Detecting Rumors from Microblogs with Recurrent Neural Networks(IJCAI-16)
記錄一下,很久之前看的論文-基於RNN來從微博中檢測謠言及其程式碼復現。
1 引言
現有傳統謠言檢測模型使用經典的機器學習演算法,這些演算法利用了根據帖子的內容、用戶特徵和擴散模式手工製作的各種特徵,或者簡單地利用使用正則表達式表達的模式來發現推特中的謠言(規則加詞典)。
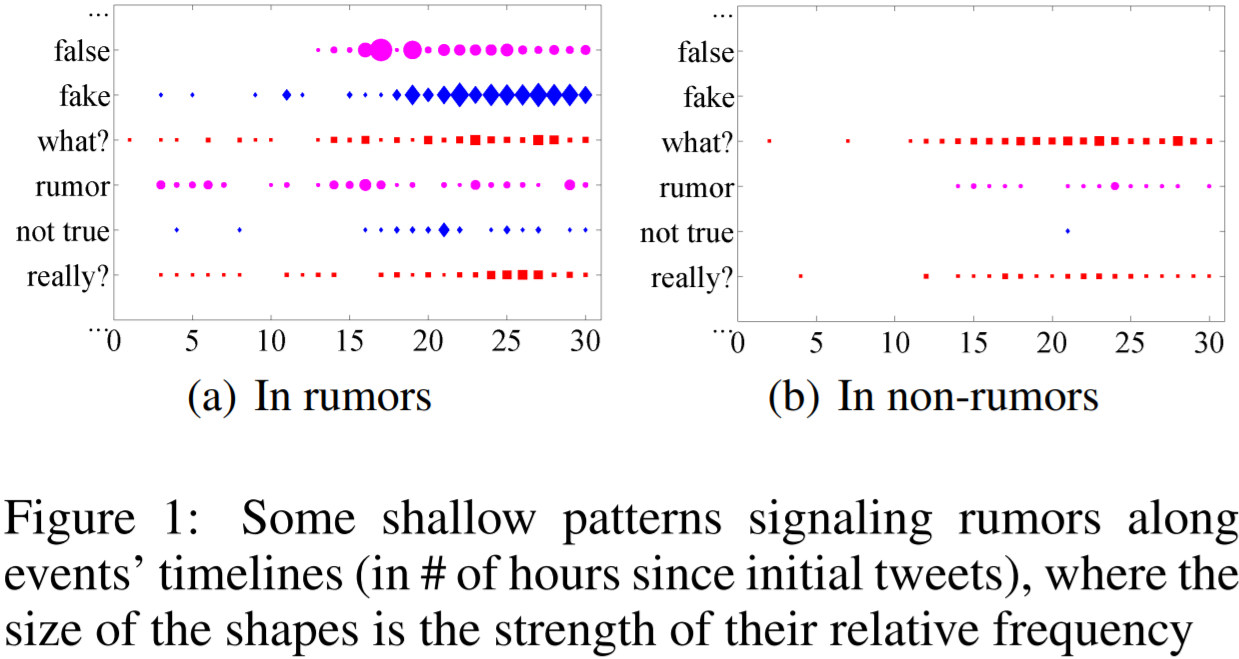
特徵工程是至關重要的,但手工特徵工程是繁瑣複雜、有偏見和耗時費力的。例如,圖1中的兩個時間序列圖描述了典型的謠言訊號的淺層模式。雖然它們可以表明謠言和非謠言事件的時間特徵(微博文本中關鍵詞的時序變化),但這兩種情況之間的差異對於特徵工程來說既不明確,也不明顯。
另一方面,深度神經網路在許多機器學習問題上已經顯示出了明顯的優勢。本文利用了循環神經網路RNN來進行有效的謠言檢測。RNN適用於處理社交媒體中的文本(retweet)流的序列性質 。這是因為RNN可以捕獲謠言傳播的動態時序特性。
本文提出基於RNN的方法,將謠言檢測視為一個序列分類問題。具體地,本文將社會上下文資訊(源微博的轉帖文本或相關帖子文本)建模為可變長度的時間序列,然後用RNN來學習捕獲微博相關帖子的上下文特徵隨時間的變化。
2 模型
2.1 問題描述
-
基於事件的謠言檢測(單個微博帖子都很短,上下文非常有限。Claim通常與一些與Claim相關的帖子有關)
-
事件集E={ E_i }, E_i= { (m_i,j,t_i,j) },事件Ei由時間戳 ti,j內的帖子 mi,j組成。
-
任務是判斷每一個Event是謠言還是不是謠言
2.2 數據預處理-構造可變長度時間序列
將輸入的序列中的post進行劃分,從而將處理後的序列長度限定在在一定範圍。
可將每個帖子建模作為一個輸入實例,並構建一個序列長度等於帖子數的時間序列的用於RNN建模。然而,一個流行的事件可能會有成千上萬個的帖子。我們只有一個輸出單元(僅適用最終隱狀態,有資訊瓶頸問題)來指示在每個事件的最後一個時間步長中的類。通過大量的時間步長進行反向傳播,而只有一個最後階段的損失,計算代價高昂且無效的。(處理長序列時,RNN的BPTT存在的梯度消失問題會導致有偏的權重,即離Loss越遠的時間步的梯度對參數的貢獻越小,從而使其難以建模好長期依賴)
因此,為了妥善處理短時間內密集的帖子序列,本文將一批帖子構成一個時間間隔,並將它作為一個時間序列中的一個輸入單元,然後使用RNN進行序列建模。簡而言之,就是將原始的帖子序列按相對時間間隔劃分成固定長度(例如k個)的子序列,其中子序列中帖子的數量不一定相同。
具體地,給定事件相關帖子的數據集,先將每條帖子視為輸入實例,其序列長度等於帖子數量。進一步將帖子按照時間間隔進行批處理,視為時間序列中的單元,然後使用RNN序列進行建模,採用RNN序列的參考長度來構造時間序列。
動態時間序列演算法:
1. 將整個事件線均分為N個internal,形成初始集合U0;
2. 遍歷U0,刪除沒有包含帖子的internal,形成U1;
3. 從U1中選出總時間跨度最長的連續internal,形成集合U2(找到一個最長的時間序列);
4. 如果U2中internal的數量小於N且大於之前一輪,將internal減半,返回步驟1,繼續分區(使最終internal數量接近N);
5. 否則,返回該總時間跨度最長的連續internal集合U2。
根據上述演算法,其實現如下所示(針對常用的微博數據集,其每一個樣本的原始資訊存儲在JSON文件中):
def load_rawdata(file_path):
