4種Kafka網路中斷和網路分區場景分析
摘要:本文主要帶來4種Kafka網路中斷和網路分區場景分析。
本文分享自華為雲社區《Kafka網路中斷和網路分區場景分析》,作者: 中間件小哥。
以Kafka 2.7.1版本為例,依賴zk方式部署
3個broker分布在3個az,3個zk(和broker合部),單分區3副本
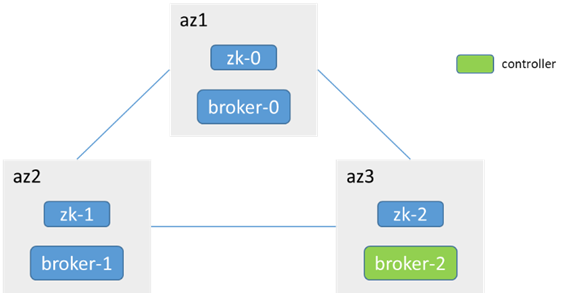
1. 單個broker節點和leader節點網路中斷
網路中斷前:
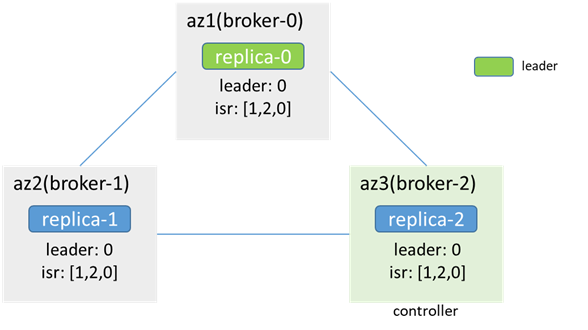
broker-1和broker-0(leader)間的網路中斷後,單邊中斷,zk可用(zk-1為leader,zk-0和zk-2為follower,zk-0會不可用,但zk集群可用,過程中可能會引起原本連在zk-0上的broker節點會先和zk斷開,再重新連接其他zk節點,進而引起controller切換、leader選舉等,此次分析暫不考慮這種情況),leader、isr、controller都不變
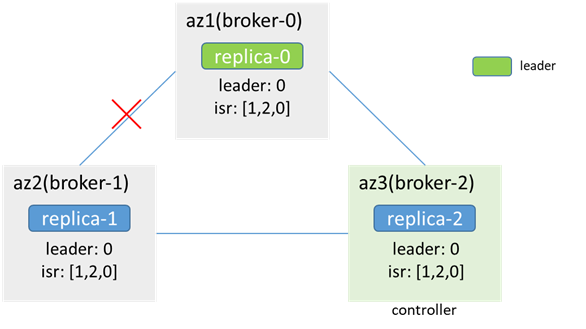
az2內的客戶端無法生產消費(metadata指明leader為broker-0,而az2連不上broker-0),az1/3內的客戶端可以生產消費,若acks=-1,retries=1,則生產消息會失敗,error_code=7(REQUEST_TIMED_OUT)(因為broker-1在isr中,但無法同步數據),且會發兩次(因為retries=1),broker-0和broker-2中會各有兩條重複的消息,而broker-1中沒有;由於broker-0沒有同步數據,因此會從isr中被剔除,controller同步metadata和leaderAndIsr,isr更新為[2,0]
