 00000000) (395808)
12 132 (alignment/padding gap)
144 8 long Data.a 0
152 128 (alignment/padding gap)
280 8 long Data.b 0
288 8 long Data.c 0
296 128 (loss due to the next object alignment)
Instance size: 424 bytes
Space losses: 260 bytes internal + 128 bytes external = 388 bytes total
上面的內容是通過下面程式碼列印的,你只要在pom文件當中引入包jol即可:
import org.openjdk.jol.info.ClassLayout;
import sun.misc.Contended;
class Data {
@Contended("a")
public volatile long a;
@Contended("bc")
public volatile long b;
@Contended("bc")
public volatile long c;
}
public class FalseSharing {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
System.out.println(ClassLayout.parseInstance(data).toPrintable());
}
}
從更低層次C語言看假共享
前面我們是使用Java語言去驗證假共享,在本小節當中我們通過一個C語言的多執行緒程式(使用pthread)去驗證假共享。(下面的程式碼在類Unix系統都可以執行)
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#define CHOOSE // 這裡定義了 CHOOSE 如果不想定義CHOOSE 則將這一行注釋掉即可
// 定義一個全局變數
int data[1000];
void* add(void* flag) {
// 這個函數的作用就是不斷的往 data 當中的某個數據進行加一操作
int idx = *((int *)flag);
for (long i = 0; i < 10000000000; ++i) {
data[idx]++;
}
}
int main() {
pthread_t a, b;
#ifdef CHOOSE // 如果定義了 CHOOSE 則執行下面的程式碼 讓兩個執行緒操作的變數隔得遠一點 讓他們不在同一個快取行當中
int flag_a = 0;
int flag_b = 100;
printf("遠離\n");
#else // 如果沒有定義 讓他們隔得近一點 也就是說讓他們在同一個快取行當中
int flag_a = 0;
int flag_b = 1;
printf("臨近\n");
#endif
pthread_create(&a, NULL, add, &flag_a); // 創建執行緒a 執行函數 add 傳遞參數 flag_a 並且啟動
pthread_create(&b, NULL, add, &flag_b); // 創建執行緒b 執行函數 add 傳遞參數 flag_b 並且啟動
long start = time(NULL);
pthread_join(a, NULL); // 主執行緒等待執行緒a執行完成
pthread_join(b, NULL); // 主執行緒等待執行緒b執行完成
long end = time(NULL);
printf("data[0] = %d\t data[1] = %d\n", data[0], data[1]);
printf("cost time = %ld\n", (end - start));
return 0;
}
上面程式碼的輸出結果如下圖所示:
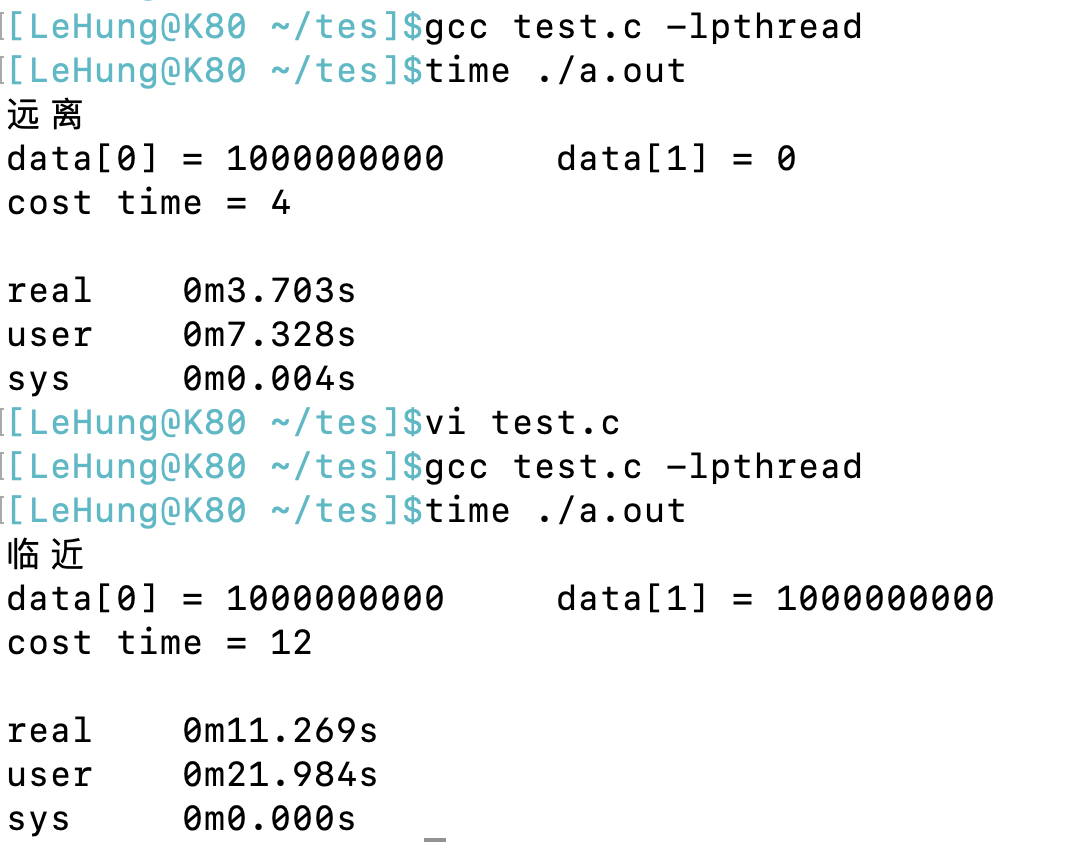
我們首先來解釋一下上面time命令的輸出:
readl:這個表示真實世界當中的牆鍾時間,就是表示這個程式執行所花費的時間,這個秒單位和我們平常說的秒是一樣的。user:這個表示程式在用戶態執行的CPU時間,CPU時間和真實時間是不一樣的,這裡需要注意區分,這裡的秒和我們平常的秒是不一樣的。sys:這個表示程式在內核態執行所花費的CPU時間。
從上面程式的輸出結果我們可以很明顯的看出來當操作的兩個整型變數相隔距離遠的時候,也就是不在同一個快取行的時候,程式執行的速度是比數據隔得近在同一個快取行的時候快得多,這也從側面顯示了假共享很大程度的降低了程式執行的效率。
總結
在本篇文章當中主要討論了以下內容:
- 當多個執行緒操作同一個快取行當中的多個不同的變數時,雖然他們事實上沒有對數據進行共享,但是他們對同一個快取行當中的數據進行修改,而由於快取一致性協議的存在會導致程式執行的效率降低,這種現象叫做假共享。
- 在Java程式當中我們如果想讓多個變數不在同一個快取行當中的話,我們可以在變數的旁邊通過增加其他變數的方式讓多個不同的變數不在同一個快取行。
- JDK也為我們提供了
Contended註解可以在欄位的後面通過增加空位元組的方式讓多個數據不在同一個快取行,而且你需要在JVM參數當中加入-XX:-RestrictContended,同時你可以通過JVM參數-XX:ContendedPaddingWidth=64調整空位元組的數目。JDK8之後註解Contended在JDK當中的位置有所變化,大家可以查詢一下。 - 我們也是用了C語言的API去測試了假共享,事實上在Java虛擬機當中底層的執行緒也是通過調用
pthread_create進行創建的。
更多精彩內容合集可訪問項目://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,了解更多電腦(Java、Python、電腦系統基礎、演算法與數據結構)知識。