""" json file, like a list of dict """
with open(file_path, encoding="utf-8") as f:
data = json.loads(f.read())
return data
def GetContinueInterval(inter_index):
"""根據初步劃分的間隔索引列表,得出最大連續間隔的索引"""
max_inters = []
temp_inters = [inter_index[0]]
for q in range(1, len(inter_index)):
if inter_index[q] - inter_index[q - 1] > 1:
if len(temp_inters) > len(max_inters):
max_inters = temp_inters
temp_inters = [inter_index[q]]
else:
temp_inters.append(inter_index[q])
if len(max_inters) == 0:
max_inters = temp_inters
return max_inters
def ConstructSeries(tweet_list, interval_num, time_interval):
"""基於相對時間間隔,按照時間戳對post序列進行劃分
Params:
tweet_list (list), 由Post Index以及時間戳二元組構成的序列
interval_num (int), 依據基準序列長度N,計算出的當前序列的時間間隔數
time_interval (float), 單位時間間隔長度
Returns:
Output (list), 劃分好的post batch,每一個batch包含的一個時間間隔內的post
inter_index (list), Interval的index列表
"""
# 遍歷每一個間隔
tweet_index = 0
output, inter_index = [], []
start_time = tweet_list[0][1]
for inter in range(0, interval_num):
non_empty = 0
interval_post = [] # 存儲當前間隔內的post
for q in range(tweet_index, len(tweet_list)):
if start_time <= tweet_list[q][1] < start_time + time_interval:
non_empty += 1
interval_post.append(tweet_list[q][0])
elif tweet_list[q][1] >= start_time + time_interval:
# 記錄超出interval的tweet位置,下次可直接從此開始
tweet_index = q - 1
break
if non_empty == 0:
output.append([]) # 空間隔不會記錄其索引
else:
if tweet_list[-1][1] == start_time + time_interval:
interval_post.append(tweet_list[-1][0]) # add the last tweet
inter_index.append(inter)
output.append(interval_post)
start_time = start_time + time_interval # 更新間隔開始時間
return output, inter_index
以下程式碼為動態時間序列演算法主函數,其中N為RNN的參考長度,即超參數:
def SplitSequence(weibo_id, N=50):
"""將source post對應的posts劃分成不定長的post batch序列
Params:
weibo_id (str), source post對應的id,用於讀取對應數據
N (int), 時間序列的基準time steps個數
Returns:
output (list), interval list, 每一個interval包含一定數量的post index
"""
# 不同時間間隔內的post數量不必相同)
path = "Weibo" + os_sep + "{}.json".format(weibo_id)
data = load_rawdata(data_path + path) # 基於weibo id載入包含轉帖文本及時間戳的原始數據
tweet_list = [(idx, tweet["t"]) for idx, tweet in enumerate(data)]
total_timespan = tweet_list[-1][1] - tweet_list[0][1] # L(i)
time_interval = total_timespan / N # l
k = 0
pre_max_inters = [] # U_(k_1)
while True:
# Spliting series by the current time interval
k += 1
interval_num = int(total_timespan / time_interval)
output, inter_index = ConstructSeries(tweet_list, interval_num, time_interval)
max_inters = GetContinueInterval(inter_index) # maximum continue interval index
if len(pre_max_inters) < len(max_inters) < N:
time_interval = int(time_interval * 0.5) # Shorten the intervals
pre_max_inters = max_inters
if time_interval == 0:
output = output[max_inters[0]:max_inters[-1] + 1]
break
else:
output = output[max_inters[0]:max_inters[-1] + 1]
break
return output
2.3 模型結構(two-layer GRU)
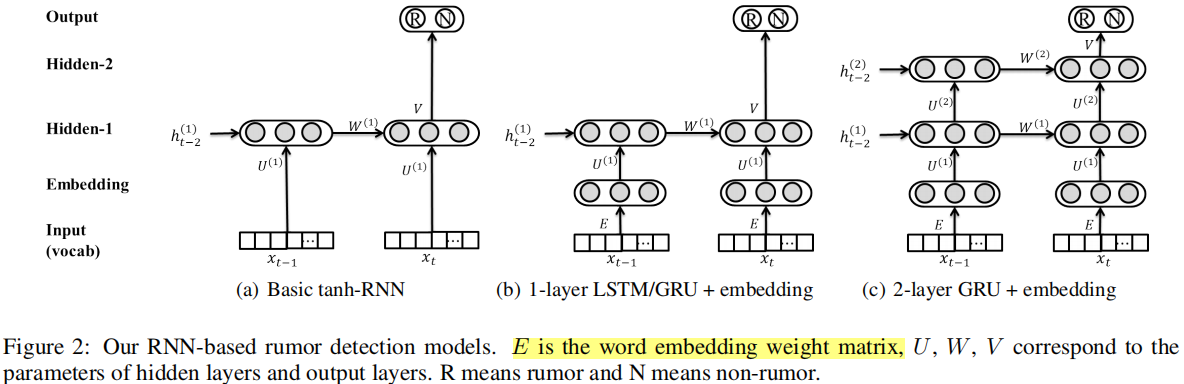
首先,將每一個post的tf-idf向量和一個詞嵌入矩陣相乘,這等價於加權求和詞向量。由於本文較老,詞嵌入是基於監督訊號從頭開始學習的,而非使用word2vec或預訓練的BERT。
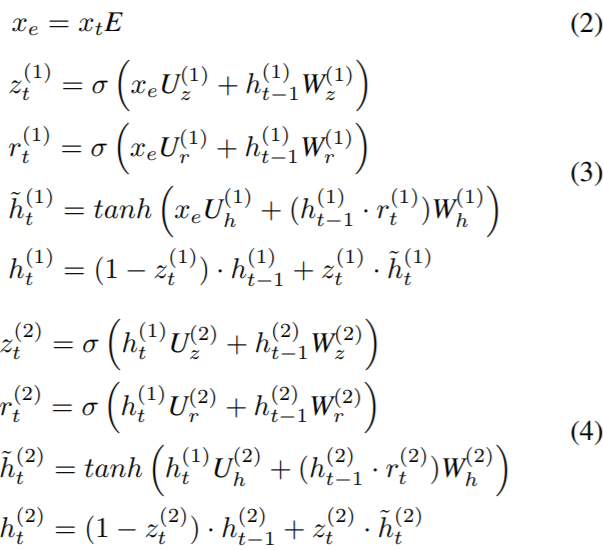
以下是載入數據的部分的程式碼。為了便於實現,這裡並沒有使用torch自帶的dataset和dataloader,也沒有沒有對序列進行截斷和填充。
class Data():
def __init__(self, text_data):
self.text_data = text_data
def get_wordindices(self):
return [torch.from_numpy(inter_text) for inter_text in self.text_data]
def load_data(ids):