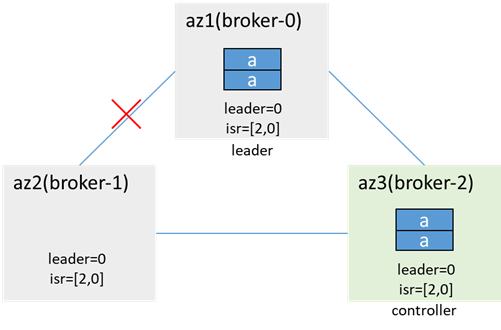
網路恢復後,數據同步,更新isr
2. 單個broker節點和controller節點網路中斷
broker和controller斷連,不影響生產消費,也不會出現數據不一致的情況
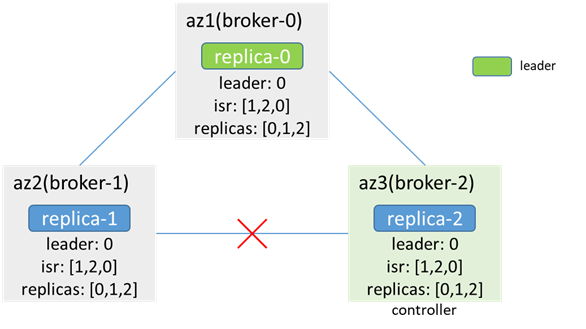
而當發生leader和isr變化時,controller無法將leader和isr的變化更新給broker,導致元數據不一致
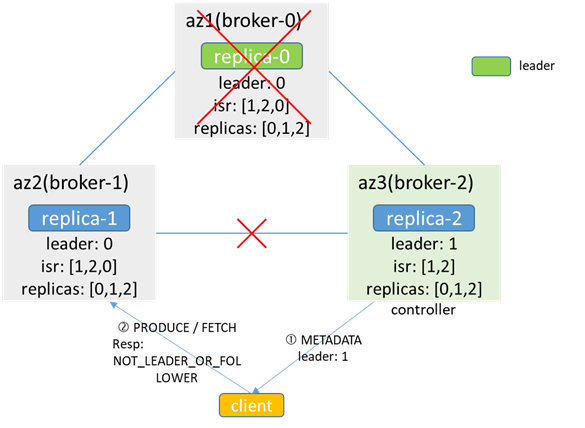
broker-0故障時,controller(broker-2)感知,並根據replicas選舉新的leader為broker-1,但因為和broker-1網路中斷,無法同步給broker-1,broker-1快取的leader依然是broker-0,isr為[1,2,0];當客戶端進行生產消費時,如果從broker-2拿到metadata,認為leader為1,訪問broker-1會返回NOT_LEADER_OR_FOLLOWER;如果從broker-1拿到metadata,認為leader為0,訪問broker-0失敗,都會導致生產消費失敗
3. 非controller節點所在az被隔離(分區)

zk-0和zk-1、zk-2不通,少於半數,az1內zk不可用,broker-0無法訪問zk,不會發生controller選舉,controller還是在broker-1
網路恢復後,broker-0加入集群,並同步數據
3.1 三副本partition(replicas:[1,0,2]),原leader在broker-1(或broker-2)
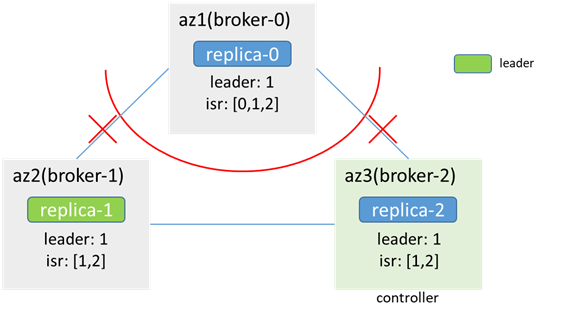
