解決這兩個世界級難題,自動駕駛就能夠實現超進化?
引言
自動駕駛領域近幾年來一直備受關注,但截止目前,自動駕駛在現實複雜場景下的大規模部署應用卻一再延後。
其中一個很重要的原因是,目前業界對於動態和強交互性場景下的行為、軌跡預測問題(behavior prediction)始終沒有得出很好的解決方案。缺乏對其他道路參與者的行為理解與預測,自動駕駛車輛便無法進行安全高效的決策、規劃以及控制。
於是對於認知科學與行為預測的研究,成為了自動駕駛破局的關鍵。
1. 自動駕駛中的認知科學與行為預測問題
作為自動駕駛研究的重要細分方向之一,認知科學與行為預測問題吸引了大量專業人員的關注與研究。近年來,伴隨著深度學習在自動駕駛領域的應用不斷加深,行為預測的精度更是得到了大幅度的提升。
然而,現實世界中的駕駛場景極其複雜多樣,不同的駕駛場景(高速、交叉路口、環島等),無論是道路結構,還是駕駛模式都存在不小的差異。
從駕駛場景來看,當前的行為預測方法通過訓練後可以在訓練集內的場景中表現良好,但是一旦遇到一個全新的或者稍有差異的場景,模型的預測性能往往會崩潰或大幅下降。
通過上述行為預測方法訓練出的模型,由於可遷移性/泛化能力(transferability/generalizability)的缺失,會極大地限制自動駕駛進行大規模部署應用。倘若需要針對每一個駕駛場景專門訓練一個模型,可想而知開發成本會多麼高昂。
除此以外,對真實駕駛環境中複雜多樣的駕駛行為實現高效精準預測,也是一項不小的挑戰。駕駛行為因人而異(heterogeneous) ,不同的駕駛員展現出的駕駛行為存在著較大差異,不同的駕駛員也有著不同的駕駛風格,有粗魯莽撞的駕駛員,也有謹慎禮貌的駕駛員。
而目前的大部分預測方法,通過訓練後僅僅能夠預測出平均意義上的駕駛行為,卻無法捕捉到駕駛員的個體差異。智慧體對個體行為差異理解的缺失,將會始終制約行為預測的精度,因而自動駕駛行為的安全性也將難以得到保障。

針對以上兩個問題,我們向大家介紹一種分層框架:
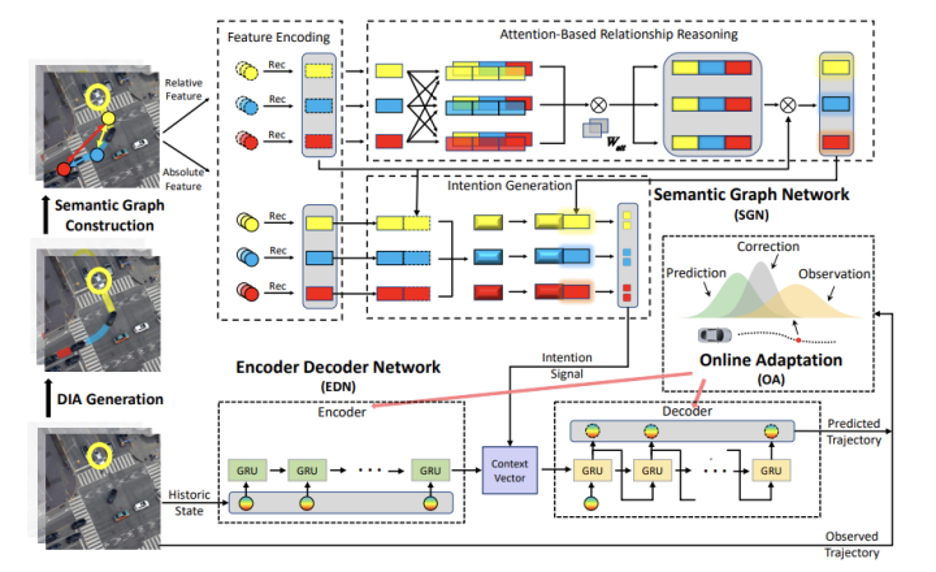
HATN(hierarchical,adaptable and transferable network)
此框架可在多智體密集交通環境中生成高品質的駕駛行為預測。
該方法從人類在駕駛過程中的認知模型和語義理解得到啟發,對駕駛任務進行分層定義和並設計通用的環境表徵,可以實現在不同駕駛場景上的遷移。此外,HATN方法還能通過在線適應模組捕捉個體和場景之間駕駛行為的變化。
HATN行為預測框架由三部分組成:
-
負責上層意圖決策任務的高級語義圖網路(SGN);
-
一個底層編碼器-解碼器網路(EDN),根據歷史資訊和上層意圖訊號執行動作;
-
改進的擴展卡爾曼濾波器(MEKF)演算法,執行在線自適應,實現更好的個性化訂製和場景遷移。
下文將會圍繞以下幾個問題,對HATN展開詳細的介紹:
-
如何實現預測模型在不同駕駛場景中的可遷移性?