""" 依據weibo的id,載入所有的結點特徵
Params:
ids (list), 微博id list
Returns:
instance_list: a list of numpy ndarray, 每一個numpy ndarray是一個B by k的tf-idf矩陣
"""
instance_list = []
for weibo_id in tqdm(ids):
text_matrix = load_sptext(weibo_id).toarray() # 所有post的numpy tfidx矩陣
split_interval = SplitSequence(weibo_id)
text_data = [text_matrix[interval] for interval in split_interval]
instance_list.append(Data(text_data))
return instance_list
模型程式碼:本文的模型對每一個時間間隔內的post的embedding直接使用了最大池化操作。
class GlobalMaxPool1d(nn.Module):
def __init__(self):
super(GlobalMaxPool1d, self).__init__()
def forward(self, x):
return torch.max_pool1d(x, kernel_size=x.shape[2])
class GRU2_origin(nn.Module):
def __init__(self, dim_in, dim_word, dim_hid, dim_out):
"""
Detecting Rumors with Recurrent Neural Network-IJCAI16
:Params:
dim_in (int): post的初始輸入特徵維度 k
dim_word(int): word嵌入的維度
dim_hid (int): GRU hidden unit
dim_out (int): 模型最終的輸出維度,用於分類
"""
super(GRU2_origin, self).__init__()
self.word_embeddings = nn.Parameter(nn.init.xavier_uniform_(
torch.zeros(dim_in, dim_word, dtype=torch.float, device=device), gain=np.sqrt(2.0)), requires_grad=True)
# GRU for modeling the temporal dynamics
rnn_num_layers = 2
self.MaxPooling = GlobalMaxPool1d()
self.GRU = nn.GRU(dim_word, dim_hid, rnn_num_layers)
self.H0 = torch.zeros(rnn_num_layers, 1, dim_hid, device=device)
self.prediction_layer = nn.Linear(dim_hid, dim_out)
nn.init.xavier_normal_(self.prediction_layer.weight)
def forward(self, text_data):
batch_posts = []
for idx in range(len(text_data)):
# words_indices is a sparse tf-idf vector with N * 5000 dimension
words_indices = text_data[idx].to(device)