az1內:
broker-0無法訪問zk,感知不到節點變化,metadata不更新(leader:1,isr:[1,0,2]),依然認為自己是follower,leader在1;az1內的客戶端無法生產消費
az2/3內:
zk可用,感知到broker-0下線,metadata更新,且不發生leader切換(isr:[1,0,2] -> [1,2],leader:1);az2和az3內的客戶端可正常生產消費
3.2 三副本partition(replicas:[0,1,2]),原leader在broker-0
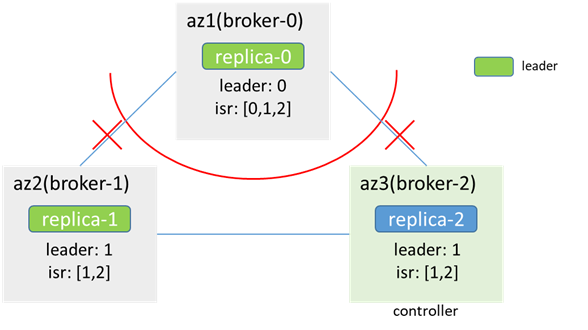
az1內:
zk-0和zk-1、zk-2連接中斷,少於一半,az1內zk集群不可用,Broker-0連不上zk,無法感知節點變化,且無法更新isr,metadata不變,leader和isr都不變;az1內客戶端可以繼續向broker-0生產消費
az2/3內:
zk-1和zk-2連通,zk可用,集群感知到broker-0下線,觸發leader切換,broker-1成為新的leader(時間取決於 zookeeper.session.timeout.ms),並更新isr;az2/3內的客戶端可以向broker-1生產消費
此時,該分區出現了雙主現象,replica-0和replica-1均為leader,均可以進行生產消費
若兩個隔離域內的客戶端都生產了消息,就會出現數據不一致的情況
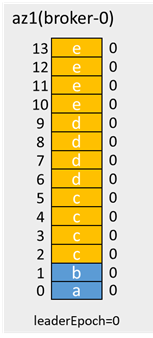
示例:(假設網路隔離前有兩條消息,leaderEpoch=0)
網路隔離前:
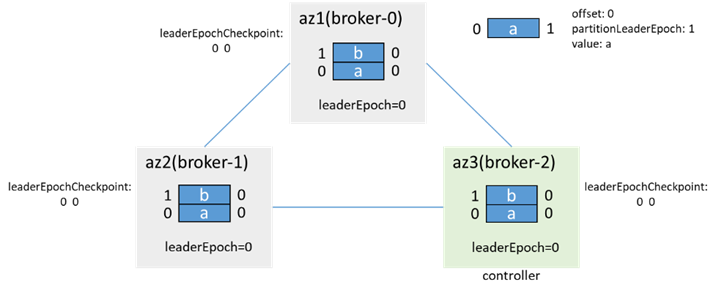
az1隔離後,分區雙主,az1內的客戶端寫入3條消息:c、d、e,az2/3內的客戶端寫入2條消息:f、g:
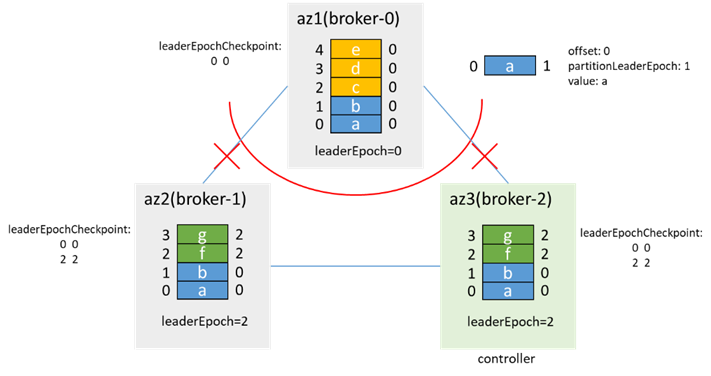
這裡leaderEpoch增加2,是因為有兩次增加leaderEpoch的操作:一次是PartitionStateMachine的handleStateChanges to OnlinePartition時的leader選舉,一次是ReplicationStateMachine 的 handleStateChanges to OfflineReplica 時的removeReplicasFromIsr
網路恢復後:
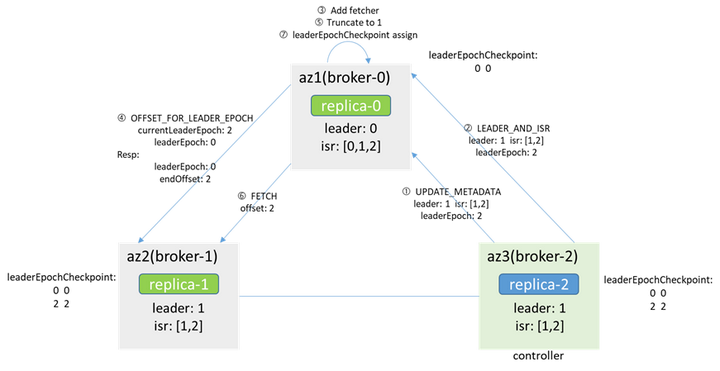
由於controller在broker-2,快取和zk中的leader都是broker-1,controller會告知broker-0 makerFollower,broker-0隨即add fetcher,會先從leader(broker-1)獲取leaderEpoch對應的endOffset(通過OFFSET_FOR_LEADER_EPOCH),根據返回的結果進行truncate,然後開始FETCH消息,並根據消息中的leaderEpoch進行assign,以此和leader保持一致
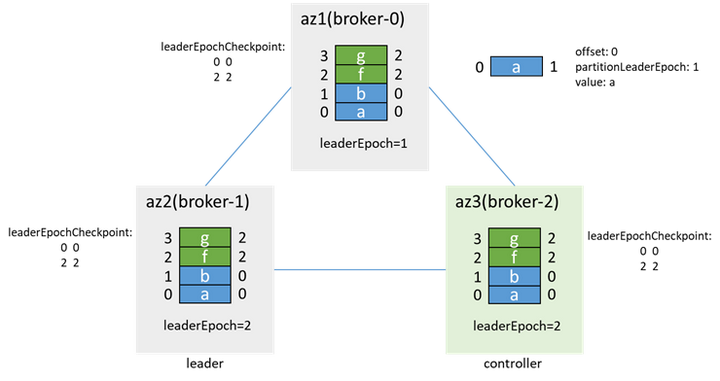
待數據同步後,加入isr,並更新isr為[1,2,0]。之後在觸發preferredLeaderElection時,broker-0再次成為leader,並增加leaderEpoch為3
在網路隔離時,若az1內的客戶端acks=-1,retries=3,會發現生產消息失敗,而數據目錄中有消息,且為生產消息數的4倍(每條消息重複4次)
