聊聊如何用 Redis 實現分散式鎖?
作者:小林coding
電腦八股文網站://xiaolincoding.com
哈嘍,我是小林。
今天跟大家聊聊兩個問題:
- 如何用 Redis 實現分散式鎖?
- Redis 是如何解決集群情況下分散式鎖的可靠性問題的?
如何用 Redis 實現分散式鎖的?
分散式鎖是用於分散式環境下並發控制的一種機制,用於控制某個資源在同一時刻只能被一個應用所使用。如下圖所示:
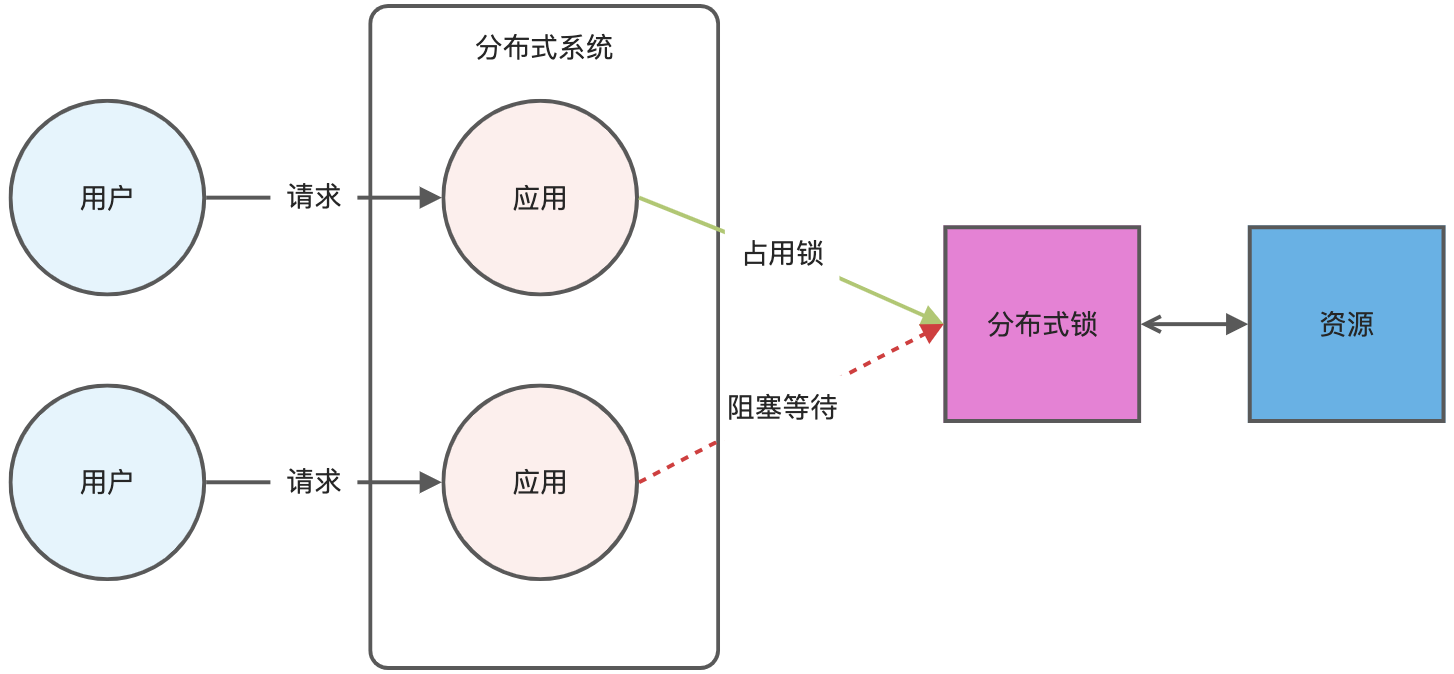
Redis 本身可以被多個客戶端共享訪問,正好就是一個共享存儲系統,可以用來保存分散式鎖,而且 Redis 的讀寫性能高,可以應對高並發的鎖操作場景。
Redis 的 SET 命令有個 NX 參數可以實現「key不存在才插入」,所以可以用它來實現分散式鎖:
- 如果 key 不存在,則顯示插入成功,可以用來表示加鎖成功;
- 如果 key 存在,則會顯示插入失敗,可以用來表示加鎖失敗。
基於 Redis 節點實現分散式鎖時,對於加鎖操作,我們需要滿足三個條件。
- 加鎖包括了讀取鎖變數、檢查鎖變數值和設置鎖變數值三個操作,但需要以原子操作的方式完成,所以,我們使用 SET 命令帶上 NX 選項來實現加鎖;
- 鎖變數需要設置過期時間,以免客戶端拿到鎖後發生異常,導致鎖一直無法釋放,所以,我們在 SET 命令執行時加上 EX/PX 選項,設置其過期時間;
- 鎖變數的值需要能區分來自不同客戶端的加鎖操作,以免在釋放鎖時,出現誤釋放操作,所以,我們使用 SET 命令設置鎖變數值時,每個客戶端設置的值是一個唯一值,用於標識客戶端;
滿足這三個條件的分散式命令如下:
SET lock_key unique_value NX PX 10000
- lock_key 就是 key 鍵;
- unique_value 是客戶端生成的唯一的標識,區分來自不同客戶端的鎖操作;
- NX 代表只在 lock_key 不存在時,才對 lock_key 進行設置操作;
- PX 10000 表示設置 lock_key 的過期時間為 10s,這是為了避免客戶端發生異常而無法釋放鎖。
而解鎖的過程就是將 lock_key 鍵刪除(del lock_key),但不能亂刪,要保證執行操作的客戶端就是加鎖的客戶端。所以,解鎖的時候,我們要先判斷鎖的 unique_value 是否為加鎖客戶端,是的話,才將 lock_key 鍵刪除。
可以看到,解鎖是有兩個操作,這時就需要 Lua 腳本來保證解鎖的原子性,因為 Redis 在執行 Lua 腳本時,可以以原子性的方式執行,保證了鎖釋放操作的原子性。
// 釋放鎖時,先比較 unique_value 是否相等,避免鎖的誤釋放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
這樣一來,就通過使用 SET 命令和 Lua 腳本在 Redis 單節點上完成了分散式鎖的加鎖和解鎖。
基於 Redis 實現分散式鎖有什麼優缺點?