tmp_posts = []
for i in range(words_indices.shape[0]):
word_indice = torch.nonzero(words_indices[i], as_tuple=True)[0]
if word_indice.shape[0] == 0:
word_indice = torch.tensor([0], dtype=torch.long).to(device)
words = self.word_embeddings.index_select(0, word_indice) # select out embeddings
word_tensor = words_indices[i][word_indice].unsqueeze(dim=0) # select out weights
post_embedding = word_tensor.mm(words).squeeze(dim=1)
tmp_posts.append(post_embedding)
# Interval中的post batch取平均 (矩陣乘法)
tmp_embeddings = torch.cat(tmp_posts, dim=0).unsqueeze(1)
batch_embedding = self.MaxPooling(tmp_embeddings.transpose(0, 2)) # transpose(0, 2)
batch_posts.append(batch_embedding.squeeze(1).transpose(0, 1))
x = torch.cat(batch_posts, dim=0)
gru_output, _ = self.GRU(x.unsqueeze(1), self.H0)
return self.prediction_layer(gru_output[-1]) # Using the last hidden vector of GRU
後續的完整的數據載入、模型初始化、訓練和評估,可自行添加。
3 實驗
模型訓練設置:
- 使用TF-IDF來獲取post的初始文本表示
- AdaGrad演算法進行參數更新
- 根據經驗,將辭彙量大小設為k=5000,待從頭學的詞嵌入維度為100,隱藏單元的尺寸為100,學習率為0.5
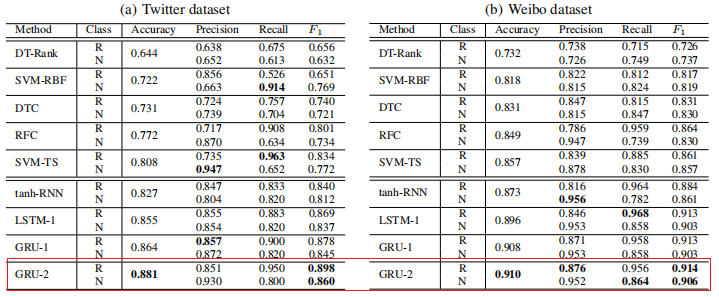
論文中報告的實驗結果(復現的結果與其相差不大):
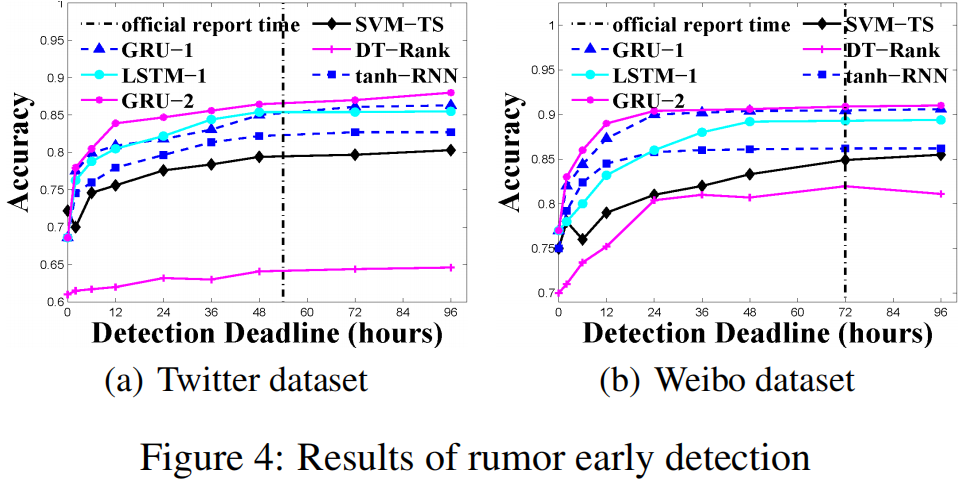
4 總結
這篇文章算是將深度學慣用於虛假資訊檢測的開山之作,開始了利用深度網路來自動提取具備判別性的高階特徵的範式,後續很多文章都是在此基礎上改進的。
由於文章較老,所以在目前看,待改進的點其實挺多的。首先要注意,原始的TF-IDF特徵一般不能在全局數據上提取(訓練集、驗證集和測試集,暫不考慮半監督的情況),相同的詞的在驗證集和測試集的TF-IDF特徵和訓練集取同樣的值。而對於新出現的詞,取默認值。推廣到一般情況,如果提取特徵時,不區分訓練測試,或許使用了相應特徵的對比方法取得的結果過於樂觀,並不符合實際情況。
此外,可以考慮文本特徵的獲取、序列的層次化建模、注意力機制、其他特徵的使用(用戶資訊、傳播結構特徵)、外部知識的引入(知識圖譜)、非線性傳播結構的利用、多任務學習(結合立場分類)等等。
值得注意的是,當演算法實際應用時,並不是越複雜的模型的效果就越好,而且需要考慮實際的業務需求和數據。有時候,或許假設簡單、模型結構簡單的演算法或許在大量人工特徵的引入和大量數據的支援下,也能取得不錯的效果,畢竟數據決定演算法的上限。


