Hinton團隊新作:無需重構,無監督比肩有監督,北郵畢業生一作
- 2020 年 2 月 21 日
- 筆記
魚羊 發自 麥蒿寺 量子位 報道 | 公眾號 QbitAI
最新研究表明,無需重構,無監督表示學習也可以表現出色。
來自圖靈獎得主 Hinton 團隊的最新研究,提出了一種名為 SimCLR 的視覺表示對比學習簡單框架。
作者表示,SimCLR 簡化了自監督對比學習演算法,使其不再依賴於專門的架構和存儲庫。

△灰色x表示有監督ResNet-50
SimCLR
SimCLR 學習表示的方式,是通過對比損失最大化了同一示例不同增強視圖的隱藏層之間的一致性。

使其表現出色的關鍵因素,有四點:
1. 多個數據增強的組合

研究人員發現,即使模型可以在對比任務中幾乎完美地識別出正對,也無法通過單個變換來學習良好的表示。
採用數據增強組合時,對比預測任務會變得更加困難,但表示品質會大大提高。
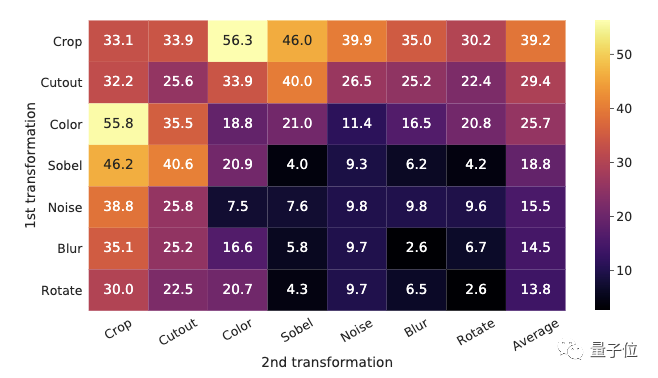
並且,研究還指出,比起監督學習,對比學習需要更強大的數據增強。
2. 在表示(the representation)和對比(the contrastive)之間引入可學習的非線性變換
下圖顯示了使用三種不同頭架構的線性評估結果。

非線性投影要好於線性投影,並且比沒有投影要好得多。
3. 更大的批處理規模和更多的訓練步驟
與監督學習相反,在對比學習中,較大的批處理量產生了更多的負面樣本,從而促進了收斂。

4. 溫度標度交叉熵損失的歸一化
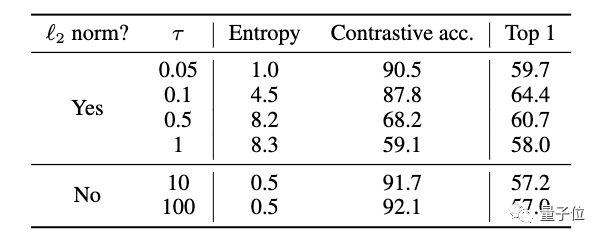
實驗結果
在 ImageNet 上,SimCLR 方法訓練出的線性分類器與有監督的 ResNet-50 性能相匹配,達到了 76.5% 的 top-1 準確率。相比於 SOTA,提升了7個百分點。

僅對 1% 的標籤進行微調時,SimCLR 可以達到 85.8% 的 top-5 準確率。並且相比於 AlexNet,標籤數量減少了 100 倍。

一作:北郵畢業生
SimCLR 的研究團隊來自Google大腦,圖靈獎得主 Geoffrey Hinton 名列其中。
論文一作,則是本科畢業於北京郵電大學的 Ting Chen。
本科畢業後,Ting Chen 赴美留學,先在東北大學(Northeastern University),後隨導師轉至加州大學洛杉磯分校獲CS博士學位。
2017年開始,他先後在GoogleAI、Google大腦等部門實習,2019年正式成為Google大腦的研究科學家。
傳送門
論文地址: https://arxiv.org/abs/2002.05709
Ting Chen 推特: https://twitter.com/tingchenai/status/1228337240708874241

