8000字講透OBSA原理與應用實踐
摘要:OBSA項目是圍繞OBS建立的大數據和AI生態,其在不斷的發展和完善中,目前有如下子項目:hadoop-obs項目和flink-obs項目。
文章作者:存儲服務產品部開發者支援團隊
OBS存儲服務概述
華為雲OBS存儲服務提供了「對象存儲服務」和」並行文件系統服務」。
1.對象存儲服務:提供傳統的對象存儲語義。
2.並行文件系統服務:簡稱文件桶,基於對象存儲服務提供了一種經過優化的高性能文件系統,其實現了追加寫,文件截斷,目錄重命名原子操作等一系列特性,並和對象存儲服務一樣提供了毫秒級別訪問時延,TB級別頻寬和百萬級別的IOPS,因此非常適用於大數據分析等場景,華為雲的MRS,DLI等大數據分析服務均已支援OBS服務作為其底層的存儲服務。
OBSA項目概述
1.OBSA項目是圍繞OBS建立的大數據和AI生態,其在不斷的發展和完善中,目前有如下子項目:
(1)hadoop-obs項目:基於華為雲OBS存儲服務實現了hadoop文件系統抽象;
(2)flink-obs項目:基於華為雲OBS存儲服務實現了Flink文件系統抽象;
2.OBSA官方文檔://support.huaweicloud.com/bestpractice-obs/obs_05_1501.html
hadoop-obs原理和實踐建議
簡述
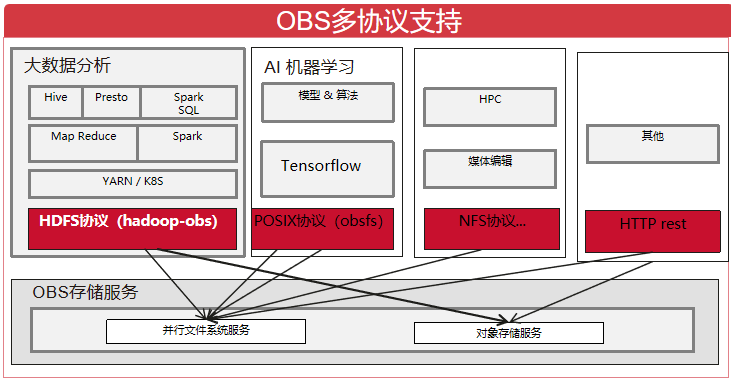
1.hadoop-obs項目基於OBS並行文件系統服務/對象存儲服務實現了hadoop的FileSystem抽象(即HDFS協議)OBSFileSystem,可以像使用 HDFS分散式文件系統一樣訪問OBS中的數據,實現大數據計算引擎Spark、MapReduce、Hive等與OBS存儲服務的對接,為大數據計算提供「數據湖」存儲。
2.OBSFileSystem繼承實現了FileSystem抽象類,適配為對OBS http/https rest API介面的訪問,下述章節將詳細剖析OBSFileSystem的實現和實踐。
3.hadoop-obs以jar包的形式對外發布,hadoop-huaweicloud-x.x.x-hw-y.jar包含義:前三位x.x.x為配套hadoop版本號;最後一位y為hadoop-obs版本號;如:hadoop-huaweicloud-3.1.1-hw-40.jar,3.1.1是配套hadoop版本號,40是hadoop-obs的版本號。
認證和鑒權機制
在了解OBSFileSystem的認證和鑒權機制之前,我們先對OBS服務的認證和鑒權機製做一個簡單的介紹。其主要支援兩種認證鑒權機制:
1.桶策略:桶擁有者通過桶策略可為IAM用戶或其他帳號授權桶及桶內對象精確的操作許可權,桶策略有20KB的大小限制,超出此限制可以選擇IAM策略
2.IAM策略:IAM許可權是作用於雲資源的,IAM許可權定義了允許和拒絕的訪問操作,以此實現雲資源許可權訪問控制
