Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列1:深刻理解高性能Redis的本質
Redis系列2:數據持久化提高可用性
Redis系列3:高可用之主從架構
1 背景
從第三篇 Redis系列3:高可用之主從架構 ,我們知道,為Redis配置主從模式,可以大幅度的提高Redis服務的可用性,減少甚至避免Redis服務發生宕機的可能。
它有如下能力:
- 故障隔離和恢復:無論主節點或者從節點宕機,其他節點依然可以保證服務的正常運行,並可以手動切換主從。
- 讀寫隔離:Master 節點提供寫服務,Slave 節點提供讀服務,分攤流量壓力,均衡流量的負載。
- 提供高可用保障:主從模式是高可用的最基礎版本,也是哨兵模式和 cluster模式實施的前置條件。
但是依然存在不小的問題,我們知道,在衡量系統可用性這邊有個指標叫做MTTR,即平均修復時間。雖然主從模式支援手動切換,但是我們從知道服務故障到手動切換止損到恢復,這可能是一個比較長的過程。這期間的損失將難以計量,對於超高並發大系統是一個絕對災難。所以我們需要系統自動的感知到Master故障,並選擇一個 Slave 切換為 Master,實現故障自動轉移的能力。
平均修復時間(Mean time to repair,MTTR),是描述產品由故障狀態轉為工作狀態時修理時間的平均值。
2 什麼是哨兵模式
在實際生產環境中,伺服器難免會遇到一些突髮狀況:伺服器宕機,停電,硬體損壞等等,一旦發生,後果不堪設想。
哨兵模式的核心還是主從模式的演變,只不過相對於主從模式在主節點宕機導致不可寫的情況下,多了探活,以及競選機制:從所有的從節點競選出新的主節點,然後自動切換。競選機制的實現,是依賴於在系統中啟動sentinel進程,對各個伺服器進行監控。如下圖所示:

3 哨兵模式的主要職責
我們知道,要讓Redis服務實現故障自動切換會有很多細節需要考慮,比如:
- 判定節點故障的條件是什麼,有沒有可能是假死或者響應延遲。
- 既然是競選機制,那麼所有slave節點都可以參與競爭,也都有機會成為master。選擇哪個slave成為master是關鍵。
- 競選出新的master,其他slave需要從新的master中replicaof,所以消息通知和通訊也是核心。
帶著這些思考,我們來看看官方對Redis哨兵的定義:
哨兵作為 Redis 的一種運行模式,專註於對 Redis 實例(master、slaves)運行狀態進行監控,並能夠在主節點發生故障時通過一系列的操作,實現新的master競選、主從切換、故障轉移,確保整個 Redis 服務的可用性。
所以,哨兵的能力至少應該包含如下幾點:
- 監控:持續監控 master 、slave 是否健康,是否處於預期工作狀態。
- 主從動態切換:當 Master 運行故障,哨兵啟動自動故障恢複流程:從 slave 中選擇一台作為新 master。
- 通知機制:競選出新的master之後,通知客戶端與新 master 建立連接;slave 從新的 master 中 replicaof,保障主從數據的一致性。
接下來我們一個個來看這幾個能力的實現過程。
3.1 監控能力
哨兵模式啟用的時候,會同步啟用叫做Sentinel的進程。sentinel程會向所有的master 和 slaves 以及其他sentinel進程 發送心跳包(1s一次),看看是否正常返迴響應。
- 如果slave 沒有在規定的時間內響應 sentinel 的 PING 命令 , sentinel 會認為該實例已經掛了,將它tag為:下線狀態;
- 同理,如果master 沒有在規定時間響應 sentinel 的 PING 命令,也會被判定為 offline 狀態,只是會多做一步 自動切換 master 的流程。
PING 命令的回復有兩種情況:
- 有效回復:返回 +PONG、-LOADING、-MASTERDOWN 任何一種;
- 無效回復:有效回復之外的回復,或者指定時間內返回任何回復。
但是可能存在一些誤判的情況,比如說網路擁塞、master實例假死、請求延遲,導致實例在某個短暫時間段不可用,後續又快速恢復了。
如果這時候被我們主動下線了,其實整個系統的可用性反而遭到了退化。而且 誤判之後的一系列操作,master競選、消息通知,slave 與新 master 同步數據,都會消耗大量資源。所以,誤判要不得啊。
為了保證判斷的可靠性,我們對下線的標識做了區分:一種是 主觀下線,一種是客觀下線。
-
主觀下線
哨兵利用 PING 命令來監測 master、 slave 實例節點的生命狀態。如果是無效回復,哨兵就把這個實例節點標記為 主觀下線 。如果是slave,一般是有多從概念,直接下線即可,但如果是master,就要小心了。一個人sentinel容易誤判,那就多個sentinel進投票裁決。哨兵機制就是這樣的,採用多個實例組成sentinel集群模式進行部署,即哨兵集群。多個哨兵實例一起來判斷,就可以避免單個哨兵因為自身網路狀況不好,而誤判主庫下線的情況。
同時,多個哨兵的網路同時不穩定的概率較小,由它們一起做決策,誤判率也能降低。 -
客觀下線
master 是否要下線不能是單個sentinel能夠決定的,上面說了我們一幫會有個sentinel集群 ,所以這個集群就發揮作用了,大家一起投票,超過一半的sentinel 都判斷了 主觀下線 ,這時候我們就把 master 標記為 客觀下線,認為它是真的不行了。
當 master 被判定為 客觀下線 後,就算正式沒有master了,當務之急就是趕緊競選出一個新的master。
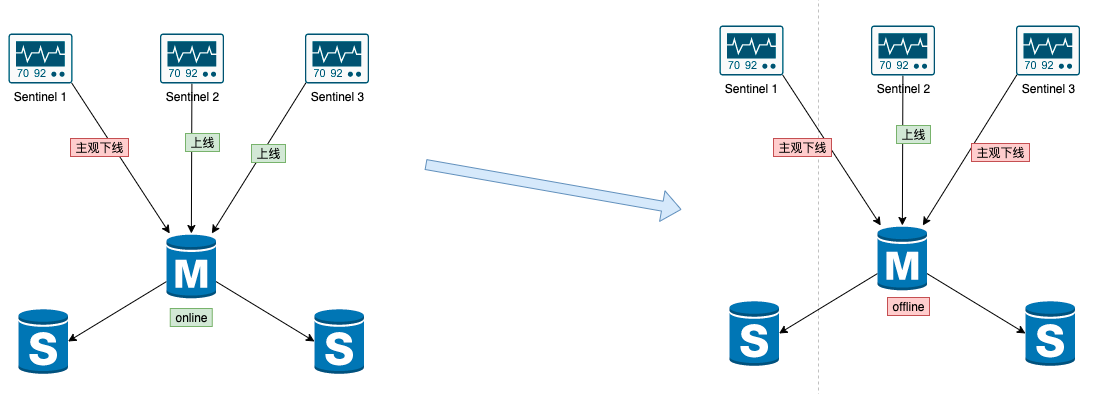
-
如何區別主、客觀下線
主觀下線是sentinel自己認為節點offline,這時候節點並不是真正的下線;而客觀下線是達到一定數量的哨兵(比如超過一半)都認為節點offline了,這時候會進一步觸發離線、重新競選主等一系列操作。

這裡的「一定數量」是一個法定數量(Quorum),是由哨兵監控配置決定的,解釋一下該配置:
# sentinel monitor <master-name> <master-host> <master-port> <quorum>
# 舉例如下:
sentinel monitor mymaster 127.0.0.1 6379 2
這條配置項用於告知哨兵需要監聽的主節點:
- sentinel monitor:代表監控。
- mymaster:代表主節點的名稱,可以自定義。
- 192.168.11.128:代表監控的主節點 ip,6379 代表埠。
- 2:法定數量,代表只有兩個或兩個以上的哨兵認為主節點不可用的時候,才會把 master 設置為客觀下線狀態,然後進行 failover 操作。
客觀下線 的標準就是,當有 N 個哨兵實例時,要有 N/2 + 1 個實例判斷 master 為 主觀下線 ,才能最終判定 master 為 客觀下線 ,其實就是過半機制。
3.2 主從動態切換
sentinel 的一個很重要工作,就是從多個slave中選舉出一個新的master。當然,這個選舉的過程會比較嚴謹,需要通過 篩選 + 綜合評估 方式進行選舉,
3.2.1 篩選
- 過濾掉不健康的(下線或者斷線),沒有回復哨兵ping響應的從節點。
- 評估實例過往的網路連接狀況
down-after-milliseconds,如果一定周期內(如24h)從庫和主庫經常斷連,而且超出了一定的閾值(如 10 次),則該slave不予考慮。
這樣,就保留下比較健康的實例了。
3.2.2 綜合評估
篩選掉不健康的實例之後,我們就可以對於剩下健康的實例按順序進行綜合評估了。
- slave 優先順序,通過 slave-priority 配置項(redis.conf),可以給不同的從庫設置不同優先順序,優先順序高的優先成為master。
- 選擇數據偏移量差距最小的,即slave_repl_offset與 master_repl_offset進度差距,其實就是比較 slave 與 原master 複製進度差距。
- slave runID,在優先順序和複製進度都相同的情況下,選用runID最好的,runID越小說明創建時間越早,優先選為master。先來後到原則。
等這幾個條件都評估完,我們就會選擇出最適合slave,把他推舉為新的master。