-
如何使得預測模型能夠自適應地捕捉駕駛行為的差異?
-
在對真實數據的預測任務中,可遷移性和自適應性預測性能有幫助嗎?

2. 如何實現預測模型在不同駕駛場景中的可遷移性?
相比起大多數預測演算法在場景遷移中的無力,人類早已掌握了駕駛的精髓。當一個新手駕駛員在某一個駕駛場景練習駕駛時,他通過練習獲得的駕駛經驗以及駕駛技巧是可以遷移到其他場景上的。即使面對一個陌生的駕駛場景,人類依然能夠復用以往的駕駛經驗,毫不費力地駕駛車輛穿梭其間。
而現有的自動駕駛技術在面對陌生場景時的遷移能力與人類駕駛員之間仍然存在明顯的差距。人類神奇駕駛能力背後所蘊含的認知和決策機制,自然而然地引起技術研究人員的好奇心。
受認知科學(cognition science)研究的啟發,筆者觀察到人類在密集的交通流和複雜的環境中之所以擁有強大的知識遷移能力,主要受益於兩種認知機制:
1)分層結構(hierarchy):將複雜的任務分解為多個簡單的子任務;
2)選擇性注意(selective attention):在巨大的資訊池中篩選識別出有效的、與任務相關的低維環境表徵。
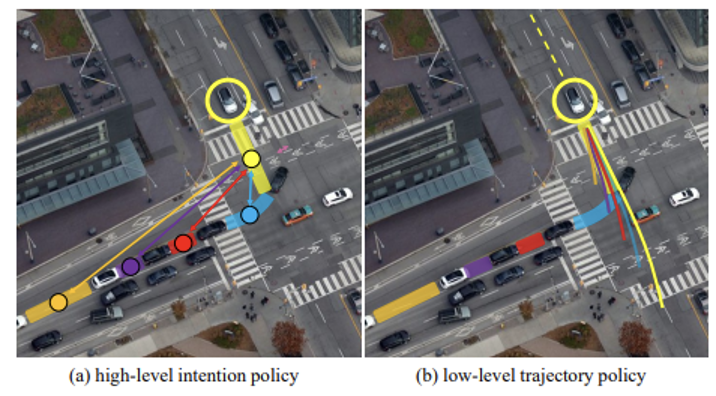
我們基於上述兩種認知機制分析人類在駕駛過程中的駕駛行為,其決策過程是自然分層的。如圖3所示,在上層的意圖層面(high-level intention),人類開車時通常在做的一件事就是在不停尋找合適的「插入區域」。這些「插入區域」一般由車道線與道路參與者組成,在本文中將其稱為Dynamic Insertion Area(DIA)。
文章的作者將每個DIA建立為一個結點(node),把所有節點進行有向連接便得到了一個語義圖semantic graph。
在這樣一個多智慧體setting下的圖表徵中,車輛之間的交互行為由節點之間的連接edge所描述。而在底層的動作層面(low-level action),在決定了插入哪一個區域以後,人類將根據車輛當前以及歷史的動力學狀態,進行一系列的底層動作以實現目標。
從具體的方法上來看,文章中所提出的分層行為預測框架主要分為以下幾個步驟:
1) 從環境中抓取動態插入區域(dynamic insertion area),並構建語義圖(semantic graph)作為環境的一種通用表徵(generic representation)。
2) 提出語義圖網路(semantic graph network,SGN),對語義圖中各個車輛之間的交互行為進行理解推理,預測出每個車輛未來將要插入的區域,以及所需要的時間以及行駛路程。其數學表示以及loss設計為:
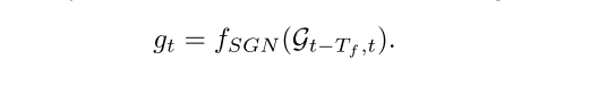
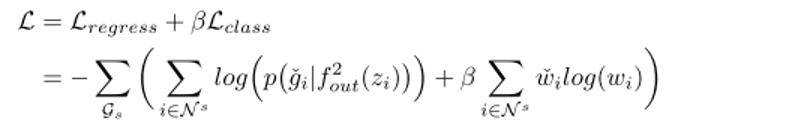