不管上述哪種機制,訪問OBS時均需要IAM用戶對應的永久aksk或是臨時aksk(其包含ak,sk,securityToken三部分,其是有時效限制的,一般為24小時)
在通過OBSFileSystem訪問OBS時首先需要配置永久aksk或是臨時aksk,OBSFileSystem支援如下幾種方式獲取aksk:(優先順序由高到低排序)
1.從core-site配置文件中獲取:通過fs.obs.access.key和fs.obs.secret.key和fs.obs.session.token配置項獲取。其支援hadoop的CredentialProvider機制,即通過CredentialProvider機制對aksk進行保護,避免aksk的明文暴露,注意不能將其保存在OBSFileSystem存儲系統的路徑上因為循環依賴問題//hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html
附:關於CredentialProvider機制相關配置項:
hadoop.security.credential.provider.path:存放機密資訊的keystore文件路徑,例如aksk可以存儲在其中
hadoop.security.credential.clear-text-fallback:當從keystore文件中獲取不到機密資訊時回落到配置項的明文中去獲取hadoop.security.credstore.java-keystore-provider.password-file:keystore被加密時,其密碼文件的路徑
2.從URL中獲取:其格式為obs://{ak}:{sk}@obs-bucket/
3.從Provider中獲取:自定義aksk提供器,通過fs.obs.security.provider配置項進行配置Provider需要繼承com.obs.services.IObsCredentialsProvider介面,目前支援的Provider:
(1)com.obs.services.EnvironmentVariableObsCredentialsProvider:從環境變數里尋找aksk,需要在環境變數中定義OBS_ACCESS_KEY_ID和OBS_SECRET_ACCESS_KEY分別代表永久的AK和SK
(2)com.obs.services.EcsObsCredentialsProvider:從ECS元數據中自動獲取臨時aksk並進行定期自動刷新
(3)com.obs.services.OBSCredentialsProviderChain:以鏈式的形式依次從環境變數,ECS伺服器上進行搜索以獲取對應的訪問密鑰,且會以第一組成功獲取到的訪問密鑰訪問obs
也可以自定義Provider完成符合您架構和安全要求的實現。
(MRS和DLI等華為雲服務有自己的provider實現)
注意事項:
(1)對於類似mapreduce的分散式任務,因為分散式任務通過OBSFileSystem訪問OBS且分散式任務被不確定的分配到集群節點上,所以需要能在集群的每一個節點上都能夠獲取aksk,例如如果通過EnvironmentVariableObsCredentialsProvider方式獲取,則需要在每一個節點上都進行環境變數設置
(2)當通過臨時aksk機制訪問OBS時注意臨時aksk的時效性
(3)注意EcsObsCredentialsProvider機制中訪問ECS元數據時的流控,即訪問ECS元數據獲取aksk是有頻次限制的
寫相關流程
覆蓋寫
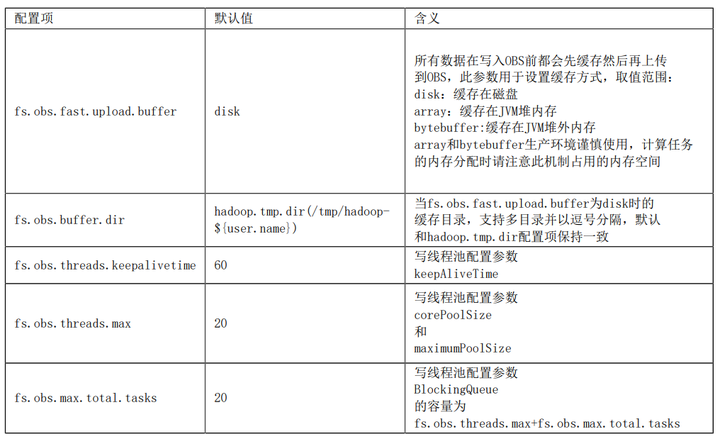
當調用OBSFileSystem的create相關方法時將獲取FSDataOutputStream,通過該流寫數據到OBS中。此流程總的實現思路是通過「快取」和「並發多段上傳」來實現較高的寫性能:
(1)通過FSDataOutputStream寫入數據時,數據首先將被快取然後並發多段上傳到OBS
(2)通過參數fs.obs.multipart.size設置快取的大小,當數據寫入量達到此閾值時將對應產生一次range上傳請求,且是非同步發起的range上傳請求,當非同步range上傳任務完成時將及時清理其對應的快取,例如當快取機製為disk時,將及時清理本地磁碟中的快取文件;
(3)當調用FSDataOutputStream的close方法時將等待所有的range上傳非同步任務完成,並發起多段合併請求完成文件的真正寫入;並發多段上傳執行緒池相關配置參數:
附obs java sdk 多段上傳://support.huaweicloud.com/sdk-java-devg-obs/obs_21_0607.html
實踐建議:
(1)當快取fs.obs.fast.upload.buffer設置為disk時(默認),建議使用高性能存儲介質(例如SSD盤)承載,且當集群中有大量並行任務時,確保快取盤的空間足夠(可以配置多個目錄)
(2)當快取fs.obs.fast.upload.buffer設置為array或bytebuffer時,生產環境謹慎使用,計算任務的記憶體分配時請注意此機制佔用的記憶體空間
追加寫
當調用OBSFileSystem的append方法時將獲取FSDataOutputStream,通過該流追加寫數據到OBS中,其依賴於OBS服務的追加寫特性:
(1)通過流write數據時當達到快取閾值fs.obs.multipart.size時將立刻寫入數據到OBS;
(2)OBS的追加寫特性不支援「並發range追加寫」,所以其失去了「並發range寫」的優勢,相對覆蓋寫性能將會有所下降;
(3)OBS的追加寫特性在頻繁小數據追加寫的場景其性能表現並不是很好
flush/hflush/hsync/sync
OBSFileSystem的create或是append相關方法將返回FSDataOutputStream,其實現了flush/hflush/hsync/sync等相關方法。
文件桶場景:

對象桶場景:

注意:hadoop-obs 46版本才開始支援fs.obs.outputstream.hflush.policy策略,之前的版本實現機制等同於fs.obs.outputstream.hflush.policy=Sync的行為。
截斷
OBSFileSystem真正實現了FileSystem定義的截斷介面truncate,其依賴於OBS文件桶的截斷特性。
(1)此介面將可以很好的支撐flink的StreamingFileSink的exactly once場景或是其他場景
(2)普通對象桶不具備截斷特性;
讀相關流程
當調用OBSFileSystem的open相關方法時將獲取FSDataInputStream,通過該流讀取OBS中的數據。此流程總的實現思路是通過obs的「range讀取」特性進行實現,相關配置項如下:
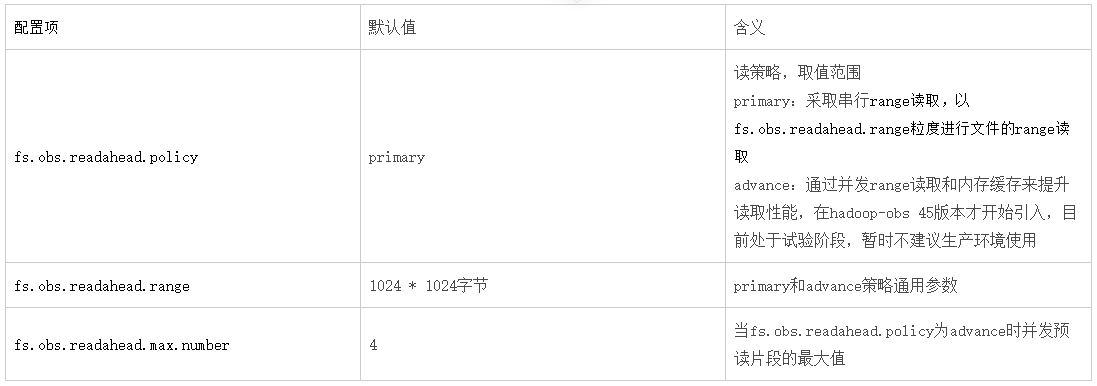
附OBS range讀:當讀取一個較大的文件時例如1000MB,可以將其分為0-100MB,100MB-200MB。。。10個段並發讀取以提升性能。//support.huaweicloud.com/sdk-java-devg-obs/obs_21_0703.html
實踐建議:
(1)對於需要順序讀取文件的場景:例如hdfs命令下載文件,DistCp,sql查詢文本文件
- 在primary策略下:可以大幅度提高fs.obs.readahead.range的值(默認1MB),例如可以設置為100MB
例如hadoop fs -Dfs.obs.readahead.range=104857600 -get obs://obs-bucket/xxx
- 在advance策略下:可以適度提高fs.obs.readahead.range和fs.obs.readahead.max.number的值或是保持默認值不變
(2)對於大量隨機訪問的場景:例如orc或parquet文件讀取
在primary策略和advance策略下均保持默認值即可,或是針對你的場景進行調優測試。
list相關流程
因為對象存儲的特點,其邏輯模型是KV模型,因此其list操作是耗時的,其每次最多只能返回1000條數據,類似分頁查詢。因此在超大目錄場景,OBSFileSystem中的listXXX介面其性能是相對低的,因為其要發起多次list請求才能獲取完整的列表。
並行文件桶場景下OBSFileSystem對於list的優化:
1.根據目錄結構嘗試並發list。
2.例如當要列舉A目錄時,A目錄下有B,C,D目錄,將會並發列舉B,C,D目錄以提升列舉性能。

實踐建議:
1.對於超大目錄的list或是getContentSummary(即hdfs du命令):
(1)不要在前台列舉或是du一個超大目錄
(2)可以精確到某一個分區目錄以避免超大目錄場景下前台進行列舉或是du操作時出現的長時間等待
刪除相關流程
目錄刪除操作在OBSFileSystem中不是O(1)操作,其實現分為兩個步驟:
1.先遞歸列舉出目錄下的所有文件
2.利用對象存儲的批量刪除特性將其刪除,批量刪除的最大條數1000,對於文件桶必須先刪除目錄下的文件才能刪除父目錄
hadoop-obs的快速刪除機制:即將刪除操作轉為rename操作,rename到指定目錄,目的是利用文件桶rename的高效性解決刪除性能

實踐建議:
1.對於超大目錄的刪除:建議可以採用OBS服務的生命周期特性,通過OBS後台任務進行刪除。
2.快速刪除機制:開啟後需要配合OBS服務的生命周期特性,定期刪除fs.obs.trash.dir目錄中的數據
rename相關流程
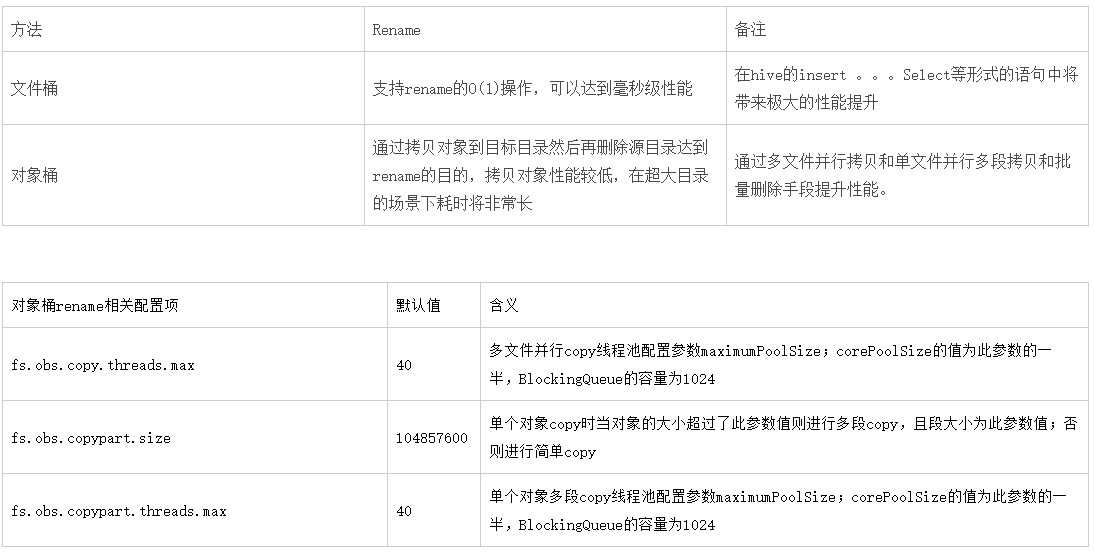
垃圾回收機制
在大數據應用場景中,往往存在防止數據誤刪除的訴求,通過OBSFileSystem的垃圾回收機制實現。
1.在相關組件的core-site.xml文件中配置如下內容:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>垃圾回收機制開關,設置為大於0 的值即可</description>
</property>
2.配置OBS服務的生命周期策略:垃圾目錄中的文件無法自動清除,需通過OBS生命周期策略進行定期清除
3.場景:
(1)hdfs命令:
hadoop fs -rm obs://obs-bucket/test.txt;
會將test目錄轉移到obs://obs-bucket/user/${username}/.Trash/Current垃圾目錄下
(2)hive語句:
drop table obstable;
如果obstable是一張內表,會將obstable表對應的目錄轉移到obs://obs-bucket/user/${username}/.Trash/Current垃圾目錄下
日誌機制
1.hadoop-obs項目對應的jar包放置於hadoop,hive,spark等組件的目錄下,受這些組件的日誌機制控制;例如對於hadoop組件,在${HADOOP_HOME}/etc/hadoop/log4j.properties文件中增加如下配置項以避免產生大量info級別的日誌:
log4j.logger.com.obs=ERROR或是WARN
log4j.logger.org.apache.hadoop.fs.obs=INFO
2.關於warn級別的404狀態碼:OBSFileSystem在實現一些FileSystem的介面時為了語義的準確實現,在一些流程中會去探測文件是否存在,例如在實現create介面時會先獲取文件的狀態用以判斷是文件還是目錄,當為目錄時則拋出異常,當為文件或是文件不存在時則正常創建文件,在此過程中會列印warn級別的帶404狀態碼的日誌(當日誌級別調整為info或是warn時),此warn級別的日誌屬於正常現象。
重試機制
1.訪問OBS服務時可能會因為網路短暫抖動,服務突發故障,服務突發流控等瞬時故障導致訪問失敗,hadoop-obs為了應對上述瞬時故障進行了必要的重試機制;
註:對於OBS服務處於長期故障狀態重試機制是無力解決的