3.3 資訊通知
等推選出最新的master之後,後續所有的寫操作都會進入這個master中。所以需要儘快通知到所有的slave,讓他們重新 replacaof 到 master上,重新建立runID和slave_repl_offset ,來保證數據的正常傳輸和主從一致性。如下圖所示:

4 關於哨兵集群
前面說過了,單個哨兵對redis實例的離線判斷可能會有誤判,所以會有一個sentinel集群的概念,超過一定比例的sentinel(比如 > 1/2)的判斷為主觀下線,才能形成實質的客觀下線。
那這邊有幾個知識點我們需要梳理清楚。
4.1 集群中的哨兵如何實現通訊
使用redis的pub/sub 訂閱能力實現哨兵間通訊 和 slave 發現。
哨兵之間可以相互通訊,主要歸功於 Redis 的 pub/sub 發布/訂閱機制。哨兵與 master 建立通訊之後,可以利用 master 提供發布/訂閱機制發布自己的IP、port等資訊
master 有一個 sentinel:hello 的專用通道,用於哨兵之間發布和訂閱消息。哨兵們都可以通過該通道發布自己的Name、IP、Port消息,同時訂閱其他哨兵發布的Name、IP、Port消息。互相發現之後建立起了連接,後續的消息通訊就可以直接進行了。
★這個與微服務中的服務註冊與發現,以及RPC通訊類似的整套做法類似。

4.2 哨兵如何與slave實現連接
- sentinel向master發送
INFO命令 - master返回與之關聯的slave 列表
- sentinel 根據 master 返回的 slave 列表,逐個與 salve 建立連接,並且根據這個連接持續監控


4.3 哨兵如何與客戶端進行事件通知
依舊是通過 pub/sub 機制,發布不同事件,讓客戶端在這裡訂閱消息。客戶端可以訂閱哨兵的消息,哨兵提供的消息訂閱頻道有很多,不同頻道包含了主從庫切換過程中的不同關鍵事件。
5 總結
5.1 哨兵主要任務
Redis 哨兵機制是實現 Redis 不間斷服務的高可用手段之一。主從架構集群的數據同步,是數據可靠的基礎保障;主庫宕機,自動執行主從切換是服務不間斷的關鍵支撐。
Redis 哨兵機制實現了主從庫的自動切換,再也不怕跟女盆友么么噠的時候 master 宕機了:
- 監控 master 與 slave 運行狀態,判斷是否客觀下線;
- master 客觀下線後,選擇一個 slave 切換成 master;
- 通知 slave 和客戶端新 master 資訊。
5.2 哨兵集群原理
為了避免單個哨兵故障後無法進行主從切換,以及為了減少誤判率,又引入了哨兵集群;哨兵集群又需要有一些機制來支撐它的正常運行:
- 基於 pub/sub 機制實現哨兵集群之間的通訊;
- 基於 INFO 命令獲取 slave 列表,幫助 哨兵與 slave 建立連接;
- 通過哨兵的 pub/sub,實現了與客戶端和哨兵之間的事件通知。
主從切換,並不是隨意選擇一個哨兵就可以執行,而是通過投票仲裁,選擇一個 Leader,由這個 Leader 負責主從切換。