基於 Redis 實現分散式鎖的優點:
- 性能高效(這是選擇快取實現分散式鎖最核心的出發點)。
- 實現方便。很多研發工程師選擇使用 Redis 來實現分散式鎖,很大成分上是因為 Redis 提供了 setnx 方法,實現分散式鎖很方便。
- 避免單點故障(因為 Redis 是跨集群部署的,自然就避免了單點故障)。
基於 Redis 實現分散式鎖的缺點:
-
超時時間不好設置。如果鎖的超時時間設置過長,會影響性能,如果設置的超時時間過短會保護不到共享資源。比如在有些場景中,一個執行緒 A 獲取到了鎖之後,由於業務程式碼執行時間可能比較長,導致超過了鎖的超時時間,自動失效,注意 A 執行緒沒執行完,後續執行緒 B 又意外的持有了鎖,意味著可以操作共享資源,那麼兩個執行緒之間的共享資源就沒辦法進行保護了。
-
- 那麼如何合理設置超時時間呢? 我們可以基於續約的方式設置超時時間:先給鎖設置一個超時時間,然後啟動一個守護執行緒,讓守護執行緒在一段時間後,重新設置這個鎖的超時時間。實現方式就是:寫一個守護執行緒,然後去判斷鎖的情況,當鎖快失效的時候,再次進行續約加鎖,當主執行緒執行完成後,銷毀續約鎖即可,不過這種方式實現起來相對複雜。
-
Redis 主從複製模式中的數據是非同步複製的,這樣導致分散式鎖的不可靠性。如果在 Redis 主節點獲取到鎖後,在沒有同步到其他節點時,Redis 主節點宕機了,此時新的 Redis 主節點依然可以獲取鎖,所以多個應用服務就可以同時獲取到鎖。
Redis 如何解決集群情況下分散式鎖的可靠性?
為了保證集群環境下分散式鎖的可靠性,Redis 官方已經設計了一個分散式鎖演算法 Redlock(紅鎖)。
它是基於多個 Redis 節點的分散式鎖,即使有節點發生了故障,鎖變數仍然是存在的,客戶端還是可以完成鎖操作。
Redlock 演算法的基本思路,是讓客戶端和多個獨立的 Redis 節點依次請求申請加鎖,如果客戶端能夠和半數以上的節點成功地完成加鎖操作,那麼我們就認為,客戶端成功地獲得分散式鎖,否則加鎖失敗。
這樣一來,即使有某個 Redis 節點發生故障,因為鎖的數據在其他節點上也有保存,所以客戶端仍然可以正常地進行鎖操作,鎖的數據也不會丟失。
Redlock 演算法加鎖三個過程:
-
第一步是,客戶端獲取當前時間。
-
第二步是,客戶端按順序依次向 N 個 Redis 節點執行加鎖操作:
-
- 加鎖操作使用 SET 命令,帶上 NX,EX/PX 選項,以及帶上客戶端的唯一標識。
- 如果某個 Redis 節點發生故障了,為了保證在這種情況下,Redlock 演算法能夠繼續運行,我們需要給「加鎖操作」設置一個超時時間(不是對「鎖」設置超時時間,而是對「加鎖操作」設置超時時間)。
-
第三步是,一旦客戶端完成了和所有 Redis 節點的加鎖操作,客戶端就要計算整個加鎖過程的總耗時(t1)。
加鎖成功要同時滿足兩個條件(簡述:如果有超過半數的 Redis 節點成功的獲取到了鎖,並且總耗時沒有超過鎖的有效時間,那麼就是加鎖成功):
- 條件一:客戶端從超過半數(大於等於 N/2+1)的 Redis 節點上成功獲取到了鎖;
- 條件二:客戶端獲取鎖的總耗時(t1)沒有超過鎖的有效時間。
加鎖成功後,客戶端需要重新計算這把鎖的有效時間,計算的結果是「鎖的最初有效時間」減去「客戶端為獲取鎖的總耗時(t1)」。
加鎖失敗後,客戶端向所有 Redis 節點發起釋放鎖的操作,釋放鎖的操作和在單節點上釋放鎖的操作一樣,只要執行釋放鎖的 Lua 腳本就可以了。
系列《圖解Redis》文章:
面試篇:
數據類型篇:
持久化篇:
功能篇:
高可用篇:
快取篇:


