java-Stream的總結
JAVA中的Stream
01.什麼是Stream
Stream是JDK8中引入,Stream是一個來自數據源的元素序列並支援聚合操作。可以讓你以一種聲明的方式處理數據,Stream 使用一種類似用 SQL 語句從資料庫查詢數據的直觀方式來提供一種對 Java 集合運算和表達的高階抽象。Stream API可以極大提高Java程式設計師的生產力,讓程式設計師寫出高效率、乾淨、簡潔的程式碼。
02.Stream特點
- 元素:是特定類型的對象,形成一個序列。 Java中的Stream並不會存儲元素,而是按需計算。
- 數據源:流的來源可以是集合,數組,I/O channel等。
- 過濾、聚合、排序等操作:類似SQL語句一樣的操作, 比如filter, map, reduce, find, match, sorted等
- Pipelining(流水線/管道): 中間操作都會返迴流對象本身。 這樣多個操作可以串聯成一個管道, 如同流式風格(fluent style)。 這樣做可以對操作進行優化, 比如延遲執行(laziness)和短路( short-circuiting)。
- 內部迭代: 以前對集合遍歷都是通過Iterator或者For-Each的方式, 顯式的在集合外部進行迭代, 這叫做外部迭代。 Stream提供了內部迭代的方式。
- 只能遍歷一次:數據流的從一頭獲取數據源,在流水線上依次對元素進行操作,當元素通過流水線,便無法再對其進行操作
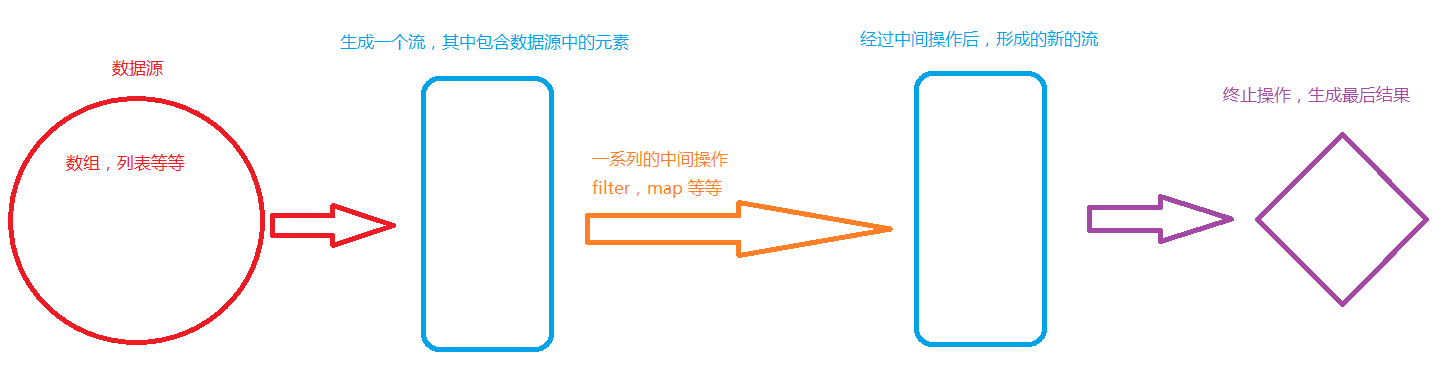
一個stream是由三部分組成的。數據源,零個或一個或多個中間操作,一個或零個終止操作。
中間操作是對數據的加工,注意:中間操作是lazy操作,並不會立馬啟動,需要等待終止操作才會執行。
終止操作是stream的啟動操作,只有加上終止操作,stream才會真正的開始執行。
03.Stream入門案例
//要求把list1中的空字元串過濾掉,並把結果保存在列表中
public class Test {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("ab", "", "cd", "ef", "mm","", "hh");
System.out.println(list1);//[ab, , cd, ef, mm, , hh]
List<String> result = list1.stream().filter(s -> !s.isEmpty()).collect(Collectors.toList());
System.out.println(result);//[ab, cd, ef, mm, hh]
}
}
上面這個例子可以看出list1是一個字元串的列表,其中有兩個空字元串,在stream的操作過程中,我們使用了stream()、filter()、collect()等方法,在filter()過程中,我們引入了Lambda表達式s->!s.isEmpty(),結果是把兩個空字元串過濾掉後,形成了一個新的列表result。
上面這個需求如果我們使用傳統的程式碼完成如下:
public class Test {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("ab", "", "cd", "ef", "mm","", "hh");
List<String> result = new ArrayList<>();
for (String str : list1) {
if(str.isEmpty()){
continue;
}
result.add(str);
}
System.out.println(result);
}
}
比較兩段程式碼,我們可以發現在第二段程式碼中我們自己創建了一個字元串對象列表,開啟一個for循環遍歷字元串對象列表,在for循環中判斷是否當前的字元串是空串,如果不是,加到結果列表中。而在第一段程式中,我們並不需要自己開啟for循環遍歷,stream會在內部做迭代,我們只需要傳入我們的過濾條件就可以了,最後這個字元串列表也是程式碼自動創建出來的,並且把結果放入了列表中,可以看出,第一段程式碼簡潔優雅。
04.Stream操作分類
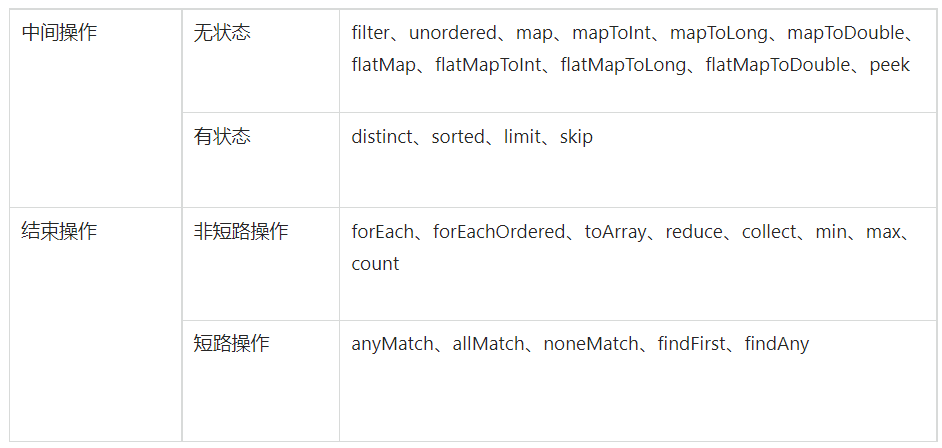
- 無狀態:指元素的處理不受之前元素的影響;
- 有狀態:指該操作只有拿到所有元素之後才能繼續下去。
- 非短路操作:指必須處理所有元素才能得到最終結果;
- 短路操作:指遇到某些符合條件的元素就可以得到最終結果,如 A || B,只要A為true,則無需判斷B的結果。
05.Stream使用案例
5.1.創建流
5.1.1.使用Collection下的 stream() 和 parallelStream() 方法
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); //獲取一個串列流
Stream<String> parallelStream = list.parallelStream(); //獲取一個並行流
}
}
5.1.2.使用Arrays 中的 stream() 方法,將數組轉成流
public class Test {
public static void main(String[] args) {
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
}
}
5.1.3.使用Stream中的靜態方法:of()、iterate()、generate()
public class Test {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
stream.forEach(System.out::print);//1 2 3 4 5 6
System.out.println("==========");
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::print); // 0 2 4 6 8 10
System.out.println("==========");
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::print);//隨機產生兩個小數
}
}
5.1.4.使用 BufferedReader.lines() 方法,將每行內容轉成流
public class Test {
public static void main(String[] args) throws FileNotFoundException {
BufferedReader reader = new BufferedReader(new FileReader("d:\\study\\demo\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
}
}
5.1.5.使用 Pattern.splitAsStream() 方法,將字元串分隔成流
public class Test {
public static void main(String[] args) {
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("tom,jack,jerry,john");
stringStream.forEach(System.out::println);
}
}
5.2.中間操作
5.2.1.篩選與切片
- filter:過濾流中的某些元素
- limit(n):獲取n個元素
- skip(n):跳過n元素,配合limit(n)可實現分頁
- distinct:通過流中元素的 hashCode() 和 equals() 去除重複元素
//filter 測試
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd","eeeee","hhhhhhh");
//把字元串長度大於3的過濾掉
Stream<String> stringStream = list.stream().filter(s -> s.length() <= 3);
stringStream.forEach(System.out::println);
System.out.println("===================");
//驗證整個流只遍歷一次
//stream只有遇到終止操作才會觸發流啟動,中間操作都是lazy
Stream.of(1, 2, 3, 4, 5)
.filter(i -> {
System.out.println("filter1的元素:" + i);
return i > 0;
}).filter(i -> {
System.out.println("filter2的元素:" + i);
return i == 5;
}).forEach(i-> System.out.println("最後結果:"+i));
}
}
//limit 測試
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd","eeeee","hhhhhhh");
//取三個元素
List<String> result = list.stream().limit(3).collect(Collectors.toList());
System.out.println(result);
}
}
//limit 和 skip 測試
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("11", "22", "33","44","55","66","77","88","99");
//演示skip:跳過前三條記錄
list.stream().skip(3).forEach(System.out::println);
//模擬翻頁,每頁3條記錄
//第一頁
List<String> page1= list.stream().skip(0).limit(3).collect(Collectors.toList());
System.out.println(page1);
//第二頁
List<String> page2= list.stream().skip(3).limit(3).collect(Collectors.toList());
System.out.println(page2);
//第三頁
List<String> page3= list.stream().skip(6).limit(3).collect(Collectors.toList());
System.out.println(page3);
//limit和skip順序換一下
//可以看出,最終的結果會收到執行順序的影響
List<String> page4= list.stream().limit(3).skip(1).collect(Collectors.toList());
System.out.println(page4);
}
}
//distinct去重測試
//注意:當我們自己重寫hashcode和equals的方法的時候,要遵循一個原則:
//如果兩個對象的hashcode相等,那麼用equals比較不一定相等;反之,如果兩個對象用equals比較相等,那麼他們的hashcode也一定相等
public class Student {
private Integer id;
private String name;
public Student(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return getId().equals(student.getId()) &&
getName().equals(student.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName());
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
//去掉重複的student
//1.Student類的hashcode和equals包含了id和name
//2.Student類的hashcode和equals中只包含name
public class Test {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student(1, "zhangsan"),
new Student(6, "zhangsan"),
new Student(2, "lisi"),
new Student(5, "lisi"),
new Student(3, "wangwu"));
//1.學生對象去重
List<Student> result = studentList.stream().distinct().collect(Collectors.toList());
System.out.println(result);
//2.普通字元串去重
Stream<String> stringStream = Stream.of("a", "a", "b", "c", "d");
List<String> stringList = stringStream.distinct().collect(Collectors.toList());
System.out.println(stringList);
}
}
5.2.2.映射(map和flatMap)
public class Test {
public static void main(String[] args) {
//第一個例子對比
List<String> list = Arrays.asList("a,b,c", "1,2,3");
//將每個元素轉成一個新的且不帶逗號的元素
//注意:這裡元素是值在list中的元素,一共有兩個,分別是"a,b,c" 和"1,2,3"
//map函數傳入的lambda表達式就是我們的轉換邏輯,需要返回一個轉換之後的元素
Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", ""));
s1.forEach(System.out::println); // abc 123
System.out.println("===============");
List<Integer> integerList = Arrays.asList(1, 2, 3);
integerList.stream().map(i->i*2).forEach(System.out::println);
System.out.println("===============");
//將每個元素轉換成一個stream
//注意:flatMap跟上面的map函數對比
//兩者傳入的lambda都是轉換邏輯,但是map中的lambda返回的是一個轉換後的新元素,
//flatMap可以把每一個元素進一步處理:例如"a,b,c"進一步分隔成a b c三個元素
//返回的是這三個元素形成的三個stream,最終把這些單獨的stream合併成一個stream返回
//總結:可以看出,flatMap相比於map,它可以把每一個元素再進一步拆分成更多的元素,
// 最後,拆分出來的元素個數會多於最初輸入的列表中的元素個數
//就這個例子而言,最初輸入兩個元素"a,b,c" 和"1,2,3",結果是6個元素 a b c 1 2 3
Stream<String> s3 = list.stream().flatMap(s -> {
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
});
s3.forEach(System.out::println); // a b c 1 2 3
System.out.println("===============");
//第二個例子(嵌套的list)[["a","b","c"],["d","e","f"],["h","k"]]
//輸出結果要求是:["A","B","C","D","E","F","G","H"]
List<List<String>> nestedList = Arrays.asList(
Arrays.asList("a","b","c"),
Arrays.asList("d","e","f"),
Arrays.asList("h","k")
);
Stream<String> s4 = nestedList.stream()
.flatMap(Collection::stream)
.map(s -> s.toUpperCase());
s4.forEach(System.out::print);
}
}
5.2.3.排序
- sorted():自然排序,流中元素需實現Comparable介面
- sorted(Comparator com):訂製排序,自定義Comparator排序器
//字元串排序
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd");
//String 類自身已實現Compareable介面,可以按照字元的自然順序【升序】排序
list.stream().sorted().forEach(System.out::println);// aaa dddd ff
System.out.println("=====");
//給sorted函數傳入一個lambda表達式
//1.自定義排序規則,按照字元串的長度【升序】排序,也就是字元串長度最短的排在最前面
list.stream().sorted((s1,s2)->s1.length()-s2.length()).forEach(System.out::println);//ff aaa dddd
System.out.println("=====");
//2.自定義排序規則,按照字元串的長度【降序】排序,也就是字元串長度最長的排在最前面
list.stream().sorted((s1,s2)->s2.length()-s1.length()).forEach(System.out::println);//dddd aaa ff
}
}
//對象排序
public class Employee {
private String name;
private Integer salary;
public Employee(String name,Integer salary) {
this.name = name;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getSalary() {
return salary;
}
public void setSalary(Integer salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", salary=" + salary +
'}';
}
}
//測試類
public class Test {
public static void main(String[] args) {
List<Employee> list = Arrays.asList(
new Employee("Tom",1000),
new Employee("Jack",900),
new Employee("John",1300),
new Employee("Jack",2000)
);
//自定義排序規則,先按照名稱【升序】,如果名稱相同,再按照工資【降序】
list.stream().sorted((e1,e2)->{
if(e1.getName().equals(e2.getName())){
return e2.getSalary()-e1.getSalary();
}else{
return e1.getName().compareTo(e2.getName());
}
}).forEach(System.out::println);
//輸出結果:
// Employee{name='Jack', salary=2000}
// Employee{name='Jack', salary=900}
// Employee{name='John', salary=1300}
// Employee{name='Tom', salary=1000}
//列印原始列表,看看是否被改變,注意我們通過stream進行排序操作,原始的列表元素順序沒有變化,也就是說我們沒有修改原始的list
System.out.println(list);
//Stream排序和集合本身的排序方法對比
//我們使用List介面本身的sort方法再來排序一下看看
list.sort((e1,e2)->{
if(e1.getName().equals(e2.getName())){
return e2.getSalary()-e1.getSalary();
}else{
return e1.getName().compareTo(e2.getName());
}
});
//排序後再次列印一下list本身,可以發現,list本身元素的順序被修改過了
System.out.println(list);
}
}
5.2.4.消費
peek:如同於map,能得到流中的每一個元素。但map接收的是一個Function表達式,有返回值;而peek接收的是Consumer表達式,沒有返回值。
//為Tom增加500工資
public class Test {
public static void main(String[] args) {
List<Employee> list = Arrays.asList(
new Employee("Tom",1000),
new Employee("John",1300),
new Employee("Jack",2000)
);
//如果是Tom,工資增加500
list.stream().peek(e->{
if("Tom".equals(e.getName())){
e.setSalary(500+e.getSalary());
}
}).forEach(System.out::println);
//輸出結果
// Employee{name='Tom', salary=1500}
// Employee{name='John', salary=1300}
// Employee{name='Jack', salary=2000}
}
}
5.3.終止操作
5.3.1.匹配
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(2, 1, 3, 4, 5);
//流中所有的元素都匹配,返回true,否則返回false
boolean allMatch = list.stream().allMatch(e -> {
System.out.println(e);
return e > 10;
}); //false
System.out.println("allMatch:"+allMatch);
//流中沒有任何的元素匹配,返回true,否則返回false
boolean noneMatch = list.stream().noneMatch(e -> {
System.out.println(e);
return e > 10;
}); //true
System.out.println("noneMatch:"+noneMatch);
//流中只要有任何一個元素匹配,返回true,否則返回false
boolean anyMatch = list.stream().anyMatch(e -> {
System.out.println(e);
return e > 1;
}); //true
System.out.println("anyMatch:"+anyMatch);
//返迴流的第一個元素
Integer findFirst = list.stream().findFirst().get(); //2
System.out.println("findFirst"+findFirst);
//返迴流中的任意元素
Integer findAny = list.stream().findAny().get(); //2
System.out.println("findAny:"+findAny);
}
}
5.3.2.聚合
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
//計算元素總的數量
long count = list.stream().count(); //5
System.out.println(count);
//找出最大的元素(需要傳入Lambda比較器)
Integer max = list.stream().max(Integer::compareTo).get(); //5
System.out.println(max);
//找出最小元素(需要傳入Lambda比較器)
Integer min = list.stream().min(Integer::compareTo).get(); //1
System.out.println(min);
}
}
5.3.3.歸約
在java.util.stream.Stream介面中,reduce有下面三個重載的方法
/**
第一次執行時,accumulator函數的第一個參數為流中的第一個元素,第二個參數為流中元素的第二個元素;第二次執行時,第一個參數為第一次函數執行的結果,第二個參數為流中的第三個元素;依次類推。
*/
Optional<T> reduce(BinaryOperator<T> accumulator);
/**
流程跟上面一樣,只是第一次執行時,accumulator函數的第一個參數為identity,而第二個參數為流中的第一個元素。
*/
T reduce(T identity, BinaryOperator<T> accumulator);
/**
在串列流(stream)中,該方法跟第二個方法一樣,即第三個參數combiner不會起作用。
在並行流(parallelStream)中,我們知道流被fork join創建出多個執行緒進行執行,此時每個執行緒的執行流程就跟第二個方法reduce(identity,accumulator)一樣,而第三個參數combiner函數,則是將每個執行緒的執行結果當成一個新的流,然後使用第一個方法reduce(accumulator)流程進行歸約。
*/
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
歸約應用舉例
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer v = list.stream().reduce((a1, a2) -> a1 + a2).get();
System.out.println("reduce計算v="+v); // 55
Integer v1 = list.stream().reduce(10, (a1, a2) -> a1 + a2);
System.out.println("reduce計算v1="+v1); //65
Integer v2 = list.stream().reduce(0,
(a1, a2) -> {
return a1 + a2;
},
(a1, a2) -> {
return 1000; //第二個表達式在串列流中無效,這裡返回1000測試
});
System.out.println("reduce計算v2="+v2);
//並行流reduce傳三個參數
Integer v3 = list.parallelStream().reduce(0,
(a1, a2) -> {
System.out.println(Thread.currentThread().getName()+":parallelStream accumulator: a1:" + a1 + " a2:" + a2);
return a1 + a2;
},
(a1, a2) -> {
System.out.println(Thread.currentThread().getName()+":parallelStream combiner: a1:" + a1 + " a2:" + a2);
return a1 + a2;
});
System.out.println("並行流reduce計算v3=:"+v3);
}
}
5.3.4.收集
collect:接收一個Collector實例,將流中元素收集成另外一個數據結構
<R, A> R collect(Collector<? super T, A, R> collector);
應用舉例:
//創建一個Person類
public class Person {
private String name;
private String sex;
private Integer age;
public Person(String name, String sex, Integer age) {
this.name = name;
this.sex = sex;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
public class Test {
public static void main(String[] args) {
//1.collect(Collectors.toList()) 把流轉換成一個列表(允許重複值)
Stream<String> stringStream = Stream.of("aa","bb","dd","ee","bb");
List<String> listResult = stringStream.collect(Collectors.toList());
System.out.println(listResult);//[aa, bb, dd, ee, bb]
//2.collect(Collectors.toSet()) 把流轉換成一個集合(去重)
Stream<String> stringStream1 = Stream.of("aa","bb","dd","ee","bb");
Set<String> setResult = stringStream1.collect(Collectors.toSet());
System.out.println(setResult);//[aa, bb, dd, ee]
//3.collect(Collectors.toCollection(LinkedList::new)) 把流轉換成一個指定的集合類型(LinkedList)
Stream<String> stringStream2 = Stream.of("aa","bb","dd","ee","bb");
LinkedList<String> linkedListResult = stringStream2.collect(Collectors.toCollection(LinkedList::new));
System.out.println(linkedListResult);//[aa, bb, dd, ee, bb]
//4.collect(Collectors.toCollection(ArrayList::new)) 把流轉換成一個指定的集合類型(ArrayList)
Stream<String> stringStream3 = Stream.of("aa","bb","dd","ee","bb");
ArrayList<String> arrayListResult = stringStream3.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayListResult);//[aa, bb, dd, ee, bb]
//5.collect(Collectors.toCollection(TreeSet::new)) 把流轉換成一個指定的集合類型(TreeSet)
Stream<String> stringStream4 = Stream.of("aa","bb","dd","ee","bb");
TreeSet<String> treeSetResult = stringStream4.collect(Collectors.toCollection(TreeSet::new));
System.out.println(treeSetResult);//[aa, bb, dd, ee]
//6.collect(Collectors.joining()) 使用joining拼接流中的元素
Stream<String> stringStream5 = Stream.of("A","B","C","D","E");
String result5 = stringStream5.collect(Collectors.joining());
System.out.println(result5);//ABCDE
//7.collect(Collectors.joining("-")) 使用joining拼接流中的元素並指定分隔符
Stream<String> stringStream6 = Stream.of("A","B","C","D","E");
String result6 = stringStream6.collect(Collectors.joining("-"));
System.out.println(result6);//A-B-C-D-E
//7.collect(Collectors.joining("-","<",">")) 使用joining拼接流中的元素並指定分隔符
Stream<String> stringStream7 = Stream.of("A","B","C","D","E");
String result7 = stringStream7.collect(Collectors.joining("-","<",">"));
System.out.println(result7);//<A-B-C-D-E>
//8.collect(Collectors.groupingBy(Person::getSex) 對person流按照性別進行分組
Stream<Person> stringStream8 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, List<Person>> resultMap1 = stringStream8.collect(Collectors.groupingBy(Person::getSex));
System.out.println(resultMap1.toString());//{女=[Person{name='lisi', sex='女', age=11}, Person{name='xiaoming', sex='女', age=13}], 男=[Person{name='zhangsan', sex='男', age=10}, Person{name='wangwu', sex='男', age=15}, Person{name='zhaoliu', sex='男', age=12}]}
//9.collect(Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getName, Collectors.toList())))
// 對person流按照性別進行分組,並且把每一組對象流中人員的姓名轉成列表
Stream<Person> stringStream9 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, List<String>> listMap = stringStream9.collect(
Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getName, Collectors.toList()))
);
System.out.println(listMap.toString());//{女=[lisi, xiaoming], 男=[zhangsan, wangwu, zhaoliu]}
//10.collect(Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getAge, Collectors.maxBy(Integer::compareTo))))
// 對person流按照性別進行分組,並統計每一組中年齡最大的人的年齡
Stream<Person> stringStream10 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, Optional<Integer>> listMap1 = stringStream10.collect(
Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getAge, Collectors.maxBy(Integer::compareTo)))
);
System.out.println(listMap1.toString());//{女=Optional[13], 男=Optional[15]}
//11.collect(
// Collectors.groupingBy(Person::getName,
// Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Person::getAge)))
// )
//對person流按照性別進行分組,並統計每一組中年齡最大的人
//這個案例使用了groupingBy和reducing組合
Stream<Person> stringStream111 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Optional<Person>> resultMap111 = stringStream111.collect(
Collectors.groupingBy(Person::getSex,
Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Person::getAge)))
)
);
System.out.println(resultMap111.toString());//{女=Optional[Person{name='lisi', sex='女', age=13}], 男=Optional[Person{name='zhangsan', sex='男', age=15}]}
//12.collect(Collectors.groupingBy(Person::getSex,
// Collectors.reducing(0,Person::getAge,(x,y)->x+y)
// )
// )
//對person流按照性別進行分組,並統計每一組人員年齡和
Stream<Person> stringStream121 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Integer> resultMap121 = stringStream121.collect(
Collectors.groupingBy(Person::getSex,
Collectors.reducing(0,Person::getAge,(x,y)->x+y)
)
);
/*上面這段如果不使用reducing,還可以用下面這中方式完成
Map<String, Integer> resultMap121 = stringStream121.collect(
Collectors.groupingBy(Person::getSex, Collectors.summingInt(Person::getAge))
);*/
System.out.println(resultMap121.toString());//{女=24, 男=37}
//12.collect(Collectors.groupingBy(Person::getName, TreeMap::new, Collectors.toList()))
// 對person流按照name進行分組,結果轉成TreeMap,key是name,value是這個組的對象列表
//groupingBy的第一個參數就是獲取分組的屬性,第二個參數指定返回類型,第三個是把每個分組裡面的對象元素轉成一個列表
Stream<Person> stringStream11 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("lisi", "男", 12),
new Person("xiaoming", "女", 13)
);
TreeMap<String, List<Person>> listMap2 = stringStream11.collect(
Collectors.groupingBy(Person::getName, TreeMap::new, Collectors.toList())
);
System.out.println(listMap2.toString());//{lisi=[Person{name='lisi', sex='女', age=11}, Person{name='lisi', sex='男', age=12}], xiaoming=[Person{name='xiaoming', sex='女', age=13}], zhangsan=[Person{name='zhangsan', sex='男', age=10}, Person{name='zhangsan', sex='男', age=15}]}
//13.collect(Collectors.collectingAndThen(
// Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
// ArrayList::new))
//對Person流先通過TreeSet去重,去重的比較屬性是name,然後在把這個TreeSet中的元素轉換成ArrayList
Stream<Person> stringStream12 = Stream.of(
new Person("lisi", "女", 11),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhangsan", "男", 15),
new Person("xiaoming", "女", 13)
);
List<Person> list = stringStream12.collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
ArrayList::new));//這裡的ArrayList::new等同於pset->new ArrayList(pset),是把前面生成的TreeSet賦值給ArrayList構造函數
System.out.println(list);//[Person{name='lisi', sex='女', age=11}, Person{name='xiaoming', sex='女', age=13}, Person{name='zhangsan', sex='男', age=15}]
//14.collect(Collectors.groupingBy(Person::getName, Collectors.summingInt(Person::getAge)))
// 對person流按照姓名進行分組,並對每一個組內的人員的年齡求和
Stream<Person> stringStream13 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Integer> resultMap2 = stringStream13.collect(Collectors.groupingBy(Person::getName, Collectors.summingInt(Person::getAge)));
System.out.println(resultMap2.toString());//{lisi=28, zhaoliu=12, zhangsan=21}
//15.collect(Collectors.groupingBy(Person::getName, Collectors.averagingInt(Person::getAge)))
// 對person流按照姓名進行分組,並對每一個組內的人員的年齡求平均值
Stream<Person> stringStream14 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Double> resultMap3 = stringStream14.collect(Collectors.groupingBy(Person::getName, Collectors.averagingInt(Person::getAge)));
System.out.println(resultMap3.toString());//{lisi=14.0, zhaoliu=12.0, zhangsan=10.5}
//16.parallel().collect(
// Collectors.groupingByConcurrent(Person::getSex, Collectors.summingInt(Person::getAge))
// )
//使用並行流,把人員按照性別分組,計算每一組中的年齡和,返回的類型是ConcurrentMap,保證執行緒安全
Stream<Person> stringStream16 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("zhaoliu", "男", 16),
new Person("zhaoliu", "男", 17),
new Person("lisi", "女", 13));
ConcurrentMap<String, Integer> resultMap4 = stringStream16.parallel().collect(
Collectors.groupingByConcurrent(Person::getSex, Collectors.summingInt(Person::getAge))
);
System.out.println(resultMap4.toString());//{女=24, 男=70}
//17.collect(Collectors.partitioningBy(p -> p.getAge() > 12))
//把流中元素根據年齡是否大於12分成兩組,保存在Map中,key是true或者false,value是對象列表
Stream<Person> stringStream17 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("wangwu", "男", 10),
new Person("lisi", "男", 15),
new Person("zhaoliu", "女", 13));
Map<Boolean, List<Person>> resultMap5 = stringStream17.collect(Collectors.partitioningBy(p -> p.getAge() > 12));
System.out.println(resultMap5.toString());//{false=[Person{name='zhangsan', sex='女', age=11}], true=[Person{name='lisi', sex='男', age=15}, Person{name='lisi', sex='女', age=13}]}
//18.collect(Collectors.partitioningBy(p -> p.getAge() > 12,Collectors.summingInt(Person::getAge)))
//把流中元素根據年齡是否大於12分成兩組,保存在Map中,key是true或者false,每一組的年齡的和
Stream<Person> stringStream18 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("wangwu", "男", 10),
new Person("lisi", "男", 15),
new Person("zhaoliu", "女", 13));
Map<Boolean, Integer> resultMap6 = stringStream18.collect(Collectors.partitioningBy(p -> p.getAge() > 12,Collectors.summingInt(Person::getAge)));
System.out.println(resultMap6.toString());//{false=21, true=28}
//19.Collectors.toMap:有兩個參數的toMap方法,流中對象的key是不允許存在相同的,否則報錯
//toMap的第二個參數需要創建一個列表,並且key對應的元素對象放入列表
Stream<Person> stringStream19 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "女", 13));
Map<String, List<Person>> resultMap7 = stringStream19.collect(Collectors.toMap(Person::getName, p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
}));
System.out.println(resultMap7.toString());//{zhaoliu=[Person{name='zhaoliu', sex='女', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}]}
//20.Collectors.toMap:有兩個參數的toMap方法,流中對象的key是不允許存在相同的,否則報錯
//toMap的第二個參數直接使用流中的對象作為key所對應的value
Stream<Person> stringStream20 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "女", 13));
Map<String, Person> resultMap8 = stringStream20.collect(Collectors.toMap(Person::getName, p -> p));
System.out.println(resultMap8.toString());//{zhaoliu=Person{name='zhaoliu', sex='女', age=13}, zhangsan=Person{name='zhangsan', sex='女', age=11}}
//21.Collectors.toMap:有三個參數的toMap方法,流中對象的key是允許存在相同的,
// 第三個參數表示key重複的處理方式(這裡是把重複的key對應的value用新的替換老的)
//toMap的第二個參數直接使用流中的對象作為key所對應的value
Stream<Person> stringStream21 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "男", 12),
new Person("zhaoliu", "男", 13)
);
Map<String, Person> resultMap9 = stringStream21.collect(
Collectors.toMap(Person::getName,
p -> p,
(oldPerson,newPerson)->newPerson
)
);
System.out.println(resultMap9.toString());//{zhaoliu=[Person{name='zhaoliu', sex='男', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}]}
//22.Collectors.toMap:有三個參數的toMap方法,流中對象的key是允許存在相同的,第三個參數表示key重複的處理方式(這裡是把重複的key對應的value放入列表)
//toMap的第二個參數直接使用流中的對象作為key所對應的value
Stream<Person> stringStream22 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "男", 13)
);
Map<String, List<Person>> resultMap10 = stringStream22.collect(
Collectors.toMap(Person::getName,
p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
},
(oldList,newList)->{
oldList.addAll(newList);
return oldList;
})
);
System.out.println(resultMap10.toString());//{zhaoliu=[Person{name='zhaoliu', sex='男', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}]}
//23.Collectors.toMap:有四個參數的toMap方法,流中對象的key是允許存在相同的,
//toMap的第二個參數直接使用流中的對象作為key所對應的value
//第三個參數表示key重複的處理方式(這裡是把重複的key對應的value放入列表)
//第四個參數可以指定一個返回的Map具體類型
Stream<Person> stringStream23 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "男", 13)
);
Map<String, List<Person>> resultMap11 = stringStream23.collect(
Collectors.toMap(Person::getName,
p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
},
(oldList,newList)->{
oldList.addAll(newList);
return oldList;
},
LinkedHashMap::new
)
);
System.out.println(resultMap11.toString());//{zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}], zhaoliu=[Person{name='zhaoliu', sex='男', age=13}]}
//24.Collectors.summarizingInt((a -> a.getAge()))
//針對Integer類型的元素進行匯總計算
//得到1、元素數量 2、元素的和 3、元素的最大值 4、元素的最小值 5、平均值
Stream<Person> personStream24=Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 25),
new Person("zhaoliu", "男", 13)
);
IntSummaryStatistics intSummaryStatistics = personStream24.collect(Collectors.summarizingInt((a -> a.getAge())));
System.out.println(intSummaryStatistics);//IntSummaryStatistics{count=3, sum=49, min=11, average=16.333333, max=25}
}
}