有前面所述可知,網路恢復後,offset2-13的消息會被覆蓋,但因為這些消息在生產時,acks=-1,給客戶端返回的是生產失敗的,因此也不算消息丟失
因此,考慮此種情況,建議客戶端acks=-1
4. Controller節點所在az被隔離(分區)
4.1 Leader節點未被隔離
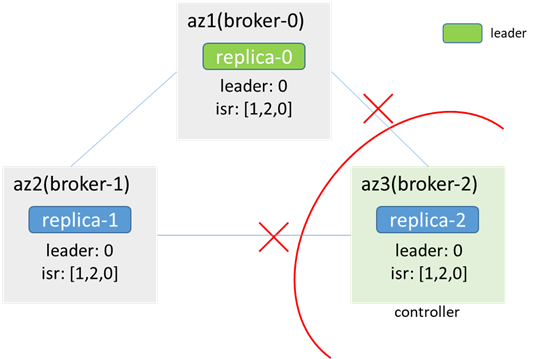
網路中斷後,az3的zk不可用,broker-2(原controller)從zk集群斷開,broker-0和broker-1重新競選controller
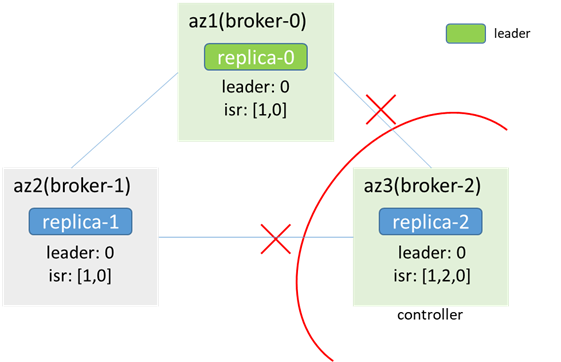
最終broker-0選舉為controller,而broker-2也認為自己是controller,出現controller雙主,同時因連不上zk,metadata無法更新,az3內的客戶端無法生產消費,az1/2內的客戶端可以正常生產消費
故障恢復後,broker-2感知到zk連接狀態發生變化,會先resign,再嘗試競選controller,發現broker-0已經是controller了,放棄競選controller,同時,broker-0會感知到broker-2上線,會同步LeaderAndIsr和metadata到broker-2,並在broker-2同步數據後加入isr
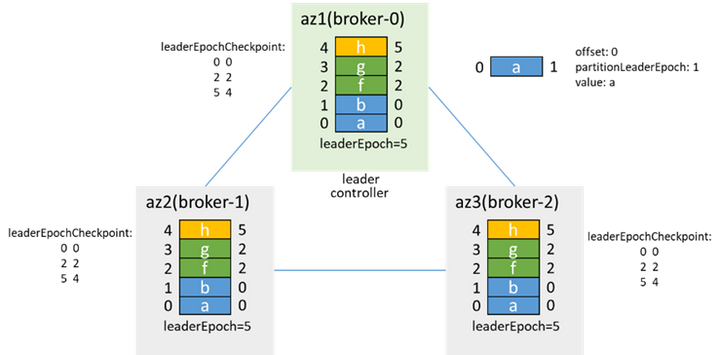
4.2 Leader節點和controller為同一節點,一起被隔離
隔離前,controller和leader都在broker-0:
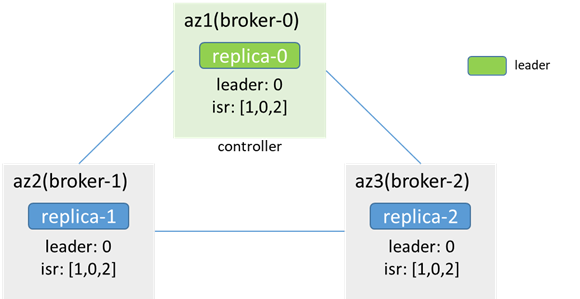
隔離後,az1網路隔離,zk不可用,broker-2競選為controller,出現controller雙主,同時replica-2成為leader,分區也出現雙主