2.重試策略:採取退讓重試策略,即隨著失敗次數的增加重試間隔梯次增加
1.hadoop-obs的通用重試策略: fs.obs.retry.maxtime:默認值180000ms,控制最大重試時間,重試間隔為max(fs.obs.retry.sleep.basetime*2的重試次數次方,fs.obs.retry.sleep.maxtime) fs.obs.retry.sleep.basetime:默認值50ms,重試間隔的基數 fs.obs.retry.sleep.maxtime:默認值30000ms,重試間隔最大等待時間 2.hadoop-obs的流控重試策略:您可視您的業務情況獨立配置 fs.obs.retry.qos.maxtime:默認值180000ms fs.obs.retry.qos.sleep.basetime:默認值1000ms fs.obs.retry.qos.sleep.maxtime:默認值30000ms 3.什麼情況下會進行重試: (1)尚未與obs服務建立連接或是IO中斷,例如ConnectException,SocketTimeoutException等 (2)obs服務返回5xx:obs服務指示服務狀態不正常 註: (1)50.1版本開始才實現了獨立的流控重試策略 (2)50.1版本開始寫入流程才被施加重試機制
flink-obs原理和實踐建議(待完善)
大數據各組件優化

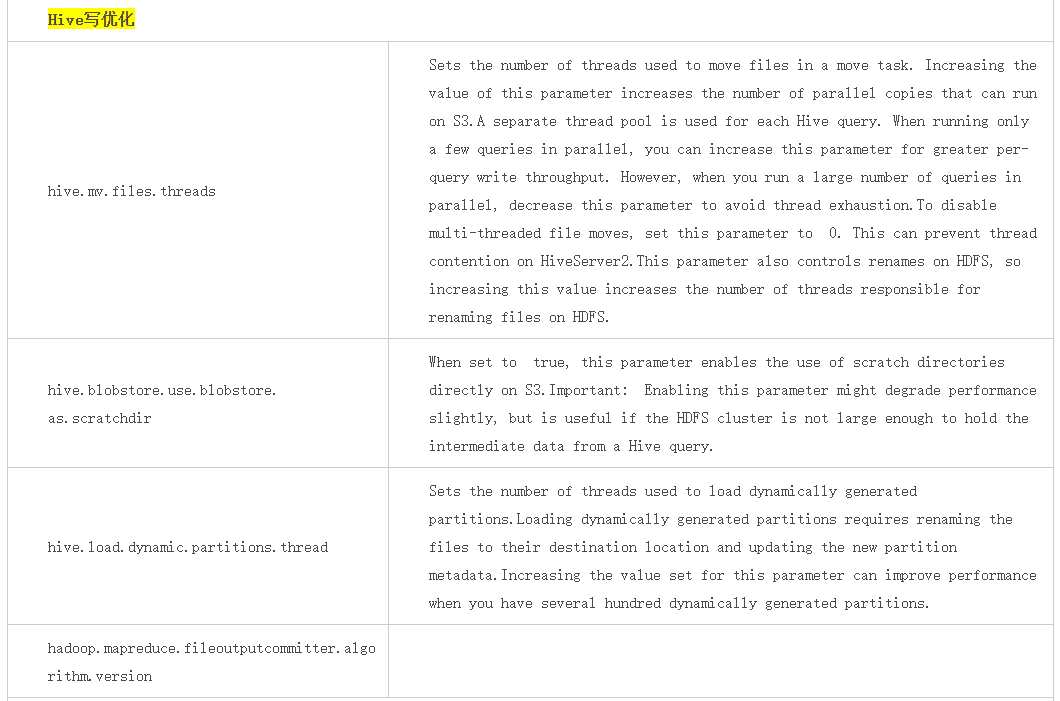


其他
OBS 頻寬評估
在基於OBS的大數據存算分離解決方案中OBS側QOS(主要是讀寫頻寬)的評估沒有一個準確的計算公式,也因業務場景的複雜性導致難有一個一以貫之的公式。根據經驗和理論的沉澱現階段能夠採用的OBS QOS評估方法如下:
演算法一:根據CPU核數估算
此演算法的依據是現網觀察後的經驗估算。

演算法二:根據POC估算
此演算法的依據是根據客戶在POC測試時的真實業務場景觀測到的OBS側的實際頻寬消耗峰值,然後依據計算集群的規模進行推算。
例如:POC時搭建了10個計算節點,對OBS的讀頻寬需求峰值能達到200Gb,寫頻寬需求峰值能達到15Gb;
商用時需要搭建120個計算節點,OBS的讀頻寬=200Gb/8*(120/10)=300GB; OBS的讀頻寬=15Gb/8*(120/10)=22.5GB;
HDFS-OBS映射
通過HDFS地址映射到OBS地址的方式,支援將HDFS中的數據遷移到OBS後,不需要變動業務邏輯中的數據地址,即可完成數據訪問。
//support.huaweicloud.com/usermanual-mrs/mrs_01_0769.html
附:hadoop-obs約束與限制
hadoop-obs不支援以下HDFS語義:
- Lease
- Symbolic link operations
- Proxy users
- File concat
- File checksum
- File replication factor