3) 提出編碼解碼網路(encoder decoder network,EDN),在預測出的意圖intention基礎上,對每輛車未來具體的行駛軌跡進行生成預測。其數學表示以及loss設計為:
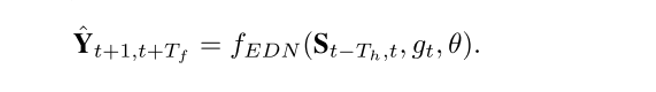
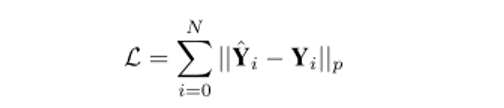
這種分層的任務劃分方式,不僅大大降低了學習難度,也通過對於每一個子任務(sub-task)選取通用的環境表徵,使得各個子策略(sub-policy)可以跨場景地泛化學習。
3. 如何使得預測模型能夠自適應地捕捉駕駛行為的差異?
人類行為天然是異質的、隨機的和隨時間變化的(heterogeneous, stochastic, and time-varying)。不同的駕駛場景也會產生不同的駕駛模式(driving pattern)。捕捉駕駛行為的個體以及環境差異,有益於進一步提升預測方法的精度以及泛化能力。因此,文中使用一個在線自適應模組(online adaptation)將個體以及場景的差異注入模型當中。
在線自適應的原理是,雖然人類駕駛員之間不能夠直接進行溝通與交流,但其歷史的駕駛行為(historic behavior)暴露了其個體的駕駛特點。通過挖掘歷史行為中的線索,我們可以對模型參數進行微調,以更好地貼合個體的駕駛行為。
具體而言,本文使用了改進的拓展卡爾曼濾波(Modified Extended Kalman Filter, MEKF)以對模型參數進行在線更新。我們將模型參數視為想要估計的state,預測出的歷史軌跡作為prediction,觀察到的歷史真實軌跡作為observation,對模型參數進行最優估計。其數學表示如下:
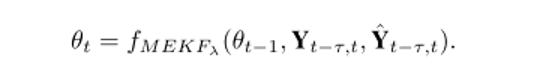
4. 實驗驗證
本文在真實的人類駕駛數據集INTERACTION DATASET中對所提出的方法進行驗證,以測試所提出方法的預測精度,遷移能力,以及自適應能力。該論文中對每個模組進行了大量的ablation study以尋找最優的模型結構,數據表徵,以及超參數,本文簡略地介紹案例分析以及性能比較。細節實驗請參考文章末尾列出的原文。
4.1 案例分析
首先,本文給出三個案例分析以展示預測效果:
1)一次交互:在交叉路口中,自車與其他車輛交互,通過共同的衝突點(conflict point);
2)系列交互:在交叉路口中,自車與其他車輛交互,通過一系列衝突點;
3)場景遷移:將自車直接遷移到環島場景,自車與其他車輛交互,通過衝突點。
🌟重要注釋:
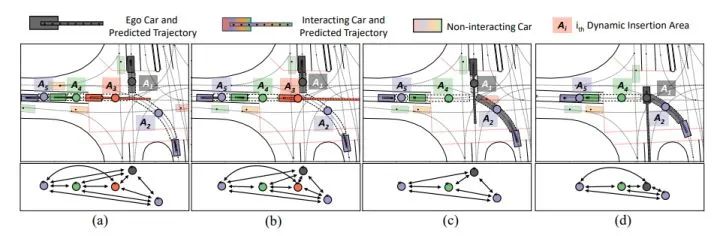
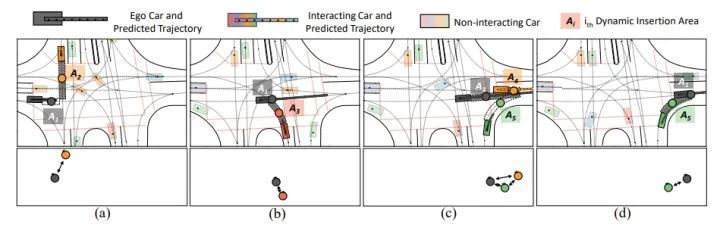
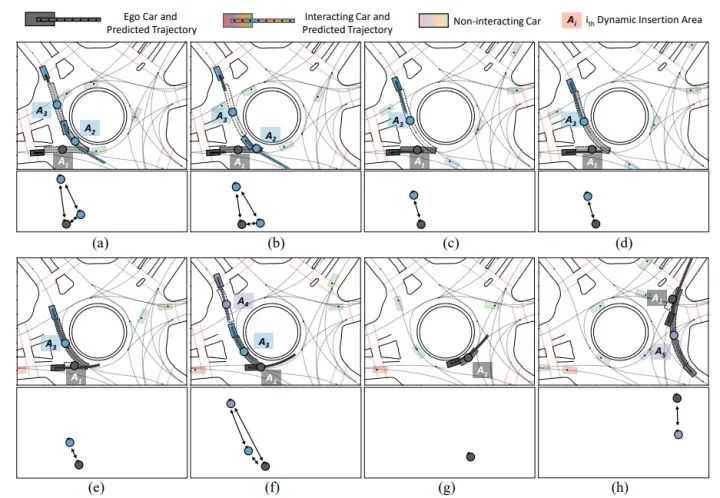
在下方圖4/5/6中,黑車代表自車;透明色車表示非交互汽車;鮮艷的汽車表示與自車交互的車輛。每個提取出的DIA用虛線和一個節點標記。同一個DIA的節點與其隊形的後方車輛使用相同的顏色。每一個場景的語義圖如每個場景圖下方所示。每個DIA顏色越暗,自我汽車越有可能插入該區域。預測出的自車及其交互車輛的未來最可能軌跡於每輛車的顏色相同。
案例1 一次交互
在本次交互中,在 (a)(b) 時,自車首先讓出紅色汽車,然後在 (c)(d) 中的其他汽車之前通過。
案例2 系列交互
本文方法可以不斷識別交互的車輛,並提取可插入區域。自車首先在(a)中與黃車交互,然後與(b)中的橙車交互,最後和 (c)(d) 中的綠色和橙色汽車交互並駛出交叉路口。
案例3 場景遷移
在交叉路口場景中訓練後,本文的方法可在無需額外訓練的情況下,直接遷移到環島場景中。自車首先在(a)(b)中對右側的藍色汽車讓車,然後在(c)(d)(e)(f)搶在上方的藍色汽車之前通過 。值得一提的是,由DIA的顏色深淺所示,本文的方法捕獲了人類的猶豫和意圖轉換。自車隨後繼續在 (g) 中獨自行駛,並在 (h) 中紫色車前離開環島。
4.2 性能比較

我們在圖7中,將所提出方法與傳統的Rule-based方法,以及Learning-based方法進行了多個場景,多個metric,以及多個horizon下的細緻比較。
其中包含了Grip++以及Trajectron++兩種近兩年的SOTA方法。根據圖7的數據,我們可以看出,該論文提出的HATN性能明顯超越了其它方法,尤其是在長期(long horizon 3s)的行為預測上,在各個metric與場景下相比Trajectron++性能提升了30%-50%。
參考文獻
[1] Conference Version: Letian Wang, Yeping Hu, Liting Sun, Wei Zhan, Masayoshi Tomizuka, Changliu Liu. “Hierarchical Adaptable and Transferable Networks (HATN) for Driving Behavior Prediction”. Neurips 2021 ML4AD.
[2] Extended Version: Letian Wang, Yeping Hu, Liting Sun, Wei Zhan, Masayoshi Tomizuka, Changliu Liu. “Transferable and Adaptable Driving Behavior Prediction”. arXiv preprint arXiv:2202.05140.