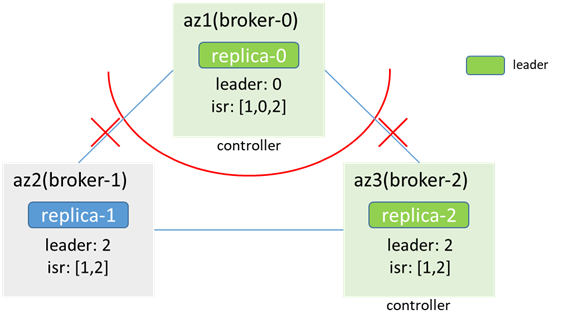
此時的場景和3.2類似,此時生產消息,可能出現數據不一致
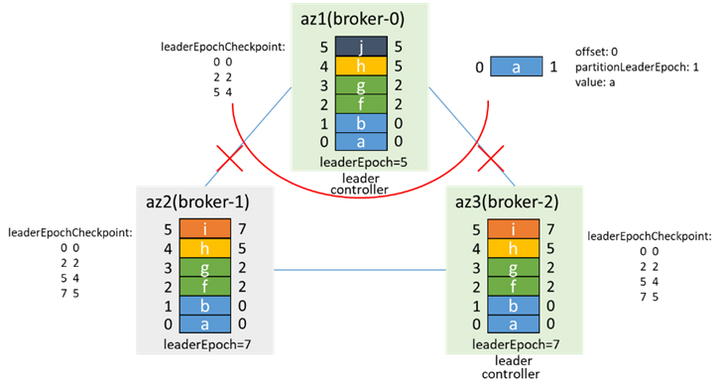
網路恢復後的情況,也和3.2類似,broker-2為controller和leader,broker-0根據leaderEpoch進行truncate,從broker-2同步數據
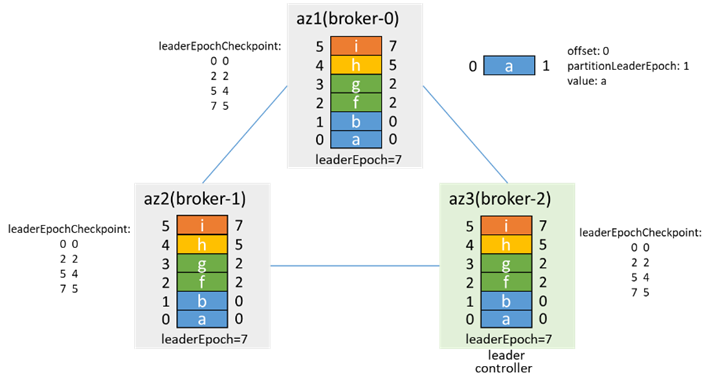
加入isr,然後通過preferredLeaderElection再次成為leader,leaderEpoch加1
5. 補充:故障場景引起數據不一致
5.1 數據同步瞬間故障
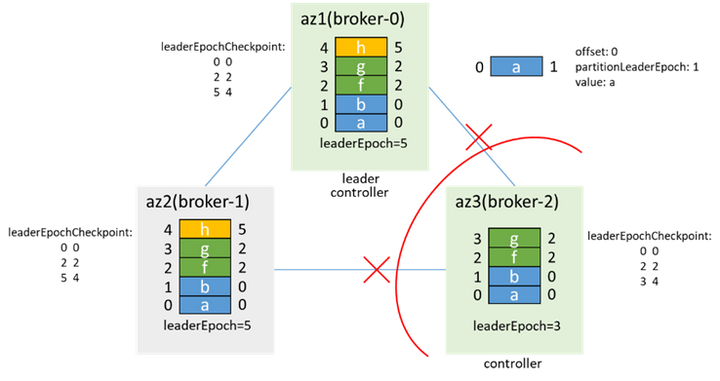
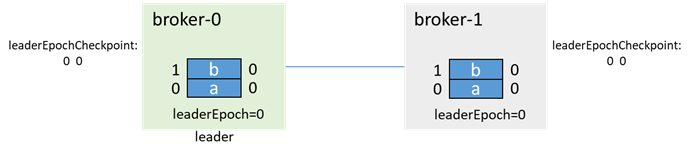
初始時,broker-0為leader,broker-1為follower,各有兩條消息a、b:
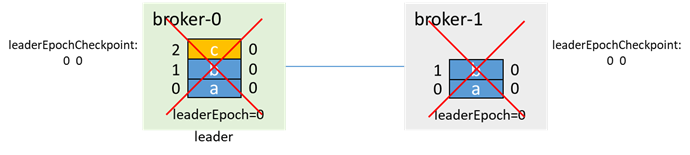
leader寫入一條消息c,還沒來得及同步到follower,兩個broker都故障了(如下電):
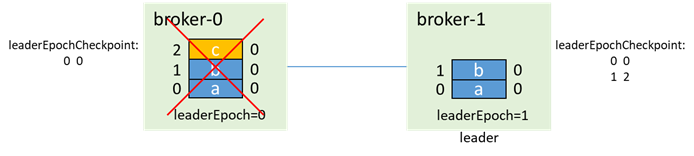
之後broker-1先啟動,成為leader(0和1都在isr中,無論unclean.leader.election.enable是否為true,都能升主),並遞增leaderEpoch:
然後broker-0啟動,此時為follower,通過OFFSET_FOR_LEADER_EPOCH從broker-1獲取leaderEpoch=0的endOffset
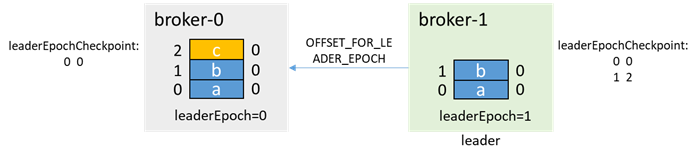