- Extended Attributes(XAttrs) operations
- Snapshot operations
- Storage policy
- Quota
- POSIX ACL
- Delegation token operations
附:hadoop-obs常見問題
0.大數據場景強烈建議使用並行文件系統,即文件桶
1.hadoop-obs性能基準測試
可以通過開源的DFSIO和NNbench基準測試工具進行大數據場景的性能基準測試
註:OBS服務是基於HDD存儲介質,請不要和基於ssd的HDFS服務進行性能對比
2.OBS服務流控問題
(1)每個region可以獨立設置租戶級別和桶級別的流控閾值
(2)OBS服務流控相關閾值:主要包含讀寫頻寬Gb/s,讀寫TPS,並發連接數三個閾值
(3)流控準則:
當達到頻寬/TPS閾值時HTTP請求依然會成功返回200狀態碼,但訪問時延會增大;
當達到並發連接數閾值時OBS服務將拒絕訪問返503/GetQosTokenException

3.hadoop-obs許可權問題
通過hadoop-obs訪問OBS時需要aksk/臨時aksk才能訪問OBS服務,OBSFileSystem支援如下幾種方式獲取aksk:(優先順序由高到低排序)
- (1)通過core-site.xml的fs.obs.access.key和fs.obs.secret.key和fs.obs.session.token配置項獲取。 其支援hadoop的CredentialProvider機制,即通過CredentialProvider機制對aksk進行保護,避免aksk的明文暴露
- (2)從provider中獲取:自定義aksk提供器,通過fs.obs.security.provider配置項進行配置。 provider實現需要繼承com.obs.services.IObsCredentialsProvider介面,目前hadoop-obs內置的provider如下: com.obs.services.EnvironmentVariableObsCredentialsProvider:從環境變數里尋找aksk,需要在環境變數中定義OBS_ACCESS_KEY_ID和OBS_SECRET_ACCESS_KEY分別代表永久的AK和SK
- com.obs.services.EcsObsCredentialsProvider:從ECS元數據中自動獲取臨時aksk並進行定期自動刷新 com.obs.services.OBSCredentialsProviderChain:以鏈式的形式依次從環境變數,ECS伺服器上進行搜索以獲取對應的訪問密鑰,且會以第一組成功獲取到的訪問密鑰訪問obs 也可以自定義provider實現完成符合您架構和安全要求的實現,例如MRS服務提供了自己的provider實現
4.寫入操作快取盤注意事項
當通過hadoop-obs寫數據到obs時,其通過快取機制提升寫入性能,當快取介質fs.obs.fast.upload.buffer設置為disk時(默認),可以通過fs.obs.buffer.dir配置項設置快取目錄(默認與hadoop.tmp.dir相同目錄),可以設置多目錄以逗號分隔;建議使用高性能存儲介質(例如SSD盤)承載,且當集群中有大量並行任務時,確保快取盤的空間足夠(可以配置多個目錄)

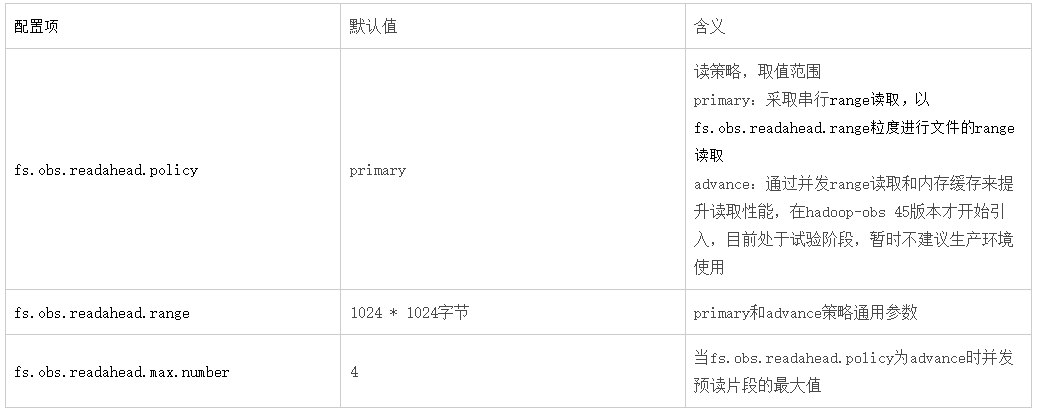
5.讀取操作實踐建議:
(1)對於需要順序讀取文件的場景:例如hdfs命令下載文件,DistCp,sql查詢文本文件
- 在primary策略下:可以大幅度提高fs.obs.readahead.range的值(默認1MB),例如可以設置為100MB
例如hadoop fs -Dfs.obs.readahead.range=104857600 -get obs://obs-bucket/xxx - 在advance策略下:可以適度提高fs.obs.readahead.range和fs.obs.readahead.max.number的值或是保持默認值不變
(2)對於大量隨機訪問的場景:例如orc或parquet文件讀取
在primary策略和advance策略下均保持默認值即可,或是針對你的場景進行調優測試。
6.快速刪除特性實踐建議
因為hadoop-obs的刪除操作不是O(1)操作,其操作耗時和目錄大小成正比例,即隨著目錄結構的增大其操作耗時將持續增長;如果您的應用場景存在頻繁的刪除操作,且刪除的是超大目錄,建議可以開啟快速刪除特性。相關配置項:

註:文件桶才支援快速刪除特性,普通對象桶不支援,因為快速刪除是利用文件桶的rename性能優勢實現的
註:快速刪除開啟後需要配合OBS服務的生命周期特性,定期刪除fs.obs.trash.dir目錄中的數據
7.OBS服務監控
通過華為雲的雲監控服務CES,其是華為雲資源的監控平台,提供了實時監控、及時告警、資源分組、站點監控等能力。
8.問題排查
通過客戶端日誌和服務端日誌進行問題排查,通常以客戶端日誌為問題排查的優先手段。
(1)客戶端日誌: OBS服務兩層返回碼用於指示訪問狀態: 狀態碼:符合HTTP規範的HTTP狀態碼,例如2xx,4xx,5xx 錯誤碼:在狀態碼之下又細分了錯誤碼,例如403狀態碼/InvalidAccessKeyId錯誤碼錶示 註:錯誤碼描述//support.huaweicloud.com/api-obs/obs_04_0115.html
(2)服務端日誌:開啟桶日誌功能,OBS會自動對這個桶的訪問請求記錄日誌,並生成日誌文件寫入用戶指定的桶中,可用於進行請求分析或日誌審計 6.問題回饋渠道 華為雲工單系統
9.跨雲訪問obs問題(待完善)
附:hadoop-obs完整配置項
見//clouddevops.huawei.com/domains/2301/wiki/8/WIKI2021080300343
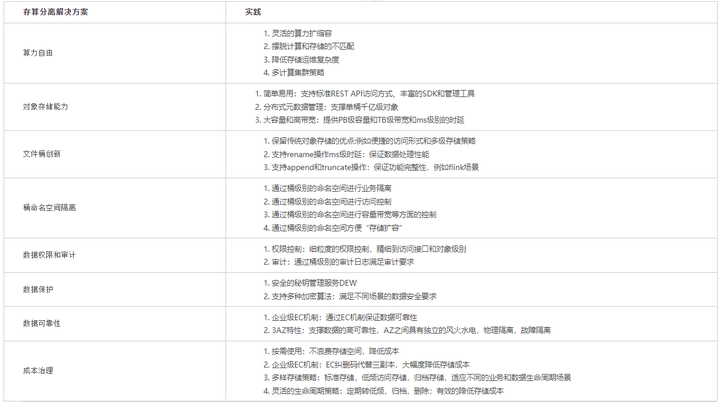
附:存算分離解決方案