broker-0根據leader epoch endOffset進行truncate:
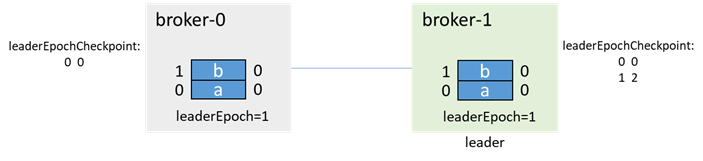
之後正常生產消息和副本同步:

該過程,如果acks=-1,則生產消息c時,返回客戶端的是生產失敗,不算消息丟失;如果acks=0或1,則消息c丟失
5.2 unclean.leader.election.enable=true引起的數據丟失
還是這個例子,broker-0為leader,broker-1為follower,各有兩條消息a、b,此時broker-1宕機,isr=[0]
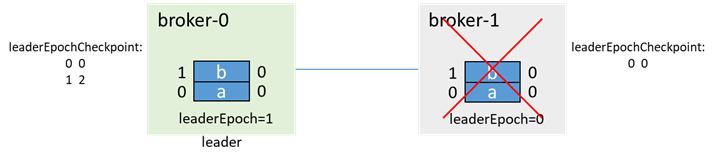
在broker-1故障期間,生產消息c,因為broker-1已經不在isr中了,所以即使acks=-1,也能生產成功
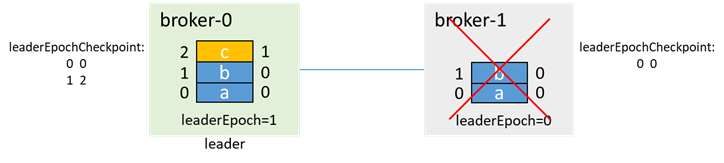
然後broker-0也宕機,leader=-1,isr=[0]

此時broker-1先拉起,若 unclean.leader.election.enable=true,那麼即使broker-1不在isr中,因為broker-1是唯一活著的節點,因此broker-1會選舉為leader,並更新leaderEpoch為2
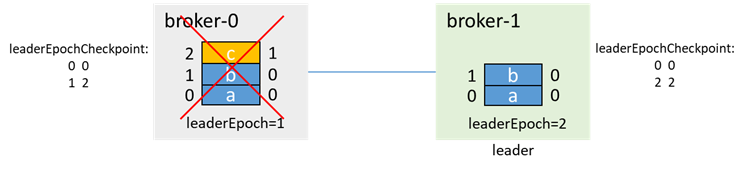
這時,broker-0再拉起,會先通過 OFFSET_FOR_LEADER_EPOCH,從broker-1獲取epoch資訊,並進行數據截斷
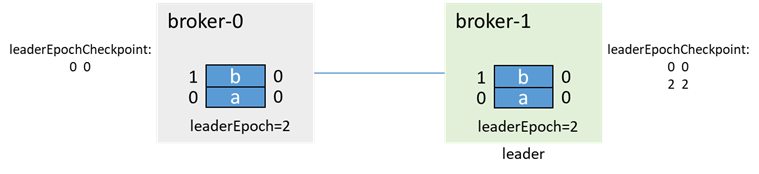
再進行生產消息和副本同步
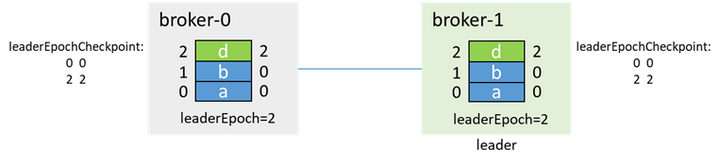
消息c丟失


